
最初の数サービスは簡単です。1回のローテーション、1つのチャネル、そしてバックアップです。
しかし、企業が数十のマイクロサービス、複数のリージョン、階層化された所有権構造に到達すると、手動によるエスカレーションはワークフローではなく、負担となる。
このガイドでは、エンジニアリング組織の規模拡大に合わせて拡張可能なインシデントエスカレーション経路を自動化する方法を説明します。これにより、オンコール体制に抜け穴が生じることを防ぎます。
さらに、エンジニアリングチームが信頼できるエスカレーションシステム構築に、ClickUpがどのように活用できるかもご紹介します。🎯
⭐ 機能テンプレート
自然災害からデータ侵害まで、緊急事態発生時に迅速かつ効果的に対応するため、ClickUpインシデントアクションプラン(IAP)テンプレートを活用しましょう。

このテンプレートには、以下の目的で事前に定義されたセクションが用意されています:
- インシデントの目的と対応優先度を定義する
- 明確な指揮系統を確立する
- チーム間でリアルタイムにアクションを調整する
- 意思決定、タイムライン、重要な更新情報を発生時に即座に記録する
- エスカレーションとフォローアップを確実に把握する
ClickUp内に組み込まれているため、静的なチェックリストではなく、リアルタイムのインシデント対応文書として機能します。
インシデントエスカレーション経路を自動化する理由
厳格なSLAが設定された複雑なシステムを運用する場合、手動でのエスカレーションは対応を遅らせるだけです。自動化されたエスカレーションにより、高圧的なインシデント発生時でも、予測可能でストレスの少ない対応プロセスを実現します。
組織のエスカレーション経路を自動化すべき理由はこちら。👇
手動エスカレーションのリスク
数十のサービス、複数のオンコールローテーション、絶えず変動する所有権を扱うようになると、人的なステップはすぐに問題となります。
よくある落とし穴には以下が含まれます:
- 通知の漏れや遅延(電子メール、SMS、チャット通知の未確認時)
- 引き継ぎ時の混乱、特にエスカレーション経路が明確に文書化されていない場合
- 所有権マップが更新されていないため、誤ったチームにエスカレーションする
- 1人の担当者に依存して「アラートを次へ渡す」ことで生じるボトルネック
📖 こちらもご覧ください:インシデントレポートの作成方法
自動化のメリット
ITSM自動化はエスカレーション経路に構造と推進力を与えます。誰かがアラートを確認するのを待つ代わりに、システムが事前に定義された手順を即座に一貫して実行します。
AIを活用したタスク自動化により、チームが得られるメリットは以下の通りです:
- 迅速な対応時間:アラートが数秒以内に適切な担当者やチームに届くため
- 一貫した実行により、意思決定が遅くなる深夜3時であっても、エスカレーションステップを確実に遂行します
- 組み込みの冗長性により、プライマリオンコール担当者がアラートを見逃した場合でも、バックアップ担当者に確実に通知されます
- チーム間の明確な可視性:全員がエスカレーションのフローを理解できるため
- 緊急対応の頻度を減らし、予測可能なオンコール体験を実現
📖 こちらもご覧ください:事業継続プランの例
アラート疲労と人的ミスを削減
アラート疲労はオンコール対応の有効性を損ないます。チームが頻繁に、あるいは不適切な理由で通知を受けると、緊急性を持って対応しなくなります。自動化により、真に人的対応が必要な事象のみをフィルタリングしエスカレーションできます。
自動化されたエスカレーションロジックにより:
- 低優先度または重複アラートは、オンコール担当者に届く前に抑制されます
- 重大度に基づくルールにより、軽微な問題で不必要に誰かを起こすことはありません
- アラートは、システムが定義された時間枠内で応答がないことを検出した場合にのみエスカレーションされます
- Teamsはノイズの選別に費やす時間を減らし、真の問題解決により多くの時間を割けるようになります
SLAおよびオンコールポリシーの遵守をサポート
自動化されたエスカレーションにより、継続的な手動監視なしでもコンプライアンス維持が容易になります。厳格なSLAや内部信頼性コミットメントを管理するIT運用責任者にとって、AIは期待される動作を強制するガードレールとして機能します。これにより以下の実現を支援します:
- インシデント通知がルーティングに関する事前定義ルールに従うことを保証する
- タイムドエスカレーションにより、SLA対応タイムラインを自動的に維持
- 時代遅れのスプレッドシートに頼らず、オンコールスケジュールを確実に運用する
- すべてのアラート、エスカレーション、および確認に対して監査証跡を作成する
🎥 エスカレーション経路のワークフロー全体を自動化したいですか?スーパーエージェントが実現します 。👇🏼
🔍 ご存知ですか? NASAのミッションコントロールは、基本的に自動化されたエスカレーションロジックで稼働しています。テレメトリの範囲が許容範囲を外れると、システムは即座に自動アラートを専門分野ごとに担当スペシャリストへルーティングします。
インシデント管理におけるエスカレーションポリシーとは?
エスカレーションポリシーとは、誰に通知するか、いつ通知するか、責任を上位または他チームへどのように引き継ぐかを決定する事前定義された一連のルールです。
これは構造化されたロードマップと捉えてください。インシデントの停滞を防ぎ、適切な専門家が適切なタイミングで対応に当たり、チームがSLAを達成するのを支援します。
適切に構築されたエスカレーション管理ポリシーには通常、以下の要素が含まれます:
- ルールベースのルーティング:インシデントの承認応答がない場合や解決不能な場合に、次に担当すべき者を定義します
- 時間指定トリガー:深刻度に基づき5分、15分、30分後に自動的にエスカレーション
- 通知方法(電話、SMS、チャット、電子メールなど)
- エスカレーションプランの階層:レベル1(一次オンコール担当)>レベル2(シニアエンジニア/専門家)>レベル3(経営陣)
- ドキュメントの要件:新規対応者が重要な文脈を損なわずに引き継げるようにする
📖 こちらもご覧ください:タスクをP0、P1、P2、P3、P4として優先順位付けする方法
エスカレーションポリシーの種類
チームが理解すべき主要なポリシーの種類は以下の通りです:
1. 階層的エスカレーション(垂直型)
アラートは指揮系統を上へ伝達され、ジュニアエンジニアからシニアスペシャリスト、そして経営陣へと移行します。状況により高度な専門知識、意思決定権限、または経営陣の可視性が必要な場合に活用してください。
2. 機能別エスカレーション(水平方向)
アラートは上位へではなく、影響を受けたシステムを管理する機能を持つチームへ横断的に伝達されます。これはデータベース、ネットワーク、支払い、APIなど特定の領域に関連するインシデントに最適です。
3. 時間ベースのエスカレーション
これはほとんどの自動化システムの基盤となる仕組みです。このタイプでは、アラートは特定の時間枠(多くの場合SLAに直接連動)を経た後、次の階層へ移行します。特に営業時間外に確実な対応が必要な場合に不可欠です。
4. インパクトベースのエスカレーション
影響度に基づくエスカレーションは、階層や時間ではなく深刻度やビジネスへの影響度を基準とします。サービス停止、支払い失敗、顧客対応問題、セキュリティ侵害などに有効です。
5. 並列エスカレーション
ここでは複数の人員またはチームが同時に通知されます。並列エスカレーションは、複数の専門知識を必要とする重大な問題や、いかなる遅延も許容できない状況に適用されます。
🔍 ご存知ですか? アラート信号に関する最近の研究では、特に予期しないアラートの場合、非常に目立つ(つまり「音量が大きい/明るい」)アラートは反応時間を遅らせる可能性があることが判明しました。しかし、アラートの種類が予測可能(つまり、事前に設計されたエスカレーション/通知システムの一部)になると、反応時間は改善します。これは、エスカレーション経路を自動化する際、単に高優先度のアラームで人々を圧倒すべきではないことを示唆しています。
自動エスカレーションをトリガーするタイミング
エスカレーション経路の構造を理解したところで、次のステップはこれらのルールを自動的に実行するタイミングを決定することです。
以下は自動エスカレーションをトリガーする主要な状況であり、ポリシーの背後にあるロジック層を形成します。💁
深刻度に基づくエスカレーション
インシデントの深刻度や影響が一定の閾値を超えた時点で自動エスカレーションが発動します。深刻度の高いインシデントには上級者の即時対応が必要であり、自動エスカレーションによりボトルネックを回避し、数秒以内に専門家をループに組み込むことが可能です。
📌 例: サービス全体の停止、支払いゲートウェイの障害、または多数のユーザーや基幹システムに影響を与える重大な性能低下は、自動的なエスカレーションを必要とします。
時間ベースのエスカレーション
定義された時間枠内にインシデントが承認または解決されない場合、アラートは自動的に次のレベルへエスカレーションされます。これにより、特に通常勤務時間外や、最初の対応者が不在または過負荷状態にある場合に、チケットが滞留するのを防ぎます。
📌 例: 最初の対応者から10~15分間応答がない場合、上級エンジニアへエスカレーションされます。さらに30~60分間未解決の場合、さらに上位へエスカレーションされます。
状況に応じたエスカレーション
このエスカレーションロジックは、影響を受けたサービスやシステム、サービス所有者、影響を受けた顧客セグメント(内部 vs 外部、VIP vs 一般)、機能ドメイン(データベース、ネットワーク、統合)など、インシデントのコンテキスト属性を考慮します。そのコンテキストに基づき、アラートは最も関連性の高い担当者またはチームにルーティングされます。
これにより、チームが不要なインシデントで過負荷になるのを防ぎ、対応時間を短縮し、専門家が担当領域の問題を確実に処理できるようになります。
📌 例:支払いサービスで遅延が急増した場合は支払いチームに直接通知し、課金マイクロサービスでバックエンドエラーが発生した場合は課金チームに通知する。
メタデータに基づくエスカレーション
最新のアラートおよびインシデント管理ツールは、発生元(どの監視ツールやアラートルールがトリガーされたか)、ユーザー/顧客の識別情報、場所、類似インシデントの過去の発生頻度、ラベルなどのメタデータを捕捉します。これにより、単純な深刻度や時間ベースのルールに依存するのではなく、より細分化されたインテリジェントなロジックを適用することが可能になります。
📌 例: 同一サブシステムからの繰り返しアラートは、より深刻なシステム的な問題を示している可能性があり、迅速なエスカレーションが必要となる場合があります。あるいは、VIP顧客向けのアラートは追加通知をトリガーする可能性があります。
トリガーを組み合わせて、よりスマートで適応性の高いエスカレーションポリシーを構築する
実際には、多くのチームは単一のトリガータイプだけに依存していません。代わりに、深刻度、時間、コンテキスト、メタデータルールを組み合わせたハイブリッドなエスカレーションポリシーを構築しています。
この階層的なアプローチにより、チームは迅速性(必要な時には速やか)と選択性(ノイズを最小限に抑える)を兼ね備えたエスカレーションポリシーを構築できます。これによりインシデント対応の結果が向上し、リソース配分がより効率的になります。
🔍 ご存知でしたか? 18世紀、海軍の乗組員は緊急時に厳格なエスカレーション手順を採用していました。下級水兵が危険を発見すると、ベルを鳴らしてメッセージを階層の上へ伝達し、最終判断を艦長が行う仕組みでした。
効果的なエスカレーション経路の設計方法
エスカレーション経路の設計とは、最小限の摩擦で適切なアラートを適切な担当者に確実にルーティングするシステムを構築することです。
複雑な分散環境で活用できる、実践的なステップフレームワークをご紹介します。
P.S. 特定のClickUp機能がここでどのように役立つかもご紹介します!🤩
ステップ1:明確なエスカレーション基準、レベル、責任範囲を定義する
まず、エスカレーションが必要なインシデントの定義を明確にします。客観的な基準を文書化することで、新規のL1対応者から経験豊富なSREまで、すべてのオンコールエンジニアがインシデントの深刻度を同じ基準で解釈できるようにします。
これにより明確なエスカレーションワークフローが提供され、曖昧さが排除され、自動化が真に必要な時のみ作動するよう保証されます。
以下のような基準を含める:
- 重大度閾値:サービス停止、支払い失敗、認証問題、データ破損、セキュリティアラート
- 影響:顧客向けサービス停止、内部サービスの劣化、パートナーAPI障害、コンプライアンス違反、または安全リスク
- ビジネス上重要な状況:高価値顧客への影響、収益に影響するフロー、高リスクシステム(例:支払い、請求)
基準とトリガーを定義したら、各エスカレーションポイントで誰に通知が行われ、それぞれの担当者がどのような責任を負うかを明確にします。
レベルを明確に定義する:
- レベル1(一次オンコールインシデント担当者): 最初の対応者として、インシデントの受理、初期トリアージ、および緩和策の実施を担当します。
- レベル2(バックアップ/スペシャリスト/SME):高度な技術的専門知識を提供し、複雑なシステム問題を解決します
- レベル3(エンジニアリングマネージャー/リーダーシップ):重大なインシデントを監督し、主要な対応策を承認し、チーム横断的な連携を調整し、必要に応じてベンダーへのエスカレーションを実行する
🚀 ClickUpの利点:ClickUpドキュメントを活用し、エスカレーション基準・レベル・責任範囲の単一の情報源を維持。役割と責任を文書化し、以下を含む担当者を明確化:
- 認識し、軽減する
- 関係者と連携する
- ベンダーまたは外部パートナーからのエスカレーションを処理します
- インシデント指揮を統括する
また、これらの特定の役割を関連するClickUpタスクにリンクすることで、文脈を接続し続けることができます。
独自のナレッジベースを構築する:
エスカレーション基準と所有権を定義したら、チームは技術的インシデントを捕捉・追跡・分析するための一貫した方法が必要です。ClickUpインシデントレポートテンプレートは、ITおよび運用上のインシデントを一元的に記録するための構造化された、アクセスしやすいシステムを提供します。
ClickUp Docs内に構築されたこの機能は、インシデント対応チームが重大な詳細情報を記録するのに役立ちます。具体的には、インシデントの深刻度、影響を受けたサービス、タイムライン、根本原因の要約、緩和ステップ、およびフォローアップアクションなどです。
ステップ #2: インシデント作成の標準化
エスカレーション経路が作動する前に、チームはインシデントデータを確実に収集・標準化・強化する手段が必要です。初期のインシデント記録が不完全または矛盾している場合、最も洗練されたエスカレーションロジックでさえ機能しません。
標準化は以下を実現すべきです:
- アラートのトリアージ: アラートを「深刻度」「カテゴリ」「影響を受けたサービス」「インシデントタイプ」「確認済みステータス」などの一貫したカスタムフィールドに変換します
- インシデントを自動的に充実させる:クラスタ、デプロイメントID、サービス所有者、依存関係などのメタデータを自動的に取り込みます
- すべてのインシデントでコンテキストを確実に記録:報告者、検知方法、環境(本番/ステージング)、関連するログやスクリーンショットを記録する
インシデントを追跡するリストから直接ClickUpフォームを作成し、運用実態とエスカレーションロジックに必要な関連データを反映した設計を行います。これにより、チャット・電子メール・ダッシュボードに分散したメッセージではなく、すべてのインシデントが一貫したフォーマットでシステムに取り込まれ、自動化が確実に動作する基盤が整います。

意図的にフィールドをグループ化し、すべてのインシデントが完全に文脈化されるようにします:
- 識別情報(タイトル、要約)
- 分類(深刻度、種類、影響を受けたサービス)
- ソース(監視、ユーザー、API)
- 証拠(ログ、スクリーンショット)
- ビジネスコンテキスト(SLAレベル、顧客への影響)
フォーム提出のたびに自動的に新しいClickUpタスクが作成され、すべての回答がClickUpカスタムフィールドにマッピングされます。これによりインシデント作成時に標準化が保証され、曖昧さが排除され、手動でのインシデント対応が不要になります。
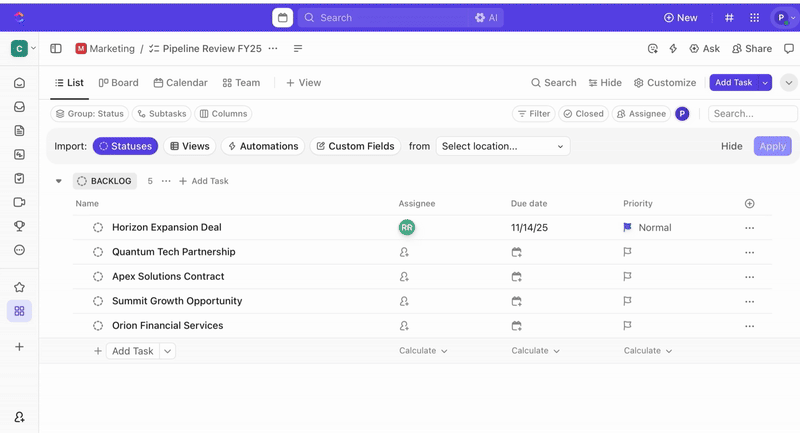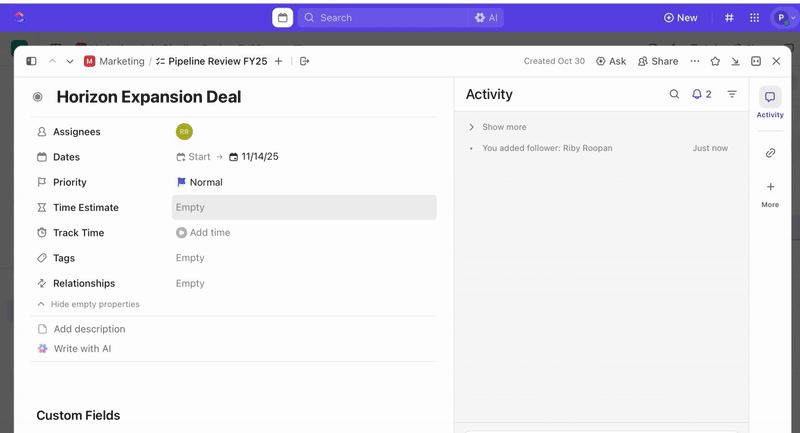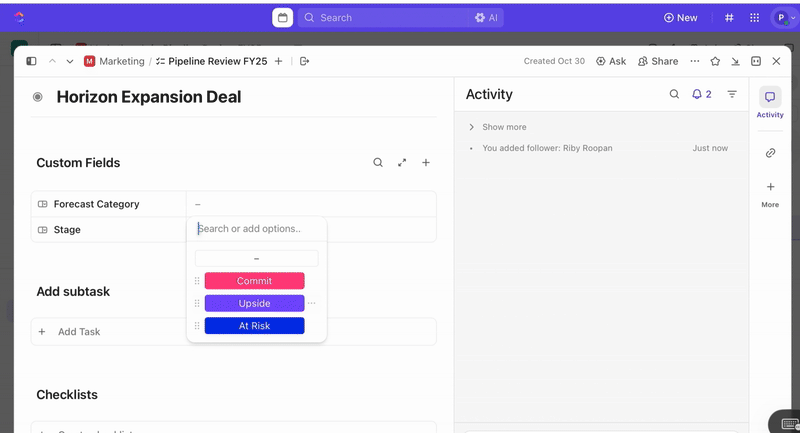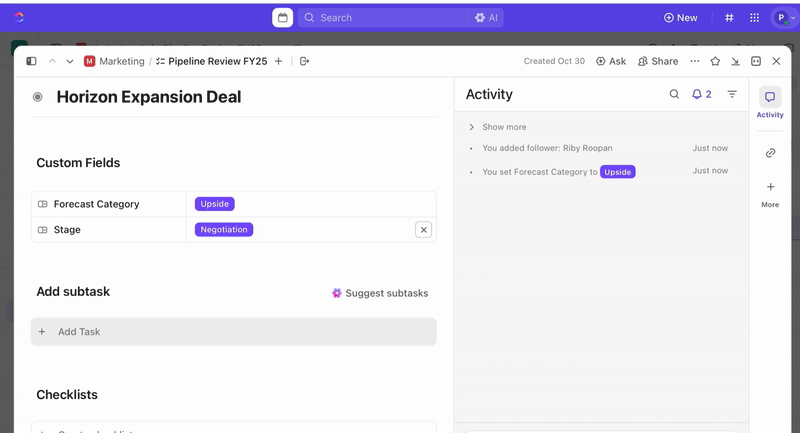
タスク作成後はカスタムフィールドを活用し、トリアージと優先順位付け(例:深刻度、影響範囲、対応担当者グループ)を推進。さらにインシデントのフェーズ(新規 > トリアージ > 調査中 > 対応中 > 解決)を反映するClickUpカスタムステータスを定義できます。
ステップ #3: エスカレーション経路の構築(順序+タイミング+チャネル)
これがプロセスの核心です。通知対象者、通知手段、および応答・解決がない場合の経過時間を各フェーズで定義し、段階的に構成します。
- 「承認タイムアウト」と「解決タイムアウト」を定義する。
- 第一フェーズ: 最初のオンコール担当者はSMS/チャットチャネルで即時通知を受け、5~10分以内に応答する必要があります。
- フェーズ2: 15~20分以内に確認応答または対応がない場合、SMS/チャットチャネル/電子メールでバックアップ/SREチーム+シニアエンジニアへエスカレーションする
- フェーズ3: さらに30~60分経過しても未解決の場合、エンジニアリングマネージャー/リーダーシップへエスカレーションし、必要に応じて「重大インシデント」チャネルをトリガーする。
- エスカレーション経路を「繰り返し」(同一レベルへの再通知)するか「次へ進む」かを決定する
- 重大なインシデントについては、誰かが対応するまで繰り返し通知を設定します。優先度の低いインシデントについては、単一のエスカレーションフローを設定することをお勧めします。
- カスタマーサービス対応テンプレートを使用して経路を文書化し、関連する全担当者がアクセスできるようにする
❗️ 注:「確認タイムアウト」とは、最初の対応者がアラートを確認したことを通知するまでの制限時間です。一方、「解決タイムアウト」とは、次のエスカレーションが開始される前にチームが問題を修正または軽減するための制限時間です。
ステップ #4: 自動化とツールサポートの組み込み
基準、トリアージプロセス、強化基準が整ったら、次に必要なステップは、エスカレーションのタイミングや対象者を人間が記憶に頼らずに実行できるようにすることです。ここでClickUp自動化がワークフローの中核となります。

インシデント発生時にチームが使用するのと同じシグナルに反応する自動化の機会を設定できます。例をいくつか挙げます:
- 深刻度がSEV-1に更新された場合 ➡️ 直ちに上級SREを割り当て + オンコールチャットチャンネルに通知
- ステータスがX分間変更されない場合 ➡️ 次のレベルへのエスカレーションをトリガーする
- 期日が過ぎた場合(例:確認期限)➡️ L2へエスカレーション
そしてここがClickUp Brainの真価を発揮する場面です。ワークスペースのコンテキストを活用し、即座に回答を提供、更新を自動生成、ナレッジへのアクセスをサポートします。
AI Prioritizeなどのツールを活用し、独自のロジックに基づいてインシデントを自動評価し適切な優先度を設定します。例となるプロンプト:
- インシデントが本番環境に影響し、顧客に影響を与える場合は、優先度: 緊急を設定してください
- 担当者がSREチームであり、ログに「レイテンシー」のメンションがある場合、優先度を「高」に設定する
- 説明に「侵害」などのセキュリティ関連キーワードが含まれる場合、優先度を「緊急」に設定してください。
優先度が設定されると、AIアサインが自動的に引き継ぎ、定義した条件に基づいてインシデントを割り当てます。
以下のようなプロンプトを作成できます:
- 優先度が「緊急」で、影響を受けたサービスに「支払い」が含まれる場合、シニアSREに割り当て
- インシデントタイプがデータベースで、リージョンがUS-Eastの場合、DBオンコール担当者に割り当てます
- タスク名に「セキュリティ」が含まれる場合は、SecOpsリーダーに割り当ててください
リスト全体に適用する前に、最初の3つのタスクでこれらのプロンプトをテストしてください。
🚀 ClickUpの優位性:ワークスペース内に常駐するインテリジェント自動化ボットを展開し、ClickUp Super Agentsでリアルタイムのアクティビティに対応します。
タスク、ドキュメント、チャット、プロセスを完全に把握しているため、あらゆる自動化されたアクションは文脈に沿ったものとなります。
例えば、Team StandUp Agentを「本番環境インシデントフォルダ」に配置すれば、毎朝自動的に日次要約を投稿します。チームは即座にスナップショットを受け取り、開かれたインシデントの数、未解決のインシデント、過去24時間での変更内容を把握できます。
次に、これを「#インシデントルーム」チャンネル内のAmbient Answers Agentと連携させます。対応担当者が「SEV-1ランブックはどこにある?」や「このAPIは過去に失敗したことがあるか?」といった質問をすると、ワークスペースのナレッジから情報を取得し、即座に正確な回答を提供します。

ステップ #5: コミュニケーションチャネルの標準化
インシデントがエスカレートするにつれ、通知対象者と同様に、チームがどのように、どこでコミュニケーションを取るかが重要になります。標準化されたチャネルがなければ、更新情報が失われ、意思決定が重複し、関係者が矛盾した情報を受け取ることになります。
インシデントライフサイクルの各フェーズに明確なエスカレーションチャネルを定義し、チーム間で一貫して活用します:
| 基準 | チャンネル名 | 目的 |
| SEV-1またはSEV-2が検出されました | #インシデント-クリティカル | 高深刻度アラートと即時トリアージのための中央管理スペース |
| 現在トラブルシューティング中 | #インシデント対策室 | エンジニア、プロダクト、QA、サポートのためのリアルタイムコラボレーションhub |
| 経営陣の可視性が必須 | #インシデント管理 | 管理職・経営陣向け重要度が高い更新情報 |
| 顧客対応のコミュニケーションが必要 | #インシデント対応 | 外部顧客向けコミュニケーションの草案作成、レビュー、調整のためのスペース |
| インシデント事後レビューを開始 | #インシデント事後検証 | 振り返りメモ、学び、アクションアイテムのための構造化されたディスカッション |
各チャネルには明確な対象者と目的が設定されており、チーム間の不要な情報流通を抑えつつ、適切なチームへの情報伝達を保証します。
🚀 ClickUpの優位性:ClickUpチャットの組み込みコミュニケーション機能でチャネル戦略を最適化。すべてのアラート、更新、決定事項が、仕事が行われるインシデントのタスク、リスト、スペースに直接紐付けられます。
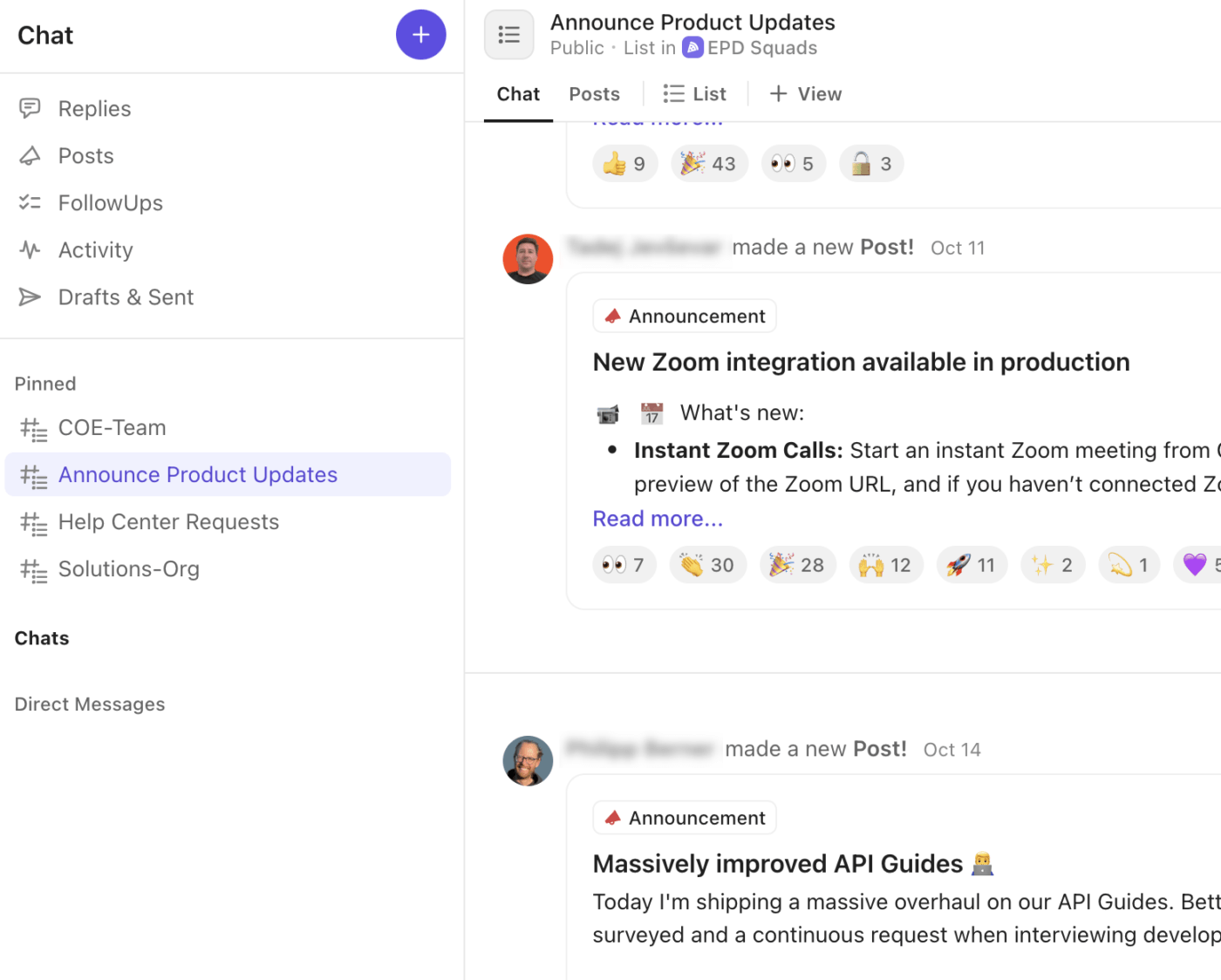
ClickUpチャットがインシデントワークフローを向上させる方法:
- 専用チャットスレッドを作成し、重要事項、緊急対策室、経営陣、顧客対応に関する議論を管理します
- チャットメッセージを即座にClickUpタスクに変換し、意思決定やフォローアップが会話の流れで埋もれるのを防ぎます
- ClickUp SyncUpsで即座に音声またはビデオ通話に参加し、リアルタイムのインシデント調整やリーダー向けブリーフィングを実施
- 「お知らせ」や更新情報を投稿し、全社に向けてインシデントのステータスを周知する
- チームメイトをタグ付けし、スクリーンショットを共有し、ログを添付ファイルとして添付して、技術的な文脈を常に手元に保ちながらチャットで直接やり取りしましょう。
ステップ6:エスカレーション経路のテスト、監査、改善
エスカレーションポリシーはシステムと共に進化させる必要があります。定期的にやることは以下の通りです:
| アクティビティ | テストまたは確認すべき事項 | 重要性 |
| オンコール訓練(四半期ごと) | P1およびP2インシデントをシミュレートし、エスカレーションのタイミングとルーティングを確認する | プレッシャー下でも自動化とエスカレーション経路が確実に機能することを保証します |
| エスカレーション経路の検証 | 行き止まりのエスカレーションや所有者の不在を確認する | 可視性がないままインシデントが停滞するのを防止します |
| 承認・解決プロセスタイマー | 設定済みタイマーと実際のMTTA(平均対応時間)およびMTTR(平均修復時間)を比較する | エスカレーションのタイミングを現実的かつ効果的に維持します |
| アラート疲労の評価 | 過剰または繰り返しのアラートを受信している対応者を特定する | バーンアウトの軽減と重要なアラートの見逃し防止 |
| 深刻度と優先度の正確性 | インシデントが正しく分類されたかどうかを確認する | ルーティング、応答速度、エスカレーションの精度を向上させます |
| インシデント後のフォローアップ | 振り返り会議で決定したアクションアイテムを確実に完了する | インシデントの再発とシステム障害を防止します |
エスカレーション自動化のためのツールと統合
このセクションでは、インシデント管理ソフトウェアの活用方法をご紹介します。これにより、インシデントの迅速な検知、即時的なルーティング、手動フォローアップなしで全チームの連携維持が可能になります。
1. ClickUp(クロスファンクショナルなエスカレーションを一つの接続されたインシデントワークスペースに統合するのに最適)
従来のエスカレーション手法では、チームは電子メール、スプレッドシート、チャットスレッド、散在するメモを同時に処理せざるを得ず、状況の明確なリアルタイム把握がほぼ不可能となっています。
ClickUpのエスカレーション管理用タスク管理ソフトウェアは、すべてのエスカレーション詳細を単一の整理されたワークスペースに集約することで、不要な情報を排除します。
大量のエスカレーションや複雑なインシデントワークフローを管理するチームにとって、ClickUpが最適な選択肢となるIT資産管理ソフトウェアの機能を見ていきましょう。
自分のやり方で仕事をする
ClickUpビューでタスクを多角的に可視化し、運用ニーズに適合させましょう:
- ClickUpリストビューを活用し、SREリーダーがインシデントを深刻度、SLA残り時間、またはオンコールグループで分類し、迅速なトリアージを実現
- ClickUpボードビューを活用し、エスカレーション時の引き継ぎとチームの所有権をエンジニアリングマネージャーが可視化できるようにします
- プログラムリーダー向けClickUpガントチャートビューで、サービス横断的な解決マイルストーンと依存関係を可視化
- エンジニアがインシデント多発時間帯に過負荷にならないよう確保するオンコールスケジューラー向けClickUpワークロードビュー
ミーティングでの議論を具体的な行動に変える
エスカレーションやインシデントレビューでは、議論内容やアクションアイテムを確実に記録することが課題となる場合があります。ClickUp AI Notetakerは、Google カレンダー、Outlook、Zoom、Teamsで予定されたミーティングに自動的に参加し、会話を録音・文字起こしします。
ミーティング終了後:
- 検索可能な議事録とアクションアイテムの要約にアクセス
- ClickUpドキュメントに保存したメモを活用して明確性を確保。これにより、インシデントタスクや振り返りレポートへのリンクが容易になります
- ClickUp AIに質問して、ミーティングのコンテンツを確認し、意思決定を明確化したり、見落とされたフォローアップを発見したりしましょう。
既存のテクノロジースタック内のツールと接続する
バックエンドでは、ClickUpの統合機能とwebhookエコシステムが、他のシステムとのシームレスな接続を保証します。
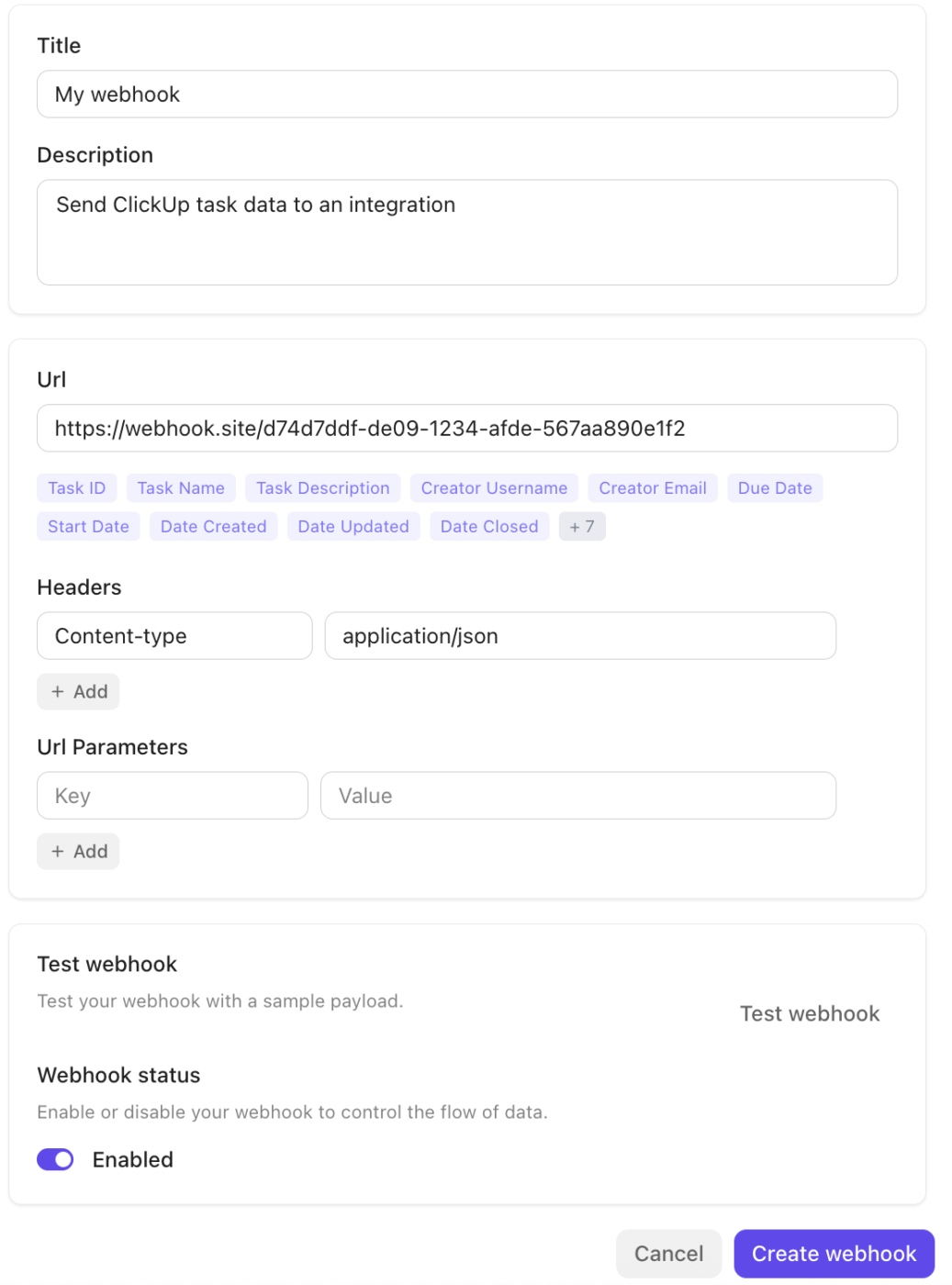
本プラットフォームはSlack、GitHub、Zoomなどのツールとネイティブ連携し、公開API経由のwebhookをサポートすることで、外部サービスや自動化パイプラインへイベント(タスク更新やステータス変更)を配信します。これにより、手動での引き継ぎなしに、ワークフローのトリガー、データの同期、システム横断的なインシデントのエスカレーションを容易に行えます。
すべてのAIツールを統合する
自動化とコンテキストを次のレベルへ引き上げるため、ClickUp BrainGPTはエスカレーションワークフロー全体にコンテキストAIを導入します。タスク、ドキュメント、過去の文脈を理解する、文脈認識型スーパーAIアプリです。
エンタープライズ検索と連携アプリを活用すれば、ワークスペース、Slack、Google Drive、GitHubなどから瞬時に情報を取得できます。インシデント対応中の通話中、ClickUpの「音声入力」機能でエスカレーションメモや指示をハンズフリーで入力可能。重要な情報を見逃す心配がありません。
また、カスタムAIプロンプトや保存済みプロンプトで繰り返しタスクを標準化できます。例:「未解決のインシデントをすべて要約し、エスカレーションアクションを推奨してください。」
ClickUpの主な機能
- 重大な問題を優先:ClickUpタスク優先度機能を活用し、緊急性が高いまたは影響の大きいエスカレーションを強調表示
- 複雑なエスカレーション手順を整理:関連タスク(例:「待機中」や「ブロック中」)をリンクさせるため、ClickUpタスク依存関係を設定し、エスカレーションステップで時期尚早なアクションやボトルネックを回避します
- インシデントを実行可能な単位に分割: エスカレーションを細分化されたアクションアイテムに分解し、ネストサブタスク機能でチーム間へ割り当てます
- 解決速度を正確に追跡:ClickUpのプロジェクト時間追跡機能で、エスカレーションタスクの承認から解決までの所要時間を記録・監視
ClickUpの制限事項
- 機能やビュー、カスタマイズオプションが非常に多いため、チームは直感的に操作できるようになるまでに学習曲線を経験することが多い
ClickUpの料金プラン
[価格表]
ClickUpの評価とレビュー
- G2: 4.7/5 (10,300件以上のレビュー)
- Capterra: 4.6/5 (4,400件以上のレビュー)
実際のユーザーはClickUpについてどう評価しているのか?
このレビューがすべてを物語っています:
ClickUpはタスク、プロジェクト、コミュニケーションを一元管理できるため、整理整頓が驚くほど簡単です。ビューやワークフローからダッシュボードまですべてがカスタマイズ可能な点が気に入っています。必要な通りにワークスペースを構築できるのです。ツールを切り替えずにリアルタイムで共同作業し、タスクを割り当て、進捗を追跡できる機能は大きな強みです。
ClickUpはタスク、プロジェクト、コミュニケーションを一元管理できるため、整理整頓が驚くほど簡単です。ビューやワークフローからダッシュボードまで全てがカスタマイズ可能な点が気に入っています。必要な通りにワークスペースを構築できるのです。ツールを切り替えずにリアルタイムで共同作業し、タスクを割り当て、進捗を追跡できる機能は大きな強みです。
📮 ClickUpインサイト: 回答者の21%が「業務時間の80%以上を反復タスクに費やしている」と回答。さらに20%が「反復タスクに少なくとも40%の時間を消費している」と回答しています。
これは、戦略的思考や創造性をあまり必要としないタスク(フォローアップ電子メールなど👀)に、週の労働時間のほぼ半分(41%)が費やされていることを意味します。
ClickUpのスーパーエージェントがこの煩雑な作業を解消します。タスク作成、リマインダー、更新、ミーティングメモ、電子メール下書き作成、さらにはエンドツーエンドのワークフロー構築まで!これらすべて(そしてそれ以上)が、仕事のための万能アプリClickUpで瞬時に自動化できます。
💫 実証済み結果: Lulu Pressでは、ClickUpの自動化機能により従業員1人あたり1日1時間の時間短縮を実現。これにより仕事の効率が12%向上しました。
2. PagerDuty(リアルタイムアラートとインテリジェントなオンコール対応に最適)
PagerDutyはクラウドベースのITインシデント管理およびデジタルオペレーションプラットフォームであり、サービス停止やセキュリティ脅威などの重大なインシデントを迅速に検知・対応・解決する支援を提供します。SRE、DevOps、サポートリーダーに対し、自動化、AIを活用したトリアージ、深く統合されたワークフローによって支えられた、シグナルから解決までの明確な道筋を提供します。
Jeliインシデント分析、PagerDutyアナリティクス、ランブック自動化といった機能により、チームはダウンタイムの削減、ルーチンタスクの排除、各インシデントからの学習を実現します。
PagerDutyの優れた機能
- 組み込みのオンコール管理と動的なエスカレーションポリシーでインシデントのルーティングを自動化
- AIOpsを活用してトリアージを加速させましょう。アラートのノイズをフィルタリングし、イベントを相関分析し、真のシグナルを強調します。
- ステークホルダー向けコミュニケーション、ステータス更新テンプレート、ステータスページを活用し、社内外のステークホルダー間の連携を強化しましょう。
- 監視、ロギング、CI/CD、サポートシステムを活用し、700以上の統合機能と拡張可能なAPIでツールスタックを統合しましょう。
PagerDutyのリミット
- 統合とスマートしきい値が調整されていない場合、アラート量が急増し、ノイズと疲労を引き起こす
- トラフィック急増時には重複または繰り返しアラートが発生する可能性があり、プレッシャー下での確認作業が困難になる場合があります
PagerDutyの料金体系
- Free
- プロフェッショナル: ユーザーあたり月額25ドル
- Businessプラン: ユーザーあたり月額49ドル
- 企業: カスタム見積もり
PagerDutyの評価とレビュー
- G2: 4.5/5 (900件以上のレビュー)
- Capterra: 4.6/5 (200件以上のレビュー)
実際のユーザーはPagerDutyについてどう評価しているのか?
実際のユーザーの声:
PagerDutyはインシデントアラートを迅速かつ確実に届けます。適切な通知を適切なタイミングで送信し、チームの連携を円滑にします。[…] アラートのフィルタリングが不十分な場合、PagerDutyは時に煩わしく感じられることがあります。一部の設定は新規ユーザーにとってやや複雑です。
PagerDutyはインシデントアラートを迅速かつ確実に届けます。適切な通知を適切なタイミングで送信し、チームの連携を円滑にします。[…] アラートのフィルタリングが不十分な場合、PagerDutyは時に煩わしく感じられることがあります。一部の設定は新規ユーザーにとってやや複雑です。
💡 プロの秘訣: 明確なエスカレーション経路でも例外処理を構築しましょう。重大なサービス停止、セキュリティアラート、規制対象環境のインシデントは、上級担当者や専門対応者へ直接エスカレーションできるようにします。
3. GLPi(エンドツーエンドの資産ガバナンスとITIL準拠のサービス運用に最適)
Gestionnaire Libre de Parc Informatique (GLPi) は、フルスケールのオープンソースITサービス管理(ITSM)およびIT資産管理(ITAM)プラットフォームです。チームはインフラストラクチャ(ハードウェア、ソフトウェア、ライセンス、ネットワーク機器)のエンドツーエンドの可視性を獲得し、ITIL準拠のプロセスを用いてインシデント、サービスリクエスト、変更を管理できます。
保証書やサービス契約を含む全ての契約書と文書は、異なるシステム間で紛失することなく、整然と整理されます。データセンターを管理している場合、GLPiではレイアウト、配線経路、エネルギー使用量を可視化できるため、常にバックエンドの状況を把握できます。
GLPiの主な機能
- GLPI Inventory、OCS Inventory、またはFusionInventoryプラグインを使用して、新しいIT資産を自動的に検出・カタログ化します
- 反復的なタスク、チケット割り当て、通知、定期的なイベントを自動化し、手作業を削減します
- FAQ、ドキュメント、記事のナレッジベースを構築し、チケットにリンクされている状態でセルフサービスと技術者サポートを実現します。
- Azure/Entra、Centreon、Google、OAuth2、webhookと接続し、データを同期、ワークフローをトリガーし、CMDBを強化します。
GLPiの制限事項
- プラグインの互換性はバージョン間で破綻する可能性があり、メンテナンスのオーバーヘッドを引き起こします
- レポート作成、分析、エクスポート機能はリミットを感じさせ、改善が必要です
GLPiの価格設定
- カスタム価格設定
GLPiの評価とレビュー
- G2: 4.6/5 (30件以上のレビュー)
- Capterra: 4.5/5 (40件以上のレビュー)
GLPiについて実際のユーザーはどのように評価しているのか?
あるユーザーはこう語っています:
大規模なサポートコミュニティを有する、高度にカスタマイズ可能なオープンソースのIT資産管理&サポートチケットシステム。ユーザーインターフェースは初心者にはやや複雑です。プラグインは旧バージョンから新バージョンへ常に互換性が保証されるわけではありません。
大規模なサポートコミュニティを有する、高度にカスタマイズ可能なオープンソースのIT資産管理&サポートチケットシステム。ユーザーインターフェースは初心者にはやや複雑です。プラグインは旧バージョンから新バージョンへ常に互換性が保証されるわけではありません。
4. Splunk On-Call(監視アラートをエンジニアに直接ルーティングするのに最適)
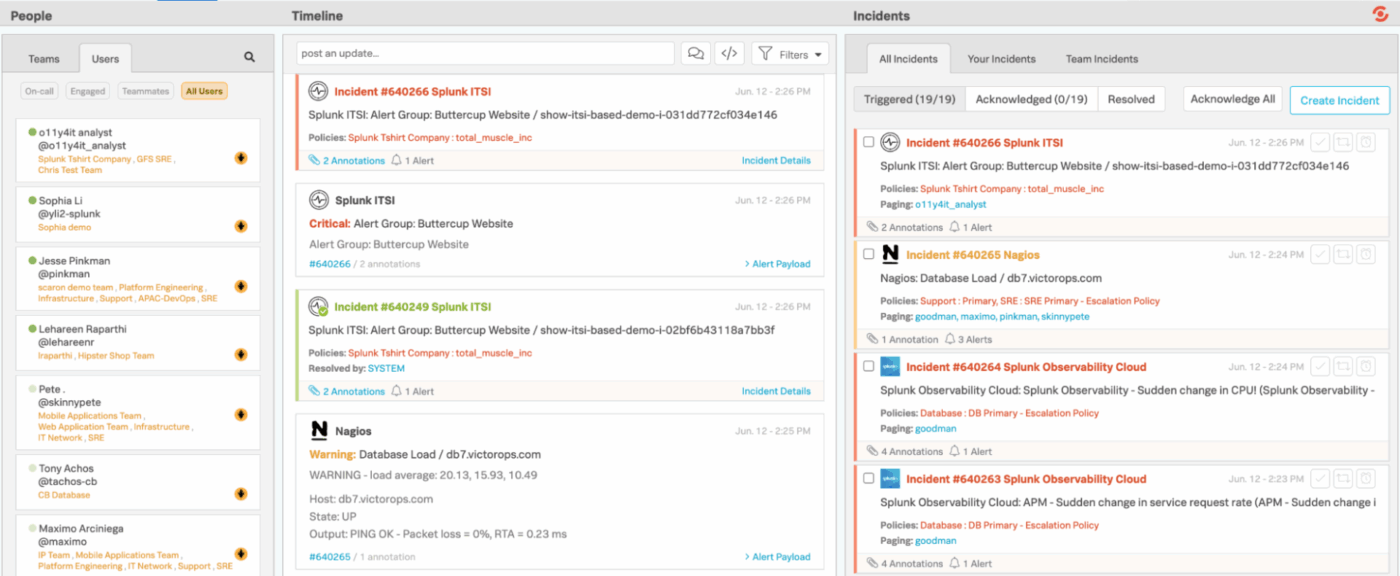
Splunk On-Callは、エンジニアリングチームやオンコールチームに、インシデント管理をより迅速かつ効率的に行う手段を提供し、従来の遅延を伴うチケット処理ワークフローを不要にします。アラートを汎用的なキューに投入する代わりに、監視および可観測性スタックと直接連携し、スケジュール、ルール、コンテキストに基づいて問題を即座に適切な担当者にルーティングします。
モバイルおよびチャット統合により、どこからでもインシデントの受理、再ルーティング、解決が容易になります。また、バックグラウンドではSplunk On-Callが傾向、実績のあるパターン、エスカレーションの挙動に関する詳細な記録を保持します。
Splunk On-Call の主な機能
- Splunkおよび広範なコミュニティから提供される1,000以上の検証済み統合機能とアドオンを活用し、プラットフォームの機能を拡張します。
- カスタムダッシュボードと視覚的レポートを構築し、アラート量、インシデントの状態、対応者のパフォーマンス、チームの作業負荷を監視します。
- 自身のアクティビティ、チームのインシデント、または組織全体で発生しているすべての事象に基づいて、インシデントを素早くフィルタリングします。
- トリガー済み、確認済み、解決済みビューを切り替えて、各インシデントの進捗状況を確認できます
Splunk On-Call のリミット
- 複数のチームにまたがるシフトのスケジュール設定は、ルールが事前に定義されていないと複雑になる可能性があります
- 詳細な日付別インシデントレポートを生成する機能が限定的
Splunk On-Call の価格設定
- カスタム価格設定
Splunk On-Callの評価とレビュー
- G2: 4.6/5 (40件以上のレビュー)
- Capterra: 4.5/5 (30件以上のレビュー)
Splunk On-Callについて、実際のユーザーはどのように評価しているのでしょうか?
あるユーザーはこう要約しています:
モバイルアプリからインシデント対応やエスカレーション処理、チームメイトの当直引き継ぎができるのは素晴らしい。[…]緊急のスケジュール変更時には、モバイルアプリからオーバーライドのスケジュール設定や通常スケジュールの変更ができるようにしてほしい。
モバイルアプリからインシデント対応やエスカレーション処理、チームメイトの当直引き継ぎができるのは素晴らしい。[…]緊急のスケジュール変更時に、モバイルアプリからオーバーライドのスケジュール設定や通常スケジュールの変更ができるようになりたい。
🔍 ご存知でしたか? 「一次対応者が失敗した場合に適切な担当者に転送する」というロジックは、初期の電話交換機に起源があります。手動オペレーターが通話を接続できなかった場合、システムは別のオペレーターや交換局へ転送(またはエスカレーション)したのです。
5. ServiceNow(AI支援型自動化による企業規模のオーケストレーションに最適)
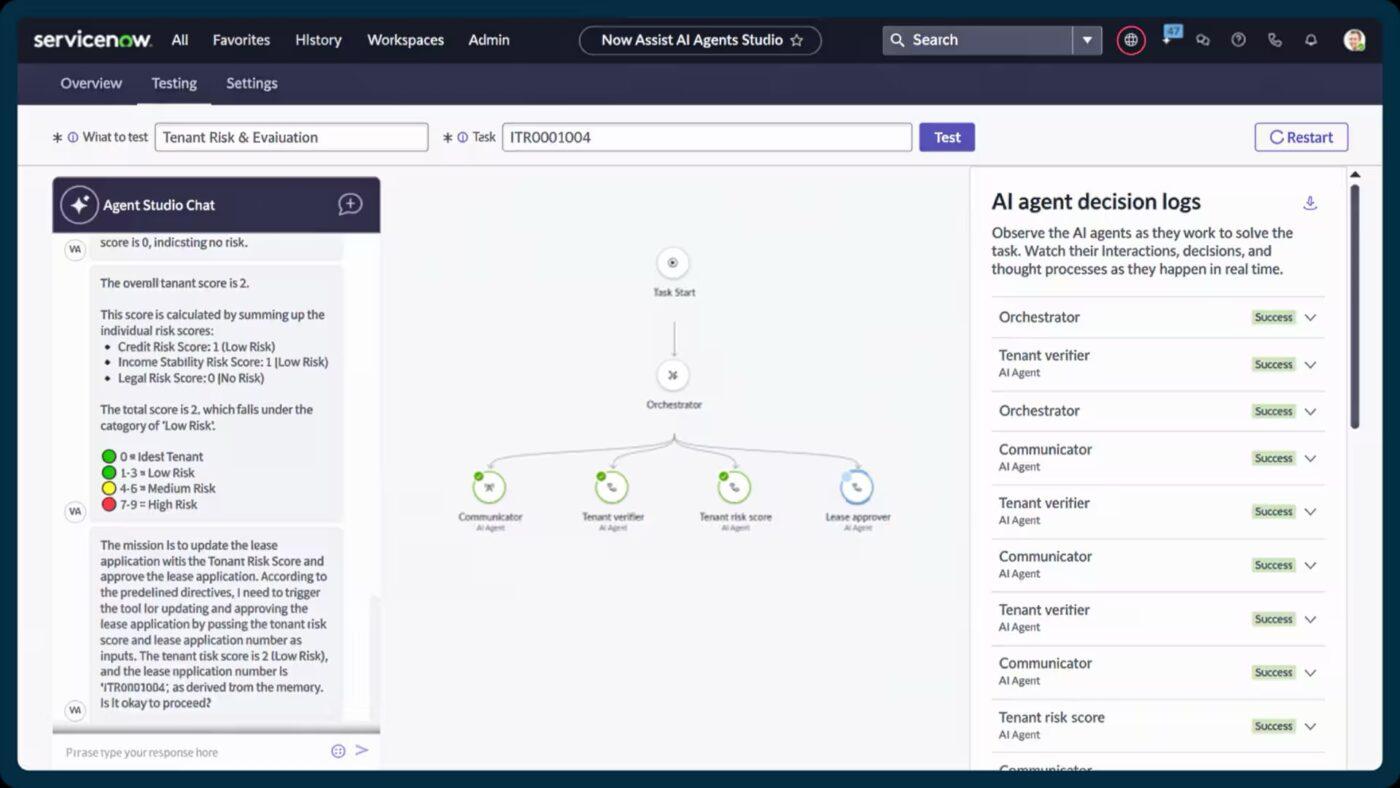
ServiceNowはインシデントが記録された瞬間に自動的に分類、優先順位付け、ルーティングを行います。自動化されたインシデントチケットの推奨やスマートコンテンツ生成を実現するNow Assistなどの機能により、対応担当者はより多くのコンテキストを把握しながら問題を迅速に解決できます。
インシデント管理、変更管理、資産管理を統合します。これにより、サービス間の接続状況、ボトルネックの発生箇所、再発障害の原因となり得るコンポーネントのリアルタイムビューを把握できます。
ServiceNowの優れた機能
- フィールドサービス管理とディスパッチャーワークスペースを通じて、フィールドタスクの割り当て、ルーティング、監視を行います。
- AI検索とバーチャルエージェントを活用したセルフサービスポータルで、従業員と顧客のエンパワーメントを実現
- App Engineの組み込みワークフローとローコードツールを活用し、サービスプロセスを拡張またはカスタムします
- Flow DesignerとAutomation Engineで、チーム横断的な反復タスクとワークフローを自動化しましょう
ServiceNowのリミット
- UIとポータルのブランディングオプションは時代遅れか制限的だと感じられる
- 実装において熟練した人材やコンサルタントとの依存関係が強い
ServiceNowの価格設定
- カスタム価格設定
ServiceNowの評価とレビュー
- G2: 4. 4/5 (3,300件以上のレビュー)
- Capterra: 4.5/5 (300件以上のレビュー)
ServiceNowについて、実際のユーザーはどのように評価しているのでしょうか?
あるユーザーはこう述べています:
[…] 事前構築済みのフローは私にとってもう一つの強みです。プロセスを合理化し大幅な時間節約を実現するため、カスタム設定の必要性を最小限に抑え、よりスムーズで効率的なワークフローを可能にします。[…] さらに、カスタマーサービス管理システムに独自ソリューションを組み込む際に困難が生じ、かなりの反復作業が必要でした。
[…] 事前構築済みのフローは私にとってもう一つの強みです。プロセスを合理化し大幅な時間節約を実現するため、カスタム設定の必要性を最小限に抑え、よりスムーズで効率的なワークフローを可能にします。[…] さらに、カスタマーサービス管理システムに独自ソリューションを組み込む際に困難が生じ、かなりの反復作業が必要でした。
ベストプラクティスとガバナンス
自動化を正確に維持し、アラート疲労を回避し、ビジネスおよび規制上の期待に沿うためのベストプラクティスを以下に示します。
- 必須のエスカレーション基準を定義する:トリガーをSLO違反、異常値の急増、顧客階層への影響、規制上の機密性といった測定可能な指標に紐付ける
- 各階層で役割を明確化: 各エスカレーションレベルにシンプルなRACIマップを活用し、プレッシャーの高いインシデント発生時にも責任範囲が曖昧にならないようにする
- 動的なオンコール管理の徹底:週末・休日・キャパシティリミット・引き継ぎ時におけるエスカレーション経路の自動調整により、バーンアウトを軽減しサイレントページングを防止
- 高リスクシナリオへの人的チェックポイント導入:自動化を実施する場合でも、顧客データの漏洩、支払い、規制対象ワークフローに関連するインシデントについては、必ず手動での承認を義務付けます。
- 完全な監査証跡を維持:誰が通知を受け、いつ応答したか、どの自動化ステップが実行され、どのような決定がなされたかを不変のログとして記録します
🧠 豆知識:世界最古の文書による苦情は紀元前1750年頃に粘土板に刻まれたものです。これは初期のプロジェクトステータスエスカレーションと言えるもので、顧客のナンニが商人イーナシル宛に書いたものでした。彼は受け取った銅の品質が約束より劣っていたこと、そして使いの者が粗末に扱われたことに激怒していました。
よくある課題とその克服方法
明確なエスカレーション方針があっても、チームはしばしば運用上の障害に直面し、インシデント対応が遅れたり混乱が生じたりします。
このテーブルでは、基本的なセットアップステップを超えた一般的な課題を強調し、それらを克服するための実践的な戦略を提供します。
| 課題 ❌ | ソリューション ✅ |
| 引き継ぎ時のコンテキストの不整合 | ClickUpのタスク連携機能とインシデント報告テンプレートを活用し、各エスカレーションレベルにおけるインシデントの詳細、影響を受けたシステム、過去の対応履歴を完全に監査可能な形で記録します。 |
| 低優先度のアラートで対応者を過負荷状態に陥らせない | ClickUpカスタムフィールドとAI優先順位付け機能を活用した動的優先順位付けを実装し、深刻度、影響度、SLA閾値に基づいてインシデントをフィルタリングします。 |
| チーム間の可視性の欠如 | 共有ワークスペースを設定し、コメントを追加し、視覚的なClickUpホワイトボードを作成して、関係者にリアルタイムの更新情報を提示しましょう。 |
| 重大なインシデント発生時の意思決定遅延 | ClickUp Brain Maxの推奨アクションを活用し、インシデントの種類・深刻度・過去のパターンに基づいて適切な担当者に即時通知する自動化を実現します。 |
| 再発する問題の追跡が困難 | ClickUpのカスタムレポート作成と定期的なタスクテンプレートを活用し、パターンや根本原因を特定し、再発インシデントをプロアクティブに防止しましょう。 |
| エスカレーション時の断片化された知識 | ClickUp Docsで標準手順書(SOP)、ランブック、インシデントドキュメントを一元管理し、関連タスクにリンクさせることで、エスカレーション発生時に即座に参照可能にします。 |
| シフト間の責任の非整合 | ClickUpのワークロードビューとタイムラインビューを活用し、割り当てを可視化。シフト交代時や引き継ぎ時の重複や手落ちを防止します。 |
| 手動によるコンプライアンス追跡と監査のギャップ | ClickUp Brainで監査対応可能な要約を自動生成し、インシデントの全アクション・通知・解決内容を記録 |
自動化によるエスカレーションの効果測定
自動化されたエスカレーションの効果を追跡するには、量・効率・品質にわたる主要メトリクスに焦点を当てる必要があります。これらのメトリクスは、エスカレーションプロセスがより迅速で正確になり、チームと顧客の双方にとってストレスが軽減されているかを明らかにします。
以下のメトリクスを追跡してください:
- エスカレーション率(件数): 最初の対応レベルを超えてエスカレーションされた問題の割合。高い率は、初期トリアージやナレッジベースの不足を示している可能性があります。
- 再エスカレーション率(件数): 同一の問題が複数回エスカレーションされる頻度。不完全な解決や文脈の喪失を示唆します。
- エスカレーションまでの期間(効率性): 検知からエスカレーションまでの期間。各フェーズの期間が短いほど、重大な問題の自動認識が迅速に行われていることを示します。
- 引き継ぎ遅延時間(効率性): エスカレーションから次のチームが仕事を開始するまでの間隔。ルーティングや通知の摩擦を可視化します。
- エスカレーションされたケースの解決時間(効率性): エスカレーションから解決までの総時間。解決時間の短縮は自動化の有効性を示す
- 顧客満足度(CSAT)スコア(品質): エスカレーションされた対応に関するフィードバック。経路の円滑さを測定します。
- コンテキストパススルー(品質):エージェントがインシデントの完全な履歴を受け取り、顧客が情報を繰り返し説明する必要がないようにするかどうか
- 初回対応解決率(FCR)(品質指標): 単一の対応で解決された問題の割合
🚀 ClickUpの優位性:ClickUpダッシュボードで、すべてのエスカレーションメトリクスをリアルタイムかつ視覚的に、AIを活用したインサイトとして把握できます。
テーブル、円グラフ、棒グラフ、折れ線グラフ、計算、時間レポートカードでエスカレーションの傾向、ボトルネック、パフォーマンスを追跡できます。タスク、カスタムフィールド、ステータスにリンクされているカードで、エスカレーション率、再エスカレーション、エスカレーションまでの時間も監視可能です。
さらに一歩進めるには、AIエグゼクティブ要約、AIプロジェクトアップデート、AIスタンドアップなどのAIカードを活用し、傾向、遅延、解決結果を可視化しましょう。
ClickUpでインシデント管理を高速化
多くの人がインシデントエスカレーションを単なるチケットの引き継ぎと考えていますが、実際にはそれ以上のものです。トリアージから解決に至るまでの各ステップが調和して機能する体系的なシステムなのです。
ClickUpは理想的な統合ワークスペースを提供します。ClickUp Automationsを使えば、アラートのトリガー、タスクのルーティング、ステータスの更新を自動化できます。さらにClickUp Brainはインシデントの優先順位付け、要約生成、次のアクションの提案を支援します。
ClickUp AIエージェントはワークスペース内で知的なアシスタントとして機能し、ClickUpダッシュボードではエスカレーション状況をリアルタイムで可視化します。
よくある質問(FAQ)
インシデントエスカレーションパスとは、深刻度、影響範囲、発生タイミングに基づいて問題を適切なチームや担当者に確実に振り分けるための、事前に定義されたステップの連鎖です。これによりインシデントが効率的に処理され、責任の所在が明確になります。
明確な基準(例:サービス停止、セキュリティ侵害)が設定された優先度の高いインシデントには自動化を活用します。人間の判断や追加の文脈が必要な曖昧な状況や重大な状況には、手動でのエスカレーションを留保します。
ClickUp、PagerDuty、Jira Service Management、ServiceNowなどのプラットフォームでは、自動ルーティング、通知、更新が可能です。これらはチームの遅延削減と構造化されたインシデントワークフローの維持を支援します。
アラートの明確な閾値を設定し、深刻度で優先順位付けを行い、インテリジェント通知を活用します。重大なインシデントにのみ通知を集中させ、ダッシュボードやAIツールを活用して更新情報を要約し、些細な変更を逐一送信しないようにします。
エスカレーションポリシーは少なくとも四半期ごと、または重大なインシデント発生後に定期的に見直してください。これにより、基準、責任範囲、自動化ルールが現在のワークフロー、チーム構成、ビジネスの優先度を反映していることが保証されます。