
Awarie IT mogą wystąpić bez ostrzeżenia.
Od awarii serwerów po cyberataki — bez solidnego planu odzyskiwania danych Twoja firma może stanąć w obliczu wielogodzinnych przestojów, utraty danych i poważnych strat finansowych, przy czym 54% poważnych awarii kosztuje ponad 100 000 USD.
Ten blog przeprowadzi Cię przez proces tworzenia kompleksowego planu odzyskiwania danych po awarii, który chroni Twoje systemy, określa jasne cele odzyskiwania i zapewnia, że Twój zespół dokładnie wie, co zrobić, gdy coś pójdzie nie tak.
Czym jest plan odzyskiwania danych po awarii IT?
Gdyby Twoje serwery uległy awarii w tej chwili, czy Twój zespół wiedziałby dokładnie, co zrobić? 🛠️
Plan odzyskiwania danych po awarii (DR) to udokumentowana strategia przywracania systemów informatycznych i danych po wszelkich zakłóceniach — od klęsk żywiołowych po cyberataki. Jest to zasadniczo podręcznik postępowania w celu przywrócenia działania technologii w przypadku wystąpienia problemów.
💡 DR a ciągłość działania
Odzyskiwanie danych po awarii (DR) koncentruje się w szczególności na przywróceniu infrastruktury IT i danych. Ciągłość działania (BC) ma szerszy zakres i ma na celu utrzymanie działalności całej firmy podczas kryzysu i po jego zakończeniu, nawet jeśli systemy IT nie działają. DR należy traktować jako kluczowy element ogólnej strategii BC.
💡 DR a ciągłość działania
Odzyskiwanie danych po awarii (DR) koncentruje się w szczególności na przywróceniu infrastruktury IT i danych. Ciągłość działania (BC) ma szerszy zakres i ma na celu utrzymanie działalności całej firmy podczas kryzysu i po jego zakończeniu, nawet jeśli systemy IT nie działają. DR należy traktować jako kluczowy element ogólnej strategii BC.
Twój plan odzyskiwania danych po awarii ma znaczenie, ponieważ przestoje kosztują więcej niż tylko pieniądze. Każda minuta, w której Twoje systemy są wyłączone, może podważyć zaufanie klientów, zakłócić działalność, a nawet prowadzić do kar za nieprzestrzeganie przepisów. Kompleksowy plan odzyskiwania danych po awarii to Twój plan działania na rzecz odporności.
Dobry plan obejmuje:
- Procedury tworzenia kopii zapasowych danych: Jak i gdzie przechowujesz kopie krytycznych informacji, aby móc je przywrócić
- Kroki przywracania systemu: dokładna sekwencja przywracania usług online we właściwej kolejności.
- Obowiązki zespołu: kto co robi podczas incydentu, aby uniknąć zamieszania
- Protokoły komunikacyjne: Jak będziesz informować interesariuszy, od swojego zespołu po klientów
- Cele odzyskiwania: konkretne cele dotyczące szybkości przywrócenia systemów i dopuszczalnej utraty danych.
Typowe scenariusze awarii IT i ich skutki
Awarie nie są tylko scenariuszami z filmów hollywoodzkich — zdarzają się w firmach każdego dnia. Zrozumienie, przed czym się chronisz, pomoże Ci zbudować znacznie silniejszą ochronę.
Klęski żywiołowe i szkody fizyczne
Wydarzenia takie jak powodzie, pożary, trzęsienia ziemi i poważne awarie zasilania mogą w ciągu kilku minut zniszczyć całe centra danych. Na przykład, gdy poważna powódź nawiedziła centrum danych w Nashville, niektóre firmy straciły dane z kilku tygodni i musiały poświęcić miesiące na ich odzyskanie. Najlepszą ochroną przed takimi wydarzeniami jest redundancja geograficzna, czyli rozłożenie infrastruktury w wielu fizycznych lokalizacjach, dzięki czemu jedno wydarzenie nie spowoduje całkowitej awarii.
Cyberataki i naruszenie bezpieczeństwa danych
Oprogramowanie ransomware, ataki typu distributed denial-of-service (DDoS) i naruszenia bezpieczeństwa danych różnią się od katastrof fizycznych. Często są trudniejsze do wykrycia, mogą rozprzestrzeniać się w sposób niezauważalny poprzez połączone systemy i często są celem systemów kopii zapasowych, co sprawia, że odzyskiwanie danych jest szczególnie trudne. Częstotliwość i stopień zaawansowania tych cyberataków stale rośnie we wszystkich branżach, a oprogramowanie ransomware stanowi obecnie 44% wszystkich potwierdzonych naruszeń bezpieczeństwa, co czyni je jednym z największych zagrożeń.
📖 Więcej informacji: 10 sposobów na zmniejszenie ryzyka związanego z cyberbezpieczeństwem w zarządzaniu projektami
Awarie sprzętu i utrata danych
Czasami nawet najlepiej przetestowane i sprawdzone systemy kopii zapasowych po prostu ulegają awarii. Awarie serwerów, uszkodzenia pamięci masowej i nieprawidłowe działanie sprzętu sieciowego mogą wystąpić bez ostrzeżenia. Nawet jeśli dysponujesz redundantnymi systemami (kopii zapasowych), mogą one ulec awarii w tym samym czasie, jeśli udostępniają one wspólne komponenty lub źródła zasilania, tworząc pojedynczy punkt awarii.
👀 Czy wiesz, że: W październiku 2025 r. firma AWS doświadczyła poważnej awarii, gdy błąd w wewnętrznym systemie zarządzania DNS dla Amazon DynamoDB spowodował niepowodzenie rozpoznawania nazw domen w regionie centrum danych US-EAST-1. Ta „niewielka” usterka techniczna była wyzwalaczem kaskadowej awarii dziesiątek usług AWS i unieruchomiła setki popularnych aplikacji i platform na całym świecie — od komunikatorów i aplikacji społecznościowych po banki, serwisy z grami i wiele innych. Dla wielu osób awaria ta spowodowała tymczasowe „zniknięcie” znacznej części Internetu, uwypuklając kruchość naszej infrastruktury cyfrowej, która w tak dużym stopniu jest zależna od kilku dostawców usług w chmurze.
Błędy oprogramowania i zakłócenia w świadczeniu usług
Uszkodzona baza danych, nieudana aktualizacja oprogramowania lub prosty błąd konfiguracji mogą spowodować awarię całych platform. Być może zauważyłeś, że jedna nieprawidłowo skonfigurowana linia kodu może wywołać kaskadę błędów w połączonych systemach, powodując rozległą awarię o dużym zasięgu. Odpowiednie zarządzanie zmianami i dedykowane środowiska testowe to najlepsze sposoby na zminimalizowanie tych ryzyk.
Błędy ludzkie i nieprawidłowe konfiguracje
Przypadkowe usunięcia, nieprawidłowe konfiguracje i nieautoryzowane zmiany pozostają jedną z najczęstszych przyczyn awarii IT. Jedna nieprawidłowa komenda lub usunięty plik może być wyzwalaczem dla wielu godzin przestoju i pogorszenia jakości usług. Szkolenia i kontrole dostępu są pomocne, ale nie są w stanie całkowicie wyeliminować błędów ludzkich.
📮ClickUp Insight: 92% pracowników stosuje niespójne metody śledzenia elementów, co ma dla nich następujące wyniki: pominięcie decyzji i opóźnienia w realizacji zadań.
Niezależnie od tego, czy wysyłasz notatki z dalszymi informacjami, czy korzystasz z arkuszy kalkulacyjnych, proces ten jest często chaotyczny i nieefektywny. Dzięki funkcjom zarządzania zadaniami ClickUp nie musisz się już tym martwić. Twórz zadania z czatu, komentarzy do zadań ClickUp, dokumentów i e-maili za pomocą jednego kliknięcia!
Kluczowe elementy planu odzyskiwania danych po awarii
Solidny plan DR to zakończony scenariusz przywrócenia dostępności online. Każdy z tych elementów opiera się na pozostałych, tworząc kompleksową ochronę dla Twojej firmy.
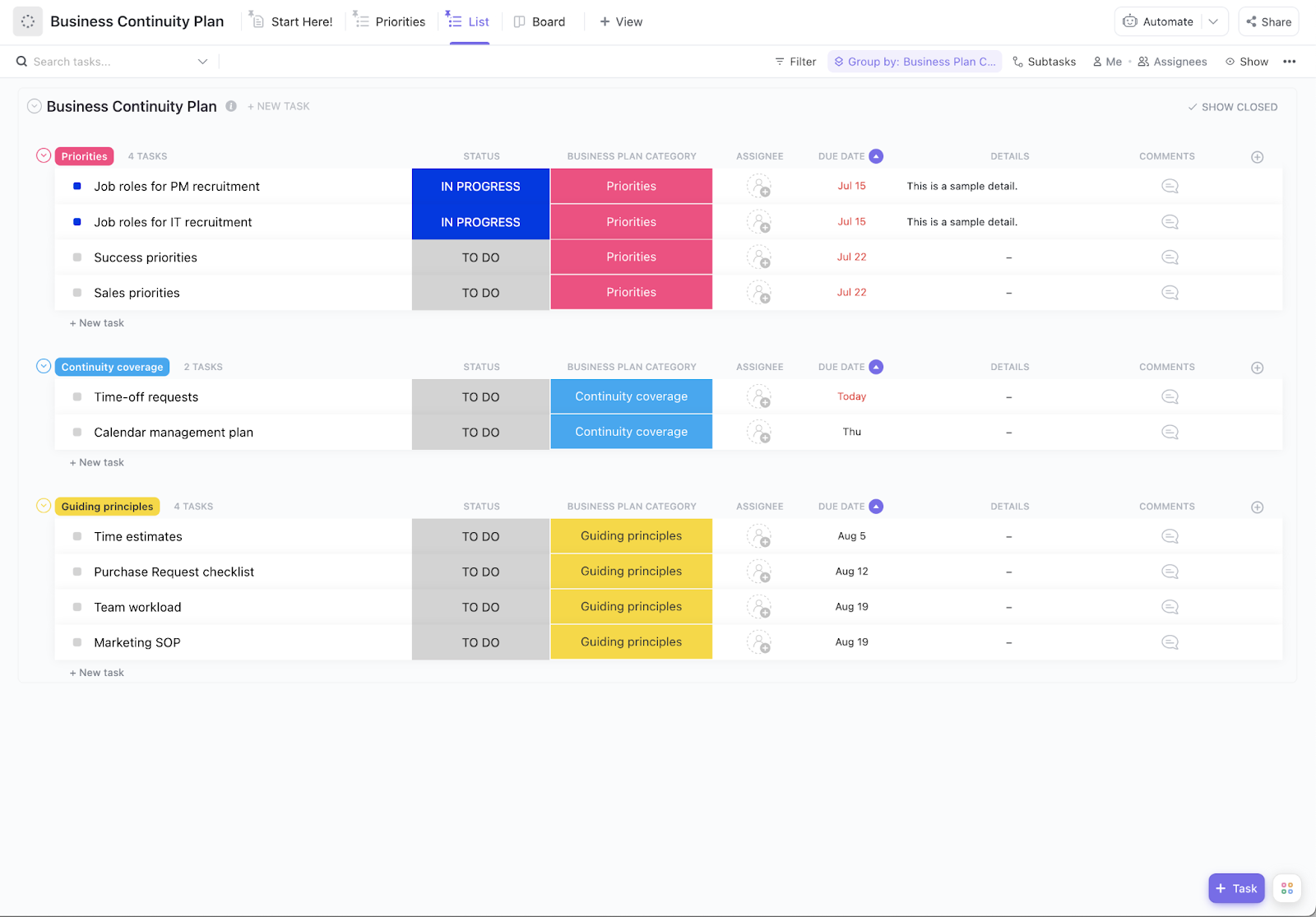
Ocena ryzyka i ustalanie priorytetów
Najpierw musisz wiedzieć, z czym masz do czynienia. Ocena ryzyka to proces identyfikacji słabych punktów oraz oceny prawdopodobieństwa i skutków każdego potencjalnego zagrożenia. Możesz to uporządkować w matrycy ryzyka, aby zobaczyć, które zagrożenia są najpoważniejsze.
Twoja ocena powinna obejmować:
- Systemy krytyczne: co musi działać bez przerwy, aby Twoja firma mogła funkcjonować
- Wrażliwość danych: Jakie informacje wymagają najwyższego poziomu ochrony (np. dane klientów)?
- Zależności: Jakie inne systemy lub procesy ulegają awarii w przypadku awarii każdego z systemów?
📖 Więcej informacji: Jak wdrożyć zarządzanie infrastrukturą IT
Analiza wpływu na działalność i krytyczność
Następnie oblicz rzeczywisty koszt przestoju. Analiza wpływu na działalność (BIA) pomaga określić finansowe i operacyjne skutki awarii każdego systemu. Dzięki temu można sklasyfikować systemy według poziomu krytyczności, aby ustalić priorytety wysiłków związanych z odzyskiwaniem danych.
| Krytyczne | Mniej niż godzina | Przetwarzanie płatności, bazy danych klientów |
| Wysoki | Od jednej do czterech godzin | E-mail, narzędzia komunikacji wewnętrznej |
| Średni | Od czterech do 24 godzin | Środowiska programistyczne, narzędzia do raportowania |
| Niski | Ponad 24 godziny | Systemy archiwizacji, serwery testowe nieprodukcyjne |
Cele RTO i RPO
Te dwa akronimy stanowią sedno strategii odzyskiwania danych.
- Cel czasu przywrócenia (RTO): Jest to maksymalny czas, przez jaki system może pozostawać nieczynny. Odpowiada on na pytanie: „Jak szybko musimy przywrócić działanie systemu?”.
- Cel punktu odzyskiwania (RPO): Jest to maksymalna ilość danych, którą można stracić, mierzona w czasie. Odpowiada na pytanie: „Ile danych możemy stracić bez większych szkód?”.
Na przykład, Twój wewnętrzny system e-maila może mieć RTO wynoszące cztery godziny, ale Twoja baza danych e-commerce obsługująca klientów może mieć RPO wynoszące zaledwie 15 minut, co oznacza, że nie możesz stracić więcej niż 15 minut danych związanych z transakcjami.
Plan tworzenia kopii zapasowych i odzyskiwania danych
Plan tworzenia kopii zapasowych to Twoja najlepsza ochrona. Najlepszą praktyką jest zasada 3-2-1: trzymaj co najmniej trzy kopie ważnych danych, przechowuj je na dwóch różnych nośnikach, a jedną z nich trzymaj poza siedzibą firmy.
Będziesz również wybierać spośród różnych typów kopii zapasowych:
- Pełne kopie zapasowe: kompletna kopia wszystkich danych, zazwyczaj zrobione co tydzień lub co miesiąc.
- Kopia zapasowa przyrostowa: Tworzy kopię zapasową tylko zmian wprowadzonych od momentu wykonania ostatniej kopii zapasowej dowolnego typu.
- Kopie zapasowe różnicowe: tworzą kopię zapasową wszystkich zmian wprowadzonych od czasu ostatniej pełnej kopii zapasowej.
Co najważniejsze, należy regularnie testować proces przywracania kopii zapasowych. Niesprawdzona kopia zapasowa to tylko nadzieja, a nie plan.
💟 Bonus: Rejestruj kluczowe szczegóły podczas stresujących incydentów, korzystając z funkcji zamiany mowy na tekst ClickUp Brain MAX, dzięki czemu nigdy nie przegapisz ważnych informacji, nawet gdy pisanie na klawiaturze jest niepraktyczne. Po prostu opowiedz o swoich obserwacjach, a AI zajmie się dokumentacją.
Plan komunikacji i aktualizacje dla interesariuszy
W przypadku wystąpienia awarii kluczowe znaczenie ma jasny plan komunikacji. Plan musi określać łańcuchy powiadomień, częstotliwość przekazywania aktualnych informacji oraz kanały, które będą wykorzystywane w przypadku każdego rodzaju incydentu.
Różne grupy potrzebują różnych informacji:
- Zespoły wewnętrzne: Potrzebują szczegółowych informacji technicznych i konkretnych elementów działań.
- Klienci: Potrzebują informacji o statusie usługi i przewidywanym terminie rozwiązania problemu.
- Dostawcy: może być konieczne zaangażowanie ich w celu uzyskania wsparcia lub eskalacji problemów.
- Organy regulacyjne: w zależności od branży mogą wymagać formalnych powiadomień.
Narzędzia takie jak gotowy do użycia szablon planu komunikacji od ClickUp mogą pomóc Ci działać szybciej dzięki ustalonemu protokołowi w sytuacji kryzysowej.

Program testów i szkoleń
Plan, którego nigdy nie przetestujesz, jest planem, który zawiedzie. Regularne testy pozwalają wykryć luki i słabe punkty, zanim nastąpi prawdziwa awaria.
Zaplanuj różne rodzaje testów w ciągu roku:
- Ćwiczenia symulacyjne: Twój zespół przechodzi przez scenariusz awarii na papierze, aby sprawdzić logikę planu.
- Częściowe przełączenia awaryjne: Testujesz odzyskiwanie określonych, niekrytycznych komponentów lub usług.
- Pełne testy odzyskiwania po awarii: wykonujesz zakończone przełączenie awaryjne na systemy zapasowe (test ostateczny).
Po każdym teście należy aktualizować dokumentację i natychmiast szkolić nowych członków zespołu w zakresie procedur.
📖 Więcej informacji: Jak opracować skuteczne zasady i procedury IT
Kroki niezbędne do stworzenia planu odzyskiwania danych po awarii
Opracowanie planu odzyskiwania danych po awarii nie musi być przytłaczającym zadaniem.
Oto jak możesz to osiągnąć krok po kroku. 🙌
Krok 1: Stwórz spis zasobów
Nie można chronić tego, czego się nie zna. Zacznij od stworzenia listy zasobów, która zawiera wszystkie elementy sprzętu, oprogramowania, repozytoria danych i zależności systemowe w Twoim środowisku. Pamiętaj, aby uwzględnić dane kontaktowe dostawców, klucze licencyjne i szczegóły konfiguracji, które będą przydatne podczas przywracania danych.

Szablon ITAM ClickUp łączy zarządzanie incydentami, zarządzanie problemami, zarządzanie zmianami, proste rozwiązania do zarządzania zasobami oraz zarządzanie wiedzą. Nasz szablon znanych błędów ITSM upraszcza śledzenie znanych błędów w systemach. Zapoznaj się ze wszystkimi naszymi szablonami IT, gdy tylko zmieni się Twój cel.
Dostosuj cykle pracy do własnych potrzeb na każdym etapie zarządzania zasobami IT (ITAM), od wdrożenia i konfiguracji po konserwację i wycofanie z eksploatacji.
Krok 2: Klasyfikacja usług krytycznych
Teraz określ, które z tych zasobów są krytyczne dla działalności, a które są tylko dodatkowym atutem. Utwórz mapy zależności usług, które pokazują, w jaki sposób systemy są ze sobą połączone i wzajemnie od siebie zależne. Zwróć szczególną uwagę na wszelkie usługi dla klientów, które mają bezpośredni wpływ na przychody lub doświadczenia użytkowników.
🎥 Obejrzyj ten praktyczny przewodnik, który pokazuje, jak stworzyć uporządkowany, ogólny plan przy użyciu zaawansowanych funkcji ClickUp — od wyznaczania celów po przydzielanie zadań i śledzenie postępów.
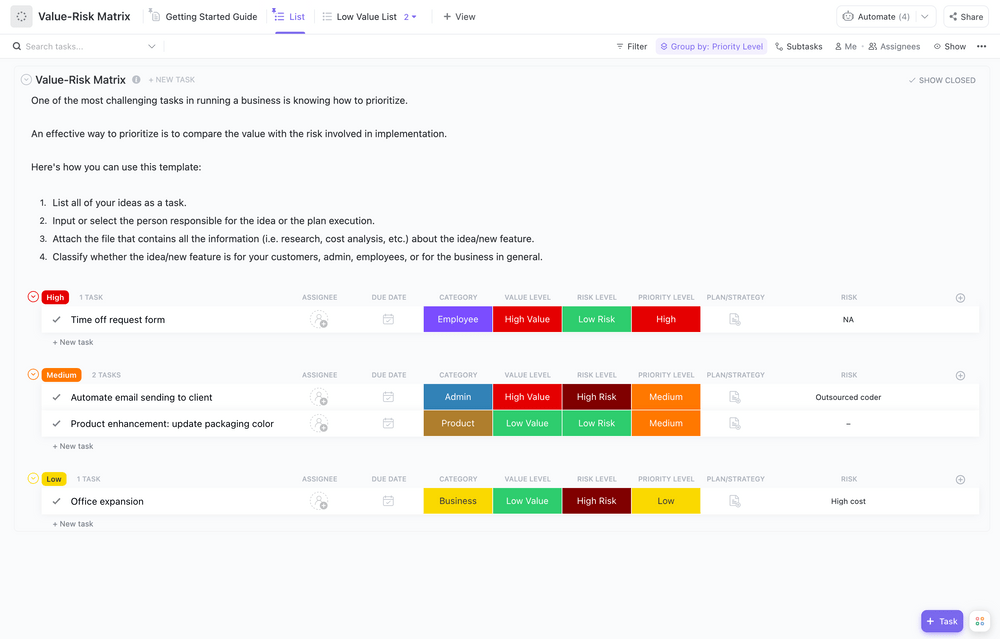
Krok 3: Ocena ryzyka i zagrożeń
Oceń ryzyko i zagrożenia, analizując prawdopodobieństwo wystąpienia i wpływ każdego rodzaju zagrożenia w konkretnej sytuacji. Weź pod uwagę ryzyko geograficzne (czy znajdujesz się w strefie sejsmicznej lub na terenie zalewowym?) oraz wszelkie zagrożenia specyficzne dla branży (takie jak zmiany regulacyjne lub ukierunkowane cyberataki). Udokumentuj wszystko w rejestrze ryzyka, aby móc prowadzić śledzenie zmian w czasie.

Szablon tablicy do oceny ryzyka ClickUp tworzy wizualny wymiar procesu oceny ryzyka. Pomaga w ocenie ryzyka i kategoryzacji, inspirując zespół do udostępniania spostrzeżeniówek i współpracy w angażującym i wizualnym formacie.
Ten szablon umożliwia:
- Oceń kategorie ryzyka i potencjalne skutki
- Analizuj dane, aby zidentyfikować potencjalne obszary wymagające uwagi.
- Określ środki zapobiegawcze w celu zmniejszenia narażenia na ryzyko.
Dzięki funkcjom umożliwiającym rysowanie, pisanie i dodawanie karteczek samoprzylepnych ten szablon tablicy do zarządzania ryzykiem idealnie nadaje się do oceny ryzyka związanego z projektem.
Krok 4: Ustal cele RTO i RPO
Współpracuj bezpośrednio z interesariuszami biznesowymi, aby określić, jaki czas przestoju i utratę danych uznają za dopuszczalne dla każdego zidentyfikowanego wcześniej poziomu usług. Konieczne będzie zrównoważenie kosztów szybszego odzyskiwania danych z wpływem na działalność firmy — nie wszystko wymaga natychmiastowego odzyskania danych bez żadnych strat. Uzyskaj zgodę kierownictwa na te cele.
Krok 5: Zdefiniuj ścieżki tworzenia kopii zapasowych i przełączania awaryjnego
Po ustaleniu celów możesz teraz zaprojektować rozwiązania techniczne. Stwórz strategie tworzenia kopii zapasowych dostosowane do RPO każdego systemu i planuj szczegółowe procedury przełączania awaryjnego, w tym alternatywne lokalizacje przetwarzania danych i metody dostępu awaryjnego. Dołącz schematy sieci i instrukcje krok po kroku, aby zapewnić niezawodność wykonania.
Krok 6: Przypisz role i eskalację
Określ strukturę zespołu ds. odzyskiwania danych po awarii, przypisując jasno określone obowiązki i uprawnienia decyzyjne. Stwórz kompleksowe listy kontaktów z głównymi i zastępczymi pracownikami dla każdej roli. Matryca RACI (odpowiedzialny, rozliczalny, konsultowany, informowany) jest doskonałym narzędziem pozwalającym wyeliminować niejasności podczas sytuacji kryzysowych.
Krok 7: Udokumentuj i przekaż plan
Sporządź dokumentację i przekaż plan wraz z jasnymi, szczegółowymi procedurami, które każdy członek zespołu będzie w stanie wykonać, nawet w sytuacji stresowej. Bardzo ważne jest, aby dokumentacja ta była przechowywana w łatwo dostępnej lokalizacji, oddzielonej od podstawowej infrastruktury. Upewnij się, że każdy członek zespołu dokładnie wie, gdzie znaleźć plan w sytuacji kryzysowej.
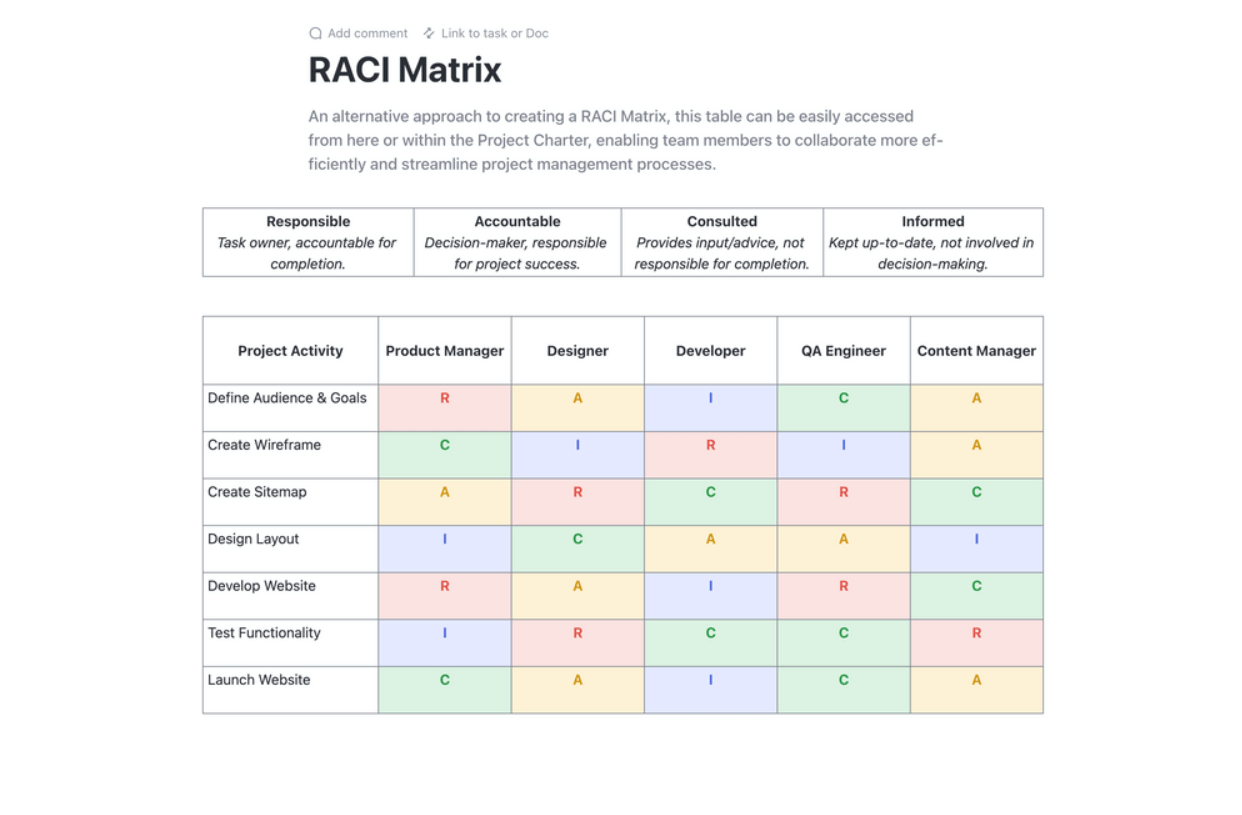
Usprawnij planowanie projektów dzięki szablonowi planowania RACI firmy ClickUp. Ten szablon dokumentu zmienia zasady gry, oferując przejrzystą tabelę do definiowania ról i obowiązków zespołu w odniesieniu do zadań projektowych. Wykorzystaj strukturę RACI (odpowiedzialny, rozliczalny, konsultowany i informowany), aby wszyscy byli na bieżąco, zapewniając odpowiedzialność i zgodność z celami organizacyjnymi.
Krok 8: Testuj, sprawdzaj i ulepszaj
Na koniec zaplanuj kwartalne testy, aby zweryfikować procedury i zidentyfikować ewentualne luki. Udokumentuj wszystkie wnioski wyciągnięte z każdego testu i rzeczywistych incydentów, a następnie wykorzystaj je do aktualizacji planu. Stwórz systematyczny system śledzenia ulepszeń, aby zapewnić rozwiązanie wszystkich wykrytych problemów.
🌼 Czy wiesz, że: W 2017 roku GitLab doświadczył poważnej awarii bazy danych. Podczas przywracania danych odkryto, że kilka metod tworzenia kopii zapasowych nie działało prawidłowo od kilku dni. Incydent ten dał całej branży technologicznej ważną lekcję: weryfikacja kopii zapasowych jest sprawą priorytetową. Niesprawdzona kopia zapasowa nie jest tak naprawdę kopią zapasową.
🌼 Czy wiesz, że: W 2017 roku GitLab doświadczył poważnej awarii bazy danych. Podczas przywracania danych odkryto, że kilka metod tworzenia kopii zapasowych nie działało prawidłowo od kilku dni. Incydent ten dał całej branży technologicznej ważną lekcję: weryfikacja kopii zapasowych jest sprawą priorytetową. Niesprawdzona kopia zapasowa nie jest tak naprawdę kopią zapasową.
Strategie i rozwiązania w zakresie odzyskiwania danych po awarii
Nie każda organizacja potrzebuje takiego samego podejścia do odzyskiwania danych po awarii. Przyjrzyjmy się dostępnym opcjom w oparciu o budżet, potrzeby w zakresie odzyskiwania danych i dostępne zasoby.
Podejście do tworzenia kopii zapasowych i przywracania danych
Jest to najprostsza i najbardziej opłacalna metoda. Polega ona na regularnym tworzeniu kopii zapasowych w lokalizacji poza siedzibą firmy (np. w chmurze lub dodatkowym centrum danych), a następnie ręcznym przywracaniu ich w razie potrzeby. Takie podejście najlepiej sprawdza się w przypadku systemów niekrytycznych, które mogą tolerować dłuższy czas przywrócenia działania (RTO), ponieważ odzyskiwanie danych może trwać kilka godzin, a nawet dni.
Wysoka dostępność i nadmiarowość
Strategia ta ma na celu wyeliminowanie pojedynczych punktów awarii poprzez wykorzystanie wielu aktywnych systemów. Techniki takie jak równoważenie obciążenia, klastrowanie serwerów i pamięć masowa RAID gwarantują, że w przypadku awarii jednego komponentu natychmiast przejmuje jego funkcję inny. Chociaż takie rozwiązanie jest droższe w ustawieniu i utrzymaniu, pozwala ono zminimalizować przestoje do zaledwie kilku sekund lub minut, dzięki czemu idealnie nadaje się do usług o krytycznym znaczeniu.
Opcje replikacji i przełączania awaryjnego
Replikacja polega na kopiowaniu danych w czasie zbliżonym do rzeczywistego do lokalizacji zapasowej, co zapewnia minimalną utratę danych podczas awarii.
- Replikacja synchroniczna: zapisuje dane jednocześnie w lokalizacji głównej i dodatkowej, gwarantując zerową utratę danych. Wymaga jednak dużej przepustowości i może spowolnić działanie systemu głównego.
- Replikacja asynchroniczna: najpierw zapisuje dane w lokalizacji głównej, a następnie kopiuje je do lokalizacji pomocniczej z niewielkim opóźnieniem. Jest tańsza i ma mniejszy wpływ na wydajność, ale wiąże się z niewielkim ryzykiem utraty danych.
Odzyskiwanie danych po awarii w chmurze i DRaaS
Usługa Disaster Recovery as a Service (DRaaS) stała się popularnym wyborem dla wielu firm. Oferuje ona rozliczenie zgodnie z rzeczywistym zużyciem, natychmiastową dystrybucję geograficzną i zautomatyzowaną koordynację odzyskiwania danych bez konieczności budowania i utrzymywania własnych fizycznych lokalizacji DR. Usługa Cloud DR eliminuje ogromne nakłady kapitałowe związane z centrum danych kopii zapasowych, zapewniając jednocześnie szybsze skalowanie i większą elastyczność niż tradycyjne podejścia oparte na lokalizacjach typu hot, warm lub cold.
Jak ClickUp usprawnia planowanie odzyskiwania danych po awarii IT
Zarządzanie planem odzyskiwania danych po awarii za pomocą rozproszonych arkuszy kalkulacyjnych, dokumentów i łańcuchów wiadomości e-mail stwarza własne ryzyko awarii.
Tego rodzaju rozproszenie pracy, fragmentacja zadań między wieloma niepołączonymi ze sobą narzędziami, które nie komunikują się między sobą, oraz rozproszenie kontekstu, gdy zespoły tracą godziny na wyszukiwanie informacji rozproszonych w różnych aplikacjach i platformach, prowadzą do zamieszania, nieaktualnych informacji i powolnych czasów reakcji, gdy liczy się każda sekunda.
Dzięki ClickUp Converged AI Obszarowi Roboczemu — jednej, bezpiecznej platformie, na której wszystkie aplikacje, dane i cykle pracy współistnieją z kontekstową sztuczną inteligencją jako warstwą inteligencji — łączącej zarządzanie projektami, dokumentację i komunikację zespołową. Przestań żonglować wieloma platformami i przenieś planowanie DR, testowanie i reagowanie na incydenty do jednego, ujednoliconego systemu.
Scentralizowana dokumentacja DR dzięki ClickUp Docs i wbudowanej pomocy AI.
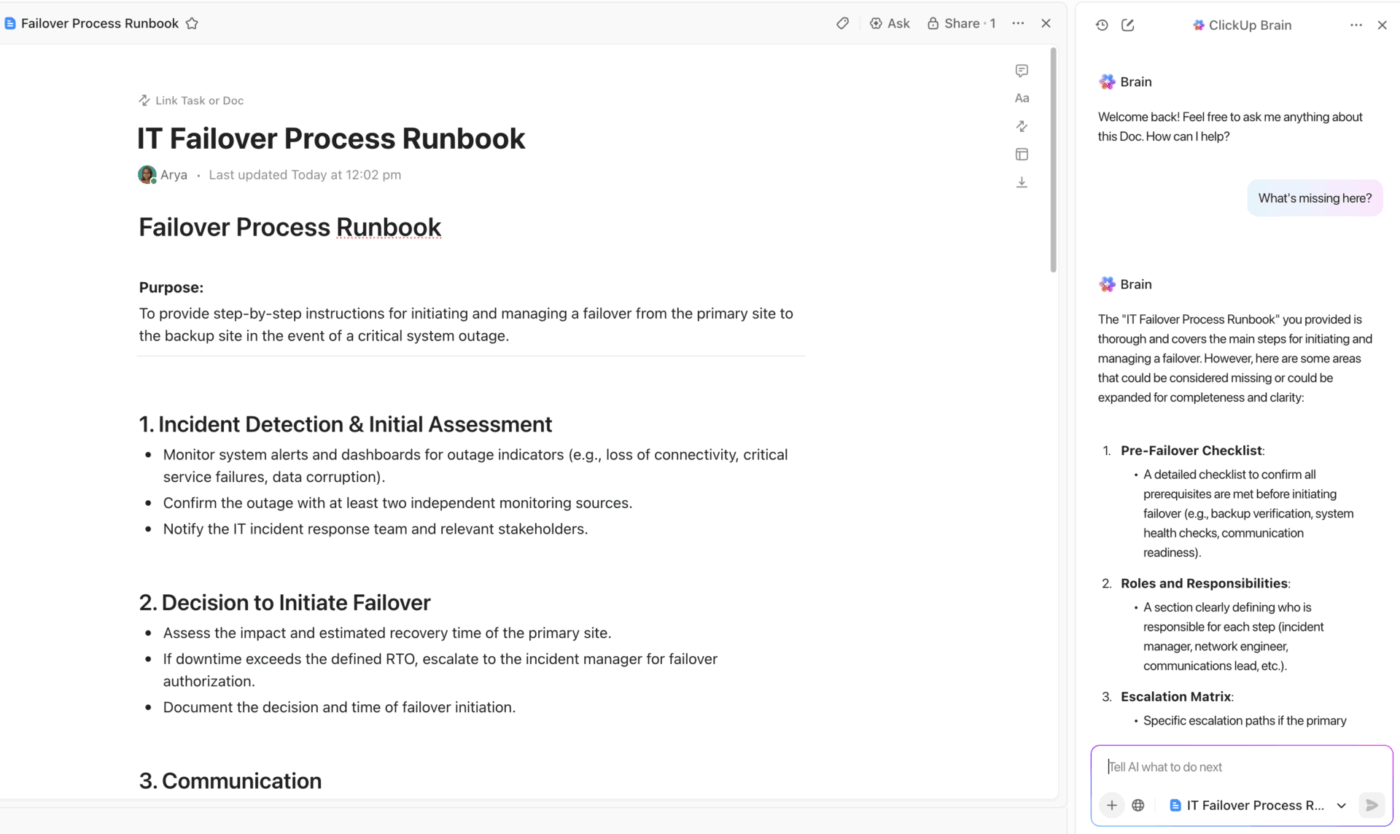
Dzięki ClickUp Docs Twój zespół zawsze będzie miał dostęp do jednego źródła prawdziwych informacji.
Opracuj cały plan odzyskiwania danych po awarii w przestrzeni współpracy, gdzie każdy może wnieść swój wkład w czasie rzeczywistym podczas incydentu. Połącz dokumenty bezpośrednio z zadaniami i projektami związanymi z incydentem, aby zapewnić płynną nawigację, oraz osadź diagramy lub skrypty, aby przechowywać kluczowe informacje dokładnie tam, gdzie są potrzebne.
Co najważniejsze, możesz chronić swoje dokumenty przed przypadkowymi zmianami i korzystać z szczegółowych uprawnień ClickUp, aby kontrolować, kto może przeglądać lub zmieniać poufne procedury odzyskiwania danych. Każda zmiana jest śledzona w historii dokumentu, co zapewnia pełną ścieżkę audytu.
Tworzenie planów oparte na AI dzięki ClickUp Brain
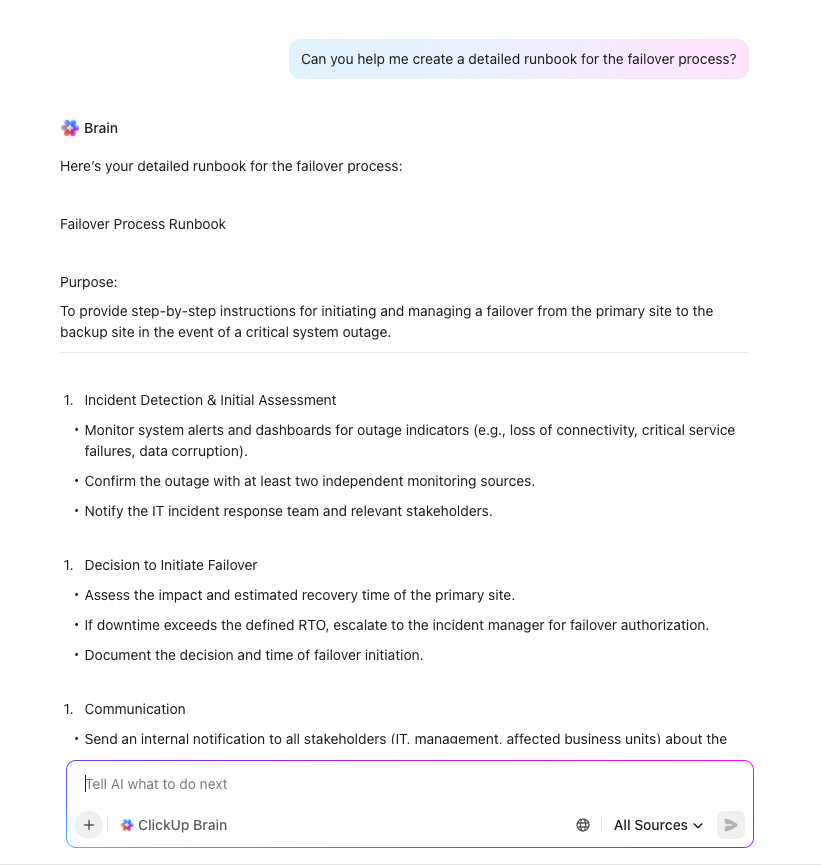
Przyspiesz planowanie odzyskiwania danych po awarii i wyeliminuj krytyczne luki dzięki ClickUp Brain — kontekstowemu asystentowi AI, który rozumie całe Twoje środowisko pracy. W przeciwieństwie do ogólnych narzędzi AI, ClickUp Brain wykorzystuje rzeczywiste zadania, dokumenty i cykle pracy Twojej organizacji, aby zapewnić precyzyjne i praktyczne wsparcie dla inicjatyw związanych z odzyskiwaniem danych po awarii.
Wystarczy poprosić ClickUp Brain o „utworzenie listy kontrolnej odzyskiwania danych po awarii dla naszej platformy e-commerce”, aby natychmiast otrzymać kompleksowy, dostosowany do potrzeb szablon, który jest zgodny z systemami, procesami i wymogami zgodności. Może on pomóc w:
- Świadomość kontekstowa: ClickUp Brain ma dostęp do struktury, zawartości i uprawnień Twojego obszaru roboczego ClickUp. Może odwoływać się do zadań, dokumentów, komentarzy, a nawet połączonych aplikacji, dostarczając odpowiedzi i działania dostosowane do Twojej rzeczywistej pracy — a nie tylko ogólne sugestie.
- Rozwiązywanie problemów i wskazówki: Natychmiast rozwiązuj problemy, uzyskaj szczegółowe instrukcje lub zapytaj o najlepsze praktyki dotyczące dowolnej funkcji ClickUp. Brain może przeprowadzić Cię przez złożone procesy, zautomatyzować powtarzalne zadania i pomóc w usuwaniu przeszkód.
- Automatyzacja i przyspieszenie cyklu pracy: użyj gotowych lub niestandardowych agentów AI do automatyzacji wieloetapowych cykli pracy, segregowania zgłoszeń lub zarządzania powtarzalnymi zadaniami — oszczędzając wiele godzin tygodniowo.
- Wyszukiwanie zaawansowane: znajdź informacje ukryte w dowolnym miejscu w obszarze roboczym, w tym zadania, dokumenty i zintegrowane narzędzia, nawet jeśli są one stare lub trudne do zlokalizowania za pomocą standardowej wyszukiwarki.
- Podsumowania i aktualizacje w czasie rzeczywistym: generuj na bieżąco aktualizacje projektu, podsumowania spotkań lub raporty z postępów, korzystając z danych z obszarów roboczych na żywo.
- Uproszczenie dokumentacji technicznej: przekształć złożone dokumenty techniczne w jasne, praktyczne procedury lub listy kontrolne, które Twój zespół może stosować nawet pod presją.
- Wielomodelowa inteligencja: wybierz spośród wiodących modeli AI (OpenAI GPT-4. 1, GPT-5, Claude, Gemini i inne), aby uzyskać najlepsze wyniki w każdym zadaniu — bez konieczności wykupywania oddzielnych subskrypcji.
- Bezpieczeństwo i uwzględnienie uprawnień: Brain uzyskuje dostęp wyłącznie do informacji, do których masz już uprawnienia, zachowując ścisłe standardy prywatności i zgodności z przepisami.
- Interfejs konwersacyjny: użyj @brain w komentarzach lub czacie, aby uzyskać kontekstowe informacje, sporządzić projekty odpowiedzi lub być wyzwalaczem automatyzacji bez opuszczania swojego cyklu pracy.
- Niestandardowe podpowiedzi i zapisane cykle pracy: zapisuj i ponownie wykorzystuj podpowiedzi w przypadku powtarzających się potrzeb, zapewniając spójność i oszczędzając czas całego zespołu.
💡Wskazówka dla profesjonalistów: Nie przegap żadnej lekcji z spotkań poświęconych analizie incydentów, rejestrując wszystkie szczegóły za pomocą ClickUp AI Notetaker. Aplikacja ta może dołączyć do wirtualnych spotkań, transkrybować całą dyskusję i automatycznie generować listę elementów wynikających z wyciągniętych wniosków. Tworzy to przeszukiwalną historię incydentów, dzięki czemu można szybko odwołać się do przeszłych wydarzeń i ich rozwiązań.

Zautomatyzowane cykle pracy odzyskiwania danych po awarii dzięki ClickUp Automatyzacjom
Wyobraź sobie, że Twój zespół ma do czynienia z nagłą awarią — liczy się każda sekunda i nie możesz sobie pozwolić na pominięcie ani jednego kroku. Dzięki agentom ClickUp AI i automatyzacji nie musisz się spieszyć ani polegać na pamięci. Gdy tylko zgłoszona zostanie awaria, sztuczna inteligencja ClickUp wkracza do akcji, kierując zespołem i zajmując się rutynowymi zadaniami, abyś mógł skupić się na rozwiązaniu problemu.
Oto jak to działa w rzeczywistej sytuacji:
- Gdy ktoś oznaczy zadanie jako „Zgłoszono incydent”, ClickUp Agent automatycznie tworzy listę kontrolną kroków reagowania, przypisuje je odpowiednim osobom i uruchamia timer, aby śledzić, ile czasu zajmuje przywrócenie sprawności.
- Jeśli incydent zostanie oznaczony jako „krytyczny”, agent może natychmiast wysłać wiadomość e-mail z alertem do kierownictwa i utworzyć specjalny czat — „centrum dowodzenia” — aby wszyscy mogli komunikować się w jednym miejscu.
- AI może wyświetlić raporty z poprzednich incydentów i odpowiednią dokumentację, dzięki czemu Twój zespół ma wszystko, czego potrzebuje, w zasięgu ręki.
Zobacz cykl pracy tutaj:
Dzięki ClickUp AI Agents zyskujesz niezawodnego cyfrowego współpracownika, który pomaga Twojemu zespołowi zachować spokój, organizację i skuteczność — nawet w sytuacjach stresowych.
Śledzenie w czasie rzeczywistym dzięki pulpitom ClickUp
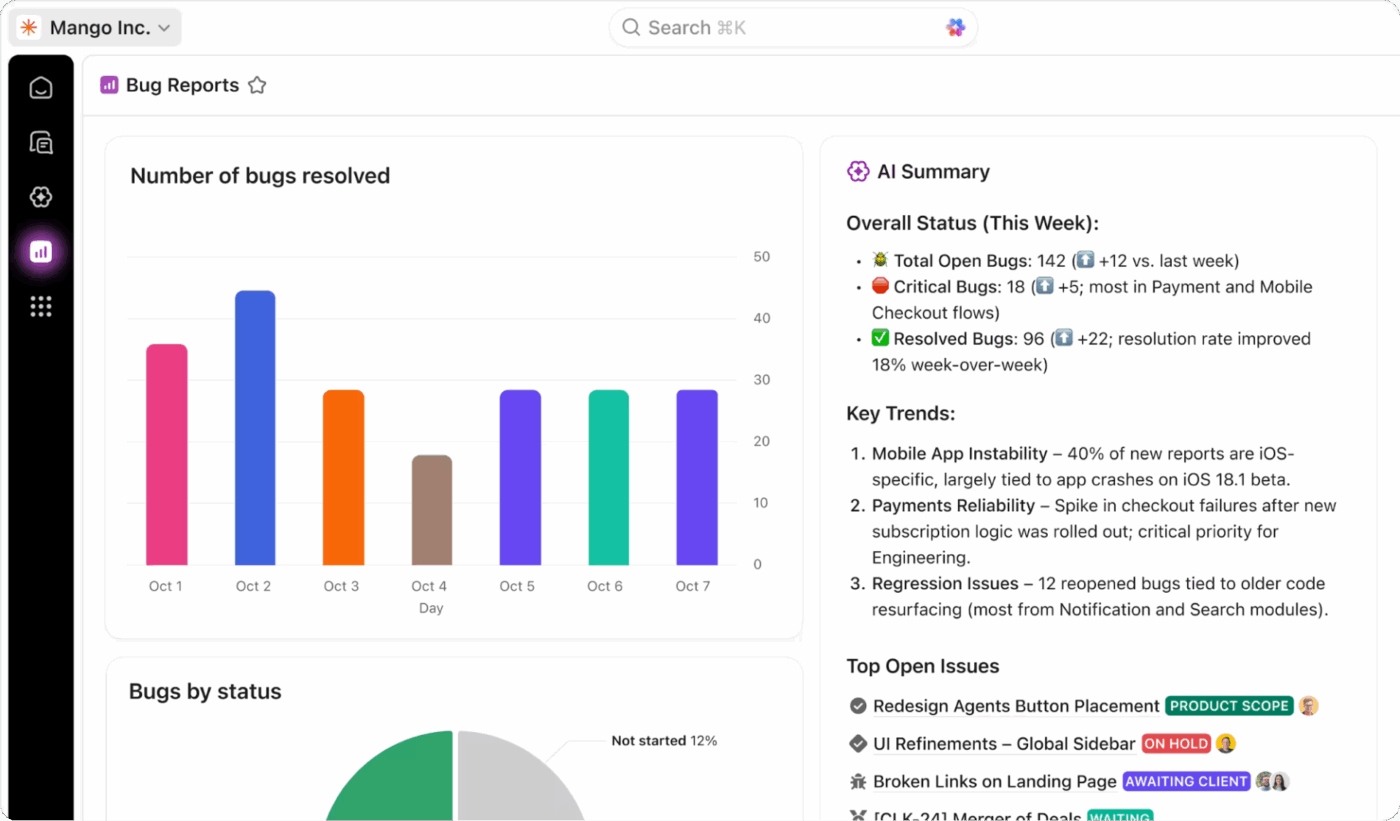
Uzyskaj pełny wgląd w stan swojego programu DR, śledząc wszystko w czasie rzeczywistym za pomocą pulpitów nawigacyjnych ClickUp. Możesz tworzyć widżety do monitorowania wydajności RTO i RPO podczas testów, śledzić wskaźniki ukończenia testów i przeglądać trendy dotyczące incydentów w czasie.
Dodaj pola niestandardowe ClickUp do swoich zadań, aby śledzić krytyczność systemu, status odzyskiwania i wyniki testów, a następnie przenieś wszystkie te dane do jednego widoku ogólnego. Te pulpity nawigacyjne zapewniają gotowe do użycia raporty, które są zawsze aktualne dzięki danym w czasie rzeczywistym pochodzącym z testów i działań zespołu w odpowiedzi na incydenty.
📖 Więcej informacji: Jak stworzyć listę kontrolną do oceny ryzyka
Stwórz swój plan odzyskiwania danych już dziś
Każdy dzień pracy bez planu odzyskiwania danych po awarii to ryzyko, na które nie możesz sobie pozwolić. Katastrofy są nieuniknione — niezależnie od tego, czy są spowodowane przez siły natury, awarie technologiczne czy błędy ludzkie — ale to Twoje przygotowanie decyduje o tym, czy będą one stanowić drobną niedogodność, czy poważną katastrofę.
Kompleksowy plan odzyskiwania danych po awarii wymaga zrozumienia ryzyka, udokumentowania jasnych procedur i regularnego ich testowania. Odpowiednie narzędzia ułatwiają ten proces, eliminując chaos związany z rozproszonymi dokumentami i ręcznymi procesami.
Nawet podstawowe plany awaryjne są lepsze niż brak jakichkolwiek planów w przypadku wystąpienia awarii. Regularne testy i aktualizacje sprawią, że plan odzyskiwania danych po awarii przestanie być zakurzonym dokumentem, a stanie się żywym systemem, który naprawdę chroni Twoją firmę.
Zrób pierwszy krok i już dziś zacznij tworzyć swój plan DR z ClickUp. Zacznij korzystać z ClickUp za darmo i zgromadź wszystkie swoje plany odzyskiwania danych po awarii, dokumentację i reagowanie na incydenty w jednej zunifikowanej platformie. ✨
Często zadawane pytania
Plan odzyskiwania danych po awarii należy przeglądać co najmniej cztery razy w roku i aktualizować natychmiast po wszelkich istotnych zmianach infrastruktury lub rzeczywistych incydentach. Większość organizacji przeprowadza co roku gruntowną, dogłębną rewizję planu, aby uwzględnić wszystkie zdobyte doświadczenia i dostosować się do nowych technologii.
Zespoły IT, zespoły ds. bezpieczeństwa i osoby odpowiedzialne za planowanie ciągłości działania zazwyczaj kierują wysiłkami związanymi z planowaniem i testowaniem odzyskiwania danych po awarii. Potrzebują jednak istotnych informacji od kierowników działów operacyjnych i biznesowych, aby zapewnić zgodność planu z rzeczywistymi potrzebami i priorytetami biznesowymi.
Używaj stoperów i wyraźnych znaczników czasu, aby podczas każdego testu mierzyć rzeczywisty czas przywracania w odniesieniu do zdefiniowanych celów. Bardzo ważne jest, aby w raportach z testów dokumentować wszelkie rozbieżności między celami a rzeczywistą wydajnością, aby móc wprowadzać ulepszenia w przyszłości.
Platformy do zarządzania projektami, takie jak ClickUp, idealnie nadają się do centralizacji dokumentacji, automatyzacji cyklu pracy i śledzenia wskaźników dla całego programu odzyskiwania danych po awarii. Można je następnie połączyć ze specjalistycznymi narzędziami do odzyskiwania danych po awarii, które obsługują techniczne aspekty replikacji danych i przełączania awaryjnego systemu.