
U brengt de nieuwste software-update uit en de rapporten stromen binnen.
Plotseling bepaalt één statistiek alles, van CSAT/NPS tot vertragingen in de roadmap: de tijd die nodig is om bugs op te lossen.
Leidinggevenden zien het als een maatstaf voor het nakomen van beloften: kunnen we op schema leveren, leren en inkomsten beschermen? Praktijkmensen voelen de pijn in de praktijk: dubbele tickets, onduidelijke eigendom, luidruchtige escalaties en context verspreid over Slack, spreadsheets en afzonderlijke tools.
Die fragmentatie verlengt cycli, verbergt de onderliggende oorzaken en maakt van prioritering giswerk.
Het resultaat? Trager leren, gemiste toewijzingen en een backlog die elke Sprint stilletjes belast.
Deze gids is uw complete handleiding voor het meten, benchmarken en verkorten van de tijd die nodig is om bugs op te lossen. Ook laat hij concreet zien hoe AI de werkstroom verandert in vergelijking met traditionele, handmatige processen.
Wat is de tijd die nodig is om bugs op te lossen?
De tijd die nodig is om een bug op te lossen, is de tijd die verstrijkt tussen het moment dat de bug wordt gemeld en het moment dat deze volledig is opgelost.
In de praktijk begint de klok te lopen wanneer een probleem wordt gemeld of gedetecteerd (via gebruikers, QA of monitoring) en stopt deze wanneer de oplossing is geïmplementeerd en samengevoegd, klaar voor verificatie of release, afhankelijk van hoe uw team 'klaar' definieert
Voorbeeld: een P1-crash gemeld om 10:00 uur op Monday, met een fix samengevoegd om 15:00 uur op Tuesday, heeft een oplostijd van ~29 uur.
Dit is niet hetzelfde als de tijd die nodig is om een bug te detecteren. De detectietijd meet hoe snel u een defect herkent nadat het zich heeft voorgedaan (alarmen afgaan, QA-testtools die het defect vinden, klanten die het melden).
De oplostijd meet hoe snel u van bewustwording naar oplossing gaat: triage, reproduceren, diagnosticeren, implementeren, controleren, testen en voorbereiden voor release. Zie detectie als 'we weten dat het kapot is' en oplossing als 'het is gerepareerd en klaar voor gebruik'
Teams gebruiken iets andere grenzen; kies er één en wees consistent, zodat uw trends realistisch zijn:
- Gerapporteerd → Opgelost: Eindigt wanneer de code is samengevoegd en klaar is voor QA. Goed voor de doorvoercapaciteit van engineering
- Gemeld → Gesloten: Inclusief QA-validatie en release. Het beste voor SLA's die van invloed zijn op klanten
- Gedetecteerd → Opgelost: Begint wanneer monitoring/QA het probleem detecteert, zelfs voordat er een ticket bestaat. Handig voor teams die veel in productie werken
🧠 Leuk weetje: Een eigenaardige maar hilarische bug in Final Fantasy XIV werd geprezen omdat hij zo specifiek was dat lezers hem de 'Meest specifieke bugfix in een MMO 2025' noemden. Hij manifesteerde zich wanneer spelers items tussen precies 44.442 gil en 49.087 gil in een bepaalde gebeurteniszone, waardoor de verbinding werd verbroken als gevolg van wat mogelijk een integer overflow-glitch was.
Waarom dit belangrijk is
De tijd die nodig is om een probleem op te lossen, is een hefboom voor de releasecyclus. Lange of onvoorspelbare tijden dwingen tot beperkingen van de scope, hotfixes en release freezes. Ze creëren een planningstekort omdat de long tail (uitbijters) sprints meer ontsporen dan het gemiddelde doet vermoeden.
Dit hangt ook rechtstreeks samen met de klanttevredenheid. Klanten tolereren problemen wanneer deze snel worden erkend en op voorspelbare wijze worden opgelost. Trage oplossingen – of erger nog, variabele oplossingen – leiden tot escalaties, een lagere CSAT/NPS en brengen verlengingen in gevaar.
Kortom, als u de tijd die nodig is om bugs op te lossen nauwkeurig meet en systematisch verkort, zullen uw roadmaps en relaties verbeteren.
Hoe meet u de tijd die nodig is om bugs op te lossen?
Bepaal eerst waar uw klok begint en stopt.
De meeste teams kiezen voor Gemeld → Opgelost (de oplossing is samengevoegd en klaar voor verificatie) of Gemeld → Gesloten (QA heeft de wijziging gevalideerd en deze is vrijgegeven of anderszins gesloten).
Kies één definitie en gebruik deze consequent, zodat uw trends betekenisvol zijn.
Nu hebt u een aantal meetbare statistieken nodig. Laten we deze eens op een rijtje zetten:
Sleutelcijfers voor het bijhouden van bugs waar u op moet letten:
| 📊 Metriek | 📌 Wat het inhoudt | 💡 Hoe dit helpt | 🧮 Formule (indien van toepassing) |
|---|---|---|---|
| Aantal bugs 🐞 | Totaal aantal gerapporteerde bugs | Geeft een overzicht van de systeemstatus. Hoog nummer? Tijd om te onderzoeken. | Totaal aantal bugs = alle bugs die in het systeem zijn geregistreerd {Open + Gesloten} |
| Open bugs 🚧 | Bugs die nog niet zijn opgelost | Toont de huidige werklast. Helpt bij het stellen van prioriteiten. | Open bugs = totaal aantal bugs - Gesloten bugs |
| Gesloten bugs ✅ | Opgeloste en geverifieerde bugs | Houdt de voortgang en het voltooide werk bij. | Gesloten bugs = Aantal bugs met de status 'Gesloten' of 'Opgelost' |
| Bugernst 🔥 | Kritieke aard van de bug (bijv. kritiek, ernstig, minder ernstig) | Helpt bij triage op basis van impact. | Bijgehouden als categorisch veld, geen formule. Gebruik filters/groepering. |
| Prioriteit van bugs 📅 | Hoe urgent een bug moet worden opgelost | Helpt bij het plannen van sprints en releases. | Ook een categorisch veld, meestal gerangschikt (bijv. P0, P1, P2). |
| Tijd om op te lossen ⏱️ | Tijd tussen bugrapportage en oplossing | Meet de reactiesnelheid. | Tijd tot oplossing = datum gesloten - datum gemeld |
| Heropeningspercentage 🔄 | % van de bugs die opnieuw worden geopend nadat ze zijn gesloten | Geeft de kwaliteit van oplossingen of regressieproblemen weer. | Percentage heropende bugs (%) = {heropende bugs ÷ totaal aantal gesloten bugs} × 100 |
| Buglekkage 🕳️ | Bugs die in de productie zijn geslopen | Geeft de effectiviteit van QA/ softwaretests aan. | Lekpercentage (%) = {Productfouten ÷ Totaal aantal fouten} × 100 |
| Defectdichtheid 🧮 | Bugs per grootte-eenheid van code | Markeert risicovolle code. | Foutdichtheid = aantal bugs ÷ KLOC {Kilo Lines of Code} |
| Toegewezen versus niet-toegewezen bugs 👥 | Verdeling van bugs op basis van eigendom | Zorgt ervoor dat niets door de mazen van het net glipt. | Gebruik een filter: Niet toegewezen = bugs waarbij 'Toegewezen aan' leeg is |
| Leeftijd van open bugs 🧓 | Hoe lang een bug onopgelost blijft | Signaleert stagnatie en risico's op achterstanden. | Bugleeftijd = huidige datum - datum van rapportage |
| Dubbele bugs 🧬 | Aantal dubbele meldingen | Benadrukt fouten in intake-processen. | Dubbele rate = duplicaten ÷ totaal aantal bugs × 100 |
| MTTD (gemiddelde tijd tot detectie) 🔎 | Gemiddelde tijd die nodig is om bugs of incidenten te detecteren | Meet de efficiëntie van monitoring en bewustwording. | MTTD = Σ(tijd van detectie - tijd van introductie) ÷ nummer van bugs |
| MTTR (gemiddelde tijd om op te lossen) 🔧 | Gemiddelde tijd om een bug volledig te verhelpen na detectie | Houdt de reactiesnelheid van technici en de tijd die nodig is om problemen op te lossen bij. | MTTR = Σ(opgeloste tijd - gedetecteerde tijd) ÷ nummer opgeloste bugs |
| MTTA (gemiddelde tijd tot bevestiging) 📬 | Tijd tussen detectie en het moment waarop iemand aan de bug begint te werken | Toont de reactiesnelheid van teams en de responsiviteit van waarschuwingen. | MTTA = Σ(bevestigde tijd - gedetecteerde tijd) ÷ nummer van bugs |
| MTBF (gemiddelde tijd tussen storingen) 🔁 | Tijd tussen het oplossen van een storing en het optreden van de volgende storing | Geeft de stabiliteit in de loop van de tijd aan. | MTBF = totale uptime ÷ nummer van storingen |
⚡️ Sjabloonarchief: 15 gratis sjablonen en formulieren voor bugrapportage voor het bijhouden van bugs
Factoren die van invloed zijn op de tijd die nodig is om bugs op te lossen
De tijd die nodig is om een bug op te lossen, wordt vaak gelijkgesteld aan 'hoe snel engineers code schrijven'
Maar dat is slechts een deel van het proces.
De tijd die nodig is om bugs op te lossen, is de som van de kwaliteit bij ontvangst, de efficiëntie van de werkstroom door uw systeem en het risico op afhankelijkheid. Wanneer een van deze factoren hapert, wordt de cyclustijd langer, neemt de voorspelbaarheid af en worden escalaties luider.
De kwaliteit van de intake bepaalt de toon
Rapporten die binnenkomen zonder duidelijke stappen voor reproductie, omgevingsdetails, logboeken of informatie over de versie/build zorgen voor extra heen-en-weer-gepraat. Dubbele rapporten uit meerdere kanalen (ondersteuning, QA, monitoring, Slack) zorgen voor ruis en versnippering van de eigendom.
Hoe eerder u de juiste context vastlegt en duplicaten verwijdert, hoe minder overdrachten en verduidelijkingen u later nodig hebt.
Prioritering en routing bepalen wie de bug aanpakt en wanneer
Severity labels die niet in kaart brengen wat de impact is op klanten/het bedrijf (of die in de loop van de tijd veranderen) zorgen voor chaos in de wachtrij: de luidste tickets springen naar voren, terwijl defecten met een grote impact blijven liggen.
Duidelijke routeringsregels per component/eigenaar en één enkele wachtrij zorgen ervoor dat P0/P1-werk niet onder 'recent en luidruchtig' begraven raakt
Eigendom en overdrachten zijn stille moordenaars
Als het onduidelijk is of een bug bij mobiel, backend-authenticatie of een platformteam hoort, wordt deze teruggestuurd. Elke terugzending reset de context.
Tijdzones maken dit nog ingewikkelder: een bug die laat op de dag wordt gemeld zonder dat er een eigenaar is aangewezen, kan 12 tot 24 uur verloren gaan voordat iemand zelfs maar begint met reproductie. Strakke definities van 'wie is verantwoordelijk voor wat', met een on-call of wekelijkse DRI, voorkomen dat dit gebeurt.
Reproduceerbaarheid hangt af van observeerbaarheid
Schaarse logs, ontbrekende correlatie-ID's of een gebrek aan crashtraces maken diagnose tot giswerk. Bugs die alleen verschijnen met specifieke vlaggen, tenants of data-vormen zijn moeilijk te reproduceren in dev.
Als engineers geen veilige toegang hebben tot gezuiverde productiegegevens, zijn ze dagenlang bezig met instrumenteren, opnieuw implementeren en wachten, in plaats van uren.
Omgeving en gegevenspariteit zorgen voor eerlijkheid
"Werkt op mijn machine" betekent meestal "productiegegevens zijn anders". Hoe meer uw dev/staging afwijkt van de productie (configuratie, services, versies van derden), hoe langer u bezig bent met het achtervolgen van spoken. Beveiligde gegevenssnapshots, seed-scripts en pariteitscontroles verkleinen die kloof.
Lopende werkzaamheden (WIP) en focus zorgen voor daadwerkelijke doorvoer
Overbelaste teams krijgen te veel bugs tegelijk te verwerken, versnipperen hun aandacht en schakelen voortdurend tussen taken en vergaderingen. Contextwisselingen zorgen voor onzichtbare extra uren.
Een zichtbare limiet voor werk in uitvoering en een voorkeur om eerst af te maken wat begonnen is voordat er nieuw werk wordt aangenomen, zullen uw mediaan sneller omlaag brengen dan welke individuele heldendaad dan ook.
Code review, CI en QA-snelheid zijn klassieke knelpunten
Trage buildtijden, onbetrouwbare tests en onduidelijke SLA's voor reviews vertragen anders snelle fixes. Een patch van 10 minuten kan twee dagen in beslag nemen omdat er op een reviewer moet worden gewacht of omdat deze in een urenlange pijplijn terechtkomt.
Op dezelfde manier kunnen QA-wachtrijen die batches testen of afhankelijk zijn van handmatige smoke passes, hele dagen toevoegen aan 'Gemeld → Gesloten', zelfs als 'Gemeld → Opgelost' snel gaat.
Afhankelijkheden vergroten wachtrijen
Teamoverschrijdende wijzigingen (schema, platformmigraties, SDK-updates), bugs van leveranciers of app store-recensies (mobiel) zorgen voor wachttijden. Zonder expliciet bijhouden van 'Geblokkeerd/Pauzeert' worden deze wachttijden onzichtbaar opgeteld bij uw gemiddelden en blijft onduidelijk waar de echte bottleneck zich bevindt.
Het releasemodel en de rollback-strategie zijn belangrijk
Als u in grote releasetrains met handmatige gates werkt, blijven zelfs opgeloste bugs liggen totdat de volgende train vertrekt. Functievlaggen, canary releases en hotfix-lanes verkorten de tail, vooral voor P0/P1-incidenten, doordat u de implementatie van fixes kunt loskoppelen van volledige releasecycli.
Architectuur en technische schulden bepalen uw plafond
Nauwe koppelingen, ontbrekende testnaden en ondoorzichtige verouderde modules maken eenvoudige fixes riskant. Teams compenseren dit met extra tests en langere reviews, waardoor cycli langer duren. Omgekeerd kunt u met modulaire code met goede contracttests snel handelen zonder aangrenzende systemen te verstoren.
Communicatie en statushygiëne beïnvloeden de voorspelbaarheid
Vage updates ('we kijken ernaar') zorgen voor extra werk wanneer belanghebbenden vragen naar de verwachte aankomsttijd, ondersteuning tickets heropent of het product wordt geëscaleerd. Duidelijke statusovergangen, aantekeningen over reproductie en de hoofdoorzaak, en een gepubliceerde verwachte aankomsttijd verminderen het aantal afvallende klanten en zorgen ervoor dat uw engineeringteam gefocust blijft.
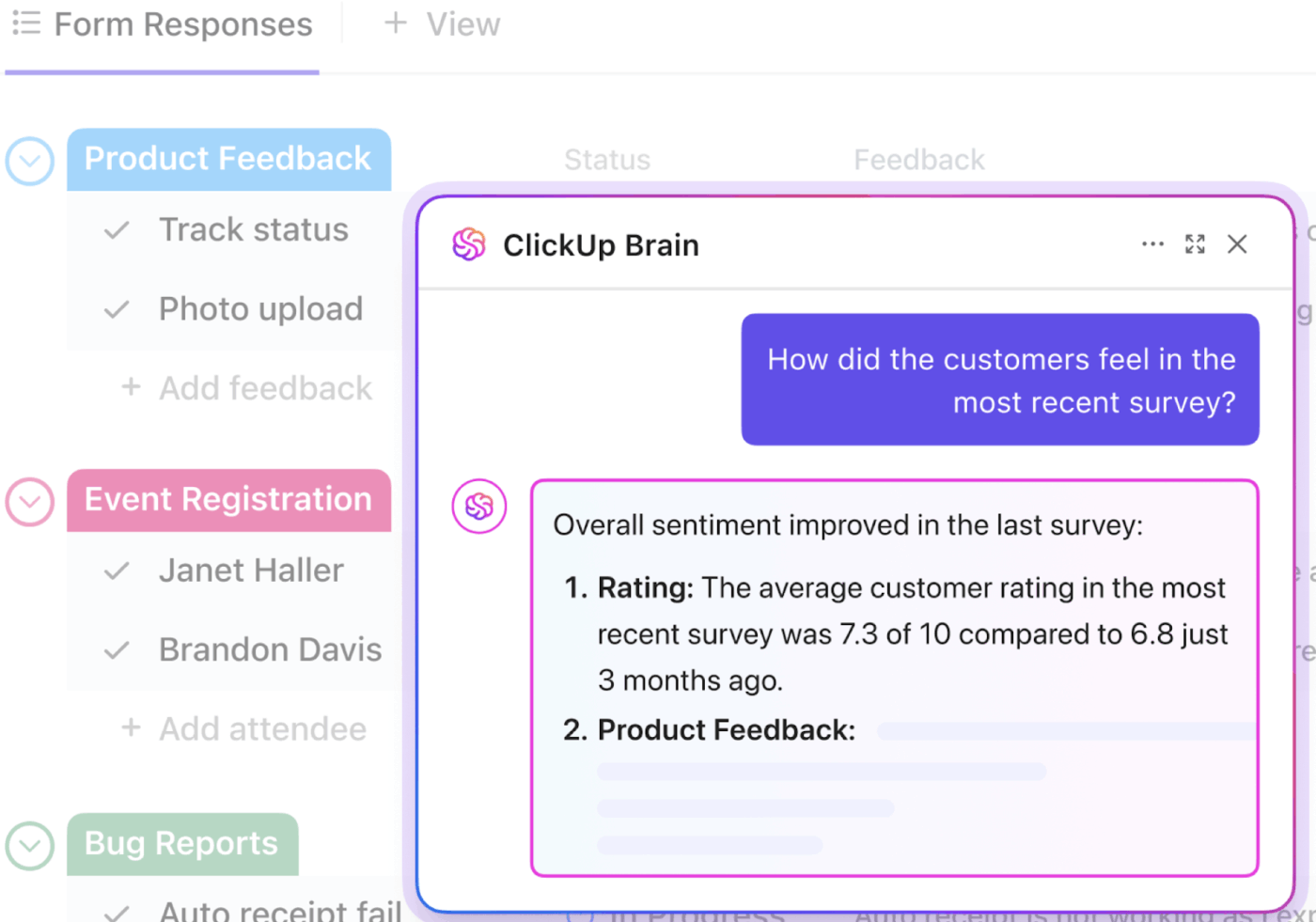
📮ClickUp Insight: De gemiddelde professional besteedt meer dan 30 minuten per dag aan het zoeken naar werkgerelateerde informatie. Dat is meer dan 120 uur per jaar die verloren gaat aan het doorzoeken van e-mails, Slack-threads en verspreide bestanden.
Een intelligente AI-assistent die in uw werkruimte is ingebouwd, kan daar verandering in brengen. Maak kennis met ClickUp Brain. Het biedt direct inzicht en antwoorden door binnen enkele seconden de juiste documenten, gesprekken en taakdetails te vinden, zodat u kunt stoppen met zoeken en aan het werk kunt gaan.
💫 Echte resultaten: Teams zoals QubicaAMF hebben met ClickUp meer dan 5 uur per week teruggewonnen – dat is meer dan 250 uur per jaar per persoon – door verouderde kennisbeheerprocessen te elimineren. Stel je eens voor wat je team zou kunnen bereiken met een extra week productiviteit per kwartaal!
Leidende indicatoren dat uw oplostijd zal verslechteren
❗️Toenemende 'tijd tot erkenning' en veel tickets zonder eigenaar gedurende >12 uur
❗️Groeiende 'Time in Review/CI'-segmenten en frequente testfouten
❗️Hoog percentage duplicaten bij intake en inconsistente labels voor ernst bij verschillende teams
❗️Verschillende bugs die in "Geblokkeerd" staan zonder een benoemde externe afhankelijkheid
❗️Heropeningspercentage stijgt (oplossingen zijn niet reproduceerbaar of definities van 'klaar' zijn vaag)
Verschillende organisaties ervaren deze factoren op verschillende manieren. Leidinggevenden ervaren ze als gemiste leercycli en gemiste omzetkansen; operators ervaren ze als triagegeluid en onduidelijkheid over eigendom.
Door de intake, werkstroom en afhankelijkheid af te stemmen, kunt u de hele curve – mediaan en P90 – naar beneden halen.
Wilt u meer informatie over het schrijven van betere bugrapporten? Begin hier. 👇🏼
📖 Meer informatie: De levenscyclus van softwaretesten (STLC): Overzicht en fasen
Branchebenchmarks voor bugoplossingstijd
Benchmarks voor bugoplossing veranderen naargelang de risicotolerantie, het releasemodel en hoe snel u wijzigingen kunt doorvoeren.
Hier kunt u medianen (P50) gebruiken om uw typische werkstroom te begrijpen en P90 om beloften en SLA's in te stellen, op basis van ernst en bron (klant, QA, monitoring).
Laten we eens kijken wat dat precies inhoudt:
| 🔑 Term | 📝 Beschrijving | 💡 Waarom dit belangrijk is |
|---|---|---|
| P50 (mediaan) | De gemiddelde waarde: 50% van de bugfixes is sneller dan dit en 50% is langzamer | 👉 Geeft uw typische of meest voorkomende oplostijd weer. Handig om inzicht te krijgen in normale prestaties |
| P90 (90e percentiel) | 90% van de bugs wordt binnen deze tijd opgelost. Slechts 10% duurt langer | 👉 Vertegenwoordigt een worst-case (maar nog steeds realistische) grens. Handig voor het instellen van externe beloften |
| SLA's (Service Level Agreements) | Toewijzingen die u doet – intern of aan klanten – over hoe snel problemen worden opgelost | 👉 Voorbeeld: "We lossen P1-bugs in 90% van de gevallen binnen 48 uur op. " Helpt bij het opbouwen van vertrouwen en verantwoordelijkheid |
| Op basis van ernst en bron | Segmenteer uw statistieken op basis van twee sleuteldimensies: • Ernst (bijv. P0, P1, P2)• Bron (bijv. klant, QA, monitoring) | 👉 Maakt nauwkeuriger bijhouden en prioriteren mogelijk, zodat kritieke bugs sneller worden opgemerkt |
Hieronder vindt u richtbereiken op basis van sectoren die volwassen teams vaak als target hebben; beschouw deze als startpunten en pas ze vervolgens aan uw context aan.
SaaS
Altijd beschikbaar en CI/CD-vriendelijk, dus hotfixes zijn gebruikelijk. Kritieke problemen (P0/P1) worden vaak binnen een werkdag opgelost, met P90 binnen 24-48 uur. Niet-kritieke problemen (P2+) worden doorgaans binnen 3-7 dagen opgelost, met P90 binnen 10-14 dagen. Teams met robuuste functie-indicatoren en geautomatiseerde tests neigen naar de snellere kant.
E-commerceplatforms
Omdat conversie en winkelwagen-werkstromen cruciaal zijn voor de omzet, ligt de lat hoger. P0/P1-problemen worden doorgaans binnen enkele uren opgelost (rollback, markeren of configureren) en volledig opgelost op dezelfde dag; P90 aan het einde van de dag of <12 uur is gebruikelijk in piekperiodes. P2+-problemen worden vaak binnen 2-5 dagen opgelost, met P90 binnen 10 dagen.
Enterprise-software
Zwaardere validatie en langere wijzigingsvensters voor klanten vertragen de cadans. Voor P0/P1 streven teams naar een tijdelijke oplossing binnen 4-24 uur en een definitieve oplossing binnen 1-3 werkdagen; P90 binnen 5 werkdagen. P2+-items worden vaak gebundeld in releasetrains, met een gemiddelde van 2-4 weken, afhankelijk van de implementatieschema's van de klant.
Gaming- en mobiele apps
Live-service backends gedragen zich als SaaS (vlaggen en rollbacks binnen enkele minuten tot uren; P90 dezelfde dag). Client-updates worden beperkt door winkelrecensies: P0/P1 maken vaak onmiddellijk gebruik van server-side hefbomen en verzenden een client-patch binnen 1-3 dagen; P90 binnen een week met versnelde beoordeling. P2+-fixes worden doorgaans gepland in de volgende sprint of content drop.
Bankwezen/Fintech
Risico- en compliancepoorten zorgen voor een patroon van 'snel mitigeren, zorgvuldig veranderen'. P0/P1 worden snel gemitigeerd (vlaggen, rollbacks, verkeersverschuivingen binnen enkele minuten tot uren) en binnen 1-3 dagen volledig opgelost; P90 binnen een week, rekening houdend met wijzigingsbeheer. P2+ duurt vaak 2-6 weken om de beoordelingen op het gebied van veiligheid, audit en CAB te doorlopen.
Als uw nummers buiten deze bereiken vallen, kijk dan naar de kwaliteit van de intake, routing/eigendom, code review en QA-doorvoer, en goedkeuringen van afhankelijkheid voordat u ervan uitgaat dat de 'engineering snelheid' het kernprobleem is.
🌼 Wist u dat: Volgens een Stack Overflow-enquête uit 2024 gebruikten ontwikkelaars steeds vaker AI als hun trouwe sidekick tijdens het coderen. Maar liefst 82% gebruikte AI om daadwerkelijk code te schrijven – over creatieve samenwerking gesproken! Wanneer ze vastliepen of op zoek waren naar oplossingen, vertrouwde 67, 5% op AI om antwoorden te zoeken, en meer dan de helft (56, 7%) gebruikte AI om bugs op te sporen en hulp te krijgen.
Voor sommigen bleken AI-tools ook handig voor het documenteren van projecten (40,1%) en zelfs voor het genereren van synthetische data of content (34,8%). Benieuwd naar een nieuwe codebase? Bijna een derde (30,9%) gebruikt AI om snel op gang te komen. Het testen van code is voor velen nog steeds een handmatig karwei, maar 27,2% heeft ook hier AI omarmd. Andere gebieden, zoals codereview, projectplanning en voorspellende analyses, zien een lagere AI-acceptatie, maar het is duidelijk dat AI zich gestaag in elke fase van de softwareontwikkeling nestelt.
📖 Lees meer: Hoe AI te gebruiken voor kwaliteitsborging
Hoe u de tijd voor het oplossen van bugs kunt verkorten
Snelheid bij het oplossen van bugs komt neer op het wegnemen van frictie bij elke overdracht, van intake tot release.
De grootste winst wordt behaald door de eerste 30 minuten slimmer te maken (schone intake, juiste eigenaar, juiste prioriteit) en vervolgens de daaropvolgende loops te comprimeren (reproduceren, beoordelen, verifiëren).
Hier zijn negen strategieën die als een systeem samenwerken. AI versnelt elke stap en de werkstroom verloopt overzichtelijk op één plek, zodat leidinggevenden voorspelbaarheid krijgen en medewerkers een goede werkstroom.
1. Centraliseer de intake en leg de context vast bij de bron
De tijd die nodig is om bugs op te lossen wordt langer wanneer u context moet reconstrueren uit Slack-threads, supporttickets en spreadsheets. Leid alle rapporten – support, QA, monitoring – naar één wachtrij met een gestructureerd sjabloon dat componenten, ernst, omgeving, app-versie/build, stappen om te reproduceren, verwacht versus werkelijk en bijlagen (logs/HAR/schermafbeeldingen) verzamelt.
AI kan lange rapporten automatisch samenvatten, stappen voor het reproduceren van bugs en omgevingsdetails uit bijlagen halen en mogelijke duplicaten markeren, zodat triage begint met een samenhangend, verrijkt dossier.
Te controleren statistieken: MTTA (bevestiging binnen enkele minuten, niet binnen enkele uren), percentage duplicaten, tijd die nodig is voor het verzamelen van informatie.

2. AI-ondersteunde triage en routing om MTTA drastisch te verminderen
De snelste oplossingen zijn die welke onmiddellijk op het juiste bureau terechtkomen.
Gebruik eenvoudige regels en AI om de ernst te classificeren, waarschijnlijke eigenaren te identificeren op basis van component/code gebied, en automatisch toe te wijzen met een SLA-klok. Stel duidelijke swimlanes in voor P0/P1 versus al het andere en maak duidelijk wie de eigenaar is.
Automatisering kan prioriteit instellen op basis van velden, naar een team routeren op basis van component, een SLA-timer starten en een engineer op afroep waarschuwen. AI kan op basis van eerdere patronen de ernst en de eigenaar voorstellen. Wanneer triage een kwestie van 2-5 minuten wordt in plaats van een debat van 30 minuten, daalt uw MTTA en volgt uw MTTR.
Te controleren statistieken: MTTA, kwaliteit van eerste reactie (wordt in de eerste reactie om de juiste informatie gevraagd?), aantal overdrachten per bug.
Zo ziet dat er in de praktijk uit:
3. Prioriteer op basis van de impact op de business met expliciete SLA-niveaus
"De luidste stem wint" maakt wachtrijen onvoorspelbaar en ondermijnt het vertrouwen van leidinggevenden die CSAT/NPS en verlengingen in de gaten houden.
Vervang dat door een score die de ernst, frequentie, beïnvloede ARR, kritieke functie en nabijheid van verlengingen/lanceringen combineert, en ondersteun dit met SLA-niveaus (bijv. P0: binnen 1-2 uur mitigeren, binnen een dag oplossen; P1: dezelfde dag; P2: binnen een Sprint).
Houd een zichtbare P0/P1-baan met WIP-limieten, zodat niets blijft liggen.
Te monitoren statistieken: P50/P90-oplossingspercentage per niveau, SLA-overtredingspercentage, correlatie met CSAT/NPS.
💡Pro-tip: Met de velden Taakprioriteiten, Aangepaste velden en Afhankelijkheden van ClickUp kunt u een impactscore berekenen en bugs koppelen aan accounts, feedback of roadmap-items. Bovendien helpen de doelen in ClickUp u om de naleving van SLA's te koppelen aan doelstellingen op bedrijfsniveau, wat direct inspeelt op de zorgen van leidinggevenden over afstemming.
4. Maak reproductie en diagnose een eenmalige activiteit
Elke extra stap met de vraag 'kunt u de logbestanden sturen?' verlengt de oplostijd.
Standaardiseer wat 'goed' is: verplichte velden voor build/toewijzing, omgeving, stappen voor reproductie, verwacht versus werkelijk, plus bijlagen voor logboeken, crash dumps en HAR-bestanden. Implementeer client/server-telemetrie zodat crash-ID's en verzoek-ID's kunnen worden gekoppeld aan traces.
Gebruik Sentry (of iets vergelijkbaars) voor stacktraces en koppel dat probleem rechtstreeks aan de bug. AI kan logs en traces lezen om een waarschijnlijk foutdomein voor te stellen en een minimale reproductie genereren, waardoor een uur zoeken wordt omgezet in een paar minuten gericht werk.
Sla runbooks op voor veelvoorkomende soorten bugs, zodat engineers niet steeds opnieuw hoeven beginnen.
Te controleren statistieken: Tijd besteed aan 'wachten op informatie', percentage gereproduceerd bij eerste poging, heropeningspercentage gekoppeld aan ontbrekende reproductie.
📖 Meer informatie: AI gebruiken bij softwareontwikkeling (gebruiksscenario's en tools)
5. Verkort de code review en testcyclus
Grote PR's vertragen. Streef naar chirurgische patches, trunk-based development en feature flags, zodat fixes veilig kunnen worden geleverd. Wijs reviewers vooraf toe op basis van eigendom van de code om stilstand te voorkomen en gebruik checklists (tests bijgewerkt, telemetrie toegevoegd, vlag achter een kill switch) zodat kwaliteit gegarandeerd is.
Automatisering moet de bug naar "In Review" verplaatsen bij het openen van een PR en naar "Opgelost" bij het samenvoegen; AI kan unit-tests voorstellen of risicovolle verschillen markeren om de review te focussen.
Te monitoren statistieken: Tijd in 'In Review', percentage mislukte wijzigingen voor PR's voor bugfixes en P90-reviewlatentie.
U kunt GitHub/GitLab -integraties in ClickUp gebruiken om de status van uw oplossingen te synchroniseren; automatisering kan de 'definitie van klaar' afdwingen
📖 Meer informatie: Taken automatiseren met AI
6. Voer verificatie parallel uit en zorg voor een gelijkwaardige QA-omgeving
Verificatie mag niet dagen later beginnen of in een omgeving die geen van uw klanten gebruikt.
Houd 'klaar voor QA' strak: vlaggestuurde hotfixes gevalideerd in productie-achtige omgevingen met seed-gegevens die overeenkomen met gerapporteerde gevallen.
Stel waar mogelijk tijdelijke omgevingen in vanuit de bugvertakking, zodat QA onmiddellijk kan valideren. AI kan vervolgens testcases genereren op basis van de bugbeschrijving en eerdere regressies.
Te controleren statistieken: Tijd in 'QA/verificatie', bouncepercentage van QA terug naar dev, gemiddelde tijd tot afsluiting na samenvoegen.

📖 Lees meer: Hoe schrijf je effectieve testcases?
7. Communiceer de status duidelijk om coördinatiekosten te verminderen
Een goede update voorkomt drie statusmeldingen en één escalatie.
Behandel updates als een product: kort, specifiek en afgestemd op de doelgroep (ondersteuning, leidinggevenden, klanten). Stel een cadans vast voor P0/P1 (bijvoorbeeld elk uur totdat het probleem is opgelost, daarna om de vier uur) en zorg voor één bron van waarheid.
AI kan klantveilige updates en interne samenvattingen opstellen op basis van de taakgeschiedenis, inclusief de live status op basis van ernst en team. Voor leidinggevenden zoals uw productdirecteur kunt u bugs doorsturen naar initiatieven, zodat zij kunnen zien of kritieke kwaliteitswerkzaamheden de leveringsbeloften in gevaar brengen.
Te monitoren statistieken: Tijd tussen statusupdates op P0/P1, CSAT van belanghebbenden op communicatie.
8. Beheer de ouderdom van de backlog en voorkom dat tickets 'voor altijd open' blijven staan
Een groeiende, verouderde backlog belast elke Sprint ongemerkt.
Stel verouderingsbeleid in (bijv. P2 > 30 dagen triggert herziening, P3 > 90 dagen vereist rechtvaardiging) en plan een wekelijkse 'verouderingstriage' om duplicaten samen te voegen, verouderde rapporten te sluiten en bugs met een lage waarde om te zetten in productbacklog-items.
Gebruik AI om de backlog te clusteren op thema (bijvoorbeeld 'auth token expiry', 'image upload flakiness'), zodat u thematische fix-weken kunt plannen en een klasse van defecten in één keer kunt verwijderen.
Te monitoren statistieken: aantal achterstallige taken per leeftijdscategorie, % problemen gesloten als duplicaten/verouderd, thematische burn-down-snelheid.
9. Sluit de cirkel met oorzaak en preventie
Als dezelfde klasse van defecten steeds terugkomt, verhullen uw MTTR-verbeteringen een groter probleem.
Voer snelle, foutloze oorzaakanalyses uit op P0/P1 en hoogfrequente P2's; tag oorzaken (specificatiegaten, testgaten, toolinggaten, integratieproblemen), koppel deze aan getroffen componenten en incidenten en houd vervolgacties (bewakingen, tests, lintregels) bij totdat ze zijn voltooid.
AI kan RCA-samenvattingen opstellen en preventieve tests of lintregels voorstellen op basis van de wijzigingsgeschiedenis. Zo gaat u van brandjes blussen naar minder brandjes.
Te controleren statistieken: Percentage heropende tickets, regressiepercentage, tijd tussen herhalingen en percentage RCA's met voltooide preventiemaatregelen.

Samen zorgen deze veranderingen voor een kortere doorlooptijd: snellere bevestiging, duidelijkere triage, slimmere prioritering, minder vertragingen bij beoordeling en kwaliteitscontrole en duidelijkere communicatie. Leidinggevenden krijgen voorspelbaarheid gekoppeld aan CSAT/NPS en omzet; medewerkers krijgen een rustigere wachtrij met minder contextwisselingen.
📖 Lees meer: Hoe voert u een analyse van de onderliggende oorzaak uit?
AI-tools die helpen de tijd voor het oplossen van bugs te verkorten
AI kan de oplossingstijd bij elke stap verkorten: intake, triage, routing, reparatie en verificatie.
De echte voordelen komen echter pas wanneer tools de context begrijpen en het werk zonder begeleiding laten verlopen.
Zoek naar systemen die rapporten automatisch verrijken (reproductiestappen, omgeving, duplicaten), prioriteiten toekennen op basis van impact, naar de juiste eigenaar doorsturen, duidelijke updates opstellen en nauw integreren met uw code, CI en observability.
De beste tools ondersteunen ook agentachtige werkstromen: bots die SLA's bewaken, reviewers aansporen, vastgelopen items escaleren en resultaten samenvatten voor belanghebbenden. Hier is onze selectie van AI-tools voor een betere bugoplossing:
1. ClickUp (het beste voor contextuele AI, automatisering en agentische werkstromen)
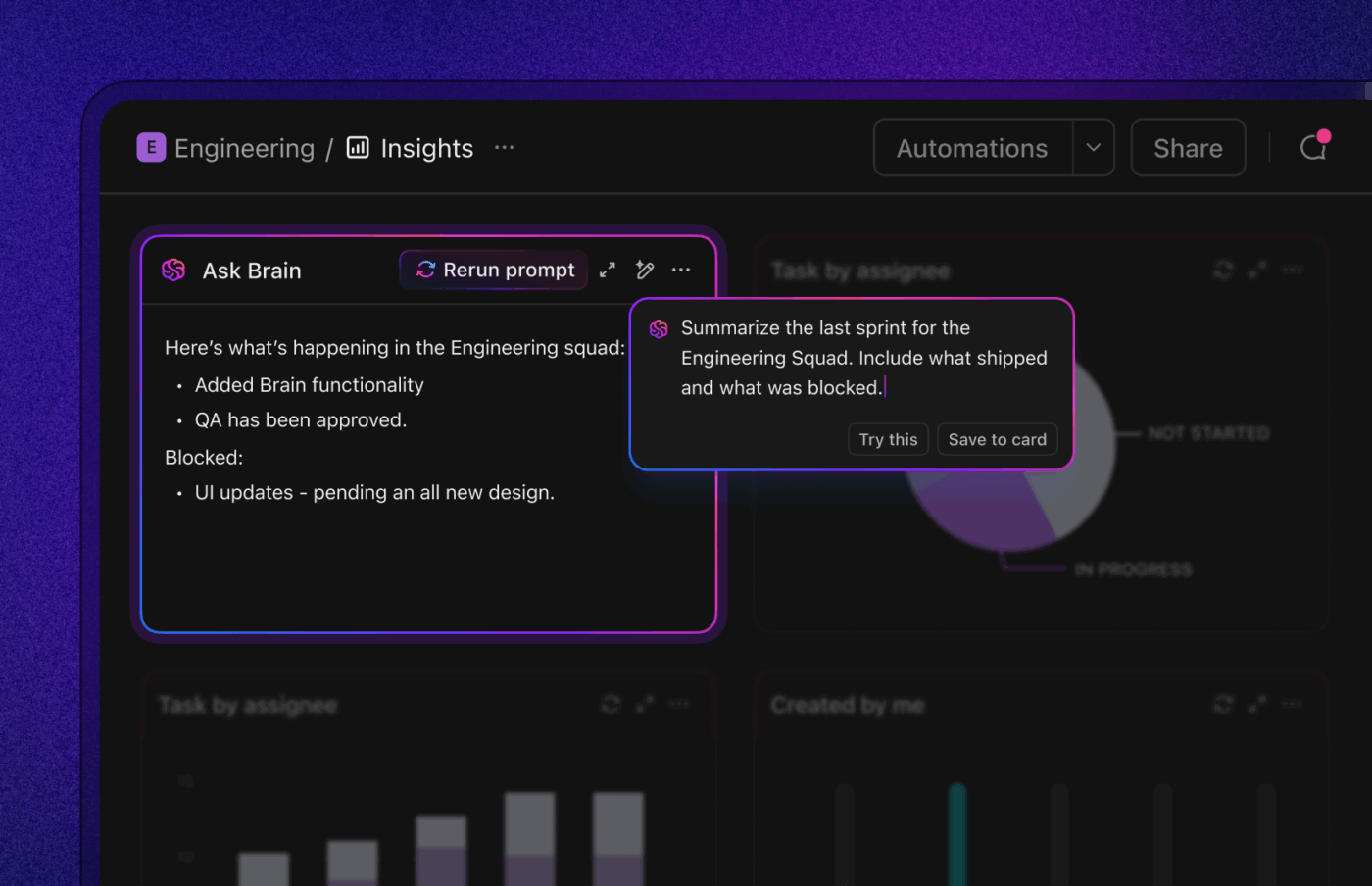
Als u een gestroomlijnde, intelligente werkstroom voor bugoplossing wilt, brengt ClickUp, de alles-in-één app voor werk, AI, automatisering en agentische werkstroomondersteuning samen op één plek.
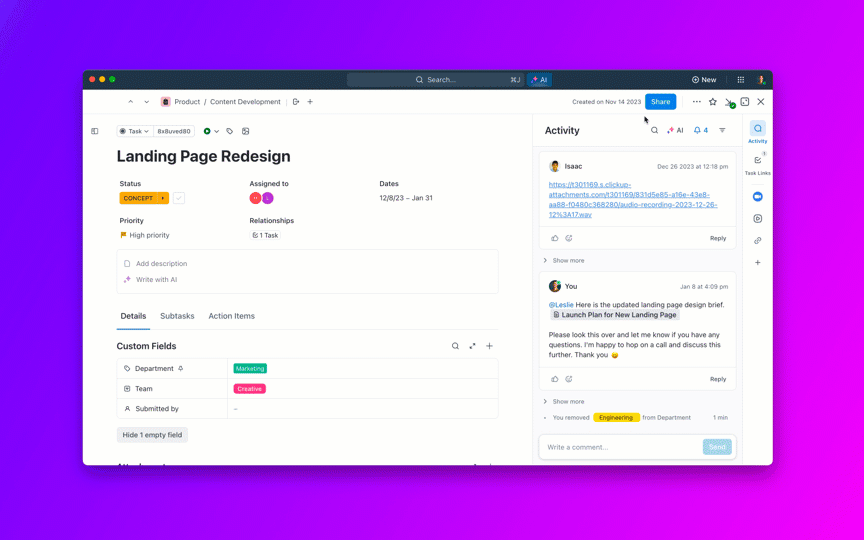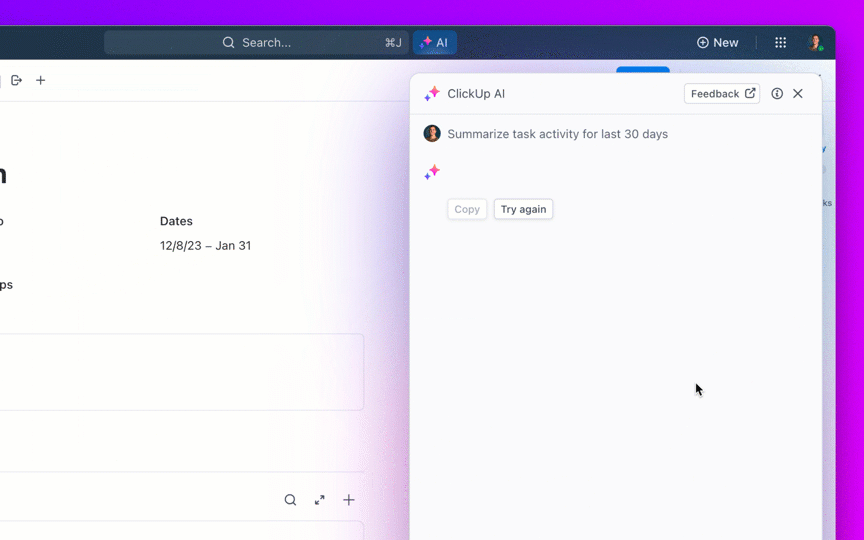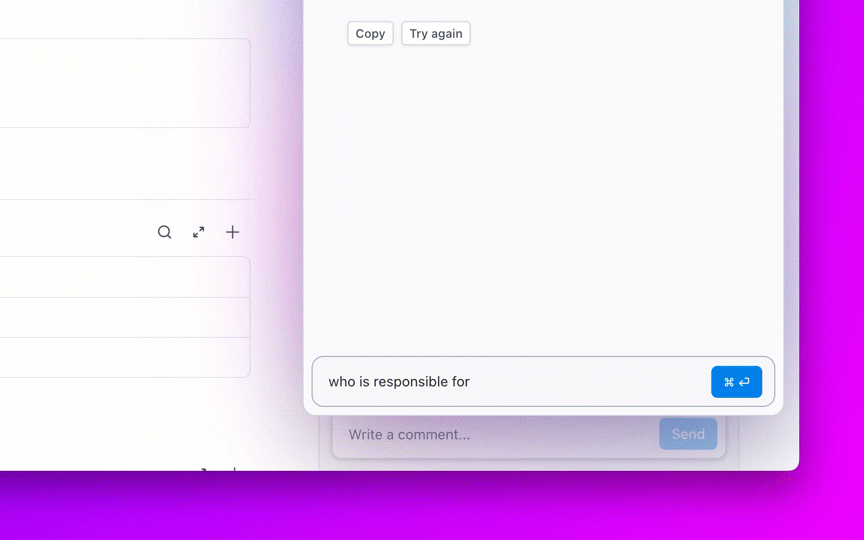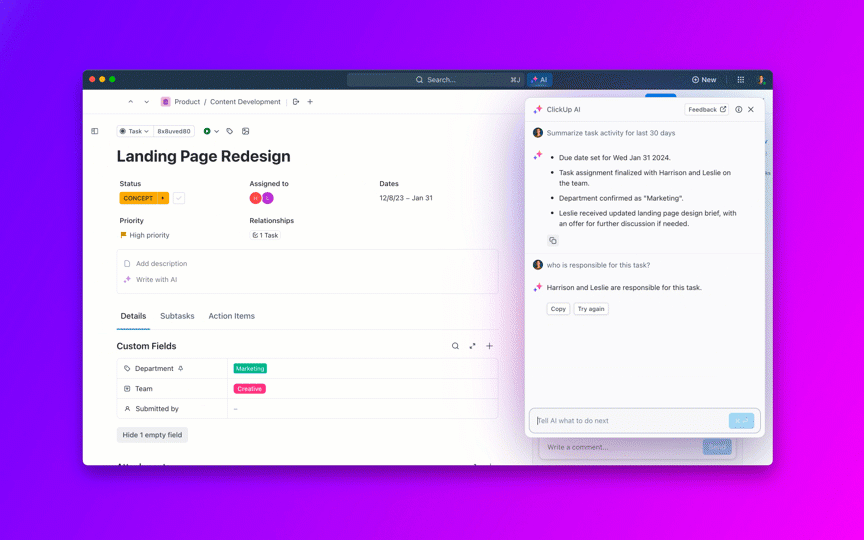
ClickUp Brain brengt direct de juiste context naar voren: het vat lange bugthreads samen, haalt stappen om bugs te reproduceren en omgevingsdetails uit bijlagen, markeert mogelijke duplicaten en stelt vervolgacties voor. In plaats van zich door Slack, tickets en logs te worstelen, krijgen teams een overzichtelijk, uitgebreid rapport waarop ze direct actie kunnen ondernemen.
Automatisering en Autopilot Agents in ClickUp houden het werk op gang zonder dat u voortdurend hoeft in te grijpen. Bugs worden automatisch doorgestuurd naar het juiste team, eigenaren worden toegewezen, SLA's en deadlines worden ingesteld, statussen worden bijgewerkt naarmate het werk vordert en belanghebbenden ontvangen tijdig notificaties.

Deze agents kunnen zelfs problemen triëren en categoriseren, vergelijkbare meldingen clusteren, verwijzen naar eerdere oplossingen om mogelijke oplossingen voor te stellen en urgente items escaleren, zodat MTTA en MTTR dalen, zelfs wanneer het volume piekt.
🛠️ Wilt u een kant-en-klare toolkit? De sjabloon voor het bijhouden van bugs en problemen van ClickUp is een krachtige oplossing van ClickUp voor software die is ontworpen om ondersteuningsteams, engineeringteams en productteams te helpen om softwareproblemen en bugs gemakkelijk op te lossen. Met aanpasbare weergaven zoals lijst, bord, werklast, formulier en tijdlijn kunnen teams hun proces voor het bijhouden van bugs visualiseren en beheren op de manier die het beste bij hen past.
De 20 aangepaste statussen en 7 aangepaste velden van de sjabloon maken een op maat gemaakte werkstroom mogelijk, zodat elk probleem wordt bijgehouden vanaf het moment dat het wordt ontdekt tot het moment dat het wordt opgelost. Ingebouwde automatisering zorgt voor repetitieve taken, waardoor u kostbare tijd bespaart en handmatige inspanningen vermindert.
💟 Bonus: Brain MAX is uw AI-aangedreven desktop-assistent, ontworpen om bugoplossing te versnellen met slimme, praktische functies.
Wanneer u een bug tegenkomt, gebruikt u gewoon de spraak-naar-tekstfunctie van Brain MAX om het probleem te dicteren. Uw gesproken aantekeningen worden direct getranscribeerd en kunnen worden toegevoegd aan een nieuw of bestaand bugticket. De Enterprise Search doorzoekt al uw verbonden tools, zoals ClickUp, GitHub, Google Drive en Slack, om gerelateerde bugrapporten, foutlogboeken, codefragmenten en documentatie te vinden, zodat u alle context hebt die u nodig hebt zonder van app te hoeven wisselen.
Moet u een oplossing coördineren? Met Brain MAX kunt u de bug aan de juiste ontwikkelaar toewijzen, automatische herinneringen voor statusupdates instellen en de voortgang bijhouden – allemaal vanaf uw desktop!
2. Sentry (het beste voor het vastleggen van fouten)
Sentry vermindert MTTD en reproductietijd door fouten, traces en gebruikerssessies op één plek vast te leggen. AI-gestuurde probleemgroepering vermindert ruis; 'Suspect Commit' en eigendomsregels identificeren de waarschijnlijke eigenaar van de code, zodat routering direct plaatsvindt. Session Replay geeft engineers het exacte pad van de gebruiker en console-/netwerkdetails om te reproduceren zonder eindeloos heen en weer te gaan.
De AI-functies van Sentry kunnen de context van een probleem samenvatten en in sommige stacks Autofix-patches voorstellen die verwijzen naar de foutieve code. Het praktische resultaat: minder dubbele tickets, snellere toewijzing en een kortere weg van rapportage naar werkende patch.
3. GitHub Copilot (het beste voor het sneller beoordelen van code)
Copilot versnelt de fix-loop binnen de editor. Het legt stacktraces uit, stelt gerichte patches voor, schrijft unit-tests om de fix vast te leggen en bouwt repro-scripts op.
Copilot Chat kan foutieve code doorlopen, veiligere refactors voorstellen en opmerkingen of PR-beschrijvingen genereren die de codereview versnellen. In combinatie met de vereiste reviews en CI bespaart dit uren aan 'diagnosticeren → implementeren → testen', vooral voor bugs met een duidelijk bereik en een duidelijke reproductie.
4. Snyk by DeepCode AI (het beste voor het herkennen van patronen)
De AI-aangedreven statische analyse van DeepCode vindt defecten en onveilige patronen terwijl u codeert en in PR's. Het markeert problematische werkstromen, legt uit waarom ze optreden en stelt veilige oplossingen voor die passen bij uw codebase-idiomen.
Door regressies vóór het samenvoegen op te sporen en ontwikkelaars naar veiligere patronen te leiden, vermindert u het aantal nieuwe bugs en versnelt u het herstel van lastige logische fouten die moeilijk te vinden zijn tijdens de review. IDE- en PR-integraties houden dit dicht bij de plek waar het werk gebeurt.
5. Datadog's Watchdog en AIOps (het beste voor logboekanalyse)
Datadog's Watchdog gebruikt ML om afwijkingen in logboeken, statistieken, traces en monitoring van echte gebruikers aan het licht te brengen. Het correleert pieken met implementatiemarkeringen, infrastructuurwijzigingen en topologie om mogelijke oorzaken voor te stellen.
Voor defecten die van invloed zijn op klanten betekent dit dat ze binnen enkele minuten worden gedetecteerd, automatisch worden gegroepeerd om het aantal waarschuwingen te verminderen en concrete aanwijzingen geven over waar u moet zoeken. De triagetijd neemt af omdat u begint met "deze implementatie had invloed op deze services en het aantal fouten op dit eindpunt is gestegen" in plaats van met een leeg scherm.
⚡️ Sjabloonarchief: Gratis sjablonen voor het bijhouden van problemen en logboeken in Excel en ClickUp
6. New Relic AI (het beste voor het identificeren en samenvatten van trends)
De Errors Inbox van New Relic clustert vergelijkbare fouten in verschillende services en versies, terwijl de AI-assistent de impact samenvat, mogelijke oorzaken markeert en koppelt aan de betreffende traces/transacties.
Dankzij correlaties tussen implementaties en informatie over entiteitswijzigingen wordt het duidelijk wanneer een recente release de oorzaak is. Voor gedistribueerde systemen bespaart die context uren aan pings tussen teams en wordt de bug naar de juiste eigenaar gestuurd met een solide hypothese die al is geformuleerd.
7. Rollbar (het beste voor geautomatiseerde werkstromen)
Rollbar is gespecialiseerd in realtime foutmonitoring met intelligente fingerprinting om duplicaten te groeperen en trends in gebeurtenissen bij te houden. De AI-gestuurde samenvattingen en hints over de hoofdoorzaak helpen teams de omvang te begrijpen (getroffen gebruikers, betrokken versies), terwijl telemetrie en stacktraces snel aanwijzingen geven voor reproductie.
De werkstroomregels van Rollbar kunnen automatisch taken aanmaken, de ernst taggen en doorsturen naar eigenaren, waardoor luidruchtige foutmeldingen worden omgezet in geprioriteerde wachtrijen met bijgevoegde context.
8. PagerDuty AIOps en automatisering van runbooks (beste low-touch diagnostiek)
PagerDuty gebruikt gebeurteniscorrelatie en ML-gebaseerde ruisonderdrukking om waarschuwingsstormen samen te voegen tot bruikbare incidenten.
Dynamische routing zorgt ervoor dat het probleem direct bij de juiste medewerker terechtkomt, terwijl automatisering van runbooks diagnostiek of mitigatie kan starten (services opnieuw opstarten, een implementatie terugdraaien, een functie vlag schakelen) voordat een mens ingrijpt. Voor de tijd die nodig is om bugs op te lossen, betekent dit een kortere MTTA, snellere mitigatie voor P0's en minder uren verloren door alertmoeheid.
De rode draad is automatisering plus AI bij elke stap. U detecteert eerder, routeert slimmer, komt sneller bij de code en communiceert de status zonder engineers te vertragen, wat allemaal bijdraagt aan een aanzienlijke vermindering van de tijd die nodig is om bugs op te lossen.
📖 Lees meer: Hoe AI te gebruiken in DevOps
Praktijkvoorbeelden van het gebruik van AI voor bugoplossing
AI is dus officieel uit het laboratorium gekomen. Het verkort de tijd die nodig is om bugs op te lossen in de praktijk.
Laten we eens kijken hoe dat werkt!
| Domein / Organisatie | Hoe AI werd gebruikt | Impact/voordeel |
|---|---|---|
| Ubisoft | Commit Assistant ontwikkeld, een AI-tool die is getraind op basis van tien jaar aan interne code en die bugs in de codeerfase voorspelt en voorkomt. | Het doel is om tijd en kosten drastisch te verminderen: tot 70% van de kosten voor game-ontwikkeling wordt traditioneel besteed aan het oplossen van bugs. |
| Razer (Wyvrn Platform) | AI-aangedreven QA Copilot (geïntegreerd met Unreal en Unity) gelanceerd om bugdetectie te automatiseren en QA-rapporten te genereren. | Verhoog de bugdetectie met wel 25% en halveer de QA-tijd. |
| Google / DeepMind & Project Zero | Big Sleep geïntroduceerd, een AI-tool die zelfstandig kwetsbaarheden in de veiligheid van open-sourcesoftware zoals FFmpeg en ImageMagick detecteert. | 20 bugs geïdentificeerd, allemaal geverifieerd door menselijke experts en gepland voor patching. |
| Onderzoekers van UC Berkeley | Met behulp van een benchmark genaamd CyberGym hebben AI-modellen 188 open-sourceprojecten geanalyseerd , 17 kwetsbaarheden ontdekt, waaronder 15 onbekende 'zero-day'-bugs, en proof-of-concept-exploits gegenereerd. | Demonstreert de voortdurende verbetering van AI op het gebied van kwetsbaarheidsdetectie en geautomatiseerde exploit-proofing. |
| Spur (Yale Startup) | Ontwikkeling van een AI-agent die testcase-beschrijvingen in gewone taal vertaalt naar geautomatiseerde websitetestroutines – in feite een zelfschrijvende QA-werkstroom. | Maakt autonoom testen mogelijk met minimale menselijke tussenkomst |
| Android-bugrapporten automatisch reproduceren | Gebruikte NLP + reinforcement learning om de taal van bugrapporten te interpreteren en stappen te genereren om Android-bugs te reproduceren. | Bereikte 67% nauwkeurigheid, 77% recall en reproduceerde 74% van de bugrapporten, waarmee het beter presteerde dan traditionele methoden. |
Veelgemaakte fouten bij het meten van de tijd die nodig is om bugs op te lossen
Als uw metingen niet kloppen, zal uw verbeterplan dat ook niet zijn.
De meeste 'slechte cijfers' in werkstromen voor bugoplossing zijn het gevolg van vage definities, inconsistente werkstromen en oppervlakkige analyses.
Begin dus eerst met de basis: wat geldt als start/stop, hoe gaat u om met wachttijden en heropeningen? Lees vervolgens de gegevens zoals uw klanten die ervaren. Dat omvat:
❌ Onduidelijke grenzen: Door Gemeld→Opgelost en Gemeld→Gesloten in hetzelfde dashboard te combineren (of van maand tot maand te wisselen) worden trends onduidelijk. Kies één grens, documenteer deze en pas deze toe binnen alle teams. Als u beide nodig hebt, publiceer ze dan als afzonderlijke statistieken met duidelijke labels.
❌ Alleen gemiddelden: Als u alleen op het gemiddelde vertrouwt, ziet u niet de werkelijke wachtrijen met een paar langlopende uitschieters. Gebruik de mediaan (P50) voor uw 'typische' tijd, P90 voor voorspelbaarheid/SLA's en bewaar het gemiddelde voor capaciteitsplanning. Kijk altijd naar de verdeling, niet alleen naar één nummer.
❌ Geen segmentatie: Door alle bugs samen te voegen, worden P0-incidenten vermengd met cosmetische P3's. Segmenteer op ernst, bron (klant vs. QA vs. monitoring), component/team en 'nieuw vs. regressie'. Uw P0/P1 P90 is wat stakeholders ervaren; uw P2+ mediaan is waar engineering zijn abonnementen op baseert.
❌ Tijd 'in pauze' negeren: Wacht u op logboeken van klanten, een externe leverancier of een releasetermijn? Als u 'Geblokkeerd/In pauze' niet als een primaire status bijhoudt, wordt uw oplostijd een argument. Rapporteer zowel kalender- als actieve tijd, zodat knelpunten zichtbaar worden en discussies worden voorkomen.
❌ Tijdnormalisatieverschillen: Het door elkaar gebruiken van tijdzones of het halverwege overschakelen tussen kantooruren en kalenderuren verstoort vergelijkingen. Normaliseer tijdstempels naar één zone (of UTC) en bepaal eenmalig of SLA's worden gemeten in kantooruren of kalenderuren; pas dit consequent toe.
❌ Onvolledige intake en duplicaten: Ontbrekende informatie over de omgeving/build en dubbele tickets zorgen voor vertraging en verwarring over de eigendom. Standaardiseer verplichte velden bij de intake, vul deze automatisch aan (logs, versie, apparaat) en ontdubbel zonder de klok te resetten. Sluit duplicaten als gekoppelde problemen, niet als 'nieuwe' problemen.
❌ Inconsistente statusmodellen: Aangepaste statussen ("QA Ready-ish", "Pending Review 2") verbergen de tijd in een status en maken statusovergangen onbetrouwbaar. Definieer een standaard werkstroom (Nieuw → Getriageerd → In uitvoering → In beoordeling → Opgelost → Gesloten) en controleer op afwijkende statussen.
❌ Geen inzicht in de tijd in status: Een enkel nummer voor de 'totale tijd' vertelt u niet waar het werk vastloopt. Leg de tijd vast die is besteed aan triage, beoordeling, blokkering en QA, en bekijk deze. Als code review P90 de implementatie in de schaduw stelt, is uw oplossing niet 'sneller coderen', maar het vrijmaken van capaciteit voor review.
🧠 Leuk weetje: De nieuwste AI Cyber Challenge van DARPA liet een baanbrekende sprong voorwaarts zien op het gebied van automatisering van cyberbeveiliging. De wedstrijd omvatte AI-systemen die zijn ontworpen om zelfstandig kwetsbaarheden in software te detecteren, te exploiteren en te patchen, zonder menselijke tussenkomst. Het winnende team, "Team Atlanta", ontdekte op indrukwekkende wijze 77% van de geïnjecteerde bugs en repareerde 61% daarvan, waarmee het aantoonde dat AI niet alleen in staat is om fouten te vinden, maar ook om ze actief te verhelpen.
❌ Blindheid voor heropenen: Als u heropeningen als nieuwe bugs behandelt, wordt de klok opnieuw ingesteld en wordt de MTTR vertekend. Houd het percentage heropeningen en de 'tijd tot stabiele afsluiting' bij (van de eerste melding tot de definitieve afsluiting in alle cycli). Een stijgend aantal heropeningen wijst meestal op een zwakke reproductie, hiaten in de tests of een vage definitie van 'klaar'.
❌ Geen MTTA: Teams zijn geobsedeerd door MTTR en negeren MTTA (acknowledge/eigendomstijd). Een hoge MTTA is een vroege waarschuwing voor een lange oplossingstijd. Meet deze, stel SLA's in op basis van ernst en automatiseer routing/escalatie om deze laag te houden.
❌ AI/automatisering zonder vangrails: Als u AI de ernst laat bepalen of duplicaten zonder controle laat sluiten, kunnen randgevallen verkeerd worden geclassificeerd en statistieken ongemerkt worden vertekend. Gebruik AI voor suggesties, vraag menselijke bevestiging bij P0/P1 en controleer de prestaties van het model maandelijks, zodat uw gegevens betrouwbaar blijven.
Versterk deze verbindingen en uw grafieken voor de oplossingstijd zullen eindelijk de werkelijkheid weergeven. Van daaruit volgen verdere verbeteringen: een betere intake verkort de MTTA, een overzichtelijker beeld onthult echte knelpunten en gesegmenteerde P90's geven leidinggevenden beloften die u kunt nakomen.
⚡️ Sjabloonarchief: 10 sjablonen voor testcases voor het testen van software
Best practices voor een betere bugoplossing
Samenvattend zijn dit de belangrijkste punten om in gedachten te houden!
| 🧩 Best practice | 💡 Wat dit betekent | 🚀 Waarom dit belangrijk is |
| Gebruik een robuust systeem voor het bijhouden van bugs | Houd alle gemelde bugs bij met een gecentraliseerd systeem voor het bijhouden van bugs. | Zorgt ervoor dat geen enkele bug verloren gaat en biedt zichtbaarheid van de status van bugs binnen teams. |
| Schrijf gedetailleerde bugrapporten | Voeg visuele context, OS-informatie, stappen om te reproduceren en ernst toe. | Helpt ontwikkelaars bugs sneller op te lossen met alle essentiële informatie vooraf. |
| Categoriseer en prioriteer bugs | Gebruik een prioriteitsmatrix om bugs te sorteren op urgentie en impact. | Het team kan zich eerst concentreren op kritieke bugs en urgente problemen. |
| Maak gebruik van geautomatiseerd testen | Voer automatisch tests uit in uw CI/CD-pijplijn. | Ondersteunt vroege detectie en voorkomt regressies. |
| Definieer duidelijke richtlijnen voor rapportage | Bied sjablonen en training voor het rapporteren van bugs. | Dit leidt tot nauwkeurige informatie en soepelere communicatie. |
| Bijhouden van sleutelcijfers | Meet de tijd die nodig is om problemen op te lossen, de verstreken tijd en de responstijd. | Maakt het bijhouden en verbeteren van prestaties mogelijk met behulp van historische gegevens. |
| Gebruik een proactieve aanpak | Wacht niet tot gebruikers klagen, maar test proactief. | Verhoog de klanttevredenheid en verminder de werklast van de klantenservice. |
| Maak gebruik van slimme tools en ML | Gebruik machine learning om bugs te voorspellen en oplossingen voor te stellen. | Verbetert de efficiëntie bij het identificeren van de onderliggende oorzaken en het oplossen van bugs. |
| Afstemmen op SLA's | Voldoe aan overeengekomen service level agreements voor het oplossen van problemen. | Bouwt vertrouwen op en voldoet tijdig aan de verwachtingen van de client. |
| Continu beoordelen en verbeteren | Analyseer heropende bugs, verzamel feedback en pas processen aan. | Bevordert de voortdurende verbetering van uw ontwikkelingsproces en bugbeheer. |
Bugoplossing eenvoudig gemaakt met contextuele AI
De snelste teams voor bugoplossing vertrouwen niet op heldendaden. Ze ontwerpen een systeem: duidelijke start-/stopdefinities, schone intake, prioritering op basis van impact op de business, heldere eigendom en strakke feedbackloops tussen ondersteuning, QA, engineering en release.
ClickUp kan dat AI-aangedreven commandocentrum voor uw bugoplossingssysteem zijn. Centraliseer elk rapport in één wachtrij, standaardiseer de context met gestructureerde velden en laat ClickUp AI triëren, samenvatten en prioriteiten toekennen, terwijl automatisering SLA's afdwingt, escalaties doorgeeft wanneer deadlines worden overschreden en belanghebbenden op één lijn houdt. Koppel bugs aan klanten, code en releases, zodat leidinggevenden de impact zien en medewerkers in de werkstroom blijven.
Als u klaar bent om de tijd voor het oplossen van bugs te verkorten en uw roadmap voorspelbaarder te maken, meld u dan aan voor ClickUp en begin met het meten van de verbetering in dagen, niet in kwartalen.
Veelgestelde vragen
Wat is een goede bugoplossingstijd?
Er is niet één 'goed' nummer – het hangt af van de ernst, het releasemodel en de risicotolerantie. Gebruik medianen (P50) voor 'typische' prestaties en P90 voor beloften/SLA's, en segmenteer op ernst en bron.
Wat is het verschil tussen bugoplossing en bugafsluiting?
Oplossing is wanneer de fix is geïmplementeerd (bijv. code samengevoegd, configuratie toegepast) en het team het defect als verholpen beschouwt. Afsluiting is wanneer het probleem is geverifieerd en formeel is afgerond (bijv. QA gevalideerd in de target-omgeving, vrijgegeven of gemarkeerd als niet te repareren/duplicaat met reden). Veel teams meten beide: Gemeld→Opgelost geeft de snelheid van de engineering weer; Gemeld→Gesloten geeft de end-to-end kwaliteit van de werkstroom weer. Gebruik consistente definities, zodat dashboards geen verschillende fasen door elkaar halen.
Wat is het verschil tussen de tijd die nodig is om een bug op te lossen en de tijd die nodig is om een bug te detecteren?
De detectietijd (MTTD) is de tijd die nodig is om een defect te ontdekken nadat het zich heeft voorgedaan of is verzonden, via monitoring, QA of gebruikers. De oplostijd is de tijd die nodig is vanaf de detectie/rapportage totdat de oplossing is geïmplementeerd (en, indien gewenst, gevalideerd/vrijgegeven). Samen bepalen ze het impactvenster voor de klant: snel detecteren, snel erkennen, snel oplossen en veilig vrijgeven. U kunt ook MTTA (tijd om te erkennen/toewijzen) bijhouden om vertragingen in de triage op te sporen die vaak een langere oplossingstijd voorspellen.
Hoe helpt AI bij het oplossen van bugs?
AI comprimeert de loops die doorgaans vertraging opleveren: intake, triage, diagnose, reparatie en verificatie.
- Invoer en triage: Samenvatting van lange rapporten, extraheren van stappen/omgeving voor reproductie, markeren van duplicaten en voorstellen van ernst/prioriteit, zodat engineers met een schone lei kunnen beginnen (bijv. ClickUp AI, Sentry AI).
- Routing en SLA's: voorspelt de waarschijnlijke component/eigenaar, stelt timers in en escaleert wanneer MTTA of review-wachttijden oplopen, waardoor de 'tijd in status' wordt verminderd (ClickUp-automatisering en agentachtige werkstromen).
- Diagnose: Groepeer vergelijkbare fouten, breng pieken in verband met recente toewijzingen/releases en wijs mogelijke oorzaken aan met stacktraces en code context (Sentry AI en vergelijkbaar).
- Implementatie: stelt codewijzigingen en tests voor op basis van patronen uit uw opslagplaats, waardoor de 'schrijf/repareer'-cyclus wordt versneld (GitHub Copilot; Snyk Code AI door DeepCode).
- Verificatie en communicatie: schrijft testcases op basis van reproductiestappen, stelt release-aantekeningen en updates voor belanghebbenden op en vat de status samen voor leidinggevenden en klanten (ClickUp AI). Door ClickUp als commandocentrum te gebruiken in combinatie met Sentry/Copilot/DeepCode in de stack, kunnen teams de MTTA/P90-tijden verkorten zonder te vertrouwen op heldendaden.