

Os Modelos de Linguagem Grande (LLMs) abriram novas e empolgantes possibilidades para aplicativos de software. Eles permitem sistemas mais inteligentes e dinâmicos do que nunca.
Especialistas prevêem que, até 2025, os aplicativos baseados nesses modelos poderão automatizar quase metade de todo o trabalho digital.
No entanto, à medida que desbloqueamos esses recursos, surge um desafio: como medir de forma confiável a qualidade de seus resultados em grande escala? Um pequeno ajuste nas configurações e, de repente, você se depara com resultados visivelmente diferentes. Essa variabilidade pode tornar difícil avaliar seu desempenho, o que é crucial ao preparar um modelo para uso no mundo real.
Este artigo compartilhará insights sobre as melhores práticas de avaliação do sistema LLM, desde os testes pré-implantação até a produção. Então, vamos começar!
O que é uma avaliação LLM?
As métricas de avaliação do LLM são uma forma de verificar se suas instruções, configurações do modelo ou fluxo de trabalho estão atingindo os objetivos que você definiu. Essas métricas fornecem insights sobre o desempenho do seu Large Language Model e se ele está realmente pronto para uso no mundo real.
Hoje, algumas das métricas mais comuns medem a recuperação de contexto em tarefas de geração aumentada por recuperação (RAG), correspondências exatas para classificações, validação JSON para saídas estruturadas e similaridade semântica para tarefas mais criativas.
Cada uma dessas métricas garante de forma exclusiva que o LLM atenda aos padrões do seu caso de uso específico.
Por que você precisa avaliar um LLM?
Os modelos de linguagem grandes (LLMs) estão sendo usados atualmente em uma ampla gama de aplicações. É essencial avaliar o desempenho dos modelos para garantir que eles atendam aos padrões esperados e cumpram efetivamente seus objetivos.
Pense da seguinte maneira: os LLMs estão impulsionando tudo, desde chatbots de suporte ao cliente até ferramentas criativas, e à medida que se tornam mais avançados, eles estão aparecendo em mais lugares.
Isso significa que precisamos de maneiras melhores de monitorá-los e avaliá-los — os métodos tradicionais simplesmente não conseguem acompanhar todas as tarefas que esses modelos estão realizando.
Boas métricas de avaliação são como uma verificação de qualidade para LLMs. Elas mostram se o modelo é confiável, preciso e eficiente o suficiente para uso no mundo real. Sem essas verificações, erros podem passar despercebidos, levando a experiências frustrantes ou até mesmo enganosas para o usuário.
Quando você tem métricas de avaliação sólidas, é mais fácil identificar problemas, melhorar o modelo e garantir que ele esteja pronto para atender às necessidades específicas dos usuários. Dessa forma, você sabe que a plataforma de IA com a qual está trabalhando está dentro do padrão e pode entregar os resultados de que você precisa.
📖 Leia mais: LLM vs. IA generativa: um guia detalhado
Tipos de avaliações LLM
As avaliações oferecem uma perspectiva única para examinar as capacidades do modelo. Cada tipo aborda vários aspectos de qualidade, ajudando a construir um modelo de implantação confiável, seguro e eficiente.
Aqui estão os diferentes tipos de métodos de avaliação LLM:
- A avaliação intrínseca concentra-se no desempenho interno do modelo em tarefas linguísticas ou de compreensão específicas, sem envolver aplicações do mundo real. Normalmente, ela é realizada durante a fase de desenvolvimento do modelo para compreender as capacidades essenciais.
- A avaliação extrínseca avalia o desempenho do modelo em aplicações do mundo real. Esse tipo de avaliação examina o quanto o modelo atinge objetivos específicos dentro de um contexto.
- A avaliação de robustez testa a estabilidade e a confiabilidade do modelo em diversos cenários, incluindo entradas inesperadas e condições adversas. Ela identifica possíveis pontos fracos, garantindo que o modelo se comporte de maneira previsível.
- Testes de eficiência e latência examinam o uso de recursos, a velocidade e a latência do modelo. Eles garantem que o modelo possa executar tarefas rapidamente e com um custo computacional razoável, o que é essencial para a escalabilidade.
- A avaliação ética e de segurança garante que o modelo esteja alinhado com os padrões éticos e as diretrizes de segurança, o que é vital em aplicações sensíveis.
Avaliações do modelo LLM vs. avaliações do sistema LLM
A avaliação de modelos de linguagem grandes (LLMs) envolve duas abordagens principais: avaliações de modelos e avaliações de sistemas. Cada uma delas se concentra em diferentes aspectos do desempenho do LLM, e conhecer a diferença é essencial para maximizar o potencial desses modelos.
🧠 As avaliações de modelos analisam as habilidades gerais do LLM. Esse tipo de avaliação testa a capacidade do modelo de compreender, gerar e trabalhar com a linguagem de forma precisa em vários contextos. É como ver o quão bem o modelo consegue lidar com diferentes tarefas, quase como um teste de inteligência geral.
Por exemplo, as avaliações do modelo podem perguntar: “Quão versátil é este modelo?”
🎯 As avaliações do sistema LLM medem o desempenho do LLM em uma configuração ou finalidade específica, como em um chatbot de atendimento ao cliente. Aqui, o foco não é tanto as habilidades gerais do modelo, mas sim como ele executa tarefas específicas para melhorar a experiência do usuário.
As avaliações do sistema, no entanto, concentram-se em questões como: “Quão bem o modelo lida com essa tarefa específica para os usuários?”
As avaliações de modelos ajudam os desenvolvedores a entender as capacidades e limitações gerais do LLM, orientando melhorias. As avaliações do sistema se concentram em como o LLM atende às necessidades dos usuários em contextos específicos, garantindo uma experiência de usuário mais tranquila.
Juntas, essas avaliações fornecem uma visão completa dos pontos fortes e das áreas a serem melhoradas do LLM, tornando-o mais poderoso e fácil de usar em aplicações reais.
Agora, vamos explorar as métricas específicas para a avaliação do LLM.
Métricas para avaliação de LLM
Algumas métricas de avaliação confiáveis e populares incluem:
1. Perplexidade
A perplexidade mede a capacidade de um modelo de linguagem prever uma sequência de palavras. Essencialmente, ela indica a incerteza do modelo sobre a próxima palavra em uma frase. Uma pontuação de perplexidade mais baixa significa que o modelo está mais confiante em suas previsões, levando a um melhor desempenho.
📌 Exemplo: imagine que um modelo gera um texto a partir da solicitação “O gato sentou-se no...”. Se ele prevê uma alta probabilidade para palavras como “tapete” e “chão”, ele entende bem o contexto, resultando em uma pontuação de perplexidade baixa.
Por outro lado, se sugerir uma palavra não relacionada, como “nave espacial”, a pontuação de perplexidade será mais alta, indicando que o modelo tem dificuldade para prever um texto sensato.
2. Pontuação BLEU
A pontuação BLEU (Bilingual Evaluation Understudy) é usada principalmente para avaliar a tradução automática e a geração de texto.
Ela mede quantos n-gramas (sequências contíguas de n itens de uma determinada amostra de texto) na saída se sobrepõem aos de um ou mais textos de referência. A pontuação varia de 0 a 1, com pontuações mais altas indicando melhor desempenho.
📌 Exemplo: Se o seu modelo gera a frase “A rápida raposa marrom pula sobre o cachorro preguiçoso” e o texto de referência é “Uma raposa marrom veloz salta sobre um cachorro preguiçoso”, o BLEU comparará os n-gramas compartilhados.
Uma pontuação alta indica que a frase gerada corresponde à referência, enquanto uma pontuação mais baixa pode sugerir que o resultado gerado não está bem alinhado.
3. Pontuação F1
A métrica de avaliação LLM F1 score é usada principalmente para tarefas de classificação. Ela mede o equilíbrio entre precisão (a exatidão das previsões positivas) e recall (a capacidade de identificar todas as instâncias relevantes).
A pontuação varia de 0 a 1, sendo que 1 indica precisão perfeita.
📌 Exemplo: em uma tarefa de resposta a perguntas, se o modelo for questionado “De que cor é o céu?” e responder “O céu é azul” (verdadeiro positivo), mas também incluir “O céu é verde” (falso positivo), a pontuação F1 considerará tanto a relevância da resposta correta quanto a da resposta incorreta.
Essa métrica ajuda a garantir uma avaliação equilibrada do desempenho do modelo.
4. METEOR
O METEOR (Metric for Evaluation of Translation with Explicit ORdering) vai além da correspondência exata de palavras. Ele considera sinônimos, radicais e paráfrases para avaliar a semelhança entre o texto gerado e o texto de referência. Essa métrica visa se alinhar mais estreitamente com o julgamento humano.
📌 Exemplo: Se o seu modelo gerar “O felino descansava no tapete” e a referência for “O gato estava deitado no carpete”, o METEOR atribuirá uma pontuação mais alta do que o BLEU, pois reconhece que “felino” é sinônimo de “gato” e que “tapete” e “carpete” têm significados semelhantes.
Isso torna o METEOR particularmente útil para capturar as nuances da linguagem.
5. BERTScore
O BERTScore avalia a similaridade do texto com base em incorporações contextuais derivadas de modelos como o BERT (Bidirectional Encoder Representations from Transformers). Ele se concentra mais no significado do que nas correspondências exatas de palavras, permitindo uma melhor avaliação da similaridade semântica.
📌 Exemplo: Ao comparar as frases “O carro correu pela estrada” e “O veículo acelerou pela rua”, o BERTScore analisa os significados subjacentes, em vez de apenas a escolha das palavras.
Embora as palavras sejam diferentes, as ideias gerais são semelhantes, levando a uma pontuação BERTScore alta que reflete a eficácia do conteúdo gerado.
6. Avaliação humana
A avaliação humana continua sendo um aspecto crucial da avaliação do LLM. Ela envolve juízes humanos que classificam a qualidade dos resultados do modelo com base em vários critérios, como fluência e relevância. Técnicas como escalas Likert e testes A/B podem ser empregadas para coletar feedback.
📌 Exemplo: após gerar respostas de um chatbot de atendimento ao cliente, avaliadores humanos podem classificar cada resposta em uma escala de 1 a 5. Por exemplo, se o chatbot fornecer uma resposta clara e útil a uma pergunta do cliente, ele poderá receber uma nota 5, enquanto uma resposta vaga ou confusa poderá receber uma nota 2.
7. Métricas específicas para cada tarefa
Diferentes tarefas de LLM exigem métricas de avaliação personalizadas.
Para sistemas de diálogo, as métricas podem avaliar o envolvimento do usuário ou as taxas de conclusão de tarefas. Para geração de código, o sucesso pode ser medido pela frequência com que o código gerado é compilado ou passa nos testes.
📌 Exemplo: em um chatbot de suporte ao cliente, os níveis de engajamento podem ser medidos pelo tempo que os usuários permanecem em uma conversa ou pelo número de perguntas complementares que fazem.
Se os usuários pedirem informações adicionais com frequência, isso indica que o modelo está envolvendo-os com sucesso e respondendo às suas perguntas de maneira eficaz.
8. Robustez e imparcialidade
Avaliar a robustez de um modelo envolve testar como ele responde a entradas inesperadas ou incomuns. Métricas de equidade ajudam a identificar vieses nas saídas do modelo, garantindo que ele tenha um desempenho equitativo em diferentes dados demográficos e cenários.
📌 Exemplo: Ao testar um modelo com uma pergunta caprichosa como “O que você acha de unicórnios?”, ele deve lidar com a pergunta com elegância e fornecer uma resposta relevante. Se, em vez disso, ele der uma resposta sem sentido ou inadequada, isso indica uma falta de robustez.
Os testes de imparcialidade garantem que o modelo não produza resultados tendenciosos ou prejudiciais, promovendo um sistema de IA mais inclusivo.
9. Métricas de eficiência
À medida que os modelos de linguagem se tornam mais complexos, torna-se cada vez mais importante medir sua eficiência em termos de velocidade, uso de memória e consumo de energia. As métricas de eficiência ajudam a avaliar o quanto um modelo consome recursos ao gerar respostas.
📌 Exemplo: para um modelo de linguagem grande, medir a eficiência pode envolver rastrear a rapidez com que ele gera respostas às consultas dos usuários e quanta memória ele usa durante esse processo.
Se demorar muito para responder ou consumir recursos excessivos, isso pode ser um problema para aplicativos que exigem desempenho em tempo real, como chatbots ou serviços de tradução.
Agora você sabe como avaliar um modelo LLM. Mas quais ferramentas você pode usar para medir isso? Vamos explorar.
Como o ClickUp Brain pode melhorar a avaliação LLM
O ClickUp é um aplicativo completo para o trabalho, com um assistente pessoal integrado chamado ClickUp Brain.
O ClickUp Brain é uma revolução na avaliação de desempenho do LLM. Então, o que ele faz?
Ele organiza e destaca os dados mais relevantes, mantendo sua equipe no caminho certo. Com seus recursos alimentados por IA, o ClickUp Brain é um dos melhores softwares de rede neural disponíveis no mercado. Ele torna todo o processo mais suave, eficiente e colaborativo do que nunca. Vamos explorar suas capacidades juntos.
Gerenciamento inteligente do conhecimento
Ao avaliar Modelos de Linguagem de Grande Porte (LLMs), gerenciar grandes quantidades de dados pode ser uma tarefa difícil.

O ClickUp Brain pode organizar e destacar métricas e recursos essenciais, adaptados especificamente para a avaliação LLM. Em vez de vasculhar planilhas dispersas e relatórios densos, o ClickUp Brain reúne tudo em um só lugar. Métricas de desempenho, dados de benchmarking e resultados de testes estão todos acessíveis em uma interface clara e fácil de usar.
Essa organização ajuda sua equipe a eliminar o ruído e se concentrar nas informações realmente importantes, facilitando a interpretação de tendências e padrões de desempenho.
Com tudo o que você precisa em um só lugar, você pode passar da mera coleta de dados para uma tomada de decisão impactante e baseada em dados, transformando o excesso de informações em inteligência acionável.
Planejamento de projetos e gerenciamento do fluxo de trabalho
As avaliações LLM exigem um planejamento cuidadoso e colaboração, e o ClickUp facilita o gerenciamento desse processo.
Você pode delegar facilmente responsabilidades como coleta de dados, treinamento de modelos e testes de desempenho, ao mesmo tempo em que define prioridades para garantir que as tarefas mais críticas recebam atenção primeiro. Além disso, os campos personalizados permitem que você adapte os fluxos de trabalho às necessidades específicas do seu projeto.

Com o ClickUp, todos podem ver quem está fazendo o quê e quando, ajudando a evitar atrasos e garantindo que as tarefas sejam realizadas de maneira tranquila por toda a equipe. É uma ótima maneira de manter tudo organizado e dentro do prazo, do início ao fim.
Acompanhamento de métricas por meio de painéis personalizados
Quer acompanhar de perto o desempenho dos seus sistemas LLM?
Os painéis do ClickUp visualizam os indicadores de desempenho em tempo real. Eles permitem que você monitore o progresso do seu modelo instantaneamente. Esses painéis são altamente personalizáveis, permitindo que você crie gráficos e tabelas que apresentam exatamente o que você precisa, quando você precisa.
Você pode observar a evolução da precisão do seu modelo ao longo das etapas de avaliação ou detalhar o consumo de recursos em cada fase. Essas informações permitem que você identifique tendências rapidamente, identifique áreas que precisam de melhorias e faça ajustes em tempo real.
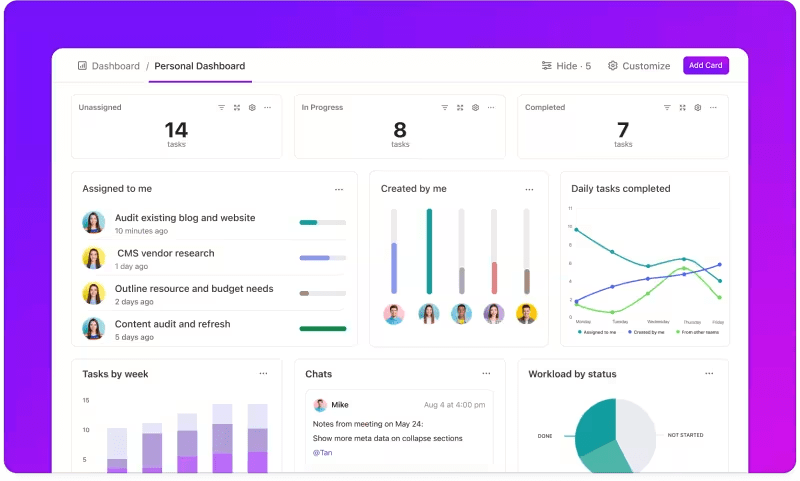
Em vez de esperar pelo próximo relatório detalhado, os painéis do ClickUp permitem que você se mantenha informado e ágil, capacitando sua equipe a tomar decisões baseadas em dados sem demora.
Insights automatizados
A análise de dados pode ser demorada, mas os recursos do ClickUp Brain facilitam o trabalho, fornecendo informações valiosas. Ele destaca tendências importantes e até sugere recomendações com base nos dados, facilitando a obtenção de conclusões significativas.
Com os insights automatizados do ClickUp Brain, não há necessidade de vasculhar manualmente os dados brutos em busca de padrões — ele os identifica para você. Essa automação libera sua equipe para se concentrar em refinar o desempenho do modelo, em vez de se perder em análises repetitivas de dados.
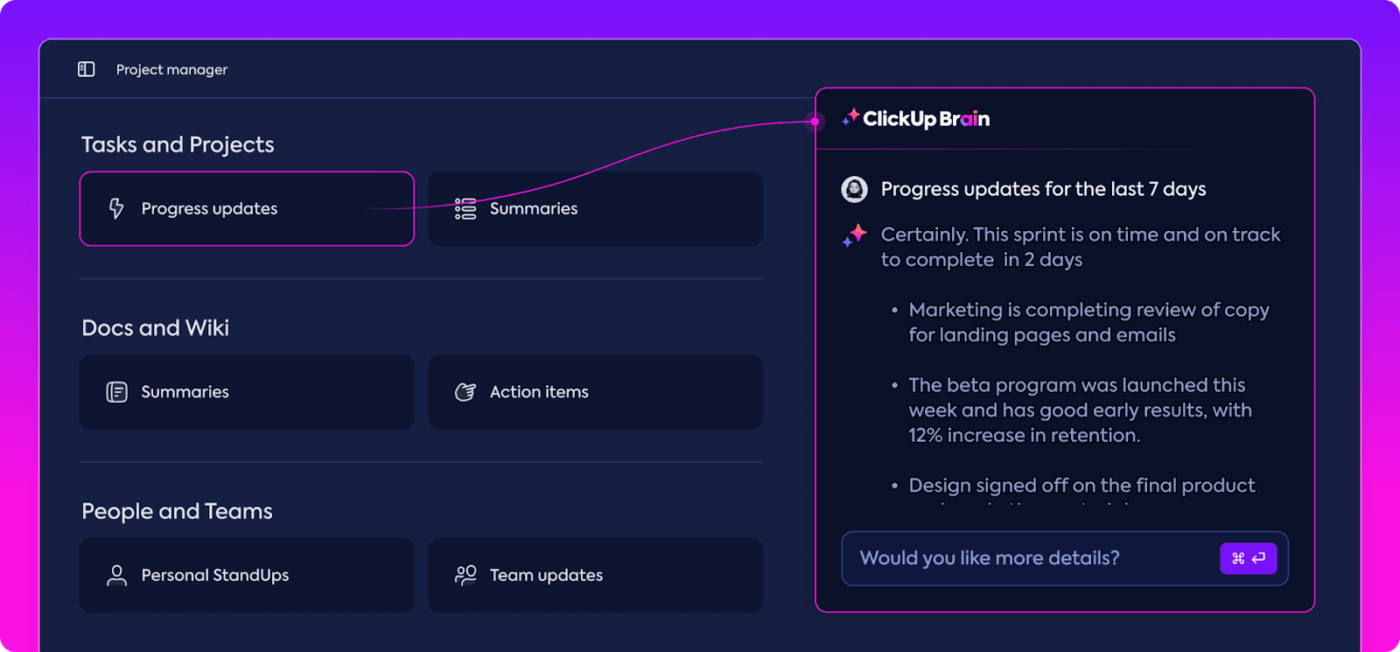
As informações geradas estão prontas para uso, permitindo que sua equipe veja imediatamente o que está funcionando e onde podem ser necessárias mudanças. Ao reduzir o tempo gasto com análises, o ClickUp ajuda sua equipe a acelerar o processo de avaliação e se concentrar na implementação.
Documentação e colaboração
Não é mais necessário vasculhar e-mails ou várias plataformas para encontrar o que você precisa; tudo está bem ali, pronto quando você estiver.
O ClickUp Docs é um hub central que reúne tudo o que sua equipe precisa para uma avaliação LLM perfeita. Ele organiza a documentação essencial do projeto — como critérios de benchmarking, resultados de testes e registros de desempenho — em um único local acessível, para que todos possam acessar rapidamente as informações mais recentes.
O que realmente diferencia o ClickUp Docs são seus recursos de colaboração em tempo real. O ClickUp Chat e os Comentários integrados permitem que os membros da equipe discutam ideias, deem feedback e sugiram alterações diretamente nos documentos.
Isso significa que sua equipe pode discutir as conclusões e fazer ajustes diretamente na plataforma, mantendo todas as discussões relevantes e objetivas.

Tudo, desde a documentação até o trabalho em equipe, acontece dentro do ClickUp Docs, criando um processo de avaliação simplificado, no qual todos podem ver, compartilhar e agir com base nas últimas novidades.
O resultado? Um fluxo de trabalho unificado e tranquilo que permite que sua equipe avance em direção aos seus objetivos com total clareza.
Você está pronto para experimentar o ClickUp? Antes disso, vamos discutir algumas dicas e truques para aproveitar ao máximo sua avaliação LLM.
Melhores práticas na avaliação do LLM
Uma abordagem bem estruturada para a avaliação do LLM garante que o modelo atenda às suas necessidades, esteja alinhado com as expectativas dos usuários e forneça resultados significativos.
Definir objetivos claros, considerar os usuários finais e usar uma variedade de métricas ajuda a moldar uma avaliação completa que revela pontos fortes e áreas a serem melhoradas. Abaixo estão algumas práticas recomendadas para orientar seu processo.
🎯 Defina objetivos claros
Antes de iniciar o processo de avaliação, é essencial saber exatamente o que você deseja que seu modelo de linguagem grande (LLM) alcance. Reserve um tempo para definir as tarefas ou objetivos específicos do modelo.
📌 Exemplo: se você deseja melhorar o desempenho da tradução automática, esclareça os níveis de qualidade que deseja atingir. Ter objetivos claros ajuda você a se concentrar nas métricas mais relevantes, garantindo que sua avaliação permaneça alinhada com essas metas e meça com precisão o sucesso.
👥 Considere seu público
Pense em quem utilizará o LLM e quais são as necessidades dessas pessoas. É fundamental adaptar a avaliação aos usuários pretendidos.
📌 Exemplo: Se o seu modelo tem como objetivo gerar conteúdo envolvente, você deve prestar muita atenção a métricas como fluência e coerência. Compreender o seu público ajuda a refinar os seus critérios de avaliação, garantindo que o modelo ofereça valor real em aplicações práticas.
📊 Utilize métricas diversas
Não confie em apenas uma métrica para avaliar seu LLM; uma combinação de métricas oferece uma visão mais completa do desempenho. Cada métrica captura aspectos diferentes, portanto, usar várias pode ajudar a identificar pontos fortes e fracos.
📌 Exemplo: embora as pontuações BLEU sejam ótimas para medir a qualidade da tradução, elas podem não cobrir todas as nuances da escrita criativa. Incorporar métricas como perplexidade para precisão preditiva e até mesmo avaliações humanas para contexto pode levar a uma compreensão muito mais completa do desempenho do seu modelo.
Referências e ferramentas LLM
A avaliação de modelos de linguagem grandes (LLMs) geralmente depende de benchmarks padrão do setor e ferramentas especializadas que ajudam a medir o desempenho do modelo em várias tarefas.
Aqui está uma lista de alguns benchmarks e ferramentas amplamente utilizados que trazem estrutura e clareza ao processo de avaliação.
Principais referências
- GLUE (Avaliação Geral de Compreensão da Linguagem): O GLUE avalia as capacidades do modelo em várias tarefas linguísticas, incluindo classificação de frases, similaridade e inferência. É uma referência obrigatória para modelos que precisam lidar com a compreensão da linguagem para fins gerais.
- SQuAD (Stanford Question Answering Dataset): A estrutura de avaliação SQuAD é ideal para compreensão de leitura e mede o desempenho de um modelo em responder perguntas com base em uma passagem de texto. É comumente usada para tarefas como suporte ao cliente e recuperação baseada em conhecimento, onde respostas precisas são cruciais.
- SuperGLUE: como uma versão aprimorada do GLUE, o SuperGLUE avalia modelos em tarefas mais complexas de raciocínio e compreensão contextual. Ele fornece insights mais profundos, especialmente para aplicações que exigem compreensão avançada da linguagem.
Ferramentas de avaliação essenciais
- Hugging Face : É amplamente popular por sua extensa biblioteca de modelos, conjuntos de dados e recursos de avaliação. Sua interface altamente intuitiva permite que os usuários selecionem facilmente benchmarks, personalizem avaliações e acompanhem o desempenho do modelo, tornando-o versátil para muitas aplicações LLM.
- SuperAnnotate: é especializado em gerenciar e anotar dados, o que é crucial para tarefas de aprendizado supervisionado. É particularmente útil para refinar a precisão do modelo, pois facilita dados de alta qualidade anotados por humanos que melhoram o desempenho do modelo em tarefas complexas.
- AllenNLP: Desenvolvido pelo Allen Institute for AI, o AllenNLP é voltado para pesquisadores e desenvolvedores que trabalham com modelos personalizados de NLP. Ele oferece suporte a uma variedade de benchmarks e fornece ferramentas para treinar, testar e avaliar modelos de linguagem, oferecendo flexibilidade para diversas aplicações de NLP.
A combinação desses benchmarks e ferramentas oferece uma abordagem abrangente para a avaliação do LLM. Os benchmarks podem definir padrões para todas as tarefas, enquanto as ferramentas fornecem a estrutura e a flexibilidade necessárias para rastrear, refinar e melhorar o desempenho do modelo de maneira eficaz.
Juntos, eles garantem que os LLMs atendam aos padrões técnicos e às necessidades práticas de aplicação.
Desafios da avaliação do modelo LLM
A avaliação de modelos de linguagem grandes (LLMs) requer uma abordagem diferenciada. Ela se concentra na qualidade das respostas e na compreensão da adaptabilidade e das limitações do modelo em diversos cenários.
Como esses modelos são treinados em conjuntos de dados extensos, seu comportamento é influenciado por uma série de fatores, tornando essencial avaliar mais do que apenas a precisão.
A verdadeira avaliação significa examinar a confiabilidade do modelo, a resiliência a prompts incomuns e a consistência geral da resposta. Esse processo ajuda a traçar um quadro mais claro dos pontos fortes e fracos do modelo e revela áreas que precisam ser aprimoradas.
Veja a seguir alguns desafios comuns que surgem durante a avaliação do LLM.
1. Sobreposição de dados de treinamento
É difícil saber se o modelo já viu alguns dos dados de teste. Como os LLMs são treinados em conjuntos de dados massivos, há uma chance de algumas questões de teste se sobreporem aos exemplos de treinamento. Isso pode fazer com que o modelo pareça melhor do que realmente é, pois ele pode estar apenas repetindo o que já sabe, em vez de demonstrar verdadeira compreensão.
2. Desempenho inconsistente
Os LLMs podem ter respostas imprevisíveis. Em um momento, eles fornecem insights impressionantes e, no outro, cometem erros estranhos ou apresentam informações imaginárias como fatos (conhecidas como “alucinações”).
Essa inconsistência significa que, embora os resultados do LLM possam se destacar em algumas áreas, eles podem ficar aquém em outras, dificultando a avaliação precisa de sua confiabilidade e qualidade gerais.
3. Vulnerabilidades adversárias
Os LLMs podem ser suscetíveis a ataques adversários, nos quais comandos habilmente elaborados os induzem a produzir respostas falhas ou prejudiciais. Essa vulnerabilidade expõe pontos fracos no modelo e pode levar a resultados inesperados ou tendenciosos. Testar essas vulnerabilidades adversárias é crucial para entender onde estão os limites do modelo.
Casos práticos de avaliação LLM
Por fim, aqui estão algumas situações comuns em que a avaliação LLM realmente faz a diferença:
Chatbots de suporte ao cliente
Os LLM são amplamente utilizados em chatbots para lidar com as dúvidas dos clientes. Avaliar a qualidade da resposta do modelo garante que ele forneça respostas precisas, úteis e contextualmente relevantes.
É fundamental medir sua capacidade de compreender a intenção do cliente, lidar com diversas perguntas e fornecer respostas semelhantes às humanas. Isso permitirá que as empresas garantam uma experiência tranquila ao cliente, minimizando a frustração.
Geração de conteúdo
Muitas empresas utilizam LLMs para gerar conteúdo para blogs, mídias sociais e descrições de produtos. Avaliar a qualidade do conteúdo gerado ajuda a garantir que ele esteja gramaticalmente correto, seja envolvente e relevante para o público-alvo. Métricas como criatividade, coerência e relevância para o tema são importantes para manter altos padrões de conteúdo.
Análise de sentimentos
Os LLMs podem analisar o sentimento do feedback dos clientes, publicações nas redes sociais ou avaliações de produtos. É essencial avaliar com que precisão o modelo identifica se um texto é positivo, negativo ou neutro. Isso ajuda as empresas a compreender as emoções dos clientes, refinar produtos ou serviços, aumentar a satisfação dos usuários e melhorar as estratégias de marketing.
Geração de código
Os desenvolvedores costumam usar LLMs para auxiliar na geração de código. É fundamental avaliar a capacidade do modelo de produzir código funcional e eficiente.
É importante verificar se o código gerado é logicamente correto, está livre de erros e atende aos requisitos da tarefa. Isso ajuda a reduzir a quantidade de codificação manual necessária e melhora a produtividade.
Otimize sua avaliação LLM com o ClickUp
Avaliar LLMs significa escolher as métricas certas que se alinham com seus objetivos. O segredo é entender seus objetivos específicos, seja melhorar a qualidade da tradução, aprimorar a geração de conteúdo ou fazer ajustes para tarefas especializadas.
Selecionar as métricas certas para avaliação de desempenho, como RAG ou métricas de ajuste fino, forma a base para uma avaliação precisa e significativa. Enquanto isso, avaliadores avançados como G-Eval, Prometheus, SelfCheckGPT e QAG fornecem insights precisos graças às suas fortes habilidades de raciocínio.
No entanto, isso não significa que essas pontuações sejam perfeitas — ainda é importante garantir que elas sejam confiáveis.
À medida que você avança na avaliação da aplicação do LLM, adapte o processo para se adequar ao seu caso de uso específico. Não existe uma métrica universal que funcione para todos os cenários. Uma combinação de métricas, juntamente com um foco no contexto, lhe dará uma visão mais precisa do desempenho do seu modelo.
Para otimizar sua avaliação LLM e melhorar a colaboração da equipe, o ClickUp é a solução ideal para gerenciar fluxos de trabalho e acompanhar métricas importantes.
Quer aumentar a produtividade da sua equipe? Inscreva-se hoje mesmo no ClickUp e veja como ele pode transformar seu fluxo de trabalho!