

You’re a departmental head hunting for the perfect person to handle a particular task. With vast company data, finding the best fit is nearly impossible, especially if your task is time-sensitive.
Plus, who has the bandwidth to ask everyone whether they’ve enough knowledge about a specific area?
But what if you could simply ask a system, ‘Who’s been assigned [task] the most?’ and get an instant, accurate answer based on real data? That’s what Information Retrieval Systems do.
These systems sift through mountains of data to find exactly what you need.
Now, scale that idea to a global database—an IR system organizes vast amounts of data, helping you find the most relevant answers in seconds. This guide will explore different information retrieval models, how they work, and the role of AI technologies in an IR system.
Enhance Data Management with Information Retrieval Systems
- What is Information Retrieval (IR)?
- Components of an Information Retrieval System
- Models of Information Retrieval
- Information Retrieval vs. Data Querying
- The Role of Machine Learning and NLP in Information Retrieval
- The Role of ClickUp in Information Retrieval
- Challenges and Future Directions in Information Retrieval
- Retrieve Documents Quickly With ClickUp’s Data Management
⏰ 60-Second Summary
📌 Information Retrieval (IR) systems help find relevant information from large data collections, functioning like a virtual assistant that sifts through data to find what you need
📌 IR systems have key components: database, indexer, search interface, query processor, retrieval models, and ranking/scoring mechanisms
📌 Four main IR models are used: Boolean (uses AND/OR/NOT operators), Vector Space (represents documents as vectors), Probabilistic (uses statistical approaches), and Term Interdependence (analyzes relationships between terms)
📌 Machine Learning and Natural Language Processing enhance IR systems by improving pattern recognition, result ranking, and understanding context
📌 Major challenges include data privacy, scalability, and maintaining data quality while processing large datasets
What is Information Retrieval (IR)?
Information Retrieval (IR) simply means finding the right information from large collections of data, such as digital libraries, databases, or Internet Archives.
It’s like having a virtual assistant who sifts through mountains of data to bring you exactly what you need.
On the surface, the user enters a query, often using keywords or phrases, to search for specific information. Behind the scenes, advanced techniques and algorithms analyze the search strings and match them to relevant data.
Instead of just identifying a single answer, IR systems provide several objects—each with different degrees of relevance to your query. Plus, they’re used everywhere and have multiple applications (more on that soon 🔔).
💡Pro Tip: Need to find the most skilled person for a task? Enter specific terms like ‘sales report analysis Q1 and Q2 tasks assigned to’ into the information retrieval system. Just like that, it quickly filters out irrelevant data and pinpoints who’s handled it the most.
Applications of IR in different fields
From healthcare to e-commerce, IR systems are used in numerous fields to manage and categorize data. Here are a few examples 👇
Healthcare
In healthcare, IR systems scan databases of medical records and research papers to help doctors and researchers find the most relevant information. As a result, they speed up disease diagnosis, identify treatment options, and find the most relevant studies using relevant feedback.
Customer service
Information retrieval techniques make customer support faster and more accurate. For example, agents can type user queries like ‘refund policy’ into a company’s system to fetch instant answers.
AI chatbots and help desks powered by information retrieval go a step further, offering real-time solutions without human involvement. That’s why your questions often get answered in seconds!
E-commerce platforms
IR systems make online shopping a breeze. They analyze databases and match customer behavior to recommend products you’ll love.
For instance, Amazon uses IR to suggest items based on your search history and previous purchases, helping you find exactly what you need.
Components of an Information Retrieval System
Now we know what information retrieval is and how it works. Let’s break down the key building blocks of an IR system. →
1. Database
Everything starts with the database. It’s a collection of interrelated data points, such as text documents, emails, web pages, images, and videos. When you enter a given query, the IR system searches through these database matches to retrieve the most relevant information for your needs.
2. Indexer
Before the system can retrieve anything, the indexer organizes the data. It’s like preparing a library catalog to make searching faster. The indexer processes documents by:
- Tokenization: Breaking content into smaller bits, like splitting sentences into words or phrases (called tokens)
- Stemming: Simplifying words to their base form (e.g., ‘running’ becomes ‘run’)
- Stop word removal: Skipping filler words like ‘and,’ ‘or,’ and ‘the’ to focus on the primary query
- Keyword extraction: Identifying the main keywords in the text
- Metadata extraction: Pulling extra details like the author, publication date, or title
3. Search interface
The search interface acts as your gateway to the IR system. This is where you type in your query using simple keywords or more detailed filters. Designed to be user-friendly, it ensures you can easily communicate your information access needs and get the relevant results you’re looking for.
4. Query processor
Once you hit ‘search,’ the query processor takes over. It refines your input by applying techniques listed in the indexer section. Plus, it also handles Boolean operators like ‘AND,’ ‘OR,’ and ‘NOT’ to make your query smarter.
5. Retrieval models
Here’s where the magic happens. The system compares your given query to the indexed documents using retrieval models. These methods decide how to match your query with the stored data. Some of the common names include:
- Boolean models
- Vector space models
- Probabilistic models
- And, more… (discussed later)
6. Ranking and scoring
Once potential matches are found, the system ranks them based on relevance. Each document gets a score using methods like TF-IDF (Term Frequency-Inverse Document Frequency) or other algorithms. This ensures the most relevant result appears at the top.
7. Presentation or display
Finally, the results are presented to you. Typically, the system shows a ranked list of text documents with extra features like snippets, filters, or sorting options. This makes it easier to pick the most relevant document. However, the number of results displayed may vary based on your preferences, query, or system settings.
🔍Did you know?: Traditional information retrieval systems relied heavily on structured databases and basic keyword matching. The result? Major relevance and personalization issues.
That’s when modern AI technologies transformed text retrieval through:
- Machine Learning (ML): Helps IR systems learn from patterns in user behavior and improve search results over time
- Deep Neural Networks: Algorithms that can process unstructured data (like images or videos) and uncover complex relationships
- Natural Language Processing (NLP): Enables systems to understand the meaning and context of queries to support image recognition and sentiment analysis, making information access more versatile
Models of Information Retrieval
There are different IR systems that streamline the process of finding relevant documents. Let’s look at the most widely used ones:
1. Set Theory and Boolean Models
The Boolean model is one of the simplest information retrieval techniques. Here’s how it works:
- AND: Retrieves documents containing all the terms in the query. For example, a search for ‘cat AND dog’ will return documents that mention both on a search engine
- OR: Finds documents containing any of the terms in the query. For ‘cat OR dog,’ it retrieves documents that mention either cat, dog, or both
- NOT: Excludes documents containing a specific term. For example, ‘cat AND NOT dog’ returns documents that mention cat but not dog
This model uses a ‘bag of words’ concept, where a 2D matrix is created. In this matrix:
- Columns represent documents
- Rows represent terms from the query
Each cell is assigned a value of 1 (if the term is present) or 0 (if it’s not).

✅ Pros
- Easy to understand and implement
- Retrieves documents that exactly match the query terms
❌ Cons
- Boolean models don’t rank documents by relevance, so all results are treated as equally important
- Focuses on exact term matches, so the results may vary within the meaning or context of the query
2. Vector Space Models
A Vector Space model is an algebraic model that represents both documents and queries as vectors in a multi-dimensional space. This is how it works:
1. A term-document matrix is created, where rows are terms and columns are documents
2. A query vector is formed based on the user’s search terms
3. The system calculates a numeric score using a measure called cosine similarity, which determines how closely the query vector matches document vectors

As an information retrieval system, the documents are then ranked based on these scores, with the highest-ranked ones being the most relevant.
✅ Pros
- Retrieves items even if only some terms match
- Variations in term usage and document length, accommodating diverse document types
❌ Cons
- Larger vocabularies and document collections make similarity calculations resource-intensive
3. Probabilistic Models
This model takes a statistical approach, using probability to estimate how relevant a document is to the query. It considers:
- Frequency of terms in the document
- How often do terms occur together (co-occurrence)
- Document length and the total number of query terms
The system treats the retrieval process as a probabilistic event, ranking documents stored based on their likelihood of relevance. This approach adds depth by evaluating data objects beyond basic term presence.
✅ Pros
- Adapts well to various applications, including reliability analysis and load-flow assessments
❌ Cons
- Relies on assumptions about data relationships, which can lead to misleading results
4. Term Interdependence Models
Unlike simpler models, Term Interdependence Models focus on relationships between terms rather than just their frequency. These models analyze how words and phrases relate to each other to improve result accuracy.
They use one of two approaches:
- Immanent mode: Explores relationships within the text itself
- Transcendent mode: Considers external data or context to infer relationships
This method is especially useful for capturing nuances in meaning, such as synonyms or context-specific phrases.
✅ Pros
- Captures nuances in language by considering term relationships
- Enhances retrieval performance by understanding term dependencies and context
❌ Cons
- Requires extensive data to accurately model term relationships, which may not always be available
That’s it! These are some of the commonly used information retrieval systems, with their own pros and cons.
➡️ Read More: 4 Spotlight Search Alternatives and Competitors
Information Retrieval vs. Data Querying
While both these terms seem almost the same, they operate differently. So, let’s put IR and Data Querying side-by-side to see how they stack up in terms of purpose, use cases, and examples:
| Aspect | Information Retrieval (IR) | Data Querying |
| Definition | Acts like a search engine that hunts through tons of data to bring you the most relevant results | Think of it as asking a database a specific question in a language it understands (like SQL) |
| Goal/Purpose | Helps you find accurate and relevant information or resources on search engines—fast and easy | Pulls exact data so you can analyze, update, or crunch numbers |
| Use Cases | Used for web searches, eCommerce recommendations, digital libraries, healthcare insights, and more | Great for tasks like managing stock in eCommerce, analyzing finances, and optimizing supply chains |
| Example | Searching ‘Best laptops between $800 and $1000’ on Google to get ranked results | Querying your inventory system for ‘SELECT * FROM Laptops WHERE Price >= 800 AND Price <= 1000’ to find what’s in stock |
The Role of Machine Learning and NLP in Information Retrieval
IR systems are like treasure hunters for data—they sift through massive amounts of information to find exactly what you’re looking for. But when ML and NLP join forces, these systems become smarter, faster, and way more accurate.
Think of ML as the brain behind IR systems. 🧠
It helps the system learn, adapt, and improve the results whenever you search for information. Here’s how it works:
- Spotting patterns: ML studies what users click on, what they ignore, and what they spend the most time reading. It then uses this knowledge to show you the most relevant results next time
- Ranking results: ML retrieves information and also ranks it. That means the best and most useful results pop up at the top of your search
- Adapting with time: With every query, ML gets better. It picks up on trends, refines its understanding, and handles even the trickiest questions easily
For example, if you search for ‘best budget laptops’ today and interact with specific results, ML will know to prioritize similar options when you search for ‘affordable notebooks’ later. By combining AI with ML, web search engines can even predict what you might need next.
Now let’s talk about NLP. It helps IR systems understand what you mean, not just the words you type. In simple words:
- It understands context: NLP knows that when you say ‘jaguar,’ you could mean the animal or the car—and it figures that out based on the rest of your query
- It handles complex language: Whether your query is simple (‘cheap flights’) or detailed (‘direct flights to Tokyo under $500’), NLP makes sure the system understands and delivers the right results
Together, NLP and IR make searching feel intuitive, like talking to someone who just gets you. This means less scrolling, less frustration, and more “wow, this is exactly what I needed!” moments.
The Role of ClickUp in Information Retrieval
ClickUp, the ‘everything app for work,’ enhances data management with IR models.
Its built-in AI uniquely identifies and matches results to a user’s query, taking intelligent technology to the next level.
And to sweeten the deal, ClickUp’s Connected Search makes it a breeze to get everything you need ‘immediately’ at your fingertips. That means:
- Search anything: Who likes shuffling through emails and knowledge management systems to locate important files? Find any file in seconds using the Connected Search option. Better yet, search files across your connected apps and access everything in one place
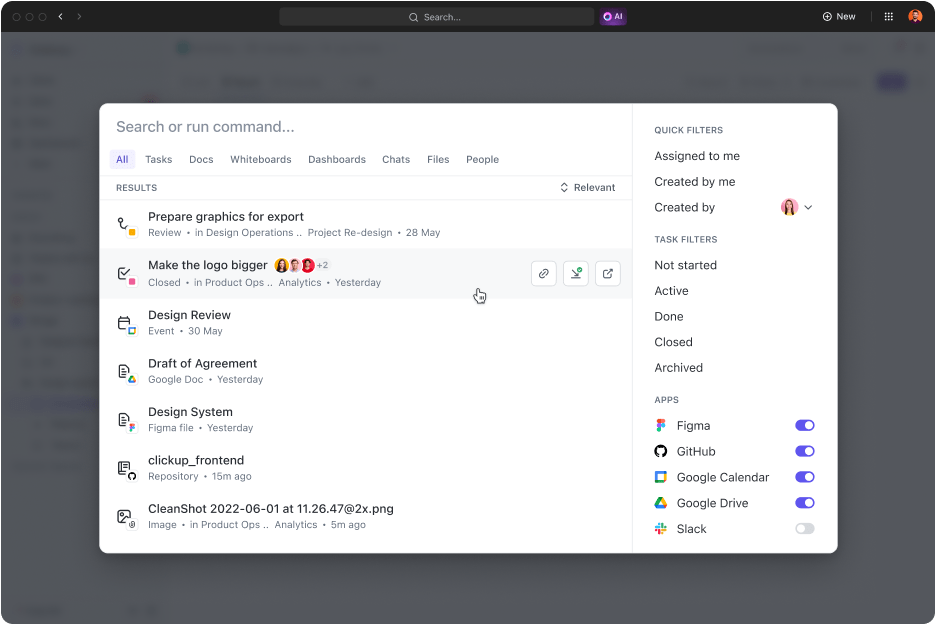
- Connect your favorite apps: ClickUp has some of the best integrations that extend its search capabilities to third-party apps like Google Drive, Slack, Dropbox, Figma, and more

- Refine results: The more you use it, the better it gets at understanding what you’re looking for, delivering results tailored just for you
- Search your way: Access Connected Search and search PDF files quickly from anywhere in your workspace. For instance, you can initiate a search from the Command Center, Global Action Bar, or your desktop
- Create custom search commands: Add custom search commands like shortcuts to links, storing text for later, and more to streamline your workflow
To top it off, what if there was a way to automate tedious tasks, work faster, and get more things done in no time?
ClickUp Brain, the inbuilt AI assistant, makes this a reality for you. It’s the ultimate assistant for data management—smart, fast, and always ready to help.
In a nutshell 👇
- All-in-one knowledge hub: Never again rely on emails and messages for updates. Ask anything about your Tasks, Docs, or People and sit back while ClickUp Brain maps out answers based on the context from within and connected apps

- Find what you need faster: ClickUp Brain ranks results intelligently like an advanced IR system. It prioritizes relevant files, suggests related tasks, and even helps you discover hidden workloads in your data
- Automate tasks: Brain automates generating reports or tracking deadlines through its AI tools. It’s a personal assistant that frees up your time for bigger decisions while keeping everything on track
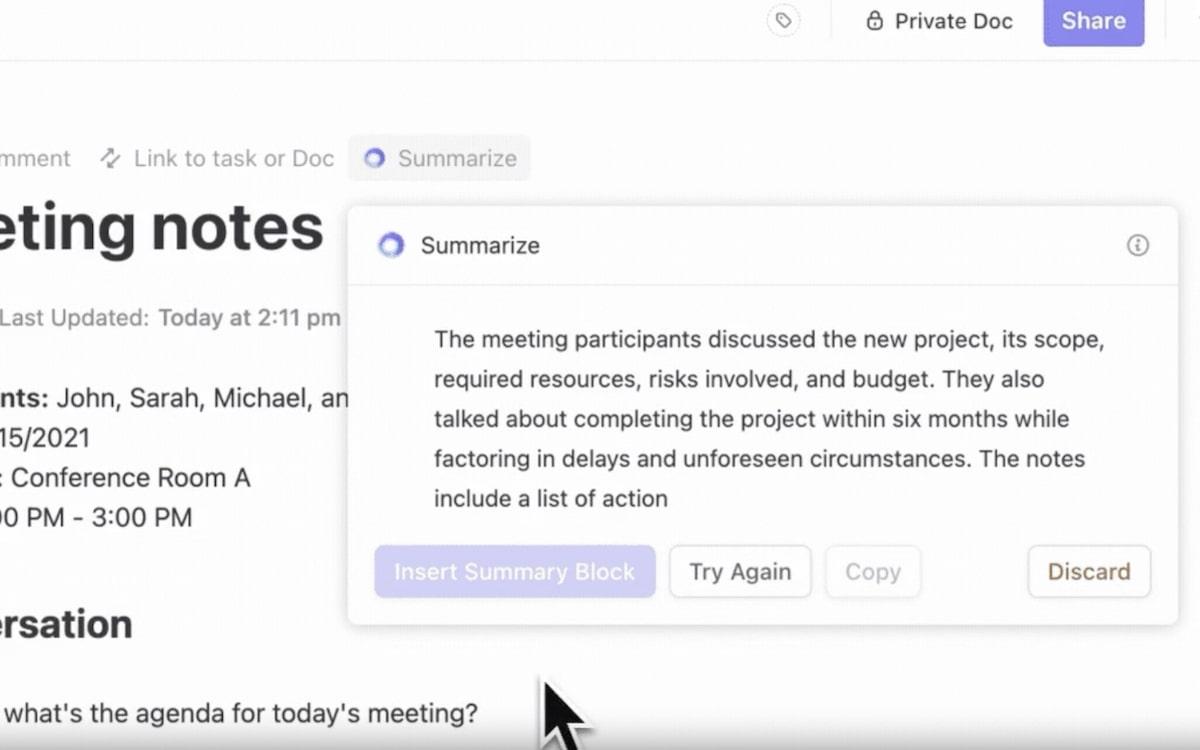
- Context-aware search: With NLP, it understands your question—even if your query is complex or vague. For example, searching ‘report on Q1 sales’ gives you the exact report tied to your task
Challenges and Future Directions in Information Retrieval
The world of information retrieval is all about making sense of vast amounts of data, but even the most advanced IR systems face a few bumps along the way.
Let’s explore the common challenges and the exciting trends shaping the future of this essential scientific discipline:
- Data privacy and security: For an IR model to provide factual results, it often needs access to sensitive data. However, protecting user data is not a walk in the park for information retrieval resources
- Scalability and performance: As users search through large datasets, handling rising content collection can overwhelm even the most robust retrieval models. The challenge is ensuring efficient retrieval without compromising the search result relevance
- Data quality and contextual understanding: Ambiguous queries or poorly organized metadata can lead to mismatches, making it difficult for the system to uniquely identify user intent
Emerging trends and advancements in IR technology
Despite the many hurdles, recent technological advancements have enabled us to build smarter, more efficient systems.
Modern information retrieval systems now use advanced methods like graph-based analysis to interpret the numbers and text and the context, metadata, and relationships between the data points.
What does this mean for users? It allows more precise text retrieval and detailed analysis, especially in fields like research and data-heavy industries.
Combined with semantic web technologies, it focuses on search strings and user intent. These systems can go beyond literal matches and fetch highly relevant documents, even for complicated user queries in the information retrieval process.
For example, searching ‘benefits of remote work’ can deliver results related to productivity, mental health, and work-life balance—all because the system understands the connections.
Retrieve Documents Quickly With ClickUp’s Data Management
Digging through endless files, apps, and tools to find that one important document is exhausting. Imagine trying to analyze retrieved documents as a researcher, student, IT professional, or data scientist—and it just becomes a hotchpotch of information overload.
But with ClickUp, you’ll never waste time hunting for information again.
It’s the all-in-one solution that brings your work together in one place. With features like Connected Search and ClickUp Brain, it doesn’t matter where your data lives—ClickUp makes it easy to find, manage, and act on it.
Why settle for ‘just okay’ when you can have ‘amazing?’ Try ClickUp for free and see how it transforms your workflow into something bold, efficient, and downright unstoppable!

Everything you need to stay organized and get work done.
