

Drie providers, twaalf verschillende prompts en geen enkele manier om je beste resultaten te reproduceren – dat is waar de meeste multi-LLM-experimenten zonder systeem om resultaten bij te houden op uitlopen.
Deze ClickUp-sjablonen bieden je team een gedeeld, consistent raamwerk voor het plannen, uitvoeren en vergelijken van multi-LLM-experimenten. En het beste? Ze dekken alles, van het vastleggen van hypothesen en kwaliteitsscores tot goedkeuring door belanghebbenden en definitieve onderzoeksrapporten.
Laten we beginnen! 👀
Sjablonen voor het bijhouden van multi-LLM-experimenten in één oogopslag
Hier volgt een kort overzicht van de sjablonen voor het bijhouden van multi-LLM-experimenten die in deze gids worden behandeld:
| Sjabloon | Downloaden | Ideaal voor | Belangrijkste functies |
|---|---|---|---|
| ClickUp-sjabloon voor experimentplannen en resultaten | Ontvang een gratis sjabloon | LLM-experimenten van begin tot eind plannen en documenteren | Hypothese-logging, velden voor testconfiguratie, samenvattingen van beslissingen |
| ClickUp-sjabloon voor Whiteboard voor groeiexperimenten | Ontvang een gratis sjabloon | Experimentideeën beheren en prioriteren | Visuele backlog, stemsysteem, omzetting van ideeën naar taken |
| ClickUp-spreadsheetsjabloon | Ontvang een gratis sjabloon | Het loggen van herhaalbare experimenten op schaal | Gestructureerde kolommen, filteren en sorteren, triggers voor automatisering |
| ClickUp-sjabloon voor softwarevergelijking | Ontvang een gratis sjabloon | LLM-providers vergelijken op basis van verschillende criteria | Zij-aan-zij-vergelijkingen, dashboardvisualisaties, evaluatiescores |
| ClickUp-sjabloon voor projectmanagementdashboard | Ontvang een gratis sjabloon | Monitoring van de prestaties van experimenten binnen verschillende teams | Status bijhouden, vergelijking van providers, inzicht in de werklast |
| ClickUp-sjabloon voor wekelijks statusrapport | Ontvang een gratis sjabloon | Rapportage over de voortgang van experimenten en belemmeringen | Wekelijkse samenvattingen, door AI gegenereerde updates, bijhouden van blokkades |
| ClickUp-sjabloon voor activiteitenrapport | Ontvang een gratis sjabloon | Experimentgeschiedenis en audittrails bijhouden | Activiteitenlogboeken, records met tijdstempels, voortgang bijhouden |
| ClickUp-sjabloon voor kwaliteitscontrolechecklist | Ontvang een gratis sjabloon | De installatie van het experiment valideren vóór uitvoering | Parametercontroles, beoordeling van gereedheid, gated werkstroomen |
| ClickUp-sjabloon voor UAT-goedkeuring | Ontvang een gratis sjabloon | Documenteren van definitieve modelbeslissingen en goedkeuringen | Goedkeuringsregistratie, audittrail, goedkeuringen door belanghebbenden |
| ClickUp-sjabloon voor onderzoeksrapporten | Ontvang een gratis sjabloon | Presentatie van experimentresultaten en aanbevelingen | Gestructureerde rapporten, AI-ondersteunde samenvattingen, gezamenlijke bewerking |
📚 Lees ook: ClickUp PromptOps-sjablonen voor AI-werkstroomen
Wat is het bijhouden van multi-LLM-experimenten?
Het bijhouden van multi-LLM-experimenten is het systematisch vastleggen, vergelijken en analyseren van de output van twee of meer grote taalmodellen aan de hand van dezelfde prompts of evaluatiecriteria. Elk team dat beslist welk LLM-model het gaat inzetten – of modellen combineert voor verschillende taken – heeft een herhaalbare manier nodig om vast te leggen wat er is gebeurd, wat werkte en waarom.
Zonder structuur eindigen teams met versnipperde aantekeningen verspreid over verschillende tools. Niemand kan zien welke versie met welke prompt is getest, en het delen van bevindingen met mensen die er niet bij waren, wordt giswerk.
Deze AI-wildgroei – de ongeplande proliferatie van AI-tools, -modellen en -platforms zonder toezicht of strategie – treft elk team dat met meerdere AI-tools jongleert zonder een geconvergeerde werkruimte.
Dit is waar het bij het bijhouden van multi-LLM-experimenten om draait:
| Component | Voorbeelden |
|---|---|
| Modellen | ClickUp Brain, Claude 3.7, GPT-4o, Gemini 1.5 |
| Prompts | Systeemprompts, gebruikersprompts, few-shot-voorbeelden |
| Parameters | Temperatuur, max. tokens, top-p |
| Uitkomsten | Ruwe reacties, latentie, tokengebruik |
| Evaluatiestatistieken | Nauwkeurigheid, BLEU/ROUGE-scores, menselijke beoordelingen, kosten |
| Metadata | Tijdstempels, versies van datasets, omgevingsinformatie |
📝 Aantekening: Het bijhouden van experimenten en ML-observability zijn niet hetzelfde. Bijhouden is de gestructureerde laag voor het bijhouden van gegevens. Observability zorgt voor realtime monitoring en waarschuwingen. De sjablonen dekken het bijhouden zonder dat er een installatie nodig is.
Waar je op moet letten bij sjablonen voor het bijhouden van multi-LLM-experimenten
Voordat je een sjabloon kiest, heb je duidelijke evaluatiecriteria nodig. ✨
- Gestructureerde experimentvelden: Speciale velden voor modelnaam, promptversie, parameters en uitvoer – geen leeg document dat u zelf moet opbouwen
- Layout voor zij-aan-zij-vergelijking: Bekijk de resultaten van Model A versus Model B in één weergave zonder tussen tabbladen te hoeven schakelen
- Bijhouden van evaluatiestatistieken: Ingebouwde kolommen voor het scoren van nauwkeurigheid, relevantie, latentie, kosten per token en hallucinatiepercentage
- Status en werkstroom: Markeer experimenten als gepland, in uitvoering, voltooid of afgewezen, zodat iedereen kan zien hoe de status is
- Samenwerkingsfuncties: Opmerkingen, vermeldingen en toegewezen personen zorgen ervoor dat de onderzoeker en de besluitvormer synchroniseren
- Dashboard of rapportagelaag: Breng individuele resultaten samen in een weergave voor beoordeling door het management
- Flexibiliteit voor verschillende soorten experimenten: Verwerk zowel vergelijkingen tussen twee modellen als variaties in prompts voor één model zonder dat u het ontwerp hoeft aan te passen
🧠 Leuk weetje: De Transformer werd geïntroduceerd met een van de meest zelfverzekerde titels ooit: “Attention Is All You Need.” Het artikel stelde een model voor dat uitsluitend op aandachtsmechanismen was gebaseerd, waarbij herhaling en convoluties volledig werden weggelaten — en die architectuur vormde vervolgens de basis voor moderne LLM's.
📚 Lees ook: Gratis AI-prompt-werkstroom-sjablonen
10 ClickUp-sjablonen voor het bijhouden van multi-LLM-experimenten
Alle hier genoemde sjablonen zijn te vinden in de sjabloonbibliotheek van ClickUp. U kunt ze allemaal aanpassen met aangepaste velden, statussen, weergaven, automatiseringen en nog veel meer.
1. ClickUp-sjabloon voor experimentplan en resultaten
Multi-LLM-experimenten zijn eenvoudig uit te voeren, maar veel moeilijker achteraf te interpreteren. Een resultaat kan op dat moment veelbelovend lijken, maar verliest snel zijn waarde als het team niet kan achterhalen wat er is getest, welke instellingen zijn gebruikt of hoe de uiteindelijke beslissing tot stand is gekomen.
De ClickUp-sjabloon voor experimentplannen en -resultaten biedt teams één plek om het experiment te definiëren voordat het wordt uitgevoerd en om de resultaten vast te leggen nadat het is uitgevoerd. Dat maakt het eenvoudiger om modellen, prompts en configuraties tussen experimenten te vergelijken zonder de redenering achter de uiteindelijke beslissing uit het oog te verliezen.
✨ Waarom je deze sjabloon geweldig zult vinden:
- Veld 'Hypothese': Geef uw voorspelling aan voordat u een test uitvoert om bevestigingsvertekening te voorkomen
- Sectie Testconfiguratie: Registreer provider, modelversie en temperatuurinstelling met ClickUp aangepaste velden
- Beslissingslogboek: Laat ClickUp Brain automatisch experimentoverzichten genereren op basis van de resultaten
✅ Meest geschikt voor: AI-productmanagers die gestructureerde LLM-evaluaties uitvoeren.
💡 Pro-tip: Multi-LLM-experimenten kunnen snel een berg aan output genereren. ClickUp Brain helpt je hierin overzicht te scheppen door bevindingen samen te vatten, conclusies te standaardiseren en resultaten om te zetten in traceerbaar werk in één geconvergeerde werkruimte. Op die manier eindigt het experiment niet als een stapel antwoorden. Het eindigt als iets dat je team kan beoordelen, waarop het kan reageren en waarop het kan voortbouwen.
2. ClickUp-sjabloon voor Whiteboard voor groeiexperimenten
Zodra je team meer ideeën voor experimenten heeft dan het daadwerkelijk kan uitvoeren, verschuift de uitdaging van testen naar kiezen. Eén vergelijking van prompts leidt tot nog drie andere, verschillende providers openen nieuwe variabelen, en al snel groeit de backlog sneller dan het team deze kan evalueren.
De ClickUp Growth Experiments Whiteboard-sjabloon biedt je een visuele ruimte om die eerste ideeën te ordenen in de eerste fase van het bedrijf. De sjabloon is gebaseerd op een visueel canvas en helpt teams om ideeën in kaart te brengen, de sterkste vergelijkingen te identificeren en de beste ideeën in de praktijk te brengen.
✨ Waarom je deze sjabloon geweldig zult vinden:
- Visuele experimentenbacklog: Groepeer tests per use case of provider op een vrij vormbaar canvas met ClickUp Whiteboards
- Prioriteringsstemming: Laat teamleden stemmen over welke vergelijkingen het belangrijkst zijn
- AI-brainstormen: Gebruik ClickUp Brain om ideeën voor experimenten te genereren of hypothesen te herformuleren
✅ Meest geschikt voor: projectmanagers en onderzoeksleiders die een grote achterstand aan experimenten beheren.
3. ClickUp-spreadsheetsjabloon
Als je team experimenten tot nu toe in Google Spreadsheets of Excel heeft bijgehouden, zal de ClickUp-spreadsheetsjabloon er erg bekend uitzien. Deze is gebaseerd op de tabelweergave van ClickUp.
Elke rij vertegenwoordigt één experiment (model + prompt + parameters), en de kolommen bevatten outputs, scores, latentie, kosten en aantekeningen – maar dan met ingebouwde samenwerking en automatisering.
✨ Waarom je deze sjabloon geweldig zult vinden:
- Typbare, filterbare kolommen: Gebruik ClickUp aangepaste velden voor dropdown-menu's (modelprovider), nummers (latentie) en beoordelingen (kwaliteitsscore)
- Bulk sorteren en filteren: Sorteer honderden experimenten op elk gewenst veld zonder dat dit problemen oplevert voor de prestaties van de spreadsheet
- Geautomatiseerde notificaties: trigger waarschuwingen wanneer de status van een experiment verandert in 'Voltooid' met behulp van ClickUp automatiseringen
✅ Meest geschikt voor: AI-ops-teams die herhaalbare experimentlogboeken beheren.
🧠 Leuk weetje: Neurale netwerken bestaan al langer dan de term “AI”. In 1943 publiceerden Warren McCulloch en Walter Pitts het eerste wiskundige model van een kunstmatig neuron
4. ClickUp-sjabloon voor softwarevergelijking
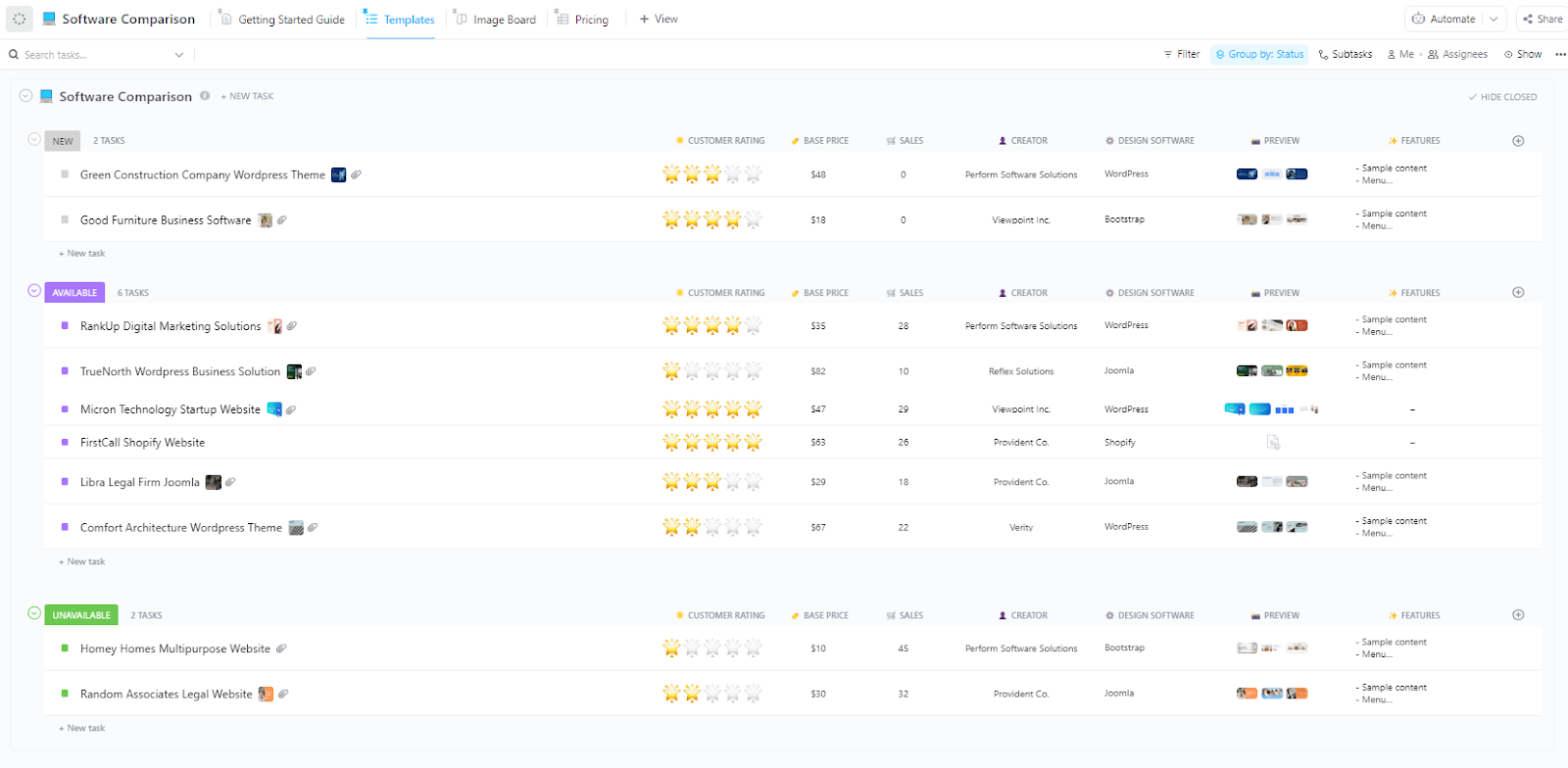
De ClickUp-sjabloon voor softwarevergelijking, oorspronkelijk ontworpen om tools te beoordelen aan de hand van gedeelde criteria, is perfect geschikt om LLM-providers rechtstreeks met elkaar te vergelijken.
In plaats van leveranciers vergelijkt u OpenAI, Anthropic, Google en Mistral op het gebied van outputkwaliteit, snelheid, kosten, contextvenstergrootte en veiligheidsfuncties.
Wanneer meerdere modellen om verschillende redenen veelbelovend lijken, helpt deze sjabloon je om ze te vergelijken aan de hand van dezelfde beslissingscriteria en met meer vertrouwen de uiteindelijke keuze te maken.
✨ Waarom je deze sjabloon geweldig zult vinden:
- Bekijk de voor- en nadelen van providers vanuit verschillende invalshoeken: Gebruik ClickUp weergaven om te schakelen tussen vergelijkingsformaten
- Visuele vergelijkingsgrafieken: Zet gegevens om in grafieken of samenvattingskaarten voor presentaties aan belanghebbenden met behulp van ClickUp dashboard
- AI-ondersteunde synthese: Laat ClickUp Brain context uit bestaande experimentdocumenten halen om vergelijkingsantekeningen te vullen
✅ Meest geschikt voor: Product- en engineeringmanagers die de afwegingen van modellen bespreken met belanghebbenden op het gebied van veiligheid of inkoop.
📮 ClickUp Insight: 45% van de respondenten in onze enquête geeft aan dat ze werkgerelateerde onderzoekstabbladen wekenlang open laten staan. Voor nog eens 23% bevatten deze waardevolle tabbladen AI-chatthreads vol context.
Kort gezegd: de overgrote meerderheid besteedt geheugen en context uit aan kwetsbare browsertabbladen. Zeg ons na: tabbladen zijn geen kennisbanken. 👀
ClickUp Brain MAX zorgt hier voor een doorbraak.
Met deze AI-superapp kun je je werkruimte doorzoeken, communiceren met meerdere AI-modellen en zelfs spraakcommando’s gebruiken om context op te halen vanuit één enkele interface. Omdat MAX op je pc draait, neemt het geen tabbladruimte in beslag en kun je gesprekken opslaan totdat je ze verwijdert!
📮 ClickUp Insight: 45% van de respondenten in onze enquête geeft aan dat ze werkgerelateerde onderzoekstabbladen wekenlang open laten staan. Voor nog eens 23% bevatten deze waardevolle tabbladen AI-chatthreads vol context.
Kort gezegd: de overgrote meerderheid besteedt geheugen en context uit aan kwetsbare browsertabbladen. Zeg ons na: tabbladen zijn geen kennisbanken. 👀
ClickUp Brain MAX zorgt hier voor een doorbraak.
Met deze AI-superapp kun je je werkruimte doorzoeken, communiceren met meerdere AI-modellen en zelfs spraakcommando’s gebruiken om context op te halen vanuit één enkele interface. Omdat MAX op je pc draait, neemt het geen tabbladruimte in beslag en kun je gesprekken opslaan totdat je ze verwijdert!
5. ClickUp-sjabloon voor projectmanagementdashboard

Wanneer je meer dan 50 experimenten bij vier verschillende providers beheert, volstaan individuele weergaven van taken niet meer. De ClickUp-sjabloon voor projectmanagement-dashboards verzamelt gegevens van je experimenttaken in widgets en visualiseert alles op één scherm.
Dat maakt het ongelooflijk handig wanneer uw experimentprogramma zich uitbreidt tot meer dan een paar eenmalige tests. In plaats van elke run afzonderlijk te beoordelen, kunt u de status van de volledige testpijplijn monitoren en zien waar het momentum afneemt.
✨ Waarom je deze sjabloon geweldig zult vinden:
- Verdeling van de experimentstatus: Zie in één oogopslag hoeveel experimenten er gepland, in uitvoering of voltooid zijn
- Resultaten per provider: Vergelijk welk model het beste presteert in alle voltooide experimenten
- Inzicht in de werklast: Houd bij wie in je team overbelast is met experimenttaken met ClickUp werklastweergave
✅ Meest geschikt voor: leidinggevenden op het gebied van toegepaste AI die de doorvoer van experimenten beheren voor onderzoekers, prompt-engineers en beoordelaars.
🔮 Bonus: Zichtbaarheid is slechts één onderdeel van het opschalen van multi-LLM-experimenten. ClickUp Super Agents bieden uw team AI-collega's waarmee u rechtstreeks kunt communiceren, werk kunt toewijzen en die u kunt configureren met hun eigen kennis en geheugen.
Lees hier meer informatie:
6. ClickUp-sjabloon voor wekelijks statusrapport
De ClickUp-sjabloon voor wekelijkse statusrapporten is handig voor het bijhouden van voltooide tests en eerste bevindingen. Bovendien helpt het je om eventuele knelpunten op te sporen, zoals vertragingen bij API-toegang, ontbrekende datasets of het wachten op feedback van reviewers.
Secties zoals projectoverzicht, belangrijkste resultaten en wekelijkse updates maken het gemakkelijker om de voortgang te laten zien zonder dat je het rapport elke keer opnieuw hoeft op te stellen.
Dit werkt uitstekend wanneer experimenten zich in hoog tempo ontwikkelen en het management duidelijk inzicht nodig heeft in wat er deze week is veranderd.
✨ Waarom je deze sjabloon geweldig zult vinden:
- Automatisch gegenereerde rapportagetaken: Maak elke week een nieuwe rapportagetaak aan met het vooraf toegepaste sjabloon via ClickUp-automatiseringen
- AI-opgestelde samenvattingen: Laat ClickUp Brain gegevens uit voltooide taken halen en binnen enkele minuten een status-samenvatting opstellen
- Blocker-bijhouden: Markeer afhankelijkheden zodat het management weet wat er moet worden opgelost
✅ Meest geschikt voor: evaluatieteams die terugkerende testcycli uitvoeren voor verschillende prompts, providers en use cases.
💟 Bonus: Werk slimmer – laat een Super Agent het werk van het opstellen van dagelijkse statusrapporten voor je experimenten overnemen! Hier is een video die laat zien hoe je dat doet.
7. ClickUp-sjabloon voor activiteitenrapport
Een modelwijziging wordt doorgevoerd. Twee weken later vraagt iemand waarom de prompt is aangepast, wie de nieuwe versie heeft goedgekeurd en of het team het resultaat ergens heeft vastgelegd. Als die geschiedenis verspreid is over opmerkingen, taken en losse aantekeningen, duurt het langer dan nodig is om het antwoord te vinden.
De ClickUp-sjabloon voor activiteitenrapporten biedt teams een duidelijk overzicht van wat er tijdens een experimentcyclus is gebeurd. Je kunt deze gebruiken om voltooide en openstaande taken, volgende stappen, kleine successen en procesproblemen op één plek vast te leggen. Voor teams die in gereguleerde omgevingen werken of in een werkstroom waar traceerbaarheid vereist is, is dat overzicht van groot belang.
✨ Waarom je deze sjabloon geweldig zult vinden:
- Zelfinvullend audittraject: registreer automatisch taakwijzigingen, toegevoegde opmerkingen en statusupdates met de ingebouwde activiteitentracking van ClickUp
- Zorg dat de rapportages overzichtelijk blijven: Gebruik ClickUp Docs om voltooid werk, openstaande items, volgende stappen en aantekeningen over het proces in één doorlopend overzicht vast te leggen
- Records met tijdstempel: Zorg ervoor dat elke invoer een datum- en tijdstempel bevat voor volledige traceerbaarheid
✅ Meest geschikt voor: AI-governanceteams die de geschiedenis van prompts, modellen en goedkeuringen gedurende experimentcycli beoordelen.
📚 Lees ook: De beste LLM's voor taalsamenvattingen
💡 Pro-tip: Bij het uitvoeren van multi-LLM-experimenten moet je meestal met te veel tabbladen jongleren. ClickUp Brain MAX brengt ChatGPT, Claude en Gemini samen in één desktop-app, zodat je van model kunt wisselen zonder je aantekeningen, vragen en vervolgwerk over verschillende tools te hoeven verdelen.
8. ClickUp-sjabloon voor kwaliteitschecklist
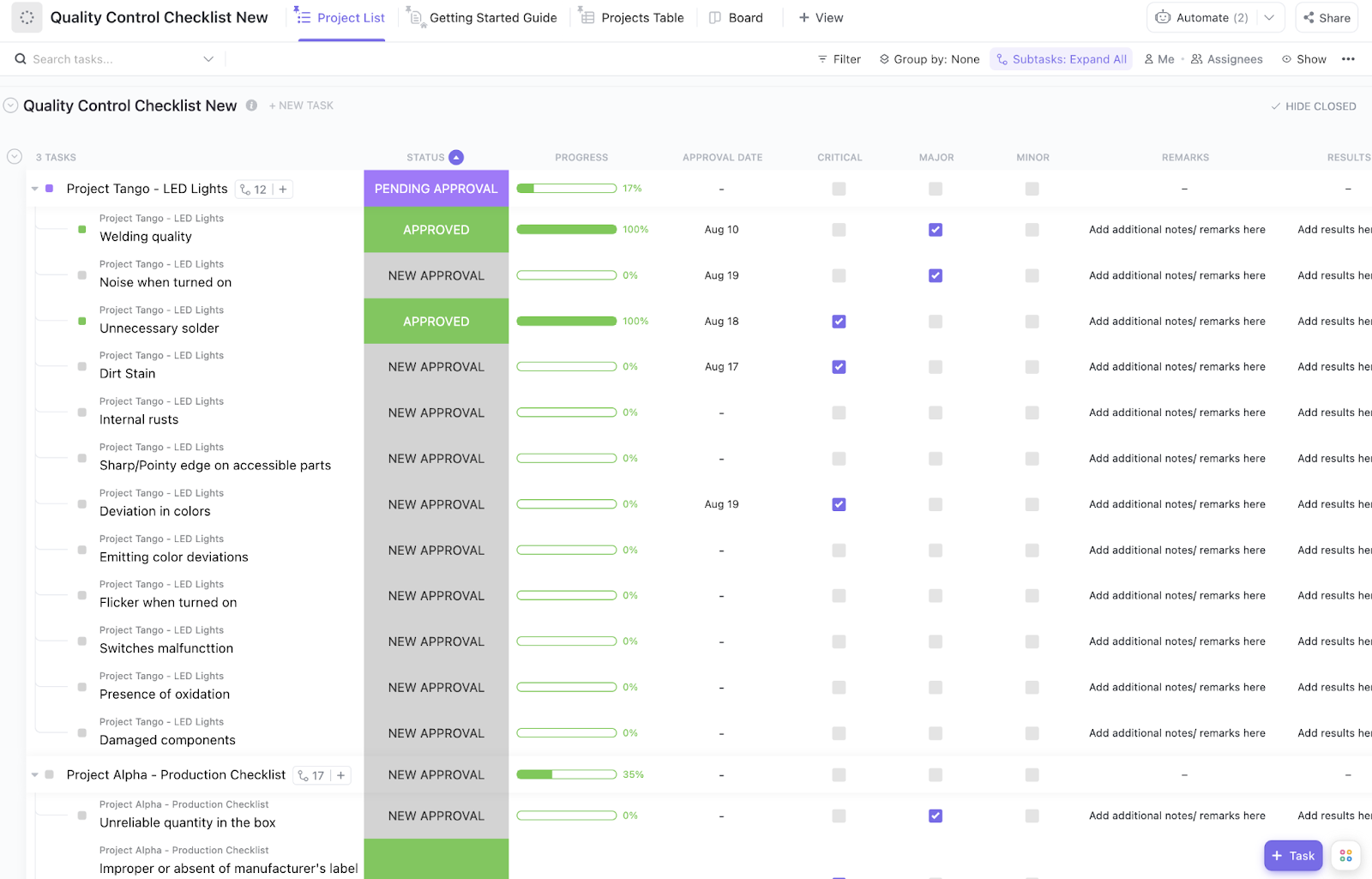
Eén verkeerde installatie kan een zuivere modelvergelijking verpesten. Een gemiste temperatuurinstelling, een gewijzigde prompt of een te laat gedefinieerde beoordelingsrubriek kan het resultaat vertekenen voordat je het doorhebt. Wanneer dat gebeurt, lijkt het experiment op papier compleet, maar zijn de bevindingen moeilijk te vertrouwen.
De ClickUp-sjabloon voor de kwaliteitscontrolechecklist biedt teams een gestructureerde manier om de kwaliteit van de installatie te beoordelen voordat een experiment van start gaat. In de lijstweergave van ClickUp kan elk experiment zijn eigen ClickUp-checklist hebben om de consistentie van prompts, de beoordeling van parameters, de gereedheid voor scoring en de definitieve goedkeuring te waarborgen.
✨ Waarom je deze sjabloon geweldig zult vinden:
- Controles op parameterconsistentie: Controleer of prompts, temperatuur, max. tokens en andere parameters overeenkomen in alle geteste modellen
- Bevestiging van de beoordelingsrubriek: Zorg ervoor dat de beoordelingscriteria zijn vastgesteld voordat de outputs worden beoordeeld
- Statusgating: Voorkom dat een experiment de status 'Voltooid' krijgt totdat alle checklistitems zijn afgevinkt met behulp van ClickUp automatiseringen
✅ Meest geschikt voor: AI-QA-managers die behoefte hebben aan een herhaalbare pre-launchcontrole voor het vergelijken van modellen.
📚 Lees ook: Hoe kun je AI-bias verminderen?
9. ClickUp-sjabloon voor UAT-goedkeuring
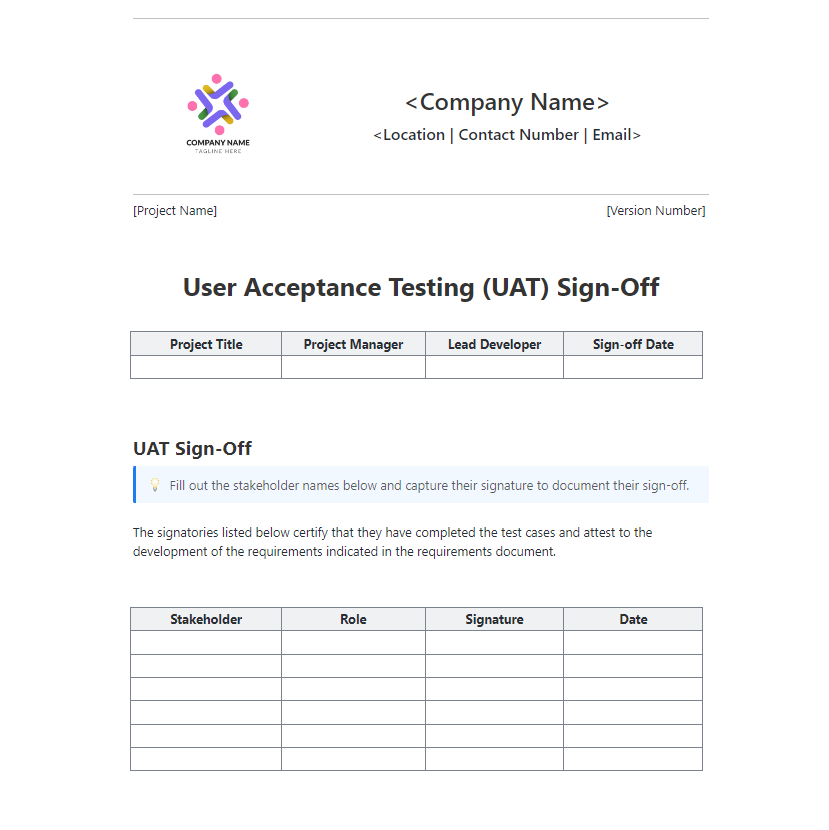
Een model kan het experiment winnen en toch nog niet klaar zijn voor productie. Iemand moet de aanbeveling nog bevestigen, de bekende risico's beoordelen en de uitrol goedkeuren.
De ClickUp UAT Sign-Off-sjabloon biedt teams een formele manier om die kloof te dichten. Gebruik deze om de samenvatting van het experiment, de aanbevolen modelinstallatie, belangrijke resultaten, bekende beperkingen en definitieve goedkeuringen op één plek vast te leggen.
Dit werkt goed voor multi-LLM-programma's waarbij de uiteindelijke beslissing meer vereist dan alleen een mondeling 'ja'.
✨ Waarom je deze sjabloon geweldig zult vinden:
- Status van goedkeuring bijhouden: Leg de beslissing van elke belanghebbende vast (goedgekeurd, afgewezen, in behandeling) via ClickUp aangepaste velden
- Geautomatiseerde goedkeuringsnotificaties: activeer notificaties wanneer goedkeuring nodig is met behulp van ClickUp-automatiseringen
- Voeg context toe vóór de definitieve beslissing: Gebruik ClickUp Clips om een korte uitleg op te nemen over de output, randgevallen of limieten van het winnende model, zodat beoordelaars de beslissing sneller kunnen nemen
✅ Meest geschikt voor: product-, engineering- en compliance-managers die een gedocumenteerd goedkeuringstraject nodig hebben voor ingrijpende AI-wijzigingen.
10. ClickUp-sjabloon voor onderzoeksrapporten
Je kunt een succesvolle reeks LLM-experimenten afronden en toch moeite hebben om uit te leggen wat het team heeft geleerd. De gegevens staan misschien in taken, scorekaarten, dashboards en opmerkingen. De aanbeveling staat misschien ergens anders. Dat vertraagt de evaluatie en maakt het moeilijker om het werk later opnieuw te gebruiken.
Met de ClickUp-sjabloon voor onderzoeksrapporten kunt u experimenteel werk omzetten in een duidelijk verslag. De sjabloon is gebaseerd op ClickUp Docs en bevat secties voor de samenvatting, methodologie, resultaten, referenties en meer.
Dit werkt goed voor interne evaluaties waarbij teams moeten documenteren waarom een model is getest, hoe het is beoordeeld en wat de resultaten lieten zien.
✨ Waarom je deze sjabloon geweldig zult vinden:
- Houd rapportgegevens gekoppeld aan de uitvoering: Gebruik ClickUp-taken om experimenten, eigenaren, statussen en resultaten te koppelen aan het eindrapport
- AI-ondersteund opstellen: Laat ClickUp Brain gegevens uit voltooide experimenttaken halen en de resultaten samenvatten, waardoor de tijd die nodig is voor het opstellen van rapporten aanzienlijk wordt verkort
- Samen bewerken: Ontvang feedback via opmerkingen en vermeldingen direct in het document
✅ Meest geschikt voor: AI-onderzoekers of productleiders die methodologie, bevindingen en implementatieaanbevelingen presenteren aan het management.
Begin met het bijhouden van uw multi-LLM-experimenten
Naarmate uw team overgaat van het evalueren van één of twee LLM's naar het beheren van strategieën met meerdere modellen voor verschillende use cases, wordt het gestructureerd bijhouden vrijwel onmisbaar.
U hebt gezien hoe elke sjabloon een ander onderdeel van de experimentcyclus afhandelt. Begin met de sjabloon Experimentplan en resultaten voor uw volgende modelvergelijking, en voeg vervolgens de Dashboard-sjabloon toe naarmate u opschaalt.
De echte belemmering voor het effectief bijhouden van experimenten is het ontbreken van een gedeelde structuur om vast te leggen wat je hebt getest, ontdekt en uiteindelijk besloten. Wanneer die gegevens verspreid zijn over notitieboeken, chatthreads en persoonlijke spreadsheets, kan je team niet leren van eerdere tests en geen zelfverzekerde beslissingen nemen over modellen.
Dat is waar de geconvergeerde AI-werkruimte van ClickUp van pas komt. Door je experimenttaken, gegevens en teamgesprekken op één plek te houden, allemaal verbonden door AI, biedt ClickUp je team de uniforme structuur die ze nodig hebben.
Ga gratis aan de slag met ClickUp en stel vandaag nog je eerste sjabloon voor het bijhouden van experimenten in. ✅
Veelgestelde vragen over multi-LLM-experimenten
Waarin verschillen sjablonen voor het bijhouden van multi-LLM-experimenten van ML-observatietools zoals Langfuse of Arize?
Sjablonen bieden gestructureerde kaders voor het documenteren van experimenten, zodat alle belangrijke details worden vastgelegd voor toekomstige analyse. Observability-tools maken daarentegen realtime monitoring van systeemprestaties mogelijk, met geautomatiseerde waarschuwingen voor afwijkingen en uitgebreide telemetriegegevens die geschikt zijn voor productieomgevingen. Veel teams gebruiken beide tools samen, waarbij ze de gestructureerde aanpak van sjablonen combineren met de directe inzichten van observability-tools.
Kan ik experimenten van OpenAI, Anthropic en open-source LLM-providers in dezelfde ClickUp-sjabloon bijhouden?
Ja, natuurlijk! In ClickUp beschik je over aangepaste velden waarmee je providerspecifieke metadata kunt definiëren voor elke experimentvermelding. Zo kun je resultaten van elke provider vastleggen en vergelijken zonder van tool te wisselen. En je kunt dashboards toevoegen om een beter, overzichtsmatig beeld van elk experiment te krijgen.
Welke statistieken moet ik vastleggen wanneer ik meerdere LLM's naast elkaar vergelijk in ClickUp?
Bij het vergelijken van meerdere LLM's in ClickUp omvatten de belangrijkste te loggen statistieken vier gebieden: prestaties (latentie, tokens per seconde, gebruik van het contextvenster), kwaliteit (nauwkeurigheid, hallucinatiepercentage, relevantiescore en consistentie bij het opvolgen van instructies), kosten (aantal input-/output-tokens en kosten per verzoek) en betrouwbaarheid (foutpercentage, aantal herhalingspogingen en time-outs). Voor taakspecifieke evaluaties moet u ook BLEU/ROUGE-scores voor samenvatting, Pass@k voor codegeneratie of de nauwkeurigheid van tool-aanroepen voor agentische taken opnemen.
Heb ik technische expertise nodig om het bijhouden van multi-LLM-experimenten in ClickUp in te stellen?
Nee, sjablonen in ClickUp zijn vooraf gestructureerd, zodat u direct kunt beginnen met het loggen van experimenten. Bovendien helpt ClickUp Brain u bij het aanpassen van velden en het instellen van automatiseringen met behulp van natuurlijke taal.