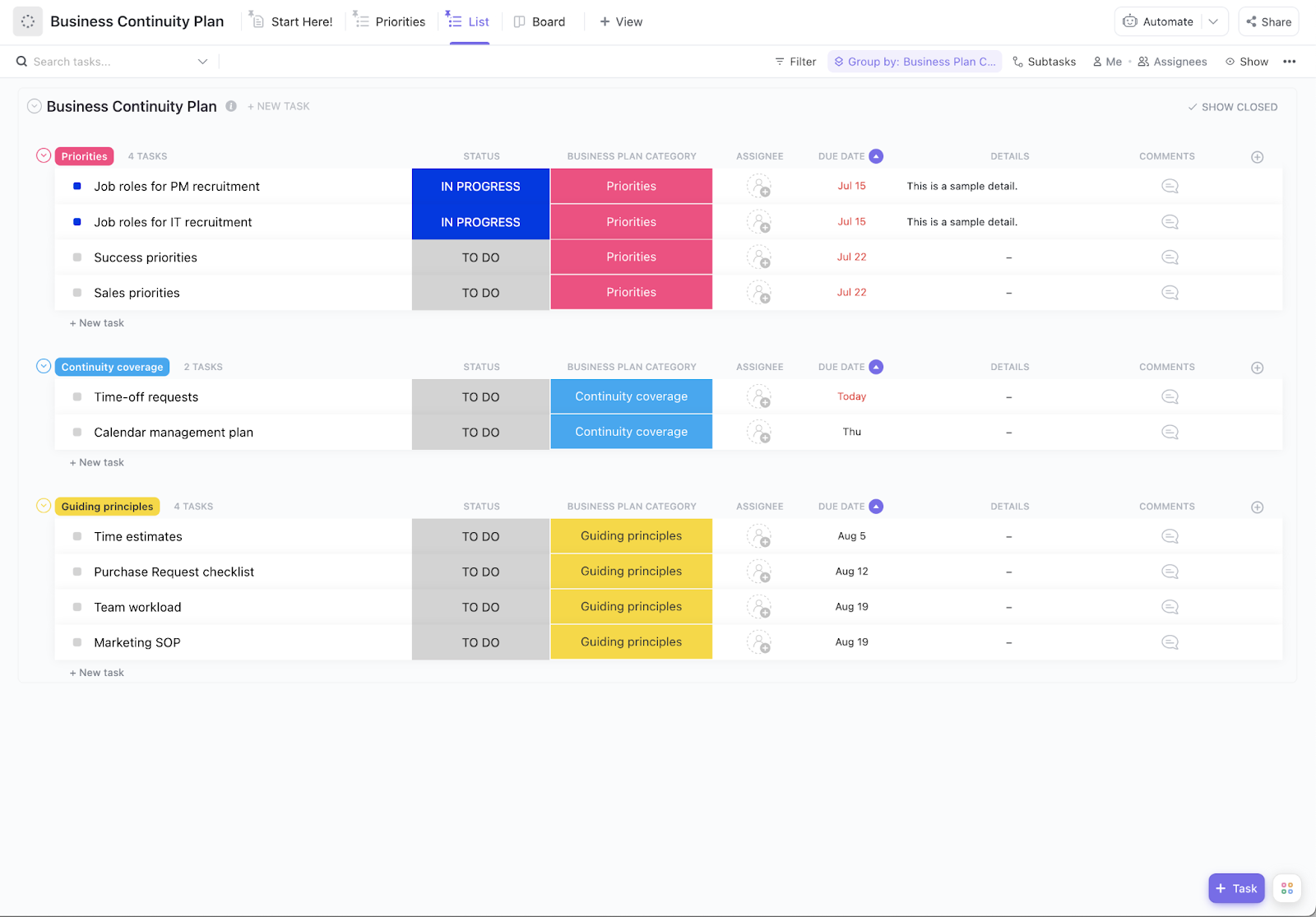

I disastri IT possono verificarsi senza avviso.
Da crash dei server ad attacchi informatici, senza un solido piano di ripristino la tua azienda potrebbe andare incontro a ore di downtime, perdita di dati e gravi danni finanziari, con il 54% delle interruzioni gravi che costa oltre 100.000 dollari.
Questo blog ti guida nella creazione di un piano completo di disaster recovery IT che protegga i tuoi sistemi, definisca chiari obiettivi di ripristino e garantisca che il tuo team sappia esattamente cosa fare quando qualcosa va storto.
Che cos'è un piano di disaster recovery IT?
Se i tuoi server si bloccassero in questo momento, il tuo team saprebbe esattamente cosa fare? 🛠️
Un piano di disaster recovery (DR) IT è la vostra strategia documentata per ripristinare i sistemi e i dati IT dopo qualsiasi interruzione, dai disastri naturali agli attacchi informatici. Si tratta essenzialmente del vostro piano d'azione per riportare la tecnologia online quando le cose vanno male.
💡 DR vs. Continuità operativa
Il disaster recovery (DR) si concentra specificamente sul ripristino dell'infrastruttura IT e dei dati. La business continuity (BC) ha una portata più ampia e mira a mantenere operativa l'intera azienda durante e dopo una crisi, anche in caso di interruzione dei servizi IT. Considera il DR come una parte fondamentale della tua strategia complessiva di BC.
💡 DR vs. Continuità operativa
Il disaster recovery (DR) si concentra specificamente sul ripristino dell'infrastruttura IT e dei dati. La business continuity (BC) ha una portata più ampia e mira a mantenere operativa l'intera azienda durante e dopo una crisi, anche in caso di interruzione dei servizi IT. Considera il DR come una parte fondamentale della tua strategia complessiva di BC.
Il tuo piano di disaster recovery è importante perché i tempi di inattività non comportano solo costi economici. Ogni minuto in cui i tuoi sistemi sono offline può minare la fiducia dei clienti, interrompere le operazioni e persino comportare sanzioni per non conformità. Un piano di DR completo è la tua roadmap verso la resilienza.
Un ottimo piano comprende:
- Procedura di backup dei dati: come e dove archiviare le copie delle informazioni critiche in modo da poterle ripristinare
- Passaggi di ripristino del sistema: la sequenza esatta per riportare i servizi online nel giusto ordine
- Responsabilità del team: chi fa cosa durante un incidente per evitare confusione
- Protocolli di comunicazione: come aggiornare gli stakeholder, dal tuo team ai tuoi clienti
- Obiettivi di ripristino: i tuoi obiettivi specifici relativi alla rapidità con cui i sistemi devono tornare operativi e alla quantità di perdita di dati accettabile.
Scenari comuni di disastri IT e impatto
I disastri non sono solo scenari hollywoodiani, ma eventi che si verificano ogni giorno nelle aziende. Comprendere ciò da cui vi state proteggendo vi aiuta a costruire una difesa molto più solida.
Catastrofi naturali e danni fisici
Eventi come inondazioni, incendi, terremoti e gravi interruzioni di corrente possono distruggere interi data center in pochi minuti. Quando un grave alluvione ha colpito un data center di Nashville, ad esempio, alcune aziende hanno perso settimane di dati e hanno dovuto affrontare mesi di ripristino. La migliore protezione contro questo tipo di eventi è la ridondanza geografica, che consiste nel distribuire l'infrastruttura su più posizioni fisiche in modo che un singolo evento non possa mettere fuori uso tutto.
Attacchi informatici e compromissione dei dati
Il ransomware, gli attacchi DDoS (Distributed Denial-of-Service) e le violazioni dei dati sono diversi dai disastri fisici. Spesso sono più difficili da rilevare, possono diffondersi silenziosamente attraverso i sistemi connessi e spesso prendono di mira anche i sistemi di backup, rendendo il ripristino particolarmente difficile. La frequenza e la sofisticazione di questi attacchi informatici continuano ad aumentare in tutti i settori, con il ransomware che ora rappresenta il 44% di tutte le violazioni confermate, rendendoli una delle principali minacce.
📖 Per saperne di più: 10 modi per ridurre i rischi di sicurezza informatica nel project management
Guasti hardware e perdita di dati
A volte, anche i sistemi di backup più collaudati e affidabili possono smettere di funzionare. Crash dei server, guasti allo spazio di archiviazione e malfunzionamenti delle apparecchiature di rete possono verificarsi senza avviso. Anche se disponi di sistemi ridondanti (di backup), questi possono comunque guastarsi contemporaneamente se condividono componenti o fonti di alimentazione comuni, creando un singolo punto di errore.
👀 Lo sapevate? Nel mese di ottobre 2025, AWS ha subito un grave guasto quando un bug nel suo sistema interno di gestione DNS per Amazon DynamoDB ha causato il malfunzionamento della risoluzione dei nomi di dominio nella regione del data center US-EAST-1. Questo "piccolo" difetto tecnico ha triggerato un guasto a catena su decine di servizi AWS e ha causato l'interruzione di centinaia di app e piattaforme popolari a livello globale, dalle app di messaggistica e social ai siti bancari, di gioco e altro ancora. Per molte persone, l'interruzione ha temporaneamente fatto "scomparire" gran parte di Internet, evidenziando quanto sia fragile la nostra infrastruttura digitale quando così tanto dipende da una manciata di provider di servizi cloud.
Errori software e interruzioni del servizio
Un database danneggiato, un aggiornamento software non riuscito o un semplice errore di configurazione possono mettere fuori uso intere piattaforme. Potreste notare che una riga di codice configurata in modo errato può propagarsi a cascata attraverso i sistemi collegati, creando un'interruzione diffusa con un ampio raggio d'azione. Una corretta gestione delle modifiche e ambienti di test dedicati sono i vostri migliori alleati per ridurre al minimo questi rischi.
Errori umani e configurazioni errate
Cancellazioni accidentali, configurazioni errate e modifiche non autorizzate rimangono una delle cause più comuni di interruzioni IT. Un singolo comando errato o un file cancellato possono trigger ore di downtime e degrado del servizio. Sebbene la formazione e i controlli di accesso siano utili, non possono eliminare completamente gli errori umani.
📮ClickUp Insight: il 92% dei lavoratori utilizza metodi incoerenti per il monitoraggio delle azioni da intraprendere, con il risultato di mancata adozione di decisioni e ritardi nell'esecuzione.
Che si tratti di inviare note di follow-up o di utilizzare fogli di calcolo, il processo è spesso frammentato e inefficiente. Con le funzionalità di gestione delle attività di ClickUp, non dovrai più preoccuparti di questo. Crea attività dalla chat, dai commenti alle attività di ClickUp, dai documenti e dalle email con un solo clic!
Componenti chiave di un piano di disaster recovery IT
Un solido piano di DR è il tuo playbook completo per tornare online. Ciascuno di questi componenti si basa sugli altri per creare una protezione completa per la tua azienda.
Valutazione dei rischi e definizione delle priorità
Innanzitutto, devi sapere con cosa hai a che fare. La valutazione dei rischi è il processo che consente di identificare le vulnerabilità e valutare la probabilità e l'impatto di ciascuna potenziale minaccia. Puoi organizzare questi dati in una matrice dei rischi per individuare le minacce più gravi.
La tua valutazione dovrebbe comprendere:
- Sistemi critici: ciò che deve assolutamente rimanere in funzione affinché la tua azienda possa operare
- Sensibilità dei dati: quali informazioni richiedono il massimo livello di protezione (come i dati dei clienti)
- Dipendenze: quali altri sistemi o processi smettono di funzionare quando un sistema si guasta?
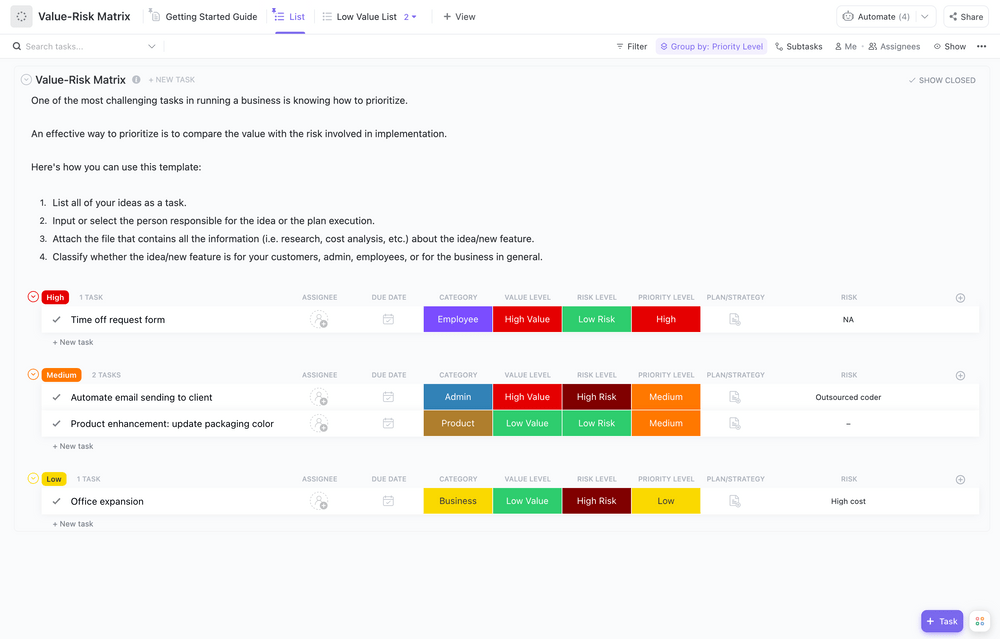
📖 Per saperne di più: Come implementare la gestione dell'infrastruttura IT
Analisi dell'impatto aziendale e criticità
Successivamente, calcola il costo reale dei tempi di inattività. Un'analisi dell'impatto aziendale (BIA) ti aiuta a determinare l'impatto finanziario e operativo di un'interruzione per ciascun sistema. Ciò ti consente di classificare i tuoi sistemi in livelli di criticità per dare priorità al lavoro richiesto per il ripristino.
| Critico | Meno di un'ora | Elaborazione dei pagamenti, database dei clienti |
| Alto | Da una a quattro ore | Email, strumenti di comunicazione interna |
| Medio | Da quattro a 24 ore | Ambienti di sviluppo, strumenti di reportistica |
| Basso | 24+ ore | Sistemi di archiviazione, server di test non di produzione |
Obiettivi RTO e RPO
Questi due acronimi sono il cuore della tua strategia di ripristino.
- Obiettivo di tempo di ripristino (RTO): è il tempo massimo che puoi permetterti che un sistema rimanga inattivo. Risponde alla domanda: "Quanto velocemente dobbiamo ripristinare il funzionamento?"
- Obiettivo di punto di ripristino (RPO): è la quantità massima di dati che puoi permetterti di perdere, misurata in tempo. Risponde alla domanda: "Quanti dati possiamo perdere senza subire danni gravi?"
Ad esempio, il tuo sistema di email interno potrebbe avere un RTO di quattro ore, ma il tuo database di e-commerce rivolto ai clienti potrebbe avere un RPO di soli 15 minuti, il che significa che non puoi perdere più di 15 minuti di dati sulle transazioni.
Piano di backup e ripristino dei dati
Il tuo piano di backup è la tua rete di sicurezza definitiva. Una best practice comune è la regola 3-2-1: conserva almeno tre copie dei tuoi dati importanti, archiviali su due diversi tipi di supporto e conserva una di queste copie fuori sede.
Potrai anche scegliere tra diversi tipi di backup:
- Backup completi: una copia completa di tutti i dati, solitamente eseguita con cadenza settimanale o mensile.
- Backup incrementali: eseguono il backup solo delle modifiche apportate dall'ultimo backup di qualsiasi tipo.
- Backup differenziali: esegue il backup di tutte le modifiche apportate dall'ultimo backup completo.
Ma soprattutto, devi testare regolarmente il processo di ripristino dei backup. Un backup non testato è solo una speranza, non un piano.
💟 Bonus: Cattura i dettagli critici durante gli incidenti ad alto stress utilizzando la funzione talk-to-text di ClickUp Brain MAX, in modo da non perdere mai informazioni importanti anche quando digitare non è pratico. Basta pronunciare le tue osservazioni e lasciare che l'IA si occupi della documentazione.
Piano di comunicazione e aggiornamenti per gli stakeholder
Quando si verifica un disastro, un piano di comunicazione chiaro è tutto. Il tuo piano deve definire le catene di notifica, la frequenza con cui fornire aggiornamenti e i canali da utilizzare per ogni tipo di incidente.
Gruppi diversi necessitano di informazioni diverse:
- Team interni: necessitano di dettagli tecnici e elementi specifici da intraprendere.
- Clienti: è necessario conoscere lo stato del servizio e quando si prevede che venga risolto.
- Fornitori: potrebbe essere necessario coinvolgerli per supporto o escalation.
- Organismi di regolamentazione: potrebbero richiedere notifiche formali a seconda del settore in cui operi.
Strumenti come questo modello di piano di comunicazione pronto all'uso di ClickUp possono aiutarti ad agire più rapidamente con un protocollo consolidato durante una crisi.

Programma di test e formazione
Un piano che non viene mai testato è un piano destinato a fallire. Test regolari consentono di individuare lacune e punti deboli prima che si verifichi un vero e proprio disastro.
Pianifica diversi tipi di test durante l'anno:
- Esercitazioni teoriche: il tuo team esamina uno scenario di emergenza su carta per verificare la logica del piano.
- Failover parziali: si verifica il ripristino di componenti o servizi specifici non critici.
- Test completi di DR: esegui un failover completo sui tuoi sistemi di backup (il test definitivo)
Dopo ogni test, aggiorna la documentazione e forma immediatamente i nuovi membri del team sulle procedure.
📖 Per saperne di più: Come sviluppare politiche e procedure IT efficaci
Passaggi per creare un piano di disaster recovery IT
Creare un piano di DR non deve essere necessariamente un compito arduo.
Ecco come puoi affrontarlo un passaggio alla volta. 🙌
Passaggio 1: Creare l'inventario delle risorse
Non puoi proteggere ciò che non sai di avere. Inizia creando un inventario delle risorse che elenchi ogni componente hardware, software, repository dati e dipendenza di sistema nel tuo ambiente. Assicurati di includere i contatti dei fornitori, le chiavi di licenza e i dettagli di configurazione per poterli consultare rapidamente durante il ripristino.

Il modello ITAM di ClickUp riunisce la gestione degli incidenti, la gestione dei problemi, la gestione delle modifiche, soluzioni semplici per la gestione delle risorse e la gestione delle conoscenze. Il nostro modello ITSM Known Errors semplifica il monitoraggio degli errori noti nei vostri sistemi. Esplorate tutti i nostri modelli IT non appena cambia il vostro obiettivo.
Personalizza i tuoi flussi di lavoro nello stile che preferisci per ogni fase dell'ITAM, dall'implementazione e configurazione alla manutenzione e al ritiro.
Passaggio 2: Classificare i servizi critici
Ora, identifica quali di queste risorse sono fondamentali per la tua attività e quali sono semplicemente utili. Crea mappe di dipendenza dei servizi che mostrano come i tuoi sistemi sono collegati e dipendono l'uno dall'altro. Presta particolare attenzione ai servizi rivolti ai clienti che hanno un impatto diretto sui ricavi o sull'esperienza degli utenti.
🎥 Guarda questa pratica guida che mostra come creare un piano strutturato e di alto livello utilizzando le potenti funzionalità/funzioni di ClickUp, dall'impostazione degli obiettivi all'assegnazione delle attività e al monitoraggio dello stato.
Passaggio 3: Valutare rischi e minacce
Valuta i rischi e le minacce valutando la probabilità e l'impatto di ciascun tipo di minaccia per la tua situazione specifica. Considera i rischi geografici (ti trovi in una zona sismica o in una pianura alluvionale?) e le minacce specifiche del settore (come modifiche normative o attacchi informatici mirati). Documenta tutto in un registro dei rischi in modo da poterlo monitorare nel tempo.

Il modello di lavagna online per la valutazione dei rischi di ClickUp crea una dimensione visiva per il tuo processo di valutazione dei rischi. Aiuta a valutare i rischi e a classificarli, stimolando il tuo team a promuovere la condivisione di idee e a collaborare in un formato coinvolgente e visivo.
Questo modello consente di:
- Valuta le categorie di rischio e i potenziali impatti
- Analizza i dati per identificare potenziali aree di preoccupazione
- Stabilisci misure preventive per ridurre l'esposizione al rischio
Con funzionalità che consentono di disegnare, scrivere e aggiungere note adesive, questo modello di lavagna per la gestione dei rischi è perfetto per valutare i rischi del tuo progetto.
Passaggio 4: Imposta i traguardi RTO e RPO
Collabora direttamente con gli stakeholder aziendali per definire quali sono i tempi di inattività e la perdita di dati accettabili per ciascun livello di servizio identificato in precedenza. Dovrai trovare un equilibrio tra il costo di un ripristino più rapido e l'impatto sul business: non tutto richiede un ripristino immediato e senza perdita di dati. Ottieni l'approvazione dei dirigenti su questi traguardi.
Passaggio 5: Definizione dei percorsi di backup e failover
Una volta definiti i traguardi, puoi progettare le soluzioni tecniche. Crea piani di backup su misura per l'RPO di ciascun sistema e pianifica procedure di failover dettagliate, inclusi siti di elaborazione alternativi e metodi di accesso di emergenza. Includi diagrammi di rete e runbook dettagliati per rendere l'esecuzione infallibile.
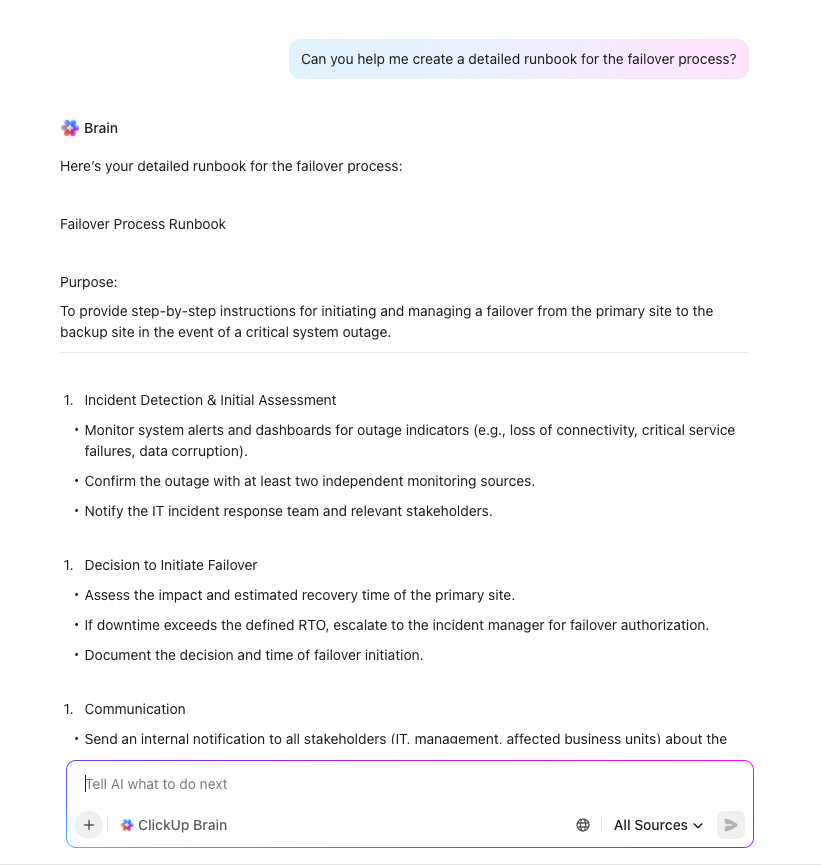
Passaggio 6: Assegnare i ruoli e l'escalation
Definisci la struttura del tuo team DR con responsabilità e poteri decisionali chiari. Crea elenchi di contatti completi con il personale principale e di backup per ogni ruolo. Una matrice RACI (Responsible, Accountable, Consulted, Informed) è un ottimo strumento per eliminare la confusione durante un incidente ad alto stress.
Passaggio 7: Documentare e comunicare il piano
Documentate e comunicate il piano con procedure chiare e dettagliate che chiunque nel vostro team possa seguire, anche sotto pressione. È fondamentale conservare questa documentazione in un luogo facilmente accessibile e separato dalla vostra infrastruttura principale. Assicuratevi che ogni membro del team sappia esattamente dove trovare il piano durante una crisi.
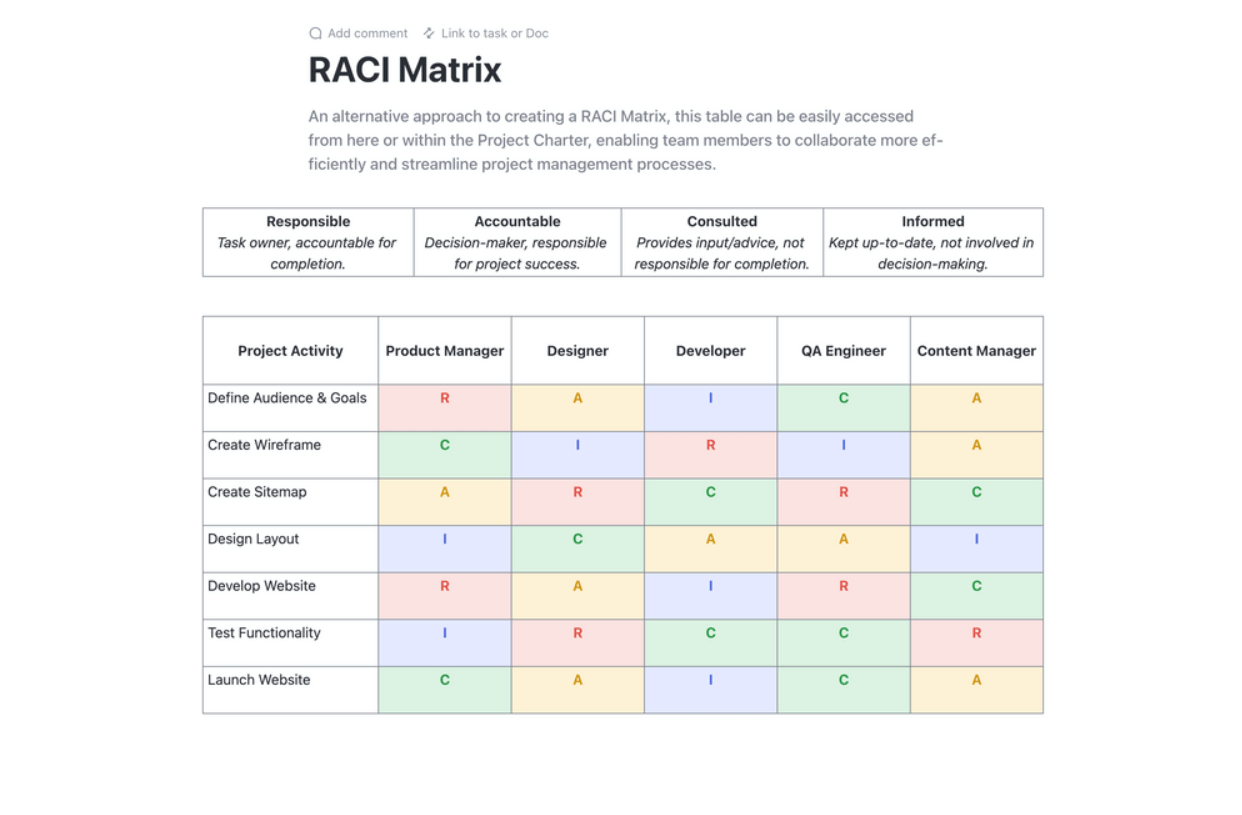
Semplifica la pianificazione dei tuoi progetti con il modello di pianificazione RACI di ClickUp. Questo modello di documento è rivoluzionario e offre un grafico chiaro per definire i ruoli e le responsabilità del team in relazione alle attività del progetto. Adotta il framework RACI (Responsible, Accountable, Consulted e Informed) per mettere tutti sulla stessa lunghezza d'onda, garantendo la responsabilità e l'allineamento con gli obiettivi organizzativi.
Passaggio 8: Testare, rivedere e migliorare
Infine, pianifica test trimestrali per convalidare le tue procedure e identificare eventuali lacune. Documenta tutte le lezioni apprese da ogni test e da eventuali incidenti reali e utilizzale per aggiornare il tuo piano. Crea un sistema di monitoraggio sistematico dei miglioramenti per garantire che tutti i problemi individuati vengano risolti.
🌼 Lo sapevate? Nel 2017 Gitlab ha subito un grave guasto al database. Durante il ripristino, ha scoperto che diversi metodi di backup non funzionavano correttamente già da giorni. Questo incidente ha insegnato all'intero settore tecnologico una lezione fondamentale: la convalida dei backup è imprescindibile. Un backup non testato non è affatto un backup.
🌼 Lo sapevate? Nel 2017 Gitlab ha subito un grave guasto al database. Durante il ripristino, ha scoperto che diversi metodi di backup non funzionavano correttamente già da giorni. Questo incidente ha insegnato all'intero settore tecnologico una lezione fondamentale: la convalida dei backup è imprescindibile. Un backup non testato non è affatto un backup.
Strategie e soluzioni di disaster recovery
Non tutte le organizzazioni necessitano dello stesso approccio al DR. Esploriamo le opzioni disponibili in base al tuo budget, alle esigenze di ripristino e alle risorse disponibili.
Approccio al backup e al ripristino
Questo è il metodo più semplice ed economico. Consiste nell'effettuare backup regolari in una posizione esterna (come il cloud o un data center secondario) e poi ripristinarli manualmente quando necessario. Questo approccio è ideale per i sistemi non critici che possono tollerare un RTO più lungo, poiché il ripristino può richiedere ore o addirittura giorni.
Alta disponibilità e ridondanza
Questa strategia mira a eliminare i singoli punti di errore utilizzando più sistemi attivi. Tecniche come il bilanciamento del carico, il clustering dei server e lo spazio di archiviazione RAID garantiscono che, in caso di guasto di un componente, un altro subentri immediatamente. Sebbene più costoso da configurare e mantenere, questo approccio può ridurre al minimo i tempi di inattività a pochi secondi o minuti, rendendolo ideale per i servizi critici.
Opzioni di replica e failover
La replica comporta la copia dei dati quasi in tempo reale su un sito secondario, garantendo una perdita minima di dati in caso di disastro.
- Replica sincrona: scrive i dati contemporaneamente sia sul sito primario che su quello secondario, garantendo zero perdite di dati. Tuttavia, richiede un'elevata larghezza di banda e può rallentare il sistema primario.
- Replica asincrona: scrive prima i dati nel sito primario e poi li copia nel sito secondario con un leggero ritardo. È meno costosa e ha un impatto minore sulle prestazioni, ma comporta un piccolo rischio di perdita di dati.
Disaster recovery basato sul cloud e DRaaS
Il Disaster Recovery as a Service (DRaaS) è diventato una scelta popolare per molte aziende. Offre prezzi pay-as-you-go, distribuzione geografica istantanea e automazione dell'orchestrazione del ripristino senza la necessità di creare e mantenere siti DR fisici propri. Il Cloud DR elimina l'enorme spesa in conto capitale di un data center di backup, fornendo al contempo una scalabilità più rapida e una maggiore flessibilità rispetto ai tradizionali approcci hot, warm o cold site.
Come ClickUp semplifica la pianificazione del piano di disaster recovery IT
La gestione di un piano di DR attraverso fogli di calcolo, documenti e catene di email sparsi crea un rischio di disastro a sé stante.
Questo tipo di proliferazione del lavoro, la frammentazione delle attività su più strumenti scollegati tra loro che non comunicano tra loro e la proliferazione del contesto, quando i team perdono ore alla ricerca di informazioni sparse tra app e piattaforme, porta a confusione, informazioni obsolete e tempi di risposta lenti quando ogni secondo è prezioso.
Con ClickUp Converged AI Workspace, un'unica piattaforma sicura che riunisce tutte le tue app di lavoro, i dati e i flussi di lavoro con l'AI contestuale come livello di intelligenza, che combina project management, documentazione e comunicazione del team. Smetti di destreggiarti tra più piattaforme e riunisci la pianificazione, i test e la risposta agli incidenti di DR in un unico sistema unificato.
Documentazione DR centralizzata con ClickUp Docs e assistenza IA integrata
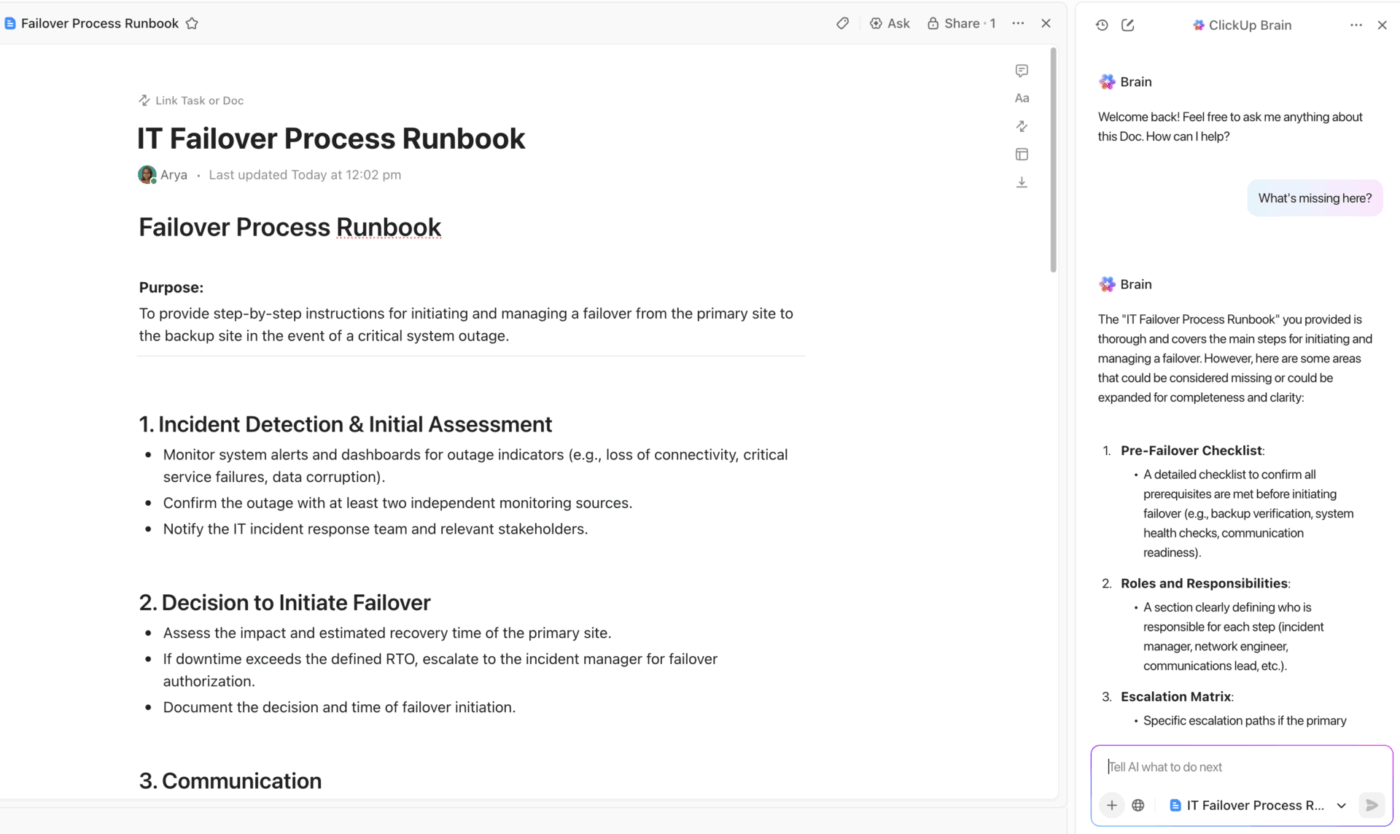
Assicuratevi che il vostro team abbia sempre a disposizione un'unica fonte di informazioni affidabili con ClickUp Docs.
Crea il tuo piano di disaster recovery in uno spazio collaborativo in cui tutti possono contribuire in tempo reale durante un incidente. Collega i documenti direttamente alle attività e ai progetti relativi all'incidente per una navigazione fluida e incorpora diagrammi o runbook per conservare le informazioni critiche proprio dove ti servono.
Ma soprattutto, puoi proteggere i tuoi documenti per impedire modifiche accidentali e utilizzare le autorizzazioni granulari di ClickUp per controllare chi può visualizzare o modificare le procedure di ripristino sensibili. Ogni modifica viene monitorata nella cronologia del documento, fornendoti una traccia di controllo completa.
Creazione di piani basati sull'IA con ClickUp Brain
Accelerate la pianificazione del disaster recovery ed eliminate le lacune critiche con ClickUp Brain, il vostro assistente AI contestuale che comprende l'intero spazio di lavoro. A differenza degli strumenti di IA generici, ClickUp Brain sfrutta le attività, i documenti e i flussi di lavoro reali della vostra organizzazione per fornire un supporto preciso e concreto alle iniziative di DR.
Basta inviare a ClickUp Brain una richiesta del tipo "Crea una lista di controllo di disaster recovery per la nostra piattaforma di e-commerce" per ricevere immediatamente un modello completo e personalizzato in linea con i tuoi sistemi, processi ed esigenze di conformità. Può aiutarti a:
- Consapevolezza contestuale: ClickUp Brain ha accesso alla struttura, ai contenuti e alle autorizzazioni del tuo spazio di lavoro. Può fare riferimento ad attività, documenti, commenti e persino app collegate, fornendo risposte e azioni su misura per il tuo lavoro effettivo, non solo suggerimenti generici.
- Risoluzione dei problemi e guida: risolvi immediatamente i problemi, ottieni istruzioni dettagliate o richiedi le best practice su qualsiasi funzionalità di ClickUp. Brain può guidarti attraverso processi complessi, effettuare l'automazione di attività ripetitive e aiutarti a risolvere gli ostacoli.
- Automazioni e accelerazione del flusso di lavoro: utilizza agenti IA predefiniti o personalizzati per automatizzare flussi di lavoro in più passaggi, smistare le richieste o gestire il lavoro ricorrente, risparmiando ore ogni settimana.
- Ricerca approfondita: trova informazioni nascoste ovunque nella tua area di lavoro, inclusi compiti, documenti e strumenti integrati, anche se risalgono a anni fa o sono difficili da individuare con la ricerca standard.
- Riepiloghi e aggiornamenti in tempo reale: genera istantaneamente aggiornamenti sui progetti, riepiloghi delle riunioni o rapporti sullo stato di avanzamento, attingendo dai dati in tempo reale dell'area di lavoro.
- Semplificazione della documentazione tecnica: converti documenti tecnici complessi in procedure o liste di controllo chiare e attuabili che il tuo team può seguire anche sotto pressione.
- Intelligenza multimodello: scegli tra i principali modelli di IA (OpenAI GPT-4. 1, GPT-5, Claude, Gemini e altri) per ottenere i migliori risultati in qualsiasi attività, senza bisogno di sottoscrizioni separate.
- Sicuro e sensibile alle autorizzazioni: Brain accede solo alle informazioni che sei già autorizzato a vedere, mantenendo rigorosi standard di privacy e conformità.
- Interfaccia conversazionale: utilizzate @brain nei commenti o durante la chat per ottenere approfondimenti contestuali, redigere bozze di risposte o trigger automazioni senza interrompere il vostro flusso di lavoro.
- Prompt personalizzati e flussi di lavoro salvati: salva e riutilizza i prompt per esigenze ricorrenti, garantendo coerenza e risparmiando tempo a tutto il tuo team.
💡Suggerimento professionale: non perdetevi mai una lezione delle vostre riunioni di revisione degli incidenti catturando ogni dettaglio con ClickUp AI Notetaker. Può partecipare alle vostre riunioni virtuali, trascrivere l'intera discussione e generare automaticamente un elenco di elementi da intraprendere sulla base delle lezioni apprese. In questo modo si crea una cronologia degli incidenti ricercabile, che consente di consultare rapidamente gli eventi passati e le relative risoluzioni.

Flussi di lavoro DR automatizzati con ClickUp Automazioni
Immagina che il tuo team si trovi ad affrontare un'interruzione improvvisa: ogni secondo è prezioso e non puoi permetterti di perdere nemmeno un passaggio. Con gli agenti e le automazioni AI di ClickUp, non dovrai affrettarti né affidarti alla memoria. Non appena viene segnalato un incidente, l'IA di ClickUp entra in azione, guidando il tuo team e occupandosi delle attività più impegnative, così tu potrai concentrarti sulla risoluzione del problema.
Ecco come funziona in uno scenario reale:
- Quando qualcuno contrassegna un'attività come "Incidente dichiarato", ClickUp Agent crea automaticamente una lista di controllo dei passaggi di risposta, li assegna alle persone giuste e avvia un timer per effettuare il monitoraggio del tempo necessario al ripristino.
- Se l'incidente viene contrassegnato come "critico", un agente può inviare immediatamente un'email di avviso al tuo team dirigenziale e creare una chat room speciale, la tua "war room", in modo che tutti possano comunicare in un unico posto.
- L'IA è in grado di recuperare i rapporti sugli incidenti passati e la documentazione pertinente, in modo che il tuo team abbia tutto ciò di cui ha bisogno a portata di mano.
Guarda qui il flusso di lavoro:
Con ClickUp AI Agents, avrai un compagno di squadra digitale affidabile che aiuterà il tuo team a mantenere la calma, l'organizzazione e l'efficacia, anche quando la pressione è alta.
Monitoraggio in tempo reale con i dashboard ClickUp
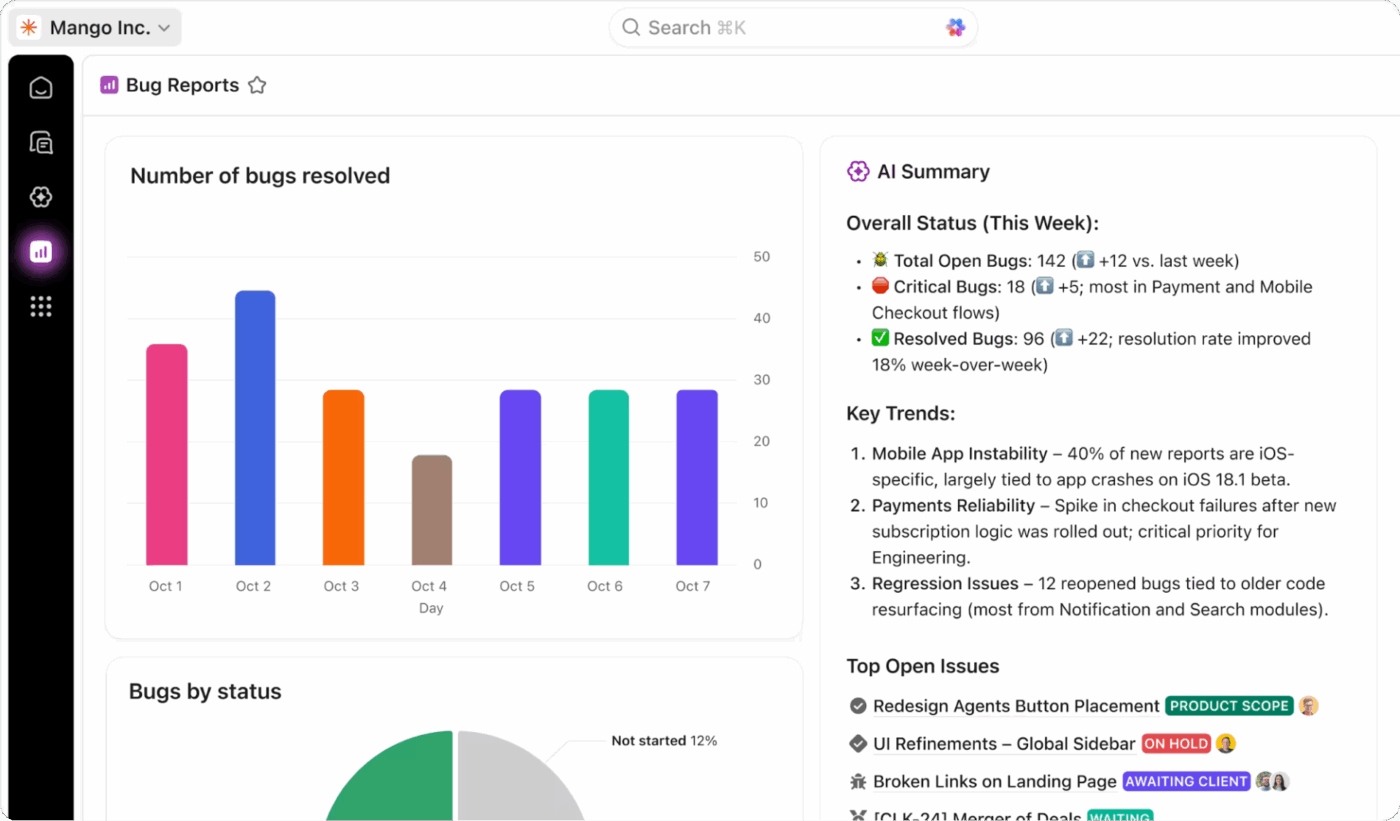
Ottieni una visibilità completa sullo stato del tuo programma di DR monitorando tutto in tempo reale con i dashboard di ClickUp. Puoi creare widget per monitorare le prestazioni RTO e RPO durante i test, tenere traccia dei tassi di completamento dei test e visualizzare l'andamento degli incidenti nel tempo.
Aggiungi i campi personalizzati ClickUp alle tue attività per monitorare la criticità del sistema, lo stato di ripristino e i risultati dei test, quindi raccogli tutti questi dati in una vista dettagliata. Questi dashboard ti forniscono report pronti per i dirigenti, sempre aggiornati con dati in tempo reale provenienti dai test e dalle attività di risposta agli incidenti del tuo team.
📖 Per saperne di più: Come creare una lista di controllo per la valutazione dei rischi
Crea oggi stesso il tuo piano di DR
Ogni giorno in cui operi senza un piano di DR è una scommessa che non puoi permetterti di perdere. I disastri sono inevitabili, che siano causati da eventi naturali, guasti tecnologici o errori umani, ma è la tua preparazione a determinare se si tratterà di piccoli inconvenienti o di gravi catastrofi.
Un piano di DR completo richiede la comprensione dei rischi, la documentazione di procedure chiare e il loro test regolare. Gli strumenti giusti rendono questo processo gestibile eliminando il caos di documenti sparsi e processi manuali.
Anche i piani di emergenza più semplici sono meglio di niente quando si verifica un disastro. Test e aggiornamenti regolari trasformeranno il tuo piano di DR da un documento polveroso a un sistema vivo che protegge davvero la tua attività.
Fai il primo passaggio e inizia oggi stesso a costruire il tuo piano di DR con ClickUp. Inizia gratis con ClickUp e riunisci tutta la tua pianificazione di disaster recovery, la documentazione e la risposta agli incidenti in un'unica piattaforma unificata. ✨
Domande frequenti
È necessario rivedere il piano di DR almeno quattro volte all'anno e aggiornarlo immediatamente dopo ogni cambiamento significativo dell'infrastruttura o incidente reale. La maggior parte delle organizzazioni esegue una revisione approfondita ogni anno per incorporare tutte le lezioni apprese e adattarsi alle nuove tecnologie.
I team IT, i team di sicurezza e i responsabili della pianificazione della continuità operativa guidano in genere le attività di pianificazione e test del DR. Tuttavia, hanno bisogno di input fondamentali da parte dei responsabili delle operazioni e delle unità aziendali per garantire che il piano sia in linea con le esigenze e le priorità aziendali reali.
Utilizza cronometri e timestamp chiari per misurare i tempi di ripristino effettivi rispetto ai traguardi definiti durante ogni test. È fondamentale documentare eventuali discrepanze tra i traguardi e le prestazioni effettive nei rapporti di test, al fine di orientare i miglioramenti futuri.
Le piattaforme di project management come ClickUp sono ideali per centralizzare la documentazione, automatizzare i flussi di lavoro e effettuare il monitoraggio delle metriche dell'intero programma di DR. È quindi possibile abbinarle a strumenti DR specializzati che gestiscono gli aspetti tecnici della replica dei dati e del failover del sistema.