
Você passou horas criando o prompt “perfeito”. Você tem a visão, o modelo e o potencial para um enorme ganho de produtividade. Mas um pequeno ajuste faz com que sua saída saia dos trilhos. Sem uma maneira padronizada de avaliar os resultados, não dá para saber se sua IA está realmente melhorando ou apenas mudando.
De fato, de acordo com o Relatório Prompting Science da Wharton, simplesmente reformular um prompt pode alterar o desempenho em até 60 pontos percentuais.
Este guia apresenta os melhores modelos de benchmark de desempenho de prompts no ClickUp. São planos de ação repetíveis para avaliar resultados, acompanhar cada iteração e, por fim, conectar seus dados de avaliação ao trabalho em seu espaço de trabalho. ✨
Visão geral dos modelos de benchmark de desempenho de prompts
Aqui está uma rápida visão geral dos modelos de benchmark de desempenho de prompts abordados neste guia e a parte do fluxo de trabalho de avaliação que cada um deles suporta 👇
| Modelo | Link para download | Ideal para | Principais recursos |
|---|---|---|---|
| Modelo de análise de benchmark da ClickUp | Obtenha o modelo gratuitamente | Comparando variantes de prompts e avaliando resultados | Tela visual de benchmarking, campos de pontuação, análise com múltiplas visualizações |
| Modelo de plano e resultados de experimento da ClickUp | Obtenha o modelo gratuitamente | Executando experimentos estruturados com prompts | Acompanhamento de hipóteses, registro da configuração de testes, documentação de resultados |
| Modelo de gerenciamento de testes da ClickUp | Obtenha o modelo gratuitamente | Gerenciamento de fluxos de trabalho de avaliação em grande escala | Acompanhamento de casos de teste, status de execução, gatilhos de automação |
| Modelo de caso de teste da ClickUp | Obtenha o modelo gratuitamente | Documentação de falhas granulares de prompts | Registro de entradas/saídas, comparação entre valores esperados e reais, acompanhamento de aprovação/reprovação |
| Modelo de relatório de desempenho da ClickUp | Obtenha o modelo gratuitamente | Comunicação dos resultados da avaliação de desempenho às partes interessadas | Resumos executivos, visualização de dados, seções de recomendações |
| Modelo de relatório de atividades da ClickUp | Obtenha o modelo gratuitamente | Acompanhamento do progresso da avaliação e da carga de trabalho | Registros de atividades, filtragem por tempo, visibilidade da carga de trabalho |
| Modelo de Balanced Scorecards da ClickUp | Obtenha o modelo gratuitamente | Alinhando o desempenho dos prompts com as metas de negócios | Pontuação multidimensional, métricas ponderadas, mapeamento de estratégias |
| Modelo de avaliação de projetos da ClickUp | Obtenha o modelo gratuitamente | Aprimorando os processos de benchmarking ao longo do tempo | Avaliação de processos, lições aprendidas, acompanhamento de riscos |
| Modelo de revisão heurística da ClickUp | Obtenha o modelo gratuitamente | Realização de avaliações qualitativas dos resultados da IA | Categorias heurísticas, classificações de gravidade, captura de feedback de especialistas |
| Modelo de OKRs e metas da empresa pelo ClickUp | Obtenha o modelo gratuitamente | Vinculando resultados de benchmarking a metas estratégicas | Hierarquia de OKRs, acompanhamento do progresso, visibilidade entre equipes |
🧠 Curiosidade: O termo “benchmark” não surgiu nas equipes de software ou de produtos. Originalmente, significava o ponto de referência de um agrimensor no século XIX, muito antes de se tornar o padrão para medir tudo, desde experimentos em sites até o desempenho de prompts.
O que é um modelo de benchmark de desempenho?
Um modelo de benchmark de desempenho de prompts é uma estrutura para avaliar, comparar e pontuar os resultados de prompts de IA. Ele é usado para medir se um prompt de inteligência artificial está realmente funcionando ou se está piorando discretamente a cada atualização do modelo.
Pense nisso como uma configuração de experimento padronizada:
- Ele define o que você está testando
- Como você está medindo o sucesso
- Quais entradas você está executando
- Como você está registrando os resultados
👀 Você sabia? Um dos experimentos mais famosos da estatística começou com um debate sobre se o leite ou o chá deveriam ser servidos primeiro. Ronald Fisher transformou essa pequena discordância em um teste formal com xícaras aleatórias, e isso se tornou uma das histórias clássicas por trás do desenho experimental moderno.
O que torna um modelo de benchmark de desempenho de prompts eficaz
Um bom modelo de prompt precisa realizar bem tarefas específicas, ou ficará esquecido após o primeiro sprint:
- Critérios de avaliação padronizados: Defina dimensões como precisão, relevância, tom e taxa de alucinação antes que alguém comece a testar. Sem critérios de avaliação predefinidos, cada avaliador atribui pontuações diferentes, e os resultados tornam-se incomparáveis
- Acompanhamento de versões: Cada execução de benchmark precisa estar vinculada a uma versão específica do prompt, modelo e conjunto de parâmetros para que você possa rastrear o que mudou e por quê
- Pontuação numérica e qualitativa: uma resposta factualmente correta ainda pode soar robótica. Os melhores modelos combinam classificações numéricas com notas escritas estruturadas, lado a lado
- Estrutura pronta para comparação: você deve poder colocar duas versões de prompts lado a lado e ver as diferenças instantaneamente
- Resultado prático: Uma avaliação que termina com “pontuação: 7/10” está incompleta. Os avaliadores precisam observar por que a pontuação ficou nesse nível e o que deve ser alterado a seguir
- Conectado ao trabalho: Resultados de benchmark isolados perdem o contexto rapidamente. O modelo funciona melhor quando está vinculado às tarefas e fluxos de trabalho onde o desenvolvimento de prompts realmente ocorre
📮ClickUp Insight: 92% dos profissionais do conhecimento correm o risco de perder decisões importantes espalhadas por chats, e-mails e planilhas. Sem um sistema unificado para capturar e acompanhar decisões, insights críticos de negócios se perdem no ruído digital. Com os recursos de gerenciamento de tarefas do ClickUp, você nunca precisa se preocupar com isso. Crie tarefas a partir de chats, comentários em tarefas, documentos e e-mails com um único clique!
📮ClickUp Insight: 92% dos profissionais do conhecimento correm o risco de perder decisões importantes espalhadas por chats, e-mails e planilhas. Sem um sistema unificado para capturar e acompanhar decisões, insights críticos de negócios se perdem no ruído digital. Com os recursos de gerenciamento de tarefas do ClickUp, você nunca precisa se preocupar com isso. Crie tarefas a partir de chats, comentários de tarefas, documentos e e-mails com um único clique!
10 modelos de benchmark de desempenho de prompts para sua equipe
Cada modelo abaixo aborda um ângulo diferente da avaliação de desempenho de prompts — desde casos de teste detalhados até relatórios estratégicos. Alguns foram criados especificamente para avaliação; outros são estruturas adaptáveis que permitem que equipes de engenharia as reutilizem para fluxos de trabalho de avaliação.
Vamos dar uma olhada:
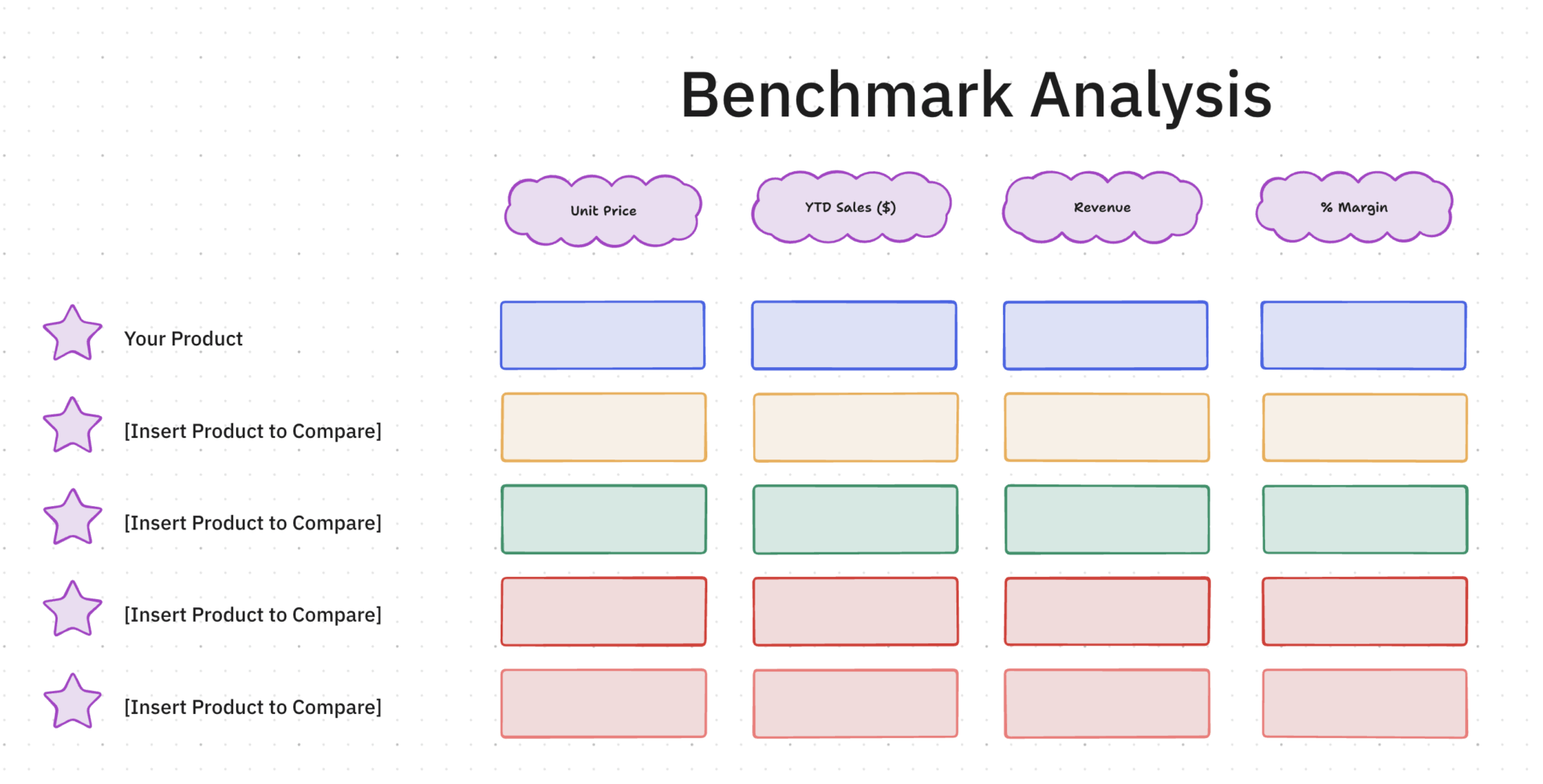
1. Modelo de análise comparativa da ClickUp™
Avaliar o desempenho de prompts geralmente se transforma em uma confusão subjetiva sem uma linha de base fixa para comparação. Se você estiver apenas lendo os resultados, nunca saberá realmente qual ajuste na lógica corrigiu uma alucinação ou melhorou uma resposta.
O modelo de análise de benchmark da ClickUp™ funciona como um laboratório de avaliação visual no ClickUp Whiteboard. Ele permite que você trace variantes de prompts, critérios de pontuação e resultados de modelos em uma única tela infinita, para que você possa identificar padrões na lógica do modelo que uma visualização de lista padrão ocultaria.
✨ Por que você vai adorar este modelo
- Campos de pontuação personalizados: Mapeie cada dimensão de avaliação (precisão factual, comprimento da resposta e frequência de alucinações) para um campo personalizado dedicado no ClickUp
- Várias visualizações: Alterne entre a Visualização em Tabela do ClickUp para comparação de dados brutos, a Visualização em Quadro do ClickUp para acompanhamento baseado no status (Aguardando Revisão → Avaliado → Precisa de Iteração) e mais de 15 visualizações personalizáveis do ClickUp
- Acompanhamento histórico: Cada execução de benchmark é uma tarefa com histórico completo, permitindo que você navegue pelas avaliações anteriores sem precisar vasculhar planilhas nomeadas por versão
✅ Ideal para: pesquisadores de IA e engenheiros de prompts que coordenam testes A/B rigorosos em várias variantes de modelos, lógicas de produção e casos de uso de dados confidenciais.
⚡️ Quer mais modelos de análise de benchmark para escolher? Selecionamos uma lista para você aqui: Modelos gratuitos de análise de benchmark para equipes
2. Modelo de plano e resultados de experimento da ClickUp

Como avaliar um prompt sem obscurecer as condições por trás de seu desempenho? O modelo “Plano de Experimento e Resultados” do ClickUp confere rigor metodológico ao exercício. Nesse modelo, cada teste de prompt começa com uma hipótese declarada, uma configuração de teste e um registro das alterações ocorridas entre as execuções.
À medida que os resultados chegam, o modelo transforma observações dispersas em um rastro de evidências. Variantes de prompts, critérios de benchmark e notas de resultados permanecem vinculados ao mesmo fluxo de trabalho, proporcionando à sua equipe uma visão mais clara do desempenho.
✨ Por que você vai adorar este modelo
- Padronize o envio de benchmarks: use os formulários do ClickUp para coletar cada variante de prompt, objetivo de teste, rubrica e cenário de caso extremo em um fluxo de entrada consistente antes do início da avaliação
- Transforme cada execução de prompt em trabalho responsável: use as Tarefas do ClickUp para designar responsáveis, definir etapas de revisão, acompanhar dependências e manter cada ciclo de benchmark em andamento por meio de um caminho de execução visível
- Preserve a lógica por trás de cada resultado: Registre a hipótese, as condições de teste e as observações finais em um único registro de experimento
✅ Ideal para: Líderes de conteúdo ou suporte que estejam criando uma biblioteca de prompts mais confiável para uso em produção.
👀 Você sabia? Com a previsão de que 40% dos aplicativos corporativos serão executados por agentes de IA até o final deste ano, nossa equipe no ClickUp já migrou todo o nosso sistema de conteúdo para o Super Agents.
Esses colegas de equipe autônomos cuidam de todo o processo de elaboração, encaminhamento e publicação, deixando-nos livres para nos concentrarmos exclusivamente na estratégia de alto nível.
Veja abaixo como eles operam nosso espaço de trabalho:
3. Modelo de gerenciamento de testes da ClickUp
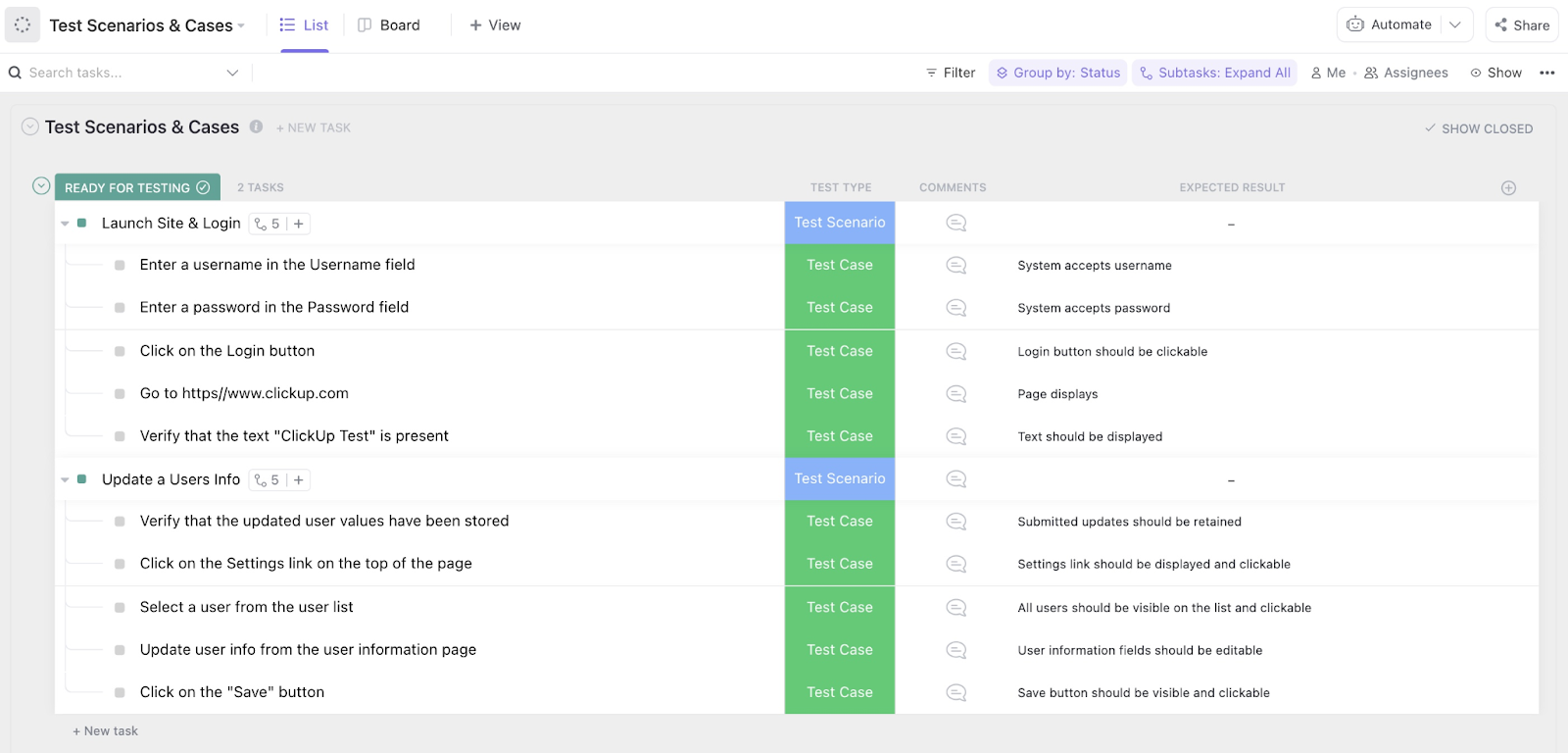
A expansão de uma biblioteca de prompts geralmente fracassa porque ninguém sabe quais testes estão realmente concluídos. Se você estiver acompanhando manualmente os estados “aprovado” ou “reprovado” em um documento aleatório, provavelmente está perdendo dias com testes redundantes e ciclos de comunicação.
O modelo de gerenciamento de testes da ClickUp oferece uma camada de orquestração de alto nível para seus conjuntos de avaliação. Ele transforma pares dispersos de prompts e entradas em um pipeline controlado, onde cada caso de teste tem um responsável definido e um status em tempo real, mantendo seu cronograma de implantação dentro do planejado.
✨ Por que você vai adorar este modelo
- Monitore a integridade da execução: use status personalizados do ClickUp, como “Precisa ser testado novamente” ou “Aprovado”, para acompanhar o progresso do seu conjunto de benchmarks rapidamente
- Sincronize ciclos de iteração: Configure as automações do ClickUp para sinalizar casos de teste específicos para uma nova execução sempre que a lógica central do prompt for modificada
- Descentralize o trabalho de avaliação: atribua lotes de testes a diferentes membros da equipe para eliminar gargalos e reduzir o viés do avaliador humano
✅ Ideal para: líderes de controle de qualidade e gerentes de operações de prompts que coordenam conjuntos de avaliação de alto volume em várias versões de modelos e fluxos de trabalho técnicos.
💡 Dica profissional: Precisa de respostas rápidas? Use o ClickUp Brain. Ele pode extrair notas de teste, casos com falha, alterações de prompts e contexto de reexecução do seu espaço de trabalho e dos aplicativos conectados. Assim, você pode ver o que aconteceu antes de executar a próxima avaliação.
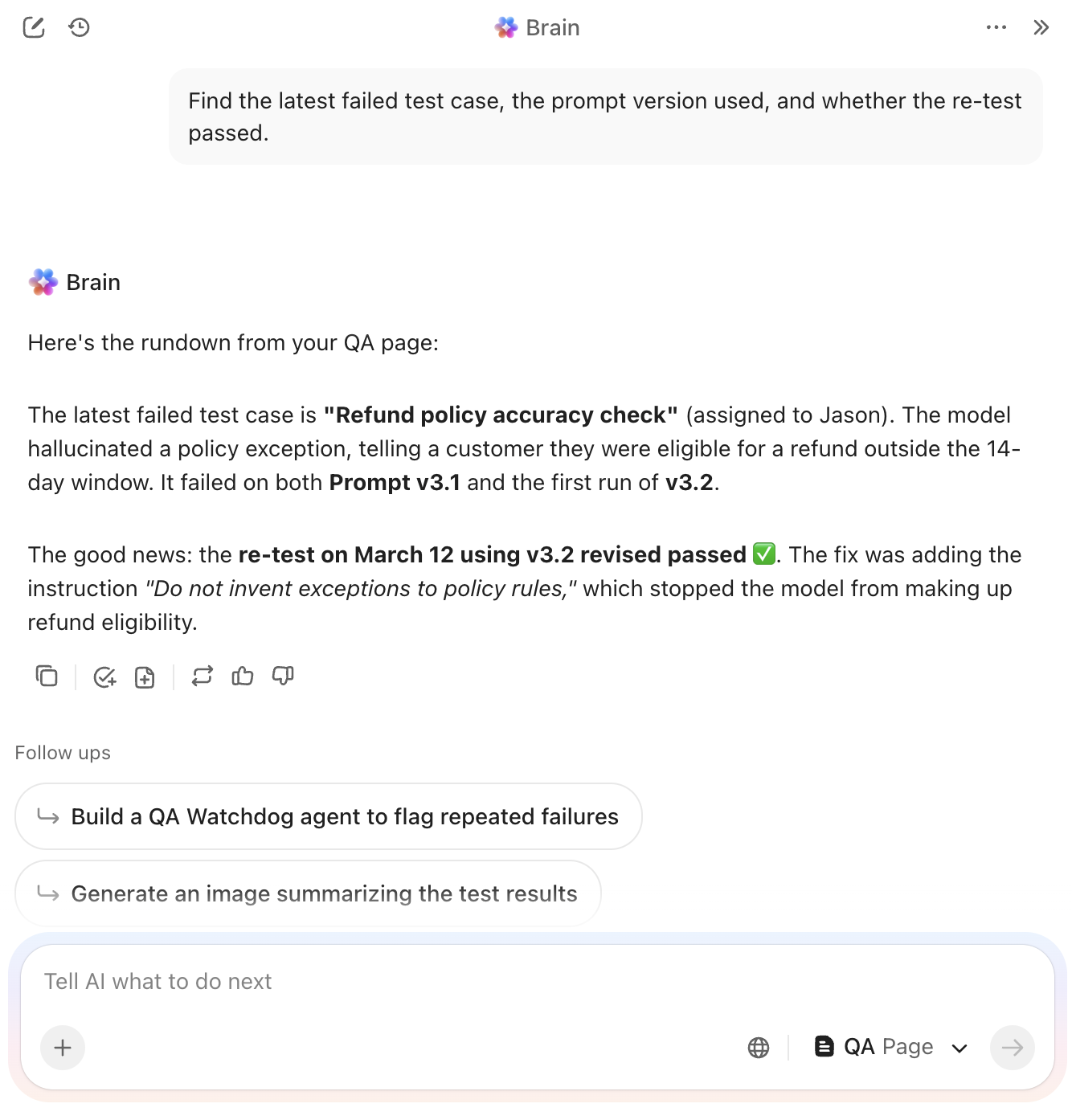
4. Modelo de caso de teste da ClickUp

Falhas atômicas na lógica do seu prompt são quase impossíveis de corrigir se estiverem ocultas em uma atualização de status genérica. Você precisa ver exatamente onde o modelo cometeu um erro ou ignorou uma restrição específica sem precisar vasculhar horas de histórico de bate-papo manualmente.
O modelo de caso de teste do ClickUp funciona como uma camada de documentação detalhada para seu conjunto de avaliações. Ele divide cada combinação de prompt e entrada em uma tarefa atômica, forçando uma comparação direta entre os resultados esperados e a saída real do modelo.
✨ Por que você vai adorar este modelo
- Padronize trilhas de auditoria: Registre variáveis de entrada, resultados esperados e notas de delta em campos estruturados para eliminar interpretações subjetivas durante as revisões
- Classifique os resultados instantaneamente: Marque cada caso de teste com indicadores binários de aprovação/reprovação para separar falhas lógicas imediatas de pequenos problemas de formatação
- Crie links rastreáveis: conecte casos de teste individuais a tarefas pai por meio das Relações de Tarefas do ClickUp para ver exatamente como falhas em casos extremos afetam suas pontuações agregadas de benchmark
✅ Ideal para: Analistas de controle de qualidade e engenheiros -chefe de prompts que gerenciam testes de regressão para aplicações de IA de alto risco ou fluxos de trabalho sensíveis voltados para o cliente.
🔮 Encontrou uma falha que vale a pena corrigir? Use o Agente de Reprodução de Bugs do ClickUp. Ele ajuda a transformar um caso de teste com falha em etapas de reprodução claras, para que a equipe de engenharia possa depurá-lo mais rapidamente. Isso é especialmente útil quando um prompt falha apenas sob entradas ou condições específicas.

📚 Leia também: Modelos de fluxo de trabalho para prompts de IA
5. Modelo de relatório de desempenho da ClickUp™
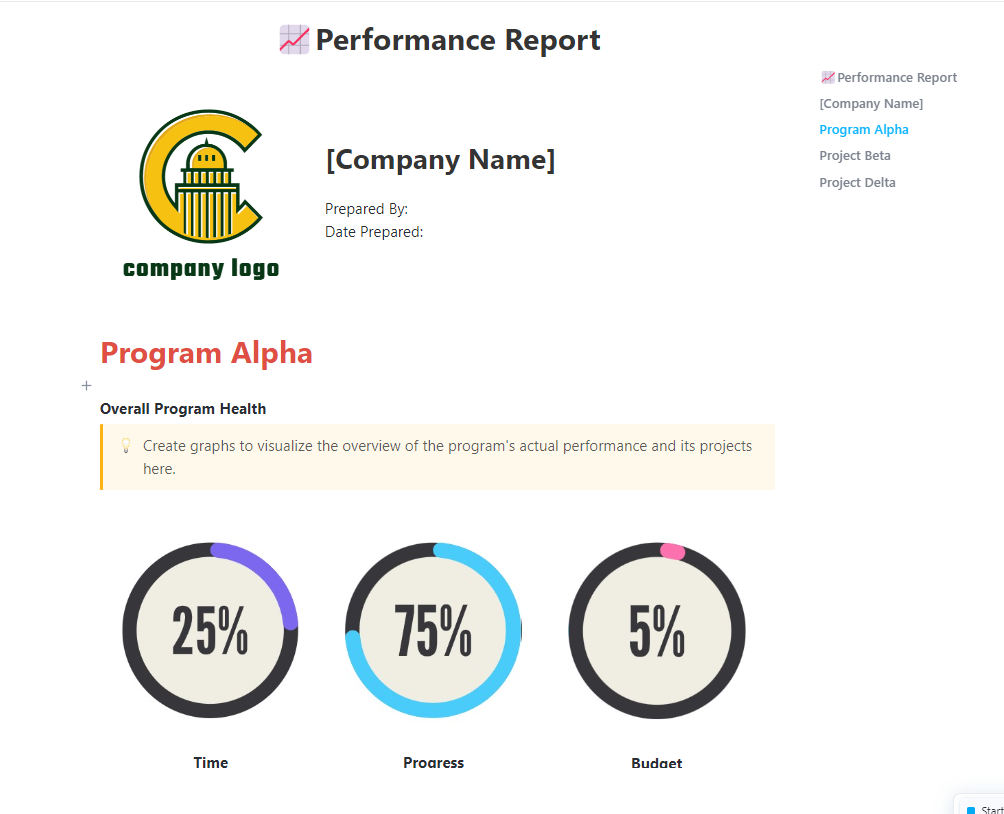
As partes interessadas raramente têm paciência para vasculhar registros de teste brutos ou planilhas de pontuação técnica. Quando uma rodada de benchmarking termina, geralmente você fica com a tarefa manual de traduzir esses números em uma narrativa que justifique sua próxima implantação.
O modelo de relatório de desempenho da ClickUp™ funciona como a ponte de comunicação definitiva para suas operações de IA. Ele organiza suas descobertas em um documento de resumo de alto nível que destaca melhorias no modelo e riscos de regressão.
✨ Por que você vai adorar este modelo
- Seções de resumo: Áreas pré-estruturadas para principais conclusões, melhores e piores desempenhos e próximas etapas recomendadas
- Visualização de dados em tempo real : importe dados em tempo real de tarefas de benchmark para os painéis do ClickUp — uma representação visual de alto nível dos dados do seu Workspace que é atualizada à medida que as avaliações são concluídas
- Simplifique a análise de dados: aplique gráficos e indicadores de status para tornar as tendências complexas de benchmarking mais fáceis de entender para equipes sem conhecimentos técnicos
✅ Ideal para: gerentes de programas de IA e proprietários de produtos técnicos que apresentam a confiabilidade dos modelos e a prontidão das versões à liderança executiva.
6. Modelo de relatório de atividades da ClickUp™
Uma rotina de benchmarking só tem valor se sua equipe realmente a seguir. Quando as tarefas de teste se acumulam, é fácil pular as etapas de documentação que mantêm sua trilha de auditoria.
O modelo de relatório de atividades da ClickUp™ funciona como o coração operacional do seu ciclo de testes. Ele acompanha quais avaliações já foram entregues e quais ainda estão na fila. Essa visibilidade ajuda a manter todo o seu processo de governança dentro do cronograma.
✨ Por que você vai adorar este modelo
- Registro de atividades: captura automática de atualizações de tarefas, alterações de status e comentários do ClickUp vinculados a fluxos de trabalho de benchmark
- Filtragem por período: visualize as atividades por semana, sprint ou rodada de benchmark para identificar tendências de rendimento
- Visibilidade da carga de trabalho: Veja quais avaliadores estão sobrecarregados e quais têm capacidade disponível com a Visualização de Carga de Trabalho do ClickUp
✅ Ideal para: líderes de equipes de IA e gerentes de operações que precisam garantir que os fluxos de trabalho de benchmarking não sejam ignorados ou atrasados.
💡 Dica profissional: Agende uma “reunião rápida de revisão de atividades” semanal de 15 minutos para analisar o Relatório de Atividades e sinalizar avaliações que permanecem no mesmo status por mais de 3 dias. Use o ClickUp AI Notetaker para registrar automaticamente as ações a serem tomadas e os obstáculos discutidos durante a reunião.

7. Modelo de Balanced Scorecards da ClickUp
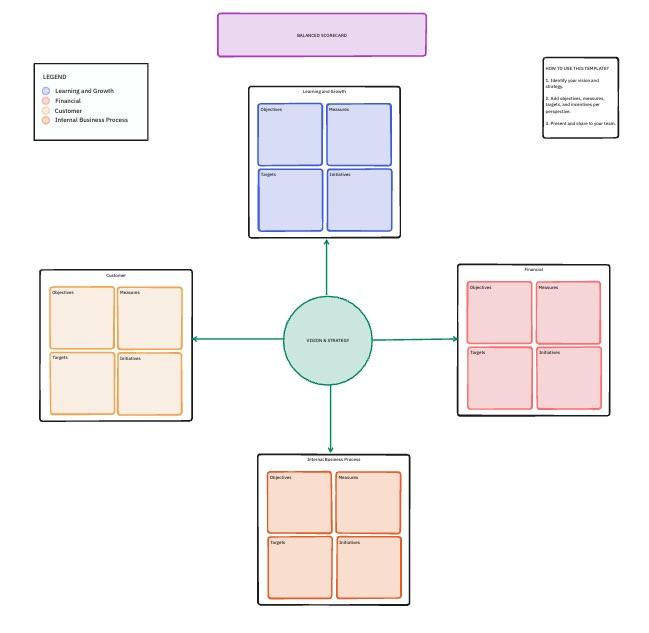
Um prompt com 98% de precisão ainda pode ser muito caro ou lento para ser usado na prática. Você precisa de uma maneira de verificar se os ajustes de engenharia estão atingindo os benchmarks técnicos e, ao mesmo tempo, apoiando suas metas de negócios mais amplas.
O modelo de Balanced Scorecard da ClickUp usa um quadro branco para mapear essas conexões. É um espaço colaborativo para vincular dados técnicos a categorias estratégicas, como impacto financeiro, satisfação do cliente e crescimento interno.
✨ Por que você vai adorar este modelo
- Pontuação multidimensional: Quatro perspectivas estratégicas com métricas no nível do prompt integradas em cada uma delas
- Mapeamento de alinhamento: Conecte visualmente os resultados individuais das avaliações de desempenho aos objetivos da equipe ou do produto
- Campos ponderados: Defina pontuações ponderadas por dimensão usando os Campos Personalizados do ClickUp para que o desempenho agregado reflita as prioridades estratégicas
✅ Ideal para: Gerentes de produto e líderes de IA/ML que precisam alinhar o desempenho da engenharia de prompts com objetivos de negócios de alto nível e alocação de recursos.
8. Modelo de avaliação de projetos da ClickUp
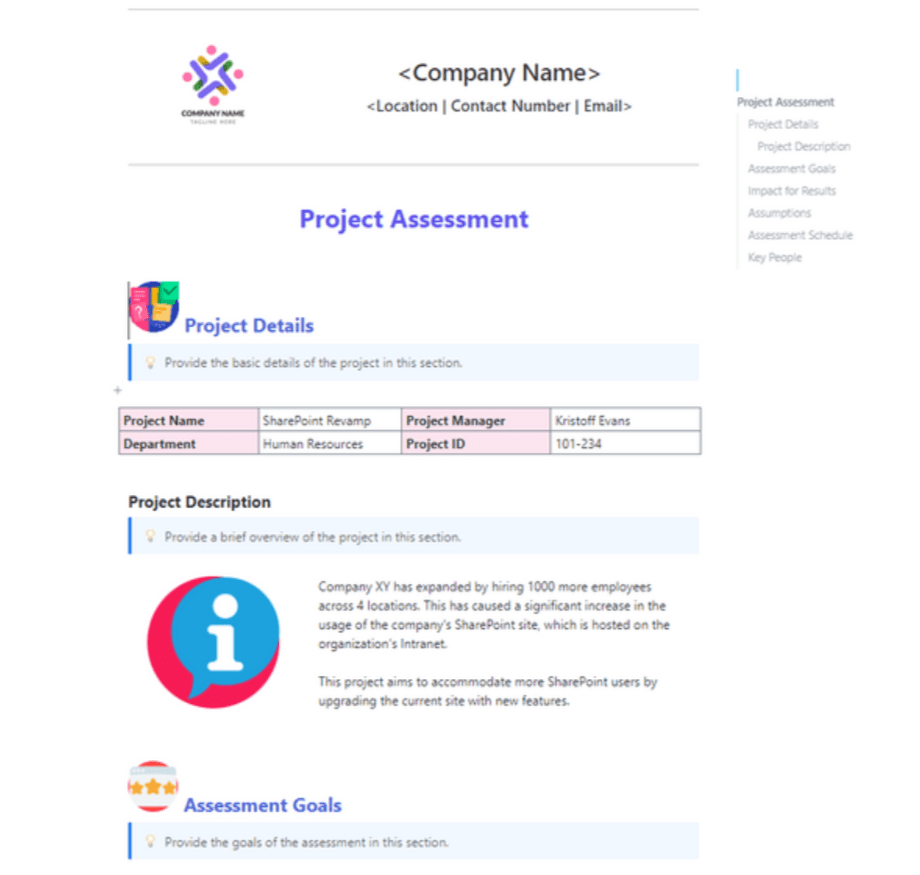
Ignorar uma análise pós-teste em seu ciclo de benchmarking é uma oportunidade perdida de corrigir os gargalos em seus testes. Você precisa saber se seus casos de teste foram realmente representativos ou se seus critérios de avaliação eram muito vagos antes de iniciar a próxima rodada de implantações.
O modelo de avaliação de projetos da ClickUp ajuda você a avaliar a própria avaliação. Ele vai além das pontuações brutas dos prompts para examinar a saúde geral do seu pipeline de testes, de modo que cada ciclo leve a melhorias reais na lógica.
✨ Por que você vai adorar este modelo
- Avalie a integridade do processo: Use campos de status codificados por cores para classificar o escopo dos testes, o cronograma e a eficiência dos recursos rapidamente
- Registre as lições aprendidas: Registre o que funcionou e o que falhou em uma seção estruturada do Doc para melhorar sua próxima rodada de avaliação
- Identifique riscos futuros: Registre obstáculos específicos, como tempo de inatividade da API ou lacunas de dados, para evitar que eles atrasem seu próximo sprint de prompts
✅ Ideal para: gerentes de operações de IA e líderes de controle de qualidade que precisam aprimorar suas metodologias de teste e comprovar o ROI de seus esforços de benchmarking.
9. Modelo de revisão heurística da ClickUp

Pontuações numéricas revelam apenas parte da história ao avaliar os resultados da IA. Um prompt pode passar em um teste de precisão factual, mas ainda assim parecer robótico, confuso ou um pouco fora do tom da marca para seus usuários.
O modelo de revisão heurística da ClickUp traz a intuição humana especializada para o seu fluxo de trabalho PromptOps. Ele usa um quadro branco colaborativo para mapear os resultados em relação a princípios fundamentais, como clareza e prevenção de erros. Sua equipe pode fixar feedback específico em diferentes categorias heurísticas usando notas adesivas digitais para manter a auditoria organizada.
✨ Por que você vai adorar este modelo
- Padronize as verificações qualitativas: Avalie os resultados em relação a princípios personalizados para manter a voz da marca e a utilidade consistentes em todo o conteúdo gerado
- Priorize correções lógicas: categorize os problemas por gravidade para separar riscos críticos de segurança de erros cosméticos menores
- Consolide insights de especialistas: Registre as observações dos revisores em notas adesivas do Whiteboard para facilitar a análise e a ação sobre dados qualitativos
✅ Ideal para: redatores de UX e equipes de PromptOps que realizam auditorias manuais especializadas para garantir que o conteúdo gerado por IA atenda a altos padrões de qualidade e segurança.
📮ClickUp Insight: Enquanto 34% dos usuários operam com total confiança nos sistemas de IA, um grupo ligeiramente maior (38%) mantém uma abordagem do tipo “confie, mas verifique”. Uma ferramenta independente que não está familiarizada com o seu contexto de trabalho geralmente apresenta um risco maior de gerar respostas imprecisas ou insatisfatórias.
É por isso que criamos o ClickUp Brain, a IA que conecta seu gerenciamento de projetos, gerenciamento de conhecimento e colaboração em todo o seu espaço de trabalho e ferramentas de terceiros integradas. Obtenha respostas contextuais sem a necessidade de alternar entre interfaces e experimente um aumento de 2 a 3 vezes na eficiência do trabalho, assim como nossos clientes na Seequent.
📮ClickUp Insight: Enquanto 34% dos usuários operam com total confiança nos sistemas de IA, um grupo ligeiramente maior (38%) mantém uma abordagem do tipo “confie, mas verifique”. Uma ferramenta independente que não está familiarizada com o seu contexto de trabalho geralmente apresenta um risco maior de gerar respostas imprecisas ou insatisfatórias.
É por isso que criamos o ClickUp Brain, a IA que conecta seu gerenciamento de projetos, gerenciamento de conhecimento e colaboração em todo o seu espaço de trabalho e ferramentas de terceiros integradas. Obtenha respostas contextuais sem a necessidade de alternar entre interfaces e experimente um aumento de 2 a 3 vezes na eficiência do trabalho, assim como nossos clientes na Seequent.
10. Modelo de OKRs e metas da empresa da ClickUp
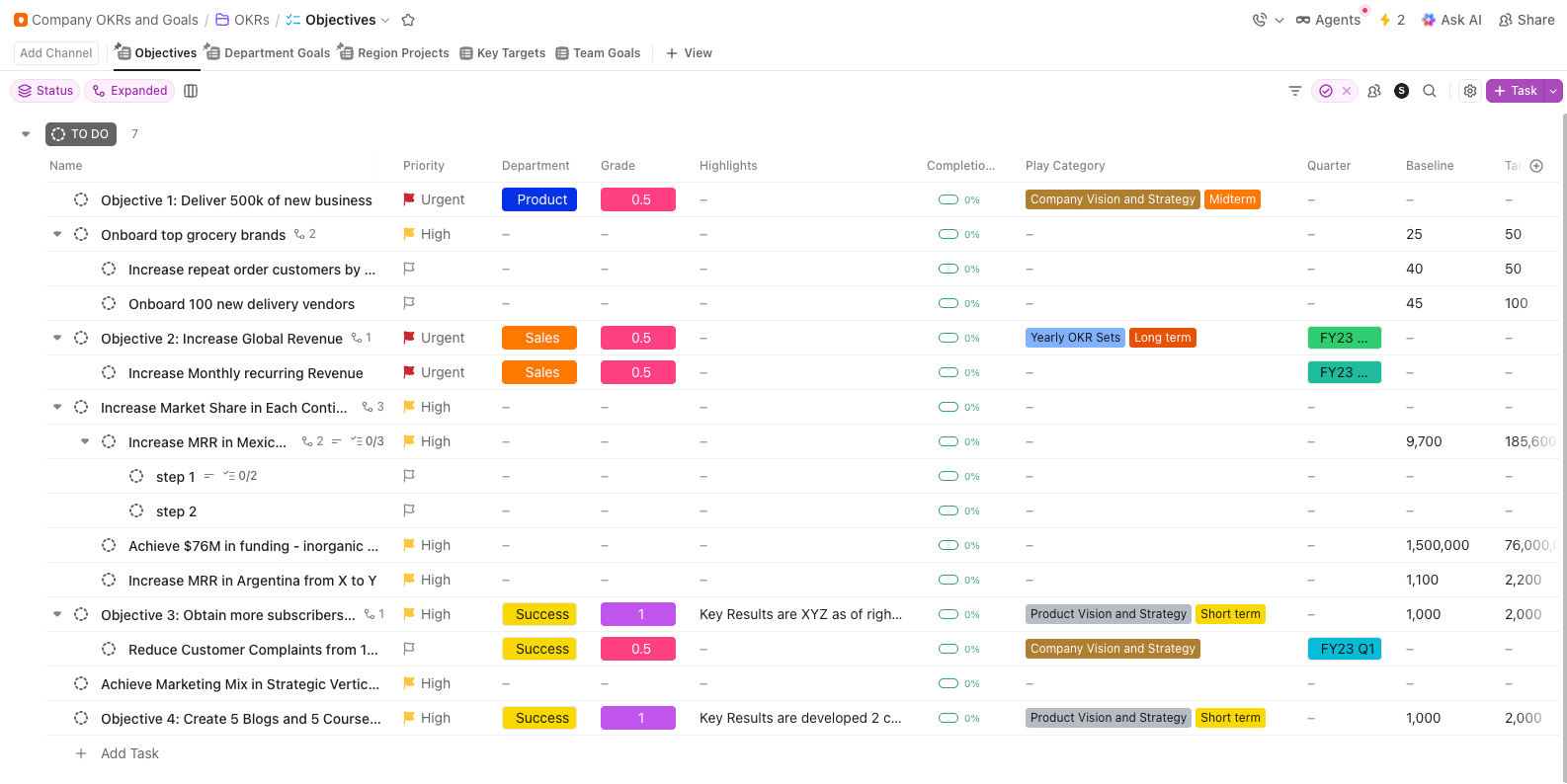
Aumentar a precisão dos prompts de 72% para 88% é uma grande conquista técnica. No entanto, esse número só terá peso se a liderança compreender como essas melhorias impactam diretamente o seu crescimento trimestral.
O modelo de OKRs e metas da empresa da ClickUp preenche a lacuna entre a avaliação comparativa técnica e a estratégia de alto nível. Ele permite que você aninhe metas de desempenho específicas sob os principais objetivos do produto. Isso mantém a equipe focada nos resultados técnicos que fazem a diferença para o negócio.
✨ Por que você vai adorar este modelo
- Hierarquia de objetivos e resultados-chave: Agrupe as metas de benchmarking de prompts sob os objetivos da equipe ou do produto para garantir um alinhamento claro
- Acompanhamento do progresso: Indicadores visuais de progresso que são atualizados à medida que as pontuações de benchmark melhoram ao longo dos ciclos de avaliação
- Visibilidade multifuncional: Planeje os OKRs da empresa e compartilhe metas de benchmarking com as equipes de produto, engenharia e liderança para que todos vejam como a qualidade dos prompts se relaciona com as prioridades do roteiro
✅ Ideal para: equipes de IA/ML que formalizam a avaliação comparativa como um objetivo recorrente com resultados mensuráveis.
Aumente a qualidade da sua IA com o ClickUp
Mais prompts significam mais variáveis, mais iterações e mais chances de a qualidade dos resultados diminuir.
Com o ClickUp, você cria um espaço de trabalho convergente onde a avaliação comparativa começa com uma análise estruturada nas Tarefas, e o refinamento permanece alinhado por meio dos Documentos e Quadros Brancos. Além disso, a IA está integrada a todos os modelos e soluções, gerenciando automaticamente as análises repetitivas e o controle de versões.
Então, o que você está esperando? Comece a usar o ClickUp gratuitamente e transforme suas avaliações em resultados.
Perguntas frequentes
As métricas principais incluem precisão, relevância, coerência e latência. Você também deve acompanhar a taxa de alucinações, a adesão ao tom e a taxa de conclusão de tarefas. A combinação certa depende, em última análise, do seu caso de uso específico. Por exemplo, resultados voltados para o cliente priorizam o tom e a segurança, enquanto prompts internos se concentram mais na precisão e na velocidade.
Para adaptar seu modelo, comece adicionando campos para o nome do modelo, a versão e as configurações de parâmetros, como temperatura e limites de tokens. Você também deve incluir uma seção para comparações entre resultados esperados e reais, a fim de medir o desempenho. Por fim, adicione o acompanhamento de versões a cada execução. Isso garante que cada benchmark esteja vinculado a uma iteração específica do prompt, permitindo uma avaliação precisa a longo prazo.
A avaliação comparativa quantitativa utiliza pontuações numéricas (por exemplo, porcentagem de precisão, tempo de resposta) para uma comparação objetiva. Em contrapartida, a avaliação comparativa qualitativa utiliza a análise de especialistas com base em princípios como clareza, utilidade e voz da marca — os programas de teste de prompts mais eficazes utilizam ambos.
A avaliação comparativa estruturada detecta regressões nos prompts antes que elas cheguem aos usuários. Ela cria um ciclo contínuo de feedback entre avaliação e iteração, permitindo que você refine o desempenho ao longo do tempo. Esse processo constrói uma base sólida de evidências para suas decisões de engenharia de prompts.