
Les premiers services sont faciles. Une rotation, un canal, puis une sauvegarde.
Cependant, dès que votre entreprise compte des dizaines de microservices, plusieurs régions et une propriété hiérarchisée, les escalades manuelles cessent d'être un flux de travail et deviennent un handicap.
Ce guide explique comment réaliser l'automatisation des processus d'escalade des incidents qui s'adaptent à votre organisation technique sans créer de failles dans votre système d'astreinte.
Nous verrons également comment ClickUp s'intègre dans la création d'un système d'escalade auquel vos équipes d'ingénieurs peuvent faire confiance. 🎯
⭐ Modèle présenté
Réagissez rapidement et efficacement en cas d'urgence, qu'il s'agisse d'une catastrophe naturelle ou d'une violation de données, à l'aide du modèle de plan d'action en cas d'incident (IAP) de ClickUp.

Le modèle vous propose des sections prédéfinies pour :
- Définissez les objectifs et les priorités d'intervention en cas d'incident.
- Mettez en place une structure hiérarchique claire.
- Coordonnez les actions entre les équipes en temps réel.
- Enregistrez les décisions, les échéanciers et les mises à jour importantes au fur et à mesure qu'ils surviennent.
- Restez connecté à l'escalade et assurez le suivi
Et comme il est intégré à ClickUp, il fonctionne comme un document de commande d'incident en direct, et non comme une checklist statique.
Pourquoi réaliser l'automatisation des processus d'escalade des incidents ?
Lorsque votre équipe gère des systèmes complexes soumis à des accords de niveau de service (SLA) stricts, l'escalade manuelle ne fait que vous ralentir. L'escalade automatisée rend votre processus de réponse prévisible et moins stressant, même lors d'incidents à forte pression.
Voici pourquoi vous devez réaliser l'automatisation des processus d'escalade de votre organisation. 👇
Le risque lié à l'escalade manuelle
Lorsque vous devez gérer des dizaines de services, plusieurs rotations d'astreinte et des changements constants de propriété, les étapes manuelles deviennent rapidement un problème.
Les pièges courants sont les suivants :
- Notifications manquées ou retardées lorsqu'une personne néglige un e-mail, un SMS ou une notification de chat
- Confusion lors des transferts, en particulier lorsque les processus d'escalade ne sont pas clairement documentés
- Escalade vers la mauvaise équipe parce que la carte des responsabilités n'est pas mise à jour
- Goulots d'étranglement causés par le fait de compter sur une seule personne pour « transmettre l'alerte ».
📖 À lire également : Comment rédiger un rapport d'incident
Avantages de l'automatisation
L'automatisation ITSM structure et dynamise vos processus d'escalade. Au lieu d'espérer que quelqu'un voie l'alerte, votre système exécute instantanément et systématiquement une séquence prédéfinie.
Voici ce que les équipes gagnent lorsqu'elles utilisent l'IA pour automatiser les tâches:
- Des temps de réponse plus rapides grâce à des alertes qui parviennent à la bonne personne ou à la bonne équipe en quelques secondes.
- Exécution cohérente des étapes d'escalade, même à 3 heures du matin, lorsque la prise de décision est plus lente.
- Redondance intégrée qui garantit que les intervenants de la sauvegarde sont avertis si le responsable principal n'a pas reçu l'alerte.
- Une visibilité claire pour toutes les équipes, car tout le monde comprend le flux des escalades.
- Moins d'interventions d'urgence et des expériences d'astreinte plus prévisibles
📖 À lire également : Exemples de plans de continuité des activités
Réduire la fatigue liée aux alertes et les erreurs humaines
La fatigue liée aux alertes nuit à l'efficacité des équipes d'astreinte. Lorsque votre équipe est trop souvent sollicitée, ou pour de mauvaises raisons, elle cesse de réagir avec urgence. L'automatisation permet de filtrer et de ne transmettre que les incidents qui nécessitent réellement une intervention humaine.
Grâce à la logique d'escalade automatisée :
- Les alertes à faible signal ou les alertes en double sont supprimées avant d'atteindre le service d'astreinte.
- Des règles basées sur la gravité garantissent que les problèmes mineurs ne réveillent personne inutilement.
- Les alertes ne sont escaladées que si le système détecte une absence de réponse dans un délai défini.
- Les équipes passent moins de temps à trier les informations superflues et plus de temps à résoudre les problèmes réels.
Assistance pour le respect des accords de niveau de service (SLA) et des politiques d'astreinte
L'automatisation de l'escalade facilite la mise en conformité sans nécessiter une surveillance manuelle constante. Pour les responsables des opérations informatiques qui gèrent des SLA stricts ou des engagements de fiabilité internes, l'IA sert de garde-fou qui garantit le respect des comportements attendus. Elle vous aide à :
- Assurez-vous que les notifications d'incident suivent les règles prédéfinies pour le routage.
- Effectuez la maintenance automatique des échéanciers de réponse prévus dans les accords de niveau de service (SLA) grâce à des escalades programmées.
- Appliquez les plannings d'astreinte sans vous fier à des feuilles de calcul obsolètes.
- Créez des pistes d'audit pour chaque alerte, escalade et accusé de réception.
🎥 Vous souhaitez gérer l'ensemble de votre flux de travail d'escalade sans intervention manuelle ? Super Agents est là pour vous aider . 👇🏼
🔍 Le saviez-vous ? Le centre de contrôle de mission de la NASA fonctionne essentiellement selon une logique d'escalade automatisée. Si la télémétrie sort de l'intervalle défini, le système envoie instantanément des alertes automatisées aux spécialistes par domaine.
Qu'est-ce qu'une politique d'escalade dans la gestion des incidents ?
Une politique d'escalade est un ensemble prédéfini de règles qui détermine qui est averti, quand il est averti et comment la responsabilité est transmise vers le haut ou entre les équipes.
Considérez cela comme une feuille de route structurée qui empêche les incidents de stagner, garantit l'intervention des bons experts au bon moment et aide les équipes à respecter les accords de niveau de service (SLA).
Une politique de gestion des escalades bien structurée comprend généralement :
- Routage basé sur des règles qui définit qui est le prochain sur la liste lorsqu'une personne ne reconnaît pas ou n'est pas en mesure de résoudre l'incident.
- Déclencheurs temporisés qui escaladent automatiquement après 5, 15 ou 30 minutes en fonction de la gravité.
- Méthodes de notification telles que les appels téléphoniques, les SMS, le chat ou les e-mails
- Niveaux du plan d'escalade : niveau 1 (astreinte principale) > niveau 2 (ingénieurs seniors/experts) > niveau 3 (direction)
- Attentes en matière de documentation afin que les nouveaux intervenants puissent prendre le relais sans perdre le contexte essentiel
📖 À lire également : Comment hiérarchiser les tâches en P0, P1, P2, P3 et P4
Types de politiques d'escalade
Voici les principaux types de politiques que votre équipe doit comprendre :
1. Escalade hiérarchique (verticale)
Les alertes remontent la chaîne hiérarchique, des ingénieurs juniors aux spécialistes seniors, puis à la direction. Utilisez cette fonctionnalité lorsque la situation nécessite une expertise plus approfondie, un pouvoir décisionnel ou une visibilité exécutive.
2. Escalade fonctionnelle (horizontale)
Au lieu de remonter la hiérarchie, l'alerte est transmise à travers les équipes jusqu'à la fonction responsable du système concerné. Cette solution est idéale pour les incidents liés à un domaine spécifique, tel que les bases de données, les réseaux, les paiements ou les API.
3. Escalade basée sur le temps
Il s'agit de la colonne vertébrale de la plupart des systèmes d'automatisation. Dans ce type de système, l'alerte passe au niveau supérieur après un délai spécifique, souvent directement lié aux accords de niveau de service (SLA). Cela est particulièrement essentiel lorsque vous avez besoin d'une réactivité garantie en dehors des heures de bureau.
4. Escalade basée sur l'impact
L'escalade basée sur l'impact dépend de la gravité ou de l'impact commercial, et non de la hiérarchie ou du temps. Elle est utile en cas de pannes, d'échecs de paiement, de problèmes liés à la clientèle ou de failles de sécurité.
5. Escalade parallèle
Dans ce cas, plusieurs personnes ou équipes sont averties simultanément. L'escalade parallèle est utilisée pour les problèmes graves qui nécessitent plusieurs spécialités ou pour les situations où tout retard est inacceptable.
🔍 Le saviez-vous ? Une étude récente sur les signaux d'alerte a révélé que les alertes extrêmement saillantes ou « bruyantes/lumineuses » peuvent ralentir les temps de réaction, en particulier si l'alerte est inattendue. Mais une fois que le type d'alerte devient prévisible (c'est-à-dire qu'il fait partie d'un système d'escalade/de notification préconçu), les temps de réponse s'améliorent. Cela suggère que lorsque vous effectuez l'automatisation des chemins d'escalade, vous ne devez pas simplement inonder les gens d'alarmes à haute priorité.
Quand déclencher une escalade automatique ?
Maintenant que vous savez comment les chemins d'escalade sont structurés, l'étape suivante consiste à décider quand ces règles doivent s'appliquer automatiquement.
Vous trouverez ci-dessous les principales situations qui déclenchent une escalade automatique, formant ainsi la couche logique derrière vos politiques. 💁
Escalade basée sur la gravité
L'escalade automatique se déclenche lorsque la gravité ou l'impact de l'incident dépasse un certain seuil. Les incidents de gravité élevée nécessitent une attention immédiate de la part des responsables, et l'escalade automatique permet de contourner les goulots d'étranglement et d'impliquer les experts en quelques secondes.
📌 Exemple : une interruption totale du service, une défaillance de la passerelle de paiement ou une dégradation majeure affectant de nombreux utilisateurs ou systèmes centraux nécessite une escalade automatique.
Escalade basée sur le temps
Si personne ne prend en charge ou ne résout l'incident dans un délai défini, l'alerte est automatiquement transmise au niveau supérieur. Cela évite que les tickets ne restent en suspens, en particulier en dehors des heures de travail normales ou lorsque le premier intervenant n'est pas disponible ou est surchargé.
📌 Exemple : après 10 à 15 minutes sans réponse, l'incident est escaladé du premier intervenant vers un ingénieur senior ; après 30 à 60 minutes supplémentaires sans résolution, il est escaladé à un niveau supérieur.
Escalade contextuelle
Cette logique d'escalade tient compte des attributs contextuels de l'incident, tels que le service ou le système affecté, le propriétaire du service, le segment de clientèle concerné (interne ou externe, VIP ou standard) ou le domaine fonctionnel (base de données, réseau, intégration). En fonction de ce contexte, les alertes sont acheminées vers le répondant ou l'équipe le plus pertinent.
Vous évitez ainsi de surcharger les équipes avec des incidents non pertinents, réduisez le temps de réponse et vous assurez que les spécialistes traitent les problèmes relevant de leur domaine.
📌 Exemples : un pic de latence dans le service de paiement doit alerter directement l'équipe chargée des paiements, ou une erreur backend dans le microservice de facturation doit être signalée à l'équipe chargée de la facturation.
Escalade basée sur les métadonnées
Les outils modernes d'alerte et de gestion des incidents capturent des métadonnées telles que la source d'origine (quel outil de surveillance ou quelle règle d'alerte a été déclenché), l'identité de l'utilisateur/du client, l'emplacement, la fréquence historique d'incidents similaires ou les libellés. Cela vous aide à appliquer une logique plus granulaire et plus intelligente plutôt que de vous fier à des règles grossières basées sur la gravité ou le temps.
📌 Exemples : les alertes récurrentes provenant du même sous-système peuvent indiquer un problème systémique plus profond, justifiant une escalade plus rapide. Ou encore, les alertes concernant les clients VIP peuvent déclencher des notifications supplémentaires.
Combiner des déclencheurs pour créer des politiques d'escalade plus intelligentes et adaptatives
Dans la pratique, de nombreuses équipes ne s'appuient pas sur un seul type de déclencheur. Elles élaborent plutôt des politiques d'escalade hybrides qui combinent des règles de gravité, de temps, de contexte et de métadonnées.
Cette approche par couches permet aux équipes de créer des politiques d'escalade à la fois réactives (rapides lorsque nécessaire) et intelligentes (sélectives pour minimiser le bruit), ce qui se traduit par une amélioration des résultats en matière d'incidents et une allocation plus efficace des ressources.
🔍 Le saviez-vous ? Au XVIIIe siècle, les équipages navals utilisaient une chaîne d'escalade stricte en cas d'urgence. Si un marin de rang inférieur repérait un danger, il sonnait une cloche et transmettait le message à ses supérieurs jusqu'à ce que le capitaine prenne la décision finale.
Comment concevoir des processus d'escalade efficaces
La conception de processus d'escalade consiste à mettre en place un système qui achemine de manière fiable les alertes appropriées vers les personnes concernées, avec un minimum de friction.
Voici un cadre pratique, étape par étape, que vous pouvez utiliser dans des environnements complexes et de distribution.
P. S. Nous verrons également comment certaines fonctionnalités de ClickUp peuvent vous aider dans ce domaine ! 🤩
Étape n° 1 : définissez des critères, des niveaux et des responsabilités clairs en matière d'escalade
Commencez par définir ce qui constitue un incident nécessitant une escalade. Documentez des critères objectifs afin que tous les ingénieurs d'astreinte, qu'ils soient nouveaux intervenants L1 ou SRE expérimentés, interprètent la gravité des incidents de la même manière.
Cela permet d'obtenir un flux de travail d'escalade clair, d'éliminer toute ambiguïté et de garantir que l'automatisation ne se déclenche que lorsque cela est vraiment nécessaire.
Incluez des critères tels que :
- Seuils de gravité : interruption de service, échecs de paiement, problèmes d'authentification, corruption des données et alertes de sécurité.
- Impact : pannes affectant les clients, dégradation des services internes, défaillances des API des partenaires, conformité ou risques pour la sécurité.
- Contexte critique pour l'entreprise : impact sur les clients à forte valeur ajoutée, flux ayant une incidence sur les revenus, systèmes à haut risque (par exemple, paiements, facturation).
Une fois les critères et les déclencheurs définis, mappez les personnes qui seront alertées et leurs responsabilités à chaque étape de l'escalade.
Définissez clairement les niveaux :
- Niveau 1 (responsable principal des incidents en service) : agit en tant que premier intervenant et est chargé de la reconnaissance, du triage initial et des tentatives d'atténuation.
- Niveau deux (sauvegarde/spécialiste/expert) : fournit une expertise technique approfondie et résout les problèmes système complexes.
- Niveau trois (responsable ingénierie/direction) : supervise les incidents majeurs, approuve les mesures importantes, coordonne la communication entre les équipes et déclenche l'escalade vers le fournisseur si nécessaire.
🚀 Avantage ClickUp : utilisez ClickUp Docs pour conserver une source unique d'informations fiables concernant les critères, les niveaux et les responsabilités d'escalade, et documentez les rôles et les responsabilités, y compris qui :
- Reconnaît et atténue
- Communique avec les parties prenantes
- Gère les escalades des fournisseurs ou des partenaires externes
- Dirige la gestion des incidents
Vous pouvez également lier ces rôles spécifiques aux tâches ClickUp pertinentes afin de conserver la connexion.
Construisez votre propre base de connaissances :
Une fois les critères d'escalade et la propriété définis, les équipes ont besoin d'un moyen cohérent pour saisir, suivre et analyser les incidents techniques. Le modèle de rapport d'incident ClickUp fournit un système structuré et facile d'accès pour documenter les incidents informatiques et opérationnels en un seul endroit.
Intégré à ClickUp Docs, cet outil aide les équipes chargées de la réponse aux incidents à enregistrer des informations essentielles telles que la gravité de l'incident, les services affectés, les échéanciers, les résumés des causes profondes, les étapes d'atténuation et les actions de suivi.
Étape n° 2 : standardiser la création des incidents
Avant même que les processus d'escalade ne soient activés, votre équipe a besoin d'un moyen fiable pour saisir, normaliser et enrichir les données relatives aux incidents. Si l'enregistrement initial de l'incident est incomplet ou incohérent, même la logique d'escalade la plus sophistiquée échouera.
La normalisation doit :
- Triage des alertes entrantes : convertissez les alertes en champs personnalisés cohérents tels que la gravité, la catégorie, le service affecté, le type d'incident et le statut d'accusé de réception.
- Enrichissez automatiquement l'incident : récupérez les métadonnées, notamment le cluster, l'identifiant de déploiement, les propriétaires de services ou les dépendances.
- Assurez-vous que chaque incident est accompagné de son contexte : enregistrez qui l'a signalé, comment il a été détecté, l'environnement (production/préproduction) et tout journal ou capture d'écran pertinent.
Créez un formulaire ClickUp directement à partir de la liste où les incidents sont suivis et concevez-le de manière à refléter votre réalité opérationnelle et les données pertinentes dont dépend votre logique d'escalade. Ainsi, au lieu d'avoir des messages fragmentés dans les chats, les e-mails ou les tableaux de bord, chaque incident est saisi dans votre système dans un format cohérent sur lequel l'automatisation peut agir de manière fiable.

Regroupez les champs de manière intentionnelle afin que chaque incident soit entièrement contextualisé :
- Identification (titre, résumé)
- Classification (gravité, type, service affecté)
- Source (surveillance, utilisateur, API)
- Preuves (journaux, captures d'écran)
- Contexte commercial (niveau SLA, impact sur le client)
Chaque envoi de formulaire crée automatiquement une nouvelle tâche ClickUp, toutes les réponses étant mappées aux champs personnalisés ClickUp. Cela garantit que les incidents sont normalisés au moment de leur création, ce qui élimine toute ambiguïté et rend inutile toute intervention manuelle.
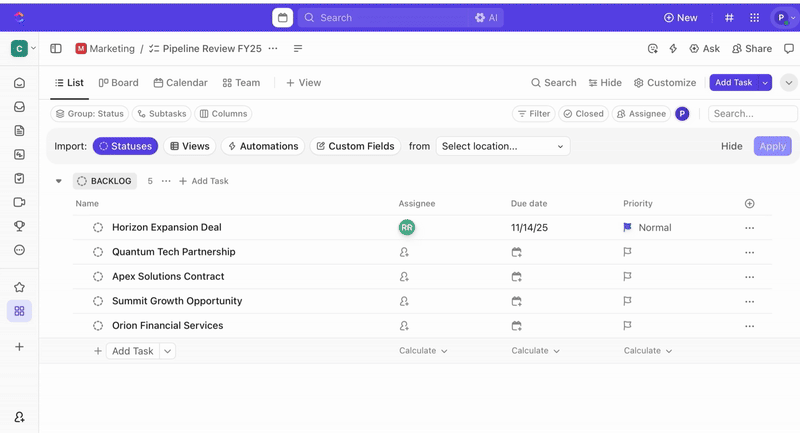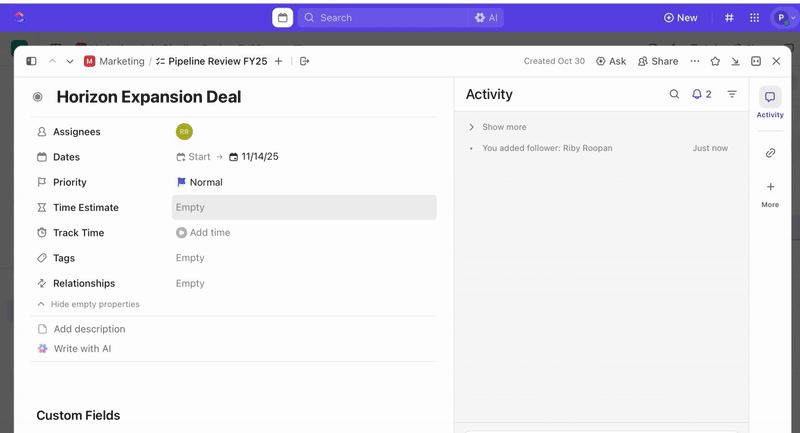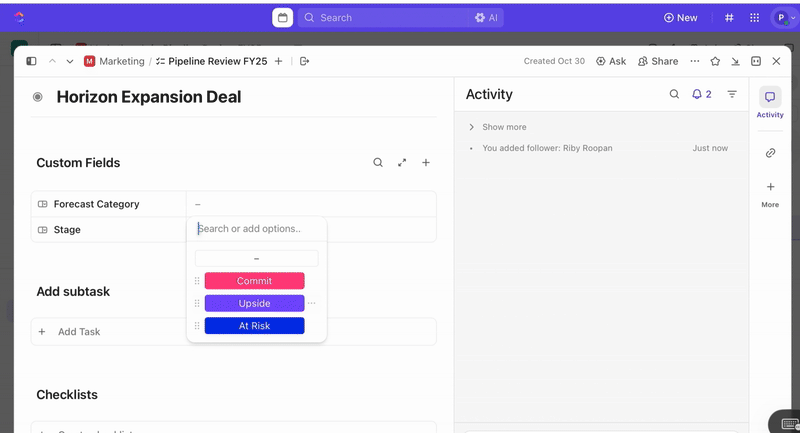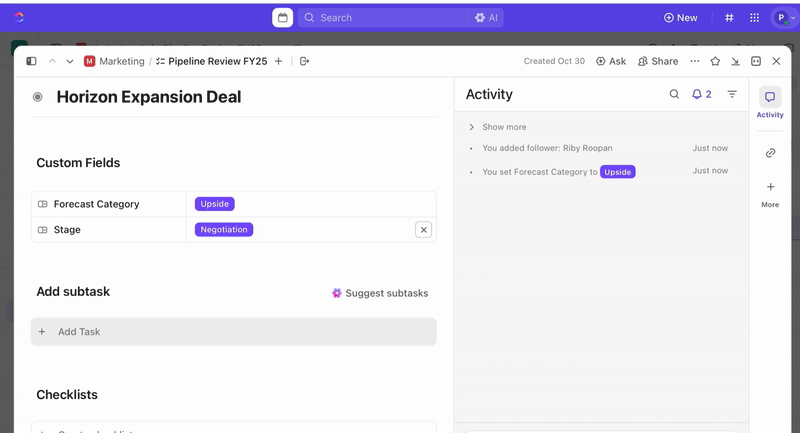
Une fois les tâches créées, vous pouvez utiliser les champs personnalisés pour effectuer le triage et la hiérarchisation (par exemple, gravité, impact, groupe d'intervenants) et définir des statuts personnalisés ClickUp qui reflètent les étapes de votre incident (Nouveau > Triage > Enquête > Atténuation > Résolu).
Étape n° 3 : Créez le processus d'escalade (c'est-à-dire la séquence, le timing et les canaux)
C'est le cœur du processus. Définissez le processus par étapes, chacune d'entre elles précisant qui doit être averti, par quel(s) canal(aux) et après combien de temps sans confirmation ni résolution.
- Définissez le « délai d'accusé de réception » et le « délai de résolution ».
Voici un exemple de flux de travail:
- Première étape : la première personne d'astreinte avertie immédiatement par SMS/chat doit accuser réception dans les 5 à 10 minutes.
- Deuxième étape : si aucune confirmation ou aucune action n'est reçue dans les 15 à 20 minutes suivantes, escaladez l'incident à l'équipe de sauvegarde/SRE + ingénieur senior via SMS/chat/e-mail.
- Troisième étape : si le problème n'est toujours pas résolu après 30 à 60 minutes supplémentaires, escaladez-le au responsable technique/à la direction et déclenchez éventuellement un canal « incident majeur ».
- Décidez si le processus d'escalade doit être « répété » (renotification au même niveau) ou « poursuivi ».
- Pour les incidents critiques, configurez des notifications répétées jusqu'à ce que quelqu'un réponde. Pour les incidents à faible priorité, vous pouvez opter pour un flux d'escalade unique.
- Assurez-vous que le processus est documenté à l'aide d'un modèle de réponse du service client et accessible à tout le personnel concerné.
❗️ Note : le « délai de confirmation » correspond au temps dont dispose le premier intervenant pour confirmer qu'il a pris connaissance de l'alerte, tandis que le « délai de résolution » correspond au temps dont dispose l'équipe pour résoudre ou atténuer le problème avant que la prochaine escalade ne soit déclenchée.
Étape n° 4 : intégrer l'automatisation et l'assistance pour les outils
Une fois vos critères, votre processus de triage et vos normes d'enrichissement en place, l'étape suivante consiste à permettre l'escalade sans compter sur des humains pour se souvenir quand et à qui l'escalader. C'est là que les automatisations ClickUp deviennent un élément central de votre flux de travail.

Vous pouvez configurer des possibilités d'automatisation qui réagissent aux mêmes signaux que ceux utilisés par votre équipe lors d'incidents. Voici quelques exemples :
- Si la gravité passe à SEV-1 ➡️ Affectez immédiatement un SRE senior + informez le canal de discussion d'astreinte.
- Si le statut reste inchangé pendant X minutes ➡️ Déclenchez l'escalade au niveau supérieur.
- Si la date d'échéance est dépassée (par exemple, la date limite de confirmation) ➡️ Escaladez vers le niveau 2.
Et c'est là que ClickUp Brain va encore plus loin. Il utilise le contexte de votre environnement de travail pour fournir des réponses instantanées, générer automatiquement des mises à jour et faciliter l'accès aux connaissances.
Utilisez des outils tels que AI Prioritize pour évaluer automatiquement les incidents et définir la priorité appropriée à l'aide de votre propre logique. Exemples d'invites :
- Si l'incident affecte la production et a un impact sur les clients, définissez la priorité : Urgent.
- Si l'équipe SRE est assignée et que les journaux mentionnent une « latence », définissez la priorité sur « Élevée ».
- Si la description comprend des mots-clés liés à la sécurité tels que « violation », définissez la priorité : Urgent.
Une fois la priorité définie, AI Assign prend le relais et attribue automatiquement les incidents en fonction des conditions que vous avez définies.
Vous pouvez créer des invitations telles que :
- Si la priorité est urgente et que le service concerné comprend des « paiements », attribuez la tâche à un SRE senior.
- Si le type d'incident est « base de données » et que la région est « US-East », attribuez-le à DB On-Call.
- Si le nom de la tâche comprend le mot « sécurité », attribuez-la au responsable SecOps.
Testez ces instructions sur les trois premières tâches avant de les appliquer à l'ensemble de la liste.
🚀 Avantage ClickUp : déployez des robots d'automatisation intelligents qui résident dans votre environnement de travail ClickUp et réagissent en temps réel à l'activité grâce aux super agents ClickUp.
Ils connaissent parfaitement vos tâches, vos documents, vos discussions et vos processus, de sorte que chaque action d’automatisation est contextuelle.
Par exemple, vous pouvez placer un Team StandUp Agent dans votre « dossier des incidents de production » afin qu'il publie automatiquement un résumé quotidien chaque matin. Votre équipe reçoit un aperçu instantané indiquant le nombre d'incidents ouverts, ceux qui restent non résolus et les changements survenus au cours des dernières 24 heures.
Associez maintenant cela à un agent Ambient Answers dans votre canal « #incident-room ». Lorsque les intervenants posent des questions telles que « Où se trouve le runbook SEV-1 ? » ou « Cette API a-t-elle déjà connu des défaillances ? », celui-ci puisera dans les connaissances de votre environnement de travail pour fournir des réponses instantanées et précises.

Étape n° 5 : standardiser les canaux de communication
Lorsque les incidents s'aggravent, la manière dont les équipes communiquent et le lieu où elles le font sont tout aussi importants que les personnes qui sont averties. Sans canaux standardisés, les mises à jour se perdent, les décisions sont dupliquées et les parties prenantes reçoivent des informations contradictoires.
Définissez des canaux d'escalade clairs pour chaque étape du cycle de vie des incidents et utilisez-les de manière cohérente dans toutes les équipes :
| Critères | Nom du canal | Objectif |
| SEV-1 ou SEV-2 détecté | #incident-critical | Espace centralisé pour les alertes de gravité élevée et le triage immédiat |
| Dépannage en cours | #incident-warroom | Hub de collaboration en temps réel pour les ingénieurs, les responsables produit, l'assurance qualité et l'assistance technique |
| Visibilité de la direction requise | #incident-leadership | Mises à jour importantes pour les responsables et les cadres dirigeants |
| Communication avec les clients requise | #incident-comms | Espace pour rédiger, réviser et harmoniser les communications avec les clients externes |
| Examen post-incident lancé | #incident-retro | Discussion structurée pour les notes rétrospectives, les enseignements tirés et les éléments à prendre. |
Chaque canal a un public et un objectif bien définis, ce qui aide les équipes à réduire le bruit tout en tenant informées les équipes concernées.
🚀 Avantage ClickUp : adaptez votre stratégie de communication à une couche de communication intégrée à l'aide de ClickUp Chat. Chaque alerte, mise à jour et décision reste directement liée à la tâche, à la liste ou à l'espace où le travail est effectué.
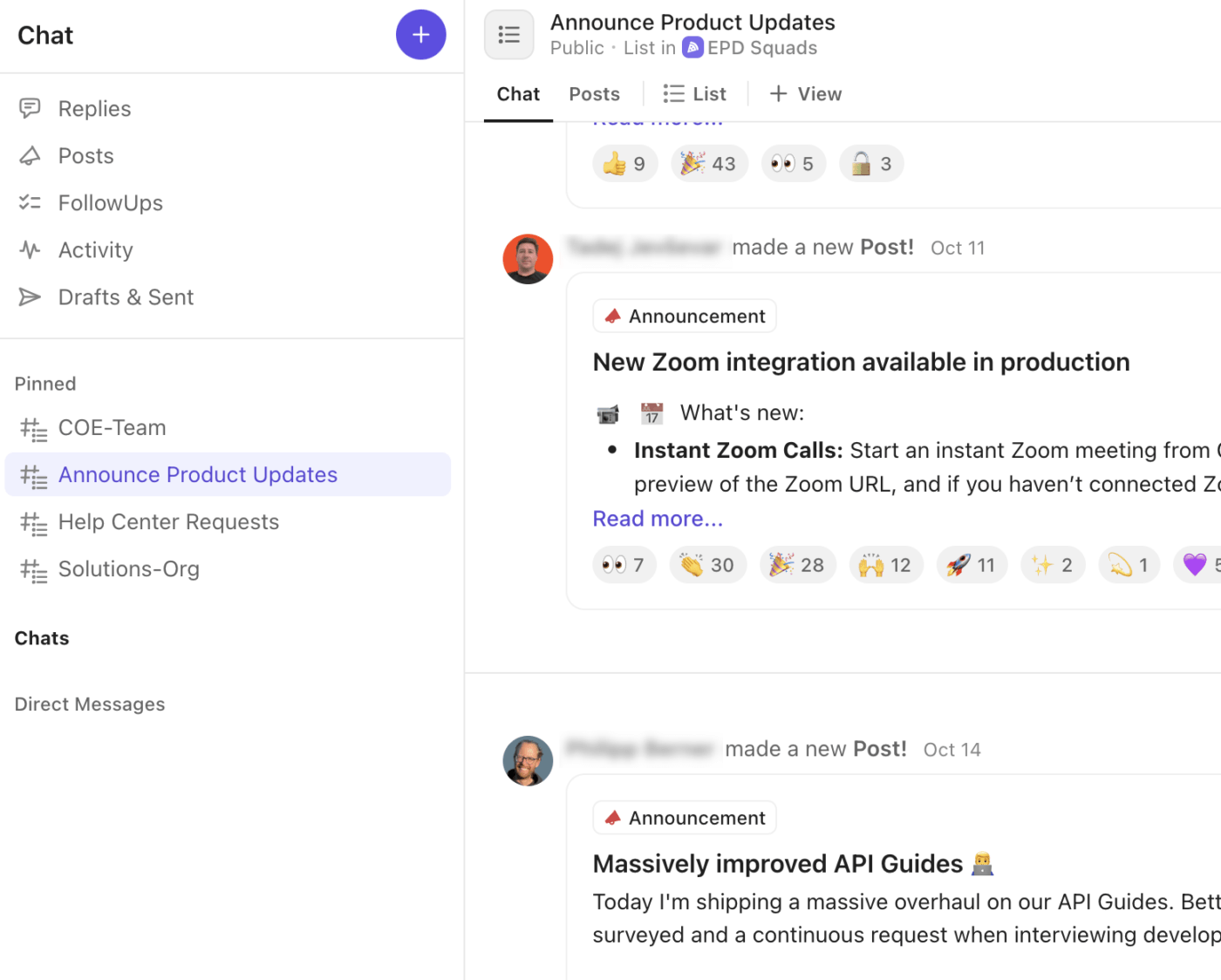
Voici comment ClickUp Chat améliore votre flux de travail en cas d'incident :
- Créez des fils de discussion dédiés pour les discussions critiques, les réunions de crise, les discussions entre dirigeants ou les communications avec les clients.
- Transformez instantanément les messages de chat en tâches ClickUp , afin que les décisions et les suivis ne se perdent pas dans la discussion.
- Passez rapidement à des visioconférences audio ou vidéo avec ClickUp SyncUps pour coordonner les incidents en direct ou organiser des réunions d'information avec la direction.
- Publiez des « annonces » ou des mises à jour pour diffuser le statut général des incidents dans toute l'entreprise.
- Identifiez vos collègues, ajoutez des captures d'écran et joignez des pièces jointes de journaux directement dans le chat, afin de conserver le contexte technique à portée de main.
Étape n° 6 : testez, auditez et affinez votre processus d'escalade
Les politiques d'escalade doivent évoluer avec vos systèmes. Voici ce que vous devez faire régulièrement :
| Activité | Ce qu'il faut tester ou examiner | Pourquoi est-ce important ? |
| Exercices d'alerte d'urgence (trimestriels) | Simulez des incidents P1 et P2, vérifiez le timing et le routage de l'escalade. | Garantit le bon fonctionnement des automatisations et des processus d'escalade en situation de pression. |
| Validation des processus d'escalade | Vérifiez s'il existe des escalades sans issue ou des propriétaires manquants. | Empêche les incidents de stagner sans visibilité |
| Chronomètres pour le processus de reconnaissance et de résolution | Comparez les chronomètres configurés avec les MTTA et MTTR réels. | Gardez un calendrier d'escalade réaliste et efficace. |
| Évaluation de la fatigue liée aux alertes | Identifiez les intervenants qui reçoivent des alertes excessives ou répétées. | Réduit l'épuisement professionnel et les alertes critiques manquées. |
| Précision de la gravité et de la hiérarchisation | Vérifiez si les incidents ont été correctement classés. | Améliore le routage, la vitesse de réponse et la précision de l'escalade. |
| Suivi post-incident | Assurez-vous que les éléments à prendre en compte issus des rétrospectives sont achevés. | Empêche la répétition des incidents et les défaillances systémiques |
Outils et intégrations pour l'automatisation de l'escalade
Cette section vous présente un logiciel de gestion des incidents qui vous aide à détecter plus rapidement les incidents, à les acheminer instantanément et à tenir toutes les équipes informées sans suivi manuel.
1. ClickUp (idéal pour regrouper les escalades interfonctionnelles dans un environnement de travail unique dédié aux incidents)
Les méthodes d'escalade traditionnelles obligent les équipes à jongler entre les e-mails, les feuilles de calcul, les fils de discussion et les notes éparpillées, ce qui rend presque impossible d'avoir une vue claire et en temps réel de ce qui se passe.
Le logiciel de gestion des tâches ClickUp pour la gestion des escalades élimine le bruit en consolidant tous les détails des escalades dans un espace de travail unique et organisé.
Examinons quelques fonctionnalités du logiciel de gestion des actifs informatiques qui font de ClickUp le choix idéal pour les équipes qui gèrent un volume élevé d'escalades et des flux de travail d'incidents complexes.
Travaillez à votre façon
Visualisez vos tâches sous plusieurs angles pour répondre à vos besoins opérationnels grâce à ClickUp Views:
- Vue Liste ClickUp afin que les responsables SRE puissent trier les incidents par gravité, temps restant avant l'échéance du SLA ou groupes d'astreinte pour un triage rapide.
- Cliquez sur la vue Tableau de ClickUp pour permettre aux responsables techniques de visualiser les transferts et la propriété des équipes lors des escalades.
- ClickUp vue Gantt pour les responsables de programme afin de cartographier les jalons importants de la résolution et les dépendances entre les services.
- ClickUp Vue Charge de travail pour les planificateurs d'astreinte qui veillent à ce que les ingénieurs ne soient pas surchargés pendant les périodes de forte activité d'incident.
Transformez les discussions lors des réunions en actions concrètes
Lors des escalades et des examens d'incidents, il peut être difficile de consigner de manière fiable les discussions et les éléments à prendre en compte. Le ClickUp AI Notetaker se joint automatiquement aux réunions programmées dans Google Agenda, Outlook, Zoom ou Teams, enregistrant et transcrivant la discussion.
Après la réunion :
- Accédez aux transcriptions consultables et aux résumés des éléments à prendre en compte.
- Assurez-vous de la clarté des informations grâce aux notes enregistrées dans ClickUp Docs. Cela facilite la création de liens vers les tâches liées aux incidents ou les rapports rétrospectifs.
- Posez des questions à ClickUp AI sur le contenu des réunions afin de clarifier les décisions ou de découvrir les suivis manqués.
Effectuez la connexion aux outils existants dans votre pile technologique
En coulisses, les intégrations ClickUp et l'écosystème de webhooks assurent une connexion transparente avec le reste de votre pile.
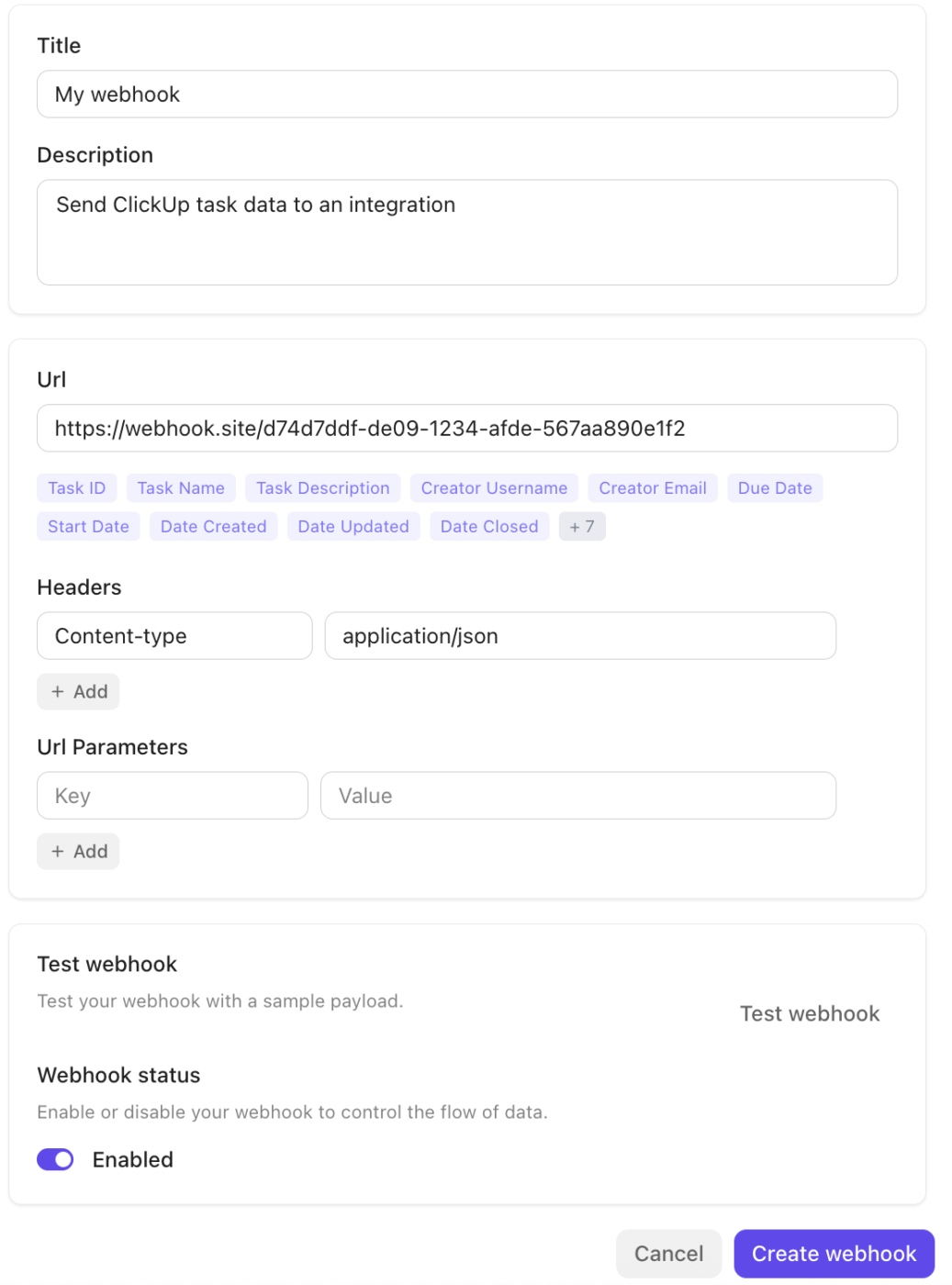
La plateforme s'intègre nativement à des outils tels que Slack, GitHub, Zoom et bien d'autres, et prend en charge les webhooks via son API publique pour diffuser des évènements (mises à jour de tâches et changements de statut) vers des services externes ou des pipelines d'automatisation. Cela facilite le déclenchement de flux de travail, la synchronisation des données ou l'escalade des incidents entre les systèmes sans transfert manuel.
Regroupez tous vos outils d'IA
Pour faire passer l'automatisation et le contexte au niveau supérieur, ClickUp BrainGPT intègre l'IA contextuelle à vos flux de travail d'escalade. Il s'agit d'une super application d'IA contextuelle qui comprend vos tâches, vos documents et votre contexte historique.
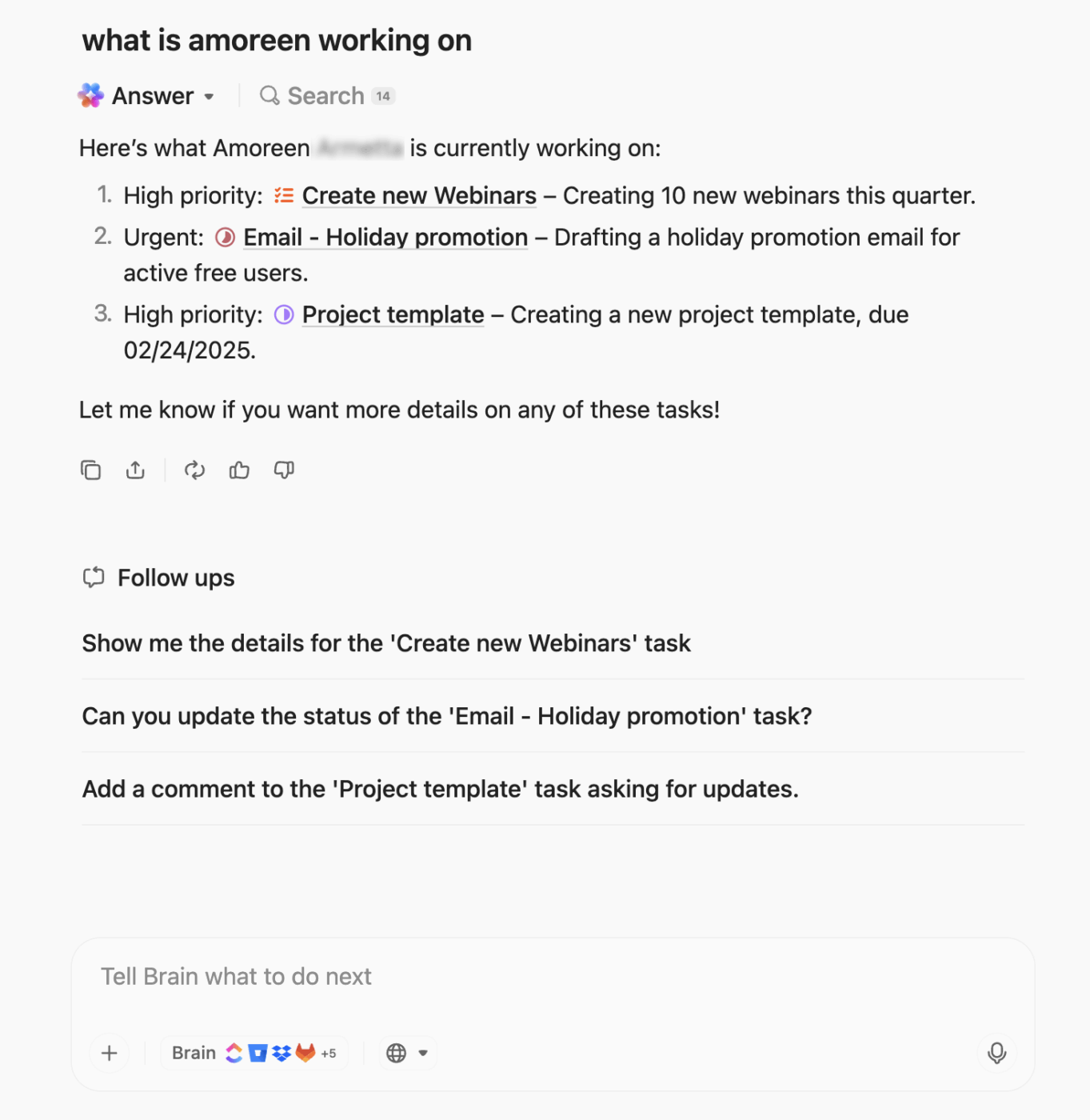
Grâce à Enterprise Search et Connected Apps, vous pouvez instantanément extraire des informations de votre environnement de travail, Slack, Google Drive, GitHub, etc. Lors des appels en direct liés à des incidents, la fonction Talk-to-Text de ClickUp vous permet de dicter des notes ou des instructions d'escalade en mode mains libres, afin de ne rien manquer.
Vous pouvez également standardiser les tâches répétitives à l'aide des invites IA personnalisées et des invites enregistrées, telles que : « Résumez tous les incidents non résolus et recommandez des mesures d'escalade. »
Les meilleures fonctionnalités de ClickUp
- Hiérarchisez les problèmes critiques : utilisez les priorités des tâches ClickUp pour mettre en évidence les escalades urgentes ou à fort impact.
- Organisez des séquences d'escalade complexes : configurez les dépendances des tâches ClickUp pour lier les tâches connexes (par exemple, « En attente » ou « Bloquant ») afin que les étapes d'escalade évitent les actions prématurées ou les goulots d'étranglement.
- Divisez les incidents en éléments exploitables : divisez les escalades en actions granulaires et attribuez-les aux différentes équipes à l'aide de sous-tâches imbriquées.
- Suivez avec précision la vitesse de résolution : enregistrez et surveillez le temps nécessaire pour traiter et résoudre les tâches d'escalade grâce au suivi du temps passé sur les projets de ClickUp.
Limitations de ClickUp
- Avec autant de fonctionnalités, d'affichages et d'options de personnalisation, les équipes doivent souvent passer par une phase d'apprentissage avant que tout ne devienne intuitif.
Tarifs ClickUp
[Tableau des tarifs]
Évaluations et avis sur ClickUp
- G2 : 4,7/5 (plus de 10 300 avis)
- Capterra : 4,6/5 (plus de 4 400 avis)
Que disent les utilisateurs réels à propos de ClickUp ?
Cet avis résume bien la situation :
ClickUp regroupe toutes mes tâches, tous mes projets et toutes mes communications en un seul endroit, ce qui me permet de rester organisé très facilement. J'apprécie particulièrement la personnalisation de tous les éléments, des vues aux flux de travail en passant par les tableaux de bord, qui me permet de structurer mon environnement de travail exactement comme je le souhaite. La possibilité de collaborer en temps réel, d'attribuer des tâches et de suivre la progression sans changer d'outil est un avantage considérable.
ClickUp regroupe toutes mes tâches, tous mes projets et toutes mes communications en un seul endroit, ce qui me permet de rester organisé très facilement. J'apprécie particulièrement la personnalisation de tous les éléments, des vues aux flux de travail en passant par les tableaux de bord, qui me permet de structurer mon environnement de travail exactement comme je le souhaite. La possibilité de collaborer en temps réel, d'attribuer des tâches et de suivre les progrès sans changer d'outil est un avantage considérable.
📮 ClickUp Insight : 21 % des personnes interrogées déclarent consacrer plus de 80 % de leur journée de travail à des tâches répétitives. Et 20 % d'entre elles affirment que les tâches répétitives occupent au moins 40 % de leur journée.
Cela représente près de la moitié de la semaine de travail (41 %) consacrée à des tâches qui ne nécessitent pas beaucoup de réflexion stratégique ou de créativité (comme les e-mails de suivi 👀).
Les super agents de ClickUp vous aident à éliminer cette corvée. Pensez à la création de tâches, aux rappels, aux mises à jour, aux notes de réunion, à la rédaction d'e-mails et même à la création de flux de travail de bout en bout ! Tout cela (et bien plus encore) peut être automatisé en un clin d'œil avec ClickUp, votre application tout-en-un pour le travail.
💫 Résultats concrets : Lulu Press gagne 1 heure par jour et par employé grâce à ClickUp Automatisations, ce qui se traduit par une augmentation de 12 % de l'efficacité au travail.
2. PagerDuty (idéal pour les alertes en temps réel et les réponses intelligentes en cas d'appel)
PagerDuty est une plateforme cloud de gestion des incidents informatiques et des opérations numériques qui aide les équipes à détecter, traiter et résoudre rapidement les incidents critiques tels que les pannes ou les menaces de sécurité. Elle offre aux responsables SRE, DevOps et d'assistance une voie claire, du signalement à la résolution, grâce à l'automatisation, au triage basé sur l'IA et à des flux de travail profondément intégrés.
Des fonctionnalités telles que Jeli Incident Analysis, PagerDuty Analytics et Runbook Automatisation aident les équipes à réduire les temps d'arrêt, à éliminer les tâches routinières et à tirer des enseignements de chaque incident.
Les meilleures fonctionnalités de PagerDuty
- Automatisez le routage des incidents grâce à la fonctionnalité intégrée Gestion des astreintes et aux politiques d'escalade dynamiques.
- Accélérez le triage à l'aide d'AIOps, qui filtre les alertes parasites, corrèle les évènements et met en évidence les signaux réels.
- Assurez la coordination entre les parties prenantes internes et externes grâce à Stakeholder Comms, Modèles d'actualisation du statut et Pages de statut.
- Unifiez votre pile d'outils grâce à plus de 700 intégrations et API extensibles utilisant des systèmes de surveillance, de journalisation, de CI/CD et d'assistance.
Limitations de PagerDuty
- Volume d'alertes élevé si les intégrations et les seuils intelligents ne sont pas ajustés, ce qui entraîne du bruit et de la fatigue.
- Des alertes en double ou répétées peuvent se produire pendant les pics d'activité, ce qui rend la confirmation plus difficile sous la pression.
Tarifs PagerDuty
- Free
- Professionnel : 25 $/mois par utilisateur
- Business : 49 $/mois par utilisateur
- Enterprise : tarification personnalisée
Évaluations et avis sur PagerDuty
- G2 : 4,5/5 (plus de 900 avis)
- Capterra : 4,6/5 (plus de 200 avis)
Que disent les utilisateurs réels à propos de PagerDuty ?
Selon les mots d'un utilisateur réel:
PagerDuty rend les alertes d'incident rapides et fiables. Il envoie les bonnes notifications au bon moment et permet à notre équipe de rester organisée. […] PagerDuty peut parfois sembler bruyant lorsque les alertes ne sont pas bien filtrées. Certains paramètres sont un peu complexes pour les nouveaux utilisateurs.
PagerDuty rend les alertes d'incident rapides et fiables. Il envoie les bonnes notifications au bon moment et permet à notre équipe de rester organisée. […] PagerDuty peut parfois sembler bruyant lorsque les alertes ne sont pas bien filtrées. Certains paramètres sont un peu complexes pour les nouveaux utilisateurs.
💡 Conseil de pro : Créez des exceptions, même dans un chemin d'escalade clair. Faites en sorte que les pannes critiques, les alertes de sécurité ou les incidents dans un environnement réglementé soient directement transmis aux intervenants seniors ou spécialisés.
3. GLPi (Idéal pour la gouvernance des actifs de bout en bout et les opérations de service alignées sur ITIL)
Gestionnaire Libre de Parc Informatique (GLPi) est une plateforme open source complète de gestion des services informatiques (ITSM) et des actifs informatiques (ITAM). Les équipes bénéficient d'une visibilité de bout en bout sur leur infrastructure (matériel, logiciels, licences et périphériques réseau) et peuvent gérer les incidents, les demandes de service et les changements à l'aide de processus conformes à l'ITIL.
Tous vos contrats et documents, y compris les garanties et les contrats de service, restent parfaitement organisés, ce qui évite qu'ils ne se perdent entre différents systèmes. Si vous gérez des centres de données, GLPi vous permet même de visualiser les dispositions, les chemins de câblage et la consommation d'énergie afin que vous sachiez toujours ce qui se passe en coulisses.
Les meilleures fonctionnalités de GLPi
- Utilisez les plugins GLPI Inventory, OCS Inventory ou FusionInventory pour détecter et cataloguer automatiquement les nouveaux actifs informatiques.
- Automatisez les tâches répétitives, l'attribution des tickets, les notifications et les évènements récurrents afin de réduire le travail manuel.
- Créez une base de connaissances pour les FAQ, la documentation et les articles liés aux tickets afin de faciliter le libre-service et l'assistance technique.
- Connectez-vous à Azure/Entra, Centreon, Google, OAuth2 et aux webhooks pour synchroniser les données, déclencher des flux de travail et améliorer votre CMDB.
Limitations de GLPi
- La compatibilité des plugins peut être compromise entre les versions, ce qui entraîne des frais de maintenance supplémentaires.
- Les fonctionnalités de rapports, d'analyse et d'exportation semblent limitées et doivent être améliorées.
Tarifs GLPi
- Tarification personnalisée
Évaluations et avis sur GLPi
- G2 : 4,6/5 (plus de 30 avis)
- Capterra : 4,5/5 (plus de 40 avis)
Que disent les utilisateurs réels à propos de GLPi ?
Voici ce qu'un utilisateur avait à dire :
Système open source très personnalisable de gestion des actifs informatiques et de tickets d'assistance, bénéficiant d'une large communauté d'assistance. L'interface utilisateur est un peu compliquée pour un novice. Les plugins ne sont pas toujours pris en charge d'une ancienne version à une nouvelle.
Système open source très personnalisable de gestion des actifs informatiques et de tickets d'assistance, bénéficiant d'une large communauté d'assistance. L'interface utilisateur est un peu compliquée pour un novice. Les plugins ne sont pas toujours pris en charge d'une ancienne version à une nouvelle.
4. Splunk On-Call (idéal pour acheminer les alertes de surveillance directement vers les ingénieurs)
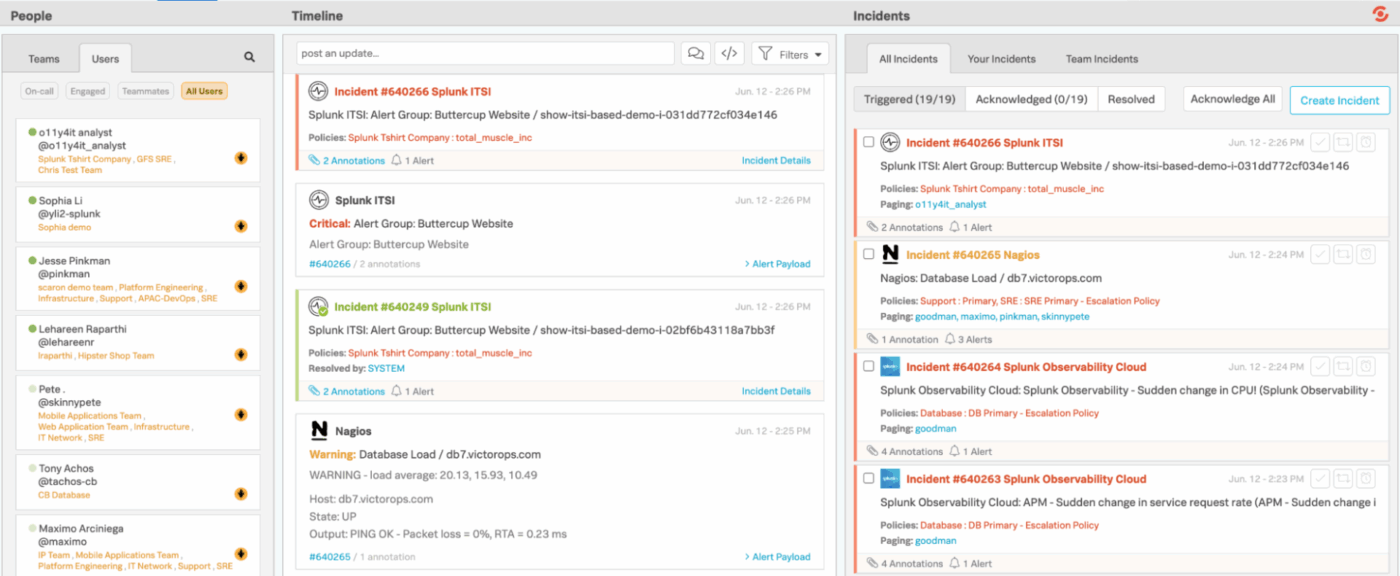
Splunk On-Call offre aux équipes d'ingénieurs et d'astreinte un moyen plus rapide et plus efficace de gérer les incidents, éliminant ainsi les flux de travail traditionnels et lents de gestion des tickets. Au lieu d'envoyer les alertes dans une file d'attente générique, il s'intègre directement à votre pile de surveillance et d'observabilité, acheminant immédiatement les problèmes vers les bonnes personnes en fonction des calendriers, des règles et du contexte.
Les intégrations mobiles et de chat facilitent la prise en compte, le réacheminement ou la résolution des incidents depuis n'importe où. En coulisses, Splunk On-Call conserve un enregistrement détaillé des tendances, des modèles éprouvés et des comportements d'escalade.
Les meilleures fonctionnalités de Splunk On-Call
- Développez les capacités de la plateforme grâce à plus de 1 000 intégrations et modules complémentaires vérifiés provenant de Splunk et de la communauté au sens large.
- Créez des tableaux de bord personnalisés et des rapports visuels pour surveiller le volume des alertes, l'état des incidents, les performances des intervenants et la charge de travail de l'équipe.
- Filtrez rapidement les incidents en fonction de votre propre activité, des incidents de votre équipe ou de tout ce qui se passe dans l'organisation.
- Passez d'une vue Déclenché à une vue Confirmé ou Résolu pour voir où en est chaque incident.
Limitations de Splunk On-Call
- La planification des équipes peut s'avérer compliquée si les règles ne sont pas prédéfinies.
- Capacité limitée à générer des rapports d'incidents détaillés et classés par date
Tarifs Splunk On-Call
- Tarification personnalisée
Évaluations et avis sur Splunk On-Call
- G2 : 4,6/5 (plus de 40 avis)
- Capterra : 4,5/5 (plus de 30 avis)
Que disent les utilisateurs réels à propos de Splunk On-Call ?
Un utilisateur l'a résumé ainsi :
La possibilité de gérer les incidents, les escalades et de prendre le relais de mes collègues depuis l'application mobile est géniale. […] J'aimerais pouvoir programmer des dérogations et modifier les plannings habituels depuis l'application mobile en cas de changements de planning urgents.
La possibilité de gérer les incidents, les escalades et de prendre le relais de mes collègues depuis l'application mobile est géniale. […] J'aimerais pouvoir programmer des dérogations et modifier les plannings habituels depuis l'application mobile en cas de changements de planning urgents.
🔍 Le saviez-vous ? La logique consistant à « acheminer l'appel vers la bonne personne si le premier niveau échoue » trouve son origine dans les premiers centraux téléphoniques : lorsque les opérateurs manuels ne parvenaient pas à réaliser une connexion pour un appel, le système l'acheminait (ou l'escaladait) vers un autre opérateur ou central.
5. ServiceNow (idéal pour orchestrer à l'échelle de l'entreprise grâce à l'automatisation assistée par l'IA)
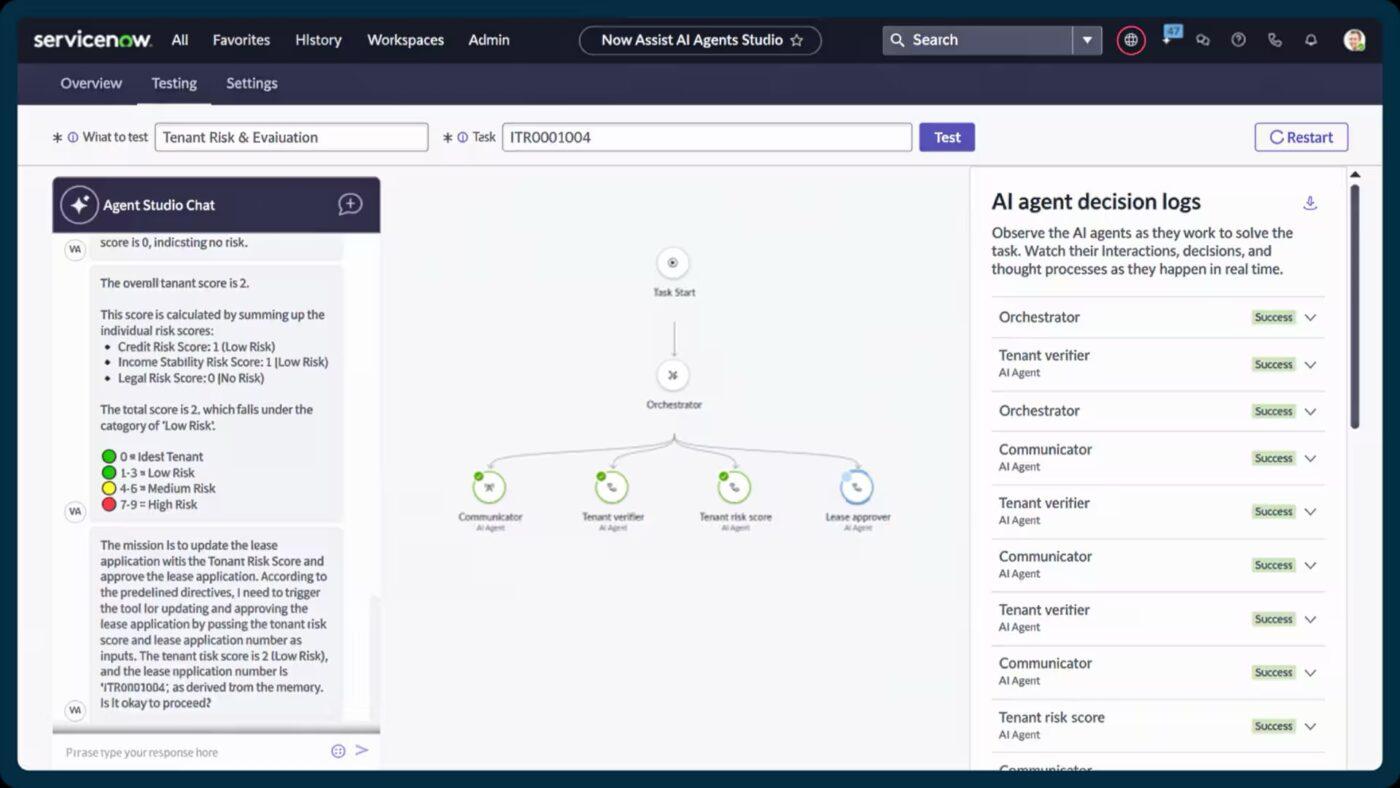
ServiceNow classe, hiérarchise et achemine automatiquement les incidents dès leur enregistrement. Grâce à des fonctionnalités telles que Now Assist pour les recommandations automatisées de tickets d'incident et la génération intelligente de contenu, les intervenants peuvent résoudre les problèmes plus rapidement et avec plus de contexte.
Il regroupe la gestion des incidents, des changements et des actifs. Ainsi, vous obtenez une vue en temps réel de la manière dont les services sont connectés, des goulots d'étranglement et des composants susceptibles de contribuer à des perturbations récurrentes.
Les meilleures fonctionnalités de ServiceNow
- Attribuez, acheminer et surveillez les tâches sur le terrain grâce à Field Service Management et Dispatcher Workspace.
- Donnez plus d'autonomie à vos employés et à vos clients grâce à un portail en libre-service optimisé par IA Search et des agents virtuels.
- Utilisez les flux de travail intégrés et les outils low-code d'App Engine pour étendre ou personnaliser les processus de service.
- Automatisez les tâches répétitives et les flux de travail entre les équipes grâce à Flow Designer et Automation Engine.
Limitations de ServiceNow
- L'interface utilisateur et les options de personnalisation du portail semblent obsolètes ou restrictives.
- Forte dépendance vis-à-vis du personnel qualifié ou des consultants pour la mise en œuvre
Tarifs ServiceNow
- Tarification personnalisée
Évaluations et avis sur ServiceNow
- G2 : 4,4/5 (plus de 3 300 avis)
- Capterra : 4,5/5 (plus de 300 avis)
Que disent les utilisateurs réels à propos de ServiceNow ?
Voici comment un utilisateur l'a formulé :
[…] Les flux prédéfinis sont un autre point fort pour moi, car ils rationalisent les processus et permettent un gain de temps considérable, en minimisant le besoin de configurations personnalisées et en permettant un flux de travail plus fluide et plus efficace. […] De plus, j'ai eu des difficultés à intégrer ma solution personnalisée dans le système de gestion du service client, ce qui a nécessité de nombreuses itérations.
[…] Les flux prédéfinis sont un autre point fort pour moi, car ils rationalisent les processus et permettent un gain de temps considérable, en minimisant le besoin de configurations personnalisées et en permettant un flux de travail plus fluide et plus efficace. […] De plus, j'ai eu des difficultés à intégrer ma solution personnalisée dans le système de gestion du service client, ce qui a nécessité de nombreuses itérations.
Bonnes pratiques et gouvernance
Voici quelques bonnes pratiques qui garantissent la précision de l'automatisation, évitent la fatigue liée aux alertes et répondent aux attentes de l'entreprise et des autorités réglementaires.
- Définissez des critères d'escalade non négociables : associez les déclencheurs à des signaux mesurables tels que les violations des SLO, les pics d'anomalies, l'impact sur les niveaux de clientèle ou la sensibilité réglementaire.
- Définissez clairement les rôles à chaque niveau : utilisez une carte RACI simple pour chaque niveau d'escalade afin que les responsabilités ne soient jamais ambiguës lors d'incidents à forte pression.
- Appliquez une gouvernance dynamique des astreintes : ajustez automatiquement les processus d'escalade en fonction des week-ends, des jours fériés, des limites de capacité et des transferts afin de réduire l'épuisement professionnel et d'éviter les pages silencieuses.
- Insérez des points de contrôle humains pour les scénarios à haut risque : même avec l'automatisation, imposez une confirmation manuelle pour les incidents impliquant l'exposition des données clients, les paiements ou les flux de travail réglementés.
- Conservez des pistes d'audit complètes : conservez des journaux immuables indiquant qui a été alerté, quand la personne a accusé réception, quelles étapes d'automatisation ont été déclenchées et quelles décisions ont été prises.
🧠 Anecdote amusante : la plus ancienne plainte écrite connue au monde a été gravée sur une tablette d'argile vers 1750 avant J.-C. Il s'agissait essentiellement d'une escalade précoce du statut d'un projet. Un client nommé Nanni a écrit au marchand Ea-nāṣir, furieux que le cuivre qu'il avait reçu était de qualité inférieure à celle promise et que son messager avait été maltraité.
Défis courants et comment les surmonter
Même avec une politique d'escalade claire, les équipes sont souvent confrontées à des obstacles opérationnels qui ralentissent la réponse aux incidents ou créent de la confusion.
Ce tableau met en évidence les défis courants qui vont au-delà des étapes d’installation de base et fournit des stratégies concrètes pour les surmonter.
| Défis ❌ | Solutions ✅ |
| Contexte incohérent lors des transferts | Utilisez les modèles de liaison de tâches et de rapport d'incident de ClickUp pour conserver une piste d'audit complète des détails de l'incident, des systèmes affectés et des actions précédentes à chaque niveau d'escalade. |
| Surcharger les intervenants avec des alertes de faible priorité | Mettez en place une hiérarchisation dynamique grâce aux champs personnalisés ClickUp et à l'IA Prioritize pour filtrer les incidents en fonction de leur gravité, de leur impact et des seuils SLA. |
| Manque de visibilité entre les équipes | Configurez des environnements de travail partagés, ajoutez des commentaires et créez des tableaux blancs ClickUp visuels pour présenter des mises à jour en temps réel aux parties prenantes. |
| Retard dans la prise de décision lors d'incidents critiques | Automatisez les notifications à l'aide des actions suggérées de ClickUp Brain Max pour alerter instantanément le personnel concerné en fonction du type d'incident, de sa gravité et des tendances historiques. |
| Difficulté au suivi des problèmes récurrents | Tirez parti des modèles de rapports personnalisés et des tâches récurrentes de ClickUp pour identifier les schémas, les causes profondes et les incidents récurrents afin de les prévenir de manière proactive. |
| Connaissances fragmentées lors de l'escalade | Conservez vos procédures opératoires normalisées, vos manuels d'intervention et vos documents relatifs aux incidents dans ClickUp Docs, en les liant aux tâches pertinentes pour pouvoir les consulter instantanément lors des escalades en direct. |
| Responsabilités mal réparties entre les équipes | Utilisez les vues Charge de travail et Échéancier de ClickUp pour visualiser les affectations et vous assurer qu'il n'y a pas de chevauchements ou de lacunes lors des changements d'équipe ou des transferts. |
| Suivi manuel de la conformité et lacunes en matière d'audit | Automatisez les résumés prêts pour l'audit avec ClickUp Brain afin d'enregistrer toutes les actions, notifications et résolutions liées aux incidents. |
Mesurer l'impact de l'escalade automatisée
Pour suivre l'efficacité de l'escalade automatisée, il faut se concentrer sur des indicateurs clés tels que le volume, l'efficacité et la qualité. Ces indicateurs révèlent si vos processus d'escalade sont plus rapides, plus précis et moins frustrants pour les équipes et les clients.
Suivez ces indicateurs :
- Taux d'escalade (volume) : pourcentage de problèmes escaladés au-delà du premier niveau. Des taux élevés peuvent indiquer des lacunes dans le triage initial ou les bases de connaissances.
- Taux de remontée répété (volume) : fréquence à laquelle le même problème est remonté plusieurs fois. Indique des résolutions incomplètes ou une perte de contexte.
- Délai d'escalade (efficacité) : durée entre la détection et l'escalade. Plus la durée de chaque étape est courte, plus l'automatisation de la reconnaissance des problèmes critiques est rapide.
- Délai de transfert (efficacité) : écart entre l'escalade et le moment où l'équipe suivante commence à effectuer du travail afin de mettre en évidence les frictions au niveau du routage ou de la notification.
- Temps de résolution des cas escaladés (efficacité) : temps total entre l'escalade et la résolution. Une résolution plus rapide démontre l'efficacité de l'automatisation.
- Score de satisfaction client (CSAT) (qualité) : commentaires sur les interactions escaladées afin de mesurer la fluidité du processus.
- Transfert du contexte (qualité) : les agents reçoivent-ils l'historique complet de l'incident afin de s'assurer que les clients ne répètent pas les informations ?
- Résolution au premier contact (FCR) (qualité) : pourcentage de problèmes résolus en une seule interaction.
🚀 Avantage ClickUp : obtenez des informations en temps réel, visuelles et alimentées par l'IA sur tous les indicateurs d'escalade grâce aux tableaux de bord ClickUp.
Vous pouvez suivre les tendances d'escalade, les goulots d'étranglement et les performances à l'aide des cartes Tableau, Tarte, Barre, Ligne, Calcul et Rapport temporel. Surveillez le taux d'escalade, les escalades répétées et le délai d'escalade à l'aide de cartes liées aux tâches, aux champs personnalisés et aux statuts.
Pour aller plus loin, utilisez des cartes IA telles que AI Résumé, AI Actualisation du projet et Compte rendu par l'IA pour mettre en évidence les tendances, les retards et les résultats des résolutions.
Gérez vos incidents plus rapidement avec ClickUp
Beaucoup pensent que l'escalade des incidents consiste simplement à transmettre un ticket à la personne suivante, mais c'est bien plus que cela. Il s'agit d'un système structuré où chaque étape, du triage à la résolution, fonctionne en harmonie.
ClickUp vous offre un espace de travail unifié idéal. Grâce à ClickUp Automations, vous pouvez déclencher des alertes, acheminer des tâches et mettre à jour les statuts automatiquement. Et ClickUp Brain vous aide à hiérarchiser les incidents, générer des résumés et suggérer les prochaines étapes.
Les agents ClickUp AI agissent comme des assistants intelligents au sein de votre environnement de travail, tandis que les tableaux de bord ClickUp fournissent une vue en direct de vos escalades.
Inscrivez-vous gratuitement à ClickUp dès aujourd'hui !
Foire aux questions (FAQ)
Un processus d'escalade des incidents est une séquence prédéfinie d'étapes qui détermine comment les problèmes sont acheminés vers la bonne équipe ou la bonne personne en fonction de leur gravité, de leur impact et du moment où ils surviennent. Il garantit que les incidents sont traités efficacement et que les responsabilités sont clairement définies. TEXTE
Utilisez l'automatisation pour les incidents bien définis et à haute priorité avec des critères clairs (par exemple, les interruptions de service, les failles de sécurité). Réservez l'escalade manuelle aux situations ambiguës ou critiques qui nécessitent un jugement humain ou un contexte supplémentaire.
Des plateformes telles que ClickUp, PagerDuty, Jira Service Management et ServiceNow permettent l'automatisation du routage, des notifications et des mises à jour. Elles aident les équipes à réduire les retards et à maintenir des flux de travail structurés pour la gestion des incidents.
Définissez des seuils clairs pour les alertes, hiérarchisez-les en fonction de leur gravité et utilisez des notifications intelligentes. Limitez les notifications répétées aux incidents critiques et utilisez des tableaux de bord ou des outils d'IA pour résumer les mises à jour plutôt que d'envoyer chaque modification mineure.
Réexaminez régulièrement les politiques d'escalade, au moins une fois par trimestre ou après chaque incident majeur. Cela permet de s'assurer que les critères, les responsabilités et les règles d'automatisation reflètent les flux de travail, les structures d'équipe et les priorités de l'entreprise actuelles.