
La maggior parte dei team considera la generazione di SQL come un trucco di magia. Digiti una domanda e ottieni una query.
Ma ecco la realtà: Snowflake Cortex Analyst funziona bene solo quanto il modello semantico che si crea in precedenza, e tale configurazione non è banale. Imparando a utilizzare Snowflake Cortex per la generazione di SQL, i team di dati possono ora trasformare il linguaggio naturale in query complesse ed eseguibili in pochi secondi.
Questa guida ti accompagna attraverso il processo di implementazione vero e proprio, dalla definizione del tuo modello semantico YAML all'esecuzione di query sul tuo data warehouse utilizzando il linguaggio naturale, in modo che tu possa comprendere sia le potenzialità che i prerequisiti prima di iniziare.
Esamineremo inoltre i limiti di Snowflake Cortex e come ClickUp possa fornire supporto ai flussi di lavoro più ampi che ruotano attorno alla generazione di SQL.
Che cos'è Snowflake Cortex Analyst?
Snowflake Cortex Analyst è un servizio completamente gestito che consente di creare applicazioni conversazionali basate sui tuoi dati analitici.
Utilizza un agente text-to-SQL specializzato per trasformare le domande in linguaggio naturale in query accurate ed eseguibili. Questo servizio colma il divario tra strutture di dati complesse e utenti aziendali che necessitano di risposte senza dover scrivere codice.
Le funzionalità principali includono:
- Fornire un'interfaccia altamente accurata per interagire con i dati strutturati
- Utilizzo di modelli semantici per comprendere la tua logica aziendale e la tua terminologia specifiche
- Offre un'API REST per una facile integrazione in applicazioni personalizzate o strumenti di BI
- Garantire la privacy dei dati elaborando le richieste all'interno dei confini di sicurezza di Snowflake
📮 ClickUp Insight: L'88% degli intervistati nel nostro sondaggio utilizza l'IA per le proprie attività personali, ma oltre il 50% esita a usarla sul lavoro. I tre ostacoli principali? Mancanza di integrazione perfetta, lacune di conoscenza o preoccupazioni relative alla sicurezza.
Ma cosa succederebbe se l'IA fosse integrata nel tuo spazio di lavoro e fosse già sicura? ClickUp Brain, l'assistente IA integrato di ClickUp, lo rende realtà. Comprende i prompt in linguaggio semplice, risolvendo tutte e tre le preoccupazioni relative all'adozione dell'IA e creando al contempo una connessione tra chat, attività, documenti e conoscenze in tutto lo spazio di lavoro.
Trova risposte e approfondimenti con un solo clic!
Prerequisiti per la generazione di SQL con Snowflake Cortex
Affrontare Snowflake Cortex senza la configurazione corretta porta a frustrazione. Potresti ottenere risultati imprecisi, perdere tempo nella risoluzione dei problemi e concludere erroneamente che lo strumento non funziona, quando il vero problema è una base debole.
Per evitare ciò, devi prima mettere in atto tre elementi fondamentali.
1. Configura il database e le tabelle
La tua IA è intelligente solo quanto i dati a cui può accedere. Se lo schema del tuo database è un labirinto di nomi di colonne criptici come cust_dat_v2_final, sia i tuoi analisti che l'IA faranno fatica a capirci qualcosa.
Questa confusione porta l'IA a generare join errati o a estrarre dati dalle colonne sbagliate, e il tuo team spreca ore solo cercando di decifrare lo schema prima ancora di poter scrivere una query.
Inizia assicurandoti che il tuo software di data warehouse contenga le tabelle che desideri vengano queryate da Cortex Analyst. Quando possibile, utilizza nomi di colonne chiari e descrittivi. Ad esempio, una colonna denominata customer_lifetime_value è molto più intuitiva sia per gli esseri umani che per l'IA rispetto a clv_01.
Per procedere con la configurazione, il tuo ruolo Snowflake dovrà disporre delle seguenti autorizzazioni:
- UTILIZZO: Sul database e sullo schema contenenti le tue tabelle
- SELECT: Sulle tabelle che desideri che Cortex Analyst query
- CREATE FASE: Nello schema, necessario per caricare il file del modello semantico
📖 Leggi anche: Come utilizzare Snowflake Cortex per la Business Intelligence aziendale
2. Crea il tuo file di modello semantico
L'ostacolo maggiore con qualsiasi strumento di conversione da testo a SQL è che l'IA non parla il linguaggio specifico della tua azienda. Non sa di per sé che "ARR" significa "Annual Recurring Revenue" (ricavi ricorrenti annuali) o che la tabella dei clienti si unisce alla tabella degli ordini sul campo customer_id.
Senza questo contesto, l'IA potrebbe generare un codice SQL tecnicamente valido ma logicamente errato, fornendo risposte che sembrano corrette ma sono pericolosamente fuorvianti.
La soluzione è il modello semantico. Si tratta di un file YAML che funge da "livello di traduzione" personalizzato, insegnando a Cortex Analyst il vocabolario e la logica specifici della tua azienda. La creazione e la manutenzione di questo file richiedono un lavoro collaborativo tra i data engineer, che utilizzano strumenti ETL per conoscere lo schema, e i business analyst, che conoscono la terminologia.
Il tuo file del modello semantico dovrebbe contenere questi componenti chiave:
| Componente | Scopo |
| Tabella | Elenca ogni tabella con una descrizione in linguaggio semplice del suo scopo |
| Colonne | Definisce il tipo semantico di ciascuna colonna (come categoria o metrica) e può includere valori di esempio |
| Relazioni | Specifica come le tabelle si collegano tramite join, eliminando ogni margine di incertezza per l'IA |
| Queries verificate | Fornisce coppie di domande e SQL di esempio che fungono da guide efficaci per l'LLM |
3. Configurare Cortex Search Service (facoltativo)
A volte, le risposte di cui hai bisogno sono nascoste in testi non strutturati, come descrizioni di prodotti, ticket di supporto o trascrizioni di chiamate. Le query SQL standard non sono in grado di elaborare questi dati, il che significa che spesso ti sfugge il "perché" dietro al "cosa".
Qui puoi aggiungere, se lo desideri, Snowflake Cortex Search Service. Si tratta di un livello di ricerca come servizio che ti consente di eseguire query sia sulle tue tabelle strutturate che sui tuoi dati di testo non strutturati utilizzando contemporaneamente agenti IA per l'analisi dei dati.
Dovresti configurare Cortex Search se i tuoi analisti devono porre domande che richiedono l'estrazione del contesto dal testo prima di generare l'SQL. Ad esempio, potresti prima cercare tutte le recensioni dei prodotti contenenti la frase "problema di batteria" e poi generare una query SQL per aggregare i dati di vendita solo di quei prodotti.
Per la generazione di SQL puro su tabelle strutturate, questo servizio non è necessario.
🧠 Curiosità: All'inizio degli anni '70, i ricercatori IBM Donald Chamberlin e Raymond Boyce crearono lo "Structured English Query Language". Dovettero cambiare il nome in SQL perché "SEQUEL" era già un marchio registrato da un'azienda aeronautica britannica.
Guida passo passo alla generazione di SQL con Cortex Analyst
Hai terminato il lavoro preparatorio, ma ora ti trovi di fronte a una schermata vuota, senza sapere bene quale sia il flusso di lavoro effettivo. Come si fa a passare da una domanda nella tua mente a una query SQL eseguibile? Quando la gestione del flusso di lavoro non è chiara, spesso i nuovi strumenti rimangono inutilizzati e l'investimento nella configurazione va sprecato.
Il processo pratico è piacevolmente semplice. Ecco una panoramica più dettagliata!
Passaggio n. 1: prepara i tuoi dati in Snowflake
Prima di tutto, i tuoi dati strutturati devono risiedere all'interno di Snowflake. Ogni applicazione Cortex Analyst è indirizzata a una singola tabella o a una vista composta da una o più tabelle. Assicurati che le tue tabelle siano state create e sottoposte a popolazione.
Se stai caricando da file flat:
- Carica i tuoi file di dati (ad es. CSV) su una fase di Snowflake
- Utilizza il comando COPY INTO per caricare i dati dalla fase nelle tue tabelle
- Verifica che l'esito del caricamento dei dati sia positivo prima di proseguire
📖 Leggi anche: Come utilizzare Snowflake Cortex per l'analisi dell'azienda
Passaggio n. 2: Crea un modello semantico (o una vista semantica)
Questo è il passaggio più importante della configurazione. La potenza di Cortex Analyst deriva dalla combinazione di modelli linguistici di grandi dimensioni (LLM) con modelli semantici, un file YAML che affianca lo schema del database e codifica il contesto aziendale.
Le viste semantiche sono ora il metodo consigliato da Snowflake per Cortex Analyst. Esse memorizzano metriche aziendali, relazioni e definizioni direttamente all'interno di Snowflake. I file di modelli semantici YAML legacy funzionano ancora, ma Snowflake indirizza le nuove implementazioni verso le viste semantiche.
Il tuo modello semantico o la tua vista dovrebbero includere:
- Descrizioni delle tabelle e delle colonne: spiegazioni in linguaggio semplice del significato di ciascun campo
- Metriche aziendali: definizioni per campi calcolati come fatturato, tasso di abbandono o tasso di conversione
- Filtri e sinonimi: termini alternativi che gli utenti potrebbero utilizzare (ad es. "annullato" mappato a un valore di stato specifico)
- Query verificate: il Verified Query Repository di Snowflake memorizza coppie approvate di domande e SQL. Quando una domanda dell'utente assomiglia a una di queste voci, Cortex Analyst può farvi riferimento durante la generazione di SQL
🤝 Promemoria: Snowflake consiglia di utilizzare non più di 10 tabelle e non più di 50 colonne selezionate per ottenere prestazioni ottimali nel flusso di lavoro Snowsight.
Passaggio n. 3: carica il modello semantico su una fase Snowflake
Se stai utilizzando un modello semantico basato su YAML, è necessario che sia caricato in modo che Cortex Analyst possa farvi riferimento in fase di esecuzione.
- Carica il tuo file .yaml in una fase interna di Snowflake (ad es. RAW_DATA)
- Verifica che il file sia presente nella fase tramite l'interfaccia utente di Snowsight o il comando LIST @stage_name
- Prendi nota del percorso della fase; lo utilizzerai nelle tue chiamate API o nella configurazione dell'app
Se stai utilizzando una vista semantica, questo passaggio viene gestito in modo nativo all'interno di Snowflake e non è necessario alcun caricamento separato.
🔍 Lo sapevi? In SQL, NULL non significa zero o vuoto. Rappresenta dati sconosciuti o mancanti, il che porta a comportamenti controintuitivi come confronti che non restituiscono né vero né falso.
Passaggio n. 4: invia una domanda in linguaggio naturale tramite l'API REST
Ora inizia la generazione effettiva dell'SQL. L'API REST genera una query SQL per una determinata domanda utilizzando un modello semantico o una vista semantica forniti nella richiesta.
Struttura la tua richiesta API con:
- messaggi; una matrice contenente la domanda dell'utente con ruolo: “user”
- Un riferimento al tuo modello semantico o alla tua vista semantica
- Il tuo modello preferito (oppure lascia l'impostazione su "Auto" affinché Cortex effettui la selezione del modello migliore)
Puoi avere conversazioni a più turni in cui puoi porre domande di approfondimento che si basano sulle query precedenti.
Passaggio n. 5: Analizza la risposta dell'API
Ogni messaggio in una risposta può contenere più blocchi di contenuto di tipi diversi. I tre valori attualmente supportati per il campo type sono: testo, suggerimenti e SQL.
Ecco cosa significa ogni tipo:
- SQL: Cortex ha generato correttamente una query; questa è quella che dovrai eseguire
- testo: Una spiegazione o una risposta in linguaggio naturale che accompagna l'SQL
- suggerimenti: Il tipo di contenuto "suggerimento" viene incluso in una risposta solo se la domanda dell'utente era ambigua e Cortex Analyst non è riuscito a restituire un'istruzione SQL per quella query. Utilizzali per chiarire o perfezionare la domanda
🔍 Lo sapevi? L'ordine in cui scrivi l'SQL non è l'ordine in cui viene eseguito. Anche se scrivi SELECT per primo, i database in realtà elaborano FROM e WHERE prima della selezione delle colonne. Questo confonde sia i principianti che gli utenti esperti.
Passaggio n. 6: Esegui l'SQL generato in Snowflake
Una volta ottenuto il blocco SQL dalla risposta, eseguilo sul tuo magazzino virtuale Snowflake. La query SQL generata viene eseguita nel tuo magazzino virtuale Snowflake per generare l'output finale. I dati rimangono all'interno dei confini di governance di Snowflake.
Aspetti fondamentali da conoscere al momento dell'esecuzione:
- Cortex Analyst si integra completamente con le politiche di controllo degli accessi basato sui ruoli (RBAC) di Snowflake, garantendo che le query SQL generate ed eseguite rispettino tutti i controlli di accesso stabiliti
- Se un utente non ha accesso a una tabella, la query fallirà in fase di esecuzione, proprio come accadrebbe con un codice SQL scritto manualmente
- In questa fase si applicano i costi di elaborazione del data warehouse, separatamente dai costi di utilizzo di Cortex Analyst
Passaggio n. 7: perfeziona e ripeti
Non è sempre garantito ottenere una query perfetta al primo tentativo. Ecco come migliorare i risultati nel tempo:
- Aggiungi query verificate al tuo modello semantico per le domande che ricorrono più volte
- Arricchisci il tuo modello semantico con descrizioni, sinonimi e filtri più efficaci quando Cortex interpreta erroneamente un termine
- Utilizza le conversazioni a più turni per approfondire, ad esempio: "Ora filtra per regione"; le conversazioni a più turni consentono di porre domande di approfondimento che si basano sulle query precedenti
- Monitora l'utilizzo tramite CORTEX_ANALYST_USAGE_HISTORY e la cronologia delle query di Snowflake per individuare modelli ricorrenti nelle query non riuscite o imprecise
🧠 Curiosità: Una sola condizione JOIN mancante può causare enormi problemi. Dimenticare una condizione JOIN può generare un prodotto cartesiano, moltiplicando drasticamente le righe e talvolta causando il crash dei sistemi.
Best practice per la precisione di Snowflake Text-to-SQL
La qualità del tuo modello semantico determina direttamente l'accuratezza delle query che genera. Ecco le best practice per migliorare l'accuratezza. 🛠️
- Aggiungi query verificate al tuo modello semantico: questa è la cosa più efficace che puoi fare. Includi numerose coppie di domande-SQL di esempio che riflettano il modo in cui il tuo team pone realmente le domande
- Utilizza nomi descrittivi per colonne e tabelle: il modello funziona meglio quando i nomi delle colonne e delle tabelle sono intuitivi. Se non puoi modificare lo schema, aggiungi descrizioni chiare nel tuo file YAML per eventuali nomi di colonne poco chiari
- Includi valori di esempio: l'aggiunta di dati di esempio per le colonne categoriali (come stato o regione) aiuta il modello a comprendere le opzioni di filtro valide disponibili
- Esegui test con casi limite: durante lo sviluppo, poni intenzionalmente domande ambigue o complesse per identificare dove il tuo modello semantico necessita di maggiore contesto o chiarimenti
- Iterare sul modello semantico: Considera il tuo modello semantico come un documento in continua evoluzione. Dovrebbe essere aggiornato costantemente attraverso un processo iterativo basato sulle query che hanno esito positivo e su quelle che falliscono
ClickUp: un'alternativa più semplice a Snowflake Cortex
Snowflake Cortex è particolarmente indicato quando i team desiderano generare SQL ed eseguire query su dati strutturati. I team definiscono schemi, mappano relazioni e scrivono query per estrarre informazioni. Questa configurazione è ideale per ambienti con grandi volumi di dati, specialmente quando la responsabilità della reportistica ricade sugli analisti.
Molti team, tuttavia, non hanno bisogno di un livello SQL completo per rispondere alle domande operative quotidiane. I product manager, i responsabili di programma e i team operativi spesso desiderano risposte rapide legate al lavoro in corso.
ClickUp offre un percorso più accessibile. I team pongono domande in linguaggio semplice, esaminano dashboard in tempo reale e agiscono sulla base delle informazioni ottenute senza dover scrivere codice SQL o creare modelli semantici.
Genera e perfeziona il codice SQL più rapidamente
Snowflake Cortex si concentra sulla generazione di query SQL da set di dati strutturati all'interno di un ambiente di data warehouse. Questo funziona bene quando i tuoi dati risiedono già in Snowflake e hai mappato gli schemi.

ClickUp Brain supporta la generazione di SQL in modo più flessibile e incentrato sull'esecuzione. I team generano, perfezionano e archiviano le query SQL direttamente all'interno del proprio spazio di lavoro, dove già avvengono analisi, discussioni e decisioni.
Supponiamo che un analista di prodotto stia lavorando a un'analisi di fidelizzazione all'interno di ClickUp. Invece di cambiare strumento per scrivere le query, chiede a ClickUp Brain:
📌 Prova questo prompt: Scrivi una query SQL per calcolare la ritenzione su sette giorni degli utenti raggruppati per coorte di registrazione.
ClickUp Brain genera una query strutturata che include raggruppamenti per coorte, filtri di data e logica di ritenzione. L'analista incolla la query in Snowflake o in un altro data warehouse ed esegue immediatamente l'operazione.
È utile per:
- Scrivi join su più tabelle, come utenti, ordini ed eventi
- Converti domande sui prodotti in inglese semplice in logica SQL pronta per l'esecuzione
- Esegui il debug delle query non funzionanti e spiega i problemi, come join errati o condizioni mancanti
- Riscrivi le query per migliorare le prestazioni o la leggibilità
Ad esempio, durante la revisione di un esperimento di crescita, un marketer chiede: "Scrivi una query SQL per confrontare i tassi di conversione tra due pagine di landing negli ultimi 14 giorni".
ClickUp Brain genera la query utilizzando l'aggregazione condizionale e i filtri di data. Il team la esegue in Snowflake e convalida i risultati dell'esperimento.
📌 Prova questo prompt: Correggi questa query SQL in cui il join duplica le righe e spiega il problema.
ClickUp Brain identifica il problema di join, corregge la query e spiega come si sono verificati i record duplicati a causa di condizioni di join errate.
Sostituisci la reportistica basata su SQL
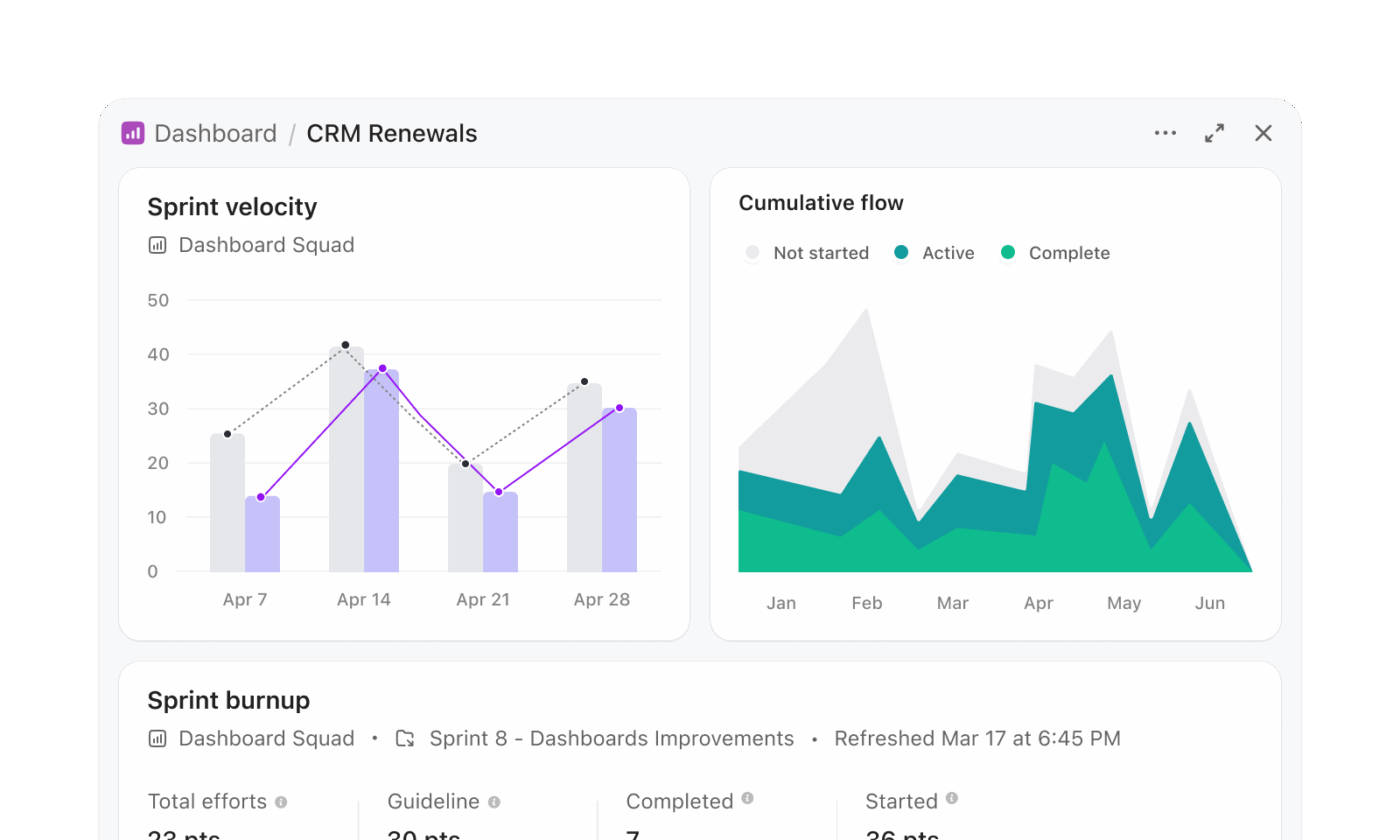
I flussi di lavoro di Snowflake Cortex spesso comportano la generazione di SQL, l'esecuzione di query e la visualizzazione dei risultati in un livello separato. Le dashboard di ClickUp eliminano questo processo in più passaggi e presentano le informazioni direttamente dal lavoro in tempo reale.
Un team di gestione del programma che effettua il monitoraggio dello stato di preparazione al rilascio può creare una dashboard senza scrivere query. Ad esempio, una dashboard di rilascio può includere:
- Una scheda dell'elenco delle attività filtrata per mostrare le attività scadute in tutti i team di prodotto
- Una scheda del carico di lavoro che mostra la distribuzione delle attività tra gli ingegneri
- Un grafico a barre che mette a confronto le attività completate con quelle in sospeso per sprint
- Una scheda di calcolo che effettua il monitoraggio del tempo medio di completamento
Supponiamo che un responsabile di programma esamini questa dashboard prima di una riunione di rilascio. Noterà immediatamente che i servizi di backend mostrano tassi di ritardo più elevati. Aprirà la scheda dell'elenco delle attività e verificherà quali sono esattamente le attività che causano il rischio.
Un utente reale di ClickUp condivide:
ClickUp ci permette di scambiarci i progetti RAPIDAMENTE, controllare FACILMENTE lo stato dei progetti e offre alla nostra responsabile una panoramica del nostro carico di lavoro in qualsiasi momento senza che debba interromperci. Abbiamo sicuramente risparmiato un giorno alla settimana utilizzando ClickUp, se non di più. Il numero di email è notevolmente diminuito.
ClickUp ci permette di scambiarci i progetti RAPIDAMENTE, controllare FACILMENTE lo stato dei progetti e offre alla nostra responsabile una panoramica del nostro carico di lavoro in qualsiasi momento senza che debba interromperci. Utilizzando ClickUp abbiamo sicuramente risparmiato un giorno alla settimana, se non di più. Il numero di email è notevolmente diminuito.
Agisci sulla base delle informazioni ottenute senza pipeline
Snowflake Cortex si concentra sulla generazione di insight dai dati. I team devono comunque interpretare i risultati e trigger le azioni separatamente.
I Super Agent di ClickUp AI colmano questa lacuna e trasformano le informazioni in azioni concrete. Operano come compagni di squadra basati sull'IA che monitorano continuamente i dati dell'area di lavoro e agiscono in base alle condizioni.
Supponiamo che un program manager supervisioni diverse iniziative di prodotto. Un Super Agent può:
- Monitora le attività tra i vari progetti e individua quando le attività in ritardo superano una soglia definita
- Identifica modelli ricorrenti, come ritardi ripetuti nella stessa fase del flusso di lavoro
- Crea un'attività che riepiloghi i progetti interessati e assegnala al responsabile del programma
- Avvisa i titolari dei team quando le attività critiche rimangono irrisolte oltre le scadenze
Ad esempio, durante un ciclo di rilascio, un Super Agent rileva che più di 10 attività ad alta priorità non hanno rispettato le scadenze in due team. Crea un'attività di ClickUp intitolata "Rischio di rilascio: scadenze non rispettate", allega tutti gli allegati pertinenti e la assegna al responsabile del programma per una revisione immediata.
I team possono anche interagire direttamente con il Super Agent: “Analizza tutti i progetti attivi ed evidenzia i rischi di consegna per questo sprint”.
Il Super Agent esamina scadenze, dipendenze e stato delle attività, quindi pubblica un riepilogo/riassunto strutturato all'interno dell'area di lavoro.
Ecco come configurare il tuo Super Agent in ClickUp:
Centralizza i tuoi flussi di lavoro relativi ai dati con ClickUp
Strumenti di conversione da testo a SQL come Snowflake Cortex rendono i dati più accessibili. Allo stesso tempo, ottenere risultati affidabili richiede ancora un certo lavoro richiesto.
I team hanno bisogno di schemi puliti, modelli semantici solidi e iterazioni continue per garantire l'accuratezza dei risultati. Anche dopo aver generato la query corretta, il lavoro non si ferma qui. Qualcuno deve comunque interpretare i risultati, effettuare la condivisione delle informazioni e trasformarle in decisioni.
ClickUp offre un approccio diverso. Anziché separare l'analisi dall'esecuzione, ClickUp le collega entrambe. I team generano SQL, documentano gli insight, collaborano sui risultati e agiscono di conseguenza all'interno dello stesso spazio di lavoro.
ClickUp Brain aiuta a scrivere e perfezionare le query, mentre le dashboard e gli agenti AI aiutano i team a monitorare i risultati e portare avanti il lavoro senza dover passare da uno strumento all'altro.
Snowflake Cortex ti aiuta a ottenere risposte. ClickUp ti aiuta a metterle in pratica. Iscriviti a ClickUp oggi stesso!
Domande frequenti
Snowflake Cortex Analyst è un servizio specializzato all'interno della più ampia suite Snowflake Cortex IA. Cortex Analyst è incentrato specificamente sulla generazione di SQL da testo utilizzando modelli semantici, mentre Cortex IA include un intervallo più ampio di funzioni LLM, inferenza di modelli di machine learning e funzionalità di ricerca.
Sì, Cortex Analyst può eseguire query sulle tabelle Apache Iceberg gestite tramite Snowflake. Purché le tabelle siano accessibili all'interno del tuo ambiente Snowflake e correttamente definite nel tuo modello semantico, puoi generare query su di esse.
L'accuratezza delle query complesse dipende quasi interamente dalla qualità del tuo modello semantico. Un modello con relazioni tra le tabelle ben definite, numerose query verificate e metadati descrittivi produrrà risultati significativamente più accurati per i join su più tabelle e le aggregazioni complesse.
Il prezzo di Snowflake Cortex Analyst segue il modello basato sul consumo di Snowflake, il che significa che il costo viene addebitato in base ai crediti di calcolo utilizzati durante il processo di generazione delle query. Per conoscere le tariffe più aggiornate, ti consigliamo di consultare sempre la documentazione ufficiale sui prezzi di Snowflake.