

Grote taalmodellen (LLM's) hebben opwindende nieuwe mogelijkheden voor softwaretoepassingen ontsloten. Ze maken intelligentere en dynamischere systemen mogelijk dan ooit tevoren.
Experts voorspellen dat in 2025 apps die met deze modellen werken bijna alle taken kunnen automatiseren de helft van al het digitale werk automatiseren .
Maar terwijl we deze mogelijkheden ontsluiten, doemt er een uitdaging op: hoe kunnen we de kwaliteit van hun uitvoer op grote schaal betrouwbaar meten? Een kleine aanpassing in de instellingen en plotseling zie je een merkbaar andere uitvoer. Deze variabiliteit kan het een uitdaging maken om hun prestaties te meten, wat cruciaal is bij het voorbereiden van een model voor gebruik in de echte wereld.
Dit artikel geeft inzicht in de beste manieren om LLM systemen te evalueren, van pre-deployment testen tot productie. Dus laten we beginnen!
Wat is een LLM evaluatie?
LLM evaluatiecijfers zijn een manier om te zien of uw prompts, modelinstellingen of werkstroom de doelen bereiken die u hebt gesteld. Deze statistieken geven u inzicht in hoe goed uw Groot Taalmodel presteert en of het echt klaar is voor gebruik in de echte wereld.
Vandaag de dag meten enkele van de meest gebruikte metrieken contextherinnering in retrieval-augmented generation (RAG) taken, exacte overeenkomsten voor classificaties, JSON-validatie voor gestructureerde uitvoer en semantische gelijkenis voor creatievere taken.
Elk van deze metingen zorgt er op unieke wijze voor dat de LLM voldoet aan de normen voor uw specifieke toepassing.
Waarom moet u een LLM evalueren?
Grote taalmodellen (LLM's) worden nu gebruikt in een breed bereik van toepassingen. Het is essentieel om de prestaties van modellen te evalueren om ervoor te zorgen dat ze aan de verwachte normen voldoen en hun beoogde doelen effectief dienen.
Bekijk het zo: LLM's voeden alles, van chatbots voor klantenservice tot creatieve tools, en naarmate ze geavanceerder worden, verschijnen ze op steeds meer plaatsen.
Dit betekent dat we betere manieren nodig hebben om ze te controleren en te beoordelen - traditionele methoden kunnen alle Taken die deze modellen uitvoeren gewoon niet bijhouden.
Goede evaluatiemetrieken zijn als een kwaliteitscontrole voor LLM's. Ze laten zien of het model betrouwbaar, nauwkeurig en efficiënt genoeg is voor gebruik in de echte wereld. Zonder deze controles kunnen er fouten worden gemaakt, wat kan leiden tot frustrerende of zelfs misleidende ervaringen voor gebruikers.
Als je sterke evaluatiecijfers hebt, is het gemakkelijker om problemen op te sporen, het model te verbeteren en ervoor te zorgen dat het klaar is voor de specifieke behoeften van de gebruikers. Op deze manier weet je dat de AI-platform waarmee je werkt op niveau is en de resultaten kan leveren die je nodig hebt.
📖 Lees meer: LLM vs. Generatieve AI: een gedetailleerde gids
Soorten LLM-evaluaties
Evaluaties bieden een unieke lens om de mogelijkheden van het model te onderzoeken. Elk type richt zich op verschillende kwaliteitsaspecten en helpt bij het bouwen van een betrouwbaar, veilig en efficiënt implementatiemodel.
Hier volgen de verschillende soorten LLM evaluatiemethoden:
- Intrinsieke evaluatie richt zich op de interne prestaties van het model op specifieke taal- of begripstaken zonder gebruik te maken van echte toepassingen. Dit wordt meestal uitgevoerd tijdens de ontwikkelingsfase van het model om inzicht te krijgen in de kerncapaciteiten
- Extrinsieke evaluatie beoordeelt de prestaties van het model in echte toepassingen. Dit type evaluatie onderzoekt hoe goed het model specifieke doelen binnen een context vervult
- Evaluatie van de robuustheid test de stabiliteit en betrouwbaarheid van het model in verschillende scenario's, waaronder onverwachte invoer en tegenstrijdige voorwaarden. Het identificeert mogelijke zwakke punten en zorgt ervoor dat het model zich voorspelbaar gedraagt
- Efficiëntie- en latentietests onderzoeken het gebruik van bronnen, de snelheid en de latentie van het model. Het zorgt ervoor dat het model Taken snel en tegen redelijke kosten kan uitvoeren, wat essentieel is voor schaalbaarheid
- Evaluatie van ethiek en veiligheid zorgt ervoor dat het model voldoet aan ethische normen en veiligheidsrichtlijnen, wat essentieel is voor gevoelige toepassingen
LLM modelevaluaties vs. LLM systeemevaluaties
Bij het evalueren van grote taalmodellen (LLM's) zijn er twee hoofdbenaderingen: modelevaluaties en systeemevaluaties. Beide richten zich op verschillende aspecten van de prestaties van LLM's en het is essentieel om het verschil te weten om het potentieel van deze modellen te maximaliseren
🧠 Model evaluaties kijken naar de algemene vaardigheden van de LLM. Dit type evaluatie test het model op zijn vermogen om taal te begrijpen, te genereren en er nauwkeurig mee te werken in verschillende contexten. Het is alsof je kijkt hoe goed het model verschillende Taken aankan, bijna als een algemene intelligentietest.
Bij een modelevaluatie wordt bijvoorbeeld gevraagd: "Hoe veelzijdig is dit model?"
🎯 LLM systeemevaluaties meten hoe de LLM presteert binnen een specifieke installatie of doel, zoals in een chatbot voor klantenservice. Hier gaat het minder om de brede capaciteiten van het model en meer om hoe het specifieke Taken uitvoert om de gebruikerservaring te verbeteren.
Systeemevaluaties richten zich echter op vragen als: "Hoe goed voert het model deze specifieke taak uit voor gebruikers?"
Modelevaluaties helpen ontwikkelaars inzicht te krijgen in de algemene mogelijkheden en limieten van de LLM, zodat ze verbeteringen kunnen doorvoeren. Systeemevaluaties zijn gericht op hoe goed de LLM tegemoet komt aan de behoeften van gebruikers in specifieke contexten, zodat de gebruikerservaring soepeler verloopt.
Samen geven deze evaluaties een compleet beeld van de sterke punten en verbeterpunten van de LLM, waardoor deze krachtiger en gebruiksvriendelijker wordt in echte toepassingen.
Laten we nu eens kijken naar de specifieke meetgegevens voor de evaluatie van LLM.
Metriek voor LLM-evaluatie
Enkele betrouwbare en trendy evaluatiecijfers zijn:
1. Perplexiteit
Perplexiteit meet hoe goed een taalmodel een reeks woorden voorspelt. In wezen geeft het de onzekerheid van het model over het volgende woord in een zin aan. Een lagere perplexiteitsscore betekent dat het model meer vertrouwen heeft in zijn voorspellingen, wat leidt tot betere prestaties.
📌 Voorbeeld: Stel dat een model tekst genereert van de prompt "De kat zat op de." Als het een hoge waarschijnlijkheid voorspelt voor woorden als "mat" en "vloer", begrijpt het de context goed, wat resulteert in een lage perplexiteitsscore.
Aan de andere kant, als het een ongerelateerd woord als "ruimteschip" suggereert, zou de perplexiteitsscore hoger zijn, wat aangeeft dat het model moeite heeft om zinnige tekst te voorspellen.
2. BLEU-score
De BLEU-score (Bilingual Evaluation Understudy) wordt voornamelijk gebruikt om automatische vertalingen en tekstgeneratie te evalueren.
Het meet hoeveel n-grammen (aaneengesloten reeksen van n items uit een gegeven steekproef van teksten) in de uitvoer overlappen met die in een of meer referentieteksten. De score bereikt een bereik van 0 tot 1, waarbij een hogere score een betere prestatie aangeeft.
📌 Voorbeeld: Als je model de zin "De snelle bruine vos springt over de luie hond" genereert en de referentietekst is "Een snelle bruine vos springt over een luie hond", dan vergelijkt BLEU de gedeelde n-grammen.
Een hoge score geeft aan dat de gegenereerde zin goed overeenkomt met de referentie, terwijl een lagere score aangeeft dat de gegenereerde uitvoer niet goed overeenkomt.
3. F1 Score
De F1 score LLM evaluatiemetriek is vooral bedoeld voor classificatietaken. Het meet de balans tussen precisie (de nauwkeurigheid van de positieve voorspellingen) en terughalen (het vermogen om alle relevante Instances te identificeren).
De score bereikt een bereik van 0 tot 1, waarbij een score van 1 staat voor perfecte nauwkeurigheid.
📌 Voorbeeld: In een vraag-antwoord taak, als het model wordt gevraagd, "Welke kleur heeft de lucht?" en antwoordt met "De lucht is blauw" (echt positief) maar ook "De lucht is groen" (vals positief), zal de F1 score zowel de relevantie van het goede antwoord als van het foute antwoord in overweging nemen.
Deze metriek zorgt voor een evenwichtige evaluatie van de prestaties van het model.
4. METEOR
METEOR (Metric for Evaluation of Translation with Explicit ORdering) gaat verder dan exacte woordvergelijking. Het houdt rekening met synoniemen, stemming en parafrases om de gelijkenis tussen gegenereerde tekst en referentietekst te evalueren. Deze metriek is bedoeld om beter aan te sluiten bij het menselijk oordeel.
📌 Voorbeeld:Als uw model "De katachtige rustte op het tapijt" genereert en de referentie is "De kat lag op het tapijt", dan zou METEOR dit een hogere score geven dan BLEU omdat het herkent dat "katachtige" een synoniem is voor "kat" en "tapijt" en "tapijt" soortgelijke betekenissen hebben.
Dit maakt METEOR bijzonder nuttig voor het vastleggen van de nuances van taal.
5. BERTScore
BERTScore evalueert de overeenkomst tussen teksten op basis van contextuele inbeddingen die zijn afgeleid van modellen zoals BERT (Bidirectional Encoder Representations from Transformers). Het richt zich meer op betekenis dan op exacte woordovereenkomsten, waardoor de semantische gelijkenis beter kan worden beoordeeld.
📌 Voorbeeld: Bij het vergelijken van de zinnen "De auto raasde over de weg" en "Het voertuig raasde over de straat" analyseert BERTScore de onderliggende betekenissen in plaats van alleen de woordkeuze.
Hoewel de woorden verschillen, zijn de algemene ideeën vergelijkbaar, wat leidt tot een hoge BERTScore die de effectiviteit van de gegenereerde content weergeeft.
6. Menselijke evaluatie
Menselijke evaluatie blijft een cruciaal aspect van de beoordeling van LLM. Hierbij beoordelen menselijke juryleden de kwaliteit van modelresultaten gebaseerd op verschillende criteria zoals vloeiendheid en relevantie. Technieken zoals Likert-schalen en A/B-testen kunnen worden gebruikt om feedback te verzamelen.
📌 Voorbeeld:Na het genereren van antwoorden van een chatbot voor klantenservice, kunnen menselijke beoordelaars elk antwoord beoordelen op een schaal van 1 tot 5. Als de chatbot bijvoorbeeld duidelijke en relevante antwoorden geeft, kan de beoordeling worden aangepast. Als de chatbot bijvoorbeeld een duidelijk en behulpzaam antwoord geeft op een vraag van een klant, kan hij een 5 krijgen, terwijl een vaag of verwarrend antwoord een 2 kan krijgen.
7. Taakspecifieke statistieken
Verschillende LLM Taken vereisen op maat gemaakte evaluatiecijfers.
Voor dialoogsystemen kan de betrokkenheid van gebruikers of de mate van voltooiing van taken worden gemeten. Voor het genereren van code kan succes worden gemeten aan de hand van hoe vaak de gegenereerde code compileert of voor tests slaagt.
📌 Voorbeeld: In een chatbot voor klantenservice kan de betrokkenheid worden gemeten aan de hand van hoe lang gebruikers in een gesprek blijven of hoeveel vervolgvragen ze stellen.
Als gebruikers vaak om aanvullende informatie vragen, geeft dit aan dat het model succesvol is in het betrekken van gebruikers en effectief hun query's beantwoordt.
8. Robuustheid en eerlijkheid
Het beoordelen van de robuustheid van een model houdt in dat getest wordt hoe goed het model reageert op onverwachte of ongebruikelijke inputs. Eerlijkheidsmetingen helpen bij het identificeren van vertekeningen in de outputs van het model en zorgen ervoor dat het model gelijk presteert over verschillende demografische groepen en scenario's.
📌 Voorbeeld: Als je een model test met een grillige vraag als "Wat vind je van eenhoorns?", dan moet het model de vraag netjes afhandelen en een relevant antwoord geven. Als het in plaats daarvan een onzinnig of ongepast antwoord geeft, duidt dit op een gebrek aan robuustheid.
Eerlijkheidstests zorgen ervoor dat het model geen bevooroordeelde of schadelijke uitvoer produceert, wat een meer inclusieve aanpak bevordert AI-systeem .
📖 Lees meer: Het verschil tussen machinaal leren en kunstmatige intelligentie
9. Efficiëntie statistieken
Naarmate taalmodellen complexer worden, wordt het steeds belangrijker om hun efficiëntie te meten met betrekking tot snelheid, geheugengebruik en energieverbruik. Efficiëntiemaatstaven helpen evalueren hoe hulpbronintensief een model is bij het genereren van reacties.**
📌 Voorbeeld: Voor een groot taalmodel kan de efficiëntie worden gemeten door bij te houden hoe snel het antwoorden genereert op query's van gebruikers en hoeveel geheugen het gebruikt tijdens dit proces.
Als het te lang duurt om te reageren of buitensporig veel bronnen gebruikt, kan dit een probleem zijn voor toepassingen die real-time prestaties vereisen, zoals chatbots of vertaaldiensten.
Nu weet je hoe je een LLM-model kunt evalueren. Maar welke tools kun je gebruiken om dit te meten? Laten we dat eens onderzoeken.
Hoe ClickUp Brain de evaluatie van LLM kan verbeteren
ClickUp is een alles-voor-werk app met een ingebouwde persoonlijke assistent genaamd ClickUp Brain. ClickUp Brein is een game-changer voor de evaluatie van LLM-prestaties. Dus wat doet het?
Het organiseert en markeert de meest relevante gegevens en houdt zo uw team bij de les. Met zijn AI-gestuurde functies is ClickUp Brain een van de beste neurale netwerksoftware die er zijn. Het maakt het hele proces soepeler, efficiënter en meer collaboratief dan ooit. Laten we samen de mogelijkheden verkennen.
Intelligent kennisbeheer
Bij het evalueren van grote taalmodellen (LLM's) kan het beheren van enorme hoeveelheden gegevens overweldigend zijn.

gegevens samenvatten en het bijhouden van prestatiecijfers stroomlijnen met ClickUp Brain_ ClickUp Brein kan essentiële statistieken en bronnen organiseren en uitlichten die specifiek zijn afgestemd op LLM-evaluatie. In plaats van te zoeken in verspreide spreadsheets en dichte rapporten, brengt ClickUp Brain alles samen op één plaats. Prestatiecijfers, benchmarkgegevens en testresultaten zijn allemaal toegankelijk via een duidelijke en gebruiksvriendelijke interface.
Deze organisatie helpt uw team om door de ruis heen te breken en zich te concentreren op de inzichten die er echt toe doen, waardoor het gemakkelijker wordt om trends en prestatiepatronen te interpreteren.
Met alles wat je nodig hebt op één plek, kun je de overstap maken van louter gegevensverzameling naar impactvolle, datagestuurde besluitvorming, waarbij de overvloed aan informatie wordt omgezet in bruikbare informatie.
Projectplanning en projectmanagement
LLM-evaluaties vereisen zorgvuldige abonnementen en samenwerking, en ClickUp maakt het beheren van dit proces eenvoudig.
U kunt verantwoordelijkheden zoals gegevensverzameling, modeltraining en prestatietests gemakkelijk delegeren, terwijl u ook prioriteiten kunt instellen om ervoor te zorgen dat de meest kritieke taken als eerste aandacht krijgen. Daarnaast kunt u met aangepaste velden workflows aanpassen aan de specifieke behoeften van uw project.

taken maken en toewijzen en werkstroom stroomlijnen met AI in ClickUp_
Met ClickUp-taak kan iedereen zien wie wat doet en wanneer, waardoor vertragingen worden voorkomen en taken soepel door het team worden uitgevoerd. Het is een geweldige manier om alles van begin tot eind georganiseerd en op schema te houden.
Metriek bijhouden via aangepaste dashboards
Wilt u goed in de gaten houden hoe uw LLM systemen presteren? ClickUp Dashboards visualiseren de prestatie-indicatoren in realtime. Hiermee kunt u de voortgang van uw model onmiddellijk controleren. Deze dashboards zijn in hoge mate aanpasbaar, zodat u grafieken en grafieken kunt maken die precies weergeven wat u nodig hebt wanneer u het nodig hebt.
U kunt de nauwkeurigheid van uw model zien evolueren doorheen de verschillende evaluatiefasen of het verbruik van middelen per fase uitsplitsen. Met deze informatie kunt u snel trends herkennen, verbeterpunten identificeren en direct aanpassingen doorvoeren.
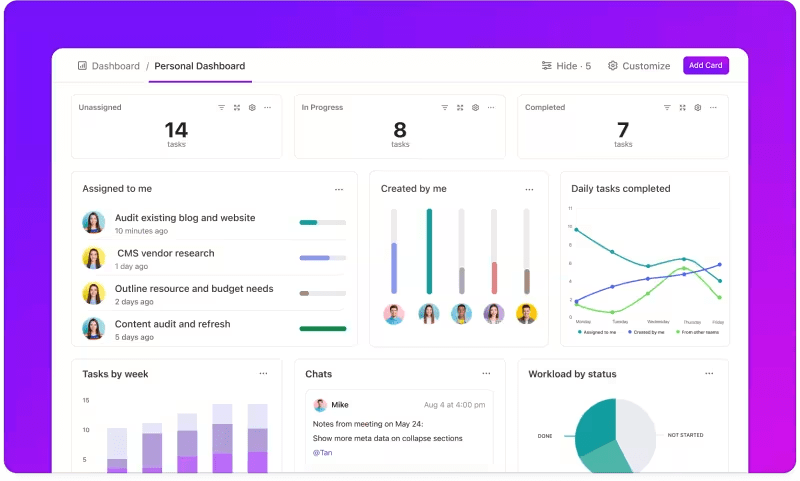
Bekijk de voortgang van je evaluatie in één oogopslag in ClickUp Dashboards
In plaats van te wachten op het volgende gedetailleerde rapport, ClickUp Dashboards stellen u in staat om op de hoogte te blijven en uw team in staat om datagestuurde beslissingen te nemen zonder vertraging.
Geautomatiseerde inzichten
Gegevensanalyse kan tijdrovend zijn, maar ClickUp Brain functies verlichten de last door waardevolle inzichten te bieden. Het markeert belangrijke trends en stelt zelfs aanbevelingen voor op basis van de gegevens, waardoor het gemakkelijker wordt om zinvolle conclusies te trekken.
Met de geautomatiseerde inzichten van ClickUp Brain is het niet nodig om ruwe gegevens handmatig uit te kammen op zoek naar patronen. Dankzij deze automatisering kan uw team zich richten op het verfijnen van de modelprestaties in plaats van zich te verliezen in repetitieve gegevensanalyses.
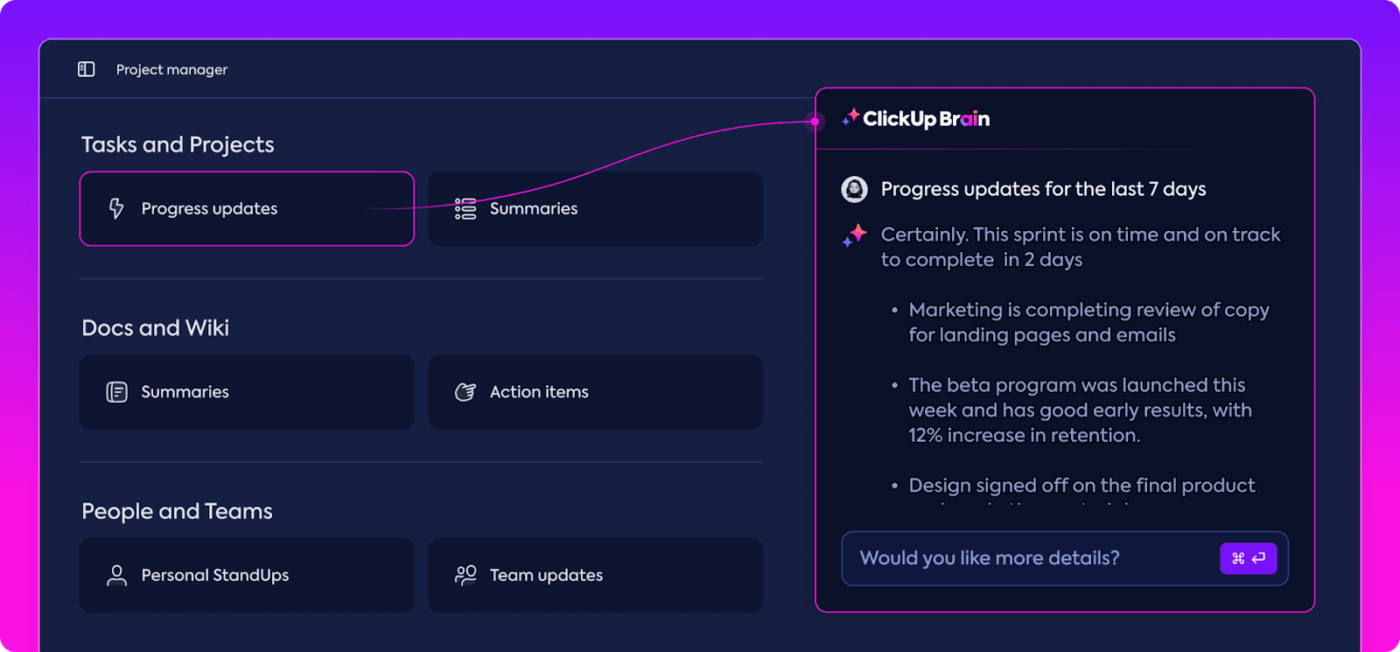
verkrijg bruikbare inzichten met ClickUp Brain_
De gegenereerde inzichten zijn klaar voor gebruik, zodat uw team onmiddellijk kan zien wat werkt en waar wijzigingen nodig zijn. Door minder tijd te besteden aan analyse helpt ClickUp uw team het evaluatieproces te versnellen en zich te concentreren op de implementatie.
Documentatie en samenwerking
U hoeft geen e-mails of verschillende platforms meer door te spitten om te vinden wat u nodig hebt; alles is daar, klaar wanneer u dat bent. ClickUp Documenten is een centrale hub die alles samenbrengt wat uw team nodig heeft voor een naadloze LLM-evaluatie. Het organiseert de sleutel documentatie voor projecten, zoals benchmarking criteria, testresultaten en prestatielogboeken, op één toegankelijke plek zodat iedereen snel toegang heeft tot de meest recente informatie.
Wat ClickUp Docs echt onderscheidt, zijn de functies voor samenwerking in realtime. De geïntegreerde ClickUp chatten en Commentaren Geef leden van het team de mogelijkheid om inzichten te bespreken, feedback te geven en wijzigingen voor te stellen, direct binnen de documenten
Dit betekent dat je team bevindingen kan bespreken en direct op het platform aanpassingen kan doen, zodat alle discussies relevant en relevant blijven.

Collaborate en bewerk ClickUp documenten met uw team in real time
Alles van documentatie tot teamwerk gebeurt binnen ClickUp Docs, waardoor een gestroomlijnd evaluatieproces ontstaat waarin iedereen de laatste ontwikkelingen kan zien, delen en erop kan reageren.
Het resultaat? Een soepele, uniforme werkstroom die uw team in alle duidelijkheid naar hun doelen laat toewerken.
Ben je klaar om ClickUp uit te proberen? Laten we eerst een aantal tips en trucs bespreken om het meeste uit uw LLM Evaluatie te halen.
Best Practices in LLM-evaluatie
Een goed gestructureerde aanpak van LLM-evaluatie zorgt ervoor dat het model aan uw behoeften voldoet, in lijn is met de verwachtingen van gebruikers en zinvolle resultaten oplevert.
Door duidelijke doelstellingen in te stellen, rekening te houden met de eindgebruikers en verschillende meetmethoden te gebruiken, wordt vorm gegeven aan een grondige evaluatie die sterke punten en verbeterpunten aan het licht brengt. Hieronder vindt u enkele best practices om uw proces te begeleiden.
🎯 Bepaal duidelijke doelstellingen
Voordat u begint met het evaluatieproces, is het essentieel om precies te weten wat u met uw grote taalmodel (LLM) wilt bereiken. Neem de tijd om de specifieke Taken of doelen voor het model te schetsen.
📌 Voorbeeld: Als u de prestaties van machinevertalingen wilt verbeteren, maak dan duidelijk welke kwaliteitsniveaus u wilt bereiken. Als u duidelijke doelen hebt, kunt u zich richten op de meest relevante meetgegevens en ervoor zorgen dat uw evaluatie afgestemd blijft op deze doelen en het succes nauwkeurig meet.
👥 Rekening houden met uw publiek
Bedenk wie de LLM gaat gebruiken en wat hun behoeften zijn. Het is cruciaal om de evaluatie af te stemmen op de beoogde gebruikers.
📌 Voorbeeld: Als uw model bedoeld is om boeiende content te genereren, wilt u veel aandacht besteden aan statistieken zoals vloeiendheid en samenhang. Inzicht in uw publiek helpt bij het verfijnen van uw evaluatiecriteria, zodat u zeker weet dat het model echte waarde levert in praktische toepassingen
📊 Gebruik verschillende meeteenheden
Vertrouw niet op slechts één metriek om uw LLM te evalueren; een mix van metrieken geeft u een vollediger beeld van de prestaties. Elke metriek heeft betrekking op verschillende aspecten, dus het gebruik van meerdere metrieken kan u helpen bij het identificeren van zowel sterke als zwakke punten.
📌 Voorbeeld: Hoewel BLEU-scores geweldig zijn om de kwaliteit van vertalingen te meten, dekken ze misschien niet alle nuances van creatief schrijven. Het opnemen van statistieken zoals perplexiteit voor voorspellende nauwkeurigheid en zelfs menselijke evaluaties voor context kan leiden tot een veel completer begrip van hoe goed uw model presteert
LLM benchmarks en hulpmiddelen
Bij het evalueren van grote taalmodellen (LLM's) wordt vaak gebruik gemaakt van industriestandaard benchmarks en gespecialiseerde tools die helpen de prestaties van modellen voor verschillende Taken te meten.
Hier volgt een overzicht van een aantal veelgebruikte benchmarks en hulpmiddelen die structuur en duidelijkheid brengen in het evaluatieproces.
Sleutelbenchmarks
- GLUE (General Language Understanding Evaluation): GLUE beoordeelt de capaciteiten van modellen voor meerdere taaltaken, waaronder zinsclassificatie, -overeenkomst en -inferentie. Het is een benchmark voor modellen die algemeen taalbegrip moeten kunnen verwerken
- SQuAD (Stanford Question Answering Dataset): Het SQuAD evaluatieraamwerk is ideaal voor begrijpend lezen en meet hoe goed een model vragen beantwoordt op basis van een tekstpassage. Het wordt vaak gebruikt voor taken als klantenservice en het ophalen van kennis, waarbij precieze antwoorden cruciaal zijn
- SuperGLUE: Als een verbeterde versie van GLUE evalueert SuperGLUE modellen op meer complexe redeneer- en contextuele begripstaken. Het biedt diepere inzichten, vooral voor toepassingen die geavanceerd taalbegrip vereisen
Essentiële evaluatiehulpmiddelen
- Hugging Face : Het is alom populair vanwege de uitgebreide modelbibliotheek, datasets en evaluatiefuncties. De zeer intuïtieve interface stelt gebruikers in staat om eenvoudig benchmarks te selecteren, evaluaties aan te passen en de prestaties van modellen bij te houden, waardoor het veelzijdig is voor veel LLM-toepassingen
- SuperAnnotate : Het is gespecialiseerd in het beheren en annoteren van gegevens, wat cruciaal is voor Taken op het gebied van leren onder toezicht. Het is vooral nuttig voor het verfijnen van de nauwkeurigheid van modellen, omdat het hoogwaardige, door mensen geannoteerde gegevens mogelijk maakt die de prestaties van modellen voor complexe Taken verbeteren
- AllenNLP* : AllenNLP is ontwikkeld door het Allen Institute for AI en is bedoeld voor onderzoekers en ontwikkelaars die werken aan aangepaste NLP-modellen. Het ondersteunt een bereik van benchmarks en biedt tools om taalmodellen te trainen, testen en evalueren, wat flexibiliteit biedt voor diverse NLP-toepassingen
Het gebruik van een combinatie van deze benchmarks en tools biedt een uitgebreide aanpak voor LLM evaluatie. Benchmarks kunnen normen stellen voor verschillende Taken, terwijl tools de structuur en flexibiliteit bieden die nodig zijn om de prestaties van modellen effectief bij te houden, te verfijnen en te verbeteren.
Samen zorgen ze ervoor dat LLM's zowel voldoen aan technische normen als aan praktische toepassingsbehoeften.
Uitdagingen voor evaluatie van LLM-modellen
Het evalueren van grote taalmodellen (LLM's) vereist een genuanceerde aanpak. De nadruk ligt op de kwaliteit van antwoorden en het begrijpen van het aanpassingsvermogen en de limieten van het model in verschillende scenario's.
Omdat deze modellen worden getraind op uitgebreide datasets, wordt hun gedrag beïnvloed door een bereik van factoren, waardoor het essentieel is om meer dan alleen nauwkeurigheid te beoordelen.
Een echte evaluatie houdt in dat de betrouwbaarheid van het model wordt onderzocht, evenals de bestendigheid tegen ongebruikelijke situaties vragen en de algehele consistentie van de antwoorden. Dit proces helpt om een duidelijker beeld te krijgen van de sterke en zwakke punten van het model en brengt gebieden aan het licht die verfijning behoeven.
Hieronder worden enkele veelvoorkomende uitdagingen besproken die zich voordoen bij de evaluatie van LLM.
1. Overlapping van trainingsgegevens
Het is moeilijk om te weten of het model al een deel van de testgegevens heeft gezien. Omdat LLM's worden getraind op enorme datasets, is er een kans dat sommige testvragen overlappen met de voorbeelden uit de training. Hierdoor kan het model beter lijken dan het in werkelijkheid is, omdat het misschien alleen herhaalt wat het al weet in plaats van echt begrip te tonen.
2. Inconsistente prestaties
LLM's kunnen onvoorspelbare reacties geven. Het ene moment leveren ze indrukwekkende inzichten, en het volgende moment maken ze vreemde fouten of presenteren ze denkbeeldige informatie als feiten (bekend als 'hallucinaties').
Deze inconsistentie betekent dat de resultaten van LLM's op sommige gebieden kunnen uitblinken, maar op andere gebieden tekort kunnen schieten, waardoor het moeilijk is om de algehele betrouwbaarheid en kwaliteit nauwkeurig te beoordelen.
3. Kwetsbaarheden van tegenstanders
LLM's kunnen gevoelig zijn voor aanvallen door tegenstanders, waarbij ze door slimme aanwijzingen worden misleid tot foutieve of schadelijke antwoorden. Deze kwetsbaarheid legt zwakke punten in het model bloot en kan leiden tot onverwachte of bevooroordeelde resultaten. Het testen op deze zwakke punten van tegenstanders is cruciaal om te begrijpen waar de grenzen van het model liggen.
Praktische LLM evaluatie gebruikscases
Tot slot volgen hier enkele veelvoorkomende situaties waarin LLM-evaluatie echt een verschil maakt:
Chatbots voor klantenservice
LLM's worden veel gebruikt in chatbots om query's van klanten af te handelen. Door te evalueren hoe goed het model reageert, zorgen we ervoor dat het accurate, nuttige en contextueel relevante antwoorden geeft.
Het is cruciaal om het vermogen te meten om de intentie van de klant te begrijpen, verschillende vragen te behandelen en mensachtige antwoorden te geven. Zo kunnen bedrijven zorgen voor een soepele klantervaring en frustratie tot een minimum beperken.
Content genereren
Veel bedrijven gebruiken LLM's om blog content, sociale media en productbeschrijvingen te genereren. Het evalueren van de kwaliteit van de gegenereerde content helpt ervoor te zorgen dat deze grammaticaal correct, boeiend en relevant is voor het target publiek. Metrieken zoals creativiteit, samenhang en relevantie voor het onderwerp zijn hier belangrijk om hoge normen voor content te handhaven.
Sentimentanalyse
LLM's kunnen het sentiment van feedback van klanten, berichten op sociale media of productbeoordelingen analyseren. Het is essentieel om te evalueren hoe nauwkeurig het model identificeert of een stuk tekst positief, negatief of neutraal is. Dit helpt bedrijven om emoties van klanten te begrijpen, producten of diensten te verfijnen, de tevredenheid van gebruikers te vergroten en marketingstrategieën te verbeteren.
Code genereren
Ontwikkelaars gebruiken vaak LLM's om te helpen bij het genereren van code. Het is cruciaal om te evalueren of het model in staat is om functionele en efficiënte code te produceren.
Het is belangrijk om te controleren of de gegenereerde code logisch in elkaar zit, foutloos is en voldoet aan de eisen van de Taak. Dit helpt de hoeveelheid benodigde handmatige code te verminderen en verbetert de productiviteit.
Optimaliseer uw LLM evaluatie met ClickUp
Bij het evalueren van LLM's gaat het erom de juiste meetgegevens te kiezen die aansluiten bij uw doelen. De sleutel is het begrijpen van uw specifieke doelen, of het nu gaat om het verbeteren van de vertaalkwaliteit, het verbeteren van het genereren van content of het afstemmen op gespecialiseerde taken.
Het selecteren van de juiste maatstaven voor prestatiebeoordeling, zoals RAG- of verfijningsmaatstaven, vormt de basis voor een nauwkeurige en zinvolle evaluatie. Ondertussen bieden geavanceerde scorers zoals G-Eval, Prometheus, SelfCheckGPT en QAG nauwkeurige inzichten dankzij hun sterke redeneervermogen.
Dat betekent echter niet dat deze scores perfect zijn. Het is nog steeds belangrijk om ervoor te zorgen dat ze betrouwbaar zijn.
Als je voortgang boekt met de evaluatie van je LLM-sollicitatie, pas het proces dan aan je specifieke situatie aan. Er is geen universele metriek die voor elk scenario werkt. Een combinatie van metrieken, samen met een focus op context, zal u een nauwkeuriger beeld geven van de prestaties van uw model.
Om uw LLM-evaluatie te stroomlijnen en de samenwerking tussen teams te verbeteren, is ClickUp de ideale oplossing voor het beheren van workflows en het bijhouden van belangrijke meetgegevens.
Wilt u de productiviteit van uw team verbeteren? Meld u aan voor ClickUp en ervaar hoe het uw werkstroom kan transformeren!