
De meeste AI-implementatieprojecten mislukken niet omdat teams het verkeerde model hebben gekozen, maar omdat niemand zich drie maanden later nog kan herinneren waarom ze ervoor hebben gekozen of hoe ze de installatie kunnen repliceren. 46% van de AI-projecten wordt tussen proof-of-concept en brede acceptatie geschrapt.
Deze gids leidt u door het gebruik van Hugging Face voor AI-implementatie, van de selectie en testfase van modellen tot het beheren van het implementatieproces, zodat uw team sneller kan leveren zonder cruciale beslissingen kwijt te raken in Slack-threads en verspreide spreadsheets.
Wat is Hugging Face?
Hugging Face is een open-sourceplatform en communityhub die vooraf getrainde AI-modellen, datasets en tools biedt voor het bouwen en implementeren van machine learning- toepassingen.
Zie het als een enorme digitale bibliotheek waar u kant-en-klare AI-modellen kunt vinden, in plaats van maanden en aanzienlijke middelen te besteden aan het vanaf nul opbouwen ervan.
Het is ontworpen voor machine learning-ingenieurs en datawetenschappers, maar de tools worden steeds vaker gebruikt door multifunctionele product-, ontwerp- en engineeringteams om AI in hun werkstroom te integreren.
Wist u dat: 63% van de organisaties geen goede praktijken voor gegevensbeheer voor AI heeft. Dit leidt vaak tot vertraagde projecten en verspilde middelen.
De grootste uitdaging voor veel teams is de enorme complexiteit van het implementeren van AI. Het proces omvat de selectie van het juiste model uit duizenden opties, het beheren van de onderliggende infrastructuur, het versiebeheer van experimenten en het zorgen dat technische en niet-technische belanghebbenden op één lijn zitten.
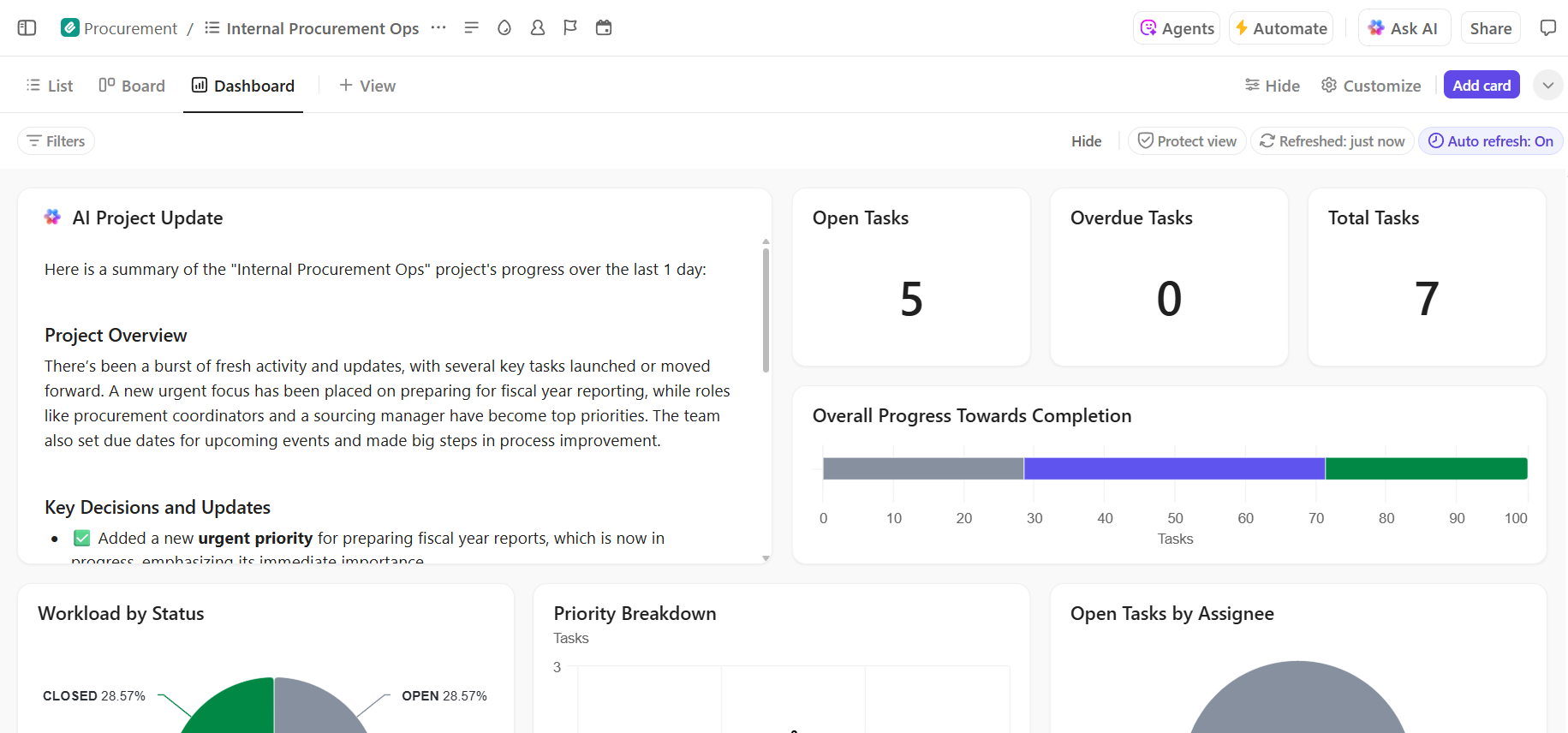
Hugging Face vereenvoudigt dit door zijn Model Hub aan te bieden, een centrale opslagplaats met meer dan 2 miljoen modellen. De transformers-bibliotheek van het platform is de sleutel die deze modellen ontsluit, waardoor u ze met slechts een paar regels Python-code kunt laden en gebruiken.
Maar zelfs met deze krachtige tools blijft AI-implementatie een uitdaging op het gebied van projectmanagement, waarbij zorgvuldig bijhouden van modelselectie, testen en uitrol vereist is om succes te garanderen.
📮ClickUp Insight: 92% van de kenniswerkers loopt het risico belangrijke beslissingen kwijt te raken die verspreid zijn over chat, e-mail en spreadsheets. Zonder een uniform systeem voor het vastleggen en bijhouden van beslissingen gaan cruciale zakelijke inzichten verloren in de digitale ruis.
Met de taakbeheerfuncties van ClickUp hoeft u zich hier nooit zorgen over te maken. Maak met één klik taken aan vanuit chats, taakopmerkingen, documenten en e-mails!
Hugging Face-modellen die u kunt implementeren
Als u net begint, kan het navigeren door de Hugging Face hub overweldigend aanvoelen. Met honderdduizenden modellen is het belangrijk om de belangrijkste categorieën te begrijpen, zodat u het juiste model voor uw project kunt vinden. De modellen variëren van kleine, efficiënte opties die voor één doel zijn ontworpen tot enorme, algemene modellen die complexe redeneringen aankunnen.
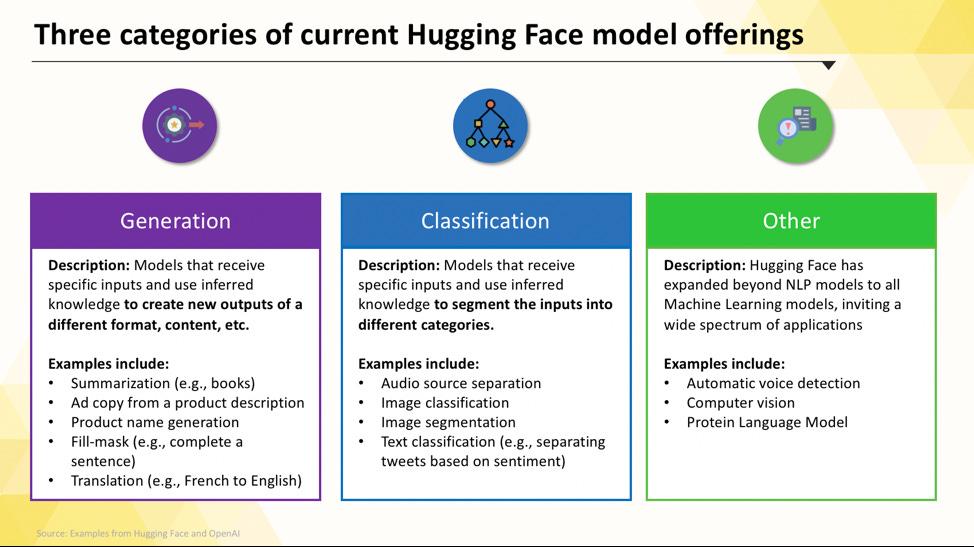
Taakspecifieke taalmodellen
Wanneer uw team één enkel, duidelijk omschreven probleem moet oplossen, hebt u vaak geen groot, algemeen model nodig. De tijd en kosten om een dergelijk model te gebruiken kunnen onbetaalbaar zijn, vooral wanneer een kleiner, meer gericht AI-hulpmiddel beter zou werken. Hier komen taakspecifieke modellen om de hoek kijken.
Dit zijn modellen die zijn getraind en geoptimaliseerd voor één specifieke functie. Omdat ze gespecialiseerd zijn, zijn ze doorgaans kleiner, sneller en zuiniger in het gebruik van middelen dan hun grotere tegenhangers.
Dit maakt ze ideaal voor productieomgevingen waar snelheid en kosten belangrijke factoren zijn. Veel modellen kunnen zelfs op standaard CPU-hardware worden uitgevoerd, waardoor ze toegankelijk zijn zonder dure GPU's.
Veelvoorkomende soorten taakspecifieke modellen zijn onder meer:
- Tekstclassificatie: gebruik dit om tekst in vooraf gedefinieerde labels te categoriseren, zoals het sorteren van klantfeedback in 'positieve' of 'negatieve' categorieën of het taggen van supporttickets op onderwerp.
- Sentimentanalyse: hiermee kunt u de emotionele toon van een tekst bepalen, wat handig is voor merkmonitoring op sociale media.
- Naamherkenning: haal specifieke entiteiten zoals personen, plaatsen en organisaties uit documenten om ongestructureerde gegevens te structureren.
- Samenvatting: Vat lange artikelen of rapporten samen in beknopte samenvattingen, zodat uw team kostbare leestijd bespaart.
- Vertaling: Converteer tekst automatisch van de ene taal naar de andere.
Grote taalmodellen
Soms vereist uw project meer dan alleen eenvoudige classificatie of samenvatting. Misschien hebt u AI nodig die creatieve marketingteksten kan genereren, code kan schrijven of complexe vragen van gebruikers op een gespreksechte manier kan beantwoorden. Voor deze scenario's zult u waarschijnlijk gebruikmaken van een Large Language Model (LLM).
LLM's zijn modellen met miljarden parameters die zijn getraind op basis van enorme hoeveelheden tekst en gegevens van het internet. Door deze uitgebreide training kunnen ze nuances, context en complexe redeneringen begrijpen. Populaire open-source LLM's die beschikbaar zijn op Hugging Face zijn onder andere modellen uit de Llama-, Mistral- en Falcon-families.
De keerzijde van deze kracht is dat er aanzienlijke rekenkracht voor nodig is. Voor de implementatie van deze modellen zijn bijna altijd krachtige GPU's met veel geheugen (VRAM) nodig.
Om ze toegankelijker te maken, kunt u technieken zoals kwantisering gebruiken, waardoor de grootte van het model met een kleine prestatievermindering wordt verkleind, waardoor het op minder krachtige hardware kan worden uitgevoerd.
📚 Lees ook: Wat zijn LLM-agenten in AI en hoe werken ze?
Tekst-naar-beeld- en multimodale modellen
Uw gegevens bestaan niet altijd alleen uit tekst. Uw team moet misschien afbeeldingen genereren voor een marketingcampagne, audio van een vergadering transcriberen of de content van een video begrijpen. Hier komen multimodale modellen, die zijn ontworpen om met verschillende soorten gegevens te werken, van essentieel belang.
Het populairste type multimodaal model is het tekst-naar-beeldmodel, dat afbeeldingen genereert op basis van een tekstbeschrijving. Modellen zoals Stable Diffusion gebruiken een techniek die diffusie wordt genoemd om verbluffende beelden te creëren op basis van eenvoudige prompts. Maar de mogelijkheden reiken veel verder dan alleen het genereren van afbeeldingen.
Andere veelgebruikte multimodale modellen die u vanuit Hugging Face kunt implementeren, zijn onder meer:
- Afbeeldingsbijschriften: genereer automatisch beschrijvende tekst voor afbeeldingen, wat ideaal is voor toegankelijkheid en contentbeheer.
- Spraakherkenning: transcribeer gesproken audio naar geschreven tekst met modellen zoals Whisper van OpenAI.
- Visuele vraagbeantwoording: stel vragen over een afbeelding en krijg een tekstueel antwoord, zoals 'Welke kleur heeft de auto op deze foto?'.
Net als LLM's zijn deze modellen rekenintensief en hebben ze doorgaans een GPU nodig om efficiënt te kunnen werken.
Bekijk dit overzicht van praktijkvoorbeelden van AI-toepassingen in verschillende sectoren en functies om te zien hoe deze verschillende soorten AI-modellen zich vertalen naar praktische zakelijke toepassingen.
Wat is de AI-volwassenheid van uw organisatie?
Uit onze enquête onder 316 professionals blijkt dat echte AI-transformatie meer vereist dan alleen het invoeren van AI-functies. Doe de AI-volwassenheidstest om te zien waar uw organisatie staat en wat u kunt doen om uw score te verbeteren.
Hoe u de instellingen voor Hugging Face voor AI-implementatie instelt
Voordat u uw eerste model kunt implementeren, moet u uw lokale omgeving en Hugging Face-account correct instellen. Het is een veelvoorkomende frustratie voor teams wanneer verschillende leden inconsistente instellingen hebben, wat leidt tot het klassieke "het werkt op mijn computer"-probleem. Door een paar minuten de tijd te nemen om dit proces te standaardiseren, bespaart u later uren aan probleemoplossing.
- Maak een Hugging Face-account aan en genereer een toegangstoken. Meld u eerst aan voor een gratis account op de website van Hugging Face. Nadat u bent ingelogd, gaat u naar uw profiel, klikt u op 'Instellingen' en gaat u vervolgens naar het tabblad 'Toegangstokens'. Genereer een nieuw token met ten minste 'leestoestemming'; u hebt dit nodig om modellen te downloaden.
- Installeer de vereiste Python-bibliotheken. Open uw terminal en installeer de kernbibliotheken die u nodig hebt. De twee essentiële bibliotheken zijn transformers en huggingface_hub. U kunt ze installeren met pip: pip install transformers huggingface_hub
- Configureer verificatie. Om uw toegangstoken te gebruiken, kunt u ofwel inloggen via de opdrachtregel door huggingface-cli login uit te voeren en uw token te plakken wanneer daarom wordt gevraagd, of u kunt het instellen als een omgevingsvariabele in uw systeem. Inloggen via de opdrachtregel is vaak de gemakkelijkste manier om aan de slag te gaan.
- Controleer de installatie. De beste manier om te controleren of alles werkt, is door een eenvoudig stukje code uit te voeren. Probeer een basismodel te laden met behulp van de pijplijnfunctie uit de transformers-bibliotheek. Als dit zonder fouten verloopt, bent u klaar om aan de slag te gaan.
Houd er rekening mee dat sommige modellen op de hub 'afgeschermd' zijn, wat betekent dat u akkoord moet gaan met de licentievoorwaarden op de modelpagina voordat u ze met uw token kunt openen.
Vergeet ook niet dat het bijhouden van wie welke referenties heeft en welke omgevingsconfiguraties worden gebruikt, een projectmanagementtaak op zich is, die steeds belangrijker wordt naarmate uw team groeit.
🌟 Als u Hugging Face-modellen in bredere softwaresystemen integreert, helpt het software-integratiesjabloon van ClickUp u bij het visualiseren van werkstroomprocessen en het bijhouden van technische integraties in meerdere stappen.
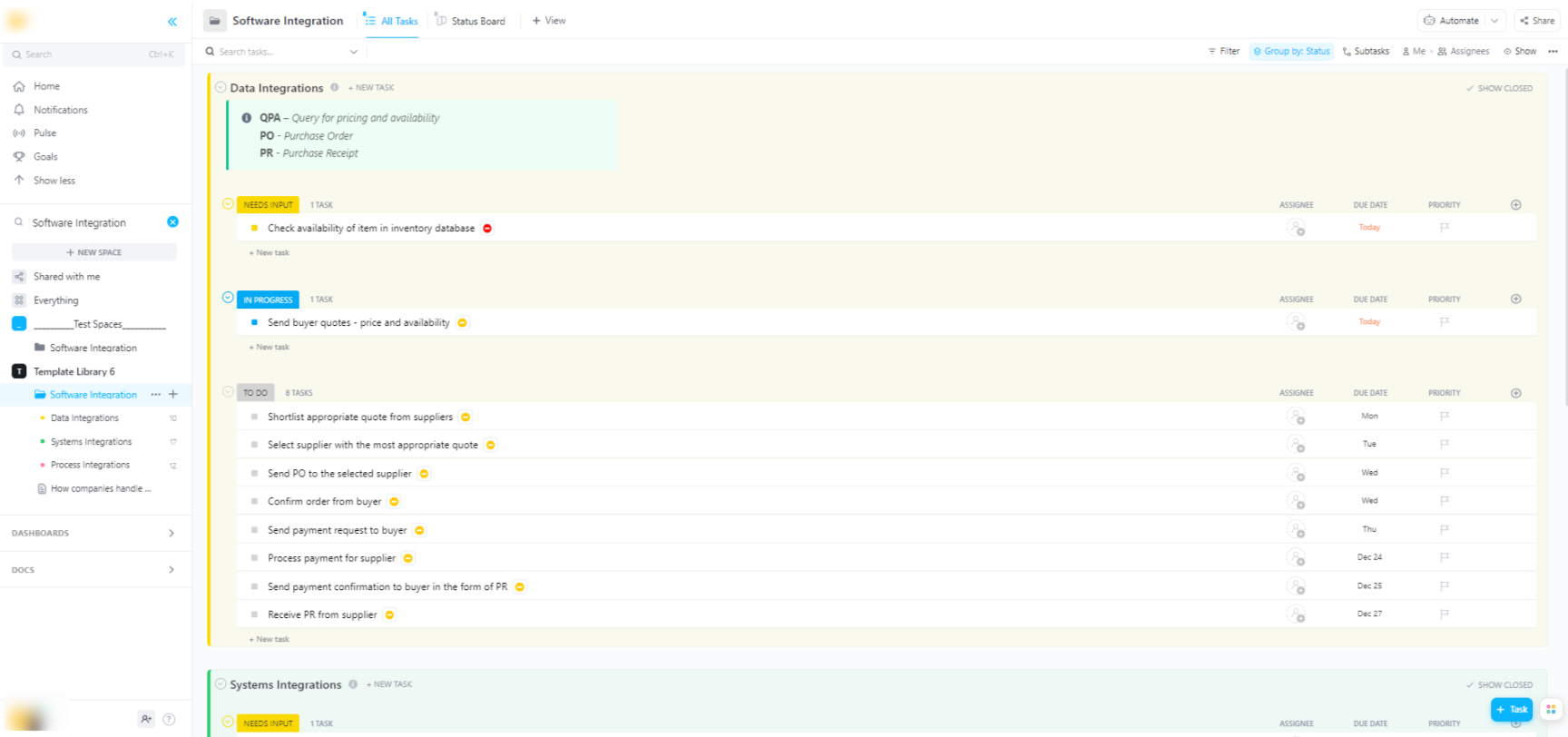
De sjabloon biedt u een eenvoudig te volgen systeem waarmee u:
- Visualiseer de verbindingen tussen verschillende softwareoplossingen
- Maak taken aan en wijs deze toe aan teamleden voor een soepelere samenwerking.
- Organiseer alle taken met betrekking tot integratie op één plek
Implementatieopties voor Hugging Face-modellen
Nadat u een model lokaal hebt getest, is de volgende vraag: waar komt het terecht? Het implementeren van een model in een productieomgeving waar het door anderen kan worden gebruikt, is een cruciale stap, maar de opties kunnen verwarrend zijn. Als u de verkeerde keuze maakt, kan dit leiden tot trage prestaties, hoge kosten of een onvermogen om het verkeer van gebruikers aan te kunnen.
Uw keuze hangt af van uw specifieke behoeften, zoals het verwachte verkeer, het budget en of u een snel prototype bouwt of een schaalbare, productieklare applicatie.
Hugging Face Ruimtes
Als u snel een demo of een interne tool moet maken, is Hugging Face Spaces vaak de beste keuze. Spaces is een gratis platform voor het hosten van machine learning-toepassingen en is perfect voor het bouwen van prototypes die u kunt delen met uw team of belanghebbenden.
U kunt de gebruikersinterface van uw app bouwen met populaire frameworks zoals Gradio of Streamlit, waarmee u eenvoudig interactieve demo's kunt maken met slechts een paar regels Python.
Het aanmaken van een Space is heel eenvoudig: u selecteert de SDK van uw voorkeur, maakt een verbinding met een Git-opslagplaats en kiest uw hardware. Spaces biedt een gratis CPU-niveau voor basisapps, maar u kunt upgraden naar betaalde GPU-hardware voor meer veeleisende modellen.
Houd rekening met de limieten:
- Niet geschikt voor API's met veel verkeer: Spaces is ontworpen voor demo's, niet voor het verwerken van duizenden gelijktijdige API-verzoeken.
- Koude starts: Als uw ruimte inactief is, kan deze in de slaapstand gaan om bronnen te besparen, wat een vertraging veroorzaakt voor de eerste gebruiker die er weer toegang toe krijgt.
- Git-gebaseerde werkstroom: al uw applicatiecode wordt beheerd via een Git-opslagplaats, wat ideaal is voor versiebeheer.
Hugging Face Inference API
Wanneer u een model in een bestaande applicatie wilt integreren, wilt u waarschijnlijk een API gebruiken. Met de Hugging Face Inference API kunt u modellen uitvoeren zonder dat u zelf de onderliggende infrastructuur hoeft te beheren. U stuurt gewoon een HTTP-verzoek met uw gegevens en krijgt een voorspelling terug.
Deze aanpak is ideaal als u zich niet wilt bezighouden met servers, schaalbaarheid of onderhoud. Hugging Face biedt twee hoofdniveaus voor deze service:
- Gratis Inference API: Dit is een gedeelde infrastructuuroptie met een limiet aan snelheid die zeer geschikt is voor ontwikkeling en testen. Het is perfect voor gebruikssituaties met weinig verkeer of wanneer u net begint.
- Inference Endpoints: Voor productietoepassingen wilt u Inference Endpoints gebruiken. Dit is een betaalde service die u voorziet van een speciale, automatisch schaalbare infrastructuur, zodat uw toepassing zelfs onder zware belasting snel en betrouwbaar blijft.
Het gebruik van de API houdt in dat u een JSON-payload naar de eindpunt-URL van het model stuurt met uw verificatietoken in de koptekst van de request.
Implementatie op cloudplatform
Voor teams die al een aanzienlijke aanwezigheid hebben bij een grote cloudprovider zoals Amazon Web Services (AWS), Google Cloud Platform (GCP) of Microsoft Azure, kan implementatie daar de meest logische keuze zijn. Deze aanpak geeft u de meeste controle en stelt u in staat om het model te integreren met uw bestaande clouddiensten en protocollen voor veiligheid.
De algemene werkstroom omvat het 'containeriseren' van uw model en de bijbehorende afhankelijkheden met behulp van Docker, en vervolgens het implementeren van die container in een cloudcomputingservice. Elke cloudprovider heeft services en integraties die dit proces vereenvoudigen:
- AWS SageMaker: biedt native integratie voor het trainen en implementeren van Hugging Face-modellen.
- Google Cloud Vertex AI: hiermee kunt u modellen vanuit de hub implementeren op beheerde eindpunten.
- Azure Machine Learning: biedt tools voor het importeren en gebruiken van Hugging Face-modellen.
Hoewel deze methode meer expertise op het gebied van installatie en DevOps vereist, is het vaak de beste optie voor grootschalige implementaties op niveau van de onderneming waarbij u volledige controle over de omgeving nodig hebt.
📚 Lees ook: Werkstroomautomatisering: automatiseer werkstroomstromen om de productiviteit te verhogen
Hoe Hugging Face-modellen voor inferentie uitvoeren
Wanneer u Hugging Face gebruikt voor AI-implementatie, is 'running inference' het proces waarbij u uw getrainde model gebruikt om voorspellingen te doen over nieuwe, onbekende gegevens. Dit is het moment waarop uw model het werk doet waarvoor u het hebt geïmplementeerd. Het is cruciaal dat u deze stap goed uitvoert om een responsieve en efficiënte applicatie te bouwen.
De grootste frustratie voor teams is het schrijven van inferentiecode die traag of inefficiënt is, wat kan leiden tot een slechte gebruikerservaring en hoge operationele kosten. Gelukkig biedt de transformers-bibliotheek verschillende manieren om inferentie uit te voeren, elk met zijn eigen afwegingen tussen eenvoud en controle.
- Pipeline API: Dit is de gemakkelijkste en meest gebruikelijke manier om aan de slag te gaan. De functie pipeline() abstraheert het grootste deel van de complexiteit en verzorgt de voorbewerking van gegevens, het doorsturen van modellen en de nabewerking voor u. Voor veel standaardtaken, zoals sentimentanalyse, kunt u met slechts één regel code een voorspelling krijgen.
- AutoModel + AutoTokenizer: Als u meer controle wilt over het inferentieproces, kunt u de klassen AutoModel en AutoTokenizer rechtstreeks gebruiken. Hiermee kunt u handmatig bepalen hoe uw tekst wordt getokeniseerd en hoe de ruwe output van het model wordt omgezet in een voor mensen leesbare voorspelling. Deze aanpak is handig wanneer u met een aangepaste Taak werkt of specifieke pre- of post-processinglogica moet implementeren.
- Batchverwerking: Om de efficiëntie te maximaliseren, vooral op een GPU, moet u invoer in batches verwerken in plaats van één voor één. Het verzenden van een batch invoer door het model in één enkele forward pass is aanzienlijk sneller dan het afzonderlijk verzenden van elke invoer.
Het monitoren van de prestaties van uw inferentiecode is een belangrijk onderdeel van de implementatielevenscyclus. Het bijhouden van statistieken zoals latentie (hoe lang een voorspelling duurt) en doorvoer (hoeveel voorspellingen u per seconde kunt doen) vereist coördinatie en duidelijke documentatie, vooral wanneer verschillende leden van het team experimenteren met nieuwe versieën van het model.
📚 Lees ook: De beste tools voor samenwerking binnen AI-teams
Stapsgewijs voorbeeld: een Hugging Face-model implementeren
Laten we een voltooid voorbeeld bekijken van de implementatie van een eenvoudig sentimentanalysemodel. Door deze stappen te volgen, gaat u van het kiezen van een model naar een live, testbaar eindpunt.
- Selecteer uw model: Ga naar de Hugging Face hub en gebruik de filters aan de linkerkant om te zoeken naar modellen die "Tekstclassificatie" uitvoeren. Een goed startpunt is distilbert-base-uncased-finetuned-sst-2-english. Lees de modelkaart om inzicht te krijgen in de prestaties en het gebruik ervan.
- Installeer afhankelijkheden: Zorg ervoor dat u in uw lokale Python-omgeving de benodigde bibliotheken hebt geïnstalleerd. Voor dit model hebt u alleen transformers en torch nodig. Voer pip install transformers torch uit.
- Test lokaal: Controleer voor de implementatie altijd of het model naar verwachting werkt op uw computer. Schrijf een klein Python-script om het model te laden met behulp van de pijplijn en test het met een voorbeeldzin. Bijvoorbeeld: classifier = pipeline("sentiment-analysis", model="distilbert-base-uncased-finetuned-sst-2-english") gevolgd door classifier("ClickUp is het beste platform voor productiviteit!")
- Implementatie maken: voor dit voorbeeld gebruiken we Hugging Face Spaces voor een snelle en eenvoudige implementatie. Maak een nieuwe ruimte, voer de selectie uit van de Gradio SDK en maak een app.py-bestand dat uw model laadt en een eenvoudige Gradio-interface definieert om ermee te communiceren.
- Implementatie controleren: zodra uw Space actief is, kunt u de interactieve interface gebruiken om deze te testen. U kunt ook een direct API-verzoek indienen bij het eindpunt van de Space om een JSON-antwoord te krijgen, waarmee u kunt controleren of deze programmatisch werkt.
Na deze stappen hebt u een live model. De volgende fase van het project omvat het monitoren van het gebruik, het plannen van updates en mogelijk het opschalen van de infrastructuur als het model populair wordt.
Voor teams die complexe AI-implementatieprojecten met meerdere fasen beheren – van gegevensvoorbereiding tot productie-implementatie – biedt de geavanceerde sjabloon voor softwareprojectmanagement van ClickUp een uitgebreide structuur.
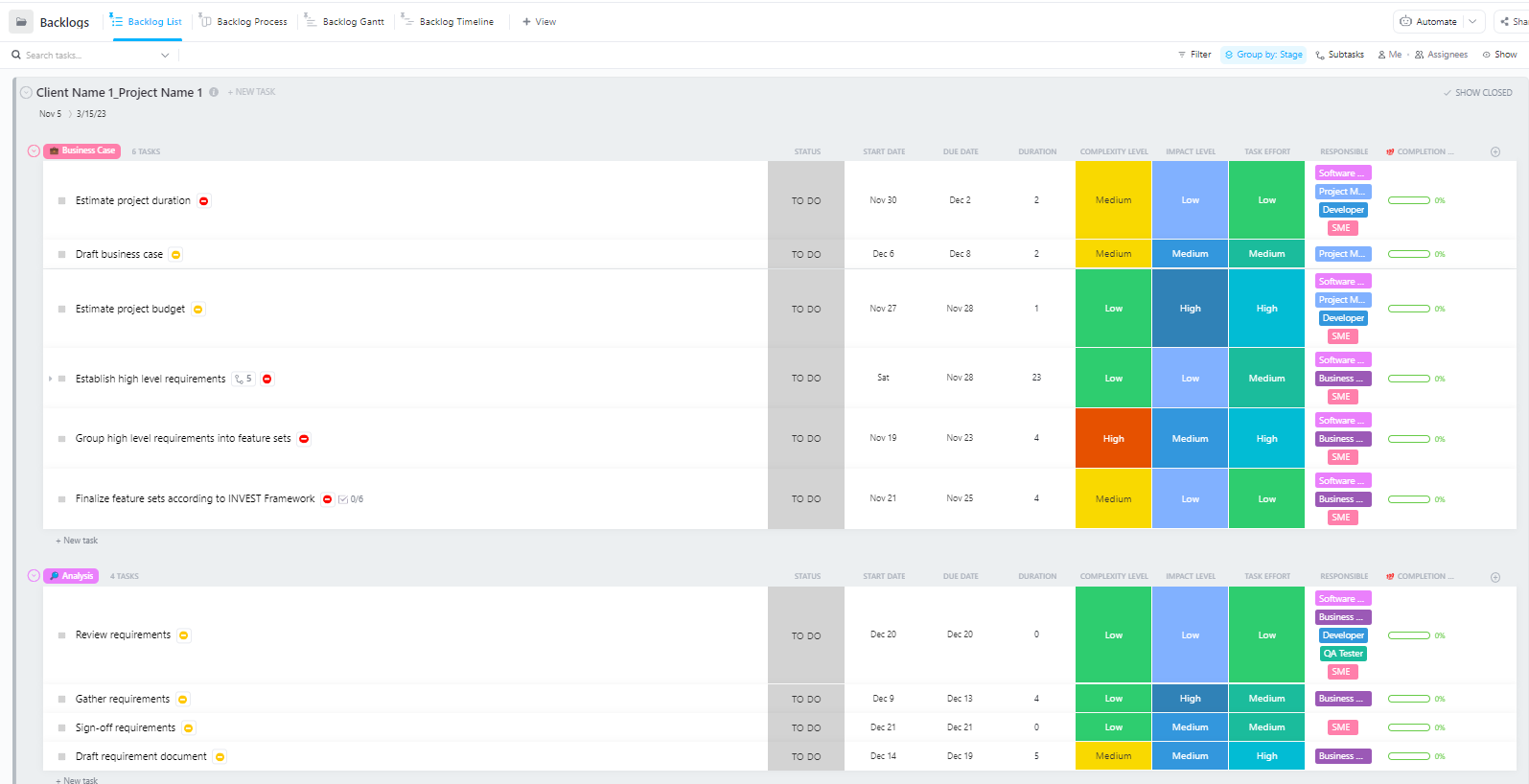
Deze sjabloon helpt teams om:
- Beheer projecten met meerdere mijlpalen, taken, middelen en afhankelijkheden.
- Visualiseer de voortgang van projecten met Gantt-grafieken en tijdlijnen.
- Werk naadloos samen met teamgenoten om een succesvolle voltooiing te garanderen.
Veelvoorkomende uitdagingen bij de implementatie van Hugging Face en hoe u deze kunt oplossen
Zelfs met een duidelijk plan zult u tijdens de implementatie waarschijnlijk een paar obstakels tegenkomen. Het kan ontzettend frustrerend zijn om naar een cryptische foutmelding te staren, en het kan de voortgang van uw team vertragen. Hier zijn enkele van de meest voorkomende uitdagingen en hoe u deze kunt oplossen. 🛠️
🚨Probleem: "Model vereist verificatie"
- Oorzaak: U probeert toegang te krijgen tot een 'afgeschermd' model waarvoor u de licentievoorwaarden moet accepteren.
- Oplossing: Ga naar de modelpagina op de hub, lees de licentieovereenkomst en accepteer deze. Zorg ervoor dat het token dat u gebruikt toestemming heeft voor 'lezen'.
🚨Probleem: "CUDA heeft onvoldoende geheugen"
- Oorzaak: Het model dat u probeert te laden is te groot voor het geheugen (VRAM) van uw GPU.
- Oplossing: De snelste oplossing is om een kleinere versie van het model of een gekwantiseerde versie te gebruiken. U kunt ook proberen de grootte van de batch tijdens de inferentie te verkleinen.
🚨Probleem: "trust_remote_code fout"
- Oorzaak: Sommige modellen op de hub vereisen aangepaste code om te kunnen worden uitgevoerd, en om redenen van veiligheid voert de bibliotheek deze code standaard niet uit.
- Oplossing: U kunt dit omzeilen door trust_remote_code=True toe te voegen wanneer u het model laadt. U moet echter altijd eerst de broncode controleren om er zeker van te zijn dat deze veilig is.
🚨Probleem: "Tokenizer mismatch"
- Oorzaak: De tokenizer die u gebruikt, is niet exact dezelfde als waarmee het model is getraind, wat leidt tot onjuiste invoer en slechte prestaties.
- Oplossing: Laad de tokenizer altijd vanuit hetzelfde modelcheckpoint als het model zelf. Als voorbeeld: AutoTokenizer. from_pretrained("model-name")
🚨Probleem: "Limiet overschreden"
- Oorzaak: u hebt in een korte periode te veel verzoeken gedaan aan de gratis Inference API.
- Oplossing: Upgrade voor productiegebruik naar een speciaal Inference Endpoint. Voor ontwikkeling kunt u caching implementeren om te voorkomen dat hetzelfde verzoek meerdere keren wordt verzonden.
Het is cruciaal om bij te houden welke oplossingen voor welke problemen werken. Zonder een centrale plek om deze bevindingen te documenteren, komen teams vaak in een situatie terecht waarin ze steeds weer hetzelfde probleem oplossen.
📮 ClickUp Insight: 1 op de 4 werknemers gebruikt vier of meer tools alleen al om context te creëren op het werk. Een belangrijk detail kan verborgen zitten in een e-mail, uitgebreid worden in een Slack-thread en gedocumenteerd worden in een aparte tool, waardoor teams tijd verspillen met het zoeken naar informatie in plaats van hun werk te doen.
ClickUp brengt uw volledige werkstroom samen in één uniform platform. Met functies zoals ClickUp E-mail Projectmanagement, ClickUp Chat, ClickUp Docs en ClickUp Brain blijft alles verbonden, gesynchroniseerd en direct toegankelijk. Zeg vaarwel tegen 'werk over werk' en win uw productieve tijd terug.
💫 Echte resultaten: teams kunnen met ClickUp meer dan 5 uur per week terugwinnen – dat is meer dan 250 uur per jaar per persoon – door verouderde kennisbeheerprocessen te elimineren. Stel je voor wat je team zou kunnen creëren met een extra week productiviteit per kwartaal!
Hoe u AI-implementatieprojecten beheert in ClickUp
Het gebruik van Hugging Face voor AI-implementatie maakt het eenvoudiger om modellen te verpakken, te hosten en aan te bieden, maar het elimineert niet de coördinatie-overhead van implementatie in de praktijk. Teams moeten nog steeds bijhouden welke modellen worden getest, afstemmen op configuraties, beslissingen documenteren en ervoor zorgen dat iedereen – van ML-engineers tot product- en operationsmedewerkers – op dezelfde lijn zit.
Wanneer uw engineeringteam verschillende modellen test, uw productteam de vereisten definieert en belanghebbenden om updates vragen, raakt de informatie verspreid over Slack, e-mail, spreadsheets en verschillende documenten.
Deze werkversnippering – de fragmentatie van werkzaamheden over meerdere, niet met elkaar verbonden tools die niet met elkaar communiceren – zorgt voor verwarring en vertraagt iedereen.
Dit is waar ClickUp, 's werelds eerste Converged AI-werkruimte, een sleutelrol speelt door projectmanagement, documentatie en teamcommunicatie samen te brengen in één enkele werkruimte.
De convergentie is vooral waardevol voor AI-implementatieprojecten, waarbij technische en niet-technische belanghebbenden gedeelde zichtbaarheid nodig hebben zonder vijf verschillende tools te hoeven gebruiken.
In plaats van updates verspreid over tickets, documenten en chatthreads, kunnen teams de volledige implementatiecyclus op één plek beheren.
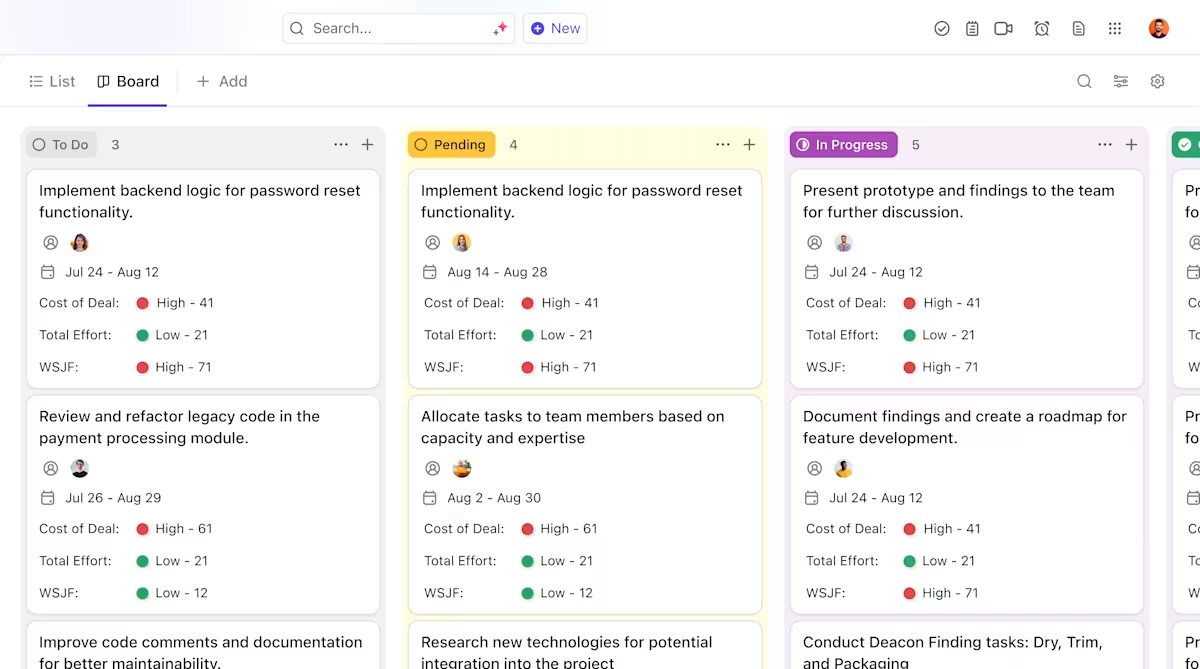
Zo kan ClickUp uw AI-implementatieproject ondersteunen:
- Duidelijke eigendom en bijhouden gedurende de hele levenscyclus van modellen: gebruik ClickUp-taaken om Hugging Face-modellen te volgen tijdens evaluatie, testen, staging en productie, met aangepaste statussen, eigenaren en blokkades die zichtbaar zijn voor het hele team.
- Gecentraliseerde, levende implementatiedocumentatie: onderhoud implementatierunbooks, omgevingsconfiguraties en probleemoplossingsgidsen in ClickUp Docs, zodat de documentatie mee evolueert met uw modellen en gemakkelijk te doorzoeken en te raadplegen blijft. Omdat Docs verbonden zijn met taken, staat uw documentatie direct naast het werk waar het betrekking op heeft.
- Samenwerking in context zonder werkverspreiding: houd discussies, beslissingen en updates direct gekoppeld aan taken en documenten, waardoor u minder afhankelijk bent van verspreide Slack-threads, e-mails en losstaande projecttools.
- End-to-end zichtbaarheid in de voortgang van de implementatie: monitor de implementatiepijplijn, identificeer risico's vroegtijdig en breng de capaciteit van het team in evenwicht met behulp van ClickUp dashboards die realtime voortgang en knelpunten weergeven.
- Snellere onboarding en besluitvorming met ingebouwde AI: gebruik ClickUp Brain om lange implementatiedocumenten samen te vatten, relevante inzichten uit eerdere implementaties naar voren te halen en nieuwe leden van het team te helpen snel aan de slag te gaan zonder zich door historische context te hoeven worstelen.
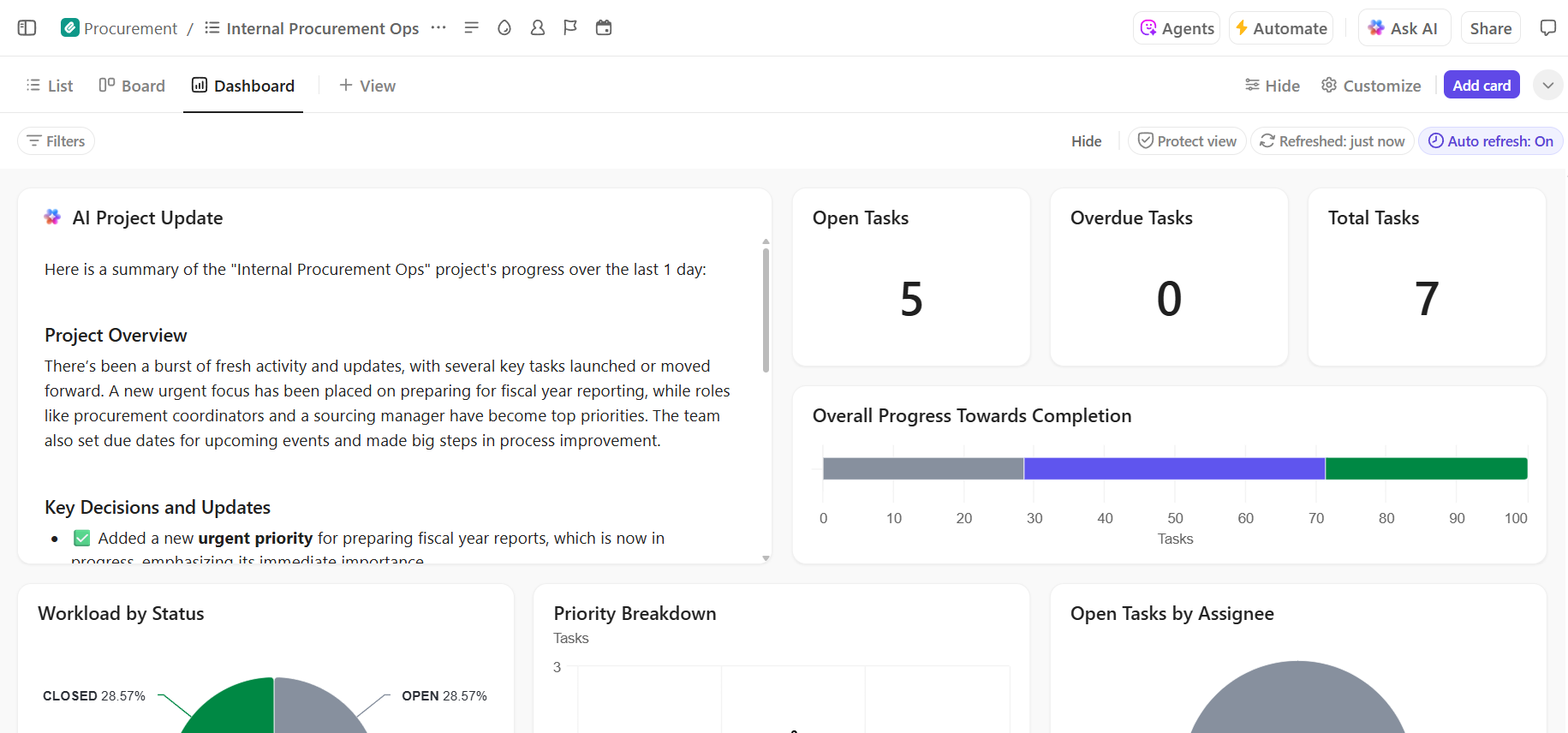
Beheer uw AI-implementatieproject naadloos in ClickUp
Een succesvolle implementatie van Hugging Face hangt af van een solide technische basis en duidelijk, georganiseerd projectmanagement. Hoewel de technische uitdagingen oplosbaar zijn, zijn het vaak de coördinatie- en communicatieproblemen die ervoor zorgen dat projecten mislukken.
Door een duidelijke werkstroom op één platform in te stellen, kan uw team sneller leveren en de frustratie van contextversnippering voorkomen – wanneer teams uren verspillen met het zoeken naar informatie, het schakelen tussen apps en het herhalen van updates op meerdere platforms.
ClickUp, de alles-in-één-app voor werk, brengt uw projectmanagement, documentatie en teamcommunicatie samen op één plek, zodat u één enkele bron van waarheid hebt voor de hele levenscyclus van uw AI-implementatie.
Breng uw AI-implementatieprojecten samen en maak een einde aan de chaos rondom tools. Ga vandaag nog gratis aan de slag met ClickUp.
Veelgestelde vragen (FAQ)
Ja, Hugging Face biedt een royale gratis versie die toegang geeft tot de Model Hub, CPU-aangedreven Spaces voor demo's en een Inference API met beperkte snelheid voor testdoeleinden. Voor productiebehoeften die speciale hardware of hogere limieten vereisen, zijn er betaalde abonnementen beschikbaar.
Spaces is ontworpen voor het hosten van interactieve applicaties met een visuele front-end, waardoor het ideaal is voor demo's en interne tools. De Inference API biedt programmatische toegang tot modellen, zodat u ze via eenvoudige HTTP-verzoeken in uw applicaties kunt integreren.
Absoluut. Via interactieve demo's op Hugging Face Spaces kunnen niet-technische leden van het team experimenteren met modellen en feedback geven zonder ook maar één regel code te schrijven.
De belangrijkste beperkingen van het gratis abonnement zijn limieten voor de Inference API, het gebruik van gedeelde CPU-hardware voor Spaces, wat traag kan zijn, en 'cold starts', waarbij inactieve apps even nodig hebben om op te starten. /