
La maggior parte dei progetti di implementazione dell'IA fallisce non perché i team abbiano scelto il modello sbagliato, ma perché nessuno ricorda, tre mesi dopo, perché lo hanno scelto o come replicarne la configurazione, con il 46% dei progetti di IA abbandonati tra la fase di proof-of-concept e quella di adozione su larga scala.
Questa guida ti illustra come utilizzare Hugging Face per l'implementazione dell'IA, dalla selezione e il test dei modelli alla gestione del processo di implementazione, in modo che il tuo team possa distribuire più rapidamente senza perdere decisioni critiche in thread Slack e fogli di calcolo sparsi.
Che cos'è Hugging Face?
Hugging Face è una piattaforma open source e un hub comunitario che fornisce modelli di IA pre-addestrati, set di dati e strumenti per la creazione e l'implementazione di applicazioni di machine learning.
Consideralo come una grande biblioteca digitale dove puoi trovare modelli di IA pronti all'uso invece di passare mesi e risorse significative a crearli da zero.
È progettato per ingegneri di machine learning e data scientist, ma i suoi strumenti sono sempre più utilizzati da team interfunzionali di prodotto, progettazione e ingegneria per integrare l'IA nei loro flussi di lavoro.
Lo sapevate? Il 63% delle organizzazioni non dispone di adeguate pratiche di gestione dei dati per l'IA. Ciò spesso porta a progetti bloccati e spreco di risorse.
La sfida principale per molti team è la complessità dell'implementazione dell'IA. Il processo prevede la selezione del modello giusto tra migliaia di opzioni, la gestione dell'infrastruttura sottostante, il versioning degli esperimenti e la garanzia che gli stakeholder tecnici e non tecnici siano allineati.
Hugging Face semplifica questo processo fornendo il suo Model Hub, un repository centrale con oltre 2 milioni di modelli. La libreria di trasformatori della piattaforma è la chiave che ti consente di usufruire di questi modelli, consentendoti di caricarli e utilizzarli con poche righe di codice Python.
Tuttavia, anche con questi potenti strumenti, l'implementazione dell'IA rimane una sfida per il project management, che richiede un attento monitoraggio della selezione dei modelli, dei test e del lancio per garantire un esito positivo.
📮ClickUp Insight: il 92% dei knowledge worker rischia di perdere decisioni importanti sparse tra chat, email e fogli di calcolo. Senza un sistema unificato per acquisire e effettuare il monitoraggio delle decisioni, le informazioni aziendali critiche vanno perse nel rumore digitale.
Con le funzionalità di gestione delle attività di ClickUp, non dovrai più preoccuparti di questo. Crea attività da chat, commenti alle attività, documenti ed e-mail con un solo clic!
Modelli Hugging Face che puoi implementare
All'inizio, navigare nell'Hugging Face Hub può sembrare complicato. Con centinaia di migliaia di modelli disponibili, la chiave è comprendere le categorie principali per trovare quello più adatto al tuo progetto. I modelli spaziano da opzioni piccole ed efficienti progettate per un unico scopo a modelli enormi e generici in grado di gestire ragionamenti complessi.
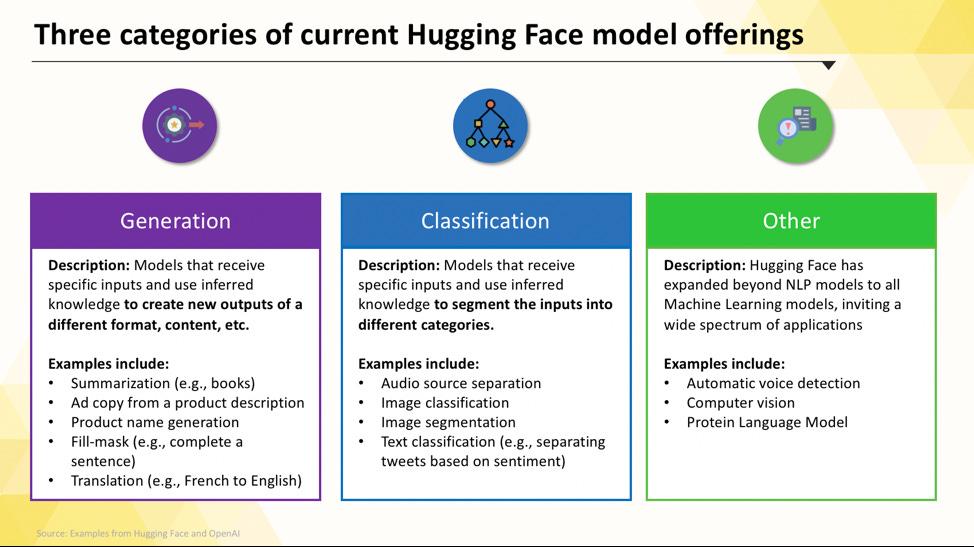
Modelli linguistici specifici per attività
Quando il tuo team deve risolvere un problema singolo e ben definito, spesso non è necessario un modello generico di grandi dimensioni. Il tempo e i costi necessari per eseguire un modello di questo tipo possono essere proibitivi, soprattutto quando uno strumento di IA più piccolo e mirato funzionerebbe meglio. È qui che entrano in gioco i modelli specifici per determinate attività.
Si tratta di modelli che sono stati addestrati e ottimizzati per una funzione particolare. Essendo specializzati, sono in genere più piccoli, più veloci e più efficienti in termini di risorse rispetto ai loro omologhi più grandi.
Questo li rende ideali per gli ambienti di produzione in cui la velocità e i costi sono fattori importanti. Molti possono funzionare anche su hardware CPU standard, rendendoli accessibili senza costose GPU.
I tipi comuni di modelli specifici per determinate attività includono:
- Classificazione del testo: utilizzala per classificare il testo in etichette predefinite, ad esempio ordinando i feedback dei clienti in categorie "positive" o "negative" o contrassegnando i ticket di supporto in base all'argomento.
- Analisi del sentiment: ti aiuta a determinare il tono emotivo di un testo, utile per il monitoraggio del marchio sui social media.
- Riconoscimento di entità denominate: estrai entità specifiche come persone, luoghi e organizzazioni dai documenti per aiutare a strutturare i dati non strutturati.
- Riassunto: riepiloga articoli o relazioni lunghi in riassunti concise, facendo risparmiare al tuo team tempo prezioso nella lettura.
- Traduzione: Converti automaticamente il testo da una lingua all'altra
📚 Leggi anche: Come utilizzare Hugging Face per la sintesi di testi
Modelli linguistici di grandi dimensioni
A volte, il tuo progetto richiede più di una semplice classificazione o riepilogazione/riassunzione. Potresti aver bisogno di un'IA in grado di generare testi di marketing creativi, scrivere codice o rispondere a domande complesse degli utenti in modo di conversazione. In questi casi, probabilmente ti rivolgerai a un modello linguistico di grandi dimensioni (LLM).
Gli LLM sono modelli con miliardi di parametri addestrati su enormi quantità di testo e dati provenienti da Internet. Questo addestramento approfondito consente loro di comprendere sfumature, contesti e ragionamenti complessi. Tra gli LLM open source più diffusi disponibili su Hugging Face figurano i modelli delle famiglie Llama, Mistral e Falcon.
Il compromesso per questa potenza è rappresentato dalle notevoli risorse di calcolo richieste. L'implementazione di questi modelli richiede quasi sempre GPU potenti con molta memoria (VRAM).
Per renderli più accessibili, puoi utilizzare tecniche come la quantizzazione, che riduce la dimensione del modello con un leggero calo delle prestazioni, consentendone l'esecuzione su hardware meno potente.
📚 Leggi anche: Cosa sono gli agenti LLM nell'IA e come funzionano?
Modelli text-to-image e multimodali
I tuoi dati non sono sempre solo testo. Il tuo team potrebbe aver bisogno di generare immagini per una campagna di marketing, trascrivere l'audio di una riunione o comprendere il contenuto di un video. È qui che diventano essenziali i modelli multimodali, progettati per funzionare con diversi tipi di dati.
Il tipo più popolare di modello multimodale è il modello testo-immagine, che genera immagini da una descrizione di testo. Modelli come Stable Diffusion utilizzano una tecnica chiamata diffusione per creare immagini straordinarie da semplici prompt. Ma le possibilità vanno ben oltre la generazione di immagini.
Altri modelli multimodali comuni che puoi implementare da Hugging Face includono:
- Didascalia immagine: genera automaticamente testi descrittivi per le immagini, ottimi per l'accessibilità e la gestione dei contenuti.
- Riconoscimento vocale: trascrivi l'audio parlato in testo scritto con modelli come Whisper di OpenAI.
- Risposte visive alle domande: fai domande su un'immagine e ottieni una risposta in forma di testo, ad esempio "Di che colore è l'auto in questa foto?"
Come gli LLM, questi modelli sono computazionalmente intensivi e in genere richiedono una GPU per funzionare in modo efficiente.
Per vedere come questi diversi tipi di modelli di IA si traducono in applicazioni aziendali pratiche, guarda questa panoramica di casi d'uso reali dell'IA in vari settori e funzioni.
Qual è il livello di maturità della tua organizzazione in materia di IA?
Il nostro sondaggio condotto su 316 professionisti rivela che una vera trasformazione dell'IA richiede molto più della semplice adozione di funzionalità/funzioni di IA. Partecipa alla valutazione della maturità dell'IA per scoprire a che punto è la tua organizzazione e cosa puoi fare per migliorare il tuo punteggio.
Come configurare Hugging Face per l'implementazione dell'IA
Prima di poter implementare il tuo primo modello, devi configurare correttamente il tuo ambiente locale e il tuo account Hugging Face. È una frustrazione comune per i team quando i diversi membri hanno configurazioni incoerenti, il che porta al classico problema "funziona sul mio computer". Dedicare qualche minuto alla standardizzazione di questo processo consente di risparmiare ore di ricerca dei guasti in seguito.
- Crea un account Hugging Face e genera un token di accesso. Per prima cosa, registrati per ottenere un account gratis sul sito web di Hugging Face. Una volta effettuato l'accesso, vai al tuo profilo, clicca su "Impostazioni" e poi vai alla scheda "Token di accesso". Genera un nuovo token con almeno le autorizzazioni di "lettura"; ti servirà per scaricare i modelli.
- Installa le librerie Python necessarie. Apri il terminale e installa le librerie principali di cui avrai bisogno. Le due librerie essenziali sono transformers e huggingface_hub. Puoi installarle utilizzando pip: pip install transformers huggingface_hub
- Configura l'autenticazione. Per utilizzare il tuo token di accesso, puoi effettuare il login tramite la riga di comando eseguendo huggingface-cli login e incollare il tuo token quando richiesto, oppure puoi impostarlo come variabile di ambiente nel tuo sistema. Il login dalla riga di comando è spesso il modo più semplice per iniziare.
- Verifica la configurazione. Il modo migliore per confermare che tutto funzioni correttamente è eseguire un semplice codice. Prova a caricare un modello di base utilizzando la funzione pipeline dalla libreria transformers. Se funziona senza errori, sei pronto per iniziare.
Tieni presente che alcuni modelli sull'hub sono "gated", il che significa che devi accettare i termini di licenza nella pagina del modello prima di poterli utilizzare con il tuo token.
Inoltre, ricorda che il monitoraggio di chi possiede quali credenziali e quali configurazioni ambientali vengono utilizzate è di per sé un'attività di project management, che diventa ancora più importante man mano che il tuo team cresce.
🌟 Se stai integrando i modelli Hugging Face in sistemi software più ampi, il modello di integrazione software di ClickUp ti aiuta a visualizzare i flussi di lavoro e a effettuare il monitoraggio delle integrazioni tecniche in più passaggi.
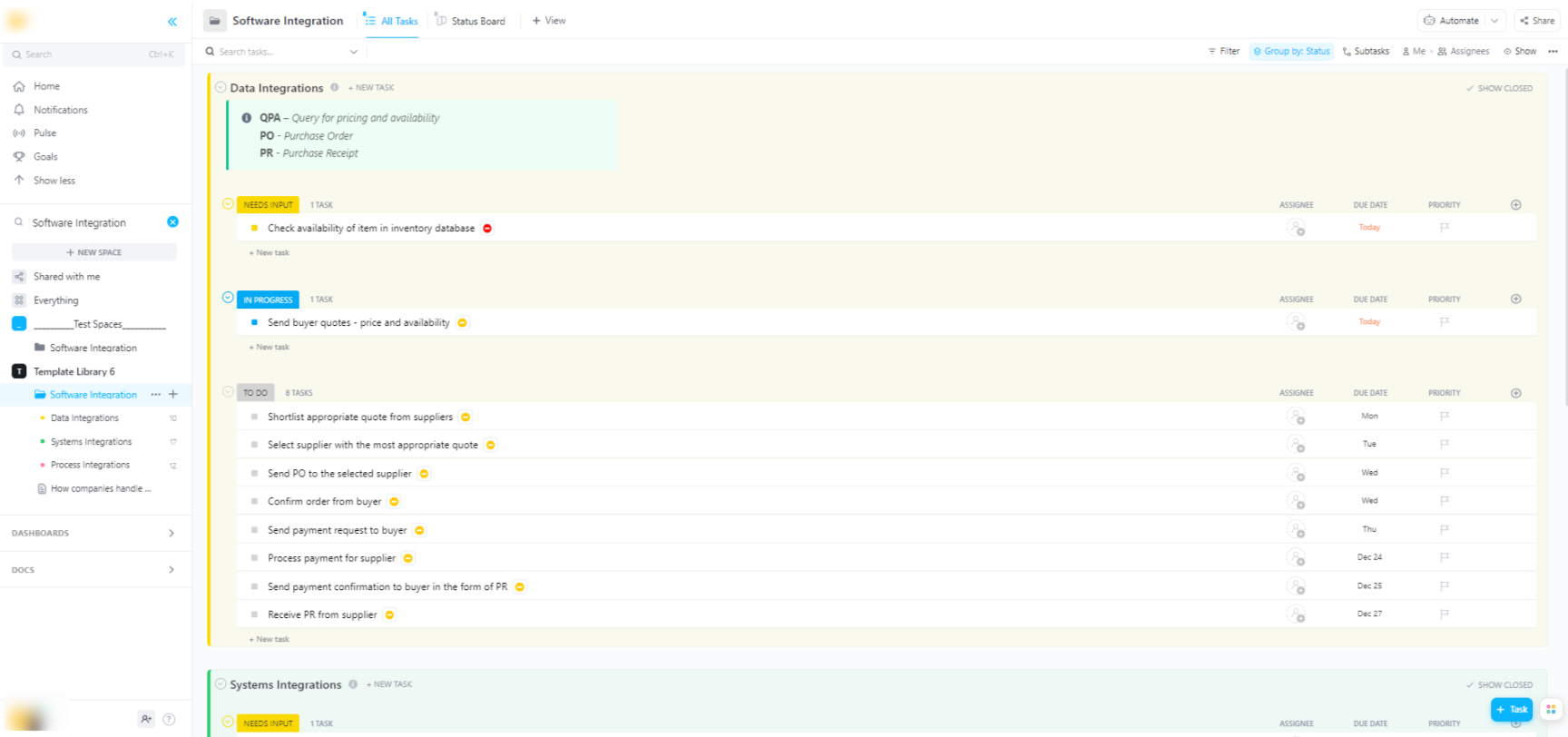
Il modello ti offre un sistema facile da seguire che ti consente di:
- Visualizza le connessioni tra diverse soluzioni software
- Crea e assegna attività ai membri del team per una collaborazione più fluida.
- Organizza tutte le attività relative all'integrazione in un unico posto
Opzioni di implementazione per i modelli Hugging Face
Una volta testato un modello a livello locale, la domanda successiva è: dove verrà implementato? L'implementazione di un modello in un ambiente di produzione in cui può essere utilizzato da altri è un passaggio fondamentale, ma le opzioni disponibili possono creare confusione. Scegliere il percorso sbagliato può comportare prestazioni lente, costi elevati o l'incapacità di gestire il traffico degli utenti.
La tua scelta dipenderà dalle tue esigenze specifiche, come il traffico previsto, il budget e se stai realizzando un prototipo rapido o un'applicazione scalabile e pronta per la produzione.
Hugging Face Spazi
Se hai bisogno di creare rapidamente una demo o uno strumento interno, Hugging Face Spaces è spesso la scelta migliore. Spaces è una piattaforma gratis per l'hosting di applicazioni di machine learning ed è perfetta per creare prototipi da condividere con il tuo team o con gli stakeholder.
Puoi creare l'interfaccia utente della tua app utilizzando framework popolari come Gradio o Streamlit, che semplificano la creazione di demo interattive con poche righe di Python.
Creare uno spazio è semplice: basta selezionare l'SDK preferito, effettuare la connessione di un repository Git con il proprio codice e scegliere l'hardware. Sebbene Spaces offra un livello CPU gratis per le app di base, è possibile passare a hardware GPU a pagamento per modelli più complessi.
Tieni presente i limiti:
- Non adatto per API ad alto traffico: Spazi è progettato per le demo, non per gestire migliaia di richieste API simultanee.
- Avvio a freddo: se il tuo spazio è inattivo, potrebbe "andare in standby" per risparmiare risorse, causando un ritardo per il primo utente che vi accede nuovamente.
- Flusso di lavoro basato su Git: tutto il codice delle tue applicazioni è gestito tramite un repository Git, ottimo per il controllo delle versioni.
API di inferenza Hugging Face
Quando devi integrare un modello in un'applicazione esistente, probabilmente vorrai utilizzare un'API. L'API Hugging Face Inference ti consente di eseguire modelli senza dover gestire personalmente l'infrastruttura sottostante. È sufficiente inviare una richiesta HTTP con i tuoi dati e otterrai una previsione.
Questo approccio è ideale quando non vuoi occuparti di server, scalabilità o manutenzione. Hugging Face offre due livelli principali per questo servizio:
- API di inferenza gratis: si tratta di un'opzione di infrastruttura condivisa con limite di frequenza, ideale per lo sviluppo e il collaudo. È perfetta per casi d'uso a basso traffico o quando si è appena agli inizi.
- Endpoint di inferenza: per le applicazioni di produzione, ti consigliamo di utilizzare gli endpoint di inferenza. Si tratta di un servizio a pagamento che ti fornisce un'infrastruttura dedicata e con scalabilità automatica, garantendo che la tua applicazione sia veloce e affidabile anche in condizioni di carico elevato.
L'utilizzo dell'API comporta l'invio di un payload JSON all'URL dell'endpoint del modello con il tuo token di autenticazione nell'intestazione della richiesta.
Implementazione su piattaforma cloud
Per i team che hanno già una presenza significativa su un importante provider di servizi cloud come Amazon Web Services (AWS), Google Cloud Platform (GCP) o Microsoft Azure, l'implementazione su tali piattaforme può essere la scelta più logica. Questo approccio offre il massimo controllo e consente di integrare il modello con i servizi cloud e i protocolli di sicurezza esistenti.
Il flusso di lavoro generale prevede la "containerizzazione" del modello e delle sue dipendenze utilizzando Docker, quindi l'implementazione di tale container in un servizio di elaborazione cloud. Ogni provider cloud dispone di servizi e integrazioni che semplificano questo processo:
- AWS SageMaker: offre integrazione nativa per l'addestramento e l'implementazione dei modelli Hugging Face.
- Google Cloud Vertex IA: consente di implementare modelli dall'hub a endpoint gestiti.
- Azure Machine Learning: fornisce strumenti per importare e utilizzare i modelli Hugging Face.
Sebbene questo metodo richieda una maggiore configurazione e competenze DevOps, spesso è l'opzione migliore per implementazioni su larga scala e di livello Enterprise in cui è necessario il pieno controllo dell'ambiente.
📚 Leggi anche: Automazione del flusso di lavoro: automatizza i flussi di lavoro per aumentare la produttività
Come eseguire i modelli Hugging Face per l'inferenza
Quando si utilizza Hugging Face per l'implementazione dell'IA, l'"esecuzione dell'inferenza" è il processo che consiste nell'utilizzare il modello addestrato per fare previsioni su dati nuovi e non visti. È il momento in cui il modello svolge il lavoro per cui è stato implementato. Eseguire correttamente questo passaggio è fondamentale per creare un'applicazione reattiva ed efficiente.
La più grande frustrazione per i team è scrivere codice di inferenza lento o inefficiente, che può portare a un'esperienza utente scadente e a costi operativi elevati. Fortunatamente, la libreria dei trasformatori offre diversi modi per eseguire l'inferenza, ciascuno con i propri compromessi tra semplicità e controllo.
- API Pipeline: questo è il modo più semplice e comune per iniziare. La funzione pipeline() elimina gran parte della complessità, gestendo per te la pre-elaborazione dei dati, l'inoltro dei modelli e la post-elaborazione. Per molte attività standard come l'analisi del sentiment, puoi ottenere una previsione con una sola riga di codice.
- AutoModel + AutoTokenizer: quando hai bisogno di un maggiore controllo sul processo di inferenza, puoi utilizzare direttamente le classi AutoModel e AutoTokenizer. Ciò ti consente di gestire manualmente la tokenizzazione del testo e la conversione dell'output grezzo del modello in una previsione leggibile dall'uomo. Questo approccio è utile quando lavori con un'attività personalizzata o devi implementare una logica di pre- o post-elaborazione specifica.
- Elaborazione in batch: per massimizzare l'efficienza, soprattutto su una GPU, è consigliabile elaborare gli input in batch anziché uno alla volta. L'invio di un batch di input attraverso il modello in un unico passaggio in avanti è significativamente più veloce rispetto all'invio di ciascuno singolarmente.
Il monitoraggio delle prestazioni del codice di inferenza è una parte fondamentale del ciclo di vita dell'implementazione. Il monitoraggio delle metriche come la latenza (il tempo necessario per una previsione) e il throughput (il numero di previsioni che è possibile effettuare al secondo) richiede coordinamento e documentazione chiara, soprattutto quando diversi membri del team sperimentano nuove versioni del modello.
Esempio passo passo: implementare un modello Hugging Face
Esaminiamo un esempio completo di implementazione di un semplice modello di analisi del sentiment. Seguendo questi passaggi, passerai dalla scelta di un modello alla creazione di un endpoint live e testabile.
- Seleziona il tuo modello: vai su Hugging Face Hub e utilizza i filtri a sinistra per cercare i modelli che eseguono la "Classificazione del testo". Un buon punto di partenza è distilbert-base-uncased-finetuned-sst-2-english. Leggi la scheda del modello per comprenderne le prestazioni e come utilizzarlo.
- Installa le dipendenze: nel tuo ambiente Python locale, assicurati di avere installato le librerie necessarie. Per questo modello, avrai solo bisogno di transformers e torch. Esegui pip install transformers torch
- Prova in locale: prima dell'implementazione, assicurati sempre che il modello funzioni come previsto sul tuo computer. Scrivi un piccolo script Python per caricare il modello utilizzando la pipeline e provalo con una frase di esempio. Ad esempio: classifier = pipeline("sentiment-analysis", model="distilbert-base-uncased-finetuned-sst-2-english") seguito da classifier("ClickUp è la migliore piattaforma per la produttività!")
- Creare l'implementazione: per questo esempio, utilizzeremo Hugging Face Spaces per un'implementazione rapida e semplice. Crea un nuovo spazio, seleziona Gradio SDK e crea un file app.py che carica il tuo modello e definisce una semplice interfaccia Gradio per interagire con esso.
- Verifica l'implementazione: una volta che il tuo spazio è in esecuzione, puoi utilizzare l'interfaccia interattiva per testarlo. Puoi anche effettuare una richiesta API diretta all'endpoint dello spazio per ottenere una risposta JSON, confermando che funziona a livello di programmazione.
Dopo questi passaggi, avrai un modello attivo. La fase successiva del progetto comporterà il monitoraggio del suo utilizzo, la pianificazione degli aggiornamenti e, potenzialmente, il ridimensionamento dell'infrastruttura se dovesse diventare popolare.
Per i team che gestiscono progetti complessi di implementazione dell'IA con più fasi, dalla preparazione dei dati all'implementazione in produzione, il modello avanzato di project management software di ClickUp offre una struttura completa.
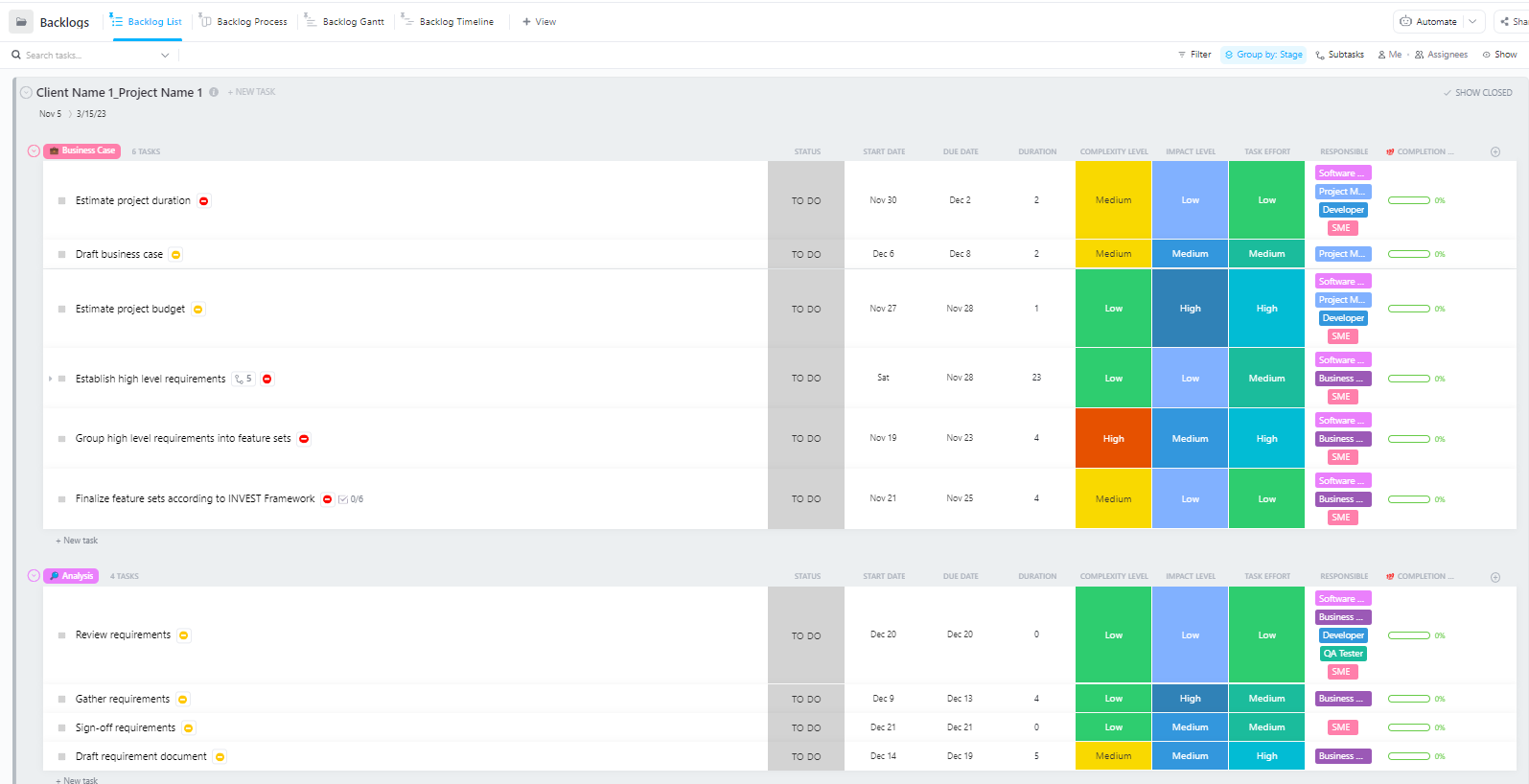
Questo modello aiuta i team a:
- Gestisci progetti con più attività cardine, attività, risorse e dipendenze
- Visualizza lo stato di avanzamento del progetto con diagrammi di Gantt e Sequenze.
- Collabora senza intoppi con i tuoi colleghi per garantire che il progetto sia completato con esito positivo.
Sfide comuni nell'implementazione di Hugging Face e come risolverle
Anche con un piano chiaro, è probabile che durante l'implementazione incontri qualche ostacolo. Fissare un messaggio di errore criptico può essere incredibilmente frustrante e può bloccare i progressi del tuo team. Ecco alcune delle sfide più comuni e come risolverle. 🛠️
🚨Problema: "Il modello richiede l'autenticazione"
- Causa: stai cercando di accedere a un modello "protetto" che richiede l'accettazione dei termini di licenza.
- Soluzione: vai alla pagina del modello sull'hub, leggi e accetta il contratto di licenza. Assicurati che il token di accesso che stai utilizzando abbia le autorizzazioni di "lettura".
🚨Problema: "CUDA out of memory"
- Causa: il modello che stai cercando di caricare è troppo grande per la memoria della tua GPU (VRAM).
- Soluzione: la soluzione più rapida consiste nell'utilizzare una versione più piccola del modello o una versione quantizzata. Puoi anche provare a ridurre la dimensione del batch durante l'inferenza.
🚨Problema: "errore trust_remote_code"
- Motivo: alcuni modelli sull'hub richiedono un codice personalizzato per funzionare e, per motivi di sicurezza, la libreria non lo esegue per impostazione predefinita.
- Soluzione: puoi aggirare questo problema aggiungendo trust_remote_code=True quando carichi il modello. Tuttavia, dovresti sempre controllare prima il codice sorgente per assicurarti che sia sicuro.
🚨Problema: "Tokenizer mismatch"
- Causa: il tokenizzatore che stai utilizzando non è esattamente quello con cui è stato addestrato il modello, il che porta a input errati e prestazioni scadenti.
- Soluzione: carica sempre il tokenizer dallo stesso checkpoint del modello stesso. Ad esempio, AutoTokenizer. from_pretrained("nome-modello")
🚨Problema: "Limite di frequenza superato"
- Causa: hai effettuato troppe richieste all'API di inferenza gratis in un breve periodo di tempo.
- Soluzione: per l'uso in produzione, esegui l'aggiornamento a un endpoint di inferenza dedicato. Per lo sviluppo, puoi implementare la cache per evitare di inviare più volte la stessa richiesta.
Il monitoraggio di quali soluzioni funzionano per quali problemi è fondamentale. Senza un luogo centrale in cui documentare questi risultati, i team spesso finiscono per risolvere lo stesso problema più e più volte.
📮 ClickUp Insight: 1 dipendente su 4 utilizza quattro o più strumenti solo per creare un contesto di lavoro. Un dettaglio fondamentale potrebbe essere nascosto in un'email, ampliato in un thread su Slack e documentato in uno strumento separato, costringendo i team a perdere tempo alla ricerca di informazioni invece di portare a termine il lavoro.
ClickUp riunisce l'intero flusso di lavoro in un'unica piattaforma unificata. Con funzionalità/funzioni come ClickUp Email Project Management, ClickUp Chat, ClickUp Docs e ClickUp Brain, tutto rimane connesso, in stato di sincronizzazione e immediatamente accessibile. Dite addio al "lavoro sul lavoro" e recuperate la vostra produttività.
💫 Risultati reali: i team sono in grado di recuperare più di 5 ore alla settimana utilizzando ClickUp, ovvero oltre 250 ore all'anno a persona, eliminando i processi di gestione delle conoscenze obsoleti. Immagina cosa potrebbe creare il tuo team con una settimana in più di produttività ogni trimestre!
Come gestire i progetti di implementazione dell'IA in ClickUp
L'utilizzo di Hugging Face per l'implementazione dell'IA semplifica il packaging, l'hosting e la fornitura dei modelli, ma non elimina il sovraccarico di coordinamento dell'implementazione nel mondo reale. I team devono comunque effettuare il monitoraggio dei modelli in fase di test, allinearsi sulle configurazioni, documentare le decisioni e mantenere tutti, dagli ingegneri ML al reparto prodotti e operazioni, sulla stessa lunghezza d'onda.
Quando il tuo team di ingegneri sta testando diversi modelli, il tuo team di prodotto sta definendo i requisiti e gli stakeholder chiedono aggiornamenti, le informazioni vengono disperse su Slack, email, fogli di calcolo e vari documenti.
Questa frammentazione del lavoro, ovvero la suddivisione delle attività lavorative tra più strumenti scollegati tra loro che non comunicano tra loro, crea confusione e rallenta il lavoro di tutti.
È qui che ClickUp, il primo spazio di lavoro AI convergente al mondo, svolge un ruolo chiave riunendo la project management, la documentazione e la comunicazione del team in un unico spazio di lavoro.
Questa convergenza è particolarmente preziosa per i progetti di implementazione dell'IA, in cui gli stakeholder tecnici e non tecnici hanno bisogno di una visibilità condivisa senza dover utilizzare cinque strumenti diversi.
Invece di disperdere gli aggiornamenti tra ticket, documenti e thread di chat, i team possono gestire l'intero ciclo di vita dell'implementazione in un unico posto.
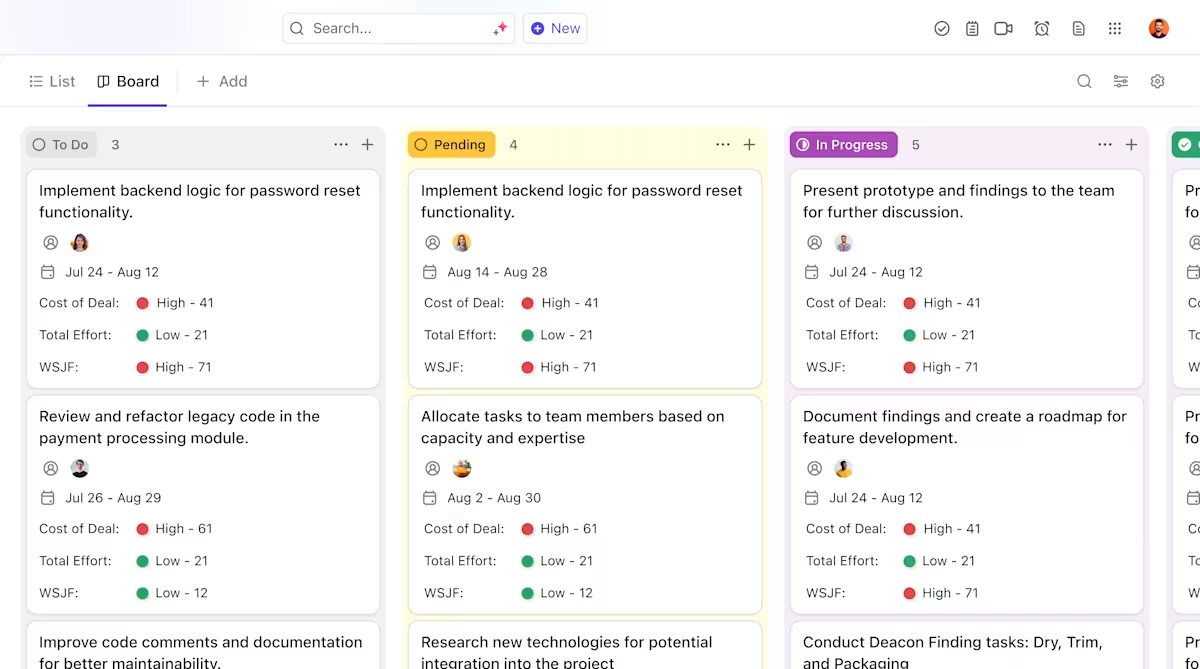
Ecco come ClickUp può fornire supporto al tuo progetto di implementazione dell'IA:
- Chiare titolarità e monitoraggio durante tutto il ciclo di vita dei modelli: utilizza le attività di ClickUp per monitorare i modelli Hugging Face attraverso la valutazione, il test, la fase di messa in scena e la produzione, con stati personalizzati, titolari e blocchi visibili a tutto il team.
- Documentazione centralizzata e aggiornata sull'implementazione: gestisci i runbook di implementazione, le configurazioni dell'ambiente e le guide alla risoluzione dei problemi in ClickUp Docs, in modo che la documentazione si evolva insieme ai tuoi modelli e rimanga facile da cercare e consultare. Poiché i documenti sono collegati alle attività, la tua documentazione rimane a fianco del lavoro a cui si riferisce.
- Collaborazione contestualizzata senza dispersione del lavoro: mantieni discussioni, decisioni e aggiornamenti direttamente collegati alle attività e ai documenti, riducendo la dipendenza da thread Slack sparsi, email e strumenti di progetto scollegati.
- Visibilità end-to-end sullo stato di avanzamento dell'implementazione: monitora la pipeline di implementazione, identifica tempestivamente i rischi e bilancia la capacità del team utilizzando i dashboard ClickUp che mostrano in tempo reale lo stato di avanzamento e i colli di bottiglia.
- Onboarding più rapido e recupero delle decisioni con l'IA integrata: utilizza ClickUp Brain per riepilogare lunghi documenti di implementazione, estrarre informazioni rilevanti dalle implementazioni passate e aiutare i nuovi membri del team a mettersi al passo senza dover scavare nel contesto storico.
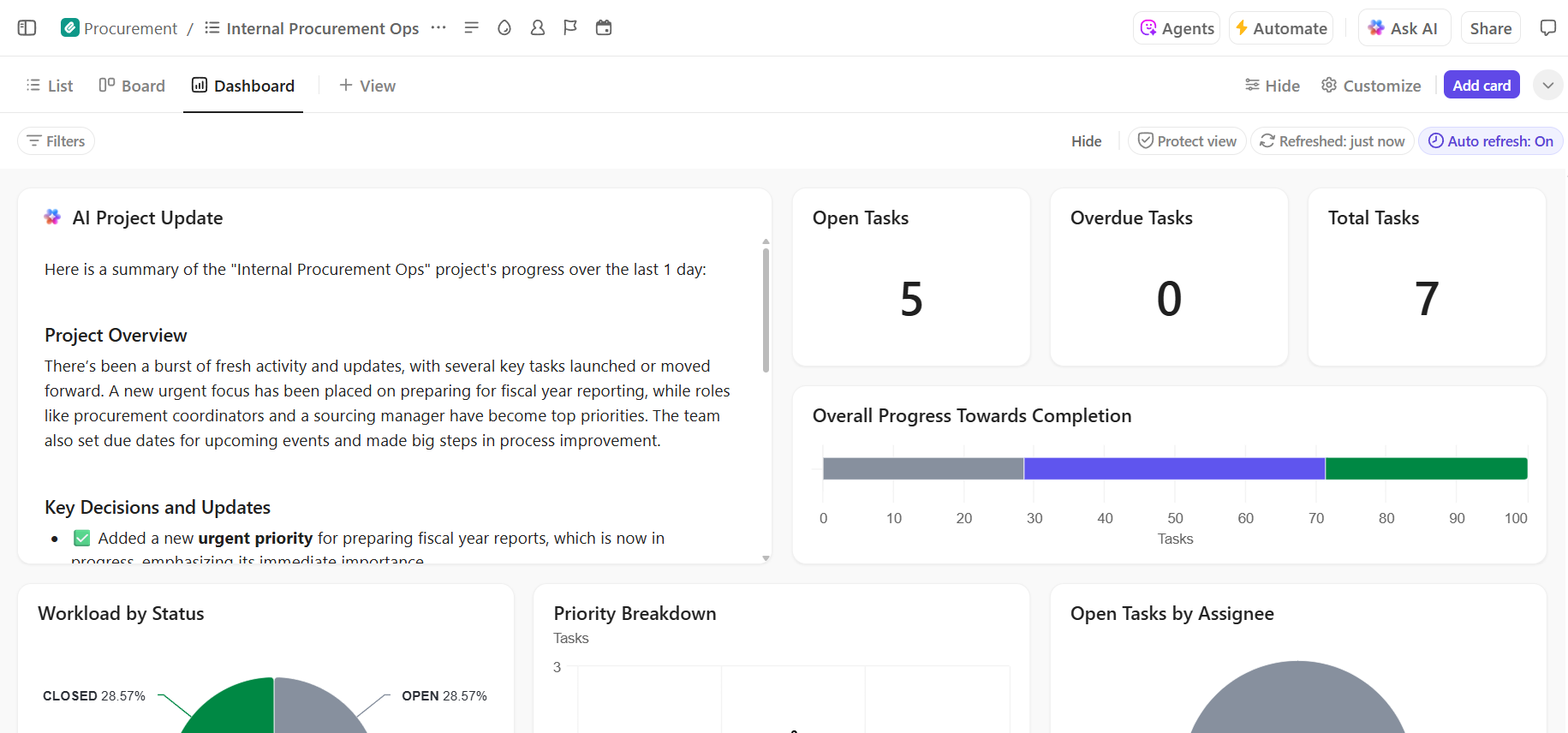
📚 Leggi anche: Come effettuare le automazioni dei processi con l'IA per flussi di lavoro più rapidi e intelligenti
Gestisci il tuo progetto di implementazione dell'IA senza intoppi in ClickUp
Il successo dell'implementazione di Hugging Face dipende da una solida base tecnica e da un project management chiaro e organizzato. Sebbene le sfide tecniche siano risolvibili, spesso sono proprio i problemi di coordinamento e comunicazione a causare il fallimento dei progetti.
Stabilendo un flusso di lavoro chiaro in un'unica piattaforma, il tuo team potrà lavorare più velocemente ed evitare la frustrazione causata dalla dispersione del contesto, ovvero quando i team perdono ore a cercare informazioni, passando da un'app all'altra e ripetendo gli aggiornamenti su più piattaforme.
ClickUp, l'app completa per il lavoro, riunisce la project management, la documentazione e la comunicazione del team in un unico posto, offrendoti un'unica fonte di verità per l'intero ciclo di vita dell'implementazione dell'IA.
Riunisci i tuoi progetti di implementazione dell'IA ed elimina la confusione degli strumenti. Inizia oggi stesso con ClickUp gratis.
Domande frequenti (FAQ)
Sì, Hugging Face offre un generoso livello gratuito che include l'accesso al Model Hub, spazi basati su CPU per le demo e un'API di inferenza con limite di frequenza per i test. Per esigenze di produzione che richiedono hardware dedicato o limiti più elevati, sono disponibili piani a pagamento.
Spazi è progettato per ospitare applicazioni interattive con un front-end visivo, rendendolo ideale per demo e strumenti interni. L'API Inference fornisce l'accesso programmatico ai modelli, consentendoti di integrarli nelle tue applicazioni tramite semplici richieste HTTP.
Assolutamente sì. Grazie alle demo interattive ospitate su Hugging Face Spaces, i membri del team non tecnici possono sperimentare i modelli e fornire feedback senza scrivere una sola riga di codice.
Le principali limitazioni del livello gratis sono i limiti di frequenza dell'API di inferenza, l'uso di hardware CPU condiviso per gli spazi, che può essere lento, e i "cold start", ovvero i momenti in cui le app inattive impiegano un po' di tempo per riattivarsi. /