
Ti è mai capitato di essere a cena quando il tuo telefono vibra con un "avviso critico" che si rivela essere nient'altro che un registro di routine? È frustrante, ma almeno sapevi che Opsgenie ti copriva le spalle.
Ora arriva la vera sfida: Atlassian ha smesso di vendere Opsgenie e presto il supporto completo terminerà. Per i team che lo utilizzano per la pianificazione dei turni di reperibilità, gli escalation e gli avvisi, questo è un campanello d'allarme che nessuno voleva sentire.
La cosa positiva è che non devi aspettare fino all'ultimo minuto. Concederti il tempo di esplorare altre opzioni ora significa che il tuo team potrà adattarsi a una nuova routine senza lo stress di decisioni affrettate.
In questo articolo, esamineremo le migliori alternative a Opsgenie, confronteremo i loro punti di forza e mostreremo perché ClickUp offre al tuo team un modo più tranquillo e di connessione per svolgere il lavoro.
⭐ Modello in primo piano
Consenti ai tuoi team IT di registrare gli incidenti in modo accurato e di individuare le tendenze che consentono miglioramenti a lungo termine. Il modello di rapporto sugli incidenti IT di ClickUp ti aiuta a registrare i dettagli degli incidenti in un formato coerente e affidabile.

Panoramica delle alternative a Opsgenie
Ecco un rapido confronto tra le migliori alternative a Opsgenie per aiutarti a scegliere quella più adatta alle tue esigenze in base alle funzionalità principali, ai prezzi e alle valutazioni degli utenti.
| Strumento | Ideale per | Funzionalità principali | Prezzi* | Valutazioni |
| ClickUp | Gestione del lavoro all-in-one con flussi di lavoro per gli incidenti, pianificazione delle risorse e automazioni per team di tutte le dimensioni. | Notifiche personalizzabili, automazioni per escalation, attività e elenchi relativi agli incidenti, stati personalizzati, chat in tempo reale, dashboard per revisioni post-incidente, oltre 1.000 integrazioni. | Piano Free disponibile; personalizzazioni per le aziende | G2: 4,7/5 (10.500+) Capterra: 4,6/5 (4.500+) |
| PagerDuty | Avvisi in tempo reale sugli incidenti e automazioni su larga scala per le grandi aziende | Avvisi multicanale, politiche di escalation, pianificazione dei turni di reperibilità, AIOps per la riduzione del rumore, integrazioni con oltre 600 strumenti | Piano Free; piani a pagamento a partire da 25 $ al mese per utente | G2: 4,5/5 (900+) Capterra: 4,6/5 (200+) |
| xMatters | Gestione degli incidenti e automazione del flusso di lavoro convenienti per team in crescita | Flussi di lavoro automatizzati, gestione adattiva degli incidenti, pianificazione dei turni di reperibilità, intelligence dei segnali, oltre 200 integrazioni | Piano Free; piani a pagamento a partire da 9 $ al mese per utente | G2: 4,5/5 (670+) Capterra: 4,6/5 (140+) |
| AlertOps | Riduzione del rumore basata sull'IA e risposta rapida per team di piccole e medie dimensioni | Riduzione del rumore IA OpsIQ, escalation flessibili, copertura dei turni di reperibilità, automazione del flusso di lavoro senza codice, oltre 200 integrazioni | Piano Free; piani a pagamento a partire da 10 $ al mese per utente | G2: 4,7/5 (150+) Capterra: 4,7/5 (20+) |
| Splunk On-Call | Semplifica la pianificazione dei turni di reperibilità e riduci il burnout per i team di grandi dimensioni | Escalation automatizzate, app mobili, bilanciamento del carico di lavoro, raccomandazioni ML, audit trail | Prezzi personalizzati | G2: 4,6/5 (50+) Capterra: 4,5/5 (30+) |
| Datadog | Osservabilità completa con monitoraggio della sicurezza per le aziende | Monitoraggio di infrastrutture, log e app, sicurezza cloud, rilevamento delle anomalie con IA, oltre 900 integrazioni | Piano Free; piani a pagamento a partire da 15 $ al mese per utente | G2: 4,4/5 (660+) Capterra: 4,6/5 (320+) |
| Squadcast | Risposta unificata alle chiamate e agli incidenti con prezzi vantaggiosi per team di medie dimensioni | Pianificazioni automatizzate, deduplicazione, runbook, pagine di stato, analisi post mortem | Piano Free; piani a pagamento a partire da 12 $ al mese per utente | G2: 4,4/5 (300+) Capterra: recensioni insufficienti |
| FireHydrant | Runbook automatizzati e titolarità dei servizi per le aziende | Runbook, programmazione dei turni di reperibilità Signals, catalogo dei servizi, collaborazione Slack/Teams, retrospettive arricchite dall'IA. | Piano Free; piani a pagamento a partire da 9.600 $/anno per utente | G2: 4,5/5 (130+) Capterra: recensioni insufficienti |
| TaskCall | Gestione degli incidenti conveniente con automazione per team di medie e grandi dimensioni | Pianificazione dinamica dei turni di reperibilità, instradamento basato sull'IA, avvisi multicanale, copertura DevOps + BizOps | Piano Free; piani a pagamento a partire da 9 $ al mese per utente | G2: recensioni insufficienti Capterra: recensioni insufficienti |
| ilert | Gestione degli incidenti basata sull'IA con attenzione alla privacy per team in espansione | Avvisi multicanale, assistente IA Responder, pianificazione dei turni di reperibilità, pagine di stato automatizzate, integrazioni con ITSM + strumenti di monitoraggio | Piano Free; piani a pagamento a partire da 24 $ al mese per utente | G2: recensioni insufficienti Capterra: 4,7/5 (60+) |
| Zenduty | Risposta agli incidenti basata sull'IA su larga scala per team di piccole e grandi dimensioni | Gestione degli incidenti ZenAI, pianificazione avanzata dei turni di reperibilità, playbook automatizzati, oltre 150 integrazioni | Piano Free; piani a pagamento a partire da 6 $ al mese per utente | G2: 4,6/5 (135+) Capterra: recensioni insufficienti |
| Incidente. io | Risposta agli incidenti nativa di Slack per aziende di medie e grandi dimensioni | Incidenti end-to-end in Slack, IA SRE, pianificazione dei turni di reperibilità, pagine di stato automatizzate, dashboard di approfondimento | Piano Free; piani a pagamento a partire da 19 $ al mese per utente | G2: 4,8/5 (180+) Capterra: recensioni insufficienti |
Criteri chiave per valutare le alternative a Opsgenie
So che abbiamo ancora quasi due anni prima che venga completamente ritirato, ma non vedo alcun motivo per aspettare 😛
So che abbiamo ancora quasi due anni prima che venga completamente ritirato, ma non vedo alcun motivo per aspettare 😛
Questo commento di un utente di Reddit riflette la realtà che molti team IT PMO si trovano ad affrontare. Sì, Opsgenie è stato un ottimo compagno per anni, ma affidarsi ad esso solo perché è familiare non sarà d'aiuto una volta terminato il supporto.
La cosa più sensata da fare ora è esaminare ciò che ha reso Opsgenie utile in primo luogo e utilizzare quelle stesse qualità come guida nella scelta della tua prossima piattaforma di gestione degli incidenti.
Ecco alcune delle caratteristiche a cui vale la pena prestare attenzione:
- Invia avvisi tempestivi attraverso più canali come telefono, email, SMS o notifiche push.
- Mantieni le notifiche mirate in modo che venga informata la persona giusta senza sovraccaricare il resto del team.
- Incorpora politiche di escalation che garantiscono che gli incidenti critici non vengano mai ignorati.
- Centralizza gli aggiornamenti sugli incidenti in modo che i team possano avere una visione completa mentre gestiscono gli incidenti.
- Fornisci revisioni post-incidente per imparare da incidenti simili e migliorare nel tempo.
- Offri funzionalità di integrazione con gli strumenti su cui già hanno una dipendenza i tuoi team IT.
Opsgenie ha costruito la propria reputazione aiutando i team DevOps a ridurre l'affaticamento da allarmi, a mantenere chiari i turni di reperibilità e a risolvere gli incidenti senza confusione. Mentre esplori ciascuna alternativa a Opsgenie, tieni a mente questi stessi valori.
Le 12 migliori alternative a Opsgenie
Opsgenie potrebbe essere in fase di chiusura, ma ciò non significa che il tuo team debba perdere slancio. Ecco alcuni sostituti adeguati che daranno fiducia ai tuoi team operativi nei momenti critici.
Come valutiamo i software su ClickUp
Il nostro team editoriale segue un processo trasparente, supportato da ricerche e indipendente dai fornitori, quindi puoi fidarti che i nostri consigli si basano sul valore reale dei prodotti.
Ecco una panoramica dettagliata di come valutiamo i software su ClickUp.
1. ClickUp (ideale per gestire i flussi di lavoro relativi agli incidenti insieme a una gestione più ampia del project management)
Quando abbandonano Opsgenie, i team si preoccupano meno di perdere gli avvisi e più di adattarsi a un nuovo flusso di lavoro per la gestione degli incidenti.
Il problema principale è il Work Sprawl, ovvero la dispersione di aggiornamenti, programmi e politiche su diverse app, email e documenti. Questa frammentazione consuma energie e costringe i team a ricominciare da zero ogni volta che si verifica un incidente.
Una ricerca mostra che i dipendenti trascorrono 117 minuti a setacciare le email e 153 minuti sui messaggi di Microsoft Teams ogni giorno feriale, con interruzioni ogni due minuti.
ClickUp si propone come alternativa a Opsgenie riunendo tutte queste attività scollegate in un unico spazio di lavoro convergente. Ecco come le sue funzionalità/funzioni rispondono in modo approfondito a queste sfide.
Flussi di lavoro di risposta automatizzati
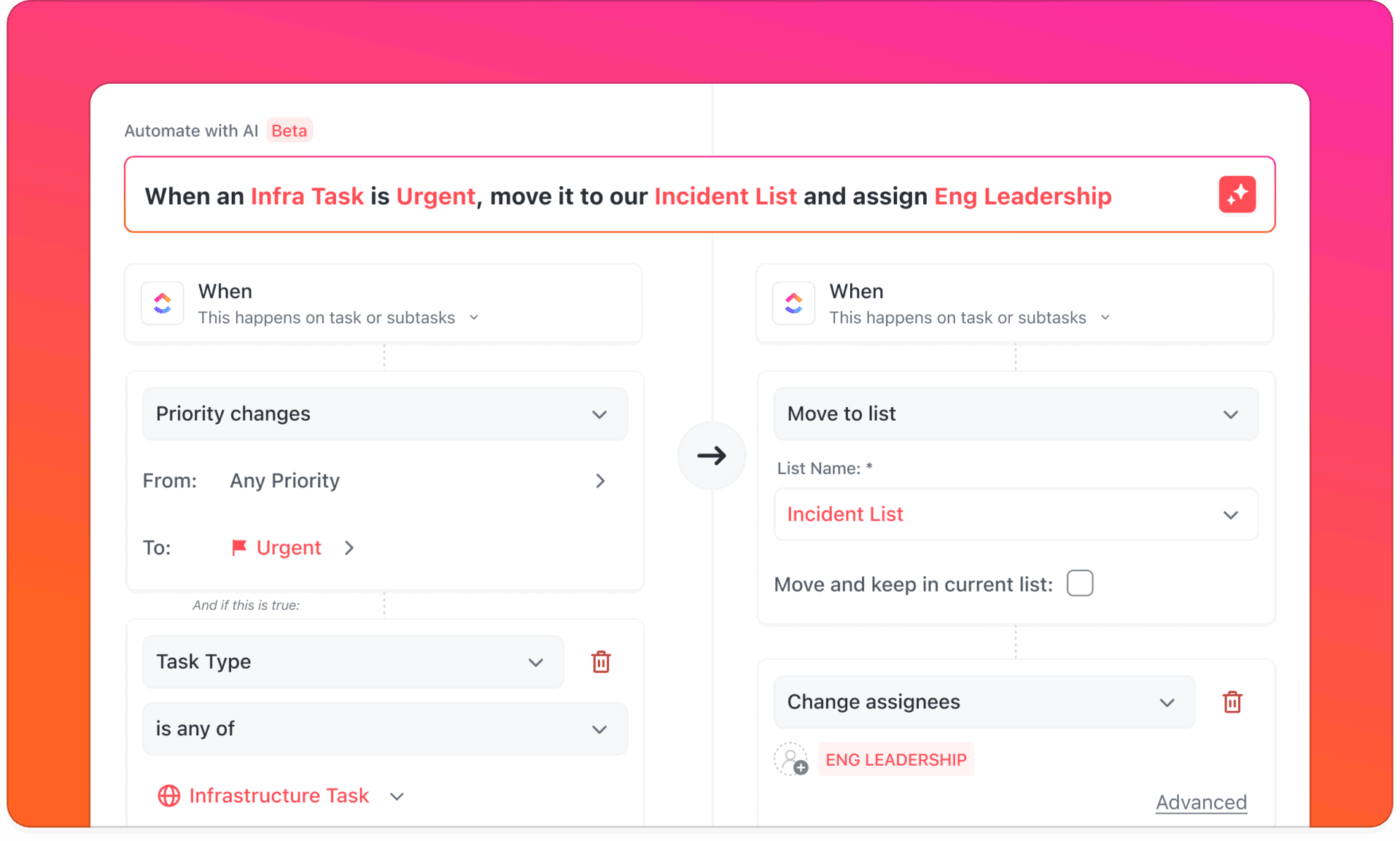
Con gli avvisi provenienti da strumenti di monitoraggio, strumenti di chat ed email, è difficile capire cosa è importante e chi dovrebbe rispondere.
Con ClickUp Automazioni e AI Agents, gli avvisi diventano azioni significative. Gli avvisi in arrivo possono creare e assegnare automaticamente attività al tecnico di turno, avvisando la persona giusta senza distrarre il resto del team.
Se non viene fornita alcuna risposta entro un determinato periodo di tempo, il sistema inoltra automaticamente il problema secondo le procedure standard.
📌 Esempio: viene segnalato un guasto al server ad alta priorità. ClickUp Automations crea una nuova attività nell'elenco degli incidenti, la contrassegna come urgente, la assegna al tecnico di turno e invia un avviso push sul cellulare. Allo stesso tempo, il tuo agente IA personalizzato pubblica un breve messaggio nel canale degli incidenti nella chat di ClickUp, in modo che il team sia informato ma non sopraffatto.
Chiarezza e responsabilità nelle attività
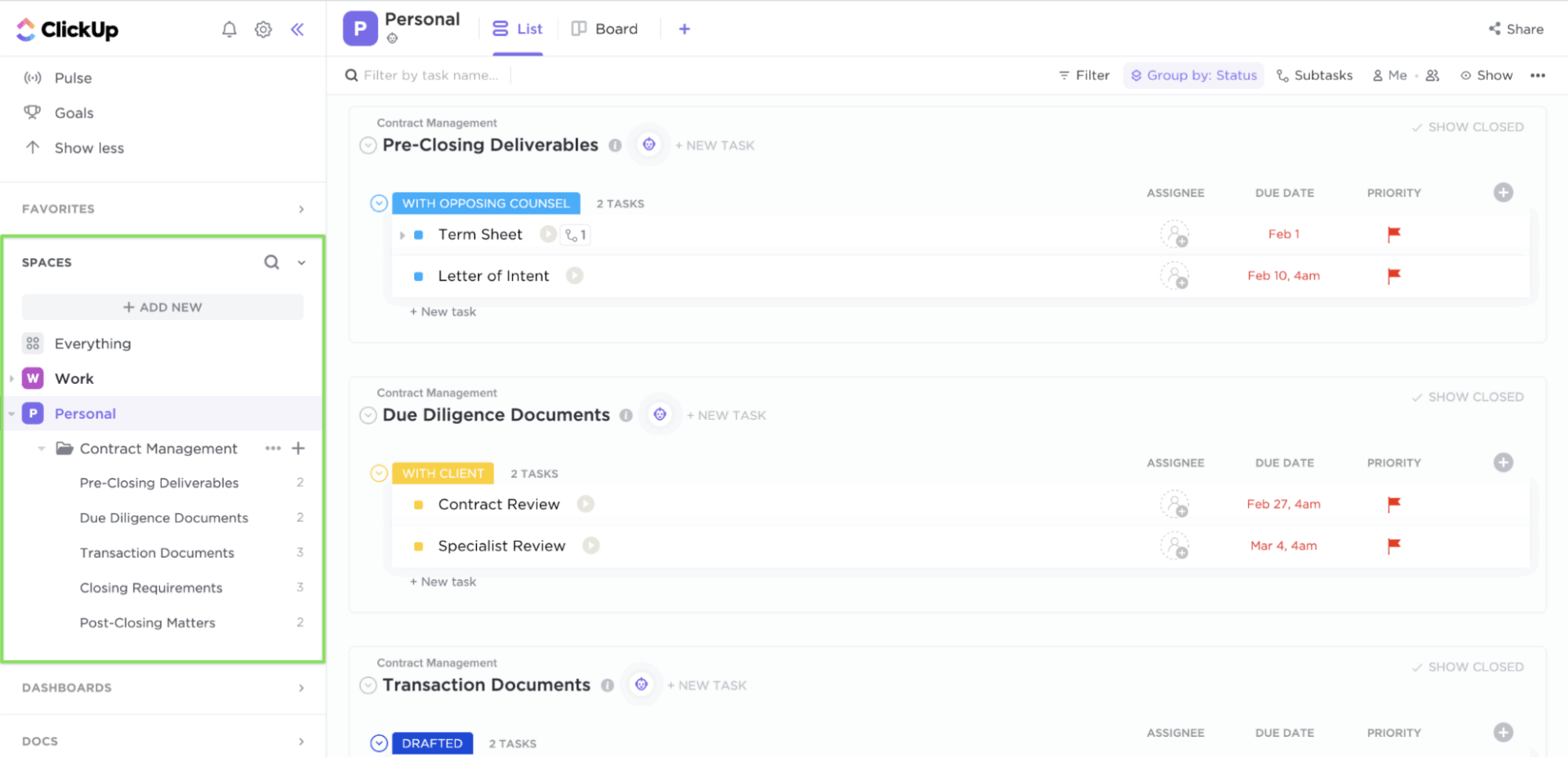
Quando si verifica un incidente, i team spesso perdono tempo a capire cosa fare e quali siano i passi successivi. ClickUp Attività porta chiarezza nei tuoi processi di gestione degli incidenti.
Ogni attività può avere un titolare, una priorità e una scadenza chiari. All'interno di ogni attività è possibile aggiungere liste di controllo, collegamenti a runbook e screenshot. I campi personalizzati registrano la gravità, i servizi interessati o la fase di escalation, mentre gli stati e gli elenchi delle attività personalizzate di ClickUp eliminano l'incertezza mappando il processo di risposta in una sequenza chiara.
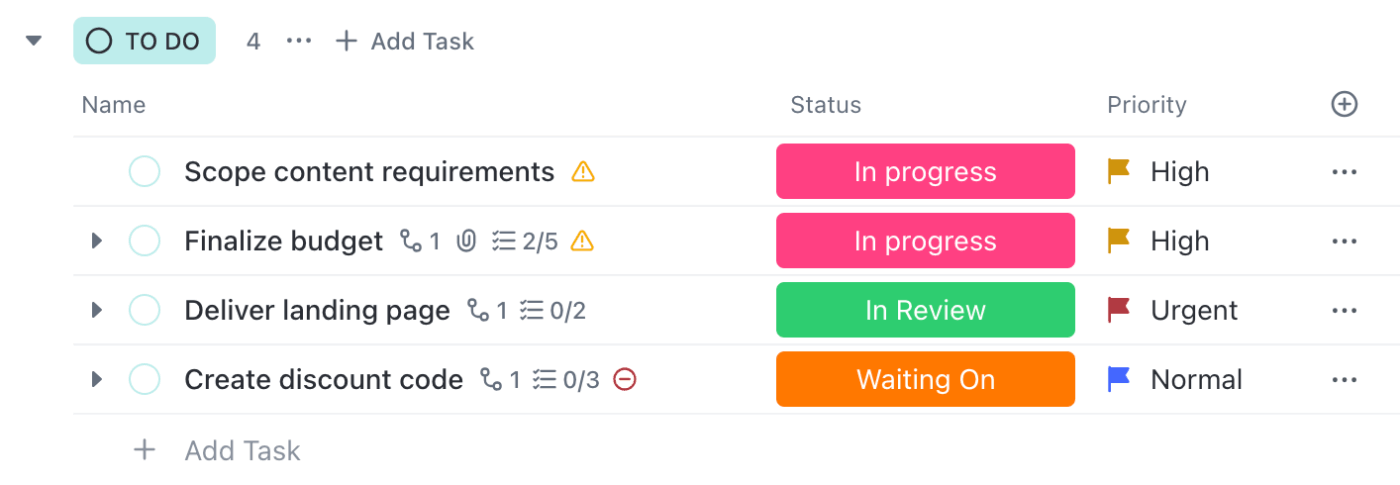
📌 Esempio: un incidente "Segnalato" passa a "In fase di indagine" una volta che il tecnico apre l'attività. Le misure di mitigazione vengono monitorate in una lista di controllo, con note e registri aggiunti nella descrizione. Ogni cambiamento di stato viene notificato solo alle persone interessate, in modo che i tecnici possano lavorare mentre i responsabili rimangono informati.
Aggiornamenti che non interrompono il flusso di lavoro
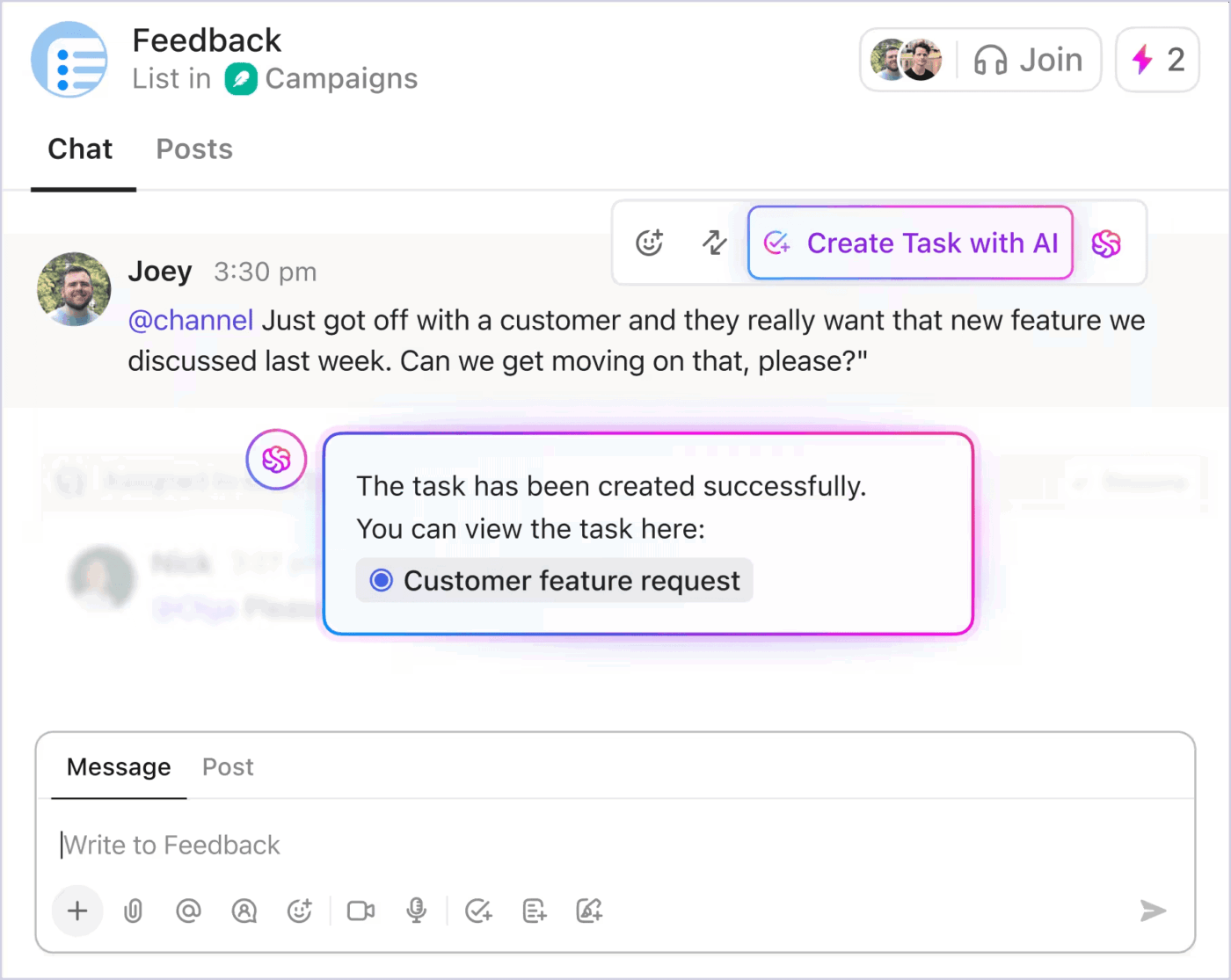
Durante gli incidenti critici, gli aggiornamenti delle parti interessate non dovrebbero interrompere il lavoro richiesto per la risposta. ClickUp Chat risolve questo problema allegando la conversazione direttamente all'attività relativa all'incidente. I membri del team e i responsabili possono seguire il thread, vedere le decisioni prese e aggiungere commenti in tempo reale.
ClickUp si integra anche con Slack e Microsoft Teams, consentendo la visualizzazione degli aggiornamenti nei canali già seguiti dagli utenti.
Cerchi i migliori consigli per la collaborazione in tempo reale? Ecco una guida:
Analisi post-incidente che portano a cambiamenti duraturi
Troppo spesso, le revisioni post-incidente vengono scritte ma poi dimenticate. ClickUp Docs le mantiene vive archiviando i post mortem standardizzati direttamente accanto alle attività relative all'incidente.
Nel frattempo, i dashboard di ClickUp visualizzano metriche quali il tempo medio di risoluzione, la frequenza degli incidenti e i modelli ricorrenti. Questa visibilità aiuta i team IT e DevOps a passare da un approccio reattivo a uno proattivo.
💡 Suggerimento professionale: le revisioni post-incidente possono richiedere ore di scrittura, modifica e ricerca del contesto. ClickUp Brain cambia tutto questo riunendo automaticamente note, Sequenze e elementi da intraprendere. È in grado di riepilogare un'attività relativa a un incidente, redigere un resoconto post mortem in ClickUp Docs e persino suggerire i passaggi successivi sulla base di incidenti simili.
Con ClickUp Brain Max, ottieni la velocità aggiuntiva di Talk to Text di ClickUp: detta i tuoi pensieri in tempo reale e guardali trasformarsi in note raffinate pronte per la condivisione. Insieme, aiutano i team a risparmiare quasi un giorno intero ogni settimana, eliminando il lavoro di scrittura e ricerca, così puoi concentrarti sulla prevenzione del prossimo incidente invece di raccontare l'ultimo.
Crea una struttura e risparmia tempo con i modelli

In caso di emergenza, si impara davvero ad apprezzare il valore di un processo chiaro e graduale.
Il modello di piano d'azione per gli incidenti di ClickUp è esattamente questo. Esso definisce con precisione cosa deve essere fatto, chi deve farlo e in quale ordine. Mantiene tutti allineati, riduce i rischi e garantisce che nessun passaggio venga trascurato.
Un'altra sfida nel settore IT è documentare gli incidenti in modo efficace, in modo da poter individuare i modelli ricorrenti e prevenirli in futuro. Il modello di reportistica sugli incidenti IT di ClickUp semplifica la reportistica, trasformando ogni problema in un prezioso dato.
Le migliori funzionalità di ClickUp
- Riduci l'affaticamento da avvisi con le notifiche personalizzabili di ClickUp che assicurano che solo le persone giuste ricevano gli avvisi.
- Automatizza la creazione, l'assegnazione e la reportistica delle attività relative agli incidenti con ClickUp Automazioni e AI Agents.
- Crea flussi di lavoro chiari per gli incidenti con le attività di ClickUp, gli elenchi e gli stati e i modelli di segnalazione degli incidenti per guidare ogni fase della risposta.
- Consenti la collaborazione in team con ClickUp Chat e ClickUp Docs, in modo che conversazioni, aggiornamenti e conclusioni siano sempre disponibili con l'incidente.
- Tieni traccia dello stato delle attività e dei rapporti sugli incidenti tramite i dashboard di ClickUp.
- Ottieni informazioni dettagliate dagli incidenti e dalle attività chiuse e crea o aggiorna le procedure operative standard per miglioramenti futuri con ClickUp Brain.
Limiti di ClickUp
- La flessibilità della piattaforma può sembrare eccessiva per i team più piccoli che desiderano solo funzionalità di base per gli avvisi e la gestione dei turni di reperibilità.
Prezzi di ClickUp
Valutazioni e recensioni di ClickUp
- G2: 4,7/5 (oltre 10.500 recensioni)
- Capterra: 4,6/5 (oltre 4.500 recensioni)
Cosa dicono gli utenti di ClickUp
Questo utente G2 ha riferito:
Lavorare insieme su un progetto è diventato molto più facile dall'implementazione di ClickUp, poiché è possibile assegnare facilmente le attività ai membri e seguire lo stato delle attività tramite la chat. È anche possibile ricevere notifiche via email e avvisi di scadenza in caso di attività non completate.
Lavorare insieme su un progetto è diventato molto più facile dall'implementazione di ClickUp, poiché è possibile assegnare facilmente le attività ai membri e seguire lo stato delle attività tramite la chat. È anche possibile ricevere notifiche via email e avvisi di scadenza in caso di attività non completate.
📖 Leggi anche: Come redigere un rapporto sugli incidenti nel lavoro
2. PagerDuty (ideale per gli avvisi in tempo reale e le automazioni su larga scala)
Se stai abbandonando Opsgenie, la tua prima preoccupazione è semplice. La persona giusta riceverà l'avviso, al momento giusto, sul canale giusto?
PagerDuty è stato creato per eliminare questo stress. Sei tu a definire i servizi, i programmi e le politiche di escalation chiare, in modo che la titolarità non sia mai in dubbio. I segnali provenienti da CloudWatch, Prometheus, Datadog, Jira, ServiceNow, Slack, Zoom e altri arrivano in un unico posto e vengono raggruppati in un unico incidente, non in 15 ping separati.
Event Intelligence riduce i duplicati e mette in correlazione i problemi correlati, riducendo l'affaticamento da avvisi senza silenziare i problemi reali. Gli addetti alla risposta possono confermare o inoltrare la segnalazione dall'app mobile o direttamente da Slack o Teams, con sale incidenti e ponti creati automaticamente.
Dopo la risoluzione, l'analisi mostra il tempo necessario per riconoscere il problema, il tempo necessario per risolverlo e i punti critici ricorrenti, in modo da poter risolvere le cause alla radice piuttosto che limitarsi a perseguire i sintomi.
Le migliori funzionalità di PagerDuty
- Consenti agli utenti di personalizzare gli avvisi tramite SMS, telefono, email, notifiche push e Slack per ridurre il rumore senza perdere incidenti critici.
- Semplifica la configurazione con avvisi di prova, integrazioni di servizi e progettazione di politiche di escalation intuitive.
- Assistenza per le pianificazioni dei turni di reperibilità e le escalation che avvisano la persona giusta e continuano fino alla conferma.
- Abilita azioni relative agli incidenti basate su Slack come confermare, risolvere ed escalare direttamente nella chat.
- Riduci l'affaticamento da avvisi con AIOps, che raggruppa i duplicati ed evidenzia gli incidenti urgenti.
Limiti di PagerDuty
- I team leader non possono personalizzare completamente i metodi di invio degli avvisi a livello di team, limitando la flessibilità quando i manager desiderano regole di escalation coerenti.
- Gli avvisi via email non consentono di rispondere direttamente, costringendo chi risponde a cliccare sulla piattaforma invece di gestire direttamente dalla finestra In arrivo.
- Funzionalità avanzate come AIOps e licenze per la comunicazione con gli stakeholder comportano costi aggiuntivi elevati.
Prezzi di PagerDuty
- Free
- Professional: 25 $ al mese per utente
- Aziendale: 49 $ al mese per utente
- Enterprise: prezzi personalizzati
Valutazioni e recensioni di PagerDuty
- G2: 4,5/5 (oltre 900 recensioni)
- Capterra: 4,6/5 (oltre 200 recensioni)
Cosa dicono gli utenti di PagerDuty
Questo utente G2 ha fatto una menzione:
Adoro il fatto che Pager Duty abbia diversi avvisi acustici, alcuni dei quali sono esilaranti. Da quando ho iniziato a usare Pager Duty, sono in grado di rispondere agli incidenti e coinvolgere i team in modo più efficiente.
Adoro il fatto che Pager Duty abbia diversi avvisi acustici, alcuni dei quali sono esilaranti. Da quando ho iniziato a usare Pager Duty, sono in grado di rispondere agli incidenti e coinvolgere i team in modo più efficiente.
📖 Leggi anche: Che cos'è un piano di emergenza e come svilupparne uno?
3. xMatters (ideale per la gestione degli incidenti e le automazioni convenienti)
Un utente di Reddit lo ha riassunto al meglio:
Ottieni quello per cui paghi, ma paghi meno. Ha tutto ciò che desideri, anche se sicuramente non è sofisticato come PagerDuty.
Ottieni quello per cui paghi, ma paghi meno. Ha tutto ciò che desideri, anche se sicuramente non è sofisticato come PagerDuty.
Questa frase riassume la posizione di xMatters: conveniente, affidabile e forte nelle aree che contano di più.
Se stai abbandonando Opsgenie, il tuo problema è solitamente duplice. Troppo rumore che sveglia le persone sbagliate e incertezza su chi debba fare la mossa successiva. xMatters affronta entrambi i problemi consentendoti di mappare i servizi e i turni di reperibilità, quindi di instradare gli avvisi con un contesto preciso in modo che la persona giusta venga raggiunta sul canale giusto.
Gli utenti hanno apprezzato le notifiche mirate con dettagli utili, oltre a una traccia di controllo completa che mostra chi è stato avvisato, chi ha confermato e quando. Tale registrazione semplifica le revisioni post-incidente e i controlli di conformità.
Il generatore di flussi di lavoro low-code trasforma un segnale proveniente da Datadog, Prometheus o ServiceNow in una sequenza chiara di azioni.
Con l'automazione del flusso di lavoro e la gestione adattiva dei progetti DevOps al centro, xMatters aiuta i team a muoversi più rapidamente e a ridurre il rumore degli avvisi.
Le migliori funzionalità/funzioni di xMatters
- Automatizza i flussi di lavoro relativi agli incidenti con integrazioni senza codice e a basso codice che accelerano la risoluzione e riducono le attività manuali.
- Gestisci senza problemi i turni di reperibilità e gli escalation, in modo che la persona giusta venga sempre avvisata al momento giusto.
- Applica una gestione adattiva degli incidenti per ridurre al minimo l'impatto sui clienti e trarre insegnamenti da ogni evento.
- Elimina il rumore di fondo con l'intelligence dei segnali, la correlazione degli avvisi e le notifiche arricchite per un contesto più chiaro.
- Accedi ad analisi fruibili per identificare le inefficienze e migliorare la collaborazione tra i team.
Limiti di xMatters
- L'interfaccia e l'esperienza dell'utente risultano meno raffinate rispetto alla concorrenza.
- I piani di livello inferiore offrono funzionalità avanzate di reportistica e analisi con limiti.
- La copertura dell'assistenza globale varia a seconda del piano selezionato.
Prezzi xMatters
- Free
- Starter (Essentials): 9 $ al mese per utente
- Base (Standard): 39 $ al mese per utente
- Avanzato: prezzi personalizzati
Valutazioni e recensioni di xMatters
- G2: 4,5/5 (oltre 670 recensioni)
- Capterra: 4,6/5 (oltre 140 recensioni)
Cosa dicono gli utenti di xMatters
Questa recensione di Capterra ha messo in evidenza la funzionalità/funzione:
Quando si verifica un incidente di sicurezza dei dati in azienda, Xmatters attiva immediatamente i protocolli di risposta: organizza i protocolli di azione del team in base alle loro funzioni. Le notifiche vengono inviate attraverso vari canali.
Quando si verifica un incidente di sicurezza dei dati in azienda, Xmatters attiva immediatamente i protocolli di risposta: organizza i protocolli di azione del team in base alle loro funzioni. Le notifiche vengono inviate attraverso vari canali.
📮 ClickUp Insight: il 28% dei dipendenti afferma che il lavoro li segue anche dopo l'orario di lavoro e un altro 8% spesso fatica a staccare la spina. Si tratta di oltre un terzo delle persone che portano lo stress a casa.
Usa i promemoria di ClickUp per proteggere la tua routine serale. Imposta un promemoria giornaliero di fine giornata, notifiche silenziose al di fuori dell'orario di lavoro e riserva del tempo per te sul tuo Calendario. Staccare la spina dovrebbe essere una tua scelta.
💫 Risultati reali: Lulu Press risparmia circa un'ora al giorno per persona grazie alle automazioni di ClickUp, con un aumento dell'efficienza del 12%.
4. AlertOps (ideale per la riduzione del rumore basata sull'IA e la risposta rapida agli incidenti)
Il volume degli avvisi continua ad aumentare: l'88% dei team ha effettuato la reportistica su un aumento nell'ultimo anno e quasi la metà ha affermato che tali picchi hanno superato il 25%. Questo tipo di rumore costante porta a una sorta di "affaticamento da avvisi", che il 76% dei SOC (Security Operations Center) cita ora come la sfida principale.
Questa è la realtà che si presenta quando si sostituisce Opsgenie. Il prossimo strumento che sceglierai dovrà essere in grado di valutare quali avvisi richiedono un intervento. AlertOps risponde a questa esigenza con OpsIQ, un nucleo IA che filtra i duplicati, correla i segnali correlati, riepiloga il contesto e suggerisce i passaggi successivi, in modo che gli addetti alla risposta vedano un unico incidente chiaro invece di un feed scorrevole.
Puoi iniziare con la pianificazione dei turni di reperibilità per impostazione predefinita o crearne una personalizzata, quindi inoltrare le chiamate tramite telefono, SMS, app mobile, chat o email con regole di escalation che continuano a funzionare fino a quando qualcuno non si assume la responsabilità del problema. L'inoltro delle chiamate in tempo reale indirizza i clienti al personale di reperibilità attuale in base a pianificazioni in tempo reale, mentre le politiche basate su SLA prevedono l'escalation prima di una violazione piuttosto che dopo.
Inoltre, la piattaforma si integra con oltre 200 strumenti, dal monitoraggio e ticketing a O365 e Slack, in modo che la selezione non si blocchi a causa di contesti mancanti.
Le migliori funzionalità di AlertOps
- Filtra ed elimina gli avvisi duplicati con la riduzione del rumore basata sull'IA di OpsIQ™, che riepiloga gli avvisi e suggerisce automaticamente le soluzioni.
- Gestisci i turni di reperibilità con regole di escalation flessibili, copertura 24 ore su 24 e instradamento delle chiamate in tempo reale per i problemi critici dei clienti.
- Automatizza il triage e i flussi di lavoro utilizzando modelli IT senza codice per accelerare la risposta e garantire che gli incidenti vengano gestiti in modo coerente.
- Integrazione immediata con oltre 200 strumenti, tra cui Slack, O365, Jira, Dynatrace e ConnectWise, oltre a integrazioni personalizzate per app interne.
Limiti di AlertOps
- All'inizio, la configurazione della pianificazione può sembrare poco intuitiva e potrebbe richiedere diversi tentativi prima di ottenere il risultato desiderato.
- L'interfaccia utente presenta occasionalmente alcune imperfezioni e alcune funzionalità avanzate richiedono passaggi aggiuntivi per la configurazione.
- Sono stati segnalati ritardi nella sincronizzazione del Calendario con sistemi esterni come Outlook.
Prezzi di AlertOps
- Starter: gratis
- Standard: 10 $ al mese per utente
- Premium: 22 $ al mese per utente
- Enterprise: 34 $ al mese per utente
Valutazioni e recensioni di AlertOps
- G2: 4,7/5 (oltre 150 recensioni)
- Capterra: 4,7/5 (oltre 20 recensioni)
Cosa dicono gli utenti di AlertOps
Questa recensione di G2 lo chiarisce:
Abbiamo trascorso gran parte del terzo trimestre dello scorso anno valutando strumenti di pianificazione/allerta per uno dei nostri team IT. Dopo aver scoperto AlertOps ho smesso di cercare: è conveniente, il team è incredibilmente disponibile e paziente nel processo di configurazione e implementazione e, da quando abbiamo completato la configurazione e l'avvio, non abbiamo avuto alcun problema!
Abbiamo trascorso gran parte del terzo trimestre dello scorso anno valutando strumenti di pianificazione/allerta per uno dei nostri team IT. Dopo aver scoperto AlertOps ho smesso di cercare: è conveniente, il team è incredibilmente disponibile e paziente nel processo di configurazione e implementazione e, da quando abbiamo completato la configurazione e l'avvio, non abbiamo avuto alcun problema!
📖 Leggi anche: Esempi di procedure operative standard: best practice per la produttività e la conformità
5. Splunk On-Call (ideale per semplificare la pianificazione dei turni di reperibilità e ridurre il burnout)
Se hai mai visto il classico sketch di Abbott e Costello "Who's on First?", sai bene quanto sia difficile capire chi sia effettivamente responsabile di cosa. Lo stesso vale per i turni di reperibilità quando non esiste un sistema chiaro.
È qui che entra in gioco Splunk On-Call. ✨
Basta mappare una volta i team e gli orari, poi gli avvisi arrivano con il contesto su qualsiasi dispositivo. Gli addetti alla risposta possono confermare, reindirizzare o posticipare dall'app iOS o Android, e la piattaforma può aprire una stanza per la collaborazione e avviare la revisione post-incidente senza passaggi aggiuntivi.
Un motore di regole aggiunge runbook e dashboard agli incidenti, in modo che la prima persona chiamata non parta mai da zero. L'apprendimento automatico suggerisce i responder più adatti sulla base di incidenti simili, contribuendo a ridurre i tempi di riconoscimento e risoluzione.
Le migliori funzionalità/funzioni di Splunk On-Call
- Effettua l'automazione delle escalation e dei flussi di lavoro di risposta agli incidenti per una conferma e una risoluzione più rapide.
- Utilizza le app iOS e Android per ricevere, posticipare, reindirizzare o risolvere gli avvisi direttamente da un dispositivo mobile.
- Semplifica la pianificazione con turni, sostituzioni e politiche di escalation progettate per bilanciare equamente i carichi di lavoro.
- Ottieni il contesto dell'incidente e le tracce di audit storiche per fornire supporto alla valutazione rapida e all'analisi post-incidente.
- Applica i consigli del machine learning per identificare i responsabili della risposta più adatti sulla base dei dati relativi alle risoluzioni passate.
Limiti di Splunk On-Call
- All'inizio l'interfaccia può sembrare complessa e la navigazione richiede un po' di tempo per abituarsi.
- Il ritardo occasionale durante i periodi di traffico intenso influisce sulla reattività in tempo reale
- Le opzioni di licenza e gestione degli utenti sono più limitate rispetto ad alcuni concorrenti.
Prezzi di Splunk On-Call
- Prezzi personalizzati
Valutazioni e recensioni di Splunk On-Call
- G2: 4,6/5 (oltre 50 recensioni)
- Capterra: 4,5/5 (oltre 30 recensioni)
Cosa dicono gli utenti di Splunk On-Call
Questa recensione di G2 nota:
La possibilità di creare team e configurare i turni tra di essi è una delle risorse più utili disponibili su questa piattaforma. Splunk On-Call offre facili integrazioni con diversi strumenti, rendendo la sua configurazione molto semplice da impostare.
La possibilità di creare team e configurare i turni tra di essi è una delle risorse più utili disponibili su questa piattaforma. Splunk On-Call offre facili integrazioni con diversi strumenti, rendendo la sua configurazione molto semplice da impostare.
📝Leggi anche: Eliminare la proliferazione dell'IA: come l'IA contestuale trasforma la produttività sul posto di lavoro
6. Datadog (ideale per l'osservabilità full-stack con monitoraggio integrato della sicurezza)
Per gli utenti di Opsgenie, il problema è il contesto. Viene emesso un avviso, ma è comunque necessario cercare log, tracce, metriche e segnali di sicurezza per capire cosa non funziona.
Datadog riunisce tutte queste visualizzazioni in un'unica Sequenza. Infrastruttura, container, serverless, database e app sono affiancati da log, tracce e RUM, così chi risponde non deve fare supposizioni.
Watchdog e le nuove funzionalità di IA evidenziano le anomalie, raggruppano i segnali correlati e riepilogano la probabilità di impatto, riducendo il tempo necessario per la valutazione. Se disponi già di uno strumento di paging, puoi inserirvi gli avvisi di Datadog.
Se desideri rimanere all'interno di Datadog, Incident Management ti offre titolari, Sequenze, aggiornamenti delle parti interessate e follow-up senza uscire dalla piattaforma.
I vantaggi pratici sono immediatamente evidenti. Meno ping fastidiosi grazie all'eliminazione dei duplicati. Analisi più rapida delle cause alla radice grazie alle metriche e ai log allegati a ogni avviso. Maggiore sicurezza grazie alla segnalazione di configurazioni errate e vulnerabilità insieme ai dati sulle prestazioni.
Con oltre 900 integrazioni, SLO (Service Level Objectives) chiari e dashboard, il tuo team può passare dal segnale alla risoluzione in un unico posto invece di passare da una scheda all'altra. Si tratta di una buona scelta per le migrazioni da Opsgenie che vogliono anche colmare le lacune di osservabilità.
Le migliori funzionalità di Datadog
- Monitora infrastrutture, registri, applicazioni, database e carichi di lavoro serverless da un'unica piattaforma.
- Ambienti cloud sicuri con gestione integrata delle vulnerabilità, mappatura della conformità e gestione dei diritti
- Utilizza il monitoraggio sintetico e il monitoraggio degli utenti reali per individuare i problemi prima che i clienti se ne accorgano.
- Automatizza i flussi di lavoro con oltre 900 integrazioni e dashboard predefinite.
- Applica funzionalità/funzioni di IA e machine learning come Watchdog e LLM Observability per il rilevamento delle anomalie e approfondimenti intelligenti.
Limitazioni di Datadog
- I prezzi possono aumentare rapidamente con un numero elevato di host e componenti aggiuntivi.
- L'interfaccia e i dashboard potrebbero risultare complessi per i nuovi utenti.
- Alcune funzionalità di sicurezza avanzate sono disponibili solo con i piani di livello superiore.
Prezzi di Datadog
- Free
- Pro: 15 $ al mese per host
- Enterprise: 23 $ al mese per host
- DevSecOps Pro: 22 $ al mese per host
- DevSecOps Enterprise: 34 $ al mese per host
Valutazioni e recensioni di Datadog
- G2: 4,4/5 (oltre 660 recensioni)
- Capterra: 4,6/5 (oltre 320 recensioni)
Cosa dicono gli utenti di Datadog
Questa recensione di Capterra cita:
Nel complesso, dopo alcuni alti e bassi, si sono dimostrati un ottimo partner. Il loro strumento è estremamente potente e consente molte pratiche eccellenti in materia di osservabilità, ma è a pagamento.
Nel complesso, dopo alcuni alti e bassi, si sono dimostrati un ottimo partner. Il loro strumento è estremamente potente e consente molte pratiche eccellenti in materia di osservabilità, ma è a pagamento.
7. Squadcast (ideale per la gestione unificata dei turni di reperibilità e della risposta agli incidenti con un ottimo valore per il rapporto qualità-prezzo)
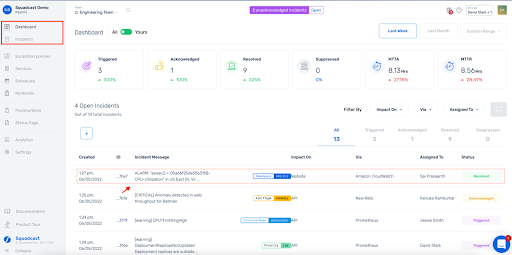
Quando gestisci più turni e regole specifiche per i clienti fuori dall'orario di lavoro, hai bisogno di avvisi che rispettino tali regole senza bisogno di assistenza.
Questa è la nicchia in cui Squadcast si è guadagnato la fiducia dei clienti. 🌟
Gli utenti hanno notato che i turni e le sostituzioni sono facili da modellare e che l'app mobile continuerà a segnalare l'escalation se il primo soccorritore non risponde, in modo che i problemi critici non sfuggano.
Per gli MSP e i team con molti clienti, è utile poter impostare una copertura 24 ore su 24, 7 giorni su 7 per determinati clienti, consentendo agli altri di triggerare avvisi fuori orario solo per incidenti critici. L'interfaccia utente rende facile vedere gli incidenti attivi e chi è responsabile.
C'è molto di più sotto il cofano che il semplice paging. L'automazione affidabile gestisce gli incidenti attraverso flussi di lavoro coerenti con runbook e aggiornamenti di stato, il monitoraggio degli SLO e le sequenze evidenziano modelli su cui è possibile agire concretamente, e i prezzi sono abbastanza trasparenti da non escludere i team più piccoli.
Le migliori funzionalità/funzioni di Squadcast
- Automatizza la pianificazione dei turni di reperibilità con escalation e override flessibili
- Riduci l'affaticamento da notifiche consolidando e deduplicando le notifiche
- Risolvi gli incidenti più rapidamente con i runbook e i flussi di lavoro
- Tieni informati gli stakeholder attraverso pagine di stato personalizzabili
- Raccogli post mortem e approfondimenti per creare una cultura dell'apprendimento
Limiti di Squadcast
- Le visualizzazioni del calendario possono diventare affollate quando sono attivi molti turni, rendendo più difficile individuare a colpo d'occhio chi è di turno.
- È stato segnalato un occasionale ritardo nella sincronizzazione degli avvisi da alcune integrazioni.
- Il piano Free è limitato per i team che desiderano pagine di stato e analisi più approfondite.
Prezzi di Squadcast
- Pro: 12 $ al mese per utente
- Premium: 19 $ al mese per utente
- Enterprise: prezzi personalizzati
Valutazioni e recensioni di Squadcast
- G2: 4,4/5 (oltre 300 recensioni)
- Capterra: recensioni insufficienti
Cosa dicono gli utenti di Squadcast
Questa recensione su G2 aveva una menzione:
Squadcast può ricevere input da vari strumenti di monitoraggio di cui disponiamo ed è facile impostare turni e sostituzioni per chi deve essere avvisato in caso di diversi tipi di problemi.
Squadcast può ricevere input dai vari strumenti di monitoraggio di cui disponiamo ed è facile effettuare le impostazioni per i turni e le sostituzioni da applicare a chi deve essere avvisato in caso di diversi tipi di problemi.
📖 Leggi anche: Gestione dei rischi di sicurezza informatica
8. FireHydrant (ideale per runbook automatizzati e titolarità dei servizi)
Questo software di gestione degli incidenti offre un processo ben strutturato che garantisce il corretto funzionamento dei servizi.
FireHydrant concentra le risposte su runbook, un catalogo di servizi e uno spazio di lavoro condiviso. Segnala un incidente e la piattaforma avvia un canale in Slack o Teams, allega il runbook corretto, estrae la titolarità dal catalogo dei servizi e avvia una Sequenza verificabile.
Nel frattempo, la sua IA mantiene bassi i costi generali con riepiloghi istantanei degli incidenti, aggiornamenti suggeriti per le parti interessate e trascrizioni delle riunioni in tempo reale, in modo che il team possa concentrarsi sulla mitigazione piuttosto che sulla presa di appunti.
I team sottolineano anche il supporto reattivo e un approccio API first con Terraform che consente ai responsabili delle operazioni di integrare FireHydrant nei flussi di lavoro esistenti senza attriti.
Le migliori funzionalità/funzioni di FireHydrant
- Automatizza la risposta agli incidenti con runbook che codificano le best practice
- Gestisci i turni di reperibilità e gli avvisi con Signals, completo di politiche di escalation.
- Centralizza la titolarità attraverso il Catalogo dei servizi in modo che gli ingegneri giusti possano rispondere immediatamente.
- Collabora direttamente su Slack o Teams con canali e aggiornamenti generati automaticamente.
- Utilizza retrospettive e analisi arricchite dall'IA per acquisire informazioni e migliorare l'affidabilità nel tempo.
Limiti di FireHydrant
- Le funzionalità di automazione avanzate richiedono piani di livello superiore.
- Curva di apprendimento per l'impostazione di flussi di lavoro e integrazioni personalizzati
- Risponditori e runbook limitati nel piano base
Prezzi di FireHydrant
- Free: versione di prova gratuita per due settimane
- Platform Pro: 9.600 $/anno per utente
- Enterprise: prezzi personalizzati
Valutazioni e recensioni di FireHydrant
- G2: 4,5/5 (oltre 130 recensioni)
- Capterra: recensioni insufficienti
Cosa dicono gli utenti di FireHydrant
Questo utente G2 ha scritto:
Funzionando interamente su Slack o su altri strumenti di chat/collaborazione, FireHydrant si integra e ti consente di aprire/aggiornare/risolvere gli incidenti senza dover lasciare il luogo in cui si sta svolgendo l'azione di risposta agli incidenti.
Funzionando interamente su Slack o su altri strumenti di chat/collaborazione, FireHydrant si integra e ti consente di aprire/aggiornare/risolvere gli incidenti senza dover lasciare il luogo in cui si sta svolgendo l'azione di risposta agli incidenti.
9. TaskCall (ideale per una gestione degli incidenti conveniente con automazioni)
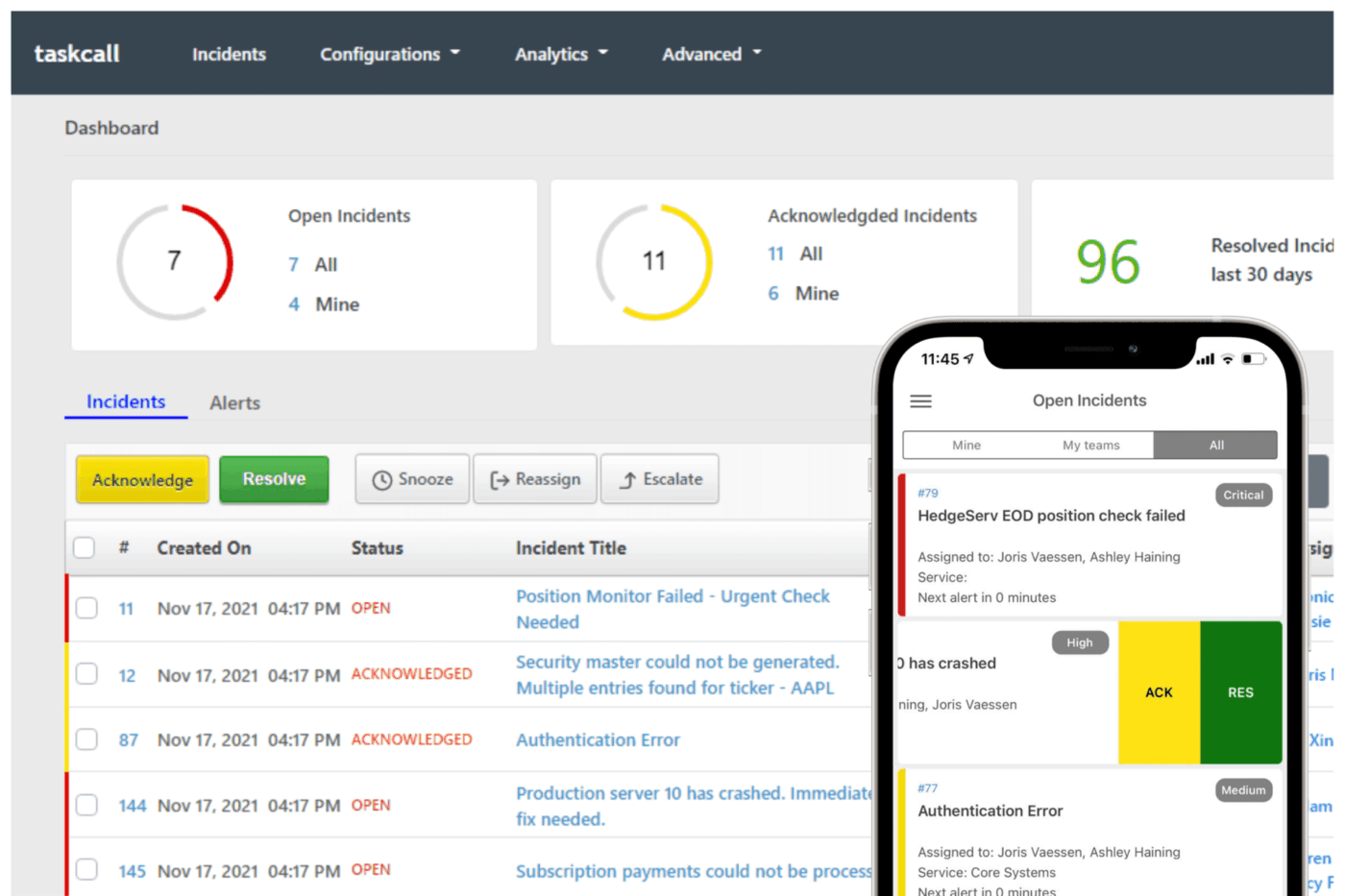
In un recente studio sui rischi informatici, la risposta agli incidenti è stata identificata come uno dei principali controlli che le organizzazioni devono rafforzare per ridurre l'esposizione.
Ciò sottolinea quanto siano diventati essenziali flussi di lavoro rapidi e affidabili per la gestione degli incidenti.
I team di solito non inciampano nell'allerta in sé, ma nella confusione che ne segue. Chi è davvero al comando in questo momento? L'allerta riguarda l'app, l'infrastruttura o le operazioni dei clienti? Come si fa a tenere informati i leader senza interferire con la risoluzione del problema?
TaskCall affronta direttamente questi momenti. La reperibilità viene determinata in base al contenuto dell'incidente, quindi l'inoltro arriva al risponditore giusto e l'escalation automatica copre le lacune. Le notifiche arrivano tramite telefono, SMS, push, email o chat.
Per ridurre il rumore, l'intelligenza degli eventi correla i duplicati e sopprime i ping di basso valore. Il contesto viene ricomposto raccogliendo segnali da strumenti come AWS, Datadog, Slack, Jira e Zendesk, il che significa che gli ingegneri vedono l'impatto e la titolarità invece di un flusso di avvisi grezzo.
Le migliori funzionalità di TaskCall
- Automatizza la pianificazione dei turni di reperibilità con rotazioni dinamiche ed escalation multilivello.
- Riduci il rumore con l'IA basata sugli eventi e l'instradamento condizionale
- Gestisci gli incidenti relativi a DevOps, IT-Ops e BizOps in un'unica piattaforma unificata.
- Integrazione con strumenti di monitoraggio, registrazione e supporto come AWS, Jira, Zendesk e Slack.
- Garantisci una copertura completa con app mobili, notifiche push, SMS e avvisi vocali.
Limiti di TaskCall
- Piano Free limitato a cinque utenti, che potrebbe non essere scalabile per team in crescita
- La maggior parte delle analisi e dei dashboard hanno un limite ai piani più costosi.
Prezzi di TaskCall
- Free
- Starter: 9 $ al mese per utente
- Aziendale: 19 $ al mese per utente
- Operazioni digitali: 29 $ al mese per utente
Valutazioni e recensioni di TaskCall
- G2: recensioni insufficienti
- Capterra: recensioni insufficienti
10. ilert (Ideale per la gestione degli incidenti basata sull'IA con particolare attenzione alla privacy)
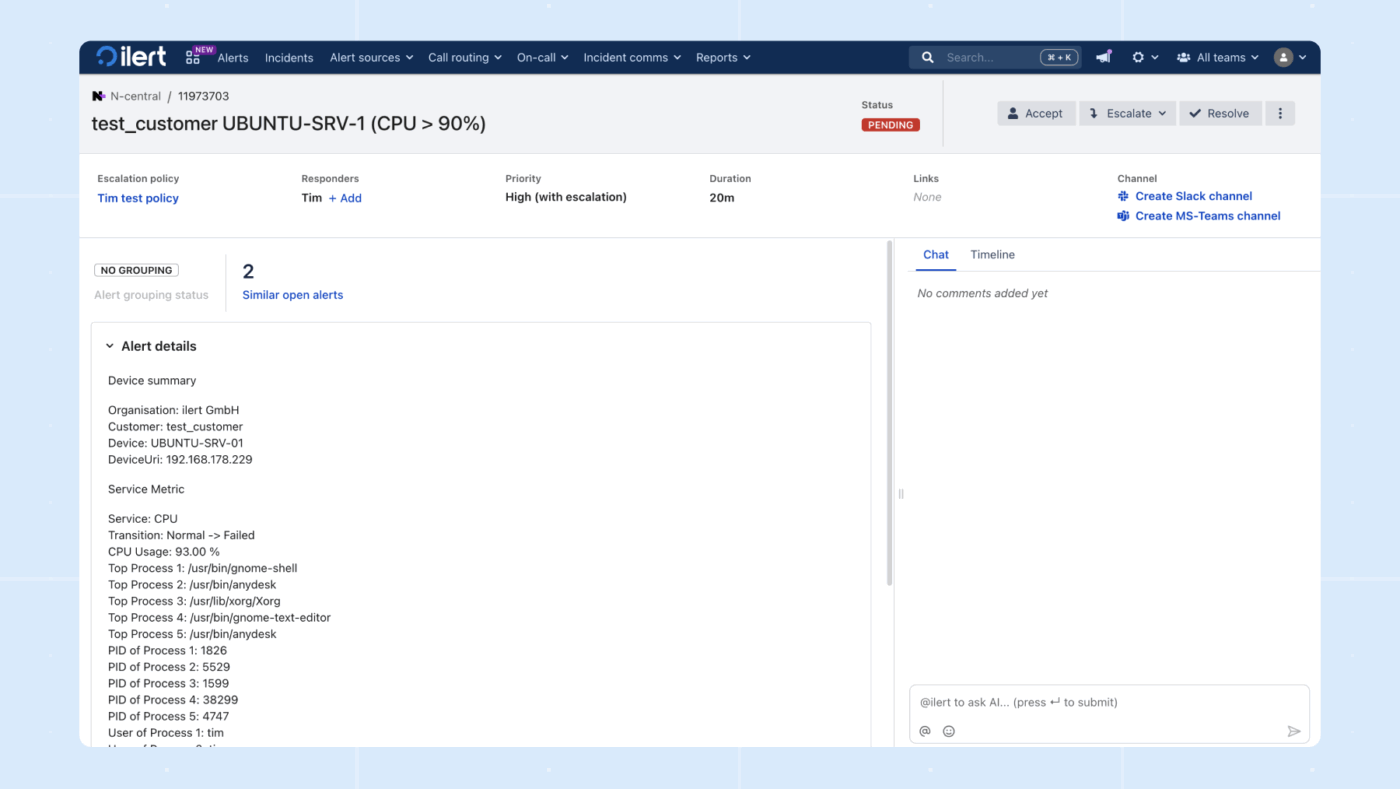
ilert è una piattaforma di gestione dei turni di reperibilità e di allerta incidenti che pone particolare attenzione all'affidabilità e alla privacy dei dati. Aiuta i team a garantire che gli avvisi critici provenienti dai sistemi di monitoraggio raggiungano tempestivamente i tecnici di reperibilità competenti.
La piattaforma offre una pianificazione flessibile dei turni di reperibilità, politiche di escalation multilivello e notifiche tramite numerosi canali, tra cui push, SMS e chiamate vocali.
Un instradamento che rispetta il programma attuale e il percorso di escalation fa sì che le chiamate dei clienti raggiungano la persona giusta invece di rimbalzare da un operatore all'altro.
In Slack o Teams, i responsabili della risposta lavorano sull'incidente nella chat mentre Ilert acquisisce il contesto, le sequenze e i follow-up.
L'agente vocale IA risponde alla tua hotline, raccoglie i dettagli corretti e avvisa immediatamente il tecnico di turno. Responder analizza le metriche, i log e le modifiche recenti nel tuo stack, individua le possibili cause principali, suggerisce chi coinvolgere e propone persino un percorso di rollback per una mitigazione più rapida.
Hai il controllo in ogni passaggio.
Le migliori funzionalità/funzioni di ilert
- Fornisci avvisi multicanale affidabili tramite voce, SMS, push e chat
- Automatizza la gestione dei turni di reperibilità con percorsi di pianificazione e escalation
- Fornisci aggiornamenti rapidi attraverso pagine di stato basate sull'IA e comunicazioni con le parti interessate.
- Utilizza ilert Responder IA per analizzare gli incidenti, individuare le cause alla radice e suggerire azioni da intraprendere.
- Integrazione con strumenti di monitoraggio e ITSM come Prometheus, Datadog, Jira e Slack
Limitazioni di ilert
- I prezzi potrebbero sembrare elevati per i team più piccoli.
- Alcune integrazioni richiedono un ulteriore lavoro di configurazione
- L'app mobile potrebbe trarre vantaggio da funzionalità/funzioni più avanzate
Prezzi di ilert
- Free
- Pro: 24 $ al mese per utente
- Scala: 49 $ al mese per utente
- Enterprise: prezzi personalizzati
Valutazioni e recensioni di ilert
- G2: recensioni insufficienti
- Capterra: 4,7/5 (oltre 60 recensioni)
Cosa dicono gli utenti di ilert
Questa recensione di Capterra riporta:
Trovo questo strumento molto intuitivo ed efficace per la gestione dei turni di reperibilità all'interno dei team IT. Offre flessibilità consentendo di rispondere direttamente tramite l'app, SMS o telefonata, il che lo rende particolarmente pratico in scenari reali.
Trovo questo strumento molto intuitivo ed efficace per la gestione dei turni di reperibilità all'interno dei team IT. Offre flessibilità consentendo di rispondere direttamente tramite l'app, SMS o telefonata, il che lo rende particolarmente pratico in scenari reali.
11. Zenduty (ideale per la risposta agli incidenti su larga scala basata sull'IA)
Zenduty aiuta i team di ingegneri e DevOps a concentrarsi sui segnali importanti, riducendo il MTTR (Mean Time To Resolution) e offrendo alle organizzazioni un'unica piattaforma affidabile per la gestione degli incidenti.
Gli utenti apprezzano costantemente gli avvisi rapidi e affidabili, con notifiche push, chiamate e SMS che arrivano senza ritardi, in modo che i tecnici di turno possano confermare la ricezione della notifica e tornare al lavoro. Ai team piace anche la possibilità di personalizzare le notifiche in base alla gravità, al servizio o al tipo di incidente, in modo che venga contattata la persona giusta al momento giusto, piuttosto che tutti contemporaneamente.
La piattaforma supporta la risposta collaborativa agli incidenti, con ruoli di incidente, modelli di attività e canali di comunicazione integrati. Una funzionalità significativa è il suo approccio basato sull'Incident Command System (ICS), che fornisce un quadro strutturato per la gestione di incidenti su larga scala.
Se stai cercando di passare da Opsgenie, Zenduty è una buona opzione, con il suo supporto alla migrazione che ha raccolto recensioni positive.
Le migliori funzionalità/funzioni di Zenduty
- Fornisci una gestione degli incidenti basata sull'IA con ZenAI
- Offre supporto per la pianificazione avanzata dei turni di reperibilità con rotazioni e escalation personalizzabili.
- Automatizza i playbook degli incidenti in modo che le attività e i follow-up siano monitorati in modo coerente.
- Integrazione perfetta con oltre 150 strumenti come Slack, Teams, Jira, Datadog e Grafana.
- Invia avvisi mobili in tempo reale su iOS, Android e persino smartwatch.
Limiti di Zenduty
- La funzione di ricerca può mescolare più incidenti, rendendo più difficile il monitoraggio
- Alcune funzionalità avanzate sono limitate ai piani di livello superiore.
- Le notifiche sovrapposte in configurazioni complesse possono portare a duplicazioni degli avvisi.
Prezzi di Zenduty
- Free
- Starter: 6 $ al mese per utente
- Crescita: 16 $ al mese per utente
- Enterprise: 25 $ al mese per utente
Valutazioni e recensioni di Zenduty
- G2: 4,6/5 (oltre 135 recensioni)
- Capterra: recensioni insufficienti
Cosa dicono gli utenti di Zenduty
Questa recensione su G2 ha osservato:
Ciò che mi piace di più di Zenduty sono le sue analisi basate sui dati. Analizzando gli incidenti, possiamo effettuare il monitoraggio delle tendenze, ad esempio quali giorni, servizi o turni hanno registrato più problemi, identificare cosa è andato storto e determinare le aree che necessitano di miglioramenti.
Ciò che mi piace di più di Zenduty sono le sue analisi basate sui dati. Analizzando gli incidenti, possiamo effettuare il monitoraggio delle tendenze, ad esempio quali giorni, servizi o turni hanno registrato più problemi, identificare cosa è andato storto e determinare le aree che necessitano di miglioramenti.
📖 Leggi anche: Il miglior software per la gestione delle operazioni IT
12. Incidente. io (ideale per la risposta agli incidenti nativa di Slack)
Immaginiamo per un attimo di trovarci nel bel mezzo di un incidente. Il cercapersone suona. Le persone si svegliano. In Opsgenie, si conferma la ricezione, poi si cerca la stanza giusta, quindi si copia il contesto in un altro posto in modo che tutti possano vedere cosa sta succedendo.
Quel salto è il momento che la maggior parte dei team vuole risolvere. È qui che incident. io fa la differenza.
Basta dichiararlo direttamente su Slack e apparirà uno spazio pulito con i ruoli, la Sequenza e i prossimi due o tre passaggi già definiti. Puoi chiamare, inviare un testo, un'email o semplicemente toccare per confermare. Il lavoro inizia immediatamente e rimane visibile.
Gli utenti continuano a descrivere lo stesso ritmo una volta effettuato il passaggio. Un canale si attiva con solo il segnale di cui hai bisogno. L'app sollecita i follow-up e redige un riepilogo/riassunto chiaro mentre stai ancora risolvendo il problema. Gli aggiornamenti di stato per i clienti sono pronti per essere inviati senza uscire dal thread. Questo da solo riduce le chiacchiere che di solito si diffondono nelle stanze laterali e nei messaggi diretti.
L'adozione è stata semplice per team di dimensioni molto diverse. I gruppi più piccoli parlano di collegarlo a Linear e New Relic in un paio di settimane e di ottenere un valore reale fin dal primo giorno. Le organizzazioni più grandi riferiscono di averlo implementato in più team in circa un mese e di non aver rallentato il lavoro sulla roadmap per farlo.
Le migliori funzionalità di Incident.io
- Gestisci gli incidenti end-to-end direttamente in Slack o Microsoft Teams
- Utilizza l'IA SRE per suggerire soluzioni, indagare sui problemi e redigere comunicazioni.
- Gestisci i turni di reperibilità con la riduzione del rumore basata sull'IA
- Automatizza gli aggiornamenti della pagina di stato per clienti e stakeholder
- Ottieni informazioni dettagliate su tendenze, sequenze e metriche MTTx con i dashboard.
Limiti di Incident.io
- L'interfaccia può sembrare affollata a causa delle numerose notifiche di Slack.
- La configurazione avanzata (come i percorsi di escalation) potrebbe richiedere una messa a punto.
- Alcune funzionalità/funzioni di IA sono disponibili solo in inglese.
Prezzi degli incidenti di Incident.io
- Base: gratis
- Team: 19 $ al mese per utente
- Pro: 25 $ al mese per utente
- Enterprise: prezzi personalizzati
Valutazioni e recensioni di Incident.io
- G2: 4,8/5 (oltre 180 recensioni)
- Capterra: recensioni insufficienti
Cosa dicono gli utenti di Incident. io
Questa recensione su G2 è stata condivisa:
A mio avviso, incident. io offre il giusto equilibrio tra non intralciare il lavoro e fornire comunque struttura, processi e raccolta dati per la gestione degli incidenti.
A mio avviso, incident. io offre il giusto equilibrio tra non intralciare il lavoro e fornire comunque struttura, processi e raccolta dati per la gestione degli incidenti.
💡Suggerimento professionale: utilizza gli agenti predefiniti per rispondere alle domande del team o effettuare la condivisione di aggiornamenti, oppure configura un agente ClickUp AI personalizzato per monitorare lo stato delle attività e le date di scadenza e inviare promemoria, segnalare problemi o aggiornare lo stato secondo necessità, per far progredire il lavoro.
Questo video ti mostra come:
Cosa aspettarsi durante e dopo la migrazione da Opsgenie
Passare da Opsgenie può sembrare come traslocare da una casa in cui hai vissuto per anni. Ogni programma, regola di escalation e integrazione ha il suo posto, e l'idea di trasferire tutto in una nuova casa può sembrare scoraggiante.
Atlassian offre uno strumento di migrazione integrato nell'app per passare a Jira Service Management o Compass. Il processo è strutturato, prevedibile e progettato per ridurre al minimo le interruzioni.
Se decidi di optare per uno di questi strumenti, ti basterà rivedere il tuo piano, impostare la data di migrazione e lasciare che lo strumento faccia il lavoro pesante. Vediamo come funziona e valutiamo se è una buona scelta per la tua organizzazione.
Panoramica del flusso di migrazione
Passaggio 1 → Esamina e scegli il tuo percorso
Valuta il tuo piano Opsgenie e decidi se Jira Service Management (incentrato sull'ITSM) o Compass (incentrato sugli sviluppatori) è la soluzione più adatta alle tue esigenze.
Passaggio 2 → Pianifica la data di migrazione
Scegli una sequenza adatta al tuo ciclo di fatturazione e alla disponibilità del tuo team.
Passaggio 3 → Approva la fatturazione
Il tuo amministratore di fatturazione Atlassian conferma il piano in modo che il nuovo prodotto possa essere fornito.
Passaggio 4 → Migrazione dei dati in background
I dati di Opsgenie iniziano a effettuare la sincronizzazione mentre il tuo team continua a lavorare come al solito.
Passaggio 5 → Transizione e chiusura
Hai 120 giorni di tempo per completare il passaggio prima che Opsgenie venga disattivato.
In breve, ecco cosa aspettarsi:
- Utilizza lo strumento di migrazione guidata per effettuare l'automazione delle operazioni più complesse.
- Mantieni l'accesso completo a Opsgenie durante e dopo la migrazione fino alla chiusura.
- Segui le guide personalizzate alla migrazione in Jira Service Management o Compass.
- Modifica i flussi di lavoro e riconfigura le impostazioni durante il periodo di transizione di 120 giorni.
- Garantisci la continuità di avvisi, pianificazioni e integrazioni senza interruzioni
Pro e contro della migrazione da Opsgenie a Jira Service Management
Pro:
- È in grado di creare un flusso di lavoro unificato e senza soluzione di continuità.
- Per i team che hanno già investito molto nell'ecosistema Atlassian, può essere una decisione conveniente ed economica.
- L'efficace analisi post-incidente di Jira semplifica il processo di monitoraggio delle azioni di follow-up.
- Il consolidamento dei dati relativi agli incidenti in JSM consente una reportistica più potente e olistica.
Contro:
- Alcune delle funzioni avanzate di Opsgenie standalone potrebbero non essere immediatamente disponibili in JSM.
- Il passaggio a un ambiente JSM più ampio può aumentare la complessità e il rumore
- I team dovranno essere riqualificati sulla nuova interfaccia e sui flussi di lavoro all'interno di JSM.
Ecco alcune opinioni degli utenti di Reddit sull'argomento
Questo utente di Reddit ha ritenuto che la mossa abbia funzionato nel complesso:
Per noi non è andata male. Devo riconsiderare le impostazioni dei ruoli e delle autorizzazioni, ma tutto sembra essere andato abbastanza bene, tranne nel caso in cui si abbiano nomi di team Jira identici a quelli equivalenti di OpsGenies. Non si sono uniti bene e alcuni di essi si sono danneggiati. Se è così, consiglio di cambiarli.
Per noi non è andata male. Devo riconsiderare l'impostazione dei ruoli e delle autorizzazioni, ma tutto sembra essere andato abbastanza bene, tranne nel caso in cui si abbiano nomi di team Jira identici a quelli equivalenti di OpsGenies. Non si sono uniti bene e alcuni di essi si sono danneggiati. Se è così, consiglio di cambiarli.
Ecco un altro utente che chiaramente non ha avuto la migliore esperienza:
Nel caso qualcuno stia valutando questa opzione: siamo passati a Jira Service Management, che fa parte del pacchetto che abbiamo già pagato (l'azienda sta risparmiando in modo aggressivo). È così pessimo che non riesco nemmeno a spiegarlo. Non consideratelo come opzione.
Nel caso qualcuno stia valutando questa opzione: siamo passati a Jira Service Management, che fa parte del pacchetto che abbiamo già pagato (l'azienda sta risparmiando in modo aggressivo). È così pessimo che non riesco nemmeno a spiegarlo. Non consideratelo come opzione.
E un altro che sta già pensando di cambiare dopo sei mesi con JSM:
JSM è terribile. Non è assolutamente paragonabile a PagerDuty, Rootly o Incident. io. Anche noi siamo passati a questo strumento circa 6 mesi fa al lavoro e stiamo già cercando delle alternative. È così poco flessibile, non ha quasi nessuna integrazione, non ha un buon supporto Slack e gli avvisi e le pagine di reperibilità vengono persi dagli ingegneri con una percentuale di esito positivo piuttosto alta (non abbiamo mai avuto questo problema con OpeGenie).
JSM è terribile. Non è assolutamente paragonabile a PagerDuty, Rootly o Incident. io. Anche noi siamo passati a questo strumento circa 6 mesi fa al lavoro e stiamo già cercando delle alternative. È così poco flessibile, non ha quasi nessuna integrazione, non ha un buon supporto Slack e gli avvisi e le pagine di reperibilità vengono persi dagli ingegneri con una percentuale di successo piuttosto alta (non abbiamo mai avuto questo problema con OpeGenie).
L'altra alternativa offerta da Atlassian, Compass, non è un'alternativa diretta a Opsgenie. Si tratta invece di una piattaforma di esperienza per sviluppatori progettata per mappare e gestire i componenti, i servizi e le dipendenze di un'architettura software complessa.
Ti consigliamo di valutare questi fattori prima di decidere quale alternativa a Opsgenie è la migliore per il tuo team.
Opsgenie squilla, ClickUp risponde
Passare da Opsgenie può sembrare un passaggio importante, ma consideralo un'opportunità per semplificare la vita al tuo team.
Hai visto come si posizionano gli altri strumenti, ciascuno con i propri punti di forza, ma anche con i propri limiti.
Tuttavia, ClickUp conquista silenziosamente i cuori. 🤗
Ecco perché: Riunisce le tue attività, le comunicazioni e i flussi di lavoro in un unico posto. Non dovrai più passare da una schermata all'altra o mettere insieme strumenti separati. Al contrario, il tuo team rimarrà connesso, avrà chiare le priorità e sarà sicuro di ciò che deve essere fatto in seguito.
Scegliere la giusta soluzione per la gestione degli incidenti non significa solo inviare avvisi, ma creare un solido framework di gestione degli incidenti che supporti l'efficienza operativa a lungo termine. Con ClickUp, il tuo team può gestire gli incidenti in modo proattivo, riducendo il rumore e garantendo la coerenza in ogni risposta. 😌
Se sei pronto per avere meno grattacapi e più chiarezza, è il momento giusto per iscriverti a ClickUp!
Domande frequenti (FAQ)
Le migrazioni da Opsgenie devono essere pianificate prima di aprile 2027. Dopo tale data, i dati di Opsgenie non saranno più accessibili.
Alcune delle alternative più valide includono Jira Service Management, PagerDuty, FireHydrant, TaskCall, ilert, Zenduty e incidente. io. Ognuna offre un diverso equilibrio tra gestione dei turni di reperibilità, automazione e integrazioni. Tuttavia, se desideri una piattaforma all-in-one basata sull'IA che mantenga i tuoi flussi di lavoro, le comunicazioni e la documentazione in un unico posto, scegli ClickUp.
Jira Service Management include la maggior parte delle funzionalità principali di Opsgenie, come gli avvisi, la pianificazione dei turni di reperibilità e i flussi di lavoro degli incidenti, ma alcune funzioni avanzate potrebbero differire. Compass è un'opzione per i team di sviluppo che si concentrano sui cataloghi di servizi e sul monitoraggio dei componenti.
Sì. Atlassian fornisce uno strumento di migrazione integrato nell'app che trasferisce automaticamente avvisi, pianificazioni e politiche di escalation. Puoi anche testare la migrazione in un account demo prima di commit.
Sì. Strumenti come Cabot, OpenDuty e Alertmanager possono essere personalizzati come sostituti open source, anche se potrebbero richiedere una maggiore configurazione e manutenzione.
I costi dipendono dalla piattaforma scelta. Jira Service Management, Compass e altre alternative offrono prezzi differenziati, spesso per utente al mese. Alcuni strumenti open source sono gratis, ma richiedono costi di infrastruttura e supporto.
Sì. Il tuo team può continuare a utilizzare Opsgenie durante il periodo di migrazione e le integrazioni rimangono attive fino a quando Opsgenie non viene disattivato definitivamente. Successivamente, dovranno essere riconfigurate nella tua nuova piattaforma.