

Istnieją dwa rodzaje asystentów AI: jeden, który wie wszystko do ostatniego tygodnia, i drugi, który wie, co wydarzyło się minutę temu.
Jeśli zapytasz pierwszego asystenta AI: „Czy mój lot nadal jest opóźniony?”, może on odpowiedzieć na podstawie wczorajszego rozkładu lotów i udzielić błędnej odpowiedzi. Drugi asystent, korzystający z aktualnych danych, sprawdza aktualizacje na żywo i udziela prawidłowej odpowiedzi.
Drugim asystentem jest to, co nazywamy wiedzą na żywo, którą można zobaczyć w akcji.
Stanowi ona podstawę systemów sztucznej inteligencji opartych na agentach — takich, które nie tylko odpowiadają na pytania, ale także działają, podejmują decyzje, koordynują i dostosowują się. W tym przypadku nacisk kładziony jest na autonomię, zdolność adaptacji i rozumowanie ukierunkowane na cel .
W tym blogu omówimy, co oznacza wiedza na żywo w kontekście AI, dlaczego ma ona znaczenie, jak działa i jak można ją wykorzystać w rzeczywistych cyklach pracy.
Niezależnie od tego, czy zajmujesz się operacjami, produktami, wsparciem czy kierownictwem, ten artykuł dostarczy Ci podstaw do zadawania właściwych pytań, oceny systemów i zrozumienia, w jaki sposób wiedza na żywo może zmienić Twoje technologie i wyniki biznesowe. Zacznijmy.
Czym jest wiedza na żywo w AI agentowej?
Wiedza na żywo odnosi się do informacji, które są aktualne, dostępne w czasie rzeczywistym i dostępne dla systemu AI w momencie, gdy musi on podjąć działanie.
Jest to termin używany zazwyczaj w kontekście sztucznej inteligencji agentowej i otoczenia — agentów AI, którzy tak dobrze znają Twoich pracowników, wiedzę, pracę i procesy, że mogą działać płynnie i proaktywnie w tle.
Wiedza na żywo oznacza, że AI nie opiera się wyłącznie na zbiorze danych, na którym została wyszkolona, ani na migawce wiedzy z momentu wdrożenia. Zamiast tego nieustannie się uczy, utrzymując połączenie z aktualnymi przepływami danych i dostosowując swoje działania w oparciu o to, co faktycznie dzieje się w danej chwili.
W kontekście agentów AI (tj. systemów, które działają lub podejmują decyzje) wiedza na żywo umożliwia im wykrywanie zmian w otoczeniu, integrowanie nowych informacji i wybieranie odpowiednich kolejnych kroków.
Czym różni się od statycznych danych szkoleniowych i tradycyjnych baz wiedzy
Większość tradycyjnych systemów AI jest szkolona na podstawie stałego zestawu danych — takich jak tekst, obrazy lub logi — a następnie wdrażana. Ich wiedza nie ulega zmianie, chyba że zostaną ponownie przeszkolone lub zaktualizowane.
To tak, jakbyś czytał książkę o komputerach wydaną w latach 90. i próbował korzystać z MacBooka z 2025 roku.
Tradycyjne bazy wiedzy (na przykład repozytorium często zadawanych pytań Twojej firmy lub statyczna baza danych specyfikacji produktów) mogą być aktualizowane okresowo, ale nie są zaprojektowane do ciągłego przesyłania nowych informacji i dostosowywania się.
Wiedza na żywo różni się tym, że jest ciągła i dynamiczna — Twój agent działa w oparciu o aktualne dane, zamiast polegać na kopii z pamięci podręcznej.
W skrócie:
- Szkolenie statyczne = „to, co model wiedział w momencie tworzenia”.
- Wiedza na żywo = „to, co model wie o zmianach zachodzących w świecie w czasie rzeczywistym”.
Powiązanie między wiedzą na żywo a autonomią agentów
Systemy AI oparte na agentach zostały stworzone, aby robić więcej niż tylko odpowiadać na pytania.
Mogą one:
- Koordynuj działania
- Planuj wieloetapowe cykle pracy
- Działaj przy minimalnym udziale człowieka
Aby do zrobienia to skutecznie, potrzebują dogłębnego zrozumienia aktualnego stanu, w tym statusu systemów, najnowszych wskaźników biznesowych, kontekstu klienta i wydarzeń zewnętrznych. Dokładnie to zapewnia wiedza na żywo.
Dzięki temu agent może wyczuwać zmiany warunków, dostosowywać ścieżkę podejmowania decyzji i działać w sposób zgodny z aktualną rzeczywistością biznesową lub środowiskową.
Jak wiedza na żywo rozwiązuje problem rozproszenia pracy i niepowiązanych cykli pracy
Wiedza na żywo — czyli połączenie w czasie rzeczywistym do informacji we wszystkich narzędziach — bezpośrednio rozwiązuje codzienne problemy spowodowane chaotycznym rozrostem pracy. Ale co to właściwie jest?
Wyobraź sobie, że pracujesz nad projektem i potrzebujesz najnowszych opinii klientów, ale są one ukryte w wątku e-mailowym, podczas gdy plan projektu znajduje się w oddzielnym narzędziu, a pliki projektowe w jeszcze innej aplikacji. Bez wiedzy na żywo tracisz czas na przełączanie się między platformami, proszenie współpracowników o aktualizacje, a nawet pomijanie kluczowych szczegółów.
Wiedza na żywo zapewnia najlepszy scenariusz, w którym możesz natychmiast wyszukiwać i znajdować informacje zwrotne, przeglądać najnowszy status projektu i uzyskać dostęp do najnowszych projektów — wszystko w jednym miejscu, niezależnie od tego, gdzie znajdują się dane.
Na przykład menedżer ds. marketingu może jednocześnie uzyskać dostęp do wyników kampanii z narzędzi analitycznych, przejrzeć zasoby kreatywne z platformy projektowej i sprawdzić dyskusje zespołu z aplikacji do czatu. Agent wsparcia technicznej może zobaczyć pełną historię klienta — e-maili, zgłoszeń i logi czatu — bez przełączania się między systemami.
Oznacza to mniej czasu poświęconego na poszukiwanie informacji, mniej pominiętych aktualizacji oraz szybsze i pewniejsze podejmowanie decyzji. Krótko mówiąc, wiedza na żywo zapewnia połączenie rozproszonego świata cyfrowego, sprawiając, że codzienna praca przebiega płynniej i jest bardziej wydajna.
Jako pierwsze na świecie zintegrowany obszar roboczy oparty na AI, agent AI Live Intelligence firmy ClickUp zapewnia to wszystko, a nawet więcej. Zobacz, jak działa. 👇🏼
📖 Więcej informacji: Sztuczna inteligencja w zarządzaniu wiedzą: korzyści, przykłady zastosowań i narzędzia
Kluczowe elementy umożliwiające funkcjonowanie systemów wiedzy na żywo
Za każdym systemem wiedzy na żywo kryje się niewidoczna sieć ruchomych elementów: nieustannie pobierających dane, tworząca połączenia źródeł i uczących się na podstawie wyników. Elementy te współpracują ze sobą, aby informacje nie pozostawały tylko w pamięci, ale miały przepływ, aktualizowały się i dostosowywały w miarę postępu pracy.
W praktyce wiedza na żywo opiera się na połączeniu przepływu danych, inteligencji integracyjnej, pamięci kontekstowej i uczenia się opartego na informacji zwrotnej. Każda z tych części odgrywa określoną rolę w utrzymywaniu Twojego obszaru roboczego w stanie informacyjnym i proaktywnym, a nie reaktywnym.
Jednym z największych wyzwań w dynamicznych organizacjach jest rozproszenie pracy. W miarę jak zespoły wdrażają nowe narzędzia i procesy, wiedza może szybko ulec fragmentacji między platformami, kanałami i formatami. Bez systemu, który ujednolica i ujawnia te rozproszone informacje, cenne spostrzeżenia zostają utracone, a zespoły tracą czas na wyszukiwanie lub powielanie pracy. Wiedza na żywo bezpośrednio rozwiązuje problem rozproszenia pracy poprzez ciągłą integrację i połączenie informacji ze wszystkich źródeł, zapewniając dostępność, aktualność i przydatność wiedzy — niezależnie od jej pochodzenia. To ujednolicone podejście zapobiega fragmentacji i umożliwia zespołom pracę w sposób bardziej inteligentny, a nie tylko cięższy.
Oto zestawienie podstawowych bloków, które to umożliwiają, oraz sposób, w jaki są one wykorzystywane w praktyce:
| Komponent | Jak to jest do zrobienia | Jak to działa |
|---|---|---|
| Potoki danych | Ciągle wprowadzaj nowe dane do systemu | Potoki danych wykorzystują API, strumienie zdarzeń i webhooki do pobierania lub przesyłania nowych informacji z wielu narzędzi i środowisk. |
| Warstwy integracji | Stwórz połączenie danych z różnych systemów wewnętrznych i zewnętrznych w jednym ujednoliconym widoku. | Warstwy integracyjne synchronizują informacje między aplikacjami, takimi jak CRM, bazy danych i czujniki IoT, eliminując silosy i powielanie danych. |
| Systemy kontekstowe i pamięciowe | Pomóż AI zapamiętać to, co istotne, i zapomnieć to, co nieistotne. | Systemy te tworzą „pamięć roboczą” dla agentów, umożliwiając im zachowanie kontekstu ostatnich rozmów, działań lub cykli pracy, jednocześnie usuwając nieaktualne dane. |
| Mechanizmy wyszukiwania i aktualizacji | Pozwól systemom uzyskać dostęp do najnowszych informacji w razie potrzeby. | Narzędzia zapytania pobierają dane tuż przed udzieleniem odpowiedzi lub podjęciem decyzji, zapewniając wykorzystanie najnowszych aktualizacji. Wewnętrzne magazyny są automatycznie aktualizowane o nowe informacje. |
| Pętle informacji zwrotnej | Umożliwiaj ciągłe uczenie się i doskonalenie na podstawie wyników. | Mechanizmy informacji zwrotnej analizują przeszłe działania w oparciu o nowe dane, porównując oczekiwane wyniki z rzeczywistymi i odpowiednio dostosowując modele wewnętrzne. |
Wszystkie te elementy razem sprawiają, że AI przechodzi od „wiedzy w jednym momencie” do „ciągłego zrozumienia w czasie rzeczywistym”.
Dlaczego wiedza na żywo ma znaczenie dla agentów AI
Systemy AI są tak dobre, jak wiedza, na podstawie której działają.
W nowoczesnych cyklach pracy wiedza ta zmienia się z minuty na minutę. Niezależnie od tego, czy chodzi o zmieniające się nastroje klientów, ewoluujące dane dotyczące produktów czy wyniki operacyjne w czasie rzeczywistym, statyczne informacje szybko tracą na znaczeniu.
Właśnie w tym miejscu wiedza na żywo staje się niezbędna.
Wiedza na żywo umożliwia agentom AI przejście od biernej reakcji do adaptacyjnego rozwiązywania problemów. Agenci ci nieustannie synchronizują się z rzeczywistymi warunkami, wykrywają zmiany w momencie ich wystąpienia i dostosowują swoje rozumowanie w czasie rzeczywistym. Ta funkcja sprawia, że AI jest bezpieczniejsza, bardziej niezawodna i lepiej dostosowana do ludzkich celów w złożonych, dynamicznych systemach.
Ograniczenia statycznej wiedzy w dynamicznych środowiskach
Gdy systemy AI wykorzystują wyłącznie dane statyczne (tj. te, które były znane w momencie szkolenia lub ostatniej aktualizacji), istnieje ryzyko, że podejmą decyzje, które nie będą już zgodne z rzeczywistością. Na przykład ceny rynkowe uległy zmianie, wydajność serwera pogorszyła się lub dostępność produktów jest inna.
Jeśli agent nie zauważy tych zmian i nie uwzględni ich, może to skutkować niedokładnymi odpowiedziami, nieodpowiednimi działaniami lub, co gorsza, wprowadzeniem ryzyka.
Badania wskazują, że wraz ze wzrostem autonomii systemów, poleganie na nieaktualnych danych staje się poważnym zagrożeniem. Bazy wiedzy AI mogą pomóc wypełnić tę lukę. Obejrzyj ten wideo, aby dowiedzieć się więcej na ten temat. 👇🏼
🌏 Gdy chatboty nie dysponują odpowiednią wiedzą na żywo:
Wirtualny asystent Air Canada oparty na AI przekazał niestandardowemu klientowi nieprawidłowe informacje dotyczące zasad przewozu osób w żałobie. Klient, Jake Moffatt, opłakiwał śmierć swojej babci i skorzystał z chatbota, aby zapytać o rabaty na bilety.
Chatbot błędnie poinformował go, że może kupić bilet w pełnej cenie i ubiegać się o zwrot kosztów w ramach rabatu z tytułu śmierci bliskiej osoby w ciągu 90 dni. Opierając się na tej poradzie, Moffatt zarezerwował drogie loty. Jednak rzeczywista polityka Air Canada wymagała, aby o rabat z tytułu śmierci bliskiej osoby wnioskować przed podróżą i nie można było go zastosować z mocą wsteczną.
Sytuacje z życia wzięte, w których wiedza na żywo ma kluczowe znaczenie
Air Canada to tylko jeden z przykładów. Oto więcej scenariuszy, w których wiedza na żywo może mieć znaczenie:
- Agenci obsługi klienta: Asystent AI, który nie może sprawdzić najnowszego statusu wysyłki lub stanu magazynowego, udzieli nieadekwatnych odpowiedzi lub straci okazję do podjęcia dalszych działań.
- Agenci finansowi: Ceny akcji, kursy waluty lub wskaźniki ekonomiczne zmieniają się z sekundy na sekundę. Model bez danych na żywo będzie pozostawał w tyle za rzeczywistością rynkową.
- Agenci opieki zdrowotnej: Dane dotyczące monitorowania pacjentów (tętno, ciśnienie krwi, wyniki badań laboratoryjnych) mogą się szybko zmieniać. Agenci, którzy nie mają dostępu do aktualnych danych, mogą przeoczyć sygnały ostrzegawcze.
- Agenci DevOps lub operacyjni : Metryki systemowe, incydenty, zachowania użytkowników — zmiany w tych obszarach mogą szybko się nasilać. Agenci potrzebują bieżącej wiedzy, aby w odpowiednim momencie powiadamiać, usuwać problemy lub eskalować je.
Firma Zillow zamknęła swoją działalność związaną z obrotem nieruchomościami (Zillow Offers) po tym, jak jej model AI służący do wyceny domów nie zdołał dokładnie przewidzieć gwałtownych zmian na rynku nieruchomości podczas pandemii, co doprowadziło do ogromnych strat finansowych wynikających z przepłacania za nieruchomości. Podkreśla to ryzyko związane z dryftem modelu w sytuacji gwałtownych zmian wskaźników ekonomicznych.
Wpływ na podejmowanie decyzji przez agentów i dokładność
Dzięki integracji wiedzy na żywo agenci stają się bardziej niezawodni, dokładni i szybcy. Mogą uniknąć „nieaktualnych” decyzji, skrócić czas wykrywania zmian i odpowiednio reagować.
Budują one również zaufanie: użytkownicy wiedzą, że agent „wie, co się dzieje”.
Z punktu widzenia podejmowania decyzji wiedza na żywo gwarantuje, że „dane wejściowe” do planowania i kroków działania agenta są aktualne w danym momencie. Prowadzi to do lepszych wyników, mniejszej liczby błędów i bardziej elastycznych procesów.
Wartość biznesowa i przewaga konkurencyjna
Dla organizacji przejście od statycznej do wiedzy na żywo w agentach AI niesie ze sobą kilka korzyści:
- Szybsza reakcja na zmiany: gdy Twoja AI wie, co się dzieje w danej chwili, możesz szybciej podjąć działania.
- Spersonalizowane i aktualne interakcje: doświadczenia klientów poprawiają się, gdy odpowiedzi odzwierciedlają najnowszy kontekst.
- Odporność operacyjna: systemy, które szybko wykrywają anomalie lub zmiany, mogą ograniczyć ryzyko.
- Przewaga konkurencyjna: jeśli Twoi agenci potrafią dostosowywać się w czasie rzeczywistym, a inni nie, zyskujesz przewagę pod względem szybkości działania i wiedzy.
Podsumowując, wiedza na żywo jest strategiczną zdolnością dla organizacji, które chcą wyprzedzać zmiany.
Jak działa wiedza na żywo: podstawowe komponenty
Wiedza na żywo oznacza cykle pracy na żywo, świadomość i zdolność adaptacyjną.
Gdy wiedza przepływa w czasie rzeczywistym, pomaga zespołom podejmować szybsze i mądrzejsze decyzje.
Oto jak działają systemy wiedzy na żywo, oparte na trzech kluczowych warstwach: źródłach danych w czasie rzeczywistym, metodach integracji i architekturze agentów.
Komponent 1: Źródła danych w czasie rzeczywistym
Każdy system wiedzy na żywo zaczyna się od danych wejściowych: danych stale napływających z narzędzi, aplikacji i codziennych cykli pracy. Dane te mogą pochodzić praktycznie z każdego miejsca, w którym odbywa się praca: od klienta zgłaszającego problem w Zendesk, przedstawiciela handlowego aktualizującego notatki dotyczące transakcji w Salesforce lub programisty przesyłającego nowy kod do GitHub.
Nawet systemy zautomatyzowane dostarczają sygnały: czujniki IoT przekazują raportowanie o wydajności sprzętu, pulpity marketingowe dostarczają dane dotyczące kampanii na żywo, a platformy finansowe aktualizują dane dotyczące przychodów w czasie rzeczywistym.
Te różnorodne strumienie danych tworzą razem podstawę wiedzy na żywo: ciągły, połączony przepływ informacji, który odzwierciedla to, co dzieje się w danej chwili w całym ekosystemie biznesowym. Gdy system AI może natychmiast uzyskać dostęp do tych danych i je zinterpretować, wykracza poza pasywne gromadzenie danych, stając się współpracownikiem działającym w czasie rzeczywistym, który pomaga zespołom szybciej działać, dostosowywać się i podejmować decyzje.
API i webhooki
API i webhooki są spoiwem nowoczesnego obszaru roboczego. API umożliwia uporządkowane udostępnianie danych na żądanie.
Na przykład integracje ClickUp pomagają w ciągu kilku sekund pobrać aktualizacje ze Slacka lub Salesforce. Webhooki idą o krok dalej, automatycznie przesyłając aktualizacje, gdy coś się zmienia, dzięki czemu dane są zawsze aktualne bez konieczności ręcznej synchronizacji. Razem eliminują one „opóźnienia informacyjne”, zapewniając, że system zawsze odzwierciedla bieżącą sytuację.
Połączenia z bazami danych
Połączenia z bazami danych w czasie rzeczywistym umożliwiają modelom monitorowanie danych operacyjnych i reagowanie na ich zmiany. Niezależnie od tego, czy są to informacje o klientach z systemu CRM, czy aktualizacje postępów z narzędzia do zarządzania projektami, ta bezpośrednia ścieżka zapewnia, że decyzje podejmowane przez sztuczną inteligencję są oparte na aktualnych, dokładnych informacjach.
Systemy przetwarzania strumieniowego
Technologie przetwarzania strumieniowego, takie jak Kafka i Flink, przekształcają surowe dane zdarzeń w natychmiastowe informacje. Może to oznaczać alerty w czasie rzeczywistym w przypadku zatrzymania projektu, automatyczne równoważenie obciążenia pracą lub identyfikowanie wąskich gardeł w cyklu pracy, zanim staną się one przeszkodami. Systemy te zapewniają zespołom puls w przebiegu operacji w miarę ich rozwoju.
Zewnętrzne bazy wiedzy
Żaden system nie może funkcjonować w izolacji. Połączenie z zewnętrznymi źródłami wiedzy — dokumentami produktów, bibliotekami badawczymi lub publicznymi zbiorami danych — zapewnia systemom na żywo globalny kontekst.
Oznacza to, że Twój asystent AI rozumie nie tylko co się dzieje w Twoim obszarze roboczym, ale także dlaczego ma to znaczenie w szerszej perspektywie.
📖 Więcej informacji: Jak korzystać z agentów opartych na wiedzy w AI
Komponent 2: Metody integracji wiedzy
Gdy dane już przepływają, kolejnym krokiem jest zintegrowanie ich z żywą, oddychającą warstwą wiedzy, która nieustannie ewoluuje.
Dynamiczne wprowadzanie kontekstu
Kontekst jest sekretnym składnikiem, który zamienia surowe dane w znaczące informacje. Dynamiczne wprowadzanie kontekstu umożliwia systemom AI uwzględnienie najbardziej istotnych, aktualnych informacji — takich jak najnowsze aktualizacje projektu lub priorytety zespołu — dokładnie w momencie podejmowania decyzji. To tak, jakbyś miał asystenta, który w idealnym momencie przypomina Ci dokładnie to, czego potrzebujesz.
Zobacz, jak Brain Agent robi to w ClickUp:
Mechanizmy wyszukiwania w czasie rzeczywistym
Tradycyjne wyszukiwanie oparte na AI opiera się na przechowywanych informacjach. Wyszukiwanie w czasie rzeczywistym idzie o krok dalej, nieustannie skanując i odświeżając połączone źródła, wyświetlając tylko najbardziej aktualną i istotną zawartość.
Na przykład, gdy poprosisz ClickUp Brain o podsumowanie projektu, nie przeszukuje on starych plików — czerpie najświeższe informacje z najnowszych danych na żywo.
Aktualizacje wykresu wiedzy
Wykresy wiedzy przedstawiają związki między ludźmi, zadaniami, celami i pomysłami. Aktualizowanie tych wykresów w czasie rzeczywistym gwarantuje, że zależności ewoluują wraz z cyklem pracy. W miarę zmiany priorytetów lub dodawania nowych zadań wykres automatycznie się równoważy, zapewniając zespołom jasny i zawsze dokładny widok połączeń między zadaniami.
Podejścia oparte na ciągłym uczeniu się
Ciągłe uczenie się pozwala modelom AI dostosowywać się na podstawie opinii użytkowników i zmieniających się wzorców. Każdy komentarz, poprawka i decyzja stają się danymi szkoleniowymi, pomagając systemowi lepiej zrozumieć rzeczywisty sposób pracy Twojego zespołu.
Komponent 3: Architektura agentów dla wiedzy na żywo
Ostatnią warstwą, często najbardziej złożoną, jest sposób, w jaki agenci AI zarządzają wiedzą, zapamiętują ją i ustalają jej priorytety, aby zachować spójność i szybkość reakcji.
Systemy zarządzania pamięcią
Podobnie jak ludzie, AI musi wiedzieć, co zapamiętać, a co odrzucić. Systemy pamięci równoważą pamięć krótkotrwałą z pamięcią długotrwałą, zachowując istotny kontekst (taki jak bieżące cele lub preferencje klientów) i odfiltrowując nieistotne informacje. Dzięki temu system pozostaje sprawny i nie jest przeciążony.
Optymalizacja okna kontekstowego
Okna kontekstowe określają, ile informacji sztuczna inteligencja może „zobaczyć” jednocześnie. Gdy okna te są zoptymalizowane, agenci mogą zarządzać długimi, złożonymi interakcjami bez utraty ważnych szczegółów. W praktyce oznacza to, że sztuczna inteligencja może przywołać całą historię projektu i rozmowy — nie tylko kilka ostatnich wiadomości — umożliwiając bardziej dokładne i trafne odpowiedzi.
Jednak wraz z wdrażaniem przez organizacje coraz większej liczby narzędzi i agentów AI pojawia się nowe wyzwanie: rozrost AI. Wiedza, działania i kontekst mogą ulec fragmentacji między różnymi botami i platformami, co prowadzi do niespójnych odpowiedzi, powielania pracy i pomijania ważnych informacji. Wiedza na żywo rozwiązuje ten problem, ujednolicając informacje i optymalizując okna kontekstowe we wszystkich systemach AI, zapewniając, że każdy agent czerpie informacje z jednego, aktualnego źródła. Takie podejście zapobiega fragmentacji i umożliwia AI zapewnienie spójnego, kompleksowego wsparcia.
Priorytetyzacja informacji
Nie każda wiedza zasługuje na taką samą uwagę. Inteligentne ustalanie priorytetów gwarantuje, że AI skupia się na tym, co naprawdę ważne: pilnych zadaniach, zmieniających się zależnościach lub istotnych zmianach w wydajności. Dzięki filtrowaniu pod kątem wpływu system zapobiega przytłoczeniu danymi i zwiększa przejrzystość.
Strategie buforowania
Szybkość napędza adopcję. Buforowanie często używanych informacji, takich jak ostatnie komentarze, aktualizacje zadań lub wskaźniki wydajności, umożliwia natychmiastowe wyszukiwanie przy jednoczesnym zmniejszeniu obciążenia systemu. Oznacza to, że Twój zespół może płynnie współpracować w czasie rzeczywistym, bez opóźnień między działaniem a uzyskaniem informacji.
Wiedza na żywo zmienia pracę z reaktywnej na proaktywną. Gdy dane w czasie rzeczywistym, ciągłe uczenie się i inteligentna architektura agentów łączą się, Twoje systemy przestają pozostawać w tyle.
To podstawa szybszego podejmowania decyzji, mniejszego ryzyka pominięcia ważnych informacji i bardziej połączonego ekosystemu AI.
📮ClickUp Insight: 18% respondentów naszej ankiety chce wykorzystać AI do organizacji swojego życia poprzez kalendarze, zadania i przypomnienia. Kolejne 15% chce, aby AI zajmowała się rutynowymi zadaniami i pracą administracyjną.
Aby to osiągnąć, AI musi być w stanie: zrozumieć poziomy priorytetów dla każdego zadania w przepływie pracy, wykonać niezbędne kroki w celu utworzenia lub dostosowania zadań oraz ustawić zautomatyzowane przepływy pracy.
Większość narzędzi realizuje jeden lub dwa z tych kroków. Jednak ClickUp pomógł użytkownikom skonsolidować ponad 5 aplikacji za pomocą naszej platformy z ClickUp Brain MAX!
Rodzaje systemów wiedzy na żywo
W tej sekcji zagłębimy się w różne wzorce architektoniczne dostarczania wiedzy na żywo agentom AI — jak wygląda przepływ danych, kiedy agent otrzymuje aktualizacje i jakie są związane z tym kompromisy.
Systemy oparte na pobieraniu danych
W modelu opartym na pobieraniu agent prosi o dane, gdy ich potrzebuje. Można to porównać do ucznia podnoszącego rękę w trakcie lekcji: „Jaka jest aktualna pogoda?” lub „Jakie są najnowsze stany magazynowe?”. Agent wyzwala zapytanie do źródła na żywo (API, baza danych) i wykorzystuje wynik w kolejnym kroku rozumowania.
👉🏽 Dlaczego warto korzystać z modelu pull? Jest on wydajny, gdy agent nie potrzebuje danych na żywo w każdej chwili. Unikasz ciągłego przesyłania wszystkich danych, co może być kosztowne lub niepotrzebne. Zapewnia to również większą kontrolę: sam decydujesz, co i kiedy pobrać.
👉🏽 Kompromisy: Może to powodować opóźnienia — jeśli żądanie danych zajmuje dużo czasu, agent może czekać i reagować wolniej. Ponadto istnieje ryzyko utraty aktualizacji między sondażami (jeśli sprawdzasz je tylko okresowo). Na przykład agent obsługi klienta może pobrać API statusu wysyłki tylko wtedy, gdy klient zapyta „Gdzie jest moje zamówienie?”, zamiast utrzymywać stały dostęp do aktualnych informacji o wydarzeniach związanych z wysyłką.
Systemy oparte na push
W tym przypadku, zamiast czekać na zapytanie agenta, system przesyła aktualizacje do agenta w momencie, gdy coś się zmienia. To tak, jakbyś subskrybował powiadomienia o nowościach: gdy coś się dzieje, natychmiast otrzymujesz powiadomienie. Dla agenta AI, który korzysta z wiedzy na żywo, oznacza to, że zawsze ma on aktualny kontekst w miarę rozwoju wydarzeń.
👉🏽 Dlaczego warto korzystać z technologii push? Zapewnia ona minimalne opóźnienia i wysoką responsywność, ponieważ agent jest świadomy zmian w momencie ich wystąpienia. Jest to cenne w kontekstach wymagających dużej szybkości lub wysokiego ryzyka (np. handel finansowy, monitorowanie stanu systemu).
👉🏽 Wady: Utrzymanie może być droższe i bardziej skomplikowane. Agent może otrzymywać wiele nieistotnych aktualizacji, które wymagają filtrowania i ustalania priorytetów. Potrzebna jest również solidna infrastruktura do obsługi ciągłych strumieni danych. Na przykład agent AI DevOps otrzymuje alerty webhook, gdy wykorzystanie procesora serwera przekroczy próg i inicjuje działanie skalujące.
Podejścia hybrydowe
W praktyce większość solidnych systemów wiedzy na żywo łączy podejście typu pull i push. Agent subskrybuje krytyczne wydarzenia (push) i od czasu do czasu pobiera szersze dane kontekstowe, gdy jest to konieczne (pull).
Ten model hybrydowy pomaga osiągnąć równowagę między responsywnością a kosztami/złożonością. Na przykład w instancji agenta sprzedaży sztuczna inteligencja może otrzymywać powiadomienia push, gdy potencjalny klient otworzy ofertę, a jednocześnie pobierać dane CRM dotyczące historii tego klienta podczas przygotowywania kolejnego kontaktu.
Architektury sterowane wydarzeniami
Podstawą zarówno systemów push, jak i hybrydowych jest koncepcja architektury sterowanej wydarzeniami.
W tym przypadku system jest zbudowany wokół wydarzeń (transakcji biznesowych, odczytów czujników, interakcji użytkowników), które pełnią rolę wyzwalaczy przepływów logicznych, decyzji lub aktualizacji stanu.
Według analiz branżowych platformy strumieniowe i „strumieniowe magazyny danych” stają się warstwami wykonawczymi dla sztucznej inteligencji agentowej, znosząc granicę między danymi historycznymi a danymi na żywo.
W takich systemach zdarzenia są przekazywane przez potoki, wzbogacane o kontekst i przekazywane do agentów, którzy je analizują, podejmują działania, a następnie mogą generować nowe zdarzenia.
Agent wiedzy na żywo staje się w ten sposób węzłem w pętli informacji zwrotnej w czasie rzeczywistym: wyczuwanie → rozumowanie → działanie → aktualizacja.
👉🏽 Dlaczego ma to znaczenie: W systemach sterowanych wydarzeniami wiedza na żywo nie jest tylko dodatkiem — staje się integralną częścią sposobu, w jaki agent postrzega rzeczywistość i na nią wpływa. Kiedy zdarza się jakieś wydarzenie, agent aktualizuje swój model świata i odpowiednio reaguje.
👉🏽 Kompromisy: Wymaga projektowania pod kątem współbieżności, opóźnień, kolejności wydarzeń, obsługi awarii (co się stanie, jeśli wydarzenie zostanie utracone lub opóźnione?) oraz logiki „co jeśli” dla nieprzewidzianych scenariuszy.
Wdrażanie wiedzy na żywo: podejścia techniczne
Budowanie wiedzy na żywo wymaga nieustannie ewoluującej inteligencji inżynieryjnej. Za kulisami organizacje łączą API, architektury strumieniowe, silniki kontekstowe i adaptacyjne modele uczenia się, aby informacje były zawsze aktualne i przydatne.
W tej sekcji przyjrzymy się, jak działają te systemy: technologie zapewniające świadomość w czasie rzeczywistym, wzorce architektoniczne zapewniające skalowalność oraz praktyczne kroki podejmowane przez zespoły w celu przejścia od statycznej wiedzy do ciągłej, aktualnej inteligencji.
Generowanie wspomagane wyszukiwaniem (RAG) z wykorzystaniem źródeł danych na żywo
Jednym z powszechnie stosowanych podejść jest połączenie dużego modelu językowego (LLM) z systemem wyszukiwania na żywo, często nazywanym RAG.
W przypadkach użycia RAG, gdy agent musi odpowiedzieć, najpierw wykonuje krok pobierania: wysyła zapytanie do aktualnych źródeł zewnętrznych (bazy danych wektorowych, interfejsy API, dokumenty). Następnie LLM wykorzystuje pobrane dane (w swojej podpowiedzi lub kontekście) do wygenerowania wyniku.
W przypadku wiedzy na żywo źródłami pobierania danych nie są statyczne archiwa — są to stale aktualizowane, bieżące źródła informacji. Dzięki temu wyniki modelu odzwierciedlają aktualny stan świata.
Kroki wdrożeniowe:
- Zidentyfikuj źródła na żywo (API, strumienie, bazy danych)
- Indeksuj lub umożliwiaj wyszukiwanie (baza danych wektorowych, graf wiedzy, magazyn relacyjny)
- Przy każdej aktywacji agenta: pobierz najnowsze istotne rekordy i wprowadź je do podpowiedzi/kontekstu.
- Generuj odpowiedź
- Opcjonalnie aktualizuj pamięć lub zasoby wiedzy o nowe odkryte fakty.
📖 Więcej informacji: Najlepsze przykłady wykorzystania generowania wspomaganego wyszukiwaniem w praktyce
Serwery MCP i protokoły czasu rzeczywistego
Nowsze standardy, takie jak Model Context Protocol (MCP), mają na celu zdefiniowanie sposobu interakcji modeli z systemami na żywo: punktami końcowymi danych, narzędziami AI, połączeniami i pamięcią kontekstową.
Według białej księgi MCP może odgrywać dla AI taką samą rolę, jaką kiedyś odgrywał protokół HTTP dla sieci (połączenie modeli z narzędziami i danymi).
W praktyce oznacza to, że architektura Twojego agenta może obejmować:
- Serwer MCP, który obsługuje przychodzące żądania z warstwy modelu lub agenta.
- Warstwa usług łącząca się z narzędziami wewnętrznymi/zewnętrznymi, interfejsami API i strumieniami danych na żywo.
- Warstwa zarządzania kontekstem, która utrzymuje stan, pamięć i istotne najnowsze dane.
Dzięki standaryzacji interfejsu system staje się modułowy — agenci mogą podłączać różne źródła danych, narzędzia i wykresy pamięci.
Aktualizacje bazy danych wektorowej
W przypadku wiedzy na żywo wiele systemów utrzymuje bazę danych wektorowych (osadzeń), której zawartość jest stale aktualizowana.
Osadzenia reprezentują nowe dokumenty, punkty danych na żywo i stany encji. Dzięki temu wyszukiwanie jest aktualne. Na przykład, gdy pojawiają się nowe dane z czujników, konwertujesz je na osadzenie i wstawiasz do magazynu wektorów, aby kolejne zapytania mogły je uwzględnić.
Kwestie związane z wdrożeniem:
- Jak często ponownie osadzasz dane na żywo?
- Jak usuwać nieaktualne osadzenia?
- Jak uniknąć nadmiernego obciążenia magazynu wektorowego i zapewnić szybkość zapytań?
Wzorce koordynacji API
Agenci rzadko wywołują pojedyncze API; często wywołują wiele punktów końcowych sekwencyjnie lub równolegle. Wdrożenia wiedzy na żywo wymagają koordynacji. Na przykład:
- Krok 1: Sprawdź API zapasów na żywo
- Krok 2: Jeśli stan magazynowy jest niski, sprawdź API dostawcy ETA.
- Krok 3: Generowanie wiadomości niestandardowej dla klienta na podstawie połączonych wyników
Ta warstwa koordynacyjna może obejmować buforowanie, logikę ponawiania prób, ograniczenie szybkości, rozwiązania awaryjne i agregację danych. Zaprojektowanie tej warstwy ma kluczowe znaczenie dla stabilności i wydajności.
Korzystanie z narzędzi i wywoływanie funkcji
W większości frameworków /AI/ agenci używają narzędzi do podejmowania działań.
Narzędzie to po prostu predefiniowana funkcja, którą agent może wywołać, np. get_stock_price(), check_server_status() lub fetch_customer_order().
Nowoczesne frameworki LLM umożliwiają to dzięki wywoływaniu funkcji, gdzie model decyduje, którego narzędzia użyć, przekazuje odpowiednie parametry i otrzymuje ustrukturyzowaną odpowiedź, którą może przetworzyć.
Agenci wiedzy na żywo idą o krok dalej. Zamiast statycznych lub symulowanych danych, ich narzędzia łączą się bezpośrednio z źródłami w czasie rzeczywistym — bazami danych na żywo, interfejsami API i strumieniami zdarzeń. Agent może pobrać aktualne wyniki, zinterpretować je w kontekście i natychmiast podjąć działanie lub odpowiedzieć. To połączenie między rozumowaniem a danymi ze świata rzeczywistego przekształca model pasywny w adaptacyjny, stale świadomy system.
Kroki wdrożeniowe:
- Zdefiniuj funkcje narzędzi, które obejmują źródła danych na żywo (API, bazy danych).
- Upewnij się, że agent może wybrać narzędzie, które ma wywołać, i generować argumenty.
- Przechwytuj wyniki działania narzędzi i integruj je z kontekstem wnioskowania.
- Zapewnij rejestrowanie, obsługę błędów i rezerwę (co się stanie, jeśli narzędzie zawiedzie?).
📖 Więcej informacji: MCP vs. RAG vs. agenci AI
Przykłady zastosowań i aplikacje
Wiedza na żywo szybko przechodzi od koncepcji do przewagi konkurencyjnej.
Od koordynacji projektów w czasie rzeczywistym po adaptacyjne obsługa klienta i konserwację predykcyjną — organizacje już teraz odnotowują wymierne korzyści w zakresie szybkości, dokładności i przewidywalności.
Poniżej przedstawiamy kilka najbardziej interesujących sposobów wykorzystania wiedzy na żywo w dzisiejszych czasach oraz sposób, w jaki zmienia ona praktyczne znaczenie pojęcia „inteligentna praca”.
Agenci obsługi niestandardowej z dostępem do aktualnych stanów magazynowych produktów
W handlu detalicznym chatbot wsparcia powiązany z systemami magazynowymi i wysyłkowymi na żywo może odpowiadać na pytania takie jak „Czy ten produkt jest dostępny?”, „Kiedy zostanie wysłany?” lub „Czy mogę otrzymać przyspieszoną dostawę?”.
Zamiast polegać na statycznych danych z sekcji FAQ (które mogą zawierać informację „brak w magazynie”, nawet jeśli towar właśnie dotarł), agent wysyła zapytanie w czasie rzeczywistym do API magazynowego i API wysyłek.
Agenci finansowi z dostępem do danych rynkowych
Procesy finansowe wymagają natychmiastowego uzyskiwania informacji.
Agent AI połączony z API danych rynkowych (notowania giełdowe, kursy walut, wskaźniki ekonomiczne) może monitorować zmiany na żywo i albo powiadamiać o nich ludzkich traderów, albo działać autonomicznie w ramach zdefiniowanego parametru.
Warstwa wiedzy na żywo odróżnia prosty pulpit analityczny (statyczne raporty) od autonomicznego agenta, który wykrywa nagły spadek wartości i uruchamia wyzwalacz zabezpieczenia lub transakcji.
Wirtualna asystentka Bank of America, „Erica”, z powodzeniem demonstruje wartość wykorzystania danych w czasie rzeczywistym dla agentów AI w sektorze finansowym. Obsługuje ona setki milionów interakcji z klientami rocznie, uzyskując dostęp do aktualnych informacji o rachunkach, zapewniając spersonalizowane i natychmiastowe wskazówki dotyczące finansów, pomagając w transakcjach i zarządzając budżetami.
Agenci opieki zdrowotnej monitorujący pacjentów
W placówkach opieki zdrowotnej wiedza na żywo oznacza połączenie z czujnikami pacjentów, urządzeniami medycznymi, elektroniczną dokumentacją medyczną (EHR) i strumieniowym przesyłaniem parametrów życiowych.
Agent AI może monitorować tętno pacjenta, poziom tlenu i wyniki badań laboratoryjnych w czasie rzeczywistym, porównywać je z wartościami progowymi lub wzorcami oraz powiadamiać lekarzy lub podejmować zalecane działania (np. eskalować warunek). Systemy wczesnego ostrzeżenia oparte na analizie danych na żywo już teraz pomagają w znacznie wcześniejszym wykrywaniu sepsy lub niewydolności serca niż tradycyjne metody.
Na przykład firma Nvidia opracowuje platformę agentów AI dla przedsiębiorstw, która obsługuje agentów wykonujących określone zadania — w tym agenta zaprojektowanego dla szpitala w Ottawie, który przez całą dobę pomaga pacjentom. Agent ten będzie prowadził pacjentów przez kroki przygotowań przedoperacyjnych, rekonwalescencji pooperacyjnej i rehabilitacji.
Jak wyjaśnia Kimberly Powell, wiceprezes i dyrektor generalna Nvidia ds. opieki zdrowotnej, celem jest zwolnienie czasu lekarzy przy jednoczesnej poprawie jakości obsługi pacjentów.
Agenci DevOps z metrykami systemowymi
W operacjach IT agenci wiedzy na żywo monitorują logi, telemetrię, zdarzenia infrastrukturalne i interfejsy API statusu usług. Gdy występują skoki opóźnień, mnożą się błędy lub wyczerpują się zasoby, agent może być wyzwalaczem działań naprawczych — ponownie uruchomić usługę, zwiększyć dodatkowe obciążenie lub przekierować ruch. Ponieważ agent na bieżąco śledzi stan systemu na żywo, może działać skuteczniej i skrócić czas przestoju.
Agenci sprzedaży z integracją CRM
W sprzedaży wiedza na żywo oznacza, że agenci są połączeni z systemem CRM, platformami komunikacyjnymi i ostatnią aktywnością potencjalnych klientów.
Wyobraź sobie agenta ds. sprzedaży, który monitoruje, kiedy potencjalny klient otwiera ofertę, a następnie podpowiedź przedstawicielowi handlowym: „Twoja oferta otrzymała właśnie widok. Czy chcesz teraz zaplanować działania następcze?”. Agent może pobrać dane dotyczące zaangażowania na żywo, kontekst potencjalnego klienta, historyczne wskaźniki skuteczności — wszystko w sposób dynamiczny — aby przedstawić aktualne, spersonalizowane sugestie. Dzięki temu działania marketingowe przestają być ogólne, a stają się dostosowane do kontekstu.
JPMorgan Chase wykorzystał agentów AI podczas ostatnich zawirowań na rynku, aby szybciej udzielać porad, obsługiwać więcej klientów i zwiększyć sprzedaż. Ich asystent „Coach” oparty na AI pomógł doradcom finansowym uzyskać wgląd w dane nawet o 95% szybciej, umożliwiając firmie zwiększenie sprzedaży brutto o około 20% w latach 2023-24 i osiągnięcie celu, czyli 50% wzrostu liczby klientów w ciągu najbliższych 3-5 lat.
Odblokuj inteligencję na żywo dla swojej organizacji dzięki ClickUp
Dzisiejsze zespoły potrzebują czegoś więcej niż statycznych narzędzi. Potrzebują obszaru roboczego, który aktywnie rozumie, łączy i przyspiesza pracę. ClickUp to pierwsza zintegrowana przestrzeń robocza oparta na AI, zaprojektowana w celu dostarczania wiedzy na żywo poprzez integrację wiedzy, automatyzacji i współpracy w jednej, ujednoliconej platformie.
Ujednolicone wyszukiwanie w przedsiębiorstwie: wiedza w czasie rzeczywistym na wyciągnięcie ręki
Znajduj odpowiedzi natychmiast, niezależnie od tego, gdzie znajdują się informacje. Funkcja Enterprise Search w ClickUp łączy zadania, dokumenty, czat i zintegrowane narzędzia innych firm w jednym pasku wyszukiwania opartym na AI. Zapytania w języku naturalnym zwracają wyniki bogate w kontekst, łącząc dane ustrukturyzowane i nieustrukturyzowane, dzięki czemu możesz szybciej podejmować decyzje.
- Wyszukuj zadania, dokumenty, czaty i zintegrowane narzędzia innych firm za pomocą jednego paska wyszukiwania opartego na sztucznej inteligencji.
- Korzystaj z zapytań w języku naturalnym, aby pobierać ustrukturyzowane i nieustrukturyzowane dane ze wszystkich źródeł zewnętrznych w połączeniu.
- Natychmiastowe wyświetlanie zasad, aktualizacji projektów, plików i wiedzy specjalistycznej wraz z wynikami bogatymi w kontekst.
- Indeksuj i łącz informacje z Google Drive, Slack i innych platform, aby uzyskać całościowy widok sytuacji.
Automatyzuj, koordynuj i analizuj cykle pracy za pomocą agentów AI
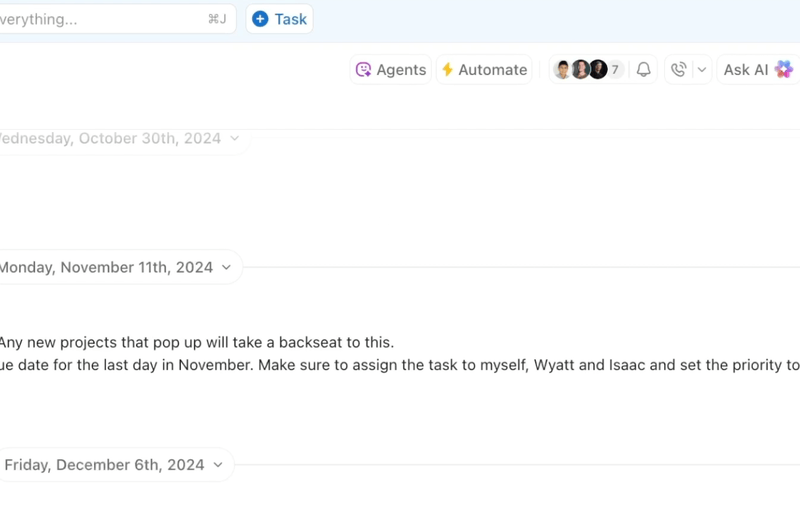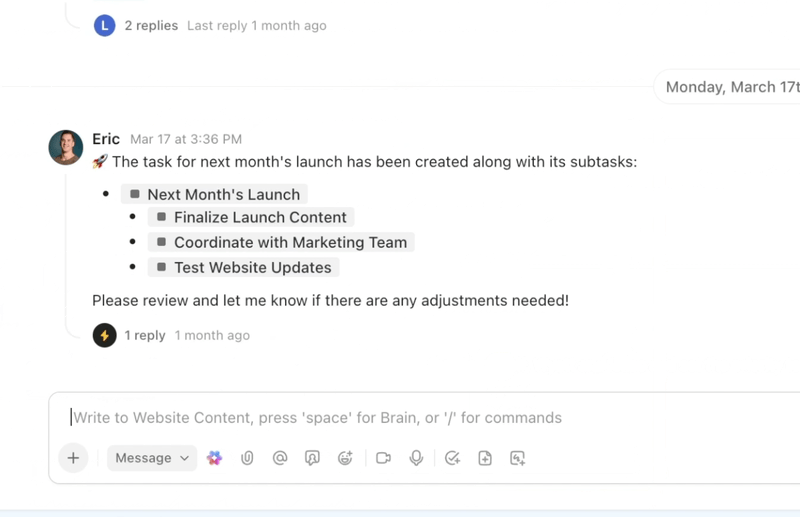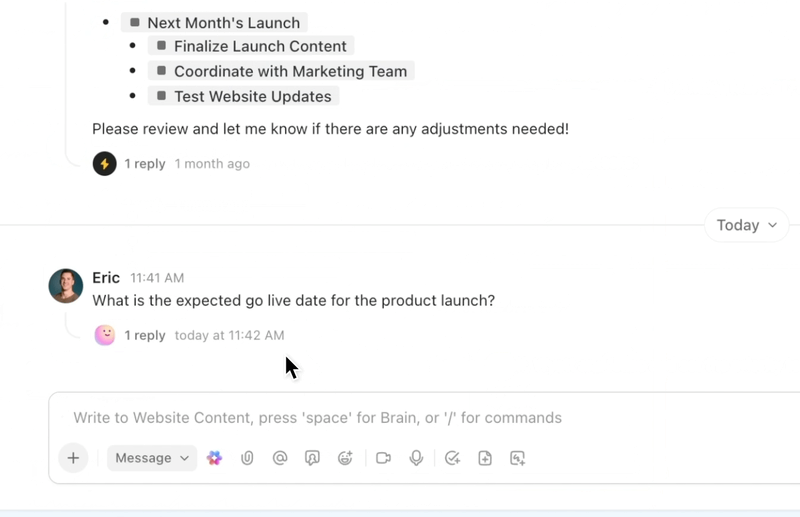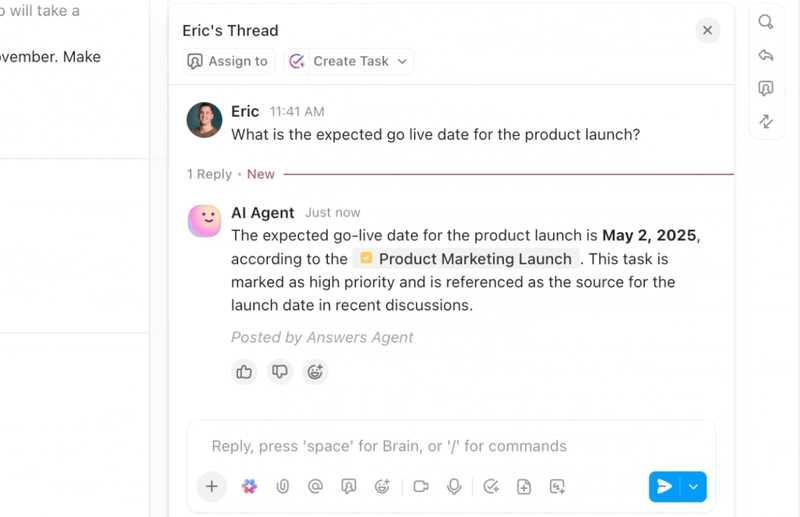
Zautomatyzuj powtarzalne zadania i koordynuj złożone procesy dzięki inteligentnym agentom AI, którzy działają jak cyfrowi współpracownicy. Agenci AI ClickUp wykorzystują dane i kontekst obszaru roboczego w czasie rzeczywistym, co pozwala im rozumować, podejmować działania i dostosowywać się do zmieniających się potrzeb biznesowych.
- Wdrażaj konfigurowalne agenty AI, które automatyzują zadania, segregują żądania i wykonują wieloetapowe cykle pracy.
- Podsumowuj spotkania, generuj zawartość, aktualizuj zadania i uruchamiaj automatyzacje w oparciu o dane w czasie rzeczywistym.
- Dostosuj działania w oparciu o kontekst, zależności i logikę biznesową, korzystając z zaawansowanych funkcji wnioskowania.
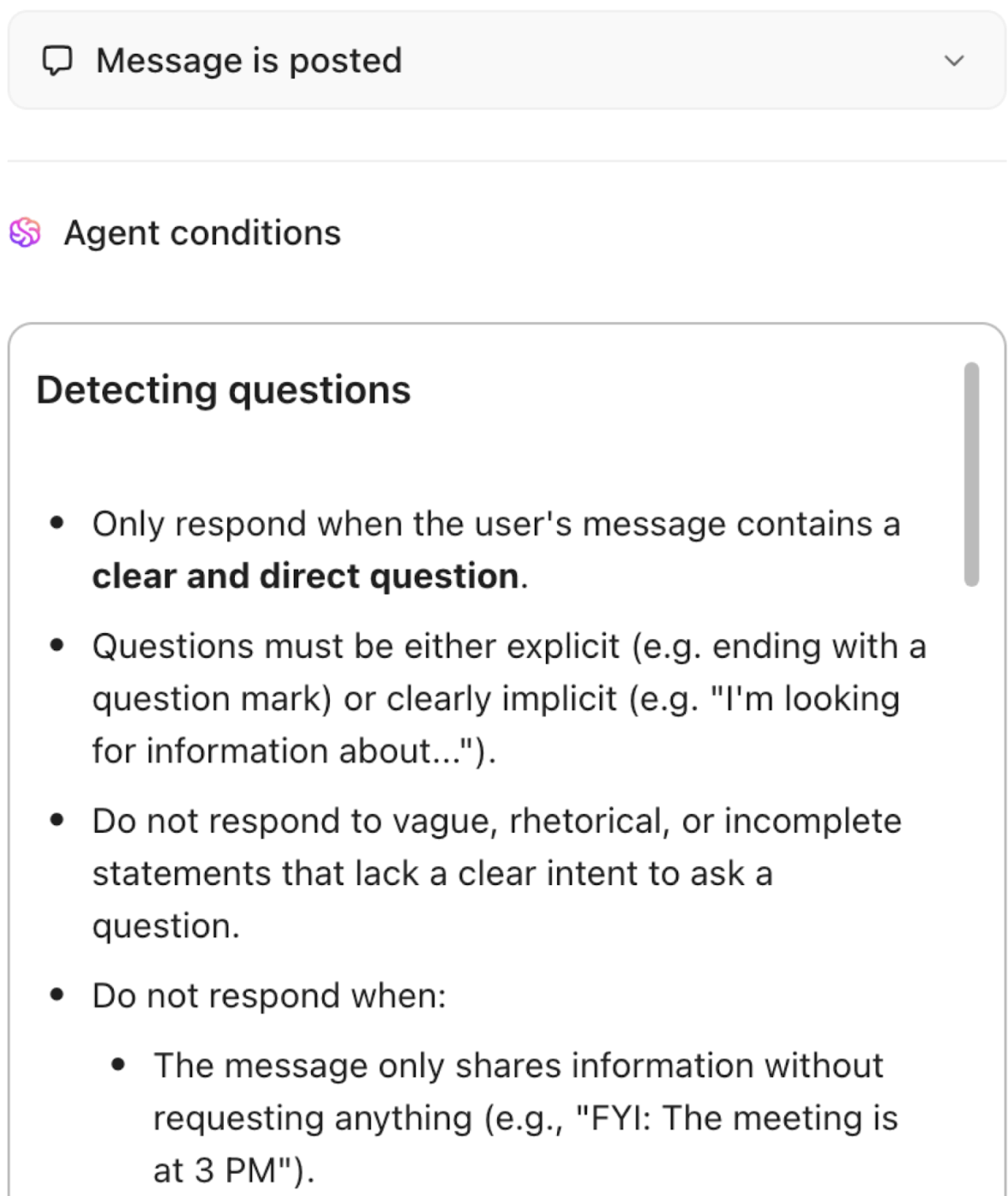
Zarządzanie wiedzą na żywo: dynamiczne, kontekstowe i zawsze aktualne
Zmień statyczną dokumentację w żywą bazę wiedzy. ClickUp Knowledge Management automatycznie indeksuje i łączy połączone informacje z zadań, dokumentów i rozmów, zapewniając, że wiedza jest zawsze aktualna i dostępna. Sugestie oparte na AI wyświetlają odpowiednią zawartość podczas pracy, a inteligentna organizacja i uprawnienia zapewniają bezpieczeństwo poufnych danych.
- Automatycznie indeksuj i łącz informacje z zadań ClickUp, dokumentów ClickUp i rozmów, tworząc żywą bazę wiedzy.
- Podczas pracy odkrywaj istotną zawartość dzięki sugestiom opartym na AI.
- Organizuj wiedzę za pomocą szczegółowych uprawnień, aby zapewnić bezpieczne i łatwe do wyszukiwania udostępnianie.
- Dbaj o to, aby dokumentacja, przewodniki dla nowych pracowników i wiedza instytucjonalna były zawsze aktualne i dostępne.
Zintegrowana współpraca: kontekstowa, połączona i umożliwiająca podejmowanie działań
Współpraca w ClickUp jest głęboko zintegrowana z Twoją pracą.
Edycja w czasie rzeczywistym, podsumowania oparte na AI i rekomendacje kontekstowe sprawiają, że każda rozmowa ma praktyczne zastosowanie. Czat ClickUp, tablice, dokumenty i zadania są ze sobą połączone, dzięki czemu burza mózgów, planowanie i realizacja odbywają się w jednym przepływie.
Pomaga to:
- Współpracuj w czasie rzeczywistym dzięki zintegrowanym dokumentom, tablicom i zadaniom, które są połączone, zapewniając płynny cykl pracy.
- Przekształcaj rozmowy w konkretne, wykonalne kroki dzięki podsumowaniom i rekomendacjom opartym na AI.
- Wizualizuj zależności, przeszkody i status projektu dzięki aktualizacjom na żywo i inteligentnym powiadomieniom.
- Umożliwiaj zespołom międzyfunkcyjnym burzę mózgów, planowanie i realizację zadań w ujednoliconym środowisku.
ClickUp to nie tylko miejsce pracy. To platforma inteligencji na żywo, która łączy wiedzę Twojej organizacji, automatyzuje pracę i zapewnia zespołom praktyczne informacje w czasie rzeczywistym.
Porównaliśmy najlepsze oprogramowanie do wyszukiwania w przedsiębiorstwach i oto wyniki:
Wyzwania i najlepsze praktyki
Chociaż wiedza na żywo oferuje ogromne korzyści, wiąże się również z ryzykiem i złożonością.
Poniżej przedstawiono kluczowe wyzwania związane z AI, przed którymi stoją organizacje, wraz z praktykami mającymi na celu ich złagodzenie.
| Wyzwanie | Opis | najlepsze praktyki |
|---|---|---|
| Optymalizacja opóźnień i wydajności | Połączenie się z danymi na żywo powoduje opóźnienia wynikające z wywołań API, przetwarzania strumieniowego i pobierania danych. Opóźnienia w odpowiedziach negatywnie wpływają na komfort użytkowania i zaufanie użytkowników. | ✅ Buforuj mniej istotne dane, aby uniknąć zbędnego pobierania✅ Nadaj priorytet krytycznym, wrażliwym na czas kanałom; inne odświeżaj rzadziej✅ Optymalizuj pobieranie i wstawianie kontekstu, aby skrócić czas oczekiwania modelu✅ Stale monitoruj wskaźniki opóźnień i ustalaj ustawienia wydajności |
| Aktualność danych a koszt obliczeniowy | Utrzymywanie danych w czasie rzeczywistym dla wszystkich źródeł może być kosztowne i nieefektywne. Nie wszystkie informacje wymagają aktualizacji co sekundę. | ✅ Klasyfikuj dane według ważności (muszą być na żywo vs. mogą być okresowe)✅ Stosuj wielopoziomowe częstotliwości aktualizacji✅ Równoważ wartość i koszt — aktualizuj tylko tak często, jak ma to wpływ na decyzje |
| Bezpieczeństwo i kontrola dostępu | Systemy na żywo często tworzą połączenia z wrażliwymi danymi wewnętrznymi lub zewnętrznymi (CRM, EHR, systemy finansowe), co stwarza ryzyko nieautoryzowanego dostępu lub wycieku danych. | ✅ Wprowadź dostęp oparty na minimalnych uprawnieniach dla API i limituj uprawnienia agentów⃟✅ Kontroluj wszystkie wywołania danych wykonywane przez agenta⃟✅ Zastosuj szyfrowanie, bezpieczne kanały, uwierzytelnianie i rejestrowanie aktywności⃟✅ Wykorzystaj wykrywanie anomalii do oznaczania nietypowych zachowań związanych z dostępem |
| Obsługa błędów i strategie awaryjne | Źródła danych na żywo mogą zawieść z powodu przestoju API, skoków opóźnień lub nieprawidłowo sformatowanych danych. Agenci muszą płynnie radzić sobie z takimi zakłóceniami. | ✅ Wdrażaj ponowne próby, limity czasu i mechanizmy awaryjne (np. dane z pamięci podręcznej, eskalacja do człowieka)✅ Rejestruj i monitoruj wskaźniki błędów, takie jak brakujące dane lub anomalie opóźnień✅ Zapewnij płynną degradację zamiast cichej awarii |
| Zgodność z przepisami i zarządzanie danymi | Wiedza na żywo często obejmuje informacje regulowane lub osobiste, co wymaga ścisłego nadzoru i identyfikowalności. | ✅ Klasyfikuj dane według wrażliwości i stosuj zasady przechowywania danych✅ Zachowaj pochodzenie danych — śledź ich źródło, aktualizacje i wykorzystanie✅ Ustal zasady zarządzania szkoleniem agentów, pamięcią i aktualizacjami danych✅ Zaangażuj zespoły prawne i ds. zgodności na wczesnym etapie, zwłaszcza w sektorach podlegających regulacjom |
📖 Więcej informacji: Najlepsze rozwiązania w zakresie oprogramowania do wyszukiwania dla przedsiębiorstw
Przyszłość wiedzy na żywo w AI
W przyszłości wiedza na żywo będzie nadal ewoluować i kształtować funkcję agentów AI — przechodząc od reakcji do przewidywania, od izolowanych agentów do sieci współpracujących agentów oraz od scentralizowanej chmury do architektur rozproszonych na obrzeżach sieci.
Predykcyjne buforowanie wiedzy
Zamiast czekać na żądania, agenci będą proaktywnie pobierać i buforować dane, które mogą być potrzebne. Modele buforowania predykcyjnego analizują historyczne wzorce dostępu, kontekst czasowy (np. godziny otwarcia rynku) i intencje użytkowników, aby wstępnie załadować dokumenty, kanały informacyjne lub dane telemetryczne do szybkich lokalnych magazynów, umożliwiając agentowi reagowanie z opóźnieniem poniżej sekundy.
Przykłady zastosowań: agent inwestycyjny wstępnie ładuje raporty dotyczące zysków i migawki płynności przed otwarciem rynku; agent obsługi klienta wstępnie pobiera najnowsze zgłoszenia i dokumenty dotyczące produktów przed zaplanowaną rozmową telefoniczną. Badania pokazują, że oparte na AI wstępne pobieranie i umieszczanie w pamięci podręcznej znacznie poprawiają współczynniki trafień i zmniejszają opóźnienia w scenariuszach związanych z dostarczaniem treści i usług.
Powstające standardy i protokoły
Interoperacyjność przyspieszy postęp. Protokoły takie jak Model Context Protocol (MCP) i inicjatywy dostawców (np. serwer MCP firmy Algolia) tworzą standardowe sposoby, dzięki którym agenci mogą żądać, wprowadzać i aktualizować kontekst na żywo z systemów zewnętrznych. Standardy ograniczają ilość niestandardowego kodu łączącego, poprawiają kontrolę bezpieczeństwa (przejrzyste interfejsy i uwierzytelnianie) oraz ułatwiają łączenie i dopasowywanie magazynów pobierania danych, warstw pamięci i silników wnioskowania różnych dostawców. W praktyce wdrożenie interfejsów typu MCP pozwala zespołom na wymianę usług pobierania danych lub dodawanie nowych źródeł danych przy minimalnej przeróbce agentów.
Integracja z systemami brzegowymi i systemami dystrybucyjnymi
Wiedza na żywo na obrzeżach sieci oferuje dwie istotne zalety: zmniejszone opóźnienia i zwiększoną prywatność/kontrolę. Urządzenia i lokalne bramy będą obsługiwać kompaktowe agenty, które wykrywają, analizują i działają lokalnie, synchronizując się selektywnie z repozytoriach w chmurze, gdy pozwala na to sieć lub polityka.
Ten model nadaje się do zastosowania w produkcji (gdzie maszyny fabryczne podejmują lokalne decyzje kontrolne), pojazdach (agentami pokładowymi reagującymi na fuzję czujników) oraz w obszarach podlegających regulacjom, gdzie dane muszą pozostać lokalne. Badania branżowe i raporty dotyczące sztucznej inteligencji na obrzeżach przewidują szybsze podejmowanie decyzji i mniejszą zależność od chmury w miarę dojrzewania technik uczenia rozproszonego i federacyjnego.
Dla zespołów tworzących stosy wiedzy na żywo oznacza to projektowanie architektur warstwowych, w których krytyczne, wrażliwe na opóźnienia wnioskowanie odbywa się lokalnie, podczas gdy długoterminowe uczenie się i intensywne aktualizacje modeli odbywają się centralnie.
Udostępnianie wiedzy między wieloma agentami
Model pojedynczego agenta ustępuje miejsca ekosystemom agentów współpracujących.
Struktury wieloagentowe umożliwiają kilku wyspecjalizowanym agentom udostępnianie świadomości sytuacyjnej, aktualizowanie wspólnych wykresów wiedzy i koordynowanie działań, co czyni je szczególnie przydatnymi w zarządzaniu flotą, łańcuchami dostaw i operacjami na dużą skalę.
Najnowsze badania nad systemami wieloagentowymi opartymi na LLM pokazują metody planowania dystrybucyjnego, specjalizacji roli i budowania konsensusu między agentami. W praktyce zespoły potrzebują schematów udostępnianych (wspólnych ontologii), wydajnych kanałów pub/sub do aktualizacji stanu oraz logiki rozwiązywania konfliktów (kto ma pierwszeństwo i kiedy).
Ciągłe uczenie się i samodoskonalenie
Wiedza na żywo połączy wyszukiwanie, rozumowanie, pamięć, działanie i ciągłe uczenie się w zamknięte pętle. Agenci będą obserwować wyniki, uwzględniać sygnały korygujące i aktualizować pamięć lub wykresy wiedzy, aby poprawić przyszłe zachowania.
Największymi wyzwaniami technicznymi są zapobieganie katastrofalnemu zapominaniu, zachowanie pochodzenia i zapewnienie bezpieczeństwa aktualizacji online. Najnowsze badania dotyczące ciągłego uczenia się online i adaptacji agentów przedstawiają praktyczne podejścia (bufory pamięci epizodycznej, strategie odtwarzania i ograniczone dostrajanie), które umożliwiają ciągłe ulepszanie modeli przy jednoczesnym limitowaniu dryftu. Dla zespołów produktowych oznacza to inwestowanie w oznaczone kanały informacji zwrotnej, bezpieczne zasady aktualizacji i monitorowanie, które łączy zachowanie modelu z rzeczywistymi wskaźnikami KPI.
Wykorzystanie wiedzy na żywo w pracy dzięki ClickUp
Kolejnym krokiem w rozwoju AI w miejscu pracy są nie tylko inteligentniejsze modele.
Wiedza na żywo stanowi pomost między statyczną inteligencją a adaptacyjnym działaniem, umożliwiając agentom AI działanie w oparciu o zrozumienie projektów, priorytetów i postępów w czasie rzeczywistym. Organizacje, które mogą zasilać swoje systemy AI świeżymi, kontekstowymi i wiarygodnymi danymi, uwolnią prawdziwy potencjał inteligencji otoczenia: płynną koordynację, szybszą realizację i lepsze decyzje we wszystkich zespołach.
ClickUp został stworzony z myślą o tej zmianie. Łącząc zadania, dokumenty, cele, czat i spostrzeżenia w jeden połączony system, ClickUp zapewnia agentom AI żywe, dynamiczne źródło informacji — a nie statyczną bazę danych. Jego kontekstowe i otoczeniowe możliwości AI pozwalają na aktualizację informacji w każdym cyklu pracy, zapewniając, że automatyzacja działa w oparciu o rzeczywistość, a nie nieaktualne dane.
W miarę jak praca staje się coraz bardziej dynamiczna, narzędzia rozumiejące kontekst w ruchu będą decydować o kolejnym etapie rozwoju wydajności. Misją ClickUp jest umożliwienie tego — aby każde działanie, aktualizacja i pomysł natychmiast wpływały na kolejne, a zespoły w końcu doświadczyły możliwości AI, gdy wiedza pozostaje aktualna.
Często zadawane pytania
Wiedza na żywo zwiększa wydajność, dostarczając aktualny kontekst: decyzje są podejmowane w oparciu o aktualne fakty, a nie nieaktualne dane. Prowadzi to do dokładniejszych odpowiedzi, szybszych czasów reakcji i zwiększenia zaufania użytkowników.
Chociaż wiele z nich może to robić, nie wszystkie muszą. Agenci działający w stabilnych kontekstach, w których zmiany są niewielkie, mogą nie odnieść tak dużych korzyści. Jednak dla każdego agenta mającego do czynienia z dynamicznym środowiskiem (rynki, niestandardowi klienci, systemy) wiedza na żywo jest potężnym narzędziem.
Testowanie polega na symulowaniu rzeczywistych zmian: zmienianiu danych wejściowych na żywo, wprowadzaniu zdarzeń, mierzeniu opóźnień, weryfikowaniu wyników agentów i sprawdzaniu błędów lub nieaktualnych odpowiedzi. Monitoruj kompleksowe cykle pracy, wyniki użytkowników i niezawodność systemu w rzeczywistych warunkach.