
Vous avez passé des heures à concevoir la « prompt » parfaite. Vous avez la vision, le modèle et le potentiel pour un gain de productivité considérable. Mais un petit ajustement suffit à faire dérailler vos résultats. Sans méthode standard pour évaluer les résultats, vous ne pouvez pas savoir si votre IA s'améliore réellement ou si elle change simplement.
En effet, selon le rapport « Prompting Science » de Wharton, le simple fait de reformuler une instruction peut faire varier les performances de près de 60 points de pourcentage.
Ce guide vous présente les meilleurs modèles de benchmark de performance des prompts disponibles dans ClickUp. Il s'agit de plans d'action reproductibles pour évaluer les résultats, effectuer le suivi de chaque itération et, enfin, établir la connexion entre vos données d'évaluation et le travail effectué dans votre environnement de travail. ✨
Aperçu des modèles de référence de performance des prompts
Voici un aperçu rapide des modèles de benchmark de performance des prompts présentés dans ce guide et de la partie du flux de travail d'évaluation que chacun d'entre eux prend en charge 👇
| Modèle | Lien pour télécharger | Idéal pour | Principales fonctionnalités |
|---|---|---|---|
| Modèle d'analyse comparative par ClickUp | Obtenir un modèle gratuit | Comparaison des variantes de prompts et évaluation des résultats | Canevas de benchmarking visuel, champs de notation, analyse multi-vues |
| Modèle de plan d'expérimentation et de résultats par ClickUp | Obtenir un modèle gratuit | Réalisation d'expériences structurées sur les invites et les instructions | Suivi des hypothèses, journalisation de l'installation des tests, documentation des résultats |
| Modèle de gestion des tests par ClickUp | Obtenir un modèle gratuit | Gestion des flux de travail d'évaluation à grande échelle | Suivi des cas de test, statuts d'exécution, déclencheurs d'automatisation |
| Modèle de cas de test par ClickUp | Obtenir un modèle gratuit | Documentation des échecs d’invites au niveau granulaire | Journalisation des entrées/sorties, comparaison entre les résultats attendus et réels, suivi des réussites/échecs |
| Modèle de rapport de performance par ClickUp | Obtenir un modèle gratuit | Communiquer les résultats des benchmarks aux parties prenantes | Résumés exécutifs, visualisation des données, sections de recommandations |
| Modèle de rapport d'activité par ClickUp | Obtenir un modèle gratuit | Suivi de la progression de l'évaluation et de la charge de travail | Journaux d'activité, filtrage par date, visibilité sur la charge de travail |
| Modèle de tableau de bord équilibré par ClickUp | Obtenir un modèle gratuit | Aligner les performances des prompts sur les objectifs de l'entreprise | Notation multidimensionnelle, indicateurs pondérés, cartographie stratégique |
| Modèle d'évaluation de projet par ClickUp | Obtenir un modèle gratuit | Améliorer les processus de benchmarking au fil du temps | Évaluation des processus, leçons tirées, suivi des risques |
| Modèle de révision heuristique par ClickUp | Obtenir un modèle gratuit | Réalisation d'évaluations qualitatives des résultats de l'IA | Catégories heuristiques, évaluations de gravité, recueil des commentaires d'experts |
| Modèle d'OKR et d'objectifs d'entreprise par ClickUp | Obtenir un modèle gratuit | Lier les résultats des benchmarks aux objectifs stratégiques | Hiérarchie OKR, suivi des progrès, visibilité inter-équipes |
🧠 Anecdote : le terme « benchmark » n'est pas né dans les équipes logicielles ou produit. À l'origine, il désignait le point de référence d'un géomètre au XIXe siècle, bien avant de devenir la norme pour tout mesurer, des expériences sur les sites web aux performances des prompts.
Qu'est-ce qu'un modèle de benchmark de performance ?
Un modèle de benchmark de performance des prompts est un cadre permettant d'évaluer, de comparer et de noter les résultats des prompts d'IA. Il sert à déterminer si un prompt d'IA fonctionne réellement ou s'il se détériore imperceptiblement à chaque mise à jour du modèle.
Considérez cela comme une installation d'expérience standardisée :
- Cela définit ce que vous testez
- Comment mesurez-vous votre réussite ?
- Quelles données d'entrée utilisez-vous ?
- Comment vous enregistrez les résultats
👀 Le saviez-vous ? L'une des expériences les plus célèbres en statistiques a commencé par un débat sur la question de savoir s'il fallait verser le lait ou le thé en premier. Ronald Fisher a transformé ce petit désaccord en un test formel avec des tasses aléatoires, et cela est devenu l'une des histoires classiques à l'origine de la conception expérimentale moderne.
Qu'est-ce qui fait un bon modèle de benchmark de performance des prompts ?
Un bon modèle de prompt doit faire certaines choses avec efficacité, sinon il finira au fond d'un tiroir après le premier sprint :
- Critères d'évaluation standardisés : Définissez des paramètres tels que la précision, la pertinence, le ton et le taux d'hallucination avant que quiconque ne commence les tests. Sans grilles d'évaluation prédéfinies, chaque évaluateur attribue des notes différentes et les résultats ne sont pas comparables.
- Suivi des versions : chaque exécution de benchmark doit être associée à une version spécifique de l’invite, à un modèle et à un ensemble de paramètres, afin que vous puissiez retracer ce qui a changé et pourquoi.
- Notation à la fois numérique et qualitative : une réponse factuellement correcte peut tout de même sembler robotique. Les meilleurs modèles associent des évaluations numériques à des commentaires écrits structurés, présentés côte à côte.
- Structure prête à la comparaison : vous devriez pouvoir placer deux versions d'invites l'une à côté de l'autre et voir les différences instantanément
- Résultat exploitable : un benchmark se terminant par « score : 7/10 » est incomplet. Les évaluateurs doivent noter pourquoi un score a été attribué et ce qu'il convient de modifier ensuite.
- En lien avec le travail : les résultats d'évaluation isolés perdent rapidement leur contexte. Le modèle fonctionne mieux lorsqu'il est lié aux tâches et aux flux de travail où le développement des prompts a réellement lieu.
📮ClickUp Insight : 92 % des travailleurs du savoir risquent de perdre des décisions importantes dispersées entre les chats, les e-mails et les feuilles de calcul. Sans système unifié pour capturer et suivre les décisions, les informations commerciales critiques se perdent dans le bruit numérique. Grâce aux fonctionnalités de gestion des tâches de ClickUp, vous n'avez plus à vous en soucier. Créez des tâches à partir de chats, de commentaires sur des tâches, de documents et d'e-mails en un seul clic !
📮ClickUp Insight : 92 % des travailleurs du savoir risquent de perdre des décisions importantes dispersées entre les chats, les e-mails et les feuilles de calcul. Sans système unifié pour capturer et suivre les décisions, les informations commerciales critiques se perdent dans le bruit numérique. Grâce aux fonctionnalités de gestion des tâches de ClickUp, vous n'avez plus à vous en soucier. Créez des tâches à partir de chats, de commentaires sur des tâches, de documents et d'e-mails en un seul clic !
10 modèles de benchmark de performance des prompts pour votre équipe
Chaque modèle ci-dessous aborde un aspect différent de l'évaluation comparative des performances des prompts, allant des cas de test détaillés aux rapports stratégiques. Certains sont spécialement conçus pour l'évaluation comparative ; d'autres sont des cadres adaptables que les équipes d'ingénierie peuvent réutiliser pour leurs flux de travail d'évaluation.
Voyons cela de plus près :
1. Modèle d'analyse comparative par ClickUp™
L'évaluation des performances des invites se transforme généralement en un chaos subjectif en l'absence d'une base de référence fixe pour la comparaison. Si vous vous contentez de parcourir les résultats, vous ne saurez jamais vraiment quelle modification logique a corrigé une hallucination ou amélioré une réponse.
Le modèle d'analyse comparative de ClickUp™ fait office de laboratoire d'évaluation visuelle sur un Tableau blanc ClickUp. Il vous permet de représenter graphiquement les variantes de prompts, les grilles d'évaluation et les résultats des modèles sur une seule toile infinie, afin de repérer les schémas dans la logique des modèles qu'une vue Liste standard masquerait.
✨ Pourquoi vous allez adorer ce modèle
- Champs de notation personnalisés : associez chaque dimension d'évaluation (exactitude factuelle, longueur de la réponse et fréquence des hallucinations) à un champ personnalisé ClickUp dédié
- Plusieurs vues : basculez entre la vue Tableur de ClickUp pour comparer les données brutes, la vue Tableau de ClickUp pour le suivi basé sur le statut (En attente de révision → Évalué → Nécessite une itération) et plus de 15 vues ClickUp personnalisables
- Suivi historique : chaque exécution de benchmark est une tâche dotée d'un historique complet, ce qui vous permet de faire défiler les évaluations passées sans avoir à fouiller dans des feuilles de calcul nommées d'après leur version
✅ Idéal pour : les chercheurs en IA et les ingénieurs de prompts qui coordonnent des tests A/B rigoureux sur plusieurs variantes de modèles, logiques de production et cas d'utilisation de données sensibles.
⚡️ Vous souhaitez disposer d'un plus grand choix de modèles d'analyse comparative ? Nous avons sélectionné une liste pour vous ici : Modèles gratuits d'analyse comparative pour les Teams
2. Modèle de plan d'expérimentation et de résultats par ClickUp

Comment évaluer une instruction sans brouiller les conditions qui sous-tendent ses performances ? Le modèle « Plan d'expérience et résultats » de ClickUp apporte une rigueur méthodologique à cet exercice. Dans ce modèle, chaque essai d'instruction commence par une hypothèse formulée, une installation de test et un enregistrement des changements intervenus entre les exécutions.
Au fur et à mesure que les résultats arrivent, le modèle transforme les observations éparses en une piste de preuves. Les variantes d’invites, les critères de référence et les notes sur les résultats restent liés au même flux de travail, offrant à votre équipe une vision plus claire des performances.
✨ Pourquoi vous allez adorer ce modèle
- Standardisez les envois de benchmark : utilisez ClickUp Forms pour collecter chaque variante de prompt, chaque objectif de test, chaque grille d'évaluation et chaque scénario limite dans un flux de saisie cohérent avant le début de l'évaluation
- Transformez chaque exécution de prompt en travail responsable : utilisez les tâches ClickUp pour désigner des propriétaires, définir des étapes de révision, suivre les dépendances et faire progresser chaque cycle de benchmarking via un chemin d'exécution visible
- Conservez la logique derrière chaque résultat : consignez l'hypothèse, les conditions de test et les observations finales dans un seul rapport d'expérience
✅ Idéal pour : les responsables de contenu ou d'assistance qui souhaitent constituer une bibliothèque de prompts plus fiable pour une utilisation en production.
👀 Le saviez-vous ? Alors que 40 % des applications d'entreprise devraient fonctionner avec des agents IA d'ici la fin de l'année, notre équipe chez ClickUp a déjà transféré l'intégralité de notre système de contenu vers Super Agents.
Ces collaborateurs autonomes se chargent de l'ensemble du processus de rédaction, de distribution et de publication, ce qui nous permet de nous concentrer exclusivement sur la stratégie globale.
Découvrez ci-dessous comment ils gèrent notre environnement de travail :
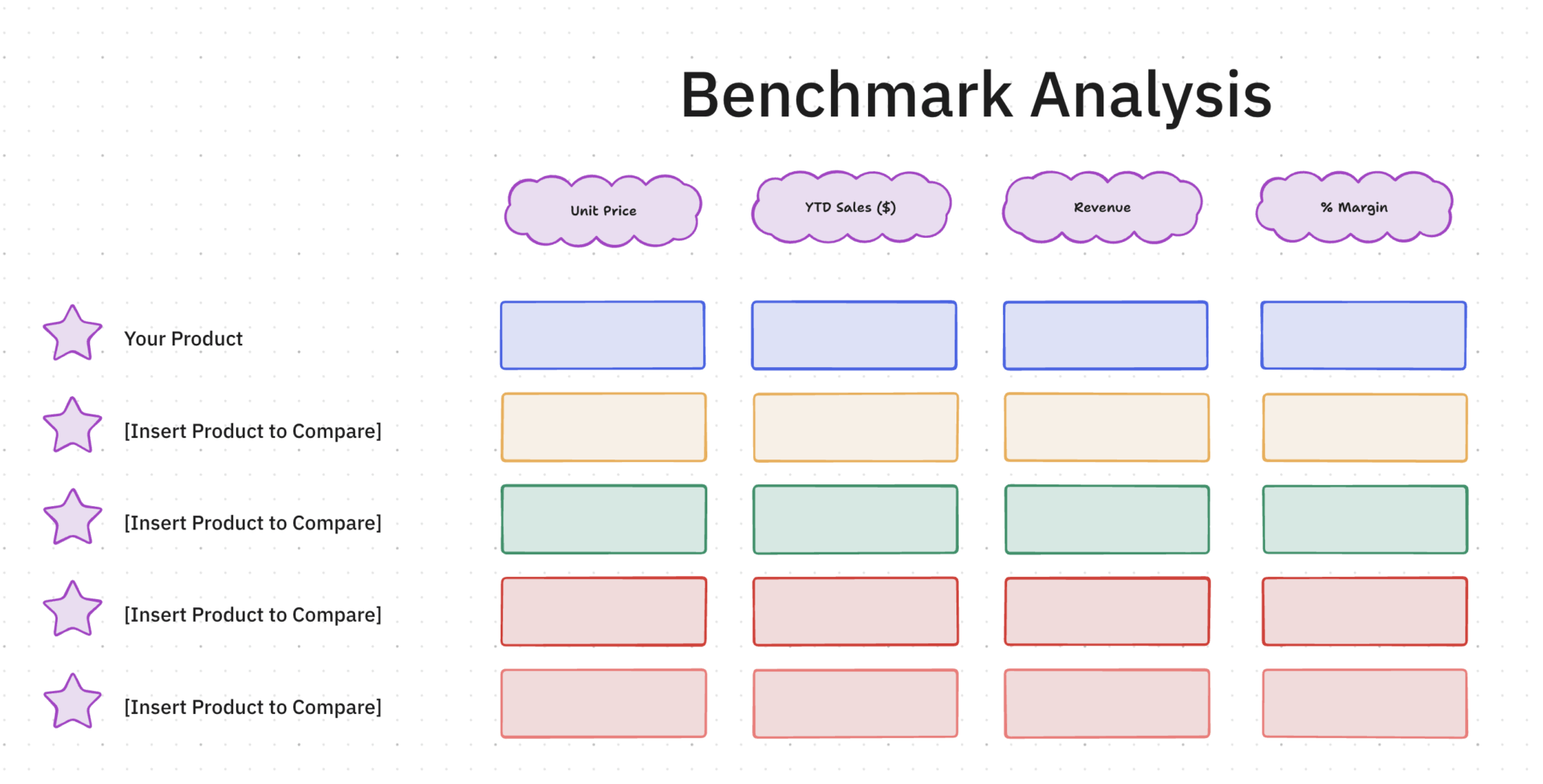
3. Modèle de gestion des tests par ClickUp
La mise à l'échelle d'une bibliothèque de prompts échoue généralement parce que personne ne sait quels tests sont réellement terminés. Si vous effectuez le suivi manuel des statuts « réussi » ou « échoué » dans un document aléatoire, vous perdez probablement des jours à effectuer des tests redondants et à gérer des boucles de communication.
Le modèle de gestion des tests de ClickUp offre une couche d'orchestration de haut niveau pour vos suites d'évaluation. Il transforme les paires de prompts et d'entrées dispersées en un pipeline contrôlé, où chaque cas de test a un propriétaire clairement identifié et un statut en temps réel, ce qui vous permet de respecter votre calendrier de déploiement.
✨ Pourquoi vous allez adorer ce modèle
- Surveillez l'état d'exécution : utilisez les statuts personnalisés de ClickUp tels que « À retester » ou « Réussi » pour suivre d'un seul coup d'œil la progression de votre suite de tests de performance.
- Synchronisez les cycles d'itération : configurez les automatisations ClickUp pour marquer des cas de test spécifiques en vue d'une nouvelle exécution chaque fois que la logique de base des invites est modifiée
- Décentralisez le travail d'évaluation : attribuez des lots de tests à différents membres de l'équipe afin d'éliminer les goulots d'étranglement et de réduire les biais liés à l'évaluation humaine.
✅ Idéal pour : les responsables de l'assurance qualité et les responsables des opérations de prompts qui coordonnent des suites d'évaluation à haut volume sur plusieurs versions de modèles et flux de travail techniques.
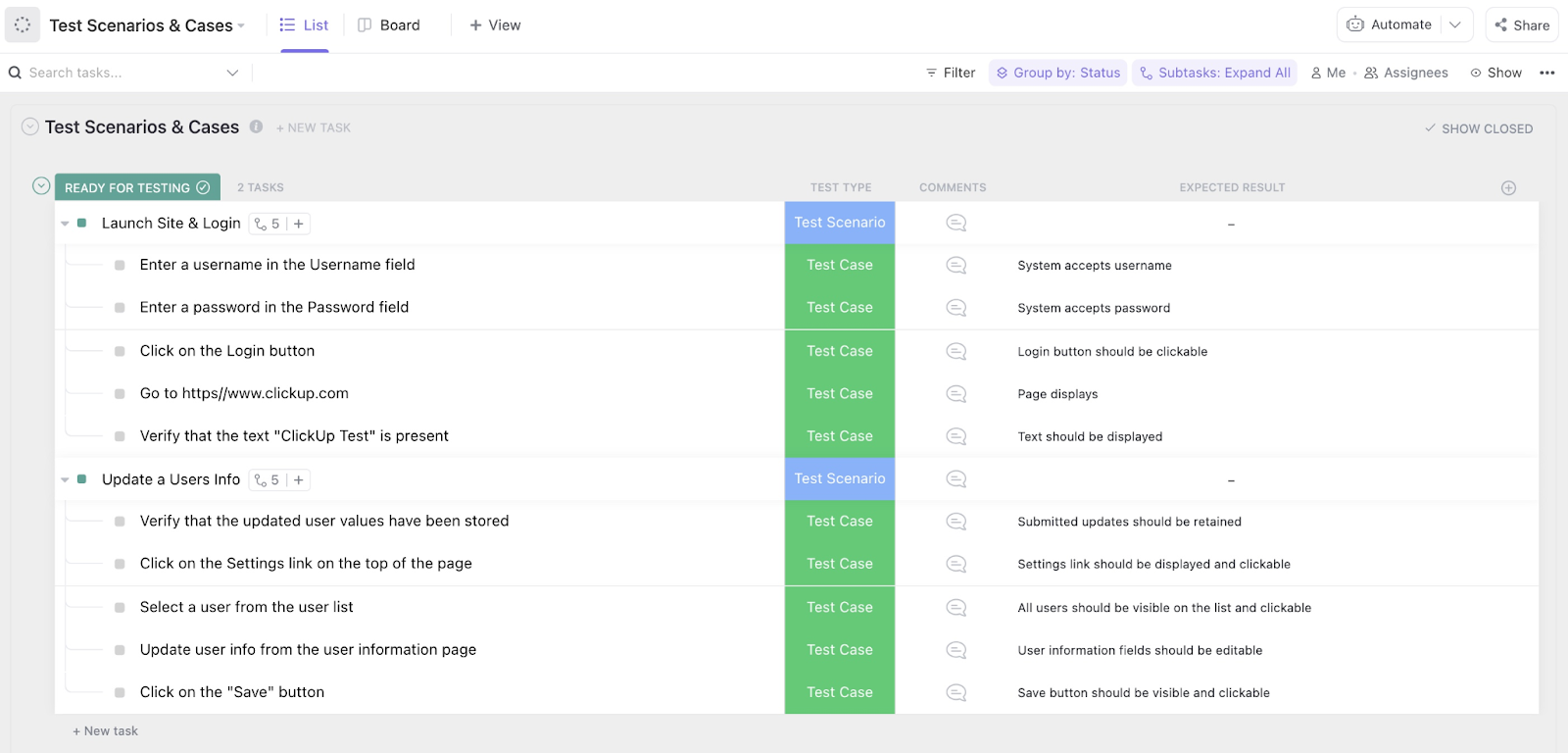
💡 Conseil de pro : Vous avez besoin de réponses rapidement ? Utilisez ClickUp Brain. Il peut extraire les notes de test, les cas d'échec, les modifications d'invite et le contexte de réexécution depuis votre environnement de travail et vos applications connectées. Ainsi, vous pouvez voir ce qui s'est passé avant de lancer la prochaine évaluation.
4. Modèle de cas de test par ClickUp

Les défaillances atomiques dans la logique de vos prompts sont pratiquement impossibles à corriger si elles sont noyées dans une mise à jour de statut générique. Vous devez voir exactement où le modèle a produit une hallucination ou ignoré une contrainte spécifique sans avoir à passer des heures à fouiller manuellement dans l'historique des conversations.
Le modèle de cas de test de ClickUp sert de couche de documentation détaillée pour votre suite d'évaluation. Il décompose chaque combinaison d'invites et d'entrées en une tâche élémentaire, ce qui permet une comparaison directe entre vos résultats attendus et la sortie réelle du modèle.
✨ Pourquoi vous allez adorer ce modèle
- Standardisez les pistes d'audit : consignez les variables d'entrée, les résultats attendus et les notes de delta dans des champs structurés afin d'éliminer toute interprétation subjective lors des revues
- Triez les résultats instantanément : marquez chaque cas de test avec des indicateurs binaires de réussite/échec afin de distinguer les ruptures logiques immédiates des problèmes de mise en forme mineurs
- Créez des liens traçables : reliez des cas de test individuels à des tâches parentes via les relations de tâches ClickUp pour voir exactement comment les échecs dans les cas limites affectent vos scores de benchmark globaux
✅ Idéal pour : les analystes QA et les ingénieurs en prompts en chef chargés de gérer les tests de régression pour les applications IA à enjeux élevés ou les flux de travail sensibles en contact avec la clientèle.
🔮 Vous avez identifié un bug qui mérite d'être corrigé ? Utilisez l'agent de reproduction des bugs de ClickUp. Il permet de transformer un cas de test échoué en étapes de reproduction claires, afin que les ingénieurs puissent le déboguer plus rapidement. Cela s'avère particulièrement utile lorsqu'une invite ne plante que sous certaines conditions ou avec des entrées spécifiques.

📚 À lire également : Modèles de flux de travail pour les invites d'IA
5. Modèle de rapport de performance par ClickUp™

Les parties prenantes ont rarement la patience de se plonger dans des journaux de test bruts ou des fiches d'évaluation techniques. À la fin d'une série de tests de performance, il vous reste généralement la tâche fastidieuse de traduire manuellement ces nombres en un rapport justifiant votre prochain déploiement.
Le modèle de rapport de performance de ClickUp™ sert de pont de communication incontournable pour vos opérations d'IA. Il organise vos résultats dans un document de résumé de haut niveau qui met en évidence les améliorations apportées aux modèles et les risques de régression.
✨ Pourquoi vous allez adorer ce modèle
- Résumés : zones pré-structurées pour les conclusions clés, les performances les plus et les moins bonnes, et les prochaines étapes recommandées
- Visualisation des données en direct : extrayez des données en temps réel à partir des tâches de benchmarking et intégrez-les dans les tableaux de bord ClickUp — une représentation visuelle de haut niveau des données de votre environnement de travail qui se met à jour à mesure que les évaluations sont achevées
- Simplifiez l'analyse des données : utilisez des diagrammes et des indicateurs de statut pour rendre les tendances complexes des benchmarks plus faciles à comprendre pour les équipes non techniques
✅ Idéal pour : les responsables de programmes d'IA et les chefs de produit techniques qui présentent la fiabilité des modèles et l'état de préparation des versions à la direction.
6. Modèle de rapport d'activité par ClickUp™
Une routine de benchmarking n'a de valeur que si votre équipe la suit réellement. Lorsque les tâches de test s'accumulent, il est facile de négliger les étapes de documentation qui permettent de conserver votre piste d'audit.
Le modèle de rapport d'activité de ClickUp™ est le cœur opérationnel de votre cycle de tests. Il permet le suivi des évaluations qui ont été livrées et celles qui sont encore en attente. Cette visibilité vous aide à respecter le calendrier de l'ensemble de votre processus de gouvernance.
✨ Pourquoi vous allez adorer ce modèle
- Journalisation des activités : enregistrement automatique des mises à jour des tâches, des changements de statut et des commentaires ClickUp liés aux flux de travail de référence
- Filtrage par période : affichez l'activité par semaine, sprint ou cycle de benchmarking pour identifier les tendances en matière de débit
- Visibilité sur la charge de travail : identifiez les évaluateurs surchargés et ceux qui disposent de capacités disponibles grâce à la vue « Charge de travail » de ClickUp
✅ Idéal pour : les responsables d'équipes IA et les responsables des opérations qui doivent s'assurer que les flux de travail de benchmarking ne sont pas ignorés ou retardés.
💡 Conseil de pro : Planifiez une réunion hebdomadaire de 15 minutes pour passer en revue le rapport d'activité et signaler les évaluations bloquées au même statut depuis plus de 3 jours. Utilisez ClickUp AI Notetaker pour enregistrer automatiquement les éléments à mener et les obstacles discutés lors de la réunion.

7. Modèle de tableau de bord prospectif par ClickUp
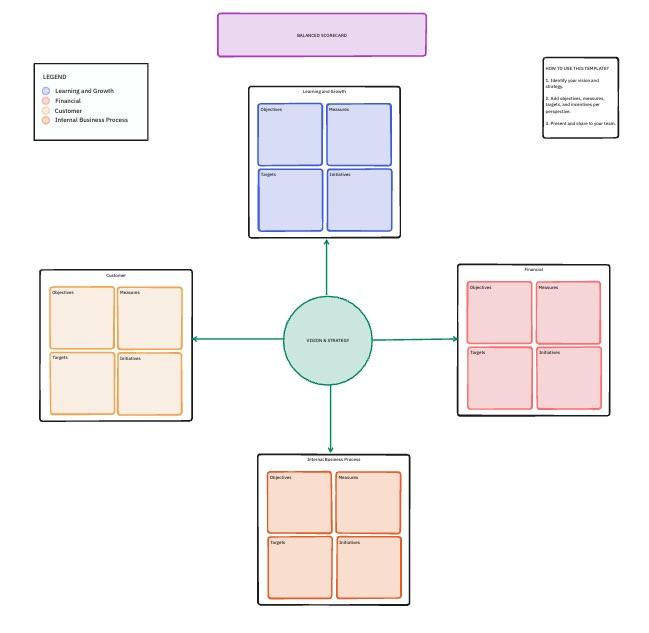
Une invite qui obtient un score de 98 % en termes de précision peut tout de même s'avérer trop coûteuse ou trop lente pour être réellement utilisée. Vous devez disposer d'un moyen de vérifier si vos ajustements techniques respectent les critères de référence tout en contribuant à vos objectifs généraux de l'entreprise.
Le modèle de tableau de bord prospectif de ClickUp utilise un Tableau blanc pour schématiser ces connexions. Il s'agit d'un espace collaboratif permettant de relier des données techniques à des catégories stratégiques telles que l'impact financier, la satisfaction client et la croissance interne.
✨ Pourquoi vous allez adorer ce modèle
- Évaluation multidimensionnelle : quatre perspectives stratégiques intégrant chacune des indicateurs au niveau des invites
- Mise en correspondance des alignements : reliez visuellement les résultats individuels des benchmarks aux objectifs au niveau de l'équipe ou du produit
- Champs pondérés : Définissez des scores pondérés par dimension à l'aide des champs personnalisés de ClickUp afin que les performances agrégées reflètent les priorités stratégiques
✅ Idéal pour : les chefs de produit et les responsables IA/ML qui ont besoin d'aligner les performances de l'ingénierie des prompts sur les objectifs commerciaux de haut niveau et l'allocation des ressources.
8. Modèle d'évaluation de projet par ClickUp
Négliger l'analyse rétrospective de votre cycle de benchmarking revient à passer à côté d'une occasion de résoudre vos goulots d'étranglement en matière de tests. Vous devez savoir si vos cas de test étaient réellement représentatifs ou si vos grilles d'évaluation étaient trop vagues avant de lancer la prochaine série de déploiements.
Le modèle d'évaluation de projet de ClickUp vous aide à évaluer l'évaluation elle-même. Il vous permet d'aller au-delà des simples scores de prompt pour examiner la santé globale de votre pipeline de tests, afin que chaque cycle débouche sur de réelles améliorations logiques.
✨ Pourquoi vous allez adorer ce modèle
- Évaluation de l'état du processus : utilisez des champs de statut codés par couleur pour évaluer d'un seul coup d'œil la portée de vos tests, l'échéancier et l'efficacité des ressources
- Consignez les enseignements tirés : consignez ce qui a fonctionné et ce qui a échoué dans une section du document structurée afin d'améliorer votre prochaine évaluation
- Identifiez les risques futurs : consignez les obstacles spécifiques, tels que les temps d'arrêt des API ou les lacunes dans les données, afin d'éviter qu'ils ne ralentissent votre prochain sprint de prompts.
✅ Idéal pour : les responsables des opérations IA et les responsables assurance qualité qui ont besoin d'affiner leurs méthodologies de test et de démontrer le retour sur investissement de leurs efforts de benchmarking.
9. Modèle de revue heuristique par ClickUp

Les notes numériques ne reflètent qu'une partie de la réalité lors de l'évaluation des résultats de votre IA. Une invite peut passer un test d'exactitude factuelle, mais sembler néanmoins robotique, déroutante ou légèrement en décalage avec l'image de marque pour vos utilisateurs.
Le modèle de révision heuristique de ClickUp intègre l'intuition humaine d'experts à votre flux de travail PromptOps. Il utilise un Tableau blanc collaboratif pour mapper les résultats contre des principes fondamentaux tels que la clarté et la prévention des erreurs. Votre équipe peut associer des commentaires spécifiques à différentes catégories heuristiques à l'aide de notes autocollantes numériques afin de garder l'audit bien organisé.
✨ Pourquoi vous allez adorer ce modèle
- Standardisez les contrôles qualitatifs : Évaluez les résultats par rapport à des principes personnalisés afin de garantir la cohérence du ton de la marque et de l'utilité de l'information dans l'ensemble du contenu généré.
- Prioriser les corrections logiques : Classez les problèmes par gravité afin de distinguer les risques critiques pour la sécurité des erreurs mineures d'ordre esthétique
- Consolidez les avis d'experts : consignez les remarques des réviseurs sur des notes autocollantes du Tableau blanc afin de faciliter l'analyse et la mise en œuvre des données qualitatives
✅ Idéal pour : les rédacteurs UX et les équipes PromptOps qui effectuent des audits manuels spécialisés afin de s'assurer que le contenu généré par l'IA répond à des normes de qualité et de sécurité élevées.
📮ClickUp Insight : Alors que 34 % des utilisateurs font entièrement confiance aux systèmes d'IA, un groupe légèrement plus important (38 %) adopte une approche « faire confiance, mais vérifier ». Un outil autonome qui ne connaît pas votre contexte de travail présente souvent un risque plus élevé de générer des réponses inexactes ou insatisfaisantes.
C'est pourquoi nous avons développé ClickUp Brain, l'IA qui relie la gestion de vos projets, la gestion des connaissances et la collaboration au sein de votre environnement de travail et des outils tiers intégrés. Obtenez des réponses contextuelles sans avoir à activer/désactiver un outil chaque fois que vous en utilisez un autre et multipliez par 2 ou 3 votre efficacité au travail, tout comme nos clients chez Seequent.
📮ClickUp Insight : Alors que 34 % des utilisateurs font entièrement confiance aux systèmes d'IA, un groupe légèrement plus important (38 %) adopte une approche « faire confiance, mais vérifier ». Un outil autonome qui ne connaît pas votre contexte de travail présente souvent un risque plus élevé de générer des réponses inexactes ou insatisfaisantes.
C'est pourquoi nous avons développé ClickUp Brain, l'IA qui assure la connexion entre la gestion de projet, la gestion des connaissances et la collaboration au sein de votre environnement de travail et des outils tiers intégrés. Obtenez des réponses contextuelles sans avoir à activer/désactiver des outils et multipliez par 2 ou 3 votre efficacité au travail, tout comme nos clients chez Seequent.
10. Modèle d'OKR et d'objectifs d'entreprise par ClickUp
Améliorer la précision des invites de 72 % à 88 % constitue une avancée technique majeure. Cependant, ce nombre n'a de poids que si la direction comprend comment ces améliorations ont un impact direct sur votre croissance trimestrielle.
Le modèle « OKR et objectifs de l'entreprise » de ClickUp comble le fossé entre l'analyse comparative technique et la stratégie de haut niveau. Il vous permet d'intégrer des objectifs de performance spécifiques à vos objectifs principaux pour le produit. Cela permet à l'équipe de rester concentrée sur les résultats techniques qui font avancer l'entreprise.
✨ Pourquoi vous allez adorer ce modèle
- Hiérarchie des objectifs et des résultats clés : Intégrez les cibles de benchmarking au niveau des prompts dans les objectifs de l'équipe ou du produit pour un alignement clair
- Suivi des progrès : des indicateurs visuels de progression qui s'actualisent à mesure que les scores de référence s'améliorent au fil des cycles d'évaluation
- Visibilité transversale : planifiez les OKR de l'entreprise et partagez les cibles de référence avec les équipes produit, ingénierie et direction afin que chacun puisse voir comment la qualité des réponses instantanées s'inscrit dans les priorités de la feuille de route
✅ Idéal pour : les équipes IA/ML qui souhaitent formaliser l'analyse comparative en tant qu'objectif récurrent avec des résultats mesurables.
Améliorez la qualité de votre IA avec ClickUp
Plus il y a d'invites, plus il y a d'éléments à gérer, plus il y a d'itérations et plus le risque de voir la qualité des résultats baisser est élevé.
Avec ClickUp, vous créez un environnement de travail convergent où l'analyse comparative commence par une évaluation structurée dans les tâches, et où le perfectionnement reste aligné grâce aux documents et aux Tableaux blancs. De plus, l'IA est intégrée à chaque modèle et solution, gérant automatiquement les analyses répétitives et la gestion des versions.
Alors, qu'attendez-vous ? Lancez-vous gratuitement avec ClickUp et transformez vos benchmarks en résultats concrets.
Foire aux questions
Les indicateurs clés comprennent la précision, la pertinence, la cohérence et la latence. Vous devriez également suivre le taux d'hallucinations, le respect du ton et le taux d'achèvement des tâches. La combinaison idéale dépend en fin de compte de votre cas d'utilisation spécifique. Par exemple, les résultats personnalisés pour les clients privilégient le ton et la sécurité, tandis que les instructions internes se concentrent davantage sur la précision et la rapidité.
Pour adapter votre modèle, commencez par ajouter des champs pour le nom du modèle, la version et les paramètres, tels que la température et les limites de jetons. Vous devriez également inclure une section permettant de comparer les résultats attendus et réels afin de mesurer les performances. Enfin, ajoutez un suivi des versions à chaque exécution. Cela garantit que chaque benchmark est lié à une itération spécifique de l’invite, ce qui permet une évaluation précise à long terme.
L'analyse comparative quantitative utilise des scores numériques (par exemple, le pourcentage de précision ou le temps de réponse) pour permettre une comparaison objective. À l'inverse, l'analyse comparative qualitative s'appuie sur l'avis d'experts qui évaluent des critères tels que la clarté, l'utilité et la voix de la marque ; les programmes de test de prompts les plus efficaces utilisent les deux approches.
Une analyse comparative structurée permet de détecter les régressions des prompts avant qu'elles n'atteignent vos utilisateurs. Elle crée une boucle de rétroaction continue entre l'évaluation et l'itération, vous permettant d'affiner les performances au fil du temps. Ce processus constitue une base factuelle solide pour vos décisions en matière d'ingénierie des prompts.