
Hai dedicato ore a progettare il prompt "perfetto". Hai la visione, il modello e il potenziale per ottenere un enorme aumento di produttività. Ma una piccola modifica manda all'aria il tuo risultato. Senza un metodo standard per valutare i risultati, non puoi capire se la tua IA sta effettivamente migliorando o semplicemente cambiando.
Infatti, secondo il Prompting Science Report della Wharton, la semplice riformulazione di un prompt può modificare le prestazioni fino a 60 punti percentuali.
Questa guida ti illustra i migliori modelli per il benchmark delle prestazioni dei prompt disponibili su ClickUp. Si tratta di schemi ripetibili per valutare i risultati, effettuare il monitoraggio di ogni iterazione e, infine, stabilire la connessione tra i dati di valutazione e il lavoro nel tuo spazio di lavoro. ✨
Panoramica dei modelli di benchmark delle prestazioni dei prompt
Ecco una rapida panoramica dei modelli di benchmark delle prestazioni dei prompt trattati in questa guida e della parte del flusso di lavoro di valutazione che ciascuno di essi supporta 👇
| Modello | Link per scaricare | Ideale per | Caratteristiche principali |
|---|---|---|---|
| Modello di analisi comparativa di ClickUp | Ottieni il modello gratis | Confronto tra varianti di prompt e valutazione dei risultati | Area di lavoro visiva per il benchmarking, campi di valutazione, analisi multi-vista |
| Modello per piano di sperimentazione e risultati di ClickUp | Ottieni il modello gratis | Esecuzione di esperimenti strutturati sui prompt | Monitoraggio delle ipotesi, registrazione della configurazione dei test, documentazione dei risultati |
| Modello per la gestione dei test di ClickUp | Ottieni il modello gratis | Gestione dei flussi di lavoro di valutazione su larga scala | Monitoraggio dei casi di test, stati di esecuzione, trigger di automazione |
| Modello di caso di test di ClickUp | Ottieni il modello gratis | Documentazione dettagliata degli errori dei prompt | Registrazione degli input/output, confronto tra valori attesi e effettivi, monitoraggio di superamento/fallimento |
| Modello di modello di report sulle prestazioni di ClickUp | Ottieni il modello gratis | Comunicare i risultati dei benchmark agli stakeholder | Riassunto esecutivo, visualizzazione dei dati, sezioni dedicate alle raccomandazioni |
| Modello di rapporto sulle attività di ClickUp | Ottieni il modello gratis | Monitoraggio dello stato della valutazione e del carico di lavoro | Registri delle attività, filtri basati sul tempo, visibilità del carico di lavoro |
| Modello di balanced scorecard di ClickUp | Ottieni il modello gratis | Allineare le prestazioni dei prompt agli obiettivi aziendali | Valutazione multidimensionale, metriche ponderate, mappatura delle strategie |
| Modello di valutazione del progetto di ClickUp | Ottieni il modello gratis | Miglioramento dei processi di benchmarking nel tempo | Valutazione dei processi, lezioni apprese, monitoraggio dei rischi |
| Modello di revisione euristica di ClickUp | Ottieni il modello gratis | Esecuzione di valutazioni qualitative dei risultati dell'IA | Categorie euristiche, valutazioni di gravità, raccolta dei feedback degli esperti |
| Modello per OKR e obiettivi aziendali di ClickUp | Ottieni il modello gratis | Collegare i risultati dei benchmark agli obiettivi strategici | Gerarchia OKR, monitoraggio dei progressi, visibilità tra i team |
🧠 Curiosità: il termine "benchmark" non ha avuto origine nei team di sviluppo software o di prodotto. Inizialmente, nel XIX secolo, indicava il punto di riferimento di un geometra, molto prima che diventasse lo standard per misurare tutto, dagli esperimenti sui siti web alle prestazioni dei prompt.
Che cos'è un modello di benchmark delle prestazioni?
Un modello di benchmark delle prestazioni dei prompt è un framework per valutare, confrontare e assegnare un punteggio ai risultati dei prompt generati dall'IA. Viene utilizzato per verificare se un prompt generato dall'IA funziona effettivamente o se sta peggiorando silenziosamente ad ogni aggiornamento del modello.
Consideralo come una configurazione sperimentale standardizzata:
- Definisce ciò che stai testando
- Come misuri l'esito positivo
- Quali input stai utilizzando
- Come stai registrando i risultati
👀 Lo sapevi? Uno degli esperimenti più famosi in statistica è nato da una discussione su cosa versare per primo: il latte o il tè. Ronald Fisher trasformò quella piccola divergenza in un test formale con tazze casuali, e questa storia è diventata uno dei classici esempi alla base della progettazione sperimentale moderna.
Cosa rende efficace un modello di benchmark delle prestazioni dei prompt
Un buon modello di prompt deve fare bene cose specifiche, altrimenti finirà nel dimenticatoio dopo il primo sprint:
- Criteri di valutazione standardizzati: definisci dimensioni quali accuratezza, pertinenza, tono e tasso di allucinazioni prima che qualcuno inizi i test. Senza rubriche predefinite, ogni revisore effettua una valutazione diversa e i risultati non sono comparabili
- Monitoraggio delle versioni: ogni esecuzione del benchmark deve essere associata a una versione specifica del prompt, al modello e al set di parametri, in modo da poter tracciare cosa è cambiato e perché
- Valutazione sia numerica che qualitativa: una risposta fattualmente corretta può comunque sembrare robotica. I modelli migliori combinano valutazioni numeriche con note scritte strutturate, affiancate l'una all'altra
- Struttura pronta per il confronto: dovresti essere in grado di affiancare due versioni di prompt e vedere immediatamente le differenze
- Risultato utilizzabile: un benchmark che termina con "punteggio: 7/10" è incompleto. I valutatori devono annotare perché il punteggio è risultato quello che è e cosa modificare in seguito
- Collegato al lavoro: i risultati dei benchmark isolati perdono rapidamente il contesto. Il modello funziona al meglio quando è collegato alle attività e ai flussi di lavoro in cui avviene effettivamente lo sviluppo dei prompt
📮ClickUp Insight: Il 92% dei knowledge worker rischia di perdere decisioni importanti sparse tra chat, email e fogli di calcolo. Senza un sistema unificato per acquisire e effettuare il monitoraggio delle decisioni, le informazioni aziendali critiche si perdono nel rumore digitale. Con le funzionalità di gestione delle attività di ClickUp, non dovrai mai preoccuparti di questo. Crea attività da chat, commenti alle attività, documenti ed email con un solo clic!
📮ClickUp Insight: Il 92% dei knowledge worker rischia di perdere decisioni importanti sparse tra chat, email e fogli di calcolo. Senza un sistema unificato per acquisire e effettuare il monitoraggio delle decisioni, le informazioni aziendali critiche si perdono nel rumore digitale. Con le funzionalità di gestione delle attività di ClickUp, non dovrai mai preoccuparti di questo. Crea attività da chat, commenti alle attività, documenti ed email con un solo clic!
10 modelli di benchmark delle prestazioni dei prompt per il tuo team
Ciascuno dei modelli riportati di seguito affronta un diverso aspetto del benchmarking delle prestazioni dei prompt, dai casi di test granulari alla reportistica strategica. Alcuni sono stati creati appositamente per il benchmarking; altri sono framework adattabili che i team di ingegneri possono riutilizzare per i flussi di lavoro di valutazione.
Diamo un'occhiata:
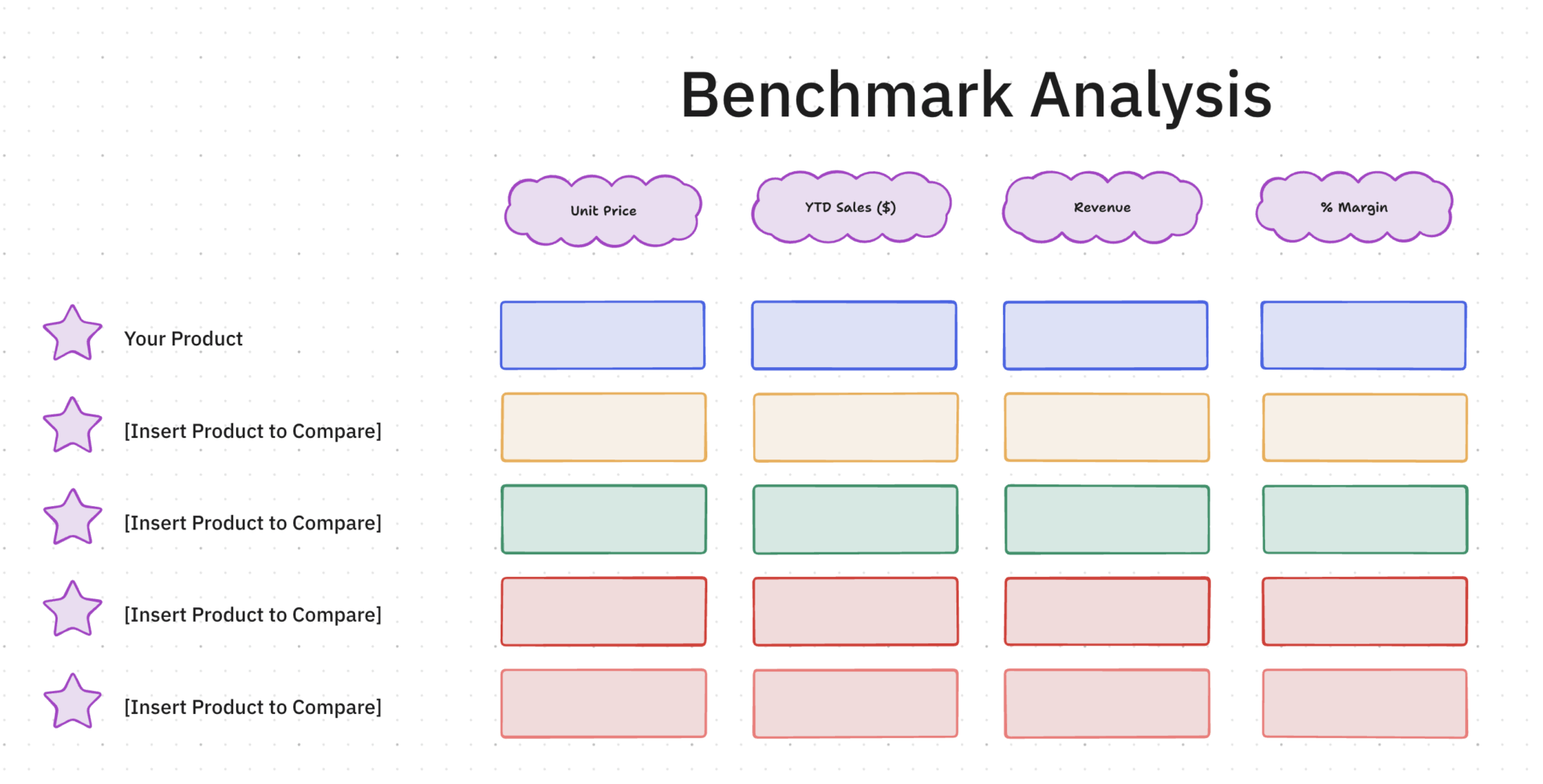
1. Modello di analisi comparativa di ClickUp™
La valutazione delle prestazioni dei prompt si trasforma solitamente in un caos soggettivo senza una linea di riferimento fissa per il confronto. Se ti limiti a leggere i risultati, non saprai mai veramente quale modifica logica abbia risolto un'allucinazione o migliorato una risposta.
Il modello di analisi di benchmark di ClickUp™ funge da laboratorio di valutazione visiva su una lavagna online di ClickUp. Ti consente di tracciare varianti di prompt, griglie di valutazione e risultati dei modelli su un'unica tela infinita, in modo da poter individuare modelli nella logica del modello che una vista Elenco standard nasconderebbe.
✨ Perché adorerai questo modello
- Campi di valutazione personalizzati: associa ogni dimensione di valutazione (accuratezza dei fatti, lunghezza della risposta e frequenza delle allucinazioni) a un campo personalizzato dedicato in ClickUp
- Viste multiple: passa dalla vista Tabella di ClickUp per il confronto dei dati grezzi alla vista Bacheca di ClickUp per il monitoraggio basato sullo stato (In attesa di revisione → Valutato → Necessita di iterazione) e a oltre 15 viste personalizzabili di ClickUp
- Monitoraggio storico: ogni esecuzione del benchmark è un'attività con cronologia completa, quindi puoi scorrere le valutazioni passate senza dover cercare tra fogli di calcolo denominati in base alla versione
✅ Ideale per: ricercatori nel campo dell'IA e ingegneri di prompt che coordinano rigorosi test A/B su più varianti di modelli, logiche di produzione e casi d'uso di dati sensibili.
⚡️ Vuoi altri modelli di analisi di benchmark tra cui scegliere? Abbiamo creato un elenco appositamente per te qui: Modelli gratuiti di analisi di benchmark per i team
2. Modello per piano di sperimentazione e risultati di ClickUp

Come si valuta un prompt senza confondere le condizioni alla base delle sue prestazioni? Il modello "Piano e risultati dell'esperimento" di ClickUp garantisce un approccio metodologico rigoroso. In questo modello, ogni versione di prova del prompt inizia con un'ipotesi dichiarata, una configurazione di test e una registrazione di ciò che è cambiato tra un'esecuzione e l'altra.
Man mano che arrivano i risultati, il modello trasforma le osservazioni sparse in una traccia di prove. Le varianti dei prompt, i criteri di benchmark e le note sui risultati rimangono collegati allo stesso flusso di lavoro, offrendo al tuo team una visione più chiara delle prestazioni.
✨ Perché adorerai questo modello
- Standardizza l'invio dei benchmark: utilizza ClickUp Moduli per raccogliere ogni variante di prompt, obiettivo di test, rubrica e scenario limite in un unico flusso di acquisizione coerente prima dell'inizio della valutazione
- Trasforma ogni esecuzione di prompt in un lavoro tracciabile: usa le attività di ClickUp per assegnare i titolari, impostare le fasi di revisione, monitorare le dipendenze e garantire che ogni ciclo di benchmark proceda lungo un percorso di esecuzione visibile
- Conserva la logica alla base di ogni risultato: registra l'ipotesi, le condizioni di test e le osservazioni finali in un unico record di esperimento
✅ Ideale per: responsabili dei contenuti o del supporto che desiderano creare una libreria di prompt più affidabile per l'uso in produzione.
👀 Lo sapevi? Con il 40% delle app aziendali che, secondo le previsioni, funzionerà su agenti IA entro la fine di quest'anno, il nostro team di ClickUp ha già trasferito l'intero sistema di contenuti su Super Agents.
Questi colleghi autonomi gestiscono l'intero processo di stesura, distribuzione e pubblicazione, lasciandoci liberi di concentrarci esclusivamente sulla strategia di alto livello.
Guarda qui sotto come gestiscono l'area di lavoro:
3. Modello per la gestione dei test di ClickUp
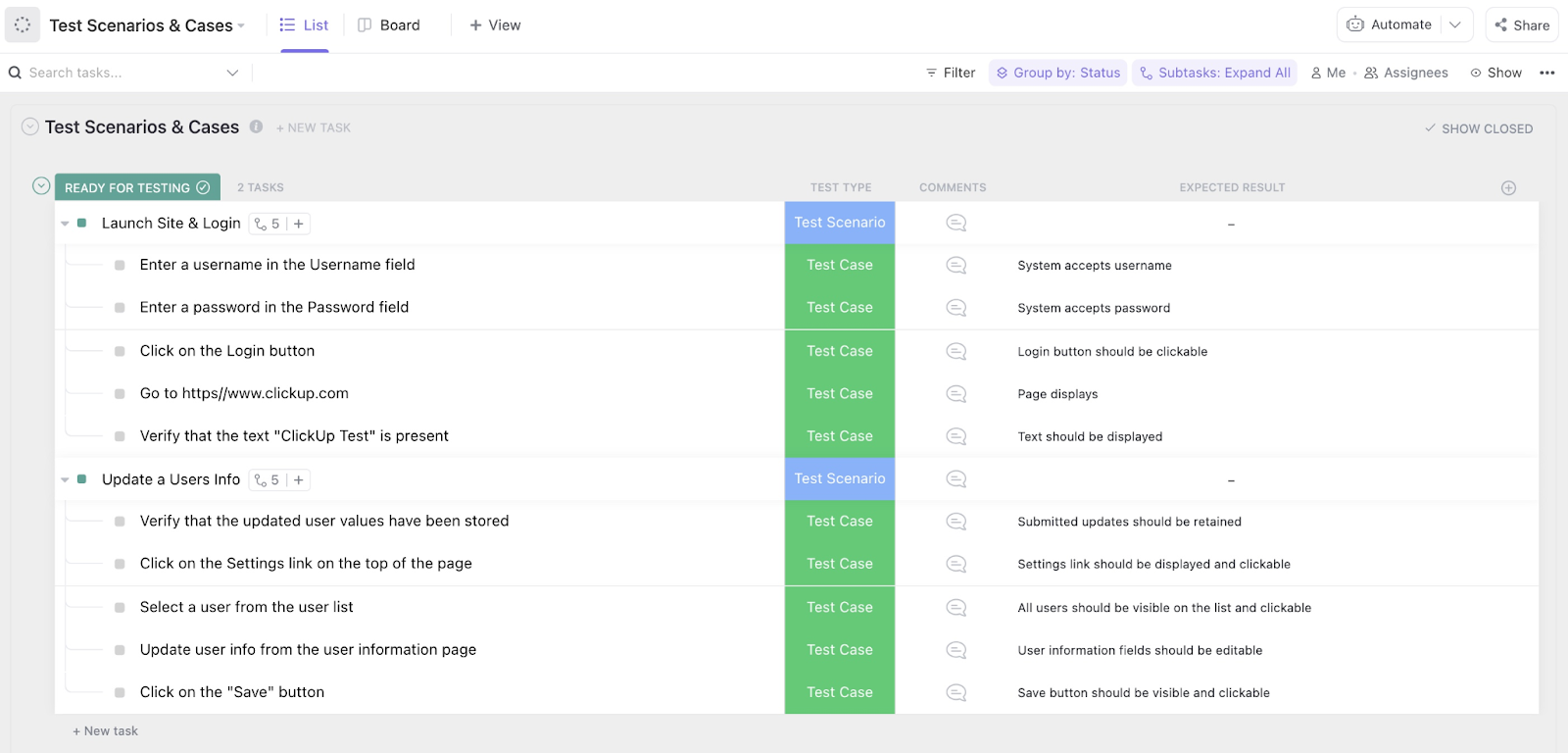
Il ridimensionamento di una libreria di prompt di solito fallisce perché nessuno sa quali test siano effettivamente stati completati. Se stai effettuando il monitoraggio manuale degli stati "superato" o "fallito" in un documento casuale, probabilmente stai perdendo giorni in test ridondanti e cicli di comunicazione.
Il modello di gestione dei test di ClickUp offre un livello di orchestrazione di alto livello per le tue suite di valutazione. Trasforma le coppie sparse di prompt e input in una pipeline controllata, in cui ogni caso di test ha un titolare chiaro e uno stato in tempo reale, mantenendo il tuo programma di implementazione in linea con gli obiettivi.
✨ Perché adorerai questo modello
- Monitora lo stato di esecuzione: utilizza gli stati personalizzati di ClickUp come "Da ripetere" o "Superato" per tenere traccia dell'avanzamento della tua suite di benchmark a colpo d'occhio
- Sincronizzazione dei cicli di iterazione: configura le automazioni di ClickUp per contrassegnare casi di test specifici per una nuova esecuzione ogni volta che viene modificata la logica di base del prompt
- Decentralizza il lavoro di valutazione: assegna i batch di test a diversi membri del team per eliminare i colli di bottiglia e ridurre il bias dei valutatori umani
✅ Ideale per: responsabili del controllo qualità e responsabili delle operazioni di prompt che coordinano suite di valutazione ad alto volume su più versioni di modelli e flussi di lavoro tecnici.
💡 Suggerimento da esperto: Hai bisogno di risposte rapide? Usa ClickUp Brain. Può estrarre note di test, casi falliti, modifiche ai prompt e il contesto delle esecuzioni precedenti dall'area di lavoro di ClickUp e dalle app collegate. In questo modo, puoi vedere cosa è successo prima di eseguire la valutazione successiva.
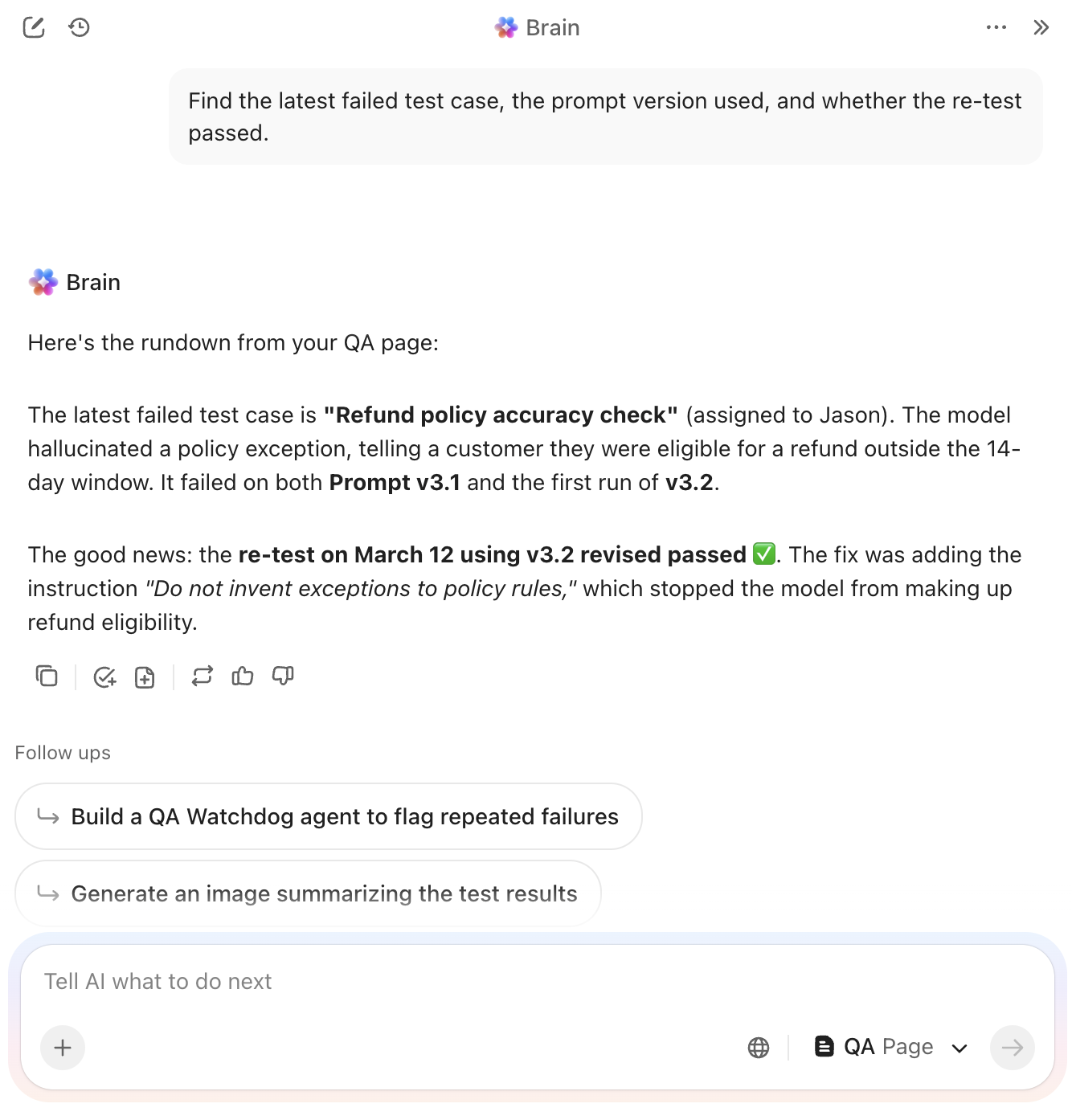
4. Modello di caso di test di ClickUp

Gli errori atomici nella logica dei prompt sono quasi impossibili da correggere se sono sepolti in un generico aggiornamento di stato. Devi vedere esattamente dove il modello ha generato un'allucinazione o ignorato un vincolo specifico senza dover scavare per ore nella cronologia manuale della chat.
Il modello Test Case di ClickUp funge da livello di documentazione granulare per la tua suite di valutazione. Scompone ogni combinazione di prompt e input in un'attività atomica, consentendo un confronto diretto tra i risultati attesi e l'output effettivo del modello.
✨ Perché adorerai questo modello
- Standardizza le tracce di audit: registra le variabili di input, i risultati attesi e le note di delta in campi strutturati per eliminare l'interpretazione soggettiva durante le revisioni
- Valuta i risultati all'istante: contrassegna ogni caso di test con indicatori binari di superamento/fallimento per distinguere gli errori logici immediati dai piccoli problemi di formattazione
- Crea collegamenti tracciabili: collega i singoli casi di test alle attività principali tramite le relazioni tra attività di ClickUp per vedere esattamente in che modo gli errori nei casi limite influenzano i tuoi punteggi complessivi dei benchmark
✅ Ideale per: analisti QA e lead prompt engineer che gestiscono i test di regressione per applicazioni di IA ad alto rischio o flussi di lavoro sensibili a contatto con i clienti.
🔮 Hai trovato un errore che vale la pena correggere? Utilizza l'agente di riproduzione dei bug di ClickUp. Aiuta a trasformare un caso di test fallito in chiari passaggi di riproduzione, in modo che i tecnici possano eseguire il debug più rapidamente. Ciò è particolarmente utile quando un prompt si interrompe solo in presenza di input o condizioni specifiche.

📚 Leggi anche: Modelli di flusso di lavoro per prompt IA
5. Modello di report sulle prestazioni di ClickUp™

Gli stakeholder raramente hanno la pazienza di scavare tra i log di test grezzi o i fogli di valutazione tecnica. Quando un ciclo di benchmarking termina, di solito ti ritrovi con il compito manuale di tradurre quei numeri in una narrazione che giustifichi la tua prossima implementazione.
Il modello di report sulle prestazioni di ClickUp™ funge da ponte di comunicazione definitivo per le tue operazioni di IA. Organizza i tuoi risultati in un documento di riepilogo/riassunto di alto livello che evidenzia i miglioramenti del modello e i rischi di regressione.
✨ Perché adorerai questo modello
- Sezioni di riepilogo/riassunto: aree predefinite per i risultati chiave, i migliori e i peggiori performer e i passaggi successivi consigliati
- Visualizzazione dei dati in tempo reale : importa i dati in tempo reale dalle attività di benchmarking nelle dashboard di ClickUp, una rappresentazione visiva di alto livello dei dati della tua area di lavoro che si aggiorna man mano che le valutazioni vengono completate
- Semplifica la revisione dei dati: utilizza grafici e indicatori di stato per rendere le complesse tendenze di benchmarking facilmente comprensibili anche ai team non tecnici
✅ Ideale per: responsabili di programmi di IA e product owner tecnici che devono presentare l'affidabilità dei modelli e lo stato di preparazione delle versioni alla dirigenza.
6. Modello di rapporto sulle attività di ClickUp™
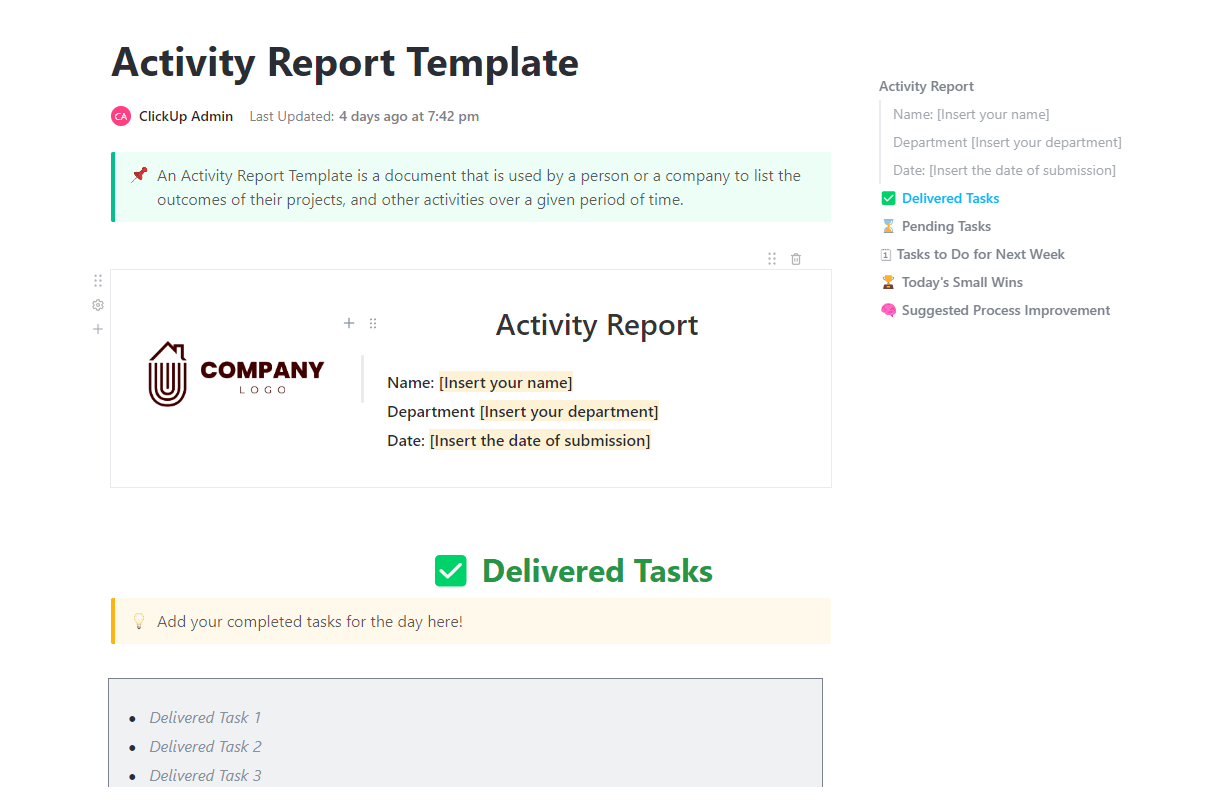
Una routine di benchmarking è utile solo se il tuo team la segue davvero. Quando le attività di test si accumulano, è facile saltare i passaggi di documentazione che mantengono la tua traccia di audit.
Il modello di rapporto sulle attività di ClickUp™ funge da cuore pulsante del tuo ciclo di test. Tiene traccia delle valutazioni che sono state consegnate e di quelle ancora in coda. Questa visibilità aiuta a mantenere l'intero processo di governance nei tempi previsti.
✨ Perché adorerai questo modello
- Registrazione delle attività: acquisizione automatica degli aggiornamenti delle attività, delle modifiche di stato e dei commenti di ClickUp collegati ai flussi di lavoro di benchmark
- Filtraggio per periodo di tempo: visualizza l'attività per settimana, sprint o ciclo di benchmark per individuare le tendenze relative alla produttività
- Visibilità del carico di lavoro: scopri quali valutatori sono sovraccarichi e quali hanno capacità disponibili con la vista Carico di lavoro di ClickUp
✅ Ideale per: responsabili dei team di IA e responsabili operativi che devono garantire che i flussi di lavoro di benchmarking non vengano ignorati o ritardati.
💡 Suggerimento da esperto: programma una riunione settimanale di 15 minuti per la "revisione delle attività" per esaminare il Rapporto sulle attività e segnalare le valutazioni rimaste nello stesso stato per oltre 3 giorni. Usa ClickUp AI Notetaker per acquisire automaticamente gli elementi da intraprendere e gli ostacoli discussi durante la riunione.

7. Modello di balanced scorecard di ClickUp
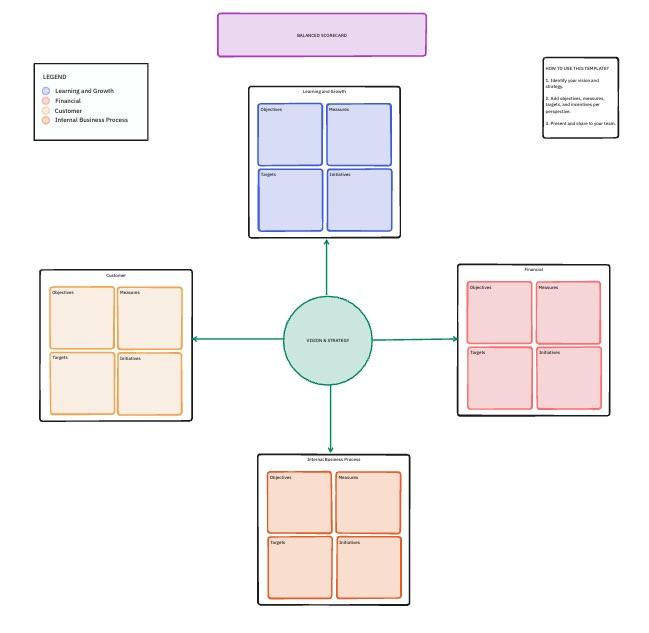
Un prompt che ottiene un punteggio del 98% in termini di accuratezza potrebbe comunque essere troppo costoso o lento per essere effettivamente utilizzato. Hai bisogno di un modo per verificare se le tue modifiche tecniche stanno raggiungendo i benchmark tecnici, fornendo al contempo il supporto necessario per raggiungere i tuoi obiettivi aziendali più ampi.
Il modello Balanced Scorecard di ClickUp utilizza una lavagna online per mappare queste connessioni. Si tratta di uno spazio collaborativo per collegare i dati tecnici a categorie strategiche quali l'impatto finanziario, la soddisfazione dei clienti e la crescita interna.
✨ Perché adorerai questo modello
- Valutazione multidimensionale: quattro prospettive strategiche con metriche a livello di prompt integrate in ciascuna
- Mappatura dell'allineamento: collega visivamente i singoli risultati dei benchmark agli obiettivi a livello di team o di prodotto
- Campi ponderati: definisci punteggi ponderati per dimensione utilizzando i campi personalizzati di ClickUp, in modo che le prestazioni aggregate riflettano le priorità strategiche
✅ Ideale per: Product manager e responsabili IA/ML che hanno bisogno di allineare le prestazioni dell'ingegneria dei prompt con gli obiettivi aziendali di alto livello e l'allocazione delle risorse.
8. Modello di valutazione del progetto di ClickUp
Saltare l'analisi post-mortem nel tuo ciclo di benchmarking significa perdere l'opportunità di risolvere i colli di bottiglia dei tuoi test. Devi sapere se i tuoi casi di test erano davvero rappresentativi o se i tuoi criteri di valutazione erano troppo vaghi prima di iniziare il prossimo ciclo di implementazioni.
Il modello di valutazione del progetto di ClickUp ti aiuta a valutare la valutazione stessa. Ti porta oltre i semplici punteggi dei prompt per esaminare lo stato generale della tua pipeline di test, in modo che ogni ciclo porti a miglioramenti concreti nella logica.
✨ Perché adorerai questo modello
- Verifica lo stato di salute del processo: utilizza campi di stato contrassegnati da colori per valutare a colpo d'occhio l'ambito dei test, la Sequenza e l'efficienza delle risorse
- Cattura le lezioni apprese: registra ciò che ha funzionato e ciò che non ha funzionato in una sezione strutturata di documento per migliorare il tuo prossimo ciclo di valutazione
- Identifica i rischi futuri: registra ostacoli specifici come tempi di inattività delle API o lacune nei dati per evitare che rallentino il tuo prossimo sprint di prompt
✅ Ideale per: responsabili delle operazioni di IA e responsabili del controllo qualità che hanno bisogno di perfezionare le loro metodologie di test e dimostrare il ROI del lavoro richiesto per il benchmarking.
9. Modello di revisione euristica di ClickUp

I punteggi numerici raccontano solo una parte della storia quando si valutano i risultati dell'IA. Un prompt potrebbe superare un test di accuratezza fattuale, ma risultare comunque robotico, confuso o leggermente fuori dal tono del marchio per gli utenti.
Il modello di revisione euristica di ClickUp integra l'intuizione umana degli esperti nel tuo flusso di lavoro PromptOps. Utilizza una lavagna online collaborativa per mappare i risultati rispetto a principi fondamentali come la chiarezza e la prevenzione degli errori. Il tuo team può associare feedback specifici a diverse categorie euristiche utilizzando post-it digitali per mantenere l'audit organizzato.
✨ Perché adorerai questo modello
- Standardizza i controlli qualitativi: valuta i risultati in base a principi personalizzati per garantire che il tono del marchio e l'utilità siano coerenti in tutti i contenuti generati
- Dai priorità alle correzioni logiche: classifica i problemi in base alla gravità per distinguere i rischi critici per la sicurezza da errori minori di natura estetica
- Consolida le opinioni degli esperti: acquisisci le note dei revisori su post-it della lavagna online per rendere i dati qualitativi facili da esaminare e su cui agire
✅ Ideale per: autori UX e team PromptOps che conducono audit manuali specialistici per garantire che i contenuti generati dall'IA soddisfino elevati standard di qualità e sicurezza.
📮ClickUp Insight: Mentre il 34% degli utenti opera con piena fiducia nei sistemi di IA, un gruppo leggermente più ampio (38%) mantiene un approccio del tipo "fidati ma verifica". Uno strumento autonomo che non conosce il tuo contesto lavorativo comporta spesso un rischio maggiore di generare risposte imprecise o insoddisfacenti.
Ecco perché abbiamo creato ClickUp Brain, l'IA che collega la project management, la gestione delle conoscenze e la collaborazione all'interno del tuo spazio di lavoro e degli strumenti di terze parti integrati. Ottieni risposte contestuali senza dover attivare/disattivare le schermate e sperimenta un aumento dell'efficienza lavorativa di 2-3 volte, proprio come i nostri clienti di Seequent.
📮ClickUp Insight: Mentre il 34% degli utenti opera con piena fiducia nei sistemi di IA, un gruppo leggermente più ampio (38%) mantiene un approccio del tipo "fidati ma verifica". Uno strumento autonomo che non conosce il tuo contesto lavorativo comporta spesso un rischio maggiore di generare risposte imprecise o insoddisfacenti.
Ecco perché abbiamo creato ClickUp Brain, l'IA che fornisce la connessione tra la project management, la gestione delle conoscenze e la collaborazione all'interno della tua area di lavoro e degli strumenti di terze parti integrati. Ottieni risposte contestualizzate senza dover attivare/disattivare le schermate e sperimenta un aumento dell'efficienza lavorativa di 2-3 volte, proprio come i nostri clienti di Seequent.
10. Modello per OKR e obiettivi aziendali di ClickUp
Migliorare la precisione dei prompt dal 72% all'88% è un enorme successo tecnico. Tuttavia, quel numero ha peso solo se la leadership comprende come tali miglioramenti incidano direttamente sulla crescita trimestrale.
Il modello "OKR e obiettivi aziendali" di ClickUp colma il divario tra il benchmarking tecnico e la strategia di alto livello. Consente di inserire obiettivi di performance specifici all'interno degli obiettivi principali del prodotto. In questo modo il team rimane concentrato sui risultati tecnici che fanno la differenza per l'azienda.
✨ Perché adorerai questo modello
- Gerarchia dagli obiettivi ai risultati chiave: inserisci gli obiettivi di benchmarking a livello di prompt sotto gli obiettivi del team o del prodotto per un chiaro allineamento
- Monitoraggio dei progressi: indicatori visivi di avanzamento che si aggiornano man mano che i punteggi di benchmark migliorano nel corso dei cicli di valutazione
- Visibilità trasversale: pianifica gli OKR aziendali e effettua la condivisione degli obiettivi di benchmarking con i team di prodotto, ingegneria e leadership, in modo che tutti possano vedere come la qualità dei prompt si colleghi alle priorità della roadmap
✅ Ideale per: team di IA/ML che intendono formalizzare il benchmarking come obiettivo ricorrente con risultati misurabili.
Migliora la qualità della tua IA con ClickUp
Un numero maggiore di prompt comporta più variabili, più iterazioni e un rischio maggiore di un calo della qualità dei risultati.
Con ClickUp, puoi creare un'area di lavoro integrata in cui il benchmarking inizia con una valutazione strutturata nelle attività e il perfezionamento rimane allineato attraverso documenti e lavagne online. Inoltre, l'IA è integrata in ogni modello e soluzione, gestendo automaticamente le analisi ripetitive e il controllo delle versioni.
Allora, cosa stai aspettando? Inizia gratis con ClickUp e trasforma i tuoi benchmark in risultati.
Domande frequenti
Le metriche principali includono accuratezza, pertinenza, coerenza e latenza. Dovresti anche effettuare il monitoraggio del tasso di allucinazioni, dell'aderenza al tono e del tasso di completamento delle attività. La giusta combinazione dipende in ultima analisi dal tuo caso d'uso specifico. Ad esempio, i risultati rivolti ai clienti danno priorità al tono e alla sicurezza, mentre i prompt interni si concentrano maggiormente sull'accuratezza e sulla velocità.
Per adattare il tuo modello, inizia aggiungendo campi per il nome del modello, la versione e le impostazioni dei parametri, come la temperatura e i limiti dei token. Dovresti anche includere una sezione per il confronto tra output previsto e effettivo per misurare le prestazioni. Infine, aggiungi il monitoraggio della versione a ogni esecuzione. Ciò garantisce che ogni benchmark sia collegato a una specifica iterazione del prompt, consentendo una valutazione accurata a lungo termine.
Il benchmarking quantitativo utilizza punteggi numerici (ad es. percentuale di accuratezza, tempo di risposta) per un confronto oggettivo. Al contrario, il benchmarking qualitativo si avvale della revisione di esperti in base a principi quali chiarezza, utilità e voce del marchio: i programmi di test dei prompt più efficaci utilizzano entrambi.
Il benchmarking strutturato rileva le regressioni dei prompt prima che raggiungano gli utenti. Crea un ciclo di feedback continuo tra valutazione e iterazione, consentendoti di perfezionare le prestazioni nel tempo. Questo processo costruisce una solida base di dati a supporto delle tue decisioni di ingegneria dei prompt.