
Die ersten Dienste sind einfach. Eine Rotation, ein Kanal und dann ein Backup.
Sobald Ihr Unternehmen jedoch Dutzende von Microservices, mehrere Regionen und eine mehrschichtige Eigentümerschaft erreicht hat, sind manuelle Eskalationen kein Workflow mehr, sondern werden zu einer Belastung.
In diesem Leitfaden wird erläutert, wie Sie Eskalationspfade für Incidents automatisieren können, die sich an Ihre technische Organisation anpassen, ohne Lücken in Ihrem Bereitschaftssystem zu verursachen.
Außerdem zeigen wir Ihnen, wie ClickUp zur Erstellung eines Eskalationssystems beiträgt, auf das sich Ihre Engineering-Teams verlassen können. 🎯
⭐ Empfohlene Vorlage
Reagieren Sie mit der ClickUp-Vorlage für Vorfallpläne (IAP) schnell und effektiv auf Notfälle, von Naturkatastrophen bis hin zu Datenverstößen.

Die Vorlage enthält vordefinierte Abschnitte für:
- Definieren Sie Ziele für Incidents und Prioritäten für die Reaktion.
- Schaffen Sie eine klare Befehlsstruktur
- Koordinieren Sie Maßnahmen teamübergreifend in Echtzeit.
- Halten Sie Entscheidungen, Zeitleisten und wichtige Aktualisierungen fest, sobald sie auftreten.
- Bleiben Sie mit der Eskalation in Verbindung und verfolgen Sie den weiteren Verlauf
Und da es in ClickUp integriert ist, fungiert es als Live-Dokument für die Bearbeitung von Incidents und nicht als statische Checkliste.
Warum sollten Eskalationspfade für Incidents automatisiert werden?
Wenn Ihr Team komplexe Systeme mit strengen SLAs verwaltet, verlangsamt eine manuelle Eskalation nur Ihre Arbeit. Eine automatisierte Eskalation macht Ihren Reaktionsprozess vorhersehbar und stressfrei, selbst bei hohen Incidents.
Hier erfahren Sie, warum Sie die Eskalationspfade Ihres Unternehmens durch Automatisierung optimieren sollten. 👇
Das Risiko einer manuellen Eskalation
Wenn Sie mit Dutzenden von Diensten, mehreren Bereitschaftsrotationen und ständig wechselnder Eigentümerschaft zu tun haben, werden manuelle Schritte schnell zu einem Problem.
Häufige Fallstricke sind:
- Versäumte oder verspätete Benachrichtigungen, wenn jemand eine E-Mail, SMS oder Benachrichtigung beim Chatten übersieht
- Verwirrung bei Übergaben, insbesondere wenn Eskalationspfade nicht klar dokumentiert sind
- Eskalation an das falsche Team, weil die Karte der Eigentümerschaft nicht aktualisiert wurde
- Engpässe, die dadurch entstehen, dass man sich auf eine Person verlässt, um „die Warnmeldung weiterzuleiten“
📖 Lesen Sie auch: Wie man einen Incident-Bericht verfasst
Vorteile der Automatisierung
Die ITSM-Automatisierung verleiht Ihren Eskalationspfaden Struktur und Dynamik. Anstatt darauf zu hoffen, dass jemand die Warnmeldung sieht, führt Ihr System sofort und konsistent eine vordefinierte Abfolge von Schritten aus.
Das sind die Vorteile für Teams, die KI zur Automatisierung von Aufgaben einsetzen:
- Schnellere Reaktionszeiten, da Warnmeldungen innerhalb von Sekunden die richtige Person oder das richtige Team erreichen.
- Konsequente Ausführung von Eskalationsschritten, selbst um 3 Uhr morgens, wenn die Entscheidungsfindung langsamer ist.
- Integrierte Redundanz, die sicherstellt, dass Backup-Einsatzkräfte benachrichtigt werden, wenn der primäre Bereitschaftsdienst die Warnmeldung verpasst.
- Klare Sichtbarkeit über alle Teams hinweg, da jeder versteht, wie Eskalationen ablaufen.
- Weniger Feuerwehreinsätze und besser planbare Bereitschaftsdienste
📖 Lesen Sie auch: Beispiele für Business-Continuity-Pläne
Reduzierung von Alarmmüdigkeit und menschlichen Versehen
Alarmüberflutung beeinträchtigt die Effektivität des Bereitschaftsdienstes. Wenn Ihr Team zu oft oder aus den falschen Gründen alarmiert wird, reagiert es nicht mehr mit der erforderlichen Dringlichkeit. Durch Automatisierung können Sie filtern und nur die Vorfälle eskalieren, die wirklich menschliche Aufmerksamkeit erfordern.
Mit automatisierter Eskalationslogik:
- Warnmeldungen mit schwachem Signal oder doppelte Warnmeldungen werden unterdrückt, bevor sie den Bereitschaftsdienst erreichen.
- Schweregradbasierte Regeln sorgen dafür, dass kleinere Probleme niemanden unnötig aus dem Schlaf reißen.
- Warnmeldungen werden nur eskaliert, wenn das System innerhalb eines definierten Zeitraums keine Reaktion feststellt.
- Teams verbringen weniger Zeit mit der Triage von Störsignalen und mehr Zeit mit der Lösung echter Probleme.
Unterstützung der Einhaltung von SLAs und Bereitschaftsrichtlinien
Durch Automatisierungen lassen sich Compliance-Vorgaben leichter einhalten, ohne dass eine ständige manuelle Überwachung erforderlich ist. Für IT-Verantwortliche, die strenge SLAs oder interne Zuverlässigkeitsverpflichtungen verwalten müssen, dient KI als Leitplanke, die das erwartete Verhalten durchsetzt. Sie hilft Ihnen dabei:
- Stellen Sie sicher, dass Benachrichtigungen zu Incidents vordefinierten Regeln für die Weiterleitung folgen.
- Halten Sie SLA-Reaktionszeiten automatisch ein, mit zeitgesteuerten Eskalationen.
- Setzen Sie Bereitschaftspläne durch, ohne sich auf veraltete Tabellenkalkulationen verlassen zu müssen.
- Erstellen Sie Prüfpfade für jede Warnmeldung, Eskalation und Bestätigung.
🎥 Möchten Sie Ihren gesamten Eskalationspfad-Workflow freihändig ausführen? Super Agents hilft Ihnen dabei. 👇🏼
🔍 Wussten Sie schon? Die Missionskontrolle der NASA basiert im Wesentlichen auf einer automatisierten Eskalationslogik. Wenn die Telemetriedaten außerhalb des zulässigen Bereichs liegen, leitet das System sofort automatisierte Warnmeldungen an die jeweiligen Spezialisten weiter.
Was ist eine Eskalationsrichtlinie im Incident Management?
Eine Eskalationsrichtlinie ist ein vordefinierter Satz von Regeln, der festlegt, wer benachrichtigt wird, wann die Benachrichtigung erfolgt und wie die Verantwortung nach oben oder zwischen Teams weitergegeben wird.
Betrachten Sie es als einen strukturierten Fahrplan, der verhindert, dass Incidents ins Stocken geraten, sicherstellt, dass die richtigen Experten zum richtigen Zeitpunkt eingreifen, und Teams dabei hilft, SLAs einzuhalten.
Eine gut strukturierte Eskalationsmanagementrichtlinie umfasst in der Regel:
- Regelbasiertes Routing, das festlegt, wer als Nächstes an der Reihe ist, wenn jemand den Incident nicht bestätigt oder nicht lösen kann.
- Zeitgesteuerte Auslöser, die je nach Schweregrad automatisch nach 5, 15 oder 30 Minuten eskalieren.
- Benachrichtigungsmethoden wie Telefonanrufe, SMS, Chatten oder E-Mail
- Eskalationspläne von Stufe 1 (primärer Bereitschaftsdienst) > Stufe 2 (leitende Ingenieure/SMEs) > Stufe 3 (Führungsebene)
- Dokumentationserwartungen, damit neue Responder ohne Verlust wichtiger Kontextinformationen übernehmen können
📖 Lesen Sie auch: Wie man Aufgaben als P0, P1, P2, P3 und P4 priorisiert
Arten von Eskalationsrichtlinien
Hier sind die wichtigsten Arten von Richtlinien, die Ihr Team verstehen sollte:
1. Hierarchische Eskalation (vertikal)
Alarme werden in der Befehlskette nach oben weitergeleitet, von Junior-Ingenieuren über Senior-Spezialisten bis hin zur Führungsebene. Verwenden Sie diese Funktion, wenn die Situation tiefergehende Fachkenntnisse, Entscheidungsbefugnisse oder die Sichtbarkeit der Führungskräfte erfordert.
2. Funktionale Eskalation (horizontal)
Anstatt nach oben weitergeleitet zu werden, wird die Warnmeldung quer durch die Teams an die Funktion weitergeleitet, die für das betroffene System zuständig ist. Dies ist ideal für Incidents, die mit einem bestimmten Bereich verbunden sind, wie z. B. Datenbanken, Netzwerke, Zahlungen oder APIs.
3. Zeitbasierte Eskalation
Dies ist das Rückgrat der meisten automatisierten Systeme. Bei dieser Art von Eskalation wird die Warnmeldung nach einem bestimmten Zeitraum, der oft direkt an SLAs gekoppelt ist, an die nächste Ebene weitergeleitet. Dies ist besonders wichtig, wenn Sie eine garantierte Reaktionsfähigkeit außerhalb der Geschäftszeiten benötigen.
4. Wirkungsbasierte Eskalation
Die wirkungsbasierte Eskalation hängt vom Schweregrad oder den geschäftlichen Auswirkungen ab, nicht von der Hierarchie oder der Zeit. Sie ist nützlich bei Ausfällen, Problemen bei Zahlungen, kundenbezogenen Problemen oder Sicherheitsverletzungen.
5. Parallele Eskalation
Hier werden mehrere Personen oder Teams gleichzeitig benachrichtigt. Die parallele Eskalation wird für Probleme mit hohem Schweregrad verwendet, die mehrere Fachgebiete erfordern, oder für Situationen, in denen jede Verzögerung inakzeptabel ist.
🔍 Wussten Sie schon? Eine aktuelle Studie zu Alarmsignalen hat ergeben, dass extrem auffällige oder „laute/helle” Alarme die Reaktionszeiten verlangsamen können, insbesondere wenn der Alarm unerwartet kommt. Sobald der Alarmtyp jedoch erwartet wird (d. h. Teil eines vorab festgelegten Eskalations-/Benachrichtigungssystems ist), verbessern sich die Reaktionszeiten. Dies deutet darauf hin, dass Sie bei der Automatisierung von Eskalationspfaden die Mitarbeiter nicht einfach mit Alarmen hoher Priorität überfluten sollten.
Wann sollte der Auslöser für eine automatische Eskalation ausgelöst werden?
Nachdem Sie nun wissen, wie Eskalationspfade strukturiert sind, müssen Sie im nächsten Schritt entscheiden, wann diese Regeln automatisch ausgeführt werden sollen.
Im Folgenden finden Sie die wichtigsten Situationen, die die Auslöser für eine automatische Eskalation sind und die Logik hinter Ihren Richtlinien bilden. 💁
Schweregradbasierte Eskalation
Die automatische Eskalation wird ausgelöst, wenn die Schwere oder die Auswirkungen des Incidents einen bestimmten Schwellenwert überschreiten. Incidents mit hoher Schwere erfordern sofortige Aufmerksamkeit durch Vorgesetzte. Durch die automatische Eskalation werden Engpässe umgangen und Experten innerhalb von Sekunden in den Kreislauf einbezogen.
📌 Beispiel: Ein vollständiger Ausfall des Dienstes, ein Ausfall des Systems für Zahlungen oder eine erhebliche Verschlechterung, von der viele Benutzer oder Kernsysteme betroffen sind, erfordern eine automatische Eskalation.
Zeitbasierte Eskalation
Wenn niemand den Incident innerhalb eines festgelegten Zeitfensters bestätigt oder löst, wird die Warnmeldung automatisch an die nächste Ebene eskaliert. Dadurch wird verhindert, dass Tickets stagnieren, insbesondere außerhalb der normalen Arbeitszeiten oder wenn der Ersthelfer nicht verfügbar oder überlastet ist.
📌 Beispiel: Nach 10–15 Minuten ohne Bestätigung erfolgt eine Eskalation vom Ersthelfer zu einem leitenden Techniker; nach weiteren 30–60 Minuten ohne Lösung wird der Vorfall weiter eskaliert.
Kontextbezogene Eskalation
Diese Eskalationslogik berücksichtigt die kontextbezogenen Attribute des Incidents, wie z. B. den betroffenen Dienst oder das betroffene System, den Eigentümer des Dienstes, das betroffene Kundensegment (intern vs. extern, VIP vs. regulär) oder den Funktionsbereich (Datenbank, Netzwerk, Integration). Basierend auf diesem Kontext werden Warnmeldungen an den relevantesten Responder oder das relevanteste Team weitergeleitet.
So vermeiden Sie eine Überlastung der Teams mit irrelevanten Incidents, verkürzen die Reaktionszeit und stellen sicher, dass Spezialisten Probleme in ihrem Bereich bearbeiten.
📌 Beispiele: Ein Latenzanstieg im Dienst für Zahlungen sollte direkt an das Team für Zahlungen gemeldet werden, oder ein Backend-Fehler im Abrechnungs-Microservice sollte das Team für Abrechnungen benachrichtigen.
Metadatenbasierte Eskalation
Moderne Alarmierungs- und Incident-Tools erfassen Metadaten wie die Ursprungsquelle (welches Überwachungstool oder welche Alarmierungsregel ausgelöst wurde), die Identität des Benutzers/Kunden, den Speicherort, die historische Häufigkeit ähnlicher Incidents oder Beschreibungen. Dies hilft Ihnen, eine detailliertere, intelligentere Logik anzuwenden, anstatt sich auf pauschale Schweregrad- oder zeitbasierte Regeln zu verlassen.
📌 Beispiele: Wiederkehrende Warnmeldungen aus demselben Subsystem können auf ein tiefer liegendes, systemisches Problem hinweisen, das eine schnellere Eskalation erforderlich macht. Oder Warnmeldungen für VIP-Kunden können zusätzliche Benachrichtigungen als Auslöser auslösen.
Kombinieren Sie Auslöser, um intelligentere, adaptive Eskalationsrichtlinien zu erstellen.
In der Praxis verlassen sich viele Teams nicht nur auf eine Art von Auslöser. Stattdessen erstellen sie hybride Eskalationsrichtlinien, die Regeln für Schweregrad, Zeit, Kontext und Metadaten kombinieren.
Dieser mehrschichtige Ansatz ermöglicht es Teams, Eskalationsrichtlinien zu erstellen, die sowohl reaktionsschnell (bei Bedarf schnell) als auch intelligent (selektiv, um Störungen zu minimieren) sind, was zu verbesserten Ergebnissen bei Incidents und einer effizienteren Ressourcenzuweisung führt.
🔍 Wussten Sie schon? Im 18. Jahrhundert verwendeten Marinebesatzungen in Notfällen eine strenge Eskalationskette. Wenn ein rangniedrigerer Matrose eine Gefahr entdeckte, läutete er eine Glocke und gab die Nachricht die Hierarchie hinauf weiter, bis der Kapitän die endgültige Entscheidung traf.
So entwerfen Sie effektive Eskalationspfade
Bei der Gestaltung von Eskalationspfaden geht es darum, ein System aufzubauen, das die richtigen Warnmeldungen zuverlässig und mit minimalem Aufwand an die richtigen Personen weiterleitet.
Hier finden Sie einen praktischen, schrittweisen Leitfaden, den Sie in komplexen, verteilten Umgebungen anwenden können.
P. S. Wir werden auch untersuchen, wie Ihnen bestimmte ClickUp-Features dabei helfen können! 🤩
Schritt 1: Definieren Sie klare Eskalationskriterien, Eskalationsstufen und Verantwortlichkeiten.
Beginnen Sie damit, zu definieren, was einen Incident ausmacht, der eine Eskalation erfordert. Dokumentieren Sie objektive Kriterien, damit jeder Bereitschaftsingenieur, egal ob neuer L1-Reaktionsbeauftragter oder erfahrener SRE, die Schwere eines Incidents auf die gleiche Weise interpretiert.
Dies sorgt für einen klaren Eskalations-Workflow, beseitigt Unklarheiten und stellt sicher, dass die Automatisierung nur dann greift, wenn es wirklich wichtig ist.
Beziehen Sie Kriterien wie die folgenden ein:
- Schweregradschwellenwerte: Ausfall des Dienstes, Probleme mit Zahlungen, Probleme mit der Authentifizierung, Datenbeschädigung und Warnungen zur Sicherheit
- Auswirkungen: Ausfälle mit Auswirkungen auf Kunden, interne Servicebeeinträchtigungen, Ausfälle von Partner-APIs, Compliance- oder Sicherheitsrisiken
- Geschäftskritischer Kontext: Auswirkungen auf hochwertige Kunden, umsatzbeeinflussende Flows, risikoreiche Systeme (z. B. Zahlungen, Rechnungsstellung)
Sobald Kriterien und Auslöser definiert sind, legen Sie fest, wer benachrichtigt wird und welche Aufgaben die einzelnen Personen an jedem Eskalationspunkt haben.
Definieren Sie Ebenen klar:
- Stufe 1 (primärer Bereitschaftsdienst-Incident-Manager): Fungiert als Ersthelfer und ist für die Bestätigung, die erste Triage und die Bemühungen zur Schadensbegrenzung verantwortlich.
- Stufe zwei (Backup/Spezialist/SME): Bietet umfassendes technisches Fachwissen und löst komplexe Systemprobleme.
- Stufe drei (Technischer Leiter/Führungsebene): Beaufsichtigt schwerwiegende Incidents, genehmigt wichtige Maßnahmen, koordiniert die teamübergreifende Kommunikation und ist als Auslöser für eine Eskalation beim Anbieter tätig, wenn nötig.
🚀 Vorteil von ClickUp: Verwenden Sie ClickUp Docs, um eine einzige Quelle für Eskalationskriterien, -stufen und -verantwortlichkeiten zu pflegen und Rollen und Verantwortlichkeiten zu dokumentieren, einschließlich wer:
- Bestätigt und mindert
- Kommuniziert mit Stakeholdern
- Behandelt Eskalationen von Lieferanten oder externen Partnern
- Leitet die Einsatzleitung des Incidents
Sie können diese spezifischen Rollen auch mit den entsprechenden ClickUp-Aufgaben verknüpfen, um eine Verbindung zum Kontext herzustellen.
Erstellen Sie Ihre eigene Wissensdatenbank:
Sobald Eskalationskriterien und Eigentümerschaft definiert sind, benötigen Teams eine einheitliche Methode, um technische Vorfälle zu erfassen, zu verfolgen und zu analysieren. Die ClickUp-Vorlage für Vorfallberichte bietet ein strukturiertes, leicht zugängliches System, um IT- und Betriebsvorfälle an einem Ort zu dokumentieren.
Die in ClickUp Docs integrierte Funktion hilft Incident-Response-Teams dabei, wichtige Details wie die Schwere des Vorfalls, betroffene Dienste, Zeitleisten, Zusammenfassungen der Ursachen, Schritte zur Schadensbegrenzung und Folgeaktionen zu dokumentieren.
Schritt 2: Standardisieren Sie die Erstellung von Incidents
Bevor Eskalationspfade überhaupt aktiviert werden, benötigt Ihr Team eine zuverlässige Methode, um Incident-Daten zu erfassen, zu normalisieren und anzureichern. Wenn die ursprüngliche Incident-Aufzeichnung unvollständig oder inkonsistent ist, versagt selbst die ausgefeilteste Eskalationslogik.
Die Standardisierung sollte:
- Eingehende Warnmeldungen triagieren: Wandeln Sie Warnmeldungen in einheitliche Benutzerdefinierte Felder wie Schweregrad, Kategorie, betroffener Dienst, Vorfalltyp und Status der Bestätigung um.
- Erweitern Sie den Incident automatisch: Beziehen Sie Metadaten ein, darunter Cluster, Bereitstellungs-ID, Service-Eigentümer oder Abhängigkeiten.
- Stellen Sie sicher, dass jeder Incident den Kontext erfasst: Protokollieren Sie, wer ihn gemeldet hat, wie er entdeckt wurde, die Umgebung (Produktion/Staging) und alle relevanten Protokolle oder Screenshots.
Erstellen Sie ein ClickUp-Formular direkt aus der Liste, in der Incidents verfolgt werden, und gestalten Sie es so, dass es Ihre betriebliche Realität und die relevanten Daten widerspiegelt, von denen Ihre Eskalationslogik abhängig ist. Auf diese Weise werden alle Incidents in einem einheitlichen Format in Ihr System eingegeben, auf das die Automatisierung zuverlässig reagieren kann, anstatt fragmentierte Nachrichten über Chat, E-Mail oder Dashboards zu erhalten.

Gruppieren Sie Felder bewusst, damit jeder Incident vollständig kontextualisiert wird:
- Identifizierung (Titel, Zusammenfassung)
- Klassifizierung (Schweregrad, Typ, betroffener Dienst)
- Quelle (Überwachung, Benutzer, API)
- Beweise (Protokolle, Screenshots)
- Geschäftskontext (SLA-Stufe, Auswirkungen auf den Kunden)
Mit jeder Formularübermittlung wird automatisch eine neue ClickUp Aufgabe erstellt, wobei alle Antworten den Benutzerdefinierten Feldern von ClickUp zugeordnet werden. Dadurch wird sichergestellt, dass Vorfälle zum Zeitpunkt ihrer Erstellung normalisiert werden, wodurch Unklarheiten beseitigt werden und manuelle Reaktionen auf Vorfälle überflüssig werden.
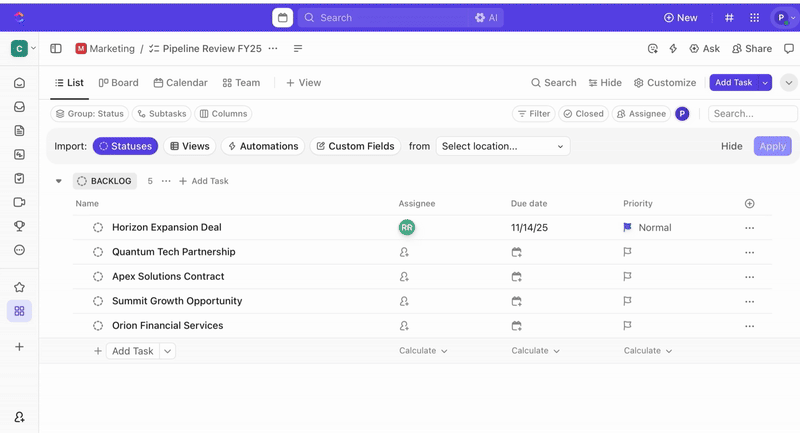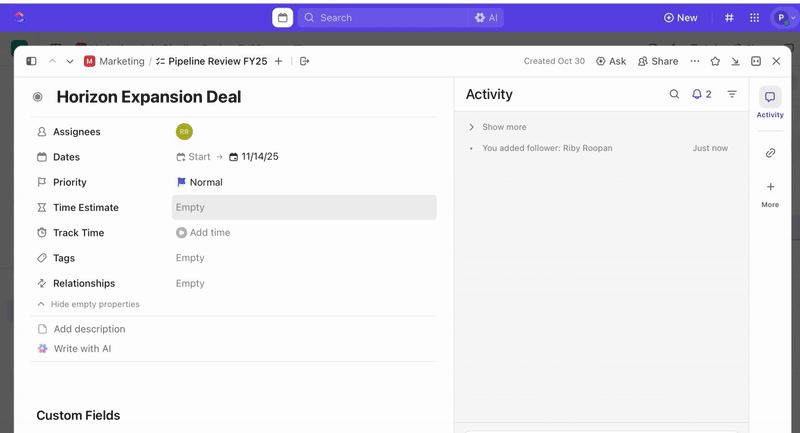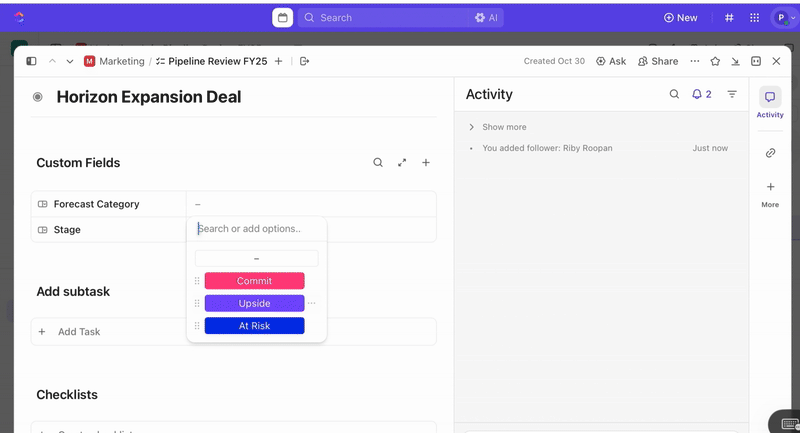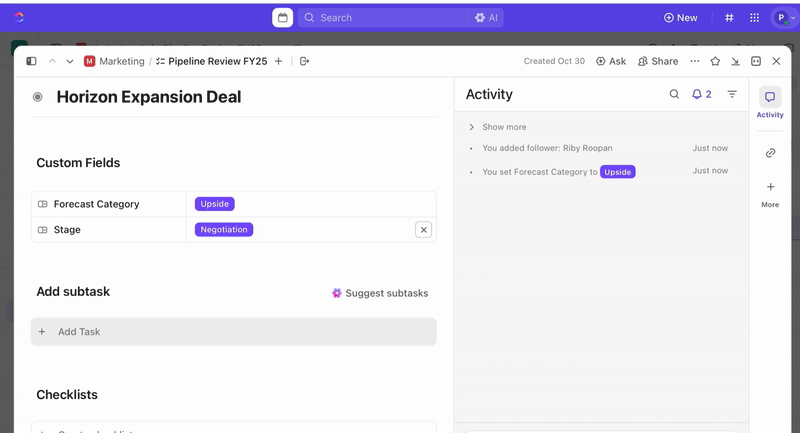
Sobald Aufgaben erstellt wurden, können Sie benutzerdefinierte Felder verwenden, um die Triage und Priorisierung voranzutreiben (z. B. Schweregrad, Auswirkungen, Responder-Gruppe), und benutzerdefinierte ClickUp-Status definieren, die Ihre Incident-Phasen widerspiegeln (Neu > Triage > Untersuchung > Minderung > Gelöst).
Schritt 3: Erstellen Sie den Eskalationspfad (d. h. Reihenfolge + Zeitplan + Kanäle)
Dies ist der Kern des Pfades. Legen Sie den Pfad in Phasen fest, wobei jede Phase definiert, wer über welchen Kanal benachrichtigt wird und nach welcher Zeit ohne Bestätigung oder Lösung.
- Definieren Sie „Zeitlimit für die Bestätigung“ und „Zeitlimit für die Lösung“.
Hier ein Beispiel für einen Workflow:
- Phase eins: Der erste Bereitschaftsdienst, der sofort per SMS/Chat benachrichtigt wird, muss innerhalb von 5–10 Minuten bestätigen.
- Phase zwei: Wenn innerhalb der nächsten 15 bis 20 Minuten keine Bestätigung oder keine Maßnahmen erfolgen, eskalieren Sie den Vorfall per SMS/Chat-Kanal/E-Mail an das Backup-/SRE-Team + Senior Engineer.
- Phase drei: Wenn das Problem nach weiteren 30 bis 60 Minuten immer noch nicht gelöst ist, eskalieren Sie es an den technischen Leiter/die Geschäftsleitung und nutzen Sie optional den Auslöser für einen „Major Incident”-Kanal.
- Entscheiden Sie, ob der Eskalationspfad „wiederholt“ (erneute Benachrichtigung derselben Ebene) oder „weitergeleitet“ werden soll.
- Richten Sie für kritische Incidents wiederholte Benachrichtigungen ein, bis jemand reagiert. Für Incidents mit niedrigerer Priorität empfiehlt sich möglicherweise ein einziger EskalationsFlow.
- Stellen Sie sicher, dass der Weg mithilfe einer benutzerdefinierten Kundendienst-Vorlage dokumentiert und für alle relevanten Mitarbeiter zugänglich ist.
❗️ Notiz: Ein „Bestätigungs-Timeout” ist die Zeit, die der Ersthelfer hat, um zu bestätigen, dass er die Warnmeldung gesehen hat, während ein „Lösungs-Timeout” die Zeit ist, die das Team hat, um das Problem zu beheben oder zu entschärfen, bevor die nächste Eskalationsstufe einsetzt.
Schritt 4: Automatisierung und Tool-Unterstützung integrieren
Sobald Ihre Kriterien, Ihr Triage-Prozess und Ihre Anreicherungsstandards festgelegt sind, besteht der nächste Schritt darin, die Eskalation zu ermöglichen, ohne sich darauf verlassen zu müssen, dass Menschen sich merken, wann und an wen sie eskalieren müssen. Hier wird ClickUp-Automatisierungen zu einem zentralen Bestandteil Ihres Workflows.

Sie können Automatisierungsmöglichkeiten einrichten, die auf dieselben Signale reagieren, die Ihr Team bei Incidents verwendet. Hier sind einige Beispiele:
- Bei einer Aktualisierung des Schweregrads auf SEV-1 ➡️ Sofort einen erfahrenen SRE zuweisen + den Chat-Kanal für Bereitschaftsdienste benachrichtigen
- Wenn der Status für X Minuten unverändert bleibt ➡️ Auslöser für die Eskalation auf die nächste Ebene
- Wenn das Fälligkeitsdatum verstreicht (z. B. Bestätigungsfrist) ➡️ Eskalation an L2
Und hier geht ClickUp Brain noch einen Schritt weiter. Es nutzt den Kontext aus Ihrem ClickUp-Workspace, um sofortige Antworten zu liefern, Updates automatisch zu generieren und den Zugriff auf Wissen zu unterstützen.
Verwenden Sie Tools wie AI Prioritize, um Incidents automatisch zu bewerten und anhand Ihrer eigenen Logik die richtige Priorität festzulegen. Beispiel-Eingabeaufforderungen:
- Wenn der Vorfall die Produktion beeinträchtigt und Auswirkungen auf Kunden hat, legen Sie die Priorität „Dringend“ fest.
- Wenn der Mitarbeiter das SRE-Team ist und in den Protokollen „Latenz“ erwähnt wird, legen Sie die Priorität auf „Hoch“ fest.
- Wenn die Beschreibung Sicherheitsbegriffe wie „Verstoß“ enthält, stellen Sie die Priorität auf „Dringend“ ein.
Sobald die Priorität eingestellt ist, übernimmt KI Assign die automatische Zuweisung von Incidents auf Grundlage der von Ihnen definierten Bedingungen.
Sie können Aufforderungen wie die folgenden erstellen:
- Wenn die Priorität „dringend“ ist und der betroffene Dienst „Zahlungen“ umfasst, weisen Sie den Fall einem Senior SRE zu.
- Wenn es sich um einen Datenbank-Incident handelt und die Region US-Ost ist, weisen Sie ihn DB On-Call zu.
- Wenn der Name der Aufgabe „Sicherheit“ enthält, weisen Sie sie dem SecOps-Leiter zu.
Testen Sie diese Eingabeaufforderungen bei den ersten drei Aufgaben, bevor Sie sie auf die gesamte Liste anwenden.
🚀 Vorteil von ClickUp: Setzen Sie intelligente Bots für die Automatisierung ein, die in Ihrem ClickUp-Workspace integriert sind und mit ClickUp Super Agents auf Aktivitäten in Echtzeit reagieren.
Sie sind vollständig über Ihre Aufgaben, Dokumente, Chats und Prozesse informiert, sodass jede Automatisierung kontextbezogen ist.
Sie können beispielsweise einen Team StandUp Agent in Ihrem „Ordner für Produktionsvorfälle” platzieren, sodass dieser jeden Morgen automatisch eine tägliche Zusammenfassung veröffentlicht. Ihr Team erhält einen sofortigen Überblick über die Anzahl der geöffneten Vorfälle, welche davon noch ungelöst sind und welche Änderungen in den letzten 24 Stunden vorgenommen wurden.
Kombinieren Sie dies nun mit einem Ambient Answers Agent in Ihrem „#incident-room channel”. Wenn Mitarbeiter Fragen stellen wie „Wo ist das SEV-1-Runbook?” oder „Ist diese API schon einmal ausgefallen?”, greift der Agent auf das Wissen Ihrer Workspace-Umgebung zurück, um sofortige und präzise Antworten zu geben.

Schritt 5: Standardisieren Sie die Kommunikationskanäle
Bei der Eskalation von Incidents ist es ebenso wichtig, wie und wo Teams kommunizieren, wie auch, wer benachrichtigt wird. Ohne standardisierte Kanäle gehen Aktualisierungen verloren, Entscheidungen werden doppelt getroffen und die Beteiligten erhalten widersprüchliche Informationen.
Definieren Sie klare Eskalationskanäle für jede Phase des Vorfalllebenszyklus und wenden Sie diese teamübergreifend einheitlich an:
| Kriterien | Kanalname | Zweck |
| SEV-1 oder SEV-2 erkannt | #Incident-critical | Zentraler Space für Warnmeldungen mit hoher Priorität und sofortige Triage |
| Aktive Fehlerbehebung läuft | #Incident-warroom | Echtzeit-Kollaborationshub für Ingenieure, Produktentwicklung, Qualitätssicherung und Support |
| Sichtbarkeit für Führungskräfte erforderlich | #Incident-leadership | Wichtige Updates für Manager und Führungskräfte |
| Kundenorientierte Kommunikation erforderlich | #Incident-comms | Platz zum Entwerfen, Überprüfen und Abstimmen der Kommunikation mit externen Kunden |
| Überprüfung nach dem Incident eingeleitet | #Incident-retro | Strukturierte Diskussion für rückblickende Notizen, Erkenntnisse und Aktionselemente |
Jeder Kanal hat eine definierte Zielgruppe und einen definierten Zweck, wodurch Teams Störungen reduzieren und gleichzeitig die entsprechenden Teams auf dem Laufenden halten können.
🚀 Vorteil von ClickUp: Passen Sie Ihre Kanalstrategie mit ClickUp Chat an eine integrierte Kommunikationsebene an. Jede Benachrichtigung, Aktualisierung und Entscheidung bleibt direkt mit der Aufgabe, Liste oder dem Space verbunden, in dem die Arbeit stattfindet.
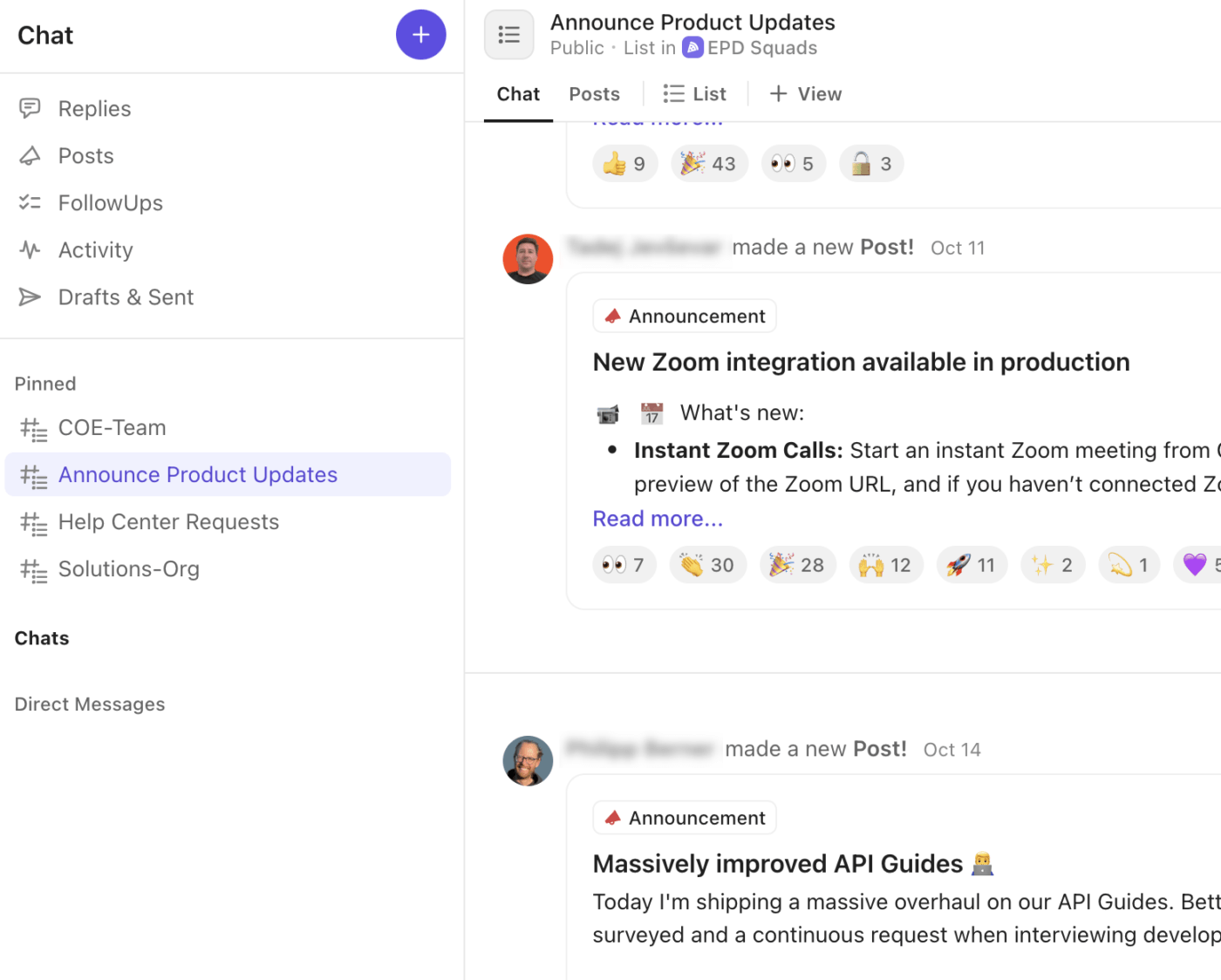
So verbessert ClickUp Chat Ihren Workflow bei Incidents:
- Erstellen Sie spezielle Chat-Threads für kritische Diskussionen, Besprechungen im Krisenstab, Führungsgespräche oder Kundengespräche.
- Verwandeln Sie Chat-Nachrichten sofort in ClickUp-Aufgaben , damit Entscheidungen und Folgemaßnahmen nicht in der Unterhaltung untergehen.
- Nutzen Sie ClickUp SyncUps für schnelle Audio- oder Videoanrufe zur Live-Koordination von Incidents oder für Führungsbesprechungen.
- Veröffentlichen Sie „Ankündigungen” oder Updates, um den Status von Incidents auf hoher Ebene im gesamten Unternehmen bekannt zu geben.
- Tag Teamkollegen, fügen Sie Screenshots ein und hängen Sie Protokolle direkt im Chat als Anhänge an, um den technischen Kontext im Blick zu behalten.
Schritt 6: Testen, prüfen und optimieren Sie Ihren Eskalationspfad
Eskalationsrichtlinien müssen sich mit Ihren Systemen weiterentwickeln. Folgendes müssen Sie regelmäßig erledigen:
| Aktivität | Was Sie testen oder überprüfen sollten | Warum das wichtig ist |
| Feuerwehrübungen im Bereitschaftsdienst (vierteljährlich) | Simulieren Sie P1- und P2-Incidents, überprüfen Sie den Zeitpunkt der Eskalation und die Weiterleitung. | Stellt sicher, dass Automatisierungen und Eskalationspfade auch unter Druck funktionieren |
| Validierung von Eskalationspfaden | Überprüfen Sie, ob es Sackgassen bei Eskalationen gibt oder Eigentümer fehlen. | Verhindert, dass Incidents ohne Sichtbarkeit ins Stocken geraten |
| Timer für Bestätigungs- und Lösungsprozesse | Vergleichen Sie konfigurierte Timer mit tatsächlichen MTTA- und MTTR-Werten. | Sorgt für realistische und effektive Eskalationszeiten |
| Bewertung der Alarmmüdigkeit | Identifizieren Sie Responder, die übermäßig viele oder wiederholte Warnmeldungen erhalten. | Reduziert Burnout und übersehene kritische Warnmeldungen |
| Schweregrad und Genauigkeit der Priorisierung | Überprüfen Sie, ob Incidents korrekt klassifiziert wurden. | Verbessert die Weiterleitung, Reaktionsgeschwindigkeit und Eskalationsgenauigkeit |
| Nachbereitung nach einem Incident | Stellen Sie sicher, dass die Elemente aus den Rückblicken fertiggestellt werden. | Verhindert wiederholte Incidents und systemische Ausfälle |
Tools und Integrationen für die Automatisierung der Eskalation
In diesem Abschnitt erfahren Sie mehr über Incident-Management-Software, mit der Sie Vorfälle schneller erkennen, sofort weiterleiten und alle Teams ohne manuelle Nachverfolgung auf dem Laufenden halten können.
1. ClickUp (am besten geeignet, um funktionsübergreifende Eskalationen in einem verbundenen Workspace für Incidents zu vereinen)
Herkömmliche Eskalationsmethoden zwingen Teams dazu, E-Mails, Tabellen, Chat-Threads und verstreute Notizen zu jonglieren, wodurch es fast unmöglich ist, eine klare Echtzeit-Ansicht der aktuellen Vorgänge zu erhalten.
Die ClickUp-Aufgabenverwaltungssoftware für das Eskalationsmanagement beseitigt Unklarheiten, indem sie alle Eskalationsdetails in einem einzigen, übersichtlichen Workspace zusammenfasst.
Werfen wir einen Blick auf einige Features der IT-Asset-Management-Software, die ClickUp zur ersten Wahl für Teams machen, die ein hohes Eskalationsaufkommen und komplexe Incident-Workflows verwalten.
Arbeit auf Ihre Weise
Visualisieren Sie Ihre Aufgaben aus verschiedenen Blickwinkeln, um sie mit Ihren betrieblichen Anforderungen abzustimmen – mit ClickUp Ansichten:
- ClickUp-Listenansicht, damit SRE-Leiter Incidents nach Schweregrad, verbleibender SLA-Zeit oder Bereitschaftsgruppen sortieren können, um eine schnelle Triage zu ermöglichen.
- ClickUp Board View ermöglicht es Engineering-Managern, Übergaben und Teamverantwortlichkeiten während Eskalationen zu visualisieren.
- ClickUp Gantt-Ansicht für Programmleiter, um Lösungsmeilensteine und Abhängigkeiten zwischen verschiedenen Diensten abzubilden.
- ClickUp Workload-Ansicht für Bereitschaftsplaner, die sicherstellen, dass Ingenieure während Zeiten mit hohem Vorfallaufkommen nicht überlastet sind.
Setzen Sie Meetings in Maßnahmen um
Während Eskalationen und Vorfallüberprüfungen kann es schwierig sein, Diskussionen und Aktionspunkte zuverlässig zu erfassen. Der ClickUp AI Notetaker nimmt automatisch an Meetings teil, die in Google Kalender, Outlook, Zoom oder Teams geplant sind, und zeichnet die Unterhaltungen auf und transkribiert sie.
Nach dem Meeting:
- Greifen Sie auf durchsuchbare Transkripte und Zusammenfassungen der Aktionselemente zu.
- Sorgen Sie für Klarheit mit den in ClickUp Docs gespeicherten Notizen. So können Sie ganz einfach auf Incident-Aufgaben oder Rückblickberichte verknüpfen.
- Stellen Sie ClickUp AI Fragen zum Inhalt von Meetings, um Entscheidungen zu klären oder versäumte Nachfassaktionen aufzudecken.
Verbinden Sie sich mit vorhandenen tools in Ihrem Tech-Stack
Hinter den Kulissen sorgen ClickUp-Integrationen und das Webhooks-Ökosystem für eine nahtlose Verbindung mit dem Rest Ihres Stacks.
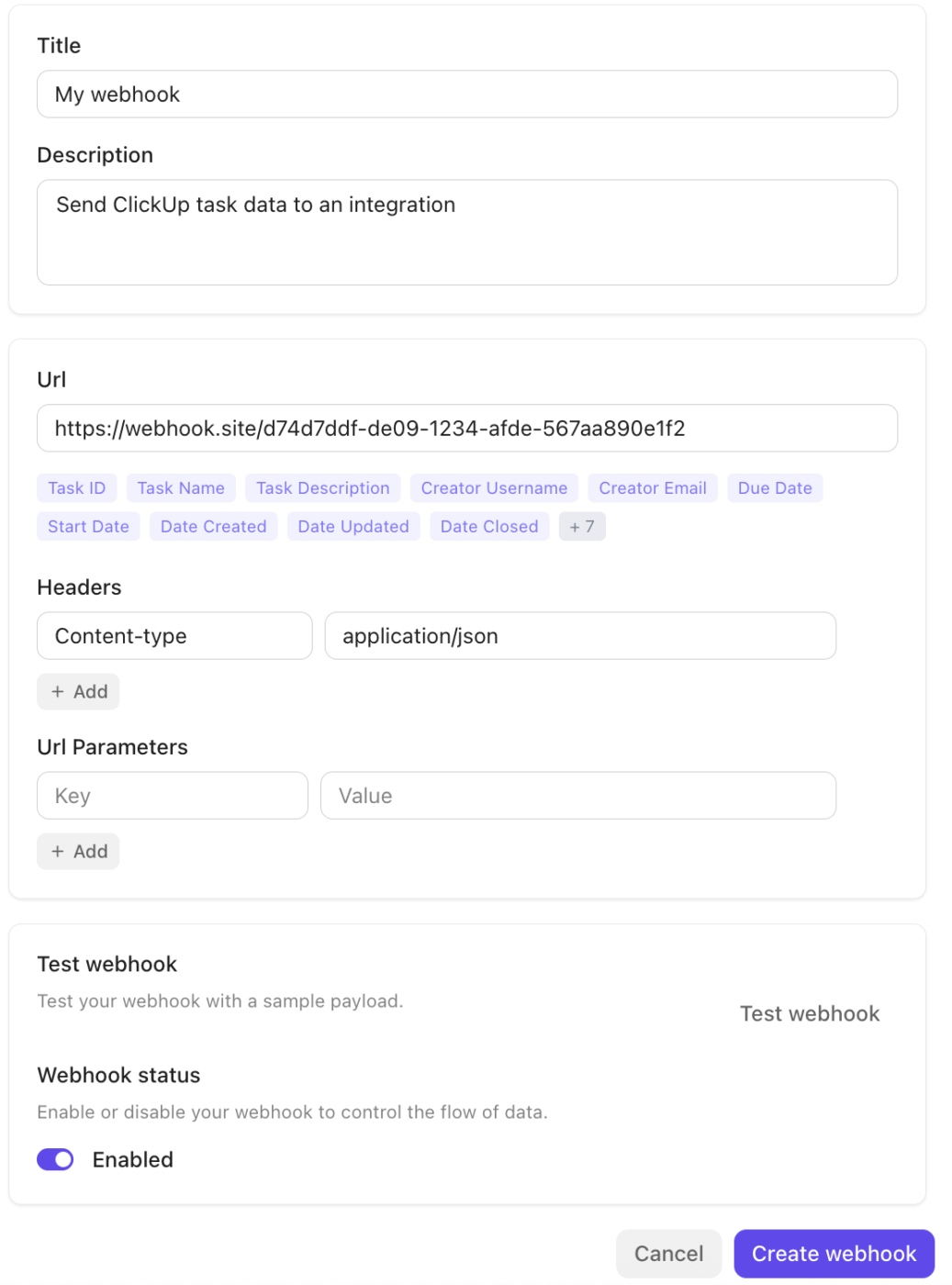
Die Plattform lässt sich nativ in Tools wie Slack, GitHub, Zoom und andere integrieren und unterstützt Webhooks über ihre öffentliche API, um Ereignisse (Aufgabenaktualisierungen und Statusänderungen) an externe Dienste oder Automatisierungspipelines zu übertragen. Dies erleichtert das Auslösen von Workflows, die Synchronisierung von Daten oder die Eskalation von Incidents über Systeme hinweg ohne manuelle Übergaben.
Führen Sie alle Ihre KI-Tools zusammen
Um Automatisierung und Kontext auf die nächste Stufe zu heben, bringt ClickUp BrainGPT kontextbezogene KI in Ihre Eskalations-Workflows. Es handelt sich um eine kontextbezogene Super-KI-App, die Ihre Aufgaben, Dokumente und den historischen Kontext versteht.
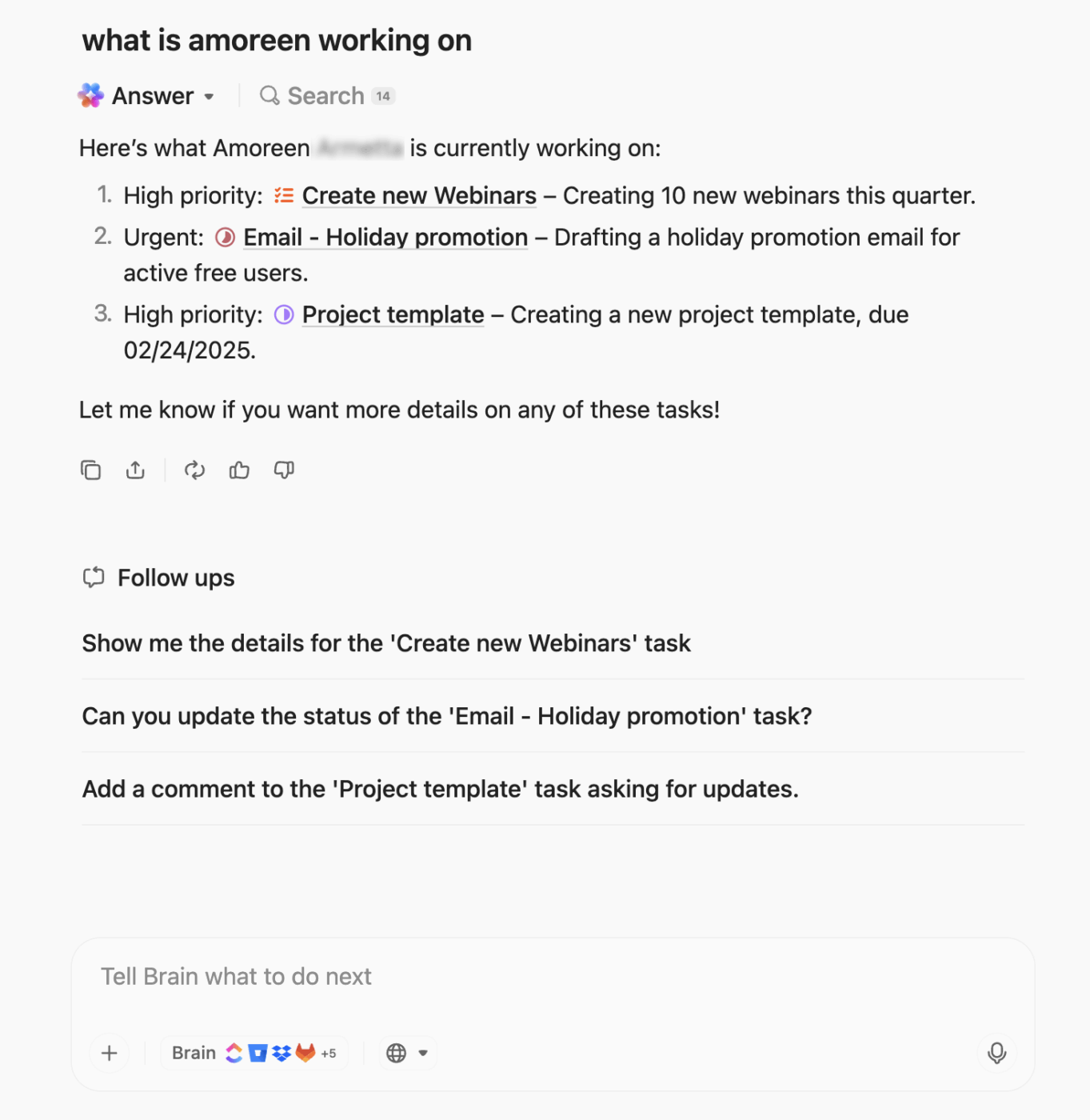
Mit Enterprise Search und Connected Apps können Sie Informationen aus Ihrem Arbeitsbereich, Slack, Google Drive, GitHub und anderen Quellen sofort abrufen. Während Live-Anrufen zu Incidents können Sie mit Talk-to-Text in ClickUp Eskalationsnotizen oder Anweisungen freihändig diktieren, sodass nichts übersehen wird.
Sie können wiederkehrende Aufgaben auch mit benutzerdefinierten KI-Eingabeaufforderungen und gespeicherten Eingabeaufforderungen standardisieren, z. B.: „Fassen Sie alle ungelösten Incidents zusammen und empfehlen Sie Eskalationsmaßnahmen.“
Die besten Features von ClickUp
- Priorisieren Sie kritische Probleme: Verwenden Sie ClickUp-Prioritäten für Aufgaben, um dringende oder besonders wichtige Eskalationen hervorzuheben.
- Organisieren Sie komplexe Eskalationsabläufe: Richten Sie ClickUp-Aufgabenabhängigkeiten ein, um verwandte Aufgaben (z. B. „Warten auf“ oder „Blockieren“) miteinander zu verknüpfen, damit Eskalationsschritte vorzeitige Maßnahmen oder Engpässe vermeiden.
- Teilen Sie Incidents in umsetzbare Teilschritte auf: Teilen Sie Eskalationen in detaillierte Aktionselemente auf und weisen Sie diese mit geschachtelten Unteraufgaben den verschiedenen Teams zu.
- Verfolgen Sie die Lösungsgeschwindigkeit genau: Protokollieren und überwachen Sie mit ClickUps Zeiterfassung, wie lange Eskalationsaufgaben dauern, bis sie bestätigt und gelöst sind.
Limitierungen von ClickUp
- Angesichts der Vielzahl an Features, Ansichten und benutzerdefinierten Anpassungsoptionen müssen Teams oft eine gewisse Lernkurve durchlaufen, bevor alles intuitiv erscheint.
Preise für ClickUp
[Preistabelle]
Bewertungen und Rezensionen zu ClickUp
- G2: 4,7/5 (über 10.300 Bewertungen)
- Capterra: 4,6/5 (über 4.400 Bewertungen)
Was sagen echte Benutzer über ClickUp?
Diese Bewertung sagt wirklich alles:
ClickUp vereint alle meine Aufgaben, Projekte und Kommunikationen an einem Ort, was es unglaublich einfach macht, organisiert zu bleiben. Ich finde es toll, wie individuell alles anpassbar ist – von Ansichten und Workflows bis hin zu Dashboards –, sodass ich meinen Workspace genau nach meinen Bedürfnissen strukturieren kann. Die Möglichkeit, in Echtzeit zusammenzuarbeiten, Aufgaben zuzuweisen und den Fortschritt zu verfolgen, ohne zwischen verschiedenen Tools wechseln zu müssen, ist ein großer Vorteil.
ClickUp vereint alle meine Aufgaben, Projekte und Kommunikationen an einem Ort, was es unglaublich einfach macht, organisiert zu bleiben. Ich finde es toll, wie individuell alles anpassbar ist – von Ansichten und Workflows bis hin zu Dashboards –, sodass ich meinen Arbeitsbereich genau nach meinen Bedürfnissen strukturieren kann. Die Möglichkeit, in Echtzeit zusammenzuarbeiten, Aufgaben zuzuweisen und den Fortschritt zu verfolgen, ohne zwischen verschiedenen tools wechseln zu müssen, ist ein großer Vorteil.
📮 ClickUp Insight: 21 % der Befragten geben an, dass sie mehr als 80 % ihres Arbeitstages mit wiederholenden Aufgaben verbringen. Weitere 20 % sagen, dass sich wiederholende Aufgaben mindestens 40 % ihres Tages in Anspruch nehmen.
Das ist fast die Hälfte der Arbeitswoche (41 %), die für Aufgaben aufgewendet wird, die weder strategisches Denken noch Kreativität erfordern (wie Folge-E-Mails 👀).
Die Super Agents von ClickUp helfen Ihnen dabei, diesen Aufwand zu vermeiden. Denken Sie an die Erstellung von Aufgaben, Erinnerungen, Aktualisierungen, Meeting-Notizen, das Verfassen von E-Mails und sogar die Erstellung von End-to-End-Workflows! All das (und noch viel mehr) lässt sich mit ClickUp, Ihrer Allround-App für die Arbeit, im Handumdrehen automatisieren.
💫 Echte Ergebnisse: Lulu Press spart mit ClickUp Automatisierungen pro Mitarbeiter täglich 1 Stunde Zeit ein – was zu einer Steigerung der Effizienz bei der Arbeit um 12 % führt.
2. PagerDuty (am besten geeignet für Echtzeit-Benachrichtigungen und intelligente Bereitschaftsreaktionen)
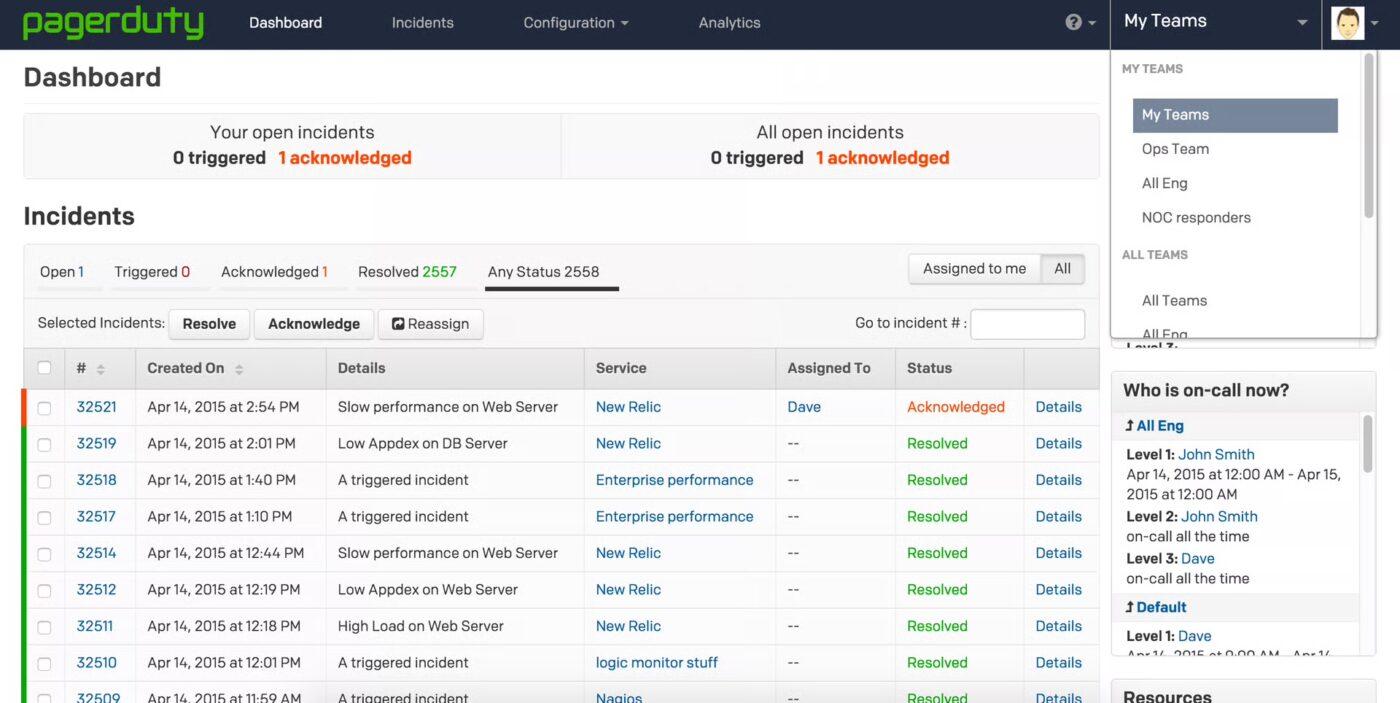
PagerDuty ist eine cloudbasierte Plattform für IT-Incident-Management und digitale Abläufe, mit der Teams kritische Vorfälle wie Ausfälle oder Sicherheitsbedrohungen schnell erkennen, darauf reagieren und beheben können. Sie bietet SRE-, DevOps- und Support-Verantwortlichen einen klaren Weg vom Signal bis zur Lösung, unterstützt durch Automatisierung, KI-gestützte Triage und tief integrierte Workflows.
Features wie Jeli Incident Analysis, PagerDuty Analytics und Runbook Automatisierung helfen Teams dabei, Ausfallzeiten zu reduzieren, Routineaufgaben zu eliminieren und aus jedem Incident zu lernen.
Die besten Features von PagerDuty
- Automatisieren Sie die Weiterleitung von Incidents mit der integrierten Bereitschaftsverwaltung und dynamischen Eskalationsrichtlinien.
- Beschleunigen Sie die Triage mit AIOps, das Alarmmeldungen filtert, Ereignisse korreliert und echte Signale hervorhebt.
- Halten Sie interne und externe Stakeholder mit Stakeholder Comms, Status-Vorlagen und Status-Seiten auf dem Laufenden.
- Vereinheitlichen Sie Ihre Tool-Landschaft mit über 700 Integrationen und erweiterbaren APIs unter Verwendung von Überwachungs-, Protokollierungs-, CI/CD- und Support-Systemen.
Limitierungen von PagerDuty
- Hohe Alarmhäufigkeit, wenn Integrationen und intelligente Schwellenwerte nicht abgestimmt sind, was zu Störungen und Ermüdung führt
- Während Spitzenzeiten kann es zu doppelten oder wiederholten Warnmeldungen kommen, was die Bestätigung unter Druck erschwert.
Preise für PagerDuty
- Free
- Professional: 25 $/Monat pro Benutzer
- Business: 49 $/Monat pro Benutzer
- Enterprise: benutzerdefinierte Preisgestaltung
Bewertungen und Rezensionen zu PagerDuty
- G2: 4,5/5 (über 900 Bewertungen)
- Capterra: 4,6/5 (über 200 Bewertungen)
Was sagen echte Benutzer über PagerDuty?
Mit den Worten eines echten Benutzers:
PagerDuty macht Vorfall-Benachrichtigungen schnell und zuverlässig. Es sendet die richtigen Benachrichtigungen zur richtigen Zeit und sorgt für eine gute Organisation unseres Teams. […] PagerDuty kann manchmal etwas laut sein, wenn die Benachrichtigungen nicht gut gefiltert werden. Einige Einstellungen sind für neue Benutzer etwas komplex.
PagerDuty macht Incidents schnell und zuverlässig. Es sendet die richtigen Benachrichtigungen zur richtigen Zeit und sorgt für eine gute Organisation unseres Teams. […] PagerDuty kann manchmal etwas laut sein, wenn die Benachrichtigungen nicht gut gefiltert werden. Einige Einstellungen sind für neue Benutzer etwas komplex.
💡 Profi-Tipp: Richten Sie auch in einem klaren Eskalationspfad Ausnahmen ein. Lassen Sie kritische Ausfälle, Warnungen zur Sicherheit oder Incidents in regulierten Umgebungen direkt an leitende oder spezialisierte Ansprechpartner weiterleiten.
3. GLPi (Am besten geeignet für End-to-End-Asset-Governance und ITIL-konforme Serviceabläufe)
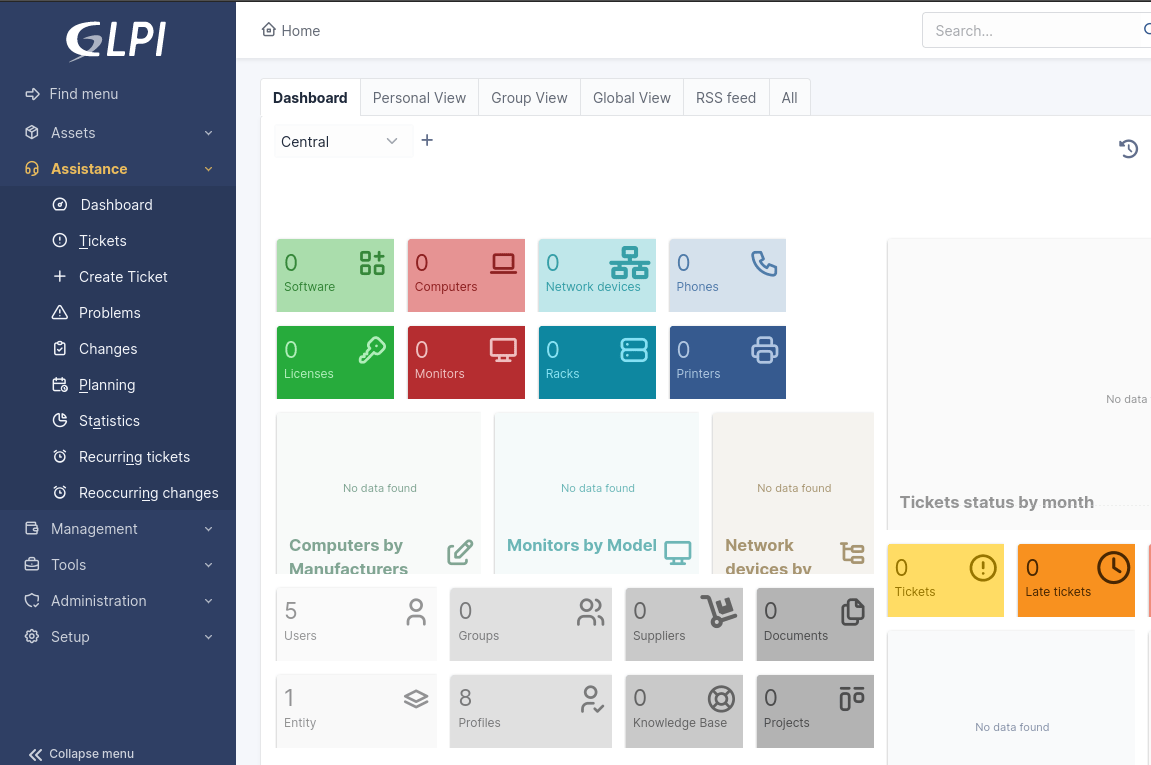
Gestionnaire Libre de Parc Informatique (GLPi) ist eine umfassende Open-Source-Plattform für IT-Service-Management (ITSM) und IT-Asset-Management (ITAM). Teams erhalten eine vollständige Sichtbarkeit auf ihre Infrastruktur (Hardware, Software, Lizenzen und Netzwerkgeräte) und können Incidents, Serviceanfragen und Änderungen mithilfe von ITIL-konformen Prozessen verwalten.
Alle Ihre Verträge und Unterlagen, einschließlich Garantien und Servicevereinbarungen, bleiben übersichtlich organisiert, sodass sie nicht in verschiedenen Systemen verloren gehen können. Wenn Sie Rechenzentren verwalten, können Sie mit GLPi sogar Layouts, Verkabelungswege und den Energieverbrauch visualisieren, sodass Sie immer wissen, was hinter den Kulissen vor sich geht.
Die besten Features von GLPi
- Verwenden Sie die Plugins GLPI Inventory, OCS Inventory oder FusionInventory, um neue IT-Assets automatisch zu erkennen und zu katalogisieren.
- Automatisieren Sie wiederholende Aufgaben, Ticketzuweisungen, Benachrichtigungen und wiederkehrende Ereignisse, um manuelle Arbeit zu reduzieren.
- Erstellen Sie eine Wissensdatenbank für FAQs, Dokumentationen und Artikel, die mit Tickets verknüpft sind, um Self-Service und Techniker-Support zu ermöglichen.
- Verbinden Sie sich mit Azure/Entra, Centreon, Google, OAuth2 und Webhooks, um eine Synchronisierung der Daten durchzuführen, Workflow-Auslöser zu aktivieren und Ihre CMDB zu verbessern.
Limitierungen von GLPi
- Die Kompatibilität von Plugins kann zwischen verschiedenen Versionen beeinträchtigt sein, was zu einem erhöhten Wartungsaufwand führt.
- Die Funktionen für Berichterstellung, Analyse und Export erscheinen mit einem Limit und sind verbesserungswürdig.
GLPi-Preise
- Benutzerdefinierte Preisgestaltung
GLPi-Bewertungen und Rezensionen
- G2: 4,6/5 (über 30 Bewertungen)
- Capterra: 4,5/5 (über 40 Bewertungen)
Was sagen Benutzer aus der Praxis über GLPi?
Hier ist, was ein Benutzer zu sagen hatte:
Sehr anpassbares Open-Source-System für die Verwaltung von IT-Assets und Support-Tickets mit einer großen Support-Community. Die Benutzeroberfläche ist für Anfänger etwas kompliziert. Plugins werden nicht immer von alten Versionen auf neue Versionen unterstützt.
Sehr anpassbares Open-Source-System für die Verwaltung von IT-Assets und Support-Tickets mit einer großen Support-Community. Die Benutzeroberfläche ist für Anfänger etwas kompliziert. Plugins werden nicht immer von alten Versionen auf neue Versionen unterstützt.
4. Splunk On-Call (am besten geeignet für die direkte Weiterleitung von Überwachungswarnungen an Techniker)
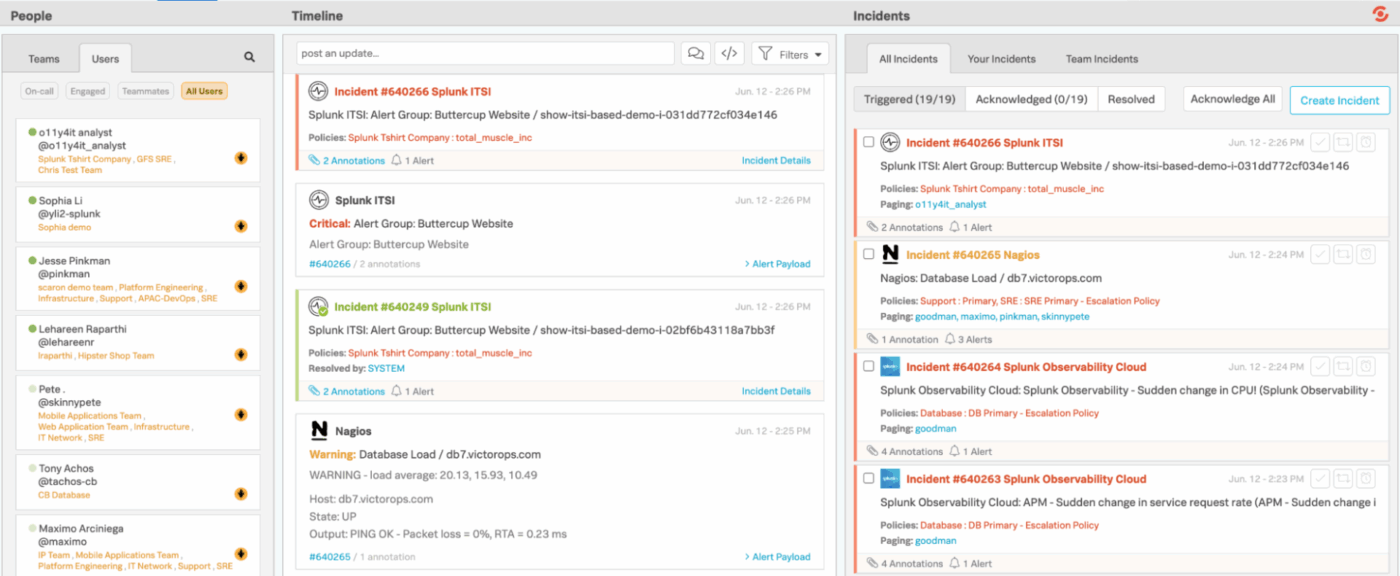
Splunk On-Call bietet Engineering- und Bereitschaftsteams eine schnellere und übersichtlichere Möglichkeit, Incidents zu verwalten, sodass langsame, herkömmliche Ticket-Workflows überflüssig werden. Anstatt Warnmeldungen in eine allgemeine Warteschlange zu verschieben, wird das System direkt in Ihre Überwachungs- und Beobachtungsstack integriert und leitet Probleme sofort anhand von Zeitplänen, Regeln und Kontext an die richtigen Personen weiter.
Dank der Mobil- und Chat-Integrationen lassen sich Incidents von überall aus einfach bestätigen, umleiten oder lösen. Und hinter den Kulissen führt Splunk On-Call detaillierte Aufzeichnungen über Trends, bewährte Muster und Eskalationsverhalten.
Die besten Features von Splunk On-Call
- Erweitern Sie die Funktionen der Plattform mit über 1.000 geprüften Integrationen und Add-Ons von Splunk und der breiteren Community.
- Erstellen Sie benutzerdefinierte Dashboards und visuelle Berichte, um das Alarmvolumen, den Status von Incidents, die Leistung der Responder und die Workload des Teams zu überwachen.
- Filtern Sie Incidents schnell nach Ihren eigenen Aktivitäten, den Incidents Ihres Teams oder Alles, was im gesamten Unternehmen passiert.
- Wechseln Sie zwischen den Ansichten „Ausgelöst“, „Bestätigt“ und „Gelöst“, um den Status jedes Incidents anzuzeigen.
Limitierungen von Splunk On-Call
- Die Planung von Schichten über mehrere Teams hinweg kann kompliziert werden, wenn keine Regeln vordefiniert sind.
- Begrenzte Möglichkeiten zur Erstellung detaillierter, datumsbezogener Incident-Berichte
Preise für Splunk On-Call
- Benutzerdefinierte Preisgestaltung
Bewertungen und Rezensionen zu Splunk On-Call
- G2: 4,6/5 (über 40 Bewertungen)
- Capterra: 4,5/5 (über 30 Bewertungen)
Was sagen Benutzer aus der Praxis über Splunk On-Call?
Ein Benutzer fasste es so zusammen:
Die Möglichkeit, Incidents und Eskalationen zu bearbeiten und meinen Teamkollegen über die App Aufgaben zuzuweisen, ist großartig. […] Ich würde gerne in der Lage sein, Übersteuerungen zu planen und den regulären Zeitplan über die App für dringende Änderungen anzupassen.
Die Möglichkeit, Incidents und Eskalationen zu bearbeiten und meinen Teamkollegen über die App Aufgaben zuzuweisen, ist großartig. […] Ich würde gerne in der Lage sein, Übersteuerungen zu planen und den regulären Zeitplan über die App für dringende Änderungen anzupassen.
🔍 Wussten Sie schon? Die Logik „Weiterleitung an die richtige Person, wenn die erste Ebene fehlschlägt“ hat ihren Ursprung in den frühen Telefonzentralen: Wenn manuelle Vermittler keine Verbindung zum Anruf herstellen konnten, leitete das System ihn an einen anderen Vermittler oder eine andere Vermittlungsstelle weiter (oder eskalierte ihn).
5. ServiceNow (am besten geeignet für die Koordination auf Unternehmensebene mit KI-gestützter Automatisierung)
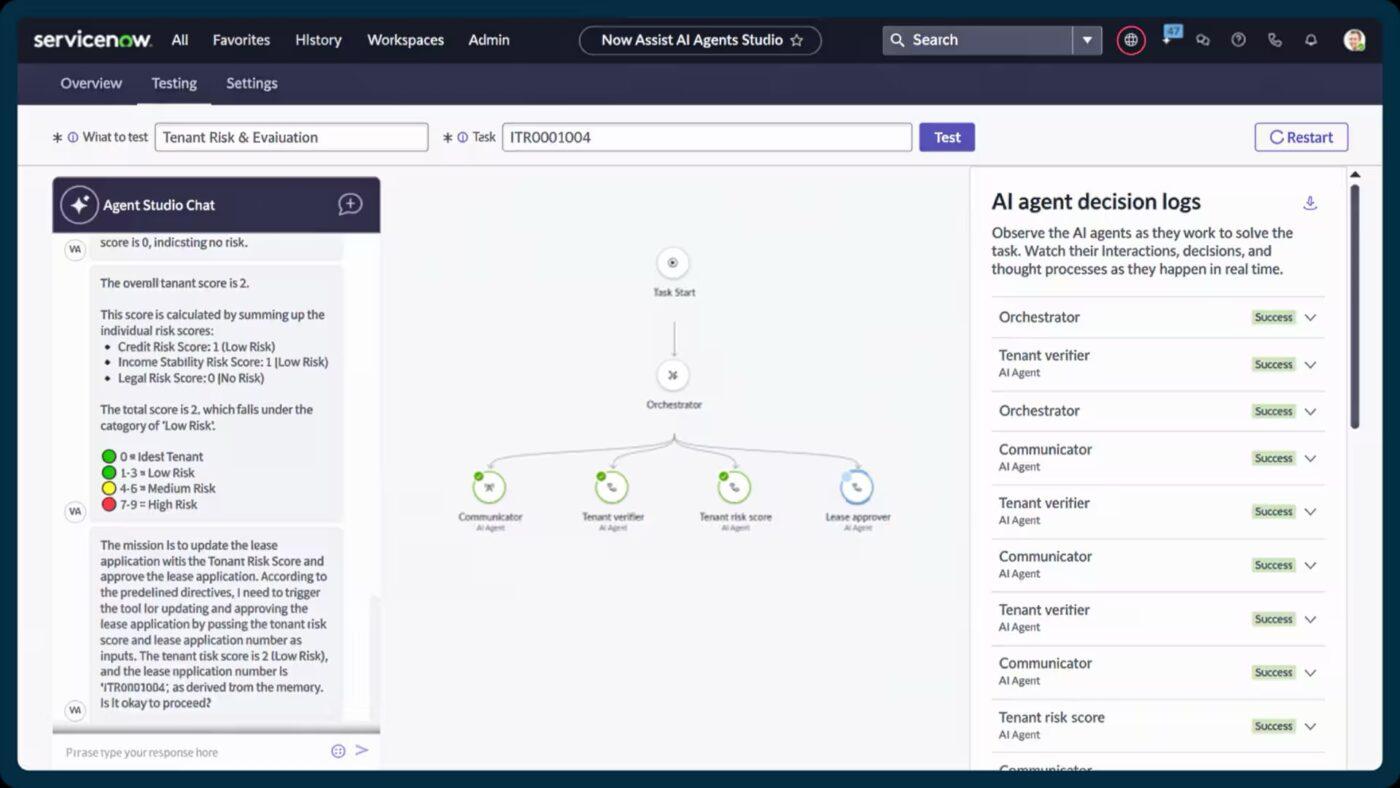
ServiceNow klassifiziert, priorisiert und leitet Vorfälle automatisch weiter, sobald sie protokolliert werden. Mit Funktionen wie Now Assist für automatisierte Empfehlungen zu Incident-Tickets und die intelligente Generierung von Inhalten können die zuständigen Mitarbeiter Probleme schneller und mit mehr Kontext lösen.
Es vereint Incident-, Change- und Asset-Management. Auf diese Weise erhalten Sie eine Echtzeit-Ansicht darüber, wie Dienste miteinander verbunden sind, wo Engpässe auftreten und welche Komponenten zu wiederkehrenden Störungen beitragen könnten.
Die besten Features von ServiceNow
- Weisen Sie Außendienstaufgaben über Field Service Management und Dispatcher Workspace zu, leiten Sie sie weiter und überwachen Sie sie.
- Befähigen Sie Mitarbeiter und Kunden mit einem Self-Service-Portal, das auf KI-Suche und virtuellen Agenten basiert.
- Verwenden Sie integrierte Workflows und Low-Code-Tools in App Engine, um Serviceprozesse zu erweitern oder benutzerdefiniert anzupassen.
- Automatisieren Sie sich wiederholende Aufgaben und Workflows teamübergreifend mit Flow Designer und Automation Engine.
Limitierungen von ServiceNow
- Die Benutzeroberfläche und die Branding-Optionen des Portals wirken veraltet oder einschränkend.
- Hohe Abhängigkeit von qualifiziertem Personal oder Beratern für die Implementierung
Preise für ServiceNow
- Benutzerdefinierte Preisgestaltung
Bewertungen und Rezensionen zu ServiceNow
- G2: 4,4/5 (über 3.300 Bewertungen)
- Capterra: 4,5/5 (über 300 Bewertungen)
Was sagen echte Benutzer über ServiceNow?
Ein Benutzer hat es so formuliert:
[…] Die vorgefertigten Flows sind für mich ein weiteres Highlight, da sie Prozesse rationalisieren und viel Zeit sparen, den Bedarf an benutzerdefinierten Konfigurationen minimieren und einen reibungsloseren, effizienteren Workflow ermöglichen. […] Außerdem hatte ich Schwierigkeiten, meine benutzerdefinierte Lösung in das Kundendienstmanagementsystem zu integrieren, was zahlreiche Iterationen erforderte.
[…] Die vorgefertigten Flows sind für mich ein weiteres Highlight, da sie Prozesse rationalisieren und viel Zeit sparen, den Bedarf an benutzerdefinierten Konfigurationen minimieren und einen reibungsloseren, effizienteren Workflow ermöglichen. […] Außerdem hatte ich Schwierigkeiten, meine benutzerdefinierte Lösung in das Kundenservice-Managementsystem zu integrieren, was zahlreiche Iterationen erforderte.
Best Practices und Governance
Hier sind einige Best Practices, die sicherstellen, dass die Automatisierung präzise bleibt, Alarmmüdigkeit vermieden wird und die Erwartungen des Geschäfts und der Aufsichtsbehörden erfüllt werden.
- Definieren Sie unverhandelbare Eskalationskriterien: Verbinden Sie Auslöser mit messbaren Signalen wie SLO-Verstößen, Anomaliespitzen, Auswirkungen auf Kundenstufen oder regulatorischer Sensibilität.
- Schaffen Sie klare Rollenverteilungen auf jeder Ebene: Verwenden Sie für jede Eskalationsstufe eine einfache RACI-Karte, damit die Zuständigkeiten bei Incidents mit hohem Druck niemals unklar sind.
- Dynamische Bereitschaftsregelungen durchsetzen: Passen Sie Eskalationspfade automatisch an Wochenenden, Feiertagen, Limiten der Kapazität und Übergaben an, um Burnout zu reduzieren und stille Seiten zu vermeiden.
- Fügen Sie für risikoreiche Szenarien menschliche Kontrollpunkte ein: Auch bei Automatisierung sollten Sie eine manuelle Bestätigung für Incidents vorschreiben, die die Offenlegung von Kundendaten, Zahlungen oder regulierte Workflows betreffen.
- Führen Sie vollständige Prüfpfade: Erstellen Sie unveränderliche Protokolle darüber, wer benachrichtigt wurde, wann die Benachrichtigung bestätigt wurde, welche automatisierten Schritte ausgelöst wurden und welche Entscheidungen getroffen wurden.
🧠 Wissenswertes: Die älteste bekannte schriftliche Beschwerde der Welt wurde um 1750 v. Chr. auf eine Tontafel geritzt. Es handelte sich im Grunde genommen um eine frühe Eskalation des Projekt-Status. Ein Kunde namens Nanni schrieb an den Kaufmann Ea-nāṣir und war wütend darüber, dass das Kupfer, das er erhalten hatte, von minderer Qualität war als versprochen und dass sein Bote schlecht behandelt worden war.
Häufige Herausforderungen und wie man sie bewältigt
Selbst mit einer klaren Eskalationsrichtlinie sehen sich Teams oft mit operativen Hürden konfrontiert, die die Reaktion auf Incidents verlangsamen oder Verwirrung stiften.
Diese Tabelle zeigt häufige Herausforderungen auf, die über die grundlegenden Setup-Schritte hinausgehen, und bietet umsetzbare Strategien zu deren Bewältigung.
| Herausforderungen ❌ | Lösungen ✅ |
| Inkonsistenter Kontext bei Übergaben | Verwenden Sie die Vorlagen für die Verknüpfung von Aufgaben und den Vorfall-Bericht von ClickUp, um einen vollständigen Prüfpfad mit Vorfalldetails, betroffenen Systemen und früheren Maßnahmen auf jeder Eskalationsebene zu führen. |
| Überlastung der Responder mit Warnmeldungen mit niedriger Priorität | Implementieren Sie eine dynamische Priorisierung mit ClickUp-Benutzerdefinierten Feldern und KI-Prioritierung, um Incidents nach Schweregrad, Auswirkungen und SLA-Schwellenwerten zu filtern. |
| Mangelnde teamübergreifende Sichtbarkeit | Richten Sie gemeinsame Workspaces ein, fügen Sie Kommentare hinzu und erstellen Sie visuelle ClickUp-Whiteboards, um Stakeholdern Echtzeit-Updates zu präsentieren. |
| Verzögerte Entscheidungsfindung bei kritischen Incidents | Automatisieren Sie Benachrichtigungen mit den vorgeschlagenen Aktionen von ClickUp Brain Max, um die richtigen Mitarbeiter basierend auf Art, Schweregrad und historischen Mustern des Incidents sofort zu benachrichtigen. |
| Schwierigkeiten bei der Nachverfolgung wiederkehrender Probleme | Nutzen Sie die benutzerdefinierten Vorlagen für die Berichterstellung und wiederholende Aufgaben von ClickUp, um Muster, Ursachen und wiederkehrende Incidents zu identifizieren und proaktiv zu verhindern. |
| Fragmentiertes Wissen während der Eskalation | Verwalten Sie zentralisierte SOPs, Runbooks und Incidents in ClickUp Docs und verknüpfen Sie diese mit relevanten Aufgaben, um sie während Live-Eskalationen sofort zur Hand zu haben. |
| Uneinheitliche Zuständigkeiten zwischen den Schichten | Verwenden Sie die Workload- und Zeitleiste-Ansichten von ClickUp, um Aufgaben zu visualisieren und sicherzustellen, dass es bei Schichtwechseln oder Übergaben zu keinen Überschneidungen oder Lücken kommt. |
| Manuelle Nachverfolgung der Compliance und Lücken bei der Prüfung | Automatisieren Sie mit ClickUp Brain auditfähige Zusammenfassungen, um alle Maßnahmen, Benachrichtigungen und Lösungen im Zusammenhang mit Incidents zu protokollieren. |
Messung der Auswirkungen automatisierter Eskalationen
Für die Nachverfolgung der Effektivität der automatisierten Eskalation müssen Sie sich auf wichtige Metriken in Bezug auf Volumen, Effizienz und Qualität konzentrieren. Diese Indikatoren zeigen, ob Ihre Eskalationsprozesse schneller, genauer und für Teams und Kunden weniger frustrierend sind.
Verfolgen Sie diese Metriken:
- Eskalationsrate (Volumen): Prozentsatz der Probleme, die über die erste Ebene hinaus eskaliert wurden. Hohe Raten können auf Lücken in der ersten Triage oder in den Wissensdatenbanken hinweisen.
- Wiederholungsrate der Eskalation (Volumen): Häufigkeit, mit der dasselbe Problem mehrfach eskaliert wird. Weist auf unvollständige Lösungen oder verlorenen Kontext hin.
- Zeit bis zur Eskalation (Effizienz): Dauer von der Erkennung bis zur Eskalation. Kürzere Phasen-Dauern bedeuten eine schnellere automatisierte Erkennung kritischer Probleme.
- Übergabeverzögerung (Effizienz): Zeit zwischen Eskalation und Beginn der Arbeit durch das nächste Team, um Probleme bei der Weiterleitung oder Benachrichtigung aufzuzeigen.
- Lösungszeit für eskalierte Fälle (Effizienz): Gesamtzeit von der Eskalation bis zur Lösung. Eine schnellere Lösung zeigt die Effektivität der Automatisierung.
- Kundenzufriedenheitswert (CSAT) (Qualität): Feedback zu eskalierten Interaktionen, um die Reibungslosigkeit des Eskalationspfads zu messen
- Kontextübergabe (Qualität): Ob Agenten die vollständige Historie des Incidents erhalten, um sicherzustellen, dass Kunden Informationen nicht wiederholen müssen.
- First Contact Resolution (FCR) (Qualität): Prozentsatz der Probleme, die in einer einzigen Interaktion gelöst wurden
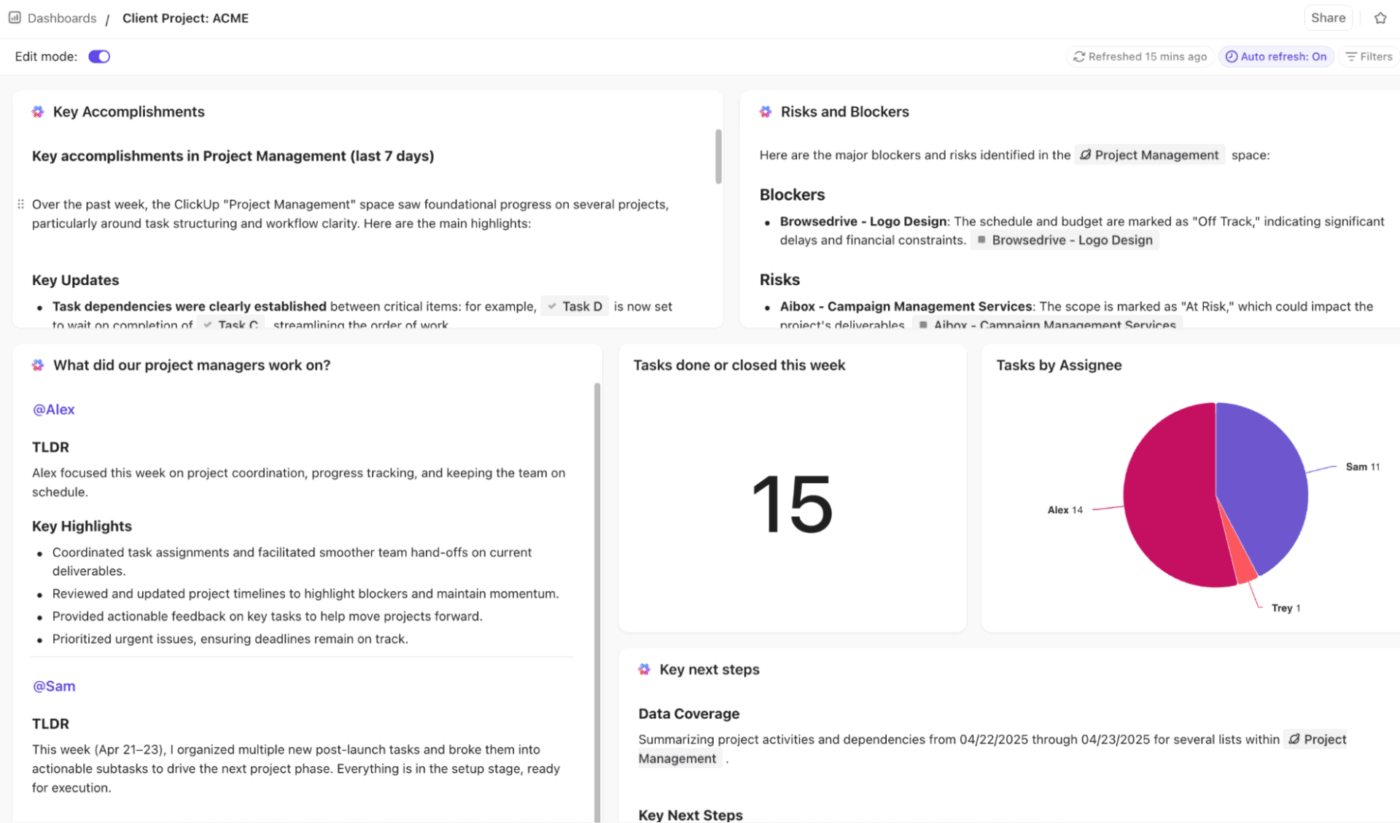
🚀 Vorteil von ClickUp: Mit den ClickUp-Dashboards erhalten Sie in Echtzeit visuelle und KI-gestützte Einblicke in alle Eskalationsmetriken.
Mit Tabellen, Kreisdiagrammen, Balkendiagrammen, Liniendiagrammen, Berechnungs- und Zeitberichtskarten können Sie Eskalationstrends, Engpässe und die Leistung verfolgen. Überwachen Sie die Eskalationsrate, wiederholte Eskalationen und die Zeit bis zur Eskalation mit Karten, die mit Aufgaben, benutzerdefinierten Feldern und Status verknüpft sind.
Um noch einen Schritt weiter zu gehen, verwenden Sie KI-Karten wie KI-Zusammenfassung, KI-Projekt-Update und KI-StandUp, um Trends, Verzögerungen und Lösungsergebnisse hervorzuheben.
Verwalten Sie Ihre Incidents schneller mit ClickUp
Viele glauben, dass es bei der Eskalation von Incidents lediglich darum geht, ein Ticket an die nächste Person weiterzuleiten, aber es ist viel mehr als das. Es handelt sich um ein strukturiertes System, in dem jeder Schritt, von der Triage bis zur Lösung, harmonisch ineinandergreift.
ClickUp bietet Ihnen den perfekten einheitlichen Arbeitsbereich. Mit ClickUp Automatisierungen können Sie automatisch Benachrichtigungen auslösen, Aufgaben weiterleiten und Status aktualisieren. Und ClickUp Brain hilft Ihnen dabei, Incidents zu priorisieren, Zusammenfassungen zu erstellen und nächste Schritte vorzuschlagen.
ClickUp AI Agents fungieren als intelligente Assistenten in Ihrer ClickUp-Workspace, während ClickUp Dashboards eine Live-Ansicht Ihrer Eskalationen bieten.
Melden Sie sich noch heute kostenlos bei ClickUp an!
Häufig gestellte Fragen (FAQ)
Ein Eskalationspfad für Vorfälle ist eine vordefinierte Abfolge von Schritten, die festlegt, wie Probleme basierend auf Schweregrad, Auswirkungen und Zeitpunkt an das richtige Team oder die richtige Person weitergeleitet werden. So wird sichergestellt, dass Vorfälle effizient behandelt werden und die Verantwortlichkeiten klar sind. TEXT
Nutzen Sie die Automatisierung für klar definierte Vorfälle mit hoher Priorität und eindeutigen Kriterien (z. B. Dienstausfälle, Verletzungen der Sicherheit). Reservieren Sie die manuelle Eskalation für unklare oder kritische Situationen, die menschliches Urteilsvermögen oder zusätzlichen Kontext erfordern.
Plattformen wie ClickUp, PagerDuty, Jira Service Management und ServiceNow ermöglichen Automatisierung der Weiterleitung, Benachrichtigungen und Aktualisierungen. Sie helfen Teams dabei, Verzögerungen zu reduzieren und strukturierte Incident-Workflows aufrechtzuerhalten.
Legen Sie klare Schwellenwerte für Warnmeldungen fest, priorisieren Sie diese nach Schweregrad und nutzen Sie intelligente Benachrichtigungen. Beschränken Sie wiederholte Benachrichtigungen auf kritische Vorfälle und nutzen Sie Dashboards oder KI-Tools, um Aktualisierungen zusammenzufassen, anstatt jede kleine Änderung zu versenden.
Überprüfen Sie die Eskalationsrichtlinien regelmäßig, mindestens einmal pro Quartal oder nach größeren Incidents. So stellen Sie sicher, dass die Kriterien, Verantwortlichkeiten und Regeln der Automatisierung den aktuellen Workflows, Teamstrukturen und Prioritäten des Geschäfts entsprechen.