
Pierwsze kilka usług jest łatwych. Jedna rotacja, jeden kanał, a następnie kopia zapasowa.
Jednak gdy Twoja firma osiągnie dziesiątki mikrousług, wiele regionów i wielopoziomową strukturę własnościową, ręczne eskalacje przestają być cyklem pracy, a stają się obciążeniem.
W tym przewodniku wyjaśniono, jak zautomatyzować ścieżki eskalacji incydentów, które skalują się wraz z organizacją inżynieryjną bez powodowania luk w systemie dyżurów.
Zobaczymy również, jak ClickUp wpisuje się w tworzenie systemu eskalacji, któremu mogą zaufać Twoje zespoły inżynierów. 🎯
⭐ Polecany szablon
Reaguj szybko i skutecznie w sytuacjach awaryjnych, od klęsk żywiołowych po naruszenia bezpieczeństwa danych, korzystając z szablonu planu działania w przypadku incydentów (IAP) ClickUp.

Szablon zawiera predefiniowane sekcje, które umożliwiają:
- Określ cele związane z incydentami i priorytety reagowania.
- Ustal jasną strukturę dowodzenia
- Koordynuj działania między zespołami w czasie rzeczywistym.
- Rejestruj decyzje, osie czasu i kluczowe aktualizacje w miarę ich pojawiania się.
- Bądź na połączeniu z eskalacją i kontynuuj działania
A ponieważ znajduje się on w ClickUp, funkcjonuje jako dokument dowodzenia na żywo, a nie statyczna lista kontrolna.
Dlaczego warto przeprowadzić automatyzację ścieżek eskalacji incydentów
Gdy Twój zespół zarządza złożonymi systemami z rygorystycznymi umowami SLA, ręczna eskalacja tylko spowalnia pracę. Automatyzowana eskalacja sprawia, że proces reagowania jest przewidywalny i mniej stresujący, nawet w przypadku incydentów wymagających szybkiej reakcji.
Oto dlaczego musisz przeprowadzić automatyzację ścieżek eskalacji w swojej organizacji. 👇
Ryzyko związane z ręczną eskalacją
Gdy masz do czynienia z dziesiątkami usług, wieloma zmianami dyżurów i ciągłymi zmianami własności, kroki wykonywane ręcznie szybko stają się problemem.
Typowe pułapki to:
- Pominięte lub opóźnione powiadomienia, gdy ktoś przeoczy wiadomość e-mail, SMS lub ping czatu
- Niejasności podczas przekazywania spraw, zwłaszcza gdy ścieżki eskalacji nie są jasno udokumentowane
- Eskalacja do niewłaściwego zespołu z powodu nieaktualnej mapy odpowiedzialności
- Wąskie gardła spowodowane poleganiem na jednej osobie, która „przekazuje alert dalej”
📖 Przeczytaj również: Jak napisać raport dotyczący incydentu
Korzyści płynące z automatyzacji
Automatyzacja ITSM nadaje ścieżkom eskalacji strukturę i dynamikę. Zamiast liczyć na to, że ktoś zauważy alert, system natychmiast i konsekwentnie wykonuje wcześniej zdefiniowaną sekwencję działań.
Oto, co zyskują zespoły, korzystając ze sztucznej inteligencji do automatyzacji zadań:
- Szybszy czas reakcji, ponieważ alerty docierają do właściwej osoby lub zespołu w ciągu kilku sekund.
- Spójna realizacja kroków eskalacji, nawet o 3 nad ranem, kiedy podejmowanie decyzji przebiega wolniej.
- Wbudowana redundancja, która gwarantuje, że osoby odpowiedzialne za reagowanie w trybie awaryjnym zostaną powiadomione, jeśli osoba dyżurująca nie zareaguje na alert.
- Widoczność działań wszystkich zespołów, ponieważ każdy rozumie przepływ eskalacji
- Mniej gaszenia pożarów i bardziej przewidywalne doświadczenia związane z dyżurami
📖 Przeczytaj również: Przykłady planów ciągłości działania
Ograniczanie zmęczenia alertami i ludzkich przeoczeń
Zmęczenie alertami niszczy skuteczność dyżurów. Gdy Twój zespół otrzymuje zbyt częste powiadomienia lub otrzymuje je z niewłaściwych powodów, przestaje reagować z należytą pilnością. Automatyzacja pomaga filtrować i eskalować tylko te zgłoszenia, które naprawdę wymagają interwencji człowieka.
Dzięki zautomatyzowanej logice eskalacji:
- Alerty o niskim znaczeniu lub powtarzające się są blokowane, zanim dotrą do dyżurnego.
- Reguły oparte na stopniu ważności zapewniają, że drobne problemy nie budzą nikogo niepotrzebnie.
- Alerty są eskalowane tylko wtedy, gdy system wykryje brak odpowiedzi w określonym czasie.
- Teams poświęcają mniej czasu na segregowanie nieistotnych zgłoszeń, a więcej na rozwiązywanie rzeczywistych problemów.
Wsparcie zgodności z umowami SLA i polityką dyżurów
Automatyzacja eskalacji ułatwia zachowanie zgodności bez konieczności ciągłego ręcznego nadzoru. Dla liderów operacji IT zarządzających rygorystycznymi umowami SLA lub wewnętrznymi zobowiązaniami dotyczącymi niezawodności AI pełni rolę bariery ochronnej, która egzekwuje oczekiwane zachowania. Pomaga ona:
- Upewnij się, że powiadomienia o incydentach są zgodne z wcześniej ustalonymi zasadami przekazywania.
- Automatycznie przestrzegaj osi czasu reakcji określonych w umowie SLA dzięki eskalacjom czasowym.
- Egzekwuj harmonogramy dyżurów bez konieczności korzystania z przestarzałych arkuszy kalkulacyjnych.
- Twórz ścieżki audytu dla każdego alertu, eskalacji i potwierdzenia.
🎥 Chcesz, aby cały cykl pracy eskalacyjnej przebiegał bez Twojego udziału? Super Agents Ci w tym pomoże . 👇🏼
🔍 Czy wiesz, że... Centrum kontroli misji NASA działa w zasadzie w oparciu o zautomatyzowaną logikę eskalacji. Jeśli telemetria wykracza poza zakres, system natychmiast przekazuje automatyczne alerty do specjalistów z danej dziedziny.
Czym jest polityka eskalacji w zarządzaniu incydentami?
Polityka eskalacji to z góry określony zestaw zasad, który określa, kto jest powiadamiany, kiedy jest powiadamiany oraz w jaki sposób odpowiedzialność jest przekazywana wyżej lub między zespołami.
Pomyśl o tym jak o ustrukturyzowanym planie działania, który zapobiega opóźnieniom w rozwiązywaniu incydentów, zapewnia zaangażowanie odpowiednich ekspertów we właściwym czasie i pomaga zespołom w realizacji umów SLA.
Dobrze skonstruowana polityka zarządzania eskalacją zazwyczaj obejmuje:
- Routing oparty na regułach, który określa, kto jest następny w kolejce, gdy ktoś nie potwierdzi lub nie jest w stanie rozwiązać incydentu.
- Wyzwalacze czasowe, które automatycznie eskalują zgłoszenia po 5, 15 lub 30 minutach w zależności od stopnia ważności.
- Metody powiadomień, takie jak połączenia telefoniczne, SMS-y, czat lub e-mail
- Poziomy planu eskalacji od poziomu 1 (główny dyżurny) > poziom 2 (starszy inżynier/ekspert) > poziom 3 (kierownictwo)
- Oczekiwania dotyczące dokumentacji, aby nowi respondenci mogli przejąć obowiązki bez utraty kluczowego kontekstu.
📖 Przeczytaj również: Jak nadawać priorytety zadaniom jako P0, P1, P2, P3 i P4
Rodzaje zasad eskalacji
Oto podstawowe rodzaje zasad, które Twój zespół powinien zrozumieć:
1. Eskalacja hierarchiczna (pionowa)
Alerty są przekazywane w górę łańcucha dowodzenia, od młodszych inżynierów do starszych specjalistów i kierownictwa. Należy z tego korzystać, gdy sytuacja wymaga głębszej wiedzy specjalistycznej, uprawnień decyzyjnych lub widoczności kierownictwa.
2. Eskalacja funkcjonalna (pozioma)
Zamiast kierować alert w górę, przesyła się go między zespołami do funkcji odpowiedzialnej za dany system. Jest to idealne rozwiązanie w przypadku incydentów związanych z konkretną dziedziną, taką jak bazy danych, sieci, płatności lub API.
3. Eskalacja oparta na czasie
Jest to podstawa większości zautomatyzowanych systemów. W tym typie alert przechodzi do następnego poziomu po upływie określonego czasu, często bezpośrednio powiązanego z umowami SLA. Jest to szczególnie istotne, gdy potrzebna jest gwarantowana responsywność po godzinach pracy.
4. Eskalacja oparta na wpływie
Eskalacja oparta na wpływie zależy od powagi lub wpływu na działalność, a nie od hierarchii lub czasu. Jest to przydatne w przypadku awarii, niepowodzeń płatności, problemów związanych z obsługą klienta lub naruszeń bezpieczeństwa.
5. Równoległa eskalacja
W tym przypadku powiadomienia wysyłane są jednocześnie do wielu osób lub zespołów. Eskalacja równoległa jest stosowana w przypadku problemów o wysokim stopniu ważności, które wymagają zaangażowania wielu specjalistów, lub w sytuacjach, w których wszelkie opóźnienia są niedopuszczalne.
🔍 Czy wiesz, że... Ostatnie badania dotyczące sygnałów alarmowych wykazały, że bardzo wyraźne lub „głośne/jasne ” alarmy mogą spowolnić czas reakcji, zwłaszcza jeśli alarm jest nieoczekiwany. Jednak gdy typ alarmu staje się oczekiwany (tj. stanowi część wcześniej zaprojektowanego systemu eskalacji/powiadomień), czas reakcji ulega poprawie. Sugeruje to, że podczas automatyzacji ścieżek eskalacji nie należy po prostu zasypywać ludzi alarmami o wysokim priorytecie.
Kiedy użyć wyzwalacza automatycznej eskalacji
Teraz, gdy już wiesz, jak zbudowane są ścieżki eskalacji, następnym krokiem jest podjęcie decyzji, kiedy te reguły powinny być uruchamiane automatycznie.
Poniżej przedstawiono podstawowe sytuacje, które są wyzwalaczami automatycznej eskalacji, tworząc warstwę logiczną leżącą u podstaw Twoich zasad. 💁
Eskalacja oparta na stopniu ważności
Automatyczna eskalacja uruchamia się, gdy powaga lub wpływ incydentu przekroczy określony próg. Incydenty o wysokim stopniu powagi wymagają natychmiastowej uwagi kierownictwa, a automatyczna eskalacja pozwala ominąć wąskie gardła i w ciągu kilku sekund powiadomić ekspertów.
📌 Przykład: Całkowita awaria usługi, awaria bramki płatniczej lub poważne pogorszenie jakości usług, które ma wpływ na wielu użytkowników lub podstawowe systemy, wymaga automatycznego eskalowania.
Eskalacja oparta na czasie
Jeśli nikt nie potwierdzi ani nie rozwiąże incydentu w określonym czasie, alert automatycznie przechodzi na wyższy poziom. Zapobiega to stagnacji zgłoszeń, zwłaszcza poza normalnymi godzinami pracy lub gdy pierwsza osoba reagująca jest niedostępna lub przeciążona.
📌 Przykład: Po 10–15 minutach braku potwierdzenia następuje eskalacja od pierwszej osoby reagującej do starszego inżyniera; po kolejnych 30–60 minutach bez rozwiązania problem eskaluje dalej.
Eskalacja kontekstowa
Ta logika eskalacji uwzględnia atrybuty kontekstowe incydentu, takie jak usługa lub system, którego dotyczy incydent, właściciel usługi, segment klientów, którego dotyczy incydent (wewnętrzny vs. zewnętrzny, VIP vs. zwykły) lub domena funkcjonalna (baza danych, sieć, integracja). Na podstawie tego kontekstu alerty są kierowane do najbardziej odpowiedniej osoby lub zespołu reagującego.
W ten sposób unikniesz przeciążania zespołów nieistotnymi incydentami, skrócisz czas reakcji i zapewnisz, że specjaliści zajmą się problemami w swojej dziedzinie.
📌 Przykłady: Gwałtowny wzrost opóźnień w usłudze płatności powinien bezpośrednio powiadomić zespół ds. płatności, a błąd zaplecza w mikrousłudze rozliczeniowej powinien powiadomić zespół ds. rozliczeń.
Eskalacja oparta na metadanych
Nowoczesne narzędzia do powiadamiania i obsługi incydentów rejestrują metadane, takie jak źródło pochodzenia (które narzędzie monitorujące lub reguła powiadamiania zostało uruchomione), tożsamość użytkownika/klienta, lokalizacja, częstotliwość występowania podobnych incydentów w przeszłości lub etykiety. Pomaga to zastosować bardziej szczegółową, inteligentną logikę zamiast polegać na ogólnych regułach dotyczących ważności lub czasu.
📌 Przykłady: Powtarzające się alerty z tego samego podsystemu mogą wskazywać na głębszy, systemowy problem, wymagający szybszej eskalacji. Albo alerty dotyczące klientów VIP mogą być wyzwalaczem dodatkowych powiadomień.
Łączenie wyzwalaczy w celu tworzenia inteligentniejszych, adaptacyjnych zasad eskalacji
W praktyce wiele zespołów nie polega tylko na jednym rodzaju wyzwalacza. Zamiast tego tworzą hybrydowe zasady eskalacji, które łączą reguły dotyczące ważności, czasu, kontekstu i metadanych.
To wielopoziomowe podejście umożliwia zespołom tworzenie zasad eskalacji, które są zarówno responsywne (szybkie w razie potrzeby), jak i inteligentne (selektywne w celu zminimalizowania szumu), co skutkuje lepszymi wynikami w zakresie incydentów i bardziej efektywnym przydzielaniem zasobów.
🔍 Czy wiesz, że... W XVIII wieku załogi okrętów stosowały ścisłą hierarchię eskalacji w sytuacjach awaryjnych. Jeśli marynarz niższej rangi dostrzegł niebezpieczeństwo, dzwonił dzwonkiem i przekazywał wiadomość w górę hierarchii, aż kapitan podejmował ostateczną decyzję.
Jak zaprojektować skuteczne ścieżki eskalacji
Projektowanie ścieżek eskalacji polega na stworzeniu systemu, który niezawodnie kieruje odpowiednie alerty do właściwych osób przy minimalnym wysiłku.
Oto praktyczna, szczegółowa struktura, którą można wykorzystać w złożonych, rozproszonych środowiskach.
P.S. Przyjrzymy się również, w jaki sposób niektóre funkcje ClickUp mogą Ci w tym pomóc! 🤩
Krok 1: Określ jasne kryteria eskalacji, poziomy i obowiązki
Zacznij od zdefiniowania, co stanowi incydent wymagający eskalacji. Udokumentuj obiektywne kryteria, aby każdy inżynier dyżurny, niezależnie od tego, czy jest nowym respondentem L1, czy doświadczonym SRE, interpretował powagę incydentu w ten sam sposób.
Zapewnia to przejrzysty cykl pracy eskalacji, eliminuje niejasności i gwarantuje, że automatyzacja uruchamia się tylko wtedy, gdy jest to naprawdę konieczne.
Uwzględnij takie kryteria, jak:
- Progi ważności: awaria usługi, niepowodzenia płatności, problemy z uwierzytelnianiem, uszkodzenie danych i alerty bezpieczeństwa.
- Skutki: przerwy w obsłudze klientów, pogorszenie jakości usług wewnętrznych, awarie API partnerów, ryzyko związane z przestrzeganiem przepisów lub bezpieczeństwem.
- Kontekst krytyczny dla działalności: wpływ na klientów o wysokiej wartości, przepływy mające wpływ na przychody, systemy wysokiego ryzyka (np. płatności, fakturowanie)
Po zdefiniowaniu kryteriów i wyzwalaczy należy określić, kto otrzymuje powiadomienia i jakie są jego obowiązki na każdym etapie eskalacji.
Jasno określ poziomy:
- Poziom pierwszy (główny kierownik ds. incydentów): Pełni rolę pierwszej osoby reagującej i jest odpowiedzialny za potwierdzenie, wstępną klasyfikację i próby złagodzenia skutków.
- Poziom drugi (wsparcie techniczne/specjalista/SME): Zapewnia dogłębną wiedzę techniczną i rozwiązuje złożone problemy systemowe.
- Poziom trzeci (kierownik ds. inżynierii/kierownictwo): Nadzoruje poważne incydenty, zatwierdza poważne działania, koordynuje komunikację między zespołami i w razie potrzeby uruchamia wyzwalacz eskalacji do dostawcy.
🚀 ClickUp Advantage: Użyj ClickUp Docs, aby utrzymać jedno źródło informacji o kryteriach eskalacji, poziomach i obowiązkach oraz dokumentować role i obowiązki, w tym kto:
- Potwierdza i łagodzi
- Komunikacja z interesariuszami
- Obsługuje eskalacje dostawców lub partnerów zewnętrznych.
- Kieruje dowodzeniem w przypadku incydentów
Możesz również połączyć te konkretne role z odpowiednimi zadaniami ClickUp, aby zachować połączenie kontekstu.
Zbuduj własną bazę wiedzy:
Po zdefiniowaniu kryteriów eskalacji i własności zespoły potrzebują spójnego sposobu rejestrowania, śledzenia i analizowania incydentów technicznych. Szablon raportu incydentów ClickUp zapewnia uporządkowany, łatwo dostępny system dokumentowania incydentów informatycznych i operacyjnych w jednym miejscu.
Zbudowany w ramach ClickUp Docs, pomaga zespołom reagującym na incydenty rejestrować kluczowe szczegóły, takie jak powaga incydentu, usługi, na które miał on wpływ, osie czasu, podsumowania przyczyn źródłowych, kroki łagodzące i działania następcze.
Krok 2: Standaryzacja danych powstania incydentów
Zanim ścieżki eskalacji zostaną aktywowane, Twój zespół potrzebuje niezawodnego sposobu na rejestrowanie, normalizowanie i wzbogacanie danych dotyczących incydentów. Jeśli początkowy zapis incydentu jest niekompletny lub niespójny, nawet najbardziej zaawansowana logika eskalacji zawiedzie.
Standaryzacja powinna:
- Segreguj przychodzące alerty: przekształcaj alerty w spójne pola niestandardowe, takie jak poziom ważności, kategoria, usługa, na którą ma wpływ incydent, typ incydentu i status potwierdzenia.
- Automatyczne wzbogacanie incydentów: pobieranie metadanych, w tym klastra, ID wdrożenia, właścicieli usług lub zależności.
- Upewnij się, że każdy incydent zawiera kontekst: zapisz, kto go zgłosił, w jaki sposób został wykryty, środowisko (produkcyjne/testowe) oraz wszelkie istotne logi lub zrzuty ekranu.
Utwórz formularz ClickUp bezpośrednio z listy, na której śledzone są incydenty, i zaprojektuj go tak, aby odzwierciedlał rzeczywistość operacyjną i istotne dane, od których zależy logika eskalacji. W ten sposób, zamiast fragmentarycznych wiadomości na czacie, w e-mailach lub na pulpitach nawigacyjnych, każdy incydent trafia do systemu w spójnym formacie, który można niezawodnie przetwarzać w ramach automatyzacji.

Celowo grupuj pola, aby każdy incydent był w pełni kontekstualizowany:
- Identyfikacja (tytuł, streszczenie)
- Klasyfikacja (ważność, typ, usługa, na którą ma wpływ)
- Źródło (monitorowanie, użytkownik, API)
- Dowody (logi, zrzuty ekranu)
- Kontekst biznesowy (poziom SLA, wpływ na klienta)
Każde przesłanie formularza automatycznie tworzy nowe zadanie ClickUp, a wszystkie odpowiedzi są przypisywane do pól niestandardowych ClickUp. Dzięki temu incydenty są normalizowane w momencie ich powstania, co eliminuje niejasności i konieczność ręcznego reagowania na incydenty.
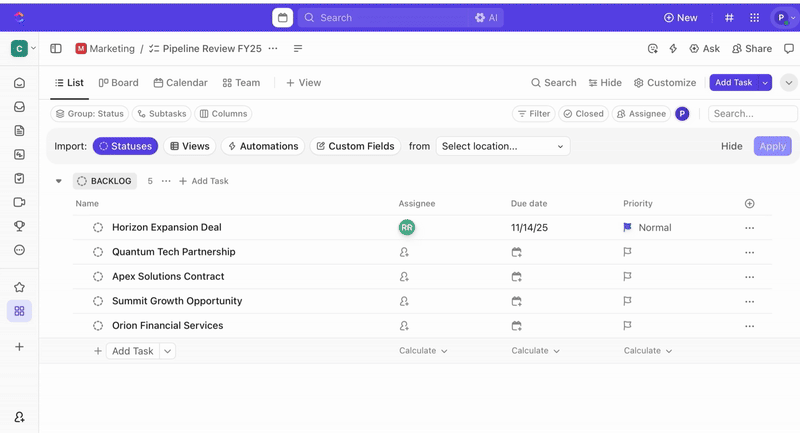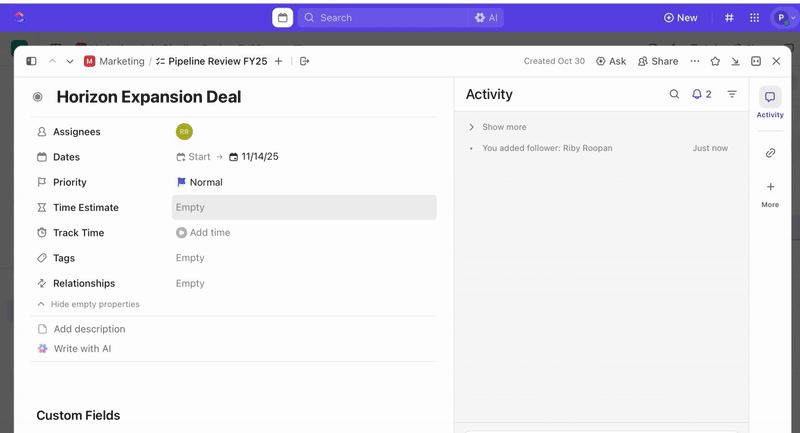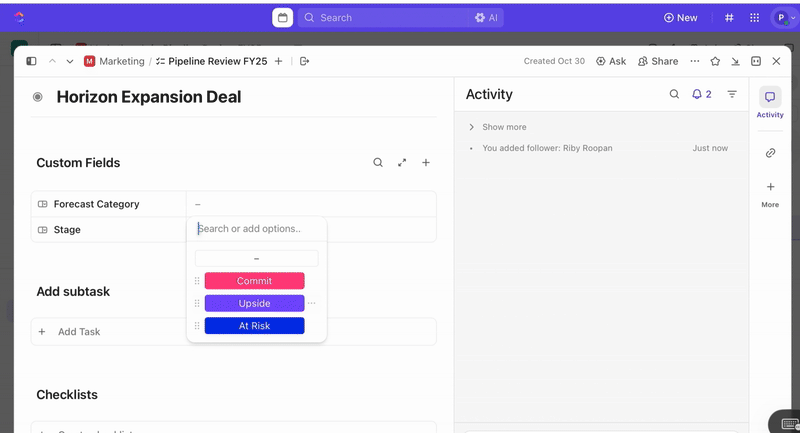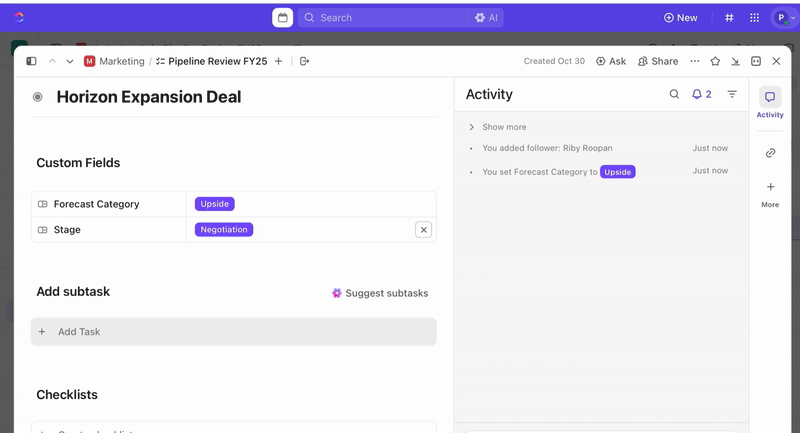
Po utworzeniu zadań możesz użyć pól niestandardowych, aby przeprowadzić segregację i ustalić priorytety (np. ważność, wpływ, grupa osób reagujących) oraz zdefiniować niestandardowe statusy ClickUp, które odzwierciedlają etapy incydentu (Nowy > Segregacja > Badanie > Łagodzenie skutków > Rozwiązany).
Krok 3: Stwórz ścieżkę eskalacji (tj. sekwencję + harmonogram + kanały)
To jest sedno ścieżki. Rozplanuj ścieżkę etapami, gdzie każdy etap określa, kto jest powiadamiany, za pośrednictwem jakich kanałów i po jakim czasie bez potwierdzenia lub rozwiązania.
- Zdefiniuj „limit czasu potwierdzenia” i „limit czasu rozwiązania”.
- Etap pierwszy: Pierwsza osoba dyżurna powiadomiona natychmiast za pośrednictwem kanału SMS/czatu musi potwierdzić odbiór w ciągu 5–10 minut.
- Etap drugi: Jeśli w ciągu następnych 15–20 minut nie otrzymasz potwierdzenia lub nie zostaną podjęte żadne działania, eskaluj zgłoszenie do zespołu wsparcia/SRE + starszego inżyniera za pośrednictwem SMS-a/kanału czatu/e-maila.
- Etap trzeci: Jeśli po upływie kolejnych 30–60 minut problem nadal nie zostanie rozwiązany, eskaluj go do kierownika ds. inżynierii/kierownictwa i opcjonalnie użyj wyzwalacza kanału „poważnych incydentów”.
- Zdecyduj, czy ścieżka eskalacji powinna się „powtarzać” (ponowne powiadomienie tego samego poziomu) czy „przechodzić dalej”.
- W przypadku krytycznych incydentów skonfiguruj powtarzające się powiadomienia, aż ktoś zareaguje. W przypadku incydentów o niższym priorytecie możesz zdecydować się na pojedynczy przepływ eskalacji.
- Upewnij się, że ścieżka jest udokumentowana przy użyciu szablonu odpowiedzi obsługi klienta i dostępna dla wszystkich odpowiednich pracowników.
❗️ Uwaga: „Limit czasu potwierdzenia” to czas, w którym osoba odpowiedzialna za pierwszą reakcję musi potwierdzić, że widziała alert, natomiast „limit czasu rozwiązania” to czas, w którym zespół musi naprawić lub złagodzić problem, zanim nastąpi kolejna eskalacja.
Krok 4: Wbuduj automatyzację i wsparcie narzędziowe
Po ustaleniu kryteriów, procesu segregacji i standardów wzbogacania danych, następnym krokiem jest włączenie eskalacji bez konieczności polegania na ludziach, którzy muszą pamiętać, kiedy i do kogo należy eskalować zgłoszenie. W tym miejscu ClickUp Automations staje się kluczowym elementem Twojego cyklu pracy.

Możesz skonfigurować automatyzację, która będzie reagować na te same sygnały, które wykorzystuje Twój zespół podczas incydentów. Oto kilka przykładów:
- Jeśli poziom ważności zostanie zmieniony na SEV-1 ➡️ Natychmiast przydziel starszego SRE + powiadom kanał czatu dyżurnego.
- Jeśli status pozostaje niezmieniony przez X minut ➡️ Wyzwalacz eskalacji do następnego poziomu
- Jeśli termin upłynie (np. termin potwierdzenia) ➡️ Eskaluj do poziomu L2
I właśnie w tym zakresie ClickUp Brain idzie o krok dalej. Wykorzystuje kontekst z Twojego obszaru roboczego ClickUp, aby dostarczać natychmiastowe odpowiedzi, automatycznie generować aktualizacje i zapewnić wsparcie dla dostępu do wiedzy.
Korzystaj z narzędzi takich jak AI Prioritize, aby automatycznie oceniać incydenty i ustalać właściwy priorytet zgodnie z własną logiką. Przykładowe podpowiedzi:
- Jeśli incydent ma wpływ na produkcję i klientów, ustaw priorytet: pilny.
- Jeśli osoba przypisana jest zespołem SRE, a logi zawierają wzmiankę o „opóźnieniu”, ustaw priorytet: wysoki.
- Jeśli opis zawiera słowa kluczowe związane z bezpieczeństwem, takie jak „naruszenie”, ustaw priorytet: pilne.
Po ustaleniu priorytetu funkcja AI Assign przejmuje kontrolę i automatycznie przypisuje incydenty na podstawie zdefiniowanych przez Ciebie warunków.
Możesz tworzyć podpowiedzi takie jak:
- Jeśli priorytet jest pilny, a usługa, której dotyczy problem, obejmuje „płatności”, przypisz zadanie do starszego inżyniera SRE.
- Jeśli typ incydentu to baza danych, a region to US-East, przypisz do DB On-Call.
- Jeśli nazwa zadania zawiera słowo „bezpieczeństwo”, przypisz je kierownikowi SecOps.
Wypróbuj te podpowiedzi w pierwszych trzech zadaniach, zanim zastosujesz je do całej listy.
🚀 Zaleta ClickUp: Wdrażaj inteligentne boty automatyzujące, które działają w Twoim obszarze roboczym ClickUp i reagują na działania w czasie rzeczywistym dzięki ClickUp Super Agents.
Są one w pełni świadome Twoich zadań, dokumentów, czatów i procesów, więc każda zautomatyzowana akcja jest kontekstowa.
Na przykład możesz umieścić Team StandUp Agent w folderze „Production Incidents Folder” (Incydenty produkcyjne), aby codziennie rano automatycznie publikował podsumowanie. Twój zespół otrzyma natychmiastowy przegląd pokazujący liczbę otwartych incydentów, które pozostają nierozwiązane oraz zmiany, które zaszły w ciągu ostatnich 24 godzin.
Teraz połącz to z agentem Ambient Answers w kanale „#incident-room”. Gdy osoby reagujące zadają pytania typu „Gdzie jest podręcznik SEV-1?” lub „Czy to API zawiodło już wcześniej?”, agent pobierze informacje z Twoich obszarów roboczych, aby udzielić natychmiastowych, dokładnych odpowiedzi.

Krok 5: Standaryzacja kanałów komunikacji
W miarę eskalacji incydentów sposób i miejsce komunikacji zespołów ma równie duże znaczenie, jak to, kto otrzymuje powiadomienia. Bez ustandaryzowanych kanałów komunikacji aktualizacje giną, decyzje są powielane, a interesariusze otrzymują sprzeczne informacje.
Zdefiniuj jasne kanały eskalacji dla każdego etapu cyklu życia incydentu i stosuj je konsekwentnie we wszystkich zespołach:
| Kryteria | Nazwa kanału | Cel |
| Wykryto SEV-1 lub SEV-2 | #incident-critical | Centralna przestrzeń dla alertów o wysokim stopniu ważności i natychmiastowej klasyfikacji |
| Trwa aktywne rozwiązywanie problemów | #incident-warroom | Hub współpracy w czasie rzeczywistym dla inżynierów, działu produktu, kontroli jakości i wsparcia technicznego |
| Wymagana widoczność kierownictwa | #incident-leadership | Aktualizacje o wysokim znaczeniu dla menedżerów i kadry kierowniczej |
| Wymagana komunikacja z klientami | #incident-comms | Przestrzeń do tworzenia, przeglądania i uzgadniania komunikacji z klientami zewnętrznymi |
| Rozpoczęto przegląd po incydencie | #incident-retro | Strukturalna dyskusja dotycząca notatek retrospektywnych, wniosków i elementów działań, które należy podjąć. |
Każdy kanał ma określoną grupę odbiorców i cel, co pomaga zespołom ograniczyć zakłócenia, jednocześnie zapewniając odpowiednim zespołom dostęp do informacji.
🚀 Zaleta ClickUp: Dostosuj swoją strategię kanałów komunikacyjnych do wbudowanej warstwy komunikacyjnej za pomocą ClickUp Chat. Każde powiadomienie, aktualizacja i decyzja pozostają bezpośrednio powiązane z zadaniem, listą lub przestrzenią, w której odbywa się praca.
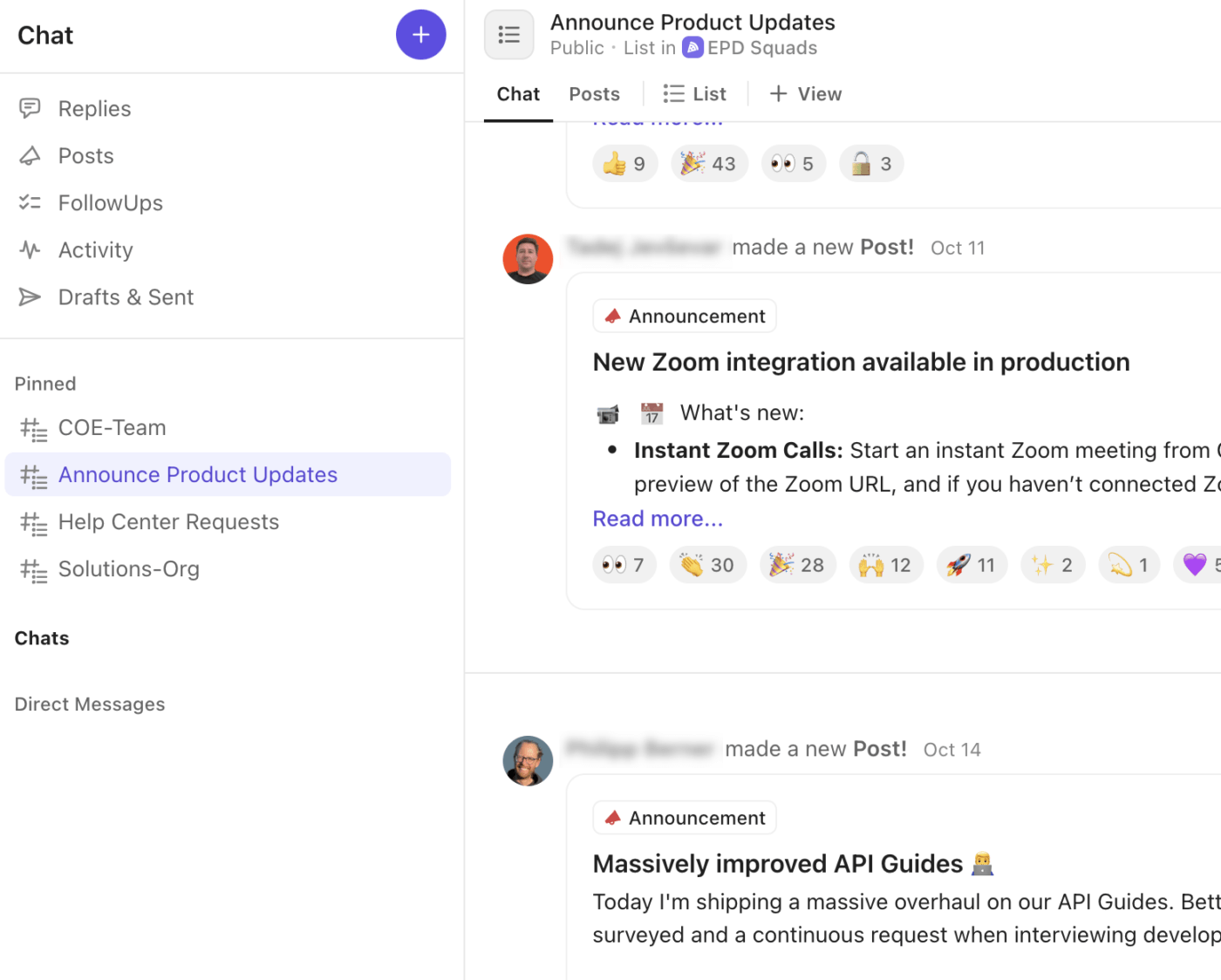
Oto, w jaki sposób ClickUp Chat usprawnia cykl pracy związany z incydentami:
- Twórz dedykowane wątki czatu do dyskusji dotyczących spraw krytycznych, pokoju operacyjnego, kierownictwa lub komunikacji z klientami.
- Natychmiast przekształcaj wiadomości czatu w zadania ClickUp , dzięki czemu decyzje i działania następcze nie zginą w gąszczu rozmów.
- Skorzystaj z szybkich połączeń audio lub wideo za pomocą ClickUp SyncUps, aby koordynować incydenty na żywo lub przekazywać informacje kierownictwu.
- Publikuj „ogłoszenia” lub aktualizacje , aby przekazywać informacje o statusie incydentów na wysokim szczeblu w całej firmie.
- Oznaczaj członków zespołu, wrzucaj zrzuty ekranu i dodawaj logi bezpośrednio na czacie, żeby mieć pod ręką kontekst techniczny.
Krok 6: Przetestuj, sprawdź i udoskonal ścieżkę eskalacji
Zasady eskalacji muszą ewoluować wraz z systemami. Oto, co należy zrobić regularnie:
| Aktywność | Co należy przetestować lub sprawdzić | Dlaczego ma to znaczenie |
| Ćwiczenia przeciwpożarowe w trybie dyżurnym (co kwartał) | Symuluj incydenty P1 i P2, sprawdź czas eskalacji i trasę przekazywania. | Zapewnia działanie automatyzacji i ścieżek eskalacji w sytuacjach stresowych. |
| Weryfikacja ścieżki eskalacji | Sprawdź, czy nie ma eskalacji bez rozwiązania lub brakujących właścicieli. | Zapobiega blokowaniu incydentów bez widoczności |
| Timery procesu potwierdzania i rozwiązywania problemów | Porównaj skonfigurowane timery z rzeczywistymi wartościami MTTA i MTTR. | Zapewnia realistyczny i skuteczny czas eskalacji |
| Ocena zmęczenia alertami | Zidentyfikuj osoby reagujące, które otrzymują nadmierną liczbę powtarzających się alertów. | Zmniejsza wypalenie zawodowe i liczbę pominiętych krytycznych alertów. |
| Dokładność oceny powagi i priorytetów | Sprawdź, czy incydenty zostały poprawnie sklasyfikowane. | Poprawia routing, szybkość reakcji i dokładność eskalacji |
| Działania po incydencie | Upewnij się, że elementy wynikające z retrospektyw są zakończone. | Zapobiega powtarzającym się incydentom i awariom systemowym. |
Narzędzia i integracje do automatyzacji eskalacji
W tej sekcji omówiono oprogramowanie do zarządzania incydentami, które pomaga szybciej wykrywać incydenty, natychmiast je przekazywać i informować wszystkie zespoły bez konieczności ręcznego śledzenia.
1. ClickUp (najlepsze rozwiązanie do ujednolicenia eskalacji międzyfunkcyjnych w jednym połączonym obszarze roboczym zdarzeń)
Tradycyjne metody eskalacji zmuszają zespoły do żonglowania wiadomościami e-mail, arkuszami kalkulacyjnymi, wątkami czatu i rozproszonymi notatkami, co sprawia, że uzyskanie jasnego, aktualnego widoku sytuacji jest prawie niemożliwe.
Oprogramowanie ClickUp do zarządzania zadaniami w zakresie eskalacji eliminuje zakłócenia, konsolidując wszystkie szczegóły dotyczące eskalacji w jednym, uporządkowanym obszarze roboczym.
Przyjrzyjmy się niektórym funkcjom oprogramowania do zarządzania zasobami IT, które zajmują pozycję lidera wśród narzędzi dla zespołów zarządzających dużą liczbą eskalacji i złożonymi cyklami pracy dotyczącymi obsługi incydentów.
Pracuj na swój sposób
Wizualizuj swoje zadania z różnych perspektyw, aby dopasować je do swoich potrzeb operacyjnych dzięki widokom ClickUp:
- Widok listy ClickUp, dzięki któremu kierownicy SRE mogą sortować incydenty według ważności, pozostałego czasu SLA lub grup dyżurnych w celu szybkiej segregacji.
- ClickUp Tablica pozwala kierownikom ds. inżynierii wizualizować przekazywanie zadań i własność zespołów podczas eskalacji.
- Widok Gantta ClickUp dla liderów programów, umożliwiający mapowanie kamieni milowych rozwiązań i zależności między usługami.
- Widok obciążenia pracą ClickUp dla osób odpowiedzialnych za planowanie dyżurów, który zapewnia, że inżynierowie nie są przeciążeni podczas okresów dużej liczby incydentów.
Przekształć dyskusje podczas spotkań w działania
Podczas eskalacji i przeglądów incydentów niezawodne rejestrowanie dyskusji i elementów działań może stanowić wyzwanie. ClickUp AI Notetaker automatycznie dołącza do spotkań zaplanowanych w Kalendarzu Google, Outlooku, Zoomie lub Teams, nagrywając i transkrybując rozmowę.
Po spotkaniu:
- Uzyskaj dostęp do przeszukiwalnych transkrypcji i podsumowań elementów działań.
- Zapewnij przejrzystość dzięki notatkom zapisanym w ClickUp Docs. Ułatwia to tworzenie odnośników do zadań związanych z incydentami lub raportów retrospektywnych.
- Zadaj pytania ClickUp AI dotyczące zawartości spotkań, aby wyjaśnić decyzje lub odkryć pominięte działania następcze.
Nałóż połączenie z istniejącymi narzędziami w swoim stosie technologicznym
Za kulisami integracje ClickUp i ekosystem Webhooks zapewniają płynne połączenia z pozostałymi elementami Twojego stosu.
Platforma integruje się natywnie z narzędziami takimi jak Slack, GitHub, Zoom i innymi oraz oferuje wsparcie dla Webhooków poprzez swoje publiczne API w celu przekazywania zdarzeń (aktualizacji zadań i zmian statusu) do usług zewnętrznych lub potoków automatyzacji. Ułatwia to wyzwalanie cykli pracy, synchronizację danych lub eskalację incydentów między systemami bez konieczności ręcznego przekazywania zadań.
Połącz wszystkie swoje narzędzia AI
Aby przenieść automatyzację i kontekst na wyższy poziom, ClickUp BrainGPT wprowadza kontekstową sztuczną inteligencję do wszystkich cykli pracy eskalacji. Jest to kontekstowa super aplikacja AI, która rozumie Twoje zadania, dokumenty i kontekst historyczny.
Dzięki Enterprise Search i Connected Apps możesz natychmiast pobierać informacje ze swojego obszaru roboczego, Slacka, Dysku Google, GitHub i innych. Podczas rozmów na żywo dotyczących incydentów funkcja Talk-to-Text w ClickUp pozwala dyktować notatki lub instrukcje dotyczące eskalacji bez użycia rąk, dzięki czemu nic nie zostanie pominięte.
Możesz również standaryzować powtarzalne zadania za pomocą niestandardowych podpowiedzi AI i zapisanych podpowiedzi, takich jak: „Podsumuj wszystkie nierozwiązane incydenty i zaproponuj działania eskalacyjne”.
Najlepsze funkcje ClickUp
- Priorytetowe traktowanie krytycznych problemów: użyj funk cji Priorytety zadań ClickUp, aby wyróżnić pilne lub mające duże znaczenie eskalacje.
- Organizuj złożone sekwencje eskalacji: Skonfiguruj zależności zadań ClickUp, aby połączyć powiązane zadania (np. „Oczekiwanie na” lub „Blokowanie”), dzięki czemu kroki eskalacji pozwolą uniknąć przedwczesnych działań lub wąskich gardeł.
- Podziel incydenty na możliwe do wykonania elementy: podziel eskalacje na szczegółowe elementy i przypisz je zespołom za pomocą zagnieżdżonych podzadań.
- Dokładnie śledź szybkość rozwiązywania problemów: rejestruj i monitoruj czas potrzebny na potwierdzenie i rozwiązanie zadań eskalacyjnych za pomocą funkcji śledzenia czasu projektu ClickUp.
Limity ClickUp
- Przy tak wielu funkcjach, widokach i opcjach dostosowywania zespoły często muszą przejść proces nauki, zanim wszystko stanie się intuicyjne.
Ceny ClickUp
[Tabela cen]
Oceny i recenzje ClickUp
- G2: 4,7/5 (ponad 10 300 recenzji)
- Capterra: 4,6/5 (ponad 4400 recenzji)
Co użytkownicy mówią o ClickUp w praktyce?
Ta recenzja naprawdę mówi wszystko:
ClickUp gromadzi wszystkie moje zadania, projekty i komunikację w jednym miejscu, co sprawia, że niezwykle łatwo jest zachować porządek. Bardzo podoba mi się możliwość dostosowania wszystkiego — od widoków i cykli pracy po pulpity — dzięki czemu mogę zorganizować swoje miejsce pracy dokładnie tak, jak tego potrzebuję. Ogromną zaletą jest możliwość współpracy w czasie rzeczywistym, przydzielania zadań i śledzenia postępów bez konieczności zmiany narzędzi.
ClickUp gromadzi wszystkie moje zadania, projekty i komunikację w jednym miejscu, co sprawia, że niezwykle łatwo jest zachować porządek. Bardzo podoba mi się to, że wszystko można dostosować do własnych potrzeb — od widoków i cykli pracy po pulpity — dzięki czemu mogę zorganizować swoje miejsce pracy dokładnie tak, jak tego potrzebuję. Możliwość współpracy w czasie rzeczywistym, przydzielania zadań i śledzenia postępów bez konieczności zmiany narzędzi jest ogromną zaletą.
📮 ClickUp Insight: 21% osób twierdzi, że ponad 80% swojego dnia pracy poświęca na powtarzalne zadania. Kolejne 20% twierdzi, że powtarzalne zadania zajmują co najmniej 40% ich dnia.
To prawie połowa tygodnia pracy (41%) poświęcona na zadania, które nie wymagają zbytniego myślenia strategicznego ani kreatywności (jak np. wysyłanie e-maili z informacjami zwrotnymi 👀).
Super agenci ClickUp pomagają wyeliminować tę żmudną pracę. Pomyśl o tworzeniu zadań, przypomnieniach, aktualizacjach, notatkach ze spotkań, redagowaniu e-maili, a nawet tworzeniu kompleksowych cykli pracy! Wszystko to (i wiele więcej) można zautomatyzować w mgnieniu oka dzięki ClickUp, aplikacji do pracy, która spełnia wszystkie Twoje potrzeby.
💫 Rzeczywiste wyniki: Dzięki automatyzacji ClickUp firma Lulu Press oszczędza 1 godzinę dziennie na każdym pracowniku, co przekłada się na 12-procentowy wzrost wydajności pracy.
2. PagerDuty (najlepsze rozwiązanie do powiadamiania w czasie rzeczywistym i inteligentnej reakcji na wezwania)
PagerDuty to oparta na chmurze platforma do zarządzania incydentami IT i operacjami cyfrowymi, która pomaga zespołom szybko wykrywać, reagować i rozwiązywać krytyczne incydenty, takie jak awarie lub zagrożenia bezpieczeństwa. Zapewnia ona liderom SRE, DevOps i wsparcia jasną ścieżkę od sygnału do rozwiązania, wspieraną przez automatyzację, segregację opartą na AI i głęboko zintegrowane cykle pracy.
Funkcje takie jak Jeli Incident Analysis, PagerDuty Analytics i automatyzacja Runbooków pomagają zespołom skrócić przestoje, wyeliminować rutynowe zadania i wyciągać wnioski z każdego incydentu.
Najlepsze funkcje PagerDuty
- Zautomatyzuj kierowanie incydentów dzięki wbudowanemu zarządzaniu dyżurami i dynamicznym zasadom eskalacji.
- Przyspiesz segregację przy użyciu AIOps, które filtruje niepotrzebne alerty, koreluje wydarzenia i wyróżnia prawdziwe sygnały.
- Zapewnij spójność działań wewnętrznych i zewnętrznych interesariuszy dzięki komunikacji z interesariuszami, szablonom aktualizacji statusu i stronom statusu.
- Ujednolicenie zestawu narzędzi dzięki ponad 700 integracjom i rozszerzalnym interfejsom API z wykorzystaniem monitorowania, rejestrowania, CI/CD i systemów wsparcia.
Limity PagerDuty
- Duża liczba alertów, jeśli integracje i inteligentne progi nie są odpowiednio dostosowane, co prowadzi do szumu i zmęczenia.
- W okresach wzmożonego ruchu mogą pojawiać się zduplikowane lub powtarzające się alerty, co utrudnia potwierdzanie ich pod presją czasu.
Ceny PagerDuty
- Free
- Profesjonalny: 25 USD miesięcznie za użytkownika
- Business: 49 USD miesięcznie za użytkownika
- Enterprise: ceny niestandardowe
Oceny i recenzje PagerDuty
- G2: 4,5/5 (ponad 900 recenzji)
- Capterra: 4,6/5 (ponad 200 recenzji)
Co użytkownicy mówią o PagerDuty w praktyce?
W słowach prawdziwego użytkownika:
PagerDuty sprawia, że alerty dotyczące incydentów są szybkie i niezawodne. Wysyła odpowiednie powiadomienia we właściwym czasie i pomaga naszemu zespołowi zachować porządek. […] PagerDuty może czasami wydawać się zbyt hałaśliwy, gdy alerty nie są dobrze filtrowane. Niektóre ustawienia są nieco skomplikowane dla nowych użytkowników.
PagerDuty sprawia, że alerty dotyczące incydentów są szybkie i niezawodne. Wysyła odpowiednie powiadomienia we właściwym czasie i pomaga naszemu zespołowi zachować porządek. […] PagerDuty może czasami wydawać się zbyt hałaśliwy, gdy alerty nie są dobrze filtrowane. Niektóre ustawienia są nieco skomplikowane dla nowych użytkowników.
💡 Wskazówka dla profesjonalistów: Stwórz wyjątki, nawet w przypadku jasnej ścieżki eskalacji. Niech krytyczne awarie, alerty bezpieczeństwa lub incydenty w środowisku regulowanym trafiają bezpośrednio do starszych lub wyspecjalizowanych osób odpowiedzialnych za reagowanie.
3. GLPi (najlepsze rozwiązanie do kompleksowego zarządzania zasobami i operacji serwisowych zgodnych z ITIL)
Gestionnaire Libre de Parc Informatique (GLPi) to kompleksowa platforma typu open source do zarządzania usługami IT (ITSM) i zasobami IT (ITAM). Teams zyskują pełną widoczność swojej infrastruktury (sprzętu, oprogramowania, licencji i urządzeń sieciowych) i mogą zarządzać incydentami, zgłoszeniami serwisowymi i zmianami przy użyciu procesów zgodnych z ITIL.
Wszystkie umowy i dokumentacja, w tym gwarancje i umowy serwisowe, są uporządkowane, co zapobiega ich zagubieniu w różnych systemach. Jeśli zarządzasz centrami danych, GLPi umożliwia nawet wizualizację układów, ścieżek okablowania i zużycia energii, dzięki czemu zawsze wiesz, co dzieje się za kulisami.
Najlepsze funkcje GLPi
- Użyj wtyczek GLPI Inventory, OCS Inventory lub FusionInventory, aby automatycznie wykrywać i katalogować nowe zasoby IT.
- Zautomatyzuj powtarzające się zadania, przypisywanie zgłoszeń, powiadomienia i cykliczne zdarzenia, aby ograniczyć pracę ręczną.
- Stwórz bazę wiedzy zawierającą często zadawane pytania, dokumentację i artykuły połączone z zgłoszeniami, aby zapewnić obsługę samoobsługową i wsparcie techniczne.
- Zainicjuj połączenie z Azure/Entra, Centreon, Google, OAuth2 i webhookami, aby synchronizować dane, uruchamiać wyzwalacze cykli pracy i ulepszać swoją bazę danych CMDB.
Limity GLPi
- Kompatybilność wtyczek może ulec zmianie między wersjami, powodując dodatkowe koszty związane z konserwacją.
- Funkcje raportowania, analizy i eksportu wydają się mieć limit i wymagają ulepszeń.
Ceny GLPi
- Niestandardowe ceny
Oceny i recenzje GLPi
- G2: 4,6/5 (ponad 30 recenzji)
- Capterra: 4,5/5 (ponad 40 recenzji)
Co użytkownicy mówią o GLPi w praktyce?
Oto, co powiedział jeden z użytkowników:
Bardzo konfigurowalny system zarządzania zasobami IT i zgłoszeniami w zakresie wsparcia technicznego typu open source, wspierany przez dużą społeczność. Interfejs użytkownika jest nieco skomplikowany dla początkujących. Wtyczki nie zawsze są obsługiwane przez starsze wersje.
Bardzo konfigurowalny system zarządzania zasobami IT i zgłoszeniami w zakresie wsparcia technicznego typu open source, wspierany przez dużą społeczność. Interfejs użytkownika jest nieco skomplikowany dla początkujących. Wtyczki nie zawsze są obsługiwane przez starsze wersje.
4. Splunk On-Call (najlepsze rozwiązanie do kierowania alertów monitorujących bezpośrednio do inżynierów)
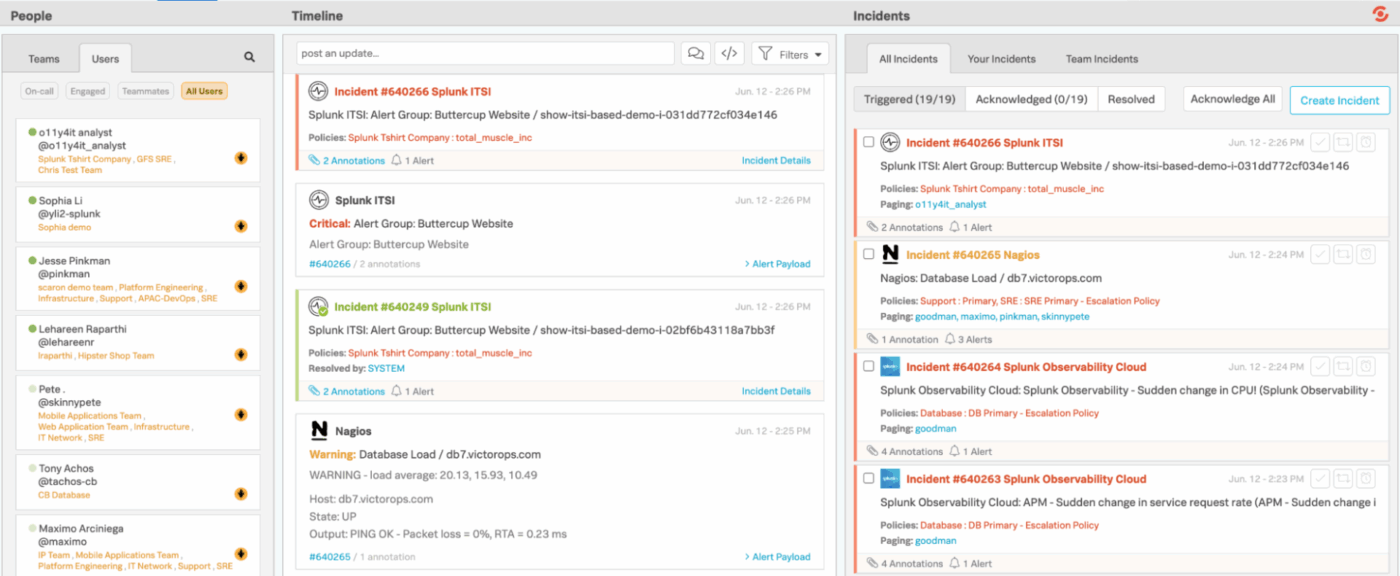
Splunk On-Call zapewnia zespołom inżynierów i dyżurnym szybszy i bardziej przejrzysty sposób zarządzania incydentami, eliminując potrzebę stosowania powolnych, tradycyjnych cykli pracy zgłaszania problemów. Zamiast przesyłać alerty do ogólnej kolejki, integruje się bezpośrednio z Twoim stosem monitorowania i obserwowalności, natychmiast kierując problemy do odpowiednich osób w oparciu o harmonogramy, zasady i kontekst.
Integracja z urządzeniami mobilnymi i czatem ułatwia potwierdzanie, przekierowywanie lub rozwiązywanie incydentów z dowolnego miejsca. Za kulisami Splunk On-Call przechowuje szczegółowe dane dotyczące trendów, sprawdzonych wzorców i zachowań związanych z eskalacją.
Najlepsze funkcje Splunk On-Call
- Rozszerz możliwości platformy, korzystając z ponad 1000 sprawdzonych integracji i dodatków od Splunk i szerszej społeczności.
- Twórz niestandardowe pulpity nawigacyjne i raporty wizualne, aby monitorować liczbę alertów, stan incydentów, wydajność osób reagujących i obciążenie pracą zespołu.
- Szybko filtruj incydenty według własnej aktywności, incydentów zespołu lub Wszystkiego, co dzieje się w całej organizacji.
- Przełączaj się między widokami Wyzwalane, Potwierdzone i Rozwiązane, aby sprawdzić status każdego incydentu.
Limity Splunk On-Call
- Planowanie zmian w wielu zespołach może być skomplikowane, jeśli zasady nie są z góry określone.
- Ograniczona możliwość generowania szczegółowych raportów dotyczących incydentów z podaniem daty
Ceny Splunk On-Call
- Niestandardowe ceny
Oceny i recenzje Splunk On-Call
- G2: 4,6/5 (ponad 40 recenzji)
- Capterra: 4,5/5 (ponad 30 recenzji)
Co użytkownicy mówią o Splunk On-Call w praktyce?
Jeden z użytkowników podsumował to w następujący sposób:
Możliwość obsługi incydentów, eskalacji i przejmowania obowiązków od moich kolegów z zespołu za pomocą aplikacji mobilnej jest niesamowita. […] Chciałbym mieć możliwość planowania nadpisywania i zmiany regularnego harmonogramu za pomocą aplikacji mobilnej w przypadku awaryjnych zmian w harmonogramie.
Możliwość obsługi incydentów, eskalacji i przejmowania obowiązków od członków zespołu za pomocą aplikacji mobilnej jest niesamowita. […] Chciałbym mieć możliwość planowania nadpisywania i zmiany regularnego harmonogramu za pomocą aplikacji mobilnej w przypadku awaryjnych zmian harmonogramu.
🔍 Czy wiesz, że... Logika „przekierowania do właściwej osoby, jeśli pierwszy poziom zawiedzie” ma swoje korzenie we wczesnych centralach telefonicznych: gdy operatorzy ręczni nie mogli przeprowadzić połączenia, system przekierowywał ją (lub eskalował) do innego operatora lub centrali.
5. ServiceNow (najlepsze rozwiązanie do koordynacji działań na skalę Enterprise z wykorzystaniem automatyzacji wspomaganej AI)
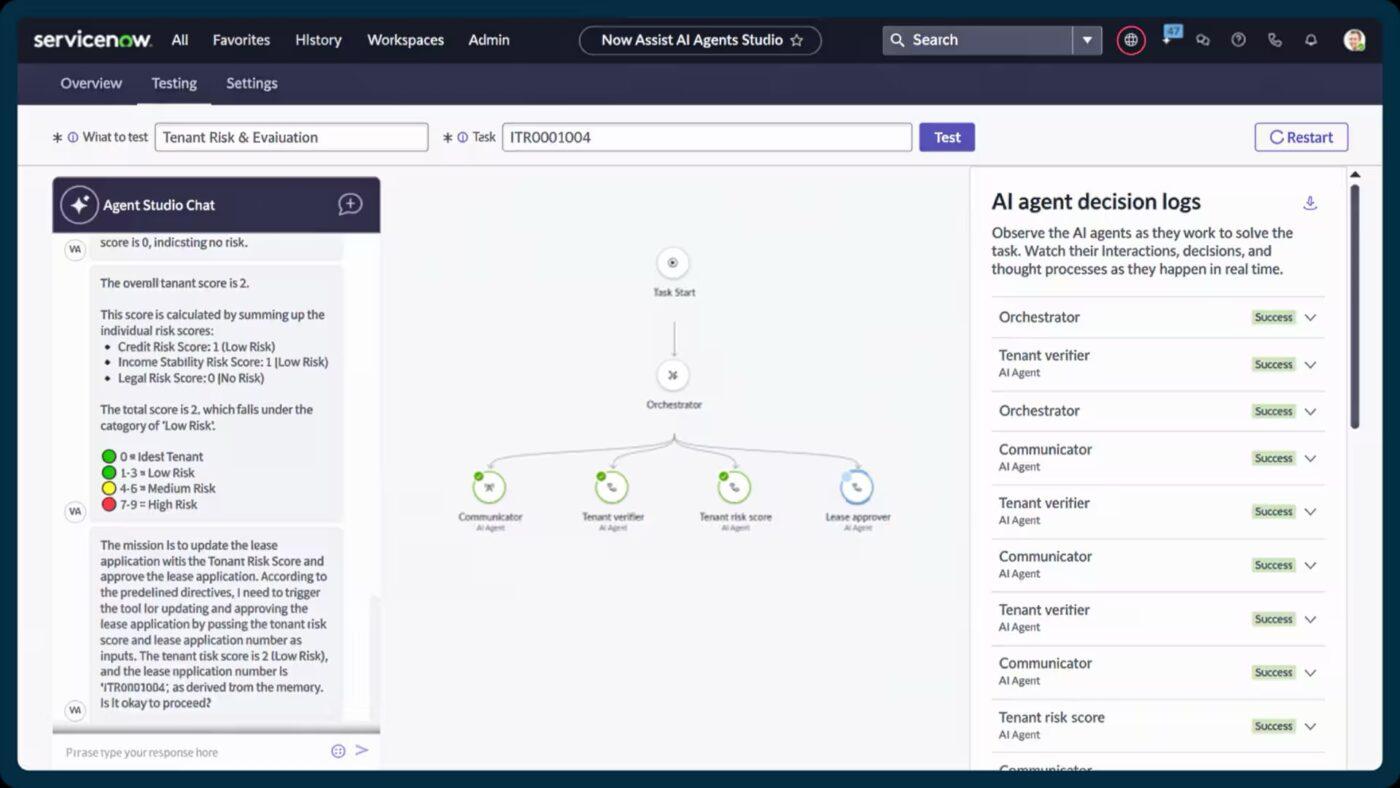
ServiceNow automatycznie klasyfikuje, nadaje priorytety i kieruje incydenty w momencie ich zarejestrowania. Dzięki funkcjom takim jak Now Assist do automatycznego rekomendowania zgłoszeń incydentów i inteligentnego generowania zawartości, osoby reagujące mogą szybciej rozwiązywać problemy, dysponując większą ilością kontekstu.
Łączy zarządzanie incydentami, zmianami i zasobami. W ten sposób uzyskujesz widok w czasie rzeczywistym na połączenia między usługami, miejsca występowania wąskich gardeł oraz elementy, które mogą przyczyniać się do powtarzających się zakłóceń.
Najlepsze funkcje ServiceNow
- Przydzielaj, kieruj i monitoruj zadania terenowe za pomocą zarządzania usługami terenowymi i obszaru roboczego dyspozytora.
- Zapewnij pracownikom i klientom dostęp do portalu samoobsługowego opartego na wyszukiwarce AI i wirtualnych agentach.
- Wykorzystaj wbudowane cykle pracy i narzędzia low-code w App Engine, aby rozszerzyć lub dostosować procesy serwisowe niestandardowe.
- Zautomatyzuj powtarzalne zadania i cykle pracy w różnych zespołach za pomocą Flow Designer i Automation Engine.
Limity ServiceNow
- Interfejs użytkownika i opcje brandingu portalu wydają się przestarzałe lub ograniczające.
- Duża zależność od wykwalifikowanego personelu lub konsultantów w zakresie wdrażania
Ceny ServiceNow
- Niestandardowe ceny
Oceny i recenzje ServiceNow
- G2: 4,4/5 (ponad 3300 recenzji)
- Capterra: 4,5/5 (ponad 300 recenzji)
Co użytkownicy mówią o ServiceNow w praktyce?
Oto jak ujął to jeden z użytkowników:
[…] Gotowe przepływy są dla mnie kolejną zaletą, ponieważ usprawniają procesy i pozwalają zaoszczędzić sporo czasu, minimalizując potrzebę dostosowywania konfiguracji i umożliwiając płynniejszy i bardziej wydajny cykl pracy. […] Dodatkowo miałem trudności z dopasowaniem mojego niestandardowego rozwiązania do systemu zarządzania obsługą klienta, co wymagało wielu iteracji.
[…] Gotowe przepływy są dla mnie kolejną zaletą, ponieważ usprawniają procesy i pozwalają zaoszczędzić sporo czasu, minimalizując potrzebę dostosowywania konfiguracji i umożliwiając płynniejszy i bardziej wydajny przepływ pracy. […] Dodatkowo miałem trudności z dopasowaniem mojego niestandardowego rozwiązania do systemu zarządzania obsługą klienta, co wymagało wielu iteracji.
Najlepsze praktyki i zarządzanie
Oto kilka najlepszych praktyk, które zapewniają dokładność automatyzacji, pozwalają uniknąć nadmiaru alertów i są zgodne z oczekiwaniami biznesowymi i regulacyjnymi.
- Określ niepodlegające negocjacjom kryteria eskalacji: Powiąż wyzwalacze z mierzalnymi sygnałami, takimi jak naruszenia SLO, skoki anomalii, wpływ na poziom klienta lub wrażliwość regulacyjna.
- Określ jasno role na każdym poziomie: użyj prostej mapy RACI dla każdego poziomu eskalacji, aby obowiązki nigdy nie były niejasne podczas incydentów wymagających szybkiej reakcji.
- Wprowadź dynamiczne zarządzanie dyżurami: automatycznie dostosowuj ścieżki eskalacji w weekendy, święta, w przypadku limitów obciążenia i przekazywania zadań, aby zmniejszyć wypalenie zawodowe i zapobiegać cichym wezwaniom.
- Wprowadź punkty kontrolne dla scenariuszy wysokiego ryzyka: Nawet przy automatyzacji wymagaj ręcznego potwierdzania incydentów związanych z ujawnieniem danych klientów, płatnościami lub regulowanymi cyklami pracy.
- Utrzymuj pełną ścieżkę audytu: prowadź niezmienne rejestry zawierające informacje o tym, kto został powiadomiony, kiedy potwierdził otrzymanie powiadomienia, jakie kroki automatyzacyjne zostały podjęte i jakie decyzje zostały podjęte.
🧠 Ciekawostka: Najstarsza znana skarga na świecie została wyryta na glinianej tabliczce około 1750 roku p.n.e. Była to w zasadzie wczesna forma eskalacji statusu projektu. Klient o imieniu Nanni napisał do kupca Ea-nāṣira, wyrażając swoje oburzenie, że otrzymana miedź była gorszej jakości niż obiecano, a jego posłaniec został źle potraktowany.
Typowe wyzwania i sposoby ich pokonywania
Nawet przy jasnej polityce eskalacji zespoły często napotykają przeszkody operacyjne, które spowalniają reagowanie na incydenty lub powodują zamieszanie.
W tabeli tej przedstawiono typowe wyzwania wykraczające poza podstawowe kroki ustawień oraz praktyczne strategie pozwalające je pokonać.
| Wyzwania ❌ | Rozwiązania ✅ |
| Niespójny kontekst podczas przekazywania zadań | Skorzystaj z funkcji połączonych zadań i szablonów raportów incydentów ClickUp, aby zachować pełną ścieżkę audytu szczegółów incydentów, systemów, na które miały one wpływ, oraz wcześniejszych działań na każdym poziomie eskalacji. |
| Przeciążanie osób reagujących alertami o niskim priorytecie | Wprowadź dynamiczne ustalanie priorytetów za pomocą pól niestandardowych ClickUp i funkcji AI Prioritize, aby filtrować incydenty na podstawie ich ważności, wpływu i progów SLA. |
| Brak widoczności między zespołami | Skonfiguruj wspólne obszary robocze, dodawaj komentarze i twórz wizualne tablice ClickUp, aby prezentować aktualizacje w czasie rzeczywistym dla interesariuszy. |
| Opóźnienia w podejmowaniu decyzji podczas krytycznych incydentów | Zautomatyzuj powiadomienia za pomocą funkcji Sugerowane działania w ClickUp Brain Max, aby natychmiast powiadamiać odpowiedni personel w oparciu o rodzaj incydentu, jego powagę i historyczne wzorce. |
| Trudności w śledzeniu powtarzających się problemów | Wykorzystaj niestandardowe narzędzia raportowania i szablony powtarzających się zadań ClickUp, aby zidentyfikować wzorce, przyczyny źródłowe i powtarzające się incydenty w celu proaktywnego zapobiegania. |
| Fragmentaryczna wiedza podczas eskalacji | Przechowuj scentralizowane procedury operacyjne, instrukcje i dokumentację incydentów w ClickUp Docs, łącząc je z odpowiednimi zadaniami, aby mieć do nich natychmiastowy dostęp podczas eskalacji na żywo. |
| Niewłaściwy podział obowiązków między zmianami | Skorzystaj z widoków obciążenia pracą i osi czasu w ClickUp, aby wizualizować zadania i zapewnić brak nakładania się lub luk podczas zmian zmian lub przekazywania zadań. |
| Ręczne śledzenie zgodności i luki audytowe | Zautomatyzuj tworzenie gotowych do audytu podsumowań za pomocą ClickUp Brain, aby rejestrować wszystkie działania związane z incydentami, powiadomienia i rozwiązania. |
Pomiar wpływu automatycznej eskalacji
Śledzenie skuteczności automatyzacji eskalacji wymaga skupienia się na kluczowych wskaźnikach dotyczących ilości, wydajności i jakości. Wskaźniki te pokazują, czy procesy eskalacji są szybsze, dokładniejsze i mniej frustrujące zarówno dla zespołów, jak i klientów.
Śledź następujące wskaźniki:
- Wskaźnik eskalacji (ilość): Odsetek problemów eskalowanych powyżej pierwszego poziomu. Wysokie wskaźniki mogą wskazywać na luki w początkowej klasyfikacji lub bazach wiedzy.
- Wskaźnik powtarzalności eskalacji (wolumen): Częstotliwość wielokrotnej eskalacji tego samego problemu. Sygnalizuje niekompletne rozwiązania lub utratę kontekstu.
- Czas eskalacji (wydajność): czas trwania od wykrycia do eskalacji. Krótszy czas trwania etapu oznacza szybsze automatyczne rozpoznawanie krytycznych problemów.
- Czas opóźnienia przekazania (wydajność): Różnica między eskalacją a momentem, w którym następny zespół rozpoczyna pracę, aby podkreślić problemy związane z routingiem lub powiadomieniami.
- Czas rozwiązania eskalowanych spraw (wydajność): Całkowity czas od eskalacji do rozwiązania. Szybsze rozwiązanie świadczy o skuteczności automatyzacji.
- Wynik satysfakcji klienta (CSAT) (jakość): Informacje zwrotne dotyczące eskalowanych interakcji w celu oceny płynności ścieżki
- Przekazywanie kontekstu (jakość): Czy agenci otrzymują pełną historię incydentów, aby klienci nie musieli powtarzać informacji?
- Rozwiązanie problemu przy pierwszym kontakcie (FCR) (jakość): Odsetek problemów rozwiązanych podczas jednej interakcji.
🚀 Zaleta ClickUp: Uzyskaj w czasie rzeczywistym wizualne i oparte na AI informacje na temat wszystkich wskaźników eskalacji dzięki pulpitom nawigacyjnym ClickUp.
Możesz śledzić trendy eskalacji, wąskie gardła i wydajność za pomocą kart tabelarycznych, koláčowych, słupkowych, liniowych, obliczeniowych i raportów czasowych. Monitoruj wskaźnik eskalacji, powtarzające się eskalacje i czas do eskalacji za pomocą kart połączonych z zadaniami, polami niestandardowymi i statusami.
Aby pójść o krok dalej, użyj kart AI, takich jak AI Executive Summary, AI Project Update i AI StandUp, aby podkreślić trendy, opóźnienia i wyniki rozwiązań.
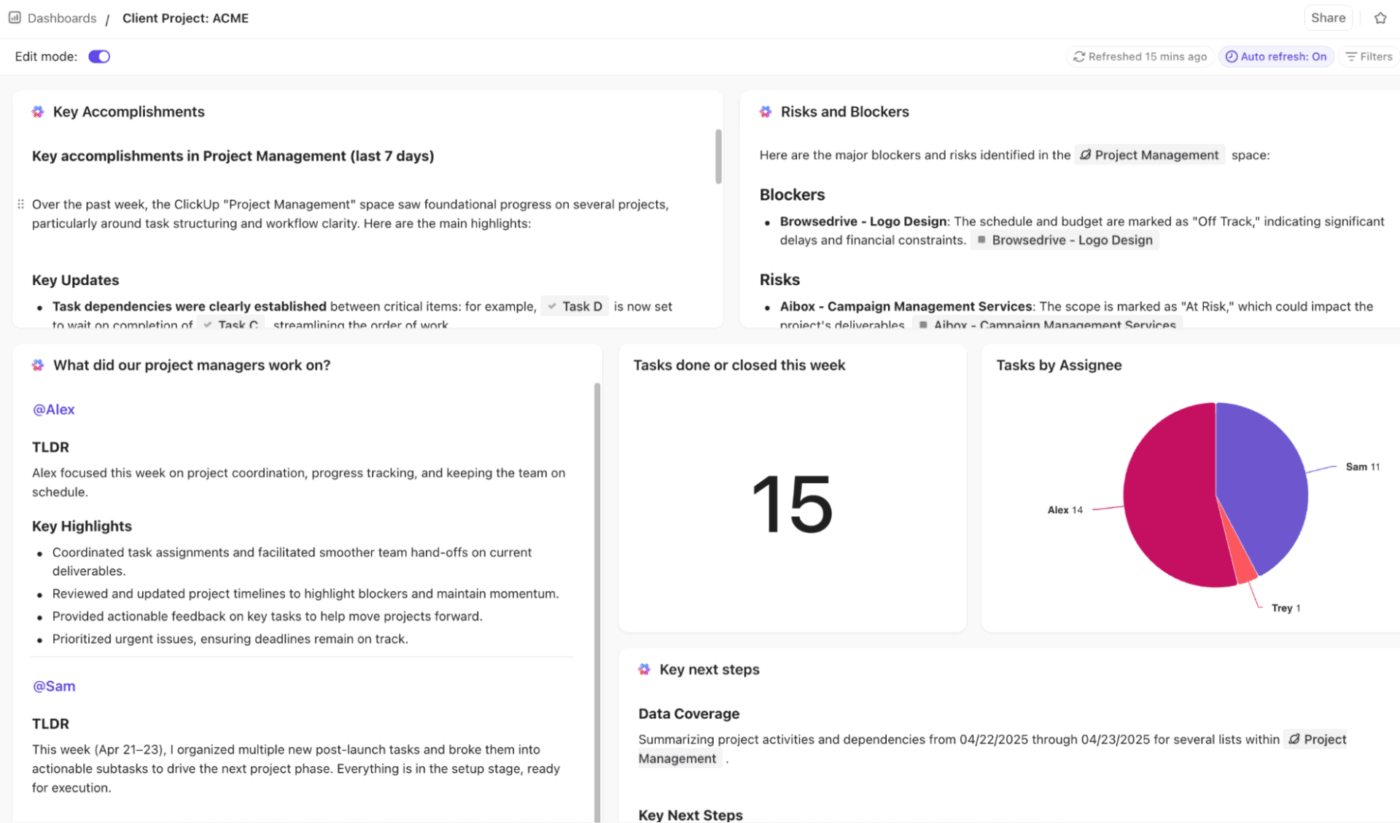
Zarządzaj incydentami szybciej dzięki ClickUp
Wiele osób uważa, że eskalacja incydentów polega jedynie na przekazaniu zgłoszenia kolejnej osobie, ale to znacznie więcej. Jest to ustrukturyzowany system, w którym każdy krok, od segregacji do rozwiązania, działa w harmonii.
ClickUp zapewnia idealną, ujednoliconą przestrzeń roboczą. Dzięki ClickUp automatyzacjom możesz automatycznie uruchamiać alerty, kierować zadania i aktualizować statusy. A ClickUp Brain pomaga ustalać priorytety incydentów, generować podsumowania i sugerować kolejne kroki.
Agenci ClickUp AI działają jak inteligentni asystenci w Twoim obszarze roboczym ClickUp, a pulpity nawigacyjne ClickUp zapewniają widok eskalacji na żywo.
Zarejestruj się w ClickUp już dziś za darmo!
Często zadawane pytania (FAQ)
Ścieżka eskalacji incydentów to z góry określona sekwencja kroków, która określa, w jaki sposób problemy są kierowane do odpowiedniego zespołu lub osoby w oparciu o ich ważność, wpływ i czas. Zapewnia to skuteczne rozwiązywanie incydentów i jasność odpowiedzialności. TEKST
Wykorzystaj automatyzację w przypadku dobrze zdefiniowanych incydentów o wysokim priorytecie i jasnych kryteriach (np. przerwy w świadczeniu usług, naruszenia bezpieczeństwa). Ręczną eskalację zarezerwuj dla niejednoznacznych lub krytycznych sytuacji, które wymagają ludzkiej oceny lub dodatkowego kontekstu.
Platformy takie jak ClickUp, PagerDuty, Jira Service Management i ServiceNow umożliwiają automatyczne przekierowywanie, powiadomienia i aktualizacje. Pomagają zespołom ograniczyć opóźnienia i utrzymać uporządkowany cykl pracy związany z incydentami.
Ustal jasne progi dla alertów, ustal priorytety według ważności i korzystaj z inteligentnych powiadomień. Limit powtarzające się powiadomienia do krytycznych incydentów i wykorzystaj pulpity nawigacyjne lub narzędzia AI do podsumowywania aktualizacji zamiast wysyłania informacji o każdej drobnej zmianie.
Regularnie przeglądaj zasady eskalacji, co najmniej raz na kwartał lub po poważnych incydentach. Dzięki temu kryteria, obowiązki i reguły automatyzacji będą odzwierciedlać aktualne cykle pracy, struktury zespołów i priorytety biznesowe.