
Wprowadzasz najnowszą aktualizację oprogramowania i zaczynają napływać raporty.
Nagle jeden wskaźnik zaczyna regulować wszystko, od CSAT/NPS po opóźnienia w realizacji planu działania: czas rozwiązywania problemów
Kierownictwo postrzega to jako wskaźnik dotrzymywania obietnic — czy jesteśmy w stanie dostarczyć produkt, zdobyć wiedzę i chronić przychody zgodnie z harmonogramem? Praktycy odczuwają trudności w codziennej pracy — zduplikowane zgłoszenia, niejasna własność, hałaśliwe eskalacje i kontekst rozproszony w Slacku, arkuszach kalkulacyjnych i oddzielnych narzędziach.
Ta fragmentacja wydłuża cykle, ukrywa przyczyny źródłowe i sprawia, że ustalanie priorytetów staje się zgadywanką.
Wynik? Wolniejsze uczenie się, niedotrzymane zobowiązania i zaległości, które po cichu obciążają każdy sprint.
Ten przewodnik jest kompletnym podręcznikiem dotyczącym mierzenia, porównywania i skracania czasu rozwiązywania błędów oraz konkretnego pokazania, w jaki sposób AI zmienia cykl pracy w porównaniu z tradycyjnymi, ręcznymi procesami.
Czym jest czas usuwania błędów?
Czas usuwania błędów to czas potrzebny do naprawienia błędu, mierzony od momentu zgłoszenia błędu do jego całkowitego usunięcia.
W praktyce zegar zaczyna tykać w momencie zgłoszenia lub wykrycia problemu (przez użytkowników, dział kontroli jakości lub monitorowanie) i zatrzymuje się po wdrożeniu i scalenianaprawy, gotowej do weryfikacji lub wydania — w zależności od tego, jak zespół definiuje „gotowe”
Przykład: awaria P1 zgłoszona o godz. 10:00 w poniedziałek, z poprawką wprowadzoną o godz. 15:00 we wtorek, ma czas rozwiązania wynoszący około 29 godzin.
Nie jest to to samo, co czas wykrycia błędu. Czas wykrycia mierzy, jak szybko rozpoznajesz defekt po jego wystąpieniu (uruchomienie alarmów, wykrycie przez narzędzia do testowania jakości, zgłoszenie przez klientów).
Czas rozwiązania mierzy szybkość przejścia od wykrycia do naprawy — klasyfikację, odtworzenie, diagnozę, wdrożenie, przegląd, testowanie i przygotowanie do wydania. Wykrycie można traktować jako „wiemy, że coś nie działa”, a rozwiązanie jako „zostało naprawione i jest gotowe”
Teams stosuje nieco inne granice; wybierz jedną i stosuj ją konsekwentnie, aby trendy były rzeczywiste:
- Zgłoszone → Rozwiązane: Kończy się po scalenianiu poprawki kodu i przygotowaniu go do kontroli jakości. Dobre dla przepustowości inżynierii
- Zgłoszone → Zamknięte: Obejmuje walidację kontroli jakości i wydanie. Najlepsze dla umów SLA mających wpływ na klientów
- Wykryte → Rozwiązane: Rozpoczyna się w momencie wykrycia problemu przez monitorowanie/kontrolę jakości, nawet przed utworzeniem zgłoszenia. Przydatne dla zespołów intensywnie wykorzystujących produkcję
🧠 Ciekawostka: Dziwaczny, ale zabawny błąd w grze Final Fantasy XIV zyskał uznanie dzięki swojej specyfice, dzięki czemu czytelnicy nazwali go „Najbardziej szczegółową poprawką błędu w grze MMO 2025 roku”. Błąd pojawiał się, gdy gracze wyceniali elementy na dokładnie 44 442 gilów i 49 087 gilów w określonej strefie wydarzenia, powodując rozłączenia z powodu prawdopodobnej awarii przepełnienia liczby całkowitej.
Dlaczego to ważne
Czas rozwiązywania problemów ma wpływ na częstotliwość wydawania nowych wersji. Długie lub nieprzewidywalne czasy wymuszają ograniczenia zakresu, poprawki i wstrzymanie wydawania nowych wersji; powodują one powstanie długu planistycznego, ponieważ długi ogon (wartości odstające) zakłóca sprinty bardziej niż sugeruje średnia.
Ma to również bezpośredni wpływ na satysfakcję klientów. Klienci tolerują problemy, gdy są one szybko rozpoznawane i rozwiązywane w przewidywalny sposób. Powolne naprawy — lub, co gorsza, zmienne naprawy — powodują eskalacje, obniżają wskaźniki CSAT/NPS i zagrażają odnowieniu umów.
Krótko mówiąc, jeśli będziesz dokładnie mierzyć czas rozwiązywania błędów i systematycznie go skracać, poprawisz swoje plany działania i relacje.
📖 Więcej informacji: Jak ustalać priorytety błędów w celu efektywnego rozwiązywania problemów
Jak mierzyć czas rozwiązywania błędów?
Najpierw zdecyduj, gdzie zaczyna i kończy się czas pomiaru.
Większość zespołów wybiera opcję Zgłoszone → Rozwiązane (poprawka została scalona i jest gotowa do weryfikacji) lub Zgłoszone → Zamknięte (kontrola jakości zatwierdziła zmianę i została ona opublikowana lub zamknięta w inny sposób).
Wybierz jedną definicję i stosuj ją konsekwentnie, aby trendy były miarodajne.
Teraz potrzebujesz kilku mierzalnych wskaźników. Przedstawmy je w skrócie:
Kluczowe wskaźniki śledzenia błędów, na które należy zwrócić uwagę:
| 📊 Metryka | 📌 Co to oznacza | 💡 Jak to pomaga | 🧮 Formuła (jeśli dotyczy) |
|---|---|---|---|
| Liczba błędów 🐞 | Całkowita liczba zgłoszonych błędów | Uzyskaj widok stanu systemu z lotu ptaka. Wysoka liczba? Czas na zbadanie sprawy. | Całkowita liczba błędów = wszystkie błędy zarejestrowane w systemie {otwarte + zamknięte} |
| Otwarte błędy 🚧 | Błędy, które nie zostały jeszcze naprawione | Pokazuje aktualne obciążenie pracą. Pomaga w ustalaniu priorytetów. | Otwarte błędy = całkowita liczba błędów – zamknięte błędy |
| Zamknięte błędy ✅ | Błędy, które zostały rozwiązane i zweryfikowane | Śledzenie postępów i wykonanych zadań. | Zamknięte błędy = liczba błędów o statusie „Zamknięte” lub „Rozwiązane” |
| Waga błędu 🔥 | Krytyczność błędu (np. krytyczny, poważny, drobny) | Pomaga w segregacji na podstawie wpływu. | Śledzone jako pole kategoryczne, bez formuły. Użyj filtrów/grupowania. |
| Priorytet błędu 📅 | Jak pilna jest naprawa błędu | Pomaga w planowaniu sprintów i wydawania nowych wersji. | Jest to również pole kategoryczne, zazwyczaj uszeregowane (np. P0, P1, P2). |
| Czas rozwiązania ⏱️ | Czas od zgłoszenia błędu do naprawy | Mierzy szybkość reakcji. | Czas rozwiązania = data zamknięcia - data zgłoszenia |
| Wskaźnik ponownego otwarcia 🔄 | procent błędów ponownie otwartych po zamknięciu | Odzwierciedla jakość poprawek lub problemy związane z regresją. | Wskaźnik ponownego otwarcia (%) = {ponownie otwarte błędy ÷ całkowita liczba zamkniętych błędów} × 100 |
| Wyciek błędów 🕳️ | Błędy, które przedostały się do produkcji | Wskazuje skuteczność kontroli jakości /testowania oprogramowania. | Wskaźnik wycieków (%) = {błędy produkcyjne ÷ całkowita liczba błędów} × 100 |
| Gęstość defektów 🧮 | Liczba błędów na jednostkę rozmiaru kodu | Wskazuje obszary kodu podatne na ryzyko. | Gęstość defektów = liczba błędów ÷ KLOC {tysiące linii kodu} |
| Przypisane vs nieprzypisane błędy 👥 | Dystrybucja błędów według własności | Gwarantuje, że nic nie zostanie pominięte. | Użyj filtra: Nieprzypisane = błędy, dla których pole „Przypisane do” jest puste |
| Wiek otwartych błędów 🧓 | Jak długo błąd pozostaje nierozwiązany | Wykrywa stagnację i ryzyko powstania zaległości. | Wiek błędu = bieżąca data – data zgłoszenia |
| Duplikaty błędów 🧬 | Liczba zduplikowanych zgłoszeń | Podkreśla błędy w procesach przyjmowania zgłoszeń. | Wskaźnik duplikatów = liczba duplikatów ÷ całkowita liczba błędów × 100 |
| MTTD (średni czas wykrycia) 🔎 | Średni czas wykrycia błędów lub incydentów | Mierzy skuteczność monitorowania i świadomości. | MTTD = Σ(czas wykrycia – czas wprowadzenia) ÷ liczba błędów |
| MTTR (średni czas rozwiązania) 🔧 | Średni czas całkowitego usunięcia błędu po wykryciu | Śledź szybkość reakcji inżynierów i czas naprawy. | MTTR = Σ(czas rozwiązania – czas wykrycia) ÷ liczba rozwiązanych błędów |
| MTTA (średni czas potwierdzenia) 📬 | Czas od wykrycia do momentu rozpoczęcia pracy nad błędem | Pokazuje reaktywność zespołu i szybkość reagowania na alerty. | MTTA = Σ(czas potwierdzenia – czas wykrycia) ÷ liczba błędów |
| MTBF (średni czas między awariami) 🔁 | Czas między rozwiązaniem jednej awarii a wystąpieniem kolejnej | Wskazuje stabilność w czasie. | MTBF = całkowity czas pracy ÷ liczba awarii |
⚡️ Archiwum szablonów: 15 darmowych szablonów i formularzy raportów błędów do śledzenia błędów
Czynniki wpływające na czas usuwania błędów
Czas rozwiązywania problemów często utożsamiany jest z „szybkością kodowania inżynierów”
Ale to tylko jedna część procesu.
Czas rozwiązywania błędów to suma jakości na etapie przyjmowania zgłoszenia, wydajności przepływu w systemie oraz ryzyka zależności. Gdy którykolwiek z tych elementów zawodzi, czas cyklu wydłuża się, spada przewidywalność, a eskalacje stają się coraz głośniejsze.
Jakość przyjmowanych zgłoszeń nadaje ton
Raporty, które nie zawierają jasnych kroków odtworzenia, szczegółów środowiska, logów lub informacji o wersji/kompilacji, powodują konieczność dodatkowej komunikacji. Duplikaty raportów z wielu kanałów (wsparcie, kontrola jakości, monitorowanie, Slack) powodują zamieszanie i rozdzielenie własności.
Im wcześniej uchwycisz właściwy kontekst i wyeliminujesz duplikaty, tym mniej będzie później potrzebnych przekazywania spraw i wyjaśnień.
Priorytetyzacja i kierowanie zgłoszeń decydują o tym, kto zajmie się błędem i kiedy
Etykiety ważności, które nie są powiązane z wpływem na klienta/biznes (lub które zmieniają się w czasie), powodują przepełnienie kolejki: najgłośniejsze zgłoszenia przeskakują do przodu, podczas gdy defekty o dużym wpływie pozostają bez działania.
Przejrzyste reguły kierowania zgłoszeń według komponentów/właścicieli oraz pojedyncza kolejka zgłoszeń sprawiają, że zadania o priorytecie P0/P1 nie giną wśród „najnowszych i najgłośniejszych” zgłoszeń
Własność i przekazywanie zadań to ciche zabójcy
Jeśli nie jest jasne, czy błąd dotyczy urządzenia mobilnego, uwierzytelniania zaplecza, czy zespołu platformy, jest on odrzucany. Każde odrzucenie resetuje kontekst.
Sytuację komplikują strefy czasowe: błąd zgłoszony późno w ciągu dnia bez wskazania właściciela może stracić 12–24 godziny, zanim ktokolwiek rozpocznie jego odtwarzanie. Ścisłe definicje „kto jest właścicielem czego” wraz z dyżurnym lub cotygodniowym DRI eliminują takie opóźnienia.
Powtarzalność zależy od obserwowalności
Nieliczne logi, brakujące identyfikatory korelacji lub brak śladów awarii sprawiają, że diagnoza staje się zgadywanką. Błędy, które pojawiają się tylko przy określonych flagach, dzierżawcach lub formatach danych, są trudne do odtworzenia w środowisku programistycznym.
Jeśli inżynierowie nie mają bezpiecznego dostępu do oczyszczonych danych produkcyjnych, muszą przeprowadzać instrumentację, ponowne wdrażanie i czekać — zamiast kilku godzin, trwa to kilka dni.
Środowisko i spójność danych zapewniają uczciwość
„Działa na moim komputerze” oznacza zazwyczaj „dane produkcyjne są inne”. Im bardziej środowisko programistyczne/testowe różni się od produkcyjnego (konfiguracja, usługi, wersje oprogramowania innych firm), tym więcej czasu spędzisz na poszukiwaniu błędów. Bezpieczne migawki danych, skrypty seed i kontrole parzystości zmniejszają tę lukę.
Praca w toku (WIP) i skupienie uwagi wpływają na rzeczywistą wydajność
Przeciążone zespoły zajmują się zbyt wieloma błędami naraz, rozpraszają swoją uwagę i przechodzą od zadania do zadania i od spotkania do spotkania. Zmiana kontekstu powoduje niewidoczne wydłużenie czasu pracy.
Widoczny limit WIP i nastawienie na dokończenie rozpoczętych zadań przed podjęciem nowych sprawi, że mediana spadnie szybciej niż w przypadku wysiłków pojedynczego bohatera.
Przegląd kodu, ciągła integracja i szybkość kontroli jakości to klasyczne wąskie gardła
Powolne kompilacje, niestabilne testy i niejasne umowy SLA dotyczące przeglądów opóźniają szybkie naprawy. 10-minutowa poprawka może czekać dwa dni na recenzenta lub trafić do wielogodzinnego procesu.
Podobnie kolejki kontroli jakości, które testują partie lub opierają się na ręcznych testach dymnych, mogą wydłużyć czas od zgłoszenia do zamknięcia nawet o kilka dni, nawet jeśli czas od zgłoszenia do rozwiązania jest krótki.
Zależności wydłużają kolejki
Zmiany między zespołami (schematy, migracje platform, aktualizacje SDK), błędy dostawców lub recenzje w sklepach z aplikacjami (urządzenia mobilne) powodują pojawienie się stanów oczekiwania. Bez wyraźnego śledzenia „zablokowanych/wstrzymanych” zadań oczekiwania te niewidocznie zawyżają średnie i ukrywają rzeczywiste wąskie gardła.
Ważne znaczenie mają model wydania i strategia wycofania
Jeśli dostarczasz duże partie aktualizacji z ręcznymi bramkami, nawet rozwiązane błędy pozostają w systemie do momentu uruchomienia kolejnej partii. Flagi funkcji, wersje kanarkowe i ścieżki poprawek skracają czas oczekiwania — zwłaszcza w przypadku incydentów P0/P1 — umożliwiając oddzielenie wdrażania poprawek od pełnych cykli aktualizacji.
Architektura i dług technologiczny wyznaczają górną granicę
Ścisłe powiązania, brak połączeń testowych i nieprzejrzyste starsze wersje modułów sprawiają, że proste poprawki są ryzykowne. Teams rekompensuje to dodatkowymi testami i dłuższymi przeglądami, co wydłuża cykle. Z drugiej strony modułowy kod z dobrymi testami kontraktowymi pozwala na szybkie działanie bez zakłócania pracy sąsiednich systemów.
Komunikacja i higiena statusu wpływają na przewidywalność
Niejasne aktualizacje („sprawdzamy”) powodują konieczność ponownej pracy, gdy interesariusze pytają o przewidywany czas rozwiązania, zespół wsparcia ponownie otwiera zgłoszenia lub problem trafia do eskalacji. Jasne zmiany statusu, notatki dotyczące odtworzenia i przyczyny źródłowej oraz podanie przewidywanego czasu rozwiązania zmniejszają liczbę rezygnacji i pozwalają zespołowi inżynierów skupić się na pracy.
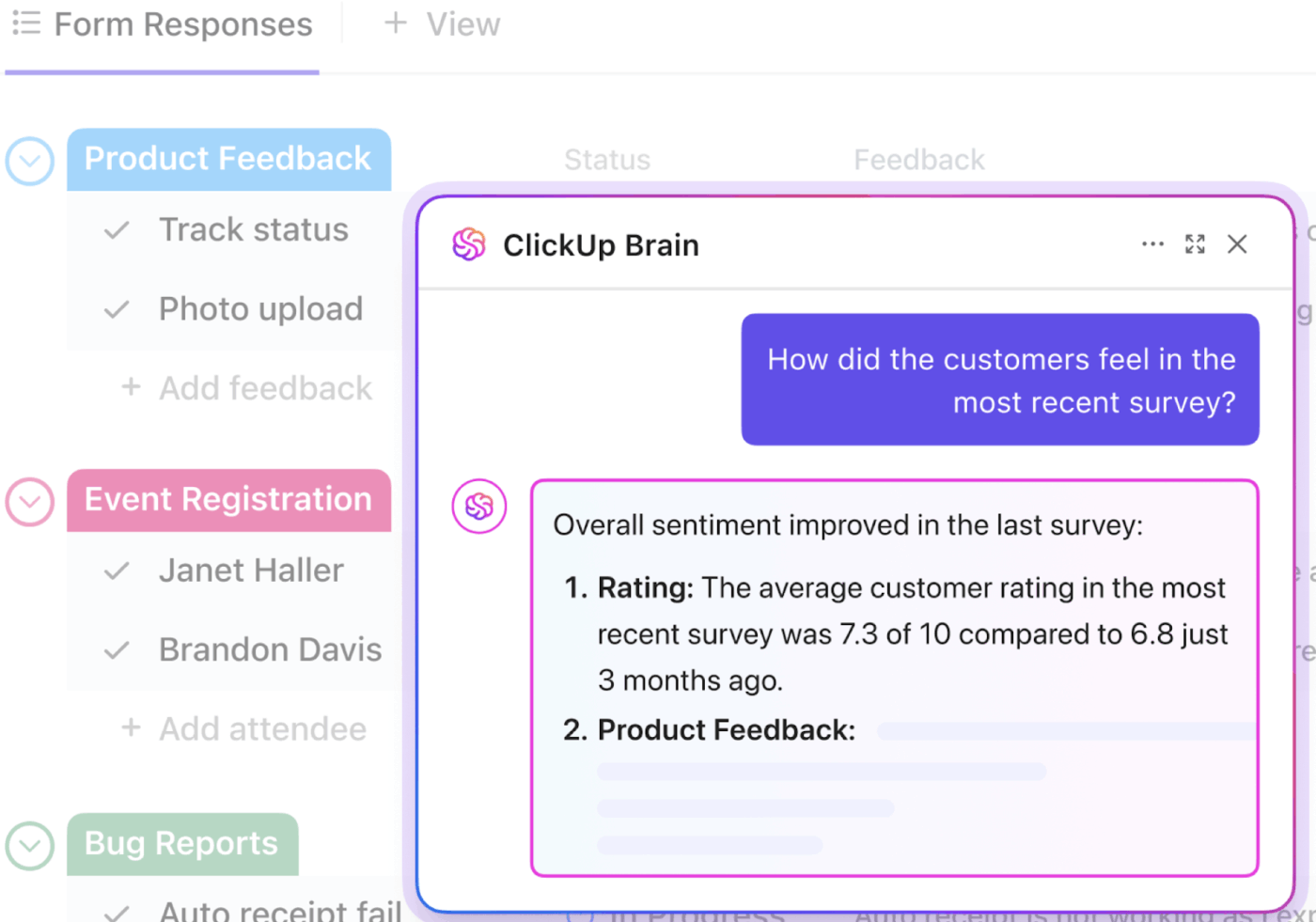
📮ClickUp Insight: Przeciętny pracownik spędza ponad 30 minut dziennie na wyszukiwaniu informacji związanych z pracą — to ponad 120 godzin rocznie straconych na przeglądanie e-maili, wątków Slacka i rozproszonych plików.
Inteligentny asystent AI wbudowany w obszar roboczy może to zmienić. Poznaj ClickUp Brain. Dostarcza natychmiastowych informacji i odpowiedzi, wyświetlając odpowiednie dokumenty, rozmowy i szczegóły zadań w ciągu kilku sekund — dzięki czemu możesz przestać szukać i zacząć pracować.
💫 Rzeczywiste wyniki: Dzięki ClickUp zespoły takie jak QubicaAMF odzyskały ponad 5 godzin tygodniowo — to ponad 250 godzin rocznie na osobę — eliminując przestarzałe procesy zarządzania wiedzą. Wyobraź sobie, co Twój zespół mógłby osiągnąć, mając dodatkowy tydzień wydajności w każdym kwartale!
Wiodące wskaźniki wskazujące, że czas rozwiązania problemu ulegnie wydłużeniu
❗️Wydłużający się czas potwierdzenia zgłoszenia i duża liczba zgłoszeń bez właściciela przez ponad 12 godzin
❗️Rosnące fragmenty „Czas przeglądu/CI” i częste awarie testów
❗️Wysoki wskaźnik duplikatów w zgłoszeniach i niespójne etykiety ważności w różnych zespołach
❗️Kilka błędów pozostaje w stanie „Zablokowane” bez nazwy zewnętrznej zależności
❗️Wzrost wskaźnika ponownego otwierania zgłoszeń (poprawki nie są powtarzalne lub definicje „zrobione” są niejasne)
Różne organizacje różnie postrzegają te czynniki. Kierownictwo odbiera je jako stracony cykl nauki i utratę możliwości uzyskania przychodów, a operatorzy jako zakłócenia w segregacji i niejasność co do własności.
Dostosowanie przyjmowania zgłoszeń, przepływu i zależności pozwala obniżyć całą krzywą — medianę i P90.
Chcesz dowiedzieć się więcej o pisaniu lepszych raportów o błędach? Zacznij tutaj. 👇🏼
📖 Więcej informacji: Cykl życia testowania oprogramowania (STLC): przegląd i fazy
Wskaźniki branżowe dotyczące czasu rozwiązywania błędów
Wskaźniki rozwiązywania błędów zmieniają się wraz z tolerancją ryzyka, modelem wydawania wersji i szybkością wprowadzania zmian.
W tym miejscu możesz użyć median (P50) do zrozumienia typowego przepływu oraz P90 do ustalenia obietnic i umów SLA — według ważności i źródła (klient, kontrola jakości, monitorowanie).
Przyjrzyjmy się bliżej, co to oznacza:
| 🔑 Termin | 📝 Opis | 💡 Dlaczego to ważne |
|---|---|---|
| P50 (mediana) | Średnia wartość — 50% poprawek błędów jest szybszych, a 50% wolniejszych | 👉 Odzwierciedla typowy lub najczęstszy czas rozwiązywania problemów. Przydatne do zrozumienia normalnej wydajności |
| P90 (90. percentyl) | 90% błędów jest naprawianych w tym czasie. Tylko 10% zajmuje więcej czasu | 👉 Reprezentuje najgorszy (ale nadal realistyczny) przypadek. Przydatne do ustawiania zewnętrznych obietnic |
| Umowy SLA (umowy o gwarantowanym poziomie usług) | Zobowiązania dotyczące szybkości rozwiązywania problemów, podjęte wewnętrznie lub wobec klientów | 👉 Przykład: „W 90% przypadków usuwamy błędy P1 w ciągu 48 godzin”. Pomaga budować zaufanie i odpowiedzialność |
| Według ważności i źródła | Segmentacja wskaźników według dwóch kluczowych wymiarów: • Waga (np. P0, P1, P2)• Źródło (np. klient, kontrola jakości, monitorowanie) | 👉 Umożliwia dokładniejsze śledzenie i ustalanie priorytetów, dzięki czemu krytyczne błędy są szybciej wykrywane |
Poniżej przedstawiono orientacyjne zakresy oparte na branżach, które często stanowią cel dojrzałych zespołów. Należy traktować je jako punkty wyjścia, a następnie dostosować do własnego kontekstu.
SaaS
Rozwiązanie jest zawsze dostępne i zgodne z CI/CD, więc poprawki są często wprowadzane. W przypadku problemów krytycznych (P0/P1) często dąży się do rozwiązania w ciągu jednego dnia roboczego, a w przypadku P90 — w ciągu 24–48 godzin. Problemy niekrytyczne (P2+) są zazwyczaj rozwiązywane w ciągu 3–7 dni, a w przypadku P90 — w ciągu 10–14 dni. Zespoły korzystające z solidnych flag funkcji i automatycznych testów osiągają lepsze wyniki.
Platformy e-commerce
Ponieważ konwersja i przepływ koszyków mają kluczowe znaczenie dla przychodów, pasek jest wyższy. Problemy P0/P1 są zazwyczaj łagodzone w ciągu kilku godzin (cofnięcie, oznaczenie lub konfiguracja) i całkowicie rozwiązywane tego samego dnia; P90 do końca dnia lub <12 godzin jest powszechne w szczycie sezonu. Problemy P2+ często rozwiązuje się w ciągu 2–5 dni, a P90 w ciągu 10 dni.
Oprogramowanie Enterprise
Bardziej rygorystyczna walidacja i okna zmian wprowadzanych przez klientów spowalniają tempo pracy. W przypadku P0/P1 zespoły dążą do znalezienia rozwiązania tymczasowego w ciągu 4–24 godzin i naprawy w ciągu 1–3 dni roboczych, a w przypadku P90 — w ciągu 5 dni roboczych. Elementy P2+ są często grupowane w serie wydawnicze, których średni czas realizacji wynosi 2–4 tygodnie, w zależności od harmonogramów wdrożeń klientów.
Gry i aplikacje mobilne
Backendy usług na żywo zachowują się jak SaaS (flagi i przywracanie stanu poprzedniego w ciągu minut lub godzin; P90 tego samego dnia). Aktualizacje klientów są ograniczone przez recenzje sklepów: P0/P1 często natychmiast wykorzystują dźwignie po stronie serwera i wysyłają poprawkę dla klienta w ciągu 1–3 dni; P90 w ciągu tygodnia z przyspieszoną recenzją. Poprawki P2+ są zazwyczaj planowane w następnym sprincie lub aktualizacji zawartości.
Bankowość/Fintech
Bramki ryzyka i zgodności napędzają model „szybkiego łagodzenia i ostrożnych zmian”. Błędy P0/P1 są szybko łagodzone (flagi, cofanie zmian, zmiany ruchu w ciągu kilku minut lub godzin) i całkowicie naprawiane w ciągu 1–3 dni; błędy P90 w ciągu tygodnia, z uwzględnieniem kontroli zmian. Błędy P2+ często wymagają 2–6 tygodni, aby przejść przeglądy bezpieczeństwa, audytu i CAB.
Jeśli Twoje wyniki wykraczają poza te zakresy, zanim uznasz, że podstawowym problemem jest „szybkość pracy inżynierów”, przyjrzyj się jakości zgłoszeń, kierowaniu/własności, przeglądowi kodu i przepustowości kontroli jakości oraz zatwierdzaniu zależności.
🌼 Czy wiesz, że: Według badania Stack Overflow z 2024 r. programiści coraz częściej korzystają z AI jako niezawodnego pomocnika podczas pisania kodu. Aż 82% używało AI do pisania kodu — to dopiero kreatywny współpracownik! Kiedy utknęli lub szukali rozwiązań, 67,5% polegało na AI w poszukiwaniu odpowiedzi, a ponad połowa (56,7%) korzystała z niej do debugowania i uzyskiwania pomocy.
Dla niektórych narzędzia AI okazały się również przydatne do dokumentowania projektów (40,1%), a nawet do tworzenia danych syntetycznych lub treści (34,8%). Ciekawi Cię nowa baza kodu? Prawie jedna trzecia (30,9%) używa AI, aby nadążyć za zmianami. Testowanie kodu nadal jest dla wielu żmudnym zadaniem wykonywanym ręcznie, ale 27,2% również w tym obszarze postawiło na AI. W innych obszarach, takich jak przegląd kodu, planowanie projektów i analityka predykcyjna, AI jest stosowana w mniejszym stopniu, ale jasne jest, że sztuczna inteligencja stopniowo wkracza na każdą scenę tworzenia oprogramowania.
📖 Więcej informacji: Jak wykorzystać AI do zapewnienia jakości
Jak skrócić czas rozwiązywania problemów
Szybkość rozwiązywania błędów sprowadza się do eliminowania tarć na każdym etapie przekazywania zadań, od zgłoszenia do wydania.
Największe korzyści płyną z inteligentnego wykorzystania pierwszych 30 minut (prawidłowe przyjęcie zgłoszenia, przypisanie właściwego właściciela, ustalenie priorytetu), a następnie skrócenia kolejnych etapów (odtworzenie, przegląd, weryfikacja).
Oto dziewięć strategii, które współdziałają jako system. AI przyspiesza każdy krok, a cykl pracy przebiega sprawnie w jednym miejscu, dzięki czemu kadra kierownicza zyskuje przewidywalność, a praktycy — przepływ.
1. Scentralizuj przyjmowanie zgłoszeń i rejestruj kontekst u źródła
Czas rozwiązywania błędów wydłuża się, gdy rekonstruujesz kontekst na podstawie wątków Slacka, zgłoszeń do pomocy technicznej i arkuszy kalkulacyjnych. Skieruj wszystkie raporty — dotyczące pomocy technicznej, kontroli jakości, monitorowania — do jednej kolejki za pomocą ustrukturyzowanego szablonu, który gromadzi informacje o komponentach, ważności, środowisku, wersji/kompilacji aplikacji, krokach niezbędnych do odtworzenia błędu, oczekiwanych i rzeczywistych wynikach oraz załącznikach (dzienniki/HAR/zrzuty ekranu).
AI może automatycznie podsumowywać długie raporty, wyodrębniać kroki odtworzenia i szczegóły środowiska z załączników oraz oznaczać prawdopodobne duplikaty, dzięki czemu segregacja rozpoczyna się od spójnego, wzbogaconego zapisu.
Wskaźniki, na które należy zwrócić uwagę: MTTA (potwierdzenie w ciągu minut, a nie godzin), wskaźnik duplikatów, czas „Potrzebne informacje”.

📖 Więcej informacji: Możliwości formularzy ClickUp: usprawnianie pracy zespołów programistów
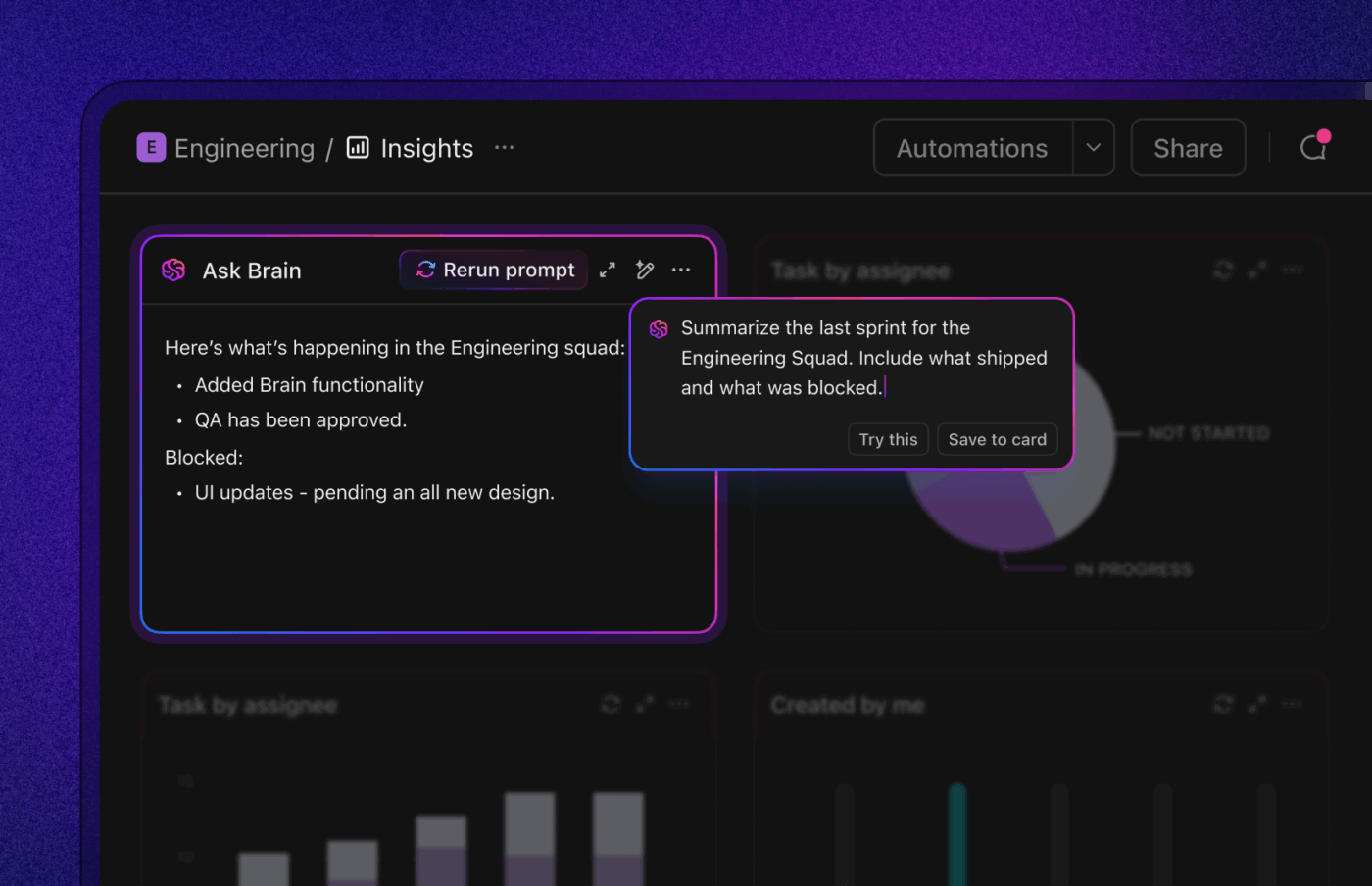
2. Segregacja i kierowanie wspomagane przez AI w celu skrócenia MTTA
Najszybsze rozwiązania to te, które trafiają od razu na właściwe biurko.
Wykorzystaj proste reguły i AI do klasyfikacji ważności, identyfikacji prawdopodobnych właścicieli według komponentu/obszaru kodu oraz automatycznego przypisywania zadań z uwzględnieniem zegara SLA. Ustal jasne ścieżki dla P0/P1 w odróżnieniu od wszystkich pozostałych zadań i jednoznacznie określ, kto jest za nie odpowiedzialny.
Automatyzacja pozwala ustawić priorytety na podstawie pól, przekierować zgłoszenie do odpowiedniego zespołu, uruchomić timer SLA i powiadomić inżyniera dyżurnego. AI może zaproponować poziom ważności i właściciela na podstawie wcześniejszych wzorców. Gdy segregacja zajmuje 2–5 minut zamiast 30 minut dyskusji, MTTA spada, a wraz z nim MTTR.
Wskaźniki, na które należy zwrócić uwagę: MTTA, jakość pierwszej odpowiedzi (czy w pierwszym komentarzu poproszono o właściwe informacje?), liczba przekazanych zgłoszeń na błąd.
Oto jak to wygląda w praktyce:
3. Priorytetyzuj zadania według wpływu na działalność dzięki jasnym poziomom SLA
„Najgłośniejszy głos wygrywa” sprawia, że kolejki są nieprzewidywalne i podważa zaufanie kierownictwa obserwującego wskaźniki CSAT/NPS i odnowienia.
Zastąp to wynikiem, który łączy w sobie ważność, częstotliwość, wpływ na ARR, krytyczność funkcji i bliskość odnowień/wprowadzeń na rynek — i poprzyj go poziomami SLA (np. P0: złagodzenie w ciągu 1–2 godzin, rozwiązanie w ciągu jednego dnia; P1: tego samego dnia; P2: w ramach sprintu).
Zachowaj widoczność ścieżki P0/P1 dzięki limitom WIP, aby żadne zadania nie zostały pominięte.
Wskaźniki, na które należy zwrócić uwagę: Rozwiązanie P50/P90 według poziomu, wskaźnik naruszeń SLA, korelacja z CSAT/NPS.
💡Wskazówka dla profesjonalistów: Pola priorytetów zadań, pól niestandardowych i zależności w ClickUp umożliwiają obliczenie wskaźnika wpływu i powiązanie błędów z kontami, opiniami lub elementami planu działania. Ponadto cele w ClickUp pomagają powiązać przestrzeganie umów SLA z celami na poziomie firmy, co bezpośrednio odpowiada na obawy kadry kierowniczej dotyczące spójności działań.
4. Spraw, aby odtwarzanie i diagnozowanie stało się czynnością jednokrotną
Każda dodatkowa pętla z pytaniem „czy możesz przesłać logi?” wydłuża czas rozwiązywania problemów.
Ustandiusz, co oznacza „dobry”: wymagane pola dla kompilacji/commit, środowisko, kroki odtworzenia, oczekiwane vs rzeczywiste, a także załączniki dla logów, zrzuty awarii i pliki HAR. Wprowadź telemetrię klienta/serwera, aby identyfikatory awarii i identyfikatory żądań można było powiązać ze śladami.
Wprowadź Sentry (lub podobne narzędzie) do śledzenia stosu i połącz ten problem bezpośrednio z błędem. AI może odczytywać logi i ślady, aby zaproponować prawdopodobną domenę błędu i wygenerować minimalną reprodukcję, zamieniając godzinę obserwacji na kilka minut skoncentrowanej pracy.
Przechowuj instrukcje postępowania dla typowych klas błędów, aby inżynierowie nie musieli zaczynać od zera.
Wskaźniki, na które należy zwrócić uwagę: czas spędzony na „oczekiwaniu na informacje”, odsetek przypadków odtworzonych przy pierwszym przejściu, wskaźnik ponownego otwarcia powiązany z brakiem odtworzenia.
📖 Dowiedz się więcej: Jak wykorzystać AI w tworzeniu oprogramowania (przykłady zastosowań i narzędzia)
5. Skróć proces przeglądu kodu i pętlę testową
Duże aktualizacje PR powodują opóźnienia. Staraj się stosować precyzyjne poprawki, rozwój oparty na trunkach i flagi funkcji, aby poprawki mogły być dostarczane bezpiecznie. Przypisz recenzentów z wyprzedzeniem według własności kodu, aby uniknąć przestojów, i korzystaj z list kontrolnych (aktualizacja testów, dodanie telemetrii, flaga za przełącznikiem awaryjnym), aby zapewnić wysoką jakość.
Automatyzacja powinna przenieść błąd do statusu „W trakcie przeglądu” po otwarciu PR i do statusu „Rozwiązany” po scalenianiu; AI może sugerować testy jednostkowe lub wyróżniać ryzykowne różnice, aby skoncentrować się na przeglądzie.
Wskaźniki, na które należy zwrócić uwagę: Czas w statusie „W trakcie przeglądu”, wskaźnik niepowodzeń zmian dla PR dotyczących poprawek błędów oraz opóźnienie przeglądu P90.
Możesz korzystać z integracji GitHub/GitLab w ClickUp, aby zsynchronizować status rozwiązań; automatyzacja może egzekwować „definicję gotowości”
📖 Więcej informacji: Jak wykorzystać AI do automatyzacji zadań
6. Równoległa weryfikacja i rzeczywista równowaga środowiska kontroli jakości
Weryfikacja nie powinna rozpoczynać się kilka dni później lub w środowisku, z którego nie korzysta żaden z Twoich klientów.
Zachowaj gotowość do kontroli jakości: poprawki oparte na flagach, sprawdzane w środowiskach zbliżonych do produkcyjnych przy użyciu danych początkowych odpowiadających zgłoszonym przypadkom.
Tam, gdzie to możliwe, skonfiguruj środowiska efemeryczne z gałęzi błędów, aby dział kontroli jakości mógł natychmiast przeprowadzić walidację. Następnie AI może wygenerować przypadki testowe na podstawie opisu błędu i wcześniejszych regresji.
Wskaźniki, na które należy zwrócić uwagę: Czas w „QA/weryfikacji”, współczynnik odrzuceń z QA z powrotem do deweloperów, średni czas zamknięcia po scaleniu.

📖 Więcej informacji: Jak pisać skuteczne przypadki testowe
7. Przejrzysta komunikacja statusu w celu ograniczenia nakładów na koordynację
Dobra aktualizacja pozwala uniknąć trzech pingów statusu i jednej eskalacji.
Traktuj aktualizacje jak produkt: krótkie, konkretne i dostosowane do odbiorców (obsługa klienta, kadra kierownicza, klienci). Ustal częstotliwość dla P0/P1 (np. co godzinę do momentu złagodzenia, a następnie co cztery godziny) i zachowaj jedno źródło informacji.
AI może tworzyć bezpieczne dla klientów aktualizacje i wewnętrzne podsumowania na podstawie historii zadań, w tym statusu na żywo według ważności i zespołu. Kierownictwo, takie jak dyrektor ds. produktów, może przekazywać błędy do inicjatyw, aby sprawdzić, czy krytyczne prace związane z jakością zagrażają dotrzymaniu terminów dostaw.
Wskaźniki, na które należy zwrócić uwagę: Czas między aktualizacjami statusu na P0/P1, CSAT interesariuszy w zakresie komunikacji.
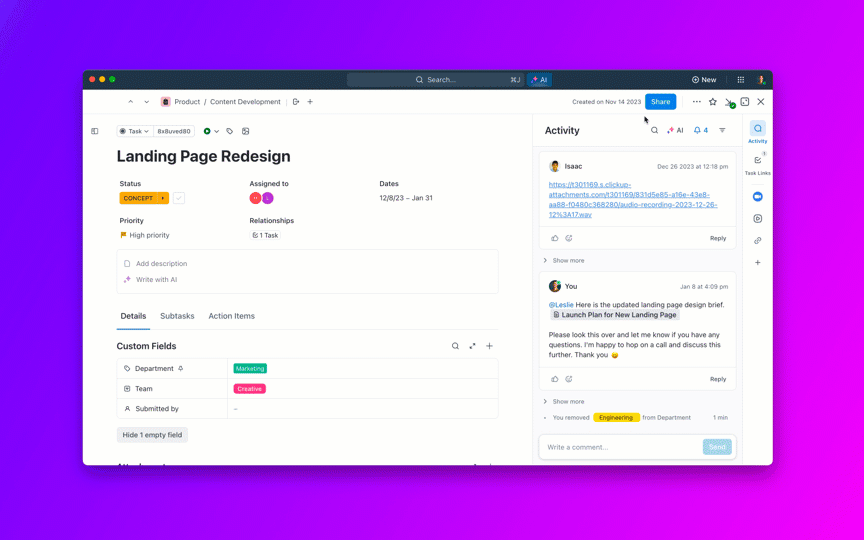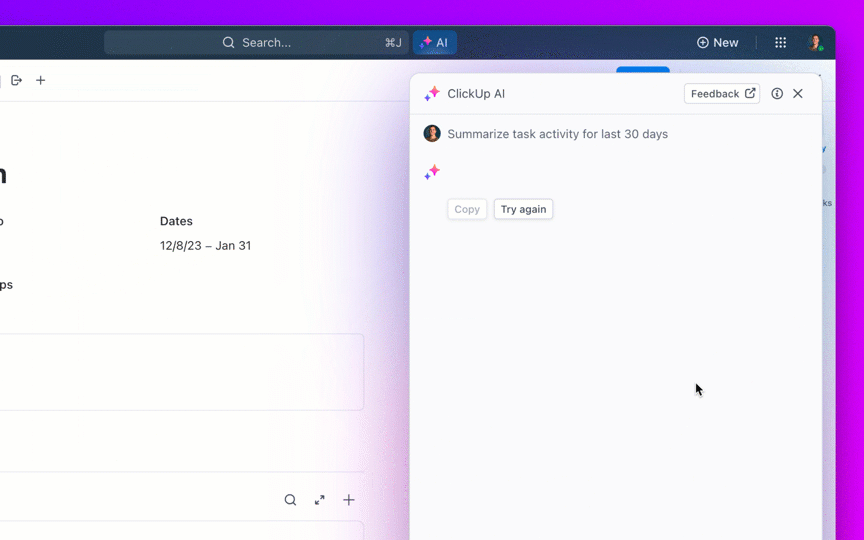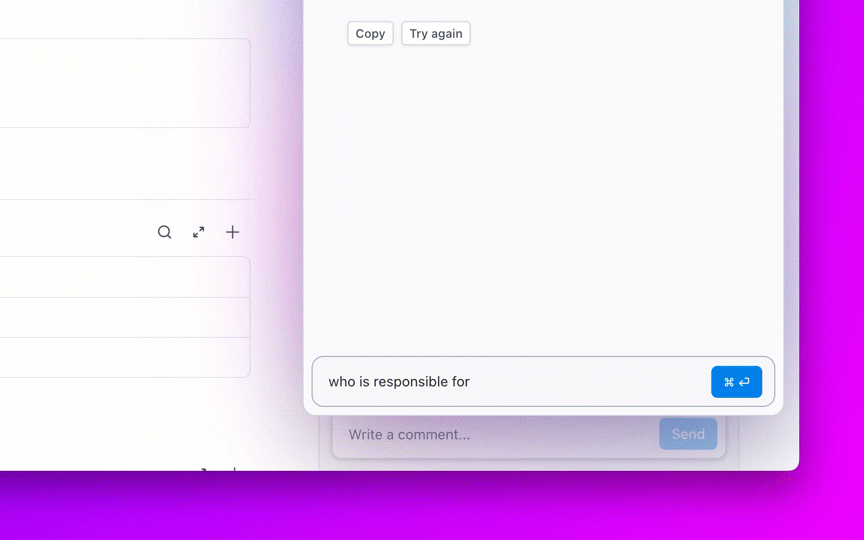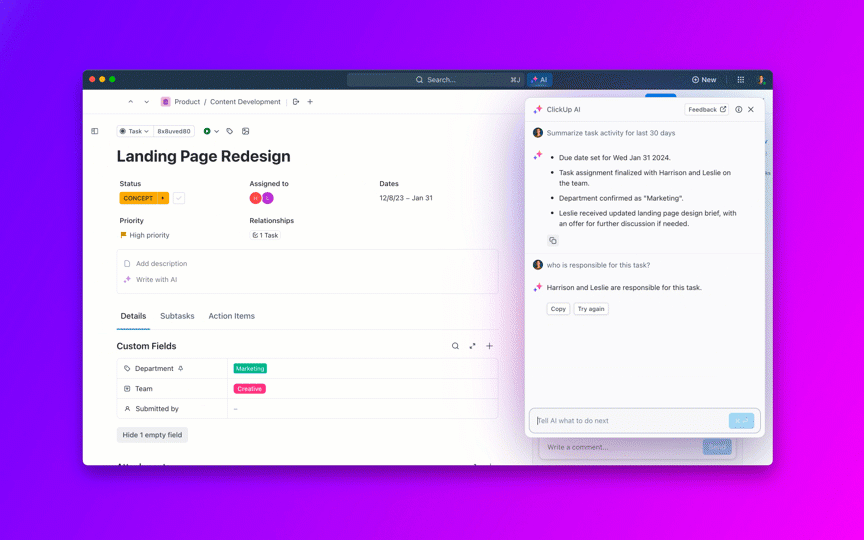
8. Kontroluj starzenie się zaległości i zapobiegaj tworzeniu się „wiecznie otwartych” zgłoszeń
Rosnące zaległości po cichu obciążają każdy sprint.
Ustaw zasady starzenia się zgłoszeń (np. P2 > 30 dni wyzwalacz przeglądu, P3 > 90 dni wymaga uzasadnienia) i zaplanuj cotygodniową „segregację zgłoszeń według wieku”, aby scalić duplikaty, zamknąć nieaktualne zgłoszenia i przekształcić błędy o niskiej wartości w elementy zaległości produktu.
Wykorzystaj AI do grupowania zaległości według tematu (np. „wygaśnięcie tokenu autoryzacyjnego”, „niestabilność przesyłania obrazów”), aby zaplanować tygodnie poświęcone na naprawę poszczególnych problemów i wyeliminować całą klasę defektów jednocześnie.
Wskaźniki, na które należy zwrócić uwagę: liczba zaległych zadań według przedziału czasowego, % problemów zamkniętych jako duplikaty/przestarzałe, tematyczna prędkość realizacji.
9. Zamknij pętlę dzięki identyfikacji przyczyn źródłowych i zapobieganiu
Jeśli ta sama klasa defektów powraca, poprawa wskaźnika MTTR maskuje większy problem.
Przeprowadź szybką i bezbłędną analizę przyczyn źródłowych błędów P0/P1 i często występujących błędów P2; oznacz przyczyny źródłowe (braki w specyfikacji, braki w testach, braki w narzędziach, niestabilność integracji), połącz je z komponentami i incydentami, których dotyczą, oraz śledź zadania następcze (zabezpieczenia, testy, reguły lint) aż do ich zakończenia.
AI może tworzyć podsumowania RCA i proponować testy zapobiegawcze lub reguły lint na podstawie historii zmian. W ten sposób przechodzisz od gaszenia pożarów do zmniejszenia ich liczby.
Wskaźniki, na które należy zwrócić uwagę: wskaźnik ponownego otwarcia, wskaźnik regresji, czas między cyklicznością i procent RCA z zakończonymi działaniami zapobiegawczymi.

Wszystkie te zmiany skracają ścieżkę od początku do końca: szybsze potwierdzanie, czystsza klasyfikacja, inteligentniejsze ustalanie priorytetów, mniej przestojów w procesie przeglądu i kontroli jakości oraz jaśniejsza komunikacja. Kierownictwo zyskuje przewidywalność powiązaną z CSAT/NPS i przychodami, a praktycy — spokojniejszą kolejkę zadań i mniej zmian kontekstu.
📖 Więcej informacji: Jak przeprowadzić analizę przyczyn źródłowych
Narzędzia AI, które pomagają skrócić czas rozwiązywania problemów
AI może skrócić czas rozwiązywania problemów na każdym kroku — od zgłoszenia, przez klasyfikację, kierowanie, naprawę, aż po weryfikację.
Jednak prawdziwe korzyści pojawiają się, gdy narzędzia rozumieją kontekst i kontynuują pracę bez konieczności ręcznego sterowania.
Poszukaj systemów, które automatycznie wzbogacają raporty (kroki odtworzenia, środowisko, duplikaty), ustalają priorytety według wpływu, kierują do właściwego właściciela, tworzą jasne aktualizacje i ściśle integrują się z kodem, CI i obserwowalnością.
Najlepsze z nich oferują również wsparcie dla cyklu pracy podobnego do pracy agentów: boty monitorujące umowy SLA, przypominające recenzentom o zadaniach, eskalujące zablokowane elementy i podsumowujące wyniki dla interesariuszy. Oto nasze narzędzia AI ułatwiające rozwiązywanie błędów:
1. ClickUp (najlepsze rozwiązanie w zakresie kontekstowej sztucznej inteligencji, automatyzacji i cyklu pracy agentów)
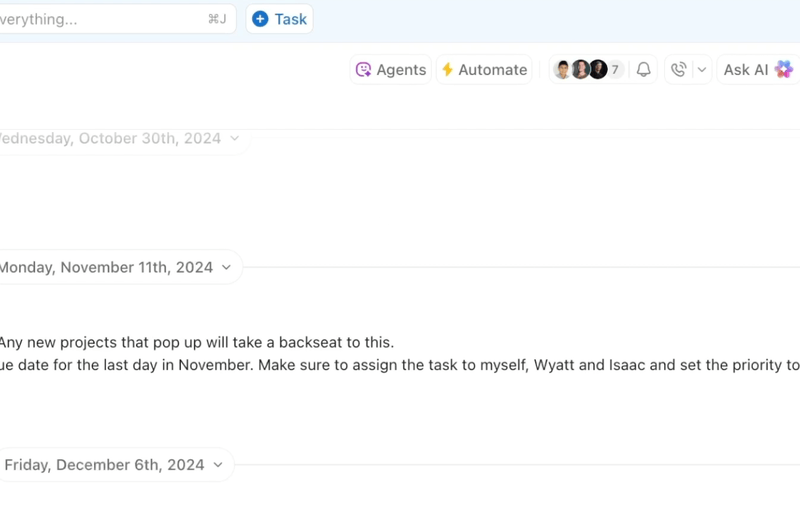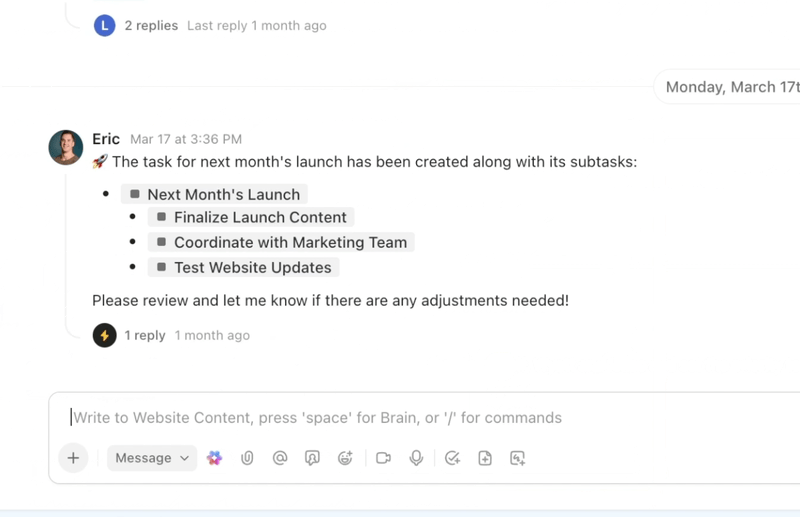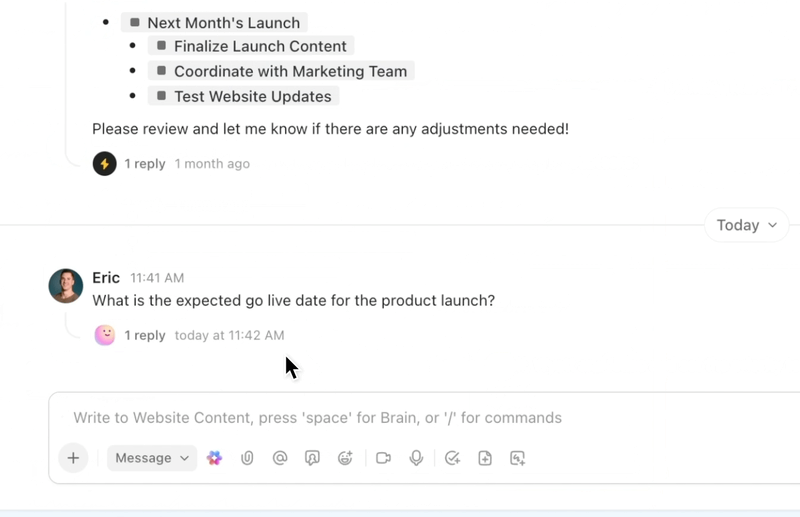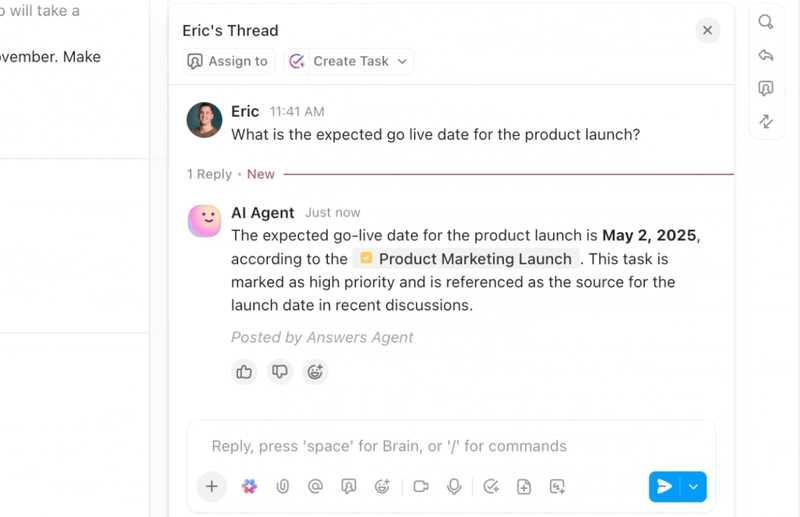
Jeśli chcesz usprawnić i zinteligentyzować cykl pracy związany z rozwiązywaniem błędów, ClickUp, aplikacja do pracy, która oferuje wszystko, łączy w jednym miejscu AI, automatyzację i pomoc w cyklu pracy agentów.
ClickUp Brain natychmiast wyświetla odpowiedni kontekst — podsumowuje długie wątki dotyczące błędów, wyodrębnia kroki niezbędne do odtworzenia błędu i szczegóły środowiska z załączników, oznacza prawdopodobne duplikaty i sugeruje kolejne działania. Zamiast przedzierać się przez Slack, zgłoszenia i logi, zespoły otrzymują przejrzysty, bogaty zapis, na podstawie którego mogą natychmiast podjąć działania.
Automatyzacja i agenci Autopilot w ClickUp zapewniają ciągłość pracy bez konieczności ciągłego nadzoru. Błędy są automatycznie kierowane do odpowiedniego zespołu, przypisywani są właściciele, ustalane są umowy SLA i terminy, statusy są aktualizowane w miarę postępu prac, a interesariusze otrzymują powiadomienia w odpowiednim czasie.

Agenci mogą nawet segregować i kategoryzować problemy, grupować podobne zgłoszenia, odwoływać się do historycznych poprawek, aby zaproponować prawdopodobne rozwiązania, oraz eskalować pilne elementy — dzięki czemu MTTA i MTTR spadają nawet w przypadku gwałtownych wzrostów liczby zgłoszeń.
🛠️ Chcesz gotowy zestaw narzędzi? Szablon ClickUp do śledzenia błędów i problemów to potężne rozwiązanie firmy ClickUp dla oprogramowania, zaprojektowane , aby pomóc zespołom wsparcia, inżynierii i produktu z łatwością nadążać za błędami i problemami oprogramowania. Dzięki konfigurowalnym widokom, takim jak lista, tablica, obciążenie pracą, formularz i oś czasu, zespoły mogą wizualizować i zarządzać procesem śledzenia błędów w sposób, który najbardziej im odpowiada.
20 niestandardowych statusów i 7 pól niestandardowych szablonu umożliwiają dostosowanie cyklu pracy, zapewniając śledzenie każdego problemu od momentu wykrycia do rozwiązania. Wbudowane funkcje automatyzacji zajmują się powtarzalnymi zadaniami, zwalniając cenny czas i zmniejszając wysiłek ręczny.
💟 Bonus: Brain MAX to oparty na sztucznej inteligencji towarzysz na pulpicie, zaprojektowany w celu przyspieszenia rozwiązywania błędów dzięki inteligentnym, praktycznym funkcjom.
Gdy napotkasz błąd, po prostu użyj funkcji zamiany mowy na tekst w Brain MAX, aby opisać problem — Twoje notatki głosowe zostaną natychmiast przepisane i można je dołączyć do nowego lub istniejącego zgłoszenia błędu. Funkcja Enterprise Search przeszukuje wszystkie połączone narzędzia, takie jak ClickUp, GitHub, Google Drive i Slack, aby wyświetlić powiązane raporty o błędach, dzienniki błędów, fragmenty kodu i dokumentację, dzięki czemu masz dostęp do wszystkich potrzebnych informacji bez konieczności przełączania się między aplikacjami.
Musisz skoordynować naprawę? Brain MAX pozwala przypisać błąd do odpowiedniego programisty, ustawić automatyczne przypomnienia o aktualizacji statusu i śledzić postępy — wszystko z pulpitu!
2. Sentry (najlepsze rozwiązanie do wykrywania błędów)
Sentry skraca czas MTTD i czas odtworzenia błędu poprzez przechwytywanie błędów, śladów i sesji użytkowników w jednym miejscu. Grupowanie problemów oparte na AI ogranicza szum informacyjny, a reguły „podejrzanego commitu” i własności identyfikują prawdopodobnego właściciela kodu, dzięki czemu routing jest natychmiastowy. Funkcja Session Replay zapewnia inżynierom dokładną ścieżkę użytkownika oraz szczegóły konsoli/sieci, które można odtworzyć bez niekończących się poszukiwań.
Funkcje Sentry AI mogą podsumować kontekst problemu, a w niektórych stosach zaproponować poprawki Autofix, które odwołują się do błędnego kodu. Praktyczny efekt: mniej zduplikowanych zgłoszeń, szybsze przypisywanie zadań i krótsza droga od zgłoszenia do działającej poprawki.
3. GitHub Copilot (najlepsze rozwiązanie do szybszego przeglądania kodu)
Copilot przyspiesza pętlę naprawczą w redaktorze. Wyjaśnia ślady stosu, sugeruje ukierunkowane poprawki, pisze testy jednostkowe w celu zablokowania poprawki i tworzy szkielety skryptów odtwarzających.
Copilot Chat może przechodzić przez błędny kod, proponować bezpieczniejsze refaktoryzacje i generować komentarze lub opisy PR, które przyspieszają przeglądanie kodu. W połączeniu z wymaganymi przeglądami i CI skraca czas potrzebny na „diagnozowanie → wdrażanie → testowanie”, zwłaszcza w przypadku dobrze zdefiniowanych błędów z jasną reprodukcją.
4. Snyk by DeepCode AI (najlepsze do wykrywania wzorców)
Analiza statyczna oparta na sztucznej inteligencji DeepCode wykrywa defekty i niebezpieczne wzorce podczas kodowania i w PR. Podkreśla problematyczne przepływy, wyjaśnia przyczyny ich występowania i proponuje bezpieczne poprawki dostosowane do idiomów bazy kodu.
Wykrywanie regresji przed scaleniem i kierowanie programistów do bezpieczniejszych wzorców pozwala zmniejszyć liczbę nowych błędów i przyspieszyć usuwanie trudnych do wykrycia podczas przeglądu błędów logicznych. Integracja z IDE i PR sprawia, że wszystko odbywa się blisko miejsca pracy.
5. Watchdog i AIOps firmy Datadog (najlepsze rozwiązanie do analizy logów)
Watchdog firmy Datadog wykorzystuje uczenie maszynowe do wykrywania anomalii w logach, metrykach, śladach i monitorowaniu rzeczywistych użytkowników. Koreluje skoki z markerami wdrożeń, zmianami infrastruktury i topologią, aby zasugerować prawdopodobne przyczyny źródłowe.
W przypadku defektów mających wpływ na klientów oznacza to wykrywanie w ciągu kilku minut, automatyczne grupowanie w celu ograniczenia liczby alertów oraz konkretne wskazówki dotyczące miejsc, które należy sprawdzić. Czas segregacji ulega skróceniu, ponieważ zaczynasz od informacji „to wdrożenie dotyczyło tych usług, a wskaźniki błędów wzrosły w tym punkcie końcowym” zamiast od zera.
⚡️ Archiwum szablonów: Darmowe szablony śledzenia problemów i dzienników w Excelu i ClickUp
6. New Relic AI (najlepsze rozwiązanie do identyfikowania i podsumowywania trendów)
Skrzynka odbiorcza błędów New Relic grupuje podobne błędy w różnych usługach i wersjach, a asystent AI podsumowuje ich wpływ, wskazuje prawdopodobne przyczyny i łączy je z odpowiednimi śladami/transakcjami.
Korelacje wdrożeń i inteligencja zmian jednostek pozwalają jednoznacznie stwierdzić, kiedy winę ponosi najnowsza wersja. W przypadku systemów rozproszonych kontekst ten skraca godziny pingowania między zespołami i pozwala przekazać błąd właściwemu właścicielowi wraz z gotową hipotezą.
7. Rollbar (najlepszy do automatyzacji cyklu pracy)
Rollbar specjalizuje się w monitorowaniu błędów w czasie rzeczywistym za pomocą inteligentnego identyfikowania odcisków palców w celu grupowania duplikatów i śledzenia trendów występowania. Podsumowania oparte na AI i wskazówki dotyczące przyczyn źródłowych pomagają zespołom zrozumieć zakres (użytkownicy, których dotyczy problem, wersje, na które ma wpływ), a telemetria i ślady stosu zapewniają szybkie wskazówki dotyczące odtworzenia błędu.
Reguły cyklu pracy Rollbar mogą automatycznie tworzyć zadania, etykietować stopień ważności i kierować je do właścicieli, zamieniając natłok błędów w kolejki priorytetowe z dołączonym kontekstem.
8. PagerDuty AIOps i automatyzacja runbooków (najlepsze rozwiązania w zakresie diagnostyki wymagającej niewielkiej interwencji użytkownika)
PagerDuty wykorzystuje korelację wydarzeń i redukcję szumów opartą na uczeniu maszynowym, aby przekształcić lawinę alertów w konkretne zdarzenia wymagające podjęcia działań.
Dynamiczne kierowanie sprawia, że problem trafia natychmiast do właściwej osoby dyżurnej, a automatyzacja runbooków może uruchomić diagnostykę lub działania łagodzące (restart usług, wycofanie wdrożenia, przełączenie flagi funkcji) przed interwencją człowieka. W przypadku czasu rozwiązywania błędów oznacza to krótszy MTTA, szybsze łagodzenie skutków błędów P0 i mniej godzin straconych na reagowanie na alerty.
Wszystko opiera się na automatyzacji i AI na każdym kroku. Wykrywasz błędy wcześniej, kierujesz je mądrzej, szybciej docierasz do kodu i komunikujesz status bez spowalniania pracy inżynierów — wszystko to składa się na znaczące skrócenie czasu rozwiązywania błędów.
📖 Więcej informacji: Jak korzystać z AI w DevOps
Praktyczne przykłady wykorzystania AI do rozwiązywania błędów
AI oficjalnie opuściło laboratorium. Skraca czas rozwiązywania błędów w praktyce.
Zobacz, jak to zrobić!
| Domena / Organizacja | Jak wykorzystano AI | Wpływ / korzyści |
|---|---|---|
| Ubisoft | Opracowaliśmy Commit Assistant, narzędzie AI przeszkolone na podstawie dziesięciu lat wewnętrznego kodu, które przewiduje i zapobiega błędom na scenie kodowania. | Celem jest znaczne skrócenie czasu i obniżenie kosztów — tradycyjnie nawet 70% wydatków na tworzenie gier przeznacza się na naprawianie błędów. |
| Razer (platforma Wyvrn) | Wprowadziliśmy oparty na AI QA Copilot (zintegrowany z Unreal i Unity) do automatyzacji wykrywania błędów i generowania raportów QA. | Zwiększa wykrywalność błędów nawet o 25% i skraca czas kontroli jakości o połowę. |
| Google / DeepMind i Project Zero | Wprowadzono Big Sleep, narzędzie AI, które autonomicznie wykrywa luki w zabezpieczeniach oprogramowania open source, takiego jak FFmpeg i ImageMagick. | Zidentyfikowano 20 błędów, wszystkie zweryfikowane przez ekspertów i przeznaczone do naprawy. |
| Naukowcy z Uniwersytetu Kalifornijskiego w Berkeley | Korzystając z benchmarku o nazwie CyberGym, modele AI przeanalizowały 188 projektów open source, odkrywając 17 luk w zabezpieczeniach — w tym 15 nieznanych błędów typu „zero-day” — i generując exploity typu proof-of-concept. | Zobacz, jak sztuczna inteligencja rozwija się w zakresie wykrywania luk w zabezpieczeniach i automatycznego zabezpieczania przed exploitami. |
| Spur (startup z Yale) | Opracowano agenta AI, który tłumaczy opisy przypadków testowych napisane prostym językiem na automatyczne procedury testowania stron internetowych — w efekcie tworząc samopisujący się cykl pracy kontroli jakości. | Umożliwia autonomiczne testowanie przy minimalnym udziale człowieka |
| Automatyczne odtwarzanie raportów o błędach systemu Android | Wykorzystano NLP + uczenie się przez wzmocnienie do interpretacji języka raportów o błędach i generowania kroków umożliwiających odtworzenie błędów systemu Android. | Osiągnęliśmy 67% precyzji, 77% skuteczności i odtworzyliśmy 74% zgłoszeń błędów, przewyższając tradycyjne metody. |
Typowe błędy w pomiarze czasu rozwiązywania błędów
Jeśli pomiary są nieprawidłowe, plan poprawy również będzie nieprawidłowy.
Większość „złych wyników” w cyklach pracy związanych z usuwaniem błędów wynika z niejasnych definicji, niespójnych cykli pracy i powierzchownej analizy.
Zacznij od podstaw — od tego, co oznacza rozpoczęcie/zakończenie, jak radzisz sobie z oczekiwaniem i ponownym otwieraniem zgłoszeń — a następnie przeczytaj dane tak, jak widzą je Twoi klienci. Obejmuje to:
❌ Niejasne granice: Mieszanie statusów Zgłoszone→Rozwiązane i Zgłoszone→Zamknięte w tym samym pulpicie (lub przełączanie się między miesiącami) sprawia, że trendy tracą sens. Wybierz jedną granicę, udokumentuj ją i egzekwuj w wszystkich zespołach. Jeśli potrzebujesz obu, opublikuj je jako oddzielne wskaźniki z jasnymi etykietami.
❌ Podejście oparte wyłącznie na średnich: Opieranie się na średniej ukrywa rzeczywistość kolejek z kilkoma długotrwałymi wartościami odstającymi. Używaj mediany (P50) jako „typowego” czasu, P90 do przewidywania/SLA, a średnią zachowaj do planowania obciążenia. Zawsze patrz na dystrybucję, a nie tylko na pojedynczą liczbę.
❌ Brak segmentacji: Połączenie wszystkich błędów powoduje zmieszanie incydentów P0 z kosmetycznymi P3. Segmentuj według ważności, źródła (klient vs. kontrola jakości vs. monitorowanie), komponentu/zespołu oraz „nowe vs. regresja”. Twój P0/P1 P90 odzwierciedla odczucia interesariuszy, a mediana P2+ stanowi podstawę planów inżynierów.
❌ Ignorowanie czasu „wstrzymanego”: Czekasz na logi od klienta, zewnętrznego dostawcę lub okno wydania? Jeśli nie śledzisz statusu „Zablokowane/Wstrzymane” jako statusu pierwszego rzędu, czas rozwiązania staje się argumentem. Raportuj zarówno czas kalendarzowy, jak i czas aktywny, aby widoczne były wąskie gardła i nie dochodziło do dyskusji.
❌ Różnice w normalizacji czasu: Mieszanie stref czasowych lub przełączanie się między godzinami pracy a godzinami kalendarzowymi w trakcie procesu zniekształca porównania. Normalizuj znaczniki czasu do jednej strefy (lub UTC) i zdecyduj, czy umowy SLA będą mierzone w godzinach roboczych, czy kalendarzowych, a następnie stosuj tę zasadę konsekwentnie.
❌ Nieprawidłowe zgłoszenia i duplikaty: Brakujące informacje o środowisku/kompilacji i zduplikowane zgłoszenia wydłużają czas pracy i utrudniają ustalenie własności. Ustandarnij wymagane pola podczas przyjmowania zgłoszeń, automatycznie uzupełniaj informacje (dzienniki, wersja, urządzenie) i deduplikuj bez resetowania zegara — zamykaj duplikaty jako połączone, a nie jako „nowe” problemy.
❌ Niespójne modele statusów: Indywidualne statusy („QA Ready-ish”, „Pending Review 2”) ukrywają czas trwania statusu i sprawiają, że przejścia między statusami są niewiarygodne. Zdefiniuj standardowy cykl pracy (Nowy → Sklasyfikowany → W trakcie → W trakcie przeglądu → Rozwiązany → Zamknięty) i kontroluj statusy odbiegające od normy.
❌ Brak informacji o czasie w statusie: Pojedyncza wartość „całkowitego czasu” nie pozwala stwierdzić, gdzie praca utknęła. Rejestruj i przeglądaj czas spędzony w statusach „Segregacja”, „W przeglądzie”, „Zablokowane” i „Kontrola jakości”. Jeśli przegląd kodu P90 znacznie przewyższa wdrożenie, rozwiązaniem nie jest „szybsze kodowanie”, ale odblokowanie obciążenia przeglądu.
🧠 Ciekawostka: Najnowszy konkurs DARPA AI Cyber Challenge pokazał przełomowy postęp w automatyzacji cyberbezpieczeństwa. W konkursie wykorzystano systemy AI zaprojektowane do samodzielnego wykrywania, wykorzystywania i łatania luk w oprogramowaniu — bez udziału człowieka. Zwycięska drużyna, „Team Atlanta”, wykryła 77% wprowadzonych błędów i z powodzeniem załatała 61% z nich, demonstrując potęgę AI nie tylko w wykrywaniu błędów, ale także w ich aktywnym naprawianiu.
❌ Ślepota na ponowne otwarcia: Traktowanie ponownych otwarć jako nowych błędów resetuje zegar i zawyża MTTR. Śledź wskaźnik ponownych otwarć i „czas do stabilnego zamknięcia” (od pierwszego zgłoszenia do ostatecznego zamknięcia we wszystkich cyklach). Rosnąca liczba ponownych otwarć zwykle wskazuje na słabą reprodukcję, luki w testach lub niejasną definicję „gotowe”.
❌ Brak MTTA: Teams skupiają się na MTTR i ignorują MTTA (czas potwierdzenia/własności). Wysoki MTTA jest wczesnym ostrzeżeniem o długim czasie rozwiązywania problemów. Mierz go, ustaw umowy SLA według ważności i zautomatyzuj kierowanie/eskalację, aby go obniżyć.
❌ AI/automatyzacja bez zabezpieczeń: Pozwolenie AI na ustawianie poziomu ważności lub zamykanie duplikatów bez weryfikacji może spowodować błędną klasyfikację skrajnych przypadków i niejawne zafałszowanie wskaźników. Wykorzystaj AI do sugerowania rozwiązań, wymagaj potwierdzenia przez człowieka w przypadku P0/P1 i co miesiąc kontroluj wydajność modelu, aby Twoje dane pozostały wiarygodne.
Wyrównaj te różnice, a wykresy czasu rozwiązywania problemów w końcu będą odzwierciedlać rzeczywistość. Od tego momentu poprawy będą się nawarstwiać: lepsze przyjmowanie zgłoszeń skraca MTTA, czystsze stany ujawniają prawdziwe wąskie gardła, a segmentowane P90 dają liderom obietnice, które można dotrzymać.
⚡️ Archiwum szablonów: 10 szablonów przypadków testowych do testowania oprogramowania
Najlepsze praktyki w zakresie usuwania błędów
Podsumowując, oto najważniejsze wskazówki, o których należy pamiętać!
| 🧩 Najlepsze praktyki | 💡 Co to oznacza | 🚀 Dlaczego to ma znaczenie |
| Korzystaj z solidnego systemu śledzenia błędów | Śledź wszystkie zgłoszone błędy za pomocą scentralizowanego systemu śledzenia błędów. | Zapewnia, że żadna usterka nie zostanie pominięta, oraz umożliwia widoczność statusu usterek we wszystkich zespołach. |
| Pisz szczegółowe raporty o błędach | Dodaj kontekst wizualny, informacje o systemie operacyjnym, kroki niezbędne do odtworzenia błędu oraz poziom ważności. | Pomaga programistom szybciej naprawiać błędy dzięki dostępności wszystkich niezbędnych informacji z góry. |
| Kategoryzuj i ustalaj priorytety błędów | Użyj matrycy priorytetów, aby sortować błędy według pilności i wpływu. | Skupia uwagę zespołu na krytycznych błędach i pilnych problemach. |
| Wykorzystaj automatyczne testowanie | Automatycznie przeprowadzaj testy w ramach procesu CI/CD. | Wsparcie w zakresie wczesnego wykrywania i zapobiegania regresji. |
| Określ jasne wytyczne dotyczące raportowania | Zapewnij szablony i szkolenia dotyczące raportowania błędów. | Zapewnia dokładne informacje i płynniejszą komunikację. |
| Śledź kluczowe wskaźniki | Mierz czas rozwiązywania problemów, czas, który upłynął, oraz czas reakcji. | Umożliwia śledzenie wydajności i jej poprawę na podstawie danych historycznych. |
| Zastosuj proaktywne podejście | Nie czekaj na skargi użytkowników — testuj proaktywnie. | Zwiększ satysfakcję klientów i zmniejsz obciążenie działu obsługi. |
| Wykorzystaj inteligentne narzędzia i uczenie maszynowe | Wykorzystaj uczenie maszynowe do przewidywania błędów i sugerowania poprawek. | Zwiększa efektywność identyfikowania przyczyn źródłowych i usuwania błędów. |
| Dostosuj się do umów SLA | Spełniaj uzgodnione umowy dotyczące poziomu usług w zakresie rozwiązywania problemów. | Buduj zaufanie i spełniaj oczekiwania klientów w odpowiednim czasie. |
| Ciągła weryfikacja i doskonalenie | Analizuj ponownie otwarte błędy, zbieraj opinie i dostosowuj procesy. | Promuje ciągłe ulepszanie procesu rozwoju i zarządzania błędami. |
Proste rozwiązywanie błędów dzięki kontekstowej sztucznej inteligencji
Najszybsze zespoły zajmujące się rozwiązywaniem błędów nie polegają na heroizmie. Projektują system: jasne definicje rozpoczęcia/zakończenia, przejrzyste przyjmowanie zgłoszeń, priorytetyzację wpływu na działalność, wyraźny podział własności i ścisłe pętle informacji zwrotnej między działami wsparcia, kontroli jakości, inżynierii i wydania.
ClickUp może być centrum dowodzenia opartym na sztucznej inteligencji dla Twojego systemu rozwiązywania błędów. Scentralizuj wszystkie raporty w jednej kolejce, ujednolicie kontekst dzięki ustrukturyzowanym polom i pozwól ClickUp AI sortować, podsumowywać i ustalać priorytety, podczas gdy automatyzacja egzekwuje umowy SLA, eskaluje opóźnienia i zapewnia spójność działań wszystkich zainteresowanych stron. Powiąż błędy z klientami, kodem i wersjami, aby kierownictwo widziało wpływ i praktycy mogli utrzymać przepływ pracy.
Jeśli chcesz skrócić czas rozwiązywania błędów i uczynić swój plan działania bardziej przewidywalnym, zarejestruj się w ClickUp i zacznij mierzyć wzrost w ciągu kilku dni, a nie kwartałów.
Często zadawane pytania
Jaki jest dobry czas rozwiązywania błędów?
Nie ma jednej „dobrej” liczby — zależy to od ważności, modelu wydania i tolerancji ryzyka. Używaj median (P50) dla „typowej” wydajności i P90 dla obietnic/umów SLA, a także segmentuj według ważności i źródła.
Jaka jest różnica między rozwiązaniem błędu a zamknięciem błędu?
Rozwiązanie ma miejsce, gdy poprawka zostanie wdrożona (np. kod scalony, konfiguracja zastosowana), a zespół uzna, że usterka została usunięta. Zamknięcie ma miejsce, gdy problem zostanie zweryfikowany i formalnie zakończony (np. zatwierdzony przez kontrolę jakości w środowisku docelowym, wydany lub oznaczony jako nie do naprawienia/duplikat z uzasadnieniem). Wiele zespołów mierzy oba parametry: zgłoszone→rozwiązane odzwierciedla szybkość pracy inżynierów, a zgłoszone→zamknięte odzwierciedla przepływ jakości od początku do końca. Należy stosować spójne definicje, aby pulpity nie mieszały scen.
Jaka jest różnica między czasem usuwania błędów a czasem wykrywania błędów?
Czas wykrycia (MTTD) to czas potrzebny na wykrycie defektu po jego wystąpieniu lub dostarczeniu — poprzez monitorowanie, kontrolę jakości lub użytkowników. Czas rozwiązania to czas potrzebny od wykrycia/zgłoszenia do wdrożenia poprawki (lub, jeśli wolisz, zatwierdzenia/wydania). Razem definiują one okno wpływu na klienta: szybkie wykrywanie, szybkie potwierdzanie, szybkie rozwiązywanie i bezpieczne wydawanie. Można również śledzić MTTA (czas potwierdzenia/przypisania), aby wykryć opóźnienia w segregacji, które często zapowiadają dłuższe rozwiązywanie problemów.
W jaki sposób AI pomaga w usuwaniu błędów?
AI kompresuje pętle, które zazwyczaj powodują opóźnienia: przyjmowanie zgłoszeń, segregacja, diagnozowanie, naprawa i weryfikacja.
- Przyjmowanie i segregacja: Automatyczne podsumowywanie długich raportów, wyodrębnianie kroków/środowiska powtórzeń, oznaczanie duplikatów i sugerowanie poziomu ważności/priorytetu, dzięki czemu inżynierowie mogą rozpocząć pracę od czystego kontekstu (np. ClickUp AI, Sentry AI).
- Przekazywanie i umowy SLA: Przewiduje prawdopodobny komponent/właściciela, ustawia timery i eskaluje, gdy MTTA lub oczekiwanie na przegląd się wydłuża, zmniejszając czas bezczynności „w statusie” (automatyzacja ClickUp i cykle pracy podobne do pracy agentów).
- Diagnoza: Grupuje podobne błędy, koreluje skoki z ostatnimi commitami/wydaniami i wskazuje prawdopodobne przyczyny źródłowe za pomocą śladów stosu i kontekstu kodu (Sentry AI i podobne).
- Wdrożenie: Sugeruje zmiany kodu i testy na podstawie wzorców z repo, przyspieszając pętlę „pisz/napraw” (GitHub Copilot; Snyk Code AI by DeepCode).
- Weryfikacja i komunikacja: zapisuje przypadki testowe na podstawie kroków odtworzenia, tworzy szkice notatek o wydaniu i aktualizacji dla interesariuszy oraz podsumowuje status dla kadry kierowniczej i klientów (ClickUp AI). Dzięki połączeniu ClickUp jako centrum dowodzenia ze Sentry/Copilot/DeepCode w stosie, zespoły skracają czas MTTA/P90 bez konieczności polegania na heroicznych wysiłkach.