
Sorry, there were no results found for “”
Sorry, there were no results found for “”
Sorry, there were no results found for “”
AI has changed what engineers should document themselves. GitHub Copilot, Cursor, and Mintlify can generate first-pass docs: parameter descriptions, function summaries, and README scaffolds. What they can’t write is the Intent Layer: the decision made, the tradeoff accepted, the constraint that mattered, and the option the team rejected.
Code shows behavior. It rarely preserves rationale. That rationale usually lives in a Slack thread, ticket comment, incident review, or someone’s memory.
Stack Overflow’s 2024 Developer Survey found that 61% of professional developers spend more than 30 minutes a day searching for answers at work, with one in four spending over an hour. Some search is unavoidable, of course. But the real waste is sprint context that never made it into a doc.
This guide shows what engineers should write themselves, where AI can help, and how to keep code docs useful after the sprint ends.
Want a walkthrough? Here’s how the process looks in practice:
TL;DR
AI can draft the mechanical layer of documentation: docstrings, parameter types, function summaries, and README scaffolds. Engineers still need to write the intent layer: the decisions, tradeoffs, constraints, and rejected options behind the code.
Engineers should still write that themselves, in Architecture Decision Records, PR descriptions, and why-comments committed alongside the code. The intent layer prevents the next developer from reverse-engineering decisions from variable names, commit messages, and old PRs. AI can now draft the routine parts: parameter types, return descriptions, and basic function summaries.
Code documentation should help the next developer understand what the code does, how to use it safely, and why it was built that way. It appears in two places: inside source files as comments and docstrings, and outside source files as READMEs, API references, runbooks, and architecture notes.
Most codebases become hard to read after the decision context disappears. The original developer may have made a smart tradeoff. The next developer only sees the artifact, not the reasoning.
The result: every new team member reverse-engineers intent from variable names, commit messages, and old PRs. That slows onboarding, reviews, debugging, and future changes to the same area.
Good documentation answers four questions:
The “why” question deserves the most human attention.
Search is already a major knowledge-work tax outside engineering too. ClickUp’s knowledge management survey found that 57% of employees waste time searching internal docs or knowledge bases for work-related information. When they can’t find what they need, 1 in 6 falls back to personal workarounds: digging through old emails, notes, or screenshots.
Code documentation breaks the same way: if developers cannot find the explanation, the explanation might as well not exist.
The cost of getting it wrong is heavy. One r/AskProgramming commenter described an RPA workflow where an undocumented button nearly triggered automated bank charges and customer letters.
The five main types are inline comments, docstrings, README files, internal wikis, and external API documentation. Each serves a different reader at a different moment. Mixing them up makes docs harder to write and harder to use. A README that reads like a docstring loses new contributors. A docstring that reads like a wiki page becomes dead weight inside source files.
Inline comments should explain non-obvious reasoning. A comment restating x = x + 1 as “increment x” adds nothing. A comment that says “offset for zero-indexed API response” earns its place because the code cannot show that external constraint. Reserve inline comments for non-obvious logic within a function body.
Docstrings are structured descriptions attached to functions, classes, or modules. They cover parameters, return values, exceptions, and usage examples. Each language has its own conventions. Follow the convention your language already expects: PEP 257 for Python docstrings, Javadoc for Java, and JSDoc for JavaScript and TypeScript.
Compare these two:
Weak docstring:
def calculate_tax(price, quantity):
"""Calculate tax."""
return price * quantity * 0.0825
Strong docstring:
def calculate_sales_tax(price: float, quantity: int) -> float:
"""Calculate total sales tax for a line item.
Args:
price: Unit price in USD.
quantity: Number of units purchased.
Returns:
Sales tax amount using the 8.25% rate required for this checkout flow.
Raises:
ValueError: If price or quantity is negative.
"""
if price < 0 or quantity < 0:
raise ValueError("Price and quantity must be non-negative.")
return price * quantity * 0.0825
The second names the function clearly, documents its parameters, and surfaces an assumption: the checkout flow uses an 8.25% tax rate.
A README should answer five questions in order: What does this project do? How do I install it? How do I use it? How do I contribute? Where do I get help? If a new contributor cannot find the setup path quickly, the README is either overloaded or poorly ordered.
Wikis and knowledge bases work best for content spanning multiple repositories or services: architecture decisions, onboarding guides, and runbooks. A wiki nobody links to from the code becomes a second search problem.
External documentation covers API references, SDK guides, and user-facing docs. It serves consumers of your code, not contributors. External docs need more setup detail, clearer authentication steps, and reference-style structure because the reader may not know your codebase at all.
If the team has no structure yet, start with a technical documentation template for architecture and setup notes, or a project documentation template for goals, owners, milestones, and decisions. Adapt the sections instead of inventing a format from scratch.
| Type | Primary audience | Update frequency | Typical location |
|---|---|---|---|
| Inline comments | Developers reading a specific code path | When code behavior changes | Source files |
| Docstrings | Developers calling a function, class, or module | When the interface changes | Source files |
| README | New contributors and evaluators | Per major release or project change | Repository root |
| Wiki or knowledge base | Internal teams and cross-team stakeholders | As decisions or processes change | Repository wiki or shared knowledge base |
| External API docs | API consumers and end users | Per release or API version | Documentation platform |
Use AI for the parts it can draft. Spend human time on decisions, constraints, and tradeoffs.
AI can now draft much of the mechanical work: parameter types, return descriptions, and basic function summaries. Human documentation work falls into two categories.
The best documentation is code that barely needs it. Descriptive names, single-purpose functions, and consistent conventions reduce the documentation burden before you write a single comment.
Self-documenting code makes behavior easier to read. It rarely explains the reasoning behind that behavior. Names help developers identify what something does. Documentation should explain the reasoning that naming cannot carry.
Before adding a comment, ask whether renaming a variable or extracting a function would make the comment unnecessary. If the answer is yes, refactor first. A clear name removes comments that only translate bad naming.
Before:
# Check if the user can access the resource
def chk(u, r):
# Get user role from database
role = db.get(u)
# Compare against allowed roles for this resource
return role in r.allowedAfter:
def user_has_access(user_id: str, resource) -> bool:
user_role = database.get_user_role(user_id)
return user_role in resource.allowed_rolesThe refactored version communicates the same information through naming alone. The only useful comment now would explain why certain roles are excluded, which is a policy decision the code cannot express on its own.
Implementation is visible in the code. Intent disappears unless someone writes it down. Code rarely preserves why a tradeoff was made, what constraint drove a design, or which alternative was rejected.
A common developer rule captures this well: document the why, not the what. A top-voted comment on r/coding:
I can read that this conditional branches between red and blue users. Tell me why users are classified that way and why we branch between them.
A commit message may help during review, but it is a poor long-term home for design rationale because future readers rarely find it at the moment they need it.
Will Larson, former CTO of Calm and author of An Elegant Puzzle, has written about the value of Architecture Decision Records because they preserve engineering rationale outside the codebase.
ADRs are useful because they give design rationale a stable home. If your team does not have a format, borrow a lightweight ADR template: decision, context, options considered, tradeoffs, and consequences.
Focus your documentation on these categories:
Different contexts need different homes. Docstrings capture function-level intent. Code comments handle line-level reasoning. PR descriptions provide change-level context. ADRs handle system-level decisions. Commit messages help too, but they should not be the only record of an important decision.
A common anti-pattern: documenting how a sorting algorithm works line by line. The real question is why a custom sort was used instead of the standard library. For custom code paths, document the decision behind the implementation.
Five practices make documentation more likely to stay useful after the sprint ends. Most other documentation advice depends on these habits working first.
Documentation tools fall into two groups: traditional generators and AI assistants. They handle different jobs.
Traditional generators parse structured comments in your source and produce browsable references. The right generator usually depends on your language.
| Tool | Language/Ecosystem | What it generates |
|---|---|---|
| Javadoc | Java | API reference from doc comments |
| JSDoc | JavaScript/TypeScript | API reference from annotated comments |
| Sphinx | Python (supports others via plugins) | Full documentation sites from reStructuredText or Markdown |
| Doxygen | C, C++, Java, Python, and others | Cross-language reference documentation |
| Godoc | Go | Package documentation from source comments |
Output quality depends entirely on your docstrings. They format and publish what you wrote. They do not invent missing intent.
AI-powered assistants add a second layer. GitHub Copilot, Cursor, and Windsurf can draft comments and docstrings inside the editor. Mintlify can help generate and maintain developer docs from code and existing documentation. Swimm focuses on keeping internal docs tied to code changes. ReadMe and GitBook help teams publish API references and developer-facing documentation, often with AI-assisted search or authoring features.
The Stack Overflow study found that documentation was the most frequently requested AI-automation category, cited in about 33.9% of open-ended developer responses. These tools are strongest when the source code already exposes the behavior clearly.
AI gets weaker when the explanation depends on decisions made outside the codebase: a Slack thread, a planning meeting, a ticket, or an incident review. It can summarize the function. It cannot know which constraint was negotiable, which option was rejected, or why the tradeoff was accepted.
Practical workflow:
ClickUp is not a code-level documentation generator. It will not replace Javadoc, Sphinx, JSDoc, or Godoc. It helps with the documentation around the code: READMEs, runbooks, onboarding guides, ADRs, and decision logs that should stay connected to the tasks, tickets, and sprints that produced them.
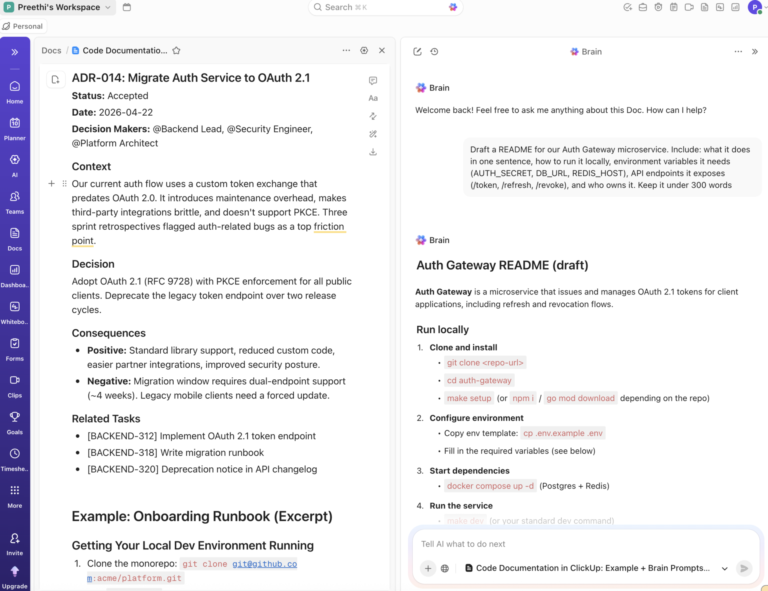
ClickUp Docs lets you draft these alongside your engineering work, and ClickUp Brain can draft a Doc from task or project context, then developers can add the decision rationale, constraints, and tradeoffs.
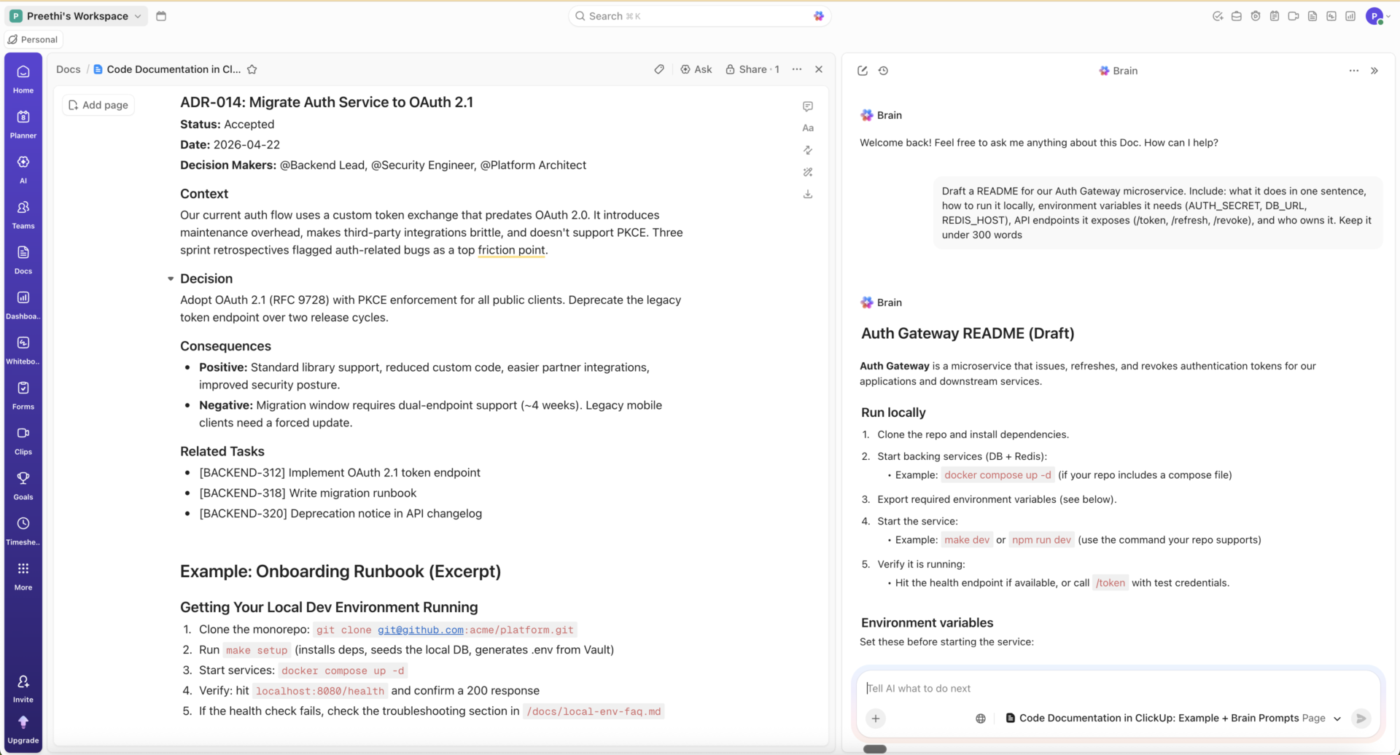
For engineering teams, that means less time hunting through scattered docs, chats, and tickets, and more time preserving the decisions those tools usually bury.
If your problem is “our docs are technically complete, but nobody can find them,” that is a discoverability problem. A connected workspace can help.
If your problem is “our API reference is out of date,” that is a generator and review problem. Sphinx, Javadoc, JSDoc, or Godoc will help more than a workspace tool. Do not confuse the two.
There’s a recurring joke across r/developersIndia, r/webdev, and r/AskProgramming threads about engineering documentation. When someone asks how the team handles docs, the top reply is usually some version of: “I am the documentation.”
It’s funny because it’s true. For years, the workaround for missing documentation has been the engineer who happens to remember.
AI changes the baseline. It can draft routine documentation quickly, which makes undocumented decisions harder to excuse. When AI can scaffold the mechanical parts of your docs in seconds, “I’ll just remember” stops being acceptable as the system of record.
That shifts the engineer’s job toward intent, decisions, and tradeoffs: the parts syntax alone cannot explain.
Much of the old documentation advice was written for a pre-AI workflow. It focuses heavily on parameter descriptions, function signatures, and exhaustive setup notes.
AI can now draft much of that work. If engineers spend most of their documentation time on mechanical summaries, they are spending human attention on the lowest-value layer.
Spend that time on intent: why the function exists, which option you rejected, and what assumption the code depends on. Those are the notes your future team, AI coding agents, and the engineer who inherits the codebase in 2027 will need.
If your documentation problem is scattered context, ClickUp can help keep decision history closer to the tasks, Docs, and projects that created it.
A README passes its first test when a contributor can find five things fast: what the project does, how to install it, how to use it, how to contribute, and where to get help. If setup is buried under badges, architecture notes, or changelog details, the README is poorly ordered.
Code comments sit inside source files and explain specific lines or blocks. Documentation usually sits outside source files in READMEs, wikis, generated reference sites, or API docs. Comments help the next developer reading your function. Documentation helps the next person trying to use, run, or contribute to your project.
The Intent Layer is the part of code documentation that captures why the code exists, not what it does: the decision made, the tradeoff accepted, the constraint that drove the design, and the option the team rejected. Code shows behavior; the Intent Layer preserves rationale. AI tools like GitHub Copilot and Mintlify can draft the mechanical layer (parameter types, function summaries) but cannot infer the Intent Layer from syntax. It usually lives in Architecture Decision Records, PR descriptions, or comments that explain why rather than what.
Update documentation in the same pull request that changes the underlying behavior. If a function signature changes, the docstring changes in that PR. For READMEs and architecture docs, audit at least once per release or quarterly. Stale documentation is dangerous because it teaches readers the wrong behavior, API, or process.
The widely-adopted Diátaxis framework splits documentation into four types: tutorials (learning-oriented, for beginners), how-to guides (task-oriented, for users solving a specific problem), reference (information-oriented, for users looking up details), and explanation (understanding-oriented, for users wanting context). Mixing them creates documentation nobody can use. A README that tries to be a full tutorial can bury the setup path. A reference page written like an essay can hide the API call.
Use AI for the mechanical layer and write the intent layer yourself. Tools like GitHub Copilot, Cursor, and Mintlify can draft docstrings, parameter descriptions, return values, and function summaries directly in your editor. Review the draft against actual code behavior, then add the parts AI can’t infer: the decision rationale, the constraint that drove it, the option you rejected, and any assumption the code depends on. For system-level decisions, write an Architecture Decision Record. Never publish AI-generated docs without a human review pass.
AI-generated documentation is useful for mechanical work like parameter descriptions, return values, and basic function summaries, but it still needs human review. Tools like GitHub Copilot, Cursor, Codeium, and Mintlify handle these well. AI cannot infer why a tradeoff was made, what alternatives were rejected, or what product, business, or infrastructure constraint shaped the design. Use AI for the first draft. Add intent and context yourself.
No. Public APIs and any function another developer will call need docstrings. Private helpers used in one file usually do not unless the logic is non-obvious. Over-documenting trivial code creates a maintenance burden without adding clarity. Match documentation depth to the function’s audience.
The right tool depends on your language. Java teams use Javadoc, JavaScript and TypeScript teams use JSDoc, Python teams use Sphinx, Go teams use Godoc, and Doxygen handles C, C++, and several others. AI-assisted tools like Mintlify, Swimm, Copilot, and Cursor can help draft or maintain documentation across parts of the workflow, but they do not replace language-native generators.
Long enough to answer the basics quickly: what the project does, how to install it, how to use it, how to contribute, and where to get help. Put deeper setup, architecture, and API details in linked docs or subdirectories.

Manasi Nair
Max 22min read

Sean Hardy
Max 26min read
Manasi Nair
Max 26min read

© 2026 ClickUp


