
Czy kiedykolwiek zdarzyło Ci się być w trakcie kolacji, gdy Twój telefon zawibrował z powodu „krytycznego alertu”, który okazał się być niczym więcej niż rutynowym logiem? To frustrujące, ale przynajmniej wiedziałeś, że Opsgenie Cię wspiera.
Teraz nadchodzi prawdziwe wyzwanie: firma Atlassian zaprzestała sprzedaży Opsgenie, a wkrótce zakończy się pełne wsparcie techniczne. Dla zespołów, które polegają na tym narzędziu w zakresie planowania dyżurów, eskalacji i alertów, jest to sygnał alarmowy, którego nikt nie chciał.
Zaletą jest to, że nie musisz czekać do ostatniej chwili. Poświęcenie czasu na zapoznanie się z innymi opcjami już teraz oznacza, że Twój zespół będzie mógł oswoić się z nową rutyną bez stresu związanego z podjęciem pochopnych decyzji.
W tym artykule omówimy najlepsze alternatywy dla Opsgenie, porównamy ich mocne strony i pokażemy, dlaczego ClickUp oferuje Twojemu zespołowi spokojniejszy i bardziej połączony sposób pracy.
⭐ Funkcjonalny szablon
Pozwól swoim zespołom IT dokładnie rejestrować incydenty i wykrywać trendy, które pomogą wprowadzić długoterminowe ulepszenia. Szablon raportu incydentów IT ClickUp pomaga rejestrować szczegóły incydentów w spójnym i niezawodnym formacie.

Alternatywy dla Opsgenie w skrócie
Oto krótkie porównanie najlepszych alternatyw dla Opsgenie, które pomoże Ci wybrać odpowiednie rozwiązanie na podstawie kluczowych funkcji, cen i ocen użytkowników.
| Narzędzie | Najlepsze dla | Najważniejsze funkcje | Ceny* | Oceny |
| ClickUp | Kompleksowe zarządzanie pracą z cyklami pracy w przypadku incydentów, planowaniem zasobów i automatyzacją dla zespołów każdej wielkości | Konfigurowalne powiadomienia, automatyzacja eskalacji, zadania i listy incydentów, niestandardowe statusy, czat w czasie rzeczywistym, pulpity nawigacyjne do przeglądów po incydentach, ponad 1000 integracji | Dostępny Free Plan; niestandardowe dostosowania dla przedsiębiorstw | G2: 4,7/5 (10 500+) Capterra: 4,6/5 (4500+) |
| PagerDuty | Powiadamianie o incydentach w czasie rzeczywistym i automatyzacja na dużą skalę dla dużych firm | Wielokanałowe alerty, zasady eskalacji, planowanie dyżurów, AIOps do redukcji szumu, integracja z ponad 600 narzędziami | Free Plan; plany płatne od 25 USD/miesiąc za użytkownika | G2: 4,5/5 (900+) Capterra: 4,6/5 (200+) |
| xMatters | Ekonomiczne zarządzanie incydentami i automatyzacja cyklu pracy dla rozwijających się zespołów | Automatyzowane cykle pracy, adaptacyjne zarządzanie incydentami, planowanie dyżurów, analiza sygnałów, ponad 200 integracji | Free Plan; plany płatne od 9 USD/miesiąc za użytkownika | G2: 4,5/5 (670+) Capterra: 4,6/5 (140+) |
| AlertOps | Redukcja szumów oparta na AI i szybka reakcja dla małych i średnich zespołów | Redukcja szumu AI OpsIQ, elastyczne eskalacje, dyżury, automatyzacja przepływu pracy bez kodowania, ponad 200 integracji | Free Plan; plany płatne od 10 USD/miesiąc za użytkownika | G2: 4,7/5 (150+) Capterra: 4,7/5 (20+) |
| Splunk On-Call | Uproszczenie planowania dyżurów i zmniejszenie wypalenia zawodowego w dużych zespołach | Automatyzacja eskalacji, aplikacje mobilne, równoważenie obciążenia pracą, rekomendacje ML, ścieżki audytu | Niestandardowe ceny | G2: 4,6/5 (50+) Capterra: 4,5/5 (30+) |
| Datadog | Pełna obserwowalność z monitorowaniem bezpieczeństwa dla przedsiębiorstw | Monitorowanie infrastruktury, logów i aplikacji, bezpieczeństwo w chmurze, wykrywanie anomalii za pomocą AI, ponad 900 integracji | Free Plan; plany płatne od 15 USD/miesiąc za użytkownika | G2: 4,4/5 (660+) Capterra: 4,6/5 (320+) |
| Squadcast | Ujednolicone dyżury i reagowanie na incydenty z ceną wartości dla średnich zespołów | Harmonogramy automatyzacji, deduplikacja, instrukcje postępowania, strony statusowe, analizy po zakończeniu | Free Plan; plany płatne od 12 USD/miesiąc za użytkownika | G2: 4,4/5 (300+) Capterra: zbyt mało recenzji |
| FireHydrant | Zautomatyzowane instrukcje postępowania i własność usług dla przedsiębiorstw | Runbooki, planowanie dyżurów Signals, katalog usług, współpraca Slack/Teams, retrospektywy wzbogacone o AI | Free Plan; plany płatne od 9600 USD/rok za użytkownika | G2: 4,5/5 (130+) Capterra: zbyt mało recenzji |
| TaskCall | Niedrogie zarządzanie incydentami z automatyzacją dla średnich i dużych zespołów | Dynamiczne planowanie dyżurów, routing oparty na AI, wielokanałowe alerty, obsługa DevOps + BizOps | Free Plan; plany płatne od 9 USD/miesiąc za użytkownika | G2: zbyt mało recenzji Capterra: zbyt mało recenzji |
| ilert | Zarządzanie incydentami oparte na AI, z naciskiem na prywatność, dla rozwijających się zespołów | Wielokanałowe alerty, asystent AI Responder, planowanie dyżurów, automatyczne strony statusowe, integracje z ITSM + narzędzia monitorujące | Free Plan; plany płatne od 24 USD/miesiąc za użytkownika | G2: zbyt mało recenzji Capterra: 4,7/5 (60+) |
| Zenduty | Reagowanie na incydenty oparte na AI na dużą skalę dla małych i dużych zespołów | Zarządzanie incydentami ZenAI, zaawansowane planowanie dyżurów, automatyzacja skryptów, ponad 150 integracji | Free Plan; plany płatne od 6 USD/miesiąc za użytkownika | G2: 4,6/5 (135+) Capterra: zbyt mało recenzji |
| Incident. io | Reagowanie na incydenty w Slacku dla średnich i dużych firm | Kompleksowe zarządzanie incydentami w Slacku, AI SRE, planowanie dyżurów, automatyczne strony statusowe, pulpity analityczne | Free Plan; plany płatne od 19 USD/miesiąc za użytkownika | G2: 4,8/5 (180+) Capterra: zbyt mało recenzji |
Kluczowe kryteria oceny alternatyw dla Opsgenie
Wiem, że mamy jeszcze prawie 2 lata, zanim całkowicie wycofają tę usługę, ale nie widzę powodu, aby czekać 😛
Wiem, że mamy jeszcze prawie 2 lata, zanim całkowicie wycofają tę usługę, ale nie widzę powodu, aby czekać 😛
Ten komentarz użytkownika Reddit oddaje rzeczywistość, z jaką boryka się wiele zespołów IT PMO. Tak, Opsgenie przez lata było dobrym towarzyszem, ale poleganie na nim tylko dlatego, że jest znane, nie pomoże po zakończeniu wsparcie.
Teraz warto zastanowić się, co sprawiło, że Opsgenie było tak przydatne, i wykorzystać te same cechy jako wskazówki przy wyborze kolejnej platformy do zarządzania incydentami.
Oto kilka cech, na które warto zwrócić uwagę:
- Wysyłaj powiadomienia na czas za pośrednictwem wielu kanałów, takich jak telefon, e-mail, SMS lub powiadomienia push.
- Utrzymuj ukierunkowane powiadomienia, aby odpowiednia osoba została poinformowana, nie przytłaczając reszty zespołu.
- Wprowadź zasady eskalacji, które zapewnią, że krytyczne incydenty nigdy nie zostaną zignorowane.
- Scentralizuj aktualizacje dotyczące incydentów, aby zespoły miały pełny obraz sytuacji podczas zarządzania incydentami.
- Przeprowadzaj analizy po incydentach, aby wyciągać wnioski z podobnych zdarzeń i z czasem wprowadzać ulepszenia.
- Oferuj możliwości integracji z narzędziami, z których Twoje zespoły IT już zależą.
Opsgenie zyskało renomę, pomagając zespołom DevOps zmniejszyć zmęczenie alertami, zachować przejrzystość harmonogramów dyżurów i rozwiązywać incydenty bez zamieszania. Odkrywając każdą alternatywę dla Opsgenie, pamiętaj o tych samych wartościach.
📖 Przeczytaj również: Najlepsze narzędzia do zarządzania incydentami dla zespołów IT
12 najlepszych alternatyw dla Opsgenie
Opsgenie może kończyć działalność, ale nie oznacza to, że Twój zespół musi stracić impet. Oto kilka odpowiednich zamienników, które zapewnią Twoim zespołom operacyjnym pewność siebie w krytycznych momentach.
Jak oceniamy oprogramowanie w ClickUp
Nasz zespół redakcyjny stosuje przejrzysty, poparty badaniami i niezależny od dostawców proces, dzięki czemu możesz mieć pewność, że nasze rekomendacje opierają się na rzeczywistej wartości produktów.
Oto szczegółowy opis tego , jak oceniamy oprogramowanie w ClickUp.
ClickUp (najlepszy do obsługi cykli pracy związanych z incydentami oraz szeroko pojętego zarządzania projektami)
Opuszczając Opsgenie, zespoły mniej martwią się utratą alertów, a bardziej dostosowaniem się do nowego cyklu pracy związanego z zarządzaniem incydentami.
Głównym problemem jest rozproszenie pracy, gdzie aktualizacje, harmonogramy i zasady są rozrzucone po różnych aplikacjach, wiadomościach e-mail i dokumentach. Ta fragmentacja pochłania energię i zmusza zespoły do rozpoczynania pracy od nowa przy każdym incydencie.
Badania pokazują, że pracownicy spędzają 117 minut na przeglądaniu wiadomości e-mail i 153 minuty na wiadomościach w Teams w każdy dzień roboczy, z przerwami co kilka minut.
ClickUp zastępuje Opsgenie, łącząc wszystkie rozdzielone zadania w jednym, zintegrowanym obszarze roboczym. Oto, w jaki sposób jego funkcje spotykają te wyzwania w głębi.
Zautomatyzowane cykle pracy reagowania
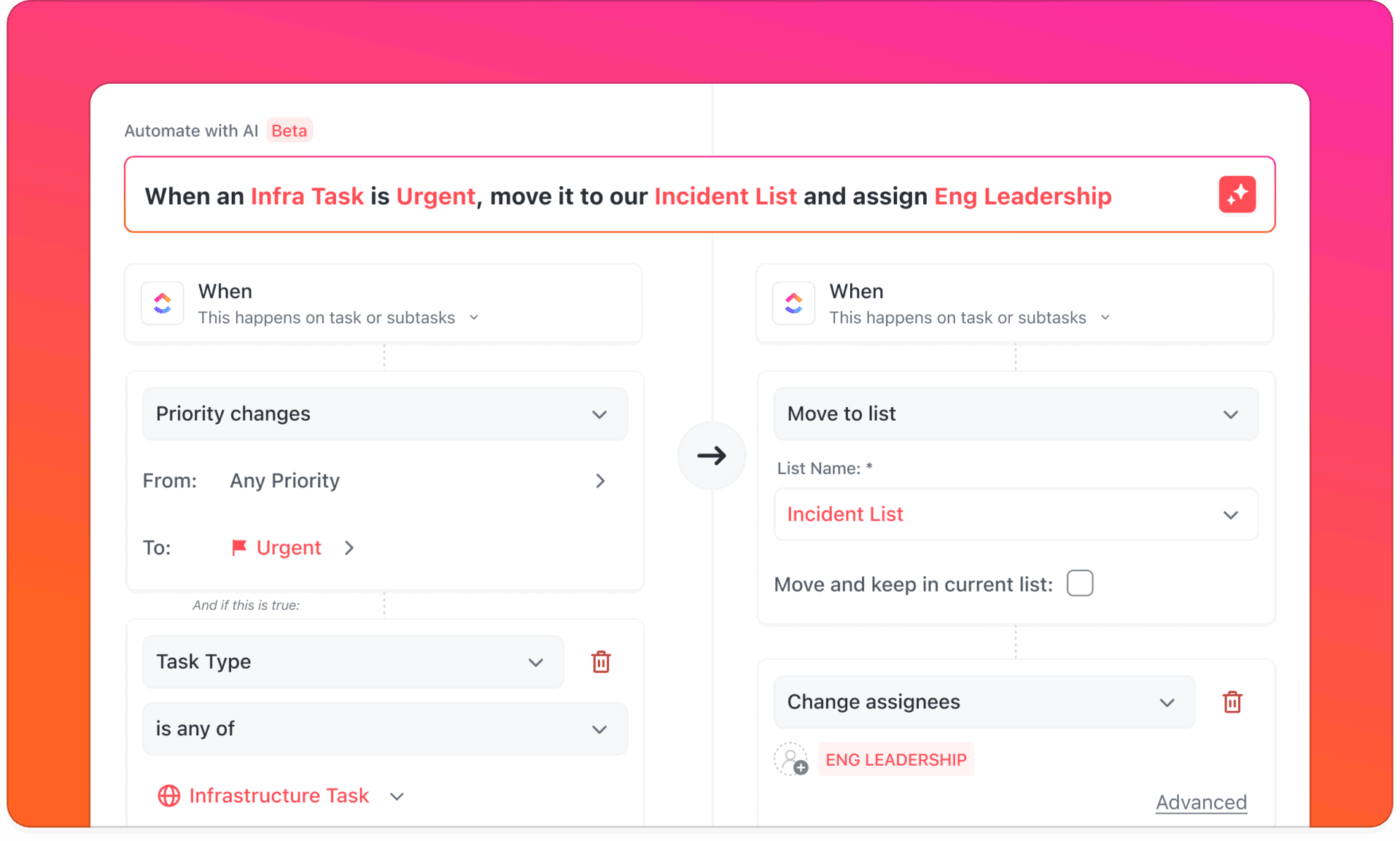
W przypadku alertów pochodzących z narzędzi monitorujących, komunikatorów i e-mail trudno jest określić, co jest ważne i kto powinien zareagować.
Dzięki automatyzacji ClickUp i agentom AI alerty stają się znaczącymi działaniami. Przychodzące alerty mogą automatycznie tworzyć i przypisywać zadania inżynierowi dyżurnemu, powiadamiając odpowiednią osobę bez rozpraszania reszty zespołu.
Jeśli w określonym czasie nie ma odpowiedzi, system automatycznie eskaluje problem zgodnie z Twoimi standardowymi procedurami.
📌 Przykład: Zgłoszono awarię serwera o wysokim priorytecie. ClickUp Automatyzacje tworzy nowe zadanie na liście incydentów, oznacza je jako pilne, przypisuje do inżyniera dyżurnego i wysyła powiadomienie push na telefon komórkowy. W tym samym czasie Twój niestandardowy agent AI publikuje krótką wiadomość w kanale incydentów w ClickUp Chat, aby poinformować zespół, ale nie przytłoczyć go nadmiarem informacji.
Przejrzystość i odpowiedzialność za zadania
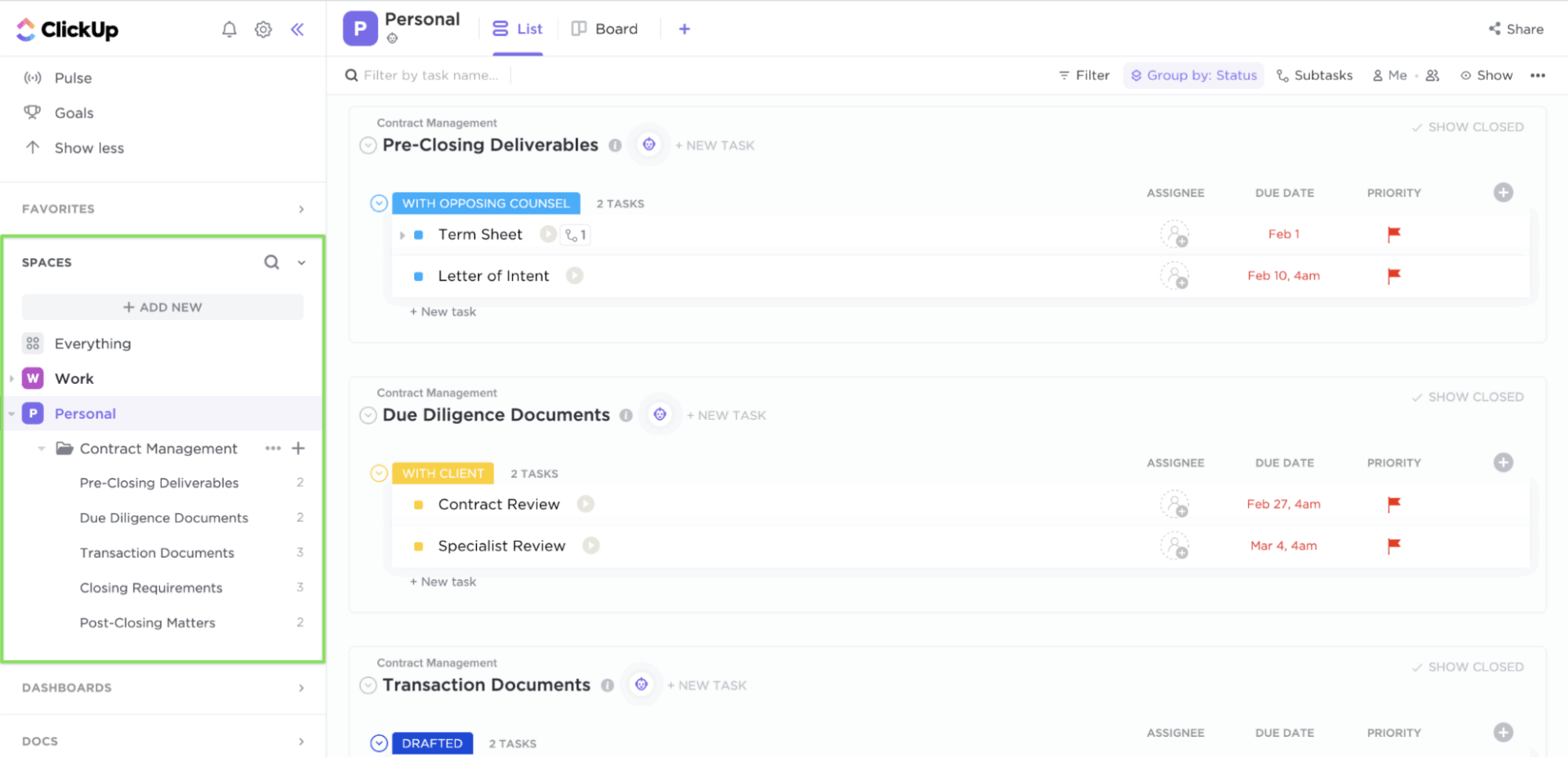
Kiedy dochodzi do incydentu, zespoły często tracą czas na zastanawianie się, co zrobić i co dalej. Zadanie ClickUp zapewnia przejrzystość procesów zarządzania incydentami.
Każde zadanie może mieć jasno określonego właściciela, priorytet i termin wykonania. W ramach każdego zadania można dodawać listy kontrolne, linki do instrukcji obsługi i zrzuty ekranu. Pola niestandardowe rejestrują stopień ważności, usługi, których dotyczy problem, lub etap eskalacji, natomiast niestandardowe statusy zadań i listy ClickUp eliminują niepewność, przedstawiając proces reagowania w postaci jasnej sekwencji.
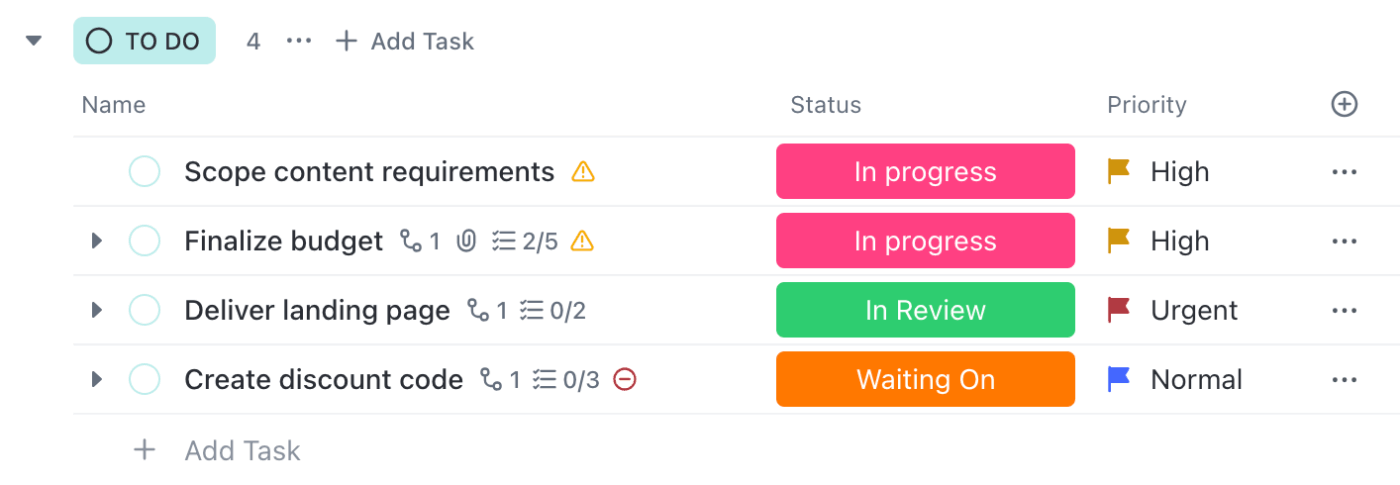
📌 Przykład: Zgłoszony incydent przechodzi do statusu „W trakcie badania” po otwarciu zadania przez inżyniera. Kroki mające na celu złagodzenie skutków są śledzone w liście kontrolnej, a notatki i logi są dodawane w opisie. Każda zmiana statusu powiadamia tylko odpowiednie osoby, dzięki czemu inżynierowie mogą pracować, a kierownictwo pozostaje na bieżąco.
Aktualizacje, które nie zakłócają przepływu pracy
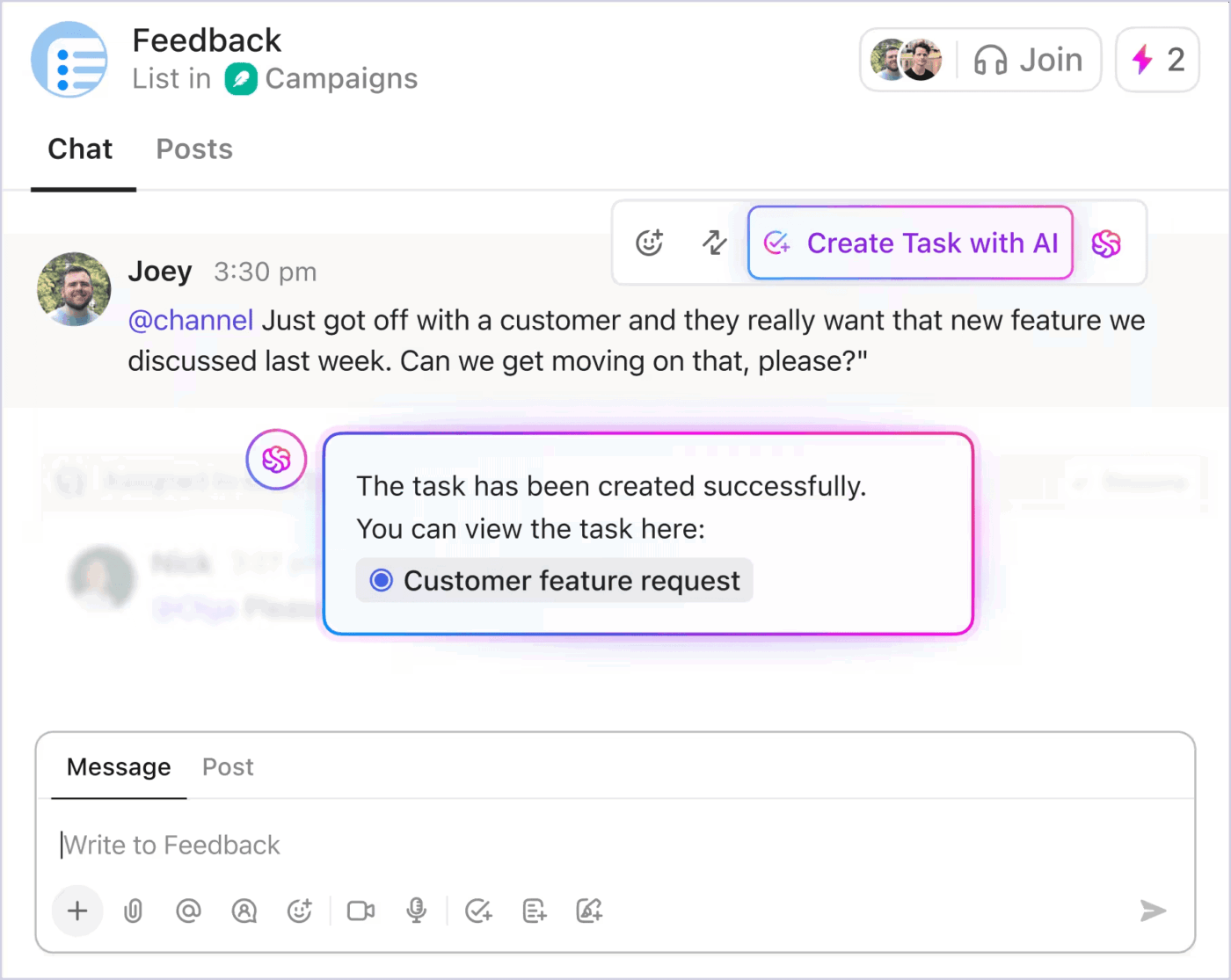
Podczas krytycznych incydentów aktualizacje dla interesariuszy nie powinny zakłócać działań reagujących. ClickUp Chat rozwiązuje ten problem, załączając rozmowę bezpośrednio do zadania związanego z incydentem. Członkowie zespołu i liderzy mogą śledzić wątek, przeglądać podjęte decyzje i dodawać komentarze w czasie rzeczywistym.
ClickUp integruje się również z aplikacjami Slack i Microsoft Teams, dzięki czemu aktualizacje pojawiają się w kanałach, które użytkownicy już śledzą.
Szukasz najlepszych wskazówek dotyczących współpracy w czasie rzeczywistym? Oto przewodnik:
Analizy po incydentach, które prowadzą do trwałych zmian
Zbyt często raporty po incydentach są sporządzane, ale potem zapominane. ClickUp Dokumenty pozwala je zachować, przechowując standardowe raporty bezpośrednio obok zadań związanych z incydentami.
Tymczasem pulpity nawigacyjne ClickUp wyświetlają takie wskaźniki, jak średni czas rozwiązania, częstotliwość incydentów i powtarzające się wzorce. Ta widoczność pomaga zespołom IT i DevOps przejść od reaktywnego gaszenia pożarów do proaktywnego doskonalenia.
💡 Wskazówka dla profesjonalistów: Analiza po incydencie może zająć wiele godzin pisania, edytowania i poszukiwania kontekstu. ClickUp Brain zmienia to, automatycznie gromadząc notatki, osie czasu i elementy do wykonania. Może podsumować zadanie związane z incydentem, sporządzić raport po incydencie w ClickUp Dokumencie, a nawet zasugerować kolejne kroki na podstawie podobnych incydentów.
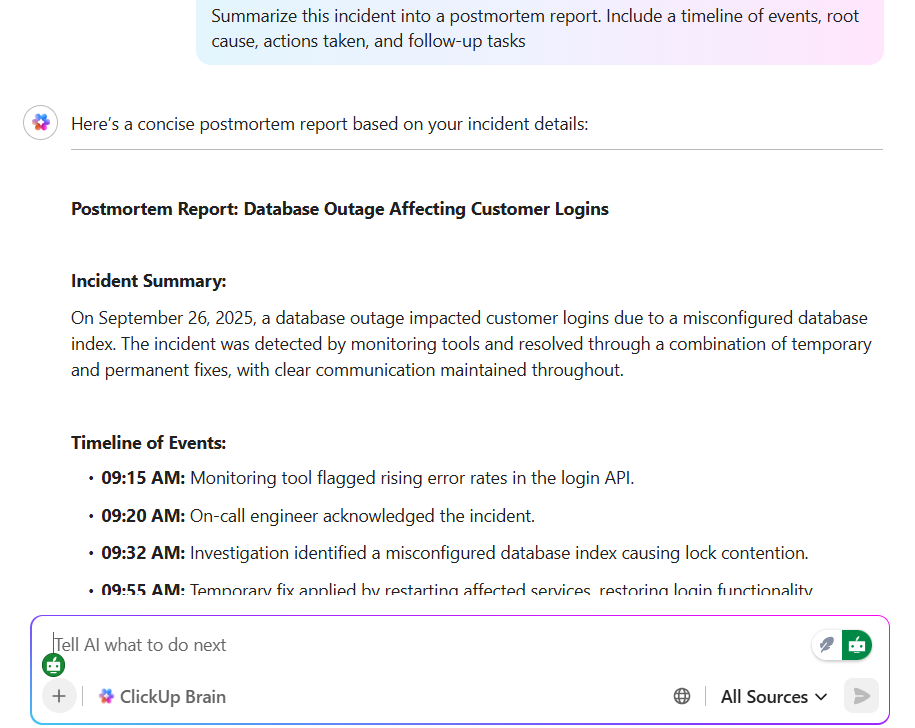
Dzięki ClickUp Brain Max zyskujesz dodatkową szybkość funkcji ClickUp Talk to Text — dyktuj swoje myśli w czasie rzeczywistym i obserwuj, jak zamieniają się one w dopracowane notatki gotowe do udostępniania. Razem pomagają one zespołom zaoszczędzić prawie cały dzień w tygodniu, eliminując żmudne pisanie i wyszukiwanie, dzięki czemu możesz skupić się na zapobieganiu kolejnym incydentom, zamiast opowiadać o poprzednich.
Zapewnij porządek i oszczędzaj czas dzięki szablonom

W sytuacji awaryjnej naprawdę doceniasz wartość jasnego, kroku po kroku procesu.
Szablon planu działania w przypadku incydentów ClickUp jest właśnie tym. Określa on dokładnie, co należy zrobić, kto ma to zrobić i w jakiej kolejności. Dzięki temu wszyscy są zgrani, ryzyko jest mniejsze i żadne kroki nie są pomijane.
Kolejnym wyzwaniem w branży IT jest skuteczne dokumentowanie incydentów, aby można było dostrzec powtarzające się wzorce i zapobiegać im w przyszłości. Szablon raportu incydentów IT ClickUp ułatwia raportowanie, zamieniając każdy problem w cenny punkt danych.
Najlepsze funkcje ClickUp
- Ogranicz zmęczenie alertami dzięki konfigurowalnym powiadomieniom ClickUp, które zapewniają, że powiadomienia otrzymują tylko właściwe osoby
- Zautomatyzuj data powstania zadań związanych z incydentami, ich przydzielanie i raportowanie dzięki automatyzacji ClickUp i agentom AI
- Twórz przejrzyste procedury reagowania na incydenty dzięki zadaniom ClickUp, listom i statusom, a także szablonom raportów incydentów, które pomogą Ci przejść przez wszystkie etapy reagowania
- Umożliwiaj współpracę zespołową dzięki ClickUp Chat i ClickUp Dokumenty, dzięki czemu rozmowy, aktualizacje i wnioski są dostępne na bieżąco wraz z incydentem
- Śledź status zadań i raporty dotyczące incydentów za pomocą pulpitów ClickUp
- Generuj wnioski na podstawie incydentów i zamkniętych zadań oraz twórz lub aktualizuj standardowe procedury operacyjne (SOP) w celu wprowadzenia przyszłych ulepszeń dzięki ClickUp Brain
Limitations ClickUp
- Elastyczność platformy może wydawać się przytłaczająca dla mniejszych zespołów, które potrzebują jedynie podstawowych funkcji powiadamiania i zarządzania dyżurami
Ceny ClickUp
Oceny i recenzje ClickUp
- G2: 4,7/5 (ponad 10 500 recenzji)
- Capterra: 4,6/5 (ponad 4500 recenzji)
Co użytkownicy mówią o ClickUp
Użytkownik G2 dokonał raportowania:
Współpraca nad projektem stała się znacznie łatwiejsza od momentu wdrożenia ClickUp, ponieważ zadania można łatwo przypisywać członkom zespołu, a postępy można śledzić za pomocą czatu. Aplikacja wysyła nawet powiadomienia e-mail i alerty o zaległych zadaniach w przypadku niezrealizowanych zadań.
Współpraca nad projektem stała się znacznie łatwiejsza od momentu wdrożenia ClickUp, ponieważ zadania można łatwo przypisywać członkom zespołu, a postępy można śledzić za pomocą czatu. Aplikacja wysyła nawet powiadomienia e-mailowe i alerty o zaległych zadaniach w przypadku niezrealizowanych zadań.
📖 Przeczytaj również: Jak napisać raport z incydentu w pracy
2. PagerDuty (najlepsze rozwiązanie do powiadamiania o incydentach w czasie rzeczywistym i automatyzacji na dużą skalę)
Jeśli rezygnujesz z Opsgenie, Twoja pierwsza obawa jest prosta. Czy właściwa osoba otrzyma alert we właściwym momencie, na właściwym kanale?
PagerDuty zostało stworzone, aby wyeliminować ten stres. Użytkownik definiuje usługi, harmonogramy i jasne zasady eskalacji, dzięki czemu nigdy nie ma wątpliwości co do własności. Sygnały z CloudWatch, Prometheus, Datadog, Jira, ServiceNow, Slack, Zoom i innych źródeł trafiają w jedno miejsce i są grupowane w jeden incydent, a nie 15 oddzielnych pingów.
Event Intelligence ogranicza powielanie i koreluje powiązane problemy, co zmniejsza liczbę alertów bez pomijania rzeczywistych problemów. Osoby reagujące na incydenty mogą potwierdzać lub eskalować zgłoszenia z poziomu aplikacji mobilnej lub bezpośrednio ze Slacka lub Teams, a pokoje incydentów i mosty są tworzone automatycznie.
Po rozwiązaniu problemu narzędzie analityczne pokazuje czas potrzebny na potwierdzenie zgłoszenia, czas potrzebny na rozwiązanie problemu oraz powtarzające się problemy, dzięki czemu możesz zająć się przyczynami, a nie tylko objawami.
Najlepsze funkcje PagerDuty
- Pozwól użytkownikom korzystać z niestandardowych powiadomień SMS, telefonicznych, e-mailowych, push i Slack, aby ograniczyć natłok informacji bez pomijania krytycznych incydentów
- Uprość ustawienia dzięki alertom testowym, integracji usług i prostemu projektowaniu zasad eskalacji
- Wsparcie harmonogramów dyżurów i eskalacji, które powiadamiają odpowiednią osobę i są kontynuowane do momentu potwierdzenia
- Włącz działania związane z incydentami oparte na Slacku, takie jak potwierdzanie, rozwiązywanie i eskalowanie bezpośrednio na czacie
- Zmniejsz zmęczenie alertami dzięki AIOps, które grupuje duplikaty i wyróżnia pilne incydenty
Limitacje PagerDuty
- Kierownicy zespołów nie mogą w pełni dostosować niestandardowych metod dostarczania alertów na poziomie zespołu, co ogranicza elastyczność, gdy menedżerowie chcą stosować spójne zasady eskalacji
- Powiadomienia e-mailowe nie umożliwiają odpowiedzi, co zmusza osoby reagujące na incydenty do przechodzenia do platformy zamiast zarządzania bezpośrednio z poziomu skrzynki odbiorczej
- Zaawansowane funkcje, takie jak AIOps i licencje na komunikację z interesariuszami, wiążą się z wysokimi dodatkowymi kosztami
Ceny PagerDuty
- Free
- Profesjonalny: 25 USD/miesiąc na użytkownika
- Biznes: 49 USD/miesiąc za użytkownika
- Przedsiębiorstwa: ceny niestandardowe
Oceny i recenzje PagerDuty
- G2: 4,5/5 (ponad 900 recenzji)
- Capterra: 4,6/5 (ponad 200 recenzji)
Co użytkownicy mówią o PagerDuty
Użytkownik G2 zrobił wzmiankę:
Podoba mi się, że pager duty ma kilka różnych alertów dźwiękowych, a niektóre z nich są naprawdę zabawne. Odkąd zacząłem korzystać z pager duty, mogę skuteczniej reagować na incydenty i angażować zespoły.
Podoba mi się, że pager duty ma kilka różnych alertów dźwiękowych, a niektóre z nich są naprawdę zabawne. Odkąd zacząłem korzystać z pager duty, mogę skuteczniej reagować na incydenty i angażować zespoły.
📖 Przeczytaj również: Co to jest plan awaryjny i jak go opracować?
3. xMatters (najlepsze rozwiązanie do ekonomicznego zarządzania incydentami i automatyzacji)
Użytkownik serwisu Reddit podsumował to najlepiej:
Otrzymujesz to, za co płacisz, ale płacisz mniej. Ma wszystko, czego potrzebujesz, choć zdecydowanie nie jest tak wyszukane jak PagerDuty.
Otrzymujesz to, za co płacisz, ale płacisz mniej. Ma wszystko, czego potrzebujesz, choć zdecydowanie nie jest tak wyszukane jak PagerDuty.
To zdanie oddaje pozycję xMatters — przystępna cenowo, niezawodna i silna w obszarach, które mają największe znaczenie.
Jeśli rezygnujesz z Opsgenie, zazwyczaj borykasz się z dwoma problemami. Zbyt dużą ilością powiadomień, które budzą niewłaściwe osoby, oraz niepewnością co do tego, kto jest odpowiedzialny za podjęcie kolejnych działań. xMatters rozwiązuje oba te problemy, umożliwiając mapowanie usług i harmonogramów dyżurów, a następnie kierowanie alertów z dokładnym kontekstem, tak aby właściwa osoba została powiadomiona we właściwym kanale.
Użytkownicy docenili ukierunkowane powiadomienia zawierające przydatne szczegóły, a także pełną ścieżkę audytu pokazującą, kto został powiadomiony, kto potwierdził otrzymanie powiadomienia i kiedy. Dzięki tym zapisom przeglądy po incydentach i kontrole zgodności są proste.
Narzędzie do tworzenia cyklu pracy typu low-code przekształca sygnał z Datadog, Prometheus lub ServiceNow w jasną sekwencję działań.
Dzięki automatyzacji przepływu pracy i adaptacyjnemu zarządzaniu projektami DevOps, xMatters pomaga zespołom działać szybciej i eliminować niepotrzebne alerty.
najlepsze funkcje xMatters
- Zautomatyzuj cykl pracy związany z incydentami dzięki integracjom bezkodowym i niskokodowym, które przyspieszają rozwiązywanie problemów i ograniczają zadania wykonywane ręcznie
- Płynnie zarządzaj harmonogramami dyżurów i eskalacjami, aby właściwa osoba była zawsze powiadamiana we właściwym czasie
- Zastosuj adaptacyjne zarządzanie incydentami, aby zminimalizować wpływ na klientów i wyciągnąć wnioski z każdego wydarzenia
- Odfiltruj szumy dzięki analizie sygnałów, korelacji alertów i rozbudowanym powiadomieniom, które zapewniają jaśniejszy kontekst
- Uzyskaj dostęp do praktycznych analiz, aby zidentyfikować nieefektywności i poprawić współpracę między zespołami
ograniczenia xMatters
- Interfejs i wrażenia użytkownika wydają się mniej dopracowane w porównaniu z konkurencją
- Zaawansowane funkcje raportowania i analizy mają limit w planach niższych poziomów
- Zakres globalnego wsparcia różni się w zależności od wybranego planu
ceny xMatters
- Free
- Starter (Essentials): 9 USD miesięcznie za użytkownika
- Podstawa (Standard): 39 USD/miesiąc na użytkownika
- Zaawansowane: Niestandardowe ceny
oceny i recenzje xMatters
- G2: 4,5/5 (ponad 670 recenzji)
- Capterra: 4,6/5 (ponad 140 recenzji)
Co użytkownicy mówią o xMatters
W recenzji Capterra funkcją było:
Kiedy w firmie dochodzi do incydentu związanego z bezpieczeństwem danych, Xmatters natychmiast uruchamia protokoły reagowania: organizuje protokoły działania zespołu zgodnie z ich funkcjami. Powiadomienia są wysyłane za pośrednictwem różnych kanałów.
Kiedy w firmie dochodzi do incydentu związanego z bezpieczeństwem danych, Xmatters natychmiast uruchamia protokoły reagowania: organizuje protokoły działania zespołu zgodnie z ich funkcjami. Powiadomienia są wysyłane za pośrednictwem różnych kanałów.
📮 ClickUp Insight: 28% pracowników twierdzi, że praca towarzyszy im po godzinach, a kolejne 8% często ma trudności z wyłączeniem się. Oznacza to, że ponad jedna trzecia pracowników przenosi stres do domu.
Użyj przypomnień ClickUp, aby chronić swoją wieczorną rutynę. Ustaw codzienne przypomnienie o podsumowaniu dnia, ciche powiadomienia poza godzinami pracy i zarezerwuj czas dla siebie w kalendarzu. Wyłączenie się powinno być Twoim wyborem.
💫 Rzeczywiste wyniki: Dzięki automatyzacji ClickUp firma Lulu Press oszczędza około godziny dziennie na osobę, co przekłada się na 12-procentowy wzrost wydajności.
4. AlertOps (najlepsze rozwiązanie do redukcji szumów opartej na AI i szybkiego reagowania na incydenty)
Liczba alertów nadal rośnie – 88% zespołów dokonało raportowania o wzroście w ciągu ostatniego roku, a prawie połowa twierdzi, że wzrost ten wyniósł ponad 25%. Tego rodzaju ciągły hałas prowadzi do zmęczenia alertami, które 76% centrów operacji bezpieczeństwa (SOC) wymienia obecnie jako swoje największe wyzwanie.
Taka jest rzeczywistość, z którą spotykasz się w przypadku każdego zamiennika Opsgenie. Kolejne narzędzie, które wybierzesz, musi być w stanie ocenić, które alerty wymagają podjęcia działań. AlertOps wykorzystuje w tym celu OpsIQ, rdzeń sztucznej inteligencji, który filtruje duplikaty, koreluje powiązane sygnały, podsumowuje kontekst i sugeruje kolejne kroki, dzięki czemu osoby reagujące widzą jeden jasny incydent zamiast przewijanego feedu.
Możesz zacząć od domyślnego harmonogramu dyżurów lub stworzyć własny, a następnie przekierowywać połączenia telefoniczne, SMS-y, wiadomości z aplikacji mobilnej, czatu lub e-maila zgodnie z regułami eskalacji, które działają do momentu, aż ktoś zajmie się problemem. Funkcja przekierowywania połączeń na żywo kieruje klientów do aktualnie dyżurującego personelu na podstawie harmonogramów w czasie rzeczywistym, a zasady oparte na umowach SLA eskalują przed naruszeniem, a nie po nim.
Ponadto platforma integruje się z ponad 200 narzędziami, od monitorowania i zgłaszania problemów po O365 i Slack, dzięki czemu segregacja zgłoszeń nie utknie z powodu braku kontekstu.
Najlepsze funkcje AlertOps
- Filtruj i blokuj powtarzające się alerty dzięki redukcji szumów opartej na AI, obsługiwanej przez OpsIQ™, która automatycznie podsumowuje alerty i sugeruje rozwiązania
- Zarządzaj harmonogramami dyżurów dzięki elastycznym regułom eskalacji, całodobowej obsłudze i przekierowywaniu połączeń na żywo w przypadku krytycznych problemów klientów
- Zautomatyzuj segregację i cykl pracy za pomocą szablonów IT bez kodowania, aby przyspieszyć reagowanie i zapewnić spójne obsługiwanie incydentów
- Zintegruj z ponad 200 gotowymi narzędziami, w tym Slack, O365, Jira, Dynatrace i ConnectWise, a także niestandardowymi integracjami dla aplikacji wewnętrznych
Ograniczenia AlertOps
- Ustawienia harmonogramu mogą początkowo wydawać się nieintuicyjne i wymagać wersji próbnej oraz błędu
- Interfejs użytkownika ma czasami pewne niedociągnięcia, a niektóre zaawansowane funkcje wymagają dodatkowych kroków w celu skonfigurowania
- Zgłoszono raportowanie opóźnień w synchronizacji kalendarza z systemami zewnętrznymi, takimi jak Outlook
Ceny AlertOps
- Starter: Free
- Standard: 10 USD/miesiąc na użytkownika
- Premium: 22 USD/miesiąc na użytkownika
- Enterprise: 34 USD/miesiąc za użytkownika
Oceny i recenzje AlertOps
- G2: 4,7/5 (ponad 150 recenzji)
- Capterra: 4,7/5 (ponad 20 recenzji)
Co użytkownicy mówią o AlertOps
Recenzja G2 jasno pokazuje:
Większość trzeciego kwartału ubiegłego roku spędziliśmy na testowaniu narzędzi do planowania dyżurów i powiadamiania dla jednego z naszych zespołów IT. Po znalezieniu AlertOps przestałem szukać dalej. Jest to niedrogie rozwiązanie, a zespół jest niezwykle pomocny i cierpliwy podczas procesu ustawienia i wdrażania. Od momentu pełnego skonfigurowania i uruchomienia systemu nie mieliśmy żadnych problemów!
Większość trzeciego kwartału ubiegłego roku spędziliśmy na testowaniu narzędzi do planowania dyżurów i powiadamiania dla jednego z naszych zespołów IT. Po znalezieniu AlertOps przestałem szukać dalej. Jest to niedrogie rozwiązanie, a zespół jest niezwykle pomocny i cierpliwy podczas procesu ustawienia i wdrażania. Od momentu pełnego skonfigurowania i uruchomienia systemu nie mieliśmy żadnych problemów!
📖 Przeczytaj również: Przykłady SOP: najlepsze praktyki w zakresie wydajności i zgodności z przepisami
5. Splunk On-Call (najlepsze rozwiązanie do uproszczenia planowania dyżurów i zmniejszenia wypalenia zawodowego)
Jeśli kiedykolwiek oglądałeś klasyczny skecz Abbotta i Costello „Who's on First?”, wiesz, jak trudno jest ustalić, kto jest za co odpowiedzialny. Podobnie może być w przypadku dyżurów, jeśli nie ma jasno określonego systemu.
To jest miejsce, gdzie Splunk On-Call wykonuje krok. ✨
Wystarczy raz skonfigurować mapy zespołów i harmonogramów, a powiadomienia będą pojawiać się wraz z kontekstem na dowolnym urządzeniu. Osoby reagujące na incydenty mogą potwierdzać, przekierowywać lub wstrzymywać powiadomienia z poziomu aplikacji na iOS lub Android, a platforma może otworzyć pokój do współpracy i rozpocząć przegląd po incydencie bez dodatkowych kroków.
Silnik reguł dodaje instrukcje postępowania i pulpity nawigacyjne jako załączniki do incydentów, dzięki czemu pierwsza osoba wezwana na miejsce nigdy nie zaczyna pracy „na zimno”. Uczenie maszynowe sugeruje odpowiednich respondentów na podstawie podobnych incydentów, co pomaga skrócić czas potrzebny na potwierdzenie i rozwiązanie problemu.
Najlepsze funkcje Splunk On-Call
- Wdrożenie automatyzacji eskalacji i cykli pracy reagowania na incydenty, aby przyspieszyć potwierdzanie i rozwiązywanie problemów
- Korzystaj z aplikacji na iOS i Androida, aby odbierać, odkładać, przekierowywać lub rozwiązywać alerty bezpośrednio z urządzenia mobilnego
- Uprość planowanie dzięki rotacjom, nadpisywaniu i zasadom eskalacji zaprojektowanym w celu sprawiedliwego rozłożenia obciążenia pracą
- Uzyskaj kontekst incydentów i historyczne ścieżki audytu w wsparciu dla szybszej segregacji i analizy po incydencie
- Wykorzystaj rekomendacje oparte na uczeniu maszynowym, aby zidentyfikować odpowiednich respondentów na podstawie danych dotyczących rozwiązań z przeszłości
Ograniczenia Splunk On-Call
- Interfejs może wydawać się początkowo skomplikowany, a nawigacja wymaga pewnego dostosowania
- Okazjonalne opóźnienia w okresach dużego ruchu mają wpływ na szybkość reakcji w czasie rzeczywistym
- Opcje licencjonowania i zarządzania użytkownikami mają większy limit w porównaniu z niektórymi konkurentami
Ceny Splunk On-Call
- Niestandardowe ceny
Oceny i recenzje Splunk On-Call
- G2: 4,6/5 (ponad 50 recenzji)
- Capterra: 4,5/5 (ponad 30 recenzji)
Co użytkownicy mówią o Splunk On-Call
W recenzji G2 znalazła się następująca notatka:
Możliwość tworzenia zespołów i konfigurowania zmian między nimi jest jedną z najbardziej pomocnych funkcji dostępnych na tej platformie. Splunk On-Call zapewnia łatwą integrację z kilkoma narzędziami, dzięki czemu jego ustawienie jest bardzo proste.
Możliwość tworzenia zespołów i konfigurowania zmian między nimi jest jedną z najbardziej pomocnych funkcji dostępnych na tej platformie. Splunk On-Call zapewnia łatwą integrację z kilkoma narzędziami, dzięki czemu jego ustawienie jest bardzo proste.
📝Przeczytaj również: Eliminacja rozrostu AI: jak kontekstowa AI zmienia wydajność w miejscu pracy
6. Datadog (najlepszy do pełnej obserwowalności stosu z zintegrowanym monitorowaniem bezpieczeństwa)
Dla użytkowników Opsgenie problemem jest kontekst. Wyświetla się alert, ale nadal trzeba szukać logów, śladów, metryk i sygnałów bezpieczeństwa, aby dowiedzieć się, co faktycznie jest uszkodzone.
Datadog łączy te widoki w jedną oś czasu. Infrastruktura, kontenery, rozwiązania bezserwerowe, bazy danych i aplikacje znajdują się obok logów, śladów i RUM, dzięki czemu osoby reagujące na incydenty nie muszą zgadywać.
Watchdog i nowe funkcje AI wskazują anomalie, grupują powiązane sygnały i podsumowują prawdopodobieństwo wpływu, co ogranicza konieczność wielokrotnego sprawdzania podczas segregacji. Jeśli masz już narzędzie do powiadamiania, możesz wprowadzić do niego alerty Datadog.
Jeśli chcesz pozostać w Datadog, funkcja zarządzania incydentami zapewnia dostęp do informacji o właścicielach, osiach czasu, aktualizacjach dla interesariuszy i działaniach następczych bez opuszczania platformy.
Praktyczne korzyści są widoczne od razu. Mniej irytujących powiadomień, ponieważ duplikaty są scalane. Szybsza analiza przyczyn źródłowych, ponieważ każde powiadomienie zawiera dane i logi, które je wyjaśniają. Wyższy poziom bezpieczeństwa, ponieważ nieprawidłowe konfiguracje i luki w zabezpieczeniach są wykrywane wraz z danymi dotyczącymi wydajności.
Dzięki ponad 900 integracjom, jasnym celom poziomu usług (SLO) i pulpitom nawigacyjnym Twój zespół może przejść od sygnału do naprawy w jednym miejscu, zamiast przechodzić między zakładkami. Jest to dobry wybór dla migracji z Opsgenie, które chcą również wyeliminować luki w obserwowalności.
Najlepsze funkcje Datadog
- Monitoruj infrastrukturę, logi, aplikacje, bazy danych i obciążenia pracą z jednej platformy.
- Zabezpiecz środowiska w chmurze dzięki wbudowanemu zarządzaniu podatnością na zagrożenia, mapowaniu zgodności i zarządzaniu uprawnieniami.
- Wykorzystaj monitorowanie syntetyczne i monitorowanie rzeczywistych użytkowników, aby wykrywać problemy, zanim zauważą je klienci.
- Zautomatyzuj cykl pracy dzięki ponad 900 integracjom i gotowym pulpitom nawigacyjnym.
- Wykorzystaj funkcje /AI i uczenia maszynowego, takie jak Watchdog i LLM Observability, do wykrywania anomalii i uzyskiwania inteligentnych informacji.
Ograniczenia Datadog
- Ceny mogą szybko rosnąć wraz z dużą liczbą hostów i dodatków.
- Interfejs i pulpity nawigacyjne mogą wydawać się przytłaczające dla nowych użytkowników.
- Niektóre zaawansowane funkcje bezpieczeństwa są dostępne tylko w planach wyższych poziomów.
Ceny Datadog
- Free
- Pro: 15 USD/miesiąc za każdego hosta
- Enterprise: 23 USD/miesiąc za każdego hosta
- DevSecOps Pro: 22 USD/miesiąc za host
- DevSecOps Enterprise: 34 USD/miesiąc za host
Oceny i recenzje Datadog
- G2: 4,4/5 (ponad 660 recenzji)
- Capterra: 4,6/5 (ponad 320 recenzji)
Co użytkownicy mówią o Datadog
W recenzji Capterra napisano:
Ogólnie rzecz biorąc, po pewnych wzlotach i upadkach, są oni dobrym partnerem. Ich narzędzie jest niezwykle wydajne i umożliwia wiele doskonałych praktyk w zakresie obserwowalności, ale trzeba za nie zapłacić.
Ogólnie rzecz biorąc, po pewnych wzlotach i upadkach, są oni dobrym partnerem. Ich narzędzie jest niezwykle wydajne i umożliwia wiele doskonałych praktyk w zakresie obserwowalności, ale trzeba za nie zapłacić.
📖 Przeczytaj również: Sposoby zmniejszenia ryzyka związanego z cyberbezpieczeństwem w zarządzaniu projektami
7. Squadcast (najlepsze rozwiązanie do zunifikowanego dyżurowania i reagowania na incydenty o dużej wartości)
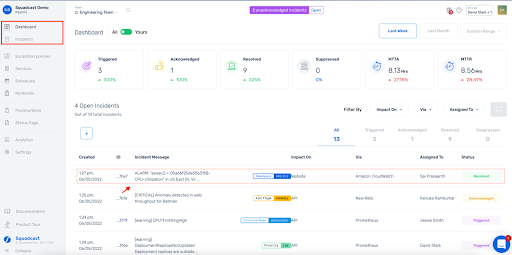
Kiedy masz do czynienia z wieloma harmonogramami i zasadami dotyczącymi godzin nadliczbowych specyficznymi dla poszczególnych klientów, potrzebujesz alertów, aby przestrzegać tych zasad bez konieczności ręcznego wprowadzania zmian.
To właśnie w tej niszy Squadcast zdobywa zaufanie. 🌟
Użytkownicy zrobili notatkę, że harmonogramy i nadpisania są łatwe do modelowania, a aplikacja mobilna będzie eskalować zgłoszenia, jeśli pierwsza osoba odpowiedzialna za reagowanie nie odpowie, dzięki czemu krytyczne problemy nie zostaną pominięte.
Dla dostawców usług zarządzanych (MSP) i zespołów obsługujących wielu klientów ważne jest, aby można było ustawić całodobową obsługę niektórych klientów, a dla innych włączyć powiadomienia po godzinach pracy tylko w przypadku krytycznych incydentów. Interfejs użytkownika ułatwia przeglądanie aktywnych incydentów i sprawdzanie, kto jest za nie odpowiedzialny.
To coś więcej niż tylko paging. Niezawodna automatyzacja pozwala na przetwarzanie incydentów w spójnych cyklach pracy dzięki runbookom i aktualizacjom statusu, śledzeniu SLO i wykrywaniu wzorców na podstawie których można podjąć rzeczywiste działania, a ceny są na tyle przejrzyste, że mniejsze zespoły nie czują się wykluczone.
Najlepsze funkcje Squadcast
- Zautomatyzuj planowanie dyżurów dzięki elastycznym eskalacjom i nadpisywaniu ustawień.
- Zmniejsz zmęczenie alertami poprzez konsolidację i deduplikację powiadomień.
- Szybciej rozwiązuj incydenty dzięki instrukcjom i cyklom pracy
- Informuj interesariuszy za pomocą konfigurowalnych stron statusu.
- Gromadź analizy po incydentach i spostrzeżenia, aby budować kulturę uczenia się.
Ograniczenia Squadcast
- Widoki harmonogramów mogą być przepełnione, gdy aktywnych jest wiele grafików, co utrudnia szybkie sprawdzenie, kto jest dyżurny.
- Raportowano sporadyczne opóźnienia w synchronizacji alertów z niektórych integracji
- Free Plan jest limitowany dla zespołów, które chcą mieć dostęp do stron statusowych i bardziej szczegółowych analiz
Ceny Squadcast
- Pro: 12 USD/miesiąc na użytkownika
- Premium: 19 USD/miesiąc na użytkownika
- Enterprise: Ceny niestandardowe
Oceny i recenzje Squadcast
- G2: 4,4/5 (ponad 300 recenzji)
- Capterra: zbyt mało recenzji
Co użytkownicy mówią o Squadcast
W recenzji G2 pojawiła się wzmianka:
Squadcast może pobierać dane z różnych narzędzi monitorujących, które posiadamy, i łatwo ustawić harmonogramy i nadpisywania dotyczące tego, kto powinien być powiadamiany o różnych typach problemów.
Squadcast może pobierać dane z różnych narzędzi monitorujących, które posiadamy, i łatwo ustawić harmonogramy i nadpisywania dotyczące tego, kto powinien być powiadamiany o różnych typach problemów.
📖 Przeczytaj również: Zarządzanie ryzykiem cyberbezpieczeństwa
8. FireHydrant (najlepsze rozwiązanie do automatyzacji skryptów i własności usług)
To oprogramowanie do zarządzania incydentami oferuje dobrze zorganizowany proces, który zapewnia płynne działanie usług.
FireHydrant skupia się na reagowaniu w oparciu o instrukcje postępowania, katalog usług i wspólną przestrzeń roboczą. Po zgłoszeniu incydentu platforma uruchamia kanał w Slacku lub Teams, załącza odpowiednią instrukcję postępowania, pobiera własność z katalogu usług i rozpoczyna tworzenie audytowalnej osi czasu.
Jednocześnie AI tego narzędzia pozwala ograniczyć koszty dzięki natychmiastowym podsumowaniom incydentów, sugerowanym aktualizacjom dla interesariuszy i transkrypcjom spotkań na żywo, dzięki czemu zespół może skupić się na łagodzeniu skutków incydentów, a nie na sporządzaniu notatek.
Teams podkreślają również responsywne wsparcie techniczne i podejście API first z Terraform, które pozwala liderom operacyjnym bezproblemowo włączyć FireHydrant do istniejących cykli pracy.
Najlepsze funkcje FireHydrant
- Zautomatyzuj reagowanie na incydenty dzięki podręcznikom zawierającym najlepsze praktyki
- Zarządzaj harmonogramami dyżurów i alertami za pomocą Signals, zakończone zasadami eskalacji
- Scentralizuj własność za pomocą katalogu usług, aby odpowiedni inżynierowie mogli natychmiast reagować
- Współpracuj bezpośrednio w Slacku lub Teams dzięki automatycznie generowanym kanałom i aktualizacjom
- Wykorzystaj wzbogacone o AI retrospektywy i analizy, aby uzyskać wgląd w dane i zwiększyć niezawodność w miarę
Limity FireHydrant
- Zaawansowane funkcje automatyzacji wymagają planów wyższego poziomu
- Krzywa uczenia się w zakresie ustawiania niestandardowych cykli pracy i integracji
- Ograniczona liczba osób reagujących i instrukcji postępowania w planie podstawowym
Ceny FireHydrant
- Free: Dwutygodniowa wersja próbna
- Platforma Pro: 9600 USD/rok na użytkownika
- Enterprise: Ceny niestandardowe
Oceny i recenzje FireHydrant
- G2: 4,5/5 (ponad 130 recenzji)
- Capterra: zbyt mało recenzji
Co użytkownicy mówią o FireHydrant
Użytkownik G2 napisał:
Działając w pełni poza Slackiem lub innym narzędziem do czatu/współpracy, FireHydrant integruje się i pozwala otwierać/aktualizować/rozwiązywać incydenty bez konieczności opuszczania miejsca, w którym odbywa się reagowanie na incydenty.
Działając w pełni poza Slackiem lub innym narzędziem do czatu/współpracy, FireHydrant integruje się i pozwala otwierać/aktualizować/rozwiązywać incydenty bez konieczności opuszczania miejsca, w którym odbywa się reagowanie na incydenty.
9. TaskCall (najlepsze rozwiązanie do niedrogiego zarządzania incydentami z automatyzacją)
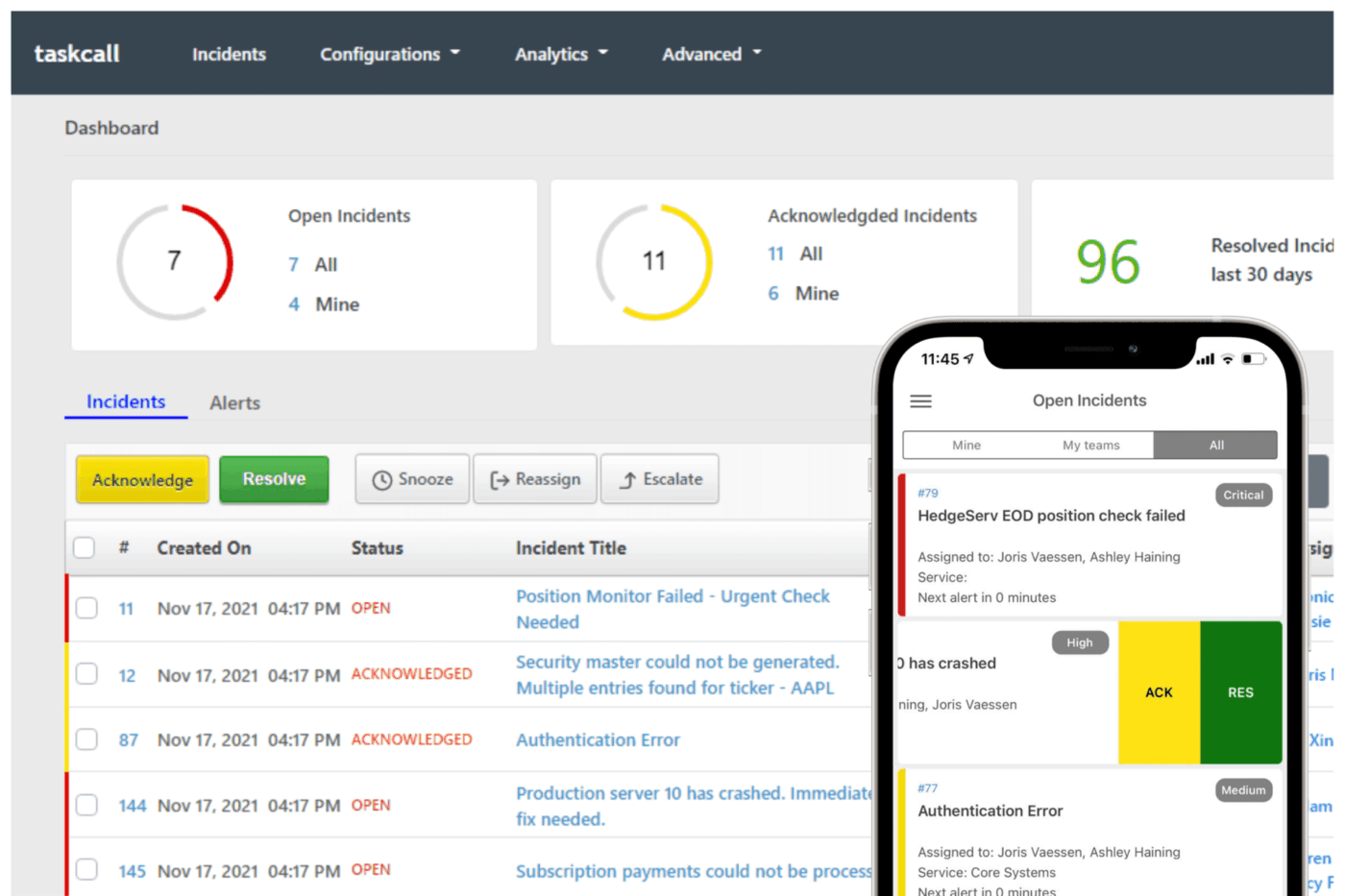
W niedawnym badaniu dotyczącym cyberzagrożeń reagowanie na incydenty zostało uznane za jeden z najważniejszych elementów kontroli, które organizacje muszą wzmocnić, aby zmniejszyć narażenie.
Podkreśla to, jak istotne stały się szybkie i niezawodne cykle pracy reagowania na incydenty.
Teams zazwyczaj nie mają problemów z samym alertem, ale z zamieszaniem, które następuje po nim. Kto jest teraz naprawdę odpowiedzialny za daną sprawę? Czy alert dotyczy aplikacji, infrastruktury czy obsługi klienta? Jak informować kierownictwo bez przejmowania kontroli nad naprawą?
TaskCall bezpośrednio zajmuje się takimi sytuacjami. Dyżur jest ustalany na podstawie zawartości incydentu, dzięki czemu zgłoszenie trafia do odpowiedniej osoby, a automatyczna eskalacja wypełnia luki. Powiadomienia są wysyłane przez telefon, SMS, push, e-mail lub czat.
Aby ograniczyć ilość niepotrzebnych informacji, funkcja analizy wydarzeń koreluje duplikaty i blokuje powiadomienia o niskiej wartości. Kontekst jest tworzony poprzez zbieranie sygnałów z narzędzi takich jak AWS, Datadog, Slack, Jira i Zendesk, co oznacza, że inżynierowie widzą wpływ i własność zamiast surowego strumienia alertów.
Najlepsze funkcje TaskCall
- Zautomatyzuj planowanie dyżurów dzięki dynamicznej rotacji i wielopoziomowej eskalacji
- Zmniejsz ilość niepotrzebnych informacji dzięki analizie wydarzeń opartej na AI i przekierowywaniu pod warunkiem
- Obsługuj incydenty w DevOps, IT-Ops i BizOps na jednej zunifikowanej platformie
- Zintegruj z narzędziami do monitorowania, rejestrowania i wsparcia, takimi jak AWS, Jira, Zendesk i Slack
- Zapewnij pełny zasięg dzięki aplikacjom mobilnym, powiadomieniom push, SMS-om i alertom głosowym
Ograniczenia TaskCall
- Free Plan ograniczony do pięciu użytkowników, co może nie wystarczyć dla rozwijających się zespołów
- Większość funkcji analitycznych i pulpitów nawigacyjnych jest limitowana do droższych planów
Ceny TaskCall
- Free
- Starter: 9 USD miesięcznie za użytkownika
- Biznes: 19 USD/miesiąc za użytkownika
- Operacje cyfrowe: 29 USD/miesiąc na użytkownika
Oceny i recenzje TaskCall
- G2: zbyt mało recenzji
- Capterra: zbyt mało recenzji
10. ilert (najlepsze rozwiązanie do zarządzania incydentami oparte na AI, z naciskiem na prywatność)
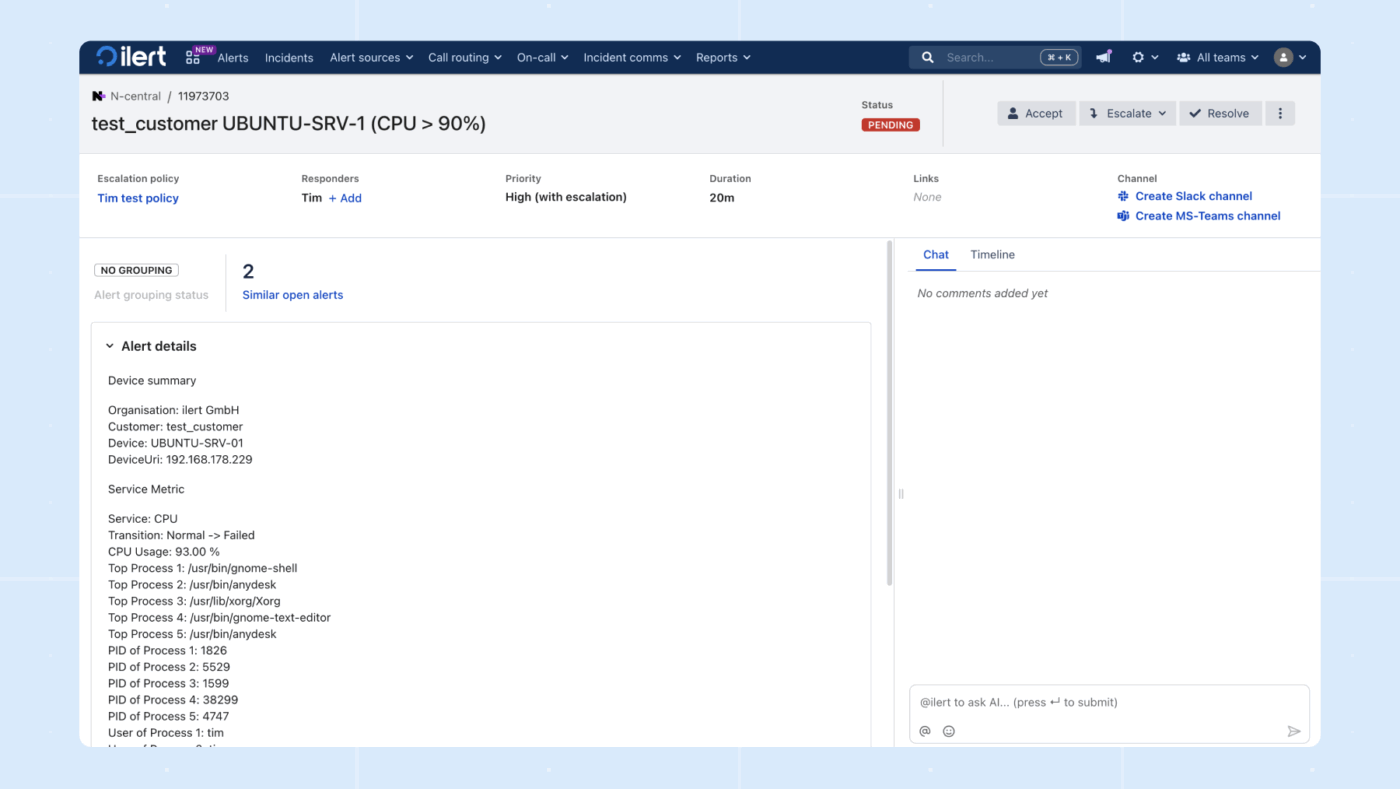
ilert to platforma do zarządzania dyżurami i powiadamiania o incydentach, która kładzie duży nacisk na niezawodność i prywatność danych. Pomaga zespołom zapewnić, że krytyczne alerty z systemów monitorowania docierają podpowiedź do odpowiednich inżynierów dyżurnych.
Platforma oferuje elastyczne planowanie dyżurów, wielopoziomowe zasady eskalacji oraz powiadomienia za pośrednictwem wielu kanałów, w tym powiadomień push, SMS-ów i połączeń głosowych.
Przekierowywanie połączeń zgodnie z aktualnym harmonogramem i ścieżką eskalacji oznacza, że połączenia niestandardowych klientów trafiają do właściwej osoby, zamiast odbijać się od jednej osoby do drugiej w drzewie telefonicznym.
W Slacku lub Teamsie osoby reagujące na incydenty pracują nad nim na czacie, podczas gdy Ilert rejestruje kontekst, osie czasu i działania następcze.
Wirtualny asystent AI odbiera połączenia na infolinię, zbiera odpowiednie informacje i natychmiast powiadamia inżyniera dyżurnego. Responder analizuje wskaźniki, logi i ostatnie zmiany w całym stosie, wskazuje prawdopodobne przyczyny, sugeruje, kogo jeszcze należy zaangażować, a nawet proponuje ścieżkę przywrócenia stanu poprzedniego w celu szybszego złagodzenia skutków.
Zachowujesz kontrolę na każdym kroku.
najlepsze funkcje ilert
- Zapewnij niezawodne powiadomienia wielokanałowe za pośrednictwem połączeń głosowych, SMS-ów, powiadomień push i czatu
- Wdrożenie automatyzacji zarządzania dyżurami dzięki harmonogramom i ścieżkom eskalacji
- Dostarczaj szybkie aktualizacje dzięki stronom statusowym opartym na AI i komunikacji z interesariuszami
- Skorzystaj z ilert Responder AI, aby analizować incydenty, wykrywać przyczyny źródłowe i sugerować działania
- Zintegruj z narzędziami do monitorowania i ITSM, takimi jak Prometheus, Datadog, Jira i Slack
ograniczenia ilert limit
- Ceny mogą wydawać się wysokie dla mniejszych zespołów
- Niektóre integracje wymagają dodatkowego wysiłku na ustawienia
- Aplikacja mobilna mogłaby skorzystać z bardziej zaawansowanych funkcji
ceny ilert
- Free
- Pro: 24 USD/miesiąc za użytkownika
- Skala: 49 USD/miesiąc na użytkownika
- Enterprise: Ceny niestandardowe
oceny i recenzje ilert
- G2: zbyt mało recenzji
- Capterra: 4,7/5 (ponad 60 recenzji)
Co użytkownicy mówią o ilert
W recenzji Capterra dokonano raportowania:
Uważam, że to narzędzie jest bardzo intuicyjne i skuteczne w zarządzaniu dyżurami w zespołach IT. Zapewnia elastyczność, umożliwiając reagowanie bezpośrednio przez aplikację, SMS-y lub połączenia telefoniczne, co sprawia, że jest szczególnie praktyczne w rzeczywistych sytuacjach.
Uważam, że to narzędzie jest bardzo intuicyjne i skuteczne w zarządzaniu dyżurami w zespołach IT. Zapewnia elastyczność, umożliwiając reagowanie bezpośrednio przez aplikację, SMS-y lub połączenia telefoniczne, co sprawia, że jest szczególnie praktyczne w rzeczywistych sytuacjach.
11. Zenduty (najlepsze rozwiązanie do reagowania na incydenty oparte na AI na dużą skalę)
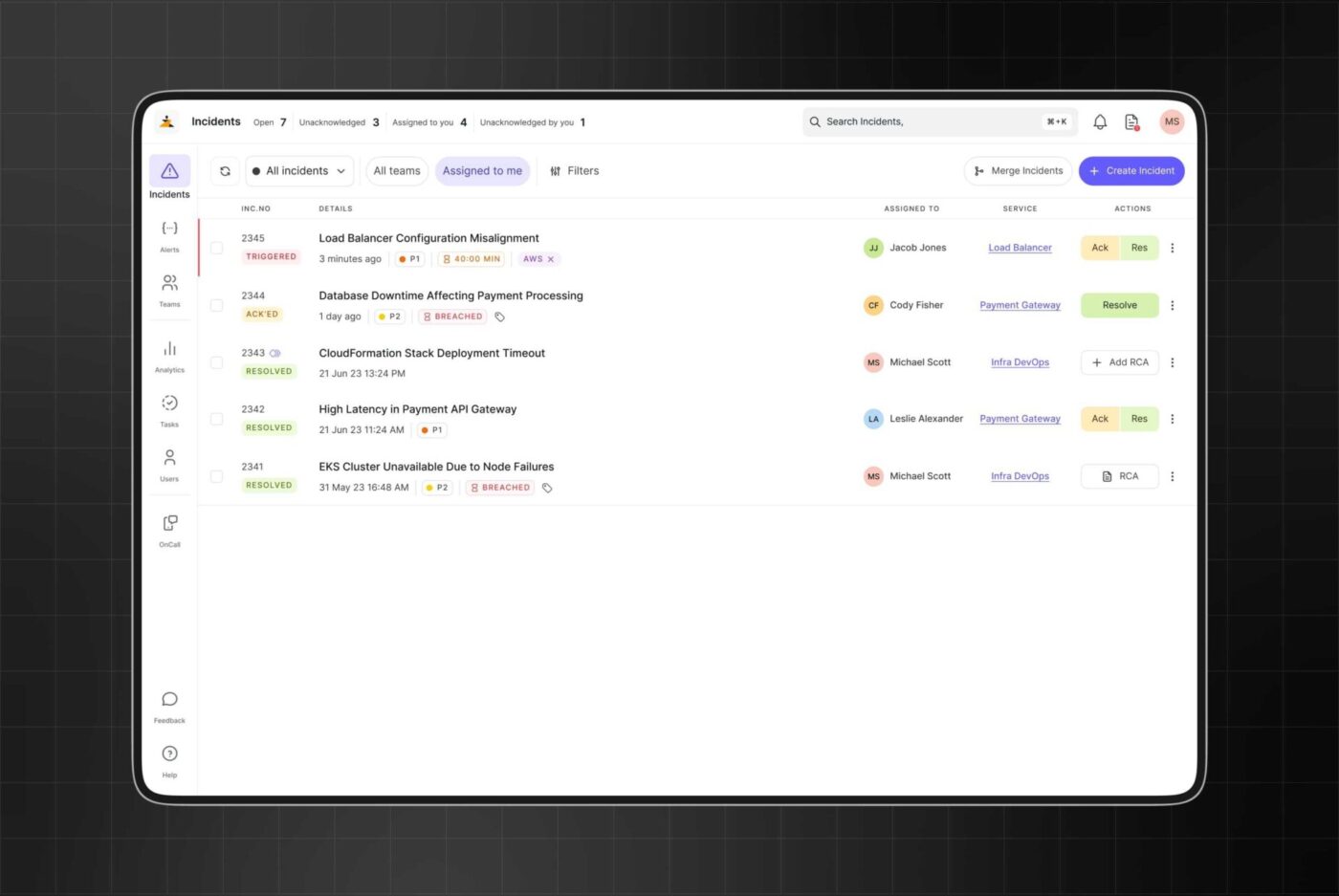
Zenduty pomaga zespołom inżynierów i DevOps skupić się na istotnych sygnałach, skracając średni czas rozwiązania problemu (MTTR) i zapewniając organizacjom jedną, niezawodną platformę do zarządzania incydentami.
Użytkownicy nieustannie chwalą szybkie i niezawodne alerty, które są wysyłane bez opóźnień w formie powiadomień push, połączeń telefonicznych i SMS-ów, dzięki czemu inżynierowie dyżurni mogą potwierdzić otrzymanie powiadomienia i wrócić do pracy. Zespoły doceniają również możliwość dostosowania powiadomień według ważności, usługi lub typu incydentu, dzięki czemu w odpowiednim momencie kontaktowana jest właściwa osoba, a nie wszyscy naraz.
Platforma oferuje wsparcie dla wspólnego reagowania na incydenty, oferując role związane z incydentami, szablony zadań i zintegrowane kanały komunikacji. Istotną funkcją jest podejście oparte na systemie dowodzenia w sytuacjach kryzysowych (ICS), które zapewnia ustrukturyzowane ramy zarządzania incydentami na dużą skalę.
Jeśli chcesz odejść od Opsgenie, Zenduty jest dobrym rozwiązaniem, a jego wsparcie migracyjne zbiera pozytywne recenzje.
Najlepsze funkcje Zenduty
- Zapewnij zarządzanie incydentami oparte na AI dzięki ZenAI
- Zapewnij wsparcie zaawansowanego planowania dyżurów dzięki konfigurowalnym rotacjom i eskalacjom
- Zautomatyzuj procedury reagowania na incydenty, aby zadania i działania następcze były konsekwentnie śledzone
- Zintegruj się płynnie z ponad 150 narzędziami, takimi jak Slack, Teams, Jira, Datadog i Grafana
- Wysyłaj powiadomienia mobilne w czasie rzeczywistym na urządzenia z systemem iOS, Android, a nawet smartwatche
Ograniczenia Zenduty
- Funkcja wyszukiwania może łączyć wiele incydentów, utrudniając ich śledzenie
- Niektóre zaawansowane funkcje są dostępne wyłącznie w planach wyższych poziomów
- W złożonych ustawieniach powtarzające się powiadomienia mogą prowadzić do powielania alertów
Ceny Zenduty
- Free
- Starter: 6 USD/miesiąc za użytkownika
- Wzrost: 16 USD/miesiąc na użytkownika
- Enterprise: 25 USD miesięcznie za użytkownika
Oceny i recenzje Zenduty
- G2: 4,6/5 (ponad 135 recenzji)
- Capterra: zbyt mało recenzji
Co użytkownicy mówią o Zenduty
W recenzji G2 zauważono:
W Zenduty najbardziej podoba mi się możliwość uzyskania analiz opartych na danych analitycznych. Analizując incydenty, możemy śledzić trendy – np. w które dni, usługi lub zmiany wystąpiło więcej problemów, zidentyfikować, co poszło nie tak, i określić obszary wymagające poprawy.
W Zenduty najbardziej podoba mi się możliwość uzyskania analiz opartych na danych analitycznych. Analizując incydenty, możemy śledzić trendy – np. w które dni, usługi lub zmiany wystąpiło więcej problemów, zidentyfikować, co poszło nie tak, i określić obszary wymagające poprawy.
📖 Przeczytaj również: Najlepsze oprogramowanie do zarządzania operacjami IT
12. Incident. io (najlepsze rozwiązanie do reagowania na incydenty w środowisku Slack)
Wyobraźmy sobie przez chwilę, że jesteśmy w trakcie incydentu. Pager zaczyna dzwonić. Ludzie budzą się. W Opsgenie potwierdzasz, a następnie szukasz odpowiedniego pomieszczenia, a następnie kopiujesz kontekst w jeszcze inne miejsce, aby wszyscy mogli zobaczyć, co się dzieje.
Właśnie ten moment większość zespołów chce naprawić. W tym zakresie incident.io wyróżnia się na tle innych rozwiązań.
Wystarczy zgłosić się w Slacku, a pojawi się przejrzysta przestrzeń z rolami, harmonogramem i dwoma lub trzema kolejnymi krokami. Możesz zadzwonić, wysłać SMS-a, e-maila lub po prostu kliknąć, aby potwierdzić. Praca rozpoczyna się natychmiast i pozostaje widoczna.
Użytkownicy po zmianie opisują ten sam rytm pracy. Kanał uruchamia się tylko z potrzebnymi sygnałami. Aplikacja przypomina o działaniach następczych i tworzy zwięzłe podsumowanie, podczas gdy Ty nadal zajmujesz się rozwiązywaniem problemów. Aktualizacje statusu dla standardowych klientów są gotowe do wysłania bez opuszczania wątku. Już samo to ogranicza rozmowy, które zwykle toczą się na czatach i w prywatnych wiadomościach.
Wdrożenie było proste dla zespołów o bardzo różnej wielkości. Mniejsze grupy mówią o podłączeniu go do Linear i New Relic w ciągu kilku tygodni i uzyskaniu rzeczywistej wartości już pierwszego dnia. Większe organizacje udostępniają, że wdrożyły go w wielu zespołach w ciągu około miesiąca i nie wstrzymały prac nad planem działania, aby to zrobić.
Najlepsze funkcje Incident.io
- Zarządzaj incydentami od początku do końca bezpośrednio w Slacku lub Microsoft Teams
- Wykorzystaj AI SRE do sugerowania poprawek, badania problemów i tworzenia komunikatów
- Zarządzaj harmonogramami dyżurów dzięki redukcji szumów opartej na AI
- Zautomatyzuj aktualizacje statusu dla klientów i interesariuszy
- Uzyskaj wgląd w trendy, osie czasu i wskaźniki MTTx dzięki pulpitom nawigacyjnym
Ograniczenia Incident.io
- Interfejs może wydawać się przepełniony wieloma powiadomieniami Slack
- Zaawansowana konfiguracja (np. ścieżki eskalacji) może wymagać dostosowania
- Niektóre funkcje AI mają limit do języka angielskiego
Ceny Incident.io
- Podstawowy: Free
- Zespół: 19 USD/miesiąc na użytkownika
- Pro: 25 USD/miesiąc za użytkownika
- Enterprise: Ceny niestandardowe
Oceny i recenzje Incident.io
- G2: 4,8/5 (ponad 180 recenzji)
- Capterra: zbyt mało recenzji
Co użytkownicy mówią o Incident. io
W tej recenzji G2 udostępniono:
Moim zdaniem incident. io zapewnia idealną równowagę między nie przeszkadzaniem a zapewnianiem struktury, procesów i gromadzenia danych do zarządzania incydentami.
Moim zdaniem incident. io zapewnia idealną równowagę między nie przeszkadzaniem a zapewnianiem struktury, procesów i gromadzenia danych do zarządzania incydentami.
💡Wskazówka dla profesjonalistów: Użyj gotowych agentów, aby odpowiadać na pytania zespołu lub udostępniać aktualizacje, albo skonfiguruj niestandardowego agenta ClickUp AI, aby monitorować statusy zadań i terminy wykonania oraz wysyłać przypomnienia, eskalować problemy lub aktualizować statusy w razie potrzeby, aby przyspieszyć realizację zadań.
Ten wideo pokazuje, jak to zrobić:
Czego można się spodziewać podczas i po migracji z Opsgenie
Przejście z Opsgenie może przypominać pakowanie domu, w którym mieszkałeś przez lata. Każdy harmonogram, zasada eskalacji i integracja mają swoje miejsce, a myśl o przeniesieniu tego wszystkiego do nowego domu może wydawać się zniechęcająca.
Atlassian oferuje narzędzie do migracji w aplikacji, które umożliwia przejście na Jira Service Management lub Compass. Proces ten jest uporządkowany, przewidywalny i zaprojektowany tak, aby zminimalizować zakłócenia.
Jeśli zdecydujesz się na jedno z tych rozwiązań, wystarczy przejrzeć swój plan, ustawić datę migracji i pozwolić narzędziu wykonać całą ciężką pracę. Zobaczmy, jak to działa, i oceńmy, czy jest to dobry wybór dla Twojej organizacji.
Przegląd przepływu migracyjnego
Krok 1 → Przejrzyj i wybierz swoją ścieżkę
Oceń swój plan Opsgenie i zdecyduj, czy Jira Service Management (skupiająca się na ITSM) lub Compass (skupiająca się na programistach) jest odpowiednim rozwiązaniem.
Krok 2 → Zaplanuj datę migracji
Wybierz osie czasu, które pasują do Twojego cyklu rozliczeniowego i gotowości zespołu.
Krok 3 → Zatwierdź rozliczenie
Administrator rozliczeń Atlassian potwierdza plan, aby nowy produkt mógł zostać dostarczony.
Krok 4 → Migracja danych w tle
Dane Opsgenie zaczynają się synchronizować, podczas gdy Twój zespół pracuje jak zwykle.
Krok 5 → Przejście i zamknięcie
Masz 120 dni na sfinalizowanie przeniesienia przed wyłączeniem Opsgenie.
Krótko mówiąc, oto czego możesz się spodziewać:
- Skorzystaj z narzędzia do migracji z przewodnikiem, aby zautomatyzować żmudne zadania
- Zachowaj pełny dostęp do Opsgenie podczas migracji i po jej zakończeniu, aż do momentu wyłączenia usługi
- Postępuj zgodnie ze spersonalizowanymi przewodnikami migracji w Jira Service Management lub Compass
- Dostosuj cykle pracy i zmień ustawienia podczas 120-dniowego okresu przejściowego
- Zapewnij ciągłość alertów, harmonogramów i integracji bez zakłóceń
Zalety i wady migracji z Opsgenie do Jira Service Management
Zalety:
- Pozwala on stworzyć płynny, ujednolicony cykl pracy
- Dla zespołów, które już zainwestowały znaczne środki w ekosystem Atlassian, może to być wygodna i opłacalna decyzja
- Skuteczna analiza po incydencie w Jira upraszcza proces śledzenia działań następczych
- Konsolidacja danych dotyczących incydentów w JSM pozwala na tworzenie bardziej rozbudowanych i kompleksowych raportów
Wady:
- Niektóre zaawansowane funkcje samodzielnego Opsgenie mogą nie być od razu dostępne w JSM
- Przejście do szerszego środowiska JSM może zwiększyć złożoność i hałas
- Teams będą musiały przejść ponowne szkolenie dotyczące nowego interfejsu i cykli pracy w ramach JSM
Oto kilka opinii użytkowników Reddita na ten temat
Ten użytkownik Reddita uznał, że zmiana ta ogólnie okazała się dla niego korzystna:
Nie poszło nam tak źle. Muszę ponownie przyjrzeć się ustawieniu ról i uprawnień, ale wszystko wydawało się działać całkiem dobrze, z wyjątkiem sytuacji, gdy masz dokładnie takie same nazwy zespołów Jira jak w OpsGenies. Nie połączyły się one dobrze i kilka z nich uległo uszkodzeniu. Zalecam zmianę tych nazw, jeśli tak jest w Twoim przypadku.
Nie poszło nam tak źle. Muszę ponownie przyjrzeć się ustawieniu ról i uprawnień, ale wszystko wydawało się działać całkiem dobrze, z wyjątkiem sytuacji, gdy masz dokładnie takie same nazwy zespołów Jira jak w OpsGenies. Nie połączyły się one dobrze i kilka z nich uległo uszkodzeniu. Zalecam zmianę tych nazw, jeśli tak jest w Twoim przypadku.
Oto kolejna osoba, która najwyraźniej nie miała najlepszych doświadczeń:
Jeśli ktoś rozważa tę opcję: przeszliśmy na Jira Service Management, jest to część naszego pakietu, za który już zapłaciliśmy (firma agresywnie oszczędza). Jest tak zły, że nie potrafię tego nawet opisać. Nie rozważajcie tej opcji.
Jeśli ktoś rozważa tę opcję: przeszliśmy na Jira Service Management, jest to część naszego pakietu, za który już zapłaciliśmy (firma agresywnie oszczędza). Jest tak zły, że nie potrafię tego nawet opisać. Nie rozważajcie tej opcji.
A oto kolejna osoba, która już po sześciu miesiącach korzystania z JSM zamierza ponownie zmienić rozwiązanie:
JSM jest okropny. Nie można go w żadnym wypadku porównać do PagerDuty, Rootly czy Incident. io. Przechodziliśmy na niego około 6 miesięcy temu w pracy i już szukamy alternatyw. Jest bardzo nieelastyczny, prawie nie ma integracji, nie ma dobrego wsparcia dla Slacka, a inżynierowie dość często przegapiają alerty dyżurów i wiadomości (nigdy nie mieliśmy tego problemu w OpeGenie).
JSM jest okropny. Nie można go w żadnym wypadku porównać do PagerDuty, Rootly czy Incident. io. Przechodziliśmy na niego około 6 miesięcy temu w pracy i już szukamy alternatyw. Jest bardzo nieelastyczny, prawie nie ma integracji, nie ma dobrego wspierania w Slacku, a inżynierowie dość często przegapiają alerty dyżurów i wiadomości (nigdy nie mieliśmy tego problemu w OpeGenie).
Inna alternatywa oferowana przez Atlassian, Compass, nie jest bezpośrednią alternatywą dla Opsgenie. Jest to raczej platforma dla programistów, zaprojektowana do mapy i zarządzania komponentami, usługami i zależnościami złożonej architektury oprogramowania.
Zalecamy rozważenie tych czynników przed podjęciem decyzji o wyborze najlepszej alternatywy dla Opsgenie dla Twojego zespołu.
Opsgenie dzwoni, ClickUp odbiera
Rezygnacja z Opsgenie może wydawać się dużym krokiem, ale potraktuj to jako okazję do ułatwienia życia swojemu zespołowi.
Widziałeś już, jak wypadają inne narzędzia, z których każde ma swoje mocne strony, ale także limit.
Jednak ClickUp po cichu podbija serca użytkowników. 🤗
Oto dlaczego: Łączy zadania, komunikację i cykle pracy w jednym miejscu. Nie musisz przełączać się między ekranami ani łączyć oddzielnych narzędzi. Zamiast tego Twój zespół pozostaje w połączeniu, ma jasność co do priorytetów i jest pewny tego, co należy zrobić dalej.
Wybór odpowiedniego rozwiązania do zarządzania incydentami to nie tylko kwestia alertów — chodzi o stworzenie solidnych ram zarządzania incydentami, które wspierają długoterminową wydajność operacyjną. Dzięki ClickUp Twój zespół może proaktywnie zarządzać incydentami, jednocześnie ograniczając zakłócenia i zapewniając spójność wszystkich reakcji. 😌
Jeśli chcesz mieć mniej zmartwień i więcej przejrzystości, teraz jest odpowiedni moment, aby zarejestrować się w ClickUp!
Często zadawane pytania (FAQ)
Migracje Opsgenie muszą zostać zaplanowane przed kwietniem 2027 r. Po tej dacie dane Opsgenie nie będą już dostępne.
Niektóre z najsilniejszych alternatyw to Jira Service Management, PagerDuty, FireHydrant, TaskCall, ilert, Zenduty i incident.io. Każda z nich oferuje inną równowagę między zarządzaniem dyżurami, automatyzacją i integracjami. Jeśli jednak chcesz mieć kompleksową platformę opartą na AI, która pozwala przechowywać przepływy pracy, komunikację i dokumentację w jednym miejscu, wybierz ClickUp.
Jira Service Management zawiera większość podstawowych funkcji Opsgenie, takich jak powiadomienia, planowanie dyżurów i cykle pracy związane z incydentami, ale niektóre zaawansowane funkcje mogą się różnić. Compass jest opcją dla zespołów programistycznych skupiających się na katalogach usług i śledzeniu komponentów.
Tak. Atlassian dostarcza narzędzie do migracji w aplikacji, które automatycznie przenosi alerty, harmonogramy i zasady eskalacji. Przed podjęciem commit możesz nawet przetestować migrację na koncie demo.
Tak. Narzędzia takie jak Cabot, OpenDuty i Alertmanager można dostosować jako niestandardowe zamienniki open source, choć mogą one wymagać więcej ustawień i konserwacji.
Koszty zależą od wybranej platformy. Jira Service Management, Compass i inne alternatywne rozwiązania oferują ceny wielopoziomowe, często w przeliczeniu na użytkownika miesięcznie. Niektóre narzędzia open source są bezpłatne, ale wymagają ponoszenia kosztów infrastruktury i wsparcia technicznego.
Tak. Twój zespół może nadal korzystać z Opsgenie w okresie migracji, a integracje pozostaną aktywne do momentu całkowitego wyłączenia Opsgenie. Następnie należy je ponownie skonfigurować na nowej platformie.