

I modelli linguistici di grandi dimensioni (LLM) consentono di usufruire di nuove entusiasmanti possibilità per le applicazioni software. Consentono di realizzare sistemi più intelligenti e dinamici che mai.
Gli esperti prevedono che entro il 2025 le app basate su questi modelli potrebbero automatizzare quasi la metà di tutto il lavoro digitale.
Tuttavia, man mano che usufruiamo di queste funzionalità, si profila una sfida: come misurare in modo affidabile la qualità dei loro risultati su larga scala? Una piccola modifica alle impostazioni e improvvisamente ti ritrovi di fronte a risultati notevolmente diversi. Questa variabilità può rendere difficile valutare le loro prestazioni, cosa fondamentale quando si prepara un modello per l'uso nel mondo reale.
Questo articolo condividerà approfondimenti sulle migliori pratiche di valutazione del sistema LLM, dai test pre-implementazione alla produzione. Allora, cominciamo!
Che cos'è una valutazione LLM?
Le metriche di valutazione LLM sono un modo per verificare se i tuoi prompt, le impostazioni del modello o il flusso di lavoro stanno raggiungendo gli obiettivi che hai fissato. Queste metriche ti forniscono informazioni dettagliate sulle prestazioni del tuo Large Language Model e sulla sua effettiva idoneità all'uso nel mondo reale.
Oggi, alcune delle metriche più comuni misurano il richiamo del contesto nelle attività di generazione aumentata dal recupero (RAG), le corrispondenze esatte per le classificazioni, la convalida JSON per gli output strutturati e la somiglianza semantica per attività più creative.
Ciascuna di queste metriche garantisce in modo univoco che l'LLM soddisfi gli standard per il tuo caso d'uso specifico.
Perché è necessario valutare un LLM?
I modelli linguistici di grandi dimensioni (LLM) vengono ora utilizzati in un ampio intervallo di applicazioni. È essenziale valutare le prestazioni dei modelli per garantire che soddisfino gli standard previsti e servano efficacemente agli scopi previsti.
Pensateci in questo modo: gli LLM alimentano tutto, dai chatbot del supporto clienti agli strumenti creativi, e man mano che diventano più avanzati, compaiono in più luoghi.
Ciò significa che abbiamo bisogno di metodi migliori per monitorarli e valutarli: i metodi tradizionali non riescono a stare al passo con tutte le attività che questi modelli stanno gestendo.
Buone metriche di valutazione sono come un controllo di qualità per gli LLM. Mostrano se il modello è affidabile, accurato ed efficiente abbastanza per essere utilizzato nel mondo reale. Senza questi controlli, potrebbero sfuggire degli errori, causando esperienze frustranti o addirittura fuorvianti per gli utenti.
Quando si dispone di metriche di valutazione solide, è più facile individuare i problemi, migliorare il modello e garantire che sia pronto a soddisfare le esigenze specifiche degli utenti. In questo modo, saprai che la piattaforma di IA con cui stai lavorando è all'altezza degli standard e in grado di fornire i risultati di cui hai bisogno.
📖 Per saperne di più: LLM vs. IA generativa: una guida dettagliata
Tipi di valutazioni LLM
Le valutazioni offrono una prospettiva unica per esaminare le capacità del modello. Ogni tipo affronta diversi aspetti qualitativi, contribuendo a creare un modello di implementazione affidabile, sicuro ed efficiente.
Ecco i diversi tipi di metodi di valutazione LLM:
- La valutazione intrinseca si concentra sulle prestazioni interne del modello in attività linguistiche o di comprensione specifiche senza coinvolgere applicazioni del mondo reale. In genere viene condotta durante la fase di sviluppo del modello per comprenderne le capacità fondamentali.
- La valutazione estrinseca valuta le prestazioni del modello in applicazioni reali. Questo tipo di valutazione esamina in che misura il modello soddisfa obiettivi specifici in un determinato contesto.
- La valutazione della robustezza verifica la stabilità e l'affidabilità del modello in diversi scenari, inclusi input imprevisti e condizioni avverse. Identifica potenziali punti deboli, garantendo che il modello si comporti in modo prevedibile.
- I test di efficienza e latenza esaminano l'utilizzo delle risorse, la velocità e la latenza del modello. Garantiscono che il modello sia in grado di eseguire le attività rapidamente e con un costo computazionale ragionevole, essenziale per la scalabilità.
- La valutazione etica e di sicurezza garantisce che il modello sia conforme agli standard etici e alle linee guida di sicurezza, aspetti fondamentali nelle applicazioni sensibili.
Valutazioni del modello LLM vs. valutazioni del sistema LLM
La valutazione dei modelli linguistici di grandi dimensioni (LLM) prevede due approcci principali: la valutazione dei modelli e la valutazione dei sistemi. Ciascuno di essi si concentra su aspetti diversi delle prestazioni dell'LLM e conoscere la differenza è essenziale per massimizzare il potenziale di questi modelli.
🧠 Le valutazioni dei modelli esaminano le competenze generali dell'LLM. Questo tipo di valutazione testa la capacità del modello di comprendere, generare e lavorare con il linguaggio in modo accurato in vari contesti. È come vedere quanto bene il modello è in grado di gestire diverse attività, quasi come un test di intelligenza generale.
Ad esempio, le valutazioni dei modelli potrebbero chiedere: "Quanto è versatile questo modello?"
🎯 Le valutazioni del sistema LLM misurano le prestazioni dell'LLM in una configurazione o per uno scopo specifico, come nel caso di un chatbot per il servizio clienti. In questo caso, non si tratta tanto delle capacità generali del modello, quanto piuttosto di come esegue attività specifiche per migliorare l'esperienza dell'utente.
Le valutazioni del sistema, invece, si concentrano su domande come: "In che misura il modello gestisce questa specifica attività per gli utenti?"
Le valutazioni dei modelli aiutano gli sviluppatori a comprendere le capacità e i limiti complessivi dell'LLM, guidando i miglioramenti. Le valutazioni del sistema si concentrano sulla capacità dell'LLM di soddisfare le esigenze degli utenti in contesti specifici, garantendo un'esperienza utente più fluida.
Insieme, queste valutazioni forniscono un quadro completo dei punti di forza e delle aree di miglioramento dell'LLM, rendendolo più potente e facile da usare nelle applicazioni reali.
Ora esploriamo le metriche specifiche per la valutazione LLM.
Metriche per la valutazione LLM
Alcuni parametri di valutazione affidabili e di tendenza includono:
1. Perplessità
La perplessità misura la capacità di un modello linguistico di prevedere una sequenza di parole. Essenzialmente, indica l'incertezza del modello riguardo alla parola successiva in una frase. Un punteggio di perplessità più basso significa che il modello è più sicuro delle sue previsioni, il che porta a prestazioni migliori.
📌 Esempio: immagina che un modello generi un testo a partire dal prompt "Il gatto era seduto sul...". Se prevede un'alta probabilità per parole come "tappeto" e "pavimento", significa che ha compreso bene il contesto, con un punteggio di perplessità basso come risultato.
D'altra parte, se suggerisce una parola non correlata come "astronave", il punteggio di perplessità sarebbe più alto, indicando che il modello fatica a prevedere un testo sensato.
2. Punteggio BLEU
Il punteggio BLEU (Bilingual Evaluation Understudy) viene utilizzato principalmente per valutare la traduzione automatica e la generazione di testi.
Misura quanti n-gram (sequenze contigue di n elementi da un dato campione di testo) nell'output si sovrappongono a quelli in uno o più testi di riferimento. L'intervallo di punteggio varia da 0 a 1, dove i punteggi più alti indicano prestazioni migliori.
📌 Esempio: se il tuo modello genera la frase "La volpe marrone veloce salta sopra il cane pigro" e il testo di riferimento è "Una volpe marrone veloce salta sopra un cane pigro", BLEU confronterà gli n-gram condivisi.
Un punteggio elevato indica che la frase generata corrisponde strettamente al riferimento, mentre un punteggio più basso potrebbe suggerire che il risultato generato non è ben allineato.
3. Punteggio F1
La metrica di valutazione LLM F1 score è utilizzata principalmente per le attività di classificazione. Misura l'equilibrio tra precisione (l'accuratezza delle previsioni positive) e richiamo (la capacità di identificare tutte le istanze rilevanti).
L'intervallo di punteggio è da 0 a 1, dove 1 indica una precisione perfetta.
📌 Esempio: in un'attività di risposta a domande, se al modello viene chiesto "Di che colore è il cielo?" e risponde "Il cielo è blu" (vero positivo) ma include anche "Il cielo è verde" (falso positivo), il punteggio F1 terrà conto sia della pertinenza della risposta corretta che di quella errata.
Questa metrica aiuta a garantire una valutazione equilibrata delle prestazioni del modello.
4. METEOR
METEOR (Metric for Evaluation of Translation with Explicit ORdering) va oltre la corrispondenza esatta delle parole. Prende in considerazione sinonimi, derivazioni e parafrasi per valutare la somiglianza tra il testo generato e il testo di riferimento. Questa metricha come obiettivo quello di allinearsi maggiormente al giudizio umano.
📌 Esempio: se il tuo modello genera "Il felino riposava sul tappeto" e il riferimento è "Il gatto giaceva sul tappeto", METEOR assegnerebbe a questa frase un punteggio più alto rispetto a BLEU perché riconosce che "felino" è un sinonimo di "gatto" e che "tappeto" e "moquette" hanno significati simili.
Questo rende METEOR particolarmente utile per cogliere le sfumature del linguaggio.
5. BERTScore
BERTScore valuta la somiglianza dei testi sulla base di incorporamenti contestuali derivati da modelli come BERT (Bidirectional Encoder Representations from Transformers). Si concentra più sul significato che sulla corrispondenza esatta delle parole, consentendo una migliore valutazione della somiglianza semantica.
📌 Esempio: quando si confrontano le frasi "L'auto sfrecciava lungo la strada" e "Il veicolo correva lungo la strada", BERTScore analizza i significati sottostanti piuttosto che la semplice scelta delle parole.
Anche se le parole sono diverse, le idee generali sono simili, il che porta a un punteggio BERTScore elevato che riflette l'efficacia del contenuto generato.
6. Valutazione umana
La valutazione umana rimane un aspetto cruciale della valutazione LLM. Prevede che dei giudici umani effettuino la valutazione della qualità dei risultati del modello sulla base di vari criteri, quali la fluidità e la pertinenza. Per raccogliere feedback è possibile ricorrere a tecniche quali le scale Likert e i test A/B.
📌 Esempio: dopo aver generato le risposte da un chatbot del servizio clienti, i valutatori umani potrebbero effettuare una valutazione per ciascuna risposta su una scala da 1 a 5. Ad esempio, se il chatbot fornisce una risposta chiara e utile a una richiesta del cliente, potrebbe ricevere un 5, mentre una risposta vaga o confusa potrebbe ottenere un 2.
7. Metriche specifiche per attività
Attività LLM diverse richiedono metriche di valutazione personalizzate.
Per i sistemi di dialogo, le metriche potrebbero valutare il coinvolgimento degli utenti o i tassi di completamento delle attività. Per la generazione di codice, l'esito positivo potrebbe essere misurato dalla frequenza con cui il codice generato viene compilato o supera i test.
📌 Esempio: in un chatbot di supporto clienti, i livelli di coinvolgimento potrebbero essere misurati in base al tempo trascorso dagli utenti in una conversazione o al numero di domande di follow-up poste.
Se gli utenti richiedono spesso ulteriori informazioni, significa che il modello ha un esito positivo nel coinvolgerli e nel rispondere efficacemente alle loro query.
8. Robustezza ed equità
Valutare la robustezza di un modello significa testare la sua capacità di rispondere a input inaspettati o insoliti. Le metriche di equità aiutano a identificare i pregiudizi nei risultati del modello, garantendo che funzioni in modo equo in diversi contesti demografici e scenari.
📌 Esempio: quando si testa un modello con una domanda stravagante come "Cosa ne pensi degli unicorni?", esso dovrebbe gestire la domanda con eleganza e fornire una risposta pertinente. Se invece fornisce una risposta senza senso o inappropriata, ciò indica una mancanza di robustezza.
I test di equità garantiscono che il modello non produca risultati distorti o dannosi, promuovendo un sistema di IA più inclusivo.
📖 Ulteriori informazioni: La differenza tra machine learning e intelligenza artificiale
9. Metriche di efficienza
Con l'aumentare della complessità dei modelli linguistici, diventa sempre più importante misurarne l'efficienza in termini di velocità, utilizzo della memoria e consumo energetico. Le metriche di efficienza aiutano a valutare quanto un modello sia dispendioso in termini di risorse durante la generazione delle risposte.
📌 Esempio: per un modello linguistico di grandi dimensioni, la misurazione dell'efficienza potrebbe comportare il monitoraggio della velocità con cui genera le risposte alle query degli utenti e della quantità di memoria utilizzata durante questo processo.
Se la risposta richiede troppo tempo o consuma risorse eccessive, potrebbe essere un problema per le applicazioni che richiedono prestazioni in tempo reale, come i chatbot o i servizi di traduzione.
Ora sai come valutare un modello LLM. Ma quali strumenti puoi utilizzare per misurarlo? Scopriamolo insieme.
Come ClickUp Brain può migliorare la valutazione LLM
ClickUp è un'app completa per il lavoro con un assistente personale integrato chiamato ClickUp Brain.
ClickUp Brain è una vera rivoluzione per la valutazione delle prestazioni LLM. Ma cosa fa esattamente?
Organizza ed evidenzia i dati più rilevanti, mantenendo il tuo team sulla strada giusta. Con le sue funzionalità/funzioni basate sull'IA, ClickUp Brain è uno dei migliori software di rete neurale disponibili sul mercato. Rende l'intero processo più fluido, efficiente e collaborativo che mai. Esploriamo insieme le sue capacità.
Gestione intelligente delle conoscenze
Quando si valutano i modelli linguistici di grandi dimensioni (LLM), la gestione di grandi quantità di dati può risultare complessa.

ClickUp Brain è in grado di organizzare e mettere in evidenza metriche e risorse essenziali su misura per la valutazione LLM. Invece di rovistare tra fogli di calcolo sparsi e report complessi, ClickUp Brain riunisce tutto in un unico posto. Le metriche delle prestazioni, i dati di benchmarking e i risultati dei test sono tutti accessibili all'interno di un'interfaccia chiara e intuitiva.
Questa organizzazione aiuta il tuo team a eliminare le distrazioni e a concentrarsi sulle informazioni davvero importanti, rendendo più facile interpretare le tendenze e i modelli di performance.
Con tutto ciò di cui hai bisogno in un unico posto, puoi passare dalla semplice raccolta di dati a un processo decisionale efficace e basato sui dati, trasformando il sovraccarico di informazioni in intelligence utilizzabile.
Pianificazione dei progetti e gestione del flusso di lavoro
Le valutazioni LLM richiedono un attento piano e collaborazione, e ClickUp semplifica la gestione di questo processo.
Puoi facilmente delegare responsabilità come la raccolta dei dati, l'addestramento dei modelli e i test delle prestazioni, stabilendo al contempo le priorità per garantire che le attività più critiche ricevano la massima attenzione. Inoltre, i campi personalizzati ti consentono di adattare i flussi di lavoro alle esigenze specifiche del tuo progetto.

Con ClickUp, tutti possono vedere chi sta facendo cosa e quando, contribuendo a evitare ritardi e assicurando che le attività procedano senza intoppi all'interno del team. È un ottimo modo per mantenere tutto organizzato e in linea con gli obiettivi dall'inizio alla fine.
Monitoraggio delle metriche tramite dashboard personalizzate
Vuoi tenere sotto controllo le prestazioni dei tuoi sistemi LLM?
I dashboard di ClickUp visualizzano gli indicatori di prestazione in tempo reale. Ti consentono di monitorare istantaneamente lo stato del tuo modello. Questi dashboard sono altamente personalizzabili e ti permettono di creare grafici e tabelle che presentano esattamente ciò di cui hai bisogno quando ne hai bisogno.
Puoi osservare l'evoluzione dell'accuratezza del tuo modello nelle diverse fasi di valutazione o analizzare il consumo di risorse in ciascuna fase. Queste informazioni ti consentono di individuare rapidamente le tendenze, identificare le aree di miglioramento e apportare modifiche al volo.
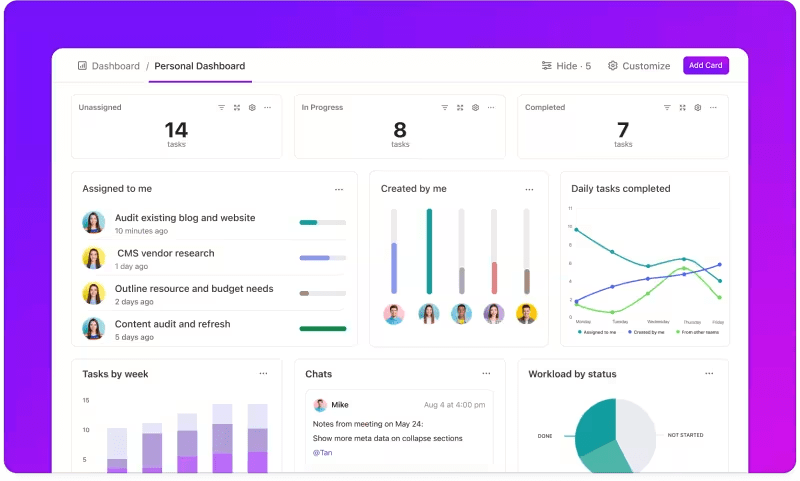
Invece di aspettare il prossimo rapporto dettagliato, le dashboard di ClickUp ti consentono di rimanere informato e reattivo, consentendo al tuo team di prendere decisioni basate sui dati senza ritardi.
Approfondimenti automatizzati
L'analisi dei dati può richiedere molto tempo, ma le funzionalità/funzioni di ClickUp Brain alleggeriscono il carico fornendo informazioni preziose. Evidenzia le tendenze importanti e suggerisce anche raccomandazioni basate sui dati, rendendo più facile trarre conclusioni significative.
Grazie alle informazioni automatizzate di ClickUp Brain, non è necessario setacciare manualmente i dati grezzi alla ricerca di modelli: è il sistema stesso a individuarli per te. Questa automazione consente al tuo team di concentrarsi sul perfezionamento delle prestazioni del modello, invece di impantanarsi in ripetitive analisi dei dati.
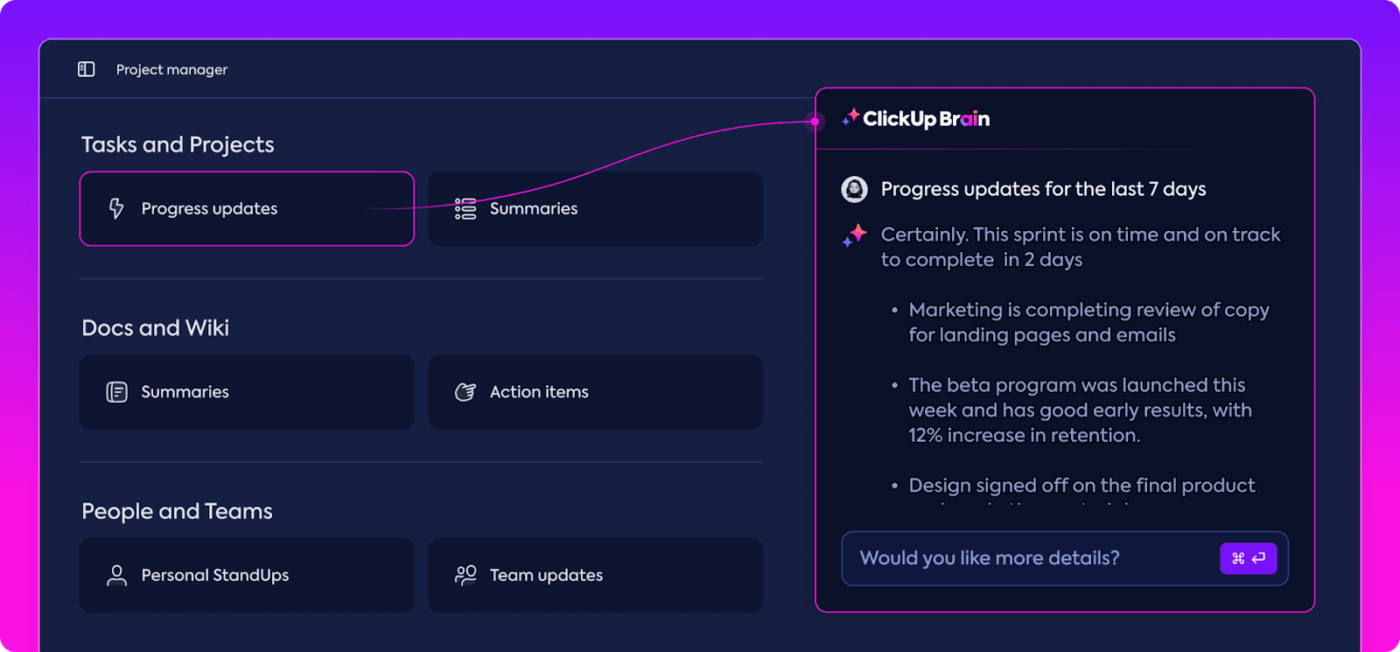
Le informazioni generate sono pronte per l'uso e consentono al tuo team di vedere immediatamente cosa funziona e dove potrebbero essere necessarie delle modifiche. Riducendo il tempo dedicato all'analisi, ClickUp aiuta il tuo team ad accelerare il processo di valutazione e a concentrarsi sull'implementazione.
Documentazione e collaborazione
Non dovrai più cercare tra le email o su più piattaforme per trovare ciò che ti serve: tutto è a portata di mano, pronto quando ne hai bisogno.
ClickUp Docs è un hub centrale che riunisce tutto ciò di cui il tuo team ha bisogno per una valutazione LLM senza intoppi. Organizza la documentazione chiave del progetto, come i criteri di benchmarking, i risultati dei test e i registri delle prestazioni, in un unico punto accessibile in modo che tutti possano accedere rapidamente alle informazioni più recenti.
Ciò che distingue davvero ClickUp Docs sono le sue funzionalità di collaborazione in tempo reale. La chat e i commenti integrati di ClickUp consentono ai membri del team di discutere approfondimenti, fornire feedback e suggerire modifiche direttamente all'interno dei documenti.
Ciò significa che il tuo team può discutere i risultati e apportare modifiche direttamente sulla piattaforma, mantenendo tutte le discussioni pertinenti e mirate.

Tutto, dalla documentazione al lavoro di squadra, avviene all'interno di ClickUp Docs, creando un processo di valutazione semplificato in cui tutti possono vedere, condividere e agire sugli ultimi sviluppi.
Il risultato? Un flusso di lavoro fluido e unificato che consente al tuo team di avanzare verso i propri obiettivi con la massima chiarezza.
Sei pronto a provare ClickUp? Prima di farlo, vediamo alcuni consigli e trucchi per ottenere il massimo dalla tua valutazione LLM.
Migliori pratiche nella valutazione LLM
Un approccio ben strutturato alla valutazione LLM garantisce che il modello soddisfi le tue esigenze, sia in linea con le aspettative degli utenti e fornisca risultati significativi.
L'impostazione corretta consiste nell'impostare obiettivi chiari, tenere conto degli utenti finali e utilizzare una serie di metriche. Questo contribuisce a definire una valutazione approfondita che rivela i punti di forza e le aree di miglioramento. Di seguito sono riportate alcune best practice che possono guidarti nel processo.
🎯 Definisci obiettivi chiari
Prima di iniziare il processo di valutazione, è essenziale sapere esattamente cosa vuoi ottenere dal tuo modello linguistico di grandi dimensioni (LLM). Prenditi il tempo necessario per delineare le attività o gli obiettivi specifici del modello.
📌 Esempio: se desideri migliorare le prestazioni della traduzione automatica, chiarisci i livelli di qualità che desideri raggiungere. Avere obiettivi chiari ti aiuta a concentrarti sulle metriche più rilevanti, garantendo che la tua valutazione rimanga in linea con questi obiettivi e misuri accuratamente l'esito positivo.
👥 Considera il tuo pubblico
Pensa a chi utilizzerà l'LLM e quali sono le sue esigenze. È fondamentale adattare la valutazione agli utenti previsti.
📌 Esempio: se il tuo modello ha lo scopo di generare contenuti coinvolgenti, dovrai prestare particolare attenzione a metriche quali fluidità e coerenza. Comprendere il tuo pubblico ti aiuta a perfezionare i criteri di valutazione, assicurandoti che il modello offra un valore reale nelle applicazioni pratiche.
📊 Utilizza metriche diverse
Non affidarti a un unico parametro per valutare il tuo LLM: una combinazione di metriche ti fornirà un quadro più completo delle sue prestazioni. Ogni metrica cattura aspetti diversi, quindi utilizzarne diversi può aiutarti a identificare sia i punti di forza che quelli deboli.
📌 Esempio: sebbene i punteggi BLEU siano ottimi per misurare la qualità della traduzione, potrebbero non coprire tutte le sfumature della scrittura creativa. L'integrazione di metriche come la perplessità per l'accuratezza predittiva e persino le valutazioni umane per il contesto può portare a una comprensione molto più completa delle prestazioni del tuo modello.
Benchmark e strumenti LLM
La valutazione dei modelli linguistici di grandi dimensioni (LLM) si basa spesso su benchmark standard del settore e strumenti specializzati che aiutano a misurare le prestazioni dei modelli in varie attività.
Ecco una panoramica di alcuni benchmark e strumenti ampiamente utilizzati che apportano struttura e chiarezza al processo di valutazione.
Parametri di riferimento chiave
- GLUE (General Language Understanding Evaluation): GLUE valuta le capacità dei modelli in diverse attività linguistiche, tra cui la classificazione delle frasi, la somiglianza e l'inferenza. È un benchmark di riferimento per i modelli che devono gestire la comprensione del linguaggio generico.
- SQuAD (Stanford Question Answering Dataset): il framework di valutazione SQuAD è ideale per la comprensione della lettura e misura la capacità di un modello di rispondere alle domande basate su un brano di testo. È comunemente utilizzato per attività come il supporto clienti e il recupero basato sulla conoscenza, dove è fondamentale fornire risposte precise.
- SuperGLUE: versione potenziata di GLUE, SuperGLUE valuta i modelli su attività di ragionamento e comprensione contestuale più complesse. Fornisce approfondimenti più dettagliati, in particolare per le applicazioni che richiedono una comprensione linguistica avanzata.
Strumenti di valutazione essenziali
- Hugging Face : è molto popolare per la sua vasta libreria di modelli, i set di dati e le funzionalità di valutazione. La sua interfaccia altamente intuitiva consente agli utenti di selezionare facilmente i benchmark, personalizzare le valutazioni e effettuare il monitoraggio delle prestazioni dei modelli, rendendolo versatile per molte applicazioni LLM.
- SuperAnnotate: è specializzato nella gestione e nell'annotazione dei dati, fondamentali per le attività di apprendimento supervisionato. È particolarmente utile per perfezionare la precisione dei modelli, poiché facilita l'ottenimento di dati di alta qualità annotati da esseri umani che migliorano le prestazioni dei modelli in attività complesse.
- AllenNLP: Sviluppato dall'Allen Institute for AI, AllenNLP è rivolto a ricercatori e sviluppatori che lavorano su modelli NLP personalizzati. Supporta una serie di benchmark e fornisce strumenti per addestrare, testare e valutare modelli linguistici, offrendo flessibilità per diverse applicazioni NLP.
L'uso combinato di questi benchmark e strumenti offre un approccio completo alla valutazione LLM. I benchmark possono definire standard per tutte le attività, mentre gli strumenti forniscono la struttura e la flessibilità necessarie per il monitoraggio, il perfezionamento e il miglioramento efficace delle prestazioni del modello.
Insieme, garantiscono che gli LLM soddisfino sia gli standard tecnici che le esigenze pratiche di applicazione.
Sfide nella valutazione del modello LLM
La valutazione dei modelli linguistici di grandi dimensioni (LLM) richiede un approccio sfumato. Si concentra sulla qualità delle risposte e sulla comprensione dell'adattabilità e dei limiti del modello in vari scenari.
Poiché questi modelli sono addestrati su set di dati estesi, il loro comportamento è influenzato da un intervallo di fattori, rendendo essenziale valutare più della semplice accuratezza.
Una vera valutazione significa esaminare l'affidabilità del modello, la sua resilienza a prompt insoliti e la coerenza complessiva delle risposte. Questo processo aiuta a delineare un quadro più chiaro dei punti di forza e di debolezza del modello e a individuare le aree che necessitano di perfezionamento.
Ecco uno sguardo più da vicino ad alcune delle sfide più comuni che si presentano durante la valutazione LLM.
1. Sovrapposizione dei dati di addestramento
È difficile sapere se il modello ha già visto alcuni dei dati di test. Poiché gli LLM vengono addestrati su enormi set di dati, è possibile che alcune domande di test coincidano con gli esempi di addestramento. Questo può far sembrare il modello migliore di quanto non sia in realtà, poiché potrebbe semplicemente ripetere ciò che già conosce invece di dimostrare una reale comprensione.
2. Prestazioni incostanti
Gli LLM possono avere risposte imprevedibili. In un momento forniscono intuizioni impressionanti e in quello successivo commettono strani errori o presentano informazioni immaginarie come fatti (fenomeno noto come "allucinazioni").
Questa incoerenza significa che, sebbene i risultati dell'LLM possano eccellere in alcuni ambiti, in altri possono risultare insufficienti, rendendo difficile valutare con precisione la sua affidabilità e qualità complessive.
3. Vulnerabilità avversarie
Gli LLM possono essere soggetti ad attacchi avversari, in cui prompt abilmente creati li inducono a produrre risposte errate o dannose. Questa vulnerabilità espone i punti deboli del modello e può portare a risultati inaspettati o distorti. Testare queste vulnerabilità avversarie è fondamentale per comprendere dove si trovano i limiti del modello.
Casi pratici di valutazione LLM
Infine, ecco alcune situazioni comuni in cui la valutazione LLM fa davvero la differenza:
Chatbot per il supporto clienti
Gli LLM sono ampiamente utilizzati nei chatbot per gestire le query dei clienti. Valutare l'efficacia delle risposte del modello garantisce che fornisca risposte accurate, utili e contestualmente pertinenti.
È fondamentale misurare la sua capacità di comprendere le intenzioni dei clienti, gestire domande diverse e fornire risposte simili a quelle umane. Ciò consentirà alle aziende di garantire un'esperienza cliente fluida, riducendo al minimo la frustrazione.
Generazione di contenuti
Molte aziende utilizzano gli LLM per generare contenuti per blog, social media e descrizioni di prodotti. Valutare la qualità dei contenuti generati aiuta a garantire che siano grammaticalmente corretti, coinvolgenti e pertinenti per il pubblico di destinazione. Metriche come la creatività, la coerenza e la pertinenza all'argomento sono importanti in questo caso per mantenere elevati standard di contenuto.
Analisi del sentiment
Gli LLM possono analizzare il sentiment dei feedback dei clienti, dei post sui social media o delle recensioni dei prodotti. È essenziale valutare con quanta precisione il modello identifica se un testo è positivo, negativo o neutro. Questo aiuta le aziende a comprendere le emozioni dei clienti, perfezionare i prodotti o i servizi, aumentare la soddisfazione degli utenti e migliorare le strategie di marketing.
Generazione di codice
Gli sviluppatori utilizzano spesso gli LLM come ausilio nella generazione di codice. È fondamentale valutare la capacità del modello di produrre codice funzionale ed efficiente.
È importante verificare che il codice generato sia logicamente corretto, privo di errori e soddisfi i requisiti dell'attività. Ciò contribuisce a ridurre la quantità di codifica manuale necessaria e migliora la produttività.
Ottimizza la tua valutazione LLM con ClickUp
La valutazione degli LLM consiste nello scegliere le metriche giuste in linea con i tuoi obiettivi. La chiave è comprendere i tuoi obiettivi specifici, che si tratti di migliorare la qualità della traduzione, potenziare la generazione di contenuti o ottimizzare attività specializzate.
La selezione delle metriche giuste per la valutazione delle prestazioni, come RAG o metriche di ottimizzazione, costituisce la base per una valutazione accurata e significativa. Nel frattempo, valutatori avanzati come G-Eval, Prometheus, SelfCheckGPT e QAG forniscono informazioni precise grazie alle loro forti capacità di ragionamento.
Tuttavia, ciò non significa che questi punteggi siano perfetti: è comunque importante assicurarsi che siano affidabili.
Man mano che procedi con la valutazione dell'applicazione LLM, adatta il processo al tuo caso d'uso specifico. Non esiste una metrica universale che funzioni per ogni scenario. Una combinazione di metriche, insieme a un'attenzione particolare al contesto, ti fornirà un quadro più accurato delle prestazioni del tuo modello.
Per semplificare la valutazione LLM e migliorare la collaborazione del team, ClickUp è la soluzione ideale per gestire i flussi di lavoro e effettuare il monitoraggio delle metriche importanti.
Vuoi migliorare la produttività del tuo team? Iscriviti oggi stesso a ClickUp e scopri come può trasformare il tuo flusso di lavoro!