
Die meisten KI-Bereitstellungsprojekte scheitern nicht, weil die Teams das falsche Modell ausgewählt haben, sondern weil sich drei Monate später niemand mehr daran erinnern kann, warum sie sich dafür entschieden haben oder wie das Setup repliziert werden kann. 46 % der KI-Projekte werden zwischen der Konzeptprüfung und der breiten Einführung verworfen.
Dieser Leitfaden führt Sie durch die Verwendung von Hugging Face für die KI-Bereitstellung – von der Auswahl und dem Testen von Modellen bis hin zur Verwaltung des Bereitstellungsprozesses –, damit Ihr Team schneller liefern kann, ohne wichtige Entscheidungen in Slack-Threads und verstreuten Tabellen zu verlieren.
Was ist Hugging Face?
Hugging Face ist eine Open-Source-Plattform und Community-Hub, die vortrainierte KI-Modelle, Datensätze und Tools für die Erstellung und Bereitstellung von Machine-Learning- Anwendungen bereitstellt.
Stellen Sie sich das Ganze wie eine riesige digitale Bibliothek vor, in der Sie gebrauchsfertige KI-Modelle finden, anstatt Monate und erhebliche Ressourcen für deren Entwicklung von Grund auf aufzuwenden.
Es wurde für Machine-Learning-Ingenieure und Datenwissenschaftler entwickelt, aber seine Tools werden zunehmend von funktionsübergreifenden Produkt-, Design- und Engineering-Teams genutzt, um KI in ihre Workflows zu integrieren.
Wussten Sie schon: 63 % der Unternehmen verfügen nicht über geeignete Datenmanagementpraktiken für KI. Dies führt häufig zu verzögerten Projekten und verschwendeten Ressourcen.
Die größte Herausforderung für viele Teams ist die schiere Komplexität der KI-Bereitstellung. Der Prozess umfasst die Auswahl des richtigen Modells aus Tausenden von Optionen, die Verwaltung der zugrunde liegenden Infrastruktur, die Versionierung von Experimenten und die Sicherstellung, dass technische und nicht-technische Stakeholder aufeinander abgestimmt sind.
Hugging Face vereinfacht dies durch seinen Model Hub, ein zentrales Repository mit über 2 Millionen Modellen. Die Transformer-Bibliothek der Plattform ist der Schlüssel zu diesen Modellen, mit dem Sie sie mit nur wenigen Zeilen Python-Code laden und verwenden können.
Doch selbst mit diesen leistungsstarken Tools bleibt die KI-Bereitstellung eine Herausforderung für das Projektmanagement, die eine sorgfältige Nachverfolgung der Modellauswahl, des Testens und der Einführung erfordert, um den Erfolg sicherzustellen.
📮ClickUp Insight: 92 % der Wissensarbeiter riskieren, wichtige Entscheidungen zu verlieren, die über Chats, E-Mails und Tabellen verstreut sind. Ohne ein einheitliches System zur Erfassung und Nachverfolgung von Entscheidungen gehen wichtige geschäftliche Erkenntnisse im digitalen Rauschen verloren.
Mit den Aufgabenverwaltungsfunktionen von ClickUp müssen Sie sich darüber keine Gedanken mehr machen. Erstellen Sie Aufgaben aus Chats, Aufgabenkommentaren, Dokumenten und E-Mails mit einem einzigen Klick!
📚 Lesen Sie auch: Die besten Hugging Face-Alternativen für LLMs, NLP und KI-Workflows
Hugging Face-Modelle, die Sie bereitstellen können
Die Navigation im Hugging Face Hub kann zu Beginn überwältigend sein. Bei Hunderttausenden von Modellen ist es wichtig, die Hauptkategorien zu verstehen, um das richtige Modell für Ihr Projekt zu finden. Die Modelle reichen von kleinen, effizienten Optionen, die für einen einzigen Zweck entwickelt wurden, bis hin zu massiven Allzweckmodellen, die komplexe Schlussfolgerungen verarbeiten können.
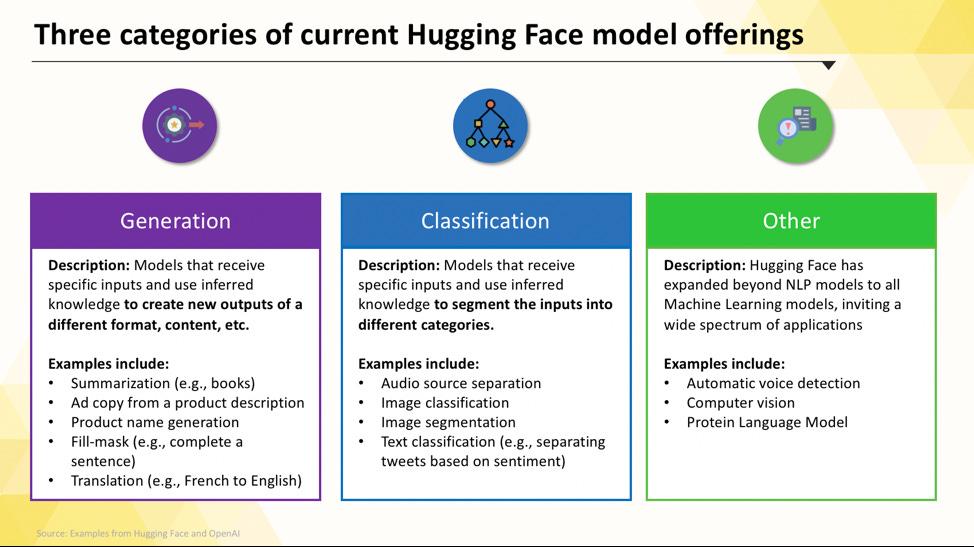
Aufgabenspezifische Sprachmodelle
Wenn Ihr Team ein einzelnes, klar definiertes Problem lösen muss, benötigen Sie oft kein umfangreiches Allzweckmodell. Der Zeit- und Kostenaufwand für den Betrieb eines solchen Modells kann unerschwinglich sein, insbesondere wenn ein kleineres, gezielteres KI-Tool besser geeignet wäre. Hier kommen aufgabenspezifische Modelle ins Spiel.
Es handelt sich hierbei um Modelle, die für eine bestimmte Funktion trainiert und optimiert wurden. Da sie spezialisiert sind, sind sie in der Regel kleiner, schneller und ressourceneffizienter als ihre größeren Pendants.
Dadurch eignen sie sich ideal für Produktionsumgebungen, in denen Geschwindigkeit und Kosten wichtige Faktoren sind. Viele können sogar auf Standard-CPU-Hardware ausgeführt werden, sodass sie ohne teure GPUs zugänglich sind.
Zu den gängigen Arten von aufgabenspezifischen Modellen gehören:
- Textklassifizierung: Verwenden Sie diese Funktion, um Texte in vordefinierte Kategorien einzuteilen, z. B. Kundenfeedback in „positiv“ oder „negativ“ zu sortieren oder Support-Tickets nach Themen zu kennzeichnen.
- Sentimentanalyse: Damit können Sie den emotionalen Ton eines Textes bestimmen, was für die Markenüberwachung in sozialen Medien nützlich ist.
- Erkennung benannter Entitäten: Extrahieren Sie bestimmte Entitäten wie Personen, Orte und Organisationen aus Dokumenten, um unstrukturierte Daten zu strukturieren.
- Zusammenfassung: Fassen Sie lange Artikel oder Berichte zu prägnanten Zusammenfassungen zusammen und sparen Sie Ihrem Team wertvolle Lesezeit.
- Übersetzung: Konvertieren Sie Text automatisch von einer Sprache in eine andere.
📚 Lesen Sie auch: Wie man Hugging Face für die Zusammenfassung von Texten nutzt
Große Sprachmodelle
Manchmal erfordert Ihr Projekt mehr als nur eine einfache Klassifizierung oder Zusammenfassung. Möglicherweise benötigen Sie eine KI, die kreative Marketingtexte generieren, Code schreiben oder komplexe Fragen von Benutzern in Form einer Unterhaltung beantworten kann. In solchen Fällen werden Sie wahrscheinlich auf ein Large Language Model (LLM) zurückgreifen.
LLMs sind Modelle mit Milliarden von Parametern, die anhand riesiger Mengen an Text und Daten aus dem Internet trainiert wurden. Durch dieses umfangreiche Training sind sie in der Lage, Nuancen, Zusammenhänge und komplexe Gedankengänge zu verstehen. Zu den beliebten Open-Source-LLMs, die auf Hugging Face verfügbar sind, gehören Modelle aus den Familien Llama, Mistral und Falcon.
Der Nachteil dieser Leistungsfähigkeit ist der erhebliche Bedarf an Rechenressourcen. Für den Einsatz dieser Modelle sind fast immer leistungsstarke GPUs mit viel Speicher (VRAM) erforderlich.
Um sie zugänglicher zu machen, können Sie Techniken wie Quantisierung verwenden, die die Größe des Modells bei geringen Leistungseinbußen reduzieren, sodass es auch auf weniger leistungsstarker Hardware ausgeführt werden kann.
📚 Lesen Sie auch: Was sind LLM-Agenten in der KI und wie funktionieren sie?
Text-zu-Bild- und multimodale Modelle
Ihre Daten bestehen nicht immer nur aus Text. Ihr Team muss möglicherweise Bilder für eine Marketingkampagne erstellen, Audioaufnahmen aus einem Meeting transkribieren oder den Inhalt eines Videos verstehen. Hier kommen multimodale Modelle zum Einsatz, die für die Verarbeitung verschiedener Datentypen ausgelegt sind.
Die beliebteste Art von multimodalen Modellen sind Text-zu-Bild-Modelle, die aus einer Textbeschreibung Bilder generieren. Modelle wie Stable Diffusion verwenden eine Technik namens Diffusion, um aus einfachen Eingaben atemberaubende Bilder zu erstellen. Die Möglichkeiten gehen jedoch weit über die Bildgenerierung hinaus.
Weitere gängige multimodale Modelle, die Sie mit Hugging Face bereitstellen können, sind:
- Bildbeschriftung: Generieren Sie automatisch beschreibenden Text für Bilder, was sich hervorragend für Barrierefreiheit und Verwaltung des Inhalts eignet.
- Spracherkennung: Transkribieren Sie gesprochene Audiodaten in geschriebenen Text mit Modellen wie Whisper von OpenAI.
- Visuelle Beantwortung von Fragen: Stellen Sie Fragen zu einem Bild und erhalten Sie eine Antwort im Text-Format, z. B. „Welche Farbe hat das Auto auf diesem Foto?“
Wie LLMs sind auch diese Modelle rechenintensiv und erfordern in der Regel eine GPU, um effizient zu laufen.
📚 Lesen Sie auch: Über 50 KI-Bildprompts zur Erstellung atemberaubender Grafiken
Um zu sehen, wie sich diese verschiedenen Arten von KI-Modellen in praktische Geschäftsanwendungen umsetzen lassen, sehen Sie sich diese Übersicht über reale KI-Anwendungsfälle in verschiedenen Branchen und Funktionen an.
Wie hoch ist der KI-Reifegrad Ihres Unternehmens?
Unsere Umfrage unter 316 Fachleuten zeigt, dass eine echte KI-Transformation mehr als nur die Einführung von KI-Features erfordert. Nehmen Sie an der KI-Reifegradbewertung teil, um zu erfahren, wo Ihr Unternehmen steht und was Sie zu erledigen haben, um Ihre Punktzahl zu verbessern.
So richten Sie Hugging Face für den Einsatz von KI ein
Bevor Sie Ihr erstes Modell bereitstellen können, müssen Sie Ihre lokale Umgebung und Ihr Hugging Face-Konto korrekt einrichten. Es ist eine häufige Frustration für Teams, wenn verschiedene Mitglieder inkonsistente Setups haben, was zu dem klassischen Problem „Auf meinem Rechner funktioniert es“ führt. Wenn Sie sich ein paar Minuten Zeit nehmen, um diesen Prozess zu standardisieren, sparen Sie später Stunden an Fehlerbehebung.
- Erstellen Sie ein Hugging Face-Konto und generieren Sie einen Zugriffstoken. Melden Sie sich zunächst für ein kostenloses Konto auf der Hugging Face-Website an. Sobald Sie angemeldet sind, navigieren Sie zu Ihrem Profil, klicken Sie auf „Einstellungen“ und gehen Sie dann zur Registerkarte „Zugriffstoken“. Generieren Sie einen neuen Token mit mindestens „Lese“-Berechtigungen; diesen benötigen Sie, um Modelle herunterzuladen.
- Installieren Sie die erforderlichen Python-Bibliotheken. Öffnen Sie Ihr Terminal und installieren Sie die benötigten Kernbibliotheken. Die beiden wichtigsten sind transformers und huggingface_hub. Sie können sie mit pip installieren: pip install transformers huggingface_hub
- Konfigurieren Sie die Authentifizierung. Um Ihr Zugriffstoken zu verwenden, können Sie sich entweder über die Befehlszeile anmelden, indem Sie huggingface-cli login ausführen und Ihr Token einfügen, wenn Sie dazu aufgefordert werden, oder Sie können es als Umgebungsvariable in Ihrem System einstellen. Die Anmeldung über die Befehlszeile ist oft der einfachste Weg, um loszulegen.
- Überprüfen Sie das Setup. Der beste Weg, um sicherzustellen, dass alles funktioniert, ist die Ausführung eines einfachen Codes. Laden Sie ein grundlegendes Modell mit der Pipeline-Funktion aus der Transformers-Bibliothek. Wenn es ohne Fehler läuft, können Sie loslegen.
Beachten Sie, dass einige Modelle auf dem Hub „geschützt” sind, d. h. Sie müssen den Lizenzbedingungen auf der Seite des Modells zustimmen, bevor Sie mit Ihrem Token darauf zugreifen können.
Denken Sie auch daran, dass die Nachverfolgung, wer über welche Berechtigungen verfügt und welche Umgebungskonfigurationen verwendet werden, eine Aufgabe des Projektmanagements an sich ist und mit zunehmender Größe Ihres Teams immer wichtiger wird.
🌟 Wenn Sie Hugging Face-Modelle in umfassendere Softwaresysteme integrieren, hilft Ihnen die Software-Integrationsvorlage von ClickUp dabei, Workflows zu visualisieren und die Nachverfolgung mehrerer Schritte bei technischen Integrationen zu gewährleisten.
Die Vorlage bietet Ihnen ein leicht verständliches System, mit dem Sie:
- Visualisieren Sie die Verbindungen zwischen verschiedenen Softwarelösungen.
- Erstellen Sie Aufgaben und weisen Sie diese Ihren Team-Mitgliedern zu, um die Zusammenarbeit zu optimieren.
- Organisieren Sie alle Aufgaben im Zusammenhang mit der Integration an einem Ort.
Bereitstellungsoptionen für Hugging Face-Modelle
Nachdem Sie ein Modell lokal getestet haben, stellt sich die nächste Frage: Wo soll es eingesetzt werden? Die Bereitstellung eines Modells in einer Produktionsumgebung, in der es von anderen genutzt werden kann, ist ein entscheidender Schritt, aber die Optionen können verwirrend sein. Die Wahl des falschen Weges kann zu langsamer Leistung, hohen Kosten oder der Unfähigkeit führen, den Benutzerverkehr zu bewältigen.
Ihre Wahl hängt von Ihren spezifischen Anforderungen ab, wie z. B. dem erwarteten Datenverkehr, dem Budget und der Frage, ob Sie einen schnellen Prototyp oder eine skalierbare, produktionsreife Anwendung erstellen möchten.
Hugging Face Spaces
Wenn Sie schnell eine Demo oder ein internes Tool erstellen müssen, ist Hugging Face Spaces oft die beste Wahl. Spaces ist eine kostenlose Plattform für das Hosting von Machine-Learning-Anwendungen und eignet sich perfekt für die Erstellung von Prototypen, die Sie mit Ihrem Team oder Ihren Stakeholdern freigeben können.
Sie können die Benutzeroberfläche Ihrer App mit beliebten Frameworks wie Gradio oder Streamlit erstellen, wodurch es einfach ist, interaktive Demos mit nur wenigen Zeilen Python zu erstellen.
Das Erstellen eines Spaces ist ganz einfach: Wählen Sie Ihr bevorzugtes SDK aus, erstellen Sie eine Verbindung zu einem Git-Repository mit Ihrem Code und wählen Sie Ihre Hardware aus. Spaces bietet zwar eine kostenlose CPU-Stufe für einfache Apps, Sie können jedoch für anspruchsvollere Modelle auf kostenpflichtige GPU-Hardware upgraden.
Beachten Sie dabei die Limite:
- Nicht für APIs mit hohem Datenverkehr geeignet: Spaces ist für Demos konzipiert und nicht für die Bearbeitung Tausender gleichzeitiger API-Anfragen.
- Kaltstarts: Wenn Ihr Space inaktiv ist, kann er in den Ruhezustand versetzt werden, um Ressourcen zu sparen, was zu einer Verzögerung für den ersten Benutzer führt, der erneut darauf zugreift.
- Git-basierter Workflow: Ihr gesamter Anwendungscode wird über ein Git-Repository verwaltet, was sich hervorragend für die Versionskontrolle eignet.
Hugging Face Inference API
Wenn Sie ein Modell in eine bestehende Anwendung integrieren möchten, werden Sie wahrscheinlich eine API verwenden wollen. Mit der Hugging Face Inference API können Sie Modelle ausführen, ohne die zugrunde liegende Infrastruktur selbst verwalten zu müssen. Sie senden einfach eine HTTP-Anfrage mit Ihren Daten und erhalten eine Vorhersage zurück.
Dieser Ansatz ist ideal, wenn Sie sich nicht mit Servern, Skalierung oder Wartung befassen möchten. Hugging Face bietet zwei Hauptstufen für diesen Service an:
- Kostenlose Inferenz-API: Hierbei handelt es sich um eine Option mit Ratenlimit und gemeinsamer Infrastruktur, die sich hervorragend für Entwicklung und Tests eignet. Sie ist ideal für Anwendungsfälle mit geringem Datenverkehr oder wenn Sie gerade erst anfangen.
- Inferenz-Endpunkte: Für Produktionsanwendungen sollten Sie Inferenz-Endpunkte verwenden. Dabei handelt es sich um einen kostenpflichtigen Dienst, der Ihnen eine dedizierte, automatisch skalierende Infrastruktur zur Verfügung stellt und sicherstellt, dass Ihre Anwendung auch unter hoher Last schnell und zuverlässig läuft.
Die Verwendung der API umfasst das Senden einer JSON-Nutzlast an die Endpunkt-URL des Modells mit Ihrem Authentifizierungstoken in der Kopfzeile des Requests.
Bereitstellung auf Cloud-Plattformen
Für Teams, die bereits über eine bedeutende Präsenz bei einem großen Cloud-Anbieter wie Amazon Web Services (AWS), Google Cloud Platform (GCP) oder Microsoft Azure verfügen, kann die Bereitstellung dort die logischste Wahl sein. Dieser Ansatz bietet Ihnen die größte Kontrolle und ermöglicht Ihnen die Integration des Modells in Ihre bestehenden Cloud-Dienste und Protokolle zur Sicherheit.
Der allgemeine Workflow umfasst die „Containerisierung“ Ihres Modells und seiner Abhängigkeiten mit Docker und die anschließende Bereitstellung dieses Containers in einem Cloud-Computing-Dienst. Jeder Anbieter von Cloud-Computing verfügt über Dienste und Integrationen, die diesen Prozess vereinfachen:
- AWS SageMaker: Bietet native Integration für das Training und die Bereitstellung von Hugging Face-Modellen.
- Google Cloud Vertex KI: Ermöglicht Ihnen die Bereitstellung von Modellen aus dem hub auf verwalteten Endpunkten.
- Azure Machine Learning: Bietet Tools zum Importieren und Bereitstellen von Hugging Face-Modellen.
Diese Methode erfordert zwar mehr Setup und DevOps-Know-how, ist jedoch oft die beste Option für groß angelegte Bereitstellungen auf Unternehmensebene, bei denen Sie die vollständige Kontrolle über die Umgebung benötigen.
📚 Lesen Sie auch: Workflow-Automatisierung: Automatisieren Sie Workflows, um die Produktivität zu steigern
So führen Sie Hugging Face-Modelle für die Inferenz aus
Bei der Verwendung von Hugging Face für die KI-Bereitstellung ist „Running Inference” der Prozess, bei dem Ihr trainiertes Modell verwendet wird, um Vorhersagen zu neuen, unbekannten Daten zu treffen. Dies ist der Moment, in dem Ihr Modell die Arbeit erfüllt, für die Sie es bereitgestellt haben. Dieser Schritt ist entscheidend für die Entwicklung einer reaktionsschnellen und effizienten Anwendung.
Die größte Frustration für Teams ist das Schreiben von Inferenz-Code, der langsam oder ineffizient ist, was zu einer schlechten Benutzererfahrung und hohen Betriebskosten führen kann. Glücklicherweise bietet die Transformers-Bibliothek mehrere Möglichkeiten zur Ausführung von Inferenz, die jeweils ihre eigenen Kompromisse zwischen Einfachheit und Kontrolle bieten.
- Pipeline-API: Dies ist der einfachste und gängigste Weg, um loszulegen. Die Funktion pipeline() abstrahiert den Großteil der Komplexität und übernimmt für Sie die Datenvorverarbeitung, Modellweiterleitung und Nachbearbeitung. Für viele Standardaufgaben wie die Sentimentanalyse erhalten Sie eine Vorhersage mit nur einer Zeile Code.
- AutoModel + AutoTokenizer: Wenn Sie mehr Kontrolle über den Inferenzprozess benötigen, können Sie die Klassen AutoModel und AutoTokenizer direkt verwenden. Auf diese Weise können Sie manuell festlegen, wie Ihr Text tokenisiert wird und wie die Rohausgabe des Modells in eine für Menschen lesbare Vorhersage umgewandelt wird. Dieser Ansatz ist nützlich, wenn Sie mit einer benutzerdefinierten Aufgabe arbeiten oder eine bestimmte Vor- oder Nachverarbeitungslogik implementieren müssen.
- Stapelverarbeitung: Um die Effizienz zu maximieren, insbesondere auf einer GPU, sollten Sie Eingaben stapelweise und nicht einzeln verarbeiten. Das Senden eines Stapels von Eingaben durch das Modell in einem einzigen Vorwärtsdurchlauf ist deutlich schneller als das Senden jeder einzelnen Eingabe.
Die Überwachung der Leistung Ihres Inferenzcodes ist ein wichtiger Teil des Bereitstellungszyklus. Die Nachverfolgung von Metriken wie Latenz (wie lange eine Vorhersage dauert) und Durchsatz (wie viele Vorhersagen Sie pro Sekunde treffen können) erfordert Koordination und klare Dokumentation, insbesondere wenn verschiedene Mitglieder des Teams mit neuen Versionen der Modelle experimentieren.
📚 Lesen Sie auch: Die besten Tools für die Zusammenarbeit im KI-Team
Schritt-für-Schritt-Beispiel: Bereitstellung eines Hugging Face-Modells
Sehen wir uns ein vollständiges Beispiel für die Bereitstellung eines einfachen Modells zur Sentimentanalyse an. Wenn Sie diese Schritte befolgen, gelangen Sie von der Auswahl eines Modells zu einem live testbaren Endpunkt.
- Wählen Sie Ihr Modell aus: Gehen Sie zum Hugging Face hub und verwenden Sie die Filter auf der linken Seite, um nach Modellen zu suchen, die „Textklassifizierung“ durchführen. Ein guter Ausgangspunkt ist distilbert-base-uncased-finetuned-sst-2-english. Lesen Sie die Karte des Modells, um die Leistung und die Verwendung des Modells zu verstehen.
- Installieren Sie Abhängigkeiten: Stellen Sie sicher, dass Sie in Ihrer lokalen Python-Umgebung die erforderlichen Bibliotheken installiert haben. Für dieses Modell benötigen Sie lediglich Transformers und Torch. Führen Sie pip install transformers torch aus.
- Lokal testen: Vergewissern Sie sich vor der Bereitstellung immer, dass das Modell auf Ihrem Rechner wie erwartet funktioniert. Schreiben Sie ein kleines Python-Skript, um das Modell mithilfe der Pipeline zu laden, und testen Sie es mit einem Beispielsatz. Zum Beispiel: classifier = pipeline("sentiment-analysis", model="distilbert-base-uncased-finetuned-sst-2-english") gefolgt von classifier("ClickUp ist die beste Plattform für Produktivität!")
- Bereitstellung erstellen: In diesem Beispiel verwenden wir Hugging Face Spaces für eine schnelle und einfache Bereitstellung. Erstellen Sie einen neuen Space, wählen Sie das Gradio SDK aus und erstellen Sie eine app.py-Datei, die Ihr Modell lädt und eine einfache Gradio-Schnittstelle für die Interaktion mit diesem definiert.
- Bereitstellung überprüfen: Sobald Ihr Space läuft, können Sie ihn über die interaktive Oberfläche testen. Sie können auch eine direkte API-Anfrage an den Endpunkt des Space senden, um eine JSON-Antwort zu erhalten, die bestätigt, dass er programmgesteuert funktioniert.
Nach diesen Schritten verfügen Sie über ein Live-Modell. Die nächste Phase des Projekts umfasst die Überwachung seiner Nutzung, die Planung von Updates und möglicherweise die Skalierung der Infrastruktur, falls es populär wird.
Für Teams, die komplexe KI-Bereitstellungsprojekte mit mehreren Phasen verwalten – von der Datenaufbereitung bis zur Produktionsbereitstellung – bietet die Software-Vorlage für Projektmanagement Advanced von ClickUp eine umfassende Struktur.
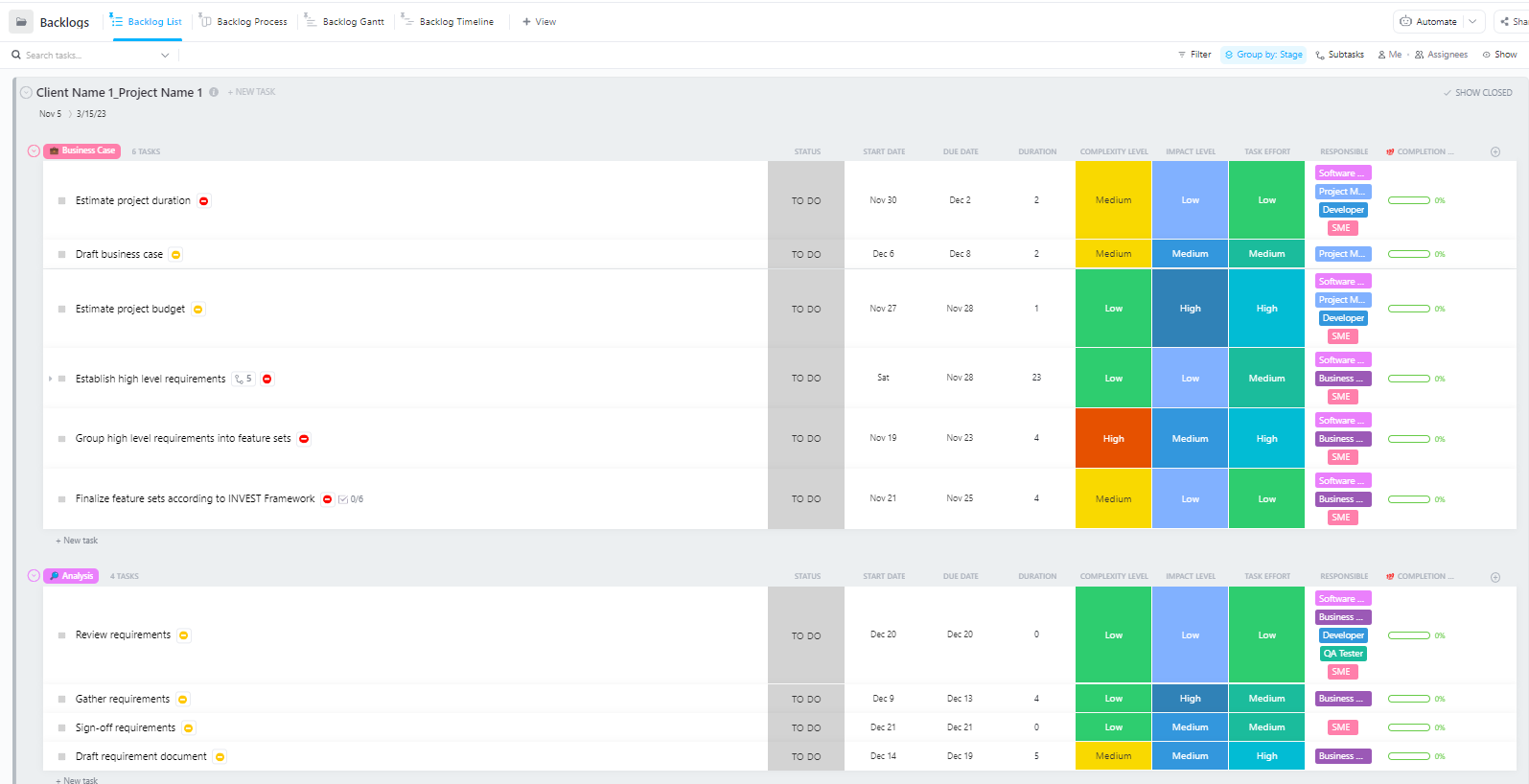
Diese Vorlage hilft Teams dabei:
- Verwalten Sie Projekte mit mehreren Meilensteinen, Aufgaben, Ressourcen und Abhängigkeiten.
- Visualisieren Sie den Projektfortschritt mit Gantt-Diagrammen und Zeitleisten.
- Arbeiten Sie nahtlos mit Ihren Teamkollegen zusammen, um den Erfolg beim Abschließen der Aufgaben sicherzustellen.
Häufige Herausforderungen bei der Bereitstellung von Hugging Face und wie man sie löst
Selbst mit einem klaren Plan werden Sie während der Bereitstellung wahrscheinlich auf einige Hindernisse stoßen. Das Starren auf eine kryptische Fehlermeldung kann unglaublich frustrierend sein und den Fortschritt Ihres Teams zum Stillstand bringen. Hier sind einige der häufigsten Herausforderungen und wie Sie diese beheben können. 🛠️
🚨Problem: „Modell erfordert Authentifizierung”
- Ursache: Sie versuchen, auf ein „geschütztes” Modell zuzugreifen, für das Sie die Lizenzbedingungen akzeptieren müssen.
- Lösung: Gehen Sie zur Modellseite im Hub, lesen Sie die Lizenzvereinbarung und akzeptieren Sie sie. Stellen Sie sicher, dass der von Ihnen verwendete Token über „Lese”-Berechtigungen verfügt.
🚨Problem: „CUDA-Speicher voll”
- Ursache: Das Modell, das Sie laden möchten, ist zu groß für den Speicher Ihrer GPU (VRAM).
- Lösung: Die schnellste Lösung besteht darin, eine kleinere Version des Modells oder eine quantisierte Version zu verwenden. Sie können auch versuchen, die Größe der Batch-Daten während der Inferenz zu reduzieren.
🚨Problem: „trust_remote_code Fehler”
- Grund: Einige Modelle auf dem Hub erfordern zur Ausführung benutzerdefinierten Code, und aus Sicherheitsgründen führt die Bibliothek diesen als Standard nicht aus.
- Lösung: Sie können dies umgehen, indem Sie beim Laden des Modells trust_remote_code=True hinzufügen. Sie sollten jedoch immer zuerst den Code überprüfen, um sicherzustellen, dass er sicher ist.
🚨Problem: „Tokenizer-Fehlanpassung”
- Ursache: Der von Ihnen verwendete Tokenizer ist nicht genau derselbe, mit dem das Modell trainiert wurde, was zu falschen Eingaben und schlechter Leistung führt.
- Lösung: Laden Sie den Tokenizer immer aus demselben Modell-Checkpoint wie das Modell selbst. Beispiel: AutoTokenizer. from_pretrained("Modellname")
🚨Problem: „Ratenlimit überschritten”
- Ursache: Sie haben innerhalb eines kurzen Zeitraums zu viele Anfragen an die kostenlose Inference-API gestellt.
- Lösung: Für den produktiven Einsatz sollten Sie auf einen dedizierten Inference Endpoint upgraden. Für die Entwicklung können Sie Caching implementieren, um zu vermeiden, dass dieselbe Anfrage mehrmals gesendet wird.
Es ist entscheidend, die Nachverfolgung zu betreiben, welche Lösungen für welche Probleme geeignet sind. Ohne einen zentralen Ort, an dem diese Erkenntnisse dokumentiert werden, lösen Teams oft immer wieder dasselbe Problem.
📮 ClickUp Insight: Jeder vierte Mitarbeiter nutzt vier oder mehr Tools, nur um sich bei der Arbeit einen Überblick zu verschaffen. Wichtige Details können in einer E-Mail versteckt, in einem Slack-Thread erweitert und in einem separaten Tool dokumentiert sein, sodass Teams Zeit mit der Suche nach Informationen verschwenden, anstatt ihre Arbeit zu erledigen.
ClickUp vereint Ihren gesamten Workflow auf einer einheitlichen Plattform. Mit Features wie ClickUp E-Mail Projektmanagement, ClickUp Chat, ClickUp Docs und ClickUp Brain bleibt alles miteinander verbunden, synchronisiert und sofort zugänglich. Verabschieden Sie sich von „Arbeit um der Arbeit willen” und gewinnen Sie Ihre produktive Zeit zurück.
💫 Echte Ergebnisse: Teams können mit ClickUp jede Woche mehr als 5 Stunden Zeit einsparen – das sind über 250 Stunden pro Person und Jahr –, indem sie veraltete Wissensmanagementprozesse eliminieren. Stellen Sie sich vor, was Ihr Team mit einer zusätzlichen Woche Produktivität pro Quartal alles schaffen könnte!
So verwalten Sie KI-Bereitstellungsprojekte in ClickUp
Die Verwendung von Hugging Face für die KI-Bereitstellung erleichtert das Packen, Hosten und Bereitstellen von Modellen – eliminiert jedoch nicht den Koordinationsaufwand für die Bereitstellung in der Praxis. Teams müssen weiterhin die Nachverfolgung der getesteten Modelle durchführen, sich über Konfigurationen abstimmen, Entscheidungen dokumentieren und alle Beteiligten – von ML-Ingenieuren bis hin zu Produkt- und Betriebsmitarbeitern – auf dem gleichen Stand halten.
Wenn Ihr Engineering-Team verschiedene Modelle testet, Ihr Produktteam Anforderungen definiert und Stakeholder nach Updates fragen, werden Informationen über Slack, E-Mails, Tabellenkalkulationen und verschiedene Dokumente verstreut.
Diese Arbeitsausbreitung – die Fragmentierung von Arbeitsaktivitäten über mehrere, nicht miteinander verbundene tools, die nicht miteinander kommunizieren – sorgt für Verwirrung und verlangsamt alle.
Hier spielt ClickUp, der weltweit erste konvergierte KI-Workspace, eine wichtige Rolle, indem er Projektmanagement, Dokumentation und Teamkommunikation in einem einzigen Workspace zusammenführt.
Diese Konvergenz ist besonders wertvoll für KI-Bereitstellungsprojekte, bei denen technische und nicht-technische Stakeholder eine gemeinsame Sichtbarkeit benötigen, ohne fünf verschiedene Tools verwenden zu müssen.
Anstatt Updates über Tickets, Dokumente und Chat-Threads zu verstreuen, können Teams den gesamten Bereitstellungszyklus an einem Ort verwalten.
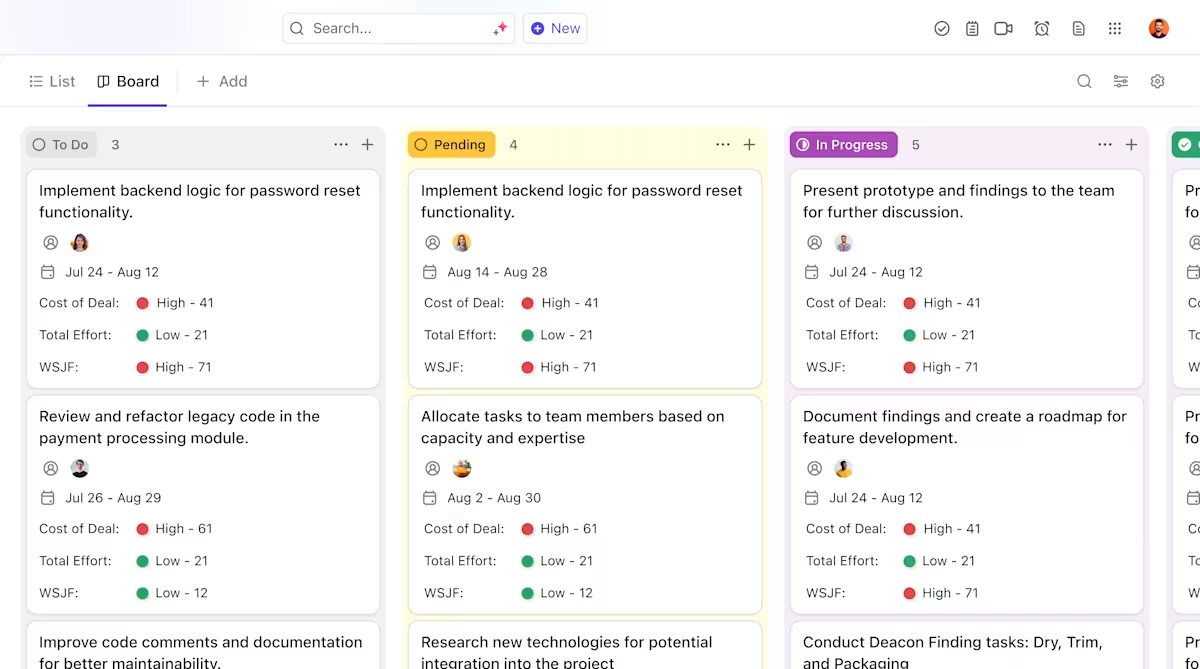
So kann ClickUp Ihr KI-Bereitstellungsprojekt unterstützen:
- Klare Zuständigkeiten und Nachverfolgung über den gesamten Modelllebenszyklus hinweg: Verwenden Sie ClickUp Aufgaben, um Hugging Face-Modelle während der Evaluierung, Testphase, Staging-Phase und Produktion zu verfolgen, wobei benutzerdefinierte Status, Eigentümer und Blockierer für das gesamte Team sichtbar sind.
- Zentralisierte, lebendige Bereitstellungsdokumentation: Verwalten Sie Bereitstellungs-Runbooks, Umgebungskonfigurationen und Fehlerbehebungsanleitungen in ClickUp Docs, damit sich die Dokumentation parallel zu Ihren Modellen weiterentwickelt und leicht zu durchsuchen und zu referenzieren bleibt. Da Docs mit Aufgaben verknüpft sind, befindet sich Ihre Dokumentation direkt neben der Arbeit, auf die sie sich bezieht.
- Kontextbezogene Zusammenarbeit ohne Arbeitsaufwand: Halten Sie Diskussionen, Entscheidungen und Aktualisierungen direkt mit Aufgaben und Dokumenten verknüpft und reduzieren Sie so die Abhängigkeit von verstreuten Slack-Threads, E-Mails und unverbundenen Projekt-Tools.
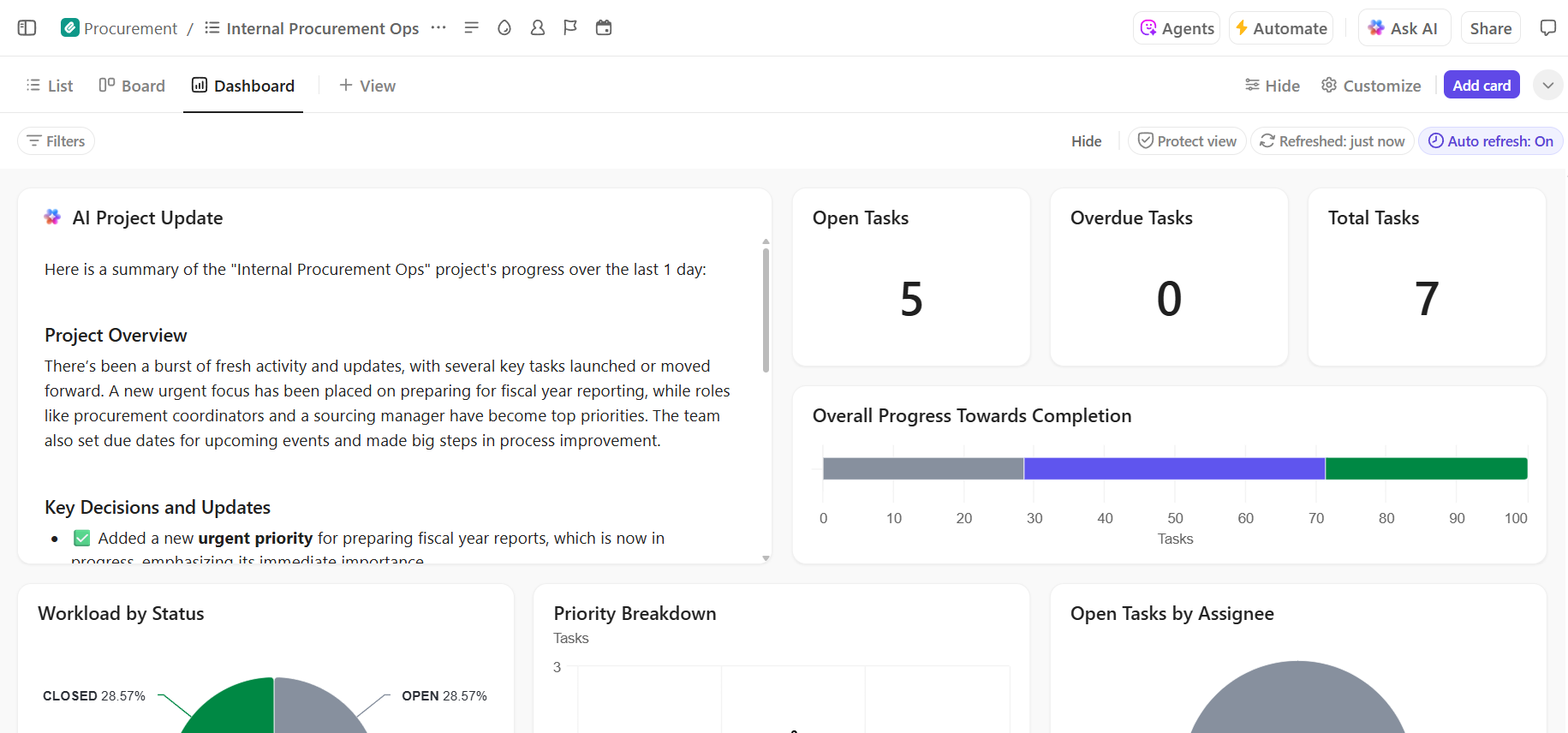
- Durchgängige Sichtbarkeit des Bereitstellungsfortschritts: Überwachen Sie die Bereitstellungspipeline, erkennen Sie Risiken frühzeitig und gleichen Sie die Team-Kapazitäten mithilfe von ClickUp-Dashboards aus, die den Fortschritt und Engpässe in Echtzeit anzeigen.
- Schnellere Einarbeitung und Entscheidungsfindung dank integrierter KI: Verwenden Sie ClickUp Brain, um lange Bereitstellungsdokumente zusammenzufassen, relevante Erkenntnisse aus früheren Bereitstellungen zu gewinnen und neuen Teammitgliedern zu helfen, sich schnell einzuarbeiten, ohne sich durch den historischen Kontext arbeiten zu müssen.
📚 Lesen Sie auch: Wie Sie die Automatisierung von Prozessen mit KI durchführen können, um schnellere und intelligentere Workflows zu erzielen
Verwalten Sie Ihr KI-Bereitstellungsprojekt nahtlos in ClickUp.
Ein erfolgreiches Hugging Face-Projekt hängt von einer soliden technischen Grundlage und einem klaren, organisierten Projektmanagement ab. Während die technischen Herausforderungen lösbar sind, sind es oft Koordinations- und Kommunikationsprobleme, die zum Scheitern von Projekten führen.
Durch die Einrichtung eines klaren Workflows auf einer einzigen Plattform kann Ihr Team schneller liefern und die Frustration durch Kontextverwirrung vermeiden – wenn Teams Stunden damit verschwenden, nach Informationen zu suchen, zwischen Apps zu wechseln und Aktualisierungen auf mehreren Plattformen zu wiederholen.
ClickUp, die Allround-App für die Arbeit, vereint Ihr Projektmanagement, Ihre Dokumentation und Ihre Teamkommunikation an einem Ort und bietet Ihnen so eine einzige Informationsquelle für den gesamten Lebenszyklus Ihrer KI-Bereitstellung.
Bringen Sie Ihre KI-Bereitstellungsprojekte zusammen und beseitigen Sie das Tool-Chaos. Starten Sie noch heute kostenlos mit ClickUp.
Häufig gestellte Fragen (FAQ)
Ja, Hugging Face bietet eine großzügige kostenlose Stufe, die den Zugriff auf den Model Hub, CPU-gestützte Spaces für Demos und eine mit Ratenlimit ausgestattete Inference-API zum Testen umfasst. Für Produktionsanforderungen, die dedizierte Hardware oder höhere Limits erfordern, sind kostenpflichtige Tarife verfügbar.
Spaces wurde für das Hosting interaktiver Anwendungen mit einer visuellen Benutzeroberfläche entwickelt und eignet sich daher ideal für Demos und interne tools. Die Inference API bietet programmatischen Zugriff auf Modelle, sodass Sie diese über einfache HTTP-Anfragen in Ihre Anwendungen integrieren können.
Auf jeden Fall. Durch interaktive Demos, die auf Hugging Face Spaces gehostet werden, können auch nicht-technische Mitglieder des Teams mit Modellen experimentieren und Feedback geben, ohne eine einzige Zeile Code schreiben zu müssen.
Die wichtigsten Einschränkungen der kostenlosen Stufe sind Ratenlimits für die Inference API, die Verwendung von gemeinsam genutzter CPU-Hardware für Spaces, was zu Verzögerungen führen kann, und „Kaltstarts“, bei denen inaktive Apps einen Moment brauchen, um hochzufahren. /