
A maioria dos projetos de implantação de IA falha não porque as equipes escolheram o modelo errado, mas porque ninguém consegue se lembrar, três meses depois, por que o escolheram ou como replicar a configuração, com 46% dos projetos de IA descartados entre a prova de conceito e a adoção ampla.
Este guia orienta você sobre como usar o Hugging Face para implantação de IA — desde a seleção e o teste de modelos até o gerenciamento do processo de implantação — para que sua equipe possa entregar mais rapidamente sem perder decisões críticas em threads do Slack e planilhas dispersas.
O que é o Hugging Face?
O Hugging Face é uma plataforma de código aberto e um centro comunitário que fornece modelos de IA pré-treinados, conjuntos de dados e ferramentas para criar e implantar aplicativos de aprendizado de máquina.
Pense nisso como uma enorme biblioteca digital onde você pode encontrar modelos de IA prontos para uso, em vez de gastar meses e recursos significativos para criá-los do zero.
Ele foi projetado para engenheiros de aprendizado de máquina e cientistas de dados, mas suas ferramentas são cada vez mais utilizadas por equipes multifuncionais de produto, design e engenharia para integrar IA em seus fluxos de trabalho.
Você sabia? 63% das organizações não possuem práticas adequadas de gerenciamento de dados para IA. Isso muitas vezes leva ao atraso de projetos e ao desperdício de recursos.
O principal desafio para muitas equipes é a enorme complexidade da implantação de IA. O processo envolve selecionar o modelo certo entre milhares de opções, gerenciar a infraestrutura subjacente, controlar as versões dos experimentos e garantir que as partes interessadas técnicas e não técnicas estejam alinhadas.
O Hugging Face simplifica isso fornecendo seu Model Hub, um repositório central com mais de 2 milhões de modelos. A biblioteca de transformadores da plataforma é a chave que desbloqueia esses modelos, permitindo que você os carregue e use com apenas algumas linhas de código Python.
No entanto, mesmo com essas ferramentas poderosas, a implantação de IA continua sendo um desafio de gerenciamento de projetos, exigindo um acompanhamento cuidadoso da seleção, teste e lançamento do modelo para garantir o sucesso.
📮ClickUp Insight: 92% dos profissionais do conhecimento correm o risco de perder decisões importantes espalhadas por chats, e-mails e planilhas. Sem um sistema unificado para capturar e rastrear decisões, insights críticos de negócios se perdem no ruído digital.
Com os recursos de gerenciamento de tarefas do ClickUp, você nunca precisará se preocupar com isso. Crie tarefas a partir de bate-papos, comentários de tarefas, documentos e e-mails com um único clique!
Modelos Hugging Face que você pode implantar
Navegar pelo Hugging Face Hub pode parecer complicado quando você está começando. Com centenas de milhares de modelos, o segredo é entender as principais categorias para encontrar o modelo certo para o seu projeto. Os modelos variam de opções pequenas e eficientes, projetadas para uma única finalidade, a modelos enormes e de uso geral, capazes de lidar com raciocínios complexos.
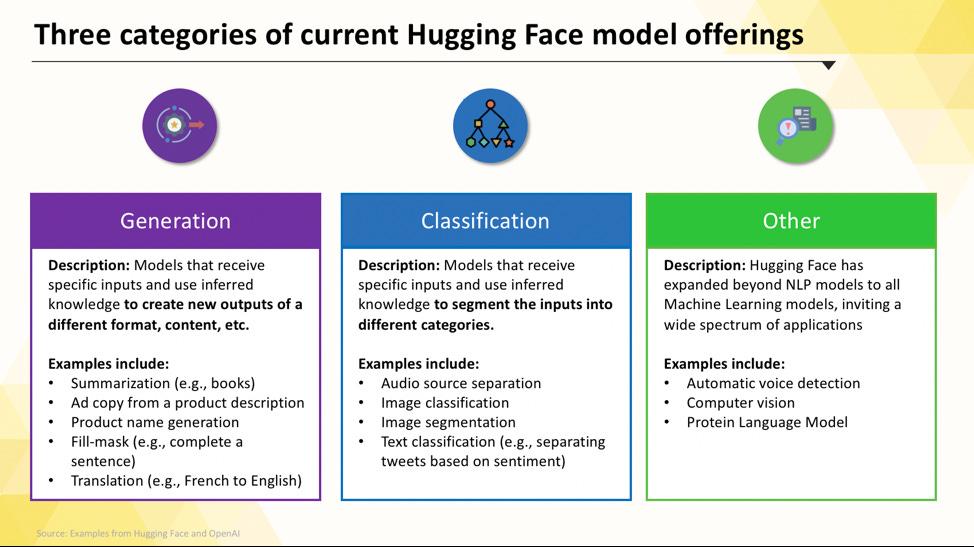
Modelos de linguagem específicos para tarefas
Quando sua equipe precisa resolver um único problema bem definido, muitas vezes você não precisa de um modelo enorme e de uso geral. O tempo e o custo para executar esse tipo de modelo podem ser proibitivos, especialmente quando uma ferramenta de IA menor e mais focada funcionaria melhor. É aí que entram os modelos específicos para tarefas.
Esses são modelos que foram treinados e otimizados para uma função específica. Por serem especializados, eles geralmente são menores, mais rápidos e mais eficientes em termos de recursos do que seus equivalentes maiores.
Isso os torna ideais para ambientes de produção onde velocidade e custo são fatores importantes. Muitos podem até mesmo ser executados em hardware de CPU padrão, tornando-os acessíveis sem GPUs caras.
Os tipos comuns de modelos específicos para tarefas incluem:
- Classificação de texto: use isso para categorizar textos em rótulos predefinidos, como classificar o feedback dos clientes em categorias “positivas” ou “negativas” ou marcar tickets de suporte por tópico.
- Análise de sentimentos: ajuda a determinar o tom emocional de um texto, o que é útil para monitorar marcas nas redes sociais.
- Reconhecimento de entidades nomeadas: extraia entidades específicas, como pessoas, lugares e organizações, de documentos para ajudar a estruturar dados não estruturados.
- Resumo: Condense artigos ou relatórios longos em resumos concisos, economizando um tempo valioso de leitura para sua equipe.
- Tradução: Converta texto de um idioma para outro automaticamente
📚 Leia também: Como usar o Hugging Face para resumo de texto
Modelos de linguagem grandes
Às vezes, seu projeto requer mais do que apenas classificação ou resumo simples. Você pode precisar de uma IA que possa gerar textos de marketing criativos, escrever códigos ou responder a perguntas complexas dos usuários de maneira coloquial. Para esses cenários, você provavelmente recorrerá a um modelo de linguagem grande (LLM).
LLMs são modelos com bilhões de parâmetros treinados em grandes quantidades de texto e dados da internet. Esse treinamento extensivo permite que eles compreendam nuances, contexto e raciocínios complexos. LLMs populares de código aberto disponíveis no Hugging Face incluem modelos das famílias Llama, Mistral e Falcon.
A desvantagem desse poder é a quantidade significativa de recursos computacionais necessários. A implantação desses modelos quase sempre requer GPUs potentes com muita memória (VRAM).
Para torná-los mais acessíveis, você pode usar técnicas como quantização, que reduz o tamanho do modelo com um pequeno custo em desempenho, permitindo que ele seja executado em hardware menos potente.
📚 Leia também: O que são agentes LLM em IA e como eles funcionam?
Modelos de texto para imagem e multimodais
Seus dados nem sempre são apenas texto. Sua equipe pode precisar gerar imagens para uma campanha de marketing, transcrever áudio de uma reunião ou entender o conteúdo de um vídeo. É aí que os modelos multimodais, projetados para funcionar com diferentes tipos de dados, se tornam essenciais.
O tipo mais popular de modelo multimodal é o modelo de texto para imagem, que gera imagens a partir de uma descrição textual. Modelos como o Stable Diffusion usam uma técnica chamada difusão para criar visuais impressionantes a partir de prompts simples. Mas as possibilidades vão muito além da geração de imagens.
Outros modelos multimodais comuns que você pode implantar a partir do Hugging Face incluem:
- Legenda de imagem: gere automaticamente textos descritivos para imagens, o que é ótimo para acessibilidade e gerenciamento de conteúdo.
- Reconhecimento de voz: transcreva áudio falado em texto escrito com modelos como o Whisper da OpenAI.
- Resposta visual a perguntas: faça perguntas sobre uma imagem e obtenha uma resposta em texto, como “Qual é a cor do carro nesta foto?”
Assim como os LLMs, esses modelos exigem muitos recursos computacionais e normalmente requerem uma GPU para funcionar com eficiência.
Para ver como esses diferentes tipos de modelos de IA se traduzem em aplicações comerciais práticas, assista a esta visão geral de casos de uso de IA no mundo real em vários setores e funções.
Qual é o nível de maturidade da IA da sua organização?
Nossa pesquisa com 316 profissionais revela que a verdadeira transformação da IA requer mais do que apenas adotar recursos de IA. Faça a avaliação de maturidade da IA para ver onde sua organização se encontra e o que você pode fazer para melhorar sua pontuação.
Como configurar o Hugging Face para implantação de IA
Antes de implantar seu primeiro modelo, você precisa configurar corretamente seu ambiente local e sua conta Hugging Face. É comum que as equipes fiquem frustradas quando diferentes membros têm configurações inconsistentes, levando ao clássico problema “funciona na minha máquina”. Dedicar alguns minutos para padronizar esse processo economiza horas de solução de problemas posteriormente.
- Crie uma conta no Hugging Face e gere um token de acesso. Primeiro, cadastre-se para obter uma conta gratuita no site do Hugging Face. Depois de fazer login, acesse seu perfil, clique em “Configurações” e vá para a guia “Tokens de acesso”. Gere um novo token com pelo menos permissões de “leitura”; você precisará dele para baixar modelos.
- Instale as bibliotecas Python necessárias. Abra seu terminal e instale as bibliotecas principais de que você precisará. As duas essenciais são transformers e huggingface_hub. Você pode instalá-las usando o pip: pip install transformers huggingface_hub
- Configure a autenticação. Para usar seu token de acesso, você pode fazer login pela linha de comando executando o comando huggingface-cli login e colando seu token quando solicitado, ou pode defini-lo como uma variável de ambiente em seu sistema. O login pela linha de comando costuma ser a maneira mais fácil de começar.
- Verifique a configuração. A melhor maneira de confirmar se tudo está funcionando é executar um código simples. Tente carregar um modelo básico usando a função pipeline da biblioteca transformers. Se ele for executado sem erros, você está pronto para começar.
Lembre-se de que alguns modelos no Hub são “restritos”, o que significa que você deve concordar com os termos de licença na página do modelo antes de poder acessá-los com seu token.
Além disso, lembre-se de que rastrear quem tem quais credenciais e quais configurações de ambiente estão sendo usadas é uma tarefa de gerenciamento de projeto em si, e isso se torna mais crítico à medida que sua equipe cresce.
🌟 Se você estiver integrando modelos Hugging Face em sistemas de software mais amplos, o modelo de integração de software do ClickUp ajuda a visualizar fluxos de trabalho e acompanhar integrações técnicas em várias etapas.
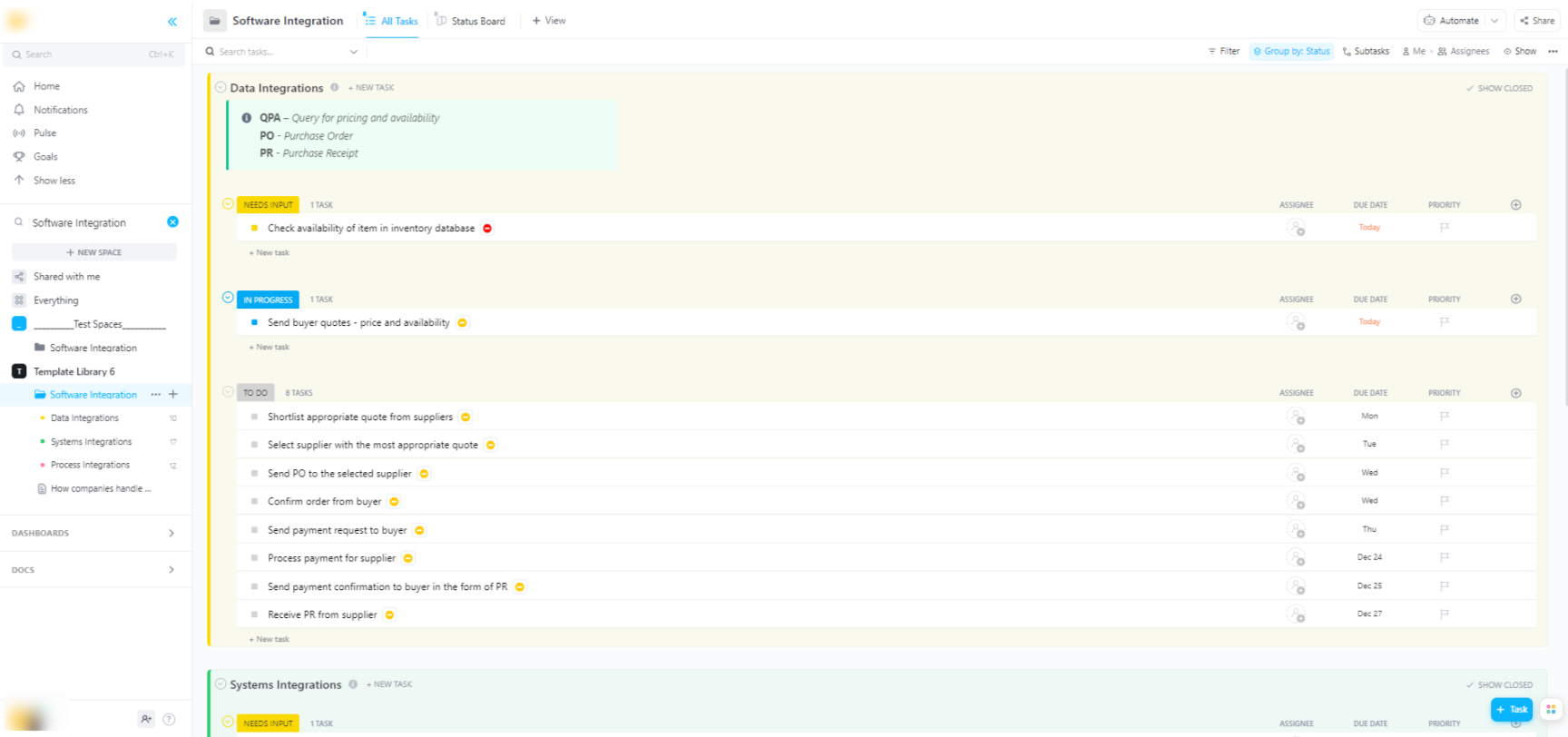
O modelo fornece um sistema fácil de seguir, no qual você pode:
- Visualize as conexões entre diferentes soluções de software
- Crie e atribua tarefas aos membros da equipe para uma colaboração mais tranquila.
- Organize todas as tarefas relacionadas à integração em um único lugar
Opções de implantação para modelos Hugging Face
Depois de testar um modelo localmente, a próxima pergunta é: onde ele ficará? Implantar um modelo em um ambiente de produção onde ele possa ser usado por outras pessoas é uma etapa crítica, mas as opções podem ser confusas. Escolher o caminho errado pode levar a um desempenho lento, custos altos ou incapacidade de lidar com o tráfego de usuários.
Sua escolha dependerá de suas necessidades específicas, como tráfego esperado, orçamento e se você está criando um protótipo rápido ou um aplicativo escalável e pronto para produção.
Espaços Hugging Face
Se você precisa criar rapidamente uma demonstração ou uma ferramenta interna, o Hugging Face Spaces costuma ser a melhor opção. O Spaces é uma plataforma gratuita para hospedar aplicativos de aprendizado de máquina e é perfeito para criar protótipos que você pode compartilhar com sua equipe ou partes interessadas.
Você pode criar a interface do usuário do seu aplicativo usando frameworks populares como Gradio ou Streamlit, o que facilita a criação de demonstrações interativas com apenas algumas linhas de Python.
Criar um Espaço é tão simples quanto selecionar seu SDK preferido, conectar um repositório Git com seu código e escolher seu hardware. Embora o Spaces ofereça um nível de CPU gratuito para aplicativos básicos, você pode atualizar para hardware GPU pago para modelos mais exigentes.
Tenha em mente as limitações:
- Não é adequado para APIs de alto tráfego: o Spaces foi projetado para demonstrações, não para atender a milhares de solicitações simultâneas de API.
- Inicializações a frio: se o seu Espaço estiver inativo, ele poderá “entrar em modo de suspensão” para economizar recursos, causando um atraso para o primeiro usuário que acessá-lo novamente.
- Fluxo de trabalho baseado em Git: todo o código do seu aplicativo é gerenciado por meio de um repositório Git, o que é ótimo para controle de versão.
API de inferência do Hugging Face
Quando você precisar integrar um modelo a um aplicativo existente, provavelmente desejará usar uma API. A API Hugging Face Inference permite executar modelos sem precisar gerenciar nenhuma infraestrutura subjacente. Basta enviar uma solicitação HTTP com seus dados e obter uma previsão.
Essa abordagem é ideal quando você não quer lidar com servidores, dimensionamento ou manutenção. O Hugging Face oferece dois níveis principais para este serviço:
- API de inferência gratuita: esta é uma opção de infraestrutura compartilhada com taxa limitada, ideal para desenvolvimento e testes. É perfeita para casos de uso com baixo tráfego ou quando você está apenas começando.
- Pontos finais de inferência: para aplicações de produção, você vai querer usar pontos finais de inferência. Este é um serviço pago que fornece uma infraestrutura dedicada e com autoescala, garantindo que sua aplicação seja rápida e confiável, mesmo sob carga pesada.
O uso da API envolve o envio de uma carga JSON para a URL do endpoint do modelo com seu token de autenticação no cabeçalho da solicitação.
Implantação em plataforma na nuvem
Para equipes que já têm uma presença significativa em um grande provedor de nuvem, como Amazon Web Services (AWS), Google Cloud Platform (GCP) ou Microsoft Azure, a implantação nessas plataformas pode ser a escolha mais lógica. Essa abordagem oferece maior controle e permite integrar o modelo aos serviços em nuvem e protocolos de segurança existentes.
O fluxo de trabalho geral envolve “containerizar” seu modelo e suas dependências usando o Docker e, em seguida, implantar esse contêiner em um serviço de computação em nuvem. Cada provedor de nuvem tem serviços e integrações que simplificam esse processo:
- AWS SageMaker: oferece integração nativa para treinamento e implantação de modelos Hugging Face.
- Google Cloud Vertex AI: permite que você implante modelos do Hub em terminais gerenciados.
- Azure Machine Learning: fornece ferramentas para importar e servir modelos Hugging Face.
Embora esse método exija mais configuração e conhecimento em DevOps, ele costuma ser a melhor opção para implantações em grande escala e de nível empresarial, nas quais você precisa ter controle total sobre o ambiente.
📚 Leia também: Automação de fluxo de trabalho: automatize fluxos de trabalho para aumentar a produtividade
Como executar modelos Hugging Face para inferência
Ao usar o Hugging Face para implantação de IA, “executar inferência” é o processo de usar seu modelo treinado para fazer previsões sobre dados novos e inéditos. É o momento em que seu modelo faz o trabalho para o qual você o implantou. Acertar nessa etapa é crucial para construir um aplicativo responsivo e eficiente.
A maior frustração para as equipes é escrever código de inferência lento ou ineficiente, o que pode levar a uma experiência ruim para o usuário e altos custos operacionais. Felizmente, a biblioteca transformers oferece várias maneiras de executar a inferência, cada uma com suas próprias vantagens e desvantagens entre simplicidade e controle.
- API Pipeline: esta é a maneira mais fácil e comum de começar. A função pipeline() abstrai a maior parte da complexidade, lidando com o pré-processamento de dados, o encaminhamento do modelo e o pós-processamento para você. Para muitas tarefas padrão, como análise de sentimentos, você pode obter uma previsão com apenas uma linha de código.
- AutoModel + AutoTokenizer: quando você precisar de mais controle sobre o processo de inferência, poderá usar as classes AutoModel e AutoTokenizer diretamente. Isso permite que você lide manualmente com a forma como seu texto é tokenizado e como a saída bruta do modelo é convertida em uma previsão legível por humanos. Essa abordagem é útil quando você está trabalhando com uma tarefa personalizada ou precisa implementar uma lógica específica de pré ou pós-processamento.
- Processamento em lote: para maximizar a eficiência, especialmente em uma GPU, você deve processar as entradas em lotes, em vez de uma por uma. Enviar um lote de entradas através do modelo em uma única passagem é significativamente mais rápido do que enviar cada uma individualmente.
Monitorar o desempenho do seu código de inferência é uma parte fundamental do ciclo de vida da implantação. Acompanhar métricas como latência (quanto tempo leva uma previsão) e rendimento (quantas previsões você pode fazer por segundo) requer coordenação e documentação clara, especialmente quando diferentes membros da equipe experimentam novas versões do modelo.
Exemplo passo a passo: implantar um modelo Hugging Face
Vamos examinar um exemplo completo de implantação de um modelo simples de análise de sentimentos. Seguir estas etapas levará você da escolha de um modelo a um endpoint ativo e testável.
- Selecione seu modelo: acesse o Hugging Face Hub e use os filtros à esquerda para pesquisar modelos que realizam “Classificação de texto”. Um bom ponto de partida é o distilbert-base-uncased-finetuned-sst-2-english. Leia o cartão do modelo para entender seu desempenho e como usá-lo.
- Instale as dependências: em seu ambiente Python local, certifique-se de ter as bibliotecas necessárias instaladas. Para este modelo, você só precisará do transformers e do torch. Execute pip install transformers torch
- Teste localmente: antes de implantar, sempre certifique-se de que o modelo funcione conforme o esperado em sua máquina. Escreva um pequeno script Python para carregar o modelo usando o pipeline e teste-o com uma frase de exemplo. Por exemplo: classificador = pipeline("sentiment-analysis", modelo="distilbert-base-uncased-finetuned-sst-2-english") seguido por classificador("ClickUp é a melhor plataforma de produtividade!")
- Crie uma implantação: para este exemplo, usaremos o Hugging Face Spaces para uma implantação rápida e fácil. Crie um novo espaço, selecione o Gradio SDK e crie um arquivo app.py que carregue seu modelo e defina uma interface Gradio simples para interagir com ele.
- Verifique a implantação: assim que seu Space estiver em execução, você poderá usar a interface interativa para testá-lo. Você também pode fazer uma solicitação direta de API ao endpoint do Space para obter uma resposta JSON, confirmando que ele está funcionando programaticamente.
Após essas etapas, você terá um modelo ativo. A próxima fase do projeto envolverá monitorar seu uso, planejar atualizações e, potencialmente, dimensionar a infraestrutura se ele se tornar popular.
Para equipes que gerenciam projetos complexos de implantação de IA com várias fases — desde a preparação de dados até a implantação em produção —, o Modelo Avançado de Gerenciamento de Projetos de Software da ClickUp oferece uma estrutura abrangente.
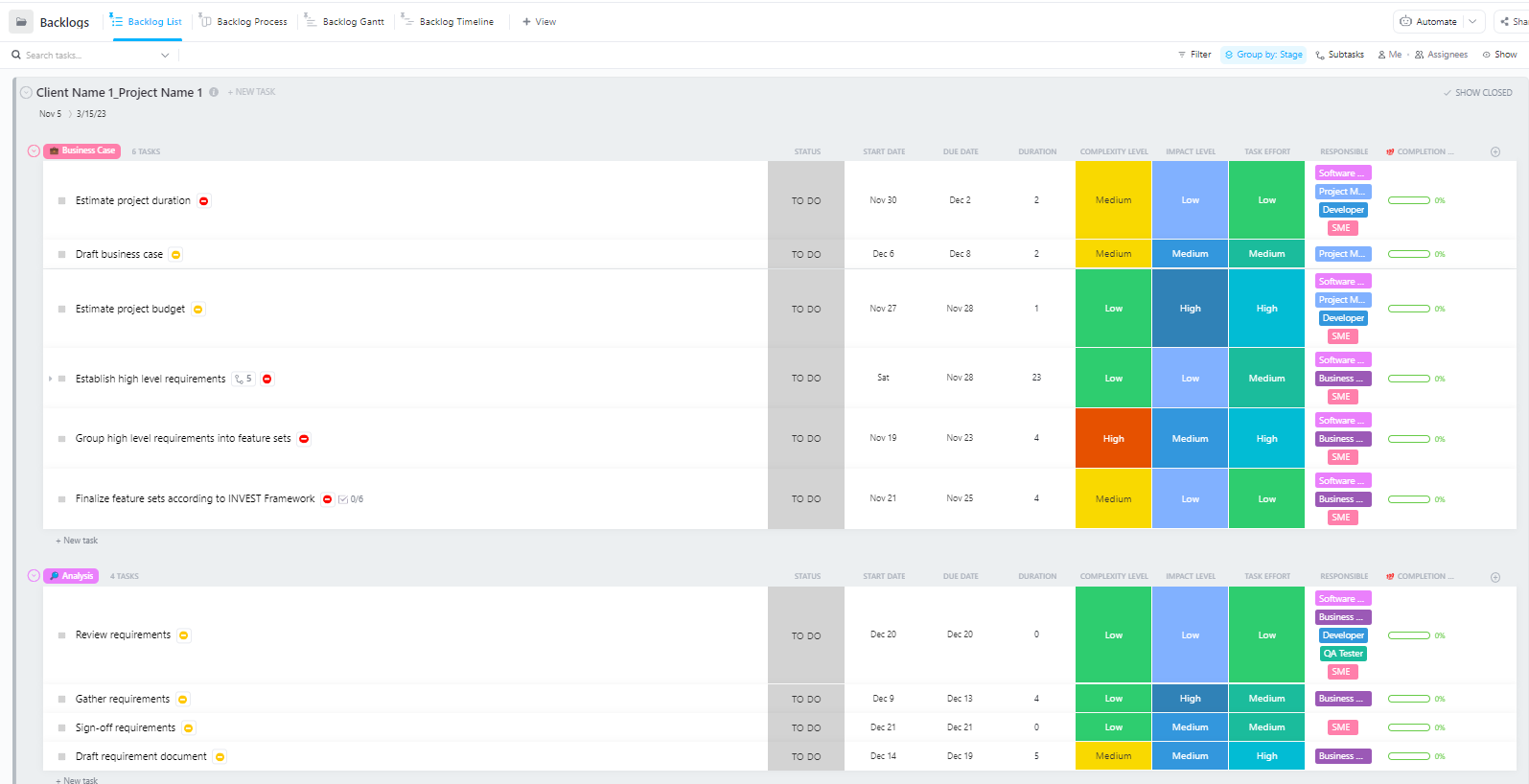
Este modelo ajuda as equipes a:
- Gerencie projetos com vários marcos, tarefas, recursos e dependências.
- Visualize o progresso do projeto com gráficos de Gantt e cronogramas.
- Colabore perfeitamente com seus colegas de equipe para garantir a conclusão bem-sucedida do projeto.
Desafios comuns na implantação do Hugging Face e como resolvê-los
Mesmo com um plano claro, é provável que você encontre alguns obstáculos durante a implantação. Ficar olhando para uma mensagem de erro enigmática pode ser incrivelmente frustrante e pode interromper o progresso da sua equipe. Aqui estão alguns dos desafios mais comuns e como resolvê-los. 🛠️
🚨Problema: “O modelo requer autenticação”
- Causa: você está tentando acessar um modelo “restrito” que exige que você aceite seus termos de licença.
- Solução: acesse a página do modelo no Hub, leia e aceite o contrato de licença. Certifique-se de que o token de acesso que você está usando tenha permissões de “leitura”.
🚨Problema: “CUDA sem memória”
- Causa: O modelo que você está tentando carregar é muito grande para a memória da sua GPU (VRAM).
- Solução: a solução mais rápida é usar uma versão menor do modelo ou uma versão quantizada. Você também pode tentar reduzir o tamanho do lote durante a inferência.
🚨Problema: “erro trust_remote_code”
- Motivo: alguns modelos no Hub exigem código personalizado para serem executados e, por motivos de segurança, a biblioteca não o executa por padrão.
- Solução: você pode contornar isso adicionando trust_remote_code=True ao carregar o modelo. No entanto, você deve sempre revisar o código-fonte primeiro para garantir que ele seja seguro.
🚨Problema: “Incompatibilidade do tokenizador”
- Causa: o tokenizador que você está usando não é exatamente o mesmo com o qual o modelo foi treinado, levando a entradas incorretas e baixo desempenho.
- Solução: sempre carregue o tokenizador do mesmo ponto de verificação do modelo que o próprio modelo. Por exemplo, AutoTokenizer. from_pretrained("nome-do-modelo")
🚨Problema: “Limite de taxa excedido”
- Motivo: você fez muitas solicitações à API de inferência gratuita em um curto período.
- Solução: para uso em produção, atualize para um ponto de inferência dedicado. Para desenvolvimento, você pode implementar o cache para evitar o envio da mesma solicitação várias vezes.
É fundamental acompanhar quais soluções funcionam para quais problemas. Sem um local central para documentar essas descobertas, as equipes muitas vezes acabam resolvendo o mesmo problema repetidamente.
📮 ClickUp Insight: 1 em cada 4 funcionários usa quatro ou mais ferramentas apenas para criar contexto no trabalho. Um detalhe importante pode estar oculto em um e-mail, expandido em um tópico do Slack e documentado em uma ferramenta separada, forçando as equipes a perder tempo procurando informações em vez de realizar o trabalho.
O ClickUp converge todo o seu fluxo de trabalho em uma plataforma unificada. Com recursos como ClickUp Email Project Management, ClickUp Chat, ClickUp Docs e ClickUp Brain, tudo fica conectado, sincronizado e instantaneamente acessível. Diga adeus ao “trabalho sobre o trabalho” e recupere seu tempo produtivo.
💫 Resultados reais: as equipes conseguem recuperar mais de 5 horas por semana usando o ClickUp — o que significa mais de 250 horas por ano por pessoa — eliminando processos desatualizados de gerenciamento de conhecimento. Imagine o que sua equipe poderia criar com uma semana extra de produtividade a cada trimestre!
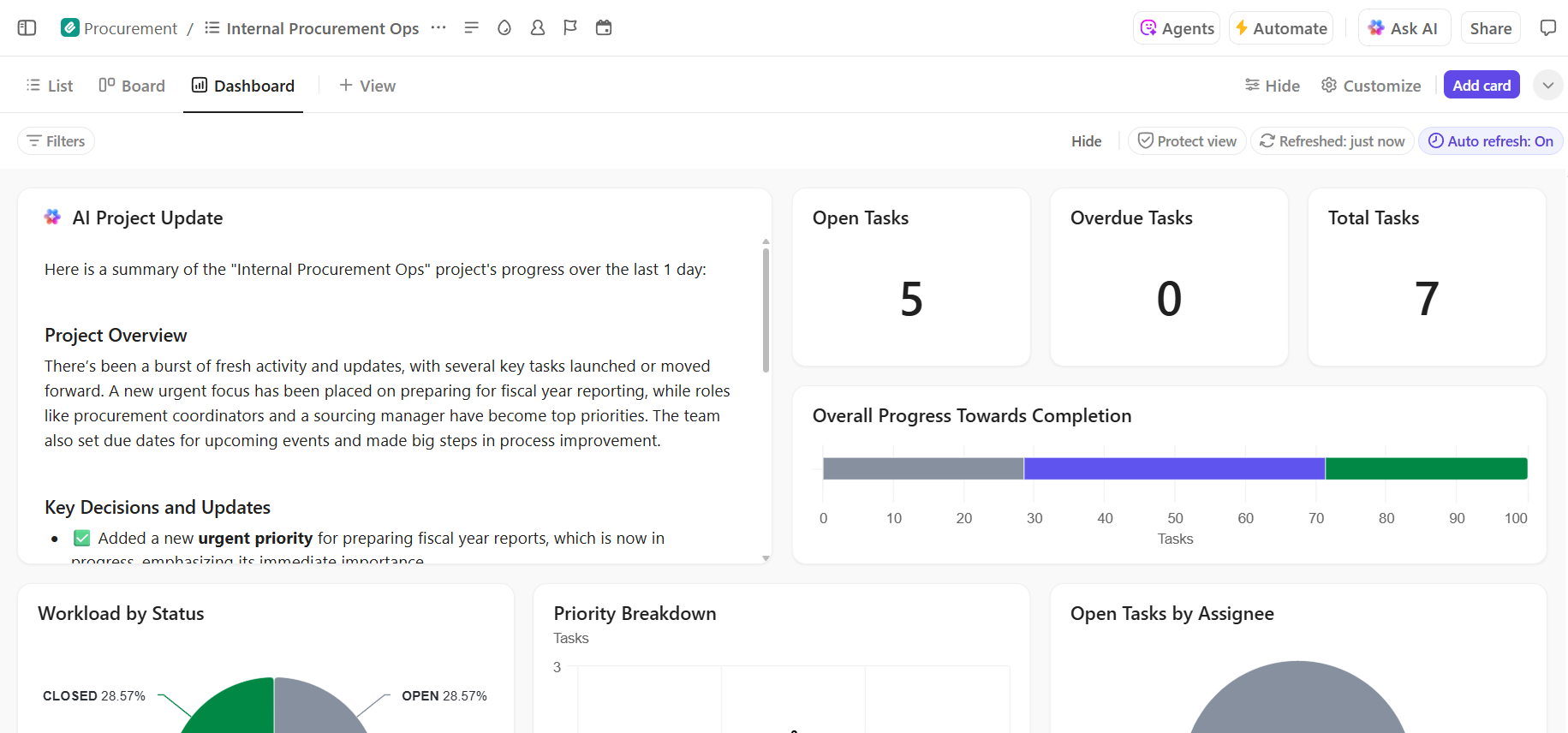
Como gerenciar projetos de implantação de IA no ClickUp
Usar o Hugging Face para implantação de IA facilita o empacotamento, a hospedagem e o fornecimento de modelos, mas não elimina a sobrecarga de coordenação da implantação no mundo real. As equipes ainda precisam rastrear quais modelos estão sendo testados, alinhar as configurações, documentar as decisões e manter todos — desde engenheiros de ML até produtos e operações — em sintonia.
Quando sua equipe de engenharia está testando diferentes modelos, sua equipe de produto está definindo requisitos e as partes interessadas estão solicitando atualizações, as informações ficam espalhadas pelo Slack, e-mails, planilhas e vários documentos.
Essa dispersão do trabalho — a fragmentação das atividades de trabalho em várias ferramentas desconectadas que não se comunicam entre si — cria confusão e atrasa todo mundo.
É aqui que o ClickUp, o primeiro espaço de trabalho de IA convergente do mundo, desempenha um papel fundamental, reunindo gerenciamento de projetos, documentação e comunicação da equipe em um único espaço de trabalho.
Essa convergência é especialmente valiosa para projetos de implantação de IA, nos quais as partes interessadas técnicas e não técnicas precisam de visibilidade compartilhada sem precisar usar cinco ferramentas diferentes.
Em vez de espalhar atualizações por tickets, documentos e conversas de chat, as equipes podem gerenciar todo o ciclo de vida da implantação em um único lugar.
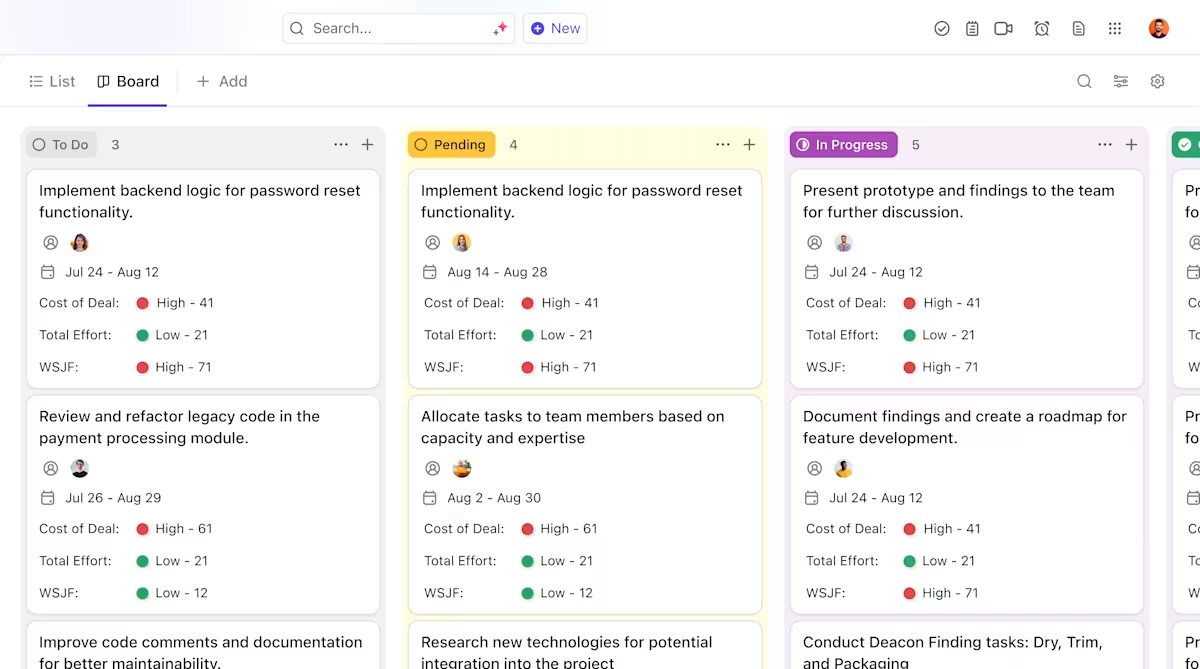
Veja como o ClickUp pode ajudar no seu projeto de implantação de IA:
- Propriedade clara e rastreamento ao longo do ciclo de vida dos modelos: use o ClickUp Tasks para rastrear os modelos do Hugging Face durante a avaliação, os testes, a preparação e a produção, com status personalizados, proprietários e bloqueadores visíveis para toda a equipe.
- Documentação de implantação centralizada e dinâmica: mantenha manuais de implantação, configurações de ambiente e guias de solução de problemas no ClickUp Docs, para que a documentação evolua junto com seus modelos e continue fácil de pesquisar e consultar. Como os documentos estão conectados às tarefas, sua documentação fica ao lado do trabalho ao qual se refere.
- Colaboração contextualizada sem dispersão de trabalho: mantenha discussões, decisões e atualizações diretamente vinculadas a tarefas e documentos, reduzindo a dependência de threads dispersas no Slack, e-mails e ferramentas de projeto desconectadas.
- Visibilidade completa do progresso da implantação: monitore o pipeline de implantação, identifique riscos antecipadamente e equilibre a capacidade da equipe usando os painéis do ClickUp, que mostram o progresso e os gargalos em tempo real.
- Integração mais rápida e recuperação de decisões com IA integrada: use o ClickUp Brain para resumir longos documentos de implantação, revelar insights relevantes de implantações anteriores e ajudar novos membros da equipe a se atualizarem sem precisar pesquisar o contexto histórico.
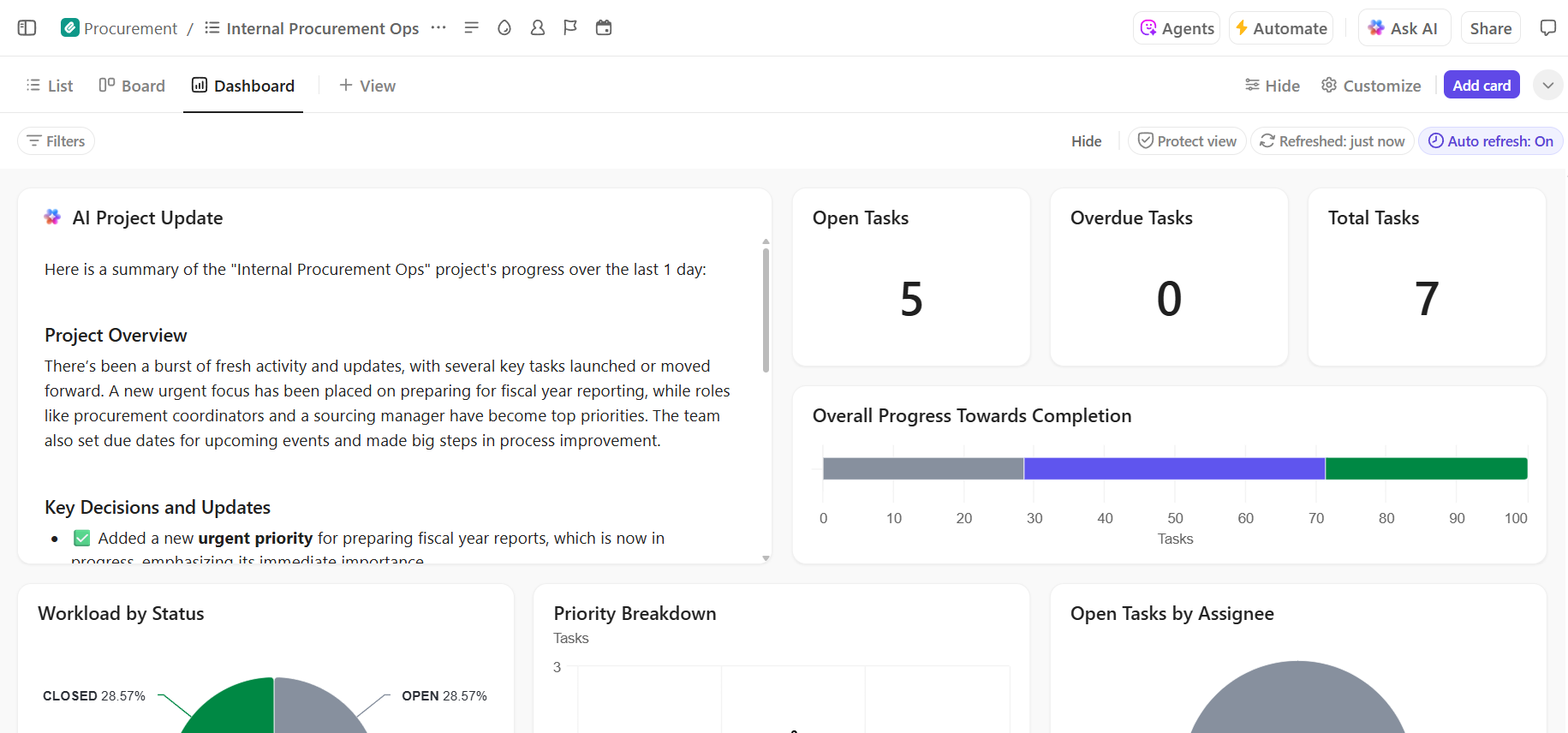
📚 Leia também: Como automatizar processos com IA para fluxos de trabalho mais rápidos e inteligentes
Gerencie seu projeto de implantação de IA de maneira integrada no ClickUp
A implantação bem-sucedida do Hugging Face depende de uma base técnica sólida e de um gerenciamento de projetos claro e organizado. Embora os desafios técnicos sejam solucionáveis, muitas vezes são as falhas de coordenação e comunicação que levam ao fracasso dos projetos.
Ao estabelecer um fluxo de trabalho claro em uma única plataforma, sua equipe pode entregar mais rapidamente e evitar a frustração da dispersão de contexto — quando as equipes perdem horas procurando informações, alternando entre aplicativos e repetindo atualizações em várias plataformas.
O ClickUp, o aplicativo completo para o trabalho, reúne o gerenciamento de projetos, a documentação e a comunicação da equipe em um só lugar para oferecer uma única fonte de verdade para todo o ciclo de vida da implantação da IA.
Reúna seus projetos de implantação de IA e elimine a confusão de ferramentas. Comece gratuitamente com o ClickUp hoje mesmo.
Perguntas frequentes (FAQ)
Sim, o Hugging Face oferece um generoso plano gratuito que inclui acesso ao Model Hub, Spaces com CPU para demonstrações e uma API de inferência com taxa limitada para testes. Para necessidades de produção que exigem hardware dedicado ou limites mais altos, estão disponíveis planos pagos.
O Spaces foi projetado para hospedar aplicativos interativos com uma interface visual, tornando-o ideal para demonstrações e ferramentas internas. A API de inferência fornece acesso programático aos modelos, permitindo que você os integre aos seus aplicativos por meio de solicitações HTTP simples.
Com certeza. Por meio de demonstrações interativas hospedadas no Hugging Face Spaces, membros da equipe sem conhecimentos técnicos podem experimentar e fornecer feedback sobre os modelos sem escrever uma única linha de código.
As principais limitações do plano gratuito são os limites de taxa na API de inferência, o uso de hardware de CPU compartilhado para Spaces, que pode ser lento, e “inicializações a frio”, em que aplicativos inativos demoram um pouco para serem ativados. /