

Große Sprachmodelle (LLMs) haben spannende neue Möglichkeiten für Softwareanwendungen eröffnet. Sie ermöglichen intelligentere und dynamischere Systeme als je zuvor.
Experten sagen voraus, dass bis 2025 Apps, die auf diesen Modellen basieren, fast die Hälfte aller digitalen Arbeiten automatisieren könnten.
Doch während wir diese Fähigkeiten erschließen, taucht eine Herausforderung auf: Wie können wir die Qualität ihrer Ergebnisse in großem Maßstab zuverlässig messen? Eine kleine Änderung in den Einstellungen, und schon sieht man deutlich unterschiedliche Ergebnisse. Diese Variabilität kann es schwierig machen, ihre Leistung zu beurteilen, was bei der Vorbereitung eines Modells für den Einsatz in der Praxis entscheidend ist.
Dieser Artikel gibt Einblicke in die Best Practices zur Bewertung von LLM-Systemen, von Tests vor der Bereitstellung bis hin zur Produktion. Also, legen wir los!
Was ist eine LLM-Bewertung?
LLM-Bewertungsmetriken sind eine Möglichkeit, um festzustellen, ob Ihre Eingabeaufforderungen, Modelleinstellungen oder Workflows die von Ihnen gesetzten Ziele erreichen. Diese Metriken geben Ihnen Aufschluss darüber, wie gut Ihr Large Language Model funktioniert und ob es wirklich für den Einsatz in der Praxis bereit ist.
Heute messen einige der gängigsten Metriken das Kontextgedächtnis bei RAG-Aufgaben (Retrieval-Augmented Generation), exakte Übereinstimmungen bei Klassifizierungen, JSON-Validierung für strukturierte Ausgaben und semantische Ähnlichkeit bei kreativeren Aufgaben.
Jede dieser Metriken stellt auf einzigartige Weise sicher, dass das LLM die Standards für Ihren spezifischen Anwendungsfall erfüllt.
Warum müssen Sie ein LLM bewerten?
Große Sprachmodelle (LLMs) werden mittlerweile in einem breiten Bereich von Anwendungen eingesetzt. Es ist unerlässlich, die Leistung der Modelle zu bewerten, um sicherzustellen, dass sie den erwarteten Standards entsprechen und ihren beabsichtigten Zweck effektiv erfüllen.
Betrachten Sie es einmal so: LLMs sind die treibende Kraft hinter Alles, von Chatbots im Kundensupport bis hin zu kreativen tools, und je fortschrittlicher sie werden, desto mehr Bereiche erschließen sie sich.
Das bedeutet, dass wir bessere Methoden zur Überwachung und Bewertung benötigen – traditionelle Methoden können einfach nicht mit all den Aufgaben Schritt halten, die diese Modelle bewältigen.
Gute Metriken sind wie eine Qualitätsprüfung für LLMs. Sie zeigen, ob das Modell zuverlässig, genau und effizient genug für den Einsatz in der Praxis ist. Ohne diese Prüfungen könnten Fehler übersehen werden, was zu frustrierenden oder sogar irreführenden Benutzererfahrungen führen könnte.
Mit aussagekräftigen Metriken lassen sich Probleme leichter erkennen, das Modell verbessern und sicherstellen, dass es den spezifischen Anforderungen der Benutzer gerecht wird. Auf diese Weise wissen Sie, dass die von Ihnen verwendete KI-Plattform den Standards entspricht und die gewünschten Ergebnisse liefert.
📖 Weiterlesen: LLM vs. generative KI: Ein detaillierter Leitfaden
Arten von LLM-Bewertungen
Bewertungen bieten eine einzigartige Perspektive, um die Fähigkeiten des Modells zu untersuchen. Jeder Typ befasst sich mit verschiedenen Qualitätsaspekten und trägt so zum Aufbau eines zuverlässigen, sicheren und effizienten Bereitstellungsmodells bei.
Hier sind die verschiedenen Arten von LLM-Bewertungsmethoden:
- Die intrinsische Bewertung konzentriert sich auf die interne Leistung des Modells bei bestimmten Sprach- oder Verständnisaufgaben, ohne reale Anwendungen einzubeziehen. Sie wird in der Regel während der Phase der Entwicklung des Modells durchgeführt, um dessen Kernfähigkeiten zu verstehen.
- Die extrinsische Bewertung beurteilt die Leistung des Modells in realen Anwendungen. Bei dieser Art der Bewertung wird untersucht, wie gut das Modell bestimmte Ziele innerhalb eines Kontexts erfüllt.
- Die Robustheitsbewertung testet die Stabilität und Zuverlässigkeit des Modells in verschiedenen Szenarien, einschließlich unerwarteter Eingaben und widriger Bedingungen. Sie identifiziert potenzielle Schwachstellen und stellt sicher, dass sich das Modell vorhersehbar verhält.
- Effizienz- und Latenztests untersuchen die Ressourcennutzung, Geschwindigkeit und Latenz des Modells. Sie stellen sicher, dass das Modell Aufgaben schnell und mit angemessenen Rechenkosten ausführen kann, was für die Skalierbarkeit unerlässlich ist.
- Die Ethik- und Sicherheitsbewertung stellt sicher, dass das Modell den ethischen Standards und Sicherheitsrichtlinien entspricht, was bei sensiblen Anwendungen von entscheidender Bedeutung ist.
LLM-Modellbewertungen vs. LLM-Systembewertungen
Die Bewertung großer Sprachmodelle (LLMs) umfasst zwei Hauptansätze: Modellbewertungen und Systembewertungen. Jeder Ansatz konzentriert sich auf unterschiedliche Aspekte der Leistung des LLM, und es ist wichtig, den Unterschied zu kennen, um das Potenzial dieser Modelle voll auszuschöpfen.
🧠 Bei der Modellbewertung werden die allgemeinen Fähigkeiten des LLM untersucht. Bei dieser Art der Bewertung wird das Modell auf seine Fähigkeit getestet, Sprache in verschiedenen Kontexten genau zu verstehen, zu generieren und zu verarbeiten. Es ist fast wie ein allgemeiner Intelligenztest, bei dem geprüft wird, wie gut das Modell verschiedene Aufgaben bewältigen kann.
Bei Modellbewertungen könnte beispielsweise die Frage gestellt werden: „Wie vielseitig ist dieses Modell?“
🎯 LLM-Systembewertungen messen, wie sich das LLM innerhalb eines bestimmten Setups oder für einen bestimmten Zweck verhält, beispielsweise in einem Kundenservice-Chatbot. Dabei geht es weniger um die allgemeinen Fähigkeiten des Modells, sondern vielmehr darum, wie es bestimmte Aufgaben ausführt, um die Benutzererfahrung zu verbessern.
Systemevaluierungen konzentrieren sich hingegen auf Fragen wie: „Wie gut bewältigt das Modell diese spezifische Aufgabe für die Benutzer?“
Modellbewertungen helfen Entwicklern, die allgemeinen Fähigkeiten und Limite des LLM zu verstehen und Verbesserungen vorzunehmen. Systembewertungen konzentrieren sich darauf, wie gut das LLM die Bedürfnisse der Benutzer in bestimmten Kontexten erfüllt, um eine reibungslosere Benutzererfahrung zu gewährleisten.
Zusammen liefern diese Bewertungen ein vollständiges Bild der Stärken und Verbesserungsmöglichkeiten des LLM, wodurch es in realen Anwendungen leistungsfähiger und benutzerfreundlicher wird.
Lassen Sie uns nun die spezifischen Metriken für die LLM-Bewertung untersuchen.
Metriken für die LLM-Bewertung
Zu den zuverlässigen und gängigen Metriken gehören:
1. Verwirrung
Perplexität misst, wie gut ein Sprachmodell eine Folge von Wörtern vorhersagt. Im Wesentlichen gibt sie die Unsicherheit des Modells hinsichtlich des nächsten Wortes in einem Satz an. Ein niedrigerer Perplexitätswert bedeutet, dass das Modell mehr Vertrauen in seine Vorhersagen hat, was zu einer besseren Leistung führt.
📌 Beispiel: Stellen Sie sich vor, ein Modell generiert Text aus der Eingabeaufforderung „Die Katze saß auf dem...“. Wenn es eine hohe Wahrscheinlichkeit für Wörter wie „Teppich“ und „Boden“ vorhersagt, versteht es den Kontext gut, was das Ergebnis eines niedrigen Perplexitätswerts ist.
Wenn hingegen ein nicht passendes Wort wie „Raumschiff“ vorgeschlagen wird, wäre der Perplexitätswert höher, was darauf hindeutet, dass das Modell Schwierigkeiten hat, sinnvolle Texte vorherzusagen.
2. BLEU-Score
Der BLEU-Score (Bilingual Evaluation Understudy) wird in erster Linie zur Bewertung von maschinellen Übersetzungen und zur Beurteilung der Textgenerierung verwendet.
Sie misst, wie viele N-Gramme (zusammenhängende Sequenzen von n Elementen aus einem bestimmten Text-Beispiel) in der Ausgabe sich mit denen in einem oder mehreren Referenztexten überschneiden. Der Bereich der Punktzahl reicht von 0 bis 1, wobei höhere Punktzahlen eine bessere Leistung anzeigen.
📌 Beispiel: Wenn Ihr Modell den Satz „The quick brown fox jumps over the lazy dog” generiert und der Referenztext „A fast brown fox leaps over a lazy dog” lautet, vergleicht BLEU die gemeinsamen N-Gramme.
Eine hohe Punktzahl bedeutet, dass der generierte Satz ziemlich genau mit der Vorlage übereinstimmt, während eine niedrigere Punktzahl darauf hindeuten könnte, dass das Ergebnis nicht so gut passt.
3. F1-Score
Die LLM-Bewertungsmetrik „F1-Score” dient in erster Linie zur Klassifizierung. Sie misst das Gleichgewicht zwischen Präzision (der Genauigkeit der positiven Vorhersagen) und Recall (der Fähigkeit, alle relevanten Instanzen zu identifizieren).
Der Bereich reicht von 0 bis 1, wobei eine Bewertung von 1 für perfekte Genauigkeit steht.
📌 Beispiel: Bei einer Frage-Antwort-Aufgabe wird das Modell gefragt: „Welche Farbe hat der Himmel?“ Es antwortet mit „Der Himmel ist blau“ (richtig positiv), fügt aber auch „Der Himmel ist grün“ hinzu (falsch positiv). Der F1-Score berücksichtigt sowohl die Relevanz der richtigen als auch der falschen Antwort.
Diese Metrik trägt dazu bei, eine ausgewogene Bewertung der Modellleistung sicherzustellen.
4. METEOR
METEOR (Metric for Evaluation of Translation with Explicit Reihenfolge) geht über die exakte Wortübereinstimmung hinaus. Es berücksichtigt Synonyme, Wortstämme und Paraphrasen, um die Ähnlichkeit zwischen generiertem Text und Referenztext zu bewerten. Diese Metrik zielt darauf ab, sich stärker an der menschlichen Beurteilung zu orientieren.
📌 Beispiel: Wenn Ihr Modell „Die Katze ruhte sich auf dem Teppich aus” generiert und die Referenz „Die Katze lag auf dem Teppich” lautet, würde METEOR dies höher bewerten als BLEU, da es erkennt, dass „Katze” ein Synonym für „Katze” ist und „Teppich” und „Teppichboden” ähnliche Bedeutungen haben.
Dadurch eignet sich METEOR besonders gut, um die Nuancen der Sprache zu erfassen.
5. BERTScore
BERTScore bewertet die Textähnlichkeit auf der Grundlage von kontextuellen Einbettungen, die aus Modellen wie BERT (Bidirectional Encoder Representations from Transformers) abgeleitet werden. Dabei wird mehr Wert auf die Bedeutung als auf exakte Wortübereinstimmungen gelegt, was eine bessere semantische Ähnlichkeitsbewertung ermöglicht.
📌 Beispiel: Beim Vergleich der Sätze „Das Auto raste die Straße entlang” und „Das Fahrzeug fuhr mit hoher Geschwindigkeit die Straße entlang” analysiert BERTScore die zugrunde liegenden Bedeutungen und nicht nur die Wortwahl.
Auch wenn sich die Begriffe unterscheiden, sind die Grundgedanken ähnlich, was zu einem hohen BERTScore führt, der die Effektivität der generierten Inhalte widerspiegelt.
6. Menschliche Bewertung
Die menschliche Bewertung bleibt ein entscheidender Aspekt der LLM-Bewertung. Dabei erfolgt die Bewertung der Qualität der Modellausgaben durch menschliche Richter anhand verschiedener Kriterien wie Flüssigkeit und Relevanz. Techniken wie Likert-Skalen und A/B-Tests können eingesetzt werden, um Feedback zu sammeln.
📌 Beispiel: Nach der Generierung von Antworten durch einen Kundenservice-Chatbot können menschliche Bewerter jede Antwort auf einer Skala von 1 bis 5 bewerten. Wenn der Chatbot beispielsweise eine klare und hilfreiche Antwort auf eine Kundenanfrage gibt, erhält er möglicherweise eine 5, während eine vage oder verwirrende Antwort eine 2 erhalten könnte.
7. Aufgabenspezifische Metriken
Unterschiedliche LLM-Aufgaben erfordern maßgeschneiderte Metriken.
Bei Dialogsystemen können Metriken das Nutzerengagement oder die Raten für den Abschluss von Aufgaben bewerten. Bei der Codegenerierung kann der Erfolg daran gemessen werden, wie oft der generierte Code kompiliert wird oder Tests besteht.
📌 Beispiel: Bei einem Chatbot für den Kundensupport kann das Engagement daran gemessen werden, wie lange Benutzer in einer Unterhaltung bleiben oder wie viele Folgefragen sie stellen.
Wenn Benutzer häufig zusätzliche Informationen anfordern, deutet dies darauf hin, dass das Modell sie erfolgreich einbindet und ihre Abfragen effektiv beantwortet.
8. Robustheit und Fairness
Die Bewertung der Robustheit eines Modells umfasst die Prüfung, wie gut es auf unerwartete oder ungewöhnliche Eingaben reagiert. Fairness-Metriken helfen dabei, Verzerrungen in den Ergebnissen des Modells zu identifizieren und sicherzustellen, dass es in verschiedenen demografischen Gruppen und Szenarien gleichberechtigt funktioniert.
📌 Beispiel: Wenn ein Modell mit einer skurrilen Frage wie „Was halten Sie von Einhörnern?“ getestet wird, sollte es die Frage elegant bearbeiten und eine relevante Antwort liefern. Gibt es stattdessen eine unsinnige oder unangemessene Antwort, deutet dies auf eine mangelnde Robustheit hin.
Fairness-Tests stellen sicher, dass das Modell keine voreingenommenen oder schädlichen Ergebnisse liefert, und fördern so ein integrativeres KI-System.
9. Metriken
Da Sprachmodelle immer komplexer werden, wird es immer wichtiger, ihre Effizienz in Bezug auf Geschwindigkeit, Speicherverbrauch und Energieverbrauch zu messen. Metriken helfen dabei, zu bewerten, wie ressourcenintensiv ein Modell bei der Generierung von Antworten ist.
📌 Beispiel: Bei einem großen Sprachmodell kann die Messung der Effizienz darin bestehen, die Nachverfolgung durchzuführen, wie schnell es Antworten auf Abfragen von Benutzern generiert und wie viel Speicher es dabei verbraucht.
Wenn die Antwort zu lange dauert oder zu viele Ressourcen verbraucht, könnte dies für Anwendungen, die Echtzeitleistung erfordern, wie Chatbots oder Übersetzungsdienste, ein Problem darstellen.
Jetzt wissen Sie, wie Sie ein LLM-Modell bewerten können. Aber mit welchen tools können Sie dies messen? Lassen Sie uns das gemeinsam herausfinden.
Wie ClickUp Brain die LLM-Bewertung verbessern kann
ClickUp ist eine All-in-One-App für die Arbeit mit einem integrierten persönlichen Assistenten namens ClickUp Brain.
ClickUp Brain ist ein echter Game-Changer für die LLM-Leistungsbewertung. Was macht es also?
Es organisiert und hebt die relevantesten Daten hervor, sodass Ihr Team immer auf dem Laufenden bleibt. Mit seinen KI-gestützten Features ist ClickUp Brain eine der besten neuronalen Netzwerk-Software auf dem Markt. Es macht den gesamten Prozess reibungsloser, effizienter und kollaborativer als je zuvor. Lassen Sie uns gemeinsam seine Fähigkeiten erkunden.
Intelligentes Wissensmanagement
Bei der Bewertung von Large Language Models (LLMs) kann die Verwaltung großer Datenmengen eine Herausforderung darstellen.

ClickUp Brain kann wichtige Metriken und Ressourcen organisieren und hervorheben, die speziell auf die LLM-Bewertung zugeschnitten sind. Anstatt verstreute Tabellen und umfangreiche Berichte zu durchforsten, fasst ClickUp Brain alles an einem Ort zusammen. Leistungskennzahlen, Benchmarking-Daten und Testergebnisse sind über eine übersichtliche und benutzerfreundliche Oberfläche zugänglich.
Diese Organisation hilft Ihrem Team, Störfaktoren auszublenden und sich auf die wirklich wichtigen Erkenntnisse zu konzentrieren, wodurch Trends und Leistungsmuster leichter zu interpretieren sind.
Mit allem, was Sie brauchen, an einem Ort können Sie von der reinen Datenerfassung zu einer wirkungsvollen, datengestützten Entscheidungsfindung übergehen und die Informationsflut in verwertbare Erkenntnisse umwandeln.
Projektmanagement und Workflow-Management
LLM-Bewertungen erfordern sorgfältige Planung und Zusammenarbeit, und ClickUp erleichtert die Verwaltung dieses Prozesses.
Sie können Aufgaben wie Datenerfassung, Modelltraining und Leistungstests ganz einfach delegieren und gleichzeitig Prioritäten festlegen, um sicherzustellen, dass die wichtigsten Aufgaben zuerst erledigt werden. Darüber hinaus können Sie mit benutzerdefinierten Feldern Workflows an die spezifischen Anforderungen Ihres Projekts anpassen.

Mit ClickUp kann jeder sehen, wer was wann macht, wodurch Verzögerungen vermieden werden und sichergestellt wird, dass die Aufgaben reibungslos im Team abgewickelt werden. Es ist eine großartige Möglichkeit, alles von Anfang bis Ende organisiert und im Blick zu behalten.
Nachverfolgung der Metriken über benutzerdefinierte Dashboards
Möchten Sie die Leistung Ihrer LLM-Systeme genau im Auge behalten?
ClickUp-Dashboards visualisieren die Leistungsindikatoren in Echtzeit. So können Sie den Fortschritt Ihres Modells sofort überwachen. Diese Dashboards sind in hohem Maße anpassbar, sodass Sie Grafiken und Diagramme erstellen können, die genau das darstellen, was Sie brauchen, wenn Sie es brauchen.
Sie können die Genauigkeit Ihres Modells über die verschiedenen Phasen hinweg beobachten oder den Ressourcenverbrauch in jeder Phase aufschlüsseln. Anhand dieser Informationen können Sie Trends schnell erkennen, Verbesserungsmöglichkeiten identifizieren und sofort Anpassungen vornehmen.
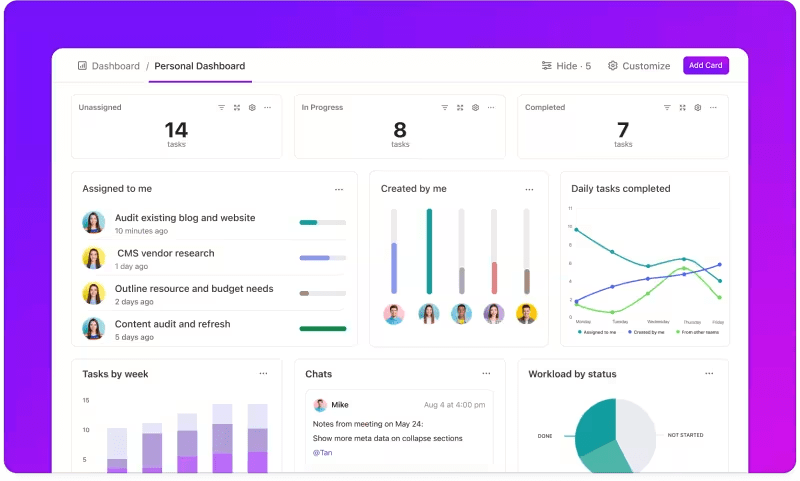
Anstatt auf den nächsten detaillierten Bericht zu warten, können Sie mit ClickUp Dashboards stets auf dem Laufenden bleiben und schnell reagieren, sodass Ihr Team ohne Verzögerung datengestützte Entscheidungen treffen kann.
Automatisierte Einblicke
Die Datenanalyse kann zeitaufwändig sein, aber die Features von ClickUp Brain erleichtern Ihnen die Arbeit, indem sie Ihnen wertvolle Einblicke liefern. Sie heben wichtige Trends hervor und geben sogar Empfehlungen auf der Grundlage der Daten, sodass Sie leichter aussagekräftige Schlussfolgerungen ziehen können.
Dank der automatisierten Erkenntnisse von ClickUp Brain müssen Sie Rohdaten nicht mehr manuell nach Mustern durchsuchen – das Programm findet sie für Sie. Durch diese Automatisierung kann sich Ihr Team auf die Optimierung der Modellleistung konzentrieren, anstatt sich mit sich wiederholenden Datenanalysen aufzuhalten.
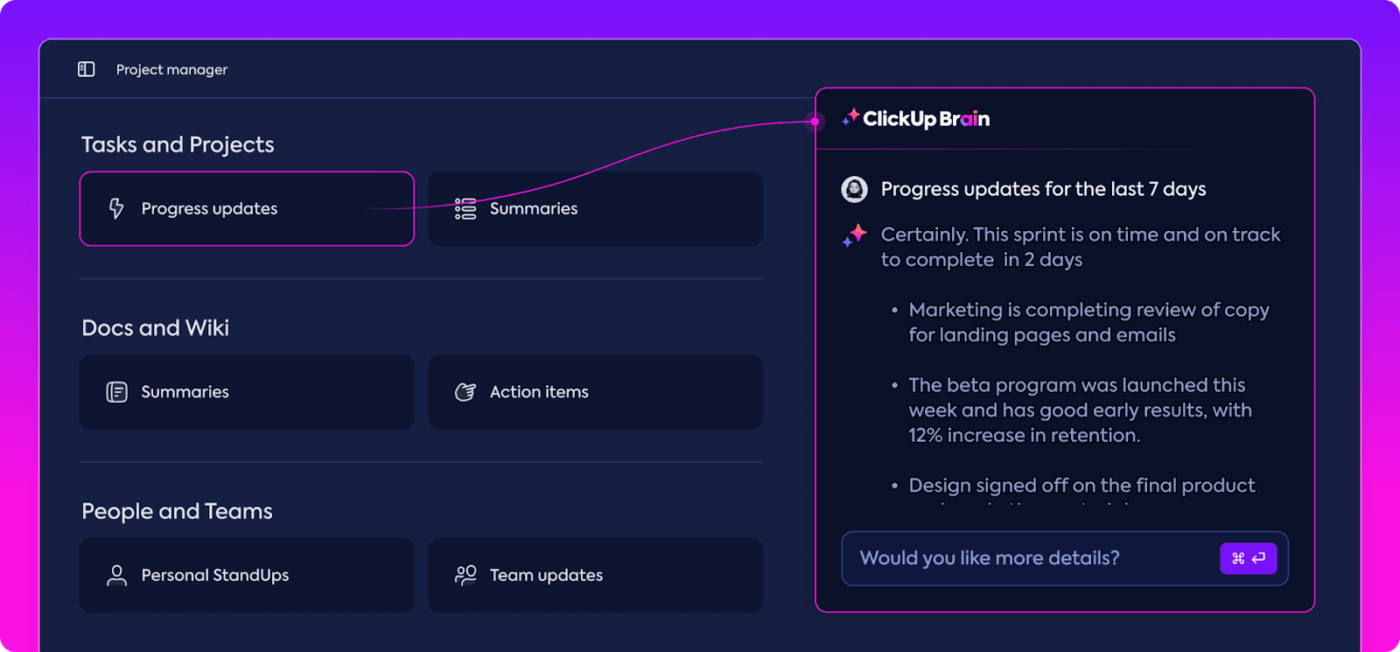
Die gewonnenen Erkenntnisse sind sofort einsetzbar, sodass Ihr Team sofort erkennen kann, was funktioniert und wo möglicherweise Änderungen erforderlich sind. Durch die Reduzierung des Zeitaufwands für die Analyse hilft ClickUp Ihrem Team, den Bewertungsprozess zu beschleunigen und sich auf die Umsetzung zu konzentrieren.
Dokumentation und Zusammenarbeit
Sie müssen nicht mehr E-Mails oder mehrere Plattformen durchsuchen, um das zu finden, was Sie brauchen – Alles ist griffbereit, wann immer Sie es brauchen.
ClickUp Docs ist ein zentraler hub, der alles zusammenführt, was Ihr Team für eine nahtlose LLM-Bewertung benötigt. Es organisiert wichtige Projektdokumente – wie Benchmarking-Kriterien, Testergebnisse und Leistungsprotokolle – an einem einzigen, leicht zugänglichen Ort, sodass jeder schnell auf die neuesten Informationen zugreifen kann.
Was ClickUp Docs wirklich auszeichnet, sind seine Features für die Zusammenarbeit in Echtzeit. Der integrierte ClickUp-Chat und die Kommentarfunktion ermöglichen es den Mitgliedern des Teams, Erkenntnisse zu diskutieren, Feedback zu geben und Änderungen direkt in den Dokumenten vorzuschlagen.
Das bedeutet, dass Ihr Team die Ergebnisse direkt auf der Plattform besprechen und Anpassungen vornehmen kann, sodass alle Diskussionen relevant und zielführend bleiben.

Von der Dokumentation bis zur Teamarbeit findet Alles in ClickUp Docs statt, wodurch ein optimierter Bewertungsprozess entsteht, in dem jeder die neuesten Entwicklungen sehen, freigeben und darauf reagieren kann.
Das Ergebnis? Ein reibungsloser, einheitlicher Workflow, mit dem Ihr Team seine Ziele mit absoluter Klarheit verfolgen kann.
Sind Sie bereit, ClickUp auszuprobieren? Bevor Sie das tun, lassen Sie uns einige Tipps und Tricks besprechen, mit denen Sie das Beste aus Ihrer LLM-Bewertung herausholen können.
Best Practices bei der LLM-Bewertung
Ein gut strukturierter Ansatz für die LLM-Bewertung stellt sicher, dass das Modell Ihren Anforderungen entspricht, den Erwartungen der Benutzer entspricht und aussagekräftige Ergebnisse liefert.
Durch das Setzen klarer Ziele, die Berücksichtigung der Endnutzer und die Verwendung verschiedener Metriken lässt sich eine gründliche Bewertung erstellen, die Stärken und Verbesserungsmöglichkeiten aufzeigt. Im Folgenden finden Sie einige Best Practices, die Ihnen als Leitfaden für Ihren Prozess dienen können.
🎯 Klare Ziele definieren
Bevor Sie mit dem Bewertungsprozess beginnen, müssen Sie genau wissen, was Sie mit Ihrem Large Language Model (LLM) erreichen möchten. Nehmen Sie sich Zeit, um die spezifischen Aufgaben oder Ziele für das Modell zu skizzieren.
📌 Beispiel: Wenn Sie die Leistung der maschinellen Übersetzung verbessern möchten, legen Sie klar fest, welche Qualitätsstufen Sie erreichen möchten. Mit klaren Zielen können Sie sich auf die relevantesten Metriken konzentrieren und sicherstellen, dass Ihre Bewertung mit diesen Zielen übereinstimmt und den Erfolg genau misst.
👥 Berücksichtigen Sie Ihre Zielgruppe
Überlegen Sie, wer das LLM nutzen wird und welche Anforderungen die Benutzer haben. Es ist entscheidend, die Bewertung auf Ihre vorgesehenen Benutzer zuzuschneiden.
📌 Beispiel: Wenn Ihr Modell dazu dient, ansprechende Inhalte zu generieren, sollten Sie besonders auf Metriken wie Sprachfluss und Kohärenz achten. Wenn Sie Ihre Zielgruppe verstehen, können Sie Ihre Bewertungskriterien verfeinern und sicherstellen, dass das Modell in der Praxis einen echten Wert bietet.
📊 Nutzen Sie verschiedene Metriken
Verlassen Sie sich bei der Bewertung Ihres LLM nicht nur auf eine einzige Metrik; eine Kombination verschiedener Metriken vermittelt Ihnen ein umfassenderes Bild seiner Leistung. Jede Metrik erfasst unterschiedliche Aspekte, sodass Sie durch die Verwendung mehrerer Metriken sowohl Stärken als auch Schwächen erkennen können.
📌 Beispiel: BLEU-Werte eignen sich zwar hervorragend zur Messung der Übersetzungsqualität, decken jedoch möglicherweise nicht alle Nuancen des kreativen Schreibens ab. Durch die Einbeziehung von Metriken wie Perplexität für die Vorhersagegenauigkeit und sogar menschliche Bewertungen für den Kontext können Sie ein viel umfassenderes Verständnis der Leistungsfähigkeit Ihres Modells gewinnen.
LLM-Benchmarks und -tools
Die Bewertung großer Sprachmodelle (LLMs) stützt sich häufig auf branchenübliche Benchmarks und spezielle tools, mit denen sich die Modellleistung bei verschiedenen Aufgaben messen lässt.
Hier finden Sie eine Übersicht über einige weit verbreitete Benchmarks und tools, die Struktur und Klarheit in den Bewertungsprozess bringen.
Schlüssel-Benchmarks
- GLUE (General Language Understanding Evaluation): GLUE bewertet die Fähigkeiten von Modellen bei verschiedenen Sprachaufgaben, darunter Satzklassifizierung, Ähnlichkeit und Schlussfolgerung. Es ist ein gängiger Maßstab für Modelle, die allgemeine Sprachverständnisaufgaben bewältigen müssen.
- SQuAD (Stanford Question Answering Dataset): Das SQuAD-Bewertungsframework eignet sich ideal für das Leseverständnis und misst, wie gut ein Modell Fragen auf der Grundlage eines Textabschnitts beantwortet. Es wird häufig für Aufgaben wie Kundensupport und wissensbasierte Suche verwendet, bei denen präzise Antworten entscheidend sind.
- SuperGLUE: Als erweiterte Version von GLUE bewertet SuperGLUE Modelle anhand komplexerer Aufgaben zum logischen Denken und zum Kontextverständnis. Es liefert tiefere Einblicke, insbesondere für Anwendungen, die ein fortgeschrittenes Sprachverständnis erfordern.
Wichtige Bewertungstools
- Hugging Face : Es ist weit verbreitet aufgrund seiner umfangreichen Modellbibliothek, Datensätze und Bewertungs-Features. Dank seiner äußerst intuitiven Benutzeroberfläche können Benutzer ganz einfach Benchmarks auswählen, benutzerdefinierte Bewertungen erstellen und die Modellleistung verfolgen, wodurch es für viele LLM-Anwendungen vielseitig einsetzbar ist.
- SuperAnnotate: Dieses Tool ist auf die Verwaltung und Annotation von Daten spezialisiert, was für überwachte Lernaufgaben von entscheidender Bedeutung ist. Es ist besonders nützlich für die Verfeinerung der Modellgenauigkeit, da es hochwertige, von Menschen annotierte Daten ermöglicht, die die Modellleistung bei komplexen Aufgaben verbessern.
- AllenNLP: AllenNLP wurde vom Allen Institute for KI entwickelt und richtet sich an Forscher und Entwickler, die an benutzerdefinierten NLP-Modellen arbeiten. Es unterstützt einen Bereich von Benchmarks und bietet Tools zum Trainieren, Testen und Bewerten von Sprachmodellen, wodurch es Flexibilität für verschiedene NLP-Anwendungen bietet.
Die Kombination dieser Benchmarks und Tools bietet einen umfassenden Ansatz für die LLM-Bewertung. Benchmarks können Standards für verschiedene Aufgaben festlegen, während Tools die Struktur und Flexibilität bieten, die erforderlich sind, um die Modellleistung effektiv zu verfolgen, zu verfeinern und zu verbessern.
Zusammen stellen sie sicher, dass LLMs sowohl technische Standards als auch praktische Anwendungsanforderungen erfüllen.
Herausforderungen bei der Bewertung von LLM-Modellen
Die Bewertung großer Sprachmodelle (LLMs) erfordert einen differenzierten Ansatz. Der Schwerpunkt liegt dabei auf der Qualität der Antworten und dem Verständnis der Anpassungsfähigkeit und Limite des Modells in verschiedenen Szenarien.
Da diese Modelle auf umfangreichen Datensätzen trainiert werden, wird ihr Verhalten von einem Bereich von Faktoren beeinflusst, sodass es unerlässlich ist, mehr als nur die Genauigkeit zu bewerten.
Eine echte Bewertung bedeutet, die Zuverlässigkeit des Modells, seine Widerstandsfähigkeit gegenüber ungewöhnlichen Eingaben und die allgemeine Konsistenz der Antworten zu untersuchen. Dieser Prozess hilft dabei, ein klareres Bild der Stärken und Schwächen des Modells zu zeichnen und Bereiche aufzudecken, die noch verbessert werden müssen.
Hier finden Sie einen genaueren Blick auf einige häufige Herausforderungen, die bei der LLM-Bewertung auftreten.
1. Überschneidung von Trainingsdaten
Es ist schwer zu sagen, ob das Modell bereits einige der Testdaten gesehen hat. Da LLMs mit riesigen Datensätzen trainiert werden, kann es sein, dass sich einige Testfragen mit Trainingsbeispielen überschneiden. Dadurch kann das Modell besser aussehen, als es eigentlich ist, weil es vielleicht nur wiederholt, was es schon weiß, anstatt echtes Verständnis zu zeigen.
2. Uneinheitliche Leistung
LLMs können unvorhersehbare Antworten geben. In einem Moment liefern sie beeindruckende Erkenntnisse, im nächsten machen sie seltsame Fehler oder präsentieren imaginäre Informationen als Fakten (bekannt als „Halluzinationen“).
Diese Inkonsistenz bedeutet, dass die LLM-Ergebnisse zwar in einigen Bereichen glänzen, in anderen jedoch zu wünschen übrig lassen, was eine genaue Beurteilung ihrer allgemeinen Zuverlässigkeit und Qualität erschwert.
3. Kontradiktorische Schwachstellen
LLMs können anfällig für gegnerische Angriffe sein, bei denen sie durch geschickt formulierte Eingabeaufforderungen dazu verleitet werden, fehlerhafte oder schädliche Antworten zu generieren. Diese Schwachstelle deckt Schwächen im Modell auf und kann zu unerwarteten oder verzerrten Ergebnissen führen. Das Testen dieser gegnerischen Schwachstellen ist entscheidend, um zu verstehen, wo die Grenzen des Modells liegen.
Praktische Anwendungsfälle für die LLM-Bewertung
Abschließend finden Sie hier einige typische Situationen, in denen die LLM-Bewertung wirklich einen Unterschied macht:
Chatbots für den Kundensupport
LLMs werden häufig in Chatbots verwendet, um Benutzerabfragen zu bearbeiten. Durch die Bewertung der Reaktionsfähigkeit des Modells wird sichergestellt, dass es genaue, hilfreiche und kontextbezogene Antworten liefert.
Es ist entscheidend, die Fähigkeit zu messen, die Absichten der Kunden zu verstehen, vielfältige Fragen zu bearbeiten und menschenähnliche Antworten zu geben. So können Geschäfte ein reibungsloses Kundenerlebnis gewährleisten und gleichzeitig Frustrationen minimieren.
Erstellung von Inhalten
Viele Geschäfte verwenden LLMs, um Blog-Inhalte, Social-Media-Beiträge und Produktbeschreibungen zu generieren. Die Bewertung der Qualität der generierten Inhalte trägt dazu bei, sicherzustellen, dass diese grammatikalisch korrekt, ansprechend und für die Zielgruppe relevant sind. Metriken wie Kreativität, Kohärenz und Relevanz für das Thema sind hier wichtig, um hohe Inhaltsstandards aufrechtzuerhalten.
Sentimentanalyse
LLMs können die Stimmung von Kundenfeedback, Social-Media-Beiträgen oder Produktbewertungen analysieren. Es ist wichtig zu bewerten, wie genau das Modell erkennt, ob ein Text positiv, negativ oder neutral ist. Dies hilft Unternehmen, die Emotionen ihrer Kunden zu verstehen, Produkte oder Dienstleistungen zu verfeinern, die Zufriedenheit der Benutzer zu steigern und ihre Marketingstrategien zu verbessern.
Codegenerierung
Entwickler verwenden häufig LLMs, um die Codegenerierung zu unterstützen. Die Bewertung der Fähigkeit des Modells, funktionalen und effizienten Code zu produzieren, ist von entscheidender Bedeutung.
Es ist wichtig zu überprüfen, ob der generierte Code logisch korrekt und ohne Fehler ist und die Anforderungen an die Aufgabe erfüllt. Dies trägt dazu bei, den manuellen Programmieraufwand zu reduzieren und die Produktivität zu steigern.
Optimieren Sie Ihre LLM-Bewertung mit ClickUp
Bei der Bewertung von LLMs geht es darum, die richtigen Metriken auszuwählen, die mit Ihren Zielen übereinstimmen. Der Schlüssel liegt darin, Ihre spezifischen Ziele zu verstehen, sei es die Verbesserung der Übersetzungsqualität, die Optimierung der Erstellung von Inhalt oder die Feinabstimmung für spezielle Aufgaben.
Die Auswahl der richtigen Metriken für die Leistungsbewertung, wie z. B. RAG- oder Fine-Tuning-Metriken, bildet die Grundlage für eine genaue und aussagekräftige Bewertung. Gleichzeitig liefern fortschrittliche Scorer wie G-Eval, Prometheus, SelfCheckGPT und QAG dank ihrer starken Argumentationsfähigkeiten präzise Erkenntnisse.
Das bedeutet jedoch nicht, dass diese Bewertungen perfekt sind – es ist nach wie vor wichtig, sicherzustellen, dass sie zuverlässig sind.
Passen Sie den Prozess im Laufe Ihrer LLM-Anwendungsbewertung an Ihren spezifischen Anwendungsfall an. Es gibt keine universelle Metrik, die für jedes Szenario geeignet ist. Eine Kombination aus Metriken und einer Fokussierung auf den Kontext vermittelt Ihnen ein genaueres Bild der Leistung Ihres Modells.
Um Ihre LLM-Bewertung zu optimieren und die Zusammenarbeit im Team zu verbessern, ist ClickUp die ideale Lösung für die Verwaltung von Workflows und die Nachverfolgung wichtiger Metriken.
Möchten Sie die Produktivität Ihres Teams steigern? Melden Sie sich noch heute bei ClickUp an und erleben Sie, wie es Ihren Workflow verändern kann!