



Still downloading templates?
There’s an easier way. Try a free AI Agent in ClickUp that actually does the work for you—set up in minutes, save hours every week.
Sorry, there were no results found for “”
Sorry, there were no results found for “”
Sorry, there were no results found for “”

There are two kinds of AI assistants: one that knows everything up to last week, and one that knows what happened a minute ago.
If you asked the first AI assistant, “Is my flight still delayed?”, it might answer based on yesterday’s schedule and could be wrong. The second assistant, powered by up-to-the-second data, checks live updates and gives you the correct answer.
The second assistant is what we call live knowledge, seen in action.
And it forms the basis of agentic AI systems—those that don’t just answer questions, but act, decide, coordinate, and adapt. Here, the focus is on autonomy, adaptability, and goal-driven reasoning.
In this blog, we’ll explore what live knowledge means in the context of AI, why it matters, how it works, and how you can use it in real workflows.
Whether you’re in operations, product, support, or leadership, this article gives you the grounding to ask the right questions, evaluate systems, and understand how live knowledge could shift your technology and business outcomes. Let’s dive in.
Live knowledge refers to information that is real-time, up-to-date, and available to an AI system at the moment it needs to act.
It is a term typically used in the context of agentic and ambient AI—AI agents that know your people, knowledge, work, and processes so well, they can operate seamlessly and proactively in the background.
Live knowledge means the AI doesn’t just rely on the dataset it was trained on or the snapshot of knowledge at deployment. Instead, it continues to learn, connecting to current data flows and adjusting its actions based on what’s actually happening now.
When we discuss this in the context of AI agents (i.e., systems that act or make decisions), live knowledge enables them to sense changes in their environment, integrate new information, and choose subsequent steps accordingly.
Most traditional AI systems are trained on a fixed dataset—such as text, images, or logs—and then deployed. And their knowledge doesn’t change unless you retrain or update them.
It’s like reading a book about computers published in the 90s and trying to use a 2025 MacBook.
Traditional knowledge bases (for example, your company’s FAQ repository or a static database of product specs) might get periodic updates, but are not designed to continuously stream new information and adapt.
Live knowledge differs because it’s continuous and dynamic—your agent is operating based on a live feed instead of relying on a cached copy.
In short:
Agentic AI systems are built to do more than answer a question.
They can:
To do this effectively, they need a deep understanding of the current state, including the status of systems, the latest business metrics, customer context, and external events. That’s exactly what live knowledge provides.
With it, the agent can sense when conditions change, adapt its decision-path, and act in ways that align with the current reality of the business or environment.
Live knowledge—having real-time, connected access to information across all your tools—directly solves everyday problems caused by sprawl at work. But what’s that anyway?
Imagine you’re working on a project and need the latest client feedback, but it’s buried in an email thread while the project plan is in a separate tool, and the design files are in yet another app. Without live knowledge, you waste time switching between platforms, asking teammates for updates, or even missing key details.
Live knowledge delivers that best-case scenario where you can instantly search and find that feedback, see the latest project status, and access the newest designs—all in one place, no matter where the data lives.
For example, a marketing manager can simultaneously access campaign results from analytics tools, review creative assets from a design platform, and check team discussions from chat apps. A support agent can see a customer’s full history—emails, tickets, and chat logs—without toggling between systems.
This means less time hunting for information, fewer missed updates, and faster, more confident decisions. In short, live knowledge connects your scattered digital world, making daily work smoother and more productive.
As the world’s first Converged AI Workspace, ClickUp’s Live intelligence AI Super Agents deliver all of this and then some more. Watch it in action here.👇🏼
Behind every live knowledge system lies an invisible network of moving parts: continuously pulling in data, connecting sources, and learning from outcomes. These components work together to ensure that information doesn’t just sit in storage, but flows, updates, and adapts as work happens.
In practical terms, live knowledge relies on a blend of data movement, integration intelligence, contextual memory, and feedback-driven learning. Each part has a specific role in keeping your workspace informed and proactive rather than reactive.
One of the biggest challenges in dynamic organizations is work sprawl. As teams adopt new tools and processes, knowledge can quickly become fragmented across platforms, channels, and formats. Without a system to unify and surface this scattered information, valuable insights are lost, and teams waste time searching or duplicating work.
Live knowledge directly addresses work sprawl by continuously integrating and connecting information from all sources, ensuring that knowledge remains accessible, up-to-date, and actionable—regardless of its origin. This unified approach prevents fragmentation and empowers teams to work smarter, not harder.
Here’s a breakdown of the core building blocks that make it possible and how they come to life in real-world use:
| Component | What it does | How it works |
|---|---|---|
| Data pipelines | Bring fresh data into the system continuously | Data pipelines use APIs, event streams, and webhooks to pull or push new information from multiple tools and environments |
| Integration layers | Connect data from different internal and external systems into one unified view | Integration layers sync information across apps like CRMs, databases, and IoT sensors, removing silos and duplications |
| Context and memory systems | Help AI recall what’s relevant and forget what’s not | These systems create “working memory” for agents, allowing them to keep context from recent conversations, actions, or workflows while pruning outdated data |
| Retrieval and update mechanisms | Allow systems to access the latest information at the moment of need | Retrieval tools query data just before a response or decision is made, ensuring the most recent updates are used. Internal stores are updated automatically with new insights |
| Feedback loops | Enable continuous learning and improvement from outcomes | Feedback mechanisms revisit past actions with new data, comparing expected versus actual results, and adjusting internal models accordingly |
Together, these components shift an AI from “knowledge at one point in time” to “continuous real-time understanding”.
AI systems are only as good as the knowledge they act on.
In modern workflows, that knowledge changes by the minute. Whether it’s shifting customer sentiment, evolving product data, or real-time operational performance, static information quickly loses relevance.
That’s where live knowledge becomes essential.
Live knowledge enables AI agents to transition from passive responders to adaptive problem-solvers. These agents continuously sync with real-world conditions, sense change as it happens, and adjust their reasoning in real time. This capability makes AI safer, more reliable, and more aligned with human goals in complex, dynamic systems.
When AI systems use only static data (i.e., what they knew at the time of training or last update), they risk making decisions that no longer align with reality. For example, market prices have changed, server performance has deteriorated, or product availability is different.
If an agent doesn’t notice and account for these changes, it can produce inaccurate responses, inappropriate actions, or worse—introduce risks.
Research indicates that as systems become increasingly autonomous, reliance on outdated data becomes a significant vulnerability. AI knowledge bases can help bridge this gap. Watch this video to learn more about them.👇🏼
🌏 When chatbots don’t have the right live knowledge:
Air Canada’s AI-powered virtual assistant provided a customer with incorrect information regarding the airline’s bereavement travel policy. The customer, Jake Moffatt, was grieving his grandmother’s death and used the chatbot to inquire about discounted fares.
The chatbot erroneously informed him that he could purchase a full-price ticket and apply for a refund of the bereavement discount within 90 days. Relying on this advice, Moffatt booked expensive flights. However, Air Canada’s actual policy required that a discounted bereavement fare be requested before travel, and could not be applied retroactively.
Air Canada is just one example. Here are more scenarios where live knowledge can make a difference:
Zillow shut down its home-flipping business (Zillow Offers) after its AI model for pricing homes failed to accurately predict the rapidly shifting housing market during the pandemic, leading to massive financial losses from overpaying for properties. This highlights the risk of model drift when economic indicators change rapidly.
When live knowledge is integrated, agents become more reliable, accurate, and timely. They can avoid “stale” decisions, reduce latency in detecting changes, and react appropriately.
They also build trust: users know that the agent “knows what’s going on”.
From a decision-making standpoint, live knowledge ensures that the “input” to the agent’s planning and action steps is valid for the moment. This leads to better outcomes, fewer errors, and more agile processes.
For organizations, the move from static to live knowledge in AI agents unlocks several advantages:
In summary, live knowledge is a strategic capability for organizations seeking to stay ahead of change.
Live knowledge stands for live workflows, awareness, and adaptability.
When knowledge flows in real time, it helps teams make faster, smarter decisions.
Here’s how live knowledge systems work behind the scenes, powered by three key layers: real-time data sources, integration methods, and agent architecture.
Every live knowledge system starts with its inputs: the data constantly streaming in from your tools, apps, and daily workflows. These inputs can come from virtually anywhere your work happens: a customer submitting a support ticket in Zendesk, a sales rep updating deal notes in Salesforce, or a developer pushing new code to GitHub.
Even automated systems contribute signals: IoT sensors report equipment performance, marketing dashboards provide live campaign metrics, and finance platforms update real-time revenue figures.
Together, these diverse data streams form the foundation of live knowledge: a continuous, interconnected flow of information that reflects what’s happening right now across your business ecosystem. When an AI system can access and interpret these inputs instantly, it moves beyond passive data collection, becoming a real-time collaborator that helps teams act, adapt, and make decisions faster.
APIs and webhooks are the connective tissue of the modern workspace. APIs enable structured, on-demand data sharing.
For example, ClickUp Integrations help you to fetch updates from Slack or Salesforce in seconds. Webhooks take it a step further by automatically pushing updates when something changes, keeping your data fresh without requiring manual syncing. Together, they eliminate “information lag,” ensuring your system always reflects what’s happening right now.
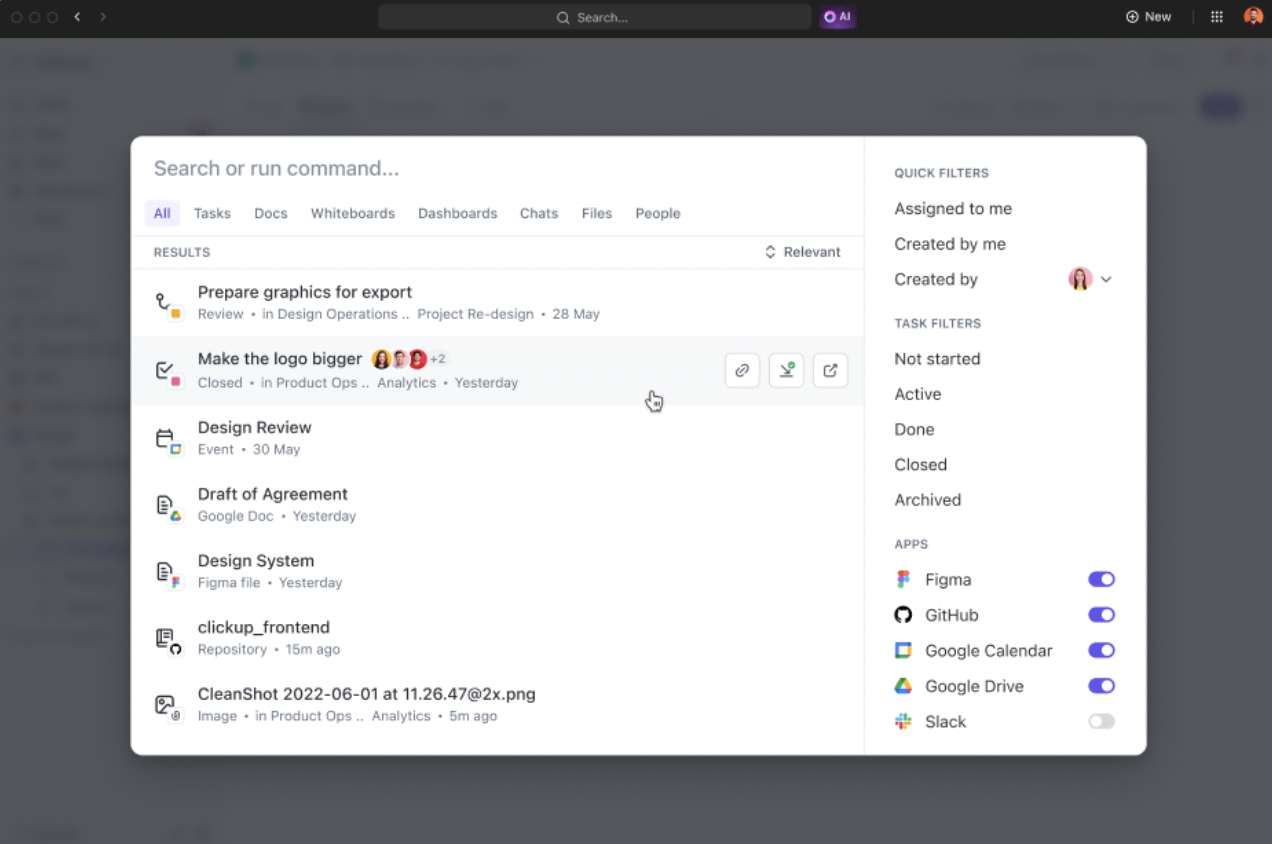
Real-time database connections allow models to monitor and react to operational data as it evolves. Whether it’s customer insights from a CRM or progress updates from your project management tool, this direct pipeline ensures that your AI decisions are grounded in live, accurate information.
Stream processing technologies like Kafka and Flink convert raw event data into instant insights. It could mean real-time alerts when a project stalls, automatic workload balancing, or identifying workflow bottlenecks before they become roadblocks. These systems give teams a pulse on their operations as they unfold.
No system can thrive in isolation. Connecting to external knowledge sources—product docs, research libraries, or public data sets—gives live systems a global context.
This means your AI assistant understands not just what’s happening in your workspace, but why it matters within the bigger picture.
📖 Read More: How to Use Knowledge-Based Agents in AI
Once the data is flowing, the next step is integrating it into a living, breathing knowledge layer that evolves continuously.
Context is the secret ingredient that turns raw data into meaningful insight. Dynamic context injection enables AI systems to incorporate the most relevant, up-to-date information—such as recent project updates or team priorities—precisely when decisions are being made. It’s like having an assistant who recalls exactly what you need at the perfect moment.
See how Brain Agent does that within ClickUp:
Traditional AI search relies on stored information. Real-time retrieval goes further by continuously scanning and refreshing connected sources, surfacing only the most current and relevant content.
For example, when you ask ClickUp Brain for a project summary, it’s not digging through old files—it’s pulling fresh insights from the latest live data.
Knowledge graphs map relationships between people, tasks, goals, and ideas. Keeping these graphs updated in real time ensures that dependencies evolve alongside your workflows. As priorities shift or new tasks are added, the graph automatically rebalances, giving teams a clear, always-accurate view of how work connects.
Continuous learning allows AI models to adapt based on user feedback and changing patterns. Every comment, correction, and decision becomes training data, helping the system get smarter about how your team actually works.
The final layer, and often the most complex, is how AI agents manage, remember, and prioritize knowledge to maintain coherence and responsiveness.
Just like people, AI needs to know what to remember and what to let go. Memory systems balance short-term recall with long-term storage, preserving essential context (such as ongoing goals or client preferences) while filtering out irrelevant information. This keeps the system sharp and not overloaded.
Context windows define how much information an AI can “see” at once. When these windows are optimized, agents can manage long, complex interactions without losing track of important details. In practice, this means your AI can recall entire project histories and conversations—not just the last few messages—enabling more accurate and relevant responses.
Yet as organizations adopt more AI tools and agents, a new challenge emerges: AI sprawl. Knowledge, actions, and context can become fragmented across different bots and platforms, leading to inconsistent answers, duplicated work, and missed insights. Live knowledge addresses this by unifying information and optimizing context windows across all AI systems, ensuring every agent draws from a single, up-to-date source of truth. This approach prevents fragmentation and empowers your AI to deliver consistent, comprehensive support.
Not all knowledge deserves equal attention. Intelligent prioritization ensures that the AI focuses on what truly matters: urgent tasks, shifting dependencies, or major performance changes. By filtering for impact, the system prevents data overwhelm and amplifies clarity.
Speed drives adoption. Caching frequently accessed information, such as recent comments, task updates, or performance metrics, enables instant retrieval while reducing system load. This means your team experiences smooth, real-time collaboration with no lag between action and insight.
Live knowledge transforms work from reactive to proactive. When real-time data, continuous learning, and intelligent agent architecture come together, your systems stop falling behind.
It’s the foundation for faster decisions, fewer blind spots, and a more connected AI ecosystem.
📮ClickUp Insight: 18% of our survey respondents want to use AI to organize their lives through calendars, tasks, and reminders. Another 15% want AI to handle routine tasks and administrative work.
To do this, an AI needs to be able to: understand the priority levels for each task in a workflow, run the necessary steps to create tasks or adjust tasks, and set up automated workflows.
Most tools have one or two of these steps worked out. However, ClickUp has helped users consolidate up to 5+ apps using our platform with ClickUp Brain MAX!
In this section, we’ll dive into the different architectural patterns for delivering live knowledge to AI agents—how the data flows, when the agent gets updates, and the trade-offs involved.
In a pull-based model, the agent asks for data when it needs it. Think of it like a student raising their hand midway through a class: “What’s the current weather?” or “What’s the latest inventory count?” The agent triggers a query to a live source (API, database) and uses the result in its next step of reasoning.
👉🏽 Why use pull-based? It’s efficient when the agent doesn’t always need live data at every moment. You avoid keeping all data continuously streaming in, which could be costly or unnecessary. It also gives more control: you decide exactly what to fetch and when.
👉🏽 Trade-offs: It may introduce latency—if the data request takes time, the agent may wait and respond more slowly. Also, you risk missing updates between polls (if you only check periodically). For example, a customer-support agent may only pull the shipping-status API when a customer asks, “Where is my order?” rather than maintaining a constant live feed of shipping events.
Here, instead of waiting for the agent to ask, the system pushes updates to the agent the moment something changes. It’s like subscribing to a news alert: when something happens, you’re notified immediately. For an AI agent that uses live knowledge, this means it always has up-to-date context as events unfold.
👉🏽 Why use push-based? It provides minimal latency and high responsiveness because the agent is aware of changes as they occur. This is valuable in high-speed or high-risk contexts (e.g., financial trading, system health monitoring).
👉🏽 Trade-offs: It can be more expensive and complex to maintain. The agent may receive many updates that are irrelevant, requiring filtering and prioritization. You also need a robust infrastructure to handle continuous streams. For example, a DevOps AI agent receives webhook alerts when the server’s CPU usage exceeds a threshold and initiates a scaling action.
In practice, most robust live-knowledge systems combine both pull and push approaches. The agent subscribes to critical events (push) and occasionally fetches broader contextual data when needed (pull).
This hybrid model helps strike a balance between responsiveness and cost/complexity. For instance, in a sales-agent scenario, the AI might receive push notifications when a lead opens a proposal, while also pulling CRM data on that customer’s history when crafting its next outreach.
Underpinning both push and hybrid systems is the concept of an event-driven architecture.
Here, the system is structured around events (business transactions, sensor readings, user interactions) that trigger logic flows, decisions, or state updates.
According to industry analysis, streaming platforms and “streaming lakehouses” are becoming execution layers for agentic AI—collapsing the boundary between historical and live data.
In such systems, events propagate through pipelines, get enriched with context, and feed into agents that reason, act, and then possibly emit new events.
The live-knowledge agent thus becomes a node in a real-time feedback loop: sense → reason → act → update.
👉🏽 Why this matters: With event-driven systems, live knowledge isn’t just an add-on—it becomes integral to how the agent perceives and influences reality. When an event happens, the agent updates its world model and responds accordingly.
👉🏽 Trade-offs: It requires designing for concurrency, latency, event ordering, failure handling (what if an event is lost or delayed?), and “what if” logic for scenarios that weren’t anticipated.
Building live knowledge involves engineering intelligence that is constantly evolving. Behind the scenes, organizations are weaving together APIs, streaming architectures, context engines, and adaptive learning models to keep information fresh and actionable.
In this section, we’ll examine how these systems come to life: the technologies that power real-time awareness, the architectural patterns that make it scalable, and the practical steps teams take to transition from static knowledge to continuous, live intelligence.
One widely used approach is to combine a large language model (LLM) with a live retrieval system, often referred to as RAG.
In RAG use cases, when the agent needs to respond, it first performs a retrieval step: querying up-to-date external sources (vector databases, APIs, documents). Then the LLM uses that retrieved data (in its prompt or context) to generate the output.
For live knowledge, the retrieval sources aren’t static archives—they are continuously updated, live feeds. This ensures that the model’s outputs reflect the current state of the world.
Implementation steps:
Newer standards, such as the Model Context Protocol (MCP) aim to define how models interact with live systems: data endpoints, AI tools, calls, and contextual memory.
According to a white paper, MCP could play the role for AI that HTTP once did for the web (connecting models to tools and data).
In practice, this means your agent architecture might have:
By standardizing the interface, you make the system modular—agents can plug in different data sources, tools, and memory graphs.
When dealing with live knowledge, many systems maintain a vector database (embeddings) whose content is continuously updated.
Embeddings represent new documents, live data points, and entity states. So retrieval is fresh. For example, as new sensor data arrives, you convert it into an embedding and insert it into the vector store, so subsequent queries consider it.
Implementation considerations:
Agents rarely call a single API; they often invoke multiple endpoints in sequence or parallel. Live knowledge implementations need orchestration. For example:
This orchestration layer may include caching, retry logic, rate limiting, fallbacks, and data aggregation. Designing this layer is critical for stability and performance.
In most AI frameworks, agents use tools to take action.
A tool is simply a predefined function that the agent can call, such as get_stock_price(), check_server_status(), or fetch_customer_order().
Modern LLM frameworks make this possible through function calling, where the model decides which tool to use, passes the right parameters, and receives a structured response it can reason over.
Live knowledge agents take this a step further. Instead of static or simulated data, their tools connect directly to real-time sources—live databases, APIs, and event streams. The agent can fetch current results, interpret them in context, and act or respond immediately. This bridge between reasoning and real-world data is what transforms a passive model into an adaptive, continuously aware system.
Implementation steps:
📖 Read More: MCP vs. RAG vs. AI Agents
Live knowledge is quickly moving from concept to competitive advantage.
From real-time project coordination to adaptive customer support and predictive maintenance, organizations are already seeing tangible gains in speed, accuracy, and foresight.
Below are some of the most compelling ways live knowledge is being applied today and how it’s redefining what “intelligent work” really means in practice.
In retail, a support chatbot tied to live inventory and shipping systems can answer questions like “Is this in stock?”, “When will it ship?”, or “Can I get expedited delivery?”.
Instead of relying on static FAQ data (which might say “out of stock” even when stock just arrived), the agent queries real-time inventory and shipping APIs.
Financial workflows demand immediate information retrieval.
An AI agent connected to market-data APIs (stock tickers, currency rates, economic indicators) can monitor live changes and either alert human traders or act autonomously within defined parameters.
The live knowledge layer is what separates a simple analytic dashboard (static reports) from an autonomous agent that senses a sudden drop in value and triggers a hedge or trade.
Bank of America’s virtual assistant, “Erica,” successfully demonstrates the value of using real-time data for AI agents in the financial sector. It handles hundreds of millions of client interactions annually by accessing current account information, providing personalized and instantaneous guidance on finances, assisting with transactions, and managing budgets.
In healthcare settings, live knowledge means connecting to patient sensors, medical devices, electronic health records (EHR), and streaming vital signs.
An AI agent can monitor a patient’s heart rate, oxygen level, and lab results in real-time, compare them against thresholds or patterns, and alert clinicians or take recommended actions (e.g., escalate the condition). Early warning systems powered by live data analytics are already helping identify sepsis or heart failure significantly earlier than traditional approaches.
Nvidia, for example, is developing an enterprise AI agent platform that powers task-specific agents—including one designed for The Ottawa Hospital to assist patients around the clock. The agent will guide patients through pre-surgery preparation, post-surgery recovery, and rehabilitation steps.
As Kimberly Powell, Nvidia’s VP and GM of healthcare, explains, the goal is to free up clinicians’ time while improving patient experiences.
In IT operations, live knowledge agents monitor logs, telemetry, infrastructure events, and service-status APIs. When latency spikes, errors proliferate, or resources are depleted, the agent can trigger remediation—restart a service, spin up additional capacity, or reroute traffic. Because the agent maintains awareness of the live system state, it can act more effectively and reduce downtime.
In sales, live knowledge means linking an agent to the CRM, communication platforms, and recent lead activity.
Imagine a sales assistant agent that monitors when a prospect opens a proposal, then prompts the rep: “Your proposal was just viewed. Would you like to schedule a follow-up now?” The agent might pull live engagement data, lead context, historical win rates—all dynamically—to produce timely, personalized suggestions. This elevates the outreach from generic to context-aware action.
JPMorgan Chase leveraged AI Agents during a recent market upheaval to deliver advice faster, service more clients, and grow sales. Their AI-driven “Coach” assistant helped financial advisors surface insights up to 95 % faster, enabling the firm to boost gross sales by ~20 % between 2023-24 and target a 50 % increase in client count over the next 3-5 years.
Today’s teams need more than static tools. They need a workspace that actively understands, connects, and accelerates work. ClickUp is the first converged AI workspace, engineered to deliver live intelligence by integrating knowledge, automation, and collaboration into a single, unified platform.
Find answers instantly, no matter where information lives. ClickUp’s Enterprise Search connects tasks, docs, chat, and integrated third-party tools into a single, AI-powered search bar. Natural language queries return context-rich results, pulling together structured and unstructured data so you can make decisions faster.
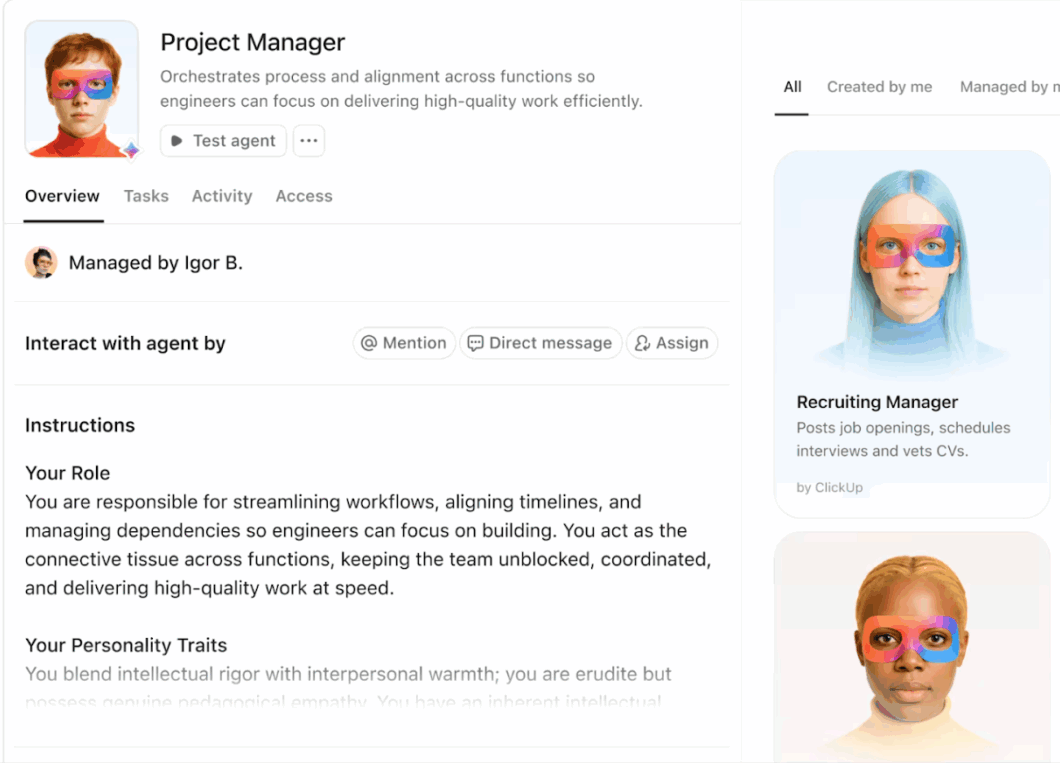
Automate repetitive tasks and orchestrate complex processes with intelligent AI Agents that act as digital teammates. ClickUp’s Super Agents leverage real-time workspace data and context, enabling them to reason, take action, and adapt to evolving business needs.
🎥 Watch this video to learn more about Super Agents in ClickUp!
Transform static documentation into a living knowledge base. ClickUp Knowledge Management automatically indexes and links information from tasks, docs, and conversations, ensuring knowledge is always current and accessible. AI-driven suggestions surface relevant content as you work, while smart organization and permissions keep sensitive data secure.
Collaboration in ClickUp is deeply integrated with your work.
Real-time editing, AI-powered summaries, and contextual recommendations ensure every conversation is actionable. ClickUp Chat, Whiteboards, Docs, and Tasks are interconnected, so brainstorming, planning, and execution happen in one flow.
It helps you:
ClickUp is not just a workspace. It’s a live intelligence platform that unifies your organization’s knowledge, automates work, and empowers teams with actionable insights, all in real time.
We compared the best enterprise search software, and here are the results:
While live knowledge offers powerful benefits, it also introduces risks and complexity.
Below are the key AI challenges organizations face, along with practices to mitigate them.
| Challenge | Description | Best practices |
|---|---|---|
| Latency & performance optimization | Connecting to live data adds latency from API calls, stream processing, and retrieval. If responses lag, user experience and trust suffer. | ✅ Cache less-critical data to avoid redundant fetches ✅ Prioritize critical, time-sensitive feeds; refresh others less frequently ✅ Optimize retrieval and context injection to reduce model wait time ✅ Continuously monitor latency metrics and set performance thresholds |
| Data freshness vs. computational cost | Maintaining real-time data for all sources can be costly and inefficient. Not all information needs second-by-second updates. | ✅ Classify data by criticality (must be live vs. can be periodic) ✅ Use tiered update frequencies ✅ Balance value versus cost — update only as often as it impacts decisions |
| Security and access control | Live systems often connect to sensitive internal or external data (CRM, EHR, financial systems), creating risks of unauthorized access or leakage. | ✅ Enforce least-privilege access for APIs and limit agent permissions ✅ Audit all data calls the agent makes ✅ Apply encryption, secure channels, authentication, and activity logging ✅ Use anomaly detection to flag unusual access behavior |
| Error handling and fallback strategies | Live data sources can fail due to API downtime, latency spikes, or malformed data. Agents must handle these disruptions gracefully. | ✅ Implement retries, timeouts, and fallback mechanisms (e.g., cached data, human escalation) ✅ Log and monitor error metrics like missing data or latency anomalies ✅ Ensure graceful degradation instead of silent failure |
| Compliance and data governance | Live knowledge often involves regulated or personal information, requiring strict oversight and traceability. | ✅ Classify data by sensitivity and apply retention policies ✅ Maintain data provenance— track origins, updates, and use ✅ Establish governance for agent training, memory, and data updates ✅ Involve legal and compliance teams early, especially in regulated sectors |
📖 Read More: Best Enterprise Search Software Solutions
Looking ahead, live knowledge will continue to evolve and shape how AI agents function—moving from reaction to anticipation, from isolated agents to networks of collaborating agents, and from centralized cloud to edge-distributed architectures.
Rather than waiting for requests, agents will proactively prefetch and cache data they’re likely to need. Predictive caching models analyze historical access patterns, temporal context (e.g., market opening times), and user intent to pre-load documents, news feeds, or telemetry into fast local stores, allowing the agent to respond with sub-second latency.
Use cases: an investment agent preloads earnings reports and liquidity snapshots before the market opens; a customer-support agent prefetches recent tickets and product documents before a scheduled support call. Research shows AI-driven predictive prefetching and cache placement significantly improve hit rates and reduce latency in edge and content-delivery scenarios.
Interoperability will accelerate progress. Protocols like the Model Context Protocol (MCP) and vendor initiatives (e.g., Algolia’s MCP Server) are building standardized ways for agents to request, inject, and update live context from external systems. Standards reduce bespoke glue code, improve safety controls (clear interfaces and authentication), and make it easier to mix and match retrieval stores, memory layers, and reasoning engines across vendors. Practically, adopting MCP-style interfaces lets teams swap retrieval services or add new data feeds with minimal agent rework.
Live knowledge at the edge offers two significant advantages: reduced latency and enhanced privacy/control. Devices and local gateways will host compact agents that sense, reason, and act locally, syncing selectively with cloud repositories when network or policy permits.
This pattern suits manufacturing (where factory machines make local control decisions), vehicles (onboard agents reacting to sensor fusion), and regulated domains where data must remain local. Industry surveys and edge-AI reports predict faster decision-making and lower cloud dependency as distributed learning and federated techniques mature.
For teams building live-knowledge stacks, this means designing tiered architectures where critical, latency-sensitive inference runs locally while long-term learning and heavy model updates happen centrally.
The single-agent model is giving way to collaborative agent ecosystems.
Multi-agent frameworks enable several specialized agents to share situational awareness, update shared knowledge graphs, and coordinate actions—making them particularly useful in fleet management, supply chains, and large-scale operations.
Emerging research on LLM-based multi-agent systems shows methods for distributed planning, role specialization, and consensus building across agents. Practically, teams need shared schemas (common ontologies), efficient pub/sub channels for state updates, and conflict-resolution logic (who overrides what and when).
Live knowledge will fuse retrieval, reasoning, memory, action, and continual learning into closed loops. Agents will observe outcomes, incorporate corrective signals, and update memories or knowledge graphs to improve future behavior.
The biggest technical challenges are preventing catastrophic forgetting, preserving provenance, and ensuring the safety of online updates. Recent surveys in online continual learning and agent adaptation outline practical approaches (episodic memory buffers, replay strategies, and constrained fine-tuning) that make perpetual model improvement feasible while limiting drift. For product teams, this implies investing in labeled feedback pipelines, safe update policies, and monitoring that ties model behavior back to real-world KPIs.
The next frontier of AI at work isn’t just smarter models.
Live knowledge is what bridges static intelligence and adaptive action, allowing AI agents to operate with a real-time understanding of projects, priorities, and progress. Organizations that can feed their AI systems fresh, contextual, and trustworthy data will unlock the true promise of ambient intelligence: seamless coordination, faster execution, and better decisions across every team.
ClickUp is built for this shift. By unifying tasks, docs, goals, chat, and insights into one connected system, ClickUp gives AI agents a living, breathing source of truth — not a static database. Its Contextual and Ambient AI capabilities enable information to stay current across every workflow, ensuring that automation runs on reality, not outdated snapshots.
As work becomes increasingly dynamic, tools that understand context in motion will define productivity’s next edge. ClickUp’s mission is to make that possible—where every action, update, and idea instantly informs the next, and where teams finally experience what AI can do when knowledge stays live.
Live knowledge boosts performance by providing current context: decisions are based on up-to-date facts rather than stale data. That leads to more accurate responses, faster reaction times, and improved user trust.
While many can, not all need to. Agents that operate in stable contexts with little change may not benefit as much. But for any agent facing dynamic environments (markets, customers, systems), live knowledge is a powerful enabler.
Testing involves simulating real-world change: vary the live inputs, inject events, measure latency, verify agent outputs, and check for errors or stale responses. Monitor end-to-end workflows, user outcomes, and system robustness under live conditions.

© 2026 ClickUp

There’s an easier way. Try a free AI Agent in ClickUp that actually does the work for you—set up in minutes, save hours every week.