
Rilasci l'ultimo aggiornamento software e inizia la reportistica.
Improvvisamente, un unico parametro governa tutto, dal CSAT/NPS allo slittamento della roadmap: il tempo di risoluzione dei bug.
I dirigenti lo considerano una metrica di affidabilità: siamo in grado di consegnare, imparare e proteggere i ricavi nei tempi previsti? I professionisti sul campo ne subiscono le conseguenze: ticket duplicati, titolarità poco chiara, escalation rumorose e contesto disperso tra Slack, fogli di calcolo e strumenti separati.
Questa frammentazione allunga i cicli, nasconde le cause alla radice e trasforma la definizione delle priorità in un'operazione aleatoria.
Il risultato? Apprendimento più lento, impegni non rispettati e un backlog che grava silenziosamente su ogni sprint.
Questa guida è il tuo manuale completo per misurare, confrontare e ridurre i tempi di risoluzione dei bug, mostrando in modo concreto come l'IA cambi il flusso di lavoro rispetto ai processi manuali tradizionali.
Che cos'è il tempo di risoluzione dei bug?
Il tempo di risoluzione dei bug è il tempo necessario per correggere un bug, misurato dal momento in cui il bug viene segnalato fino alla sua completa risoluzione.
In pratica, il tempo inizia a scorrere quando viene segnalato o rilevato un problema (tramite utenti, controllo qualità o monitoraggio) e si ferma quando la correzione viene implementata e unita, pronta per la verifica o il rilascio, a seconda di come il tuo team definisce il termine "terminato".
Esempio: un crash P1 segnalato alle 10:00 di Monday, con una correzione unita alle 15:00 di martedì, ha un tempo di risoluzione di circa 29 ore.
Non è la stessa cosa del tempo di rilevamento dei bug. Il tempo di rilevamento misura la rapidità con cui si riconosce un difetto dopo che si è verificato (attivazione di allarmi, individuazione da parte degli strumenti di test QA, reportistica da parte dei clienti).
Il tempo di risoluzione misura la rapidità con cui si passa dalla consapevolezza alla risoluzione: triage, riproduzione, diagnosi, implementazione, revisione, test e preparazione per il rilascio. Considera il rilevamento come "sappiamo che è rotto" e la risoluzione come "è riparato e pronto".
Teams utilizzano confini leggermente diversi; sceglietene uno e siate coerenti in modo che le vostre tendenze siano reali:
- Segnalato → Risolto: termina quando il codice corretto è stato unito e è pronto per il controllo qualità. Ottimo per la produttività ingegneristica.
- Segnalato → Chiuso: include la convalida QA e il rilascio. Ideale per gli SLA che hanno un impatto sui clienti.
- Rilevato → Risolto: inizia quando il monitoraggio/QA rileva il problema, anche prima che esista un ticket. Utile per i team con un carico di produzione elevato.
🧠 Curiosità: un bug bizzarro ma esilarante in Final Fantasy XIV è stato elogiato per la sua specificità, tanto che i lettori lo hanno soprannominato "il bug più specifico risolto in un MMO nel 2025". Si manifestava quando i giocatori fissavano il prezzo degli elementi tra esattamente 44.442 gil e 49.087 gil in una particolare zona dell'evento, causando disconnessioni dovute a quello che potrebbe essere un errore di overflow di interi.
Perché è importante
Il tempo di risoluzione è una leva per la cadenza di rilascio. Tempi lunghi o imprevedibili costringono a tagli di portata, hotfix e blocchi dei rilasci; creano un debito di pianificazione perché la coda lunga (i valori anomali) fa deragliare gli sprint più di quanto suggerisca la media.
Questo aspetto è direttamente collegato alla soddisfazione dei clienti. I clienti tollerano i problemi quando vengono riconosciuti rapidamente e risolti in modo prevedibile. Le riparazioni lente, o peggio ancora, variabili, causano escalation, incidono negativamente sul CSAT/NPS e mettono a rischio i rinnovi.
In breve, se misuri in modo chiaro e sistematico il tempo necessario per risolvere i bug e lo riduci, le tue roadmap e le tue relazioni miglioreranno.
📖 Per saperne di più: Come dare priorità ai bug per una risoluzione efficiente dei problemi
Come misurare il tempo necessario per risolvere i bug?
Per prima cosa, decidi dove inizia e dove finisce il tuo tempo.
La maggior parte dei team sceglie tra Segnalato → Risolto (la correzione è stata unita ed è pronta per la verifica) o Segnalato → Chiuso (il controllo qualità ha convalidato la modifica, che è stata rilasciata o comunque chiusa).
Scegli una definizione e utilizzala in modo coerente affinché le tue tendenze siano significative.
Ora avete bisogno di alcune metriche osservabili. Vediamo quali sono:
Metriche chiave da tenere d'occhio nel monitoraggio dei bug:
| 📊 Metrica | 📌 Cosa significa | 💡 Come può aiutarti | 🧮 Formula (se applicabile) |
|---|---|---|---|
| Conteggio dei bugs 🐞 | Numero totale di bug segnalati | Offre una panoramica dello stato di salute del sistema. Numero elevato? È ora di indagare. | Bug totali = Tutti i bug registrati nel sistema {Aperti + Chiusi} |
| Bugs aperti 🚧 | Bug che non sono stati ancora risolti | Mostra il carico di lavoro attuale. Aiuta a stabilire le priorità. | Bug aperti = Bug totali - Bug chiusi |
| Bugs chiusi ✅ | Bug risolti e verificati | Tiene traccia dello stato e del lavoro terminato. | Bug chiusi = Numero di bug con stato "Chiuso" o "Risolto" |
| Gravità del bug 🔥 | Criticità del bug (ad es. critico, grave, minore) | Aiuta a classificare in base all'impatto. | Tracciato come campo categoriale, nessuna formula. Utilizza filtri/raggruppamenti. |
| Priorità dei bug 📅 | Quanto è urgente risolvere un bug | Aiuta nella pianificazione degli sprint e dei rilasci. | Anche un campo categoriale, tipicamente classificato (ad esempio, P0, P1, P2). |
| Tempo di risoluzione ⏱️ | Tempo trascorso dalla segnalazione del bug alla risoluzione | Misura la reattività. | Tempo di risoluzione = Data chiusa - Data di reportistica |
| Tasso di riapertura 🔄 | Percentuale di bug riaperti dopo essere stati chiusi | Riflette la qualità della correzione o i problemi di regressione. | Tasso di riapertura (%) = {Bug riaperti ÷ Bug chiusi totali} × 100 |
| Bug Leakage 🕳️ | Bug che sono sfuggiti alla produzione | Indica l'efficacia del controllo qualità/test del software. | Tasso di perdita (%) = {Bug di produzione ÷ Bug totali} × 100 |
| Densità dei difetti 🧮 | Bug per unità di codice di codice | Evidenzia le aree di codice soggette a rischi. | Densità dei difetti = Numero di bug ÷ KLOC {Kilo Lines of Code} |
| Bugs assegnati vs non assegnati 👥 | Distribuzione dei bug in base alla titolarità | Assicurati che nulla sfugga al tuo controllo. | Usa un filtro: Non assegnato = Bug in cui "Assegnato a" è nullo |
| Età dei bug aperti 🧓 | Per quanto tempo un bug rimane irrisolto | Individua i rischi di stagnazione e accumulo di lavoro arretrato. | Età del bug = data corrente - data di segnalazione |
| Bugs duplicati 🧬 | Numero di segnalazioni duplicate | Evidenzia gli errori nei processi di acquisizione. | Tasso di duplicazione = Duplicati ÷ Bug totali × 100 |
| MTTD (tempo medio di rilevamento) 🔎 | Tempo medio necessario per rilevare bug o incidenti | Misura l'efficienza del monitoraggio e della consapevolezza. | MTTD = Σ(Tempo di rilevamento - Tempo di introduzione) ÷ Numero di bug |
| MTTR (tempo medio di risoluzione) 🔧 | Tempo medio necessario per risolvere completamente un bug dopo il rilevamento | Tiene traccia della reattività tecnica e dei tempi di risoluzione. | MTTR = Σ(Tempo risolto - Tempo rilevato) ÷ Numero di bug risolti |
| MTTA (tempo medio di riconoscimento) 📬 | Tempo trascorso dal rilevamento al momento in cui qualcuno inizia a lavorare sul bug | Mostra la reattività del team e la capacità di risposta agli avvisi. | MTTA = Σ(Tempo riconosciuto - Tempo rilevato) ÷ Numero di bug |
| MTBF (tempo medio tra i guasti) 🔁 | Tempo che intercorre tra un guasto risolto e il successivo | Indica la stabilità nel tempo. | MTBF = Tempo di attività totale ÷ Numero di guasti |
⚡️ Archivio modelli: 15 modelli e moduli gratis per la segnalazione dei bug e il monitoraggio degli stessi
Fattori che influenzano il tempo di risoluzione dei bug
Il tempo di risoluzione è spesso equiparato alla "velocità di creazione del codice degli ingegneri".
Ma questa è solo una parte del processo.
Il tempo di risoluzione dei bug è dato dalla somma della qualità in entrata, dell'efficienza del flusso attraverso il sistema e del rischio di dipendenza. Quando uno di questi elementi vacilla, la durata ciclo si allunga, la prevedibilità diminuisce e le escalation diventano più frequenti.
La qualità dell'accoglienza dà il tono
I report che arrivano senza chiari passaggi di riproduzione, dettagli sull'ambiente, log o informazioni sulla versione/build richiedono ulteriori scambi di comunicazioni. I report duplicati provenienti da più canali (supporto, controllo qualità, monitoraggio, Slack) aggiungono rumore e frammentano la titolarità.
Prima acquisisci il contesto corretto (e deduplichi), meno passaggi di consegne e chiarimenti saranno necessari in seguito.
La definizione delle priorità e l'instradamento determinano chi si occupa del bug e quando.
Le etichette di gravità che non corrispondono all'impatto sul cliente/aziendale (o che cambiano nel tempo) causano un aumento delle code: i ticket più urgenti saltano la fila, mentre i difetti ad alto impatto rimangono in sospeso.
Regole di instradamento chiare per componente/titolare e un'unica coda di verità impediscono che il lavoro P0/P1 venga sepolto sotto "recente e rumoroso".
La titolarità e i passaggi di consegne sono killer silenziosi
Se non è chiaro se un bug appartenga al team mobile, al team di autenticazione backend o al team della piattaforma, viene respinto. Ogni respinta azzera il contesto.
I fusi orari aggravano la situazione: un bug segnalato in tarda giornata senza un titolare designato può richiedere dalle 12 alle 24 ore prima che qualcuno inizi a riprodurlo. Definizioni precise di "chi è il titolare di cosa", con un DRI di turno o settimanale, eliminano questo ritardo.
La riproducibilità dipende dall'osservabilità
Log scarsi, ID di correlazione mancanti o tracce di crash insufficienti trasformano la diagnosi in una congettura. I bug che compaiono solo con flag, tenant o forme di dati specifici sono difficili da riprodurre in fase di sviluppo.
Se gli ingegneri non possono accedere in modo sicuro a dati sanitizzati simili a quelli di produzione, finiscono per strumentare, reimplementare e attendere giorni invece che ore.
L'ambiente e la parità dei dati garantiscono la massima trasparenza
"Funziona sul mio computer" di solito significa "i dati di produzione sono diversi". Più il tuo sviluppo/staging si discosta dalla produzione (configurazione, servizi, versioni di terze parti), più tempo passerai a inseguire fantasmi. Snapshot di dati sicuri, script seed e controlli di parità riducono questo divario.
Il lavoro in corso (WIP) e la concentrazione determinano la produttività effettiva
I team sovraccarichi di lavoro gestiscono troppi bug contemporaneamente, frammentano la loro attenzione e si dividono tra attività e riunioni. Il cambio di contesto aggiunge ore invisibili.
Un limite di lavoro in corso visibile e la tendenza a finire quello che hai iniziato prima di iniziare un nuovo lavoro ti aiuteranno ad abbassare la tua mediana più velocemente di qualsiasi altro lavoro richiesto.
La revisione del codice, la CI e la velocità del controllo qualità sono i classici colli di bottiglia.
Tempi di compilazione lenti, test instabili e SLA di revisione poco chiari rallentano soluzioni che altrimenti sarebbero rapide. Una patch di 10 minuti può richiedere due giorni di attesa per un revisore o inserirsi in una pipeline che richiede ore.
Allo stesso modo, le code di controllo qualità che eseguono test in batch o si basano su passaggi manuali possono aggiungere intere giornate al processo "Segnalato → Chiuso", anche quando il processo "Segnalato → Risolto" è veloce.
Le dipendenze allungano le code
Le modifiche tra team (schema, migrazioni di piattaforma, aggiornamenti SDK), i bug dei fornitori o le revisioni degli app store (mobile) introducono stati di attesa. Senza un monitoraggio esplicito "Bloccato/In pausa", tali attese gonfiano in modo invisibile le medie e nascondono dove si trova il vero collo di bottiglia.
Il modello di rilascio e la strategia di rollback sono importanti
Se distribuisci in treni di rilascio consistenti con gate manuali, anche i bug risolti rimangono in sospeso fino alla partenza del treno successivo. Gli interruttori di funzionalità, i rilasci canary e le corsie hotfix accorciano la coda, in particolare per gli incidenti P0/P1, consentendoti di separare la distribuzione delle correzioni dai cicli di rilascio completi.
L'architettura e il debito tecnologico determinano il tuo limite massimo
Il forte accoppiamento, la mancanza di giunzioni di test e i moduli legacy opachi rendono rischiose le semplici correzioni. I team compensano con test aggiuntivi e revisioni più lunghe, che allungano i cicli. Al contrario, il codice modulare con buoni test di contratto consente di muoversi rapidamente senza danneggiare i sistemi adiacenti.
La comunicazione e la pulizia dello stato influenzano la prevedibilità
Gli aggiornamenti vaghi ("stiamo esaminando la questione") creano rielaborazioni quando gli stakeholder richiedono tempi di risoluzione stimati, il supporto riapre i ticket o il prodotto viene escalato. Transizioni di stato chiare, note sulla riproduzione e sulla causa principale e un tempo di risoluzione stimato pubblicato riducono il tasso di abbandono e proteggono la concentrazione del tuo team di ingegneri.
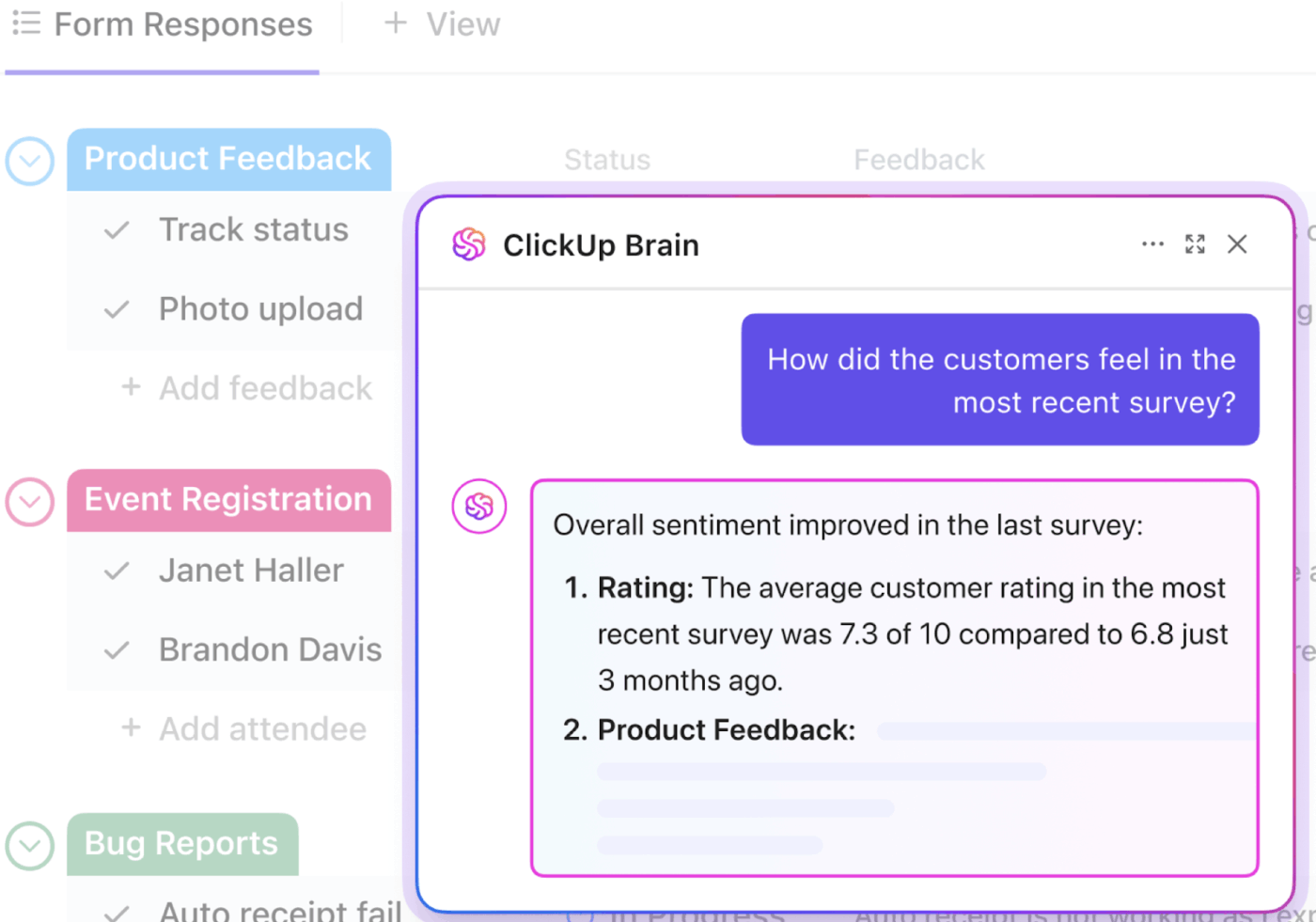
📮ClickUp Insight: in media, un professionista trascorre più di 30 minuti al giorno alla ricerca di informazioni relative al lavoro, il che significa oltre 120 ore all'anno perse a setacciare email, thread di Slack e file sparsi.
Un assistente IA intelligente integrato nella tua area di lavoro può cambiare tutto questo. Scopri ClickUp Brain. Fornisce informazioni e risposte immediate, individuando in pochi secondi i documenti, le conversazioni e i dettagli delle attività giusti, così puoi smettere di cercare e iniziare a lavorare.
💫 Risultati reali: team come QubicaAMF hanno recuperato più di 5 ore alla settimana utilizzando ClickUp, ovvero oltre 250 ore all'anno a persona, eliminando processi di gestione delle conoscenze obsoleti. Immagina cosa potrebbe realizzare il tuo team con una settimana in più di produttività ogni trimestre!
Indicatori principali che segnalano un possibile aumento del lead time
❗️Aumento del "tempo di riconoscimento" e numerosi ticket senza un titolare per più di 12 ore
❗️Aumento delle sezioni "Tempo in revisione/CI" e frequenti instabilità dei test
❗️Elevato tasso di duplicazione nell'inserimento dei dati e etichette di gravità incoerenti tra i team
❗️Diversi bug rimangono in stato "Bloccato" senza una dipendenza esterna specificata.
❗️Tasso di riapertura in aumento (le correzioni non sono riproducibili o le definizioni di terminato sono vaghe)
Le diverse organizzazioni percepiscono questi fattori in modo diverso. I dirigenti li vivono come cicli di apprendimento persi e slittamenti rispetto ai momenti di guadagno; gli operatori li percepiscono come rumore di triage e titolarità poco chiara.
Ottimizzando l'acquisizione, il flusso e le dipendenze è possibile abbassare l'intera curva, sia la mediana che il P90.
Vuoi ricevere ulteriori informazioni su come scrivere report di bug migliori? Inizia da qui. 👇🏼
📖 Per saperne di più: Il ciclo di vita del test del software (STLC): panoramica e fasi
Parametri di riferimento del settore per il tempo necessario alla risoluzione dei bug
I benchmark per la risoluzione dei bug variano in base alla tolleranza al rischio, al modello di rilascio e alla rapidità con cui è possibile distribuire le modifiche.
Qui puoi utilizzare le mediane (P50) per comprendere il tuo flusso tipico e P90 per impostare promesse e SLA in base alla gravità e alla fonte (cliente, QA, monitoraggio).
Analizziamo cosa significa:
| 🔑 Termine | 📝 Descrizione | 💡 Perché è importante |
|---|---|---|
| P50 (mediana) | Il valore medio: il 50% delle correzioni dei bug è più veloce di questo, mentre il 50% è più lento. | 👉 Riflette il tempo di risoluzione tipico o più comune. Utile per comprendere le prestazioni normali. |
| P90 (90° percentile) | Il 90% dei bug viene risolto entro questo tempo. Solo il 10% richiede più tempo. | 👉 Rappresenta un limite peggiore (ma comunque realistico). Utile per stabilire promesse esterne. |
| SLA (accordi sul livello di servizio) | Impegni assunti, internamente o nei confronti dei clienti, sulla rapidità con cui saranno risolti i problemi | 👉 Esempio: "Risolviamo i bug P1 entro 48 ore nel 90% dei casi". Aiuta a creare fiducia e responsabilità |
| Per gravità e origine | Segmenta le tue metriche in base a due dimensioni chiave: • Gravità (ad es. P0, P1, P2)• Origine (ad es. Cliente, QA, Monitoraggio) | 👉 Consente un monitoraggio e una definizione delle priorità più accurati, in modo che i bug critici ricevano maggiore attenzione più rapidamente. |
Di seguito sono riportati gli intervalli direzionali basati sui settori che i team maturi spesso prendono come traguardo; considerateli come intervalli di partenza, quindi adattateli al vostro contesto.
SaaS
Sempre attivo e compatibile con CI/CD, quindi gli hotfix sono comuni. I problemi critici (P0/P1) spesso mirano a una mediana inferiore a un giorno lavorativo, con P90 entro 24-48 ore. I problemi non critici (P2+) hanno comunemente una mediana di 3-7 giorni, con P90 entro 10-14 giorni. I team con interruttori di funzionalità robusti e test automatizzati tendono ad avere tempi più rapidi.
Piattaforme di e-commerce
Poiché la conversione e i flussi del carrello sono fondamentali per le entrate, gli standard sono più elevati. I problemi P0/P1 vengono in genere mitigati entro poche ore (rollback, segnalazione o configurazione) e risolti completamente nello stesso giorno; i problemi P90 entro la fine della giornata o in meno di 12 ore sono comuni nelle stagioni di punta. I problemi P2+ vengono spesso risolti in 2-5 giorni, con P90 entro 10 giorni.
Software aziendale
Una convalida più rigorosa e finestre di modifica dei clienti rallentano la cadenza. Per P0/P1, i team hanno come traguardo trovare una soluzione provvisoria entro 4-24 ore e una correzione entro 1-3 giorni lavorativi; P90 entro 5 giorni lavorativi. Gli elementi P2+ vengono spesso raggruppati in release train, con mediane di 2-4 settimane a seconda dei programmi di implementazione dei clienti.
Giochi e app mobili
I backend dei servizi live si comportano come SaaS (flag e rollback in pochi minuti o ore; P90 nello stesso giorno). Gli aggiornamenti dei client sono limitati dalle revisioni dello store: P0/P1 spesso utilizzano immediatamente leve lato server e distribuiscono una patch client in 1-3 giorni; P90 entro una settimana con revisione accelerata. Le correzioni P2+ sono comunemente programmate nel prossimo sprint o rilascio di contenuti.
Settore bancario/Fintech
I controlli di rischio e conformità determinano un modello di "mitigazione rapida, modifica cauta". I bug P0/P1 vengono mitigati rapidamente (segnalazioni, rollback, spostamenti di traffico in pochi minuti o ore) e risolti completamente in 1-3 giorni; i bug P90 entro una settimana, tenendo conto del controllo delle modifiche. I bug P2+ richiedono spesso 2-6 settimane per superare i controlli di sicurezza, gli audit e le revisioni CAB.
Se i tuoi numeri non rientrano in questi intervalli, esamina la qualità dell'input, l'instradamento/la titolarità, la revisione del codice e la produttività del controllo qualità, nonché le approvazioni delle dipendenze prima di supporre che il problema principale sia la "velocità di ingegnerizzazione".
🌼 Lo sapevate? Secondo un sondaggio Stack Overflow del 2024, gli sviluppatori utilizzano sempre più spesso l'IA come fidato alleato nel loro percorso di programmazione. Ben l'82% ha utilizzato l'IA per scrivere codice: un collaboratore davvero creativo! Quando si trovavano in difficoltà o alla ricerca di soluzioni, il 67,5% si affidava all'IA per cercare risposte e oltre la metà (56,7%) la utilizzava per il debug e per ottenere assistenza.
Per alcuni, gli strumenti di IA si sono rivelati utili anche per documentare i progetti (40,1%) e persino per creare dati o contenuti sintetici (34,8%). Sei curioso di conoscere un nuovo codice base? Quasi un terzo (30,9%) utilizza l'IA per mettersi al passo. Il test del codice è ancora un lavoro manuale per molti, ma il 27,2% ha adottato l'IA anche in questo caso. Altri settori come la revisione del codice, la pianificazione dei progetti e l'analisi predittiva registrano un'adozione minore dell'IA, ma è chiaro che l'IA si sta progressivamente integrando in ogni fase dello sviluppo del software.
📖 Per saperne di più: Come utilizzare l'IA per il controllo qualità
Come ridurre i tempi di risoluzione dei bug
La rapidità nella risoluzione dei bug dipende dall'eliminazione degli attriti in ogni fase del processo, dall'acquisizione al rilascio.
I vantaggi maggiori derivano dall'ottimizzazione dei primi 30 minuti (acquisizione pulita, titolare corretto, priorità corretta) e dalla compressione dei cicli successivi (riproduzione, revisione, verifica).
Ecco nove strategie che funzionano insieme come un sistema. L'IA accelera ogni passaggio e il flusso di lavoro è organizzato in modo chiaro in un unico posto, così i dirigenti ottengono prevedibilità e i professionisti ottengono fluidità.
1. Centralizza l'acquisizione e cattura il contesto alla fonte
Il tempo necessario per risolvere i bug si allunga quando si ricostruisce il contesto da thread Slack, ticket di assistenza e fogli di calcolo. Canalizza tutti i report (assistenza, controllo qualità, monitoraggio) in un'unica coda con un modello strutturato che raccoglie componenti, gravità, ambiente, versione/build dell'app, passaggi per riprodurre il problema, aspettative vs realtà e allegati (log/HAR/schermate).
L'IA è in grado di riassumere automaticamente report lunghi, estrarre passaggi di riproduzione e dettagli sull'ambiente dagli allegati e segnalare possibili duplicati, in modo che il triage possa iniziare con una documentazione coerente e arricchita.
Metriche da monitorare: MTTA (risposta entro pochi minuti, non ore), tasso di duplicazione, tempo "Needs Info" (informazioni necessarie).

📖 Per saperne di più: Il potere dei moduli ClickUp: semplificare il lavoro dei team di sviluppo software
2. Triage e instradamento assistiti dall'IA per ridurre drasticamente il tempo medio di risoluzione (MTTA)
Le soluzioni più rapide sono quelle che arrivano immediatamente sulla scrivania giusta.
Utilizza regole semplici e l'IA per classificare la gravità, identificare i probabili titolari in base al componente/area di codice e assegnare automaticamente con un timer SLA. Imposta corsie ben definite per P0/P1 rispetto a tutto il resto e rendi inequivocabile la responsabilità.
Le automazioni possono impostare la priorità dai campi, indirizzare un componente a una squadra, avviare un timer SLA e avvisare un tecnico di turno; l'IA può proporre la gravità e il titolare in base ai modelli passati. Quando il triage diventa un passaggio di 2-5 minuti invece di una discussione di 30 minuti, il tuo MTTA diminuisce e il tuo MTTR segue.
Metriche da monitorare: MTTA, qualità della prima risposta (il primo commento richiede le informazioni corrette?), numero di passaggi per bug.
Ecco come funziona nella pratica:
3. Assegnare priorità in base all'impatto aziendale con livelli SLA espliciti
Il principio "chi urla più forte vince" rende le code imprevedibili e mina la fiducia dei dirigenti che monitorano CSAT/NPS e rinnovi.
Sostituiscilo con un punteggio che combini gravità, frequenza, ARR interessato, criticità delle funzionalità/funzioni e vicinanza a rinnovi/lanci, e supportalo con livelli SLA (ad esempio, P0: mitigazione in 1-2 ore, risoluzione entro un giorno; P1: stesso giorno; P2: entro uno sprint).
Mantieni una corsia P0/P1 con visibilità e limiti di lavoro in corso (WIP) in modo che nulla rimanga in sospeso.
Metriche da monitorare: risoluzione P50/P90 per livello, tasso di violazione SLA, correlazione con CSAT/NPS.
💡Suggerimento professionale: i campi Priorità attività, Campi personalizzati e Dipendenze di ClickUp ti consentono di calcolare un punteggio di impatto e collegare i bug ad account, feedback o elementi della roadmap; inoltre, gli Obiettivi in ClickUp ti aiutano a collegare il rispetto degli SLA agli obiettivi a livello aziendale, rispondendo direttamente alle preoccupazioni dei dirigenti in merito all'allineamento.
4. Rendi la riproduzione e la diagnosi un'attività in un unico passaggio
Ogni ciclo aggiuntivo con la domanda "puoi inviare i log?" aumenta il tempo di risoluzione.
Standardizza ciò che è "buono": campi obbligatori per build/commit, ambiente, passaggi di riproduzione, previsto vs effettivo, oltre ad allegati per log, dump di crash e file HAR. Strumenta la telemetria client/server in modo che gli ID di crash e gli ID di richiesta siano collegabili alle tracce.
Utilizza Sentry (o simili) per le tracce dello stack e collega direttamente il problema al bug. L'IA è in grado di leggere i log e le tracce per proporre un probabile dominio di errore e generare una riproduzione minima, trasformando un'ora di analisi visiva in pochi minuti di lavoro mirato.
Archivia i runbook per le classi di bug più comuni, in modo che gli ingegneri non debbano partire da zero.
Metriche da tenere d'occhio: tempo trascorso in "Attesa di informazioni", percentuale riprodotta al primo passaggio, tasso di riapertura legato alla mancata riproduzione.
📖 Ulteriori informazioni: Come utilizzare l'IA nello sviluppo di software (casi d'uso e strumenti)
5. Abbrevia il ciclo di revisione del codice e di test
I grandi PR rallentano il lavoro. Punta su patch chirurgiche, sviluppo basato su trunk e interruttori di funzionalità in modo che le correzioni possano essere distribuite in modo sicuro. Preassegna i revisori in base alla titolarità del codice per evitare tempi di inattività e utilizza liste di controllo (test aggiornati, telemetria aggiunta, flag dietro un kill switch) in modo che la qualità sia garantita.
Le automazioni dovrebbero spostare il bug su "In revisione" all'apertura della PR e su "Risolto" al momento di unire i file; l'IA può suggerire test unitari o evidenziare differenze rischiose su cui concentrare la revisione.
Metriche da monitorare: tempo in "In revisione", tasso di fallimento delle modifiche per le PR di correzione dei bug e latenza di revisione P90.
Puoi utilizzare le integrazioni GitHub/Gitlab in ClickUp per mantenere sincronizzato lo stato di risoluzione; le automazioni possono applicare la "definizione di terminato".
📖 Per saperne di più: Come utilizzare l'IA per automatizzare le attività
6. Parallelizza la verifica e rendi reale la parità dell'ambiente QA
La verifica non dovrebbe iniziare giorni dopo o in un ambiente che nessuno dei tuoi clienti utilizza.
Mantieni alto il livello di "prontezza per il controllo qualità": hotfix basati su flag convalidati in ambienti simili a quelli di produzione con dati seed che corrispondono ai casi segnalati.
Ove possibile, configura ambienti effimeri dal ramo dei bug in modo che il controllo qualità possa effettuare immediatamente la convalida; l'IA può quindi generare casi di test dalla descrizione del bug e dalle regressioni passate.
Metriche da monitorare: tempo impiegato nella fase di "QA/verifica", tasso di rimbalzo dalla fase di QA alla fase di sviluppo, tempo mediano necessario per la chiusura dopo che si uniscono le due versioni.

📖 Per saperne di più: Come scrivere casi di test efficaci
7. Comunicare lo stato in modo chiaro per ridurre i costi di coordinamento
Un buon aggiornamento previene tre ping di stato e un'escalation.
Trattate gli aggiornamenti come un prodotto: brevi, specifici e consapevoli del pubblico (supporto, dirigenti, clienti). Stabilite una cadenza per P0/P1 (ad esempio, ogni ora fino alla risoluzione, poi ogni quattro ore) e mantenete un'unica fonte di verità.
L'IA può redigere aggiornamenti sicuri per i clienti e riepiloghi interni dalla cronologia delle attività, compreso lo stato in tempo reale in base alla gravità e alla squadra. Per i dirigenti come il tuo direttore di prodotto, raggruppa i bug in iniziative in modo che possano vedere se il lavoro critico sulla qualità minaccia le promesse di consegna.
Metriche da monitorare: Tempo tra gli aggiornamenti di stato su P0/P1, CSAT degli stakeholder sulle comunicazioni.
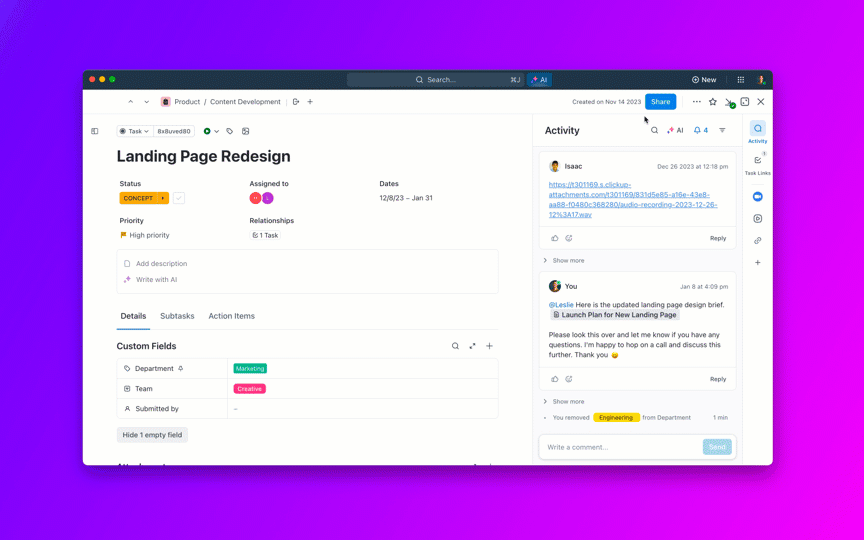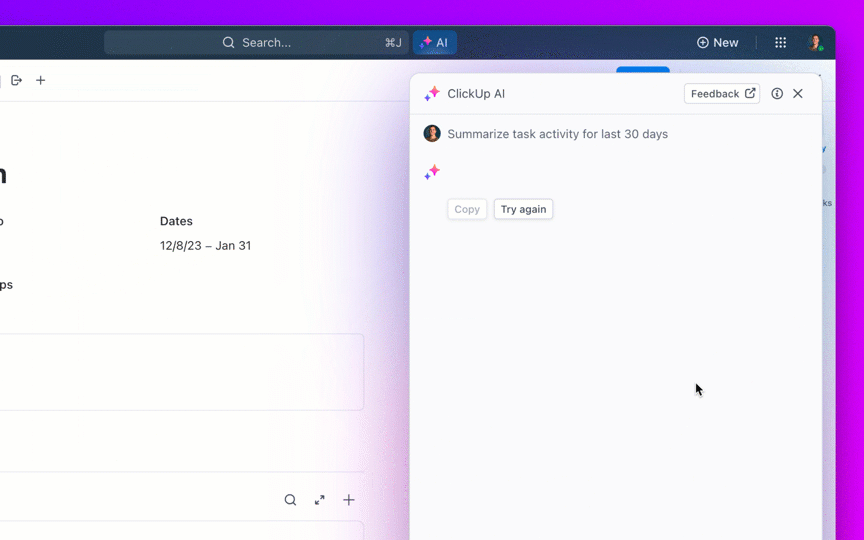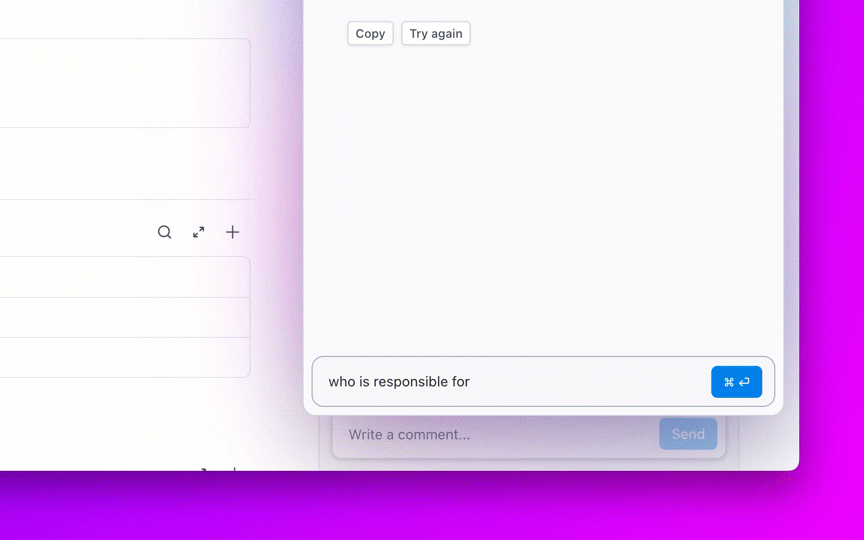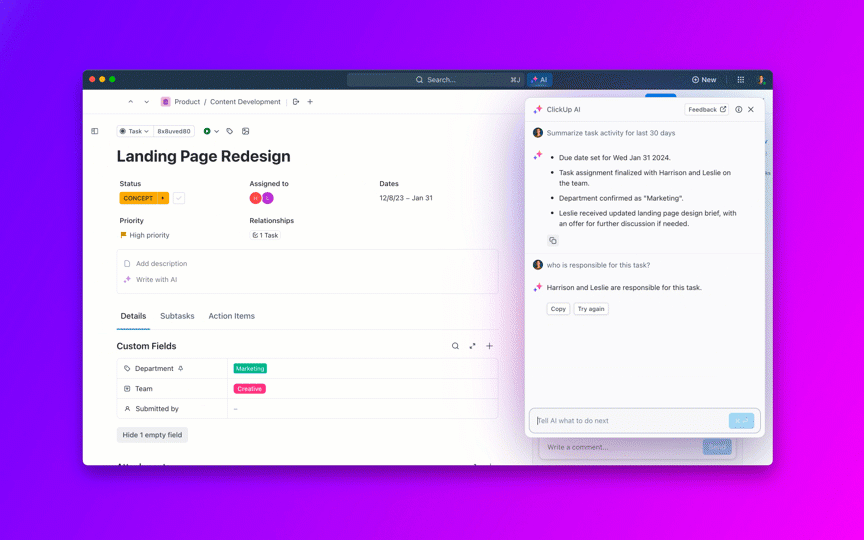
8. Controlla l'invecchiamento dei backlog e previeni i casi "permanentemente aperti"
Un backlog crescente e obsoleto grava silenziosamente su ogni sprint.
Imposta politiche di invecchiamento (ad esempio, P2 > 30 giorni attiva la revisione, P3 > 90 giorni richiede una giustificazione) e pianifica un "triage di invecchiamento" settimanale per unire i duplicati, chiudere i rapporti obsoleti e convertire i bug di basso valore in elementi del backlog del prodotto.
Utilizza l'IA per raggruppare il backlog per tema (ad esempio, "scadenza token di autenticazione", "instabilità caricamento immagini") in modo da poter pianificare settimane di correzioni tematiche ed eliminare una classe di difetti in una sola volta.
Metriche da monitorare: numero di backlog per fascia di età, percentuale di problemi chiusi come duplicati/obsoleti, velocità di burn-down tematica.
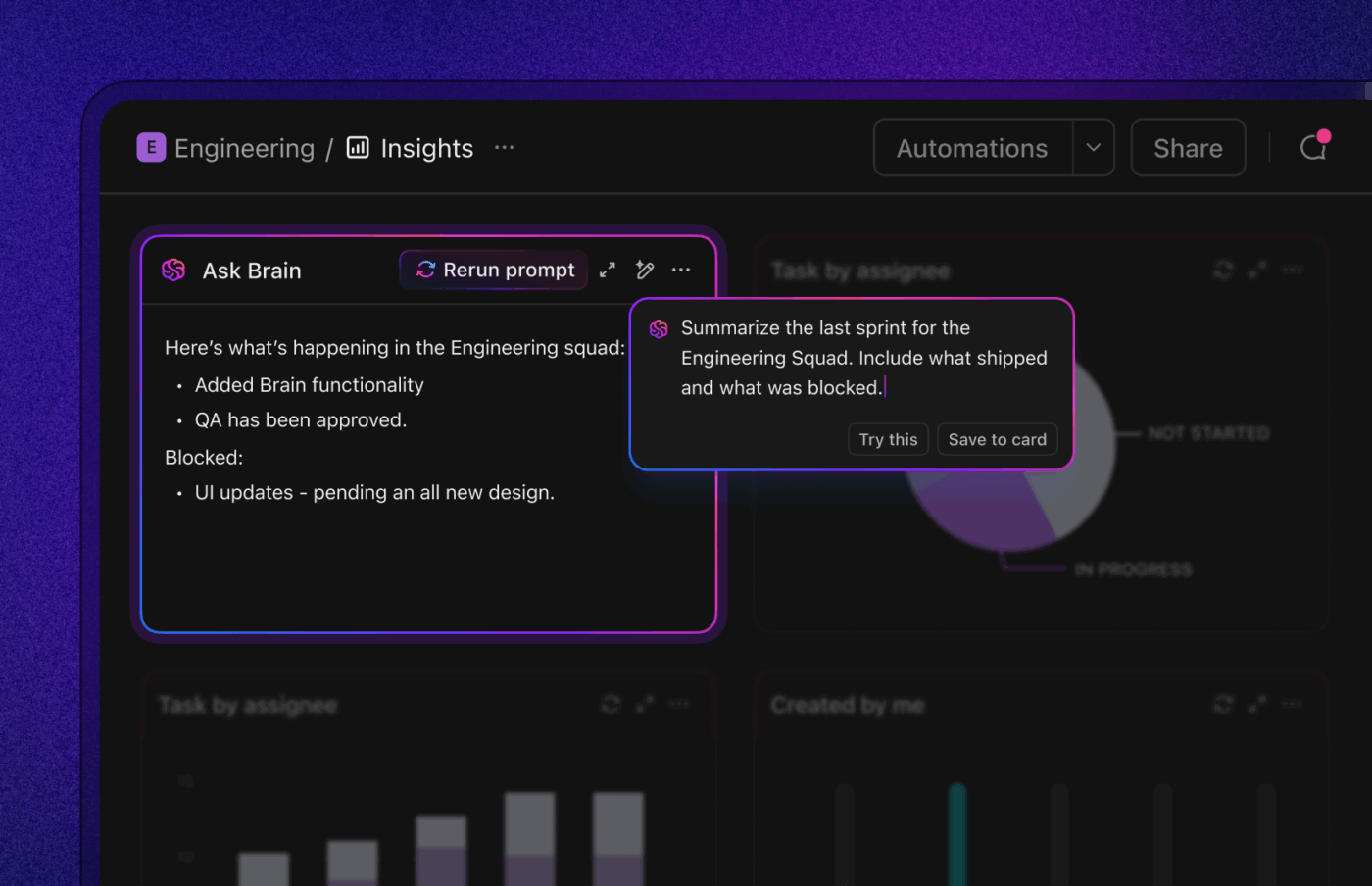
9. Chiudi il cerchio con la causa principale e la prevenzione
Se lo stesso tipo di difetto continua a ripetersi, i miglioramenti del tuo MTTR stanno mascherando un problema più grande.
Esegui analisi rapide e imparziali delle cause alla radice su P0/P1 e P2 ad alta frequenza; tagga le cause alla radice (lacune nelle specifiche, lacune nei test, lacune negli strumenti, instabilità dell'integrazione), collega i componenti e gli incidenti interessati e monitora le attività di follow-up (protezioni, test, regole di lint) fino a quando sono completate.
L'IA può redigere riassunti RCA e proporre test preventivi o regole di lint basate sulla cronologia delle modifiche. Ed è così che si passa dall'estinzione degli incendi alla riduzione degli incendi.
Metriche da monitorare: tasso di riapertura, tasso di regressione, tempo tra le ricorrenze e percentuale di RCA con azioni di prevenzione completate.

Nel loro insieme, questi cambiamenti comprimono il percorso end-to-end: riconoscimento più rapido, triage più pulito, prioritizzazione più intelligente, meno intoppi nella revisione e nel controllo qualità e comunicazione più chiara. I dirigenti ottengono prevedibilità legata al CSAT/NPS e alle entrate; i professionisti ottengono una coda più tranquilla con meno cambi di contesto.
📖 Per saperne di più: Come eseguire un'analisi delle cause alla radice
Strumenti di IA che aiutano a ridurre i tempi di risoluzione dei bug
L'IA può ridurre i tempi di risoluzione in ogni passaggio: acquisizione, triage, instradamento, correzione e verifica.
Tuttavia, i veri vantaggi si ottengono quando gli strumenti comprendono il contesto e consentono di portare avanti il lavoro senza bisogno di assistenza.
Cerca sistemi che arricchiscano automaticamente i report (passaggi di riproduzione, ambiente, duplicati), assegnino priorità in base all'impatto, indirizzino al titolare giusto, redigano aggiornamenti chiari e si integrino perfettamente con il tuo codice, CI e osservabilità.
I migliori strumenti supportano anche flussi di lavoro simili a quelli degli agenti: bot che monitorano gli SLA, sollecitano i revisori, segnalano gli elementi bloccati e riepilogano i risultati per le parti interessate. Ecco la nostra selezione di strumenti di IA per una migliore risoluzione dei bug:
1. ClickUp (ideale per IA contestuale, automazioni e flussi di lavoro agentici)
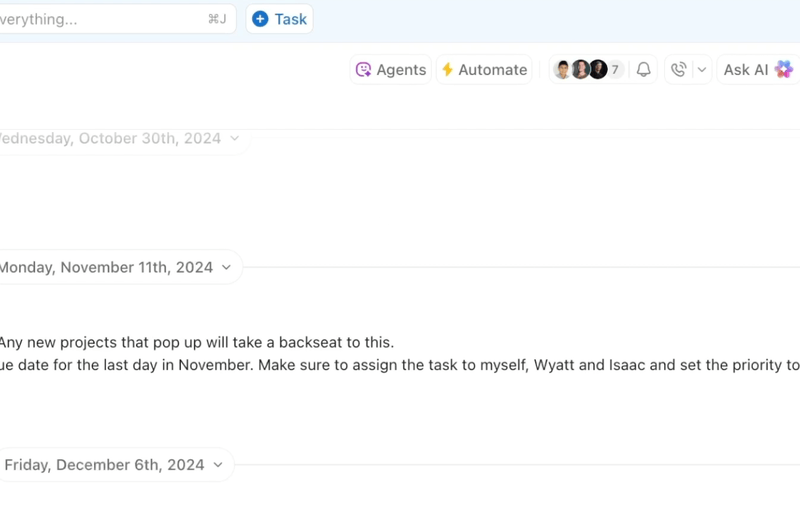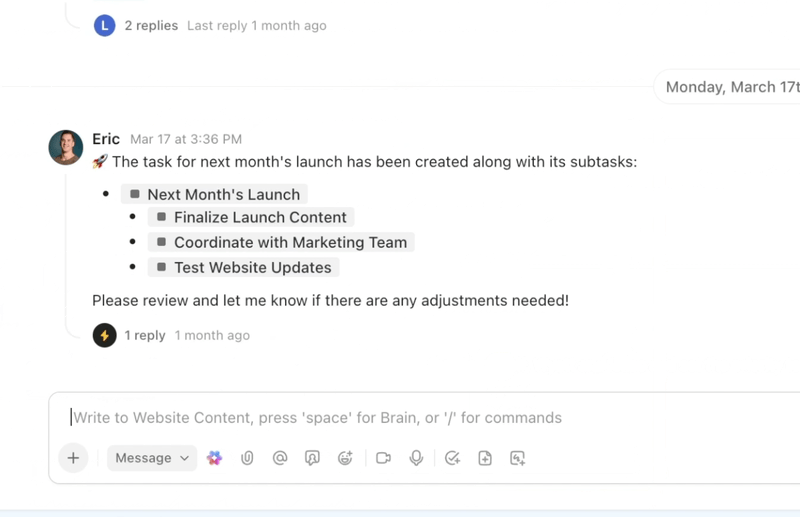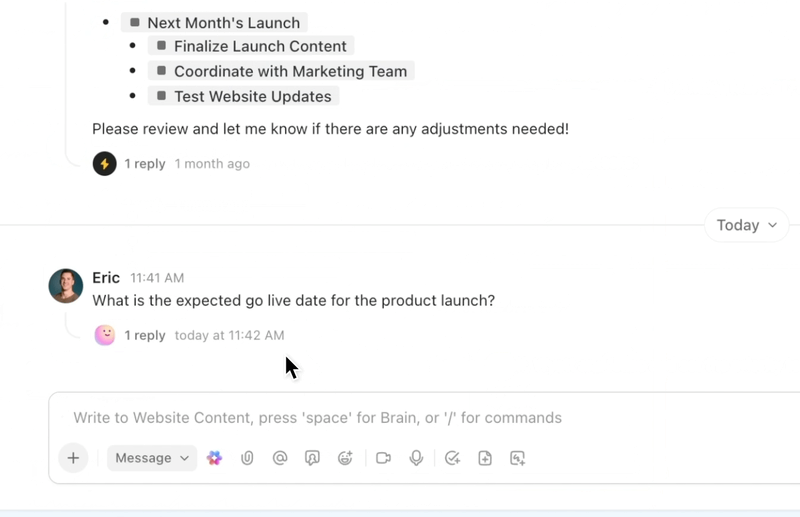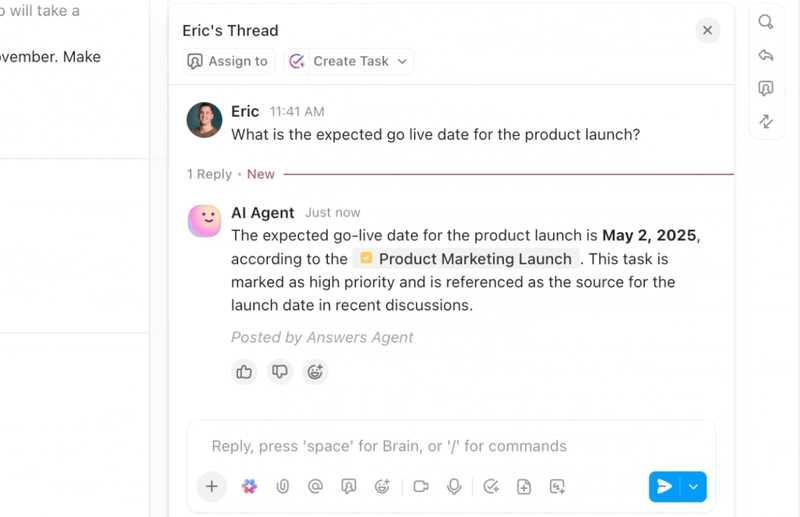
Se desideri un flusso di lavoro semplificato e intelligente per la risoluzione dei bug, ClickUp, l'app completa per il lavoro, riunisce in un unico posto IA, automazioni e assistenza al flusso di lavoro.
ClickUp Brain mostra immediatamente il contesto giusto, riepilogando lunghe discussioni sui bug, estraendo i passaggi per riprodurre il problema e i dettagli dell'ambiente dagli allegati, segnalando i possibili duplicati e suggerendo le azioni successive. Invece di dover setacciare Slack, ticket e log, i team ottengono un registro chiaro e completo su cui possono agire immediatamente.
Le automazioni e gli agenti Autopilot di ClickUp mantengono il lavoro in movimento senza bisogno di un controllo costante. I bug vengono automaticamente indirizzati al team giusto, vengono assegnati i titolari, vengono stabiliti gli SLA e le date di scadenza, gli stati vengono aggiornati man mano che il lavoro procede e le parti interessate ricevono notifiche tempestive.

Questi agenti sono in grado persino di classificare e categorizzare i problemi, raggruppare segnalazioni simili, fare riferimento a soluzioni storiche per suggerire possibili percorsi da seguire ed escalare gli elementi urgenti, in modo che MTTA e MTTR diminuiscano anche in caso di picchi di volume.
🛠️ Desideri un toolkit pronto all'uso? Il modello ClickUp Bug & Issue Tracking è una potente soluzione di ClickUp for Software progettata per aiutare i team di assistenza, ingegneria e prodotto a tenere sotto controllo con facilità i bug e i problemi del software. Grazie a visualizzazioni personalizzabili come Elenco, Bacheca, Carico di lavoro, Modulo e Sequenza, i team possono visualizzare e gestire il processo di tracciamento dei bug nel modo più adatto alle loro esigenze.
I 20 stati personalizzati e i 7 campi personalizzati del modello consentono di creare un flusso di lavoro su misura, garantendo che ogni problema venga monitorato dalla scoperta alla risoluzione. Le automazioni integrate si occupano delle attività ripetitive, liberando tempo prezioso e riducendo lo sforzo richiesto.
💟 Bonus: Brain MAX è il tuo compagno desktop basato sull'IA, progettato per accelerare la risoluzione dei bug con funzionalità/funzioni intelligenti e pratiche.
Quando incontri un bug, utilizza semplicemente la funzione di dettatura vocale di Brain MAX per descrivere il problema: le tue note vocali vengono trascritte istantaneamente e possono essere allegate a un ticket di bug nuovo o esistente. La sua funzione di ricerca aziendale setaccia tutti i tuoi strumenti collegati, come ClickUp, GitHub, Google Drive e Slack, per trovare segnalazioni di bug, registri di errori, frammenti di codice e documentazione correlati, in modo da avere tutto il contesto necessario senza dover cambiare app.
Hai bisogno di coordinare una correzione? Brain MAX ti consente di assegnare il bug allo sviluppatore giusto, impostare promemoria automatici per gli aggiornamenti di stato e effettuare il monitoraggio del progresso, tutto dal tuo desktop!
2. Sentry (ideale per rilevare gli errori)
Sentry riduce il tempo medio di rilevamento (MTTD) e il tempo di riproduzione acquisendo errori, tracce e sessioni utente in un unico posto. Il raggruppamento dei problemi basato sull'IA riduce il rumore; le regole "Suspect Commit" e di titolarità identificano il probabile titolare del codice, in modo che l'instradamento sia istantaneo. Session Replay fornisce agli ingegneri il percorso esatto dell'utente e i dettagli della console/rete per riprodurre il problema senza infinite discussioni.
Le funzionalità di Sentry AI possono riassumere il contesto del problema e, in alcuni stack, proporre patch di correzione automatica che fanno riferimento al codice difettoso. L'impatto pratico: meno ticket duplicati, assegnazione più rapida e un percorso più breve dalla segnalazione alla patch funzionante.
3. GitHub Copilot (ideale per revisionare il codice più rapidamente)
Copilot accelera il ciclo di correzione all'interno dell'editor. Spiega gli stack trace, suggerisce patch mirate, scrive test unitari per bloccare la correzione e crea script di riproduzione.
Copilot Chat è in grado di esaminare il codice difettoso, proporre rifattorizzazioni più sicure e generare commenti o descrizioni PR che velocizzano la revisione del codice. In combinazione con le revisioni richieste e la CI, riduce di ore il processo di "diagnosi → implementazione → test", in particolare per i bug ben definiti con una chiara riproducibilità.
4. Snyk di DeepCode IA (ideale per individuare modelli ricorrenti)
L'analisi statica basata sull'IA di DeepCode individua difetti e modelli non sicuri durante la codifica e nelle PR. Evidenzia i flussi problematici, spiega perché si verificano e propone correzioni sicure che si adattano al tuo codice.
Individuando le regressioni prima di unire le code e guidando gli sviluppatori verso modelli più sicuri, è possibile ridurre il tasso di comparsa di nuovi bug e accelerare la correzione di errori logici complessi difficili da individuare durante la revisione. Le integrazioni IDE e PR mantengono tutto questo vicino al luogo in cui si svolge il lavoro.
5. Watchdog e AIOps di Datadog (ideali per l'analisi dei log)
Watchdog di Datadog utilizza il machine learning per individuare anomalie nei log, nelle metriche, nelle tracce e nel monitoraggio degli utenti reali. Correlando i picchi con i marcatori di distribuzione, le modifiche infrastrutturali e la topologia, suggerisce le possibili cause alla radice.
Per i difetti che hanno un impatto sui clienti, ciò significa pochi minuti per il rilevamento, raggruppamento automatico per ridurre il rumore degli avvisi e indicazioni concrete su dove cercare. Il tempo di triage si riduce perché si parte da "questa implementazione ha interessato questi servizi e i tassi di errore sono aumentati su questo endpoint" invece che da zero.
⚡️ Archivio modelli: Modelli gratis per il monitoraggio dei problemi e la registrazione dei log in Excel e ClickUp
6. New Relic IA (ideale per identificare e riassumere le tendenze)
La casella di posta degli errori di New Relic raggruppa errori simili tra servizi e versioni, mentre il suo assistente IA riepiloga l'impatto, evidenzia le cause probabili e fornisce collegamenti alle tracce/transazioni coinvolte.
Le correlazioni di distribuzione e l'intelligenza dei cambiamenti delle entità rendono evidente quando la causa è da ricercarsi in una versione recente. Per i sistemi distribuiti, tale contesto riduce di ore i ping tra i team e indirizza il bug al titolare giusto con un'ipotesi solida già formulata.
7. Rollbar (ideale per flussi di lavoro automatizzati)
Rollbar è specializzato nel monitoraggio degli errori in tempo reale con fingerprinting intelligente per raggruppare i duplicati e tracciare le tendenze di occorrenza. I suoi riepiloghi/riassunti basati sull'IA e i suggerimenti sulle cause alla radice aiutano i team a comprendere la portata (utenti interessati, versioni coinvolte), mentre la telemetria e le tracce dello stack forniscono rapidi indizi per la riproduzione.
Le regole del flusso di lavoro di Rollbar consentono di creare automaticamente attività, taggare la gravità e indirizzare i titolari, trasformando flussi di errori rumorosi in code prioritarie con contesto allegato.
8. PagerDuty AIOps e automazione dei runbook (il meglio della diagnostica low-touch)
PagerDuty utilizza la correlazione degli eventi e la riduzione del rumore basata sul machine learning per trasformare le tempeste di avvisi in incidenti gestibili.
Il routing dinamico indirizza immediatamente il problema al tecnico di turno giusto, mentre l'automazione dei runbook può avviare la diagnostica o le misure di mitigazione (riavvio dei servizi, rollback di una distribuzione, attivazione/disattivazione di un interruttore di funzionalità) prima che intervenga un essere umano. Per quanto riguarda il tempo di risoluzione dei bug, ciò significa un MTTA più breve, misure di mitigazione più rapide per i P0 e meno ore perse a causa della fatica da alert.
Il filo conduttore è l'automazione e l'IA in ogni passaggio. È possibile rilevare prima, instradare in modo più intelligente, arrivare al codice più rapidamente e comunicare lo stato senza rallentare il lavoro degli ingegneri, il che si traduce in una significativa riduzione dei tempi di risoluzione dei bug.
📖 Per saperne di più: Come utilizzare l'IA in DevOps
Esempi reali di utilizzo dell'IA per la risoluzione dei bug
Quindi, l'IA è ufficialmente uscita dal laboratorio. Sta riducendo i tempi di risoluzione dei bug sul campo.
Vediamo come!
| Dominio / Organizzazione | Come è stata utilizzata l'IA | Impatto/Vantaggi |
|---|---|---|
| Ubisoft | Sviluppato Commit Assistant, uno strumento di IA addestrato su un decennio di codice interno, che prevede e previene i bug in fase di codifica. | L'obiettivo è ridurre drasticamente tempi e costi: tradizionalmente, fino al 70% delle spese di sviluppo dei giochi è destinato alla correzione dei bug. |
| Razer (piattaforma Wyvrn) | Lanciato QA Copilot basato sull'IA (integrato con Unreal e Unity) per automatizzare il rilevamento dei bug e generare report di controllo qualità. | Aumenta il rilevamento dei bug fino al 25% e dimezza i tempi di controllo qualità. |
| Google / DeepMind & Project Zero | È stato introdotto Big Sleep, uno strumento basato sull'IA che rileva autonomamente le vulnerabilità di sicurezza nei software open source come FFmpeg e ImageMagick. | Identificati 20 bug, tutti verificati da esperti umani e in attesa di patch. |
| Ricercatori dell'Università della California, Berkeley | Utilizzando un benchmark denominato CyberGym, i modelli di IA hanno analizzato 188 progetti open source, individuando 17 vulnerabilità, tra cui 15 bug "zero-day" sconosciuti, e generando exploit proof-of-concept. | Dimostra le capacità in continua evoluzione dell'IA nel rilevamento delle vulnerabilità e nella verifica automatizzata degli exploit. |
| Spur (startup di Yale) | Sviluppato un agente IA che traduce le descrizioni dei casi di test in linguaggio semplice in routine di test automatizzate per siti web, creando di fatto un flusso di lavoro QA auto-generato. | Consente test autonomi con un intervento umano minimo. |
| Riproduzione automatica dei rapporti sui bug Android | Utilizzo di NLP + apprendimento rinforzato per interpretare il linguaggio dei rapporti sui bug e generare passaggi per riprodurre i bug Android. | Raggiunto il 67% di precisione, il 77% di richiamo e riprodotto il 74% dei rapporti sui bug, superando i metodi tradizionali. |
Errori comuni nella misurazione dei tempi di risoluzione dei bug
Se la tua misurazione è errata, lo sarà anche il tuo piano di miglioramento.
La maggior parte dei "numeri negativi" nei flussi di lavoro di risoluzione dei bug deriva da definizioni vaghe, flussi di lavoro incoerenti e analisi superficiali.
Inizia dalle basi: cosa si intende per avvio/arresto, come gestire le attese e le riaperture, quindi leggi i dati dal punto di vista dei tuoi clienti. Ciò include:
❌ Confini sfocati: mescolare Segnalati→Risolti e Segnalati→Chiuso nella stessa dashboard (o passare da un mese all'altro) rende le tendenze prive di significato. Scegli un confine, documentalo e applicalo a tutti i team. Se hai bisogno di entrambi, pubblicali come metriche separate con etichette chiare.
❌ Approccio basato solo sulle medie: affidarsi alla media nasconde la realtà delle code con pochi valori anomali di lunga durata. Utilizza la mediana (P50) per il tempo "tipico", P90 per la prevedibilità/gli SLA e mantieni la media per la pianificazione della capacità. Guarda sempre la distribuzione, non solo un singolo numero.
❌ Nessuna segmentazione: raggruppare tutti i bug mescola gli incidenti P0 con quelli P3 di natura estetica. Segmenta in base alla gravità, alla fonte (cliente vs. QA vs. monitoraggio), al componente/team e a "nuovo vs. regressione". Il tuo P0/P1 P90 è ciò che percepiscono gli stakeholder; la tua mediana P2+ è ciò su cui si basa il piano ingegneristico.
❌ Ignorare il tempo "in pausa": Aspettate i log dei clienti, un fornitore esterno o una finestra di rilascio? Se non monitorate lo stato Bloccato/In pausa come uno stato di prima classe, il tempo di risoluzione diventa argomento di discussione. Segnalate sia il tempo di calendario che il tempo attivo, in modo che i colli di bottiglia siano visibili e le discussioni cessino.
❌ Differenze nella normalizzazione del tempo: la combinazione di fusi orari diversi o il passaggio dall'orario di lavoro all'orario solare durante il processo compromette i confronti. Normalizza i timestamp su un unico fuso orario (o UTC) e decidi una volta per tutte se gli SLA devono essere misurati in ore lavorative o solari; applica questa scelta in modo coerente.
❌ Dati di input sporchi e duplicati: le informazioni mancanti sull'ambiente/build e i ticket duplicati aumentano i tempi di risoluzione e creano confusione sulla titolarità. Standardizza i campi obbligatori al momento dell'inserimento, arricchisci automaticamente i dati (log, versione, dispositivo) ed elimina i duplicati senza azzerare i tempi di risoluzione: chiudi i duplicati come problemi collegati, non come problemi "nuovi".
❌ Modelli di stato incoerenti: gli stati personalizzati ("QA Ready-ish", "Pending Review 2") nascondono il tempo trascorso in uno stato e rendono inaffidabili le transizioni di stato. Definisci un flusso di lavoro canonico (Nuovo → Selezionato → In corso → In revisione → Risolto → Chiuso) e verifica gli stati fuori percorso.
❌ Ignorare il tempo trascorso in uno stato: un unico numero relativo al "tempo totale" non è sufficiente per capire dove si verificano i rallentamenti. Rileva e analizza il tempo trascorso negli stati "Triage", "In revisione", "Bloccato" e "QA". Se la revisione del codice P90 supera di gran lunga l'implementazione, la soluzione non è "codificare più velocemente", ma sbloccare la capacità di revisione.
🧠 Curiosità: l'ultima AI Cyber Challenge della DARPA ha mostrato un progresso rivoluzionario nell'automazione della sicurezza informatica. La competizione ha visto protagonisti sistemi di IA progettati per rilevare, sfruttare e correggere autonomamente le vulnerabilità del software, senza l'intervento umano. Il team vincitore, "Team Atlanta", ha scoperto in modo impressionante il 77% dei bug iniettati e ha ottenuto un esito positivo per quanto riguarda il 61% di essi, dimostrando la potenza dell'IA non solo nel trovare i difetti, ma anche nel correggerli attivamente.
❌ Cecità da riapertura: trattare le riaperture come nuovi bug azzera il tempo e appiattisce l'MTTR. Traccia il tasso di riapertura e il "tempo di chiusura stabile" (dal primo rapporto alla chiusura finale in tutti i cicli). L'aumento delle riaperture di solito indica una riproduzione debole, lacune nei test o una definizione vaga di terminato.
❌ Nessun MTTA: i team si concentrano sull'MTTR e ignorano l'MTTA (tempo di riconoscimento/titolarità). Un MTTA elevato è un avviso precoce che indica una risoluzione lunga. Misuralo, imposta gli SLA in base alla gravità e automatizza l'instradamento/l'escalation per mantenerlo basso.
❌ IA/automazione senza protezioni: lasciare che l'IA stabilisca la gravità o chiuda i duplicati senza revisione può portare a una classificazione errata dei casi limite e a una distorsione silenziosa delle metriche. Utilizza l'IA per i suggerimenti, richiedi la conferma umana su P0/P1 e verifica mensilmente le prestazioni del modello in modo che i tuoi dati rimangano affidabili.
Rafforzate questi aspetti e i vostri grafici sui tempi di risoluzione rifletteranno finalmente la realtà. Da lì, i miglioramenti si moltiplicano: un migliore inserimento riduce l'MTTA, stati più chiari rivelano i veri colli di bottiglia e i P90 segmentati offrono ai leader promesse che potete mantenere.
⚡️ Archivio modelli: 10 modelli di casi di test per il collaudo di software
Best practice per una migliore risoluzione dei bug
Per riassumere, ecco i punti fondamentali da tenere a mente!
| 🧩 Best practice | 💡 Cosa significa | 🚀 Perché è importante |
| Utilizza un sistema di monitoraggio dei bug affidabile | Tieni traccia di tutti i bug segnalati utilizzando un sistema centralizzato di monitoraggio dei bug. | Garantisce che nessun bug venga perso e consente la visibilità dello stato dei bug tra i team. |
| Scrivi rapporti dettagliati sui bug | Includi contesto visivo, informazioni sul sistema operativo, passaggi per riprodurre il problema e gravità. | Aiuta gli sviluppatori a correggere i bug più rapidamente con tutte le informazioni essenziali a portata di mano. |
| Categorizza e assegna priorità ai bug | Utilizza una matrice di priorità per ordinare i bug in base all'urgenza e all'impatto. | Concentra il team sui bug critici e sui problemi urgenti. |
| Sfrutta i test automatizzati | Esegui i test automaticamente nella tua pipeline CI/CD. | Offre supporto per il rilevamento precoce e previene le regressioni. |
| Definisci linee guida chiare per la reportistica | Fornisci modelli e formazione su come effettuare la reportistica per i bug. | Consente di ottenere informazioni accurate e una comunicazione più fluida. |
| Traccia le metriche chiave | Misura il tempo di risoluzione, il tempo trascorso e il tempo di risposta. | Consente il monitoraggio e il miglioramento delle prestazioni utilizzando i dati storici. |
| Adotta un approccio proattivo | Non aspettare che gli utenti si lamentino: esegui test in modo proattivo. | Aumenta la soddisfazione dei clienti e riduce il carico di supporto. |
| Sfrutta strumenti intelligenti e ML | Utilizza l'apprendimento automatico per prevedere i bug e suggerire soluzioni. | Migliora l'efficienza nell'identificazione delle cause alla radice e nella risoluzione dei bug. |
| Allineati agli SLA | Organizza riunioni per rispettare gli accordi sul livello di servizio concordati per la risoluzione. | Crea fiducia e soddisfa le aspettative dei clienti in modo tempestivo. |
| Rivedi e migliora continuamente | Analizza i bug riaperti, raccogli feedback e modifica i processi. | Promuove il miglioramento continuo del processo di sviluppo e della gestione dei bug. |
Risoluzione dei bug semplificata con l'IA contestuale
I team più veloci nella risoluzione dei bug non si affidano a soluzioni eroiche. Progettano un sistema: definizioni chiare di inizio/fine, acquisizione pulita, prioritizzazione dell'impatto aziendale, titolarità ben definita e cicli di feedback stretti tra supporto, QA, ingegneria e rilascio.
ClickUp può essere il Centro di comando basato sull'IA per il tuo sistema di risoluzione dei bug. Centralizza tutti i report in un'unica coda, standardizza il contesto con campi strutturati e lascia che ClickUp AI esegua il triage, riepiloghi e assegni le priorità, mentre le automazioni applicano gli SLA, segnalano i ritardi e mantengono allineati gli stakeholder. Collega i bug ai clienti, al codice e alle versioni, in modo che i dirigenti possano vedere l'impatto e i professionisti possano rimanere nel flusso.
Se sei pronto a ridurre i tempi di risoluzione dei bug e rendere la tua roadmap più prevedibile, registrati su ClickUp e inizia a misurare i miglioramenti in pochi giorni, non in trimestri.
Domande frequenti
Qual è un buon tempo di risoluzione dei bug?
Non esiste un unico numero "giusto": dipende dalla gravità, dal modello di rilascio e dalla tolleranza al rischio. Utilizza le mediane (P50) per le prestazioni "tipiche" e P90 per le promesse/SLA, e segmenta in base alla gravità e alla fonte.
Qual è la differenza tra risoluzione dei bug e chiusura dei bug?
La risoluzione avviene quando la correzione viene implementata (ad esempio, codice unito, configurazione applicata) e il team considera il difetto risolto. La chiusura avviene quando il problema viene verificato e formalmente risolto (ad esempio, QA convalidato nell'ambiente di destinazione, rilasciato o contrassegnato come non risolvibile/duplicato con motivazione). Molti team misurano entrambi: Segnalato→Risolto riflette la velocità di ingegnerizzazione; Segnalato→Chiuso riflette il flusso di qualità end-to-end. Utilizza definizioni coerenti in modo che i dashboard non mescolino le fasi.
Qual è la differenza tra il tempo di risoluzione dei bug e il tempo di rilevamento dei bug?
Il tempo di rilevamento (MTTD) è il tempo necessario per individuare un difetto dopo che si è verificato o è stato rilasciato, tramite monitoraggio, controllo qualità o segnalazione da parte degli utenti. Il tempo di risoluzione è il tempo necessario per passare dal rilevamento/segnalazione all'implementazione della correzione (e, se preferisci, alla convalida/rilascio). Insieme, definiscono la finestra di impatto sul cliente: rilevare rapidamente, riconoscere rapidamente, risolvere rapidamente e rilasciare in modo sicuro. È anche possibile effettuare il monitoraggio dell'MTTA (tempo di riconoscimento/assegnazione) per individuare i ritardi nella selezione che spesso predicono una risoluzione più lunga.
In che modo l'IA aiuta nella risoluzione dei bug?
L'IA comprime i cicli che in genere rallentano il processo: acquisizione, triage, diagnosi, correzione e verifica.
- Acquisizione e triage: riepiloga automaticamente i report lunghi, estrae i passaggi/l'ambiente di riproduzione, segnala i duplicati e suggerisce la gravità/priorità in modo che gli ingegneri possano iniziare con un contesto chiaro (ad esempio, ClickUp AI, Sentry AI).
- Routing e SLA: prevede il probabile componente/titolare, imposta i timer e inoltra i casi quando l'MTTA o i tempi di attesa per la revisione slittano, riducendo il "tempo in stato" di inattività (automazioni ClickUp e flussi di lavoro simili a quelli degli agenti).
- Diagnosi: raggruppa errori simili, correla i picchi ai commit/release recenti e indica le probabili cause principali con stack trace e contesto del codice (Sentry IA e simili).
- Implementazione: suggerisce modifiche al codice e test basati sui modelli del tuo repository, accelerando il ciclo "scrittura/correzione" (GitHub Copilot; Snyk Code IA di DeepCode).
- Verifica e comunicazione: scrive casi di test dai passaggi di riproduzione, redige bozze di note di rilascio e aggiornamenti per gli stakeholder e riepiloga lo stato per i dirigenti e i clienti (ClickUp AI). Utilizzati insieme, ClickUp come Centro di comando con Sentry/Copilot/DeepCode nello stack, i team riducono i tempi MTTA/P90 senza fare affidamento su azioni eroiche.