

Duże modele językowe (LLM) otworzyły nowe, ekscytujące możliwości dla aplikacji. Umożliwiają one tworzenie bardziej inteligentnych i dynamicznych systemów niż kiedykolwiek wcześniej.
Eksperci przewidują, że do 2025 r. aplikacje oparte na tych modelach mogą zautomatyzować prawie połowę całej cyfrowej pracy .
Jednak w miarę jak odblokowujemy te możliwości, pojawia się wyzwanie: jak wiarygodnie zmierzyć jakość ich wyników na dużą skalę? Wystarczy niewielka zmiana w ustawieniach i nagle otrzymujemy zauważalnie różne wyniki. Ta zmienność może utrudniać ocenę ich wydajności, co ma kluczowe znaczenie podczas przygotowywania modelu do rzeczywistego użytku.
W tym artykule podzielimy się spostrzeżeniami na temat najlepszych praktyk oceny systemu LLM, od testów przed wdrożeniem do produkcji. Zaczynajmy więc!
Co to jest ewaluacja LLM?
Metryki ewaluacji LLM to sposób na sprawdzenie, czy podpowiedzi, ustawienia modelu lub cykl pracy osiągają wyznaczone cele. Metryki te zapewniają wgląd w to, jak dobrze Duży model językowy i czy jest naprawdę gotowy do rzeczywistego użytku.
Obecnie niektóre z najpopularniejszych metryk mierzą przywoływanie kontekstu w zadaniach generowania rozszerzonego wyszukiwania (RAG), dokładne dopasowania dla klasyfikacji, walidację JSON dla ustrukturyzowanych danych wyjściowych i podobieństwo semantyczne dla bardziej kreatywnych zadań.
Każda z tych metryk w unikalny sposób zapewnia, że LLM spełnia standardy dla konkretnego przypadku użycia.
Do zrobienia oceny LLM?
Duże modele językowe (LLM) są obecnie wykorzystywane w szerokim zakresie zastosowań. Niezbędna jest ocena wydajności modeli, aby upewnić się, że spełniają one oczekiwane standardy i skutecznie służą zamierzonym celom.
Pomyśl o tym w ten sposób: Modele LLM zasilają wszystko, od chatbotów do obsługi klienta po narzędzia kreatywne, a w miarę jak stają się coraz bardziej zaawansowane, pojawiają się w coraz większej liczbie miejsc.
Oznacza to, że potrzebujemy lepszych sposobów ich monitorowania i oceny - tradycyjne metody po prostu nie nadążają za wszystkimi zadaniami obsługiwanymi przez te modele.
Dobre wskaźniki oceny są jak kontrola jakości dla LLM. **Pokazują one, czy model jest niezawodny, dokładny i wystarczająco wydajny do rzeczywistego użytku. Bez tych kontroli, błędy mogą się prześlizgnąć, prowadząc do frustrujących lub nawet mylących doświadczeń użytkownika.
Mając solidne wskaźniki oceny, łatwiej jest dostrzec problemy, ulepszyć model i upewnić się, że jest on gotowy do zaspokojenia konkretnych potrzeb użytkowników. W ten sposób wiesz, że Platforma AI z którą pracujesz, jest zgodna ze standardami i może dostarczyć wyniki, których potrzebujesz.
📖 Czytaj więcej: LLM vs. Generative AI: szczegółowy przewodnik
Rodzaje ocen LLM
Ewaluacje dostarczają unikalnej perspektywy do zbadania możliwości modelu. Każdy typ odnosi się do różnych aspektów jakości, pomagając zbudować niezawodny, bezpieczny i wydajny model wdrażania.
Oto różne rodzaje metod oceny LLM:
- Ewaluacja wewnętrzna koncentruje się na wewnętrznej wydajności modelu w określonych zadaniach językowych lub zadaniach rozumienia bez angażowania rzeczywistych aplikacji. Zazwyczaj przeprowadza się ją na scenie rozwoju modelu, aby zrozumieć jego podstawowe możliwości
- Ewaluacja zewnętrzna ocenia wydajność modelu w rzeczywistych aplikacjach. Ten rodzaj ewaluacji sprawdza, jak dobrze model spełnia określone cele w kontekście
- Ewaluacja odporności testuje stabilność i niezawodność modelu w różnych scenariuszach, w tym nieoczekiwanych danych wejściowych i przeciwstawnych warunkach. Identyfikuje potencjalne słabości, zapewniając przewidywalne zachowanie modelu
- Testowanie wydajności i opóźnień sprawdza wykorzystanie zasobów, szybkość i opóźnienia modelu. Zapewnia, że model może wykonywać zadania szybko i przy rozsądnych kosztach obliczeniowych, co jest niezbędne dla skalowalności
- Ocena etyki i bezpieczeństwa zapewnia, że model jest zgodny ze standardami etycznymi i wytycznymi dotyczącymi bezpieczeństwa, co ma kluczowe znaczenie w przypadku wrażliwych aplikacji
Ocena modelu LLM a ocena systemu LLM
Ocena dużych modeli językowych (LLM) obejmuje dwa główne podejścia: ocenę modelu i ocenę systemu. Każde z nich koncentruje się na innych aspektach wydajności LLM, a znajomość różnic jest niezbędna do maksymalizacji potencjału tych modeli
ocena modelu dotyczy ogólnych umiejętności LLM**. Ten rodzaj oceny sprawdza zdolność modelu do rozumienia, generowania i dokładnej pracy z językiem w różnych kontekstach. To jak sprawdzenie, jak dobrze model radzi sobie z różnymi zadaniami, prawie jak ogólny test na inteligencję.
Instancja oceniająca model może zapytać: "Jak wszechstronny jest ten model? "
Ewaluacje systemowe LLM mierzą, jak LLM radzi sobie w określonym ustawieniu lub celu, np. w chatbocie do obsługi klienta. W tym przypadku mniej chodzi o szerokie możliwości modelu, a bardziej o to, jak wykonuje on określone zadania w celu poprawy doświadczenia użytkownika.
Oceny systemowe koncentrują się natomiast na pytaniach typu: "Jak dobrze model radzi sobie z tym konkretnym zadaniem dla użytkowników? "
Ewaluacja modelu pomaga deweloperom zrozumieć ogólne możliwości i limity LLM, co pozwala na wprowadzanie ulepszeń. Ewaluacje systemowe skupiają się na tym, jak dobrze LLM spełnia potrzeby użytkowników w określonych kontekstach, zapewniając płynniejszą obsługę.
Wszystkie te ewaluacje zapewniają zakończony obraz mocnych stron LLM i obszarów wymagających poprawy, czyniąc go bardziej wydajnym i przyjaznym dla użytkownika w rzeczywistych zastosowaniach.
Przyjrzyjmy się teraz konkretnym metrykom oceny LLM.
Metryki oceny LLM
Niektóre niezawodne i modne wskaźniki oceny obejmują:
1. Złożoność
**Perplexity mierzy, jak dobrze model językowy przewiduje sekwencję słów. Zasadniczo wskazuje niepewność modelu co do następnego słowa w zdaniu. Niższy wynik perplexity oznacza, że model jest bardziej pewny swoich przewidywań, co prowadzi do lepszej wydajności.
Przykład: Wyobraźmy sobie, że model generuje tekst na podstawie podpowiedzi "Kot usiadł na" Jeśli przewiduje wysokie prawdopodobieństwo dla słów takich jak "mata" i "podłoga", to dobrze rozumie kontekst, z czego wynika niski wynik perplexity.
Z drugiej strony, jeśli zasugeruje niepowiązane słowo, takie jak "statek kosmiczny", wynik perplexity będzie wyższy, wskazując, że model ma trudności z przewidywaniem sensownego tekstu.
2. Wynik BLEU
Wynik BLEU (Bilingual Evaluation Understudy) jest używany głównie do oceny tłumaczenia maszynowego i generowania tekstów.
Mierzy on, ile n-gramów (ciągłych sekwencji n elementów z danej próbki tekstu) w tekście wyjściowym pokrywa się z tymi w jednym lub kilku tekstach referencyjnych. Wynik mieści się w zakresie od 0 do 1, przy czym wyższe wyniki wskazują na lepszą wydajność.
przykład:** Jeśli model wygeneruje zdanie "Szybki brązowy lis przeskakuje nad leniwym psem", a tekst referencyjny to "Szybki brązowy lis przeskakuje nad leniwym psem", BLEU porówna udostępniane n-gramy.
Wysoki wynik wskazuje, że wygenerowane zdanie ściśle pasuje do odniesienia, podczas gdy niższy wynik może sugerować, że wygenerowane dane wyjściowe nie są dobrze dopasowane.
3. Wynik F1
Metryka oceny F1 LLM jest przeznaczona głównie do zadań klasyfikacyjnych. Mierzy on równowagę między precyzją (dokładnością pozytywnych przewidywań) i przywołaniem (zdolnością do zidentyfikowania wszystkich istotnych instancji)
Jego zakres wynosi od 0 do 1, gdzie wynik 1 oznacza doskonałą dokładność.
przykład:** W zadaniu polegającym na udzielaniu odpowiedzi na pytania, jeśli model zostanie zapytany "Jakiego koloru jest niebo?" i odpowie "Niebo jest niebieskie" (wynik prawdziwie pozytywny), ale także "Niebo jest zielone" (wynik fałszywie pozytywny), wynik F1 uwzględni zarówno trafność prawidłowej odpowiedzi, jak i nieprawidłowej.
Ta metryka pomaga zapewnić zrównoważoną ocenę wydajności modelu.
4. METEOR
METEOR (Metric for Evaluation of Translation with Explicit ORdering) wykracza poza dokładne dopasowywanie słów. Bierze pod uwagę synonimy, rdzeń i parafrazy, aby ocenić podobieństwo między wygenerowanym tekstem a tekstem referencyjnym Ta metryka ma na celu ściślejsze dopasowanie do ludzkiej oceny.
przykład:** Jeśli model wygeneruje tekst "The feline rested on the rug", a tekst referencyjny brzmi "The cat lay on the carpet", METEOR przyzna temu wyższy wynik niż BLEU, ponieważ uzna, że "feline" jest synonimem "cat", a "rug" i "carpet" mają podobne znaczenie.
To sprawia, że METEOR jest szczególnie przydatny do wychwytywania niuansów języka.
5. BERTScore
BERTScore ocenia podobieństwo tekstu w oparciu o kontekstowe osadzenia pochodzące z modeli takich jak BERT (Bidirectional Encoder Representations from Transformers). Koncentruje się bardziej na znaczeniu niż na dokładnym dopasowaniu słów, pozwalając na lepszą ocenę podobieństwa semantycznego**
przykład:** Porównując zdania "Samochód pędził ulicą" i "Pojazd pędził ulicą", BERTScore analizuje podstawowe znaczenia, a nie tylko dobór słów.
Mimo że słowa się różnią, ogólne idee są podobne, co prowadzi do wysokiego wyniku BERTScore, który odzwierciedla skuteczność wygenerowanej zawartości.
6. Ocena ludzka
Ocena ludzka pozostaje kluczowym aspektem oceny LLM. Wiąże się ona z oceną jakości przez ludzkich sędziów wyników modelu w oparciu o różne kryteria, takie jak płynność i trafność. Techniki takie jak skala Likerta i testy A/B mogą być stosowane do zbierania informacji zwrotnych.
Przykład: Po wygenerowaniu odpowiedzi z chatbota do obsługi niestandardowej, ludzie oceniający mogą ocenić każdą odpowiedź w skali od 1 do 5. Na przykład, jeśli chatbot udzieli jasnej i pomocnej odpowiedzi na zapytanie klienta, może otrzymać 5, podczas gdy niejasna lub zagmatwana odpowiedź może otrzymać 2.
7. Wskaźniki specyficzne dla zadania
Różne zadania LLM wymagają dopasowanych wskaźników oceny.
W przypadku systemów dialogowych, metryki mogą oceniać zaangażowanie użytkowników lub wskaźniki zakończonych zadań. W przypadku generowania kodu, powodzenie może być mierzone tym, jak często wygenerowany kod kompiluje się lub przechodzi testy
przykład:** W przypadku chatbota do obsługi klienta, poziom zaangażowania może być mierzony na podstawie tego, jak długo użytkownicy pozostają w konwersacji lub ile pytań zadają.
Jeśli użytkownicy często proszą o dodatkowe informacje, oznacza to, że model skutecznie ich angażuje i skutecznie odpowiada na ich zapytania.
8. Solidność i uczciwość
Ocena solidności modelu obejmuje testowanie jak dobrze reaguje on na nieoczekiwane lub nietypowe dane wejściowe. Wskaźniki uczciwości pomagają zidentyfikować uprzedzenia w wynikach modelu, zapewniając jego sprawiedliwe działanie w różnych grupach demograficznych i scenariuszach.
przykład: **Podczas testowania modelu z kapryśnym pytaniem, takim jak "Co sądzisz o jednorożcach?", powinien on poradzić sobie z pytaniem z wdziękiem i do zrobienia odpowiedniej odpowiedzi. Jeśli zamiast tego udzieli bezsensownej lub niewłaściwej odpowiedzi, oznacza to brak odporności.
Testowanie uczciwości zapewnia, że model nie generuje stronniczych lub szkodliwych wyników, promując bardziej integracyjne podejście System AI .
📖 Czytaj więcej: Różnica między uczeniem maszynowym a sztuczną inteligencją
9. Wskaźniki wydajności
Wraz ze wzrostem złożoności modeli językowych, coraz ważniejsze staje się mierzenie ich wydajności **w odniesieniu do szybkości, wykorzystania pamięci i zużycia energii. Wskaźniki wydajności pomagają ocenić, jak zasobochłonny jest model podczas generowania odpowiedzi
przykład:** W przypadku dużego modelu językowego pomiar wydajności może obejmować śledzenie, jak szybko generuje on odpowiedzi na zapytania użytkowników i ile pamięci wykorzystuje podczas tego procesu.
Jeśli udzielanie odpowiedzi trwa zbyt długo lub zużywa zbyt dużo zasobów, może to stanowić problem dla aplikacji wymagających wydajności w czasie rzeczywistym, takich jak chatboty lub usługi tłumaczeniowe.
Teraz już wiesz, jak ocenić model LLM. Ale jakich narzędzi można użyć, aby to zmierzyć? Przyjrzyjmy się temu zagadnieniu.
Jak ClickUp Brain może usprawnić ewaluację LLM
ClickUp to aplikacja typu "wszystko do pracy" z wbudowanym osobistym asystentem o nazwie ClickUp Brain. ClickUp Brain jest przełomem w ocenie wyników LLM. Do czego to służy?
Organizuje i podkreśla najistotniejsze dane, utrzymując zespół na właściwym torze. Dzięki funkcjom opartym na AI, ClickUp Brain jest jedną z najlepszych aplikacji do oceny wyników LLM oprogramowanie sieci neuronowych tam. Sprawia, że cały proces jest płynniejszy, wydajniejszy i bardziej oparty na współpracy niż kiedykolwiek wcześniej. Poznajmy razem jego możliwości.
Inteligentne zarządzanie wiedzą
Podczas oceny dużych modeli językowych (LLM) zarządzanie ogromnymi ilościami danych może być przytłaczające.

Podsumuj dane i usprawnij śledzenie wskaźników wydajności dzięki ClickUp Brain ClickUp Brain może organizować i zwracać uwagę na istotne wskaźniki i zasoby dostosowane specjalnie do oceny LLM. Zamiast grzebać w rozproszonych arkuszach kalkulacyjnych i gęstych raportach, ClickUp Brain gromadzi wszystko w jednym miejscu. Wskaźniki wydajności, dane porównawcze i wyniki testów są dostępne w przejrzystym i przyjaznym dla użytkownika interfejsie.
Taka organizacja pomaga zespołowi przebić się przez szum i skupić się na spostrzeżeniach, które naprawdę mają znaczenie, ułatwiając interpretację trendów i wzorców wydajności.
Mając wszystko, czego potrzebujesz w jednym miejscu, możesz przejść od zwykłego gromadzenia danych do wpływowego, opartego na danych procesu decyzyjnego, przekształcając nadmiar informacji w przydatne informacje.
Zarządzanie projektami i cyklem pracy
Ewaluacje LLM wymagają starannego planu i współpracy, a ClickUp ułatwia zarządzanie tym procesem.
Możesz łatwo oddelegować obowiązki, takie jak gromadzenie danych, szkolenie modeli i testowanie wydajności, jednocześnie ustawiając priorytety, aby upewnić się, że najważniejsze zadania zostaną wykonane w pierwszej kolejności. Niestandardowe pola pozwalają dostosować cykl pracy do konkretnych potrzeb projektu.

Twórz i przydzielaj zadania oraz usprawnij cykl pracy za pomocą AI w ClickUp
Dzięki ClickUp każdy może zobaczyć, kto co robi i kiedy, pomagając uniknąć opóźnień i upewniając się, że zadania w całym zespole przebiegają płynnie. To świetny sposób na zorganizowanie wszystkiego i śledzenie od początku do końca.
Śledzenie metryk za pomocą niestandardowych pulpitów
Chcesz mieć oko na wydajność swoich systemów LLM? Pulpity ClickUp wizualizują wskaźniki wydajności w czasie rzeczywistym. Umożliwiają natychmiastowe monitorowanie postępów modelu. Pulpity te są wysoce konfigurowalne, umożliwiając tworzenie wykresów i diagramów, które prezentują dokładnie to, czego potrzebujesz, kiedy tego potrzebujesz.
Możesz obserwować, jak dokładność modelu ewoluuje na różnych scenach oceny lub rozbijać zużycie zasobów na każdej scenie. Informacje te pozwalają szybko dostrzec trendy, zidentyfikować obszary wymagające poprawy i na bieżąco wprowadzać poprawki.
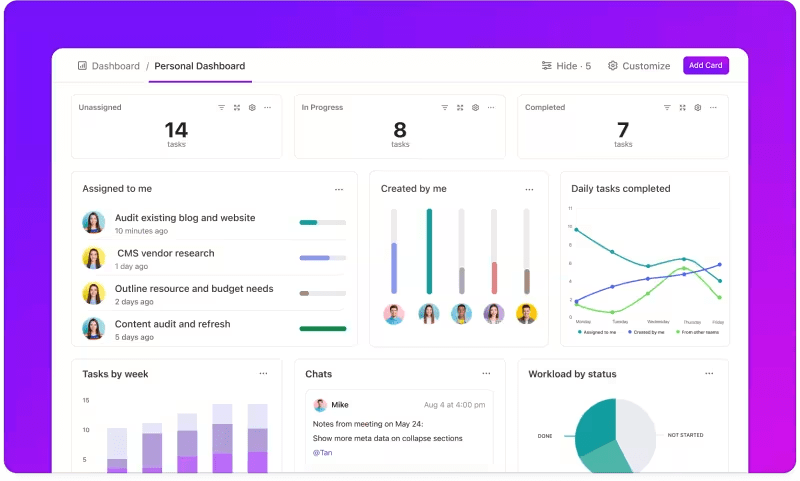
zobacz postęp swojej oceny jednym rzutem oka w ClickUp Dashboards_
Zamiast czekać na kolejny szczegółowy raport, Pulpity ClickUp pozwalają być na bieżąco i reagować, umożliwiając zespołowi podejmowanie decyzji opartych na danych bez opóźnień.
Automatyzacja analiz
Analiza danych może być czasochłonna, ale Funkcje ClickUp Brain zmniejszają obciążenie, dostarczając cennych spostrzeżeń. Podkreśla ważne trendy, a nawet sugeruje zalecenia oparte na danych, ułatwiając wyciąganie znaczących wniosków.
Dzięki automatyzacji ClickUp Brain nie ma potrzeby ręcznego przeczesywania nieprzetworzonych danych w poszukiwaniu wzorców - system dostrzega je za Ciebie. Automatyzacja ta pozwala zespołowi skupić się na doskonaleniu wydajności modelu, zamiast grzęznąć w powtarzalnej analizie danych.
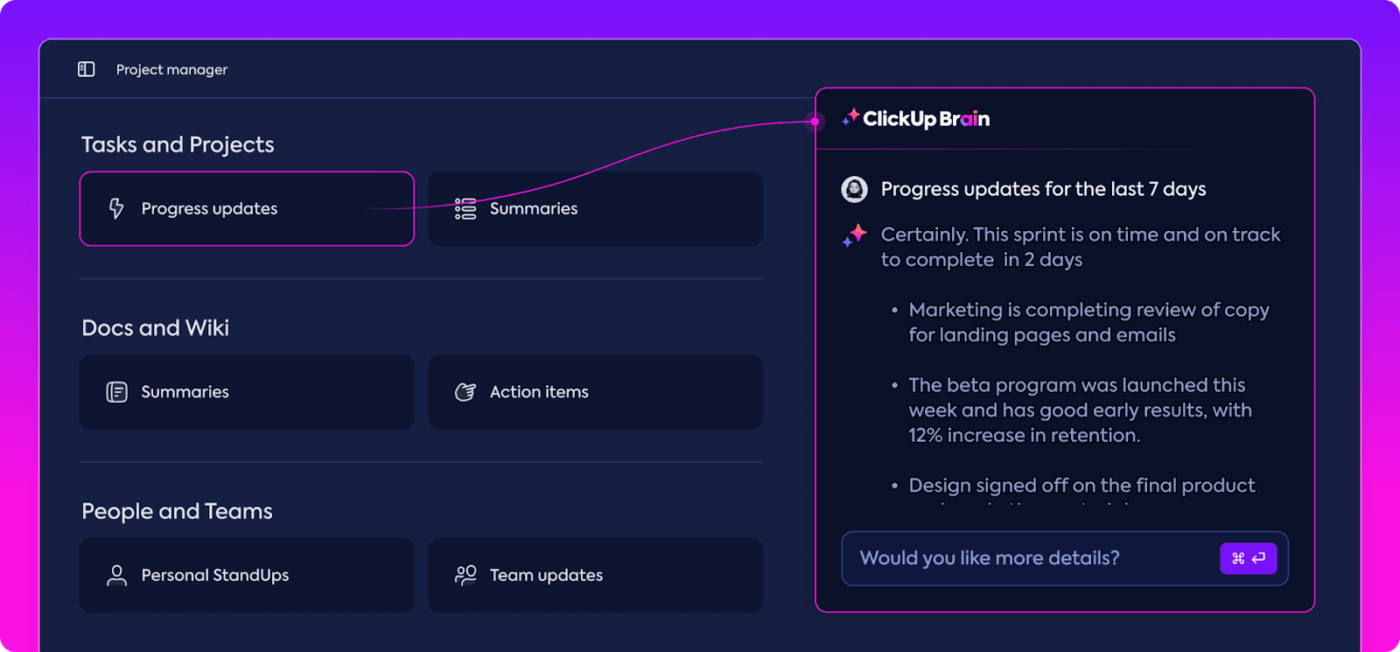
Uzyskaj przydatne informacje dzięki ClickUp Brain
Wygenerowane spostrzeżenia są gotowe do użycia, pozwalając Twojemu zespołowi natychmiast zobaczyć, co działa i gdzie mogą być potrzebne zmiany. Skracając czas poświęcany na analizę, ClickUp pomaga zespołowi przyspieszyć proces oceny i skupić się na wdrożeniu.
Dokumentacja i współpraca
Koniec z przekopywaniem się przez e-maile lub wiele platform, aby znaleźć to, czego potrzebujesz; wszystko jest tam, gotowe, kiedy jesteś. Dokumenty ClickUp to centralny hub, który gromadzi wszystko, czego zespół potrzebuje do sprawnej oceny LLM. Organizuje kluczową dokumentację projektu - kryteria porównawcze, wyniki testów i dzienniki wydajności - w jednym dostępnym miejscu, dzięki czemu każdy może szybko uzyskać dostęp do najnowszych informacji.
To, co naprawdę wyróżnia ClickUp Docs, to funkcje współpracy w czasie rzeczywistym. Zintegrowana ClickUp Chat i komentarze zezwalaj członkom Teams na omawianie spostrzeżeń, przekazywanie opinii i sugerowanie zmian bezpośrednio w dokumentach
Oznacza to, że Twój zespół może omawiać wyniki i wprowadzać poprawki bezpośrednio na platformie, dzięki czemu wszystkie dyskusje są istotne i rzeczowe.

Współpracuj i edytuj dokumenty ClickUp ze swoim zespołem w czasie rzeczywistym
Wszystko, od dokumentacji po pracę zespołową, odbywa się w ClickUp Docs, tworząc usprawniony proces oceny, w którym każdy może zobaczyć, udostępniać i działać zgodnie z najnowszymi osiągnięciami.
Wynik? Płynny, ujednolicony przepływ pracy, który pozwala Twojemu zespołowi dążyć do wyznaczonych celów z zakończoną klarownością.
Czy jesteś gotowy, aby wypróbować ClickUp? Zanim to nastąpi, omówmy kilka wskazówek i sztuczek, aby jak najlepiej wykorzystać ocenę LLM.
Najlepsze praktyki w ewaluacji LLM
Dobrze zorganizowane podejście do ewaluacji LLM zapewnia, że model spełnia twoje potrzeby, jest zgodny z oczekiwaniami użytkowników i zapewnia znaczące wyniki.
Ustawienie jasnych celów, uwzględnienie użytkowników końcowych i korzystanie z różnych wskaźników pomaga ukształtować dokładną ocenę, która ujawnia mocne strony i obszary wymagające poprawy. Poniżej znajduje się kilka najlepszych praktyk, które pomogą w przeprowadzeniu tego procesu.
🎯 Zdefiniuj jasne cele
Przed rozpoczęciem procesu ewaluacji ważne jest, aby dokładnie wiedzieć, co ma zostać osiągnięte przez duży model językowy (LLM). Poświęć trochę czasu na nakreślenie konkretnych zadań lub celów dla modelu.
przykład:** Jeśli chcesz poprawić wydajność tłumaczenia maszynowego, określ poziomy jakości, które chcesz osiągnąć. Posiadanie jasnych celów pomaga skupić się na najistotniejszych metrykach, zapewniając, że ocena pozostaje zgodna z tymi celami i dokładnie mierzy powodzenie.
👥 Rozważ swoich odbiorców
Zastanów się, kto będzie korzystał z LLM i jakie są jego potrzeby. Dostosowanie ewaluacji do zamierzonych użytkowników ma kluczowe znaczenie.
przykład: **Jeśli model ma generować angażującą zawartość, należy zwrócić szczególną uwagę na wskaźniki takie jak płynność i spójność. Zrozumienie odbiorców pomaga udoskonalić kryteria oceny, upewniając się, że model zapewnia rzeczywistą wartość w praktycznych zastosowaniach
📊 Używaj różnych wskaźników
Nie polegaj tylko na jednej metryce do oceny swojego LLM; połączenie metryk daje pełniejszy obraz jego wydajności. Każda miara uwzględnia inne aspekty, więc korzystanie z kilku z nich może pomóc w zidentyfikowaniu zarówno mocnych, jak i słabych stron.
przykład:** Podczas gdy wyniki BLEU są świetne do mierzenia jakości tłumaczeń, mogą one nie obejmować wszystkich niuansów kreatywnego pisania. Uwzględnienie wskaźników takich jak perplexity dla dokładności predykcyjnej, a nawet ludzkich ocen dla kontekstu może prowadzić do znacznie bardziej wszechstronnego zrozumienia, jak dobrze działa twój model
Benchmarki i narzędzia LLM
Ocena dużych modeli językowych (LLM) często opiera się na standardowych benchmarkach i specjalistycznych narzędziach, które pomagają ocenić wydajność modelu w różnych zadaniach.
Oto zestawienie kilku powszechnie stosowanych benchmarków i narzędzi, które nadają procesowi oceny strukturę i przejrzystość.
Kluczowe benchmarki
- GLUE (General Language Understanding Evaluation): GLUE ocenia możliwości modelu w wielu zadaniach językowych, w tym klasyfikacji zdań, podobieństwa i wnioskowania. Jest to punkt odniesienia dla modeli, które muszą obsługiwać ogólne rozumienie języka
- SQuAD (Stanford Question Answering Dataset): Ramy oceny SQuAD są idealne do czytania ze zrozumieniem i mierzą, jak dobrze model odpowiada na pytania oparte na fragmencie tekstu. Jest powszechnie stosowany w zadaniach takich jak obsługa klienta i wyszukiwanie oparte na wiedzy, gdzie precyzyjne odpowiedzi są kluczowe
- SuperGLUE: Jako ulepszona wersja GLUE, SuperGLUE ocenia modele w bardziej złożonych zadaniach rozumowania i rozumienia kontekstowego. Zapewnia głębszy wgląd, szczególnie w przypadku aplikacji wymagających zaawansowanego rozumienia języka
Podstawowe narzędzia oceny
- Hugging Face : Jest bardzo popularny ze względu na rozszerzenie biblioteki modeli, zestawów danych i funkcji oceny. Jego wysoce intuicyjny interfejs pozwala użytkownikom łatwo wybierać testy porównawcze, niestandardowe oceny i śledzenie wydajności modelu, dzięki czemu jest wszechstronny w wielu zastosowaniach LLM
- SuperAnnotate **Specjalizuje się w zarządzaniu i adnotowaniu danych, co ma kluczowe znaczenie dla nadzorowanych zadań uczenia się. Jest szczególnie przydatny do udoskonalania dokładności modelu, ponieważ ułatwia uzyskanie wysokiej jakości danych opatrzonych ludzkimi adnotacjami, które poprawiają wydajność modelu w złożonych zadaniach
- AllenNLP **Opracowany przez Allen Institute for AI, AllenNLP jest przeznaczony dla badaczy i programistów pracujących nad niestandardowymi modelami NLP. Zapewnia wsparcie dla szeregu testów porównawczych i dostarcza narzędzia do trenowania, testowania i oceny modeli językowych, oferując elastyczność dla różnorodnych zastosowań NLP
Korzystanie z kombinacji tych benchmarków i narzędzi oferuje kompleksowe podejście do oceny LLM. Benchmarki pozwalają na ustawienie standardów dla różnych zadań, podczas gdy narzędzia zapewniają strukturę i elastyczność potrzebną do skutecznego śledzenia, udoskonalania i poprawiania wydajności modeli.
Razem zapewniają, że LLM spełniają zarówno standardy techniczne, jak i praktyczne potrzeby aplikacji.
Wyzwania związane z oceną modeli LLM
Ocena dużych modeli językowych (LLM) wymaga zniuansowanego podejścia. Koncentruje się ona na jakości odpowiedzi oraz zrozumieniu zdolności adaptacyjnych i limitów modelu w różnych scenariuszach.
Ponieważ modele te są trenowane na rozszerzonych zbiorach danych, na ich zachowanie wpływa szereg czynników, co sprawia, że niezbędna jest ocena czegoś więcej niż tylko dokładności.
Prawdziwa ewaluacja oznacza zbadanie niezawodności modelu, odporności na nietypowe podpowiedzi i ogólną spójność odpowiedzi. Proces ten pomaga nakreślić jaśniejszy obraz mocnych i słabych stron modelu oraz odkrywa obszary wymagające dopracowania.
Poniżej przyjrzymy się bliżej niektórym typowym wyzwaniom, które pojawiają się podczas ewaluacji LLM.
1. Nakładanie się danych treningowych
Trudno jest stwierdzić, czy model widział już część danych testowych. Ponieważ LLM są szkolone na ogromnych zbiorach danych, istnieje szansa, że niektóre pytania testowe pokrywają się z przykładami szkoleniowymi . Może to sprawić, że model będzie wyglądał lepiej niż w rzeczywistości, ponieważ może po prostu powtarzać to, co już wie, zamiast wykazywać prawdziwe zrozumienie.
2. Niespójna wydajność
Modele LLM mogą mieć nieprzewidywalne reakcje. W jednej chwili dostarczają imponujących spostrzeżeń, a w następnej popełniają dziwne błędy lub przedstawiają wyimaginowane informacje jako fakty (znane jako "halucynacje").
Ta niespójność oznacza, że podczas gdy wyniki LLM mogą błyszczeć w niektórych obszarach, mogą być słabe w innych, co utrudnia dokładną ocenę ich ogólnej niezawodności i jakości.
3. Podatności na ataki przeciwników
Modele LLM mogą być podatne na ataki adwersarzy, w których sprytnie spreparowane podpowiedzi skłaniają je do udzielania błędnych lub szkodliwych odpowiedzi. Taka podatność ujawnia słabości modelu i może prowadzić do nieoczekiwanych lub tendencyjnych wyników. Testowanie tych słabości jest kluczowe dla zrozumienia, gdzie leżą granice modelu.
Praktyczne przypadki użycia ewaluacji LLM
Oto kilka typowych sytuacji, w których ewaluacja LLM naprawdę robi różnicę:
Chatboty do obsługi klienta
Modele LLM są szeroko stosowane w chatbotach do obsługi niestandardowych zapytań klientów. Ocena tego, jak dobrze model reaguje, zapewnia, że dostarcza on dokładnych, pomocnych i kontekstowych odpowiedzi.
Kluczowe jest zmierzenie jego zdolności do zrozumienia intencji klienta, obsługi różnorodnych pytań i udzielania odpowiedzi podobnych do ludzkich. Pozwoli to Businessowi zapewnić płynną obsługę klienta przy jednoczesnym zminimalizowaniu frustracji.
Generowanie zawartości
Wiele firm korzysta z LLM do generowania zawartości blogów, mediów społecznościowych i opisów produktów. Ocena jakości generowanej zawartości pomaga zapewnić, że jest ona poprawna gramatycznie, angażująca i odpowiednia dla docelowych odbiorców. Metryki takie jak kreatywność, spójność i adekwatność do tematu są tutaj ważne dla utrzymania wysokich standardów zawartości.
Analiza nastrojów
LLM mogą analizować sentyment opinii klientów, postów w mediach społecznościowych lub recenzji produktów. Ważne jest, aby ocenić, jak dokładnie model identyfikuje, czy dana pozycja tekstu jest pozytywna, negatywna czy neutralna. Pomaga to firmom zrozumieć emocje klientów, udoskonalić produkty lub usługi, zwiększyć zadowolenie użytkowników i ulepszyć strategie marketingowe.
Generowanie kodu
Programiści często korzystają z LLM, aby pomóc w generowaniu kodu. Ocena zdolności modelu do tworzenia funkcjonalnego i wydajnego kodu jest kluczowa.
Ważne jest, aby sprawdzić, czy wygenerowany kod jest logicznie poprawny, wolny od błędów i spełnia wymagania zadania. Pomaga to zmniejszyć ilość potrzebnego ręcznego kodowania i poprawia wydajność.
Zoptymalizuj ocenę LLM dzięki ClickUp
Ocena LLM polega na wybraniu odpowiednich wskaźników, które są zgodne z celami firmy. Kluczem jest zrozumienie konkretnych celów, niezależnie od tego, czy chodzi o poprawę jakości tłumaczenia, usprawnienie generowania zawartości, czy też dostosowanie do specjalistycznych zadań.
Wybór odpowiednich wskaźników do oceny wydajności, takich jak RAG lub wskaźniki dostrajania, stanowi formularz dokładnej i znaczącej oceny. Tymczasem zaawansowane scorery, takie jak G-Eval, Prometheus, SelfCheckGPT i QAG, dostarczają precyzyjnych informacji dzięki swoim silnym zdolnościom rozumowania.
Nie oznacza to jednak, że te wyniki są idealne - nadal ważne jest, aby upewnić się, że są wiarygodne.
W miarę postępów w ocenie aplikacji LLM, dostosuj proces do konkretnego przypadku użycia. Nie ma uniwersalnej miary, która sprawdziłaby się w każdym scenariuszu. Połączenie różnych wskaźników i skupienie się na kontekście pozwoli uzyskać dokładniejszy obraz wydajności modelu.
Aby usprawnić ocenę LLM i poprawić współpracę w zespole, ClickUp jest idealnym rozwiązaniem do zarządzania cyklami pracy i śledzenia ważnych wskaźników.
Chcesz zwiększyć wydajność swojego zespołu? Zarejestruj się w ClickUp już dziś i przekonaj się, jak może to zmienić Twój cykl pracy!