






Still downloading templates?
There’s an easier way. Try a free AI Agent in ClickUp that actually does the work for you—set up in minutes, save hours every week.
Sorry, there were no results found for “”
Sorry, there were no results found for “”
Sorry, there were no results found for “”
Have you ever received responses from Large Language Models (LLM) that make no sense?
Suppose you ask your AI virtual assistant for a choco-chip cookie recipe, but it tells you how to bake a chocolate cake instead. This is a side-effect of imbalanced LLM parameters.
One such parameter is LLM temperature, which significantly impacts a model’s responses. While a low temperature may give safe answers, a high temperature can cause the model to create stories from thin air if it is not grounded with sufficient context.
So, balancing the configuration settings of large language models is essential to maximize its full potential for generating text. Let’s explore what LLM temperature is and what other parameters impact a model’s responses.

LLM temperature is an underlying factor that influences the model’s output. It determines whether the output will be more predictable or creative. A higher LLM temperature lets the model explore beyond its patterns. This LLM setting is best for brainstorming ideas. Conversely, a low LLM temperature makes the model’s response more accurate and factual.
When should you follow a high and a low LLM temperature setting? Here’s an example:
Let’s say you’re working with AI writing tools. For creative tasks like, ‘List the five most fun things to do in South Africa, ’ a high LLM temperature setting is ideal. It will generate more creative and unconventional responses.
On the other hand, for tasks like doing data analysis, writing a technical description of new camera features, or summarizing a research paper, a low LLM temperature is ideal because it demands accuracy, conciseness, and factually correct responses.
Now that you know the concept of LLM temperature, let’s look into how it works.
When it comes to AI machine learning, large language models are trained on large datasets and algorithms. They learn the patterns and likelihood of words appearing together or apart, creating a network of possibilities. When generating outputs, LLMs consider multiple answers, each of which has a probability of being chosen. These ‘likely answers’ are represented by a set of logits.
Suppose you ask a language model to predict the last word in this sentence: ‘The puppy ate the ______.’ Considering the previous texts and training, the model will try to provide a reasonable answer (raw outputs or tokens) with their probability scores.
| Token | Logit |
| Cookies | 1.2 |
| Apples | 0.5 |
| Cakes | -0.3 |
The language model output with the highest logit makes the most sense. However, since these are raw outputs, the logits don’t sum to 1. Here, the Softmax function transforms the probabilities and totals them to 1.

Here, the LLM temperature affects the probabilities assigned to each token, affecting the output. While a higher temperature makes the model more creative, a lower temperature makes it more factual.
Let’s understand the impact of LLM temperature on outputs in detail.
LLM temperature is one of the most critical parameters that impact AI performance. It regulates the creativity, randomness, and accuracy of the model’s response. Here are the details.
When the temperature of the LLM approaches zero, the softmax function increases the differences between logits, resulting in sharp output probabilities. This makes the model choose words with higher logits, reducing randomness and generating more predictable and uniform outputs.
Most LLMs have a default temperature of one, which balances outputs between creativity and predictability. The model explores different word choices without being overly conservative or random. This LLM temperature setting generates mildly creative outputs with moderate diversity.
A higher temperature reduces the difference between logits, leading to flatter probability distributions. This makes the model explore varied words, including those with low logits. As a result, the outputs generated are more imaginative and random, which may lead to more errors.
While LLM temperature settings impact model outputs, they are important in prompt engineering. Here’s how.
LLMs trained on domain-specific data require temperature adjustment based on the specific task. If the temperature is too high, the model may generate nonsensical responses, and if it’s too low, the outputs become repetitive. Here, a strong and clear prompt with higher temperatures may generate relevant diverse outputs, while open-ended prompts may work well with lower temperatures.
If your task demands relevance, accuracy, and coherence, input prompts that are clear and formal with lower temperatures or temperatures slightly higher than one. This ensures factual and accurate responses from the language model. This LLM temperature works well for formal reports, research tasks, coding tasks, etc.
On the other hand, for creative writing tasks like writing poetry or ads, where brainstorming is crucial, high temperatures with more unspecified prompts are preferable. This encourages the model to explore and provide more diverse outputs.
Fine-tuning the LLM temperature requires experimenting and assessing outputs. By adjusting the temperature, evaluating the output quality, and experimenting with prompts, engineers can find the optimal LLM temperature needed for a task. To make things easier, prompt engineers can also use AI prompt templates to determine which prompts work well with higher and lower temperature settings.
For example, the ClickUp ChatGPT Prompts for Marketing Template offers over 600 prompts divided into 40+ categories to create keyword-rich product descriptions, ad copies, branding and positioning content, and more. Work with these prompts in different LLM temperature settings to identify the ones that generate the best model response.
Besides its role in prompt engineering, LLM temperature is significant in generative pre-trained transformers like GPT-3.
Also read: How ChatGPT works
LLM temperature plays a major role when data scientists experiment with data and model training. They tune the hyperparameters like LLM temperature to see how the model functions. In this experimental stage, engineers observe the temperature of LLMs to see what works for a specific task and what fails. Besides, here are a few uses of LLM temperature in MLOps.
LLM temperature, as a configurable parameter in the deployment pipeline, lets engineers fine-tune the model’s behavior without retraining it.
In MLOps, data scientists and engineers track the model behavior at different temperature settings. This helps them understand how the model responds to temperature variations and its impact on user experience in real-world applications.
MLOps involve documenting model versions at different temperature settings. This helps teams compare models with different LLM temperatures and roll back to versions ideal for specific tasks or user groups. If a specific model version fails in the future, engineers can come back to the fundamental model settings to improve it. Also, for controlled experiments like A/B testing, varied temperature settings help identify the optimal configuration for specific tasks.
Implementing feedback loops on LLM temperature helps data scientists and engineers improve model performance based on the feedback received on each temperature setting.
MLOps implements guidelines and best practices to mitigate ethical AI risks, such as biased or inappropriate model responses that might arise from higher temperature settings. This ensures practicing responsible AI.
Suppose you leverage AI to assess employee performance reports. The right LLM temperature setting prevents AI tools from generating biased responses and invading data privacy, ensuring the ethical use of AI in the workplace.
Besides its varied uses in MLOps, LLM temperature significantly contributes to reliability engineering and user experience design. Here’s how.
In reliability engineering, LLM temperature balances predictability and diversity in model responses. This helps ensure consistency and reliability in the language model’s output while maintaining creativity to a certain degree where appropriate.
While reliability engineering often prefers lower temperatures, it considers the need for flexibility and adaptability required in real-world applications. Let’s consider a medical diagnostic assistant powered by an LLM. Setting lower temperatures is essential as more reliability and consistency are needed for the model to diagnose correctly and give focused outputs.
However, a slightly higher temperature can effectively deal with complex cases where established methods might not be enough. A higher LLM temperature will allow the model to explore alternative treatment methods and best practices.
The key in reliability engineering is to identify the optimal LLM temperature. Reliability engineering practices such as continuous monitoring, automated testing, model fine-tuning, and feedback loops can identify problems with LLM temperature settings and ensure reliable model performance.
Pro Tip: ClickUp’s AI-powered Prompts for Engineers can help you break through roadblocks and find innovative solutions. Our curated templates provide valuable insights and ideas, allowing you to explore new approaches, improve efficiency, save time, and boost efficiency.
LLM temperature settings impact the model’s responses, making the best AI apps more engaging, intuitive, and tailored to specific user preferences. Leverage this parameter to optimize user experience by adjusting the level of diversity and predictability in model responses.
Let’s say you’re using ClickUp Brain to write a technical specification document for a model. A lower temperature setting would ensure relevance, accuracy, and coherence, which are crucial for the doc. On the other hand, if the marketing team uses ClickUp Brain features to generate a creative brief, a slightly higher temperature would enable exploring diverse responses.
ClickUp Brain also prevents AI hallucinations (where the AI outputs nonsensical content), often triggered by high-temperature settings, by generating highly professional AI content. You can easily leverage ClickUp Brain’s research-based role-specific prompts to generate desired outcomes.

Additionally, the tool can help you brainstorm creative ideas as well as build accurate and fact-based reports on company policies, task progress, employee training data, onboarding, etc. In short, it can help you with both, creative tasks like building innovative marketing campaigns and technical or routine tasks like summarizing weekly project updates and writing guidelines, SOPs, and contracts.
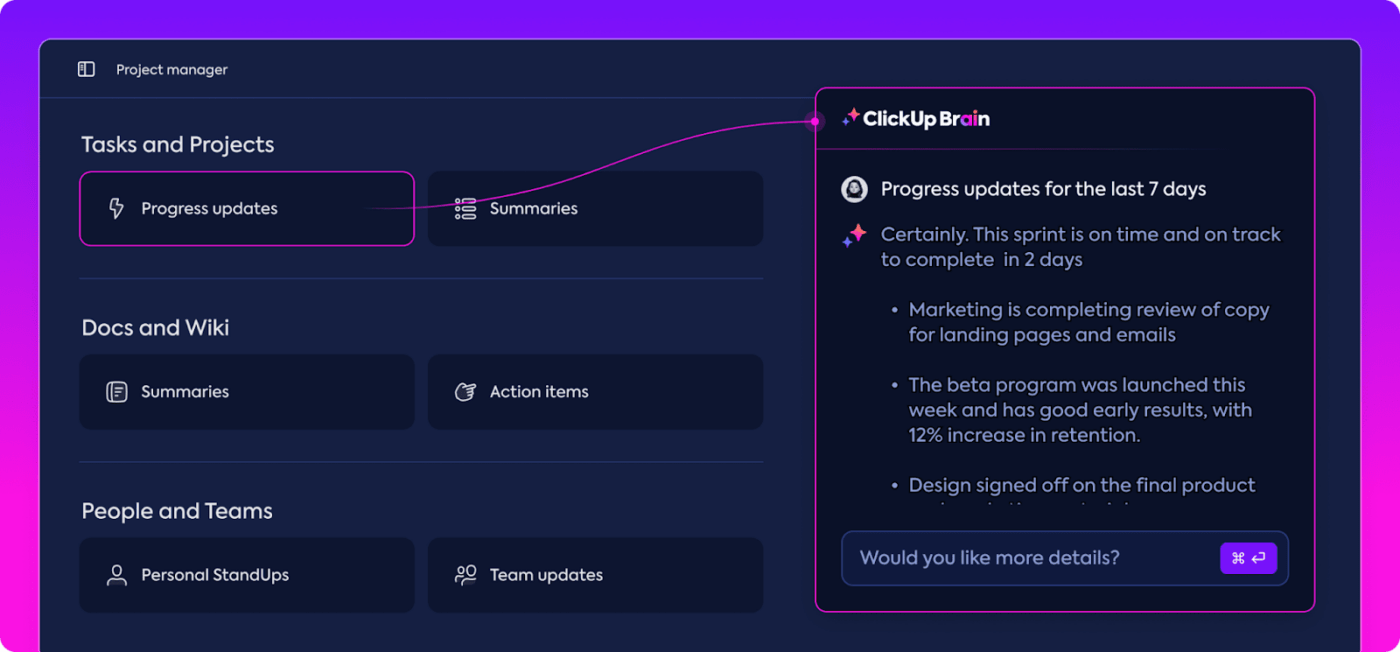
Similarly, low temperature in a customer service chatbot could be ideal for common customer queries where reliable responses are expected. For open-ended queries, a slightly higher temperature could generate more diverse responses.
Here are the important steps to configure LLM temperature.
There are two key parameters that you must understand before configuring LLM temperature.
The top-k parameter restricts the model’s predictions to the top-k tokens. It specifies the number of highest-probability tokens to consider when generating output. When setting the top-k value, you instruct the model to consider only the ‘k’ most probable tokens. This ensures that the model outputs stick to specific patterns and helps fine-tune the model performance.
This parameter filters tokens based on the cumulative probability of the tokens generated. When you set the Top-p value, the model generates tokens until the cumulative probability exceeds the value of p. This setting monitors the model’s word choices. While a low Top-p gives focused, factual outputs, a higher Top-p lets the model explore different possibilities to add uniqueness to the responses.
A slight imbalance in LLM parameters can lead to repetitive and generic responses or AI hallucinations. So, here’s how you can tune the LLM parameters to ensure optimal performance.
Start by experimenting with different temperature values to observe the impact on the model’s output
Next, adjust the top-k and top-p values to refine the model responses. While increasing the top-p or top-k promotes diversity, reducing the values gives more fact-centric outputs
Once you’ve set the parameters, monitor the model’s performance metrics, like perplexity, accuracy, coherence, etc., to the impact of different parameter configurations on the model response
Continuously iterate the model parameter settings based on the evaluation and user feedback to improve its performance
There’s no one-size-fits-all solution to choosing the best-suited LLM temperature. It involves balancing creativity, coherence, and specific task needs. However, here are a few ways to get the temperature right.
Understand the application requirements to prioritize creativity or reliability. This will help you balance both in the right measures. For instance, if you’re building an AI tool for DevOps that suggests remediation strategies, a lower LLM temperature would be preferable as it requires more relevant and focused outputs.
Evaluate the model’s performance across a range of temperature settings. Monitor the responses to see if they match the characteristics of your desired outcome, such as creativity, relevance, coherence, or accuracy.
Integrating feedback from end users will help you ensure that the temperature setting aligns with their expectations, generating quality model responses.
Monitor the model performance and continuously adapt to the evolving user requirements. This refines the model performance and ensures that the outputs meet user expectations whenever they interact.
As AI integrates more into business strategies, LLM temperature has become crucial to achieving optimal AI performance. It is the key to balancing creativity and predictability in model outputs.
For instance, dynamically adjusting LLM temperatures in AI assistants and conversational bots can enhance personalization, leading to better user experiences. Similarly, with the right temperature settings, you can explore the creative potential of AI while ensuring relevance and accuracy.
The bottom line is that LLM temperature is the way to experience the potential of AI in various fields. While lower temperatures can yield more deterministic outputs, higher temperatures can encourage exploring new possibilities for innovation.
With ClickUp Brain, you can unlock AI’s full potential for various tasks, from brainstorming marketing campaigns to generating accurate reports. It ensures your AI outputs are creative, relevant, and factual, saving you time and effort. Add to it ClickUp’s powerful project and task management features, and you have an everything solution at your disposal!
Sign up for free on ClickUp to leverage ClickUp Brain’s power!

© 2026 ClickUp

There’s an easier way. Try a free AI Agent in ClickUp that actually does the work for you—set up in minutes, save hours every week.