Sorry, there were no results found for “”
Sorry, there were no results found for “”
Sorry, there were no results found for “”
PDFs weren’t supposed to be painful. Yet here you are, copying, pasting, and scrolling endlessly, just trying to get the data you need.
Parsing through PDFs can be slow, frustrating, and let’s be real, not always the best use of your time.
A good PDF parser changes that. It pulls out the right data in seconds, automates the boring stuff, and lets you focus on things that actually matter.
But with so many tools out there, how do you pick the right one? We’ve done the digging for you. Here are the 10 best PDF parsers in 2025 to help you process documents faster and with way less hassle.
Dealing with PDFs shouldn’t be a struggle. The right parser saves time, cuts out the hassle of manual data entry, and keeps data flowing smoothly.
Here’s what to keep an eye on:
📖 Also Read: PDF Data Extraction Tools with AI in the Mix
Parsing PDFs is only one part of the problem. Once the data is extracted, where does it go? Who approves it? How does it trigger the next step? Most teams stitch together a clunky chain of tools—one for OCR, another for storing docs, and another for assigning tasks. This is when you need an app that can replace it all.
Here’s a quick snapshot of the 10 best PDF parsers available today:
| Tool | Key features | Best for | Pricing |
| ClickUp | Extract PDF data using OCR tools, Map parsed text into workflows with Custom Fields, Use AI to extract, summarize, and assign tasks from PDFs | End-to-end document workflow automation | Free plan, Customizable Plans for Enterprises |
| pdfplumber | Extract text, annotations, and metadata, render PDF pages as images Extract embedded images | Structured data analysis and table data extraction | Free |
| PDFMiner.six | Extract text, tables, and images, Preserve PDF layout and formatting Supports OCR for scanned documents, retrieves object metadata | Processing metadata and advanced image extraction | Free |
| Tabula-py | Extract tables with defined area selection, Batch process PDFs Export to CSV, TSV, JSON Integrate with Pandas | Extracting tabular data | Free |
| PyMuPDF | Extract fonts, layouts, and metadata, convert parsed content to HTML or hOCR, analyze tagged and structured content | High-speed text extraction and image rendering | Free |
| Apache PDFBox | Validate against PDF/A-1b standards, Extract Unicode text, Split and merge PDFs | Business process automation, digital archiving/signing | Free |
| Pdf.co API | Extract fonts, layouts, and metadata, convert parsed content to HTML or hOCR, and analyze tagged and structured content | Barcodes and QR codes processing | Starts at $8.99/month |
| DocParser | Use no-code parsing rules Extract data via anchor keywords, Preprocess and auto-rotate scans, Handle varying document layouts | Document parsing needs of non-technical users | Starts at $32.50/month |
| ABBYY FineReader PDF SDK | Extract and generate barcodes/QR codes Add watermarks, merge, split PDFs, and Automate document workflows via API | Integrating automated document workflows | Free; Paid plans start at $9/month per user |
| Foxit PDF SDK | Perform zonal OCR for form fields, convert to searchable PDFs Extract contact info to vCards, Scale with Azure cloud | Handling edge cases and wide PDF standards | Create cross-platform Smart Forms, Add and export annotations, implement secure digital signatures, Search large repositories efficiently |
Our editorial team follows a transparent, research-backed, and vendor-neutral process, so you can trust that our recommendations are based on real product value.
Here’s a detailed rundown of how we review software at ClickUp.
Meet ClickUp, the everything app for work.
It’s where your parsed documents live, get reviewed, acted on, and tracked. For starters, ClickUp integrates easily with OCR tools to extract data from PDFs, whether invoices, forms, contracts, or receipts.
You can also export your data in PDF, CSV, or Excel if you need to.
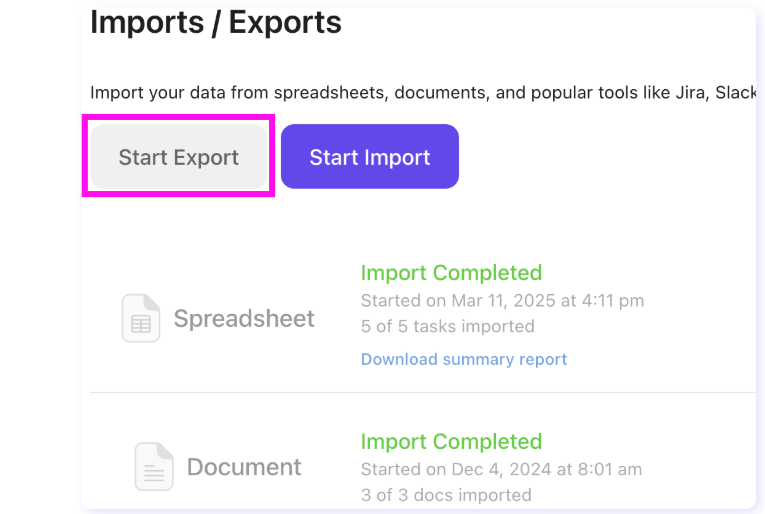
Once the text is parsed, ClickUp Custom Fields lets you map that data directly into tasks or workflows: due dates, names, values, checkboxes, whatever you need to track.
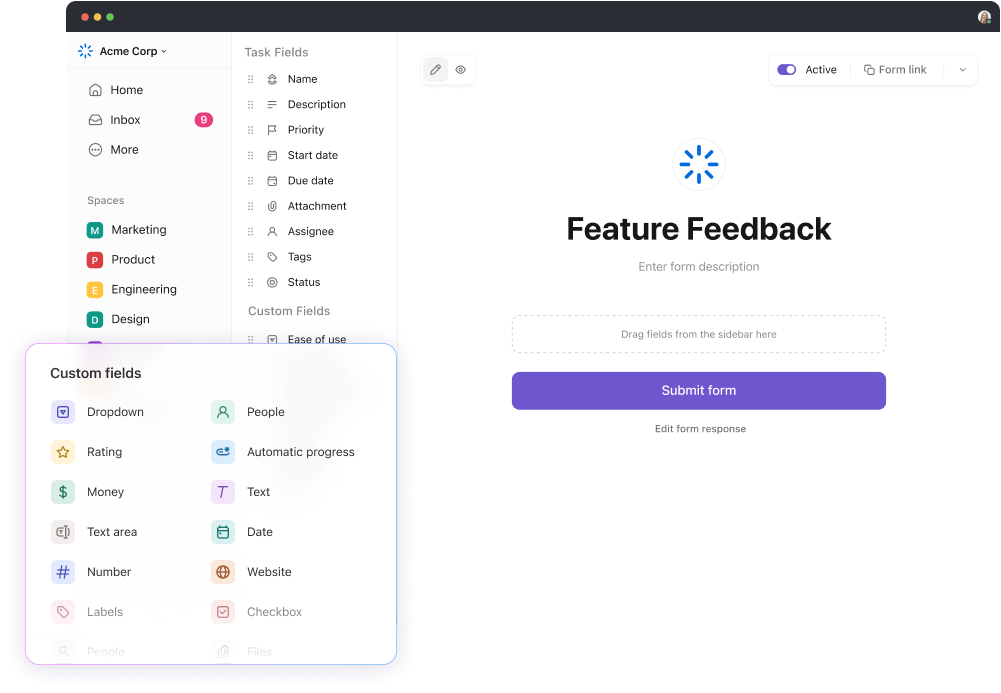
And right when you thought it couldn’t improve, ClickUp introduced its internal AI workflows with ClickUp Brain.
It can extract text from PDFs, create tasks, and assign them instantly. Just say, “Create a review task for the latest proposal,” and it handles the rest—setting deadlines, assigning teammates, and streamlining the process.
With ClickUp Ai , you can also easily find key details from PDFs, summarize them, and more. It makes decision-making run on autopilot with the tons of features it brings to the table.

📌 Some prompts to get you started:
Need a better option for documentation? ClickUp gives parsed data a place to live and evolve within ClickUp Docs. You can generate living documents from parsed inputs, attach them to tasks, and embed them into your workflows.

The best part? Comments, approvals, and updates happen in real time. And because Docs live inside ClickUp, they stay connected to the process—not floating in a drive folder, lost in version histories.
Combined with ClickUp Automations, parsed data can now trigger the next step without human friction, automating data entry completely. That invoice? Automatically assigned to accounting. That contract? Sent to legal for review. That form? Logged, tagged, and archived, all hands-free.
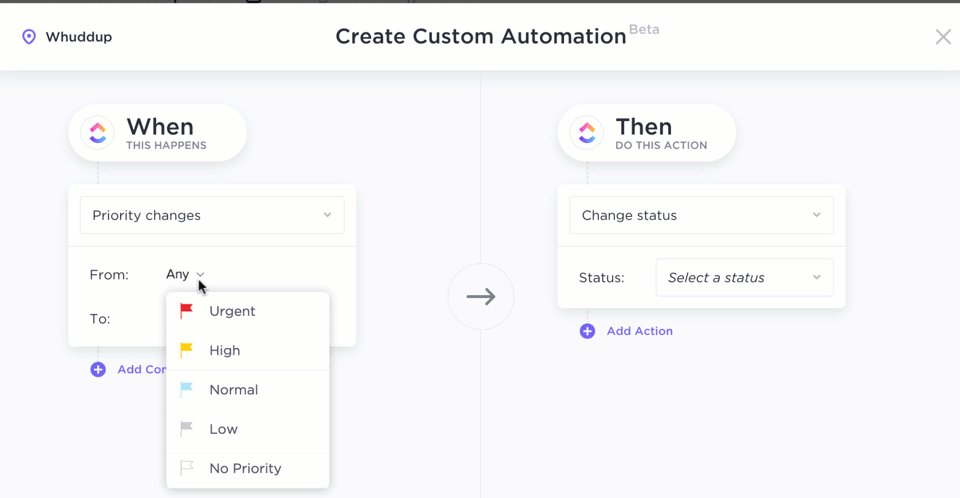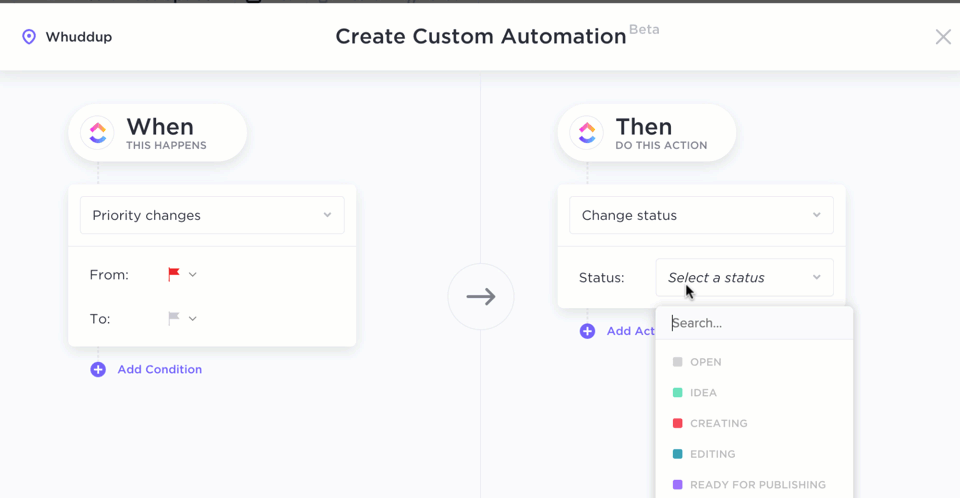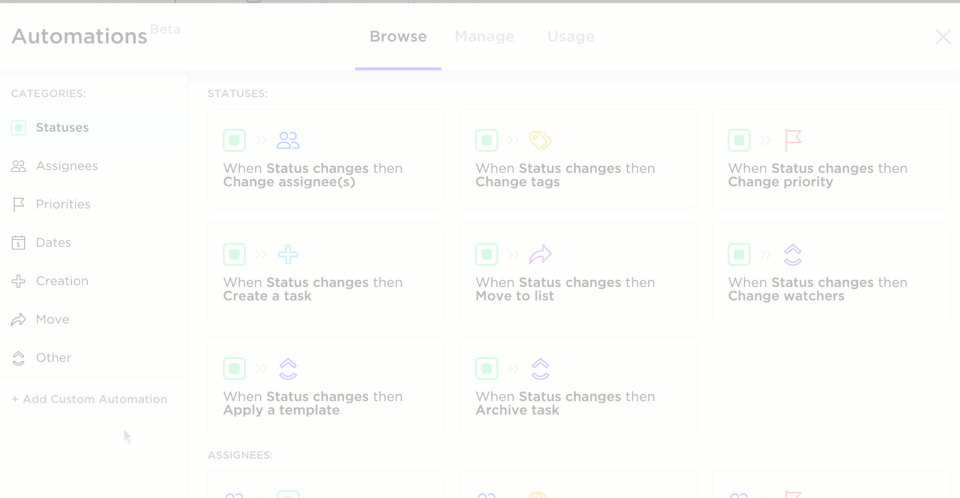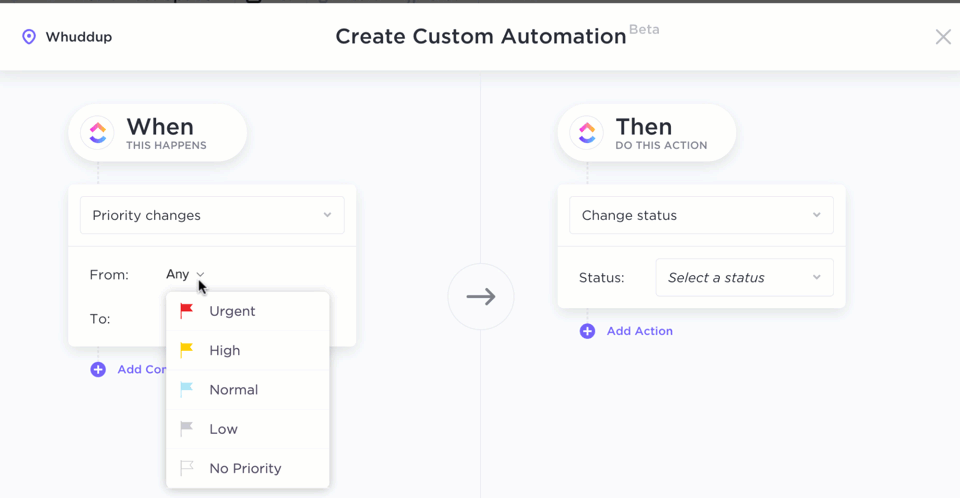
Here’s a Reddit review:
Been using ClickUp since 2017. It is great. AI is very good. I use the docs for my business second brain. No complaints other than it can be hard to figure out how to get started. The templates help with that. I’ve tried most of the other tools out there and ClickUp still beats them all as an all round project/product mamagement platform (even Jira). It lets different teams in the organization operate in whatever workflow they prefer, but out of a centralized information structure.
💡 Fact Check: 26% of companies are increasing their investments in automation solutions to ease their document management burden.
pdfplumber is a Python library for extracting text, tables, and images from PDFs with precision. Unlike basic parsers, it preserves formatting and handles scanned documents with OCR support, making PDF data extraction seamless.
🔑 Productivity hack: Batch process your PDFs instead of handling them one by one. Set up automation rules to extract key data, convert formats, or organize files in bulk. This reduces repetitive manual work and speeds up document processing.
PDFMiner.six is a PDF parsing tool with a modular design. It offers developers fine control over PDF processing. As an improved fork of PDFMiner, it enhances image extraction and Python 3 compatibility.
It’s ideal for complex tasks like analyzing text blocks while preserving formatting, and it’s for structured documents like reports and brochures.
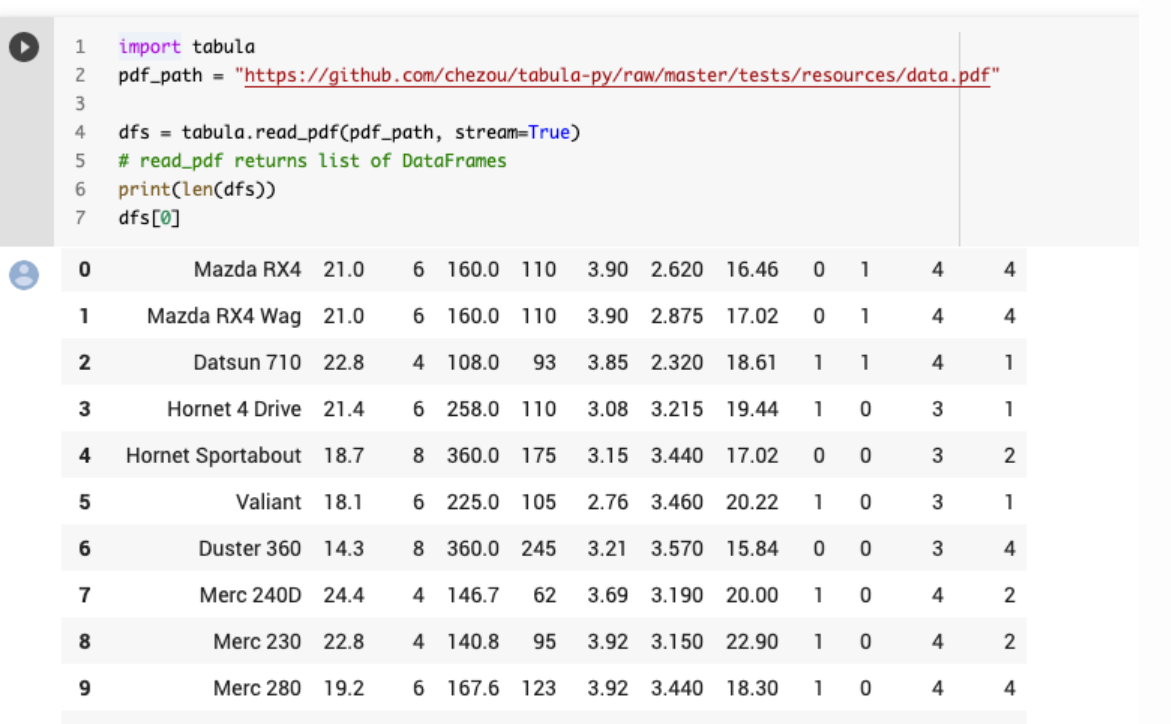
Tabula-py is a Python library for extracting valuable data tables from PDFs.
It’s helpful for data analysts and researchers who need structured data from reports, allowing them to integrate table extraction seamlessly into their workflows.
🔍 Did You Know? A U.S. healthcare insurer reduced Claims processing time by 74% using AI-powered document workflows, cutting the process from 11.5 minutes to just 3 minutes per claim.

PyMuPDF, also known as Fitz, is a lightweight and fast Python library that works with PDF and other document formats. PyMuPDF is ideal for tasks ranging from simple text extraction to advanced document manipulation.
The tool is built for developers to extract text, images, annotations, and metadata from PDFs while also supporting rendering and editing capabilities.
📖 Read More: How to Create a Product Documentation Workflow
Apache PDFBox is an open-source Java library that empowers developers to create, manipulate, and extract data from PDF files. The library doubles up as a robust toolkit suitable for simple and complex PDF processing tasks.
Whether you need to generate new PDFs, modify existing ones, or pull out specific data, Apache PDFBox is equipped for it.
Here’s a G2 review:
Great way to work with PDFs, I like that I can manipulate existing PDF files whereas before, I could only read them.
PDF.co is a cloud-based PDF parser software that automates document processing for a diverse user base, from full-stack developers to coding enthusiasts. With a powerful suite of APIs and integrations, it simplifies tasks like data extraction, conversion, and document generation, enabling seamless automation and improved efficiency in handling PDFs.
Here’s a G2 review:
I was looking for a time-saving tool to extract information from invoices, which have a very specific format. Thanks to PDF.co, the finance team won’t have to read invoices by invoice again. It’s amazing, I tried with several platforms, and Pdf.co nailed it.
🔍 Did You Know? You can turn abstract diagrams into actionable tasks with ClickUp’s Context Diagram Template.
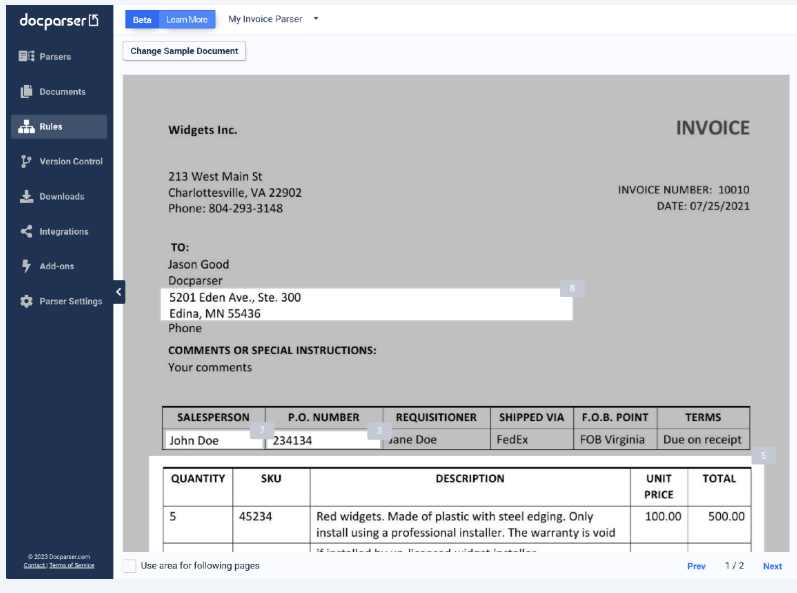
Docparser is a cloud-based, no-code data extraction and business process automation tool that leverages AI, OCR, and customizable parsing rules to turn unstructured PDFs, Word files, and scanned images into structured data.
Designed for document intensive-industries like legal, ecommerce, manufacturing, etc., it uses AI and OCR to turn unstructured documents into actionable data for spreadsheets, databases, or integrations.
Here’s a G2 review:
We used Docparser to get started on digitizing environmental product declarations. Very easy to get started and extract data from most common types of documents.
ABBYY FineReader PDF SDK is a developer-focused toolkit with document processing capabilities.
With its REST API, it integrates with other software easily and can be used by professionals with programming skills.
ABBYY leverages its OCR technology to extract text and preserve formatting from parsed data, making it a go-to for financial services and insurance businesses for tax forms, purchase orders, and the like.
Here’s a Capterra review:
Love this tool because it has the most effective OCR program I’ve used. It is one of the most cost-effective and easy-to-use products on the market. It is exceptionally user-friendly.
Last on our list of best PDF parsing solutions is Foxit PDF SDK. It is best suited for developers looking for a high-performance development toolkit to integrate advanced PDF functionality into applications across platforms like Windows, macOS, Linux, iOS, Android, and the Web.
Powered by Foxit’s industry-leading PDF engine, it enables developers to create, view, edit, annotate, and secure PDF documents with ease.
With features like Smart Forms, advanced annotations, and cross-platform compatibility, it is primarily useful for enterprises needing scalable PDF solutions.
Here’s a Capterra review:
The Optical Character Recognition feature has been the single most powerful and productivity enhancing feature introduced in new versions of Foxit PDF SDK… With this, we are steadily building a unique library of lost research materials that are not only readable, but searchable and can also be edited.
Now that you have many options of document processing tools to choose from, Mondays don’t have to feel like a never-ending PDF file scavenger hunt. No more juggling siloed files or drowning in repetitive tasks.
While every document processing tool we have discussed has its strengths, ClickUp truly redefines the game as the everything app for work.
Its cohesive approach lets you extract data, clean up PDF files, and streamline workflows effortlessly.
Developers and knowledge workers already have enough on their plates, so why make extracting data more complex?
Sign up on ClickUp for free today!
© 2026 ClickUp