
De meeste ontwikkelaars die een Hugging Face-samenvattingsscript bouwen, lopen tegen hetzelfde probleem aan: de samenvatting werkt perfect in hun terminal. Maar het maakt zelden een verbinding met het daadwerkelijke werk dat het zou moeten ondersteunen.
Deze gids leidt je door het bouwen van een tekstsummarizer met de Transformers-bibliotheek van Hugging Face en laat je vervolgens zien waarom zelfs een vlekkeloze implementatie meer problemen kan opleveren dan oplossen wanneer je team samenvattingen nodig heeft die daadwerkelijk verbinding maken met taken, projecten en beslissingen.
Wat is tekstsamenvatting?
Teams worden overspoeld met informatie. Je krijgt te maken met lange documenten, eindeloze notulen van vergaderingen, compacte onderzoeksrapporten en kwartaalverslagen die uren kosten om handmatig te verwerken. Deze voortdurende informatie-overload vertraagt de besluitvorming en ondermijnt de productiviteit.
Tekstamenvatting is het proces waarbij Natural Language Processing (NLP) wordt gebruikt om deze content samen te vatten tot een korte, samenhangende versie waarin de meest essentiële informatie behouden blijft. Zie het als een instant executive brief voor elk document. Deze NLP-samenvattingstechnologie maakt doorgaans gebruik van een van de volgende twee benaderingen:
Extractieve samenvatting: Deze methode werkt door de belangrijkste zinnen rechtstreeks uit de tekst te identificeren en te halen. Het is alsof een markeerstift automatisch de belangrijkste punten voor je selecteert. De uiteindelijke samenvatting is een verzameling van originele zinnen.
Abstractieve samenvatting: Deze meer geavanceerde methode genereert volledig nieuwe zinnen om de kernbetekenis van de brontekst weer te geven. Het parafraseert de informatie, wat het resultaat is van een vloeiendere en menselijkere samenvatting, net zoals iemand een lang verhaal in zijn eigen woorden zou uitleggen.
Je ziet de resultaten hiervan overal. Het wordt gebruikt om aantekeningen van vergaderingen samen te vatten tot actiepunten, feedback van klanten te distilleren tot trends en snelle overzichten van projectdocumentatie te maken. Het doel is altijd hetzelfde: de essentiële informatie verkrijgen zonder elk woord te lezen.
📮 ClickUp Insight: De gemiddelde professional besteedt meer dan 30 minuten per dag aan het zoeken naar werkgerelateerde informatie. Dat is meer dan 120 uur per jaar die verloren gaat aan het doorzoeken van e-mails, Slack-threads en verspreide bestanden. Een intelligente AI-assistent die in je werkruimte is ingebouwd, kan daar verandering in brengen. ClickUp Brain levert direct inzichten en antwoorden door binnen enkele seconden de juiste documenten, gesprekken en taakdetails naar boven te halen, zodat je kunt stoppen met zoeken en aan de slag kunt gaan.
💫 Echte resultaten: Teams zoals QubicaAMF hebben met ClickUp meer dan 5 uur per week teruggewonnen, meer dan 250 uur per jaar per persoon, door verouderde kennisbeheerprocessen te elimineren.
Waarom Hugging Face gebruiken voor tekstsamenvatting?
Het bouwen van een aangepast tekstsamenvattingsmodel vanaf nul is een enorme onderneming. Het vereist enorme datasets voor training, krachtige en dure rekenkracht en een team van machine learning-experts. Deze hoge toegangsdrempel weerhoudt de meeste engineering- en productteams ervan om er ooit mee te beginnen.
Hugging Face is het platform dat dit probleem oplost. Het is een open-source community en datawetenschapsplatform dat je toegang geeft tot duizenden vooraf getrainde modellen, waardoor LLM-samenvattingen voor ontwikkelaars effectief worden gedemocratiseerd. In plaats van helemaal vanaf nul te beginnen, kun je starten met een krachtig model dat al voor 99% klaar is.
Dit is waarom zoveel ontwikkelaars kiezen voor Hugging Face: 🛠️
Toegang tot vooraf getrainde modellen: De Hugging Face Hub is een enorme opslagplaats met meer dan 2 miljoen openbare modellen die zijn getraind door bedrijven als Google, Meta en OpenAI. Je kunt deze geavanceerde checkpoints downloaden en gebruiken voor je eigen projecten.
Vereenvoudigde pipeline-API: De pipeline-functie is een hoogwaardige API die alle complexe stappen, zoals tekstvoorbewerking, modelinferentie en uitvoerformat, in slechts een paar regels code afhandelt.
Modelvariatie: je bent niet gebonden aan één optie. Je kunt kiezen uit een breed bereik aan architecturen, zoals BART, T5 en Pegasus, elk met verschillende sterke punten, groottes en prestatiekenmerken.
Flexibiliteit van het framework: De Transformers-bibliotheek werkt naadloos samen met de twee populairste deep learning-frameworks, PyTorch en TensorFlow. Je kunt degene gebruiken waarmee je team al vertrouwd is.
Ondersteuning door de community: dankzij uitgebreide documentatie, officiële cursussen en een actieve community van ontwikkelaars kun je gemakkelijk tutorials vinden en hulp krijgen wanneer je tegen problemen aanloopt.
Hoewel Hugging Face ongelooflijk krachtig is voor ontwikkelaars, is het belangrijk om te onthouden dat het een op code gebaseerde oplossing is. Voor de implementatie en het onderhoud ervan is technische expertise vereist. Dit is niet altijd geschikt voor niet-technische teams die alleen hun werk willen samenvatten.
🧐 Wist je dat? Dankzij de Transformers-bibliotheek van Hugging Face is het gebruik van geavanceerde NLP-modellen met een paar regels code mainstream geworden. Daarom beginnen prototypes voor samenvattingen vaak daar.
Wat zijn Hugging Face Transformers?
Je hebt dus besloten om Hugging Face te gebruiken, maar wat is de technologie die dit mogelijk maakt? De kerntechnologie is een architectuur die Transformer heet. Toen deze in 2017 werd geïntroduceerd in een paper met de titel "Attention Is All You Need", veranderde dit het veld van NLP volledig.
Vóór Transformers hadden modellen moeite om de context van lange zinnen te begrijpen. De sleutelinnovatie van de Transformer is het aandachtsmechanisme, waarmee het model het belang van verschillende woorden in de invoertekst kan afwegen bij het verwerken van een specifiek woord. Dit helpt het om langetermijnafhankelijkheden vast te leggen en de context te begrijpen, wat cruciaal is voor het maken van samenhangende samenvattingen.
De Hugging Face Transformers-bibliotheek is een Python-pakket dat het ongelooflijk eenvoudig maakt om deze complexe modellen te gebruiken. Je hebt geen doctoraat in machine learning nodig. De bibliotheek neemt het zware werk uit handen.
De drie belangrijkste componenten die je moet kennen
- Tokenizers: Modellen begrijpen geen woorden, maar wel nummers. Een tokenizer neemt je invoertekst en zet deze om in een reeks numerieke tokens – een proces dat tokenisatie wordt genoemd – die het model kan verwerken.
- Modellen: Dit zijn de vooraf getrainde neurale netwerken zelf. Voor samenvattingen zijn dit doorgaans sequence-to-sequence-modellen met een encoder-decoderstructuur. De encoder leest de tekst om een numerieke weergave te creëren, en de decoder gebruikt die weergave om de samenvatting te genereren.
- Pijplijnen: Dit is de gemakkelijkste manier om een model te gebruiken. Een pijplijn bundelt een vooraf getraind model met de bijbehorende tokenizer en voert alle stappen van de voorbewerking van de invoer en de nabewerking van de uitvoer voor u uit.
Twee van de populairste modellen voor samenvatting zijn BART en T5. BART (Bidirectional and Auto-Regressive Transformer) is bijzonder goed in abstractieve samenvatting en produceert samenvattingen die heel natuurlijk lezen. T5 (Text-to-Text Transfer Transformer) is een veelzijdig model dat elke NLP-taak als een tekst-naar-tekstprobleem kadert, waardoor het een krachtige allrounder is.
🎥 Bekijk deze video om de beste AI-PDF-summarizers met elkaar te vergelijken en te ontdekken welke tools de snelste en meest nauwkeurige samenvattingen leveren zonder context te verliezen.
Hoe bouw je een tekstsamenvatter met Hugging Face
Klaar om je eigen voorbeeld van een samenvatting te bouwen? Het enige wat je nodig hebt is enige basiskennis van Python, een code-editor zoals VS Code en een internetverbinding. Het hele proces bestaat uit slechts vier stappen. Binnen enkele minuten heb je een werkende samenvatting.
Stap 1: Installeer de vereiste bibliotheken
Eerst moet je de benodigde bibliotheken installeren. De belangrijkste is transformers. Je hebt ook een deep learning-framework nodig, zoals PyTorch of TensorFlow. In dit voorbeeld gebruiken we PyTorch.
Open je terminal of opdrachtprompt en voer de volgende opdracht uit:

Sommige modellen, zoals T5, hebben ook de sentencepiece-bibliotheek nodig voor hun tokenizer. Het is een goed idee om deze ook te installeren.

💡 Pro-tip: Creëer een virtuele Python-omgeving voordat je deze pakketten installeert. Zo blijven de afhankelijkheden van je project geïsoleerd en voorkom je conflicten met andere projecten op je computer.
Stap 2: Laad het model en de tokenizer
De eenvoudigste manier om aan de slag te gaan is door gebruik te maken van de pijplijnfunctie. Deze zorgt er automatisch voor dat het juiste model en de juiste token voor de samenvattingstaak worden geladen.
Importeer in je Python-script de pijplijn en initialiseer deze als volgt:

Hier specificeren we twee dingen:
De taak: We vertellen de pijplijn dat we een "samenvatting" willen maken.
Het model: We kiezen een specifiek vooraf getraind modelcheckpoint uit de Hugging Face hub. facebook/bart-large-cnn is een populaire keuze die is getraind op nieuwsartikelen en goed werkt voor algemene samenvattingen. Voor snellere tests kunt u een kleiner model gebruiken, zoals t5-small.
De eerste keer dat je deze code uitvoert, worden de modelgewichten gedownload van de hub, wat enkele minuten kan duren. Daarna wordt het model op je lokale computer in de cache opgeslagen, zodat het direct kan worden geladen.
Stap 3: Maak de samenvattingsfunctie
Om je code overzichtelijk en herbruikbaar te maken, kun je de samenvattingslogica het beste in een functie verwerken. Dit maakt het ook gemakkelijk om met verschillende parameters te experimenteren.
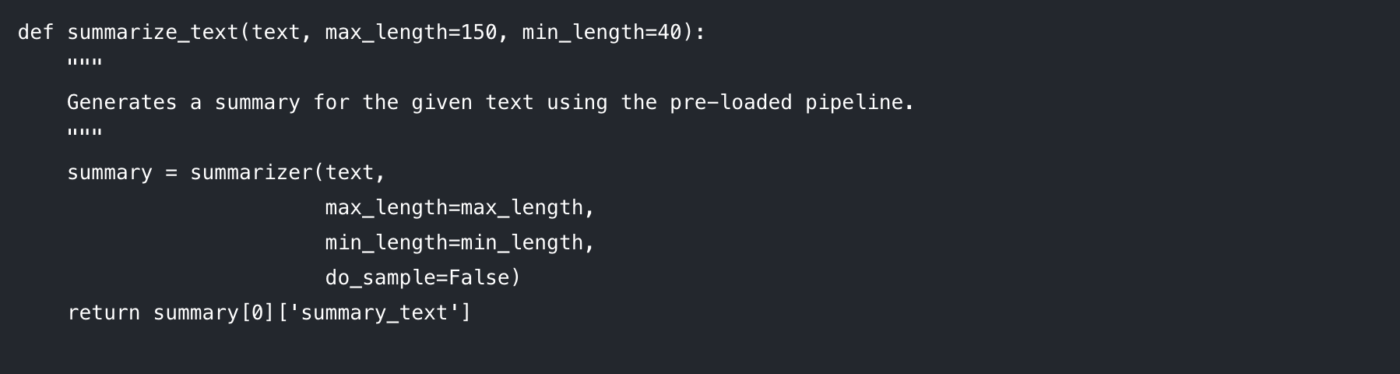
Laten we eens kijken naar de parameters die je kunt beïnvloeden:
max_length: Hiermee stelt u het maximale aantal tokens (grofweg woorden) voor de uitvoersamenvatting in.
min_length: Hiermee stelt u het minimumaantal tokens in om te voorkomen dat het model te korte of lege samenvattingen genereert.
do_sample: Wanneer ingesteld op False, gebruikt het model een deterministische methode (zoals beam search) om de meest waarschijnlijke samenvatting te genereren. Door het in te stellen op True wordt willekeurigheid geïntroduceerd, wat creatievere maar minder voorspelbare resultaten kan opleveren.
Het afstemmen van deze parameters is essentieel om de gewenste uitvoerkwaliteit te verkrijgen.
Stap 4: Genereer je samenvatting
Nu komt het leuke gedeelte. Voer je tekst in de functie in en druk het resultaat af. 🤩

Je zou een verkorte versie van het artikel op je console moeten zien verschijnen. Als je problemen ondervindt, zijn hier enkele snelle oplossingen:
De invoertekst is te lang: het model kan een fout geven als uw invoer de maximale lengte overschrijdt (vaak 512 of 1024 tokens). Voeg truncation=True toe aan de summarizer()-aanroep om lange invoer automatisch af te kappen.
De samenvatting is te algemeen: Probeer de parameter num_beams te verhogen (bijv. num_beams=4). Hierdoor zoekt het model grondiger naar een betere samenvatting, maar kan het iets langzamer werken.
Deze op code gebaseerde aanpak is fantastisch voor ontwikkelaars die aangepaste apps bouwen. Maar wat gebeurt er als je dit moet integreren in het dagelijkse werk van een team? Dan komen de beperkingen aan het licht.
Beperkingen van Hugging Face voor tekstsamenvatting
Hugging Face is een geweldige optie als je flexibiliteit en controle wilt. Maar zodra je het voor echte werkstroomen gaat gebruiken (en niet alleen voor een demo-notebook), duiken er al snel een paar voorspelbare uitdagingen op.
Tokenlimieten en hoofdpijn door lange documenten
De meeste samenvattingsmodellen hebben een vaste maximale invoerlengte. Facebook/bart-large-cnn is bijvoorbeeld geconfigureerd met max_position_embeddings = 1024. Dat betekent dat langere documenten vaak moeten worden ingekort of opgedeeld.
Als je alleen een snelle basis nodig hebt, kun je truncatie in de pijplijn inschakelen en verdergaan. Maar als je betrouwbare samenvattingen van lange documenten nodig hebt, bouw je meestal een chunking-logica en voer je vervolgens een tweede ronde uit, een 'samenvatting van samenvattingen', om de resultaten aan elkaar te knopen. Dat is extra engineering en het is gemakkelijk om inconsistente output te krijgen.
Risico op hallucinaties (en de verificatiebelasting)
Abstractieve modellen kunnen soms hallucineren en tekst genereren die aannemelijk klinkt, maar feitelijk onjuist is. Voor bedrijfskritisch gebruik levert dat een probleem op: elke samenvatting moet handmatig worden onderworpen aan verificatie. Op dat moment bespaar je niet echt tijd, maar verplaats je het werk alleen maar naar een ander deel van het proces.
Gebrek aan contextbewustzijn
Een Hugging Face-model kent alleen de tekst die je erin invoert. Het heeft geen inzicht in de doelen van je project, de betrokken personen of hoe het ene document zich tot het andere verhoudt, omdat het de contextuele intelligentie van moderne systemen mist. Het kan je niet vertellen of een samenvatting van een klantgesprek in tegenspraak is met het document met projectvereisten, omdat het geïsoleerd functioneert.
Integratieoverhead (het 'last mile'-probleem)
Het genereren van een samenvatting is meestal het makkelijke deel. Het echte werk komt daarna.
Waar gaat de samenvatting naartoe? Wie ziet deze? Hoe wordt deze omgezet in een uitvoerbare taak? Hoe maak je een verbinding tussen deze taak en het werk dat de trigger was voor de samenvatting?
Om de 'laatste mijl' te overbruggen, moeten er aangepaste integraties en glue code worden gebouwd. Dat betekent extra werk voor ontwikkelaars en leidt vaak tot een omslachtige werkstroom voor alle andere betrokkenen.
Technische barrière en doorlopend onderhoud
Een op Python gebaseerde aanpak is vooral toegankelijk voor mensen die kunnen codeen. Dat vormt een praktische barrière voor marketing-, verkoop- en operationele teams, waardoor de acceptatie beperkt blijft.
Het komt ook met doorlopend onderhoud: afhankelijkheden beheren, bibliotheken updaten en alles laten werken terwijl API's en modellen zich ontwikkelen. Wat begint als een snelle winst, kan stilletjes een ander systeem worden om op te passen.
📮 ClickUp Insight: 42% van de verstoringen op het werk komt voort uit het jongleren met platforms, het beheren van e-mails en het heen en weer springen tussen vergaderingen. Wat als je deze kostbare onderbrekingen zou kunnen elimineren? ClickUp verenigt je werkstroom (en chat) onder één gestroomlijnd platform. Start en beheer je taken vanuit chat, documenten, Whiteboards en meer, terwijl AI-aangedreven functies de context verbonden, doorzoekbaar en beheersbaar houden.
Het grotere probleem: contextverspreiding
Zelfs als je samenvattingsscript perfect werkt, kan je team nog steeds tijd verliezen omdat de output losstaat van waar het werk daadwerkelijk plaatsvindt.
Dat is contextversnippering, wanneer teams uren verspillen met het zoeken naar informatie, het schakelen tussen apps en het opsporen van bestanden op niet-gekoppelde platforms.
Dit is waar een geconvergeerde werkruimte het verschil maakt. In plaats van samenvattingen op één plek te genereren en ze later 'naar het werk te verplaatsen', houdt een geconvergeerd systeem projecten, documenten en gesprekken bij elkaar, met ClickUp Brain als ingebouwde intelligentielaag. Je samenvattingen blijven gekoppeld aan taken en documenten, zodat de volgende stap duidelijk is en de overdracht onmiddellijk plaatsvindt.
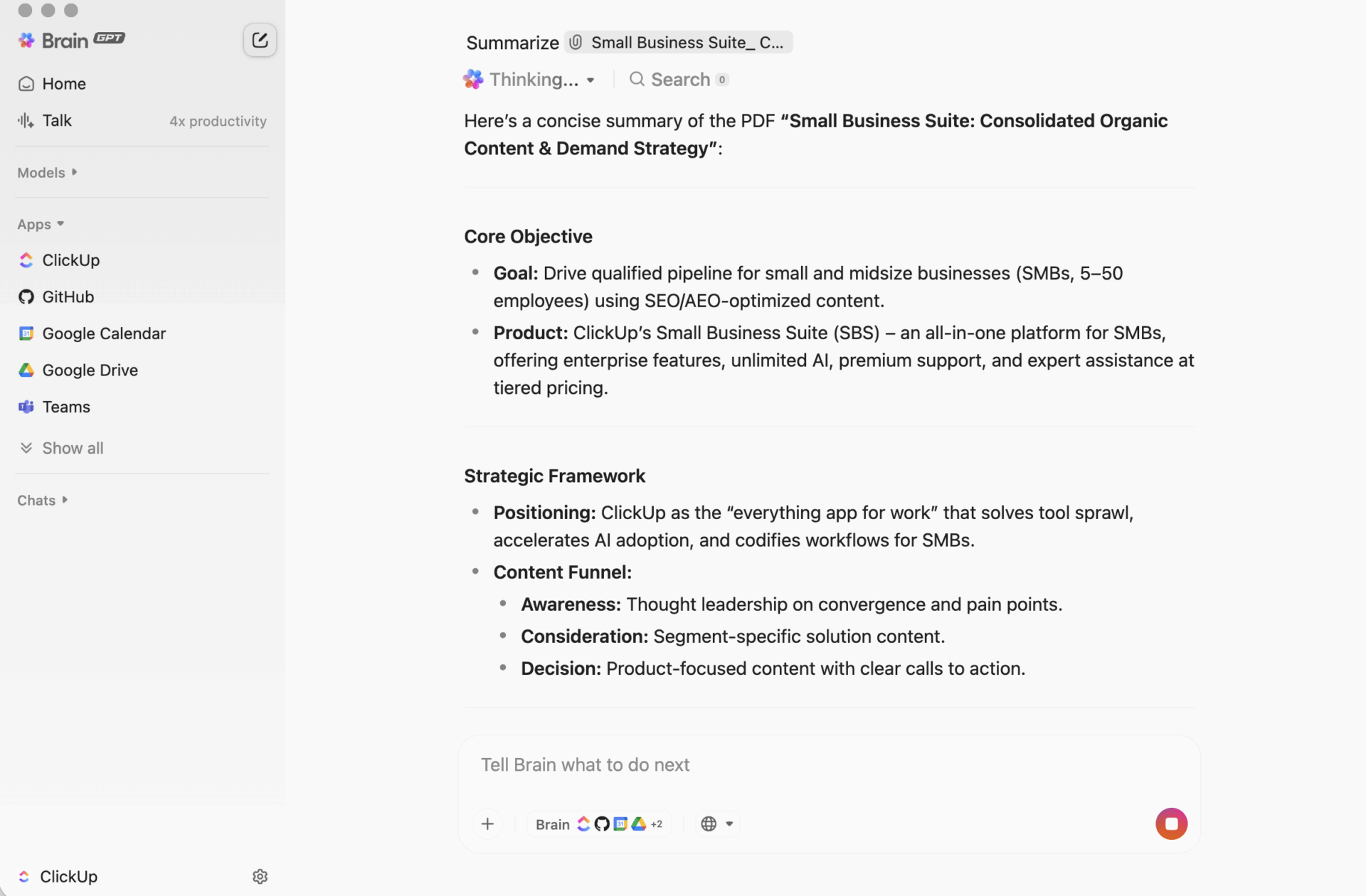
Samenvattingen die met ClickUp in actie worden omgezet
Een samenvattingsscript kan perfect werken en toch op één vervelende manier falen voor je team: de samenvatting komt ergens terecht waar het niet bij het werk hoort.
De kloof zorgt voor contextversnippering, waarbij informatie verspreid is over documenten, chatthreads, taken en 'snelle aantekeningen' in tools die geen verbinding met elkaar hebben. Mensen besteden meer tijd aan het zoeken naar de samenvatting dan aan het gebruik ervan. Het echte voordeel is niet alleen het genereren van een samenvatting. Het is het koppelen van die samenvatting aan beslissingen, eigenaars en volgende stappen waar het werk daadwerkelijk plaatsvindt.
Dat is wat ClickUp Brain anders doet. Het vat taken, documenten en gesprekken samen binnen dezelfde werkruimte waar je projecten zich bevinden, zodat je team iets kan begrijpen en ernaar kan handelen zonder van tool te wisselen.

ClickUp BrainGPT: communiceer met samenvattingen met behulp van natuurlijke taal
Op desktop is BrainGPT de conversatie-interface voor ClickUp Brain. In plaats van scripts, notitieboeken of externe AI-tools te openen, kan je team rechtstreeks in ClickUp in gewone taal vragen wat ze nodig hebben.
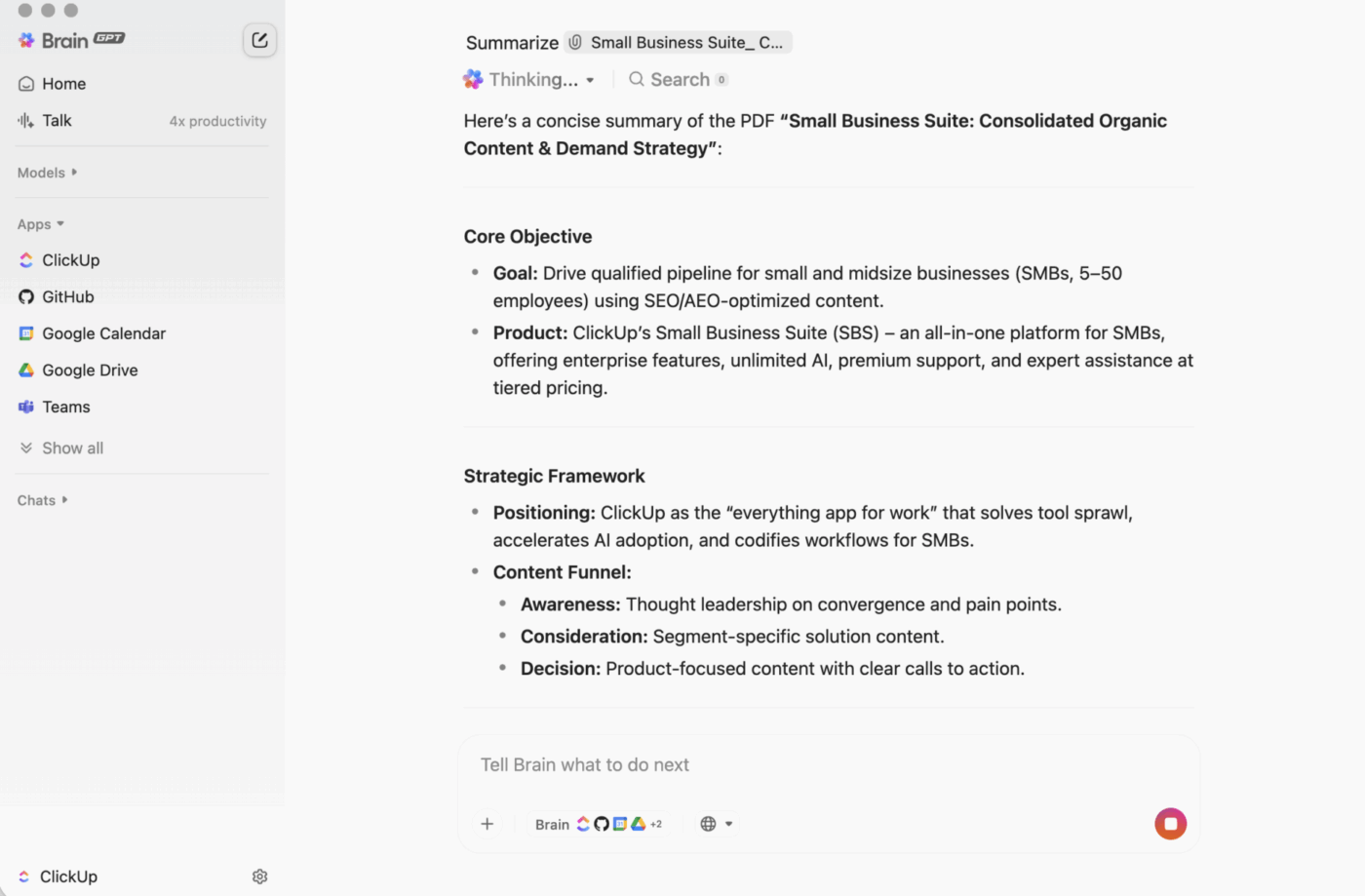
Je kunt typen (of spraak-naar-tekst gebruiken) om:
- Vat een lange beschrijving van de taak, commentaarthread of document samen.
- Vervolg met vragen als "Wat zijn de volgende stappen?" of "Wie is hiervoor verantwoordelijk?"
- Zet een samenvatting om in actie door er taken van te maken, met eigenaren en deadlines.
Omdat ClickUp Brain binnen je werkruimte werkt, is de output gebaseerd op live context: taakbeschrijvingen, opmerkingen, subtaaken, gekoppelde documenten en projectstructuur. Je plakt geen tekst in een aparte tool en hoopt dat er niets belangrijks wordt gemist.
Waarom dit voor de meeste teams beter is dan een op code gebaseerde samenvattingswerkstroom
Een door ontwikkelaars gebouwde werkstroom kan krachtige samenvattingen genereren. De wrijving ontstaat daarna, wanneer iemand de output moet kopiëren naar de plek waar het werk gebeurt, deze vervolgens moet vertalen naar taken en vervolgens moet zorgen dat deze worden uitgevoerd.
ClickUp Brain sluit de cirkel:
Geen codering vereistIedereen in het team kan een document, een taakthread of een rommelige reeks opmerkingen samenvatten zonder iets te installeren of code te schrijven.
Contextbewuste samenvattingenClickUp Brain kan de onderdelen opnemen die mensen meestal vergeten: beslissingen die verborgen zitten in opmerkingen, belemmeringen die in antwoorden worden vermeld, subtaaken die de betekenis van 'Klaar' veranderen.
Samenvattingen staan waar het werk zich afspeeltJe kunt bijpraten binnen een Taak, een samenvatting toevoegen bovenaan ClickUp Docs of snel een discussie samenvatten zonder een ander 'samenvattingsdocument' te maken dat niemand bekijkt.
Minder toolverspreidingJe hebt geen aparte scripts, Jupyter-notebooks, API-sleutels of een werkstroom nodig die slechts één persoon begrijpt. Je documenten, taken en samenvattingen blijven allemaal in hetzelfde systeem.
Dit is het praktische voordeel van een geconvergeerde werkruimte: samenvatting, actie en samenwerking vinden tegelijkertijd plaats in plaats van achteraf aan elkaar te worden gekoppeld.
Dit is het praktische voordeel van een geconvergeerde werkruimte: samenvatting, actie en samenwerking vinden tegelijkertijd plaats in plaats van achteraf aan elkaar te worden gekoppeld.
Hoe het in het echte leven werkt
Hier zijn een paar veelvoorkomende patronen die teams gebruiken:
- Vat een commentaarthread samen: open een Taak met een lange discussie, klik op de AI-optie en krijg een kort overzicht van wat er is veranderd en wat belangrijk is.
- Een document samenvatten: open een ClickUp-document en gebruik 'Ask AI' om een samenvatting van de pagina te genereren, zodat iedereen snel zijn weg kan vinden.
- Haal actiepunten eruit: neem de samenvatting en zet de volgende stappen meteen om in taken met toegewezen personen en deadlines, zodat het momentum niet verloren gaat bij de overdracht.
| Mogelijkheden | Hugging Face (op code gebaseerd) | ClickUp Brain |
|---|---|---|
| Installatie vereist | Python-omgeving, bibliotheken, code | Geen, ingebouwd |
| Contextbewustzijn | Alleen tekst (wat je invoert) | Volledige werkruimte-context (taken, documenten, opmerkingen, subtaaken) |
| Werkstroom-integratie | Handmatig exporteren/importeren | Native: samenvattingen kunnen taken en updates worden |
| Vereiste technische vaardigheden | Ontwikkelaarsniveau | Iedereen in het team |
| Onderhoud | Doorlopend onderhoud van modellen en code | Automatische updates |
Van samenvattingen tot uitvoering met Super Agents
Samenvattingen zijn nuttig. Het moeilijke deel is ervoor te zorgen dat ze consequent worden omgezet in follow-up, vooral wanneer het volume toeneemt.
Dat is waar ClickUp Super Agents om de hoek komen kijken. Ze kunnen samengevatte informatie gebruiken en het werk voortzetten op basis van triggers en voorwaarden, binnen dezelfde werkruimte.
Met Super Agents kunnen teams:
- Vat wijzigingen volgens een schema samen (wekelijkse projectoverzicht, dagelijkse statusrapporten)
- Haal actitemen eruit en wijs automatisch eigenaren toe
- Geef vastgelopen werk aan (taaken die vastzitten in beoordeling, onbeantwoorde threads, achterstallige volgende stappen)
- Houd de zichtbaarheid van het leiderschap hoog zonder handmatige rapportage
In plaats van een samenvatting als statische tekst, helpen agenten ervoor te zorgen dat de samenvatting een plan wordt en dat het plan voortgang oplevert.
Samenvattingen die leven waar het werk gebeurt
Hugging Face Transformers zijn ideaal wanneer je een aangepaste app, een op maat gemaakte pijplijn of volledige controle over het gedrag van het model nodig hebt.
Maar voor de meeste teams is het grootste probleem niet 'Kunnen we dit samenvatten?', maar 'Kunnen we dit samenvatten en het onmiddellijk omzetten in werk, met eigenaren, deadlines en zichtbaarheid?'.
Als je doel teamproductiviteit en snelle uitvoering is, geeft ClickUp Brain je samenvattingen in context, precies waar het werk plaatsvindt, met een duidelijk pad van 'dit is de kern' naar 'dit is wat we nu gaan doen'.
Klaar om de installatie over te slaan en te beginnen met samenvatten waar je werk zich daadwerkelijk bevindt? Ga gratis aan de slag met ClickUp en laat Brain het zware werk doen.