
De eerste paar diensten zijn eenvoudig. Eén rotatie, één kanaal en vervolgens een back-up.
Zodra uw bedrijf echter tientallen microservices, meerdere regio's en gelaagde eigendom bereikt, zijn handmatige escalaties niet langer een werkstroom, maar een last.
In deze gids wordt uitgelegd hoe u escalatiepaden voor incidenten kunt automatiseren die meegroeien met uw engineeringorganisatie, zonder dat dit leidt tot hiaten in uw oproepsysteem.
We zullen ook bekijken hoe ClickUp kan worden ingezet bij het opzetten van een escalatiesysteem waarop uw engineeringteams kunnen vertrouwen. 🎯
⭐ Aanbevolen sjabloon
Reageer snel en effectief tijdens noodsituaties, van natuurrampen tot datalekken, met behulp van de ClickUp Incident Action Plan (IAP)-sjabloon.

De sjabloon biedt u vooraf gedefinieerde secties om:
- Definieer incidentdoelstellingen en prioriteiten voor de respons
- Zorg voor een duidelijke commandostructuur
- Coördineer acties tussen teams in realtime
- Leg beslissingen, tijdlijnen en belangrijke updates vast op het moment dat ze plaatsvinden.
- Blijf in verbinding met escalaties en volg deze op
En omdat het in ClickUp is geïntegreerd, functioneert het als een live incidentcommandodocument, niet als een statische checklist.
Waarom incidentescalatiepaden automatiseren?
Wanneer uw team complexe systemen met strikte SLA's beheert, vertraagt handmatige escalatie u alleen maar. Geautomatiseerde escalatie maakt uw responsproces voorspelbaar en stressvrij, zelfs tijdens incidenten met hoge druk.
Hieronder leest u waarom u de escalatiepaden van uw organisatie moet automatiseren. 👇
Het risico van handmatige escalatie
Zodra u te maken krijgt met tientallen diensten, meerdere oproeproosters en voortdurend wisselend eigendom, worden door mensen gestuurde stappen al snel een probleem.
Veelvoorkomende valkuilen zijn onder meer:
- Gemiste of vertraagde notificaties wanneer iemand een e-mail, sms of notificatie tijdens het chatten over het hoofd ziet
- Verwarring tijdens overdrachten, vooral wanneer escalatiepaden niet duidelijk zijn gedocumenteerd
- Escalatie naar het verkeerde team omdat de kaart van de eigenaar niet is bijgewerkt
- Knelpunten veroorzaakt door het vertrouwen op één persoon om 'de waarschuwing door te geven'
📖 Lees ook: Hoe schrijf je een incidentrapport?
Voordelen van automatisering
ITSM-automatisering geeft uw escalatiepaden structuur en momentum. In plaats van te hopen dat iemand de waarschuwing ziet, voert uw systeem onmiddellijk en consistent een vooraf gedefinieerde reeks handelingen uit.
Dit zijn de voordelen voor teams die AI gebruiken om taken te automatiseren:
- Snellere responstijden omdat waarschuwingen binnen enkele seconden bij de juiste persoon of het juiste team terechtkomen.
- Consistente uitvoering van escalatiestappen, zelfs om 3 uur 's nachts, wanneer besluitvorming trager verloopt.
- Ingebouwde redundantie zorgt ervoor dat back-up-upresponders worden gewaarschuwd als de primaire dienstdoende medewerker de melding mist.
- Duidelijke zichtbaarheid voor alle teams, omdat iedereen begrijpt hoe de werkstroom van escalaties verloopt.
- Minder brandjes blussen en meer voorspelbare oproepdiensten
📖 Lees ook: Voorbeelden van bedrijfscontinuïteitsplannen
Vermindering van alarmmoeheid en menselijke fouten
Meldingsmoeheid ondermijnt de effectiviteit van de bereikbaarheid. Wanneer uw team te vaak of om de verkeerde redenen wordt geroepen, reageert het niet meer met de nodige urgentie. Automatisering helpt om alleen die zaken te filteren en door te geven die echt menselijke aandacht vereisen.
Met automatisering van de escalatielogica:
- Waarschuwingen met een laag signaal of dubbele waarschuwingen worden onderdrukt voordat ze de dienstdoende medewerker bereiken.
- Op ernst gebaseerde regels zorgen ervoor dat kleine problemen niemand onnodig wakker maken.
- Waarschuwingen worden alleen geëscaleerd als het systeem binnen een bepaald tijdsbestek geen reactie detecteert.
- Teams besteden minder tijd aan het triëren van ruis en meer tijd aan het oplossen van echte problemen.
Ondersteuning van naleving van SLA en oproepbeleid
Geautomatiseerde escalatie maakt het gemakkelijker om aan de regels te blijven voldoen zonder voortdurend handmatig toezicht. Voor IT-operationsmanagers die strikte SLA's of interne betrouwbaarheidsverplichtingen moeten naleven, fungeert AI als een vangrail die het verwachte gedrag afdwingt. Het helpt u om:
- Zorg ervoor dat notificaties over incidenten vooraf gedefinieerde regels voor routering volgen.
- Houd automatisch de SLA-tijdlijnen aan met getimede escalaties.
- Handhaaf oproeproosters zonder te vertrouwen op verouderde spreadsheets
- Maak audittrails voor elke waarschuwing, escalatie en bevestiging.
🎥 Wilt u uw volledige escalatiepad-werkstroom handsfree uitvoeren? Super Agents helpt u daarbij. 👇🏼
🔍 Wist u dat? De missiecontrole van NASA werkt in wezen op basis van geautomatiseerde escalatielogica. Als de telemetrie buiten bereik raakt, stuurt het systeem onmiddellijk geautomatiseerde waarschuwingen door naar specialisten per domein.
Wat is een escalatiebeleid in incidentbeheer?
Een escalatiebeleid is een vooraf gedefinieerde reeks regels die bepaalt wie er op de hoogte wordt gesteld, wanneer ze op de hoogte worden gesteld en hoe de verantwoordelijkheid naar boven of tussen teams wordt doorgegeven.
Zie het als een gestructureerd stappenplan dat voorkomt dat incidenten blijven liggen, ervoor zorgt dat de juiste experts op het juiste moment ingrijpen en teams helpt om SLA's na te komen.
Een goed gestructureerd escalatiebeleid omvat doorgaans:
- Op regels gebaseerde routing die bepaalt wie aan de beurt is wanneer iemand het incident niet bevestigt of niet kan oplossen.
- Getimede triggers die automatisch escaleren na 5, 15 of 30 minuten, afhankelijk van de ernst.
- Notificatiemethoden zoals telefoontjes, sms'jes, chatten of e-mails
- Escalatieplan niveaus van niveau 1 (primaire oproepdienst) > niveau 2 (senior engineers/SME's) > niveau 3 (leiding)
- Documentatieverwachtingen zodat nieuwe hulpverleners het kunnen overnemen zonder cruciale context te verliezen
📖 Lees ook: Hoe taken prioriteren als P0, P1, P2, P3 en P4
Soorten escalatiebeleid
Dit zijn de belangrijkste soorten beleidsregels die uw team moet begrijpen:
1. Hiërarchische escalatie (verticaal)
Waarschuwingen worden omhoog in de hiërarchie doorgegeven, van junior engineers naar senior specialisten naar het management. Gebruik dit wanneer de situatie meer expertise, beslissingsbevoegdheid of zichtbaarheid van het management vereist.
2. Functionele escalatie (horizontaal)
In plaats van naar boven te gaan, wordt de waarschuwing over teams heen doorgegeven aan de functie die verantwoordelijk is voor het betreffende systeem. Dit is ideaal voor incidenten die verband houden met een specifiek domein, zoals databases, netwerken, betalingen of API's.
3. Op tijd gebaseerde escalatie
Dit is de ruggengraat van de meeste geautomatiseerde systemen. Bij dit type wordt de waarschuwing na een bepaalde tijd, vaak direct gekoppeld aan SLA's, doorgestuurd naar het volgende niveau. Dit is vooral essentieel wanneer u buiten kantooruren gegarandeerde responsiviteit nodig hebt.
4. Op impact gebaseerde escalatie
Impactgebaseerde escalatie is afhankelijk van de ernst of de impact op het bedrijf, niet van hiërarchie of tijd. Dit is nuttig bij storingen, betalingsproblemen, klantgerichte problemen of problemen met de veiligheid.
5. Parallelle escalatie
Hier worden meerdere personen of teams tegelijkertijd op de hoogte gebracht. Parallelle escalatie wordt gebruikt voor ernstige problemen waarvoor meerdere specialismen nodig zijn of voor situaties waarin elke vertraging onaanvaardbaar is.
🔍 Wist u dat? Uit een recent onderzoek naar waarschuwingssignalen is gebleken dat extreem opvallende of 'luide/felle' waarschuwingen de reactietijd kunnen vertragen, vooral als de waarschuwing onverwacht is. Maar zodra het type waarschuwing verwacht wordt (d.w.z. onderdeel is van een vooraf ontworpen escalatie-/notificatiesysteem), verbetert de reactietijd. Dit suggereert dat wanneer u escalatiepaden automatiseert, u mensen niet alleen maar moet overspoelen met alarmen met hoge prioriteit.
Wanneer automatische escalatie triggeren
Nu u weet hoe escalatiepaden zijn gestructureerd, is de volgende stap om te beslissen wanneer deze regels automatisch moeten worden uitgevoerd.
Hieronder staan de belangrijkste situaties die automatische escalatie triggeren en die de logische basis vormen voor uw beleid. 💁
Op ernst gebaseerde escalatie
Automatische escalatie treedt in werking wanneer de ernst of impact van het incident een bepaalde drempel overschrijdt. Incidenten met een hoge ernstgraad vereisen onmiddellijke aandacht van het management. Door automatische escalatie worden knelpunten omzeild en worden experts binnen enkele seconden op de hoogte gebracht.
📌 Exemplaar: Een volledige service-uitval, storing in de betalingsgateway of ernstige verslechtering die veel gebruikers of kernsystemen treft, vraagt om een automatische escalatie.
Op tijd gebaseerde escalatie
Als niemand het incident binnen een bepaald tijdsbestek bevestigt of oplost, wordt de waarschuwing automatisch naar het volgende niveau geëscaleerd. Dit voorkomt dat tickets blijven liggen, vooral buiten de normale werktijden of wanneer de eerste responder niet beschikbaar of overbelast is.
📌 Exemplaar: Als er na 10-15 minuten nog geen reactie is, wordt het incident geëscaleerd van de eerste responder naar een senior engineer; als het na nog eens 30-60 minuten nog steeds niet is opgelost, wordt het verder geëscaleerd.
Contextuele escalatie
Deze escalatielogica houdt rekening met de contextuele kenmerken van het incident, zoals de getroffen dienst of het getroffen systeem, de eigenaar van de dienst, het getroffen klantsegment (intern versus extern, VIP versus regulier) of het functionele domein (database, netwerk, integratie). Op basis van die context worden waarschuwingen doorgestuurd naar de meest relevante responder of het meest relevante team.
Zo voorkomt u dat teams worden overbelast met irrelevante incidenten, verkort u de responstijd en zorgt u ervoor dat specialisten problemen binnen hun domein afhandelen.
📌 Voorbeelden: Een piek in de latentie van de betalingsdienst moet direct worden doorgegeven aan het betalingsteam, of een backend-fout in de factureringsmicroservice moet worden gemeld aan het factureringsteam.
Op metadata gebaseerde escalatie
Moderne waarschuwings- en incidenttools leggen metadata vast, zoals de oorspronkelijke bron (welke monitoringtool of waarschuwingsregel is geactiveerd), de identiteit van de gebruiker/klant, de locatie, de historische frequentie van soortgelijke incidenten of labels. Dit helpt u om meer gedetailleerde, intelligente logica toe te passen in plaats van te vertrouwen op botte ernst- of tijdgebaseerde regels.
📌 Voorbeelden: Terugkerende waarschuwingen van hetzelfde subsysteem kunnen wijzen op een dieper, systemisch probleem, waardoor snellere escalatie gerechtvaardigd is. Of waarschuwingen voor VIP-klanten kunnen triggers zijn voor extra notificaties.
Triggers combineren voor het opstellen van slimmere, adaptieve escalatiebeleidsregels
In de praktijk vertrouwen veel teams niet op slechts één type trigger. In plaats daarvan stellen ze hybride escalatiebeleidsregels op die regels voor ernst, tijd, context en metadata combineren.
Met deze gelaagde aanpak kunnen teams escalatiebeleid opstellen dat zowel responsief (snel wanneer dat nodig is) als slim (selectief om ruis te minimaliseren) is, wat resulteert in betere incidentresultaten en een efficiëntere toewijzing van middelen.
🔍 Wist u dat? In de 18e eeuw hanteerden bemanningen van marineschepen een strikte escalatieketen tijdens noodsituaties. Als een matroos van lagere rang gevaar zag, luidde hij een bel en gaf hij het bericht door naar de hogere hiërarchie totdat de kapitein de uiteindelijke beslissing nam.
Hoe u effectieve escalatiepaden ontwerpt
Het ontwerpen van escalatiepaden draait om het bouwen van een systeem dat op betrouwbare wijze de juiste waarschuwingen naar de juiste personen stuurt, met minimale wrijving.
Hier volgt een praktisch, stapsgewijs raamwerk dat u kunt gebruiken in complexe, gedistribueerde omgevingen.
P.S. We zullen ook bekijken hoe bepaalde ClickUp-functies u hierbij kunnen helpen! 🤩
Stap 1: Definieer duidelijke escalatiecriteria, niveaus en verantwoordelijkheden
Begin met het definiëren van wat een incident is dat escalatie vereist. Leg objectieve criteria vast, zodat elke engineer die dienst heeft, of het nu een nieuwe L1-responder of een ervaren SRE is, de ernst van een incident op dezelfde manier interpreteert.
Dit zorgt voor een duidelijke escalatiewerkstroom, neemt onduidelijkheden weg en zorgt ervoor dat automatisering alleen wordt geactiveerd wanneer dat echt nodig is.
Neem criteria op zoals:
- Ernstdrempels: Dienstonderbreking, betalingsfouten, verificatieproblemen, gegevenscorruptie en problemen met de veiligheid
- Impact: Storingen voor klanten, interne verslechtering van de dienstverlening, storingen in de API van partners, naleving of veiligheidsrisico's
- Bedrijfskritische context: grote waarde voor klanten, omzetbeïnvloedende werkstroom, risicovolle systemen (bijv. betalingen, facturering)
Zodra de criteria en triggers zijn gedefinieerd, brengt u in kaart wie er wordt gewaarschuwd en wat hun verantwoordelijkheden zijn bij elk escalatiepunt.
Definieer niveaus duidelijk:
- Niveau één (primaire incidentmanager): Fungeert als eerste hulpverlener en is verantwoordelijk voor bevestiging, eerste triage en pogingen tot mitigatie.
- Niveau twee (back-up/specialist/SME): Biedt diepgaande technische expertise en lost complexe systeemproblemen op.
- Niveau drie (engineeringmanager/leidinggevende): Houdt toezicht op grote incidenten, keurt belangrijke acties goed, coördineert de communicatie tussen teams en triggert indien nodig escalatie naar leveranciers.
🚀 Voordeel van ClickUp: Gebruik ClickUp Docs om één enkele bron van waarheid te behouden voor escalatiecriteria, niveaus en verantwoordelijkheden, en documenteer rollen en verantwoordelijkheden, inclusief wie:
- Bevestigt en beperkt
- Communiceert met belanghebbenden
- Behandelt escalaties van leveranciers of externe partners
- Leidt het incidentcommando
U kunt deze specifieke rollen ook koppelen aan de relevante ClickUp-taken om de verbinding te behouden.
Bouw uw eigen kennisbank op:
Zodra de escalatiecriteria en eigendom zijn gedefinieerd, hebben teams een consistente manier nodig om technische incidenten vast te leggen, te bijhouden en te analyseren. De ClickUp-sjabloon voor incidentrapportage biedt een gestructureerd, gemakkelijk toegankelijk systeem om IT- en operationele incidenten op één plek te documenteren.
Het is ingebouwd in ClickUp Docs en helpt incidentresponsteams bij het vastleggen van cruciale details, zoals de ernst van het incident, de getroffen diensten, tijdlijnen, samenvattingen van de onderliggende oorzaken, mitigatiestappen en vervolgacties.
Stap 2: Standaardiseer het aanmaken van incidenten
Voordat escalatiepaden zelfs maar worden geactiveerd, heeft uw team een betrouwbare manier nodig om incidentgegevens vast te leggen, te normaliseren en te verrijken. Als het eerste incidentrapport onvolledig of inconsistent is, zal zelfs de meest geavanceerde escalatielogica falen.
Standaardisatie moet:
- Inkomende waarschuwingen triëren: zet waarschuwingen om in consistente aangepaste velden, zoals ernst, categorie, getroffen service, type incident en status van bevestiging.
- Verrijk het incident automatisch: haal metadata op, waaronder cluster, implementatie-ID, service-eigenaren of afhankelijkheden.
- Zorg ervoor dat bij elk incident de context wordt vastgelegd: noteer wie het incident heeft gemeld, hoe het is ontdekt, de omgeving (productie/testomgeving) en alle relevante logbestanden of schermafbeeldingen.
Maak een ClickUp-formulier rechtstreeks vanuit de lijst waarin incidenten worden bijgehouden en ontwerp het zo dat het uw operationele realiteit en de relevante gegevens waarop uw escalatielogica is gebaseerd, weerspiegelt. Op deze manier komt elk incident in een consistent format in uw systeem terecht, waarop automatisering betrouwbaar kan reageren, in plaats van gefragmenteerde berichten via chat, e-mail of dashboards.

Groepeer velden opzettelijk zodat elk incident volledig in context wordt geplaatst:
- Identificatie (titel, samenvatting)
- Classificatie (ernst, type, getroffen dienst)
- Bron (monitoring, gebruiker, API)
- Bewijs (logboeken, schermafbeeldingen)
- Zakelijke context (SLA-niveau, impact op klanten)
Elke verzende formulier creëert automatisch een nieuwe ClickUp-taak, waarbij alle reacties worden toegewezen aan ClickUp-aangepaste velden. Dit zorgt ervoor dat incidenten bij het aanmaken worden genormaliseerd, waardoor onduidelijkheid wordt weggenomen en handmatige incidentrespons overbodig wordt.
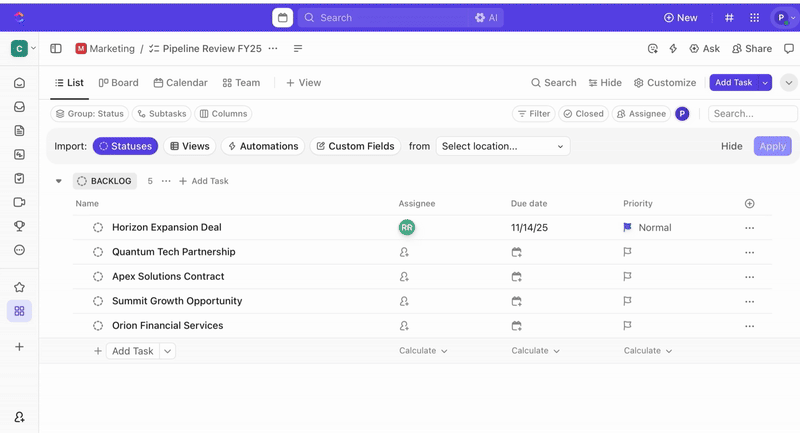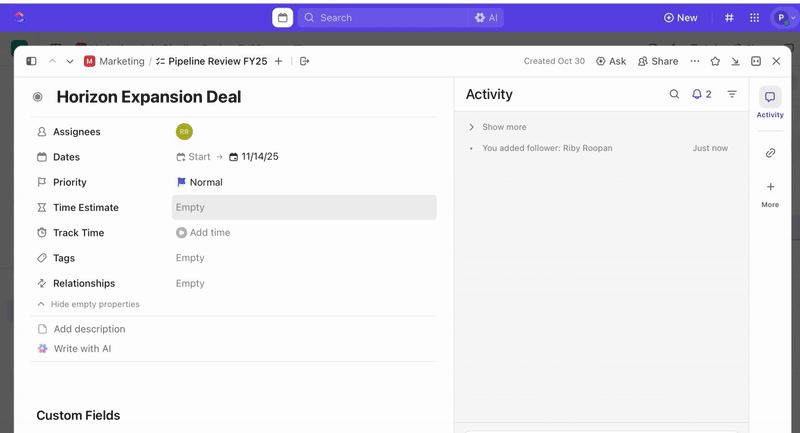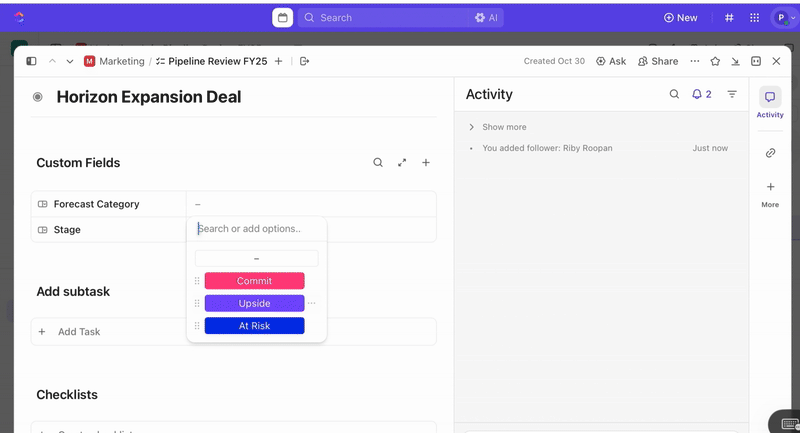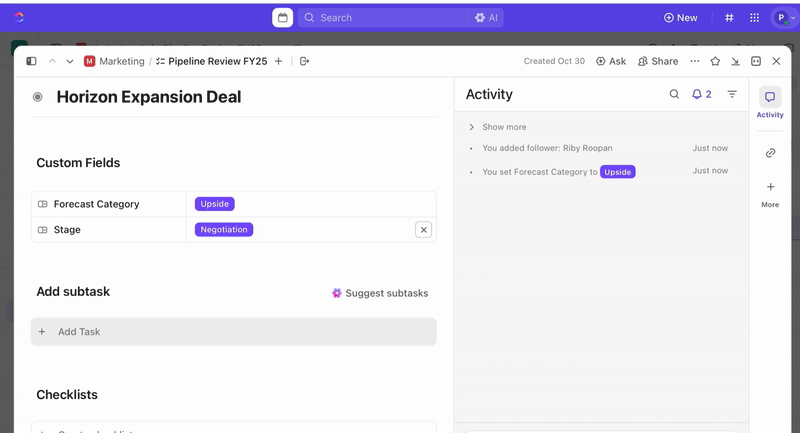
Zodra taken zijn aangemaakt, kunt u aangepaste velden gebruiken om triage en prioritering te sturen (bijv. ernst, impact, respondergroep) en aangepaste statussen in ClickUp definiëren die uw incidentfasen weerspiegelen (Nieuw > Triage > Onderzoek > Mitigatie > Opgelost).
Stap 3: Bouw het escalatiepad (d.w.z. volgorde + timing + kanalen)
Dit is de kern van het pad. Stel het pad in fasen op, waarbij elke fase bepaalt wie er op de hoogte wordt gesteld, via welke kanalen en na hoeveel tijd zonder bevestiging of oplossing.
- Definieer 'acknowledgement timeout' en 'resolution timeout'.
Hier is een voorbeeld van een werkstroom:
- Fase één: De eerste dienstdoende medewerker die onmiddellijk via sms/chatten op de hoogte wordt gesteld, moet binnen 5-10 minuten reageren.
- Fase twee: Als er binnen 15-20 minuten geen bevestiging of actie is, escaleer dan naar het back-up-/SRE-team + senior engineer via sms/chatkanaal/e-mail.
- Fase drie: Als het probleem na nog eens 30-60 minuten nog steeds niet is opgelost, escaleer het dan naar de engineeringmanager/leidinggevende en trigger eventueel een 'major incident'-kanaal.
- Beslis of het escalatiepad moet worden 'herhaald' (opnieuw melden op hetzelfde niveau) of 'doorgaan'.
- Stel voor kritieke incidenten herhaalde notificaties in totdat iemand reageert. Voor incidenten met een lagere prioriteit kunt u volstaan met één werkstroom.
- Zorg ervoor dat het pad wordt gedocumenteerd met behulp van een sjabloon voor klantenservice en toegankelijk is voor alle relevante medewerkers.
❗️ Aantekening: Een 'bevestigingstime-out' is de tijd die de eerste responder heeft om te bevestigen dat hij de waarschuwing heeft gezien, terwijl een 'oplossingstime-out' de tijd is die het team heeft om het probleem op te lossen of te verhelpen voordat de volgende escalatie in gang wordt gezet.
Stap 4: Automatisering en toolondersteuning integreren
Zodra uw criteria, triageproces en verrijkingsnormen zijn vastgesteld, is de volgende stap het mogelijk maken van escalatie zonder dat mensen hoeven te onthouden wanneer en naar wie ze moeten escaleren. Dit is waar ClickUp-automatiseringen een centraal onderdeel van uw werkstroom worden.

U kunt automatiseringsmogelijkheden instellen die reageren op dezelfde signalen die uw team gebruikt tijdens incidenten. Hier volgen enkele voorbeelden:
- Als de ernst wordt bijgewerkt naar SEV-1 ➡️ Wijs onmiddellijk een senior SRE toe + breng het kanaal voor chatten met oproepen op de hoogte.
- Als de status gedurende X minuten ongewijzigd blijft ➡️ Trigger escalatie naar het volgende niveau
- Als de deadline verstrijkt (bijv. de deadline voor bevestiging) ➡️ Escaleren naar L2
En dit is waar ClickUp Brain nog een stap verder gaat. Het gebruikt context uit uw werkruimte om direct antwoorden te geven, automatisch updates te genereren en toegang tot kennis te ondersteunen.
Gebruik tools zoals AI Prioritize om incidenten automatisch te evalueren en de juiste prioriteit in te stellen op basis van uw eigen logica. Voorbeeldprompts:
- Als het incident invloed heeft op de productie en gevolgen heeft voor klanten, stel dan Prioriteit: Urgent in.
- Als de toegewezen persoon het SRE-team is en er in de logboeken een melding is van 'latentie', stel dan de prioriteit in op 'Hoog'.
- Als de beschrijving sleutels van de veiligheid zoals 'inbreuk' bevat, stel dan Prioriteit: Urgent in.
En zodra de prioriteit is ingesteld, neemt AI Assign het over en wijst automatisch incidenten toe op basis van de door u gedefinieerde voorwaarden.
U kunt prompts maken zoals:
- Als de prioriteit urgent is en de getroffen dienst 'betalingen' omvat, wijs deze dan toe aan Senior SRE.
- Als het incidenttype database is en de regio US-East, wijs het dan toe aan DB On-Call.
- Als de taaknaam 'veiligheid' bevat, wijs deze dan toe aan de SecOps Lead.
Test deze prompts op de eerste drie taken voordat u ze op de hele lijst toepast.
🚀 Voordeel van ClickUp: Implementeer intelligente bots voor automatisering die in uw werkruimte worden uitgevoerd en in realtime reageren op activiteiten met ClickUp Super Agents.
Ze zijn volledig op de hoogte van uw taken, documenten, chats en processen, zodat elke geautomatiseerde actie contextueel is.
U kunt bijvoorbeeld een Team StandUp Agent in uw 'Productie-incidentenmap' plaatsen, zodat deze elke ochtend automatisch een dagelijks overzicht plaatst. Uw team ontvangt dan direct een overzicht met het aantal geopende incidenten, welke incidenten nog niet zijn opgelost en welke veranderingen er in de afgelopen 24 uur hebben plaatsgevonden.
Koppel dat nu aan een Ambient Answers Agent in uw '#incident-room channel'. Wanneer hulpverleners vragen stellen als 'Waar is het SEV-1-runbook?' of 'Heeft deze API eerder gefaald?', haalt het uit uw werkruimte kennis om directe, nauwkeurige antwoorden te geven.

Stap 5: Standaardiseer communicatiekanalen
Naarmate incidenten escaleren, is het net zo belangrijk hoe en waar teams communiceren als wie er op de hoogte wordt gesteld. Zonder gestandaardiseerde kanalen gaan updates verloren, worden beslissingen dubbel genomen en ontvangen belanghebbenden tegenstrijdige informatie.
Definieer duidelijke escalatiekanalen voor elke fase van de incidentcyclus en gebruik deze consistent binnen alle teams:
| Criteria | Kanaalnaam | Doel |
| SEV-1 of SEV-2 gedetecteerd | #incident-kritiek | Centrale ruimte voor ernstige waarschuwingen en onmiddellijke triage |
| Actieve probleemoplossing bezig | #incident-warroom | Real-time samenwerkingshub voor engineers, productontwikkeling, kwaliteitscontrole en ondersteuning |
| Leiderschapszichtbaarheid vereist | #incident-leadership | Belangrijke updates voor managers en leidinggevenden |
| Communicatie met klanten vereist | #incident-comms | Ruimte om externe klantcommunicatie op te stellen, te beoordelen en af te stemmen |
| Evaluatie na incident gestart | #incident-retro | Gestructureerde discussie voor retrospectieve aantekeningen, lessen en actiepunten |
Elk kanaal heeft een gedefinieerd publiek en doel, waardoor teams ruis kunnen verminderen en tegelijkertijd de juiste teams op de hoogte kunnen houden.
🚀 Voordeel van ClickUp: stem uw kanaalstrategie af op een ingebouwde communicatielaag met behulp van ClickUp Chat. Elke waarschuwing, update en beslissing blijft rechtstreeks gekoppeld aan de Taak, lijst of ruimte waar het werk plaatsvindt.
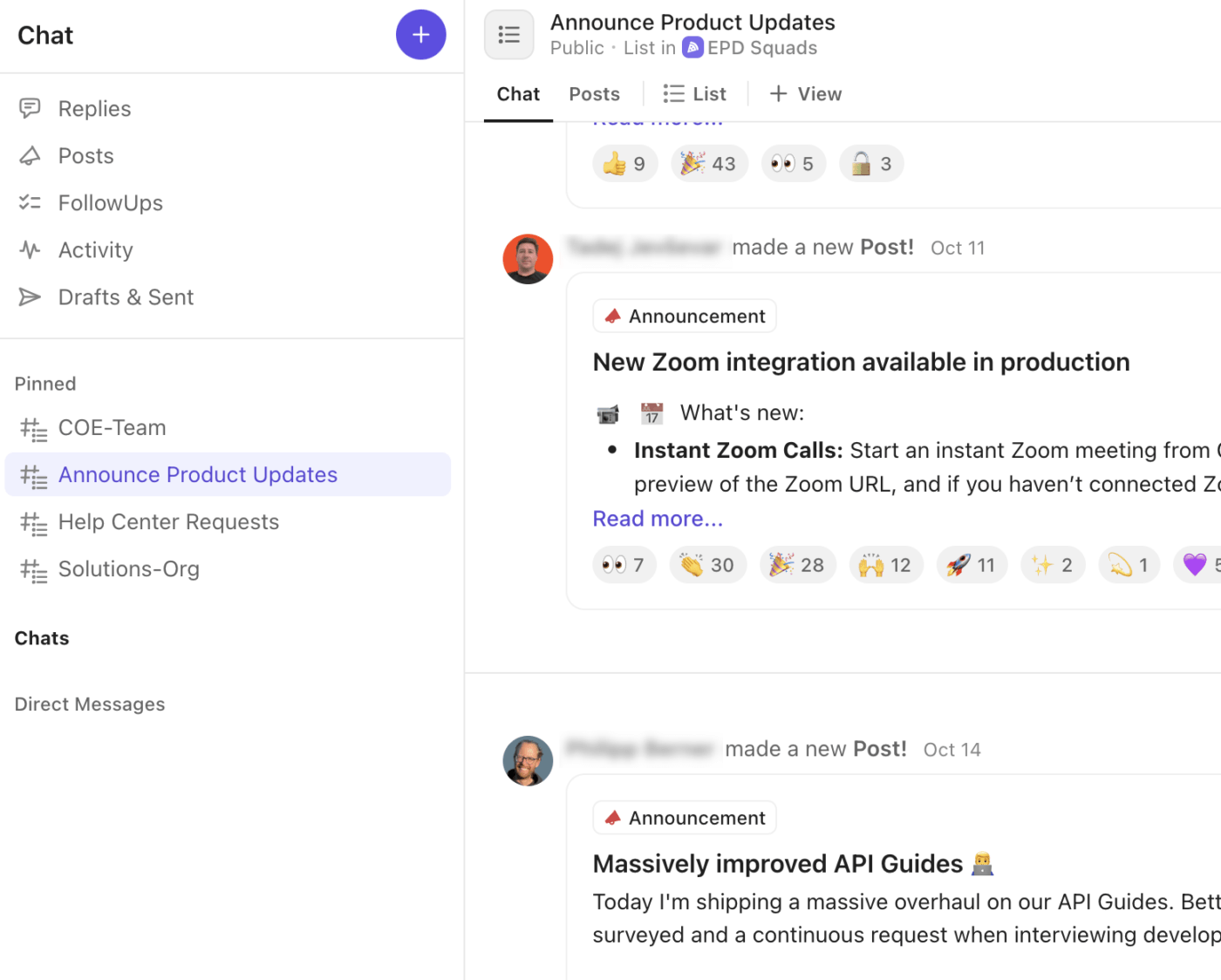
Zo verbetert ClickUp Chat uw incidentwerkstroom:
- Maak speciale chatthreads voor kritieke discussies, war room-besprekingen, leiderschapsdiscussies of communicatie met klanten.
- Zet chatberichten direct om in ClickUp-taken , zodat beslissingen en follow-ups niet verloren gaan in gesprekken.
- Maak snel audio- of video-gesprekken met ClickUp SyncUps voor live incidentcoördinatie of leiderschapsbriefings.
- Plaats 'Aankondigingen' of updates om de status van incidenten op hoog niveau binnen het hele bedrijf bekend te maken.
- Tag teamgenoten, plaats schermafbeeldingen en voeg logbestanden toe als bijlagen rechtstreeks tijdens het chatten, zodat de technische context binnen handbereik blijft.
Stap 6: Test, controleer en verfijn uw escalatiepad
Escalatiebeleid moet mee evolueren met uw systemen. Dit is nog te doen:
| Activiteit | Wat moet u testen of controleren? | Waarom dit belangrijk is |
| Oefening voor oproepdiensten (elk kwartaal) | Simuleer P1- en P2-incidenten, controleer de timing en routing van escalaties. | Zorgt ervoor dat automatiseringen en escalatiepaden onder druk blijven werken |
| Validatie van escalatiepaden | Controleer op doodlopende escalaties of ontbrekende eigenaren | Voorkomt dat incidenten vastlopen zonder zichtbaarheid |
| Timers voor bevestigings- en oplossingsprocessen | Vergelijk geconfigureerde timers met de werkelijke MTTA en MTTR | Houdt de timing van escalaties realistisch en effectief |
| Beoordeling van alarmmoeheid | Identificeer respondenten die buitensporig veel of herhaaldelijk waarschuwingen ontvangen | Vermindert burn-out en gemiste kritieke waarschuwingen |
| Nauwkeurigheid van ernst en prioritering | Controleer of incidenten correct zijn geclassificeerd. | Verbetert de routing, reactiesnelheid en escalatienauwkeurigheid |
| Opvolging na incidenten | Zorg ervoor dat actiepunten uit retrospectieven worden voltooid | Voorkomt herhaling van incidenten en systeemstoringen |
Tools en integraties voor automatisering van escalaties
In dit gedeelte wordt incidentbeheersoftware uitgelegd waarmee u incidenten sneller kunt detecteren, direct kunt doorsturen en elk team op de hoogte kunt houden zonder handmatige follow-ups.
1. ClickUp (het beste voor het samenbrengen van cross-functionele escalaties in één verbonden incidentwerkruimte)
Traditionele escalatiemethoden dwingen teams om te jongleren met e-mails, spreadsheets, chatthreads en verspreide aantekeningen, waardoor het bijna onmogelijk is om een duidelijk, realtime beeld te krijgen van wat er gebeurt.
De ClickUp-taakbeheersoftware voor escalatiebeheer elimineert ruis door alle escalatiedetails te consolideren in één georganiseerde werkruimte.
Laten we eens kijken naar enkele functies van IT-activabeheersoftware die ClickUp aan de top plaatsen van de posities voor teams die grote hoeveelheden escalaties en complexe werkstroomen beheren.
Werk op uw manier
Visualiseer uw taken vanuit meerdere invalshoeken om ze af te stemmen op uw operationele behoeften met ClickUp-weergaven:
- ClickUp-lijstweergave zodat SRE-leiders incidenten kunnen sorteren op ernst, resterende SLA-tijd of oproepgroepen voor snelle triage.
- ClickUp Board Weergave om engineeringmanagers in staat te stellen overdrachten en teameigendom tijdens escalaties te visualiseren.
- ClickUp gantt weergave voor programmaleiders om mijlpalen en afhankelijkheden voor oplossingen tussen diensten in kaart te brengen.
- ClickUp werklastweergave voor oproepbare planners die ervoor zorgen dat technici niet overbelast raken tijdens periodes met veel incidenten.
Zet besprekingen tijdens vergaderingen om in actie
Tijdens escalaties en incidentbeoordelingen kan het een uitdaging zijn om discussies en actiepunten betrouwbaar vast te leggen. De ClickUp AI Notetaker neemt automatisch deel aan vergaderingen die zijn gepland in Google Agenda, Outlook, Zoom of Teams, en neemt het gesprek op en transcribeert het.
Na de vergadering:
- Toegang tot doorzoekbare transcripties en samenvattingen van actiepunten
- Zorg voor duidelijkheid met behulp van de aantekeningen die zijn opgeslagen in ClickUp Docs. Dit maakt het gemakkelijk om terug te linken naar incidenttaken of retrospectieve rapporten.
- Stel ClickUp AI vragen over de content van vergaderingen om beslissingen te verduidelijken of gemiste follow-ups aan het licht te brengen.
Maak verbinding met bestaande tools in uw tech stack
Achter de schermen zorgen ClickUp-integraties en het Webhooks-ecosysteem voor naadloze verbinding met de rest van uw stack.
Het platform kan native worden geïntegreerd met tools zoals Slack, GitHub, Zoom en meer, en ondersteunt Webhooks via zijn openbare API om gebeurtenissen (taakuitvoeringen en wijzigingen in de status) door te geven aan externe diensten of pijplijnen voor automatisering. Dit maakt het eenvoudig om werkstroomtriggers te activeren, gegevens te synchroniseren of incidenten tussen systemen te escaleren zonder handmatige overdrachten.
Breng al uw AI-tools samen
Om automatisering en context naar een hoger niveau te tillen, brengt ClickUp BrainGPT contextuele AI in uw escalatiewerkstroom. Het is een contextuele super-AI-app die uw taken, documenten en historische context begrijpt.
Met Enterprise Search en Connected Apps kunt u direct informatie ophalen uit uw werkruimte, Slack, Google Drive, GitHub en meer. Tijdens live incidentgesprekken kunt u met Talk-to-Text in ClickUp handsfree escalatienotities of instructies dicteren, zodat u niets mist.
U kunt ook herhaalbare taken standaardiseren met aangepaste AI-prompts en opgeslagen prompts, zoals: 'Vat alle onopgeloste incidenten samen en adviseer escalatiemaatregelen. '
De beste functies van ClickUp
- Geef prioriteit aan kritieke problemen: gebruik ClickUp-taakprioriteiten om urgente of belangrijke escalaties te markeren.
- Organiseer complexe escalatieprocessen: stel ClickUp-taak-afhankelijkheden in om gerelateerde taken aan elkaar te koppelen (bijvoorbeeld 'Waiting On' of 'Blocking'), zodat escalatie-stappen voortijdige acties of knelpunten voorkomen.
- Verdeel incidenten in uitvoerbare delen: verdeel escalaties in gedetailleerde actiepunten en wijs deze toe aan teams met geneste subtaaken.
- Volg de snelheid van de oplossing nauwkeurig: Registreer en controleer hoe lang het duurt om escalatietaken te bevestigen en op te lossen met ClickUp's tijdsregistratie voor projecten.
Limieten van ClickUp
- Met zoveel functies, weergaven en aangepaste aanpassingsopties hebben teams vaak een leercurve te doorlopen voordat alles intuïtief aanvoelt.
Prijzen van ClickUp
[Prijstabel]
Beoordelingen en recensies van ClickUp
- G2: 4,7/5 (meer dan 10.300 beoordelingen)
- Capterra: 4,6/5 (meer dan 4400 beoordelingen)
Wat zeggen echte gebruikers over ClickUp?
Deze recensie zegt eigenlijk alles:
ClickUp brengt al mijn taken, projecten en communicatie samen op één plek, waardoor het ongelooflijk eenvoudig is om georganiseerd te blijven. Ik vind het geweldig dat alles aanpasbaar is, van weergaven en werkstroom tot dashboards, zodat ik mijn werkruimte precies zo kan structureren als ik nodig heb. De mogelijkheid om in realtime samen te werken, taken toe te wijzen en de voortgang bij te houden zonder van tool te wisselen, is een enorm voordeel.
ClickUp brengt al mijn taken, projecten en communicatie samen op één plek, waardoor het ongelooflijk eenvoudig is om georganiseerd te blijven. Ik vind het geweldig dat alles aanpasbaar is, van weergaven en werkstroom tot dashboards, zodat ik mijn werkruimte precies zo kan indelen als ik wil. De mogelijkheid om in realtime samen te werken, taken toe te wijzen en de voortgang bij te houden zonder van tool te wisselen, is een enorm voordeel.
📮 ClickUp Insight: 21% van de mensen zegt dat meer dan 80% van hun werkdag wordt besteed aan repetitieve taken. En nog eens 20% zegt dat repetitieve taken minstens 40% van hun dag in beslag nemen.
Dat is bijna de helft van de werkweek (41%) besteed aan taken die niet veel strategisch denken of creativiteit vereisen (zoals follow-up e-mails 👀).
De Super Agents van ClickUp helpen u deze rompslomp te elimineren. Denk aan het aanmaken van taken, herinneringen, updates, vergadernotities, het opstellen van e-mails en zelfs het creëren van end-to-end werkstroomen! Dat alles (en nog veel meer) kan in een handomdraai worden geautomatiseerd met ClickUp, uw alles-in-één app voor op het werk.
💫 Echte resultaten: Lulu Press bespaart 1 uur per dag per medewerker door ClickUp-automatiseringen te gebruiken, wat leidt tot een toename van 12% in werkefficiëntie.
2. PagerDuty (het beste voor realtime waarschuwingen en intelligente respons bij oproepen)
PagerDuty is een cloudgebaseerd platform voor IT-incidentbeheer en digitale operaties dat teams helpt om kritieke incidenten, zoals storingen of risico's op gebied van veiligheid, snel te detecteren, erop te reageren en op te lossen. Het biedt SRE-, DevOps- en ondersteuningsleiders een duidelijk pad van signaal tot oplossing, ondersteund door automatisering, AI-aangedreven triage en diep geïntegreerde werkstroom.
Functies zoals Jeli Incident Analysis, PagerDuty Analytics en Runbook automatisering helpen teams om downtime te verminderen, routinetaken te elimineren en te leren van elk incident.
De beste functies van PagerDuty
- Automatiseer incidentrouting met ingebouwd On-Call Management en dynamische Escalation Policies.
- Versnel de triage met behulp van AIOps, dat alarmruis filtert, gebeurtenissen correleert en echte signalen markeert.
- Houd interne en externe belanghebbenden op één lijn met Stakeholder Comms, Status Update sjablonen en Status pagina's.
- Breng uw toolstack op één lijn met meer dan 700 integraties en uitbreidbare API's met behulp van monitoring, logging, CI/CD en ondersteuningssystemen.
Limieten van PagerDuty
- Hoog aantal waarschuwingen als integraties en slimme drempels niet zijn afgestemd, wat leidt tot ruis en vermoeidheid
- Tijdens pieken kunnen dubbele of herhaalde waarschuwingen optreden, waardoor het onder druk moeilijker wordt om deze te bevestigen.
Prijzen van PagerDuty
- Free
- Professional: $ 25 per maand per gebruiker
- Business: $ 49/maand per gebruiker
- Onderneming: aangepaste prijzen
Beoordelingen en recensies van PagerDuty
- G2: 4,5/5 (meer dan 900 beoordelingen)
- Capterra: 4,6/5 (meer dan 200 beoordelingen)
Wat zeggen echte gebruikers over PagerDuty?
In de woorden van een echte gebruiker:
PagerDuty maakt incidentmeldingen snel en betrouwbaar. Het stuurt de juiste notificaties op het juiste moment en houdt ons team georganiseerd. […] PagerDuty kan soms wat luidruchtig zijn als notificaties niet goed worden gefilterd. Sommige instellingen zijn een beetje complex voor nieuwe gebruikers.
PagerDuty maakt incidentmeldingen snel en betrouwbaar. Het stuurt de juiste notificaties op het juiste moment en houdt ons team georganiseerd. […] PagerDuty kan soms wat luidruchtig zijn als notificaties niet goed worden gefilterd. Sommige instellingen zijn wat complex voor nieuwe gebruikers.
💡 Pro-tip: Creëer uitzonderingen, zelfs in een duidelijk escalatiepad. Laat kritieke storingen, waarschuwingen over veiligheid of incidenten in gereguleerde omgevingen direct doorsturen naar senior of gespecialiseerde respondenten.
3. GLPi (het beste voor end-to-end assetbeheer en ITIL-georiënteerde serviceactiviteiten)
Gestionnaire Libre de Parc Informatique (GLPi) is een volledig open-sourceplatform voor IT-servicemanagement (ITSM) en IT-activabeheer (ITAM). Teams krijgen end-to-end zichtbaarheid in hun infrastructuur (hardware, software, licenties en netwerkapparatuur) en kunnen incidenten, serviceverzoeken en wijzigingen beheren met behulp van ITIL-georiënteerde processen.
Al uw contracten en documentatie, inclusief garanties en serviceovereenkomsten, blijven overzichtelijk geordend, zodat ze niet verloren gaan tussen verschillende systemen. Als u datacenters beheert, kunt u met GLPi zelfs lay-outs, bekabelingspaden en energieverbruik visualiseren, zodat u altijd weet wat er achter de schermen gebeurt.
De beste functies van GLPi
- Gebruik de plug-ins GLPI Inventory, OCS Inventory of FusionInventory om nieuwe IT-middelen automatisch te detecteren en te catalogiseren.
- Automatiseer repetitieve taken, tickettoewijzingen, notificaties en terugkerende gebeurtenissen om handmatig werk te verminderen.
- Bouw een kennisbank op voor veelgestelde vragen, documentatie en artikelen die aan tickets zijn gekoppeld voor selfservice en technische ondersteuning.
- Maak verbinding met Azure/Entra, Centreon, Google, OAuth2 en webhooks om gegevens te synchroniseren, werkstroom te triggeren en uw CMDB te verbeteren.
Limieten van GLPi
- Plug-incompatibiliteit kan tussen versies verloren gaan, wat onderhoudskosten met zich meebrengt.
- De rapportage-, analyse- en exportmogelijkheden voelen beperkt aan en moeten worden verbeterd.
GLPi-prijzen
- Aangepaste prijzen
GLPi-beoordelingen en recensies
- G2: 4,6/5 (meer dan 30 beoordelingen)
- Capterra: 4,5/5 (meer dan 40 beoordelingen)
Wat zeggen echte gebruikers over GLPi?
Dit is wat een gebruiker te zeggen had:
Zeer aanpasbaar open-source IT-activabeheer- en supportticketsysteem met een grote ondersteunende community. De gebruikersinterface is een beetje ingewikkeld voor beginners. Plug-ins worden niet altijd ondersteund van oude naar nieuwe versies.
Zeer aanpasbaar open-source IT-activabeheer- en supportticketsysteem met een grote ondersteunende community. De gebruikersinterface is een beetje ingewikkeld voor beginners. Plug-ins worden niet altijd ondersteund van oude naar nieuwe versies.
4. Splunk On-Call (het meest geschikt voor het rechtstreeks doorsturen van bewakingswaarschuwingen naar technici)
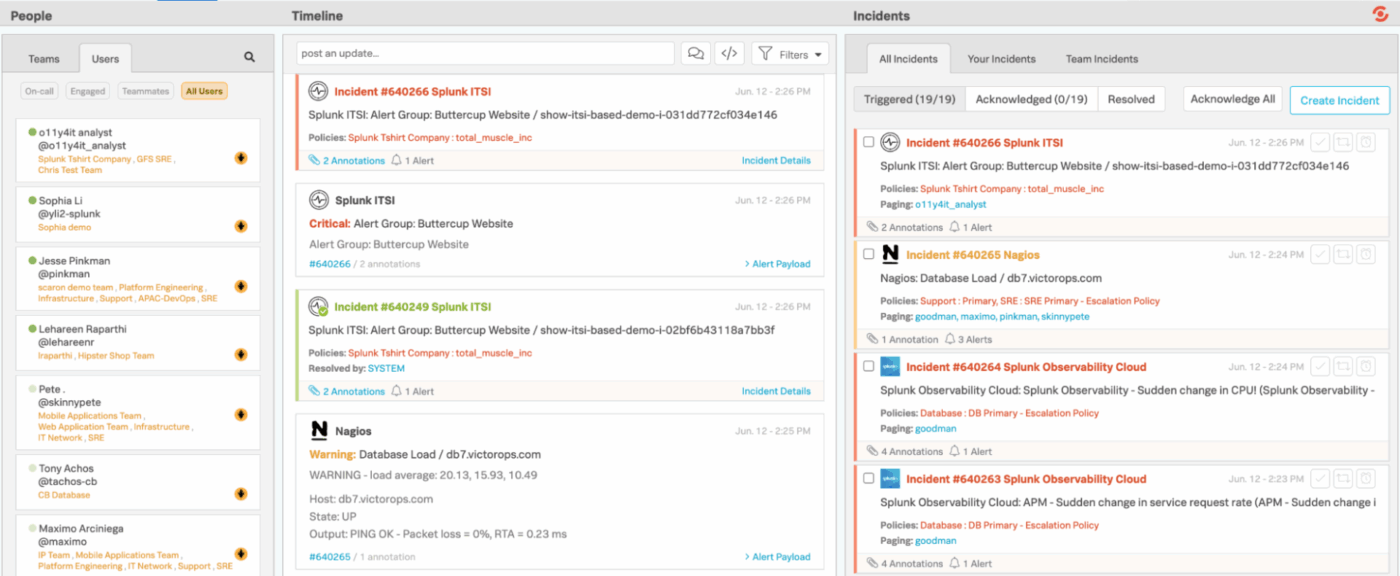
Splunk On-Call biedt engineering- en on-callteams een snellere, overzichtelijkere manier om incidenten te beheren, waardoor trage, traditionele werkstroomen overbodig worden. In plaats van waarschuwingen naar een algemene wachtrij te sturen, wordt het rechtstreeks geïntegreerd met uw monitoring- en observability-stack, waardoor problemen onmiddellijk worden doorgestuurd naar de juiste personen op basis van schema's, regels en context.
Dankzij de mobiele en chatintegraties kunt u incidenten eenvoudig vanaf elke locatie bevestigen, doorsturen of oplossen. Achter de schermen houdt Splunk On-Call een gedetailleerd overzicht bij van trends, bewezen patronen en escalatiegedrag.
De beste functies van Splunk On-Call
- Breid de mogelijkheden van het platform uit met meer dan 1000 geteste integraties en add-ons van Splunk en de bredere community.
- Bouw aangepaste dashboards en visuele rapporten om het aantal waarschuwingen, de status van incidenten, de prestaties van respondenten en de werklast van teams te monitoren.
- Filter incidenten snel op basis van uw eigen activiteiten, incidenten van uw team of alles wat er binnen de organisatie gebeurt.
- Schakel tussen Triggered, Acknowledged en Resolved weergaven om te zien hoe het met elk incident staat.
Limieten van Splunk On-Call
- Het plannen van diensten voor meerdere teams kan ingewikkeld worden als er geen vooraf vastgestelde regels zijn.
- Beperkte limiet om gedetailleerde incidentrapporten op datum te genereren
Prijzen voor Splunk On-Call
- Aangepaste prijzen
Beoordelingen en recensies van Splunk On-Call
- G2: 4,6/5 (meer dan 40 beoordelingen)
- Capterra: 4,5/5 (meer dan 30 beoordelingen)
Wat zeggen gebruikers in de praktijk over Splunk On-Call?
Een gebruiker vatte het als volgt samen:
De mogelijkheid om incidenten en escalaties af te handelen en taken van mijn teamgenoten over te nemen via de mobiele app is geweldig. […] Ik zou graag overrides kunnen plannen en de reguliere planning kunnen wijzigen via de mobiele app voor noodwijzigingen in de planning.
De mogelijkheid om incidenten en escalaties af te handelen en taken van mijn teamgenoten over te nemen via de mobiele app is geweldig. […] Ik zou graag override-taken kunnen plannen en de reguliere planning kunnen wijzigen via de mobiele app voor noodwijzigingen in de planning.
🔍 Wist u dat? De logica van 'doorverbinden naar de juiste persoon als het eerste niveau faalt' vindt zijn oorsprong in de vroege telefooncentrales: wanneer handmatige telefonisten geen verbinding konden maken met een gesprek, werd het door het systeem doorgestuurd (of geëscaleerd) naar een andere telefonist of centrale.
5. ServiceNow (het meest geschikt voor het coördineren van bedrijfsprocessen op ondernemingsniveau met AI-ondersteunde automatisering)
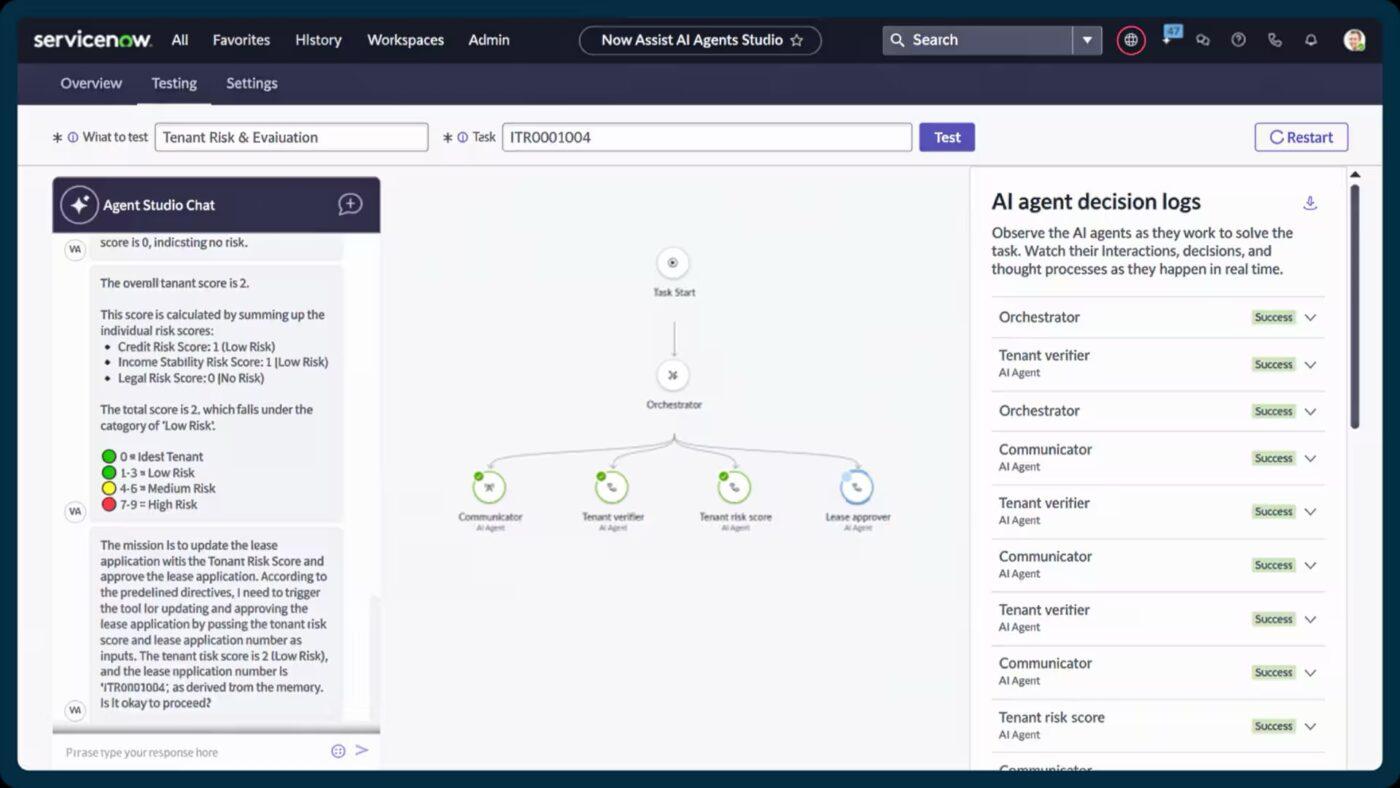
ServiceNow classificeert, prioriteert en routeert incidenten automatisch op het moment dat ze worden geregistreerd. Met functies zoals Now Assist voor geautomatiseerde aanbevelingen voor incidenttickets en slimme contentgeneratie kunnen hulpverleners problemen sneller en met meer context oplossen.
Het brengt incident-, wijzigings- en activabeheer samen. Op deze manier krijgt u een realtime weergave van hoe diensten met elkaar verbonden zijn, waar knelpunten ontstaan en welke componenten mogelijk bijdragen aan terugkerende storingen.
De beste functies van ServiceNow
- Wijs veldtaken toe, leid ze door en houd ze in de gaten via Field Service Management en Dispatcher-werkruimte.
- Geef medewerkers en klanten meer mogelijkheden met een selfserviceportaal op basis van AI Search en virtuele agents.
- Gebruik ingebouwde werkstroom-werkflows en low-code tools in App Engine om serviceprocessen uit te breiden of aan te passen.
- Automatiseer repetitieve taken en werkstroomen tussen teams met Flow Designer en Automation Engine.
Limieten van ServiceNow
- De UI en portalbrandingopties voelen verouderd of beperkend aan.
- Grote afhankelijkheid van bekwaam personeel of consultants voor de implementatie
Prijzen van ServiceNow
- Aangepaste prijzen
Beoordelingen en recensies van ServiceNow
- G2: 4,4/5 (meer dan 3300 beoordelingen)
- Capterra: 4,5/5 (meer dan 300 beoordelingen)
Wat zeggen echte gebruikers over ServiceNow?
Een gebruiker verwoordde het als volgt:
[…] De vooraf gebouwde werkstroomen zijn voor mij een ander hoogtepunt, omdat ze processen stroomlijnen en veel tijd besparen, waardoor de noodzaak voor aangepaste configuraties tot een minimum wordt beperkt en een soepelere, efficiëntere werkstroom mogelijk wordt. […] Bovendien had ik moeite om mijn aangepaste oplossing in het Customer Service Management-systeem in te passen, wat heel wat herhalingen vereiste.
[…] De vooraf gebouwde werkstroomen zijn voor mij een ander hoogtepunt, omdat ze processen stroomlijnen en veel tijd besparen, waardoor de noodzaak voor aangepaste configuraties tot een minimum wordt beperkt en een soepelere, efficiëntere werkstroom mogelijk wordt. […] Bovendien had ik moeite om mijn aangepaste oplossing in het Customer Service Management-systeem in te passen, wat heel wat herhalingen vereiste.
Best practices en governance
Hier volgen enkele best practices die ervoor zorgen dat automatisering nauwkeurig blijft, alarmmoeheid voorkomt en aansluit bij de verwachtingen van het bedrijf en de regelgeving.
- Definieer niet-onderhandelbare escalatiecriteria: koppel triggers aan meetbare signalen zoals SLO-overtredingen, pieken in afwijkingen, impact op klantniveaus of gevoeligheid voor regelgeving.
- Zorg voor duidelijke rollen op elk niveau: gebruik een eenvoudige RACI-kaart voor elk escalatieniveau, zodat de verantwoordelijkheden nooit onduidelijk zijn tijdens incidenten waarbij de druk hoog is.
- Dynamisch beheer van oproepdiensten afdwingen: Pas escalatiepaden automatisch aan rond weekends, feestdagen, limieten voor capaciteit en overdrachten om burn-out te verminderen en stille pagina's te voorkomen.
- Voeg menselijke controleposten toe voor scenario's met een hoog risico: Zelfs met automatisering moet handmatige bevestiging verplicht zijn voor incidenten waarbij klantgegevens, betalingen of gereguleerde werkstroom betrokken zijn.
- Houd volledige audittrails bij: Houd onveranderlijke logboeken bij van wie er is opgeroepen, wanneer ze hebben bevestigd, welke geautomatiseerde stappen zijn uitgevoerd en welke beslissingen zijn genomen.
🧠 Leuk weetje: De oudst bekende schriftelijke klacht ter wereld werd rond 1750 v.Chr. op een kleitablet gegraveerd. Het was in feite een vroege escalatie van de projectstatus. Een klant genaamd Nanni schreef aan de handelaar Ea-nāṣir dat hij woedend was omdat het koper dat hij had ontvangen van mindere kwaliteit was dan beloofd en omdat zijn boodschapper slecht was behandeld.
Veelvoorkomende uitdagingen en hoe u deze kunt overwinnen
Zelfs met een duidelijk escalatiebeleid worden teams vaak geconfronteerd met operationele hindernissen die de respons op incidenten vertragen of verwarring veroorzaken.
Deze tabel belicht veelvoorkomende uitdagingen die verder gaan dan de basisstappen van de installatie en biedt praktische strategieën om deze uitdagingen het hoofd te bieden.
| Uitdagingen ❌ | Oplossingen ✅ |
| Inconsistente context tijdens overdrachten | Gebruik de taakkoppelings- en incidentrapportage-sjablonen van ClickUp om een volledig controlespoor bij te houden van incidentdetails, getroffen systemen en eerdere acties op elk escalatieniveau. |
| Overbelasting van respondenten met waarschuwingen met lage prioriteit | Implementeer dynamische prioritering met aangepaste velden in ClickUp en AI Prioritize om incidenten te filteren op basis van ernst, impact en SLA-drempels. |
| Gebrek aan zichtbaarheid tussen teams | Stel gedeelde werkruimten in, voeg opmerkingen toe en maak visuele ClickUp-Whiteboards om realtime updates te presenteren aan belanghebbenden. |
| Vertraagde besluitvorming tijdens kritieke incidenten | Automatiseer notificaties met behulp van ClickUp Brain Max's Suggested Actions om direct de juiste medewerkers te waarschuwen op basis van het type incident, de ernst en historische patronen. |
| Moeilijkheden bij het bijhouden van terugkerende problemen | Maak gebruik van de aangepaste rapportage- en terugkerende taak-sjablonen van ClickUp om patronen, onderliggende oorzaken en herhalende incidenten te identificeren voor proactieve preventie. |
| Gefragmenteerde kennis tijdens escalatie | Houd gecentraliseerde SOP's, runbooks en incidentdocumentatie bij in ClickUp Docs en koppel deze aan relevante taken, zodat u ze direct kunt raadplegen tijdens live escalaties. |
| Slecht afgestemde verantwoordelijkheden tussen ploegen | Gebruik de werklast- en tijdlijnweergaven van ClickUp om opdrachten te visualiseren en ervoor te zorgen dat er geen overlappingen of hiaten ontstaan tijdens wisselingen van dienst of overdrachten. |
| Handmatig bijhouden van nalevingscontrole en auditlacunes | Automatiseer auditklare samenvattingen met ClickUp Brain om alle incidentacties, notificaties en oplossingen te registreren. |
De impact van geautomatiseerde escalatie meten
Om de effectiviteit van geautomatiseerde escalatie bij te houden, moet u zich richten op belangrijke statistieken op het gebied van volume, efficiëntie en kwaliteit. Deze indicatoren laten zien of uw escalatieprocessen sneller en nauwkeuriger zijn en minder frustrerend voor zowel teams als klanten.
Houd de volgende statistieken bij:
- Escalatiepercentage (volume): percentage van de problemen dat verder dan het eerste niveau wordt geëscaleerd. Hoge percentages kunnen wijzen op hiaten in de eerste triage of kennisbanken.
- Herhaalde escalatiefrequentie (volume): De frequentie waarmee hetzelfde probleem meerdere keren wordt geëscaleerd. Duidt op onvolledige oplossingen of verloren context.
- Tijd tot escalatie (efficiëntie): de duur van detectie tot escalatie. Kortere faseduur duidt op een snellere automatische herkenning van kritieke problemen.
- Overdrachtsvertraging (efficiëntie): Tijdsverschil tussen escalatie en het moment waarop het volgende team begint met het uitvoeren van werk om routering of notificaties te markeren.
- Oplossingstijd voor geëscaleerde gevallen (efficiëntie): totale tijd vanaf escalatie tot oplossing. Een snellere oplossing toont de effectiviteit van automatisering aan.
- Klanttevredenheidsscore (CSAT) (kwaliteit): Feedback over geëscaleerde interacties om de soepelheid van het pad te meten
- Context doorgeven (kwaliteit): of agenten de volledige incidentgeschiedenis ontvangen om ervoor te zorgen dat klanten geen informatie herhalen
- First contact resolution (FCR) (kwaliteit): Percentage problemen dat in één interactie is opgelost.
🚀 Voordeel van ClickUp: krijg realtime, visuele en AI-gestuurde inzichten in alle escalatiestatistieken met ClickUp dashboards.
U kunt escalatietrends, knelpunten en prestaties bijhouden met tabel-, cirkel-, balk-, lijn-, berekenings- en tijdrapportagekaarten. Controleer het escalatiepercentage, herhaalde escalaties en de tijd tot escalatie met kaarten die zijn gekoppeld aan taken, aangepaste velden en statussen.
Om nog een stap verder te gaan, kunt u AI-kaarten gebruiken, zoals AI Executive Summary, AI Project Update en AI StandUp, om trends, vertragingen en oplossingsresultaten te benadrukken.
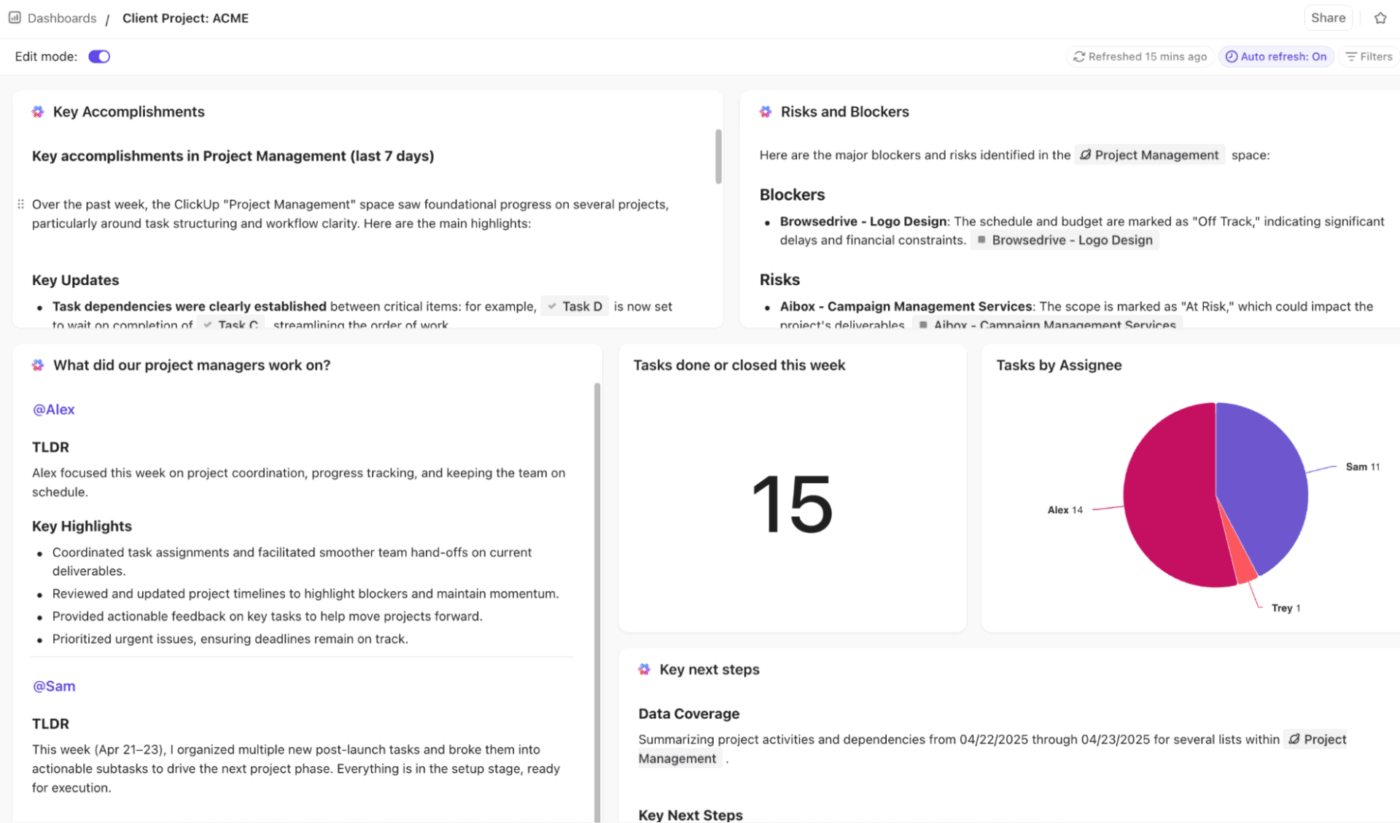
Beheer uw incidenten sneller met ClickUp
Velen denken dat incidentescalatie alleen maar inhoudt dat een ticket wordt doorgegeven aan de volgende persoon, maar het is veel meer dan dat. Het is een gestructureerd systeem waarin elke stap, van triage tot oplossing, in harmonie samenwerkt.
ClickUp biedt u de perfecte uniforme werkruimte. Met ClickUp automatiseringen kunt u automatisch waarschuwingen triggeren, taken doorsturen en statussen bijwerken. En ClickUp Brain helpt bij het prioriteren van incidenten, het genereren van samenvattingen en het voorstellen van volgende stappen.
ClickUp AI Agents fungeren als intelligente assistenten binnen uw werkruimte, terwijl ClickUp Dashboards een live weergave van uw escalaties bieden.
Meld u vandaag nog gratis aan bij ClickUp!
Veelgestelde vragen (FAQ)
Een escalatiepad voor incidenten is een vooraf gedefinieerde reeks stappen die bepaalt hoe problemen worden doorgestuurd naar het juiste team of de juiste persoon op basis van ernst, impact en timing. Het zorgt ervoor dat incidenten efficiënt worden afgehandeld en dat de verantwoordelijkheid duidelijk is. TEKST
Gebruik automatisering voor duidelijk omschreven incidenten met hoge prioriteit en duidelijke criteria (bijvoorbeeld serviceonderbrekingen, inbreuken op de veiligheid). Reserveer handmatige escalatie voor onduidelijke of kritieke situaties die menselijk oordeel of aanvullende context vereisen.
Platforms zoals ClickUp, PagerDuty, Jira Service Management en ServiceNow maken geautomatiseerde routering, notificaties en updates mogelijk. Ze helpen teams vertragingen te verminderen en gestructureerde werkstroom voor incidenten te handhaven.
Stel duidelijke limieten in voor waarschuwingen, prioriteer op ernst en maak gebruik van intelligente notificaties. Beperk herhaalde notificaties tot kritieke incidenten en maak gebruik van dashboards of AI-tools om updates samen te vatten in plaats van elke kleine wijziging te versturen.
Evalueer het escalatiebeleid regelmatig, minimaal elk kwartaal of na grote incidenten. Zo zorgt u ervoor dat de criteria, verantwoordelijkheden en regels voor automatisering aansluiten bij de huidige werkstroom, teamstructuren en prioriteiten.