
Je hebt uren besteed aan het ontwikkelen van de 'perfecte' prompt. Je hebt de visie, het model en het potentieel voor een enorme winst op gebied van productiviteit. Maar één kleine aanpassing gooit je resultaat al in de war. Zonder een standaardmanier om resultaten te beoordelen, kun je niet zien of je AI daadwerkelijk verbetert of alleen maar verandert.
Volgens het Prompting Science Report van Wharton kan het simpelweg anders formuleren van een prompt de prestaties zelfs met wel 60 procentpunten beïnvloeden.
Deze gids leidt je door de beste sjablonen voor prestatiebenchmarks van prompts in ClickUp. Dit zijn je herhaalbare blauwdrukken voor het beoordelen van outputs, het bijhouden van elke iteratie en het uiteindelijk maken van een verbinding tussen je evaluatiegegevens en het werk in je werkruimte. ✨
Sjablonen voor prestatiebenchmarks in één oogopslag
Hier volgt een kort overzicht van de sjablonen voor prestatiebenchmarks van prompts die in deze gids worden behandeld, en het deel van de evaluatiewerkstroom dat elk sjabloon ondersteunt 👇
| Sjabloon | Downloadlink | Ideaal voor | Belangrijkste functies |
|---|---|---|---|
| Sjabloon voor benchmarkanalyse door ClickUp | Ontvang een gratis sjabloon | Promptvarianten vergelijken en outputs beoordelen | Visueel benchmarking-canvas, beoordelingsvelden, analyse met meerdere weergaven |
| Sjabloon voor experimentplan en resultaten van ClickUp | Ontvang een gratis sjabloon | Gestructureerde prompt-experimenten uitvoeren | Hypothese-bijhouden, logboekregistratie van testinstallaties, documentatie van resultaten |
| Sjabloon voor testbeheer door ClickUp | Ontvang een gratis sjabloon | Beheer van grootschalige evaluatiewerkstroomen | Bijhouden van testcases, uitvoeringsstatussen, triggers voor automatisering |
| Testcasjabloon van ClickUp | Ontvang een gratis sjabloon | Het documenteren van gedetailleerde promptfouten | Logboekregistratie van input/output, vergelijking van verwacht versus werkelijk, bijhouden van geslaagd/mislukt |
| Sjabloon voor prestatierapporten van ClickUp | Ontvang een gratis sjabloon | Benchmarkresultaten communiceren aan belanghebbenden | Samenvattingen, datavisualisatie, aanbevelingssecties |
| Sjabloon voor activiteitenrapport van ClickUp | Ontvang een gratis sjabloon | De voortgang van de evaluatie en de werklast bijhouden | Activiteitenlogboeken, filteren op tijd, zichtbaarheid van de werklast |
| Sjabloon voor balanced scorecards van ClickUp | Ontvang een gratis sjabloon | De prestaties van prompts afstemmen op bedrijfsdoelen | Multidimensionale beoordeling, gewogen statistieken, strategie-in kaart brengen |
| Sjabloon voor projectbeoordeling door ClickUp | Ontvang een gratis sjabloon | Benchmarkprocessen in de loop van de tijd verbeteren | Procesevaluatie, geleerde lessen, risicobijhouden |
| Heuristische beoordelingssjabloon van ClickUp | Ontvang een gratis sjabloon | Kwalitatieve evaluaties van AI-output uitvoeren | Heuristische categorieën, ernstbeoordelingen, vastleggen van feedback van experts |
| Sjabloon voor OKR's en doelen van het bedrijf door ClickUp | Ontvang een gratis sjabloon | Benchmarkresultaten koppelen aan strategische doelen | OKR-hiërarchie, voortgang bijhouden, zichtbaarheid tussen teams |
🧠 Leuk weetje: 'Benchmark' is niet ontstaan in software- of productteams. In de 19e eeuw betekende het oorspronkelijk het referentiepunt van een landmeter, lang voordat het de standaard werd voor het meten van alles, van website-experimenten tot de prestaties van prompts.
Wat is een prestatiebenchmark-sjabloon?
Een sjabloon voor prestatiebenchmarks van prompts is een raamwerk voor het evalueren, vergelijken en beoordelen van AI-promptuitkomsten. Het wordt gebruikt om te meten of een AI-prompt daadwerkelijk werkt of stilletjes slechter wordt bij elke modelupdate.
Zie het als een gestandaardiseerde experimentinstallatie:
- Het bepaalt wat je test
- Hoe meet je succes?
- Welke inputs u gebruikt
- Hoe u resultaten vastlegt
👀 Wist je dat? Een van de beroemdste experimenten in de statistiek begon met een discussie over de vraag of melk of thee eerst moest worden ingeschonken. Ronald Fisher maakte van dat kleine meningsverschil een formele test met willekeurig verdeelde kopjes, en het werd een van de klassieke verhalen achter het moderne experimentele ontwerp.
Wat maakt een goede sjabloon voor prestatiebenchmarks voor prompts?
Een goede prompt-sjabloon moet specifieke taken goed uitvoeren, anders ligt hij na de eerste Sprint al in de la:
- Gestandaardiseerde evaluatiecriteria: Definieer dimensies zoals nauwkeurigheid, relevantie, toon en hallucinatiepercentage voordat iemand begint met testen. Zonder vooraf gedefinieerde rubrieken scoort elke beoordelaar anders, en zijn de resultaten niet vergelijkbaar
- Versiebeheer: Elke benchmarkrun moet gekoppeld zijn aan een specifieke promptversie, model en parameterset, zodat u kunt bijhouden wat er is veranderd en waarom
- Zowel numerieke als kwalitatieve beoordeling: Een feitelijk correct antwoord kan nog steeds robotachtig klinken. De beste sjablonen combineren cijferbeoordelingen met gestructureerde schriftelijke aantekeningen, naast elkaar
- Vergelijkingsklare structuur: U moet twee versies van de prompt naast elkaar kunnen plaatsen en de verschillen direct kunnen zien
- Bruikbare output: Een benchmark die eindigt met “score: 7/10” is onvolledig. Beoordelaars moeten een aantekening maken over waarom een score op dat cijfer is uitgekomen en wat er vervolgens moet worden aangepast
- Gekoppeld aan het werk: Benchmarkresultaten in een silo verliezen snel hun context. Het sjabloon werkt het beste wanneer dit is gekoppeld aan de taken en werkstroom waar de ontwikkeling van prompts daadwerkelijk plaatsvindt
📮ClickUp Insight: 92% van de kenniswerkers loopt het risico belangrijke beslissingen kwijt te raken die verspreid zijn over chat, e-mail en spreadsheets. Zonder een uniform systeem voor het vastleggen en bijhouden van beslissingen gaan cruciale zakelijke inzichten verloren in de digitale ruis. Met de taakbeheerfuncties van ClickUp hoef je je hier nooit zorgen over te maken. Maak met één klik taken aan vanuit chat, taakcommentaren, documenten en e-mails!
📮ClickUp Insight: 92% van de kenniswerkers loopt het risico belangrijke beslissingen kwijt te raken die verspreid zijn over chat, e-mail en spreadsheets. Zonder een uniform systeem voor het vastleggen en bijhouden van beslissingen gaan cruciale zakelijke inzichten verloren in de digitale ruis. Met de taakbeheerfuncties van ClickUp hoef je je hier nooit zorgen over te maken. Maak met één klik taken aan vanuit chat, taakcommentaren, documenten en e-mails!
10 sjablonen voor prestatiebenchmarks voor prompts voor uw team
Elk van de onderstaande sjablonen benadert het benchmarken van promptprestaties vanuit een andere invalshoek – van gedetailleerde testcases tot strategische rapportage. Sommige zijn speciaal ontworpen voor benchmarking; andere zijn aanpasbare frameworks die engineeringteams aanzetten om ze te hergebruiken voor werkstroom-evaluaties.
Laten we eens kijken:
1. Sjabloon voor benchmarkanalyse van ClickUp™
Het evalueren van de prestaties van prompts verandert meestal in een subjectieve puinhoop zonder vaste referentiepunt voor vergelijking. Als je alleen maar de outputs doorleest, zul je nooit echt weten welke aanpassing in de logica een hallucinatie heeft verholpen of een reactie heeft verbeterd.
De Benchmark Analysis-sjabloon van ClickUp™ fungeert als een visueel evaluatielab op een ClickUp-Whiteboard. Hiermee kunt u promptvarianten, beoordelingsrubrieken en modelresultaten op één oneindig canvas weergeven, zodat u patronen in de modellogica kunt ontdekken die in een standaard lijstweergave verborgen zouden blijven.
✨ Waarom je deze sjabloon geweldig zult vinden
- Aangepaste scorevelden: breng elke evaluatiedimensie (feitelijke nauwkeurigheid, lengte van het antwoord en frequentie van hallucinaties) in kaart aan een speciaal ClickUp-aangepast veld
- Meerdere weergaven: Schakel tussen de ClickUp-tabelweergave voor het vergelijken van ruwe gegevens, de ClickUp-bordweergave voor statusgebaseerd bijhouden (In afwachting van beoordeling → Beoordeeld → Moet worden herzien) en meer dan 15 aanpasbare ClickUp-weergaven
- Historische tracking: Elke benchmarkrun is een taak met een volledige geschiedenis, zodat u door eerdere evaluaties kunt scrollen zonder door spreadsheets met versienamen te hoeven spitten
✅ Ideaal voor: AI-onderzoekers en prompt-engineers die rigoureuze A/B-tests coördineren voor meerdere modelvarianten, productielogica en use cases met gevoelige gegevens.
⚡️ Wilt u meer sjablonen voor benchmarkanalyses om uit te kiezen? We hebben hier een lijst voor u samengesteld: Gratis sjablonen voor benchmarkanalyses voor teams
2. Sjabloon voor experimentplan en resultaten van ClickUp

Hoe benchmark je een prompt zonder de voorwaarden achter de prestaties te verdoezelen? De sjabloon voor experimentplannen en resultaten van ClickUp biedt methodologische nauwkeurigheid voor de oefening. In deze sjabloon begint elke promptproef met een geformuleerde hypothese, een testinstallatie en een overzicht van wat er tussen de runs is veranderd.
Naarmate de resultaten binnenkomen, zet de sjabloon verspreide observaties om in een bewijsketen. Promptvarianten, benchmarkcriteria en aantekeningen over de uitkomsten blijven gekoppeld aan dezelfde werkstroom, waardoor je team een duidelijker beeld krijgt van de prestaties.
✨ Waarom je deze sjabloon geweldig zult vinden
- Standaardiseer het verzenden van benchmarks: Gebruik ClickUp-formulieren om elke promptvariant, testdoelstelling, rubriek en randgeval in één consistente werkstroom te verzamelen voordat de evaluatie begint
- Maak van elke prompt-run verantwoord werk: Gebruik ClickUp-taken om eigenaren toe te wijzen, beoordelingsfasen in te stellen, afhankelijkheden bij te houden en elke benchmarkcyclus via een zichtbaar uitvoeringspad te laten verlopen
- Bewaar de logica achter elk resultaat: Leg de hypothese, testvoorwaarden en uiteindelijke observaties vast in één experimentverslag
✅ Ideaal voor: Content- of supportleads die een betrouwbaardere promptbibliotheek opbouwen voor productiegebruik.
👀 Wist je dat? Aangezien naar verwachting 40% van de apps van ondernemingen tegen het einde van dit jaar op AI-agents zal draaien, heeft ons team bij ClickUp ons volledige contentsysteem al overgezet naar Super Agents.
Deze autonome teamgenoten zorgen voor het volledige proces van opstellen, doorsturen en publiceren, waardoor wij ons volledig kunnen richten op de strategie op hoog niveau.
Bekijk hieronder hoe ze onze werkruimte gebruiken:
3. Sjabloon voor testbeheer van ClickUp
Het opschalen van een promptbibliotheek mislukt meestal omdat niemand weet welke tests daadwerkelijk zijn voltooid. Als je handmatig de statussen 'geslaagd' of 'mislukt' bijhoudt in een willekeurig document, ben je waarschijnlijk dagen kwijt aan overbodige tests en communicatielussen.
De sjabloon voor testbeheer van ClickUp biedt een overkoepelende coördinatielaag voor uw evaluatiesuites. Het zet verspreide prompt-invoerparen om in een gestructureerde pijplijn, waarin elke testcase een duidelijke eigenaar en een actuele status heeft, waardoor uw implementatieschema op schema blijft.
✨ Waarom je deze sjabloon geweldig zult vinden
- Controleer de status van de uitvoering: Gebruik aangepaste statussen in ClickUp, zoals 'Moet opnieuw worden getest' of 'Geslaagd', om de voortgang van je benchmarksuite in één oogopslag bij te houden
- Synchroniseer iteratiecyclusen: Stel ClickUp-automatiseringen in om specifieke testcases te markeren voor een nieuwe run wanneer de kernlogica van de prompt wordt gewijzigd
- Decentraliseer evaluatiewerk: wijs testbatches toe aan verschillende leden van het team om knelpunten te elimineren en de vooringenomenheid van menselijke evaluatoren te verminderen
✅ Ideaal voor: QA-leiders en managers van prompt-operaties die evaluatiesuites met grote volumes coördineren over meerdere versies van het model en technische werkstromen heen.
💡 Pro-tip: Heb je snel antwoorden nodig? Gebruik ClickUp Brain. Het kan testaantekeningen, mislukte gevallen, wijzigingen in prompts en de context van eerdere runs ophalen uit je werkruimte en gekoppelde apps. Zo kun je zien wat er is gebeurd voordat je de volgende evaluatie uitvoert.
4. Sjabloon voor testcases van ClickUp

Atomische fouten in je promptlogica zijn bijna onmogelijk op te lossen als ze verborgen zitten in een algemene statusupdate. Je moet precies kunnen zien waar het model een fout heeft gemaakt of een specifieke beperking heeft genegeerd, zonder urenlang handmatig door de chatgeschiedenis te moeten spitten.
De Test Case-sjabloon van ClickUp fungeert als de gedetailleerde documentatielaag voor uw evaluatiesuite. Het splitst elke combinatie van prompt en invoer op in een afzonderlijke taak, waardoor een directe vergelijking tussen uw verwachte resultaten en de daadwerkelijke output van het model wordt afgedwongen.
✨ Waarom je deze sjabloon geweldig zult vinden
- Standaardiseer audittrails: registreer invoervariabelen, verwachte resultaten en delta-antekeningen in gestructureerde velden om subjectieve interpretatie tijdens beoordelingen te voorkomen
- Sorteer resultaten direct: Markeer elke testcase met binaire geslaagd/mislukt-indicatoren om directe logische fouten te onderscheiden van kleine formatproblemen
- Creëer traceerbare koppelingen: koppel individuele testcases aan bovenliggende taken via ClickUp-taakrelaties om precies te zien hoe fouten in randgevallen uw totale benchmarkscores beïnvloeden
✅ Ideaal voor: QA-analisten en lead prompt engineers die regressietests beheren voor risicovolle AI-toepassingen of gevoelige werkstroomen die klantgericht zijn.
🔮 Een fout gevonden die het waard is om te verhelpen? Schakel dan ClickUp's Bug Reproduction Replicator Agent in. Deze helpt een mislukte testcase om te zetten in duidelijke stappen om de fout te reproduceren, zodat de technische afdeling deze sneller kan debuggen. Dat is vooral handig wanneer een prompt alleen onder specifieke invoer of voorwaarden faalt.

📚 Lees ook: AI-prompt-werkstroom-sjablonen
5. Sjabloon voor prestatierapporten van ClickUp™
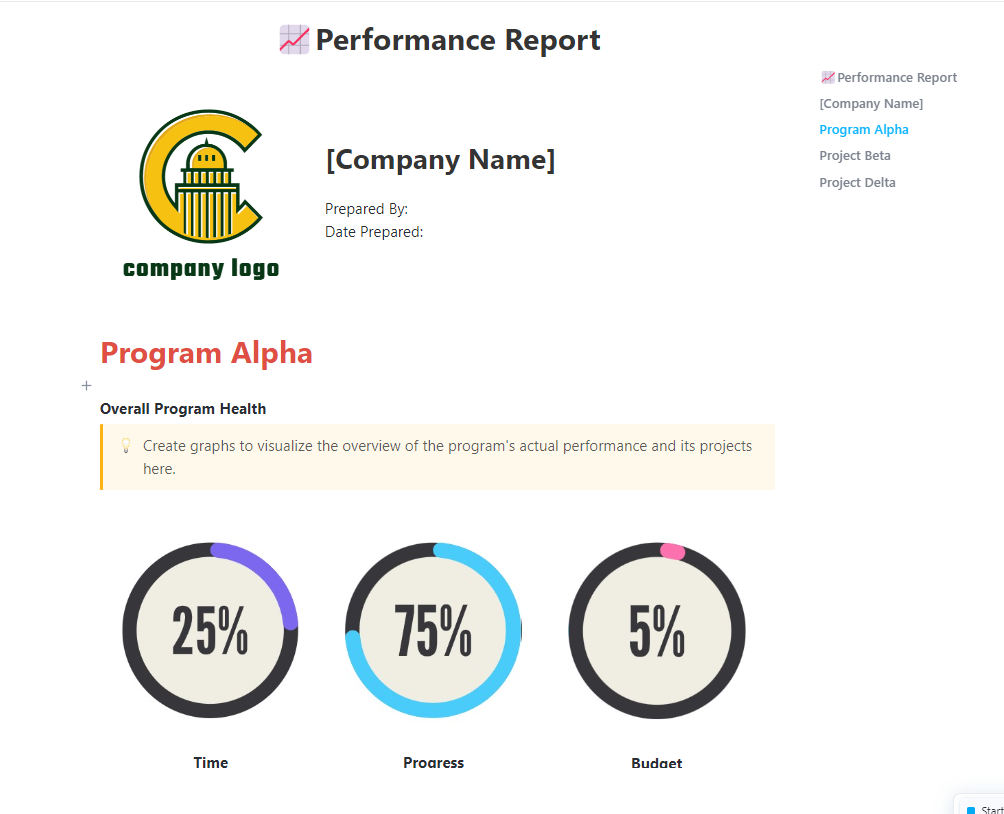
Belanghebbenden hebben zelden het geduld om ruwe testlogs of technische beoordelingsformulieren door te spitten. Wanneer een benchmarkronde is afgelopen, blijft u meestal zitten met de handmatige klus om die nummers te vertalen naar een verhaal dat uw volgende implementatie rechtvaardigt.
De Performance Report-sjabloon van ClickUp™ fungeert als de ultieme communicatiebrug voor uw AI-activiteiten. Het organiseert uw bevindingen in een overzichtelijk samenvattingsdocument dat modelverbeteringen en regressierisico's benadrukt.
✨ Waarom je deze sjabloon geweldig zult vinden
- Samenvattingssecties: Vooraf gestructureerde ruimtes voor belangrijke bevindingen, best en slechtst presterende elementen en aanbevolen vervolgstappen
- Live datavisualisatie : Haal realtime gegevens uit benchmarktaken naar ClickUp-dashboards — een visuele weergave op hoog niveau van uw ClickUp-werkruimte-gegevens die wordt bijgewerkt zodra evaluaties zijn voltooid
- Vereenvoudig het beoordelen van gegevens: Gebruik grafieken en statusindicatoren om complexe benchmarktrends inzichtelijk te maken voor niet-technische teams
✅ Ideaal voor: AI-programmamanagers en technische producteigenaren die de betrouwbaarheid van modellen en de gereedheid van versies presenteren aan het uitvoerend management.
6. Sjabloon voor activiteitenrapport van ClickUp™
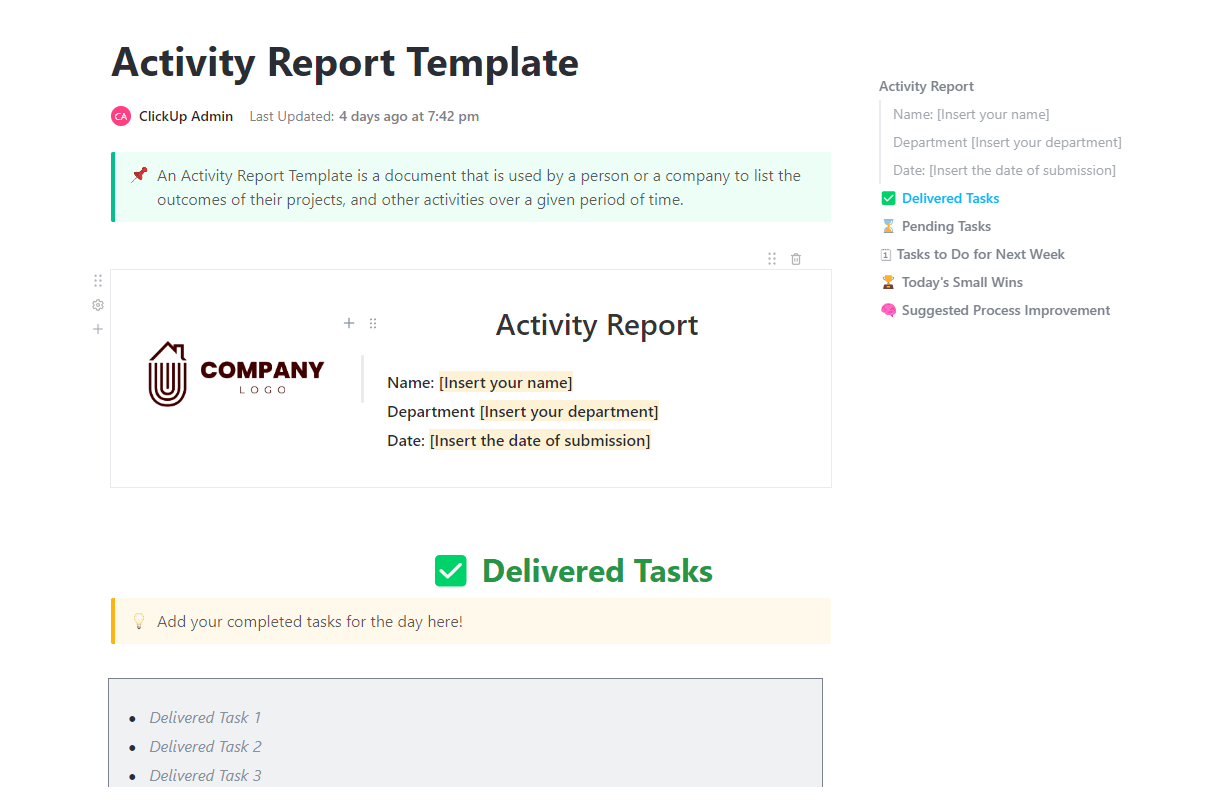
Een benchmarkingroutine is alleen waardevol als je team deze ook daadwerkelijk volgt. Wanneer testtaken zich opstapelen, is het gemakkelijk om de documentatiestappen over te slaan die je audittrail in stand houden.
De Activity Report-sjabloon van ClickUp™ fungeert als het operationele kloppende hart van uw testcyclus. Deze houdt bij welke evaluaties zijn afgeleverd en welke nog in de wachtrij staan. Deze zichtbaarheid helpt u om uw volledige governanceproces op schema te houden.
✨ Waarom je deze sjabloon geweldig zult vinden
- Activiteitenlogboek: Automatische registratie van taakupdates, statuswijzigingen en ClickUp-opmerkingen die gekoppeld zijn aan benchmark-werkstroomen
- Filteren op tijdsperiode: Bekijk activiteiten per week, Sprint of benchmarkronde om trends in de doorvoer te herkennen
- Zichtbaarheid van de werklast: Bekijk met ClickUp werklastweergave welke evaluatoren overbelast zijn en welke nog capaciteit hebben
✅ Ideaal voor: AI-teamleiders en operations managers die ervoor moeten zorgen dat benchmarking-werkstroomen niet worden genegeerd of vertraagd.
💡 Pro-tip: Plan wekelijks een 'activiteitenoverzicht-stand-up' van 15 minuten in om het activiteitenrapport door te nemen en evaluaties te markeren die al meer dan 3 dagen in dezelfde status staan. Gebruik ClickUp AI Notetaker om automatisch actiepunten en blokkades vast te leggen die tijdens de stand-up worden besproken.

7. Sjabloon voor balanced scorecards van ClickUp
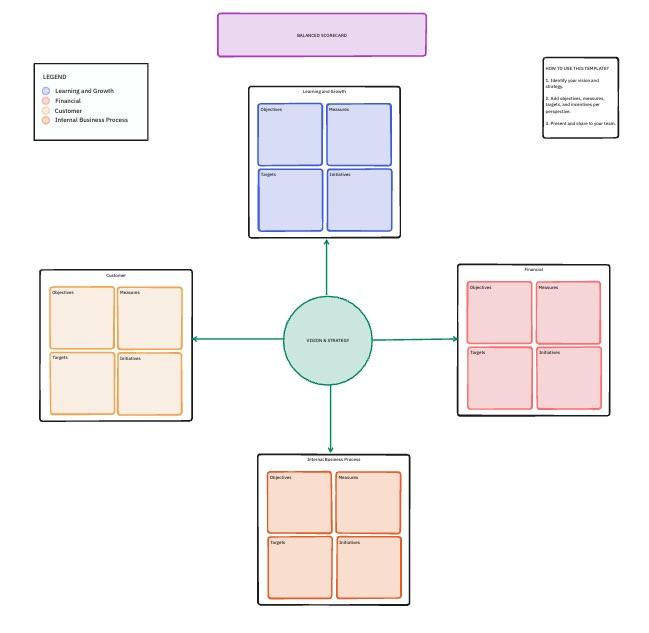
Een prompt die 98% scoort op nauwkeurigheid kan nog steeds te duur of te traag zijn om daadwerkelijk te gebruiken. U hebt een manier nodig om te zien of uw technische aanpassingen voldoen aan de technische benchmarks en tegelijkertijd uw bredere bedrijfsdoelstellingen ondersteunen.
De Balanced Scorecard-sjabloon van ClickUp maakt gebruik van een Whiteboard om deze verbindingen in kaart te brengen. Het is een samenwerkingsruimte om technische gegevens te koppelen aan strategische categorieën zoals financiële impact, klanttevredenheid en interne groei.
✨ Waarom je deze sjabloon geweldig zult vinden
- Multidimensionale beoordeling: Vier strategische perspectieven met statistieken op promptniveau samengevat in elk
- Afstemmingskaart: Breng individuele benchmarkresultaten visueel in verbinding met doelstellingen op team- of productniveau
- Gewogen velden: Definieer gewogen scores per dimensie met behulp van ClickUp aangepaste velden, zodat de geaggregeerde prestaties een afspiegeling vormen van de strategische prioriteiten
✅ Ideaal voor: Productmanagers en AI/ML-leiders die de prestaties van prompt engineering moeten afstemmen op bedrijfsdoelstellingen op hoog niveau en de toewijzing van middelen.
8. Sjabloon voor projectbeoordeling van ClickUp
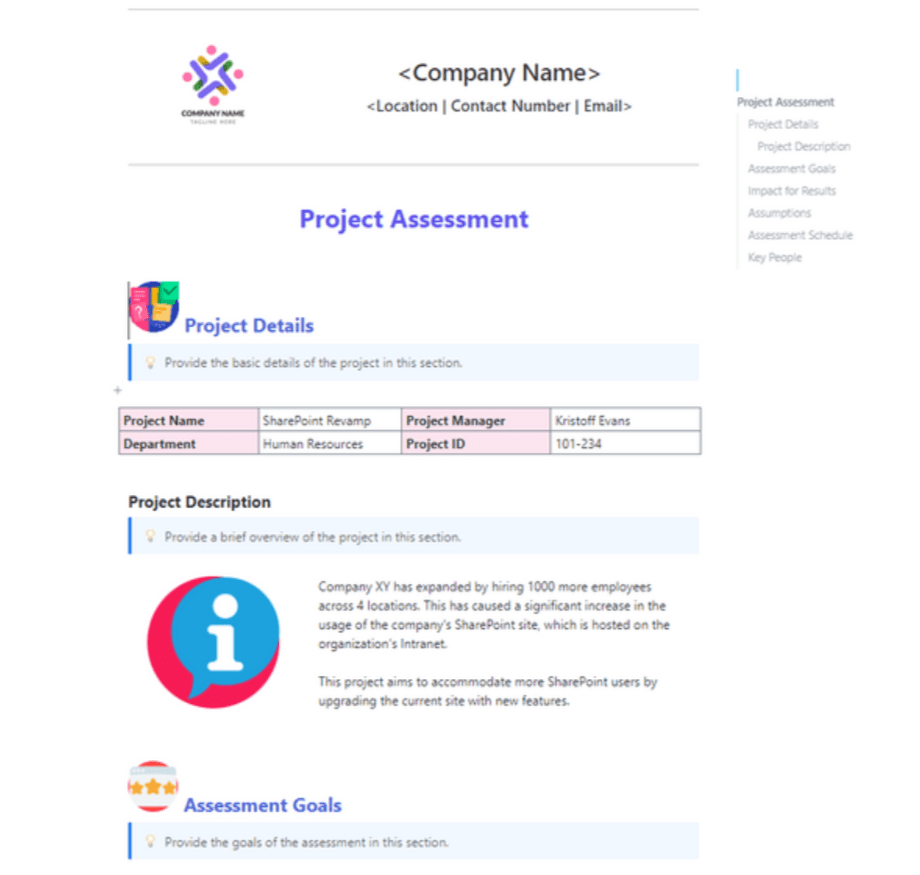
Het overslaan van een post-mortem in uw benchmarkcyclus is een gemiste kans om uw testknelpunten op te lossen. U moet weten of uw testcases echt representatief waren of dat uw beoordelingscriteria te vaag waren voordat u aan de volgende implementatieronde begint.
De Project Assessment-sjabloon van ClickUp helpt je de evaluatie zelf te beoordelen. Het gaat verder dan ruwe promptscores en onderzoekt de algehele gezondheid van je testpijplijn, zodat elke cyclus leidt tot daadwerkelijke verbeteringen in de logica.
✨ Waarom je deze sjabloon geweldig zult vinden
- Controleer de status van het proces: Gebruik statusvelden met kleurcodes om in één oogopslag de omvang van uw tests, de tijdlijn en de efficiëntie van uw middelen te beoordelen
- Leg geleerde lessen vast: Noteer wat wel en niet werkte in een gestructureerd gedeelte van het document om uw volgende evaluatieronde te verbeteren
- Identificeer toekomstige risico's: registreer specifieke obstakels, zoals API-uitval of hiaten in de gegevens, om te voorkomen dat deze uw volgende Sprint vertragen
✅ Ideaal voor: AI-operationsmanagers en QA-leiders die hun testmethodologieën moeten verfijnen en de ROI van hun benchmarkinginspanningen moeten aantonen.
9. Sjabloon voor heuristische beoordeling door ClickUp

Cijfermatige scores geven slechts een gedeeltelijk beeld bij het evalueren van je AI-output. Een prompt kan een feitelijke nauwkeurigheidstest doorstaan, maar toch robotachtig, verwarrend of enigszins afwijkend van je merk overkomen op je gebruikers.
De Heuristic Review-sjabloon van ClickUp brengt deskundige menselijke intuïtie in uw PromptOps-werkstroom. Het maakt gebruik van een gezamenlijk Whiteboard om resultaten in kaart te brengen tegen kernprincipes zoals duidelijkheid en foutpreventie. Uw team kan specifieke feedback aan verschillende heuristische categorieën vastmaken met behulp van digitale plaknotities om de audit overzichtelijk te houden.
✨ Waarom je deze sjabloon geweldig zult vinden
- Standaardiseer kwaliteitscontroles: Beoordeel outputs aan de hand van aangepaste principes om de merkstem en de bruikbaarheid consistent te houden in alle gegenereerde content
- Geef prioriteit aan logische fixes: Categoriseer problemen op ernst om kritieke veiligheidsrisico's te scheiden van kleine cosmetische fouten
- Bundel inzichten van experts: Leg aantekeningen van beoordelaars vast op Whiteboard-post-its, zodat kwalitatieve gegevens gemakkelijk te scannen en te gebruiken zijn
✅ Ideaal voor: UX-schrijvers en PromptOps-teams die deskundige handmatige audits uitvoeren om ervoor te zorgen dat door AI gegenereerde content voldoet aan hoge kwaliteits- en veiligheidsnormen.
📮ClickUp Insight: Hoewel 34% van de gebruikers volledig vertrouwen heeft in AI-systemen, hanteert een iets grotere groep (38%) een 'trust but verify'-benadering. Een op zichzelf staande tool die niet bekend is met uw werkcontext brengt vaak een groter risico met zich mee op het genereren van onnauwkeurige of onbevredigende antwoorden.
Daarom hebben we ClickUp Brain ontwikkeld, de AI die uw projectmanagement, kennisbeheer en samenwerking binnen uw ClickUp-werkruimte en geïntegreerde tools van derden met elkaar verbindt. Krijg contextuele antwoorden zonder het gedoe van schakelen tussen verschillende schermen en ervaar een 2- tot 3-voudige toename in werkefficiëntie, net als onze klanten bij Seequent.
📮ClickUp Insight: Hoewel 34% van de gebruikers volledig vertrouwen heeft in AI-systemen, hanteert een iets grotere groep (38%) een 'vertrouw maar controleer'-benadering. Een op zichzelf staande tool die niet bekend is met uw werkcontext brengt vaak een groter risico met zich mee op het genereren van onnauwkeurige of onbevredigende antwoorden.
Daarom hebben we ClickUp Brain ontwikkeld, de AI die uw projectmanagement, kennisbeheer en samenwerking binnen uw werkruimte en geïntegreerde tools van derden met elkaar verbindt. Ontvang contextuele antwoorden zonder het gedoe van schakelen tussen verschillende schermen en ervaar een 2- tot 3-voudige toename in werkefficiëntie, net als onze klanten bij Seequent.
10. Sjabloon voor OKR's en doelen van het bedrijf door ClickUp
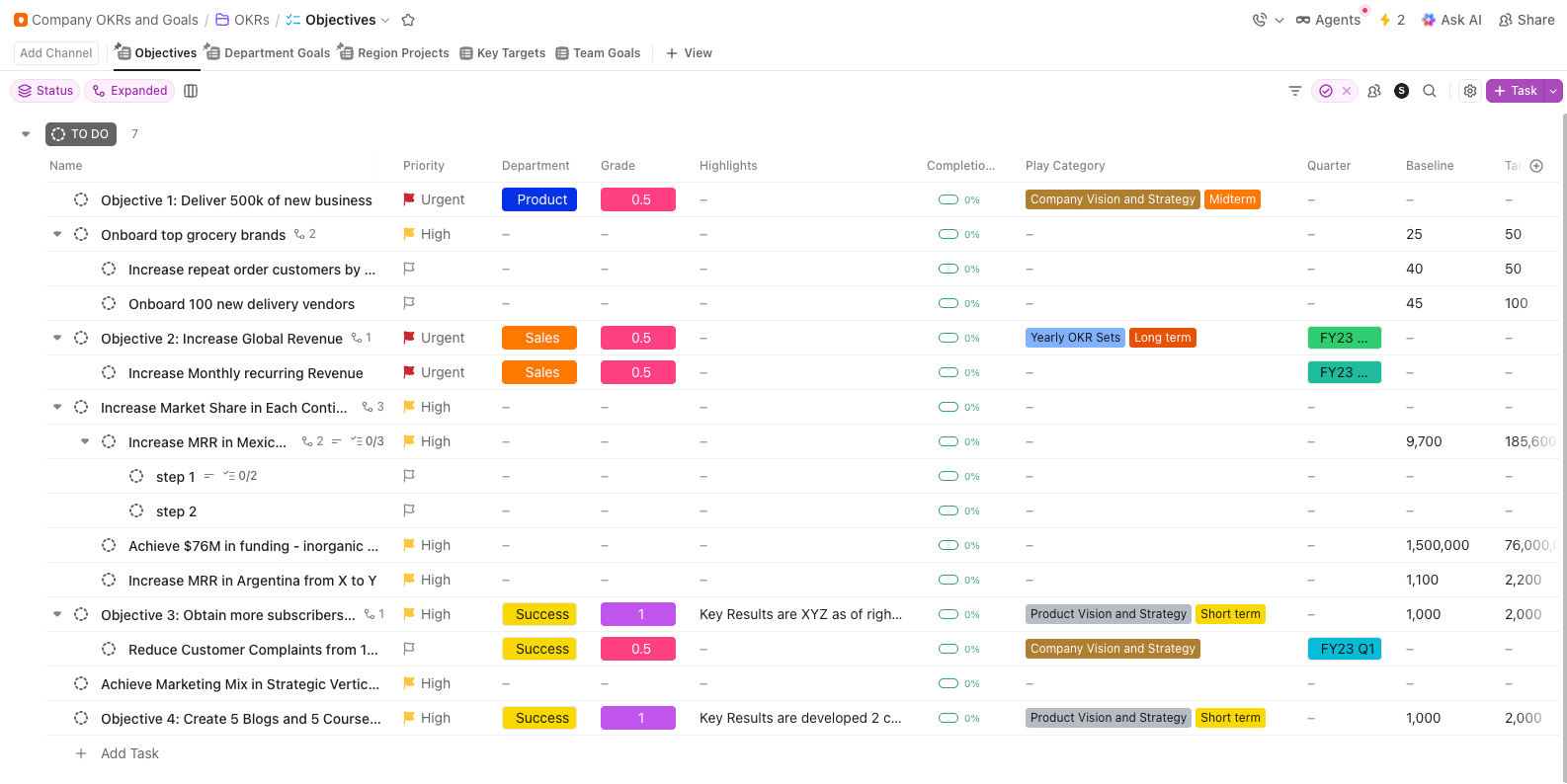
Het verbeteren van de nauwkeurigheid van prompts van 72% naar 88% is een enorme technische overwinning. Dat nummer heeft echter alleen betekenis als het management begrijpt hoe die verbeteringen direct van invloed zijn op uw kwartaalgroei.
Het sjabloon voor bedrijfs-OKR's en -doelen van ClickUp overbrugt de kloof tussen technische benchmarking en strategie op hoog niveau. Hiermee kunt u specifieke prestatiedoelen onder uw belangrijkste productdoelstellingen plaatsen. Zo blijft het team gefocust op de technische resultaten die het verschil maken voor het bedrijf.
✨ Waarom je deze sjabloon geweldig zult vinden
- Hiërarchie van doelstellingen naar kernresultaten: Plaats benchmarkdoelen op promptniveau onder team- of productdoelstellingen voor een duidelijke afstemming
- Voortgangsregistratie: Visuele indicatoren van de voortgang die worden bijgewerkt naarmate de benchmarkscores verbeteren gedurende de evaluacyclussen
- Functieoverschrijdende zichtbaarheid: Plan de OKR's van het bedrijf en deel benchmarkdoelen met product, engineering en het management, zodat iedereen ziet hoe de kwaliteit van prompts aansluit bij de prioriteiten van de roadmap
✅ Ideaal voor: AI/ML-teams die benchmarking formaliseren als een terugkerende doelstelling met meetbare resultaten.
Schaal uw AI-kwaliteit met ClickUp
Meer prompts betekenen meer bewegende delen, meer iteraties en meer kans dat de kwaliteit van de output achteruitgaat.
Met ClickUp bouw je een geïntegreerde werkruimte waar benchmarking begint met gestructureerde evaluatie in Taken, en waar verfijning op één lijn blijft via Documenten en Whiteboards. Bovendien is AI geïntegreerd in elke sjabloon en oplossing, waardoor de repetitieve analyse en versiebeheer automatisch worden beheerd.
Waar wacht je nog op? Ga gratis aan de slag met ClickUp en zet je benchmarks om in resultaten.
Veelgestelde vragen
De belangrijkste statistieken zijn onder meer nauwkeurigheid, relevantie, coherentie en latentie. U moet ook het percentage hallucinaties, de mate waarin de toon wordt aangehouden en het percentage voltooide taken bijhouden. De juiste combinatie hangt uiteindelijk af van uw specifieke gebruikssituatie. Bij output voor klanten staan toon en veiligheid bijvoorbeeld voorop, terwijl interne prompts meer gericht zijn op nauwkeurigheid en snelheid.
Om uw sjabloon aan te passen, begint u met het toevoegen van velden voor de modelnaam, versie en parameterinstellingen, zoals temperatuur en tokenlimieten. U moet ook een sectie opnemen voor vergelijkingen tussen verwachte en werkelijke output om de prestaties te meten. Voeg ten slotte versiebeheer toe aan elke run. Dit zorgt ervoor dat elke benchmark gekoppeld is aan een specifieke prompt-iteratie, waardoor een nauwkeurige evaluatie op lange termijn mogelijk is.
Kwantitatieve benchmarking maakt gebruik van numerieke scores (bijv. nauwkeurigheidspercentage, responstijd) voor een objectieve vergelijking. Kwalitatieve benchmarking daarentegen maakt gebruik van beoordelingen door experts op basis van principes zoals duidelijkheid, bruikbaarheid en merkstem – de meest effectieve programma's voor het testen van prompts maken gebruik van beide.
Gestructureerde benchmarking detecteert regressies in prompts voordat deze uw gebruikers bereiken. Het creëert een continue feedbackloop tussen evaluatie en iteratie, waardoor u de prestaties in de loop van de tijd kunt verfijnen. Dit proces vormt een solide bewijsbasis voor uw beslissingen op het gebied van prompt engineering.