




Still downloading templates?
There’s an easier way. Try a free AI Agent in ClickUp that actually does the work for you—set up in minutes, save hours every week.
Sorry, there were no results found for “”
Sorry, there were no results found for “”
Sorry, there were no results found for “”
Large Language Models (LLMs) have unlocked exciting new possibilities for software applications. They enable more intelligent and dynamic systems than ever before.
Experts predict that by 2025, apps powered by these models could automate nearly half of all digital work.
Yet, as we unlock these capabilities, a challenge looms: how do we reliably measure the quality of their output on a large scale? A small tweak in settings, and suddenly, you’re looking at noticeably different output. This variability can make it challenging to gauge their performance, which is crucial when prepping a model for real-world use.
This article will share insights into the best LLM system evaluation practices, from pre-deployment testing to production. So, let’s begin!
LLM evaluation metrics are a way to see if your prompts, model settings, or workflow are hitting the goals you’ve set. These metrics give you insights into how well your Large Language Model is performing and whether it’s truly ready for real-world use.
Today, some of the most common metrics measure context recall in retrieval-augmented generation (RAG) tasks, exact matches for classifications, JSON validation for structured outputs, and semantic similarity for more creative tasks.
Each of these metrics uniquely ensures the LLM meets the standards for your specific use case.
Large language models (LLMs) are now being used across a wide range of applications. It’s essential to evaluate models’ performance to ensure they meet the expected standards and effectively serve their intended purposes.
Think of it this way: LLMs are powering everything from customer support chatbots to creative tools, and as they get more advanced, they’re appearing in more places.
This means we need better ways to monitor and assess them—traditional methods just can’t keep up with all the tasks these models are handling.
Good evaluation metrics are like a quality check for LLMs. They show whether the model is reliable, accurate, and efficient enough for real-world use. Without these checks, mistakes could slip by, leading to frustrating or even misleading user experiences.
When you have strong evaluation metrics, it’s easier to spot issues, improve the model, and ensure it’s ready to meet the specific needs of its users. This way, you know the AI platform you’re working with is up to standard and can deliver the results you need.
📖 Read More: LLM vs. Generative AI: A Detailed Guide
Evaluations provide a unique lens to examine the model’s capabilities. Each type addresses various quality aspects, helping build a reliable, safe, and efficient deployment model.
Here are the different types of LLM evaluation methods:
Evaluating large language models (LLMs) involves two main approaches: model evaluations and system evaluations. Each focuses on different aspects of the LLM’s performance, and knowing the difference is essential for maximizing these models’ potential.
🧠 Model evaluations look at the LLM’s general skills. This type of evaluation tests the model on its ability to understand, generate, and work with language accurately across various contexts. It’s like seeing how well the model can handle different tasks, almost as a general intelligence test.
For instance, model evaluations might ask, “How versatile is this model?”
🎯 LLM system evaluations measure how the LLM performs within a specific setup or purpose, like in a customer service chatbot. Here, it’s less about the model’s broad abilities and more about how it performs specific tasks to improve user experience.
System evaluations, however, focus on questions like, “How well does the model handle this specific task for users?”
Model evaluations help developers understand the LLM’s overall abilities and limitations, guiding improvements. System evaluations are focused on how well the LLM meets user needs in specific contexts, ensuring a smoother user experience.
Together, these evaluations provide a complete picture of the LLM’s strengths and areas for improvement, making it more powerful and user-friendly in real applications.
Now, let’s explore the specific metrics for LLM Evaluation.
Some reliable and trendy evaluation metrics include:
Perplexity measures how well a language model predicts a sequence of words. Essentially, it indicates the model’s uncertainty about the next word in a sentence. A lower perplexity score means the model is more confident in its predictions, leading to better performance.
📌 Example: Imagine a model generates text from the prompt “The cat sat on the.” If it predicts a high probability for words like “mat” and “floor,” it understands the context well, resulting in a low perplexity score.
On the other hand, if it suggests an unrelated word like “spaceship,” the perplexity score would be higher, indicating the model struggles to predict sensible text.
The BLEU (Bilingual Evaluation Understudy) score is primarily used to evaluate machine translation and assess text generation.
It measures how many n-grams (contiguous sequences of n items from a given text sample) in the output overlap with those in one or more reference texts. The score ranges from 0 to 1, with higher scores indicating better performance.
📌 Example: If your model generates the sentence “The quick brown fox jumps over the lazy dog” and the reference text is “A fast brown fox leaps over a lazy dog,” BLEU will compare the shared n-grams.
A high score indicates that the generated sentence closely matches the reference, while a lower score might suggest the generated output doesn’t align well.
The F1 score LLM evaluation metric is primarily for classification tasks. It measures the balance between precision (the accuracy of the positive predictions) and recall (the ability to identify all relevant instances).
It ranges from 0 to 1, where a score of 1 indicates perfect accuracy.
📌 Example: In a question-answering task, if the model is asked, “What color is the sky?” and responds with “The sky is blue” (true positive) but also includes “The sky is green” (false positive), the F1 score will consider both the relevance of the correct answer and the incorrect one.
This metric helps to ensure a balanced evaluation of the model’s performance.
METEOR (Metric for Evaluation of Translation with Explicit ORdering) goes beyond exact word matching. It considers synonyms, stemming, and paraphrases to evaluate the similarity between generated text and reference text. This metric aims to align more closely with human judgment.
📌 Example: If your model generates “The feline rested on the rug” and the reference is “The cat lay on the carpet,” METEOR would give this a higher score than BLEU because it recognizes that “feline” is a synonym for “cat” and “rug” and “carpet” convey similar meanings.
This makes METEOR particularly useful for capturing the nuances of language.
BERTScore evaluates text similarity based on contextual embeddings derived from models like BERT (Bidirectional Encoder Representations from Transformers). It focuses more on meaning than exact word matches, allowing for a better semantic similarity assessment.
📌 Example: When comparing the sentences “The car raced down the road” and “The vehicle sped along the street,” BERTScore analyzes the underlying meanings rather than just the word choice.
Even though the words differ, the overall ideas are similar, leading to a high BERTScore that reflects the effectiveness of the generated content.
Human evaluation remains a crucial aspect of LLM assessment. It involves human judges rating the quality of model outputs based on various criteria such as fluency and relevance. Techniques like Likert scales and A/B testing can be employed to gather feedback.
📌 Example: After generating responses from a customer service chatbot, human evaluators might rate each response on a scale of 1 to 5. For instance, if the chatbot provides a clear and helpful answer to a customer inquiry, it might receive a 5, while a vague or confusing response could get a 2.
Different LLM tasks require tailored evaluation metrics.
For dialogue systems, metrics might assess user engagement or task completion rates. For code generation, success could be measured by how often the generated code compiles or passes tests.
📌 Example: In a customer support chatbot, engagement levels might be measured by how long users stay in a conversation or how many follow-up questions they ask.
If users frequently ask for additional information, it indicates that the model is successfully engaging them and effectively addressing their queries.
Assessing a model’s robustness involves testing how well it responds to unexpected or unusual inputs. Fairness metrics help identify biases in the model’s outputs, ensuring it performs equitably across different demographics and scenarios.
📌 Example: When testing a model with a whimsical question like, “What do you think about unicorns?” it should handle the question gracefully and provide a relevant response. If it instead gives a nonsensical or inappropriate answer, it indicates a lack of robustness.
Fairness testing ensures that the model doesn’t produce biased or harmful outputs, promoting a more inclusive AI system.
As language models grow in complexity, it becomes increasingly important to measure their efficiency regarding speed, memory usage, and energy consumption. Efficiency metrics help evaluate how resource-intensive a model is when generating responses.
📌 Example: For a large language model, measuring efficiency might involve tracking how quickly it generates answers to user queries and how much memory it uses during this process.
If it takes too long to respond or consumes excessive resources, it could be a concern for applications requiring real-time performance, like chatbots or translation services.
Now, you know how to evaluate an LLM model. But what tools can you use to measure this? Let’s explore.
ClickUp is an everything-for-work app with an inbuilt personal assistant called ClickUp Brain.
ClickUp Brain is a game-changer for LLM performance evaluation. So what does it do?
It organizes and highlights the most relevant data, keeping your team on track. With its AI-powered features, ClickUp Brain is one of the finest neural network software out there. It makes the whole process smoother, more efficient, and more collaborative than ever. Let’s explore its capabilities together.
When evaluating Large Language Models (LLMs), managing vast amounts of data can be overwhelming.

ClickUp Brain can organize and spotlight essential metrics and resources tailored specifically for LLM evaluation. Instead of rummaging through scattered spreadsheets and dense reports, ClickUp Brain brings everything together in one place. Performance metrics, benchmarking data, and test results are all accessible within a clear and user-friendly interface.
This organization helps your team cut through the noise and focus on the insights that really matter, making it easier to interpret trends and performance patterns.
With everything you need in one place, you can move from mere data collection to impactful, data-driven decision-making, transforming information overload into actionable intelligence.
LLM evaluations require careful planning and collaboration, and ClickUp makes managing this process easy.
You can easily delegate responsibilities like data collection, model training, and performance testing while also setting priorities to make sure the most critical tasks get attention first. Besides this, Custom Fields allow you to tailor workflows to the specific needs of your project.

With ClickUp, everyone can see who’s doing what and when, helping avoid delays and making sure tasks move smoothly across the team. It’s a great way to keep everything organized and on track from start to finish.
Want to keep a close eye on how your LLM systems are performing?
ClickUp Dashboards visualize the performance indicators in real time. It enables you to monitor your model’s progress instantly. These dashboards are highly customizable, letting you build graphs and charts that present exactly what you need when you need it.
You can watch your model’s accuracy evolve across evaluation stages or break down resource consumption at each phase. This information allows you to spot trends quickly, identify areas for improvement, and make adjustments on the fly.
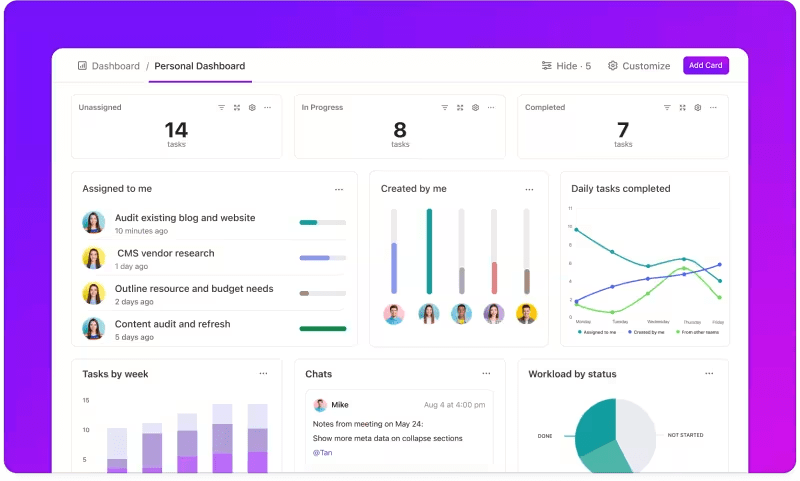
Instead of waiting for the next detailed report, ClickUp Dashboards let you stay informed and responsive, empowering your team to make data-driven decisions without delay.
Data analysis can be time-consuming, but ClickUp Brain features lighten the load by providing valuable insights. It highlights important trends and even suggests recommendations based on the data, making it easier to draw meaningful conclusions.
With ClickUp Brain’s automated insights, there’s no need to comb through raw data for patterns manually—it spots them for you. This automation frees up your team to focus on refining model performance rather than getting bogged down in repetitive data analysis.
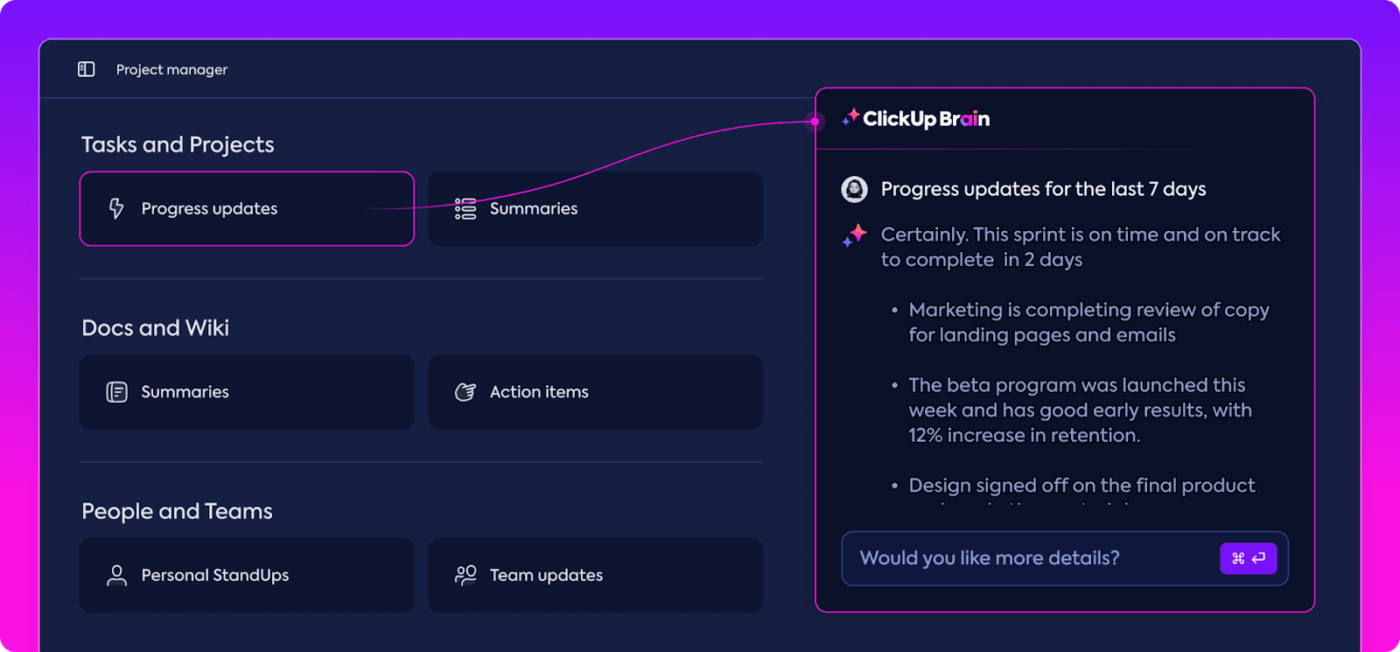
The insights generated are ready to use, allowing your team to immediately see what’s working and where changes might be needed. By reducing the time spent on analysis, ClickUp helps your team accelerate the evaluation process and focus on implementation.
No more digging through emails or multiple platforms to find what you need; everything’s right there, ready when you are.
ClickUp Docs is a central hub that brings together everything your team needs for seamless LLM evaluation. It organizes key project documentation—like benchmarking criteria, testing results, and performance logs—into one accessible spot so everyone can quickly access the latest information.
What truly sets ClickUp Docs apart is its real-time collaboration features. The integrated ClickUp Chat and Comments allow team members to discuss insights, give feedback, and suggest changes directly within the docs.
This means your team can talk through findings and make adjustments right on the platform, keeping all discussions relevant and on point.

Everything from documentation to teamwork happens within ClickUp Docs, creating a streamlined evaluation process where everyone can see, share, and act on the latest developments.
The result? A smooth, unified workflow that lets your team move toward their goals with complete clarity.
Are you ready to give ClickUp a spin? Before that, let’s discuss some tips and tricks to get the most out of your LLM Evaluation.
A well-structured approach to LLM evaluation ensures that the model meets your needs, aligns with user expectations, and delivers meaningful results.
Setting clear objectives, considering the end users, and using a variety of metrics help shape a thorough evaluation that reveals strengths and areas for improvement. Below are some best practices to guide your process.
Before starting the evaluation process, it’s essential to know exactly what you want your large language model (LLM) to achieve. Take time to outline the specific tasks or goals for the model.
📌 Example: If you want to improve machine translation performance, clarify the quality levels you want to reach. Having clear objectives helps you focus on the most relevant metrics, ensuring that your evaluation remains aligned with these goals and accurately measures success.
Think about who will be using the LLM and what their needs are. Tailoring the evaluation to your intended users is crucial.
📌 Example: If your model is meant to generate engaging content, you’ll want to pay close attention to metrics like fluency and coherence. Understanding your audience helps refine your evaluation criteria, making sure the model delivers real value in practical applications
Don’t rely on just one metric to evaluate your LLM; a mix of metrics gives you a fuller picture of its performance. Each metric captures different aspects, so using several can help you identify both strengths and weaknesses.
📌 Example: While BLEU scores are great for measuring translation quality, they might not cover all the nuances of creative writing. Incorporating metrics like perplexity for predictive accuracy and even human evaluations for context can lead to a much more rounded understanding of how well your model performs
Evaluating large language models (LLMs) often relies on industry-standard benchmarks and specialized tools that help gauge model performance across various tasks.
Here’s a breakdown of some widely used benchmarks and tools that bring structure and clarity to the evaluation process.
Using a combination of these benchmarks and tools offers a comprehensive approach to LLM evaluation. Benchmarks can set standards across tasks, while tools provide the structure and flexibility needed to track, refine, and improve model performance effectively.
Together, they ensure LLMs meet both technical standards and practical application needs.
Evaluating large language models (LLMs) requires a nuanced approach. It focuses on the quality of responses and understanding the model’s adaptability and limitations across varied scenarios.
Since these models are trained on extensive datasets, their behavior is influenced by a range of factors, making it essential to assess more than just accuracy.
True evaluation means examining the model’s reliability, resilience to unusual prompts, and overall response consistency. This process helps paint a clearer picture of the model’s strengths and weaknesses, and uncovers areas needing refinement.
Here’s a closer look at some common challenges that arise during LLM evaluation.
It’s hard to know if the model has already seen some of the test data. Since LLMs are trained on massive datasets, there’s a chance some test questions overlap with training examples. This can make the model look better than it actually is, as it might just be repeating what it already knows instead of demonstrating true understanding.
LLMs can have unpredictable responses. One moment, they deliver impressive insights, and the next, they’re making odd errors or presenting imaginary information as facts (known as ‘hallucinations’).
This inconsistency means that while the LLM outputs may shine in some areas, they can fall short in others, making it difficult to accurately judge its overall reliability and quality.
LLMs can be susceptible to adversarial attacks, where cleverly crafted prompts trick them into producing flawed or harmful responses. This vulnerability exposes weaknesses in the model and can lead to unexpected or biased outputs. Testing for these adversarial weaknesses is crucial to understanding where the model’s boundaries lie.
Finally, here are a few common situations where LLM evaluation really makes a difference:
LLMs are widely used in chatbots to handle customer queries. Evaluating how well the model responds ensures it delivers accurate, helpful, and contextually relevant answers.
It is crucial to measure its ability to understand customer intent, handle diverse questions, and provide human-like responses. This will allow businesses to ensure a smooth customer experience while minimizing frustration.
Many businesses use LLMs to generate blog content, social media, and product descriptions. Evaluating the quality of the generated content helps ensure that it’s grammatically correct, engaging, and relevant to the target audience. Metrics like creativity, coherence, and relevance to the topic are important here to maintain high content standards.
LLMs can analyze the sentiment of customer feedback, social media posts, or product reviews. It’s essential to evaluate how accurately the model identifies whether a piece of text is positive, negative, or neutral. This helps businesses understand customer emotions, refine products or services, enhance user satisfaction, and improve marketing strategies.
Developers often use LLMs to assist in generating code. Evaluating the model’s ability to produce functional and efficient code is crucial.
It’s important to check if the generated code is logically sound, error-free and meets the task requirements. This helps reduce the amount of manual coding needed and improves productivity.
Evaluating LLMs is all about choosing the right metrics that align with your goals. The key is to understand your specific goals, whether it’s improving translation quality, enhancing content generation, or fine-tuning for specialized tasks.
Selecting the right metrics for performance assessment, such as RAG or fine-tuning metrics, forms the foundation of accurate and meaningful evaluation. Meanwhile, advanced scorers like G-Eval, Prometheus, SelfCheckGPT, and QAG provide precise insights thanks to their strong reasoning abilities.
However, that doesn’t mean these scores are perfect—it’s still important to ensure they’re reliable.
As you progress with your LLM application evaluation, tailor the process to fit your specific use case. There’s no universal metric that works for every scenario. A combination of metrics, along with a focus on context, will give you a more accurate picture of your model’s performance.
To streamline your LLM evaluation and improve team collaboration, ClickUp is the ideal solution for managing workflows and tracking important metrics.
Want to enhance your team’s productivity? Sign up for ClickUp today and experience how it can transform your workflow!

© 2026 ClickUp

There’s an easier way. Try a free AI Agent in ClickUp that actually does the work for you—set up in minutes, save hours every week.