

Três provedores, doze variações de prompts e nenhuma maneira de reproduzir seus melhores resultados — é assim que a maioria dos experimentos com múltiplos LLM acaba sem um sistema de acompanhamento.
Esses modelos do ClickUp oferecem à sua equipe uma estrutura compartilhada e consistente para planejar, executar e comparar experimentos com múltiplos modelos de linguagem (LLM). E a melhor parte? Eles abrangem tudo, desde o registro de hipóteses e a avaliação de qualidade até a aprovação das partes interessadas e os relatórios finais de pesquisa.
Vamos começar! 👀
Visão geral dos modelos de acompanhamento de experimentos com múltiplos LLM
Aqui está uma rápida visão geral dos modelos de acompanhamento de experimentos com múltiplos LLM abordados neste guia:
| Modelo | Link para download | Ideal para | Principais recursos |
|---|---|---|---|
| Modelo de plano e resultados de experimento do ClickUp | Obtenha o modelo gratuitamente | Planejamento e documentação de experimentos com LLM de ponta a ponta | Registro de hipóteses, campos de configuração de testes, resumos de decisões |
| Modelo de quadro branco para experimentos de crescimento do ClickUp | Obtenha o modelo gratuitamente | Gerenciando e priorizando ideias de experimentos | Backlog visual, sistema de votação, conversão de ideia em tarefa |
| Modelo de planilha do ClickUp | Obtenha o modelo gratuitamente | Registro de execuções de experimentos repetíveis em escala | Colunas estruturadas, filtragem e classificação, gatilhos de automação |
| Modelo de comparação de software do ClickUp | Obtenha o modelo gratuitamente | Comparando provedores de LLM com base em critérios | Comparações lado a lado, visuais do painel, pontuação de avaliação |
| Modelo de painel de gerenciamento de projetos do ClickUp | Obtenha o modelo gratuitamente | Monitoramento do desempenho de experimentos entre equipes | Acompanhamento de status, comparação de provedores, visibilidade da carga de trabalho |
| Modelo de Relatório Semanal de Status do ClickUp | Obtenha o modelo gratuitamente | Relatórios sobre o andamento dos experimentos e os obstáculos | Resumos semanais, atualizações geradas por IA, acompanhamento de bloqueadores |
| Modelo de relatório de atividades do ClickUp | Obtenha o modelo gratuitamente | Manutenção do histórico de experimentos e trilhas de auditoria | Registros de atividades, registros com data e hora, acompanhamento do progresso |
| Modelo de lista de verificação de controle de qualidade do ClickUp | Obtenha o modelo gratuitamente | Validação da configuração do experimento antes da execução | Verificações de parâmetros, avaliação de prontidão, fluxos de trabalho controlados |
| Modelo de aprovação de UAT do ClickUp | Obtenha o modelo gratuitamente | Documentação das decisões finais sobre os modelos e aprovações | Acompanhamento de aprovações, trilha de auditoria, aprovações das partes interessadas |
| Modelo de relatório de pesquisa do ClickUp | Obtenha o modelo gratuitamente | Apresentação dos resultados dos experimentos e recomendações | Relatórios estruturados, resumos assistidos por IA, edição colaborativa |
📚 Leia também: Modelos PromptOps do ClickUp para fluxos de trabalho de IA
O que é o acompanhamento de experimentos com múltiplos LLM?
O acompanhamento de experimentos com múltiplos LLM é a prática de registrar, comparar e analisar sistematicamente os resultados de dois ou mais modelos de linguagem de grande porte em relação aos mesmos prompts ou critérios de avaliação. Qualquer equipe que esteja decidindo qual LLM implantar — ou combinando modelos para diferentes tarefas — precisa de uma maneira repetível de capturar o que aconteceu, o que funcionou e por quê.
Sem uma estrutura, as equipes acabam com notas fragmentadas espalhadas por várias ferramentas. Ninguém consegue dizer qual versão do modelo foi testada com qual prompt, e compartilhar as descobertas com pessoas que não estavam presentes se transforma em adivinhação.
Essa proliferação descontrolada de IA — a disseminação não planejada de ferramentas, modelos e plataformas de IA sem supervisão ou estratégia — afeta todas as equipes que lidam com várias ferramentas de IA sem um espaço de trabalho integrado.
Veja o que o acompanhamento de experimentos com múltiplos LLM analisa:
| Componente | Exemplos |
|---|---|
| Modelos | ClickUp Brain, Claude 3.7, GPT-4o, Gemini 1.5 |
| Solicitações | Solicitações do sistema, solicitações do usuário, exemplos com poucos exemplos |
| Parâmetros | Temperatura, tokens máximos, top-p |
| Resultados | Respostas brutas, latência, uso de tokens |
| Métricas de avaliação | Precisão, pontuações BLEU/ROUGE, avaliações humanas, custo |
| Metadados | Carimbos de data/hora, versões de conjuntos de dados, informações sobre o ambiente |
📝 Observação rápida: O acompanhamento de experimentos e a observabilidade de ML não são a mesma coisa. O acompanhamento é a camada de manutenção de registros estruturados. A observabilidade lida com o monitoramento e os alertas em tempo real. Os modelos cobrem a parte do acompanhamento sem exigir configuração de engenharia.
O que procurar em modelos de acompanhamento de experimentos com múltiplos LLM
Antes de escolher um modelo, você precisa de critérios de avaliação claros. ✨
- Campos estruturados para experimentos: campos dedicados para nome do modelo, versão do prompt, parâmetros e saída — não é um documento em branco que você precisa criar sozinho
- Layout de comparação lado a lado: Veja os resultados do Modelo A e do Modelo B na mesma visualização, sem precisar alternar entre abas
- Acompanhamento de métricas de avaliação: colunas integradas para pontuação de precisão, relevância, latência, custo por token e taxa de alucinação
- Status e fluxo de trabalho de decisão: Marque os experimentos como planejados, em andamento, concluídos ou rejeitados para que todos possam ver em que pé estão as coisas
- Recursos de colaboração: comentários, menções e responsáveis mantêm o pesquisador e o tomador de decisão em sincronia
- Painel ou camada de relatórios: Reúna resultados individuais em uma visualização resumida para análises da liderança
- Flexibilidade para diferentes tipos de experimentos: Lide tanto com comparações entre dois modelos quanto com variações de prompts em um único modelo sem precisar refazer o design
🧠 Curiosidade: O Transformer foi apresentado com um dos títulos de artigo mais assertivos de todos os tempos: “Attention Is All You Need”. O artigo propôs um modelo baseado exclusivamente em mecanismos de atenção, descartando totalmente a recorrência e as convoluções — e essa arquitetura passou a servir de base para os LLMs modernos.
📚 Leia também: Modelos gratuitos de fluxo de trabalho para prompts de IA
10 modelos do ClickUp para acompanhamento de experimentos com múltiplos LLM
Todos os modelos listados aqui estão disponíveis na Biblioteca de Modelos do ClickUp. Você pode personalizar cada um deles com campos personalizados, status, visualizações, automações e muito mais.
1. Modelo de plano e resultados de experimento do ClickUp
Experimentos com múltiplos LLM são fáceis de executar, mas muito mais difíceis de interpretar posteriormente. Um resultado pode parecer promissor no momento, mas perde valor rapidamente quando a equipe não consegue rastrear o que foi testado, quais configurações foram usadas ou como a decisão final foi tomada.
O modelo de plano e resultados de experimento do ClickUp oferece às equipes um único local para definir o experimento antes de executá-lo e registrar os dados após sua conclusão. Isso facilita a comparação de modelos, prompts e configurações entre experimentos sem perder o raciocínio por trás da decisão final.
✨ Por que você vai adorar este modelo:
- Campo de hipótese: Indique sua previsão antes de executar qualquer teste para evitar o viés de confirmação
- Seção de configuração de teste: Registre o provedor, a versão do modelo e a configuração de temperatura com os campos personalizados do ClickUp
- Registro de decisões: Faça com que o ClickUp Brain gere automaticamente resumos de experimentos a partir dos dados dos resultados
✅ Ideal para: gerentes de produto de IA que realizam avaliações estruturadas de LLM.
💡 Dica profissional: Experimentos com múltiplos LLM podem gerar uma enorme quantidade de resultados rapidamente. O ClickUp Brain ajuda você a dar sentido a tudo isso, resumindo as descobertas, padronizando as conclusões e transformando os resultados em tarefas rastreáveis em um único espaço de trabalho convergente. Dessa forma, o experimento não termina como uma pilha de respostas. Ele termina como algo que sua equipe pode analisar, colocar em prática e usar como base para o futuro.
2. Modelo de quadro branco para experimentos de crescimento do ClickUp
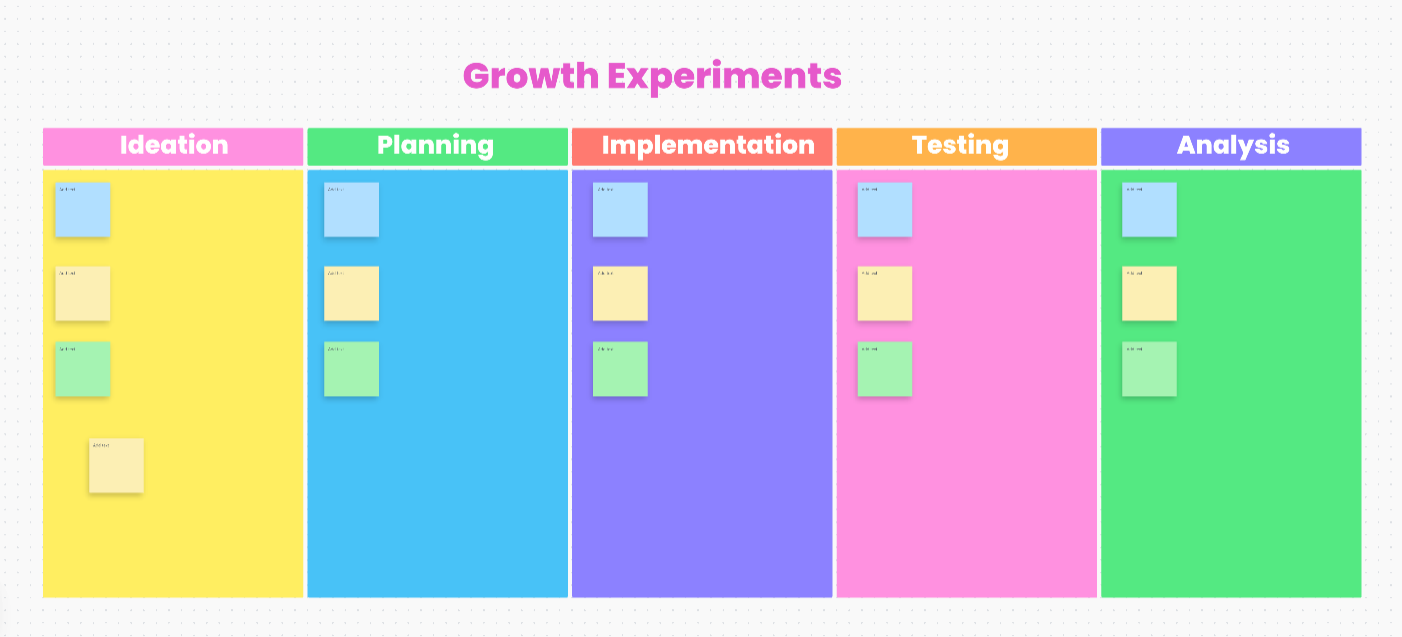
Quando sua equipe tem mais ideias de experimentos do que pode realmente executar, o desafio passa de testar para escolher. Uma comparação de prompts leva a mais três, diferentes provedores abrem novas variáveis e, em pouco tempo, o backlog começa a crescer mais rápido do que a equipe consegue avaliar.
O modelo de quadro branco para experimentos de crescimento do ClickUp oferece um espaço visual para organizar essas ideias iniciais. Construído em uma tela visual, ele ajuda as equipes a mapear ideias, identificar as comparações mais sólidas e colocar as melhores em prática.
✨ Por que você vai adorar este modelo:
- Backlog visual de experimentos: Agrupe testes por caso de uso ou provedor em uma tela de formato livre com os Quadros Brancos do ClickUp
- Votação de priorização: Deixe os membros da equipe votarem em quais comparações são mais importantes
- Brainstorming de IA: Use o ClickUp Brain para gerar ideias de experimentos ou reformular hipóteses
✅ Ideal para: gerentes de produto e líderes de pesquisa que gerenciam um grande volume de experimentos em espera.
📚 Leia também: Modelos personalizáveis gratuitos para experimentos de crescimento para expandir seus negócios
3. Modelo de planilha do ClickUp
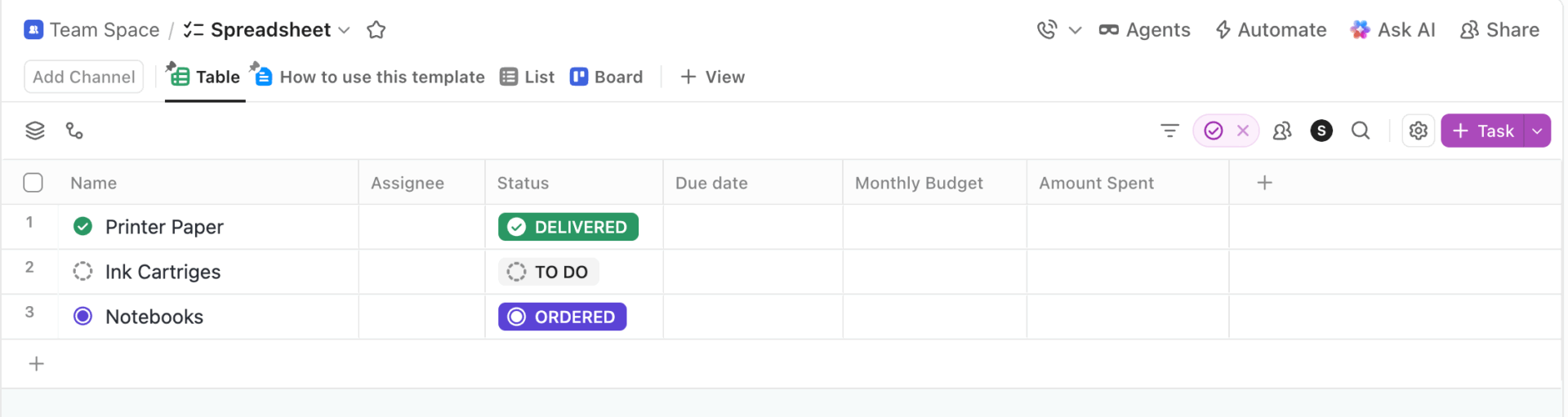
Se sua equipe tem registrado experimentos no Google Sheets ou no Excel, o modelo de planilha do ClickUp parecerá extremamente semelhante. Ele é baseado na visualização de tabela do ClickUp.
Cada linha representa uma execução de experimento (modelo + prompt + parâmetros), e as colunas registram resultados, pontuações, latência, custo e notas — mas com colaboração e automação integradas.
✨ Por que você vai adorar este modelo:
- Colunas editáveis e filtráveis: Use os campos personalizados do ClickUp para menus suspensos (provedor do modelo), números (latência) e classificações (pontuação de qualidade)
- Classificação e filtragem em massa: Classifique centenas de execuções de experimentos por qualquer campo sem problemas de desempenho de planilhas
- Notificações automatizadas: Acione alertas quando o status de um experimento mudar para “Concluído” usando as automações do ClickUp
✅ Ideal para: equipes de operações de IA que gerenciam registros de experimentos repetíveis.
🧠 Curiosidade: As redes neurais são mais antigas do que o termo “IA”. Em 1943, Warren McCulloch e Walter Pitts publicaram o primeiro modelo matemático de um neurônio artificial
4. Modelo de comparação de software do ClickUp
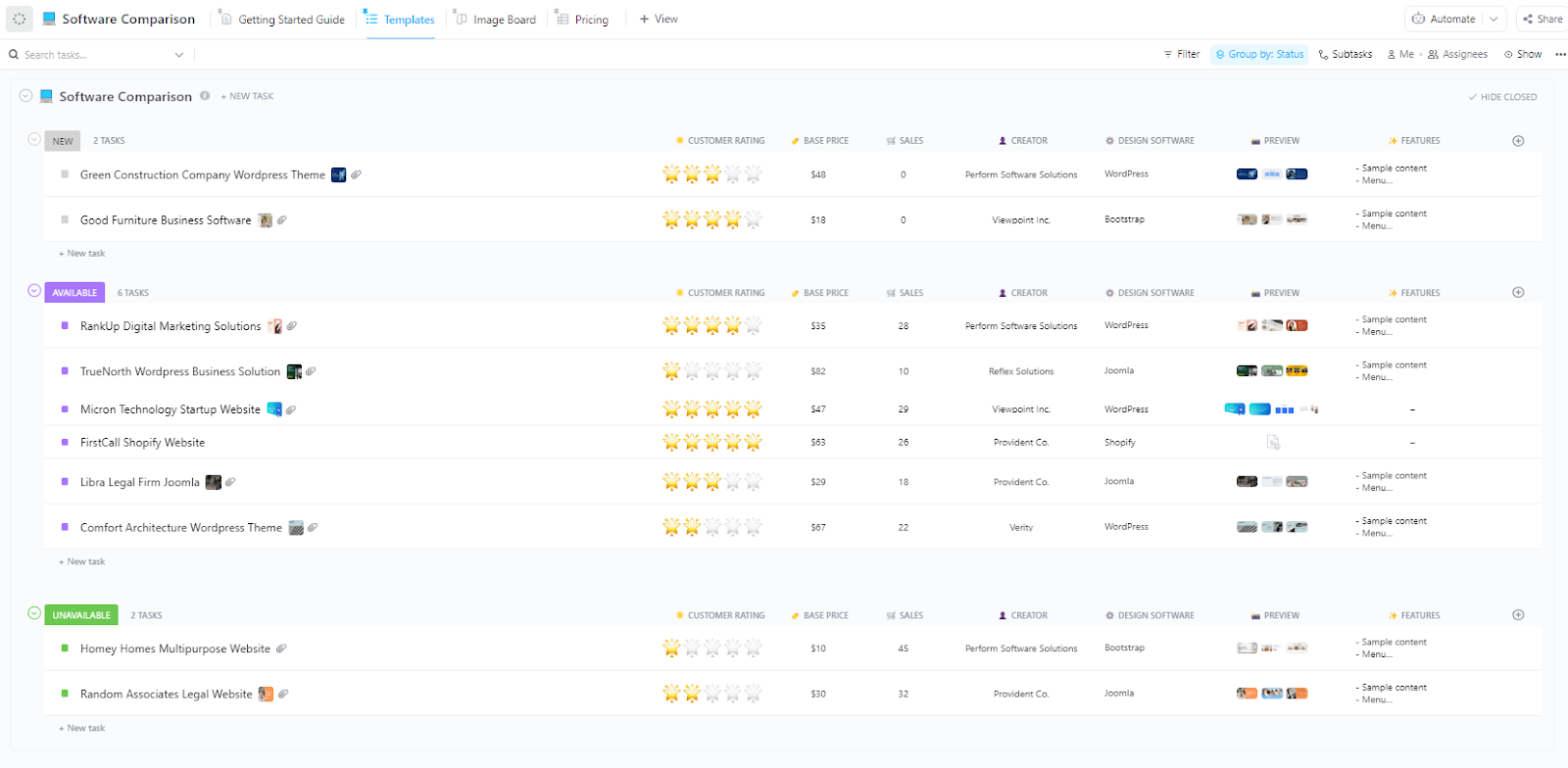
Originalmente projetado para avaliar ferramentas com base em critérios compartilhados, o modelo de comparação de software do ClickUp funciona perfeitamente para comparar fornecedores de LLM lado a lado.
Em vez de fornecedores, você está comparando OpenAI, Anthropic, Google e Mistral em termos de qualidade de saída, velocidade, custo, tamanho da janela de contexto e recursos de segurança.
Quando vários modelos parecem promissores por motivos diferentes, este modelo ajuda você a compará-los com base nos mesmos critérios de decisão e a tomar a decisão final com mais confiança.
✨ Por que você vai adorar este modelo:
- Analise as vantagens e desvantagens dos provedores sob diferentes ângulos: use as Visualizações do ClickUp para alternar entre formatos de comparação
- Gráficos de comparação visual: transforme dados em gráficos ou cartões de resumo para apresentações às partes interessadas usando os painéis do ClickUp
- Síntese assistida por IA: Peça ao ClickUp Brain para extrair o contexto de documentos de experimentos existentes e preencher notas de comparação
✅ Ideal para: Líderes de produto e engenharia que analisam as vantagens e desvantagens dos modelos com partes interessadas em segurança ou compras.
📮 ClickUp Insight: 45% dos participantes da nossa pesquisa afirmam que mantêm abas de pesquisa relacionadas ao trabalho abertas por semanas. Para outros 23%, essas abas valiosas incluem conversas de chat com IA repletas de contexto.
Basicamente, a grande maioria está terceirizando a memória e o contexto para abas de navegador frágeis. Repita conosco: abas não são bases de conhecimento. 👀
O ClickUp Brain MAX muda o jogo aqui.
Este superaplicativo de IA permite que você pesquise em seu espaço de trabalho, interaja com vários modelos de IA e até mesmo use comandos de voz para recuperar o contexto a partir de uma única interface. Como o MAX fica instalado no seu PC, ele não ocupa espaço nas abas e pode salvar conversas até que você as exclua!
📮 ClickUp Insight: 45% dos participantes da nossa pesquisa afirmam que mantêm abas de pesquisa relacionadas ao trabalho abertas por semanas. Para outros 23%, essas abas valiosas incluem conversas de chat com IA repletas de contexto.
Basicamente, a grande maioria está terceirizando a memória e o contexto para abas de navegador frágeis. Repita conosco: abas não são bases de conhecimento. 👀
O ClickUp Brain MAX muda o jogo aqui.
Este superaplicativo de IA permite que você pesquise em seu espaço de trabalho, interaja com vários modelos de IA e até mesmo use comandos de voz para recuperar o contexto a partir de uma única interface. Como o MAX fica instalado no seu PC, ele não ocupa espaço nas abas e pode salvar conversas até que você as exclua!
5. Modelo de painel de gerenciamento de projetos do ClickUp

Quando você está gerenciando mais de 50 execuções de experimentos em quatro provedores, as visualizações de tarefas individuais não são suficientes. O modelo de painel de gerenciamento de projetos do ClickUp agrega dados de suas tarefas de experimento em widgets e visualiza tudo em uma única tela.
Isso torna a ferramenta incrivelmente útil quando seu programa de experimentos começa a se expandir para além de alguns testes pontuais. Em vez de analisar cada execução isoladamente, você pode monitorar o desempenho de todo o pipeline de testes e identificar onde o ritmo está diminuindo.
✨ Por que você vai adorar este modelo:
- Distribuição do status dos experimentos: Veja rapidamente quantos experimentos estão planejados, em andamento ou concluídos
- Resultados por fornecedor de modelos: Compare qual modelo está se destacando em todas as experiências concluídas
- Visibilidade da carga de trabalho: monitore quem na sua equipe está sobrecarregado com tarefas de experimentos usando a Visualização de Carga de Trabalho do ClickUp
✅ Ideal para: Líderes de IA aplicada que gerenciam o rendimento de experimentos entre pesquisadores, engenheiros de prompts e revisores.
🔮 Bônus: A visibilidade é apenas uma parte da ampliação de experimentos com múltiplos LLM. Os Super Agentes do ClickUp oferecem à sua equipe colegas de trabalho de IA com os quais é possível enviar mensagens diretamente, atribuir tarefas e configurar com seu próprio conhecimento e memória.
Saiba mais aqui:
6. Modelo de relatório de status semanal do ClickUp
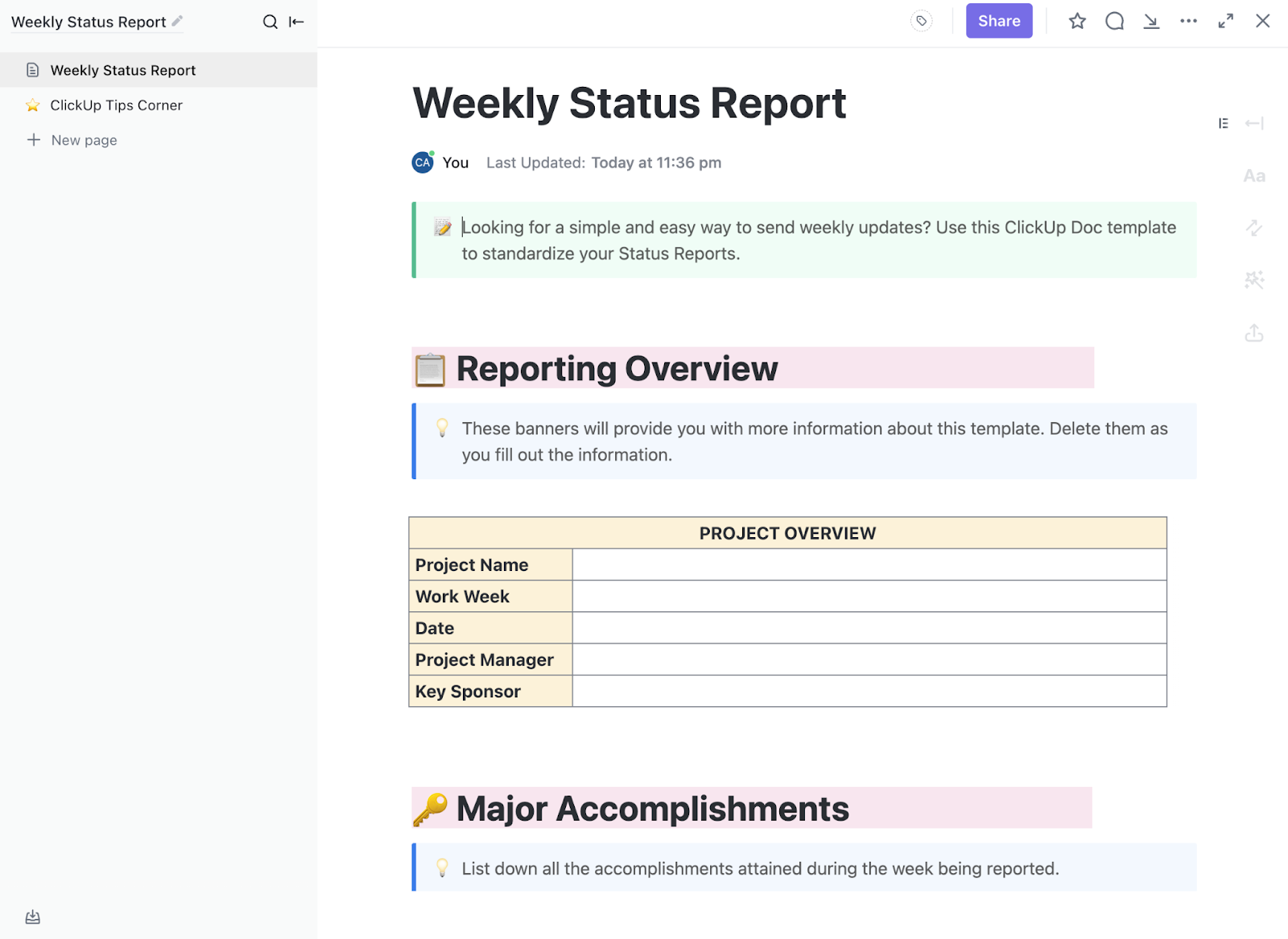
O modelo de relatório de status semanal do ClickUp é útil para acompanhar testes concluídos e resultados preliminares. Além disso, ele ajuda a identificar possíveis obstáculos, como atrasos no acesso à API, conjuntos de dados ausentes ou espera pelo feedback dos revisores.
Seções como visão geral do projeto, principais realizações e atualizações semanais facilitam a apresentação do progresso sem a necessidade de refazer o relatório a cada vez.
Funciona incrivelmente bem quando os experimentos avançam rapidamente e a liderança precisa de uma visão clara sobre o que mudou nesta semana.
✨ Por que você vai adorar este modelo:
- Tarefas de relatório geradas automaticamente: Crie uma nova tarefa de relatório toda semana com o modelo pré-aplicado usando as automações do ClickUp
- Resumos elaborados por IA: Deixe o ClickUp Brain extrair dados de tarefas concluídas e elaborar o resumo de status em poucos minutos
- Acompanhamento de bloqueios: sinalize dependências para que a liderança saiba o que precisa ser desbloqueado
✅ Ideal para: equipes de avaliação que realizam ciclos de teste recorrentes em prompts, provedores e casos de uso.
💟 Bônus: Trabalhe de forma mais inteligente — deixe que um Super Agente assuma a tarefa de preparar relatórios diários de status para suas experiências! Aqui está um vídeo mostrando como fazer isso.
7. Modelo de relatório de atividades do ClickUp
Uma alteração no modelo entra em vigor. Duas semanas depois, alguém pergunta por que o prompt foi revisado, quem aprovou a nova versão e se a equipe registrou o resultado em algum lugar. Se esse histórico estiver espalhado por comentários, tarefas e notas dispersas, a resposta demora mais do que deveria.
O modelo de relatório de atividades do ClickUp oferece às equipes um registro claro do que ocorreu ao longo de um ciclo de experimento. Você pode usá-lo para registrar tarefas concluídas e pendentes, próximas etapas, pequenas conquistas e problemas de processo em um único lugar. Para equipes que trabalham em ambientes regulamentados ou em qualquer fluxo de trabalho que exija rastreabilidade, esse registro é fundamental.
✨ Por que você vai adorar este modelo:
- Registro de auditoria preenchido automaticamente: Registre automaticamente alterações nas tarefas, adições de comentários e atualizações de status com o recurso integrado de acompanhamento de atividades do ClickUp
- Mantenha o histórico de relatórios legível: use o ClickUp Docs para registrar o trabalho concluído, itens pendentes, próximas etapas e notas do processo em um único registro contínuo
- Registros com data e hora: Garanta que cada entrada tenha um registro de data e hora para total rastreabilidade
✅ Ideal para: equipes de governança de IA que analisam o histórico de prompts, modelos e aprovações ao longo dos ciclos de experimentos.
📚 Leia também: Os melhores LLMs para resumo de texto
💡 Dica profissional: Realizar experimentos com múltiplos LLM geralmente significa ter que lidar com muitas abas ao mesmo tempo. O ClickUp Brain MAX reúne o ChatGPT, o Claude e o Gemini em um único aplicativo para desktop, para que você possa alternar entre modelos sem precisar dividir suas anotações, perguntas e tarefas de acompanhamento entre diferentes ferramentas.
8. Modelo de lista de verificação de controle de qualidade do ClickUp
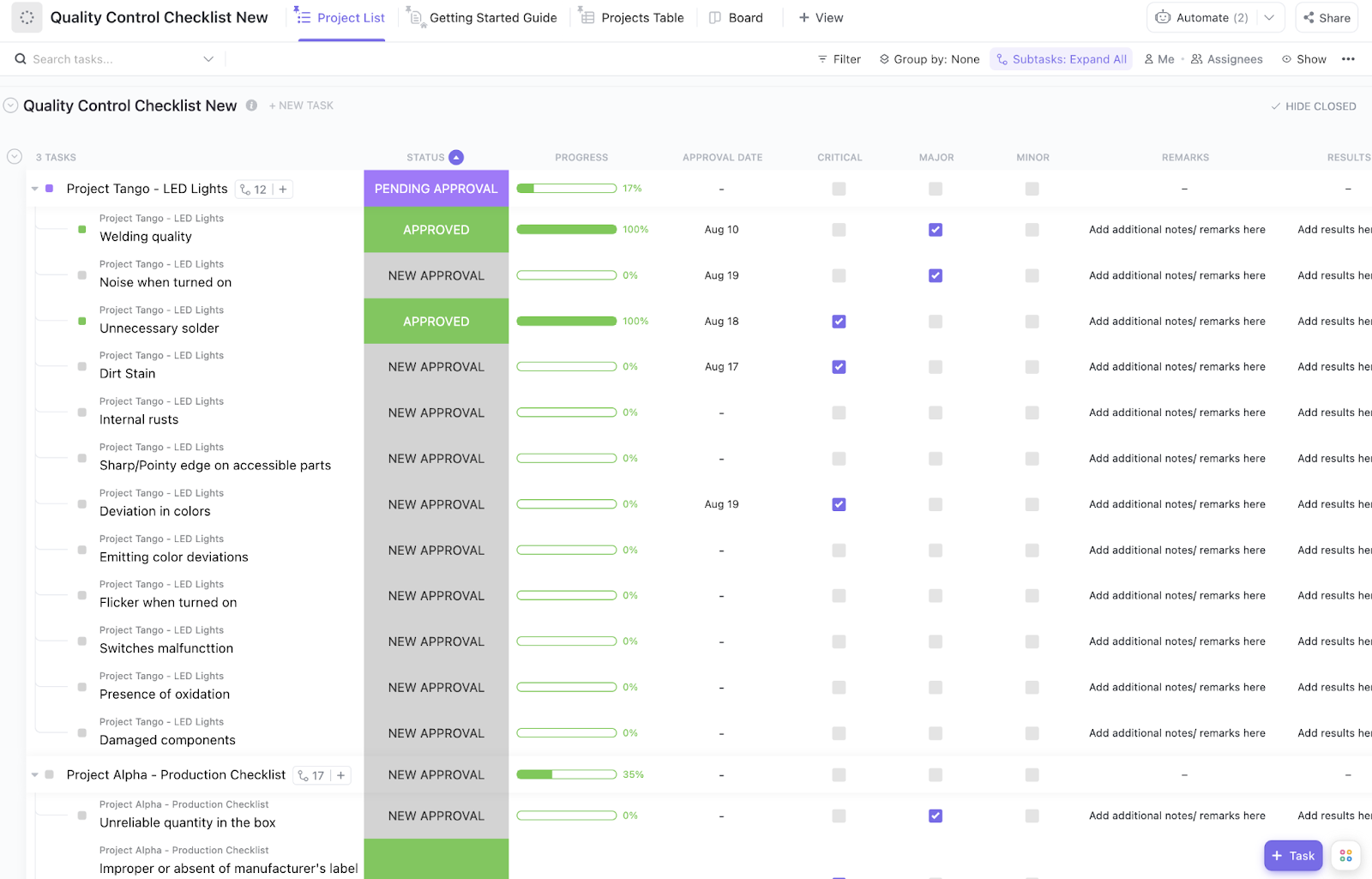
Uma configuração incorreta pode arruinar uma comparação de modelos bem feita. Uma configuração de temperatura esquecida, um prompt alterado ou uma rubrica de pontuação definida tarde demais podem distorcer o resultado antes que você perceba. Quando isso acontece, o experimento parece completo no papel, mas é difícil confiar nas conclusões.
O modelo de lista de verificação de controle de qualidade do ClickUp oferece às equipes uma maneira estruturada de revisar a qualidade da configuração antes que um experimento seja executado. Na visualização de lista do ClickUp, cada experimento pode ter sua própria lista de verificação do ClickUp para garantir a consistência dos prompts, a revisão de parâmetros, a prontidão para pontuação e a aprovação final.
✨ Por que você vai adorar este modelo:
- Verificações de consistência de parâmetros: Verifique se os prompts, a temperatura, o número máximo de tokens e outros parâmetros estão alinhados em todos os modelos que estão sendo testados
- Confirmação da rubrica de avaliação: Certifique-se de que os critérios de pontuação foram definidos antes da análise dos resultados
- Controle de status: impeça que um experimento passe para o status “Concluído” até que todos os itens da lista de verificação sejam marcados usando as automações do ClickUp
✅ Ideal para: líderes de controle de qualidade de IA que precisam de uma verificação pré-lançamento repetível para comparações de modelos.
📚 Leia também: Como mitigar o viés da IA?
9. Modelo de aprovação de UAT do ClickUp
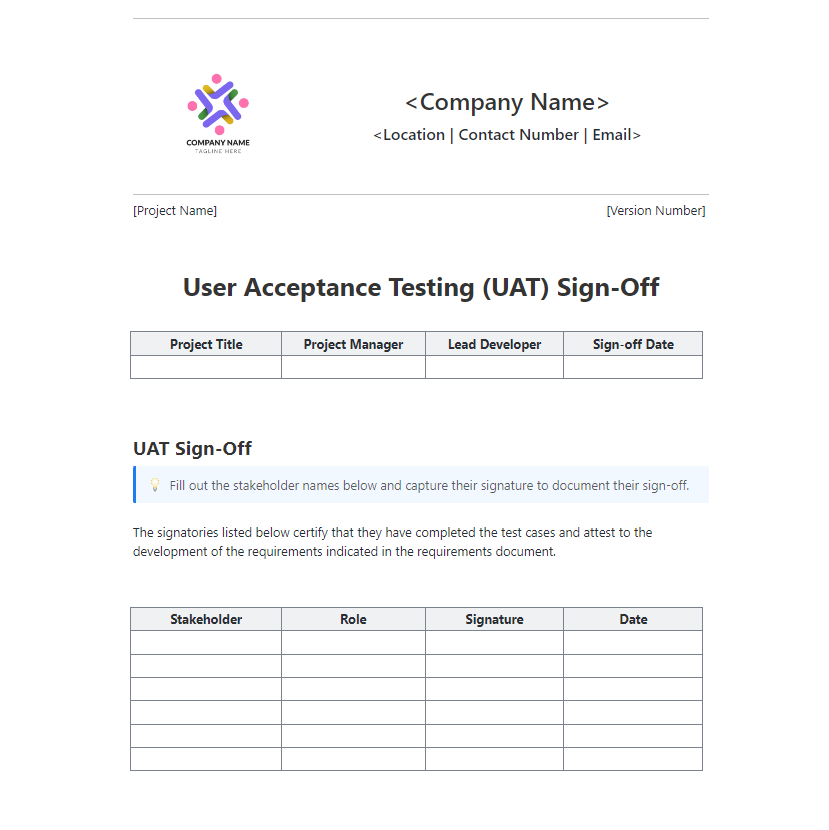
Um modelo pode vencer o experimento e ainda assim não estar pronto para produção. Alguém ainda precisa confirmar a recomendação, analisar os riscos conhecidos e aprovar a implementação.
O modelo de aprovação de UAT do ClickUp oferece às equipes uma maneira formal de preencher essa lacuna. Use-o para documentar o resumo do experimento, a configuração recomendada do modelo, os principais resultados, as limitações conhecidas e as aprovações finais em um único lugar.
Isso funciona bem para programas com múltiplos LLM em que a decisão final requer mais do que um simples “sim” verbal.
✨ Por que você vai adorar este modelo:
- Acompanhamento do status de aprovação: Registre a decisão de cada parte interessada (aprovado, rejeitado, pendente) por meio dos campos personalizados do ClickUp
- Notificações de aprovação automatizadas: acione alertas quando for necessária uma aprovação usando as automações do ClickUp
- Adicione contexto antes da decisão final: use o ClickUp Clips para gravar uma breve demonstração dos resultados, casos extremos ou limites do modelo vencedor, para que os revisores possam avaliar a decisão mais rapidamente
✅ Ideal para: Líderes de produto, engenharia e conformidade que precisam de um registro documentado de aprovações para mudanças de IA de alto impacto.
10. Modelo de relatório de pesquisa do ClickUp
Você pode concluir uma rodada sólida de experimentos com LLM e ainda assim ter dificuldade para explicar o que a equipe aprendeu. Os dados podem estar espalhados por tarefas, scorecards, painéis e comentários. As recomendações podem estar em outro lugar. Isso atrasa a revisão e dificulta a reutilização do trabalho posteriormente.
O modelo de relatório de pesquisa do ClickUp permite transformar o trabalho experimental em um relatório claro. Desenvolvido no ClickUp Docs, ele inclui seções para o resumo executivo, metodologia, resultados, referências e muito mais.
Isso funciona bem para avaliações internas, nas quais as equipes precisam documentar por que um modelo foi testado, como foi avaliado e quais foram os resultados.
✨ Por que você vai adorar este modelo:
- Mantenha as entradas do relatório vinculadas à execução: use as tarefas do ClickUp para conectar execuções de experimentos, responsáveis, status e dados de resultados ao relatório final
- Redação assistida por IA: Peça ao ClickUp Brain para extrair dados de tarefas de experimentos concluídas e resumir os resultados, reduzindo significativamente o tempo de redação
- Edição colaborativa: receba feedback por meio de comentários e menções diretamente dentro do documento
✅ Ideal para: pesquisadores de IA ou líderes de produto que apresentam metodologias, descobertas e recomendações de implementação à liderança.
Comece a acompanhar suas experiências com múltiplos LLM
À medida que sua equipe passa da avaliação de um ou dois LLMs para o gerenciamento de estratégias multimodelo em diversos casos de uso, o acompanhamento estruturado torna-se praticamente indispensável.
Você já viu como cada modelo lida com uma parte diferente do ciclo de vida do experimento. Comece com o modelo “Plano e Resultados do Experimento” para sua próxima comparação de modelos e, à medida que for expandindo, incorpore o modelo “Painel de Controle”.
A verdadeira barreira para um acompanhamento eficaz de experimentos é a falta de uma estrutura compartilhada para registrar o que você testou, descobriu e, por fim, decidiu. Quando esses dados ficam espalhados por cadernos, conversas de chat e planilhas pessoais, sua equipe não consegue aprender com testes anteriores e tomar decisões confiantes sobre os modelos.
É aí que o espaço de trabalho de IA convergente do ClickUp entra em ação. Ao manter suas tarefas de experimento, dados e conversas da equipe em um único lugar, todos conectados por IA, o ClickUp oferece à sua equipe a estrutura unificada de que ela precisa.
Comece gratuitamente com o ClickUp e configure hoje mesmo seu primeiro modelo de acompanhamento de experimentos. ✅
Perguntas frequentes sobre experimentos com múltiplos LLM
Em que os modelos de acompanhamento de experimentos com múltiplos LLM diferem de ferramentas de observabilidade de ML, como Langfuse ou Arize?
Os modelos oferecem estruturas organizadas para documentar experimentos, garantindo que todos os detalhes importantes sejam registrados para análise futura. Enquanto isso, as ferramentas de observabilidade permitem o monitoramento em tempo real do desempenho do sistema, com alertas automatizados para anomalias e dados de telemetria abrangentes, adequados para ambientes de produção. Muitas equipes utilizam ambas as ferramentas em conjunto, combinando a abordagem organizada dos modelos com os insights imediatos das ferramentas de observabilidade.
Posso acompanhar experimentos da OpenAI, da Anthropic e de provedores de LLM de código aberto no mesmo modelo do ClickUp?
Sim, claro! No ClickUp, você tem Campos Personalizados que permitem definir metadados específicos do provedor para cada entrada de experimento. Isso permite que você registre e compare resultados de qualquer provedor sem precisar trocar de ferramenta. E você pode usar painéis para obter uma visão melhor e de alto nível de cada experimento.
Quais métricas devo registrar ao comparar vários LLMs lado a lado no ClickUp?
Ao comparar vários LLMs no ClickUp, as principais métricas a serem registradas abrangem quatro áreas: desempenho (latência, tokens por segundo, uso da janela de contexto), qualidade (precisão, taxa de alucinação, pontuação de relevância e consistência no cumprimento de instruções), custo (contagem de tokens de entrada/saída e custo por solicitação) e confiabilidade (taxa de erro, contagem de tentativas e tempos limite). Para avaliações específicas de tarefas, inclua também pontuações BLEU/ROUGE para resumos, Pass@k para geração de código ou precisão de chamada de ferramentas para tarefas de agência.
Preciso ter conhecimentos de engenharia para configurar o acompanhamento de experimentos com múltiplos LLM no ClickUp?
Não — os modelos no ClickUp já vêm pré-estruturados, para que você possa começar a registrar experimentos imediatamente, e o ClickUp Brain pode ajudá-lo a personalizar campos e configurar automações usando linguagem natural.