
Os primeiros serviços são fáceis. Uma rotação, um canal e, em seguida, um backup.
No entanto, quando sua empresa atinge dezenas de microsserviços, várias regiões e propriedade em camadas, as escalações manuais deixam de ser um fluxo de trabalho e se tornam um problema.
Este guia explica como automatizar os caminhos de escalonamento de incidentes que se adaptam à sua organização de engenharia sem causar falhas no seu sistema de plantão.
E também veremos como o ClickUp se encaixa na criação de um sistema de escalonamento em que suas equipes de engenharia podem confiar. 🎯
⭐ Modelo em destaque
Responda de forma rápida e eficaz durante emergências, desde desastres naturais até violações de dados, usando o modelo de Plano de Ação para Incidentes (IAP) do ClickUp.

O modelo oferece seções predefinidas para:
- Defina os objetivos dos incidentes e as prioridades de resposta.
- Estabeleça uma estrutura de comando clara
- Coordene ações entre equipes em tempo real
- Registre decisões, cronogramas e atualizações importantes à medida que elas ocorrem.
- Mantenha-se conectado à escalonamento e acompanhe o andamento
E como ele fica dentro do ClickUp, funciona como um documento de comando de incidentes em tempo real, não como uma lista de verificação estática.
Por que automatizar os caminhos de escalonamento de incidentes
Quando sua equipe é responsável por sistemas complexos com SLAs rígidos, a escalonamento manual apenas atrasa o processo. O escalonamento automatizado torna seu processo de resposta previsível e menos estressante, mesmo durante incidentes de alta pressão.
Veja por que você deve automatizar os caminhos de escalonamento da sua organização. 👇
O risco da escalonamento manual
Quando você lida com dezenas de serviços, várias rotações de plantão e mudanças constantes de responsabilidade, as etapas realizadas por pessoas rapidamente se tornam um problema.
As armadilhas comuns incluem:
- Notificações perdidas ou atrasadas quando alguém ignora um e-mail, SMS ou mensagem de chat
- Confusão durante as transferências, especialmente quando os caminhos de escalonamento não estão claramente documentados
- Escalonamento para a equipe errada porque o mapa de responsabilidades não está atualizado
- Gargalos causados pela dependência de uma única pessoa para “encaminhar o alerta”
📖 Leia também: Como redigir um relatório de incidente
Benefícios da automação
A automação de ITSM dá estrutura e impulso aos seus caminhos de escalonamento. Em vez de esperar que alguém veja o alerta, seu sistema executa uma sequência predefinida de forma instantânea e consistente.
Veja o que as equipes ganham ao usar IA para automatizar tarefas:
- Tempos de resposta mais rápidos, pois os alertas chegam à pessoa ou equipe certa em segundos.
- Execução consistente das etapas de escalonamento, mesmo às 3 da manhã, quando a tomada de decisões é mais lenta.
- Redundância integrada que garante que os respondentes de backup sejam notificados se o plantão principal não receber o alerta.
- Visibilidade clara entre as equipes, pois todos entendem como funciona o fluxo de escalonamentos.
- Menos apagamento de incêndios e experiências de plantão mais previsíveis
📖 Leia também: Exemplos de planos de continuidade de negócios
Reduzindo a fadiga de alertas e a supervisão humana
A fadiga de alertas prejudica a eficácia do plantão. Quando sua equipe é acionada com muita frequência ou por motivos inadequados, ela deixa de responder com urgência. A automação ajuda a filtrar e elevar apenas o que realmente precisa da atenção humana.
Com a lógica de escalonamento automatizada:
- Alertas de baixo sinal ou duplicados são suprimidos antes de chegarem ao plantão.
- Regras baseadas na gravidade garantem que problemas menores não acordem ninguém desnecessariamente.
- Os alertas são escalonados somente se o sistema detectar a falta de resposta dentro de um prazo definido.
- As equipes gastam menos tempo classificando ruídos e mais tempo resolvendo problemas reais.
Apoiando a conformidade com o SLA e a política de plantão
A escalonamento automatizado facilita a conformidade sem a necessidade de supervisão manual constante. Para os líderes de operações de TI que gerenciam SLAs rigorosos ou compromissos internos de confiabilidade, a IA funciona como uma barreira de proteção que impõe o comportamento esperado. Ela ajuda você a:
- Garanta que as notificações de incidentes sigam regras predefinidas para o encaminhamento.
- Mantenha os prazos de resposta do SLA automaticamente, com escalonamentos programados.
- Aplique horários de plantão sem depender de planilhas desatualizadas.
- Crie trilhas de auditoria para cada alerta, escalonamento e confirmação.
🎥 Quer executar todo o fluxo de trabalho do caminho de escalonamento sem precisar usar as mãos? Os Super Agentes cuidam disso para você. 👇🏼
🔍 Você sabia? O Controle de Missão da NASA funciona essencialmente com base em uma lógica de escalonamento automatizada. Se a telemetria sair do alcance, o sistema encaminha instantaneamente alertas automatizados para especialistas por domínio.
O que é uma política de escalonamento no gerenciamento de incidentes?
Uma política de escalonamento é um conjunto predefinido de regras que determina quem é notificado, quando é notificado e como a responsabilidade é transferida para cima ou entre equipes.
Pense nisso como um roteiro estruturado que evita que os incidentes fiquem parados, garante que os especialistas certos entrem em ação no momento certo e ajuda as equipes a cumprir os SLAs.
Uma política de gerenciamento de escalonamento bem estruturada geralmente inclui:
- Roteamento baseado em regras que define quem é o próximo na fila quando alguém não confirma ou não consegue resolver o incidente.
- Gatilhos temporizados que escalam automaticamente após 5, 15 ou 30 minutos, com base na gravidade
- Métodos de notificação, como chamadas telefônicas, SMS, chat ou e-mail
- Níveis do plano de escalonamento: Nível 1 (plantão primário) > Nível 2 (engenheiros sênior/SMEs) > Nível 3 (liderança)
- Expectativas de documentação para que novos respondentes possam assumir sem perder o contexto crítico
📖 Leia também: Como priorizar tarefas como P0, P1, P2, P3 e P4
Tipos de políticas de escalonamento
Aqui estão os principais tipos de políticas que sua equipe deve entender:
1. Escalonamento hierárquico (vertical)
Os alertas sobem na cadeia de comando, passando de engenheiros juniores para especialistas seniores e, por fim, para a liderança. Use isso quando a situação exigir mais conhecimento especializado, autoridade para tomada de decisões ou visibilidade executiva.
2. Escalonamento funcional (horizontal)
Em vez de subir na hierarquia, o alerta é encaminhado entre as equipes para a função responsável pelo sistema afetado. Isso é ideal para incidentes relacionados a um domínio específico, como bancos de dados, redes, pagamentos ou APIs.
3. Escalonamento baseado no tempo
Essa é a espinha dorsal da maioria dos sistemas automatizados. Nesse tipo, o alerta passa para o próximo nível após um período específico, geralmente vinculado diretamente aos SLAs. Isso é especialmente essencial quando você precisa de uma resposta garantida após o expediente.
4. Escalonamento baseado no impacto
A escalonamento baseado no impacto depende da gravidade ou do impacto nos negócios, não da hierarquia ou do tempo. É útil para interrupções, falhas de pagamento, problemas relacionados ao atendimento ao cliente ou violações de segurança.
5. Escalonamento paralelo
Aqui, várias pessoas ou equipes são notificadas simultaneamente. O escalonamento paralelo é usado para problemas de alta gravidade que exigem várias especialidades ou para situações em que qualquer atraso é inaceitável.
🔍 Você sabia? Um estudo recente sobre sinais de alerta descobriu que alertas extremamente salientes ou “altos/brilhantes” podem retardar os tempos de reação, especialmente se o alerta for inesperado. Mas, uma vez que o tipo de alerta se torna esperado (ou seja, parte de um sistema de escalonamento/notificação pré-projetado), os tempos de resposta melhoram. Isso sugere que, ao automatizar os caminhos de escalonamento, você não deve simplesmente inundar as pessoas com alarmes de alta prioridade.
Quando acionar o escalonamento automático
Agora que você sabe como os caminhos de escalonamento são estruturados, o próximo passo é decidir quando essas regras devem ser executadas automaticamente.
Abaixo estão as principais situações que acionam o escalonamento automático, formando a camada lógica por trás de suas políticas. 💁
Escalonamento com base na gravidade
A escalonamento automático é acionado quando a gravidade ou o impacto do incidente ultrapassa um determinado limite. Incidentes de alta gravidade precisam de atenção imediata da gerência, e o escalonamento automático evita gargalos e coloca especialistas no circuito em questão de segundos.
📌 Exemplo: uma interrupção total do serviço, falha no gateway de pagamento ou degradação significativa que afete muitos usuários ou sistemas essenciais exige um escalonamento automático.
Escalonamento baseado no tempo
Se ninguém reconhecer ou resolver o incidente dentro de um intervalo de tempo definido, o alerta será automaticamente escalonado para o próximo nível. Isso evita que os tickets fiquem parados, especialmente fora do horário normal de trabalho ou quando o primeiro respondente estiver indisponível ou sobrecarregado.
📌 Exemplo: após 10 a 15 minutos sem confirmação, há uma escalação do primeiro respondente para um engenheiro sênior; após mais 30 a 60 minutos sem resolução, a escalação continua.
Escalonamento contextual
Essa lógica de escalonamento leva em consideração os atributos contextuais do incidente, como o serviço ou sistema afetado, o proprietário do serviço, o segmento de clientes impactado (interno x externo, VIP x regular) ou o domínio funcional (banco de dados, rede, integração). Com base nesse contexto, os alertas são encaminhados para o respondente ou equipe mais relevante.
Aqui, você evita sobrecarregar as equipes com incidentes irrelevantes, reduz o tempo de resposta e garante que os especialistas tratem das questões em suas áreas de atuação.
📌 Exemplos: Um pico de latência no serviço de pagamentos deve alertar diretamente a equipe de pagamentos, ou um erro de back-end no microsserviço de faturamento deve notificar a equipe de faturamento.
Escalonamento baseado em metadados
As ferramentas modernas de alerta e incidentes capturam metadados, como a fonte de origem (qual ferramenta de monitoramento ou regra de alerta foi acionada), identidade do usuário/cliente, localização, frequência histórica de incidentes semelhantes ou rótulos. Isso ajuda você a aplicar uma lógica mais granular e inteligente, em vez de confiar em regras baseadas em gravidade ou tempo.
📌 Exemplos: alertas recorrentes do mesmo subsistema podem indicar um problema sistêmico mais profundo, justificando uma escalação mais rápida. Ou então, alertas para clientes VIP podem acionar notificações adicionais.
Combinar gatilhos para criar políticas de escalonamento mais inteligentes e adaptáveis
Na prática, muitas equipes não dependem de apenas um tipo de gatilho. Em vez disso, elas criam políticas de escalonamento híbridas que combinam regras de gravidade, tempo, contexto e metadados.
Essa abordagem em camadas permite que as equipes criem políticas de escalonamento que sejam responsivas (rápidas quando necessário) e inteligentes (seletivas para minimizar ruídos), resultando em melhores resultados de incidentes e alocação mais eficiente de recursos.
🔍 Você sabia? No século XVIII, as tripulações navais usavam uma cadeia de escalonamento rígida durante emergências. Se um marinheiro de patente inferior detectasse um perigo, ele tocava um sino e passava a mensagem para os superiores até que o capitão tomasse a decisão final.
Como projetar caminhos de escalonamento eficazes
Projetar caminhos de escalonamento significa criar um sistema que encaminhe de forma confiável os alertas certos para as pessoas certas, com o mínimo de atrito.
Aqui está uma estrutura prática e passo a passo que você pode usar em ambientes complexos e distribuídos.
P. S. Também exploraremos como certos recursos do ClickUp podem ajudá-lo nessa tarefa! 🤩
Etapa nº 1: defina critérios, níveis e responsabilidades claros de escalonamento
Comece definindo o que constitui um incidente que requer escalonamento. Documente critérios objetivos para que todos os engenheiros de plantão, sejam eles novos respondentes L1 ou SREs experientes, interpretem a gravidade do incidente da mesma maneira.
Isso proporciona um fluxo de trabalho de escalonamento claro, elimina ambiguidades e garante que a automação seja acionada apenas quando realmente necessário.
Inclua critérios como:
- Limites de gravidade: interrupção do serviço, falhas de pagamento, problemas de autenticação, corrupção de dados e alertas de segurança.
- Impacto: Interrupções no atendimento ao cliente, degradação do serviço interno, falhas na API de parceiros, conformidade ou risco à segurança
- Contexto crítico para os negócios: impacto em clientes de alto valor, fluxos que afetam a receita, sistemas de alto risco (por exemplo, pagamentos, faturamento)
Depois de definir os critérios e gatilhos, mapeie quem será alertado e quais são suas responsabilidades em cada ponto de escalonamento.
Defina os níveis claramente:
- Nível um (gerente de incidentes de plantão principal): atua como o primeiro respondente e é responsável pelo reconhecimento, triagem inicial e tentativas de mitigação.
- Nível dois (backup/especialista/SME): oferece profundo conhecimento técnico e resolve problemas complexos do sistema.
- Nível três (gerente de engenharia/liderança): supervisiona incidentes graves, aprova ações importantes, coordena a comunicação entre equipes e aciona o escalonamento para o fornecedor, se necessário.
🚀 Vantagem do ClickUp: Use o ClickUp Docs para manter uma única fonte de verdade para critérios, níveis e responsabilidades de escalonamento, e documente funções e responsabilidades, incluindo quem:
- Reconhece e mitiga
- Comunica-se com as partes interessadas
- Lida com escalonamentos de fornecedores ou parceiros externos
- Lidera o comando de incidentes
Você também pode vincular essas funções específicas às tarefas relevantes do ClickUp para manter o contexto conectado.
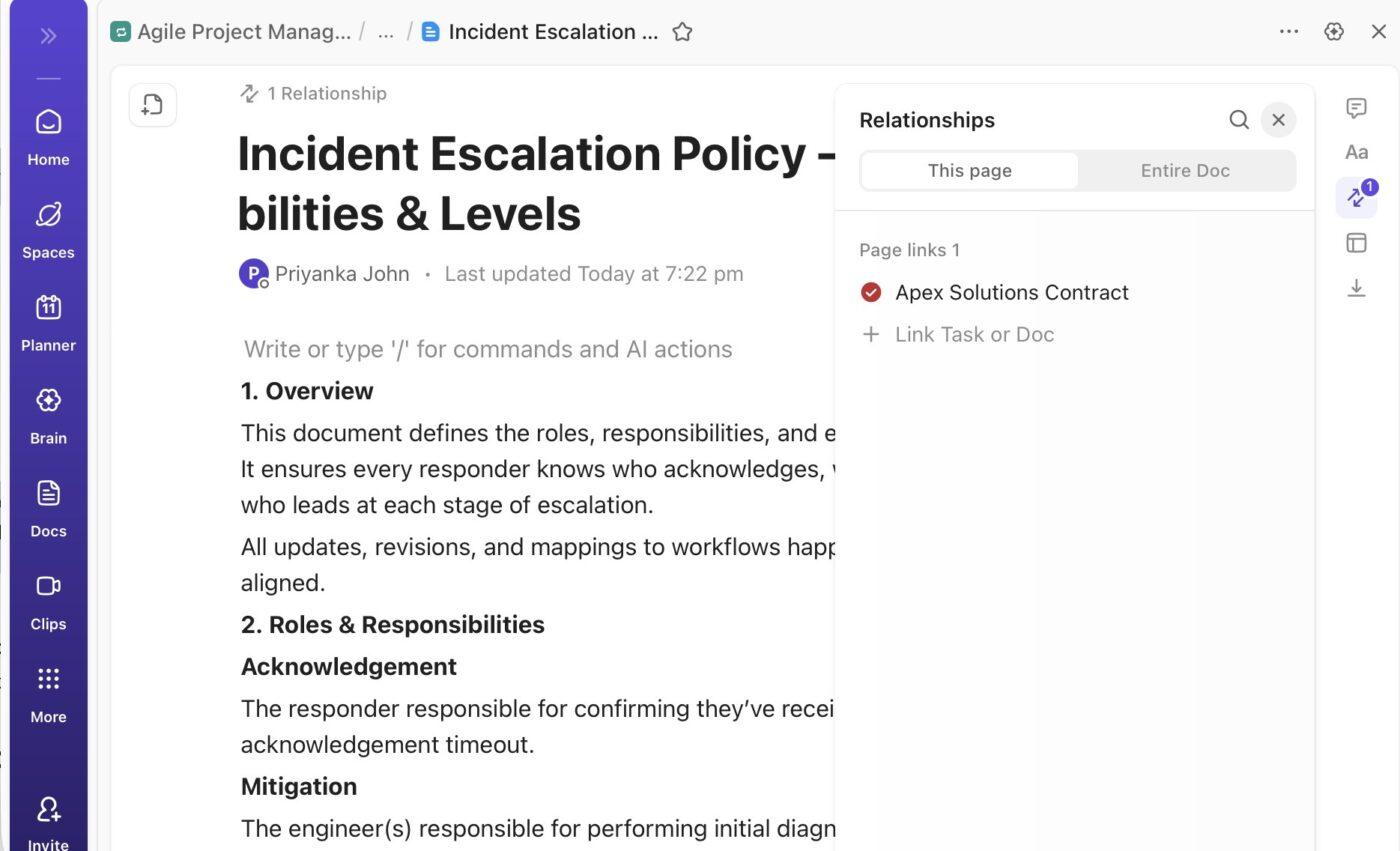
Crie sua própria base de conhecimento:
Depois que os critérios de escalonamento e a responsabilidade forem definidos, as equipes precisam de uma maneira consistente de capturar, rastrear e analisar incidentes técnicos. O modelo de relatório de incidentes do ClickUp oferece um sistema estruturado e de fácil acesso para documentar incidentes operacionais e de TI em um único lugar.
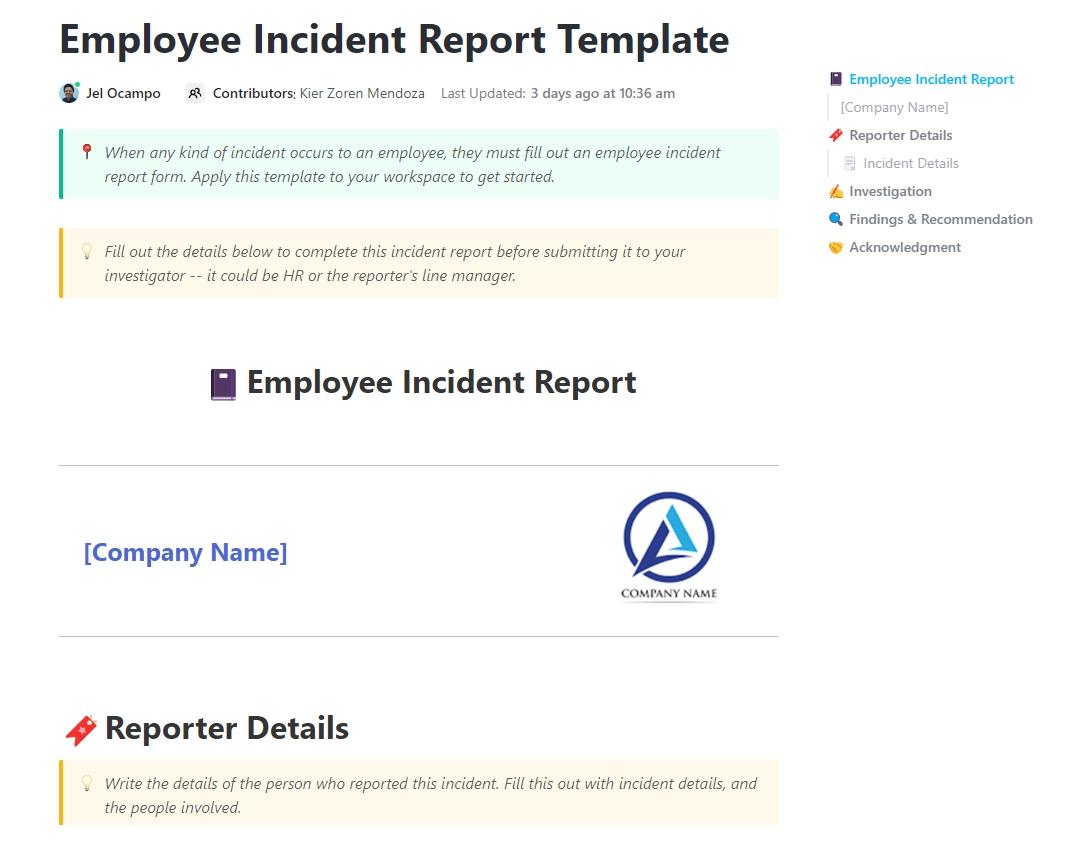
Integrado ao ClickUp Docs, ele ajuda as equipes de resposta a incidentes a registrar detalhes críticos, como gravidade do incidente, serviços afetados, cronogramas, resumos das causas principais, etapas de mitigação e ações de acompanhamento.
Etapa 2: Padronizar a criação de incidentes
Antes mesmo que os caminhos de escalonamento sejam ativados, sua equipe precisa de uma maneira confiável de capturar, normalizar e enriquecer os dados do incidente. Se o registro inicial do incidente estiver incompleto ou inconsistente, mesmo a lógica de escalonamento mais sofisticada falhará.
A padronização deve:
- Classifique os alertas recebidos: converta alertas em campos personalizados consistentes, como gravidade, categoria, serviço afetado, tipo de incidente e status de confirmação.
- Enriqueça o incidente automaticamente: Incorpore metadados, incluindo cluster, ID de implantação, proprietários de serviços ou dependências.
- Garanta que cada incidente capture o contexto: registre quem o relatou, como foi detectado, o ambiente (produção/preparação) e quaisquer registros ou capturas de tela relevantes.
Crie um formulário ClickUp diretamente da lista onde os incidentes são rastreados e projete-o para refletir sua realidade operacional e os dados relevantes dos quais sua lógica de escalonamento depende. Dessa forma, em vez de mensagens fragmentadas em chats, e-mails ou painéis, cada incidente entra em seu sistema em um formato consistente que a automação pode processar de maneira confiável.

Agrupe campos intencionalmente para que cada incidente seja totalmente contextualizado:
- Identificação (título, resumo)
- Classificação (gravidade, tipo, serviço afetado)
- Fonte (monitoramento, usuário, API)
- Evidências (registros, capturas de tela)
- Contexto comercial (nível de SLA, impacto no cliente)
Cada envio de formulário cria automaticamente uma nova tarefa no ClickUp, com todas as respostas mapeadas para os campos personalizados do ClickUp. Isso garante que os incidentes sejam normalizados no momento da criação, removendo ambiguidades e eliminando a necessidade de resposta manual aos incidentes.
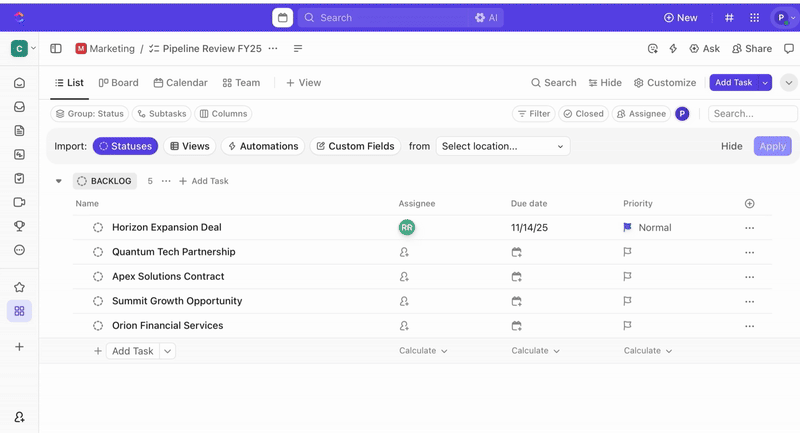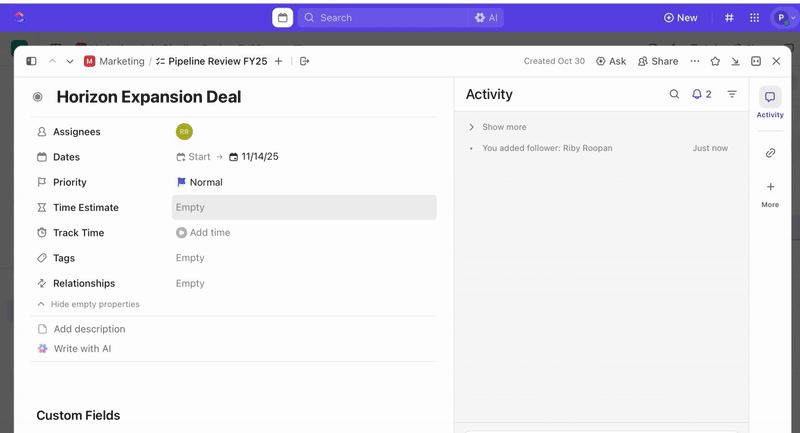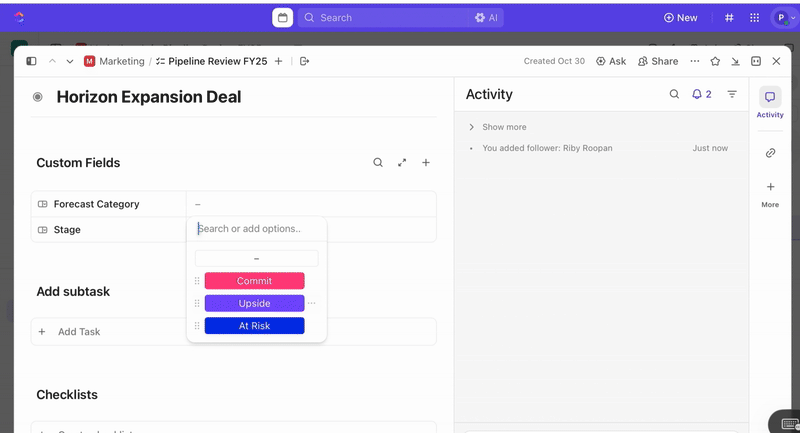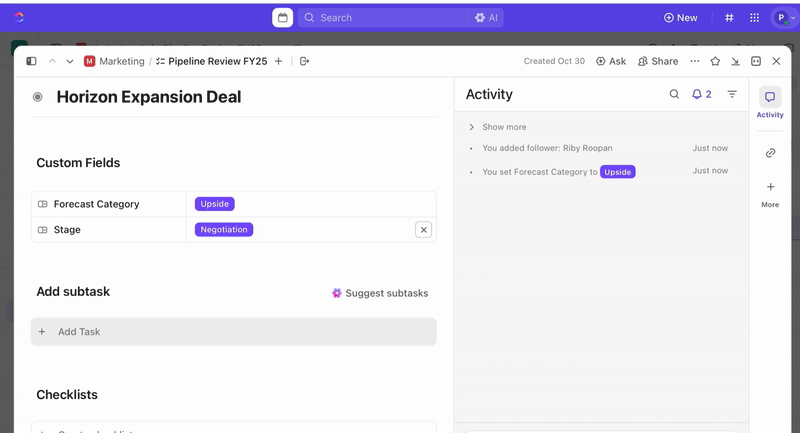
Depois que as tarefas forem criadas, você pode usar campos personalizados para orientar a triagem e a priorização (por exemplo, gravidade, impacto, grupo de resposta) e definir status personalizados do ClickUp que reflitam os estágios do incidente (Novo > Triagem > Investigação > Mitigação > Resolvido).
Etapa 3: Crie o caminho de escalonamento (ou seja, sequência + tempo + canais)
Esse é o ponto central do caminho. Defina o caminho em etapas, em que cada etapa define quem será notificado, por qual canal ou canais e após quanto tempo sem qualquer confirmação ou resolução.
- Defina o “tempo limite de reconhecimento” e o “tempo limite de resolução”.
Aqui está um exemplo de fluxo de trabalho:
- Primeira etapa: o primeiro plantão notificado imediatamente por SMS/canal de chat precisa confirmar o recebimento da notificação em 5 a 10 minutos.
- Etapa dois: se não houver confirmação ou ação nos próximos 15 a 20 minutos, encaminhe para a equipe de backup/SRE + engenheiro sênior por SMS/canal de chat/e-mail.
- Terceira etapa: se ainda não tiver sido resolvido após mais 30 a 60 minutos, encaminhe para o gerente de engenharia/liderança e, opcionalmente, acione um canal de “incidente grave”.
- Decida se o caminho de escalonamento deve “repetir” (notificar novamente o mesmo nível) ou “avançar”.
- Para incidentes críticos, configure notificações repetidas até que alguém responda. Para incidentes de menor prioridade, você pode optar por um único fluxo de escalonamento.
- Certifique-se de que o caminho esteja documentado usando um modelo de resposta de atendimento ao cliente e acessível a todo o pessoal relevante.
❗️ Observação: o “tempo limite de reconhecimento” é o tempo que o primeiro respondente tem para confirmar que viu o alerta, enquanto o “tempo limite de resolução” é o tempo que a equipe tem para corrigir ou mitigar o problema antes que a próxima escalação seja acionada.
Etapa 4: incorpore automação e suporte a ferramentas
Depois que seus critérios, processo de triagem e padrões de enriquecimento estiverem definidos, a próxima etapa é habilitar o escalonamento sem depender de pessoas para lembrar quando ou para quem escalonar. É aqui que as automações do ClickUp se tornam uma parte essencial do seu fluxo de trabalho.

Você pode configurar oportunidades de automação que reagem aos mesmos sinais que sua equipe usa durante incidentes. Aqui estão alguns exemplos:
- Se a gravidade for atualizada para SEV-1 ➡️ Atribua imediatamente um SRE sênior + notifique o canal de chat de plantão
- Se o status permanecer inalterado por X minutos ➡️ Acione o escalonamento para o próximo nível
- Se a data de vencimento passar (por exemplo, prazo de confirmação) ➡️ Escalar para L2
E é aqui que o ClickUp Brain leva as coisas ainda mais longe. Ele usa o contexto do seu espaço de trabalho para fornecer respostas instantâneas, gerar atualizações automaticamente e oferecer suporte ao acesso ao conhecimento.
Use ferramentas como o AI Prioritize para avaliar automaticamente os incidentes e definir a prioridade correta usando sua própria lógica. Exemplos de prompts:
- Se o incidente afetar a produção e impactar os clientes, defina Prioridade: Urgente.
- Se o responsável for a equipe de SRE e os registros mencionarem “latência”, defina a prioridade como alta.
- Se a descrição incluir palavras-chave de segurança como “violação”, defina Prioridade: Urgente.
E, uma vez definida a prioridade, o AI Assign assume o controle e atribui automaticamente os incidentes com base nas condições que você definir.
Você pode criar prompts como:
- Se a prioridade for urgente e o serviço afetado incluir “pagamentos”, atribua a um SRE sênior.
- Se o tipo de incidente for banco de dados e a região for US-East, atribua ao DB On-Call.
- Se o nome da tarefa incluir “segurança”, atribua-a ao líder de SecOps.
Teste essas instruções nas três primeiras tarefas antes de aplicar à lista inteira.
🚀 Vantagem do ClickUp: Implante bots de automação inteligentes que residem em seu espaço de trabalho e respondem a atividades em tempo real com os Super Agentes do ClickUp.
Eles estão totalmente cientes de suas tarefas, documentos, chats e processos, portanto, todas as ações automatizadas são contextuais.
Por exemplo, você pode colocar um Team StandUp Agent na sua “Pasta de Incidentes de Produção” para que ele publique automaticamente um resumo diário todas as manhãs. Sua equipe recebe um instantâneo mostrando o número de incidentes abertos, quais permanecem sem solução e quais mudanças ocorreram nas últimas 24 horas.
Agora, combine isso com um Ambient Answers Agent no seu canal “#incident-room”. Quando os respondentes fizerem perguntas como “Onde está o runbook SEV-1?” ou “Esta API já falhou antes?”, ele irá extrair informações do seu espaço de trabalho para fornecer respostas instantâneas e precisas.

Etapa 5: Padronize os canais de comunicação
À medida que os incidentes escalam, a forma e o local de comunicação das equipes são tão importantes quanto quem é notificado. Sem canais padronizados, as atualizações se perdem, as decisões são duplicadas e as partes interessadas recebem informações conflitantes.
Defina canais de escalonamento claros para cada estágio do ciclo de vida do incidente e use-os de maneira consistente entre as equipes:
| Critérios | Nome do canal | Objetivo |
| SEV-1 ou SEV-2 detectado | #incidente-crítico | Espaço central para alertas de alta gravidade e triagem imediata |
| Resolução de problemas ativa em andamento | #sala-de-crise-de-incidentes | Centro de colaboração em tempo real para engenheiros, produtos, controle de qualidade e suporte |
| Visibilidade da liderança necessária | #incident-leadership | Atualizações importantes para gerentes e executivos |
| É necessária comunicação com o cliente | #incident-comms | Espaço para redigir, revisar e alinhar as comunicações com clientes externos |
| Revisão pós-incidente iniciada | #incidente-retro | Discussão estruturada para notas retrospectivas, aprendizados e itens de ação |
Cada canal tem um público e um objetivo definidos, ajudando as equipes a reduzir o ruído e, ao mesmo tempo, manter as equipes apropriadas informadas.
🚀 Vantagem do ClickUp: Combine sua estratégia de canal com uma camada de comunicação integrada usando o ClickUp Chat. Todos os alertas, atualizações e decisões permanecem diretamente vinculados à tarefa, lista ou espaço do incidente onde o trabalho é realizado.
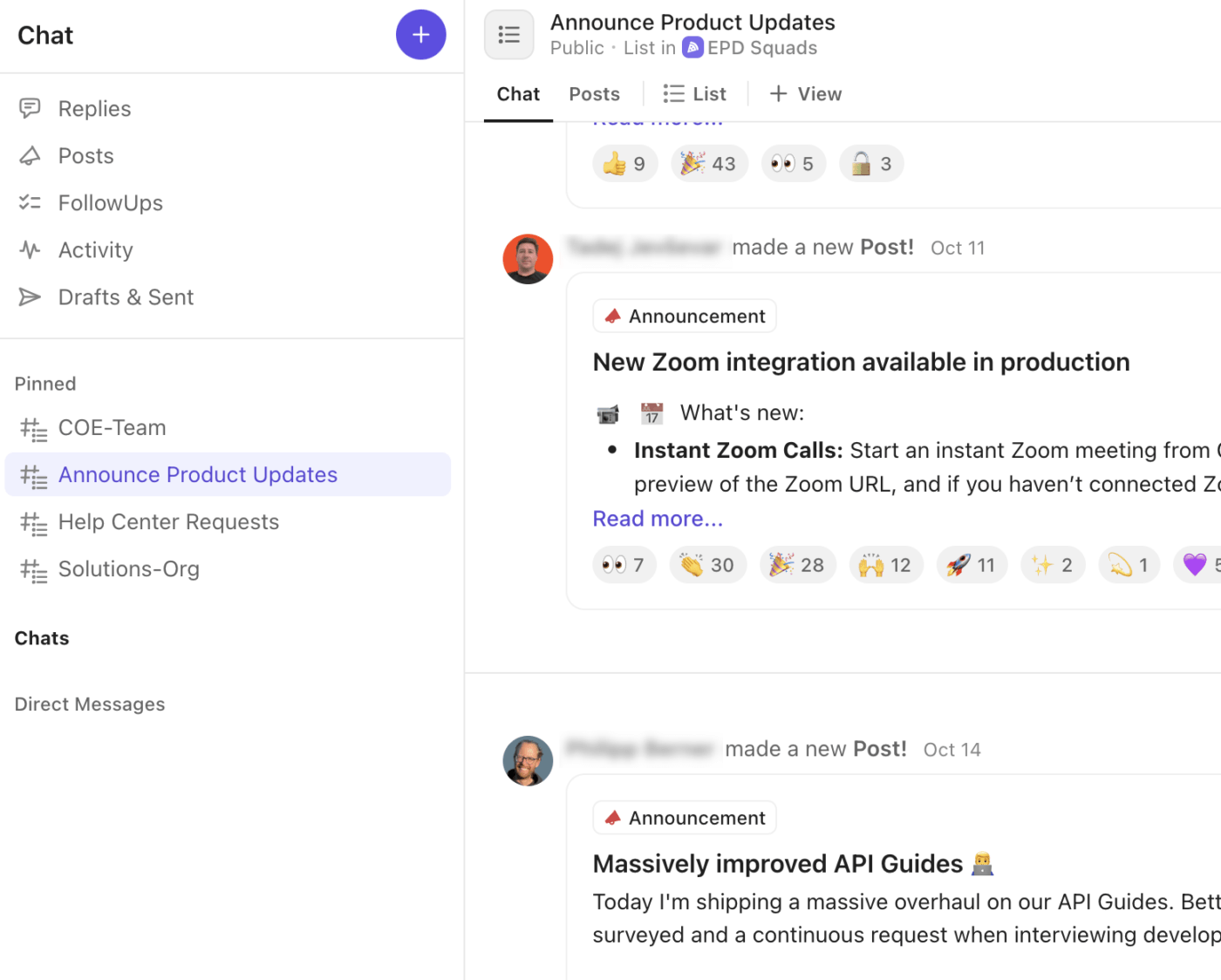
Veja como o ClickUp Chat melhora seu fluxo de trabalho de incidentes:
- Crie threads de chat dedicadas para discussões críticas, salas de guerra, liderança ou comunicações com clientes.
- Transforme mensagens de chat em tarefas do ClickUp instantaneamente, garantindo que as decisões e os acompanhamentos não se percam na conversa.
- Participe de chamadas rápidas de áudio ou vídeo com o ClickUp SyncUps para coordenação de incidentes ao vivo ou briefings de liderança.
- Publique “Anúncios” ou atualizações para divulgar o status geral dos incidentes em toda a empresa.
- Marque colegas de equipe, insira capturas de tela e anexe registros diretamente no chat, mantendo o contexto técnico à mão.
Etapa 6: teste, audite e refine seu caminho de escalonamento
As políticas de escalonamento devem evoluir com seus sistemas. Veja o que você deve fazer regularmente:
| Atividade | O que testar ou revisar | Por que isso é importante |
| Simulados de emergência (trimestrais) | Simule incidentes P1 e P2, verifique o tempo de escalonamento e o encaminhamento | Garante que as automações e os caminhos de escalonamento funcionem sob pressão |
| Validação do caminho de escalonamento | Verifique se há escalonamentos sem saída ou proprietários ausentes. | Evita que os incidentes fiquem parados sem visibilidade |
| Temporizadores do processo de reconhecimento e resolução | Compare os temporizadores configurados com o MTTA e o MTTR reais. | Mantém o tempo de escalonamento realista e eficaz |
| Avaliação da fadiga de alertas | Identifique os responsáveis pela resposta que recebem alertas excessivos ou repetidos. | Reduz o esgotamento e a perda de alertas críticos |
| Precisão na classificação de gravidade e priorização | Verifique se os incidentes foram classificados corretamente. | Melhora o encaminhamento, a velocidade de resposta e a precisão da escalonamento. |
| Acompanhamento pós-incidente | Garanta que as ações necessárias identificadas nas retrospectivas sejam concluídas. | Evita incidentes repetidos e falhas sistêmicas |
Ferramentas e integrações para automação de escalonamento
Esta seção apresenta um software de gerenciamento de incidentes que ajuda a detectar incidentes mais rapidamente, encaminhá-los instantaneamente e manter todas as equipes informadas sem a necessidade de acompanhamento manual.
1. ClickUp (ideal para unificar escalonamentos multifuncionais em um único espaço de trabalho conectado para incidentes)
Os métodos tradicionais de escalonamento obrigam as equipes a lidar com e-mails, planilhas, conversas em chats e notas dispersas, tornando quase impossível obter uma visão clara e em tempo real do que está acontecendo.
O software de gerenciamento de tarefas ClickUp para gerenciamento de escalonamento elimina ruídos ao consolidar todos os detalhes de escalonamento em um único espaço de trabalho organizado.
Vamos examinar alguns recursos do software de gerenciamento de ativos de TI que posicionam o ClickUp como a melhor opção para equipes que gerenciam escalonamentos de alto volume e fluxos de trabalho de incidentes complexos.
Veja como trabalhar do seu jeito
Visualize suas tarefas sob vários ângulos para atender às suas necessidades operacionais com o ClickUp Views:
- Visualização de lista do ClickUp para que os líderes de SRE possam classificar os incidentes por gravidade, tempo restante do SLA ou grupos de plantão para uma triagem rápida.
- Clique em ClickUp Board View para permitir que os gerentes de engenharia visualizem as transferências e a responsabilidade da equipe durante as escalações.
- ClickUp Gantt View para líderes de programa mapearem marcos de resolução e dependências entre serviços
- Visualização da carga de trabalho do ClickUp para programadores de plantão, garantindo que os engenheiros não fiquem sobrecarregados durante períodos de alto volume de incidentes.
Transforme as discussões das reuniões em ação.
Durante as escalações e análises de incidentes, pode ser um desafio registrar as discussões e as ações a serem tomadas de maneira confiável. O ClickUp AI Notetaker participa automaticamente das reuniões agendadas no Google Agenda, Outlook, Zoom ou Teams, gravando e transcrevendo a conversa.
Após a reunião:
- Acesse transcrições pesquisáveis e resumos de itens de ação
- Garanta clareza usando as notas salvas no ClickUp Docs. Isso facilita a vinculação com tarefas de incidentes ou relatórios retrospectivos.
- Faça perguntas à IA do ClickUp sobre o conteúdo da reunião para esclarecer decisões ou descobrir acompanhamentos perdidos.
Conecte-se às ferramentas existentes em sua pilha de tecnologia.
Nos bastidores, as integrações do ClickUp e o ecossistema Webhooks garantem uma conectividade perfeita com o resto da sua pilha.
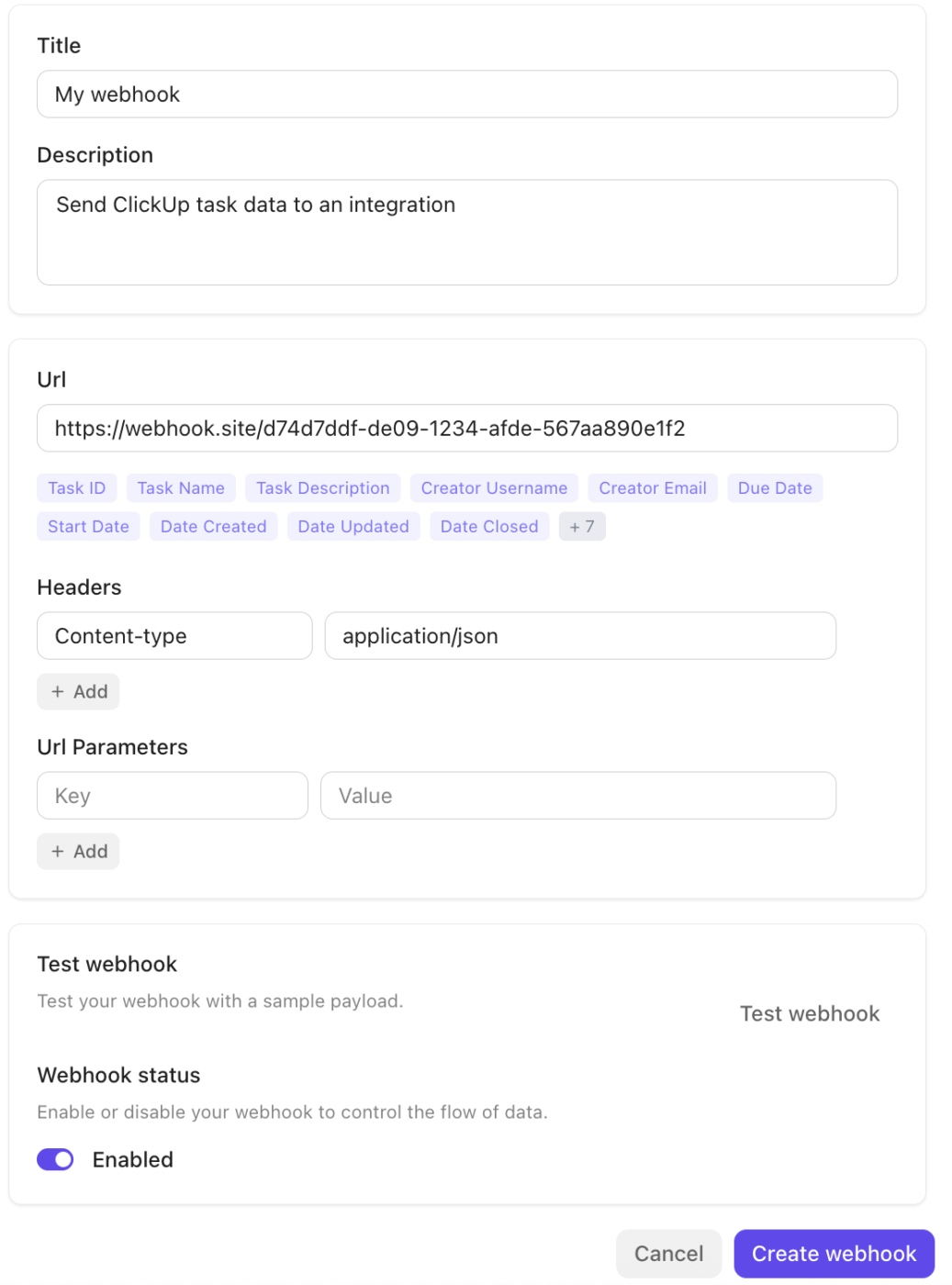
A plataforma se integra nativamente a ferramentas como Slack, GitHub, Zoom e outras, e oferece suporte a Webhooks por meio de sua API pública para transmitir eventos (atualizações de tarefas e alterações de status) para serviços externos ou pipelines de automação. Isso facilita o acionamento de fluxos de trabalho, a sincronização de dados ou o escalonamento de incidentes entre sistemas sem transferências manuais.
Converja todas as suas ferramentas de IA
Para levar a automação e o contexto a um novo patamar, o ClickUp BrainGPT traz IA contextual para seus fluxos de trabalho de escalonamento. É um aplicativo de super IA contextual que entende suas tarefas, documentos e contexto histórico.
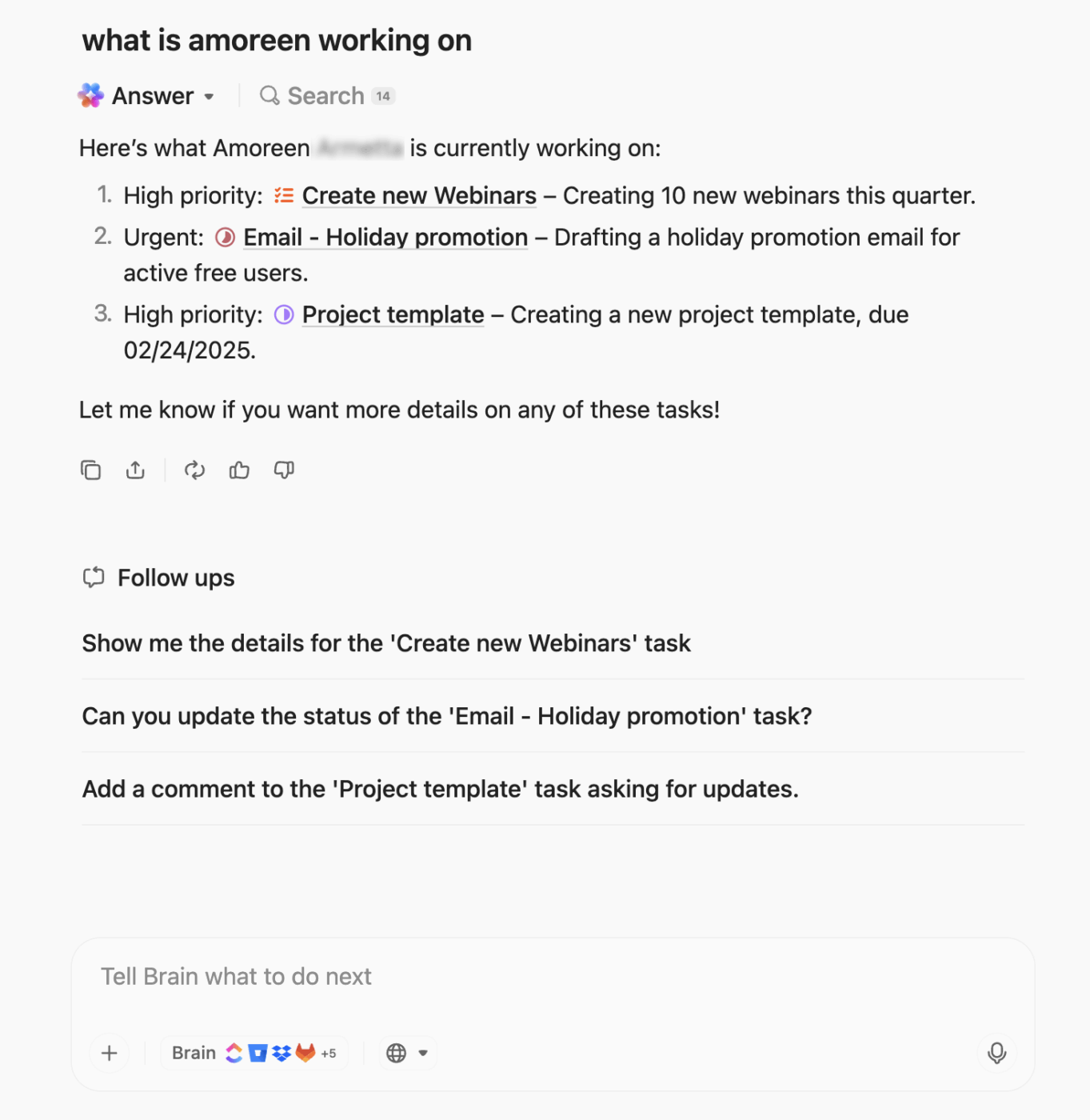
Com o Enterprise Search e o Connected Apps, você pode obter informações instantaneamente do seu espaço de trabalho, Slack, Google Drive, GitHub e muito mais. Durante chamadas de incidentes ao vivo, o Talk-to-Text no ClickUp permite que você dite notas ou instruções de escalonamento sem usar as mãos, garantindo que nada seja perdido.
Você também pode padronizar tarefas repetíveis com Prompts de IA personalizados e Prompts salvos, como: “Resuma todos os incidentes não resolvidos e recomende ações de escalonamento”.
Melhores recursos do ClickUp
- Priorize questões críticas: use as prioridades de tarefas do ClickUp para destacar escalonamentos urgentes ou de alto impacto.
- Organize sequências complexas de escalonamento: configure as dependências de tarefas do ClickUp para vincular tarefas relacionadas (por exemplo, “Aguardando” ou “Bloqueando”) para que as etapas de escalonamento evitem ações prematuras ou gargalos.
- Divida os incidentes em partes acionáveis: divida os escalonamentos em itens de ação granulares e atribua-os às equipes com subtarefas aninhadas.
- Acompanhe a velocidade de resolução com precisão: registre e monitore quanto tempo as tarefas de escalonamento levam para serem reconhecidas e resolvidas com o acompanhamento de tempo do projeto do ClickUp.
Limitações do ClickUp
- Com tantos recursos, visualizações e opções de personalização, as equipes geralmente enfrentam uma curva de aprendizado antes que tudo pareça intuitivo.
Preços do ClickUp
[Tabela de preços]
Avaliações e comentários do ClickUp
- G2: 4,7/5 (mais de 10.300 avaliações)
- Capterra: 4,6/5 (mais de 4.400 avaliações)
O que os usuários reais estão dizendo sobre o ClickUp?
Esta avaliação diz tudo:
O ClickUp reúne todas as minhas tarefas, projetos e comunicações em um só lugar, o que torna incrivelmente fácil manter-se organizado. Adoro como tudo é personalizável — desde visualizações e fluxos de trabalho até painéis —, pois assim posso estruturar meu espaço de trabalho exatamente da maneira que preciso. A capacidade de colaborar em tempo real, atribuir tarefas e acompanhar o progresso sem trocar de ferramenta é uma grande vantagem.
O ClickUp reúne todas as minhas tarefas, projetos e comunicações em um só lugar, o que torna incrivelmente fácil manter-se organizado. Adoro como tudo é personalizável — desde visualizações e fluxos de trabalho até painéis —, pois assim posso estruturar meu espaço de trabalho exatamente da maneira que preciso. A capacidade de colaborar em tempo real, atribuir tarefas e acompanhar o progresso sem trocar de ferramenta é uma grande vantagem.
📮 ClickUp Insight: 21% das pessoas afirmam que mais de 80% do seu dia de trabalho é dedicado a tarefas repetitivas. E outras 20% afirmam que as tarefas repetitivas consomem pelo menos 40% do seu dia.
Isso representa quase metade da semana de trabalho (41%) dedicada a tarefas que não exigem muito pensamento estratégico ou criatividade (como e-mails de acompanhamento 👀).
Os Super Agentes do ClickUp ajudam a eliminar esse trabalho árduo. Pense na criação de tarefas, lembretes, atualizações, notas de reuniões, rascunhos de e-mails e até mesmo na criação de fluxos de trabalho completos! Tudo isso (e muito mais) pode ser automatizado em um instante com o ClickUp, seu aplicativo completo para o trabalho.
💫 Resultados reais: a Lulu Press economiza 1 hora por dia, por funcionário, usando as automações do ClickUp, o que leva a um aumento de 12% na eficiência do trabalho.
2. PagerDuty (ideal para alertas em tempo real e resposta inteligente de plantão)
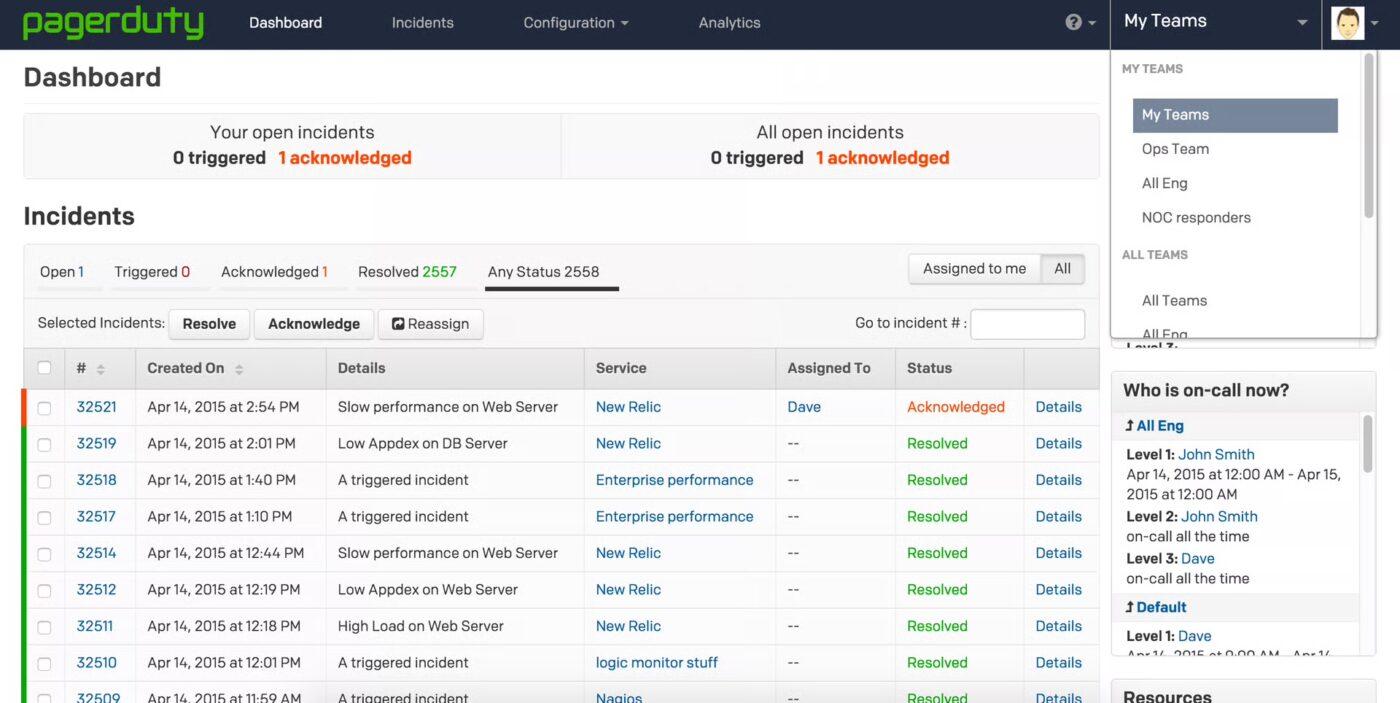
O PagerDuty é uma plataforma de gerenciamento de incidentes de TI e operações digitais baseada em nuvem que ajuda as equipes a detectar, responder e resolver rapidamente incidentes críticos, como interrupções ou ameaças à segurança. Ele oferece aos líderes de SRE, DevOps e suporte um caminho claro desde o sinal até a resolução, apoiado por automação, triagem com inteligência artificial e fluxos de trabalho profundamente integrados.
Recursos como Jeli Incident Analysis, PagerDuty Analytics e Runbook Automation ajudam as equipes a reduzir o tempo de inatividade, eliminar tarefas rotineiras e aprender com cada incidente.
Melhores recursos do PagerDuty
- Automatize o encaminhamento de incidentes com o recurso integrado Gerenciamento de plantão e Políticas de escalonamento dinâmicas.
- Acelere a triagem usando AIOps, que filtra ruídos de alerta, correlaciona eventos e destaca sinais verdadeiros.
- Mantenha as partes interessadas internas e externas alinhadas com Comunicações com as partes interessadas, Modelos de atualização de status e Páginas de status.
- Unifique seu conjunto de ferramentas com mais de 700 integrações e APIs extensíveis usando monitoramento, registro, CI/CD e sistemas de suporte.
Limitações do PagerDuty
- Alto volume de alertas se as integrações e os limites inteligentes não forem ajustados, levando a ruído e fadiga
- Alertas duplicados ou repetidos podem ocorrer durante picos, dificultando o reconhecimento sob pressão.
Preços do PagerDuty
- Gratuito
- Profissional: US$ 25/mês por usuário
- Negócios: US$ 49/mês por usuário
- Empresa: preços personalizados
Avaliações e comentários sobre o PagerDuty
- G2: 4,5/5 (mais de 900 avaliações)
- Capterra: 4,6/5 (mais de 200 avaliações)
O que os usuários reais estão dizendo sobre o PagerDuty?
Nas palavras de um usuário real:
O PagerDuty torna os alertas de incidentes rápidos e confiáveis. Ele envia as notificações certas no momento certo e mantém nossa equipe organizada. [...] O PagerDuty pode parecer barulhento às vezes, quando os alertas não são bem filtrados. Algumas configurações são um pouco complexas para novos usuários.
O PagerDuty torna os alertas de incidentes rápidos e confiáveis. Ele envia as notificações certas no momento certo e mantém nossa equipe organizada. [...] O PagerDuty pode parecer barulhento às vezes, quando os alertas não são bem filtrados. Algumas configurações são um pouco complexas para novos usuários.
💡 Dica profissional: crie exceções, mesmo em um caminho de escalonamento claro. Faça com que interrupções críticas, alertas de segurança ou incidentes em ambientes regulamentados sejam encaminhados diretamente para respondentes seniores ou especializados.
3. GLPi (ideal para governança de ativos de ponta a ponta e operações de serviço alinhadas com ITIL)
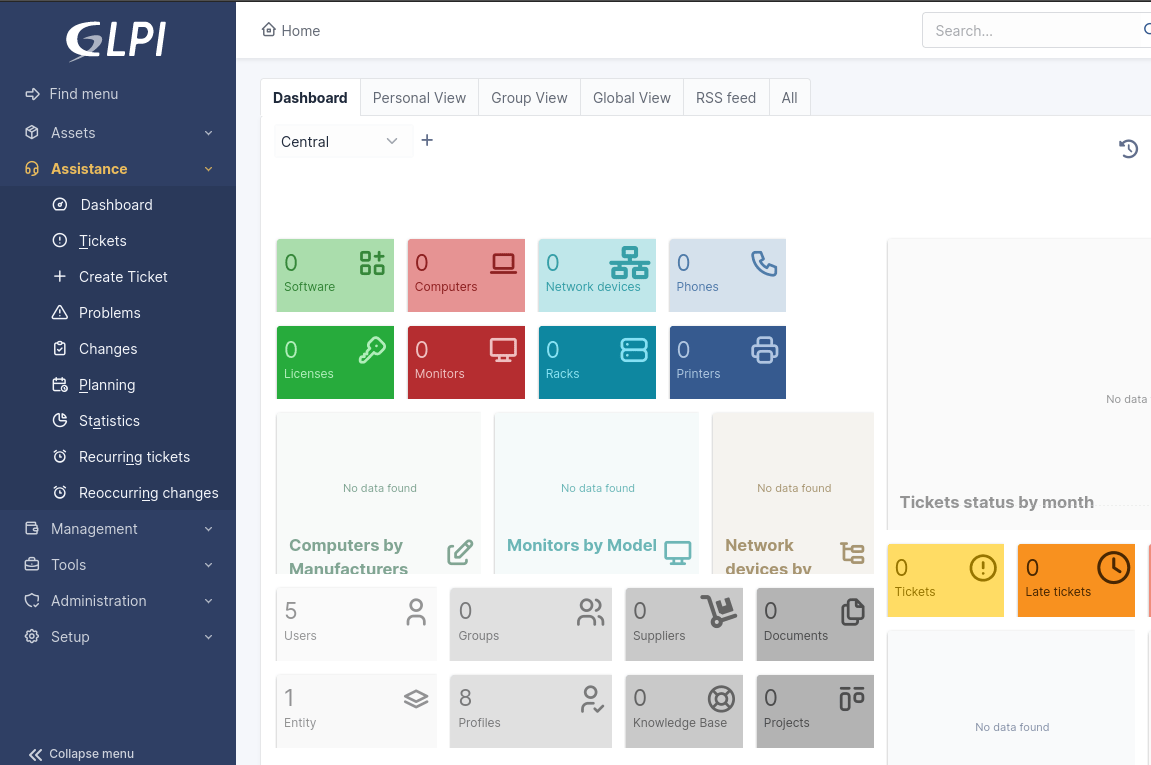
O Gestionnaire Libre de Parc Informatique (GLPi) é uma plataforma completa e de código aberto para gerenciamento de serviços de TI (ITSM) e gerenciamento de ativos de TI (ITAM). As equipes obtêm visibilidade completa de sua infraestrutura (hardware, software, licenças e dispositivos de rede) e podem gerenciar incidentes, solicitações de serviço e alterações usando processos alinhados com o ITIL.
Todos os seus contratos e documentação, incluindo garantias e contratos de serviço, ficam organizados de forma clara, evitando que se percam em diferentes sistemas. Se você gerencia centros de dados, o GLPi permite até mesmo visualizar layouts, caminhos de cabeamento e uso de energia para que você sempre saiba o que está acontecendo nos bastidores.
Melhores recursos do GLPi
- Use os plug-ins GLPI Inventory, OCS Inventory ou FusionInventory para detectar e catalogar automaticamente novos ativos de TI.
- Automatize tarefas repetitivas, atribuições de tickets, notificações e eventos recorrentes para reduzir o trabalho manual.
- Crie uma base de conhecimento para perguntas frequentes, documentação e artigos vinculados a tickets para autoatendimento e suporte técnico.
- Conecte-se ao Azure/Entra, Centreon, Google, OAuth2 e webhooks para sincronizar dados, acionar fluxos de trabalho e aprimorar seu CMDB.
Limitações do GLPi
- A compatibilidade do plug-in pode ser interrompida entre versões, causando sobrecarga de manutenção.
- Os recursos de relatórios, análises e exportação parecem limitados e precisam ser aprimorados.
Preços do GLPi
- Preços personalizados
Avaliações e comentários sobre o GLPi
- G2: 4,6/5 (mais de 30 avaliações)
- Capterra: 4,5/5 (mais de 40 avaliações)
O que os usuários reais estão dizendo sobre o GLPi?
Veja o que um usuário tem a dizer:
Sistema de gerenciamento de ativos de TI e tickets de suporte de código aberto altamente personalizável, com uma grande comunidade de suporte. A interface do usuário é um pouco complicada para um novato. Os plug-ins nem sempre são compatíveis entre versões antigas e novas.
Sistema de gerenciamento de ativos de TI e tickets de suporte de código aberto altamente personalizável, com uma grande comunidade de suporte. A interface do usuário é um pouco complicada para um novato. Os plug-ins nem sempre são compatíveis entre versões antigas e novas.
4. Splunk On-Call (ideal para encaminhar alertas de monitoramento diretamente aos engenheiros)
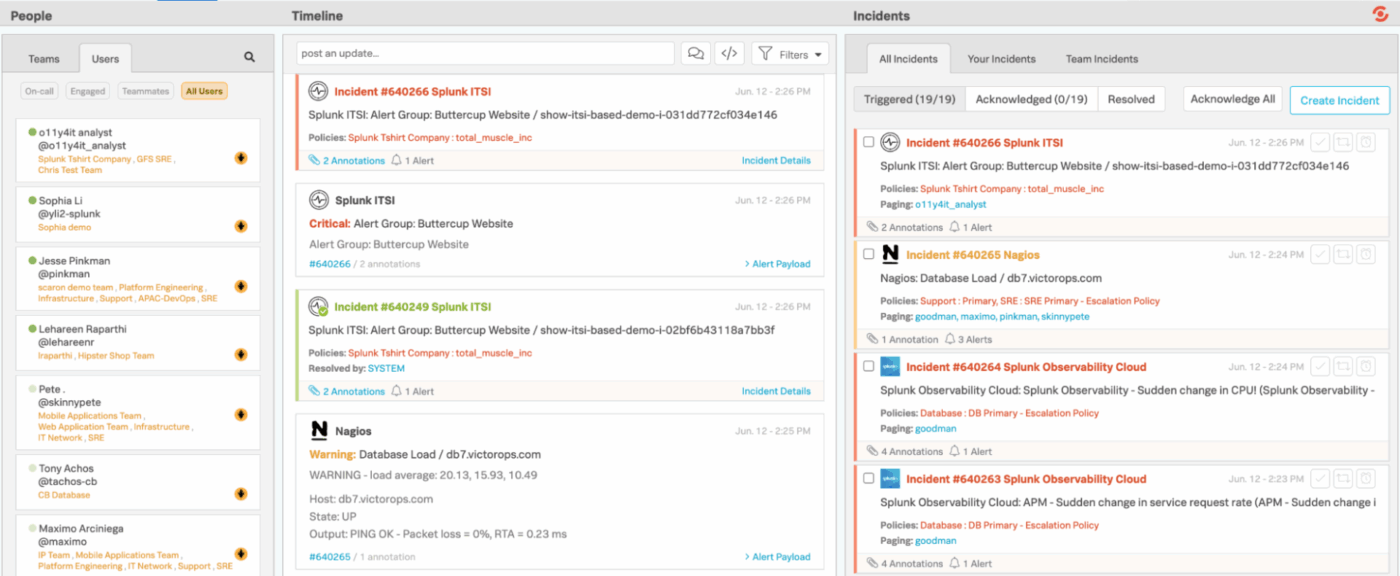
O Splunk On-Call oferece às equipes de engenharia e plantão uma maneira mais rápida e organizada de gerenciar incidentes, eliminando a necessidade de fluxos de trabalho de tickets tradicionais e lentos. Em vez de enviar alertas para uma fila genérica, ele se integra diretamente à sua pilha de monitoramento e observabilidade, encaminhando imediatamente as questões para as pessoas certas com base em programações, regras e contexto.
As integrações móveis e de chat facilitam o reconhecimento, o redirecionamento ou a resolução de incidentes de qualquer lugar. E, nos bastidores, o Splunk On-Call mantém um registro detalhado de tendências, padrões comprovados e comportamento de escalonamento.
Principais recursos do Splunk On-Call
- Expanda os recursos da plataforma usando mais de 1.000 integrações e complementos aprovados da Splunk e da comunidade em geral.
- Crie painéis personalizados e relatórios visuais para monitorar o volume de alertas, a integridade dos incidentes, o desempenho dos respondentes e a carga de trabalho da equipe.
- Filtre rapidamente os incidentes por sua própria atividade, incidentes da equipe ou tudo o que está acontecendo na organização.
- Alterne entre as visualizações Acionado, Confirmado e Resolvido para ver em que estágio cada incidente se encontra.
Limitações do Splunk On-Call
- O agendamento de turnos em várias equipes pode se tornar complicado se as regras não forem predefinidas.
- Capacidade limitada de gerar relatórios detalhados de incidentes por data
Preços do Splunk On-Call
- Preços personalizados
Avaliações e comentários sobre o Splunk On-Call
- G2: 4,6/5 (mais de 40 avaliações)
- Capterra: 4,5/5 (mais de 30 avaliações)
O que os usuários reais estão dizendo sobre o Splunk On-Call?
Um usuário resumiu assim:
A capacidade de lidar com incidentes, escalonamentos e assumir as tarefas dos meus colegas de equipe a partir do aplicativo móvel é incrível. [...] Gostaria de poder programar substituições e alterar a programação regular a partir do aplicativo móvel para mudanças de emergência na programação.
A capacidade de lidar com incidentes, escalonamentos e assumir as tarefas dos meus colegas de equipe a partir do aplicativo móvel é incrível. [...] Gostaria de poder programar substituições e alterar a programação regular a partir do aplicativo móvel para mudanças de emergência na programação.
🔍 Você sabia? A lógica de “encaminhar para a pessoa certa se o primeiro nível falhar” tem suas raízes nas primeiras centrais telefônicas: quando os operadores manuais não conseguiam conectar uma chamada, o sistema a encaminhava (ou escalava) para outro operador ou central.
5. ServiceNow (ideal para orquestrar em escala empresarial com automação assistida por IA)
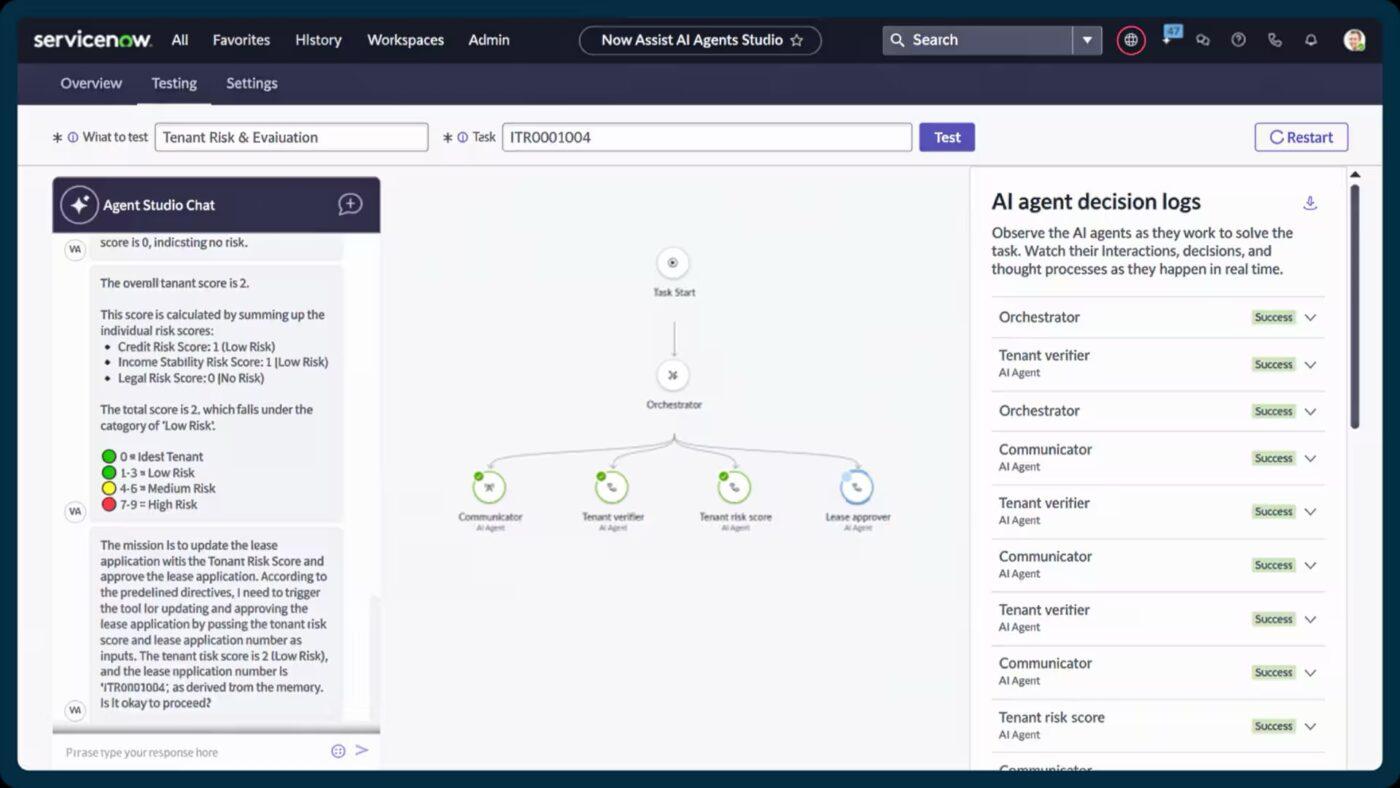
O ServiceNow classifica, prioriza e encaminha incidentes automaticamente no momento em que são registrados. Com recursos como o Now Assist para recomendações automatizadas de tickets de incidentes e geração inteligente de conteúdo, os responsáveis pela resposta podem resolver problemas mais rapidamente e com mais contexto.
Ele reúne o gerenciamento de incidentes, mudanças e ativos. Dessa forma, você obtém uma visão em tempo real de como os serviços estão conectados, onde ocorrem gargalos e quais componentes podem estar contribuindo para interrupções recorrentes.
Melhores recursos do ServiceNow
- Atribua, encaminhe e monitore tarefas de campo por meio do Gerenciamento de Serviços de Campo e do Espaço de Trabalho do Despachante.
- Capacite funcionários e clientes com um portal de autoatendimento alimentado por AI Search e agentes virtuais.
- Use fluxos de trabalho integrados e ferramentas de baixo código no App Engine para estender ou personalizar processos de serviço.
- Automatize tarefas e fluxos de trabalho repetitivos entre equipes com o Flow Designer e o Automation Engine.
Limitações do ServiceNow
- As opções de interface do usuário e branding do portal parecem desatualizadas ou restritivas.
- Alta dependência de pessoal qualificado ou consultores para implementação
Preços do ServiceNow
- Preços personalizados
Avaliações e comentários sobre o ServiceNow
- G2: 4,4/5 (mais de 3.300 avaliações)
- Capterra: 4,5/5 (mais de 300 avaliações)
O que os usuários reais estão dizendo sobre o ServiceNow?
Veja como um usuário descreveu isso:
[...] Os fluxos pré-construídos são outro destaque para mim, pois simplificam os processos e economizam tempo significativo, minimizando a necessidade de configurações personalizadas e permitindo um fluxo de trabalho mais suave e eficiente. [...] Além disso, tive dificuldades em encaixar minha solução personalizada no sistema de Gerenciamento de Atendimento ao Cliente, o que exigiu muitas iterações.
[...] Os fluxos pré-construídos são outro destaque para mim, pois simplificam os processos e economizam tempo significativo, minimizando a necessidade de configurações personalizadas e permitindo um fluxo de trabalho mais suave e eficiente. [...] Além disso, tive dificuldades em encaixar minha solução personalizada no sistema de Gerenciamento de Atendimento ao Cliente, o que exigiu muitas iterações.
Melhores práticas e governança
Aqui estão algumas práticas recomendadas que garantem que a automação permaneça precisa, evite a fadiga de alertas e se alinhe às expectativas comerciais e regulatórias.
- Defina critérios de escalonamento não negociáveis: vincule os gatilhos a sinais mensuráveis, como violações de SLO, picos de anomalias, impacto no nível do cliente ou sensibilidade regulatória.
- Estabeleça clareza de funções em cada nível: use um mapa RACI simples para cada nível de escalonamento, para que as responsabilidades nunca fiquem ambíguas durante incidentes de alta pressão.
- Imponha uma governança dinâmica de plantão: ajuste automaticamente os caminhos de escalonamento em torno de fins de semana, feriados, limites de capacidade e transferências para reduzir o esgotamento e evitar páginas silenciosas.
- Insira pontos de verificação humanos para cenários de alto risco: mesmo com a automação, exija o reconhecimento manual para incidentes envolvendo exposição de dados de clientes, pagamentos ou fluxos de trabalho regulamentados.
- Mantenha trilhas de auditoria completas: mantenha registros imutáveis de quem foi chamado, quando eles confirmaram, quais etapas automatizadas foram acionadas e quais decisões foram tomadas.
🧠 Curiosidade: A reclamação escrita mais antiga do mundo foi gravada em uma tabuinha de argila por volta de 1750 a.C. Era basicamente uma escalação antecipada do status de um projeto. Um cliente chamado Nanni escreveu ao comerciante Ea-nāṣir, furioso porque o cobre que recebeu era de qualidade inferior à prometida e porque seu mensageiro foi maltratado.
Desafios comuns e como superá-los
Mesmo com uma política de escalonamento clara, as equipes frequentemente enfrentam obstáculos operacionais que retardam a resposta a incidentes ou criam confusão.
Esta tabela destaca os desafios comuns que vão além das etapas básicas de configuração e fornece estratégias práticas para superá-los.
| Desafios ❌ | Soluções ✅ |
| Contexto inconsistente durante as transferências | Use os modelos de vinculação de tarefas e relatórios de incidentes do ClickUp para manter uma trilha de auditoria completa dos detalhes do incidente, sistemas afetados e ações anteriores em cada nível de escalonamento. |
| Sobrecarregar os respondentes com alertas de baixa prioridade | Implemente a priorização dinâmica com os campos personalizados do ClickUp e a priorização por IA para filtrar incidentes com base na gravidade, no impacto e nos limites do SLA. |
| Falta de visibilidade entre equipes | Configure espaços de trabalho compartilhados, adicione comentários e crie quadros brancos visuais do ClickUp para apresentar atualizações em tempo real para as partes interessadas. |
| Atrasos na tomada de decisões durante incidentes críticos | Automatize notificações usando as Ações Sugeridas do ClickUp Brain Max para alertar instantaneamente o pessoal certo com base no tipo de incidente, gravidade e padrões históricos. |
| Dificuldade em rastrear problemas recorrentes | Aproveite os relatórios personalizados e os modelos de tarefas recorrentes do ClickUp para identificar padrões, causas principais e incidentes repetidos para uma prevenção proativa. |
| Conhecimento fragmentado durante a escalonamento | Mantenha SOPs, manuais de operações e documentação de incidentes centralizados no ClickUp Docs, vinculando-os a tarefas relevantes para referência instantânea durante escalonamentos em tempo real. |
| Responsabilidades desalinhadas entre os turnos | Use as visualizações de carga de trabalho e cronograma do ClickUp para visualizar as atribuições e garantir que não haja sobreposições ou lacunas durante as mudanças de turno ou transferências. |
| Rastreamento manual de conformidade e lacunas de auditoria | Automatize resumos prontos para auditoria com o ClickUp Brain para registrar todas as ações, notificações e resoluções de incidentes. |
Medindo o impacto da escalonamento automatizado
Para acompanhar a eficácia da escalonamento automatizado, é necessário se concentrar em métricas-chave relacionadas ao volume, à eficiência e à qualidade. Esses indicadores revelam se seus processos de escalonamento estão mais rápidos, precisos e menos frustrantes para as equipes e os clientes.
Acompanhe estas métricas:
- Taxa de escalonamento (volume): porcentagem de problemas escalonados além do primeiro nível. Taxas altas podem indicar lacunas na triagem inicial ou nas bases de conhecimento.
- Taxa de escalonamento repetido (volume): frequência com que o mesmo problema é escalonado várias vezes. Indica resoluções incompletas ou perda de contexto.
- Tempo até a escalonamento (eficiência): duração desde a detecção até o escalonamento. Durações mais curtas indicam um reconhecimento automatizado mais rápido de problemas críticos.
- Tempo de atraso na transferência (eficiência): intervalo entre a escalonagem e o momento em que a próxima equipe começa a trabalhar para destacar o atrito no encaminhamento ou na notificação.
- Tempo de resolução para casos escalados (eficiência): tempo total desde a escalação até a resolução. Uma resolução mais rápida demonstra a eficácia da automação.
- Pontuação de satisfação do cliente (CSAT) (qualidade): feedback sobre interações escaladas para medir a fluidez do caminho.
- Transmissão de contexto (qualidade): se os agentes recebem o histórico completo do incidente para garantir que os clientes não repitam informações
- Resolução no primeiro contato (FCR) (qualidade): porcentagem de problemas resolvidos em uma única interação
🚀 Vantagem do ClickUp: obtenha insights em tempo real, visuais e alimentados por IA em todas as métricas de escalonamento com os painéis do ClickUp.
Você pode acompanhar as tendências de escalonamento, gargalos e desempenho com os cartões Tabela, Gráfico circular, Barra, Linha, Cálculo e Relatório de tempo. Monitore a taxa de escalonamento, o escalonamento repetido e o tempo até o escalonamento com cartões vinculados a tarefas, campos personalizados e status.
Para ir além, use cartões de IA, como Resumo Executivo de IA, Atualização de Projeto de IA e StandUp de IA, para destacar tendências, atrasos e resultados de resolução.
Gerencie seus incidentes mais rapidamente com o ClickUp
Muitos pensam que o escalonamento de incidentes consiste apenas em passar um ticket para a próxima pessoa, mas é muito mais do que isso. É um sistema estruturado em que todas as etapas, desde a triagem até a resolução, funcionam em harmonia.
O ClickUp oferece o espaço de trabalho unificado perfeito. Com o ClickUp Automations, você pode acionar alertas, encaminhar tarefas e atualizar status automaticamente. E o ClickUp Brain ajuda a priorizar incidentes, gerar resumos e sugerir as próximas etapas.
Os agentes de IA do ClickUp atuam como assistentes inteligentes dentro do seu espaço de trabalho, enquanto os painéis do ClickUp fornecem uma visualização em tempo real das suas escalações.
Inscreva-se gratuitamente no ClickUp hoje mesmo!
Perguntas frequentes (FAQ)
Um caminho de escalonamento de incidentes é uma sequência predefinida de etapas que determina como as questões são encaminhadas para a equipe ou pessoa certa com base na gravidade, no impacto e no tempo. Isso garante que os incidentes sejam tratados com eficiência e que a responsabilidade seja clara. TEXTO
Use a automação para incidentes bem definidos e de alta prioridade com critérios claros (por exemplo, interrupções de serviço, violações de segurança). Reserve o escalonamento manual para situações ambíguas ou críticas que exijam julgamento humano ou contexto adicional.
Plataformas como ClickUp, PagerDuty, Jira Service Management e ServiceNow permitem o encaminhamento, notificações e atualizações automatizados. Elas ajudam as equipes a reduzir atrasos e manter fluxos de trabalho estruturados para incidentes.
Defina limites claros para alertas, priorize por gravidade e use notificações inteligentes. Limite as notificações repetidas a incidentes críticos e aproveite painéis ou ferramentas de IA para resumir as atualizações, em vez de enviar todas as pequenas alterações.
Revise regularmente as políticas de escalonamento, pelo menos trimestralmente ou após incidentes graves. Isso garante que os critérios, as responsabilidades e as regras de automação reflitam os fluxos de trabalho, as estruturas da equipe e as prioridades comerciais atuais.