
I primi servizi sono facili. Una rotazione, un canale e poi un backup.
Tuttavia, una volta che la tua azienda raggiunge decine di microservizi, più regioni e titolarità stratificate, gli escalation manuali cessano di essere un flusso di lavoro e diventano un ostacolo.
Questa guida spiega come effettuare l'automazione dei percorsi di escalation degli incidenti che si adattano alla tua organizzazione ingegneristica senza causare lacune nel tuo sistema di reperibilità.
Vedremo anche come ClickUp si inserisce nella creazione di un sistema di escalation di cui i tuoi team di ingegneri possono fidarsi. 🎯
⭐ Modello in primo piano
Rispondi in modo rapido ed efficace durante le emergenze, dai disastri naturali alle violazioni dei dati, utilizzando il modello ClickUp Incident Action Plan (IAP).

Il modello fornisce sezioni predefinite per:
- Definisci gli obiettivi degli incidenti e le priorità di risposta
- Stabilisci una struttura di comando chiara
- Coordina le azioni tra i team in tempo reale
- Registra decisioni, Sequenze e aggiornamenti chiave man mano che si verificano.
- Rimani in connessione con l'escalation e il follow-up
E poiché risiede all'interno di ClickUp, funziona come un documento di comando degli incidenti in tempo reale, non come una lista di controllo statica.
Perché automatizzare i percorsi di escalation degli incidenti
Quando il tuo team gestisce sistemi complessi con SLA rigorosi, l'escalation manuale non fa altro che rallentarti. L'escalation automatizzata rende il processo di risposta prevedibile e meno stressante, anche durante incidenti ad alta pressione.
Ecco perché è necessario implementare le automazioni per i percorsi di escalation della tua organizzazione. 👇
Il rischio dell'escalation manuale
Quando si ha a che fare con decine di servizi, turni di reperibilità multipli e titolarità in continuo cambiamento, i passaggi gestiti dall'uomo diventano rapidamente un problema.
Le insidie più comuni includono:
- Notifiche mancate o ritardate quando qualcuno trascura un'email, un SMS o un messaggio di chat
- Confusione durante i passaggi di consegne, specialmente quando i percorsi di escalation non sono chiaramente documentati
- Escalation al team sbagliato perché la mappa della titolarità non è aggiornata
- Colli di bottiglia causati dall'affidarsi a una sola persona per "inoltrare l'allerta"
📖 Leggi anche: Come redigere un rapporto sugli incidenti
Vantaggi delle automazioni
L'automazione ITSM conferisce struttura e slancio ai tuoi percorsi di escalation. Invece di sperare che qualcuno veda l'avviso, il tuo sistema esegue una sequenza predefinita in modo istantaneo e coerente.
Ecco i vantaggi che i team ottengono quando utilizzano l'IA per automatizzare le attività:
- Tempi di risposta più rapidi grazie alla trasmissione degli avvisi alla persona o al team giusto in pochi secondi
- Esecuzione coerente dei passaggi di escalation, anche alle 3 del mattino, quando il processo decisionale è più lento.
- Ridondanza integrata che garantisce che i responsabili del backup vengano avvisati se il responsabile di turno principale non riceve l'allerta.
- Chiara visibilità tra i team perché tutti comprendono il flusso degli escalation
- Meno interventi di emergenza e più prevedibilità nelle esperienze di reperibilità.
📖 Leggi anche: Esempi di piani di continuità operativa
Riduzione dell'affaticamento da allerta e della supervisione umana
L'affaticamento da allerta compromette l'efficacia del servizio di reperibilità. Quando il tuo team riceve segnalazioni troppo frequenti o per motivi errati, smette di rispondere con urgenza. Le automazioni aiutano a filtrare e segnalare solo ciò che richiede realmente l'attenzione umana.
Con la logica di escalation automatizzata:
- Gli avvisi con segnale debole o duplicati vengono soppressi prima che raggiungano il personale di turno.
- Le regole basate sulla gravità assicurano che i problemi minori non disturbino inutilmente il sonno di qualcuno.
- Gli avvisi vengono escalati solo se il sistema rileva una mancata risposta entro un intervallo di tempo definito.
- Teams dedicano meno tempo alla selezione dei rumori e più tempo alla risoluzione dei problemi reali.
Assistenza alla conformità con gli SLA e alle politiche di reperibilità
L'escalation automatizzata rende più facile mantenere la conformità senza una supervisione manuale costante. Per i responsabili delle operazioni IT che gestiscono SLA rigorosi o impegni interni di affidabilità, l'IA funge da barriera di protezione che impone il comportamento previsto. Ti aiuta a:
- Assicurati che le notifiche degli incidenti seguano regole predefinite per l'instradamento
- Mantieni automaticamente la sequenza dei tempi di risposta previsti dallo SLA, con escalation programmate.
- Applica i turni di reperibilità senza affidarti a fogli di calcolo obsoleti.
- Crea audit trail per ogni avviso, escalation e conferma.
🎥 Vuoi gestire l'intero flusso di lavoro del percorso di escalation senza intervenire manualmente? Super Agents è quello che fa per te. 👇🏼
🔍 Lo sapevate? Il controllo missione della NASA funziona essenzialmente sulla base di una logica di escalation automatizzata. Se la telemetria esce dall'intervallo, il sistema invia immediatamente avvisi automatici agli specialisti del settore.
Che cos'è una politica di escalation nella gestione degli incidenti?
Una politica di escalation è un insieme predefinito di regole che determina chi viene avvisato, quando viene avvisato e come la responsabilità viene trasferita ai livelli superiori o tra i team.
Consideralo come una roadmap strutturata che impedisce il blocco degli incidenti, garantisce l'intervento degli esperti giusti al momento giusto e aiuta i team a rispettare gli SLA.
Una politica di gestione dell'escalation ben strutturata solitamente include:
- Routing basato su regole che definisce chi è il prossimo in linea quando qualcuno non conferma o non è in grado di risolvere l'incidente.
- Trigger temporizzati che eseguono automaticamente l'escalation dopo 5, 15 o 30 minuti in base alla gravità.
- Metodi di notifica quali telefonate, SMS, chat o email
- Livelli del piano di escalation da Livello 1 (reperibilità primaria) > Livello 2 (ingegneri senior/SME) > Livello 3 (dirigenza)
- Aspettative relative alla documentazione, in modo che i nuovi responsabili della risposta possano subentrare senza perdere il contesto critico.
Tipi di politiche di escalation
Ecco i tipi principali di politiche che il tuo team dovrebbe comprendere:
1. Escalation gerarchica (verticale)
Gli avvisi vengono inoltrati verso l'alto nella catena di comando, dai tecnici junior agli specialisti senior fino alla dirigenza. Utilizza questa funzione quando la situazione richiede competenze più approfondite, autorità decisionale o visibilità esecutiva.
2. Escalation funzionale (orizzontale)
Invece di salire di livello, l'allerta viene trasmessa tra i team alla funzione responsabile del sistema interessato. Questo è l'ideale per gli incidenti legati a un dominio specifico, come database, reti, pagamenti o API.
3. Escalation basata sul tempo
Questo è il fondamento della maggior parte dei sistemi automatizzati. In questo tipo di sistema, l'avviso passa al livello successivo dopo un determinato periodo di tempo, spesso legato direttamente agli SLA. È particolarmente essenziale quando è necessaria una reattività garantita fuori dall'orario di lavoro.
4. Escalation basata sull'impatto
L'escalation basata sull'impatto dipende dalla gravità o dall'impatto sul business, non dalla gerarchia o dal tempo. È utile in caso di interruzioni del servizio, errori di pagamento, problemi relativi ai clienti o violazioni della sicurezza.
5. Escalation parallela
In questo caso, più persone o team vengono avvisati contemporaneamente. L'escalation parallela viene utilizzata per problemi di grave entità che richiedono competenze multiple o per situazioni in cui qualsiasi ritardo è inaccettabile.
🔍 Lo sapevate? Un recente studio sui segnali di allarme ha rilevato che gli allarmi estremamente salienti o " forti/luminosi " possono rallentare i tempi di reazione, soprattutto se l'allarme è inaspettato. Ma una volta che il tipo di allarme diventa prevedibile (cioè parte di un sistema di escalation/notifica predefinito), i tempi di risposta migliorano. Ciò suggerisce che quando si effettua l'automazione dei percorsi di escalation, non si dovrebbe semplicemente sommergere le persone con allarmi ad alta priorità.
Quando trigger l'escalation automatica
Ora che conosci la struttura dei percorsi di escalation, il passaggio successivo è decidere quando queste regole devono essere eseguite automaticamente.
Di seguito sono riportate le situazioni principali che trigger l'escalation automatica, formando il livello logico alla base delle tue politiche. 💁
Escalation basata sulla gravità
L'escalation automatica si attiva quando la gravità o l'impatto dell'incidente supera una certa soglia. Gli incidenti di gravità elevata richiedono l'attenzione immediata dei superiori e l'escalation automatica consente di aggirare i colli di bottiglia e coinvolgere gli esperti in pochi secondi.
📌 Esempio: un'interruzione completa del servizio, un guasto al gateway di pagamento o un grave degrado che interessa molti utenti o sistemi core richiede un'escalation automatica.
Escalation basata sul tempo
Se nessuno conferma o risolve l'incidente entro un intervallo di tempo definito, l'avviso viene automaticamente inoltrato al livello successivo. Ciò impedisce che i ticket rimangano in sospeso, soprattutto al di fuori del normale orario di lavoro o quando il primo responsabile non è disponibile o è sovraccarico di lavoro.
📌 Esempio: dopo 10-15 minuti senza risposta, l'escalation passa dal primo risponditore a un ingegnere senior; dopo altri 30-60 minuti senza risoluzione, l'escalation prosegue ulteriormente.
Escalation contestuale
Questa logica di escalation tiene conto degli attributi contestuali dell'incidente, quali il servizio o il sistema interessato, il titolare del servizio, il segmento di clientela coinvolto (interno vs esterno, VIP vs normale) o il dominio funzionale (database, rete, integrazione). In base a tale contesto, gli avvisi vengono inoltrati al responsabile o al team più pertinente.
In questo modo eviterai di sovraccaricare i team con incidenti irrilevanti, ridurrai i tempi di risposta e garantirai che gli specialisti gestiscano i problemi nella loro area di competenza.
📌 Esempi: un picco di latenza nel servizio di pagamento dovrebbe avvisare direttamente il team addetto ai pagamenti, oppure un errore di backend nel microservizio di fatturazione dovrebbe avvisare il team addetto alla fatturazione.
Escalation basata sui metadati
I moderni strumenti di allerta e gestione degli incidenti acquisiscono metadati quali la fonte di origine (quale strumento di monitoraggio o regola di allerta è stato attivato), l'identità dell'utente/cliente, la posizione, la frequenza storica di incidenti simili o le etichette. Ciò consente di applicare una logica più granulare e intelligente, anziché affidarsi a regole basate sulla gravità o sul tempo.
📌 Esempi: gli avvisi ricorrenti provenienti dallo stesso sottosistema possono indicare un problema sistemico più profondo, che richiede un escalation più rapido. Oppure, gli avvisi relativi ai clienti VIP potrebbero trigger notifiche aggiuntive.
Combinazione di trigger per creare politiche di escalation più intelligenti e adattive
In pratica, molti team non si affidano a un solo tipo di trigger. Al contrario, creano politiche di escalation ibride che combinano regole di gravità, tempo, contesto e metadati.
Questo approccio a più livelli consente ai team di creare politiche di escalation che siano sia reattive (veloci quando necessario) sia intelligenti (selettive per ridurre al minimo il rumore), con conseguente miglioramento dei risultati degli incidenti e allocazione più efficiente delle risorse.
🔍 Lo sapevate? Nel XVIII secolo, gli equipaggi navali utilizzavano una rigida catena di escalation durante le emergenze. Se un marinaio di grado inferiore individuava un pericolo, suonava una campana e trasmetteva il messaggio nella gerarchia fino a quando il capitano non prendeva la decisione finale.
Come progettare percorsi di escalation efficaci
Progettare percorsi di escalation significa creare un sistema che indirizzi in modo affidabile gli avvisi giusti alle persone giuste con il minimo attrito.
Ecco un framework pratico e dettagliato che puoi utilizzare in ambienti complessi e di distribuzione.
P.S. Scopriremo anche come alcune funzionalità/funzioni di ClickUp possono aiutarti in questo! 🤩
Passaggio 1: definire criteri, livelli e responsabilità di escalation chiari
Inizia definendo cosa costituisce un incidente che richiede l'escalation. Documenta criteri oggettivi in modo che ogni ingegnere di turno, sia esso un nuovo risponditore L1 o un SRE esperto, interpreti la gravità dell'incidente allo stesso modo.
Ciò garantisce un flusso di lavoro di escalation chiaro, elimina ogni ambiguità e assicura che l'automazione entri in funzione solo quando è davvero necessario.
Includi criteri quali:
- Soglie di gravità: interruzione del servizio, errori di pagamento, problemi di autenticazione, danneggiamento dei dati e avvisi di sicurezza.
- Impatto: interruzioni del servizio per i clienti, degrado dei servizi interni, errori API dei partner, conformità o rischi per la sicurezza.
- Contesto critico aziendale: impatto sui clienti di alto valore, flussi che incidono sui ricavi, sistemi ad alto rischio (ad es. pagamenti, fatturazione)
Una volta definiti i criteri e i trigger, mappa chi viene avvisato e quali sono le sue responsabilità in ogni punto di escalation.
Definisci chiaramente i livelli:
- Livello uno (responsabile primario degli incidenti in servizio): agisce come primo soccorritore ed è responsabile della conferma, della valutazione iniziale e dei tentativi di mitigazione.
- Livello due (backup/specialista/SME): Fornisce competenze tecniche approfondite e risolve problemi di sistema complessi.
- Livello tre (responsabile tecnico/dirigenza): supervisiona gli incidenti gravi, approva le azioni importanti, coordina la comunicazione tra i team e, se necessario, trigger l'escalation al fornitore.
🚀 Vantaggio di ClickUp: utilizza ClickUp Docs per mantenere un'unica fonte di verità per i criteri, i livelli e le responsabilità di escalation e documenta i ruoli e le responsabilità, compreso chi:
- Riconosce e mitiga
- Comunica con le parti interessate
- Gestisce gli escalation dei fornitori o dei partner esterni
- Guida il comando degli incidenti
Puoi anche collegare questi ruoli specifici alle attività di ClickUp pertinenti per mantenere il contesto connesso.
Crea la tua base di conoscenze:
Una volta definiti i criteri di escalation e la titolarità, i team hanno bisogno di un metodo coerente per acquisire, effettuare il monitoraggio e analizzare gli incidenti tecnici. Il modello di rapporto sugli incidenti di ClickUp fornisce un sistema strutturato e di facile accesso per documentare gli incidenti IT e operativi in un unico posto.
Integrato in ClickUp Docs, aiuta i team di risposta agli incidenti a registrare dettagli critici quali la gravità dell'incidente, i servizi interessati, le tempistiche, i riepiloghi delle cause principali, le misure di mitigazione e le azioni di follow-up.
Passaggio n. 2: standardizzare la creazione degli incidenti
Prima ancora che i percorsi di escalation vengano attivati, il tuo team ha bisogno di un modo affidabile per acquisire, normalizzare e arricchire i dati relativi agli incidenti. Se la registrazione iniziale dell'incidente è incompleta o incoerente, anche la logica di escalation più sofisticata fallirà.
La standardizzazione dovrebbe:
- Seleziona gli avvisi in arrivo: converti gli avvisi in campi personalizzati coerenti come gravità, categoria, servizio interessato, tipo di incidente e stato di conferma.
- Arricchite automaticamente l'incidente: inserite i metadati, inclusi cluster, ID di distribuzione, titolari dei servizi o dipendenze.
- Assicurati che ogni incidente catturi il contesto: registra chi lo ha segnalato, come è stato rilevato, l'ambiente (produzione/staging) e qualsiasi log o screenshot pertinente.
Crea un modulo ClickUp direttamente dall'elenco in cui vengono tracciati gli incidenti e progettalo in modo che rifletta la tua realtà operativa e i dati rilevanti da cui dipende la tua logica di escalation. In questo modo, invece di messaggi frammentati su chat, email o dashboard, ogni incidente entra nel tuo sistema in un formato coerente su cui l'automazione può agire in modo affidabile.

Raggruppa i campi in modo intenzionale affinché ogni incidente sia completamente contestualizzato:
- Identificazione (titolo, riepilogo/riassunto)
- Classificazione (gravità, tipo, servizio interessato)
- Fonte (monitoraggio, utente, API)
- Prove (registri, screenshot)
- Contesto aziendale (livello SLA, impatto sul cliente)
Ogni invio di modulo crea automaticamente una nuova attività di ClickUp, con tutte le risposte mappate nei campi personalizzati ClickUp. Ciò garantisce che gli incidenti vengano normalizzati al momento della creazione, eliminando l'ambiguità e la necessità di una risposta manuale agli incidenti.
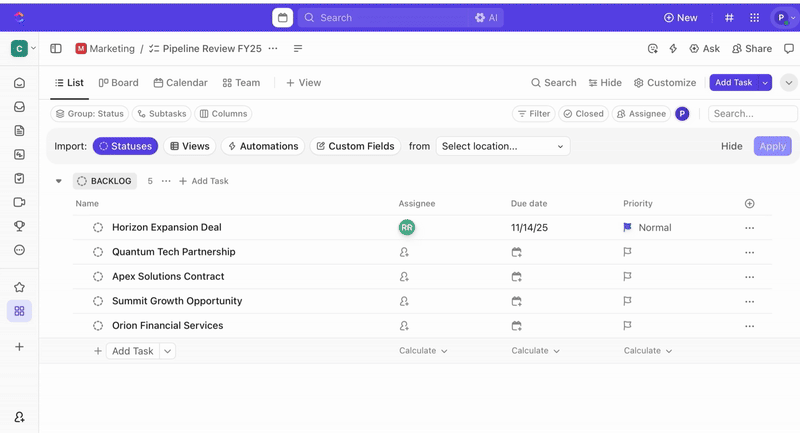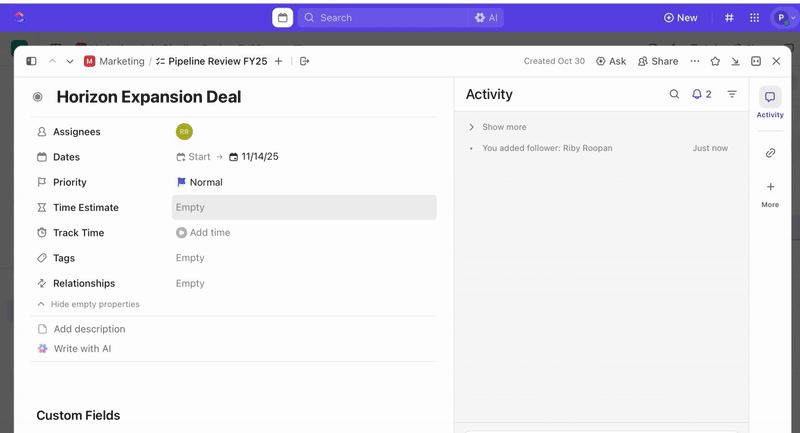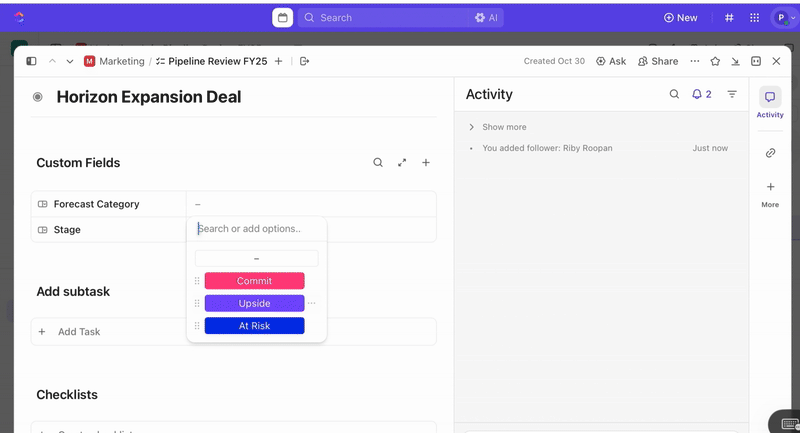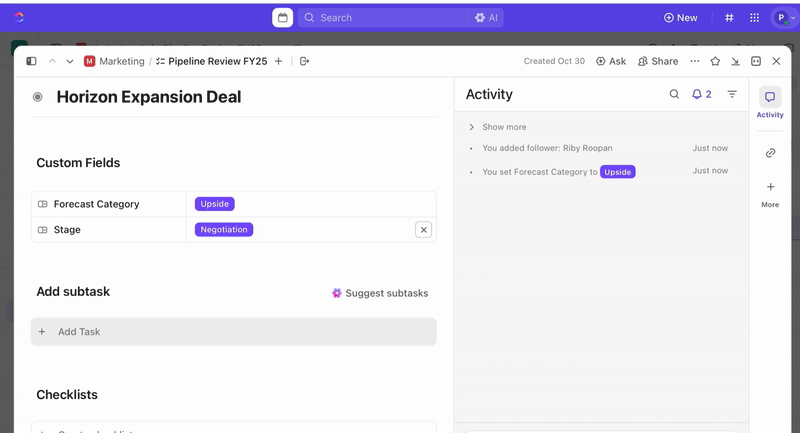
Una volta creati gli impegni, puoi utilizzare i campi personalizzati per guidare la selezione e la definizione delle priorità (ad esempio, gravità, impatto, gruppo di risposta) e definire gli stati personalizzati di ClickUp che riflettono le fasi dell'incidente (Nuovo > Selezione > Indagine > Mitigazione > Risolto).
Passaggio 3: Creare il percorso di escalation (ovvero sequenza + tempistiche + canali)
Questo è il cuore del percorso. Definisci il percorso in fasi, dove ogni fase definisce chi viene avvisato, attraverso quali canali e dopo quanto tempo senza alcuna conferma o risoluzione.
- Definisci il "timeout di conferma" e il "timeout di risoluzione".
Ecco un esempio di flusso di lavoro:
- Fase uno: il primo operatore di turno avvisato immediatamente tramite SMS/canale di chat deve confermare entro 5-10 minuti.
- Fase due: se non si riceve alcuna conferma o non viene intrapresa alcuna azione nei successivi 15-20 minuti, inoltrare la segnalazione al team di backup/SRE + ingegnere senior tramite SMS/canale di chat/email.
- Fase tre: se dopo altri 30-60 minuti il problema non è ancora stato risolto, inoltrate la segnalazione al responsabile tecnico/alla direzione e, se lo ritenete opportuno, triggerate il canale "incidente grave".
- Decidi se il percorso di escalation deve "ripetersi" (inviare nuovamente una notifica allo stesso livello) o "proseguire".
- Per gli incidenti critici, imposta notifiche ripetute fino a quando qualcuno non risponde. Per quelli con priorità inferiore, potresti preferire un unico flusso di escalation.
- Assicurati che il percorso sia documentato utilizzando un modello di risposta del servizio clienti e accessibile a tutto il personale interessato.
❗️ Nota: il "timeout di conferma" è il tempo a disposizione del primo risponditore per confermare di aver visto l'avviso, mentre il "timeout di risoluzione" è il tempo a disposizione del team per risolvere o mitigare il problema prima che scatti il successivo escalation.
Passaggio 4: integrare l'automazione e il supporto degli strumenti
Una volta definiti i criteri, il processo di triage e gli standard di arricchimento, il passaggio successivo è abilitare l'escalation senza affidarsi alla memoria umana per ricordare quando e a chi effettuare l'escalation. È qui che le automazioni di ClickUp diventano una parte fondamentale del tuo flusso di lavoro.

È possibile impostare opportunità di automazione che reagiscono agli stessi segnali utilizzati dal team durante gli incidenti. Ecco alcuni esempi:
- Se la gravità viene aggiornata a SEV-1 ➡️ Assegna immediatamente un SRE senior + avvisa il canale di chat di reperibilità
- Se lo stato rimane invariato per X minuti ➡️ Trigger l'escalation al livello successivo
- Se la data di scadenza viene superata (ad es. termine per la conferma) ➡️ Escalare a L2
Ed è qui che ClickUp Brain fa un ulteriore passo avanti. Utilizza il contesto della tua area di lavoro per fornire risposte immediate, generare automaticamente aggiornamenti e fornire supporto per l'accesso alle conoscenze.
Utilizza strumenti come AI Prioritize per valutare automaticamente gli incidenti e impostare la priorità corretta utilizzando la tua logica. Esempi di prompt:
- Se l'incidente influisce sulla produzione e ha un impatto sui clienti, imposta Priorità: Urgente.
- Se l'assegnatario è il team SRE e le menzioni dei log riguardano la "latenza", impostare la priorità: Alta
- Se la descrizione include parole chiave relative alla sicurezza come "violazione", imposta Priorità: Urgente.
Una volta effettuata l'impostazione della priorità, AI Assign subentra e assegna automaticamente gli incidenti in base alle condizioni definite dall'utente.
È possibile creare prompt come:
- Se la priorità è urgente e il servizio interessato contiene "pagamenti", assegnare al Senior SRE.
- Se il tipo di incidente è database e la regione è US-East, assegnare a DB On-Call.
- Se il nome dell'attività include "sicurezza", assegnala al responsabile SecOps.
Prova questi promoti sulle prime tre attività prima di applicarli all'intero Elenco.
🚀 Vantaggio di ClickUp: implementa bot di automazione intelligenti che risiedono all'interno della tua area di lavoro e rispondono alle attività in tempo reale con ClickUp Super Agents.
Sono pienamente consapevoli delle tue attività, dei tuoi documenti, delle tue chat e dei tuoi processi, quindi ogni azione di automazione è contestualizzata.
Ad esempio, puoi inserire un Team StandUp Agent nella tua "Cartella degli incidenti di produzione" in modo che ogni mattina pubblichi automaticamente un riepilogo/riassunto giornaliero. Il tuo team riceverà un'istantanea che mostra il numero di incidenti aperti, quelli ancora irrisolti e le modifiche avvenute nelle ultime 24 ore.
Ora abbinalo a un Ambient Answers Agent nel tuo canale "#incident-room". Quando gli addetti alla risposta pongono domande come "Dov'è il runbook SEV-1?" o "Questa API ha già avuto problemi in passato?", attingerà dalle conoscenze della tua area di lavoro per fornire risposte immediate e accurate.

Passaggio 5: standardizzare i canali di comunicazione
Man mano che gli incidenti si aggravano, il modo e il luogo in cui i team comunicano sono importanti tanto quanto chi viene avvisato. Senza canali standardizzati, gli aggiornamenti vanno persi, le decisioni vengono duplicate e le parti interessate ricevono informazioni contrastanti.
Definisci canali di escalation chiari per ogni fase del ciclo di vita dell'incidente e utilizzali in modo coerente in tutti i team:
| Criteri | Nome del canale | Scopo |
| SEV-1 o SEV-2 rilevato | #incidente-critico | Spazio centrale per avvisi di gravità elevata e triage immediato |
| Risoluzione dei problemi in corso | #incidente-warroom | Hub di collaborazione in tempo reale per ingegneri, prodotto, controllo qualità e supporto |
| Visibilità della leadership richiesta | #incidente-leadership | Aggiornamenti di alto livello per manager e dirigenti |
| È necessaria una comunicazione personalizzata orientata al cliente | #comunicazioni-incidenti | Spazio per redigere, rivedere e allineare le comunicazioni con i clienti esterni |
| Avviata la revisione post-incidente | #incidente-retro | Discussione strutturata per note retrospettive, apprendimenti e elementi da intraprendere |
Ogni canale ha un pubblico e uno scopo definiti, aiutando i team a ridurre il rumore di fondo e mantenendo informati i team appropriati.
🚀 Vantaggio di ClickUp: abbina la tua strategia di canale a un livello di comunicazione integrato utilizzando ClickUp Chat. Ogni avviso, aggiornamento e decisione rimane direttamente collegato all'attività, all'elenco o allo spazio dell'incidente in cui si svolge il lavoro.
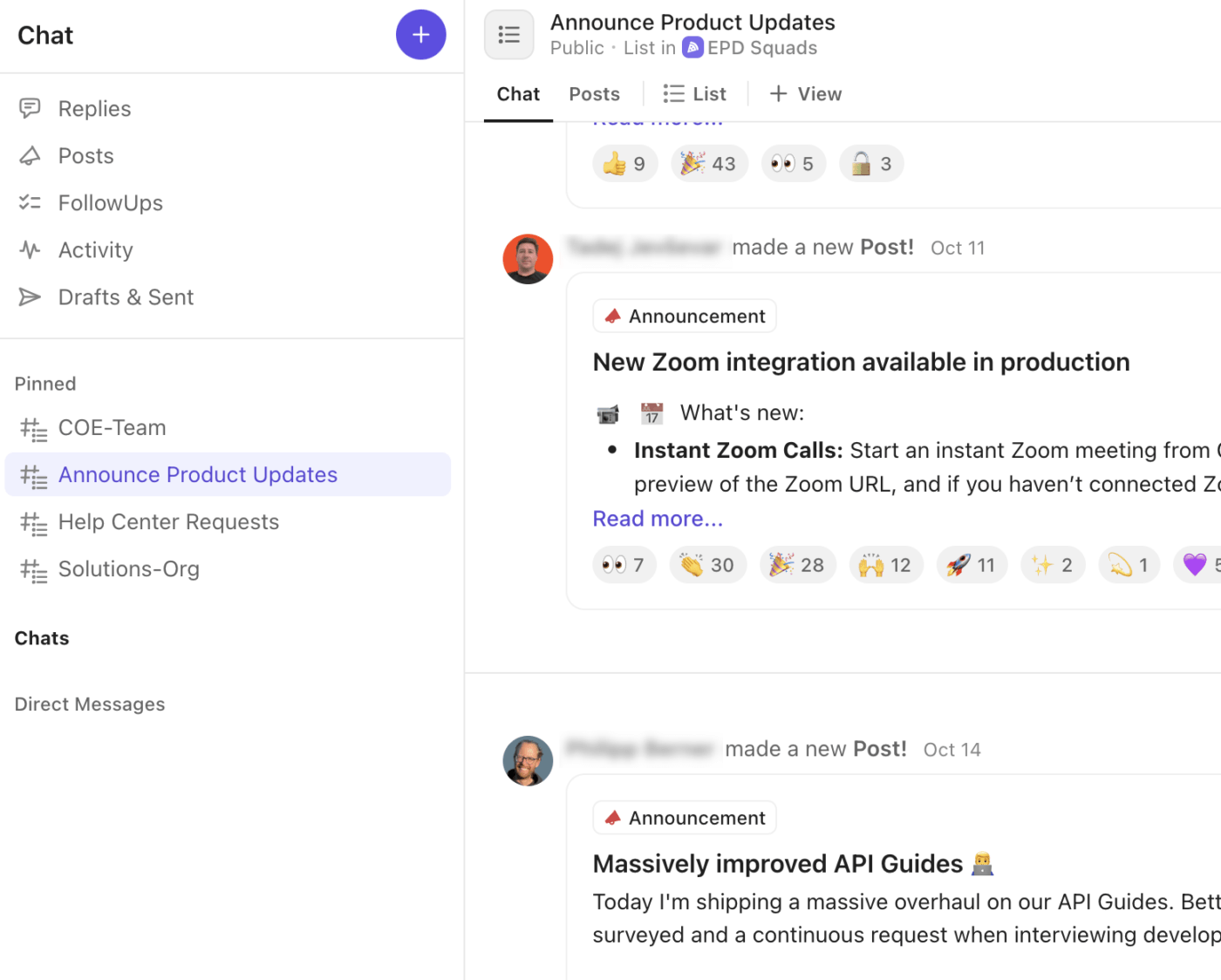
Ecco come ClickUp Chat migliora il flusso di lavoro degli incidenti:
- Crea thread di chat dedicati per discussioni critiche, war room, leadership o comunicazioni con i clienti.
- Trasforma i messaggi di chat in attività di ClickUp istantaneamente, assicurandoti che le decisioni e i follow-up non vadano persi nella conversazione.
- Effettua rapidamente chiamate audio o videochiamate con ClickUp SyncUps per il coordinamento in tempo reale degli incidenti o i briefing della dirigenza.
- Pubblica "Annunci" o aggiornamenti per comunicare lo stato degli incidenti di alto livello in tutta l'azienda.
- Tagga i colleghi, inserisci screenshot e allega log direttamente nella chat, mantenendo il contesto tecnico a portata di mano.
Passaggio n. 6: testare, verificare e perfezionare il percorso di escalation
Le politiche di escalation devono evolversi insieme ai tuoi sistemi. Ecco cosa devi fare regolarmente:
| Attività | Cosa testare o rivedere | Perché è importante |
| Esercitazioni antincendio di emergenza (trimestrali) | Simula incidenti P1 e P2, verifica i tempi e il percorso di escalation. | Garantisce che le automazioni e i percorsi di escalation funzionino anche sotto pressione. |
| Convalida del percorso di escalation | Verifica la presenza di escalation senza sbocco o titolari mancanti | Impedisce che gli incidenti rimangano in sospeso senza visibilità |
| Timer per il processo di conferma e risoluzione | Confronta i timer configurati con MTTA e MTTR effettivi | Mantiene i tempi di escalation realistici ed efficaci |
| Valutazione dell'affaticamento da allerta | Identifica i responsabili della risposta che ricevono avvisi eccessivi o ripetuti | Riduce il burnout e gli avvisi critici persi |
| Accuratezza nella valutazione della gravità e nella definizione delle priorità | Verifica se gli incidenti sono stati classificati correttamente | Migliora l'instradamento, la velocità di risposta e l'accuratezza dell'escalation |
| Follow-up post-incidente | Assicurati che gli elementi da intraprendere individuati durante le retrospettive vengano completati. | Previene il ripetersi di incidenti e guasti sistemici |
Strumenti e integrazioni per l'automazione dell'escalation
Questa sezione ti guida alla scoperta del software di gestione degli incidenti che ti aiuta a rilevare gli incidenti più rapidamente, indirizzarli istantaneamente e tenere aggiornati tutti i team senza follow-up manuali.
1. ClickUp (ideale per unificare gli escalation interfunzionali in un unico spazio di lavoro connesso dedicato agli incidenti)
I metodi di escalation tradizionali costringono i team a destreggiarsi tra email, fogli di calcolo, chat threads e note sparpagliate, rendendo quasi impossibile avere una visione chiara e in tempo reale di ciò che sta accadendo.
Il software di gestione delle attività ClickUp per la gestione dell'escalation elimina il rumore consolidando tutti i dettagli dell'escalation in un unico spazio di lavoro organizzato.
Diamo un'occhiata ad alcune funzionalità/funzioni del software di gestione delle risorse IT che rendono ClickUp la scelta migliore per i team che gestiscono escalation di grandi volumi e flussi di lavoro complessi relativi agli incidenti.
Lavora a modo tuo
Visualizza le tue attività da più angolazioni per soddisfare le tue esigenze operative con ClickUp Views:
- Vista Elenco ClickUp in modo che i responsabili SRE possano ordinare gli incidenti in base alla gravità, al tempo rimanente dello SLA o ai gruppi di reperibilità per una rapida valutazione.
- ClickUp vista Bacheca consente ai responsabili tecnici di visualizzare i passaggi di consegne e la titolarità del team durante gli escalation.
- ClickUp vista Gantt per i responsabili dei programmi per mappare le attività cardine della risoluzione e le dipendenze tra i servizi
- ClickUp Vista Carico di lavoro per i responsabili della pianificazione dei turni di reperibilità, che garantisce che gli ingegneri non siano sovraccarichi durante i periodi di picco degli incidenti.
Trasforma le discussioni delle riunioni in azioni concrete
Durante gli escalation e le revisioni degli incidenti, può essere difficile registrare in modo affidabile le discussioni e gli elementi da intraprendere. ClickUp AI Notetaker si unisce automaticamente alle riunioni pianificate in Google Calendar, Outlook, Zoom o Teams, registrando e trascrivendo la conversazione.
Dopo la riunione:
- Accedi alle trascrizioni ricercabili e ai riassunti delle azioni da intraprendere
- Garantisci la chiarezza utilizzando le note salvate in ClickUp Docs. In questo modo sarà facile ricollegarsi alle attività relative agli incidenti o ai rapporti retrospettivi.
- Poni domande a ClickUp AI sui contenuti delle riunioni per chiarire le decisioni o scoprire eventuali follow-up mancanti.
Effettua la connessione agli strumenti esistenti nel tuo stack tecnologico
Dietro le quinte, le integrazioni ClickUp e l'ecosistema webhook garantiscono una connessione perfetta con il resto del tuo stack.
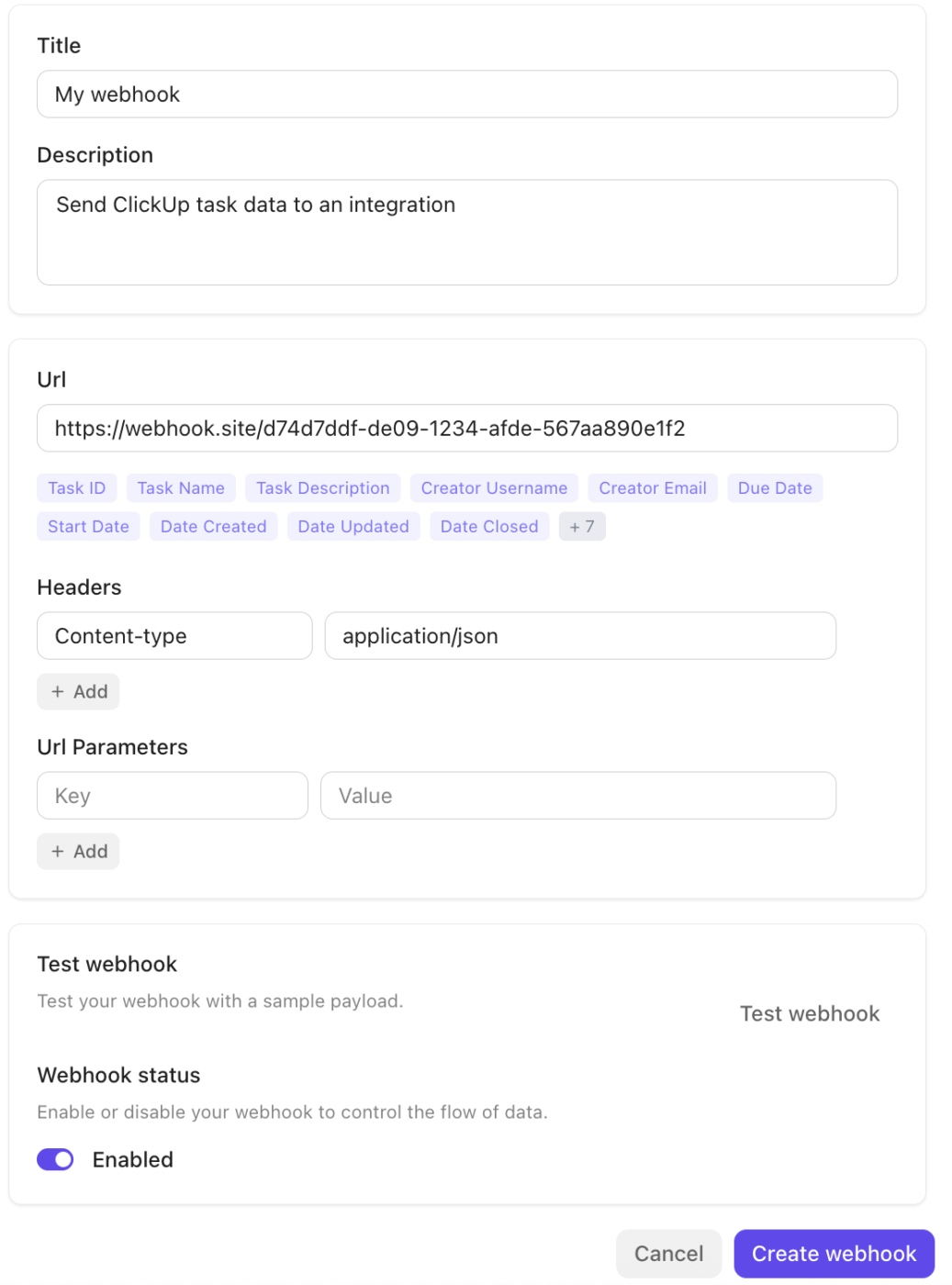
La piattaforma si integra in modo nativo con strumenti come Slack, GitHub, Zoom e altri, e supporta i webhook tramite la sua API pubblica per trasmettere eventi (aggiornamenti delle attività e modifiche di stato) a servizi esterni o pipeline di automazione. Ciò semplifica l'attivazione dei flussi di lavoro, la sincronizzazione dei dati o l'escalation degli incidenti tra i sistemi senza passaggi manuali.
Convergi tutti i tuoi strumenti di IA
Per portare l'automazione e il contesto a un livello superiore, ClickUp BrainGPT introduce l'intelligenza artificiale contestuale nei tuoi flussi di lavoro di escalation. Si tratta di un'app di super intelligenza artificiale contestuale che comprende le tue attività, i tuoi documenti e il contesto storico.
Con Enterprise Search e Connected Apps, puoi estrarre istantaneamente informazioni dal tuo spazio di lavoro, Slack, Google Drive, GitHub e altro ancora. Durante le chiamate relative agli incidenti in tempo reale, Talk-to-Text in ClickUp ti consente di dettare note o istruzioni di escalation a mani libere, assicurandoti che nulla venga tralasciato.
Puoi anche standardizzare le attività ripetibili con prompt IA personalizzati e prompt salvati, come: "Riassumi tutti gli incidenti irrisolti e consiglia azioni di escalation".
Le migliori funzionalità di ClickUp
- Dai priorità ai problemi critici: utilizza le priorità delle attività di ClickUp per evidenziare gli escalation urgenti o ad alto impatto.
- Organizza sequenze di escalation complesse: configura le dipendenze delle attività di ClickUp per collegare le attività correlate (ad esempio, "In attesa di" o "Blocco") in modo che i passaggi di escalation evitino azioni premature o colli di bottiglia.
- Suddividi gli incidenti in parti gestibili: suddividi gli escalation in elementi granulari e assegnale ai vari team con le attività secondarie annidate.
- Monitorate con precisione la velocità di risoluzione: registrate e monitorate il tempo necessario per riconoscere e risolvere le attività di escalation con il monitoraggio del tempo del progetto di ClickUp.
Limitazioni di ClickUp
- Con così tante funzionalità/funzioni, visualizzazioni e opzioni di personalizzazione, i team spesso devono affrontare una curva di apprendimento prima che tutto risulti intuitivo.
Prezzi ClickUp
[Tabella dei prezzi]
Valutazioni e recensioni di ClickUp
- G2: 4,7/5 (oltre 10.300 recensioni)
- Capterra: 4,6/5 (oltre 4.400 recensioni)
Cosa dicono gli utenti reali di ClickUp?
Questa recensione dice davvero tutto:
ClickUp riunisce tutte le mie attività, i miei progetti e le mie comunicazioni in un unico posto, rendendo incredibilmente facile rimanere organizzati. Adoro la possibilità di personalizzare tutto, dalle visualizzazioni ai flussi di lavoro fino ai dashboard, così posso strutturare il mio spazio di lavoro esattamente come mi serve. La possibilità di collaborare in tempo reale, assegnare attività e monitorare i progressi senza dover cambiare strumento è un enorme vantaggio.
ClickUp riunisce tutte le mie attività, i miei progetti e le mie comunicazioni in un unico posto, rendendo incredibilmente facile organizzarmi. Adoro la possibilità di personalizzare tutto, dalle visualizzazioni ai flussi di lavoro fino ai dashboard, così posso strutturare il mio spazio di lavoro esattamente come mi serve. La possibilità di collaborare in tempo reale, assegnare attività e monitorare lo stato dei progressi senza dover cambiare strumento è un enorme vantaggio.
📮 ClickUp Insight: il 21% delle persone afferma che oltre l'80% della propria giornata lavorativa è dedicato a attività ripetitive. Un altro 20% sostiene che le attività ripetitive occupano almeno il 40% della propria giornata.
Si tratta di quasi la metà della settimana lavorativa (41%) dedicata ad attività che non richiedono particolare pensiero strategico o creatività (come le email di follow-up 👀).
I Super Agenti di ClickUp aiutano a eliminare questa routine. Pensa alla creazione di attività, promemoria, aggiornamenti, note di riunioni, bozze di email e persino alla creazione di flussi di lavoro end-to-end! Tutto questo (e molto altro) può essere automatizzato in un attimo con ClickUp, la tua app per il lavoro.
💫 Risultati reali: Lulu Press risparmia 1 ora al giorno per ogni dipendente utilizzando ClickUp Automazioni, con un aumento del 12% dell'efficienza del lavoro.
2. PagerDuty (ideale per avvisi in tempo reale e risposta intelligente alle chiamate)
PagerDuty è una piattaforma cloud-based per la gestione degli incidenti IT e delle operazioni digitali che aiuta i team a individuare, rispondere e risolvere rapidamente incidenti critici come interruzioni di servizio o minacce alla sicurezza. Offre ai responsabili SRE, DevOps e dell'assistenza un percorso chiaro dal segnale alla risoluzione, supportato da automazione, triage basato sull'IA e flussi di lavoro profondamente integrati.
Funzionalità/funzioni come Jeli Incident Analysis, PagerDuty Analytics e Automazioni per i runbook aiutano i team a ridurre i tempi di inattività, eliminare le attività di routine e imparare da ogni incidente.
Le migliori funzionalità/funzioni di PagerDuty
- Automatizza l'instradamento degli incidenti con la funzione integrata On-Call Management e le Escalation Policies dinamiche.
- Accelerate il triage utilizzando AIOps, che filtra i rumori di fondo degli avvisi, correla gli eventi ed evidenzia i segnali reali.
- Mantieni allineati gli stakeholder interni ed esterni con Stakeholder Comms, Modelli di aggiornamento dello stato e Pagine di stato.
- Unifica il tuo stack di strumenti con oltre 700 integrazioni e API estensibili utilizzando sistemi di monitoraggio, registrazione, CI/CD e supporto.
Limiti di PagerDuty
- Elevato volume di avvisi se le integrazioni e le soglie intelligenti non sono ottimizzate, con conseguente rumore e affaticamento
- Durante i picchi di attività possono verificarsi avvisi duplicati o ripetuti, rendendo più difficile il riconoscimento sotto pressione.
Prezzi di PagerDuty
- Free
- Professional: 25 $ al mese per utente
- Aziendale: 49 $ al mese per utente
- Enterprise: prezzi personalizzati
Valutazioni e recensioni di PagerDuty
- G2: 4,5/5 (oltre 900 recensioni)
- Capterra: 4,6/5 (oltre 200 recensioni)
Cosa dicono gli utenti reali di PagerDuty?
Nelle parole di un utente reale:
PagerDuty rende gli avvisi di incidenti rapidi e affidabili. Invia le notifiche giuste al momento giusto e mantiene il nostro team organizzato. […] PagerDuty può risultare fastidioso a volte quando gli avvisi non sono filtrati bene. Alcune impostazioni sono un po' complesse per i nuovi utenti.
PagerDuty rende gli avvisi di incidenti rapidi e affidabili. Invia le notifiche giuste al momento giusto e mantiene il nostro team organizzato. […] PagerDuty può risultare fastidioso quando gli avvisi non sono filtrati bene. Alcune impostazioni sono un po' complesse per i nuovi utenti.
💡 Suggerimento professionale: crea delle eccezioni, anche in un percorso di escalation chiaro. Fai in modo che le interruzioni critiche, gli avvisi di sicurezza o gli incidenti in ambienti regolamentati vengano segnalati direttamente ai responsabili senior o agli addetti specializzati.
3. GLPi (ideale per la governance end-to-end delle risorse e le operazioni di servizio allineate a ITIL)
Gestionnaire Libre de Parc Informatique (GLPi) è una piattaforma open source completa per la gestione dei servizi IT (ITSM) e delle risorse IT (ITAM). I team ottengono una visibilità end-to-end della propria infrastruttura (hardware, software, licenze e dispositivi di rete) e possono gestire incidenti, richieste di assistenza e modifiche utilizzando processi allineati con ITIL.
Tutti i tuoi contratti e la tua documentazione, comprese le garanzie e i contratti di assistenza, rimangono ben organizzati, evitando che vadano persi tra i diversi sistemi. Se gestisci data center, GLPi ti consente anche di visualizzare layout, percorsi di cablaggio e consumo energetico, così saprai sempre cosa succede dietro le quinte.
Le migliori funzionalità/funzioni di GLPi
- Utilizza i plugin GLPI Inventory, OCS Inventory o FusionInventory per rilevare e catalogare automaticamente le nuove risorse IT.
- Automatizza le attività ripetitive, l'assegnazione dei ticket, le notifiche e gli eventi ricorrenti per ridurre il lavoro manuale.
- Crea una knowledge base per domande frequenti, documentazione e articoli collegati ai ticket per il supporto self-service e tecnico.
- Connettiti con Azure/Entra, Centreon, Google, OAuth2 e webhook per effettuare la sincronizzazione dei dati, trigger flussi di lavoro e migliorare il tuo CMDB.
Limitazioni di GLPi
- La compatibilità dei plugin può interrompersi tra le versioni, causando costi di manutenzione aggiuntivi.
- Le funzionalità di reportistica, analisi ed esportazione sembrano avere limiti e necessitano di miglioramenti.
Prezzi GLPi
- Prezzi personalizzati
Valutazioni e recensioni di GLPi
- G2: 4,6/5 (oltre 30 recensioni)
- Capterra: 4,5/5 (oltre 40 recensioni)
Cosa dicono gli utenti reali di GLPi?
Ecco cosa ha detto un utente:
Sistema di gestione delle risorse IT e dei ticket di assistenza open source altamente personalizzabile, con un'ampia comunità di supporto. L'interfaccia utente è un po' complicata per i principianti. I plugin non sono sempre supportati dalle versioni precedenti a quelle più recenti.
Sistema open source altamente personalizzabile per la gestione delle risorse IT e dei ticket di assistenza, con un'ampia comunità di supporto. L'interfaccia utente è un po' complicata per i principianti. I plugin non sono sempre supportati dalle versioni precedenti a quelle più recenti.
4. Splunk On-Call (ideale per inoltrare gli avvisi di monitoraggio direttamente ai tecnici)
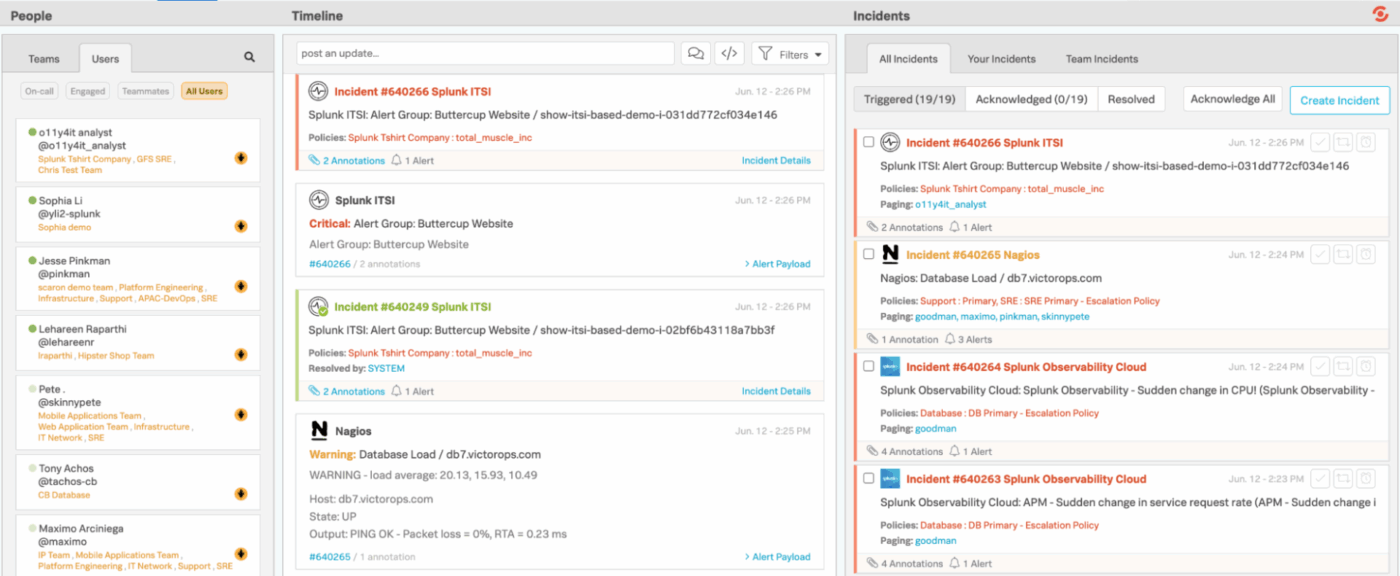
Splunk On-Call offre ai team di ingegneri e di assistenza tecnica un modo più rapido e pulito per gestire gli incidenti, eliminando la necessità dei tradizionali flussi di lavoro di ticketing, che sono lenti. Invece di inserire gli avvisi in una coda generica, si integra direttamente con il tuo stack di monitoraggio e osservabilità, indirizzando immediatamente i problemi alle persone giuste in base a programmi, regole e contesto.
Le integrazioni mobili e chat rendono facile riconoscere, reindirizzare o risolvere gli incidenti da qualsiasi luogo. E dietro le quinte, Splunk On-Call conserva una registrazione dettagliata delle tendenze, dei modelli comprovati e del comportamento di escalation.
Le migliori funzionalità/funzioni di Splunk On-Call
- Espandi le funzionalità della piattaforma utilizzando oltre 1.000 integrazioni e componenti aggiuntivi verificati da Splunk e dalla comunità più ampia.
- Crea dashboard personalizzate e report visivi per monitorare il volume degli avvisi, lo stato degli incidenti, le prestazioni dei responsabili della risposta e il carico di lavoro del team.
- Filtra rapidamente gli incidenti in base alla tua attività, agli incidenti del team o a tutto ciò che accade all'interno dell'organizzazione.
- Passa tra le visualizzazioni Attivato, Riconosciuto e Risolto per vedere lo stato di ciascun incidente.
Limiti di Splunk On-Call
- La pianificazione dei turni tra più team può diventare complicata se le regole non sono predefinite.
- Capacità limitata di generare report dettagliati sugli incidenti con riferimento alle date
Prezzi Splunk On-Call
- Prezzi personalizzati
Valutazioni e recensioni di Splunk On-Call
- G2: 4,6/5 (oltre 40 recensioni)
- Capterra: 4,5/5 (oltre 30 recensioni)
Cosa dicono gli utenti reali di Splunk On-Call?
Un utente lo ha riassunto così:
La possibilità di gestire gli incidenti, gli escalation e sostituire i miei colleghi dall'app mobile è fantastica. […] Mi piacerebbe poter programmare le sostituzioni e modificare la programmazione regolare dall'app mobile per i cambiamenti di programma di emergenza.
La possibilità di gestire gli incidenti, gli escalation e sostituire i miei colleghi dall'app mobile è fantastica. […] Mi piacerebbe poter programmare le sostituzioni e modificare la programmazione regolare dall'app mobile per i cambiamenti di programma di emergenza.
🔍 Lo sapevate? La logica del "reindirizzamento alla persona giusta in caso di fallimento del primo livello" affonda le sue radici nelle prime centrali telefoniche: quando gli operatori manuali non riuscivano a effettuare una connessione per una chiamata, il sistema la reindirizzava (o la inoltrava) a un altro operatore o centrale.
5. ServiceNow (ideale per l'orchestrazione su scala aziendale con automazione assistita dall'IA)
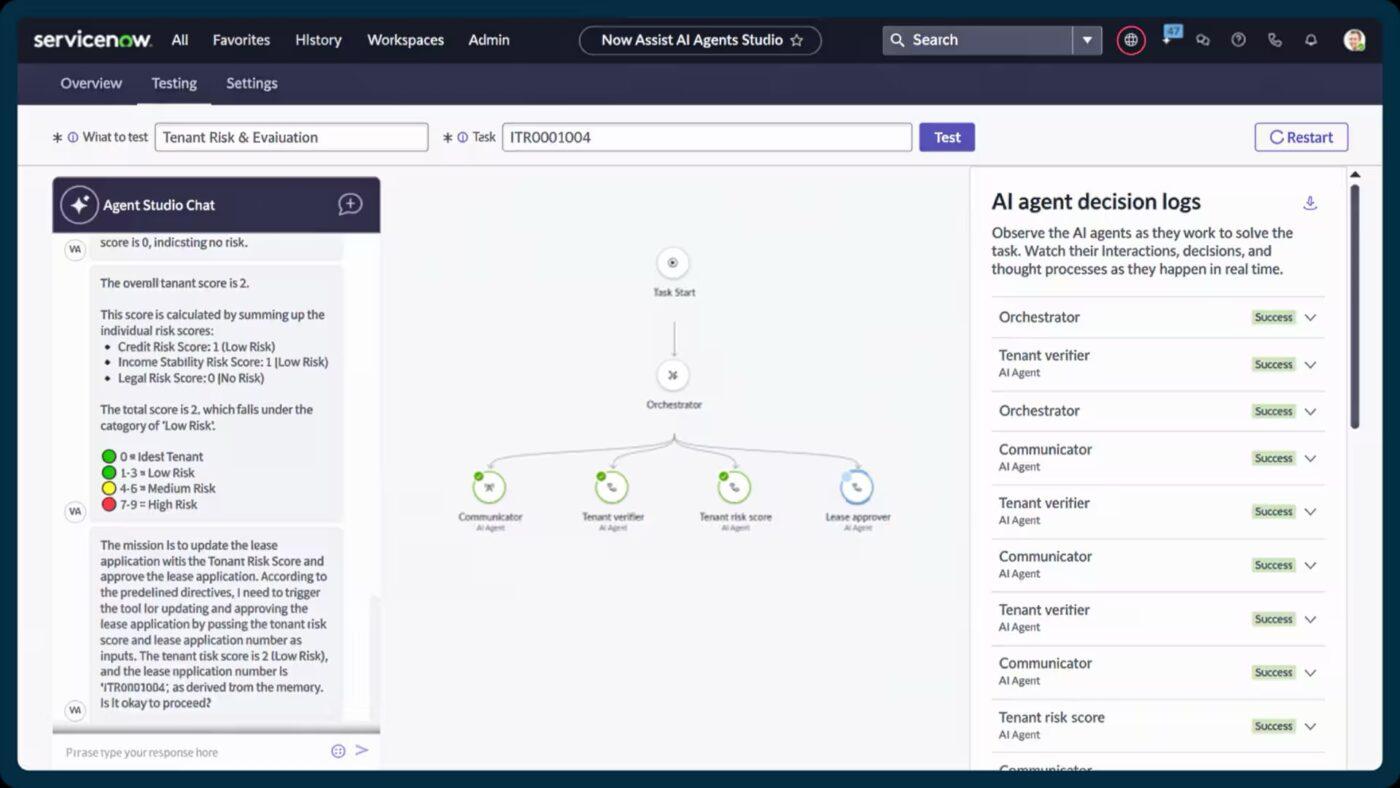
ServiceNow classifica, assegna priorità e indirizza automaticamente gli incidenti nel momento stesso in cui vengono registrati. Grazie a funzionalità come Now Assist per i consigli automatizzati sui ticket di incidente e la generazione intelligente di contenuti, gli addetti all'assistenza possono risolvere i problemi più rapidamente e con un maggiore contesto.
Questo approccio riunisce la gestione degli incidenti, dei cambiamenti e delle risorse. In questo modo, è possibile visualizzare in tempo reale come i servizi sono collegati, dove si verificano i colli di bottiglia e quali componenti potrebbero contribuire a interruzioni ricorrenti.
Le migliori funzionalità/funzioni di ServiceNow
- Assegna, instrada e monitora le attività sul campo tramite Field Service Management e Dispatcher Workspace.
- Offri a dipendenti e clienti un portale self-service basato su IA Search e agenti virtuali.
- Utilizza i flussi di lavoro integrati e gli strumenti low-code in App Engine per estendere o personalizzare i processi di servizio.
- Automatizza le attività ripetitive e i flussi di lavoro tra i team con Flow Designer e Automation Engine.
Limiti di ServiceNow
- L'interfaccia utente e le opzioni di personalizzazione del portale sembrano obsolete o limitative.
- Elevata dipendenza da personale qualificato o consulenti per l'implementazione
Prezzi ServiceNow
- Prezzi personalizzati
Valutazioni e recensioni di ServiceNow
- G2: 4,4/5 (oltre 3.300 recensioni)
- Capterra: 4,5/5 (oltre 300 recensioni)
Cosa dicono gli utenti reali di ServiceNow?
Ecco come lo ha descritto un utente:
[…] I flussi predefiniti sono un altro punto di forza per me, poiché semplificano i processi e consentono di risparmiare molto tempo, riducendo al minimo la necessità di configurazioni personalizzate e consentendo un flusso di lavoro più fluido ed efficiente. […] Inoltre, ho avuto difficoltà a integrare la mia soluzione personalizzata nel sistema di gestione del servizio clienti, che ha richiesto numerose iterazioni.
[…] I flussi predefiniti sono un altro punto di forza per me, poiché semplificano i processi e consentono di risparmiare molto tempo, riducendo al minimo la necessità di configurazioni personalizzate e consentendo un flusso di lavoro più fluido ed efficiente. […] Inoltre, ho avuto difficoltà a integrare la mia soluzione personalizzata nel sistema di gestione del servizio clienti, che ha richiesto numerose iterazioni.
Best practice e governance
Ecco alcune best practice che garantiscono l'accuratezza dell'automazione, evitano l'affaticamento da alert e si allineano alle aspettative aziendali e normative.
- Definisci criteri di escalation non negoziabili: collega i trigger a segnali misurabili come violazioni degli SLO, picchi anomali, impatto sul livello dei clienti o sensibilità normativa.
- Definisci chiaramente i ruoli a ogni livello: utilizza una semplice mappa RACI per ogni livello di escalation, in modo che le responsabilità non siano mai ambigue durante gli incidenti ad alta pressione.
- Applica una governance dinamica dei turni di reperibilità: regola automaticamente i percorsi di escalation in base a weekend, festività, limiti di capacità e passaggi di consegne per ridurre il burnout e prevenire le pagine silenziose.
- Inserisci dei controlli umani per gli scenari ad alto rischio: anche con l'automazione, richiedi la conferma manuale per gli incidenti che coinvolgono l'esposizione dei dati dei clienti, i pagamenti o i flussi di lavoro regolamentati.
- Mantieni tracce di audit complete: conserva registri immutabili di chi è stato avvisato, quando ha dato conferma, quali passaggi di automazione sono stati attivati e quali decisioni sono state prese.
🧠 Curiosità: la più antica lamentela scritta conosciuta al mondo è stata incisa su una tavoletta di argilla intorno al 1750 a.C. Si trattava fondamentalmente di una delle prime segnalazioni relative allo stato di un progetto. Un cliente di nome Nanni scrisse al mercante Ea-nāṣir, furioso perché il rame che aveva ricevuto era di qualità inferiore a quella promessa e perché il suo messaggero era stato maltrattato.
Sfide comuni e come superarle
Anche con una politica di escalation chiara, i team spesso devono affrontare ostacoli operativi che rallentano la risposta agli incidenti o creano confusione.
Questa tabella evidenzia le sfide comuni che vanno oltre i passaggi di configurazione di base e fornisce strategie concrete per superarle.
| Sfide ❌ | Soluzioni ✅ |
| Contesto incoerente durante i passaggi di consegne | Utilizza i modelli di collegamento delle attività e di segnalazione degli incidenti di ClickUp per mantenere una traccia completa dei dettagli degli incidenti, dei sistemi interessati e delle azioni precedenti a ogni livello di escalation. |
| Sovraccaricare i responsabili della risposta con avvisi di bassa priorità | Implementa una prioritizzazione dinamica con i campi personalizzati di ClickUp e AI Prioritize per filtrare gli incidenti in base alla gravità, all'impatto e alle soglie SLA. |
| Mancanza di visibilità tra i team | Configura aree di lavoro condivise, aggiungi commenti e crea lavagne online ClickUp per presentare aggiornamenti in tempo reale alle parti interessate. |
| Ritardi nel processo decisionale durante incidenti critici | Automatizza le notifiche utilizzando le Azioni suggerite di ClickUp Brain Max per avvisare immediatamente il personale competente in base al tipo di incidente, alla gravità e ai modelli storici. |
| Difficoltà nel monitoraggio dei problemi ricorrenti | Sfrutta i modelli di reportistica personalizzati e le attività ricorrenti di ClickUp per identificare modelli, cause alla radice e incidenti ricorrenti per una prevenzione proattiva. |
| Conoscenze frammentate durante l'escalation | Mantieni le procedure operative standard, i runbook e la documentazione degli incidenti centralizzati in ClickUp Docs, collegandoli alle attività pertinenti per un riferimento immediato durante gli escalation in tempo reale. |
| Responsabilità non allineate tra i turni | Utilizza la vista Carico di lavoro e la vista Sequenza di ClickUp per visualizzare gli incarichi e assicurarti che non vi siano sovrapposizioni o lacune durante i cambi di turno o i passaggi di consegne. |
| Monitoraggio manuale della conformità e lacune di audit | Automatizza i riepiloghi pronti per la revisione con ClickUp Brain per registrare tutte le azioni, le notifiche e le risoluzioni relative agli incidenti. |
Misurare l'impatto dell'escalation automatizzata
Il monitoraggio dell'efficacia dell'escalation automatizzata richiede la concentrazione su metriche chiave relative a volume, efficienza e qualità. Questi indicatori rivelano se i processi di escalation sono più rapidi, più accurati e meno frustranti sia per i team che per i clienti.
Tieni traccia di queste metriche:
- Tasso di escalation (volume): percentuale di problemi escalati oltre il primo livello. Tassi elevati possono indicare lacune nella valutazione iniziale o nelle basi di conoscenza.
- Tasso di escalation ripetuta (volume): frequenza con cui lo stesso problema viene escalato più volte. Indica risoluzioni incomplete o perdita di contesto.
- Tempo di escalation (efficienza): durata dal rilevamento all'escalation. Una durata più breve delle fasi indica un riconoscimento automatico più rapido dei problemi critici.
- Tempo di ritardo nel passaggio di consegne (efficienza): intervallo tra l'escalation e il momento in cui il team successivo inizia a svolgere il lavoro per evidenziare attriti nell'instradamento o nella notifica.
- Tempo di risoluzione dei casi escalati (efficienza): tempo totale dall'escalation alla risoluzione. Una risoluzione più rapida dimostra l'efficacia delle automazioni.
- Punteggio di soddisfazione del cliente (CSAT) (qualità): feedback sulle interazioni escalate per misurare la fluidità del percorso.
- Passaggio del contesto (qualità): gli agenti ricevono la cronologia completa dell'incidente per garantire che i clienti non ripetano le informazioni.
- Risoluzione al primo contatto (FCR) (qualità): percentuale di problemi risolti in un'unica interazione.
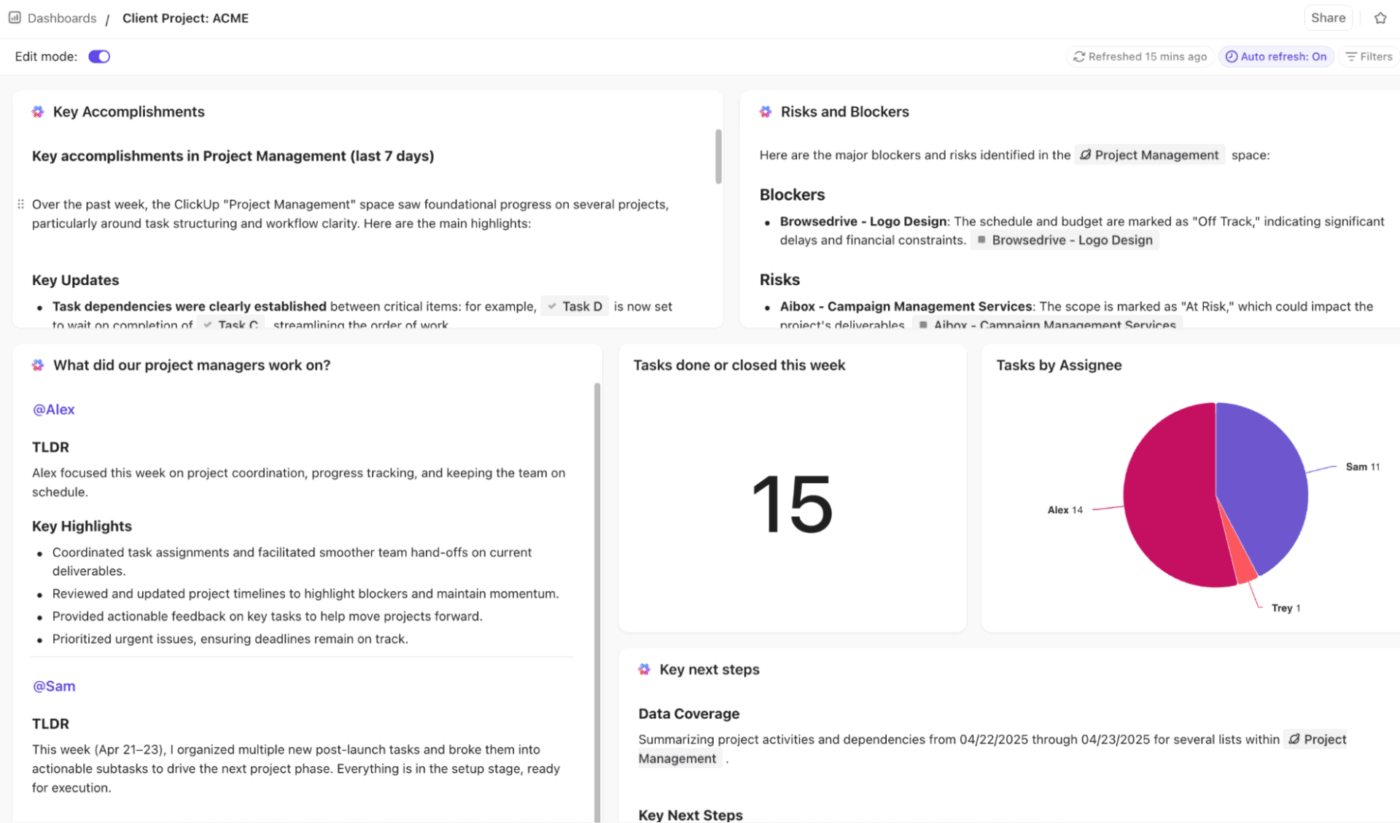
🚀 Vantaggio di ClickUp: ottieni informazioni in tempo reale, visive e basate sull'IA su tutte le metriche di escalation con i dashboard di ClickUp.
Puoi monitorare le tendenze di escalation, i colli di bottiglia e le prestazioni con le schede Tabella, Torta, Barra, Linea, Calcolo e Reportistica temporale. Monitora il tasso di escalation, l'escalation ripetuta e il tempo di escalation con schede collegate anche ad attività, campi personalizzati e stati.
Per andare oltre, utilizza le schede IA come IA Riassunto del progetto, IA Aggiornamento del progetto e IA StandUp per evidenziare tendenze, ritardi e risultati delle risoluzioni.
Gestisci i tuoi incidenti più rapidamente con ClickUp
Molti pensano che l'escalation degli incidenti consista semplicemente nel passare un ticket alla persona successiva, ma è molto più di questo. Si tratta di un sistema strutturato in cui ogni passaggio, dalla valutazione alla risoluzione, funziona in modo armonioso.
ClickUp ti offre uno spazio di lavoro unificato perfetto. Con ClickUp Automazioni, puoi trigger avvisi, instradare attività e aggiornare automaticamente gli stati. Inoltre, ClickUp Brain aiuta a dare priorità agli incidenti, generare riepiloghi/riassunti e suggerire i passaggi successivi.
Gli agenti AI di ClickUp agiscono come assistenti intelligenti all'interno della tua area di lavoro, mentre i dashboard di ClickUp forniscono una visione in tempo reale dei tuoi escalation.
Iscriviti gratis a ClickUp oggi stesso!
Domande frequenti (FAQ)
Un percorso di escalation degli incidenti è una sequenza predefinita di passaggi che determina come i problemi vengono indirizzati al team o alla persona giusta in base alla gravità, all'impatto e alla tempistica. Assicura che gli incidenti vengano affrontati in modo efficiente e che la responsabilità sia chiara. TESTO
Utilizza l'automazione per incidenti ben definiti e ad alta priorità con criteri chiari (ad esempio, interruzioni del servizio, violazioni della sicurezza). Riserva l'escalation manuale a situazioni ambigue o critiche che richiedono il giudizio umano o un contesto aggiuntivo.
Piattaforme come ClickUp, PagerDuty, Jira Service Management e ServiceNow consentono l'instradamento automatico, le notifiche e gli aggiornamenti. Aiutano i team a ridurre i ritardi e a mantenere flussi di lavoro strutturati per gli incidenti.
Imposta soglie chiare per gli avvisi, assegna priorità in base alla gravità e utilizza notifiche intelligenti. Limita le notifiche ripetute agli incidenti critici e sfrutta i dashboard o gli strumenti di IA per riepilogare gli aggiornamenti invece di inviare ogni piccola modifica.
Rivedi regolarmente le politiche di escalation almeno una volta al trimestre o dopo incidenti gravi. In questo modo ti assicurerai che i criteri, le responsabilità e le regole di automazione riflettano i flussi di lavoro, le strutture del team e le priorità aziendali attuali.