
La mayoría de los proyectos de implementación de IA fracasan no porque los equipos elijan el modelo equivocado, sino porque tres meses después nadie recuerda por qué lo eligieron o cómo replicar la configuración, lo que hace que el 46 % de los proyectos de IA se descarten entre la prueba de concepto y la adopción generalizada.
Esta guía le muestra cómo utilizar Hugging Face para la implementación de IA, desde la selección y prueba de modelos hasta la gestión del proceso de implementación, para que su equipo pueda entregar más rápido sin perder decisiones críticas en hilos de Slack y hojas de cálculo dispersas.
¿Qué es Hugging Face?
Hugging Face es una plataforma de código abierto y un hub comunitario que proporciona modelos de IA preentrenados, conjuntos de datos y herramientas para crear e implementar aplicaciones de aprendizaje automático.
Piense en ello como una enorme biblioteca digital en la que puede encontrar modelos de IA listos para usar, en lugar de dedicar meses y recursos significativos a crearlos desde cero.
Está diseñado para ingenieros de aprendizaje automático y científicos de datos, pero sus herramientas son cada vez más utilizadas por equipos multifuncionales de producto, diseño e ingeniería para integrar la IA en sus flujos de trabajo.
¿Sabía que... el 63 % de las organizaciones carecen de prácticas adecuadas de gestión de datos para la IA? Esto suele provocar el estancamiento de los proyectos y el desperdicio de recursos.
El principal reto para muchos equipos es la gran complejidad que entraña la implementación de la IA. El proceso implica la selección del modelo adecuado entre miles de opciones, la gestión de la infraestructura subyacente, la versión de los experimentos y la garantía de la coordinación entre las partes interesadas técnicas y no técnicas.
Hugging Face simplifica este proceso gracias a su Model Hub, un repositorio central con más de 2 millones de modelos. La biblioteca de transformadores de la plataforma es la clave que desbloquea estos modelos, permitiéndole cargarlos y utilizarlos con solo unas pocas líneas de código Python.
Sin embargo, incluso con estas potentes herramientas, la implementación de IA sigue siendo un reto para la gestión de proyectos, ya que requiere un seguimiento minucioso de la selección, las pruebas y la puesta en marcha de los modelos para garantizar el éxito.
📮ClickUp Insight: El 92 % de los trabajadores del conocimiento corren el riesgo de perder decisiones importantes dispersas en chats, correos electrónicos y hojas de cálculo. Sin un sistema unificado para capturar y realizar el seguimiento de las decisiones, la información empresarial crítica se pierde en el ruido digital.
Con las funciones de gestión de tareas de ClickUp, nunca tendrá que preocuparse por esto. Cree tareas a partir de chats, comentarios de tareas, documentos y correos electrónicos con un solo clic.
Modelos de Hugging Face que puede implementar
Navegar por Hugging Face Hub puede resultar abrumador cuando se empieza. Con cientos de miles de modelos, la clave es comprender las categorías principales para encontrar el más adecuado para su proyecto. Los modelos van desde opciones pequeñas y eficientes diseñadas para un único propósito hasta modelos masivos y de uso general que pueden manejar razonamientos complejos.
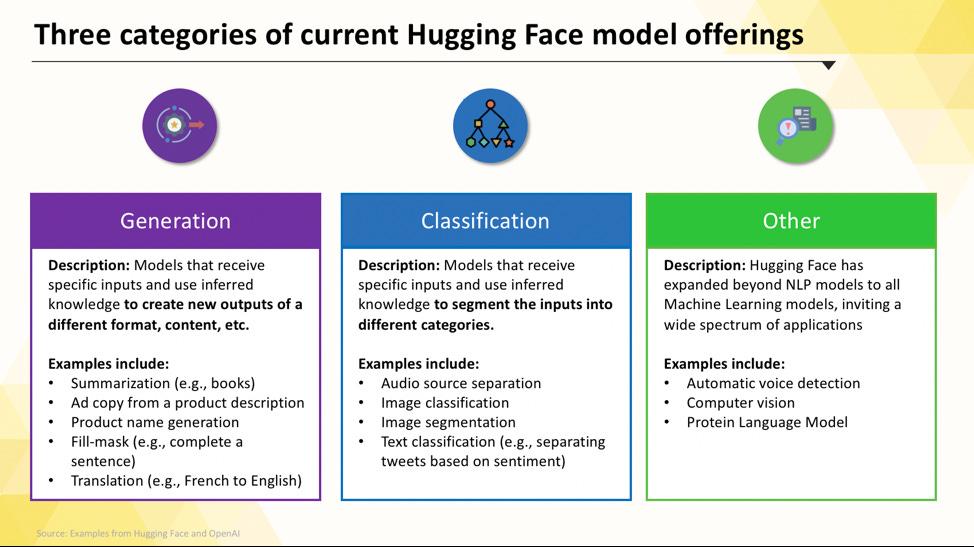
Modelos de lenguaje específicos para cada tarea
Cuando su equipo necesita resolver un problema único y bien definido, a menudo no se necesita un modelo masivo y de uso general. El tiempo y el coste de ejecutar un modelo de este tipo pueden ser prohibitivos, especialmente cuando una herramienta de IA más pequeña y específica funcionaría mejor. Aquí es donde entran en juego los modelos específicos para cada tarea.
Se trata de modelos que han sido entrenados y optimizados para una función concreta. Al ser especializados, suelen ser más pequeños, más rápidos y más eficientes en cuanto a recursos que sus homólogos de mayor tamaño.
Esto los hace ideales para entornos de producción en los que la velocidad y el coste son factores importantes. Muchos pueden incluso ejecutarse en hardware de CPU estándar, lo que los hace accesibles sin necesidad de costosas GPU.
Entre los tipos más comunes de modelos específicos para tareas concretas se incluyen:
- Clasificación de texto: utilícelo para categorizar el texto en etiquetas predefinidas, como clasificar los comentarios de los clientes en categorías «positivas» o «negativas» o etiquetar los tickets de soporte por tema.
- Análisis de sentimientos: le ayuda a determinar el tono emocional de un texto, lo que resulta útil para supervisar la marca en las redes sociales.
- Reconocimiento de entidades nombradas: extraiga entidades específicas, como personas, lugares y organizaciones, de documentos para ayudar a estructurar datos no estructurados.
- Resumir: Condense artículos o informes largos en resúmenes concisos, ahorrando a su equipo un valioso tiempo de lectura.
- Traducción: Convierta texto de un idioma a otro automáticamente.
📚 Lea también: Cómo utilizar Hugging Face para resumir textos.
Modelos de lenguaje grandes
A veces, su proyecto requiere algo más que una simple clasificación o resumen. Es posible que necesite una IA que pueda generar textos de marketing creativos, escribir código o responder a preguntas complejas de los usuarios de forma conversacional. Para estos casos, lo más probable es que recurra a un modelo de lenguaje grande (LLM).
Los LLM son modelos con miles de millones de parámetros entrenados con grandes cantidades de texto y datos de Internet. Este entrenamiento exhaustivo les permite comprender matices, contextos y razonamientos complejos. Entre los LLM de código abierto más populares disponibles en Hugging Face se incluyen modelos de las familias Llama, Mistral y Falcon.
La contrapartida de esta potencia es la gran cantidad de recursos informáticos que requieren. La implementación de estos modelos casi siempre requiere potentes GPU con mucha memoria (VRAM).
Para que sean más accesibles, puede utilizar técnicas como la cuantificación, que reduce el tamaño del modelo con un pequeño coste en rendimiento, lo que permite ejecutarlo en hardware menos potente.
📚 Lea también: ¿Qué son los agentes LLM en IA y cómo funcionan?
Modelos de texto a imagen y multimodales.
Sus datos no siempre son solo texto. Es posible que su equipo necesite generar imágenes para una campaña de marketing, transcribir el audio de una reunión o comprender el contenido de un vídeo. Aquí es donde los modelos multimodales, diseñados para funcionar con diferentes tipos de datos, se vuelven esenciales.
El tipo de modelo multimodal más popular es el modelo de texto a imagen, que genera imágenes a partir de un texto. Modelos como Stable Diffusion utilizan una técnica llamada difusión para crear impresionantes imágenes a partir de simples indicaciones. Pero las posibilidades van mucho más allá de la generación de imágenes.
Otros modelos multimodales comunes que puede implementar desde Hugging Face incluyen:
- Subtítulos de imágenes: genere automáticamente texto descriptivo para las imágenes, lo que resulta muy útil para la accesibilidad y la gestión de contenido.
- Reconocimiento de voz: transcriba audio hablado a texto escrito con modelos como Whisper de OpenAI.
- Respuesta visual a preguntas: haga preguntas sobre una imagen y obtenga una respuesta en forma de texto, como «¿De qué color es el coche de esta foto?».
Al igual que los LLM, estos modelos requieren un gran esfuerzo computacional y suelen necesitar una GPU para funcionar de manera eficiente.
Para ver cómo estos diferentes tipos de modelos de IA se traducen en aplicaciones empresariales prácticas, vea esta panorámica de casos de uso de IA en el mundo real en diversas industrias y funciones.
¿Cuál es el nivel de madurez de la IA en su organización?
Nuestra encuesta a 316 profesionales revela que la verdadera transformación de la IA requiere algo más que la simple adopción de funciones de IA. Realice la evaluación de madurez de la IA para ver en qué punto se encuentra su organización y qué puede hacer para mejorar su puntuación.
Cómo ajustar Hugging Face para la implementación de IA
Antes de poder implementar su primer modelo, debe configurar correctamente su entorno local y su cuenta de Hugging Face. Es una frustración común para los equipos cuando los diferentes miembros tienen configuraciones inconsistentes, lo que lleva al clásico problema de «funciona en mi máquina». Dedicar unos minutos a estandarizar este proceso ahorra horas de resolución de problemas más adelante.
- Cree una cuenta en Hugging Face y genere un token de acceso. En primer lugar, regístrese para obtener una cuenta gratuita en el sitio web de Hugging Face. Una vez que haya iniciado sesión, vaya a su perfil, haga clic en «Ajustes» y, a continuación, vaya a la pestaña «Tokens de acceso». Genere un nuevo token con al menos permisos de «lectura»; lo necesitará para descargar modelos.
- Instale las bibliotecas Python necesarias. Abra su terminal e instale las bibliotecas básicas que necesitará. Las dos imprescindibles son transformers y huggingface_hub. Puede instalarlas utilizando pip: pip install transformers huggingface_hub
- Configure la autenticación. Para utilizar su token de acceso, puede iniciar sesión a través de la línea de comandos ejecutando huggingface-cli login y pegando su token cuando se le indique, o puede configurarlo como una variable de entorno en su sistema. El inicio de sesión desde la línea de comandos suele ser la forma más fácil de empezar.
- Verifique la configuración. La mejor manera de confirmar que todo funciona es ejecutar un código sencillo. Intente cargar un modelo básico utilizando la función pipeline de la biblioteca transformers. Si se ejecuta sin errores, ya está listo para empezar.
Tenga en cuenta que algunos modelos del hub están «restringidos», lo que significa que debe aceptar los términos de la licencia en la página del modelo antes de poder acceder a ellos con su token.
Además, recuerde que el seguimiento de quién tiene qué credenciales y qué configuraciones de entorno se están utilizando es una tarea de gestión de proyectos en sí misma, y se vuelve más crítica a medida que su equipo crece.
🌟 Si está integrando modelos de Hugging Face en sistemas de software más amplios, la plantilla de integración de software de ClickUp le ayuda a visualizar los flujos de trabajo y realizar el seguimiento de las integraciones técnicas de varios pasos.
La plantilla le proporciona un sistema fácil de seguir en el que podrá:
- Visualice las conexiones entre diferentes soluciones de software.
- Cree y asigne tareas a los miembros del equipo para facilitar la colaboración.
- Organice todas las tareas relacionadas con la integración en un solo lugar.
Opciones de implementación para los modelos de Hugging Face
Una vez que haya probado un modelo localmente, la siguiente pregunta es: ¿dónde se alojará? Implementar un modelo en un entorno de producción donde otros puedan utilizarlo es un paso fundamental, pero las opciones pueden resultar confusas. Elegir la ruta equivocada puede provocar un rendimiento lento, costes elevados o la incapacidad de gestionar el tráfico de usuarios.
Su elección dependerá de sus necesidades específicas, como el tráfico previsto, el presupuesto y si está creando un prototipo rápido o una aplicación escalable y lista para la producción.
Hugging Face espacios
Si necesita crear rápidamente una demostración o una herramienta interna, Hugging Face Spaces suele ser la mejor opción. Spaces es una plataforma gratuita para alojar aplicaciones de aprendizaje automático, y es perfecta para crear prototipos que puede usar de forma compartida con su equipo o con las partes interesadas.
Puede crear la interfaz de usuario de su aplicación utilizando marcos populares como Gradio o Streamlit, lo que facilita la creación de demostraciones interactivas con solo unas pocas líneas de Python.
Crear un espacio es tan sencillo como seleccionar su SDK preferido, establecer una conexión con un repositorio Git y elegir su hardware. Aunque Spaces ofrece un nivel de CPU gratis para aplicaciones básicas, puede actualizar a hardware GPU de pago para modelos más exigentes.
Tenga en cuenta los límites:
- No apto para API con mucho tráfico: Espacios está diseñado para demostraciones, no para atender miles de solicitudes API simultáneas.
- Arranques en frío: si su espacio está inactivo, puede «entrar en suspensión» para ahorrar recursos, lo que provoca un retraso para el primer usuario que vuelve a acceder a él.
- Flujo de trabajo basado en Git: todo el código de su aplicación se gestiona a través de un repositorio Git, lo que resulta ideal para el control de versiones.
API de inferencia de Hugging Face
Cuando necesite integrar un modelo en una aplicación existente, es probable que desee utilizar una API. La API de inferencia de Hugging Face le permite ejecutar modelos sin tener que gestionar usted mismo la infraestructura subyacente. Solo tiene que enviar una solicitud HTTP con sus datos y obtendrá una predicción.
Este enfoque es ideal cuando no desea ocuparse de servidores, escalabilidad o mantenimiento. Hugging Face ofrece dos niveles principales para este servicio:
- API de inferencia gratuita: se trata de una opción de infraestructura de uso compartido con límite de velocidad, ideal para el desarrollo y las pruebas. Es perfecta para casos de uso con poco tráfico o cuando se está empezando.
- Puntos finales de inferencia: para aplicaciones de producción, le interesará utilizar puntos finales de inferencia. Se trata de un servicio de pago que le proporciona una infraestructura dedicada y con escalado automático, lo que garantiza que su aplicación sea rápida y fiable incluso bajo cargas pesadas.
El uso de la API implica enviar una carga JSON a la URL del punto final del modelo con su token de autenticación en el encabezado de la solicitud.
Implementación en plataforma en la nube
Para los equipos que ya tienen una presencia significativa en un proveedor de nube importante como Amazon Web Services (AWS), Google Cloud Platform (GCP) o Microsoft Azure, la implementación allí puede ser la opción más lógica. Este enfoque le brinda el máximo control y le permite integrar el modelo con sus servicios en la nube y protocolos de seguridad existentes.
El flujo de trabajo general consiste en «contenerizar» su modelo y sus dependencias utilizando Docker, y luego implementar ese contenedor en un servicio de computación en la nube. Cada proveedor de servicios en la nube cuenta con servicios e integraciones que simplifican este proceso:
- AWS SageMaker: ofrece integración nativa para entrenar e implementar modelos Hugging Face.
- Google Cloud Vertex IA: le permite implementar modelos desde el hub a puntos finales gestionados.
- Azure Machine Learning: proporciona herramientas para importar y utilizar modelos de Hugging Face.
Aunque este método requiere más configuración y conocimientos de DevOps, suele ser la mejor opción para implementaciones a gran escala y de nivel corporativo en las que se necesita un control total sobre el entorno.
📚 Lea también: Automatización de flujos de trabajo: automatice los flujos de trabajo para aumentar la productividad.
Cómo ejecutar modelos Hugging Face para la inferencia
Cuando se utiliza Hugging Face para la implementación de IA, la «ejecución de inferencias» es el proceso de utilizar su modelo entrenado para hacer predicciones sobre datos nuevos y desconocidos. Es el momento en el que su modelo realiza el trabajo para el que lo ha implementado. Hacer bien este paso es fundamental para crear una aplicación receptiva y eficiente.
La mayor frustración para los equipos es escribir código de inferencia que sea lento o ineficiente, lo que puede dar lugar a una mala experiencia de usuario y a altos costes operativos. Afortunadamente, la biblioteca transformers ofrece varias formas de ejecutar la inferencia, cada una con sus propias ventajas e inconvenientes entre simplicidad y control.
- API de canalización: esta es la forma más fácil y habitual de empezar. La función pipeline() elimina la mayor parte de la complejidad, ya que se encarga del preprocesamiento de datos, el reenvío de modelos y el posprocesamiento. Para muchas tareas estándar, como el análisis de sentimientos, puede obtener una predicción con solo una línea de código.
- AutoModel + AutoTokenizer: cuando necesite un mayor control sobre el proceso de inferencia, puede utilizar directamente las clases AutoModel y AutoTokenizer. Esto le permite gestionar manualmente cómo se tokeniza el texto y cómo se convierte la salida sin procesar del modelo en una predicción legible para los humanos. Este enfoque es útil cuando se trabaja con una tarea personalizada o se necesita implementar una lógica específica de preprocesamiento o posprocesamiento.
- Procesamiento por lotes: para maximizar la eficiencia, especialmente en una GPU, debe procesar las entradas por lotes en lugar de una por una. Enviar un lote de entradas a través del modelo en una sola pasada es significativamente más rápido que enviar cada una individualmente.
Supervisar el rendimiento de su código de inferencia es una parte clave del ciclo de vida de la implementación. El seguimiento de métricas como la latencia (el tiempo que tarda una predicción) y el rendimiento (el número de predicciones que se pueden realizar por segundo) requiere coordinación y una documentación clara, especialmente cuando los diferentes miembros del equipo experimentan con nuevas versiones del modelo.
📚 Lea también: Las mejores herramientas de colaboración para equipos de IA.
Ejemplo paso a paso: implementar un modelo Hugging Face.
Veamos un ejemplo completo de implementación de un modelo sencillo de análisis de opiniones. Si sigue estos pasos, pasará de elegir un modelo a disponer de un punto final activo y comprobable.
- Seleccione su modelo: vaya al Hugging Face Hub y utilice los filtros de la izquierda para buscar modelos que realicen «Clasificación de texto». Un buen punto de partida es distilbert-base-uncased-finetuned-sst-2-english. Lea su tarjeta de modelo para comprender su rendimiento y cómo utilizarlo.
- Instale las dependencias: en su entorno Python local, asegúrese de tener instaladas las bibliotecas necesarias. Para este modelo, solo necesitará transformers y torch. Ejecute pip install transformers torch.
- Prueba localmente: antes de implementar, asegúrate siempre de que el modelo funciona como esperabas en tu máquina. Escribe un pequeño script en Python para cargar el modelo utilizando el pipeline y pruébalo con una frase de ejemplo. Por ejemplo: classifier = pipeline("sentiment-analysis", model="distilbert-base-uncased-finetuned-sst-2-english") seguido de classifier("¡ClickUp es la mejor plataforma de productividad!").
- Crear implementación: para este ejemplo, utilizaremos Hugging Face Spaces para una implementación rápida y sencilla. Cree un nuevo espacio, seleccione el SDK de Gradio y cree un archivo app.py que cargue su modelo y defina una interfaz Gradio sencilla para interactuar con él.
- Verifique la implementación: una vez que su espacio esté en funcionamiento, puede utilizar la interfaz interactiva para probarlo. También puede realizar una solicitud API directa al punto final del espacio para obtener una respuesta JSON, lo que confirma que funciona programáticamente.
Tras estos pasos, dispondrá de un modelo activo. La siguiente fase del proyecto consistiría en supervisar su uso, planificar actualizaciones y, posiblemente, ampliar la infraestructura si gana popularidad.
Para los equipos que gestionan proyectos complejos de implementación de IA con múltiples fases, desde la preparación de datos hasta la implementación en producción, la plantilla avanzada de gestión de proyectos de software de ClickUp proporciona una estructura completa.
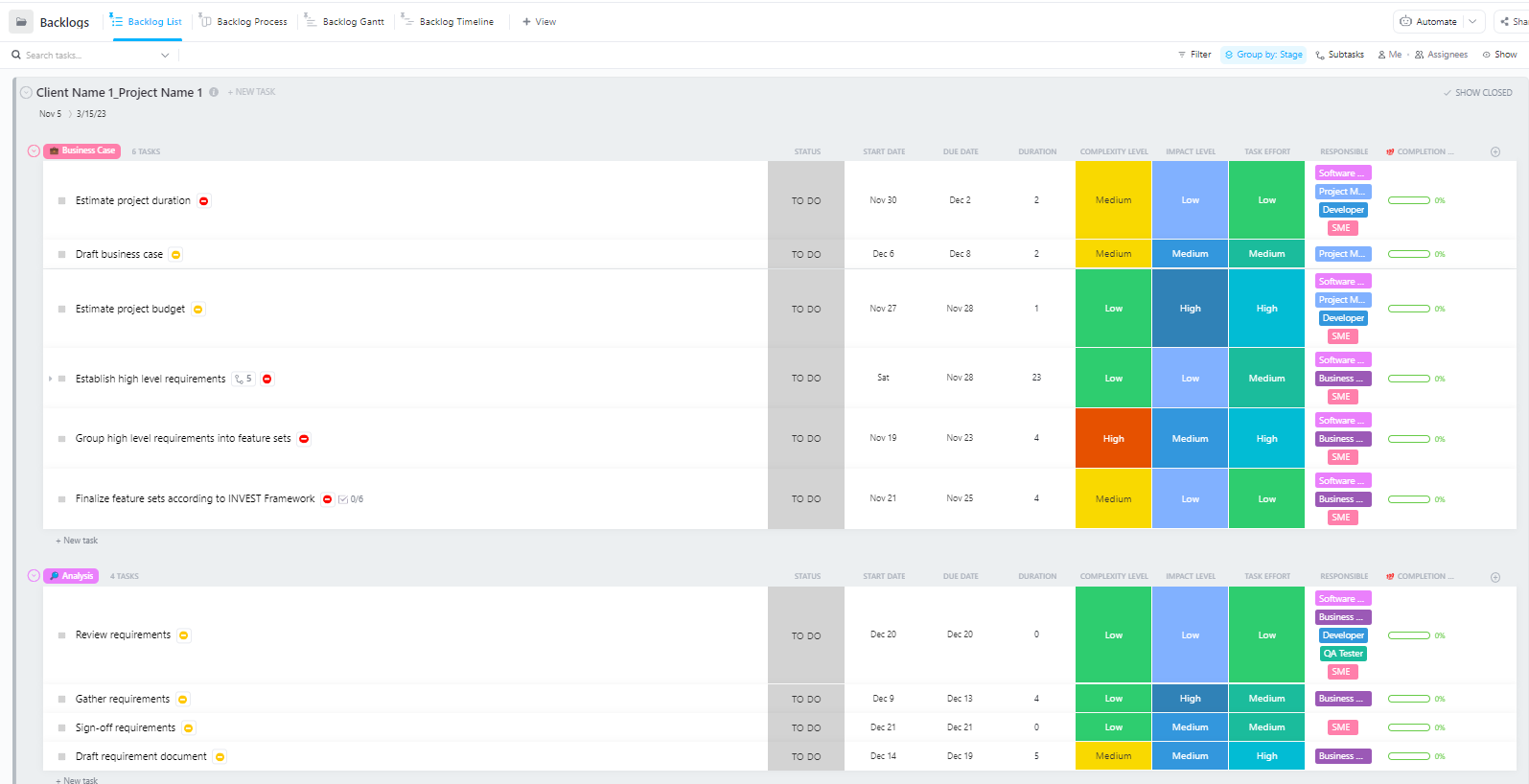
Esta plantilla ayuda a los equipos a:
- Gestión de proyectos con múltiples hitos, tareas, recursos y dependencias.
- Visualice el progreso del proyecto con diagramas de Gantt y cronogramas.
- Colabore sin problemas con sus compañeros de equipo para garantizar la completa realización del proyecto.
Retos comunes en la implementación de Hugging Face y cómo solucionarlos.
Incluso con un plan claro, es probable que te encuentres con algunos obstáculos durante la implementación. Mirar fijamente un mensaje de error críptico puede ser increíblemente frustrante y puede detener el progreso de tu equipo. A continuación, te presentamos algunos de los retos más comunes y cómo solucionarlos. 🛠️
🚨Problema: «El modelo requiere autenticación»
- Causa: Está intentando acceder a un modelo «restringido» que requiere que acepte sus términos de licencia.
- Solución: Vaya a la página del modelo en el hub, lea y acepte el acuerdo de licencia. Asegúrese de que el token de acceso que está utilizando tiene permisos de «lectura».
🚨Problema: «CUDA sin memoria»
- Causa: El modelo que está intentando cargar es demasiado grande para la memoria de su GPU (VRAM).
- Solución: La solución más rápida es utilizar una versión más pequeña del modelo o una versión cuantificada. También puede intentar reducir el tamaño del lote durante la inferencia.
🚨Problema: «error trust_remote_code»
- Causa: algunos modelos del hub requieren código personalizado para ejecutarse y, por motivos de seguridad, la biblioteca no lo ejecuta de forma predeterminada, por defecto.
- Solución: Puede evitarlo añadiendo trust_remote_code=True al cargar el modelo. Sin embargo, siempre debe revisar primero el código fuente para asegurarse de que es seguro.
🚨Problema: «Tokenizer mismatch»
- Causa: el tokenizador que está utilizando no es exactamente el mismo con el que se entrenó el modelo, lo que provoca entradas incorrectas y un rendimiento deficiente.
- Solución: Cargue siempre el tokenizador desde el mismo punto de control del modelo que el propio modelo. Por ejemplo, AutoTokenizer. from_pretrained("nombre-del-modelo")
🚨Problema: «Límite de velocidad excedido»
- Causa: Ha realizado demasiadas solicitudes a la API de inferencia gratuita en un breve periodo de tiempo.
- Solución: Para uso en producción, actualice a un punto final de inferencia dedicado. Para el desarrollo, puede implementar el almacenamiento en caché para evitar enviar la misma solicitud varias veces.
Es fundamental realizar un seguimiento de qué soluciones funcionan para cada problema. Sin un lugar centralizado donde documentar estos hallazgos, los equipos suelen acabar resolviendo el mismo problema una y otra vez.
📮 ClickUp Insight: 1 de cada 4 empleados utiliza cuatro o más herramientas solo para crear contexto en el trabajo. Un detalle clave puede estar oculto en un correo electrónico, ampliado en un hilo de Slack y documentado en una herramienta independiente, lo que obliga a los equipos a perder tiempo buscando información en lugar de realizar su trabajo.
ClickUp converge todo su flujo de trabajo en una plataforma unificada. Con funciones como ClickUp Gestión de Proyectos por Correo Electrónico, ClickUp Chat, ClickUp Documentos y ClickUp Brain, todo permanece conectado, sincronizado y accesible al instante. Diga adiós al «trabajo sobre el trabajo» y recupere su tiempo de productividad.
💫 Resultados reales: los equipos pueden recuperar más de 5 horas cada semana utilizando ClickUp, lo que supone más de 250 horas al año por persona, al eliminar los procesos obsoletos de gestión del conocimiento. ¡Imagina lo que tu equipo podría crear con una semana extra de productividad cada trimestre!
Cómo gestionar proyectos de implementación de IA en ClickUp
El uso de Hugging Face para la implementación de IA facilita el empaquetado, el alojamiento y el servicio de los modelos, pero no elimina la sobrecarga de coordinación que supone la implementación en el mundo real. Los equipos siguen teniendo que realizar el seguimiento de los modelos que se están probando, ponerse de acuerdo en las configuraciones, documentar las decisiones y mantener a todo el mundo, desde los ingenieros de ML hasta los de producto y operaciones, en sintonía.
Cuando su equipo de ingeniería está probando diferentes modelos, su equipo de producto está definiendo los requisitos y las partes interesadas solicitan actualizaciones, la información se dispersa entre Slack, el correo electrónico, las hojas de cálculo y diversos documentos.
Esta dispersión del trabajo, es decir, la fragmentación de las actividades laborales en múltiples herramientas desconectadas que no se comunican entre sí, crea confusión y ralentiza el trabajo de todos.
Aquí es donde ClickUp, el primer entorno de trabajo de IA convergente del mundo, desempeña un rol clave al reunir la gestión de proyectos, la documentación y la comunicación del equipo en un único entorno de trabajo.
Esa convergencia es especialmente valiosa para los proyectos de implementación de IA, en los que las partes interesadas técnicas y no técnicas necesitan una visibilidad compartida sin tener que utilizar cinco herramientas diferentes.
En lugar de dispersar las actualizaciones entre tickets, documentos y hilos de chat, los equipos pueden gestionar todo el ciclo de vida de la implementación en un solo lugar.
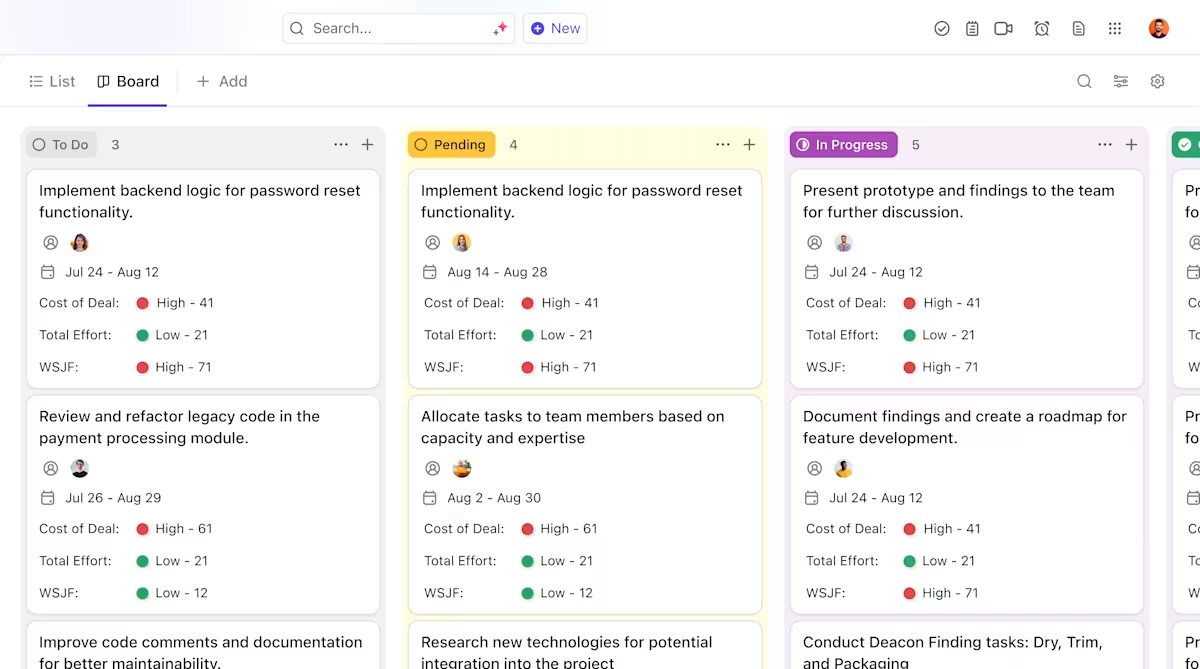
Así es como ClickUp puede ayudarte en tu proyecto de implementación de IA:
- Propiedad clara y seguimiento a lo largo del ciclo de vida de los modelos: utilice las tareas de ClickUp para realizar un seguimiento de los modelos de Hugging Face a través de la evaluación, las pruebas, la fase de puesta en escena y la producción, con estados personalizados, propietarios y bloqueadores visibles para todo el equipo.
- Documentación de implementación centralizada y actualizada: mantenga los manuales de implementación, las configuraciones del entorno y las guías de resolución de problemas en ClickUp Docs, para que la documentación evolucione junto con sus modelos y siga siendo fácil de buscar y consultar. Dado que los documentos están conectados a las tareas, su documentación se encuentra junto al trabajo al que se refiere.
- Colaboración contextual sin dispersión del trabajo: mantenga las discusiones, las decisiones y las actualizaciones directamente vinculadas a las tareas y los documentos, reduciendo la dependencia de hilos de Slack dispersos, correos electrónicos y herramientas de proyecto desconectadas.
- Visibilidad completa del progreso de la implementación: supervise el proceso de implementación, identifique los riesgos de forma temprana y equilibre la capacidad del equipo utilizando los paneles de control de ClickUp, que muestran el progreso y los cuellos de botella en tiempo real.
- Incorporación más rápida y recuperación de decisiones con IA integrada: utilice ClickUp Brain para resumir largos documentos de implementación, extraer información relevante de implementaciones anteriores y ayudar a los nuevos miembros del equipo a ponerse al día sin tener que indagar en el contexto histórico.
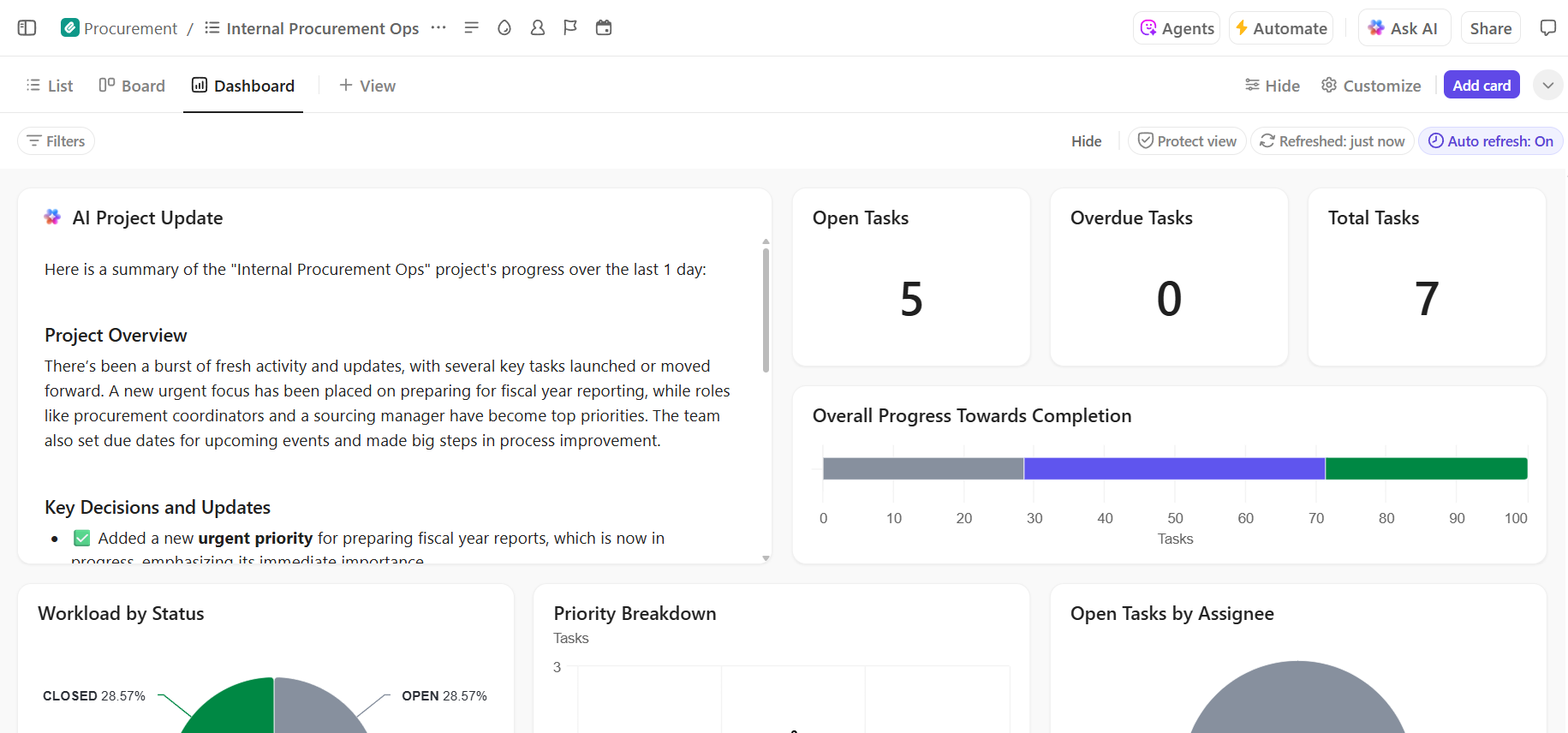
📚 Lea también: Cómo realizar la automatización de procesos con IA para obtener flujos de trabajo más rápidos e inteligentes.
Gestión del proyecto de implementación de IA sin problemas en ClickUp.
El éxito de la implementación de Hugging Face depende de una base técnica sólida y de una gestión de proyectos clara y organizada. Si bien los retos técnicos son solucionables, a menudo son los fallos de coordinación y comunicación los que provocan el fracaso de los proyectos.
Al establecer un flujo de trabajo claro en una única plataforma, su equipo podrá entregar más rápido y evitar la frustración de la dispersión del contexto, es decir, cuando los equipos pierden horas buscando información, cambiando de una aplicación a otra y repitiendo actualizaciones en múltiples plataformas.
ClickUp, la aplicación integral para el trabajo, reúne la gestión de proyectos, la documentación y la comunicación del equipo en un solo lugar para ofrecerte una única fuente de información veraz para todo el ciclo de vida de la implementación de IA.
Reúna sus proyectos de implementación de IA y elimine el caos de herramientas. Empiece hoy mismo de forma gratuita con ClickUp.
Preguntas frecuentes (FAQ)
Sí, Hugging Face ofrece un generoso nivel gratuito que incluye acceso al Model Hub, espacios con CPU para demostraciones y una API de inferencia con límite de velocidad para realizar pruebas. Para necesidades de producción que requieran hardware dedicado o límites más altos, hay planes de pago disponibles.
Espacios está diseñado para alojar aplicaciones interactivas con una interfaz visual, lo que lo hace ideal para demostraciones y herramientas internas. La API de inferencia proporciona acceso programático a los modelos, lo que le permite integrarlos en sus aplicaciones mediante simples solicitudes HTTP.
Por supuesto. A través de demostraciones interactivas alojadas en Hugging Face Spaces, los miembros del equipo sin conocimientos técnicos pueden experimentar con los modelos y proporcionar comentarios sobre ellos sin escribir una sola línea de código.
Las principales limitaciones del nivel gratuito son los límites de velocidad de la API de inferencia, el uso compartido de hardware de CPU para los espacios, que puede ser lento, y los «arranques en frío», en los que las aplicaciones inactivas tardan un momento en activarse. /