
Vroeger had u voor het voorspellen van uw business-resultaten een data science-team, maandenlange modelontwikkeling en een hoop geluk nodig.
Maar nu 78% van de organisaties volgens McKinsey AI in ten minste één bedrijfsfunctie gebruikt, is die tijd teruggebracht van maanden tot vrijwel onmiddellijke inzichten.
Door die verandering is de druk om voorspellende modellen snel te leveren nog nooit zo groot geweest.
IBM Watsonx comprimeert het proces van het bouwen en implementeren van voorspellende modellen tot een uniforme, browsergebaseerde werkstroom die uw ontwikkelteam binnen enkele minuten kan uitvoeren. Maar snelheid alleen is niet genoeg. Als de voorspellingen die deze modellen genereren geen verbinding vinden met de uitvoerende workflows waarop ze van invloed zijn, hebben ze geen echte impact.
Deze handleiding behandelt elke fase, van het uploaden van je eerste dataset en het trainen van het model tot het implementeren ervan als een live API en, het allerbelangrijkste, de verbinding tussen de gegenereerde inzichten en werkstroomprocessen voor leidinggevenden in tools zoals ClickUp. 🔨
U leert zowel hoe u het model in Watsonx bouwt als hoe u de output ervan in de praktijk brengt, zodat voorspellingen leiden tot actie binnen uw team.
U leert zowel hoe u het model in Watsonx bouwt als hoe u de resultaten ervan in de praktijk brengt, zodat voorspellingen leiden tot actie binnen uw team.
Wat is IBM Watsonx en hoe ondersteunt het voorspellende analyses?
Het implementeren van AI-modellen voor uw business kan betekenen dat u uw modellen op de ene plek traint, uw data op een andere plek beheert en governance of compliance in weer een andere tool afhandelt.
IBM Watsonx is het AI- en dataplatform voor ondernemingen van IBM, ontworpen om de technische kant van deze fragmentatie op te lossen. Het is in feite een suite van AI-producten voor het bouwen, trainen en uitvoeren van AI binnen een onderneming, zonder dat alles versnipperd of experimenteel aanvoelt.
Het platform biedt een oplossing voor gefragmenteerde werkstroomen door één enkele projectwerkruimte te bieden. U kunt gegevens uploaden, experimenten uitvoeren en monitors configureren zonder de omgeving te verlaten.
De Watsonx-suite bestaat uit drie hoofdcomponenten:
- Watsonx.ai: Bouw en train voorspellende modellen met behulp van AutoAI of aangepaste notebooks
- Watsonx. data: maak verbinding en bereid gegevens uit meerdere databronnen voor in een lakehouse-architectuur
- Watsonx. governance: Bijhoud de prestaties van modellen en handhaaf regels voor eerlijkheid
Specifiek voor voorspellende analyses is watsonx.ai het belangrijkste platform dat u zult gebruiken. Het bevat AutoAI, een no-code experimentbouwer die automatisch algoritmen selecteert en kandidaatmodellen rangschikt.
De rest van deze handleiding richt zich op de AutoAI-werkstroom binnen watsonx.ai. Dit is de snelste manier om een werkend voorspellend model van de grond te krijgen.
Stapsgewijze handleiding voor het bouwen van een voorspellend model in Watsonx
In deze handleiding wordt ervan uitgegaan dat u al een IBM Cloud-account hebt en een Watsonx-project hebt aangemaakt. De hele werkstroom kan rechtstreeks in uw browser worden voltooid zonder dat u een lokale installatie hoeft uit te voeren. Dit is hoe u te werk gaat:
Stap 1: Bereid uw gegevens voor en upload ze
Begin met het ordenen van uw gegevens in een tabelformat, zoals een CSV-bestand. Dit bestand moet een duidelijk gedefinieerde target-kolom bevatten die aangeeft wat u precies wilt voorspellen. Het heeft ook kenmerkkolommen nodig, de inputs waaruit het model leert.
Om uw gegevens te uploaden, gaat u naar uw Watsonx-project en opent u het tabblad Assets. Van daaruit kunt u een CSV-bestand rechtstreeks uploaden of een verbinding maken met een databron via watsonx.data.
Let op een aantal veelvoorkomende dataproblemen voordat u begint:
- Ontbrekende waarden: verwijder grote hiaten in cruciale kolommen voordat u de gegevens uploadt, om een hoge nauwkeurigheid te garanderen
- Type doelkolom: Zorg ervoor dat classificatiedoelen categorisch zijn en regressiedoelen numeriek
Stap 2: Train een voorspellend model met AutoAI
Hier begint het trainen van het model. Klik vanuit uw projectwerkruimte op 'Nieuw AutoAI-experiment maken'.
Selecteer uw geüploade dataset en kies uw target-kolom. Van daaruit kunt u het experimenttype en eventuele optionele instellingen configureren, zoals hoe uw gegevens worden verdeeld tussen training en testen.
Voer het experiment uit om AutoAI automatisch een pijplijn-ranglijst te laten genereren. Deze ranglijst rangschikt kandidaatmodellen op basis van de door u gekozen maatstaf, zoals nauwkeurigheid of F1-score.
Elke rij op het klassement vertegenwoordigt een unieke combinatie van machine learning-algoritmen en feature engineering. De pijplijn met de hoogste rangschikking is meestal degene die AutoAI aanbeveelt voor uw specifieke dataset.
Ga er niet vanuit dat de best gerangschikte pijplijn automatisch de juiste keuze is. Het loont de moeite om de twee of drie beste pijplijnen te vergelijken in plaats van klakkeloos de eerste te kiezen. U kunt op elk van deze pijplijnen klikken om te bekijken welke functies het belangrijkst zijn of hoe het model fouten maakt met behulp van verwarringstabellen.
Stap 3: Implementeer uw voorspellende model
Zodra u een succesvolle pijplijn hebt gekozen, slaat u deze op als een model in uw project. Vervolgens moet u dit opgeslagen model promoten naar een implementatieruimte. Een implementatieruimte is een aparte omgeving die speciaal is ontworpen voor productiewerklasten.
U kunt kiezen tussen online en batchimplementatie. Een online implementatie biedt u een realtime REST API voor voorspellingen op aanvraag. Een batchimplementatie beoordeelt grote datasets volgens een vast schema.
Gebruik het ingebouwde tabblad 'Testen' om een voorbeeld van een invoerpayload te verzenden. Zo kunt u de voorspellingsuitvoer verifiëren voordat u deze integreert met downstream-systemen. De implementatie genereert een API-eindpunt en een scoring-URL die externe applicaties kunnen aanroepen.
Stap 4: De prestaties van het model monitoren en evalueren
Een model dat is getraind op historische gegevens kan na verloop van tijd achteruitgaan naarmate patronen in de praktijk veranderen. Deze achteruitgang wordt drift genoemd en kan de kwaliteit van het model in de loop van de tijd ongemerkt verminderen.
Om continu bij te houden hoe uw model in de praktijk presteert en problemen op te sporen voordat ze een probleem worden, schakelt u monitoring in via de Watson OpenScale-component, koppelt u vervolgens uw implementatie aan de monitoringtool en configureert u uw kwaliteitsdrempels voor nauwkeurigheid en precisie.
Als uw voorspelling gevoelige kenmerken bevat, zorg er dan voor dat u fairness-monitors configureert om ervoor te zorgen dat alles onbevooroordeeld blijft.
Het systeem kan per voorspelling uitleg genereren die precies laat zien welke functies tot een specifiek resultaat hebben geleid. Vervolgens kunt u een maandelijkse frequentie instellen om deze monitoringdashboards te bekijken en het model opnieuw te trainen als de kwaliteit achteruitgaat.
Voordat we dit hoofdstuk afsluiten, is het belangrijk om te begrijpen dat bij elke stap in dit proces verschillende mensen betrokken zijn. Zonder een systeem om de uitvoering bij te houden, kan het proces snel vertragen en uit de hand lopen.
- Een data-analist is verantwoordelijk voor het opschonen en valideren van de dataset voordat deze wordt geüpload
- Een machine learning-engineer voert het AutoAI-experiment uit en vergelijkt de beste pijplijnen
- Dezelfde engineer (of een ML-ops-specialist) zorgt voor de implementatie van modellen en de installatie van API's
- Een datawetenschapper of AI-verantwoordelijke bewaakt de prestaties, bekijkt drift-rapporten en beslist wanneer hertraining nodig is
Zonder een gestructureerde manier om dit te beheren, bent u al snel aangewezen op losse aantekeningen, Slack-berichten, e-mails of uw geheugen, en dat is waar vertragingen en gemiste stappen ontstaan. Taakbeheer wordt daardoor cruciaal.
In plaats van deze stappen los van elkaar te laten staan, biedt ClickUp-taak een systeem waarin:
- Elke stap wordt een traceerbare taak
- Elke taak wordt aan de juiste persoon toegewezen
- De voortgang is zichtbaar in de gehele werkstroom
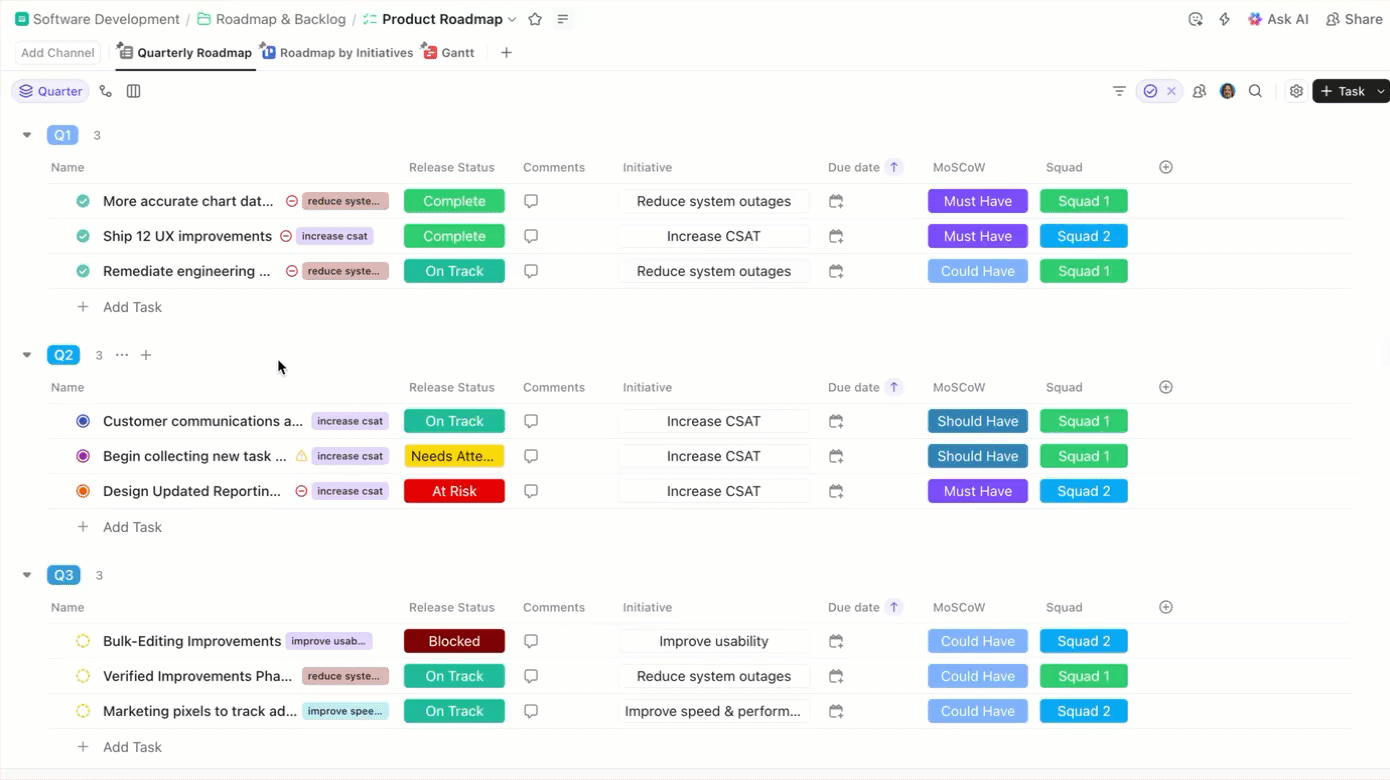
Daar blijft het niet bij. Elke taak wordt ook ondersteund door de context en gestructureerde gegevens die de uitvoering ervan mogelijk maken.
- Aangepaste velden kunnen gestructureerde gegevens vastleggen, zoals modelversie, databron, evaluatiestatistieken, implementatietype of hertrainingsfrequentie
- ClickUp Docs kan ondersteunende documentatie opslaan, zoals richtlijnen voor gegevensvoorbereiding, modelveronderstellingen, experimentantekeningen of implementatie-instructies
In plaats van vage taken worden het dus volledig gecontextualiseerde werkeenheden: duidelijk, toegewezen en klaar om te worden uitgevoerd.
Maar het blijft niet bij het bijhouden van taken; deze taken zijn geen eenmalige handelingen. Het zijn doorlopende werkstroomen die voortdurend een zekere mate van repetitieve handmatige handelingen vereisen.
Bijvoorbeeld:
- Als de nauwkeurigheid van het model onder uw drempelwaarde daalt, moet er iemand worden aangewezen om het model opnieuw te trainen
- Als OpenScale afwijkingen signaleert, moet die waarschuwing worden omgezet in een Taak met een duidelijke eigenaar
- Als een implementatie tijdens het testen mislukt, moet dit worden geregistreerd, toegewezen en snel worden opgelost
ClickUp Automatisering gaat nog een stap verder door handmatige overdrachten tussen deze werkstroomen te elimineren door automatische acties te triggeren op basis van vooraf gedefinieerde voorwaarden.
Als er een nieuwe dataset wordt geüpload, wordt er automatisch een validatietaak aangemaakt en toegewezen aan de data-analist. Zodra deze als 'Klaar' is gemarkeerd, wordt er automatisch een modeltrainingstaak toegewezen aan de machine learning-engineer. Wanneer de training is voltooid, wordt er een implementatietaak geactiveerd voor de ML-ops-specialist.
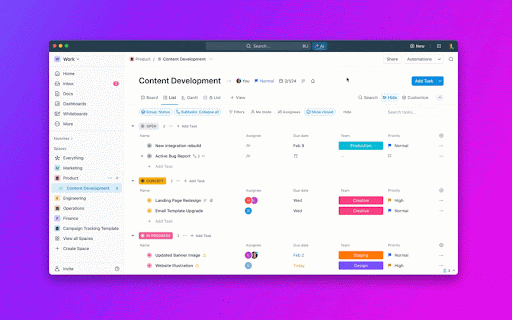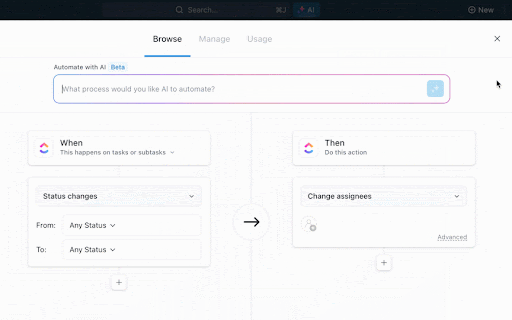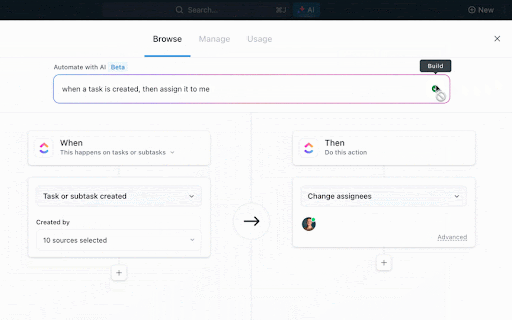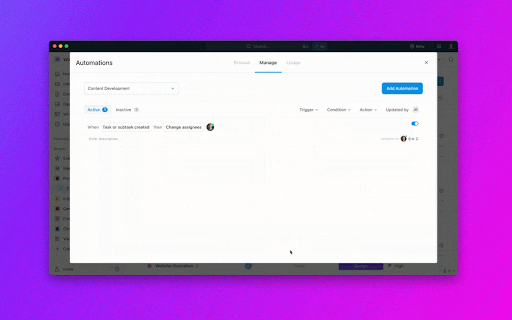
Op deze manier vloeit elke stap naadloos over in de volgende, zonder handmatige overdrachten. Taaken worden automatisch aangemaakt, toegewezen en verrijkt met context, zodat de hele werkstroom zonder onderbrekingen doorloopt.
Toepassingen van voorspellende analyses voor teams
Dit zijn de meest voorkomende manieren waarop teams voorspellende analyses gebruiken:
- Vraagprognoses : Voorspelt de vraag naar uw producten voor het komende kwartaal, zodat uw operationele team tijdig voorraad kan inslaan en tekorten kan voorkomen
- Voorspelling van klantverloop : Beoordeel uw bestaande klanten op basis van de kans dat ze vertrekken en stuur accounts met een hoog risico door naar retentiewerkstroomen
- Projectrisicoscores : Markeer uw projecten die op basis van historische patronen, zoals wijzigingen in de scope, waarschijnlijk de deadline niet zullen halen
- Prognoses voor de verkooppijplijn : Voorspelt welke deals waarschijnlijk worden gesloten en biedt uw verkoopteams een betrouwbare prognose
- Voorspelling van IT-incidenten : Identificeert infrastructuurcomponenten die waarschijnlijk zullen uitvallen op basis van logpatronen
Bij dit alles is het belangrijk om op te merken dat de waarde van deze voorspellingen pas echt tot zijn recht komt wanneer de output rechtstreeks wordt ingevoerd in de tools waarmee uw team de beslissingen uitvoert waarop deze voorspellingen van invloed zijn.
🎯 Onze suggestie: Breng die inzichten onder in een geconvergeerde AI-werkruimte zoals ClickUp.
Met ClickUp beheert u niet alleen werkstroomen voor het trainen van modellen. U voert ook uw dagelijkse activiteiten op dezelfde plek uit, zodat die voorspellingen direct concrete acties binnen teams kunnen triggeren.
- Voor marketing kan een voorspelling van segmenten met een hoge intentie automatisch campagnetaaken genereren
- Voor verkoop kunnen de resultaten van leadscoring worden omgezet in geprioriteerde outreach-taken
- Voor operaties kunnen risicovoorspellingen (zoals klantverloop of storingen) triggers zijn voor follow-ups of interventies
Elk team kan zijn eigen werkstroom structureren binnen ClickUp-taaken, net zoals uw ML-team dat doet voor training en implementatie. Het is hetzelfde systeem, alleen met verschillende use cases.
En het blijft niet bij de uitvoering. Met ClickUp Dashboards kunt u:
- Visualiseer voorspellende inzichten (bijv. segmenten met een hoog risico versus segmenten met een laag risico)
- Blijf bijhouden hoe de taken die op basis van de inzichten zijn gemaakt, voortgaan binnen verschillende teams
- Monitor de werklast binnen teams
- Zie hoe voorspellingen daadwerkelijk worden omgezet in resultaten
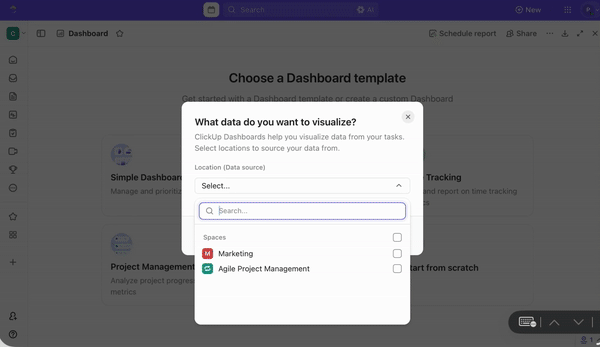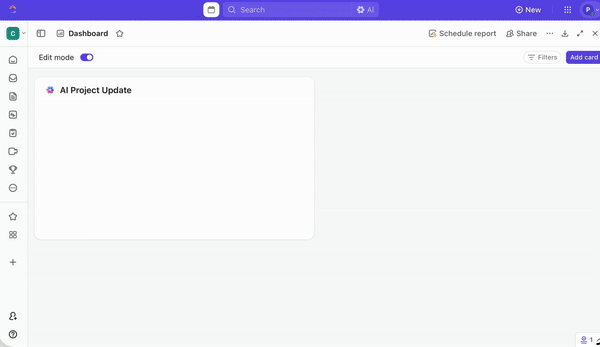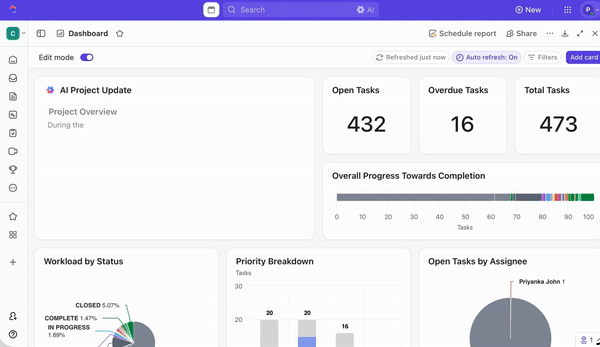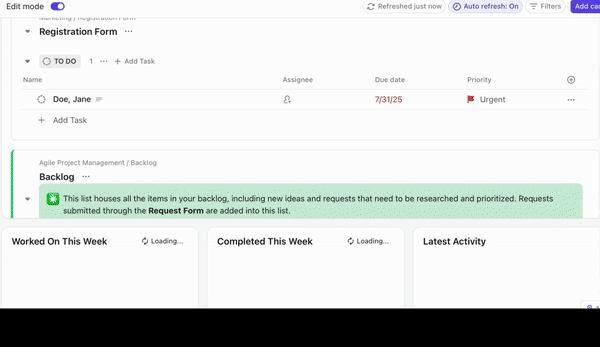
Het enige wat u hoeft te doen is de gewenste widget te kiezen, of het nu gaat om staafdiagrammen, cirkeldiagrammen, lijngrafieken of voortgangstrackers. Op deze manier zit uw model niet in de ene tool en de uitvoering in een andere; alles blijft op één plek met elkaar verbonden.
Uw inzichten vormen niet alleen de basis voor beslissingen; ze triggeren deze, worden toegewezen, bijgehouden en daadwerkelijk uitgevoerd.
💡 Pro-tip: Je kunt ClickUp Brain gebruiken als je ingebouwde AI-assistent in je hele werkruimte.
Het is geen aparte tool; het is de intelligentielaag binnen je ClickUp-werkruimte, wat betekent dat het al context heeft voor je taken, gegevens en werkstroom.
In plaats van alleen maar taken bij te houden, hebt u dus een AI-assistent die met u meedenkt, u helpt te begrijpen wat er gebeurt en sneller actie te ondernemen voor wat nog te doen is.
U kunt bijvoorbeeld een melding van Brain vermelden in een commentaar op de Taak, net zoals u dat bij een teamgenoot zou doen, en vragen:
- ‘Vat het laatste drift-rapport samen en benadruk wat aandacht vereist.’
- 'Wat is er de afgelopen 30 dagen veranderd in de prestaties van ons model?'
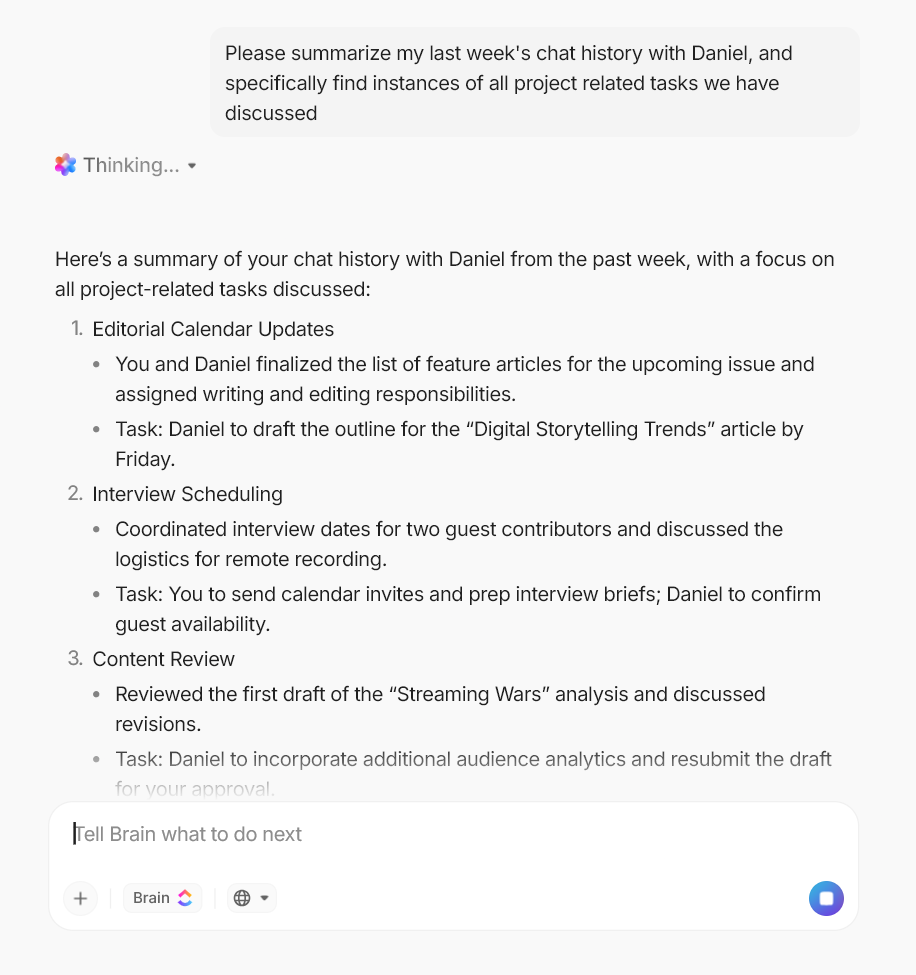
Het haalt gegevens uit uw werkruimte en geeft u direct een duidelijk antwoord. Het kan ook werk voor u genereren. U kunt het vragen om:
- Schrijf een korte update voor belanghebbenden waarin je uitlegt waarom een model opnieuw is geïmplementeerd
- Stel een hertrainingsplan op op basis van recente prestatiedalingen
- Maak een checklist voor het valideren van een nieuwe dataset vóór het trainen
Omdat ClickUp een geconvergeerde werkruimte biedt, hoeft uw team niet te jongleren met afzonderlijke tools voor communicatie en uitvoering.
Al je gesprekken kunnen rechtstreeks in ClickUp Chat plaatsvinden, of het nu gaat om het bespreken van een afname in modelnauwkeurigheid, het beoordelen van een gemarkeerde driftwaarschuwing of het bepalen van de volgende stappen na een mislukte implementatie.
Maar wat nog belangrijker is: die gesprekken blijven niet zomaar liggen.
Gebruik 'Opmerkingen toewijzen' om ervoor te zorgen dat discussies tot actie leiden. Tijdens elk gesprek kunt u een bericht toewijzen aan een specifiek teamlid, waardoor het direct een duidelijke actiepunt wordt.
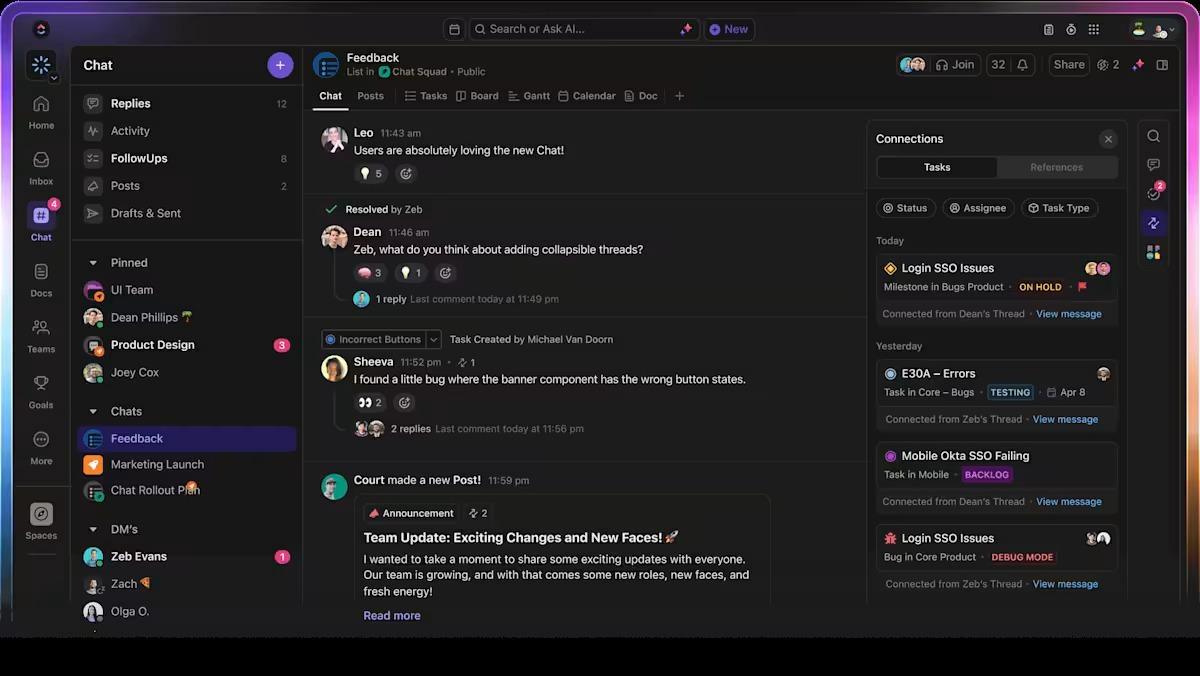
In plaats van dat gesprekken in de vergetelheid raken of eindigen met "we zouden dit moeten doen", worden het taken die daadwerkelijk worden uitgevoerd en van begin tot eind worden bijgehouden, allemaal binnen ClickUp Chat.
🎥 Bekijk dit overzicht van praktijkvoorbeelden van AI-toepassingen om een beter beeld te krijgen van het bredere landschap van AI-toepassingen in de Business. Hierin wordt getoond hoe organisaties kunstmatige intelligentie toepassen in verschillende functies en sectoren. ✨
Beperkingen bij het gebruik van IBM Watsonx voor voorspellende analyses
Elke tool heeft voor- en nadelen, en Watsonx is daarop geen uitzondering. Het is krachtig, ja, maar houd rekening met deze limieten voordat u voor het platform kiest:
- Leercurve: Het configureren van implementatieruimten en governance-monitors vereist nog steeds een goed begrip van cloudplatformconcepten, dus het is wellicht niet de juiste keuze als uw team nog niet veel ervaring heeft met cloudtools of -infrastructuur
- Handmatig gegevensbeheer : Het platform automatiseert het moeilijkste deel van het opschonen en structureren van ruwe gegevens niet, wat betekent dat uw team nog steeds een groot deel van de gegevensvoorbereiding handmatig moet uitvoeren voordat u betrouwbare resultaten kunt krijgen
- Kosten: Het trainen van experimenten en het hosten van live implementaties op IBM Watsonx wordt gefactureerd op basis van gebruik. Bij groeiende werklasten kunnen cloudresources dus snel worden verbruikt naarmate u opschaalt, wat hogere kosten met zich meebrengt
- Werkstroom-integratie: Om op voorspellingen te kunnen reageren, moet u verbinding maken met externe tools voor projectmanagement
- Complexiteit van governance : Het configureren van fairness- en driftmonitors omvat meerdere stappen die voor kleinere teams als een zware last kunnen worden ervaren
Deze limieten laten juist zien waar aanvullende tools moeten worden ingezet. Dit geldt met name voor de actiekant van de voorspellingspijplijn.
📮 ClickUp Insight: 88% van de respondenten in onze enquête gebruikt AI voor persoonlijke taken, maar meer dan 50% schrikt ervoor terug om het op het werk te gebruiken. De drie belangrijkste belemmeringen? Gebrek aan naadloze integratie, kennislacunes of bezorgdheid over de veiligheid.
Maar wat als AI al in je werkruimte is ingebouwd en al veilig is? ClickUp Brain, de ingebouwde AI-assistent van ClickUp, maakt dit mogelijk. Het begrijpt vragen in gewone taal, lost alle drie de zorgen rond AI-implementatie op en maakt tegelijkertijd de verbinding tussen je chat, taken, documenten en kennis in de hele werkruimte mogelijk. Vind antwoorden en inzichten met één enkele klik!
Alternatieve AI-tools voor voorspellende analyses
Watsonx is niet de enige optie op de markt voor voorspellende modellen. Afhankelijk van uw technische kennis kunnen andere platforms beter bij uw stack passen. In de onderstaande tabel worden ze in één oogopslag vergeleken.
| Tool | Meest geschikt voor | Belangrijkste onderscheidende factor |
| IBM Watsonx | Enterprise teams die behoefte hebben aan gecontroleerde, controleerbare AI | AutoAI + ingebouwde governance en driftmonitoring |
| Google Vertex AI | Teams die al in Google Cloud zitten | Nauwe integratie met BigQuery en GCP-services |
| Azure Machine Learning | Organisaties in het Microsoft-ecosysteem | Native verbinding met Power BI en Azure DevOps |
| Amazon SageMaker | AWS-native teams met ML-engineeringmiddelen | Uitgebreide algoritmebibliotheek en flexibele notebookomgeving |
| DataRobot | Bedrijfsanalisten die op zoek zijn naar volledig geautomatiseerde ML | End-to-end-automatisering met sterke standaardinstellingen voor verklaarbaarheid |
| ClickUp Brain | Teams die behoefte hebben aan AI-gestuurde inzichten die direct in hun werkstroomen zijn geïntegreerd | Contextbewuste AI die werkt in taken, documenten en dashboards zonder van tool te wisselen |
📮 ClickUp Insight: Het wisselen van context tast stilletjes de productiviteit van uw team aan. Uit ons onderzoek blijkt dat 42% van de verstoringen op het werk voortkomt uit het schakelen tussen platforms, het beheren van e-mails en het heen en weer springen tussen vergaderingen. Wat als u deze kostbare onderbrekingen zou kunnen elimineren?
ClickUp brengt uw werkstroom (en chat) samen op één gestroomlijnd platform. Start en beheer uw taken vanuit chat, documenten, Whiteboards en meer, terwijl AI-aangedreven functies de context verbonden, doorzoekbaar en beheersbaar houden!
Niet alleen voorspellen, maar ook uitvoeren met ClickUp
Het gebruik van IBM Watsonx voor voorspellende analyses volgt een duidelijk traject, van gegevensvoorbereiding tot driftmonitoring, maar dat is nog maar het makkelijke deel. Het echte werk begint pas wanneer u ervoor zorgt dat die voorspellingen daadwerkelijk de manier waarop uw team werkt, veranderen.
Voorspellingen die in dashboards staan die niemand bekijkt, zijn gewoon verspilde rekenkracht, en de teams die echte waarde halen, maken een directe verbinding tussen de output van hun modellen en hun uitvoeringswerkstroom via automatiserende waarschuwingen en opnieuw geprioriteerde taken.
Als je één werkruimte wilt waar AI-inzichten, projectuitvoering en teamcommunicatie al samenkomen, ga dan vandaag nog gratis aan de slag met ClickUp. ✨
Veelgestelde vragen
Het is een platform voor de onderneming voor data en AI voor het bouwen, trainen en implementeren van machine learning-modellen. Teams gebruiken het om hun data lakehouses te beheren en AI-governance te monitoren vanuit één cloudomgeving.
AutoAI is een tool zonder code die uw tabelgegevens automatisch analyseert om de beste machine learning-algoritmen te selecteren. Het ontwikkelt functies en rangschikt kandidaatmodellen op een ranglijst, zodat u de meest nauwkeurige optie kunt implementeren.
Het platform vereist een gedegen kennis van cloudconcepten om implementatieruimten en governance-monitoren te configureren. Het automatiseert ook niet het handmatige proces van het opschonen en structureren van uw ruwe gegevens vóór het uploaden.