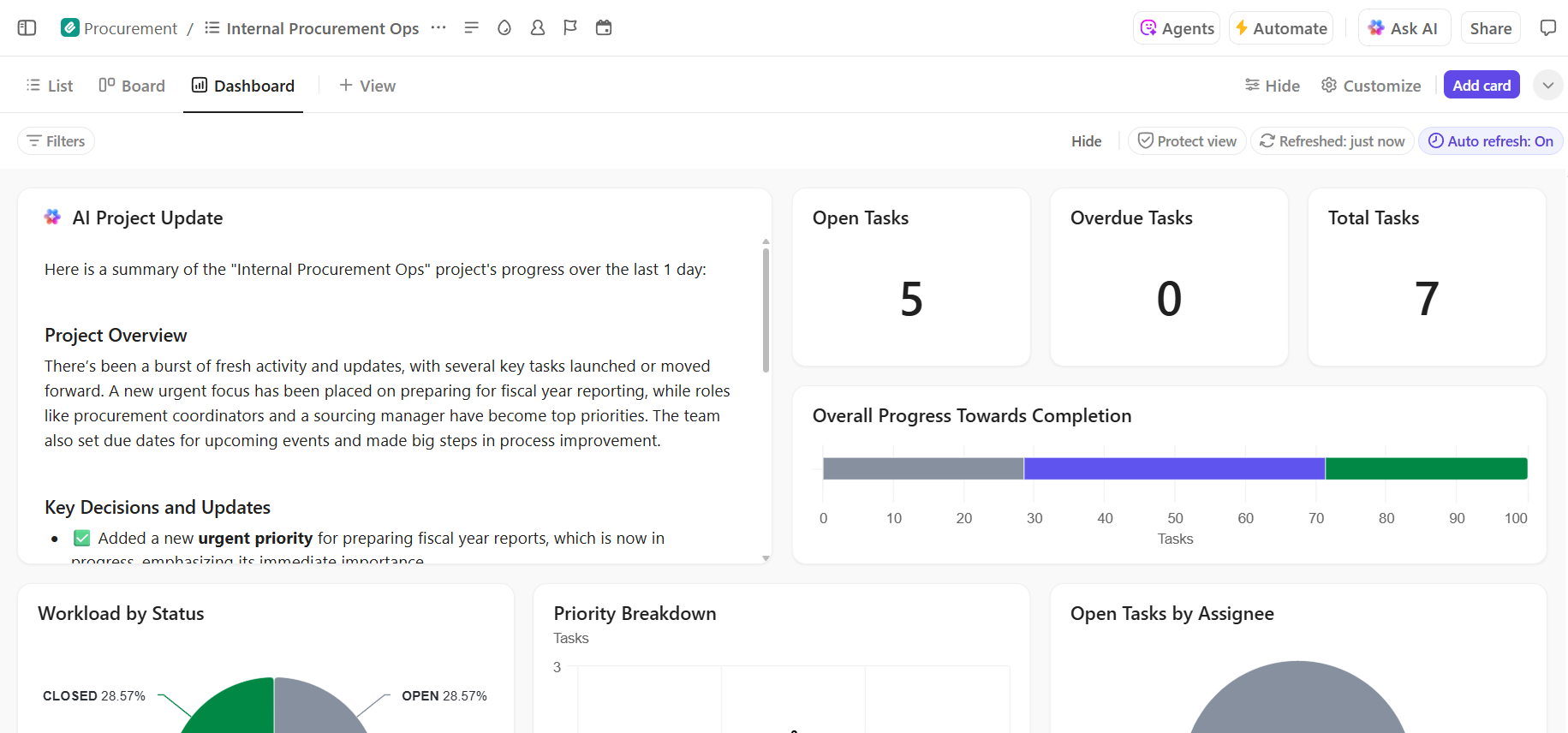

Większość projektów wdrożeniowych AI kończy się niepowodzeniem nie dlatego, że zespoły wybrały niewłaściwy model, ale dlatego, że trzy miesiące później nikt nie pamięta, dlaczego go wybrano ani jak powtórzyć ustawienia. 46% projektów AI jest porzucanych między fazą weryfikacji koncepcji a szerokim wdrożeniem.
Ten przewodnik przeprowadzi Cię przez proces wdrażania AI za pomocą Hugging Face — od wyboru i testowania modeli po zarządzanie procesem wdrażania — dzięki czemu Twój zespół będzie mógł szybciej dostarczać rozwiązania bez utraty kluczowych decyzji w wątkach Slacka i rozproszonych arkuszach kalkulacyjnych.
Czym jest Hugging Face?
Hugging Face to platforma open source i hub społecznościowy, który zapewnia wstępnie wyszkolone modele AI, zbiory danych i narzędzia do tworzenia i wdrażania aplikacji uczenia maszynowego.
Pomyśl o tym jak o ogromnej bibliotece cyfrowej, w której możesz znaleźć gotowe do użycia modele AI, zamiast poświęcać miesiące i znaczne zasoby na tworzenie ich od podstaw.
Jest przeznaczony dla inżynierów zajmujących się uczeniem maszynowym i naukowców zajmujących się danymi, ale jego narzędzia są coraz częściej wykorzystywane przez wielofunkcyjne zespoły produktowe, projektowe i inżynieryjne do integracji sztucznej inteligencji z ich cyklami pracy.
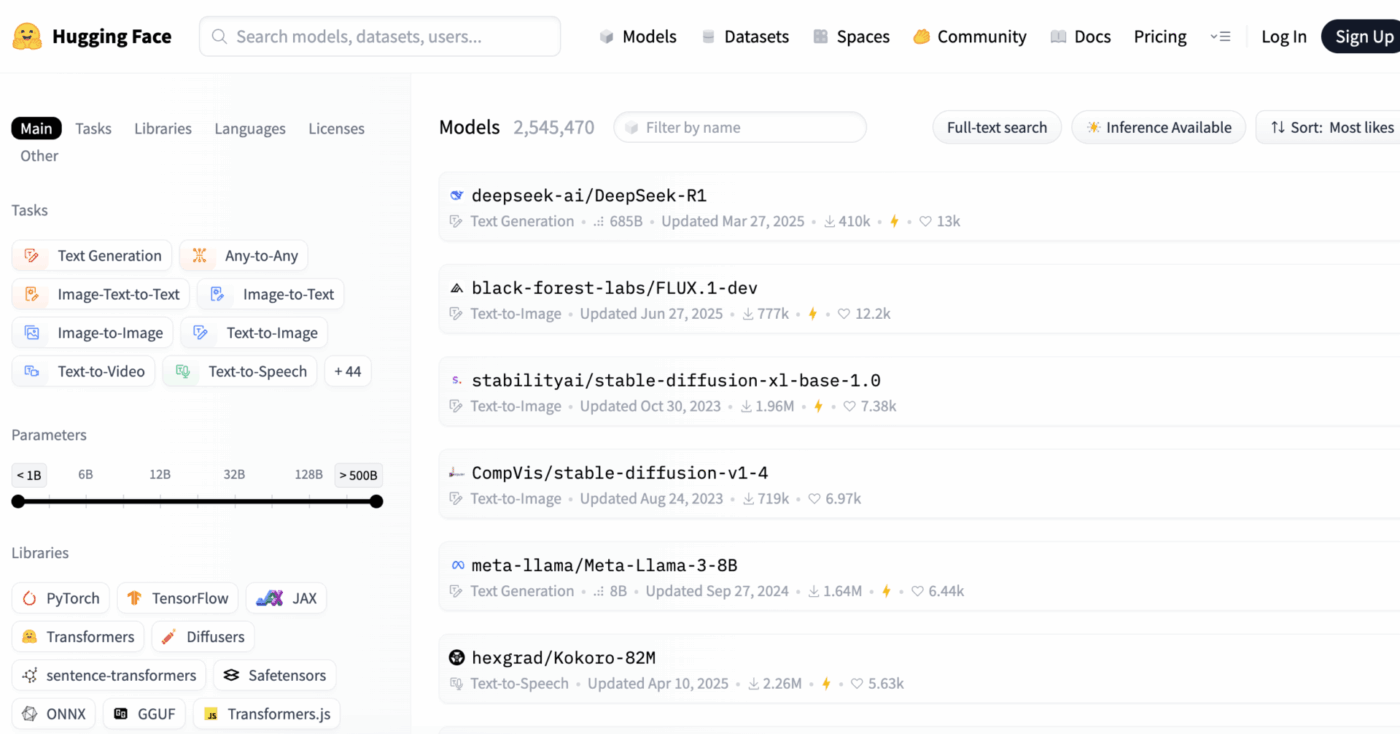
Czy wiesz, że: 63% organizacji nie posiada odpowiednich praktyk zarządzania danymi dla AI. Często prowadzi to do zastoju projektów i marnowania zasobów.
Głównym wyzwaniem dla wielu zespołów jest ogromna złożoność wdrażania AI. Proces ten obejmuje wybór odpowiedniego modelu spośród tysięcy opcji, zarządzanie infrastrukturą bazową, wersjonowanie eksperymentów oraz zapewnienie spójności działań interesariuszy technicznych i nietechnicznych.
Hugging Face upraszcza ten proces, udostępniając Model Hub, centralne repozytorium zawierające ponad 2 miliony modeli. Biblioteka transformatorów platformy jest kluczem do odblokowania tych modeli, umożliwiając ich ładowanie i używanie za pomocą zaledwie kilku linii kodu Python.
Jednak nawet przy użyciu tych potężnych narzędzi wdrażanie sztucznej inteligencji pozostaje wyzwaniem dla zarządzania projektami, wymagającym starannego śledzenia wyboru modelu, testowania i wdrażania, aby zapewnić powodzenie.
📮ClickUp Insight: 92% pracowników wiedzy ryzykuje utratę ważnych decyzji rozproszonych w czatach, wiadomościach e-mail i arkuszach kalkulacyjnych. Bez ujednoliconego systemu rejestrowania i śledzenia decyzji kluczowe informacje biznesowe giną w cyfrowym szumie.
Dzięki funkcjom zarządzania zadaniami ClickUp nie musisz się już tym martwić. Twórz zadania z czatu, komentarzy do zadań, dokumentów i e-maili za pomocą jednego kliknięcia!
📚 Przeczytaj również: Najlepsze alternatywy dla Hugging Face dla LLM, NLP i cykli pracy AI
Modele Hugging Face, które możesz wdrożyć
Poruszanie się po Hugging Face Hub może wydawać się przytłaczające, gdy zaczynasz. Przy setkach tysięcy modeli kluczem do sukcesu jest zrozumienie głównych kategorii, aby znaleźć model odpowiedni dla Twojego projektu. Modele obejmują zarówno małe, wydajne opcje zaprojektowane do jednego celu, jak i ogromne modele ogólnego przeznaczenia, które mogą obsługiwać złożone procesy rozumowania.
Modele językowe dostosowane do konkretnych zadań
Kiedy Twój zespół musi rozwiązać jeden, dobrze zdefiniowany problem, często nie potrzebujesz ogromnego modelu ogólnego przeznaczenia. Czas i koszt uruchomienia takiego modelu mogą być zbyt wysokie, zwłaszcza gdy lepiej sprawdzi się mniejsze, bardziej ukierunkowane narzędzie AI. W tym miejscu pojawiają się modele przeznaczone do konkretnych zadań.
Są to modele, które zostały przeszkolone i zoptymalizowane pod kątem jednej konkretnej funkcji. Ponieważ są one wyspecjalizowane, zazwyczaj są mniejsze, szybsze i bardziej wydajne pod względem zasobów niż ich większe odpowiedniki.
Dzięki temu idealnie nadają się do środowisk produkcyjnych, w których szybkość i koszt są ważnymi czynnikami. Wiele z nich może nawet działać na standardowym sprzęcie CPU, dzięki czemu są dostępne bez konieczności stosowania drogich procesorów graficznych.
Typowe modele przeznaczone do konkretnych zadań obejmują:
- Klasyfikacja tekstu: użyj tej funkcji, aby podzielić tekst na wcześniej zdefiniowane etykiety, np. sortując opinie klientów na „pozytywne” lub „negatywne” lub oznaczając zgłoszenia do wsparcia technicznego według tematu.
- Analiza nastrojów: pomaga określić emocjonalny ton tekstu, co jest przydatne do monitorowania marki w mediach społecznościowych.
- Rozpoznawanie nazwanych podmiotów: Wyodrębniaj konkretne podmioty, takie jak osoby, miejsca i organizacje, z dokumentów, aby pomóc w uporządkowaniu danych nieustrukturyzowanych.
- Podsumowanie: Skondensuj długie artykuły lub raporty w zwięzłe streszczenia, oszczędzając zespołowi cenny czas poświęcany na czytanie.
- Tłumaczenie: Automatyczne przekształcanie tekstu z jednego języka na inny.
📚 Przeczytaj również: Jak korzystać z Hugging Face do tworzenia streszczeń tekstów
Duże modele językowe
Czasami projekt wymaga czegoś więcej niż tylko prostej klasyfikacji lub podsumowania. Być może potrzebujesz AI, która potrafi generować kreatywne teksty marketingowe, pisać kod lub odpowiadać na złożone pytania użytkowników w formie rozmowy. W takich przypadkach prawdopodobnie sięgniesz po duży model językowy (LLM).
LLM to modele z miliardami parametrów, które zostały wytrenowane na ogromnych ilościach tekstów i danych z internetu. Takie intensywne szkolenie pozwala im rozumieć niuanse, kontekst i złożone rozumowanie. Popularne modele LLM typu open source dostępne w Hugging Face to między innymi modele z rodzin Llama, Mistral i Falcon.
Kompromisem za tę moc są znaczne zasoby obliczeniowe, których wymagają. Wdrożenie tych modeli prawie zawsze wymaga wydajnych procesorów graficznych z dużą ilością pamięci (VRAM).
Aby uczynić je bardziej dostępnymi, można zastosować techniki takie jak kwantyzacja, która zmniejsza rozmiar modelu przy niewielkim spadku wydajności, umożliwiając jego uruchomienie na mniej wydajnym sprzęcie.
📚 Przeczytaj również: Czym są agenci LLM w AI i jak działają?
Modele text-obraz i modele multimodalne
Twoje dane nie zawsze mają formę tekstową. Twój zespół może potrzebować wygenerować obrazy do kampanii marketingowej, transkrybować nagrania audio ze spotkań lub zrozumieć zawartość filmów wideo. W takich sytuacjach niezbędne stają się modele multimodalne, które są zaprojektowane do pracy z różnymi typami danych.
Najpopularniejszym typem modelu multimodalnego jest model tekst-obraz, który generuje obrazy na podstawie opisu tekstowego. Modele takie jak Stable Diffusion wykorzystują technikę zwaną dyfuzją do tworzenia oszałamiających obrazów na podstawie prostych podpowiedzi. Jednak możliwości wykraczają daleko poza generowanie obrazów.
Inne popularne modele multimodalne, które można wdrożyć za pomocą Hugging Face, to między innymi:
- Opis obrazu: Automatycznie generuj opisowy tekst do obrazów, co jest doskonałym rozwiązaniem w zakresie dostępności i zarządzania zawartością.
- Rozpoznawanie mowy: transkrybuj dźwięk na tekst pisany za pomocą modeli takich jak Whisper firmy OpenAI.
- Wizualne odpowiadanie na pytania: zadaj pytania dotyczące obrazu i uzyskaj odpowiedź w formie tekstowej, np. „Jakiego koloru jest samochód na tym zdjęciu?”.
Podobnie jak modele LLM, modele te są bardzo wymagające obliczeniowo i zazwyczaj wymagają procesora graficznego (GPU) do wydajnego działania.
📚 Przeczytaj również: Ponad 50 podpowiedzi dotyczących obrazów AI, które pozwolą Ci tworzyć oszałamiające wizualizacje
Aby zobaczyć, jak różne typy modeli AI przekładają się na praktyczne zastosowania biznesowe, obejrzyj ten przegląd rzeczywistych przypadków użycia AI w różnych branżach i funkcjach.
Jaki jest poziom dojrzałości AI w Twojej organizacji?
Nasze badanie przeprowadzone wśród 316 profesjonalistów pokazuje, że prawdziwa transformacja AI wymaga czegoś więcej niż tylko wdrożenia funkcji AI. Wypełnij ankietę dotyczącą dojrzałości AI, aby sprawdzić, na jakim etapie znajduje się Twoja organizacja i co możesz zrobić, aby poprawić swój wynik.
Jak skonfigurować Hugging Face do wdrażania AI
Zanim wdrożysz swój pierwszy model, musisz poprawnie skonfigurować swoje lokalne środowisko i konto Hugging Face. Częstym źródłem frustracji dla zespołów jest to, że różni członkowie mają niespójne ustawienia, co prowadzi do klasycznego problemu „na moim komputerze to działa”. Poświęcenie kilku minut na standaryzację tego procesu pozwala zaoszczędzić wiele godzin późniejszego rozwiązywania problemów.
- Utwórz konto Hugging Face i wygeneruj token dostępu. Najpierw zarejestruj się, aby uzyskać bezpłatne konto na stronie internetowej Hugging Face. Po zalogowaniu się przejdź do swojego profilu, kliknij „Ustawienia”, a następnie przejdź do zakładki „Tokeny dostępu”. Wygeneruj nowy token z co najmniej uprawnieniami „odczytu”; będzie on potrzebny do pobrania modeli.
- Zainstaluj wymagane biblioteki Python. Otwórz terminal i zainstaluj niezbędne biblioteki. Dwie najważniejsze to transformers i huggingface_hub. Możesz je zainstalować za pomocą pip: pip install transformers huggingface_hub
- Skonfiguruj uwierzytelnianie. Aby użyć tokenu dostępu, możesz zalogować się za pomocą wiersza poleceń, uruchamiając huggingface-cli login i wklejając token po wyświetleniu podpowiedzi, lub ustawić go jako zmienną środowiskową w systemie. Logowanie za pomocą wiersza poleceń jest często najłatwiejszym sposobem na rozpoczęcie pracy.
- Sprawdź ustawienia. Najlepszym sposobem na potwierdzenie, że wszystko działa, jest uruchomienie prostego fragmentu kodu. Spróbuj załadować podstawowy model za pomocą funkcji pipeline z biblioteki transformers. Jeśli działa bez błędów, jesteś gotowy do działania.
Pamiętaj, że niektóre modele w hubie są „ograniczone”, co oznacza, że musisz zaakceptować warunki licencji na stronie modelu, zanim będziesz mógł uzyskać do nich dostęp za pomocą swojego tokenu.
Pamiętaj również, że śledzenie, kto posiada jakie uprawnienia i jakie konfiguracje środowiska są używane, jest samo w sobie zadaniem zarządzania projektami i staje się coraz ważniejsze wraz z rozwojem zespołu.
🌟 Jeśli integrujesz modele Hugging Face z szerszymi systemami oprogramowania, szablon integracji oprogramowania ClickUp pomoże Ci zwizualizować cykle pracy i przeprowadzić śledzenie wieloetapowych integracji technicznych.
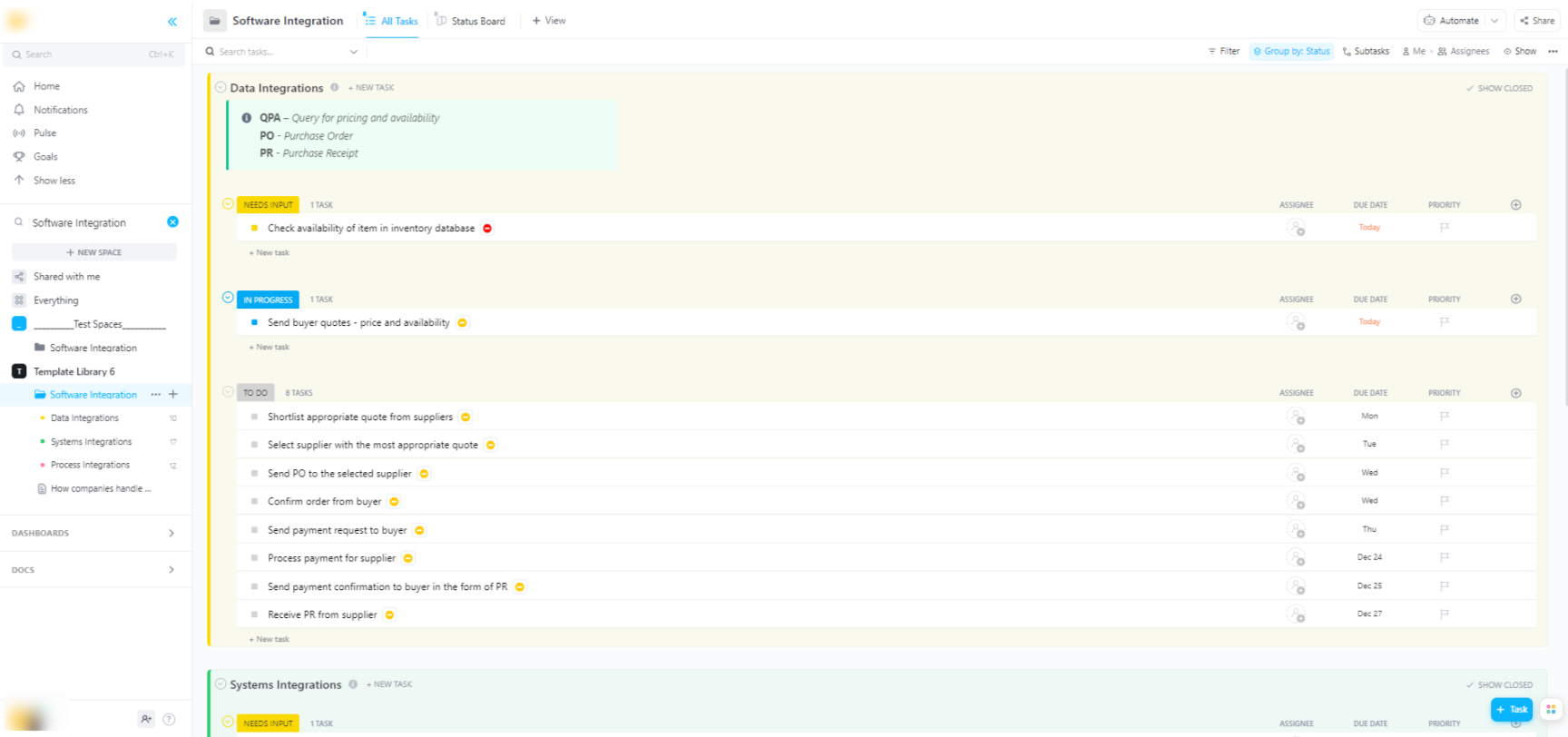
Szablon zapewnia łatwy w obsłudze system, w którym możesz:
- Wizualizuj połączenia między różnymi rozwiązaniami programowymi.
- Twórz zadania i przydzielaj je członkom zespołu, aby usprawnić współpracę.
- Zorganizuj wszystkie zadania związane z integracją w jednym miejscu.
Opcje wdrażania modeli Hugging Face
Po przetestowaniu modelu lokalnie pojawia się kolejne pytanie: gdzie będzie on działał? Wdrożenie modelu w środowisku produkcyjnym, gdzie może być używany przez innych, jest kluczowym krokiem, ale dostępne opcje mogą być mylące. Wybór niewłaściwej ścieżki może prowadzić do spowolnienia działania, wysokich kosztów lub niemożności obsługi ruchu użytkowników.
Twój wybór będzie zależał od konkretnych potrzeb, takich jak przewidywany ruch, budżet oraz to, czy tworzysz szybki prototyp, czy skalowalną aplikację gotową do produkcji.
Hugging Face Przestrzenie
Jeśli potrzebujesz szybko stworzyć wersję demonstracyjną lub narzędzie wewnętrzne, Hugging Face Spaces jest często najlepszym wyborem. Spaces to bezpłatna platforma do hostowania aplikacji uczenia maszynowego, idealna do tworzenia prototypów, które można udostępniać zespołowi lub interesariuszom.
Możesz zbudować interfejs użytkownika swojej aplikacji przy użyciu popularnych frameworków, takich jak Gradio lub Streamlit, które ułatwiają tworzenie interaktywnych wersji demonstracyjnych za pomocą zaledwie kilku linii kodu w języku Python.
Utworzenie przestrzeni jest tak proste, jak wybranie preferowanego zestawu SDK, połączenie repozytorium Git z kodem i wybór sprzętu. Chociaż przestrzenie oferują bezpłatny poziom CPU dla podstawowych aplikacji, można przejść na płatny sprzęt GPU dla bardziej wymagających modeli.
Pamiętaj o limitach:
- Nie nadaje się do API o dużym natężeniu ruchu: Przestrzeń jest przeznaczona do celów demonstracyjnych, a nie do obsługi tysięcy jednoczesnych żądań API.
- Zimny start: Jeśli Twoja przestrzeń jest nieaktywna, może „przejść w stan uśpienia”, aby oszczędzać zasoby, co spowoduje opóźnienie dla pierwszego użytkownika, który ponownie uzyska do niej dostęp.
- Cykl pracy oparty na Git: Cały kod aplikacji jest zarządzany za pomocą repozytorium Git, co doskonale sprawdza się w przypadku kontroli wersji.
Hugging Face Inference API
Jeśli chcesz zintegrować model z istniejącą aplikacją, prawdopodobnie będziesz chciał skorzystać z interfejsu API. Interfejs API Hugging Face Inference pozwala uruchamiać modele bez konieczności samodzielnego zarządzania infrastrukturą bazową. Wystarczy wysłać żądanie HTTP z danymi, aby otrzymać prognozę.
To podejście jest idealne, gdy nie chcesz zajmować się serwerami, skalowaniem czy konserwacją. Hugging Face oferuje dwa główne poziomy tej usługi:
- Bezpłatny interfejs API wnioskowania: jest to opcja infrastruktury współdzielonej z ograniczeniem szybkości, która doskonale nadaje się do rozwoju i testowania. Jest idealna do zastosowań o małym natężeniu ruchu lub gdy dopiero zaczynasz.
- Punkty końcowe wnioskowania: W przypadku aplikacji produkcyjnych warto korzystać z punktów końcowych wnioskowania. Jest to płatna usługa, która zapewnia dedykowaną infrastrukturę z automatycznym skalowaniem, gwarantując szybkie i niezawodne działanie aplikacji nawet przy dużym obciążeniu.
Korzystanie z API polega na wysłaniu ładunku JSON do adresu URL punktu końcowego modelu wraz z tokenem uwierzytelniającym w nagłówku żądania.
Wdrażanie platformy w chmurze
Dla zespołów, które mają już znaczącą obecność u dużych dostawców usług w chmurze, takich jak Amazon Web Services (AWS), Google Cloud Platform (GCP) lub Microsoft Azure, wdrożenie w tych usługach może być najbardziej logicznym wyborem. Takie podejście zapewnia największą kontrolę i umożliwia integrację modelu z istniejącymi usługami w chmurze i protokołami bezpieczeństwa.
Ogólny cykl pracy obejmuje „konteneryzację” modelu i jego zależności za pomocą Docker, a następnie wdrożenie tego kontenera w usłudze obliczeniowej w chmurze. Każdy dostawca usług w chmurze oferuje usługi i integracje, które upraszczają ten proces:
- AWS SageMaker: oferuje natywną integrację do szkolenia i wdrażania modeli Hugging Face.
- Google Cloud Vertex AI: umożliwia wdrażanie modeli z hub do zarządzanych punktów końcowych.
- Azure Machine Learning: zapewnia narzędzia do importowania i obsługi modeli Hugging Face.
Chociaż ta metoda wymaga większej wiedzy na temat ustawień i DevOps, często jest najlepszym rozwiązaniem w przypadku wdrożeń na dużą skalę, na poziomie Enterprise, gdzie potrzebna jest pełna kontrola nad środowiskiem.
📚 Przeczytaj również: Automatyzacja cyklu pracy: zautomatyzuj cykle pracy, aby zwiększyć wydajność
Jak uruchamiać modele Hugging Face do wnioskowania
Podczas korzystania z Hugging Face do wdrażania AI „uruchamianie wnioskowania” to proces wykorzystania przeszkolonego modelu do tworzenia prognoz dotyczących nowych, nieznanych danych. Jest to moment, w którym model wykonuje zadanie, do którego został wdrożony. Prawidłowe wykonanie tego kroku ma kluczowe znaczenie dla stworzenia responsywnej i wydajnej aplikacji.
Największą frustracją dla zespołów jest pisanie kodu wnioskowania, który jest powolny lub nieefektywny, co może prowadzić do złych doświadczeń użytkowników i wysokich kosztów operacyjnych. Na szczęście biblioteka transformatorów oferuje kilka sposobów uruchamiania wnioskowania, z których każdy ma swoje zalety i wady pod względem prostoty i kontroli.
- Pipeline API: Jest to najłatwiejszy i najczęściej stosowany sposób rozpoczęcia pracy. Funkcja pipeline() eliminuje większość złożoności, zajmując się wstępnym przetwarzaniem danych, przekazywaniem modeli i przetwarzaniem końcowym. W przypadku wielu standardowych zadań, takich jak analiza nastrojów, wystarczy jedna linijka kodu, aby uzyskać prognozę.
- AutoModel + AutoTokenizer: Jeśli potrzebujesz większej kontroli nad procesem wnioskowania, możesz bezpośrednio skorzystać z klas AutoModel i AutoTokenizer. Pozwala to ręcznie zarządzać tokenizacją tekstu oraz konwersją surowych wyników modelu na prognozy zrozumiałe dla człowieka. Takie podejście jest przydatne podczas pracy z niestandardowymi zadaniami lub konieczności wdrożenia określonej logiki przetwarzania wstępnego lub końcowego.
- Przetwarzanie wsadowe: Aby zmaksymalizować wydajność, zwłaszcza na procesorze graficznym, należy przetwarzać dane wejściowe partiami, a nie pojedynczo. Przesyłanie partii danych wejściowych przez model w jednym przejściu jest znacznie szybsze niż przesyłanie każdego z nich osobno.
Monitorowanie wydajności kodu wnioskowania jest kluczowym elementem cyklu życia wdrożenia. Śledzenie wskaźników, takich jak opóźnienie (czas potrzebny do wykonania prognozy) i przepustowość (liczba prognoz, które można wykonać w ciągu sekundy) wymaga koordynacji i przejrzystej dokumentacji, zwłaszcza gdy różni członkowie zespołu eksperymentują z nowymi wersjami modeli.
📚 Przeczytaj również: Najlepsze narzędzia do współpracy zespołów AI
Przykład krok po kroku: wdrożenie modelu Hugging Face
Przejdźmy przez zakończony przykład wdrożenia prostego modelu analizy nastrojów. Wykonanie tych kroków pozwoli Ci przejść od wyboru modelu do uzyskania działającego, testowalnego punktu końcowego.
- Wybierz model: przejdź do Hugging Face Hub i użyj filtrów po lewej stronie, aby wyszukać modele wykonujące „klasyfikację tekstu”. Dobrym punktem wyjścia jest distilbert-base-uncased-finetuned-sst-2-english. Przeczytaj kartę modelu, aby zrozumieć jego wydajność i sposób użytkowania.
- Zainstaluj zależności: Upewnij się, że w lokalnym środowisku Python masz zainstalowane niezbędne biblioteki. Do tego modelu potrzebujesz tylko transformers i torch. Uruchom pip install transformers torch
- Testuj lokalnie: przed wdrożeniem zawsze upewnij się, że model działa zgodnie z oczekiwaniami na Twoim komputerze. Napisz mały skrypt w języku Python, aby załadować model za pomocą potoku i przetestuj go na próbce zdania. Na przykład: classifier = pipeline("sentiment-analysis", model="distilbert-base-uncased-finetuned-sst-2-english"), a następnie classifier("ClickUp to najlepsza platforma zwiększająca wydajność!").
- Utwórz wdrożenie: w tym przykładzie użyjemy Hugging Face Spaces do szybkiego i łatwego wdrożenia. Utwórz nową przestrzeń, wybierz Gradio SDK i utwórz plik app.py, który ładuje Twój model i definiuje prosty interfejs Gradio do interakcji z nim.
- Sprawdź wdrożenie: Gdy Twoja przestrzeń już działa, możesz ją przetestować za pomocą interaktywnego interfejsu. Możesz też wysłać bezpośrednie żądanie API do punktu końcowego przestrzeni, żeby dostać odpowiedź JSON i sprawdzić, czy wszystko działa jak trzeba.
Po wykonaniu tych kroków otrzymasz model działający na żywo. Kolejny etap projektu obejmuje monitorowanie jego wykorzystania, planowanie aktualizacji i ewentualne skalowanie infrastruktury, jeśli model zyska popularność.
Dla zespołów zarządzających złożonymi projektami wdrażania sztucznej inteligencji, obejmującymi wiele etapów – od przygotowania danych po wdrożenie produkcyjne – zaawansowany szablon zarządzania projektami oprogramowania firmy ClickUp zapewnia kompleksową strukturę.
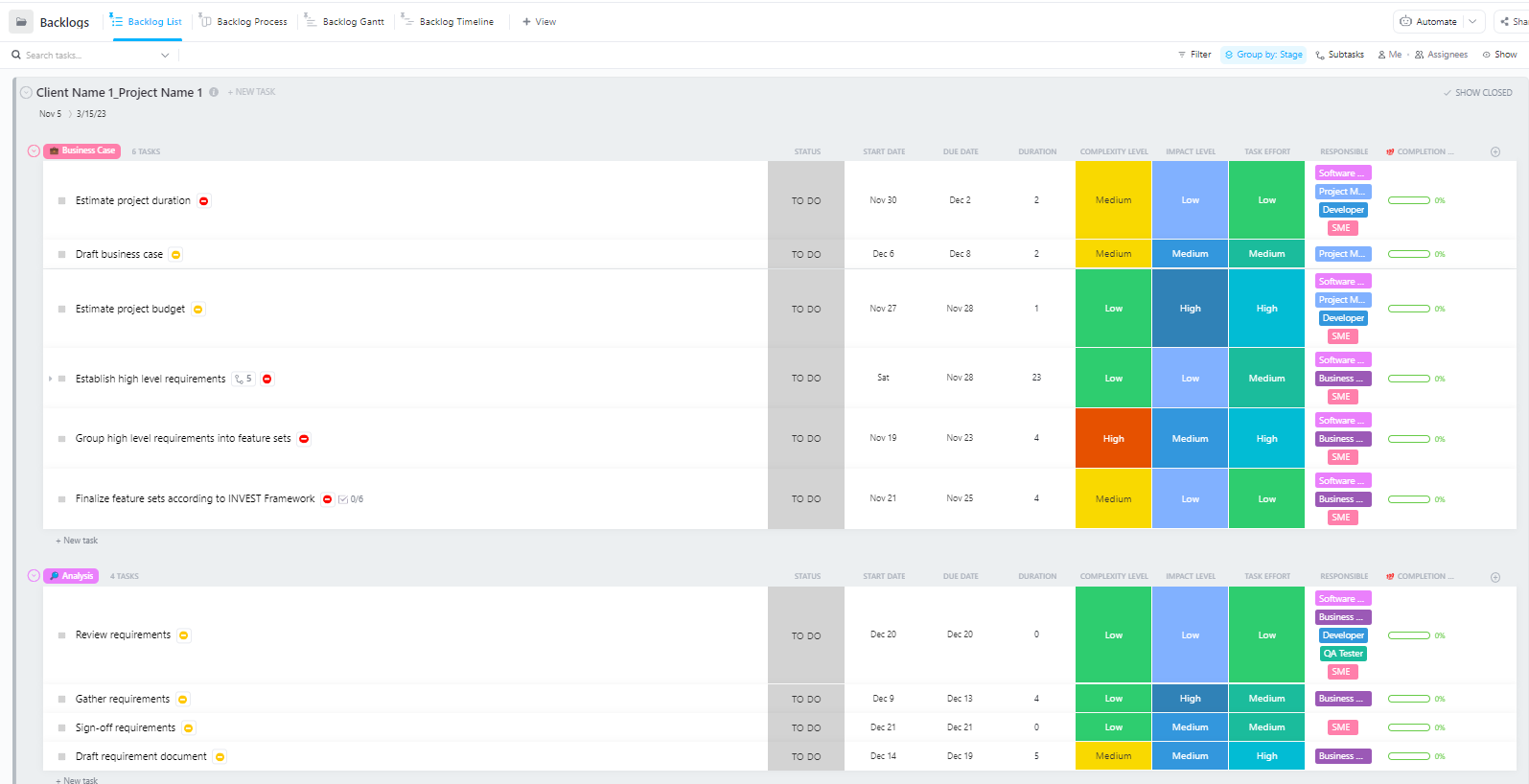
Ten szablon pomaga zespołom:
- Zarządzaj projektami z wieloma kamieniami milowymi, zadaniami, zasobami i zależnościami.
- Wizualizuj postępy projektu za pomocą wykresów Gantta i osi czasu.
- Płynnie współpracuj z członkami zespołu, aby zapewnić powodzenie w zakończeniu projektu.
Typowe wyzwania związane z wdrażaniem Hugging Face i sposoby ich rozwiązywania
Nawet mając jasny plan, podczas wdrażania prawdopodobnie napotkasz kilka przeszkód. Patrzenie na tajemniczy komunikat o błędzie może być niezwykle frustrujące i może zatrzymać postępy Twojego zespołu. Oto kilka najczęstszych wyzwań i sposoby ich rozwiązania. 🛠️
🚨Problem: „Model wymaga uwierzytelnienia”
- Przyczyna: Próbujesz uzyskać dostęp do modelu „ograniczonego”, który wymaga zaakceptowania warunków licencji.
- Rozwiązanie: Przejdź do strony modelu w hubie, przeczytaj i zaakceptuj umowę licencyjną. Upewnij się, że używany token dostępu ma uprawnienia „odczytu”.
🚨Problem: „Brak pamięci CUDA”
- Przyczyna: Model, który próbujesz załadować, jest zbyt duży dla pamięci GPU (VRAM).
- Rozwiązanie: Najszybszym rozwiązaniem jest użycie mniejszej wersji modelu lub wersji kwantyzowanej. Możesz również spróbować zmniejszyć rozmiar partii podczas wnioskowania.
🚨Problem: „błąd trust_remote_code”
- Przyczyna: Niektóre modele w hub wymagają niestandardowego kodu do działania, a ze względów bezpieczeństwa biblioteka nie wykonuje go domyślnie.
- Rozwiązanie: Możesz to obejść, dodając trust_remote_code=True podczas ładowania modelu. Jednak zawsze należy najpierw sprawdzić kod źródłowy, aby upewnić się, że jest bezpieczny.
🚨Problem: „Niezgodność tokenizatora”
- Przyczyna: Używany tokenizer nie jest dokładnie tym samym, na którym model został wytrenowany, co prowadzi do nieprawidłowych danych wejściowych i słabej wydajności.
- Rozwiązanie: Zawsze ładuj tokenizer z tego samego punktu kontrolnego modelu, co sam model. Na przykład AutoTokenizer. from_pretrained("nazwa modelu")
🚨Problem: „Przekroczono ograniczenie szybkości”
- Przyczyna: W krótkim okresie wysłałeś zbyt wiele żądań do bezpłatnego interfejsu API Inference.
- Rozwiązanie: W przypadku zastosowań produkcyjnych należy przejść na dedykowany punkt końcowy wnioskowania. W przypadku rozwoju można wdrożyć buforowanie, aby uniknąć wielokrotnego wysyłania tego samego żądania.
Śledzenie, które rozwiązania sprawdzają się w przypadku poszczególnych problemów, ma kluczowe znaczenie. Bez centralnego miejsca do dokumentowania tych ustaleń zespoły często kończą na rozwiązywaniu tych samych problemów w kółko.
📮 ClickUp Insight: 1 na 4 pracowników korzysta z co najmniej czterech narzędzi tylko po to, aby stworzyć kontekst w pracy. Kluczowe informacje mogą być ukryte w wiadomości e-mail, rozwinięte w wątku na Slacku i udokumentowane w oddzielnym narzędziu, co zmusza zespoły do marnowania czasu na poszukiwanie informacji zamiast wykonywania pracy.
ClickUp łączy cały cykl pracy w jedną zunifikowaną platformę. Dzięki funkcjom takim jak ClickUp E-mail Zarządzanie Projektami, ClickUp Chat, ClickUp Docs i ClickUp Brain Wszystko pozostaje połączone, zsynchronizowane i natychmiast dostępne. Pożegnaj się z „pracą nad pracą” i odzyskaj swoją wydajność.
💫 Rzeczywiste wyniki: Dzięki ClickUp zespoły mogą zaoszczędzić ponad 5 godzin tygodniowo, co daje ponad 250 godzin rocznie na osobę, eliminując przestarzałe procesy zarządzania wiedzą. Wyobraź sobie, co Twój zespół mógłby osiągnąć, mając dodatkowy tydzień wydajności w każdym kwartale!
Jak zarządzać projektami wdrażania AI w ClickUp
Wykorzystanie Hugging Face do wdrażania AI ułatwia pakowanie, hostowanie i obsługę modeli, ale nie eliminuje nakładów związanych z koordynacją rzeczywistego wdrożenia. Zespoły nadal muszą śledzić, które modele są testowane, uzgadniać konfiguracje, dokumentować decyzje i dbać o to, aby wszyscy — od inżynierów ML po pracowników działu produktów i operacyjnego — byli na bieżąco.
Kiedy zespół inżynierów testuje różne modele, zespół ds. produktu określa wymagania, a interesariusze proszą o aktualizacje, informacje są rozproszone w Slacku, e-mailach, arkuszach kalkulacyjnych i różnych dokumentach.
Rozproszenie pracy — fragmentacja działań roboczych między wieloma niepołączonymi narzędziami, które nie komunikują się ze sobą — powoduje zamieszanie i spowalnia pracę wszystkich.
W tym miejscu kluczową rolę odgrywa ClickUp, pierwsze na świecie zintegrowane środowisko pracy AI, które łączy zarządzanie projektami, dokumentację i komunikację zespołową w jednym miejscu.
Ta konwergencja jest szczególnie cenna w przypadku projektów wdrażania AI, gdzie interesariusze techniczni i nietechniczni potrzebują wspólnej widoczności bez konieczności korzystania z pięciu różnych narzędzi.
Zamiast rozpraszać aktualizacje między zgłoszeniami, dokumentami i wątkami czatu, Teams mogą zarządzać całym cyklem wdrażania w jednym miejscu.
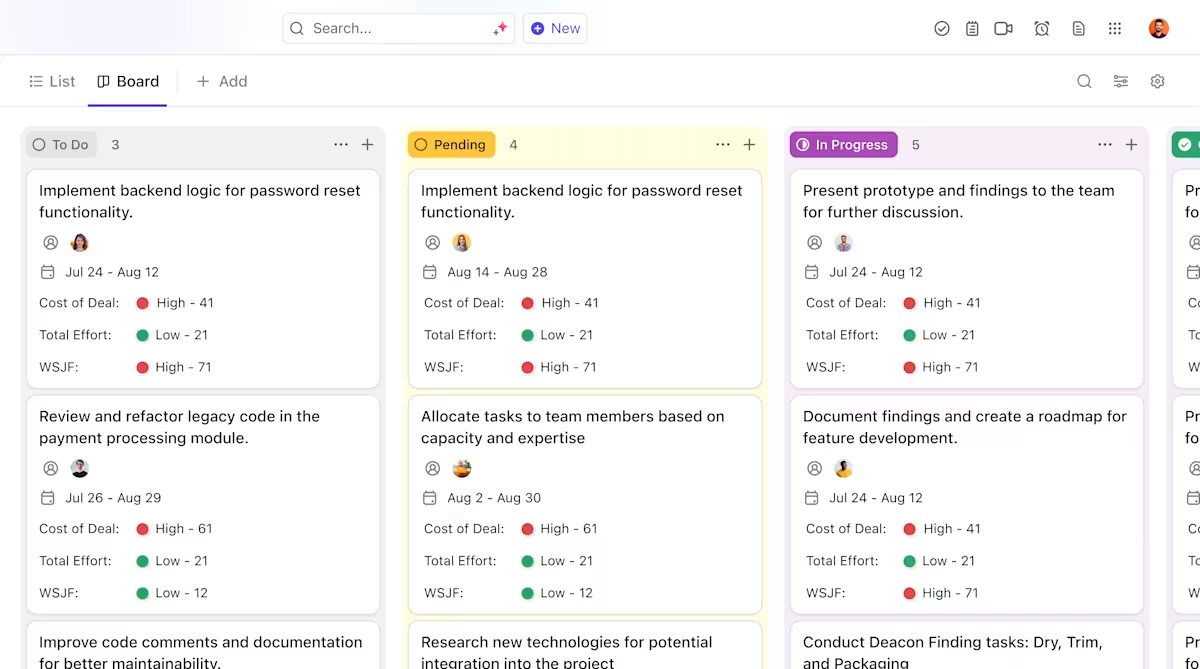
Oto, w jaki sposób ClickUp może zapewnić wsparcie dla Twojego projektu wdrożenia AI:
- Przejrzysta własność i śledzenie cyklu życia modeli: użyj zadań ClickUp, aby śledzić modele Hugging Face poprzez ocenę, testowanie, wdrażanie i produkcję, z niestandardowymi statusami, właścicielami i blokadami widocznymi dla całego zespołu.
- Scentralizowana, aktualna dokumentacja wdrożeniowa: przechowuj instrukcje wdrożeniowe, konfiguracje środowiska i przewodniki dotyczące rozwiązywania problemów w ClickUp Docs, dzięki czemu dokumentacja ewoluuje wraz z modelami i pozostaje łatwa do wyszukiwania i odwoływania się do niej. Ponieważ dokumenty są połączone z zadaniami ClickUp, dokumentacja znajduje się tuż obok pracy, której dotyczy.
- Współpraca w kontekście bez rozpraszania pracy: dyskusje, decyzje i aktualizacje są bezpośrednio powiązane z zadaniami i dokumentami, co zmniejsza zależność od rozproszonych wątków na Slacku, e-mailach i niepowiązanych narzędziach projektowych.
- Pełna widoczność postępów wdrażania: monitoruj proces wdrażania, wcześnie identyfikuj ryzyka i równoważ obciążenie zespołu, korzystając z pulpitów ClickUp, które pokazują postępy i wąskie gardła w czasie rzeczywistym.
- Szybsze wdrażanie i przywoływanie decyzji dzięki wbudowanej AI: użyj ClickUp Brain, aby podsumować długie dokumenty dotyczące wdrażania, uzyskać istotne informacje z poprzednich wdrożeń i pomóc nowym członkom zespołu szybko się wdrożyć bez konieczności przeglądania historycznego kontekstu.
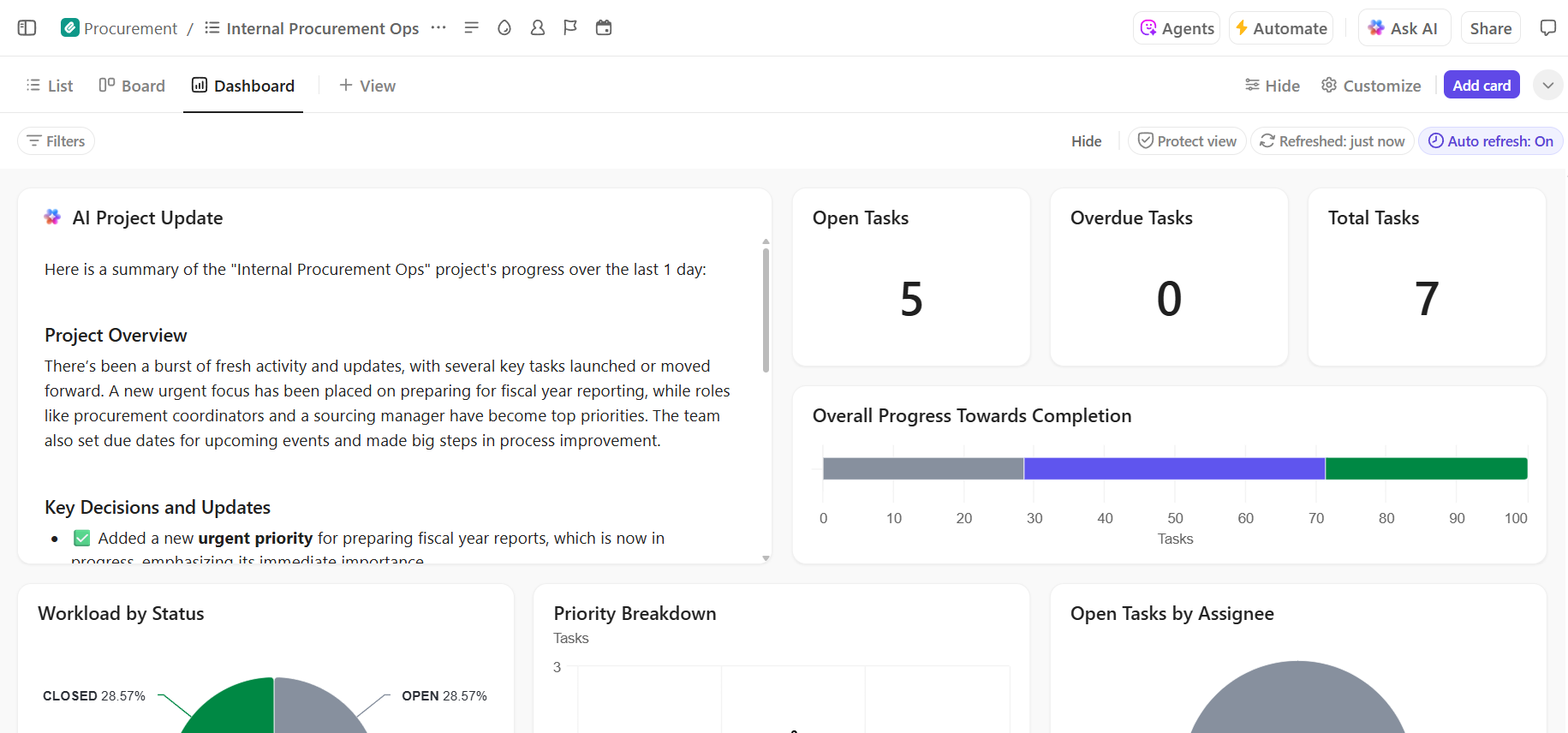
📚 Przeczytaj również: Jak zautomatyzować procesy za pomocą AI, aby uzyskać szybsze i inteligentniejsze cykle pracy
Zarządzaj swoim projektem wdrożenia AI w sposób płynny w ClickUp.
Powodzenie wdrożenia Hugging Face zależy od solidnych podstaw technicznych oraz przejrzystego i zorganizowanego zarządzania projektami. Chociaż wyzwania techniczne są możliwe do rozwiązania, to często właśnie problemy z koordynacją i komunikacją powodują niepowodzenia projektów.
Dzięki ustaleniu jasnego cyklu pracy na jednej platformie Twój zespół może działać szybciej i uniknąć frustracji związanej z rozproszeniem kontekstu – kiedy zespoły tracą godziny na szukanie informacji, przełączanie się między aplikacjami i powtarzanie aktualizacji na wielu platformach.
ClickUp, aplikacja do pracy, która łączy zarządzanie projektami, dokumentację i komunikację zespołową w jednym miejscu, zapewniając jedno źródło informacji dla całego cyklu wdrażania AI.
Połącz swoje projekty wdrożeniowe AI i wyeliminuj chaos związany z narzędziami. Zacznij korzystać z ClickUp już dziś za darmo.
Często zadawane pytania (FAQ)
Tak, Hugging Face oferuje hojny bezpłatny pakiet, który obejmuje dostęp do Model Hub, zasilane procesorem CPU przestrzenie do demonstracji oraz API wnioskowania z ograniczeniem szybkości do testowania. W przypadku potrzeb produkcyjnych wymagających dedykowanego sprzętu lub wyższych limitów dostępne są płatne plany.
Przestrzenie jest przeznaczona do hostowania interaktywnych aplikacji z wizualnym interfejsem użytkownika, dzięki czemu idealnie nadaje się do prezentacji i narzędzi wewnętrznych. API Inference zapewnia programowy dostęp do modeli, umożliwiając integrację ich z aplikacjami za pomocą prostych żądań HTTP.
Oczywiście. Dzięki interaktywnym demonstracjom udostępnianym w Hugging Face Spaces członkowie zespołu bez wiedzy technicznej mogą eksperymentować z modelami i przekazywać opinie na ich temat bez konieczności pisania ani jednej linii kodu.
Główne ograniczenia bezpłatnego pakietu to ograniczenia szybkości interfejsu API Inference, wykorzystanie współdzielonego sprzętu CPU dla przestrzeni, co może powodować spowolnienie, oraz „zimny start”, w którym nieaktywne aplikacje potrzebują chwili, aby się uruchomić. /