
Większość programistów, którzy tworzą skrypt podsumowujący Hugging Face, napotyka tę samą przeszkodę: podsumowanie działa idealnie w ich terminalu. Jednak rzadko dochodzi do połączenia z rzeczywistą pracą, której ma zapewnić wsparcie.
Ten przewodnik przeprowadzi Cię przez proces tworzenia narzędzia do tworzenia streszczeń tekstowych przy użyciu biblioteki Hugging Face Transformers, a następnie pokaże, dlaczego nawet bezbłędna implementacja może stworzyć więcej problemów niż rozwiązać, gdy Twój zespół potrzebuje streszczeń, które faktycznie tworzą połączenia z zadaniami, projektami i decyzjami.
Czym jest streszczanie tekstu?
Zespoły toną w morzu informacji. Masz do czynienia z długimi dokumentami, niekończącymi się protokołami spotkań, obszernymi artykułami naukowymi i raportami kwartalnymi, których ręczne przetworzenie zajmuje wiele godzin. Ciągłe przeciążenie informacyjne spowalnia proces podejmowania decyzji i zabija wydajność.
Podsumowanie tekstu to proces wykorzystujący przetwarzanie języka naturalnego (NLP) do skondensowania zawartości w krótką, spójną wersję, która zachowuje najważniejsze informacje. Potraktuj to jako natychmiastowe streszczenie dowolnego dokumentu. Ta technologia podsumowywania NLP zazwyczaj wykorzystuje jedno z dwóch podejść:
Podsumowanie ekstraktywne: Ta metoda polega na identyfikacji i wyodrębnieniu najważniejszych zdań bezpośrednio z tekstu źródłowego. To tak, jakby zakreślacz automatycznie wybierał dla Ciebie kluczowe punkty. Ostateczne podsumowanie jest zbiorem oryginalnych zdań.
Podsumowanie abstrakcyjne: Ta bardziej zaawansowana metoda generuje całkowicie nowe zdania, aby uchwycić podstawowe znaczenie tekstu źródłowego. Parafrazuje informacje, co daje wynik w postaci bardziej płynnego i ludzkiego podsumowania, podobnego do tego, jak osoba wyjaśniałaby długą historię własnymi słowami.
Wyniki tego działania widać wszędzie. Jest ono wykorzystywane do skracania notatek ze spotkań do elementów działania, przekształcania opinii klientów w trendy oraz tworzenia szybkich przeglądów dokumentacji projektowej. Cel jest zawsze ten sam: uzyskać niezbędne informacje bez konieczności czytania każdego słowa.
📮 ClickUp Insight: Przeciętny profesjonalista spędza ponad 30 minut dziennie na wyszukiwaniu informacji związanych z pracą. To ponad 120 godzin rocznie straconych na przeszukiwanie wiadomości e-mail, wątków Slacka i rozproszonych plików. Inteligentny asystent AI wbudowany w Twój obszar roboczy może to zmienić. ClickUp Brain dostarcza natychmiastowe informacje i odpowiedzi, wyświetlając odpowiednie dokumenty, rozmowy i szczegóły zadań w ciągu kilku sekund, dzięki czemu możesz przestać szukać i zacząć pracować.
💫 Rzeczywiste wyniki: zespoły takie jak QubicaAMF odzyskały ponad 5 godzin tygodniowo dzięki ClickUp, czyli ponad 250 godzin rocznie na osobę, eliminując przestarzałe procesy zarządzania wiedzą.
Dlaczego warto używać Hugging Face do tworzenia streszczeń tekstu?
Stworzenie od podstaw niestandardowego modelu podsumowującego tekst jest ogromnym przedsięwzięciem. Wymaga ogromnych zbiorów danych do szkolenia, potężnych i kosztownych zasobów obliczeniowych oraz zespołu ekspertów w dziedzinie uczenia maszynowego. Ta wysoka bariera wejścia powstrzymuje większość zespołów inżynierów i produktowych przed rozpoczęciem pracy.
Hugging Face to platforma, która rozwiązuje ten problem. Jest to otwarta społeczność i platforma naukowa, która zapewnia dostęp do tysięcy wstępnie wyszkolonych modeli, skutecznie demokratyzując tworzenie podsumowań LLM dla programistów. Zamiast budować od podstaw, możesz zacząć od potężnego modelu, który jest już w 99% gotowy.
Oto dlaczego tak wielu programistów decyduje się na Hugging Face: 🛠️
Dostęp do wstępnie wytrenowanych modeli: Hugging Face Hub to ogromne repozytorium zawierające ponad 2 miliony publicznych modeli wytrenowanych przez takie firmy jak Google, Meta i OpenAI. Możesz pobrać i wykorzystać te najnowocześniejsze punkty kontrolne w swoich własnych projektach.
Uproszczone API potoku: Funkcja potoku to API wysokiego poziomu, które obsługuje wszystkie złożone kroki, takie jak wstępne przetwarzanie tekstu, wnioskowanie modelu i formatowanie danych wyjściowych, za pomocą zaledwie kilku wierszy kodu.
Różnorodność modeli: Nie jesteś ograniczony do jednej opcji. Możesz wybierać spośród szerokiego zakresu architektur, takich jak BART, T5 i Pegasus, z których każda ma inne mocne strony, rozmiary i charakterystykę wydajnościową.
Elastyczność frameworka: Biblioteka Transformers płynnie współpracuje z dwoma najpopularniejszymi frameworkami głębokiego uczenia się, PyTorch i TensorFlow. Możesz używać tego, z którego Twój zespół jest już zaznajomiony.
Wsparcie społeczności: Dzięki obszernej dokumentacji, oficjalnym kursom i aktywnej społeczności programistów łatwo jest znaleźć samouczki i uzyskać pomoc w razie problemów.
Chociaż Hugging Face jest niezwykle potężnym narzędziem dla programistów, należy pamiętać, że jest to rozwiązanie oparte na kodzie. Jego wdrożenie i utrzymanie wymaga wiedzy technicznej. Nie zawsze jest to odpowiednie rozwiązanie dla zespołów nietechnicznych, które potrzebują jedynie podsumować swoją pracę.
🧐 Czy wiesz, że... Biblioteka Hugging Face Transformers sprawiła, że korzystanie z najnowocześniejszych modeli NLP za pomocą kilku linii kodu stało się powszechne, dlatego prototypy podsumowań często zaczynają się właśnie od tego.
Czym są transformatory Hugging Face?
Zdecydowałeś się więc używać Hugging Face, ale jaka technologia faktycznie za tym stoi? Podstawową technologią jest architektura o nazwie Transformer. Kiedy została ona przedstawiona w artykule z 2017 roku zatytułowanym „Attention Is All You Need” („Wszystko, czego potrzebujesz, to uwaga”), całkowicie zmieniła pole NLP.
Przed pojawieniem się modeli Transformers modele miały trudności ze zrozumieniem kontekstu długich zdań. Kluczową innowacją modelu Transformer jest mechanizm uwagi, który pozwala modelowi ocenić znaczenie różnych słów w tekście wejściowym podczas przetwarzania konkretnego słowa. Pomaga to uchwycić zależności na dużym zakresie i zrozumieć kontekst, co ma kluczowe znaczenie dla tworzenia spójnych podsumowań.
Biblioteka Hugging Face Transformers to pakiet w języku Python, który niezwykle ułatwia korzystanie z tych złożonych modeli. Nie potrzebujesz doktoratu z uczenia maszynowego. Biblioteka eliminuje najtrudniejsze zadania.
Trzy podstawowe elementy, które musisz znać
- Tokenizatory: Modele nie rozumieją słów, rozumieją liczby. Tokenizator pobiera wprowadzony tekst i przekształca go w sekwencję tokenów numerycznych — proces ten nazywa się tokenizacją — które model może przetworzyć.
- Modele: Są to wstępnie wytrenowane sieci neuronowe. W przypadku podsumowań są to zazwyczaj modele sekwencja-sekwencja o strukturze enkoder-dekoder. Enkoder odczytuje wprowadzony tekst, aby utworzyć reprezentację numeryczną, a dekoder wykorzystuje tę reprezentację do wygenerowania podsumowania.
- Pipeline: Jest to najprostszy sposób korzystania z modelu. Pipeline łączy wstępnie wyszkolony model z odpowiednim tokenizerem i obsługuje wszystkie kroki przetwarzania wstępnego danych wejściowych oraz przetwarzania końcowego danych wyjściowych.
Dwa najpopularniejsze modele podsumowań to BART i T5. BART (Bidirectional and Auto-Regressive Transformer) jest szczególnie dobry w podsumowaniach abstrakcyjnych, tworząc podsumowania, które czyta się bardzo naturalnie. T5 (Text-to-Text Transfer Transformer) to wszechstronny model, który traktuje każde zadanie NLP jako problem tekst-tekst, co czyni go potężnym wszechstronnym narzędziem.
🎥 Obejrzyj to wideo, aby zobaczyć porównanie najlepszych programów do tworzenia streszczeń PDF — i dowiedzieć się, które narzędzia zapewniają najszybsze i najdokładniejsze streszczenia bez utraty kontekstu.
Jak zbudować narzędzie do tworzenia streszczeń tekstowych za pomocą Hugging Face
Chcesz stworzyć własny przykładowy program do tworzenia streszczeń? Potrzebujesz tylko podstawowej wiedzy na temat języka Python, redaktora kodu, takiego jak VS Code, oraz połączenia internetowego. Cały proces składa się zaledwie z czterech kroków. W ciągu kilku minut będziesz mieć działający program do tworzenia streszczeń.
Krok 1: Zainstaluj wymagane biblioteki
Najpierw musisz zainstalować niezbędne biblioteki. Najważniejsza z nich to transformers. Potrzebna będzie również platforma do głębokiego uczenia się, taka jak PyTorch lub TensorFlow. W tym przykładzie użyjemy PyTorch.
Otwórz terminal lub wiersz poleceń i uruchom następującą komendę:

Niektóre modele, takie jak T5, wymagają również biblioteki sentencepiece dla swojego tokenizera. Dobrze jest ją również zainstalować.

💡 Wskazówka dla profesjonalistów: przed zainstalowaniem tych pakietów utwórz wirtualne środowisko Python. Dzięki temu zależności projektu pozostaną odizolowane i nie dojdzie do konfliktów z innymi projektami na Twoim komputerze.
Krok 2: Załaduj model i tokenizer
Najłatwiejszym sposobem na rozpoczęcie pracy jest użycie funkcji pipeline. Automatycznie zajmuje się ona załadowaniem odpowiedniego modelu i tokenizatora do zadania tworzenia podsumowań.
W skrypcie w języku Python zaimportuj potok i zainicjuj go w następujący sposób:

W tym miejscu określamy dwie rzeczy:
Zadanie: Informujemy potok, że chcemy wykonać „podsumowanie”.
Model: Wybieramy konkretny, wstępnie wytrenowany model z Hugging Face Hub. facebook/bart-large-cnn to popularny wybór, wytrenowany na artykułach prasowych i dobrze sprawdzający się w przypadku podsumowań ogólnych. Aby przyspieszyć testowanie, można użyć mniejszego modelu, takiego jak t5-small.
Przy pierwszym uruchomieniu tego kodu nastąpi pobranie wag modelu z hubu, co może potrwać kilka minut. Następnie model zostanie zapisany w pamięci podręcznej lokalnego komputera, aby umożliwić jego natychmiastowe ładowanie.
Krok 3: Utwórz funkcję podsumowującą
Aby kod był przejrzysty i nadawał się do ponownego wykorzystania, najlepiej zamknąć logikę podsumowania w funkcji. Ułatwia to również eksperymentowanie z różnymi parametrami.
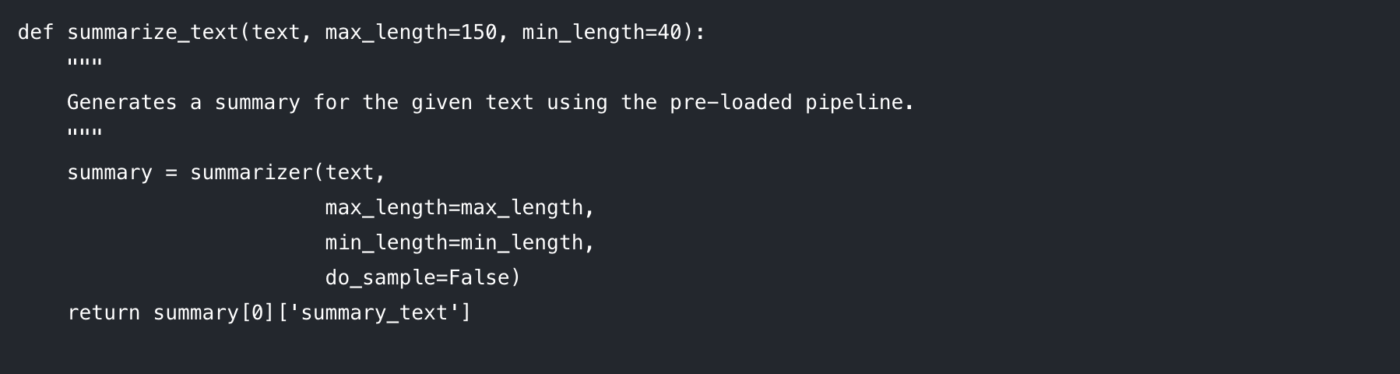
Przeanalizujmy parametry, które możesz kontrolować:
max_length: Ustawia maksymalną liczbę tokenów (w przybliżeniu słów) dla generowanego streszczenia.
min_length: Ustawienie minimalnej liczby tokenów, aby zapobiec generowaniu przez model zbyt krótkich lub pustych podsumowań.
do_sample: Gdy ustawiono na False, model wykorzystuje metodę deterministyczną (taką jak beam search) do generowania najbardziej prawdopodobnego podsumowania. Ustawienie na True wprowadza losowość, która może dać bardziej kreatywne, ale mniej przewidywalne wyniki.
Dostosowanie tych parametrów jest kluczem do uzyskania pożądanej jakości wyników.
Krok 4: Wygeneruj swoje podsumowanie
A teraz część zabawowa. Przekaż swój tekst do funkcji i wydrukuj wynik. 🤩

Na konsoli powinna pojawić się skrócona wersja artykułu. Jeśli napotkasz problemy, oto kilka szybkich rozwiązań:
Tekst wejściowy jest zbyt długi: model może wyświetlić błąd, jeśli wprowadzony tekst przekroczy maksymalną długość (często 512 lub 1024 tokeny). Dodaj truncation=True wewnątrz wywołania summarizer(), aby automatycznie skracać długie teksty wejściowe.
Podsumowanie jest zbyt ogólne: Spróbuj zwiększyć parametr num_beams (np. num_beams=4). Dzięki temu model będzie dokładniej wyszukiwał lepsze podsumowanie, ale może działać nieco wolniej.
To podejście oparte na kodzie jest fantastyczne dla programistów tworzących niestandardowe aplikacje. Ale co się stanie, gdy trzeba będzie zintegrować to z codzienną pracą zespołu? Wtedy zaczynają się ograniczenia.
Ograniczenia Hugging Face w zakresie tworzenia streszczeń tekstowych
Hugging Face to świetna opcja, jeśli zależy Ci na elastyczności i kontroli. Jednak gdy spróbujesz użyć go w rzeczywistych cyklach pracy zespołu (a nie tylko w notebooku demonstracyjnym), szybko pojawią się kilka przewidywalnych wyzwań.
Limity tokenów i problemy związane z długimi dokumentami
Większość modeli podsumowujących ma stałą maksymalną długość danych wejściowych. Na przykład facebook/bart-large-cnn jest skonfigurowany z max_position_embeddings = 1024. Oznacza to, że dłuższe dokumenty często wymagają skracania lub dzielenia na fragmenty.
Jeśli potrzebujesz tylko szybkiej podstawy, możesz włączyć skracanie w potoku i przejść dalej. Jeśli jednak potrzebujesz wiernych streszczeń długich dokumentów, zazwyczaj kończy się to tworzeniem logiki dzielenia na fragmenty, a następnie wykonaniem drugiego przejścia, „streszczenia streszczeń”, aby połączyć wyniki. Jest to dodatkowa praca inżynieryjna i łatwo uzyskać niespójne wyniki.
Ryzyko halucynacji (i koszt weryfikacji)
Modele abstrakcyjne mogą czasami generować halucynacje, tworząc tekst, który brzmi wiarygodnie, ale jest niezgodny z faktami. W przypadku zastosowań krytycznych dla działalności biznesowej stwarza to problem: każde streszczenie wymaga ręcznej weryfikacji. W tym momencie nie oszczędzasz czasu, a jedynie przenosisz pracę do innej części procesu.
Brak świadomości kontekstu
Model Hugging Face zna tylko tekst, który mu podasz. Nie rozumie celów Twojego projektu, osób zaangażowanych w jego realizację ani powiązań między dokumentami, ponieważ brakuje mu kontekstowej inteligencji nowoczesnych systemów. Nie jest w stanie stwierdzić, czy streszczenie rozmowy z klientem jest sprzeczne z dokumentacją wymagań projektu, ponieważ funkcjonuje w izolacji.
Obciążenie związane z integracją (problem „ostatniej mili”)
Generowanie podsumowania jest zazwyczaj łatwą częścią zadania. Prawdziwa trudność pojawia się dopiero później.
Gdzie trafia streszczenie? Kto je widzi? Jak zamienia się ono w zadanie, które można wykonać? Jak połączyć je z pracą, która była wyzwalaczem?
Rozwiązanie tego „ostatniego etapu” oznacza tworzenie niestandardowych integracji i kodu łączącego. Wymaga to dodatkowej pracy programistów na początku i często powoduje powstanie nieefektywnego cyklu pracy dla wszystkich pozostałych osób.
Bariera techniczna i bieżąca konserwacja
Podejście oparte na języku Python jest dostępne głównie dla osób potrafiących programować. Stanowi to praktyczną barierę dla zespołów marketingowych, sprzedażowych i operacyjnych, co oznacza, że jego zastosowanie pozostaje na poziomie limitu.
Obejmuje to również bieżącą konserwację: zarządzanie zależnościami, aktualizowanie bibliotek i utrzymywanie sprawności działania w miarę ewolucji interfejsów API i modeli. To, co zaczyna się jako szybki sukces, może po cichu stać się kolejnym systemem wymagającym opieki.
📮 ClickUp Insight: 42% zakłóceń w pracy wynika z konieczności korzystania z wielu platform, zarządzania wiadomościami e-mail i przeskakiwania między spotkaniami. A co, gdybyś mógł wyeliminować te kosztowne przerwy? ClickUp łączy Twoje cykle pracy (i czat) w ramach jednej, usprawnionej platformy. Uruchamiaj i zarządzaj zadaniami z poziomu czatu, dokumentów, tablic i innych narzędzi, a funkcje oparte na AI zapewniają spójność kontekstu, możliwość wyszukiwania i łatwość zarządzania.
Większy problem: rozrost kontekstu
Nawet jeśli skrypt podsumowujący działa idealnie, Twój zespół nadal może tracić czas, ponieważ wynik jest oderwany od rzeczywistego miejsca pracy.
Jest to rozproszenie kontekstu, kiedy Teams tracą godziny na wyszukiwanie informacji, przełączanie się między aplikacjami i poszukiwanie plików na niepołączonych platformach.
W tym miejscu zintegrowane środowisko pracy zmienia zasady gry. Zamiast generować podsumowania w jednym miejscu i próbować „przenieść je do pracy” później, zintegrowany system przechowuje projekty, dokumenty i rozmowy razem, z ClickUp Brain wbudowanym jako warstwa inteligencji. Twoje podsumowania pozostają połączone z zadaniami i dokumentami, więc następny krok jest oczywisty, a przekazanie następuje natychmiast.
Podsumowanie, które zamienia się w działanie dzięki ClickUp
Skrypt podsumowujący może działać idealnie, ale nadal zawieść Twój zespół w jeden irytujący sposób: podsumowanie kończy się gdzieś z dala od pracy.
Ta luka powoduje rozproszenie kontekstu, gdzie informacje są rozrzucone po dokumentach, wątkach czatu, zadaniach i „szybkich notatkach” w narzędziach, które nie są ze sobą połączone. Ludzie spędzają więcej czasu na szukaniu podsumowania niż na jego używaniu. Prawdziwą korzyścią nie jest tylko generowanie podsumowania. Chodzi o to, żeby podsumowanie było powiązane z decyzjami, właścicielami i kolejnymi krokami tam, gdzie faktycznie odbywa się praca.
To właśnie wyróżnia ClickUp Brain. Podsumowuje zadania, dokumenty i rozmowy w tym samym obszarze roboczym, w którym znajdują się Twoje projekty, dzięki czemu Twój zespół może zrozumieć coś i podjąć odpowiednie działania bez konieczności przechodzenia między narzędziami.

ClickUp BrainGPT: interakcja z podsumowaniami przy użyciu języka naturalnego
Na komputerze stacjonarnym BrainGPT jest interfejsem konwersacyjnym dla ClickUp Brain. Zamiast otwierać skrypty, notatniki lub zewnętrzne narzędzia AI, Twój zespół może poprosić o to, czego potrzebuje, prostym językiem, bezpośrednio w ClickUp.
Możesz wpisać (lub użyć funkcji zamiany mowy na tekst), aby:
- Podsumuj długi opis zadania, wątek komentarzy lub dokument.
- Kontynuuj pytaniami typu „Jakie są kolejne kroki?” lub „Kto jest za to odpowiedzialny?”.
- Zamień streszczenie w działanie, tworząc na jego podstawie zadania wraz z właścicielami i terminami wykonania.
Ponieważ ClickUp Brain działa w Twoim obszarze roboczym ClickUp, wynik jest oparty na kontekście na żywo: opisach zadań, komentarzach, podzadaniach, połączonych dokumentach i strukturze projektu. Nie wklejasz tekstu do oddzielnego narzędzia i nie masz nadziei, że nic ważnego nie zostanie pominięte.
Dlaczego dla większości zespołów jest to lepsze rozwiązanie niż oparty na kodzie cykl pracy tworzenia podsumowań?
Cykl pracy opracowany przez programistów może generować trafne streszczenia. Problemy pojawiają się później, gdy ktoś musi skopiować wynik do miejsca, w którym odbywa się praca, a następnie przełożyć go na zadania i dopilnować ich realizacji.
ClickUp Brain zamyka tę pętlę:
Nie jest wymagana znajomość kodowaniaKażdy członek zespołu może stworzyć podsumowanie dokumentu, wątku zadania lub chaotycznego zestawu komentarzy bez instalowania czegokolwiek lub pisania kodu.
Podsumowania uwzględniające kontekstClickUp Brain może uwzględniać elementy, o których ludzie zazwyczaj zapominają: decyzje ukryte w komentarzach, przeszkody wspomniane w odpowiedziach, podzadania, które zmieniają znaczenie słowa „zrobione”.
Podsumowania są tam, gdzie odbywa się pracaMożesz nadrobić zaległości w ramach zadania ClickUp, dodać podsumowanie na górze ClickUp Docs lub szybko podsumować dyskusję bez tworzenia kolejnego „dokumentu podsumowującego”, którego nikt nie sprawdza.
Mniej narzędziNie potrzebujesz oddzielnych skryptów, notatników Jupyter, kluczy API ani cyklu pracy, który rozumie tylko jedna osoba. Twoje dokumenty, zadania i streszczenia pozostają w tym samym systemie.
Jest to praktyczna zaleta zintegrowanego obszaru roboczego: podsumowanie, działanie i współpraca odbywają się jednocześnie, a nie są łączone po fakcie.
Jest to praktyczna zaleta zintegrowanego obszaru roboczego: podsumowanie, działanie i współpraca odbywają się jednocześnie, a nie są łączone po fakcie.
Jak to działa w rzeczywistości
Oto kilka typowych wzorców stosowanych przez zespoły:
- Podsumuj wątek komentarzy: otwórz zadanie z długą dyskusją, kliknij opcję AI i uzyskaj szybkie podsumowanie tego, co się zmieniło i co jest ważne.
- Podsumuj dokument: otwórz dokument ClickUp i użyj funkcji „Ask AI”, aby wygenerować podsumowanie strony, dzięki czemu każdy będzie mógł szybko się zorientować.
- Wyodrębnij elementy: weź podsumowanie i natychmiast przekształć kolejne kroki w zadania z osobami przypisanymi i terminami wykonania, aby nie stracić impetu podczas przekazywania zadań.
| Możliwości | Hugging Face (oparty na kodzie) | ClickUp Brain |
|---|---|---|
| Wymagane ustawienia | Środowisko Python, biblioteki, kodowanie | Brak, wbudowane |
| Świadomość kontekstu | Tylko tekst (to, co przekazujesz) | Pełny kontekst obszaru roboczego (zadania, dokumenty, komentarze, podzadania) |
| Integracja cyklu pracy | Ręczny eksport/import | Natywne: streszczenia mogą stać się zadaniami i aktualizacjami. |
| Wymagane umiejętności techniczne | Poziom programisty | Każdy członek zespołu |
| Konserwacja | Bieżąca konserwacja modelu i kodu | Automatyczne aktualizacje |
Od podsumowań do realizacji dzięki Super Agents
Podsumowania są przydatne. Trudnością jest zapewnienie, aby konsekwentnie przekładały się one na działania, zwłaszcza gdy ich ilość rośnie.
W tym miejscu do akcji wkraczają ClickUp Super Agents . Mogą oni wykorzystywać podsumowane informacje i kontynuować pracę w oparciu o wyzwalacze i warunki w ramach tego samego obszaru roboczego ClickUp.
Dzięki Super Agents zespoły mogą:
- Podsumowuj zmiany zgodnie z harmonogramem (cotygodniowe podsumowanie projektu, codzienne zestawienia statusów)
- Wyodrębnij elementy i przypisz ich właścicieli automatycznie.
- Oznacz prace wstrzymane (zadania utknięte w fazie przeglądu, wątki bez odpowiedzi, przeterminowane kolejne kroki)
- Zadbaj o wysoką widoczność kierownictwa bez ręcznego raportowania
Zamiast traktować podsumowanie jako statyczny tekst, agenci pomagają zapewnić, że podsumowanie stanie się planem, a plan przełoży się na postępy.
Podsumowanie, które powstaje tam, gdzie odbywa się praca
Transformatory Hugging Face są świetnym rozwiązaniem, gdy potrzebujesz niestandardowej aplikacji, dostosowanego do potrzeb procesu lub pełnej kontroli nad zachowaniem modelu.
Jednak dla większości zespołów większym problemem nie jest pytanie „Czy możemy to podsumować?”, ale „Czy możemy to podsumować i natychmiast przekształcić w zadanie, z właścicielami, terminami i widocznością?”.
Jeśli Twoim celem jest wydajność zespołu i szybka realizacja zadań, ClickUp Brain zapewnia podsumowania w kontekście, dokładnie tam, gdzie odbywa się praca, z jasną ścieżką od „oto sedno sprawy” do „oto, co robimy dalej”.
Chcesz pominąć ustawienia i zacząć tworzyć podsumowania tam, gdzie faktycznie pracujesz? Zacznij korzystać z ClickUp za darmo i pozwól Brain zająć się ciężką pracą.