
Los primeros servicios son fáciles. Una rotación, un canal y luego una copia de seguridad.
Sin embargo, una vez que su empresa alcanza docenas de microservicios, múltiples regiones y propiedad en capas, las escalaciones manuales dejan de ser un flujo de trabajo y se convierten en una responsabilidad.
Esta guía explica cómo realizar la automatización de las rutas de escalado de incidencias que se adaptan a su organización de ingeniería sin causar lagunas en su sistema de guardia.
También veremos cómo ClickUp encaja en la creación de un sistema de escalado en el que tus equipos de ingeniería pueden confiar. 🎯
⭐ Plantilla destacada
Responda de forma rápida y eficaz durante las emergencias, desde desastres naturales hasta violaciones de datos, utilizando la plantilla del Plan de Acción para Incidentes (IAP) de ClickUp.

La plantilla le ofrece secciones predefinidas para:
- Defina los objetivos de las incidencias y las prioridades de respuesta.
- Establezca una estructura de mando clara.
- Coordine las acciones entre los equipos en tiempo real.
- Capture las decisiones, los cronogramas y las actualizaciones clave a medida que se producen.
- Manténgase conectado a la escalada y realice un seguimiento.
Y como se encuentra dentro de ClickUp, funciona como un documento de comando de incidencias en tiempo real, no como una lista de control estática.
Por qué automatizar las rutas de escalamiento de incidencias
Cuando su equipo gestiona sistemas complejos con acuerdos de nivel de servicio (SLA) estrictos, la escalación manual solo ralentiza el proceso. La escalación automatizada hace que su proceso de respuesta sea predecible y menos estresante, incluso durante incidencias de alta presión.
He aquí por qué debe realizar la automatización de las rutas de escalado de su organización. 👇
El riesgo de la escalada manual
Cuando se trata de docenas de servicios, múltiples turnos de guardia y cambios constantes en la propiedad, los pasos realizados por personas se convierten rápidamente en un problema.
Entre los errores más comunes se incluyen:
- Notificaciones perdidas o retrasadas cuando alguien pasa por alto un correo electrónico, un SMS o un mensaje de chat.
- Confusión durante los traspasos, especialmente cuando las rutas de escalado no están claramente documentadas.
- Escalar al equipo equivocado porque el mapa de propiedad no está actualizado.
- Cuellos de botella causados por depender de una sola persona para «hacer avanzar la alerta».
📖 Lea también: Cómo redactar un informe de incidentes
Ventajas de la automatización
La automatización de ITSM aporta estructura e impulso a sus rutas de escalado. En lugar de esperar a que alguien vea la alerta, su sistema ejecuta una secuencia predefinida de forma instantánea y coherente.
Esto es lo que ganan los equipos cuando utilizan la IA para realizar la automatización de tareas:
- Tiempos de respuesta más rápidos, ya que las alertas llegan a la persona o al equipo adecuado en cuestión de segundos.
- Ejecución coherente de los pasos de escalado, incluso a las 3 de la madrugada, cuando la toma de decisiones es más lenta.
- Redundancia integrada que garantiza que los responsables de respuesta de copia de seguridad reciban una notificación si el responsable de guardia principal no ve la alerta.
- Visibilidad clara entre todos los equipos, ya que todos comprenden cómo fluye el flujo de escaladas.
- Menos apagones y experiencias de guardia más predecibles.
📖 Lea también: Ejemplos de planes de continuidad del negocio
Reducción de la fatiga por alertas y los descuidos humanos
La fatiga por alertas destruye la eficacia de las guardias. Cuando su equipo recibe alertas con demasiada frecuencia, o por motivos equivocados, deja de responder con urgencia. La automatización ayuda a filtrar y elevar solo lo que realmente necesita atención humana.
Con la lógica de escalado automatizada:
- Las alertas de baja intensidad o duplicadas se suprimen antes de que lleguen al servicio de guardia.
- Las reglas basadas en la gravedad garantizan que los problemas menores no despierten a nadie innecesariamente.
- Las alertas solo se escalan si el sistema detecta una falta de respuesta dentro de un plazo definido.
- Los equipos dedican menos tiempo a clasificar el ruido y más tiempo a resolver problemas reales.
Soporte para el cumplimiento de los acuerdos de nivel de servicio (SLA) y las políticas de guardia
La automatización de la escalación facilita el cumplimiento normativo sin necesidad de una supervisión manual constante. Para los responsables de operaciones de TI que gestionan acuerdos de nivel de servicio (SLA) estrictos o compromisos de fiabilidad internos, la IA actúa como una barrera de protección que garantiza el comportamiento esperado. Le ayuda a:
- Asegúrese de que las notificaciones de incidencias sigan las reglas predefinidas para el enrutamiento.
- Mantenga automáticamente los cronogramas de respuesta del SLA con escalamientos programados.
- Aplique los horarios de guardia sin depender de hojas de cálculo obsoletas.
- Cree registros de auditoría para cada alerta, escalamiento y acuse de recibo.
🎥 ¿Quiere gestionar todo el flujo de trabajo de la ruta de escalado sin tener que intervenir? Super Agents se encarga de todo. 👇🏼
🔍 ¿Sabías que...? El control de misiones de la NASA funciona básicamente con una lógica de escalado automatizada. Si la telemetría sale del intervalo, el sistema envía al instante alertas automatizadas a los especialistas por dominio.
¿Qué es una política de escalado en la gestión de incidencias?
Una política de escalado es un conjunto predefinido de reglas que determina a quién se notifica, cuándo se le notifica y cómo se transfiere la responsabilidad hacia arriba o entre equipos.
Considérelo como una hoja de ruta estructurada que evita que las incidencias se estanquen, garantiza que los expertos adecuados intervengan en el momento oportuno y ayuda a los equipos a cumplir los acuerdos de nivel de servicio (SLA).
Una política de gestión de escalado bien estructurada suele incluir:
- Enrutamiento basado en reglas que define quién es el siguiente en la cola cuando alguien no confirma o no puede resolver la incidencia.
- Desencadenantes temporizados que se escalan automáticamente después de 5, 15 o 30 minutos según la gravedad.
- Métodos de notificación como llamadas telefónicas, SMS, chatear o correo electrónico.
- Niveles del plan de escalado: Nivel 1 (personal de guardia principal) > Nivel 2 (ingenieros sénior/expertos en la materia) > Nivel 3 (dirección)
- Expectativas de documentación para que los nuevos responsables puedan tomar el relevo sin perder el contexto crítico.
📖 Lea también: Cómo priorizar tareas como P0, P1, P2, P3 y P4
Tipos de políticas de escalado
Estos son los tipos básicos de políticas que su equipo debe comprender:
1. Escalamiento jerárquico (vertical)
Las alertas ascienden por la cadena de mando, desde los ingenieros junior hasta los especialistas senior y los directivos. Utilícelo cuando la situación requiera una mayor experiencia, autoridad para la toma de decisiones o visibilidad ejecutiva.
2. Escalamiento funcional (horizontal)
En lugar de ascender, la alerta se transmite entre equipos a la función que sea responsable del sistema afectado. Esto es ideal para incidencias relacionadas con un dominio específico, como bases de datos, redes, pagos o API.
3. Escalado basado en el tiempo
Esta es la columna vertebral de la mayoría de los sistemas automatizados. En este tipo, la alerta pasa al siguiente nivel después de un período de tiempo específico, a menudo vinculado directamente a los SLA. Es especialmente esencial cuando se necesita una capacidad de respuesta garantizada fuera del horario laboral.
4. Escalado basado en el impacto
La escalada basada en el impacto depende de la gravedad o el impacto en la empresa, no de la jerarquía o el tiempo. Es útil para interrupciones del servicio, fallos en los pagos, problemas relacionados con los clientes o brechas de seguridad.
5. Escalado paralelo
En este caso, se notifica simultáneamente a varias personas o equipos. La escalada paralela se utiliza para problemas de alta gravedad que requieren múltiples especialidades o para situaciones en las que cualquier retraso es inaceptable.
🔍 ¿Sabías que...? Un estudio reciente sobre señales de alerta reveló que las alertas extremadamente llamativas o «ruidosas/brillantes » pueden ralentizar los tiempos de reacción, especialmente si la alerta es inesperada. Pero una vez que el tipo de alerta se convierte en algo esperado (es decir, parte de un sistema de escalado/notificación prediseñado), los tiempos de respuesta mejoran. Esto sugiere que, cuando se realiza la automatización de las rutas de escalado, no se debe inundar a las personas con alarmas de alta prioridad.
Cuándo desencadenar la escalada automática
Ahora que ya sabe cómo se estructuran las rutas de escalado, el siguiente paso es decidir cuándo deben ejecutarse estas reglas automáticamente.
A continuación se presentan las situaciones principales que son desencadenantes de la escalada automática, formando la capa lógica detrás de sus políticas. 💁
Escalado basado en la gravedad
La escalada automática se activa cuando la gravedad o el impacto de la incidencia superan un umbral determinado. Las incidencias de alta gravedad requieren la atención inmediata de los superiores, y la escalada automática evita los cuellos de botella y pone a los expertos al tanto en cuestión de segundos.
📌 Ejemplo: una interrupción total del servicio, un fallo en la pasarela de pago o una degradación importante que afecte a muchos usuarios o sistemas centrales requiere una escalada automática.
Escalado basado en el tiempo
Si nadie reconoce o resuelve la incidencia dentro de un plazo definido, la alerta se escala automáticamente al siguiente nivel. Esto evita que los tickets se estanquen, especialmente fuera del horario laboral normal, o cuando el primer respondedor no está disponible o está sobrecargado.
📌 Ejemplo: tras 10-15 minutos sin respuesta, se produce una escalada del primer respondedor a un ingeniero sénior; tras otros 30-60 minutos sin resolver, se produce una nueva escalada.
Escalado contextual
Esta lógica de escalado tiene en cuenta los atributos contextuales de la incidencia, como el servicio o sistema afectado, el propietario del servicio, el segmento de clientes afectado (interno frente a externo, VIP frente a habitual) o el dominio funcional (base de datos, red, integración). En función de ese contexto, las alertas se envían al responsable o equipo más relevante.
De este modo, evitará sobrecargar a los equipos con incidencias irrelevantes, reducirá el tiempo de respuesta y se asegurará de que los especialistas se ocupen de los problemas de su ámbito.
📌 Ejemplos: un pico de latencia en el servicio de pagos debería avisar directamente al equipo de pagos, o un error de backend en el microservicio de facturación debería notificarse al equipo de facturación.
Escalado basado en metadatos
Las herramientas modernas de alerta e incidencias capturan metadatos como la fuente de origen (qué herramienta de supervisión o regla de alerta se activó), la identidad del usuario/cliente, la ubicación, la frecuencia histórica de incidencias similares o los rótulos. Esto le ayuda a aplicar una lógica más granular e inteligente en lugar de basarse en reglas generales basadas en la gravedad o el tiempo.
📌 Ejemplos: Las alertas recurrentes del mismo subsistema pueden indicar un problema sistémico más profundo, lo que justifica una escalada más rápida. O bien, las alertas para clientes VIP pueden desencadenar notificaciones adicionales.
Combinación de desencadenantes para crear políticas de escalado más inteligentes y adaptables
En la práctica, muchos equipos no se basan en un solo tipo de desencadenante. En su lugar, crean políticas de escalado híbridas que combinan reglas de gravedad, tiempo, contexto y metadatos.
Este enfoque por capas permite a los equipos crear políticas de escalado que sean tanto receptivas (rápidas cuando sea necesario) como inteligentes (selectivas para minimizar el ruido), lo que se traduce en mejores resultados en caso de incidencias y una asignación más eficiente de los recursos.
🔍 ¿Sabías que...? En el siglo XVIII, las tripulaciones navales utilizaban una estricta cadena de escalamiento durante las emergencias. Si un marinero de rango inferior detectaba un peligro, tocaba una campana y pasaba el mensaje hacia arriba en la jerarquía hasta que el capitán tomaba la decisión final.
Cómo diseñar rutas de escalado eficaces
El diseño de rutas de escalado consiste en crear un sistema que dirija de forma fiable las alertas adecuadas a las personas adecuadas con la mínima fricción.
Aquí tiene un marco práctico y detallado que puede utilizar en entornos complejos y distribuidos.
P. D.: ¡También exploraremos cómo ciertas funciones de ClickUp pueden ayudarte en este sentido! 🤩
Paso n.º 1: Defina criterios, niveles y responsabilidades de escalado claros
Comience por definir qué constituye una incidencia que requiere escalamiento. Documente criterios objetivos para que todos los ingenieros de guardia, ya sean nuevos respondedores de nivel 1 o SRE experimentados, interpreten la gravedad de las incidencias de la misma manera.
Esto proporciona un flujo de trabajo de escalado claro, elimina la ambigüedad y garantiza que la automatización solo se active cuando realmente es necesario.
Incluya criterios como:
- Umbrales de gravedad: interrupción del servicio, fallos en los pagos, problemas de autenticación, corrupción de datos y alertas de seguridad.
- Impacto: interrupciones del servicio para los clientes, degradación del servicio interno, fallos en las API de los socios, cumplimiento normativo o riesgos de seguridad.
- Contexto crítico para la empresa: impacto en clientes de alto valor, flujos que afectan a los ingresos, sistemas de alto riesgo (por ejemplo, pagos, facturación).
Una vez definidos los criterios y los desencadenantes, correlacione quién recibe las alertas y cuáles son sus responsabilidades en cada punto de escalado.
Defina los niveles con claridad:
- Nivel uno (gestor de incidencias de guardia principal): Actúa como primer respondedor y es responsable del reconocimiento, la clasificación inicial y los intentos de mitigación.
- Nivel dos (copia de seguridad/especialista/PYME): Proporciona profundos conocimientos técnicos y resuelve problemas complejos del sistema.
- Nivel tres (gerente de ingeniería/liderazgo): Supervisa las incidencias importantes, aprueba las acciones importantes, coordina la comunicación entre equipos y actúa como desencadenante de la escalada al proveedor si es necesario.
🚀 Ventaja de ClickUp: utilice ClickUp Docs para mantener una única fuente de información veraz sobre los criterios, los niveles y las responsabilidades de escalado, y documente los roles y responsabilidades, incluyendo quién:
- Reconoce y mitiga
- Se comunica con las partes interesadas.
- Gestiona las escalaciones de proveedores o socios externos.
- Dirige el comando de incidentes.
También puede enlazar estos roles específicos con las tareas relevantes de ClickUp para mantener el contexto conectado.
Cree su propia base de conocimientos:
Una vez definidos los criterios de escalado y la propiedad, los equipos necesitan una forma coherente de capturar, realizar el seguimiento y analizar las incidencias técnicas. La plantilla de informe de incidencias de ClickUp proporciona un sistema estructurado y de fácil acceso para documentar las incidencias operacionales y de TI en un solo lugar.
Integrado en ClickUp Docs, ayuda a los equipos de respuesta a incidentes a registrar detalles críticos como la gravedad de la incidencia, los servicios afectados, los cronogramas, los resúmenes de las causas fundamentales, las medidas de mitigación y las acciones de seguimiento.
Paso n.º 2: Estandarizar la creación de incidencias
Antes incluso de que se activen las rutas de escalado, su equipo necesita una forma fiable de capturar, normalizar y enriquecer los datos de las incidencias. Si el registro inicial de la incidencia es incompleto o incoherente, incluso la lógica de escalado más sofisticada fallará.
La estandarización debe:
- Clasifique las alertas entrantes: convierta las alertas en Campos personalizados coherentes, como gravedad, categoría, servicio afectado, tipo de incidencia y estado de confirmación.
- Enriquezca la incidencia automáticamente: Incorpore metadatos, incluyendo clúster, ID de implementación, propietarios del servicio o dependencias.
- Asegúrese de que cada incidencia recoja el contexto: registre quién la ha notificado, cómo se ha detectado, el entorno (producción/prueba) y cualquier registro o captura de pantalla relevante.
Cree un formulario ClickUp directamente desde la lista en la que se realiza el seguimiento de las incidencias y diseñe este de manera que refleje su realidad operativa y los datos relevantes que generan dependencias en su lógica de escalamiento. De esta manera, en lugar de mensajes fragmentados en chats, correos electrónicos o paneles, cada incidencia ingresa a su sistema en un formato coherente sobre el que la automatización puede actuar de manera confiable.

Agrupe los campos de forma intencionada para que cada incidencia esté totalmente contextualizada:
- Identificación (título, resumen)
- Clasificación (gravedad, tipo, servicio afectado)
- Fuente (supervisión, usuario, API)
- Pruebas (registros, capturas de pantalla)
- Contexto empresarial (nivel de SLA, impacto en el cliente)
Cada envío de formulario crea automáticamente una nueva tarea de ClickUp, con todas las respuestas correlacionadas con los Campos personalizados de ClickUp. Esto garantiza que las incidencias se normalicen en el momento de su creación, lo que elimina la ambigüedad y la necesidad de responder manualmente a las incidencias.
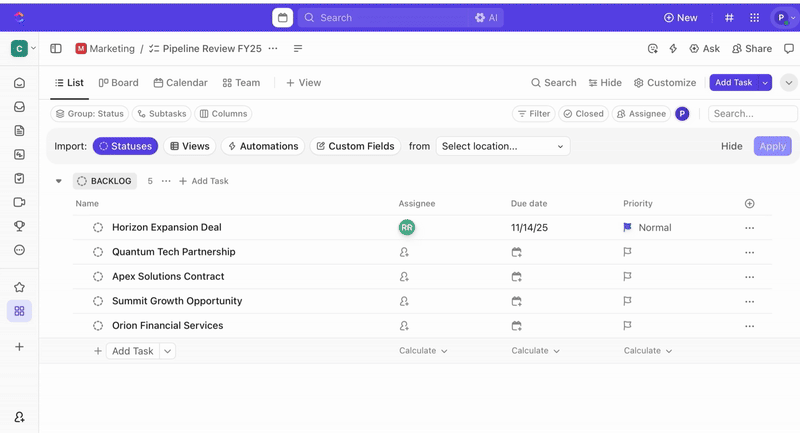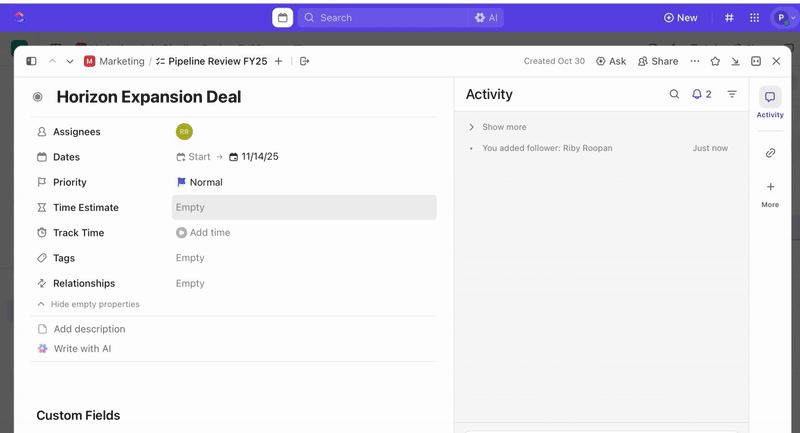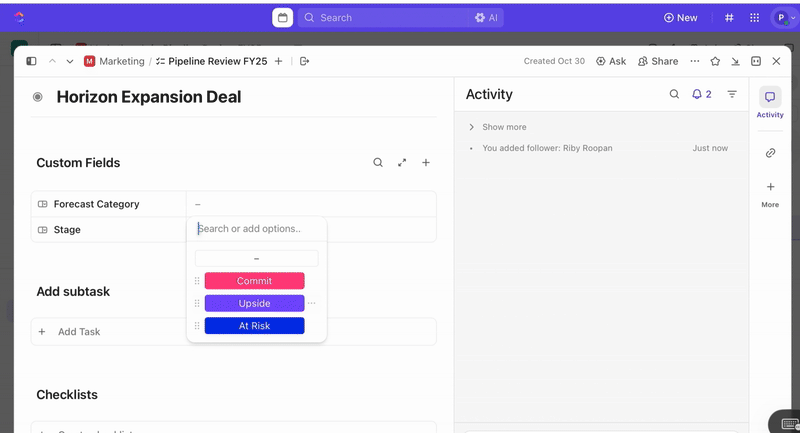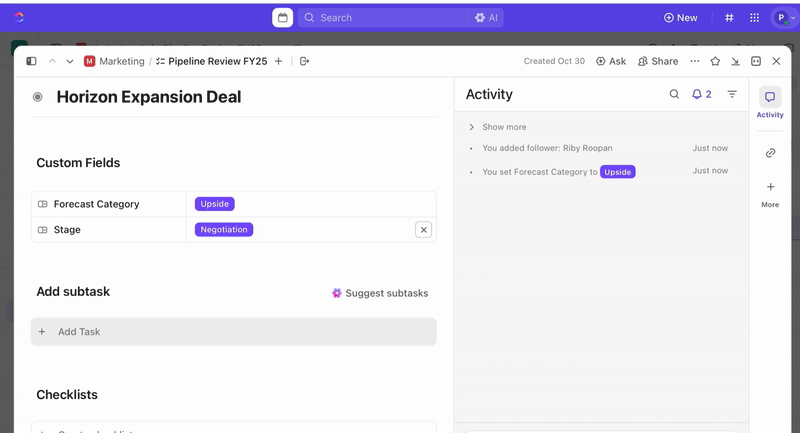
Una vez creadas las tareas, puede utilizar los Campos personalizados para impulsar la clasificación y la priorización (por ejemplo, gravedad, impacto, grupo de respuesta) y definir estados personalizados de ClickUp que reflejen las fases de su incidencia (Nuevo > Clasificación > Investigación > Mitigación > Resuelto).
Paso n.º 3: Crear la ruta de escalado (es decir, secuencia + tiempo + canales)
Este es el núcleo de la ruta. Diseñe la ruta por fases, en las que cada fase defina a quién se notifica, a través de qué canal o canales y tras cuánto tiempo sin recibir confirmación o resolución.
- Defina el «tiempo de espera de confirmación» y el «tiempo de espera de resolución».
A continuación se muestra un ejemplo de flujo de trabajo:
- Fase uno: El primer turno de guardia notificado inmediatamente a través del canal SMS/chat debe confirmar la recepción en un plazo de 5 a 10 minutos.
- Fase dos: si no se recibe confirmación ni se toma ninguna medida en los siguientes 15-20 minutos, escalar al equipo de copia de seguridad/SRE + ingeniero sénior a través de SMS/canal de chat/correo electrónico.
- Fase tres: si sigue sin resolverse tras otros 30-60 minutos, escale la incidencia al director de ingeniería/dirección y, opcionalmente, actívele un desencadenante para el canal de «incidencia grave».
- Decida si la ruta de escalado debe «repetirse» (volver a notificar al mismo nivel) o «avanzar».
- Para incidencias críticas, configure notificaciones repetidas hasta que alguien responda. Para incidencias de menor prioridad, es posible que desee un único flujo de escalamiento.
- Asegúrese de que la ruta esté documentada utilizando una plantilla de respuesta de servicio al cliente y que sea accesible para todo el personal relevante.
❗️ Nota: El «tiempo de espera de confirmación» es el tiempo que tiene el primer respondedor para confirmar que ha visto la alerta, mientras que el «tiempo de espera de resolución» es el tiempo que tiene el equipo para solucionar o mitigar el problema antes de que se active la siguiente escalada.
Paso n.º 4: Incorporar la automatización y el soporte de herramientas
Una vez que haya establecido sus criterios, el proceso de clasificación y los estándares de enriquecimiento, el siguiente paso es habilitar la escalación sin depender de que las personas recuerden cuándo o a quién escalar. Aquí es donde las automatizaciones de ClickUp se convierten en una parte fundamental de su flujo de trabajo.

Puede configurar oportunidades de automatización que reaccionen a las mismas señales que utiliza su equipo durante las incidencias. A continuación se muestran algunos ejemplos:
- Si la gravedad se actualiza a SEV-1 ➡️ Asigne inmediatamente a un SRE sénior + notifique al canal de chat de guardia.
- Si el estado permanece sin cambios durante X minutos ➡️ Desencadenante de la escalada al siguiente nivel.
- Si se supera la fecha límite (por ejemplo, la fecha límite de confirmación) ➡️ Escalar a L2
Y aquí es donde ClickUp Brain va aún más allá. Utiliza el contexto de su entorno de trabajo para ofrecer respuestas instantáneas, generar actualizaciones automáticamente y facilitar el acceso al conocimiento.
Utilice herramientas como AI Prioritize para evaluar automáticamente las incidencias y establecer la prioridad correcta utilizando su propia lógica. Ejemplos de indicaciones:
- Si la incidencia afecta a la producción y repercute en los clientes, establezca la prioridad: Urgente.
- Si la persona asignada es el equipo SRE y hay una mención en los registros sobre «latencia», establezca la prioridad: Alta.
- Si la descripción incluye palabras clave relacionadas con la seguridad, como «violación», establezca la prioridad como «Urgente».
Y, una vez establecida la prioridad, AI Assign se encarga de asignar automáticamente las incidencias en función de las condiciones que usted defina.
Puede crear indicaciones como:
- Si la prioridad es urgente y el servicio afectado contiene «pagos», asígnelo al SRE sénior.
- Si el tipo de incidencia es de base de datos y la región es US-East, asígnelo a DB On-Call.
- Si el nombre de la tarea incluye «seguridad», asígnela al responsable de SecOps.
Pruebe estas indicaciones en las tres primeras tareas antes de aplicarlas a toda la lista.
🚀 Ventaja de ClickUp: Implemente bots de automatización inteligente que residen en su entorno de trabajo de ClickUp y responden a la actividad en tiempo real con ClickUp Super Agents.
Conoce perfectamente tus tareas, documentos, chats y procesos, por lo que cada acción de automatización se adapta al contexto.
Por ejemplo, puede colocar un agente Team StandUp en su «carpeta de incidencias de producción» para que publique automáticamente un resumen diario cada mañana. Su equipo recibirá una instantánea que muestra el número de incidencias abiertas, cuáles siguen sin resolverse y qué cambios se han producido en las últimas 24 horas.
Ahora combínalo con un agente de Ambient Answers en tu canal «#incident-room». Cuando los responsables de la respuesta hagan preguntas como «¿Dónde está el libro de instrucciones SEV-1?» o «¿Ha fallado esta API anteriormente?», se extraerá información de tu entorno de trabajo para ofrecer respuestas instantáneas y precisas.

Paso n.º 5: Estandarizar los canales de comunicación
A medida que las incidencias se escalan, la forma y el lugar en que los equipos se comunican es tan importante como quién recibe la notificación. Sin canales estandarizados, las actualizaciones se pierden, las decisiones se duplican y las partes interesadas reciben información contradictoria.
Defina canales de escalado claros para cada fase del ciclo de vida de las incidencias y utilícelos de forma coherente en todos los equipos:
| Criterios | Nombre del canal | Objetivo |
| SEV-1 o SEV-2 detectado | #incidencia-crítica | Espacio central para alertas de alta gravedad y clasificación inmediata. |
| Resolución de problemas activa en curso | #incidencia-warroom | Hub de colaboración en tiempo real para ingenieros, productos, control de calidad y soporte. |
| Se requiere visibilidad del liderazgo | #liderazgo-en-incidencias | Actualizaciones de alta relevancia para gerentes y ejecutivos. |
| Se requiere comunicación personalizada con los clientes | #comunicaciones-de-incidencia | Espacio para redactar, revisar y coordinar las comunicaciones con los clientes externos. |
| Revisión posterior a la incidencia iniciada | #incidencia-retro | Debate estructurado para notas retrospectivas, aprendizajes y elementos a tomar. |
Cada canal tiene un público y un propósito definidos, lo que ayuda a los equipos a reducir el ruido y mantener informados a los equipos adecuados.
🚀 Ventaja de ClickUp: Adapta tu estrategia de canales con una capa de comunicación integrada utilizando ClickUp Chat. Cada alerta, actualización y decisión permanece vinculada directamente a la tarea, lista o espacio de la incidencia donde se realiza el trabajo.
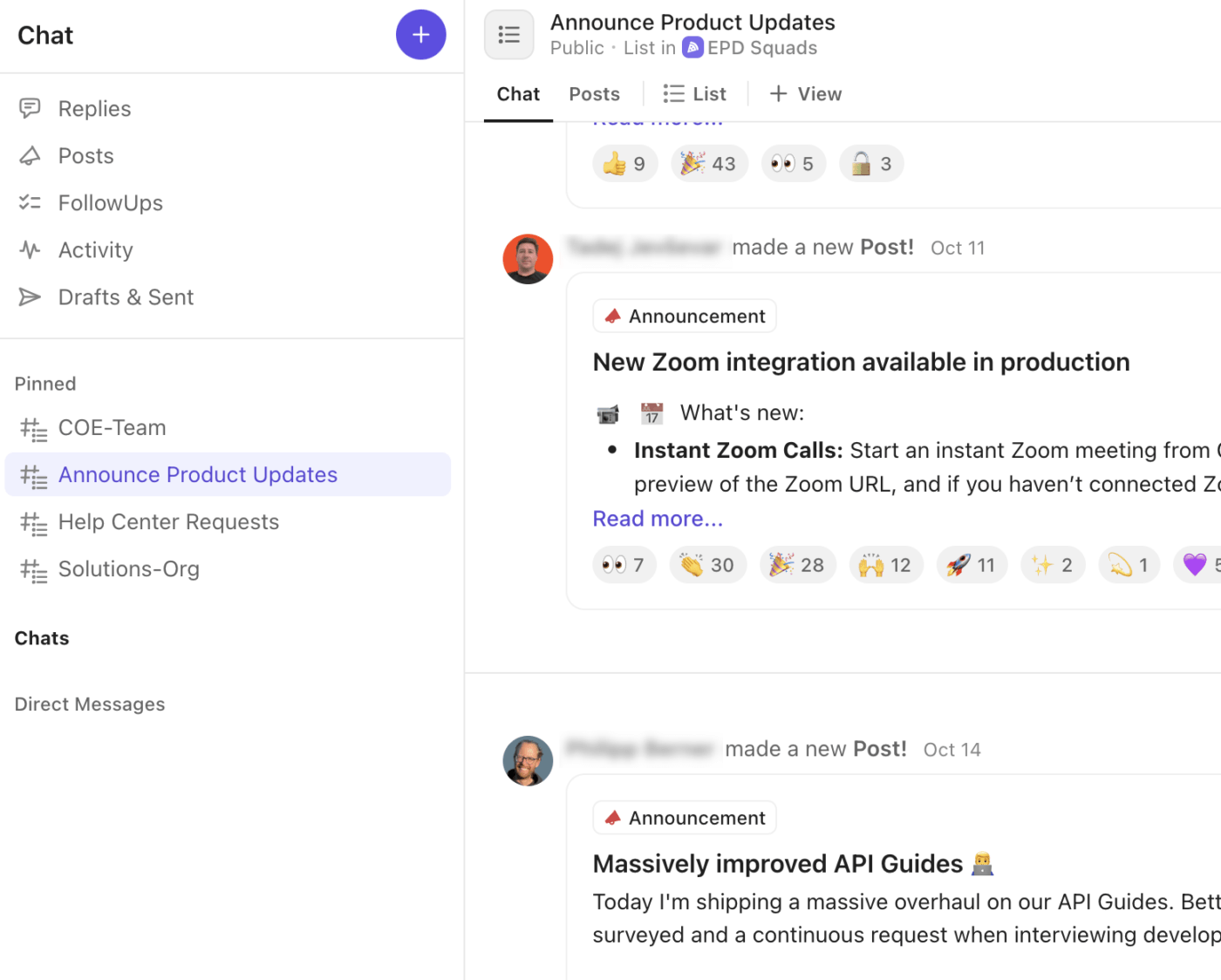
Así es como ClickUp Chat mejora su flujo de trabajo de incidencias:
- Cree hilos de chat específicos para debates críticos, de sala de crisis, de liderazgo o de comunicación con los clientes.
- Convierta los mensajes de chat en tareas de ClickUp al instante, asegurándose de que las decisiones y los seguimientos no se pierdan en la conversación.
- Realice videollamadas rápidas de audio o vídeo con ClickUp SyncUps para coordinar incidencias en directo o realizar reuniones informativas con los responsables.
- Publique «Anuncios» o actualizaciones para difundir el estado general de las incidencias en toda la empresa.
- Etiqueta a tus compañeros de equipo, añade capturas de pantalla y adjunta registros directamente en el chat, manteniendo el contexto técnico a mano.
Paso n.º 6: Pruebe, audite y perfeccione su ruta de escalado
Las políticas de escalado deben evolucionar con sus sistemas. Esto es lo que debe hacer con regularidad:
| Actividad | Qué probar o revisar | Por qué es importante |
| Simulacros de emergencia (trimestrales) | Simule incidencias P1 y P2, verifique los tiempos de escalado y el enrutamiento. | Garantiza que las automatizaciones y las rutas de escalado funcionen bajo presión. |
| Validación de la ruta de escalado | Compruebe si hay escalamientos sin salida o propietarios que faltan. | Evita que las incidencias se estanquen sin visibilidad. |
| Cronómetros del proceso de reconocimiento y resolución | Compare los cronómetros configurados con el MTTA y el MTTR reales. | Mantiene los plazos de escalado realistas y eficaces. |
| Evaluación de la fatiga por alertas | Identifique a los responsables de responder que reciben alertas excesivas o repetidas. | Reduce el agotamiento y las alertas críticas perdidas. |
| Gravedad y precisión en la priorización | Compruebe si las incidencias se han clasificado correctamente. | Mejora el enrutamiento, la velocidad de respuesta y la precisión de la escalada. |
| Seguimiento posterior a la incidencia | Asegúrese de que se completen los elementos pendientes de las retrospectivas. | Evita la repetición de incidencias y fallos sistémicos. |
Herramientas e integraciones para la automatización de la escalada
En esta sección se describe el software de gestión de incidencias que le ayuda a detectar incidencias más rápidamente, derivarlas al instante y mantener a todos los equipos informados sin necesidad de realizar seguimientos manuales.
1. ClickUp (ideal para unificar las escaladas interfuncionales en un único entorno de trabajo conectado para incidencias)
Los métodos tradicionales de escalado obligan a los equipos a hacer malabarismos con correos electrónicos, hojas de cálculo, hilos de chat y notas dispersas, lo que hace casi imposible obtener una vista clara y en tiempo real de lo que está sucediendo.
El software de gestión de tareas ClickUp para la gestión de escalamientos elimina el ruido al consolidar todos los detalles de los escalamientos en un único entorno de trabajo organizado.
Veamos algunas de las funciones del software de gestión de activos de TI que le dan a ClickUp la posición de mejor opción para los equipos que gestionan escalamientos de gran volumen y flujos de trabajo de incidencias complejos.
Realice el trabajo a su manera
Visualice sus tareas desde múltiples ángulos para adaptarlas a sus necesidades operativas con ClickUp Views:
- Vista Lista de ClickUp para que los responsables de SRE puedan clasificar las incidencias por gravedad, tiempo restante del SLA o grupos de guardia para una rápida clasificación.
- ClickUp Vista Tablero permite a los responsables de ingeniería visualizar los traspasos y la propiedad del equipo durante las escaladas.
- Vista Gantt de ClickUp para que los responsables de programas puedan correlacionar los hitos de resolución y las dependencias entre servicios.
- Vista Carga de trabajo de ClickUp para los programadores de guardias, que garantiza que los ingenieros no se vean sobrecargados durante los periodos de gran volumen de incidencias.
Convierta las discusiones de las reuniones en acciones
Durante las escaladas y las revisiones de incidencias, puede resultar complicado capturar de forma fiable los elementos de debate y las medidas a tomar. El tomador de notas con IA de ClickUp se une automáticamente a las reuniones programadas en Google Calendar, Outlook, Zoom o Teams, y graba y transcribe la conversación.
Después de la reunión:
- Acceda a transcripciones con función de búsqueda y resúmenes de elementos a tomar.
- Garantice la claridad utilizando las notas guardadas en ClickUp Docs. Esto facilita el enlace con las tareas relacionadas con la incidencia o los informes retrospectivos.
- Haga preguntas a ClickUp AI sobre el contenido de las reuniones para aclarar decisiones o descubrir seguimientos que se hayan pasado por alto.
Conéctese a las herramientas existentes en su pila tecnológica
Entre bastidores, las integraciones de ClickUp y el ecosistema de webhooks garantizan una conexión perfecta con el resto de su pila.
La plataforma se integra de forma nativa con herramientas como Slack, GitHub, Zoom y otras, y admite webhooks a través de su API pública para transmitir eventos (actualizaciones de tareas y cambios de estado) a servicios externos o canalizaciones de automatización. Esto facilita la activación de flujos de trabajo, la sincronización de datos o la escalación de incidencias entre sistemas sin necesidad de transferencias manuales.
Converja todas sus herramientas de IA
Para llevar la automatización y el contexto al siguiente nivel, ClickUp BrainGPT incorpora IA contextual en todos sus flujos de trabajo de escalamiento. Se trata de una aplicación de superinteligencia artificial contextual que comprende sus tareas, documentos y contexto histórico.
Con Enterprise Search y Connected Apps, puede extraer información al instante de su entorno de trabajo, Slack, Google Drive, GitHub y mucho más. Durante las llamadas en directo relacionadas con incidencias, la función Talk-to-Text de ClickUp le permite dictar notas o instrucciones de escalado sin necesidad de usar las manos, lo que garantiza que no se pase nada por alto.
También puede estandarizar tareas repetitivas con indicaciones de IA personalizadas e indicaciones guardadas, como: «Resuma todas las incidencias sin resolver y recomiende acciones de escalado».
Las mejores funciones de ClickUp
- Priorice los problemas críticos: utilice las prioridades de tareas de ClickUp para resaltar las escaladas urgentes o de gran impacto.
- Organice secuencias de escalado complejas: configure las dependencias de tareas de ClickUp para enlazar tareas relacionadas (por ejemplo, «En espera» o «Bloqueando») de modo que los pasos de escalado eviten acciones prematuras o cuellos de botella.
- Divida las incidencias en elementos manejables: divida las escaladas en elementos granulares y asígnelas a los equipos con subtareas anidadas.
- Realice un seguimiento preciso de la velocidad de resolución: registre y supervise el tiempo que tardan en reconocerse y resolverse las tareas de escalado con el control de tiempo del proyecto de ClickUp.
Limitaciones de ClickUp
- Con tantas funciones, vistas y opciones de personalización, los equipos suelen enfrentarse a una curva de aprendizaje antes de que todo resulte intuitivo.
Precios de ClickUp
[Tabla de precios]
Valoraciones y reseñas de ClickUp
- G2: 4,7/5 (más de 10 300 opiniones)
- Capterra: 4,6/5 (más de 4400 opiniones)
¿Qué opinan los usuarios reales sobre ClickUp?
Esta reseña lo dice todo:
ClickUp reúne todas mis tareas, proyectos y comunicaciones en un solo lugar, lo que hace que sea increíblemente fácil mantenerme organizado. Me encanta lo personalizable que es todo, desde las vistas y los flujos de trabajo hasta los paneles, lo que me permite estructurar mi entorno de trabajo exactamente como lo necesito. La posibilidad de colaborar en tiempo real, asignar tareas y realizar el seguimiento del progreso sin cambiar de herramienta es una gran ventaja.
ClickUp reúne todas mis tareas, proyectos y comunicaciones en un solo lugar, lo que hace que sea increíblemente fácil mantenerme organizado. Me encanta lo personalizable que es todo, desde las vistas y los flujos de trabajo hasta los paneles, lo que me permite estructurar mi entorno de trabajo exactamente como lo necesito. La posibilidad de colaborar en tiempo real, asignar tareas y realizar el seguimiento del progreso sin cambiar de herramienta es una gran ventaja.
📮 ClickUp Insight: El 21 % de las personas afirma que más del 80 % de su jornada laboral la dedica a tareas repetitivas. Y otro 20 % afirma que las tareas repetitivas consumen al menos el 40 % de su jornada.
Eso supone casi la mitad de la semana laboral (41 %) dedicada a tareas que no requieren mucho pensamiento estratégico ni creatividad (como los correos electrónicos de seguimiento 👀).
Los Superagentes de ClickUp ayudan a eliminar esta rutina. Piensa en la creación de tareas, recordatorios, actualizaciones, notas de reuniones, redacción de correos electrónicos e incluso la creación de flujos de trabajo de principio a fin. Todo eso (y mucho más) se puede automatizar en un santiamén con ClickUp, tu aplicación para todo lo relacionado con el trabajo.
💫 Resultados reales: Lulu Press ahorra 1 hora al día por empleado gracias al uso de ClickUp Automatizaciones, lo que se traduce en un aumento del 12 % en la eficiencia del trabajo.
2. PagerDuty (ideal para alertas en tiempo real y respuestas inteligentes de guardia)
PagerDuty es una plataforma de gestión de incidentes de TI y operaciones digitales basada en la nube que ayuda a los equipos a detectar, responder y resolver rápidamente incidencias críticas, como interrupciones del servicio o amenazas de seguridad. Ofrece a los responsables de SRE, DevOps y soporte técnico una ruta clara desde la señal hasta la resolución, respaldada por la automatización, la clasificación basada en IA y flujos de trabajo profundamente integrados.
Funciones como Jeli Incident Analysis, PagerDuty Analytics y Runbook Automatización ayudan a los equipos a reducir el tiempo de inactividad, eliminar las tareas rutinarias y aprender de cada incidencia.
Las mejores funciones de PagerDuty
- Automatice el enrutamiento de incidencias con la función integrada Gestión de guardias y las Políticas de escalado dinámicas.
- Acelere la clasificación utilizando AIOps, que filtra el ruido de las alertas, correlaciona los eventos y destaca las señales verdaderas.
- Mantenga a las partes interesadas internas y externas alineadas con Stakeholder Comms, Plantillas de actualización de estado y Páginas de estado.
- Unifique su conjunto de herramientas con más de 700 integraciones y API extensibles utilizando sistemas de supervisión, registro, CI/CD y soporte.
Límites de PagerDuty
- Alto volumen de alertas si las integraciones y los umbrales inteligentes no están ajustados, lo que provoca ruido y fatiga.
- Durante los picos de actividad pueden producirse alertas duplicadas o repetidas, lo que dificulta su reconocimiento bajo presión.
Precios de PagerDuty
- Free
- Profesional: 25 $ al mes por usuario
- Empresa: 49 $ al mes por usuario
- Corporación: precios personalizados
Valoraciones y reseñas de PagerDuty
- G2: 4,5/5 (más de 900 opiniones)
- Capterra: 4,6/5 (más de 200 opiniones)
¿Qué opinan los usuarios reales sobre PagerDuty?
En palabras de un usuario real:
PagerDuty hace que las notificaciones de incidencias sean rápidas y fiables. Envía las notificaciones adecuadas en el momento oportuno y mantiene a nuestro equipo organizado. […] PagerDuty puede resultar molesto en ocasiones cuando las notificaciones no se filtran bien. Algunos ajustes son un poco complejos para los nuevos usuarios.
PagerDuty hace que las alertas de incidencias sean rápidas y fiables. Envía las notificaciones adecuadas en el momento oportuno y mantiene a nuestro equipo organizado. […] PagerDuty puede resultar molesto en ocasiones cuando las alertas no se filtran bien. Algunos ajustes son un poco complejos para los nuevos usuarios.
💡 Consejo profesional: Cree excepciones, incluso en una ruta de escalado clara. Haga que las interrupciones críticas, las alertas de seguridad o las incidencias en entornos regulados pasen directamente a los responsables de respuesta sénior o especializados.
3. GLPi (ideal para la gestión integral de activos y operaciones de servicio alineadas con ITIL)
Gestionnaire Libre de Parc Informatique (GLPi) es una plataforma completa de código abierto para la gestión de servicios de TI (ITSM) y la gestión de activos de TI (ITAM). Los equipos obtienen una visibilidad completa de su infraestructura (hardware, software, licencias y dispositivos de red) y pueden gestionar incidencias, solicitudes de servicio y cambios mediante procesos alineados con ITIL.
Todos sus contratos y documentación, incluidas las garantías y los acuerdos de servicio, permanecen perfectamente organizados, lo que evita que se pierdan entre los diferentes sistemas. Si gestiona centros de datos, GLPi le permite incluso visualizar diseños, rutas de cableado y consumo energético para que siempre sepa lo que ocurre entre bastidores.
Las mejores funciones de GLPi
- Utilice los complementos GLPI Inventory, OCS Inventory o FusionInventory para detectar y catalogar automáticamente los nuevos activos de TI.
- Automatice las tareas repetitivas, la asignación de tickets, las notificaciones y los eventos recurrentes para reducir el trabajo manual.
- Cree una base de conocimientos con preguntas frecuentes, documentación y artículos enlazados a los tickets para el autoservicio y el soporte técnico.
- Conéctese con Azure/Entra, Centreon, Google, OAuth2 y webhooks para sincronizar datos, desencadenar flujos de trabajo y mejorar su CMDB.
Limitaciones de GLPi
- La compatibilidad de los complementos puede verse afectada entre versiones, lo que provoca gastos de mantenimiento adicionales.
- Las funciones de elaboración de informes, análisis y exportación parecen tener un límite y necesitan mejoras.
Precios de GLPi
- Precios personalizados
Valoraciones y reseñas de GLPi
- G2: 4,6/5 (más de 30 opiniones)
- Capterra: 4,5/5 (más de 40 opiniones)
¿Qué opinan los usuarios reales sobre GLPi?
Esto es lo que opinó un usuario:
Sistema de gestión de activos de TI y tickets de soporte de código abierto muy personalizable, con una gran comunidad de apoyo. La interfaz de usuario es un poco complicada para los principiantes. Los complementos no siempre tienen compatibilidad entre las versiones antiguas y las nuevas.
Sistema de gestión de activos de TI y tickets de soporte de código abierto muy personalizable, con una gran comunidad de apoyo. La interfaz de usuario es un poco complicada para los principiantes. Los complementos no siempre tienen compatibilidad entre las versiones antiguas y las nuevas.
4. Splunk On-Call (ideal para enviar alertas de supervisión directamente a los ingenieros)
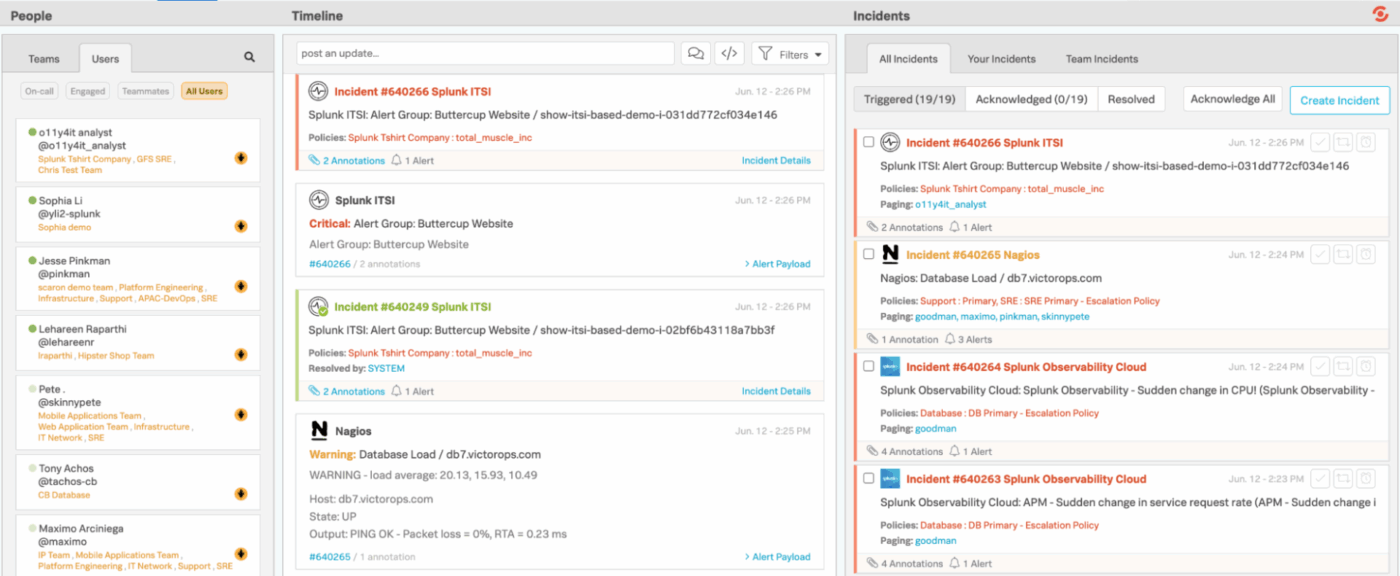
Splunk On-Call proporciona a los equipos de ingeniería y de guardia una forma más rápida y limpia de gestionar las incidencias, eliminando la necesidad de los lentos flujos de trabajo tradicionales de gestión de tickets. En lugar de enviar las alertas a una cola genérica, se integra directamente con su pila de supervisión y observabilidad, y envía inmediatamente los problemas a las personas adecuadas en función de los horarios, las reglas y el contexto.
Las integraciones móviles y de chat facilitan el reconocimiento, el redireccionamiento o la resolución de incidencias desde cualquier lugar. Y, entre bastidores, Splunk On-Call mantiene un registro detallado de las tendencias, los patrones probados y el comportamiento de la escalada.
Las mejores funciones de Splunk On-Call
- Amplíe las capacidades de la plataforma utilizando más de 1000 integraciones y complementos verificados de Splunk y la comunidad en general.
- Cree paneles personalizados e informes visuales para supervisar el volumen de alertas, el estado de las incidencias, el rendimiento de los responsables de la respuesta y la carga de trabajo del equipo.
- Filtre rápidamente las incidencias por su propia actividad, las incidencias de su equipo o todo lo que ocurre en la organización.
- Cambie entre las vistas Desencadenante, Confirmada y Resuelta para ver en qué estado se encuentra cada incidencia.
Límites de Splunk On-Call
- La programación de turnos entre varios equipos puede complicarse si no se definen reglas previamente.
- Capacidad limitada para generar informes detallados de incidencias por fecha.
Precios de Splunk On-Call
- Precios personalizados
Valoraciones y reseñas de Splunk On-Call
- G2: 4,6/5 (más de 40 opiniones)
- Capterra: 4,5/5 (más de 30 opiniones)
¿Qué opinan los usuarios reales sobre Splunk On-Call?
Un usuario lo resumió así:
La posibilidad de gestionar incidencias, escalamientos y relevar a mis compañeros de equipo desde la app es fantástica. […] Me gustaría poder programar anulaciones y cambiar la programación habitual desde la app para cambios de programación de emergencia.
La posibilidad de gestionar incidencias, escalamientos y relevar a mis compañeros de equipo desde la app es fantástica. […] Me gustaría poder programar anulaciones y cambiar la programación habitual desde la app para cambios de programación de emergencia.
🔍 ¿Sabías que...? La lógica de «redirigir a la persona adecuada si falla el primer nivel» tiene su origen en las primeras centrales telefónicas: cuando los operadores manuales no podían realizar la conexión de una llamada, el sistema la redirigía (o escalaba) a otro operador o central.
5. ServiceNow (ideal para coordinar a escala empresarial con automatización asistida por IA)
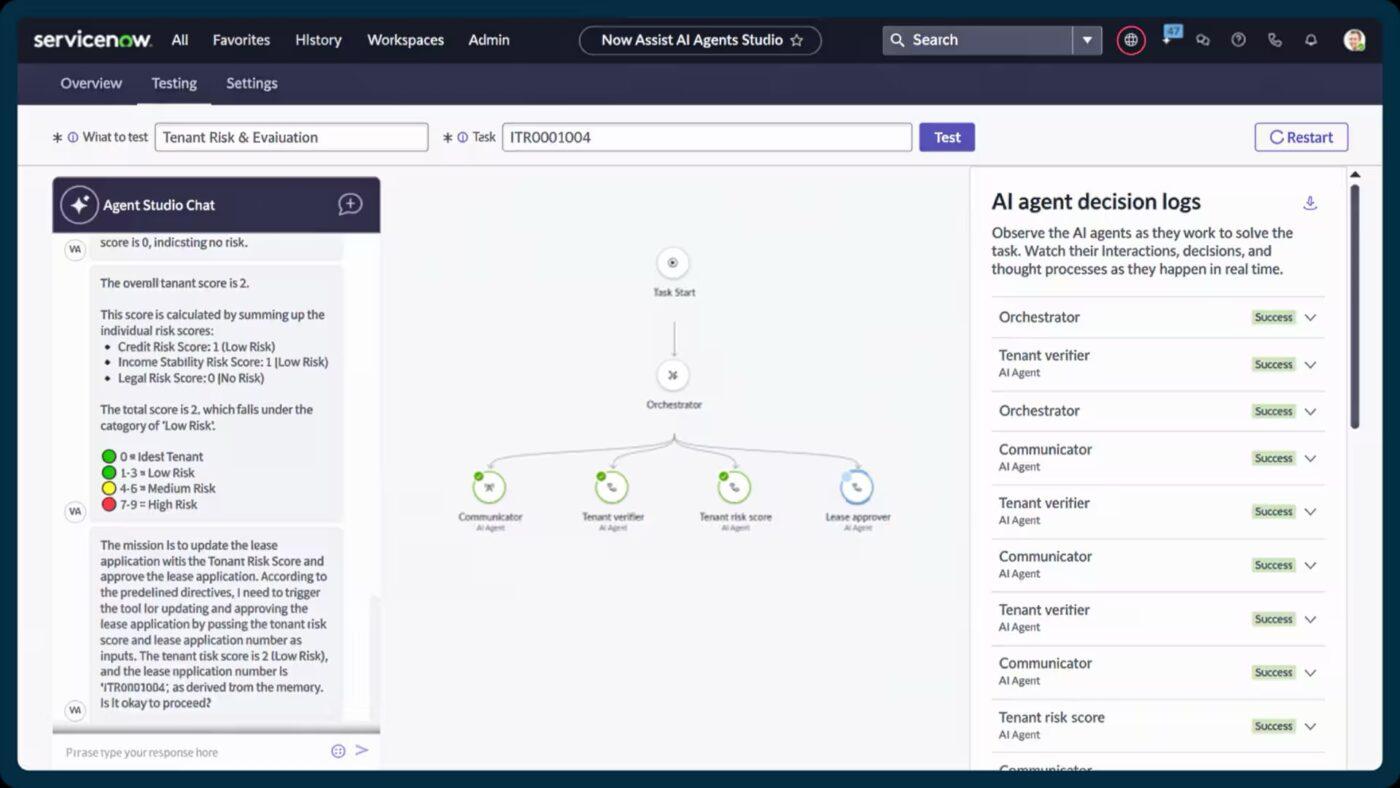
ServiceNow clasifica, prioriza y deriva automáticamente las incidencias en el momento en que se registran. Con funciones como Now Assist para recomendaciones automatizadas de tickets de incidencias y generación inteligente de contenido, los responsables de la respuesta pueden resolver los problemas más rápidamente y con más contexto.
Aúna la gestión de incidencias, cambios y activos. De este modo, obtendrá una vista en tiempo real de cómo están conectados los servicios, dónde aparecen los cuellos de botella y qué componentes pueden estar contribuyendo a las interrupciones recurrentes.
Las mejores funciones de ServiceNow
- Asigne, dirija y supervise las tareas de campo a través de Field Service Management y Dispatcher Workspace.
- Empodere a los empleados y clientes con un portal de autoservicio impulsado por IA Search y agentes virtuales.
- Utilice los flujos de trabajo integrados y las herramientas de bajo código de App Engine para ampliar o personalizar los procesos de servicio.
- Automatice las tareas repetitivas y los flujos de trabajo entre equipos con Flow Designer y Automation Engine.
Límites de ServiceNow
- Las opciones de personalización de la interfaz de usuario y el portal parecen obsoletas o restrictivas.
- Gran dependencia de personal cualificado o consultores para la implementación.
Precios de ServiceNow
- Precios personalizados
Valoraciones y reseñas de ServiceNow
- G2: 4,4/5 (más de 3300 opiniones)
- Capterra: 4,5/5 (más de 300 opiniones)
¿Qué opinan los usuarios reales sobre ServiceNow?
Así lo explica un usuario:
[…] Los flujos predefinidos son otra de las características más destacadas para mí, ya que agilizan los procesos y ahorran mucho tiempo, minimizando la necesidad de configuraciones personalizadas y permitiendo un flujo de trabajo más fluido y eficiente. […] Además, tuve dificultades para adaptar mi solución personalizada al sistema de gestión de atención al cliente, lo que requirió muchas iteraciones.
[…] Los flujos predefinidos son otra de las características más destacadas para mí, ya que agilizan los procesos y ahorran mucho tiempo, minimizando la necesidad de configuraciones personalizadas y permitiendo un flujo de trabajo más fluido y eficiente. […] Además, tuve dificultades para adaptar mi solución personalizada al sistema de gestión de atención al cliente, lo que requirió muchas iteraciones.
Buenas prácticas y gobernanza
A continuación se indican algunas buenas prácticas que garantizan que la automatización siga siendo precisa, evite la fatiga por alertas y se ajuste a las expectativas empresariales y normativas.
- Defina criterios de escalado no negociables: vincule los desencadenantes a señales medibles, como incumplimientos de SLO, picos de anomalías, impacto en el nivel de los clientes o sensibilidad normativa.
- Establezca la claridad del rol en cada nivel: utilice un mapa RACI sencillo para cada nivel de escalado, de modo que las responsabilidades nunca sean ambiguas durante incidencias de alta presión.
- Aplique una gestión dinámica de las guardias: ajuste automáticamente las rutas de escalado en función de los fines de semana, los días festivos, los límites de capacidad y los traspasos para reducir el agotamiento y evitar las páginas silenciosas.
- Inserte puntos de control humanos para situaciones de alto riesgo: incluso con la automatización, exija la confirmación manual de las incidencias relacionadas con la exposición de datos de clientes, pagos o flujos de trabajo regulados.
- Mantenga registros de auditoría completos: conserve registros inmutables de quién recibió la notificación, cuándo la acusó recibo, qué pasos de automatización se activaron y qué decisiones se tomaron.
🧠 Dato curioso: La queja escrita más antigua que se conoce fue grabada en una tablilla de arcilla alrededor del 1750 a. C. Básicamente, se trataba de una escalada temprana del estado del proyecto. Un cliente llamado Nanni escribió al comerciante Ea-nāṣir, furioso porque el cobre que había recibido era de menor calidad que la prometida y porque su mensajero había sido maltratado.
Retos comunes y cómo superarlos
Incluso con una política de escalado clara, los equipos a menudo se enfrentan a obstáculos operativos que ralentizan la respuesta a las incidencias o crean confusión.
Esta tabla destaca los retos comunes que van más allá de los pasos básicos de configuración y proporciona estrategias prácticas para superarlos.
| Retos ❌ | Soluciones ✅ |
| Contexto inconsistente durante los traspasos | Utilice las plantillas de vinculación de tareas y de informes de incidencias de ClickUp para mantener un registro completo de los detalles de las incidencias, los sistemas afectados y las acciones previas en cada nivel de escalado. |
| Sobrecargar a los responsables de la respuesta con alertas de baja prioridad | Implemente una priorización dinámica con los campos personalizados de ClickUp y AI Prioritize para filtrar las incidencias en función de la gravedad, el impacto y los umbrales del SLA. |
| Falta de visibilidad entre equipos | Configure entornos de trabajo compartidos, añada comentarios y cree pizarras visuales ClickUp para presentar actualizaciones en tiempo real a las partes interesadas. |
| Retrasos en la toma de decisiones durante incidencias críticas | Automatice las notificaciones utilizando las acciones sugeridas de ClickUp Brain Max para alertar instantáneamente al personal adecuado en función del tipo de incidencia, la gravedad y los patrones históricos. |
| Dificultad para realizar el seguimiento de los problemas recurrentes | Aproveche la elaboración de informes personalizados y las plantillas de tareas periódicas de ClickUp para identificar patrones, causas fundamentales e incidencias repetidas con el fin de prevenir de forma proactiva. |
| Conocimiento fragmentado durante la escalada | Mantenga procedimientos operativos estándar (POE), manuales de operaciones y documentación de incidencias centralizados en ClickUp Docs, enlazándolos con las tareas pertinentes para poder consultarlos al instante durante las escaladas en tiempo real. |
| Responsabilidades desalineadas entre turnos | Utilice las vistas de Carga de trabajo y Cronograma de ClickUp para visualizar las asignaciones y asegurarse de que no haya solapamientos ni lagunas durante los cambios de turno o los traspasos. |
| Seguimiento manual del cumplimiento y deficiencias en las auditorías | Automatice los resúmenes listos para auditorías con ClickUp Brain para registrar todas las acciones, notificaciones y resoluciones de incidencias. |
Medición del impacto de la escalada automatizada
Para realizar el seguimiento de la eficacia de la escalada automatizada, es necesario centrarse en métricas clave relacionadas con el volumen, la eficiencia y la calidad. Estos indicadores revelan si sus procesos de escalada son más rápidos, más precisos y menos frustrantes tanto para los equipos como para los clientes.
Realice un seguimiento de estas métricas:
- Tasa de escalamiento (volumen): Porcentaje de problemas escalados más allá del primer nivel. Las tasas elevadas pueden indicar deficiencias en la clasificación inicial o en las bases de conocimientos.
- Tasa de escalamiento repetido (volumen): Frecuencia con la que se escala el mismo problema varias veces. Indica resoluciones incompletas o pérdida de contexto.
- Tiempo hasta la escalación (eficiencia): Duración desde la detección hasta la escalación. Una duración más corta de las fases indica un reconocimiento automatizado más rápido de los problemas críticos.
- Tiempo de retraso en el traspaso (eficiencia): Diferencia entre la escalación y el momento en que el siguiente equipo comienza a trabajar para resaltar la fricción en el enrutamiento o la notificación.
- Tiempo de resolución de los casos escalados (eficiencia): tiempo total desde la escalación hasta la resolución. Una resolución más rápida demuestra la eficacia de la automatización.
- Puntuación de satisfacción del cliente (CSAT) (calidad): Comentarios sobre las interacciones escaladas para medir la fluidez de la ruta.
- Transmisión del contexto (calidad): si los agentes reciben el historial completo de la incidencia para garantizar que los clientes no repitan la información.
- Resolución en el primer contacto (FCR) (calidad): Porcentaje de problemas resueltos en una sola interacción.
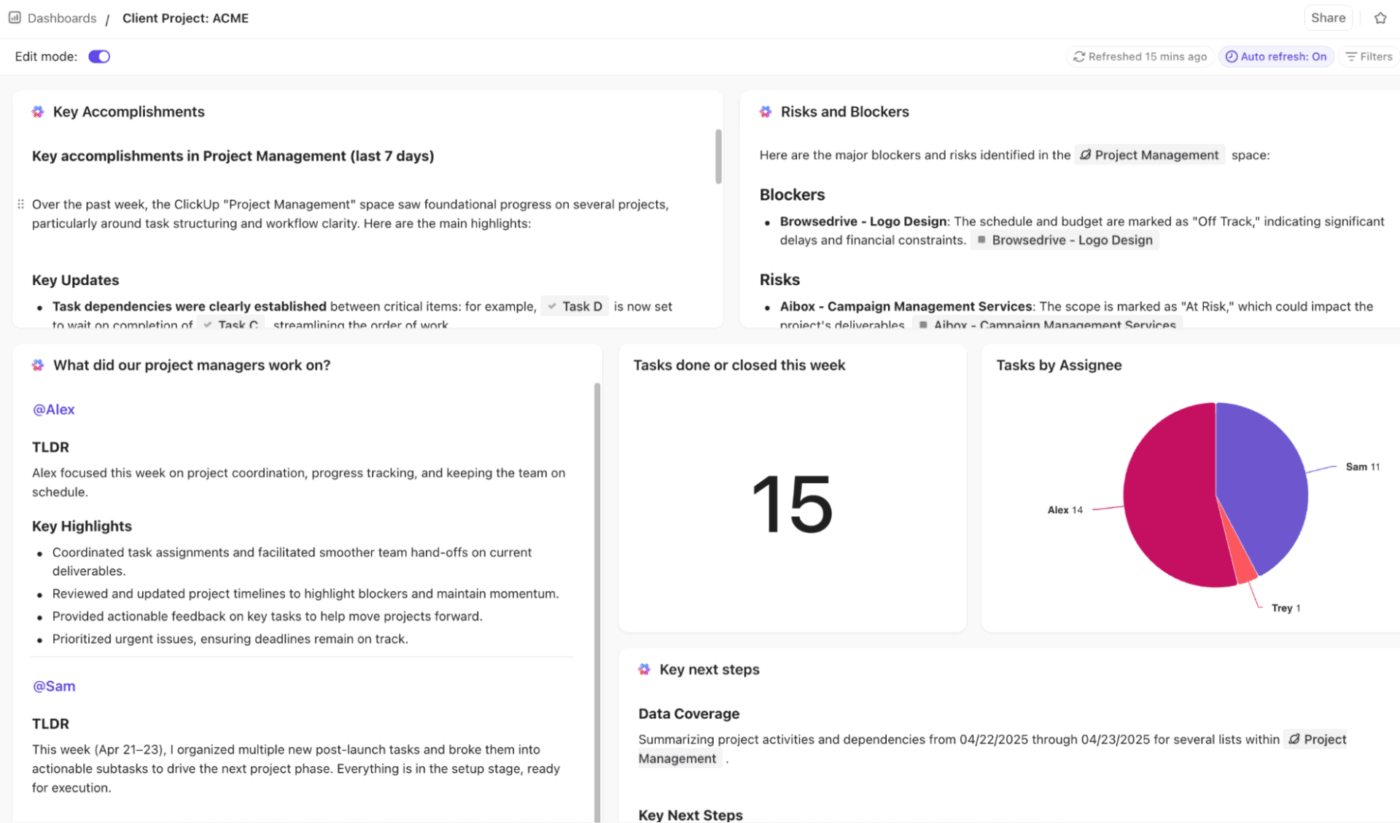
🚀 Ventaja de ClickUp: Obtenga información en tiempo real, visual y basada en IA sobre todas las métricas de escalado con los paneles de ClickUp.
Puede realizar el seguimiento de las tendencias de escalado, los cuellos de botella y el rendimiento con tarjetas de tabla, tarta, barra, línea, cálculo y informes de tiempo. Supervise la tasa de escalado, el escalado repetido y el tiempo hasta el escalado con tarjetas enlazadas a tareas, campos personalizados y estados.
Para ir más allá, utilice tarjetas de IA como IA Resumen, IA Actualización del proyecto y IA StandUp para destacar tendencias, retrasos y resultados de resolución.
Gestión de sus incidencias más rápidamente con ClickUp
Muchos piensan que la escalada de incidencias consiste simplemente en pasar un ticket a la siguiente persona, pero es mucho más que eso. Se trata de un sistema estructurado en el que todos los pasos, desde la clasificación hasta la resolución, funcionan en armonía.
ClickUp le ofrece el entorno de trabajo unificado perfecto. Con ClickUp Automatizaciones, puede activar alertas, distribuir tareas y actualizar estados automáticamente. Y ClickUp Brain ayuda a priorizar incidencias, generar resúmenes y sugerir los siguientes pasos.
Los agentes de ClickUp AI actúan como asistentes inteligentes dentro de su entorno de trabajo, mientras que los paneles de ClickUp proporcionan una vista en tiempo real de sus escalamientos.
¡Regístrese hoy mismo en ClickUp gratis!
Preguntas frecuentes (FAQ)
Una ruta de escalado de incidencias es una secuencia predefinida de pasos que determina cómo se envían los problemas al equipo o persona adecuados en función de la gravedad, el impacto y el momento. Garantiza que las incidencias se aborden de manera eficiente y que la responsabilidad sea clara. TEXTO
Utilice la automatización para incidencias bien definidas y de alta prioridad con criterios claros (por ejemplo, interrupciones del servicio, violaciones de seguridad). Reserve la escalada manual para situaciones ambiguas o críticas que requieran el criterio humano o contexto adicional.
Plataformas como ClickUp, PagerDuty, Jira Service Management y ServiceNow permiten el enrutamiento, las notificaciones y las actualizaciones automatizadas. Ayudan a los equipos a reducir los retrasos y a mantener flujos de trabajo estructurados para las incidencias.
Establezca umbrales claros para las alertas, priorice según la gravedad y utilice notificaciones inteligentes. Limite las notificaciones repetidas a incidencias críticas y aproveche los paneles de control o las herramientas de IA para resumir las actualizaciones en lugar de enviar cada pequeño cambio.
Revise periódicamente las políticas de escalado, al menos una vez al trimestre o después de incidencias importantes. De este modo, se garantiza que los criterios, las responsabilidades y las reglas de automatización reflejen los flujos de trabajo, las estructuras de los equipos y las prioridades empresariales actuales.