
Usted lanza la última actualización de software y comienzan a llegar los informes.
De repente, una métrica lo gobierna todo, desde CSAT/NPS hasta los retrasos en la hoja de ruta: el tiempo de resolución de errores.
Los ejecutivos lo ven como una métrica que cumple lo prometido: ¿podemos enviar, aprender y proteger los ingresos según lo previsto? Los profesionales sienten el dolor en las trincheras: tickets duplicados, propiedad poco clara, escaladas ruidosas y contexto disperso en Slack, hojas de cálculo y herramientas separadas.
Esa fragmentación alarga los ciclos, oculta las causas fundamentales y convierte la priorización en una mera conjetura.
¿El resultado? Un aprendizaje más lento, compromisos incumplidos y una acumulación de trabajo que afecta silenciosamente a cada sprint.
Esta guía es su manual completo para medir, comparar y reducir el tiempo de resolución de errores, y muestra de forma concreta cómo la IA cambia el flujo de trabajo en comparación con los procesos manuales tradicionales.
¿Qué es el tiempo de resolución de errores?
El tiempo de resolución de errores es el tiempo que se tarda en corregir un error, medido desde el momento en que se informa del error hasta que se resuelve por completo.
En la práctica, el reloj comienza a correr cuando se informa o se detecta un problema (a través de los usuarios, el control de calidad o la supervisión) y se detiene cuando se implementa y se combina la corrección, lista para su verificación o lanzamiento, dependiendo de cómo su equipo defina «terminado».
Ejemplo: un fallo P1 notificado a las 10:00 a. m. del lunes, con la corrección combinada a las 3:00 p. m. del martes, tiene un tiempo de resolución de ~29 horas.
No es lo mismo que el tiempo de detección de errores. El tiempo de detección mide la rapidez con la que se reconoce un error después de que se produce (activación de alarmas, detección por herramientas de pruebas de control de calidad, elaboración de informes por parte de los clientes).
El tiempo de resolución mide la rapidez con la que se pasa de la detección a la solución: clasificación, reproducción, diagnóstico, implementación, revisión, prueba y preparación para el lanzamiento. Piense en la detección como «sabemos que está roto» y en la resolución como «está arreglado y listo».
Los equipos utilizan límites ligeramente diferentes; elija uno y sea coherente para que sus tendencias sean reales:
- Notificado → Resuelto: Finaliza cuando se combina la corrección del código y está lista para el control de calidad. Bueno para el rendimiento de ingeniería.
- Notificado → Cerrada: Incluye validación de control de calidad y lanzamiento. Ideal para SLA que afectan al cliente.
- Detectado → Resuelto: Comienza cuando el equipo de supervisión/control de calidad detecta el problema, incluso antes de que exista un ticket. Útil para equipos con una gran carga de producción.
🧠 Dato curioso: Un error peculiar pero divertido en Final Fantasy XIV recibió elogios por ser tan específico que los lectores lo bautizaron como «la corrección de errores más específica en un MMO 2025». Se manifestaba cuando los jugadores ponían un precio a los elementos entre exactamente 44 442 gil y 49 087 gil en una zona de evento concreta, lo que provocaba desconexiones debido a lo que podría ser un error de desbordamiento de enteros.
Por qué es importante
El tiempo de resolución es una palanca para la cadencia de lanzamiento. Los tiempos largos o impredecibles obligan a recortar el alcance, aplicar revisiones y congelar los lanzamientos; crean una deuda de planificación porque la cola larga (los valores atípicos) descarrila los sprints más de lo que sugiere la media.
Esto también está directamente relacionado con la satisfacción del cliente. Los clientes toleran los problemas cuando se reconocen rápidamente y se resuelven de forma predecible. Las soluciones lentas, o peor aún, las soluciones variables, provocan escaladas, merman la satisfacción del cliente (CSAT/NPS) y ponen en riesgo las renovaciones.
En resumen, si mide el tiempo de resolución de incidencias de forma clara y lo reduce de manera sistemática, sus planes de trabajo y sus relaciones mejorarán.
📖 Más información: Cómo priorizar las incidencias para resolverlas de forma eficiente
¿Cómo medir el tiempo de resolución de errores?
En primer lugar, decida dónde comienza y termina su reloj.
La mayoría de los equipos eligen entre «Notificado → Resuelto» (la corrección se ha combinado y está lista para su verificación) o «Notificado → Cerrada» (el control de calidad lo ha validado y el cambio se ha publicado o se ha cerrado de otro modo).
Elija una definición y utilícela de forma coherente para que sus tendencias sean significativas.
Ahora necesita algunas métricas observables. Veamos cuáles son:
Métricas clave para el seguimiento de incidencias a tener en cuenta:
| 📊 Métrica | 📌 Qué significa | 💡 Cómo ayuda | 🧮 Fórmula (si procede) |
|---|---|---|---|
| Recuento de errores 🐞 | Número total de incidencias reportadas | Ofrece una vista general del estado del sistema. ¿El número es alto? Es hora de investigar. | Total de incidencias = Todas las incidencias registradas en el sistema {Abiertas + Cerradas} |
| Incidencias abiertas 🚧 | Incidencias que aún no se han solucionado | Muestra la carga de trabajo actual. Ayuda a establecer prioridades. | Errores abiertos = Errores totales - Errores cerrados |
| Incidencias cerradas ✅ | Incidencias resueltas y verificadas | Realiza un seguimiento del progreso y el trabajo terminado. | Errores cerrados = Recuento de incidencias con el estado «Cerrado» o «Resuelto». |
| Gravedad del error 🔥 | Criticidad del error (por ejemplo, crítico, grave, leve). | Ayuda a clasificar en función del impacto. | Seguido como campo categórico, sin fórmula. Utilice filtros/agrupación. |
| Prioridad de los errores 📅 | ¿Con qué urgencia hay que solucionar un error? | Ayuda en la planificación de sprints y lanzamientos. | También es un campo categórico, normalmente clasificado (por ejemplo, P0, P1, P2). |
| Tiempo de resolución ⏱️ | Tiempo transcurrido desde el informe del error hasta su solución. | Mide la capacidad de respuesta. | Tiempo de resolución = Fecha cerrada - Fecha de elaboración de informes |
| Tasa de reapertura 🔄 | Porcentaje de incidencias reabiertas tras haber sido cerradas | Refleja la calidad de las correcciones o los problemas de regresión. | Tasa de reapertura (%) = {Incidencias reabiertas ÷ Total de incidencias cerradas} × 100 |
| Fuga de errores 🕳️ | Errores que se colaron en la producción | Indica la eficacia del control de calidad y las pruebas de software. | Tasa de fuga (%) = {Incidencias de producción ÷ Total de incidencias} × 100 |
| Densidad de defectos 🧮 | Errores por unidad de tamaño de código | Destaca las áreas del código propensas a riesgos. | Densidad de defectos = Número de errores ÷ KLOC {Kilo Lines of Código} |
| Errores asignados frente a errores sin asignar 👥 | Distribución de errores por propiedad | Garantiza que nada se pase por alto. | Utilice un filtro: Sin asignar = Incidencias en las que «Asignado a» es nulo. |
| Antigüedad de las incidencias abiertas 🧓 | Cuánto tiempo permanece sin resolver un error | Detecta los riesgos de estancamiento y acumulación de trabajo. | Antigüedad del error = Fecha actual - Fecha en que se informó |
| Incidencias duplicadas 🧬 | Número de informes duplicados | Destaca los errores en los procesos de admisión. | Tasa de duplicados = Duplicados ÷ Total de incidencias × 100 |
| MTTD (tiempo medio de detección) 🔎 | Tiempo medio necesario para detectar errores o incidencias | Mide la eficiencia de la supervisión y la concienciación. | MTTD = Σ(tiempo de detección - tiempo de introducción) ÷ número de incidencias |
| MTTR (tiempo medio de resolución) 🔧 | Tiempo medio para solucionar completamente un error tras su detección. | Realiza un seguimiento de la capacidad de respuesta de los ingenieros y del tiempo de reparación. | MTTR = Σ(tiempo resuelto - tiempo detectado) ÷ número de incidencias resueltas |
| MTTA (tiempo medio de respuesta) 📬 | Tiempo transcurrido desde la detección hasta que alguien comienza a trabajar en el error. | Muestra la capacidad de reacción del equipo y la capacidad de respuesta a las alertas. | MTTA = Σ(Tiempo reconocido - Tiempo detectado) ÷ Número de incidencias |
| MTBF (tiempo medio entre fallos) 🔁 | Tiempo transcurrido entre la resolución de un fallo y la aparición del siguiente. | Indica estabilidad a lo largo del tiempo. | MTBF = Tiempo total de actividad ÷ Número de fallos |
⚡️ Archivo de plantillas: 15 plantillas y formularios gratuitos para el seguimiento de errores
Factores que afectan al tiempo de resolución de incidencias
El tiempo de resolución suele equipararse a «la rapidez con la que los ingenieros escriben código».
Pero eso es solo una parte del proceso.
El tiempo de resolución de incidencias es la suma de la calidad en la recepción, la eficiencia del flujo a través de su sistema y el riesgo de dependencia. Cuando cualquiera de estos elementos falla, la duración del ciclo se alarga, la previsibilidad disminuye y las escaladas se intensifican.
La calidad de la admisión marca la pauta
Los informes que llegan sin pasos de reproducción claros, detalles del entorno, registros o información sobre la versión/compilación obligan a realizar gestiones adicionales. Los informes duplicados de múltiples canales (soporte técnico, control de calidad, supervisión, Slack) añaden ruido y fragmentan la propiedad.
Cuanto antes capture el contexto adecuado y elimine los duplicados, menos traspasos y aclaraciones necesitará más adelante.
La priorización y el enrutamiento determinan quién se ocupa de la incidencia y cuándo.
Los rótulos de gravedad que no se correlacionan con el impacto en los clientes o en la empresa (o que cambian con el tiempo) provocan una rotación en la cola: los tickets más urgentes se saltan la cola, mientras que los defectos de alto impacto quedan en segundo plano.
Las reglas de enrutamiento claras por componente/propietario y una única cola de verdad evitan que el trabajo P0/P1 quede sepultado bajo «reciente y ruidoso».
La propiedad y los traspasos son asesinos silenciosos.
Si no está claro si un error pertenece al equipo móvil, al de autenticación del backend o al de la plataforma, se devuelve. Cada devolución restablece el contexto.
Las zonas horarias agravan esta situación: un error notificado a última hora del día sin un propietario designado puede perder entre 12 y 24 horas antes de que alguien empiece siquiera a reproducirlo. Las definiciones estrictas de «quién es propietario de qué», con un DRI de guardia o semanal, eliminan esa deriva.
La reproducibilidad depende de la observabilidad.
Los registros escasos, la falta de ID de correlación o la ausencia de trazas de fallos convierten el diagnóstico en una mera conjetura. Las incidencias que solo aparecen con indicadores, inquilinos o formas de datos específicos son difíciles de reproducir en el desarrollo.
Si los ingenieros no pueden acceder de forma segura a datos saneados similares a los de producción, terminan instrumentando, reimplementando y esperando, lo que les lleva días en lugar de horas.
La paridad del entorno y los datos le permiten mantener la honestidad.
«Funciona en mi máquina» suele significar «los datos de producción son diferentes». Cuanto más se aleje su desarrollo/preproducción de la producción (configuración, servicios, versiones de terceros), más tiempo pasará persiguiendo fantasmas. Las instantáneas de datos seguras, los scripts de semillas y las comprobaciones de paridad reducen esa brecha.
El trabajo en curso (WIP) y el enfoque impulsan el rendimiento real.
Los equipos sobrecargados se enfrentan a demasiadas incidencias a la vez, fragmentan su atención y se debaten entre tareas y reuniones. El cambio de contexto añade horas invisibles.
Un límite visible de WIP y la tendencia a terminar lo que se ha empezado antes de empezar un nuevo trabajo reducirán su mediana más rápido que cualquier esfuerzo individual.
La revisión del código, la integración continua y la velocidad del control de calidad son cuellos de botella clásicos.
Los tiempos de compilación lentos, las pruebas poco fiables y los SLA de revisión poco claros retrasan soluciones que, de otro modo, serían rápidas. Un parche de 10 minutos puede tardar dos días en esperar a un revisor o en encajar en un proceso de varias horas.
Del mismo modo, las colas de control de calidad que realizan pruebas por lotes o se basan en comprobaciones manuales pueden añadir días completos al proceso «Notificado → Cerrada», incluso cuando el proceso «Notificado → Resuelto» es rápido.
Las dependencias amplían las colas
Los cambios entre equipos (esquema, migraciones de plataformas, actualizaciones de SDK), las incidencias de los proveedores o las revisiones de las tiendas de aplicaciones (móviles) provocan estados de espera. Sin un seguimiento explícito de «Bloqueado/Pausado», esas esperas inflan de forma invisible sus promedios y ocultan dónde se encuentra el verdadero cuello de botella.
El modelo de lanzamiento y la estrategia de reversión son importantes.
Si realiza envíos en trenes de lanzamiento voluminosos con puertas manuales, incluso los errores resueltos permanecen sin resolver hasta que sale el siguiente tren. Los conmutadores de función, los lanzamientos canario y los carriles de hotfix acortan la cola, especialmente para las incidencias P0/P1, al permitirle desacoplar la implementación de la corrección de los ciclos de lanzamiento completos.
La arquitectura y la deuda tecnológica marcan su límite máximo.
El acoplamiento estrecho, la falta de pruebas y los módulos heredados opacos hacen que las correcciones sencillas sean arriesgadas. Los equipos lo compensan con pruebas adicionales y revisiones más largas, lo que alarga los ciclos. Por el contrario, el código modular con buenas pruebas de contrato le permite avanzar rápidamente sin romper los sistemas adyacentes.
La comunicación y la higiene del estado influyen en la previsibilidad.
Las actualizaciones vagas («lo estamos investigando») generan trabajo adicional cuando las partes interesadas solicitan estimaciones de tiempo de resolución, el servicio de asistencia vuelve a abrir tickets o el producto se escala. Las transiciones de estado claras, las notas sobre la reproducción y la causa raíz, y la publicación de una estimación de tiempo de resolución reducen la rotación y protegen la concentración de su equipo de ingeniería.
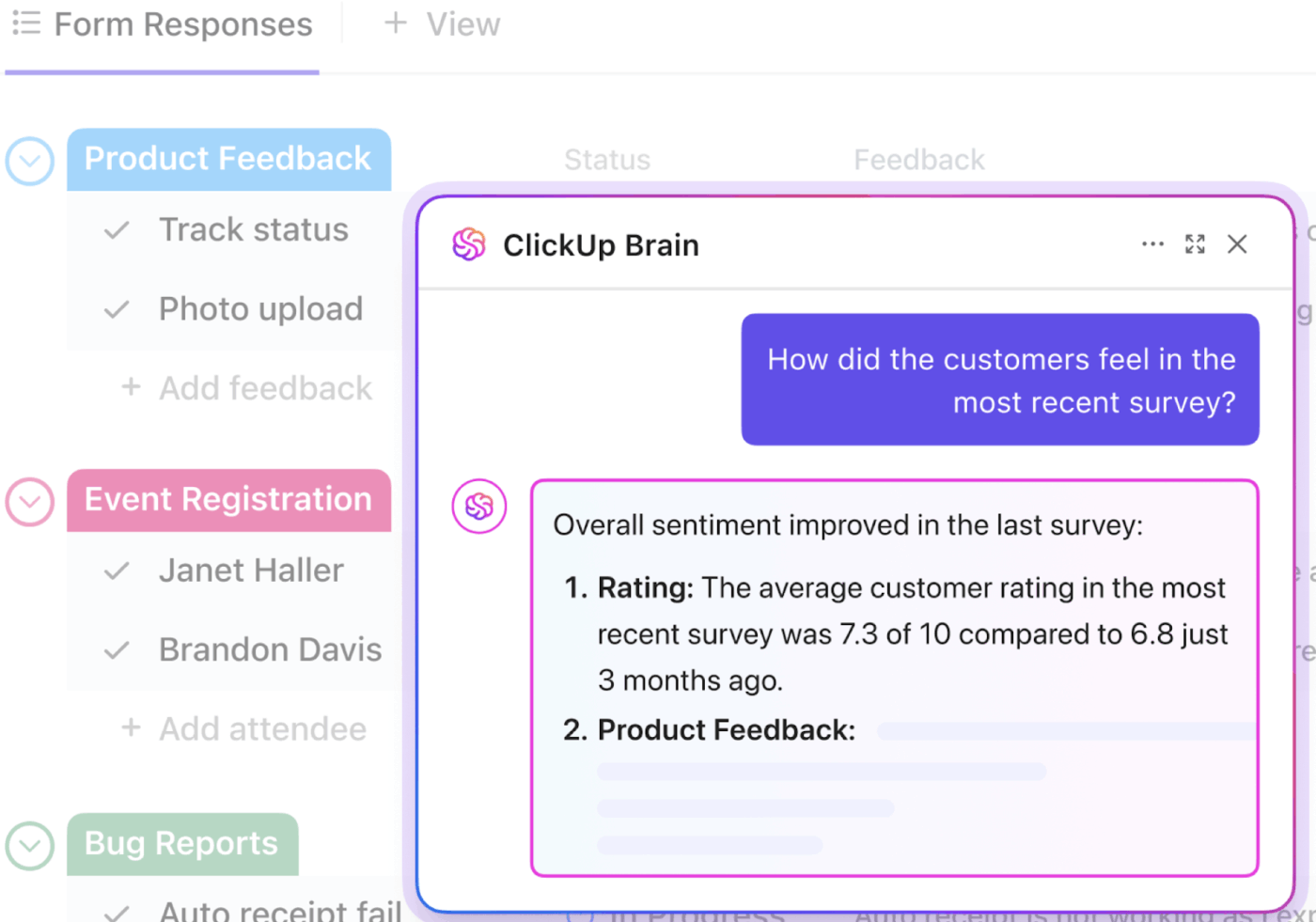
📮ClickUp Insight: El profesional medio dedica más de 30 minutos al día a buscar información relacionada con el trabajo, lo que supone más de 120 horas al año perdidas en buscar entre correos electrónicos, hilos de Slack y archivos dispersos.
Un asistente inteligente con IA integrado en su entorno de trabajo puede cambiar eso. Le presentamos ClickUp Brain. Ofrece información y respuestas instantáneas al mostrar los documentos, conversaciones y detalles de tareas adecuados en cuestión de segundos, para que pueda dejar de buscar y empezar a trabajar.
💫 Resultados reales: Equipos como QubicaAMF recuperaron más de 5 horas semanales utilizando ClickUp, lo que supone más de 250 horas anuales por persona, al eliminar los procesos obsoletos de gestión del conocimiento. ¡Imagina lo que tu equipo podría crear con una semana extra de productividad cada trimestre!
Indicadores principales de que su plazo de entrega se retrasará
❗️Aumento del «tiempo de reconocimiento» y gran cantidad de tickets sin propietario durante más de 12 horas.
❗️Aumento de los segmentos «Tiempo en revisión/CI» y frecuentes fallos en las pruebas.
❗️Alta tasa de duplicados en la recepción y rótulos de gravedad inconsistentes entre los equipos.
❗️Varias incidencias permanecen en «Bloqueados» sin una dependencia externa específica.
❗️Aumento gradual de la tasa de reapertura (las correcciones no son reproducibles o las definiciones de «terminado» son imprecisas).
Las diferentes organizaciones perciben estos factores de manera diferente. Los ejecutivos los experimentan como ciclos de aprendizaje perdidos y desviaciones con respecto a los momentos de ingresos; los operadores los perciben como ruido de clasificación y falta de claridad en la propiedad.
Ajustando la entrada, el flujo y las dependencias es como se consigue reducir toda la curva, tanto la mediana como el P90.
¿Quieres obtener más información sobre cómo redactar mejores informes de errores? Empieza aquí. 👇🏼
📖 Más información: El ciclo de vida de las pruebas de software (STLC): panorámica y fases
Puntos de referencia del sector para el tiempo de resolución de errores
Los puntos de referencia para la resolución de errores varían en función de la tolerancia al riesgo, el modelo de lanzamiento y la rapidez con la que se pueden enviar los cambios.
Aquí es donde puede utilizar las medianas (P50) para comprender su flujo habitual y P90 para realizar ajustes en los compromisos y los acuerdos de nivel de servicio (SLA), según la gravedad y la fuente (cliente, control de calidad, supervisión).
Analicemos lo que eso significa:
| 🔑 Término | 📝 Descripción | 💡 Por qué es importante |
|---|---|---|
| P50 (mediana) | El valor medio: el 50 % de las correcciones de incidencias son más rápidas que esto y el 50 % son más lentas. | 👉 Refleja su tiempo de resolución habitual o más común. Útil para comprender el rendimiento normal. |
| P90 (percentil 90) | El 90 % de las incidencias se solucionan en este tiempo. Solo el 10 % tarda más. | 👉 Representa el peor de los casos (pero sigue siendo realista). Útil para establecer promesas externas. |
| SLA (acuerdos de nivel de servicio) | Los compromisos que usted adquiere, tanto a nivel interno como con los clientes, sobre la rapidez con la que se resolverán los problemas. | 👉 Ejemplo: «Resolvemos las incidencias P1 en un plazo de 48 horas, en el 90 % de los casos». Ayuda a generar confianza y responsabilidad. |
| Por gravedad y origen | Segmente sus métricas según dos dimensiones clave: • Gravedad (por ejemplo, P0, P1, P2)• Origen (por ejemplo, cliente, control de calidad, supervisión) | 👉 Permite un seguimiento y una priorización más precisos, de modo que las incidencias críticas reciban atención más rápidamente. |
A continuación se muestran intervalos orientativos basados en los sectores en los que los equipos maduros suelen tener un objetivo; considéralos como puntos de partida y adáptalos a tu contexto.
SaaS
Siempre activo y compatible con CI/CD, por lo que las correcciones son habituales. Los problemas críticos (P0/P1) suelen tener como objetivo una mediana inferior a un día laborable, con un P90 en un plazo de 24 a 48 horas. Los no críticos (P2+) suelen tener una mediana de 3 a 7 días, con un P90 en un plazo de 10 a 14 días. Los equipos con conmutadores de función robustos y pruebas automatizadas tienden a ser más rápidos.
Plataformas de comercio electrónico
Dado que los flujos de conversión y carritos son fundamentales para los ingresos, el listón está más alto. Los problemas P0/P1 suelen mitigarse en cuestión de horas (reversión, marcado o configuración) y resolverse por completo el mismo día; los P90 suelen resolverse al final del día o en menos de 12 horas en temporada alta. Los problemas P2+ suelen resolverse en 2-5 días, con P90 en un plazo de 10 días.
Software empresarial
Las validaciones más exhaustivas y los periodos de cambio de los clientes ralentizan el ritmo. Para P0/P1, los equipos se fijan como objetivo encontrar una solución provisional en un plazo de 4 a 24 horas y una solución definitiva en un plazo de 1 a 3 días laborables; para P90, en un plazo de 5 días laborables. Los elementos P2+ se agrupan con frecuencia en trenes de lanzamiento, con una mediana de 2 a 4 semanas, dependiendo de los calendarios de implementación de los clientes.
Aplicaciones móviles y de juegos
Los backends de servicios en vivo se comportan como SaaS (indicadores y reversiones en minutos u horas; P90 el mismo día). Las actualizaciones de los clientes están limitadas por las revisiones de la tienda: P0/P1 suelen utilizar inmediatamente las palancas del lado del servidor y envían un parche al cliente en 1-3 días; P90 en una semana con revisión acelerada. Las correcciones P2+ suelen programarse para el siguiente sprint o lanzamiento de contenido.
Banca/Fintech
Las barreras de riesgo y cumplimiento impulsan un patrón de «mitigar rápidamente, cambiar con cuidado». Los P0/P1 se mitigan rápidamente (indicadores, reversiones, cambios de tráfico en cuestión de minutos u horas) y se solucionan por completo en 1-3 días; los P90, en una semana, teniendo en cuenta el control de cambios. Los P2+ suelen tardar entre 2 y 6 semanas en superar las revisiones de seguridad, auditoría y CAB.
Si sus números se encuentran fuera de estos intervalos, analice la calidad de la admisión, el enrutamiento/propiedad, la revisión del código y el rendimiento del control de calidad, así como las aprobaciones de dependencias, antes de asumir que la «velocidad de ingeniería» es el problema principal.
🌼 ¿Sabías que... Según una encuesta de Stack Overflow de 2024, los desarrolladores utilizan cada vez más la IA como su fiel compañera en el proceso de programación. Un impresionante 82 % utilizó la IA para escribir código, ¡todo un colaborador creativo! Cuando se atascaban o buscaban soluciones, el 67,5 % confiaba en la IA para buscar respuestas, y más de la mitad (56,7 %) recurría a ella para depurar y obtener ayuda.
Para algunos, las herramientas de IA también resultaron útiles para documentar proyectos (40,1 %) e incluso para generar datos o contenidos sintéticos (34,8 %). ¿Tiene curiosidad por conocer una nueva base de código? Casi un tercio (30,9 %) utiliza la IA para ponerse al día. Probar el código sigue siendo una tarea manual para muchos, pero el 27,2 % también ha adoptado la IA en este ámbito. Otras áreas, como la revisión de código, la planificación de proyectos y el análisis predictivo, registran una menor adopción de la IA, pero está claro que esta se está integrando progresivamente en todas las fases del desarrollo de software.
📖 Más información: Cómo utilizar la IA para el control de calidad
Cómo reducir el tiempo de resolución de incidencias
La rapidez en la resolución de errores se reduce a eliminar la fricción en cada traspaso, desde la recepción hasta la publicación.
Las mayores ventajas se obtienen al optimizar los primeros 30 minutos (admisión limpia, propietario adecuado, prioridad adecuada) y, a continuación, comprimir los bucles posteriores (reproducir, revisar, verificar).
Aquí tienes nueve estrategias que funcionan conjuntamente como un sistema. La IA acelera cada paso y el flujo de trabajo se mantiene ordenado en un solo lugar, por lo que los ejecutivos obtienen previsibilidad y los profesionales obtienen flujo.
1. Centralice la recepción y capture el contexto en el origen.
El tiempo de resolución de errores se alarga cuando se reconstruye el contexto a partir de hilos de Slack, tickets de soporte y hojas de cálculo. Canalice todos los informes (soporte, control de calidad, supervisión) en una única cola con una plantilla estructurada que recopile componentes, gravedad, entorno, versión/compilación de la aplicación, pasos para reproducir el error, expectativas frente a resultados reales y adjuntos (registros/HAR/capturas de pantalla).
La IA puede resumir automáticamente informes largos, extraer pasos de reproducción y detalles del entorno de los adjuntos, y marcar posibles duplicados para que la clasificación comience con un registro coherente y enriquecido.
Métricas a tener en cuenta: MTTA (reconocimiento en minutos, no en horas), tasa de duplicados, tiempo de «Necesita información».

📖 Más información: El poder de los formularios de ClickUp: optimización del trabajo para equipos de software
2. Clasificación y enrutamiento asistidos por IA para reducir el MTTA
Las soluciones más rápidas son aquellas que llegan inmediatamente al lugar adecuado.
Utilice reglas sencillas y la IA para clasificar la gravedad, identificar los posibles propietarios por componente/área de código y asignar automáticamente con un reloj SLA. Establezca carriles claros para P0/P1 frente a todo lo demás y deje claro «quién es el propietario».
Las automatizaciones pueden establecer prioridades a partir de campos, dirigir por componente a un equipo, iniciar un cronómetro de SLA y notificar a un ingeniero de guardia; la IA puede proponer la gravedad y el propietario basándose en patrones anteriores. Cuando la clasificación se convierte en un proceso de 2 a 5 minutos en lugar de un debate de 30 minutos, su MTTA se reduce y su MTTR le sigue.
Métricas a tener en cuenta: MTTA, calidad de la primera respuesta (¿la primera respuesta solicita la información correcta?), número de traspasos por error.
Así es como funciona en la práctica:
3. Priorice según el impacto en la empresa con niveles de SLA explícitos.
«La voz más alta gana» hace que las colas sean impredecibles y erosiona la confianza de los ejecutivos que observan el CSAT/NPS y las renovaciones.
Sustitúyalo por una puntuación que combine la gravedad, la frecuencia, el ARR afectado, la criticidad de la función y la proximidad a las renovaciones/lanzamientos, y respáldela con niveles de SLA (por ejemplo, P0: mitigar en 1-2 horas, resolver en un día; P1: el mismo día; P2: dentro de un sprint).
Mantenga un carril P0/P1 con visibilidad y límites WIP para que nada se quede sin recursos.
Métricas a tener en cuenta: resolución P50/P90 por nivel, tasa de incumplimiento del SLA, correlación con CSAT/NPS.
💡Consejo profesional: los campos Prioridades de tareas, Campos personalizados y Dependencias de ClickUp te permiten calcular una puntuación de impacto y enlazar las incidencias con cuentas, comentarios o elementos de la hoja de ruta. Además, las Metas de ClickUp te ayudan a enlazar el cumplimiento del SLA con los objetivos a nivel de la empresa, lo que responde directamente a las preocupaciones de los ejecutivos sobre la alineación.
4. Haga que la reproducción y el diagnóstico sean una actividad de un solo paso.
Cada bucle adicional con «¿puede enviar los registros?» aumenta el tiempo de resolución.
Estandarice lo que se considera «bueno»: campos obligatorios para la compilación/confirmación, entorno, pasos de reproducción, esperado frente a real, además de adjuntos para registros, volcados de memoria y archivos HAR. Implemente la telemetría cliente/servidor para que los ID de fallos y los ID de solicitudes se puedan vincular a los rastreos.
Utilice Sentry (o similar) para obtener trazas de pila y enlaze ese problema directamente con el error. La IA puede leer registros y trazas para proponer un posible dominio de fallo y generar una reproducción mínima, lo que convierte una hora de observación visual en unos pocos minutos de trabajo concentrado.
Almacene guías de procedimientos para clases comunes de incidencias, de modo que los ingenieros no tengan que empezar desde cero.
Métricas a tener en cuenta: tiempo dedicado a «esperar información», porcentaje reproducido en la primera pasada, tasa de reapertura vinculada a la falta de reproducción.
5. Acorta el ciclo de revisión y prueba del código.
Los grandes PR se estancan. Apueste por parches quirúrgicos, desarrollo basado en troncos y conmutadores de función para que las correcciones se puedan enviar de forma segura. Asigne previamente revisores por propiedad del código para evitar tiempos de inactividad y utilice listas de control (pruebas actualizadas, telemetría añadida, conmutador detrás de un interruptor de apagado) para garantizar la calidad.
La automatización debe mover el error a «En revisión» al abrir la solicitud de incorporación de cambios y a «Resuelto» al combinar; la IA puede sugerir pruebas unitarias o resaltar diferencias riesgosas para centrar la revisión.
Métricas a tener en cuenta: tiempo en «En revisión», tasa de fallos de cambio para PR de corrección de errores y latencia de revisión P90.
Puede utilizar las integraciones de GitHub/GitLab en ClickUp para mantener sincronizado el estado de resolución; las automatizaciones pueden hacer cumplir la «definición de terminada».
📖 Más información: Cómo utilizar la IA para automatizar tareas
6. Paralelice la verificación y haga realidad la paridad del entorno de control de calidad.
La verificación no debe comenzar días después ni en un entorno que ninguno de sus clientes utiliza.
Mantenga el «listo para control de calidad» estricto: correcciones urgentes basadas en indicadores validadas en entornos similares a los de producción con datos iniciales que coinciden con los casos notificados.
Siempre que sea posible, configure entornos efímeros desde la rama de errores para que el equipo de control de calidad pueda validarlos inmediatamente; a continuación, la IA puede generar casos de prueba a partir de la descripción del error y las regresiones anteriores.
Métricas a tener en cuenta: tiempo en «control de calidad/verificación», tasa de rebote del control de calidad al desarrollo, tiempo medio hasta el cierre tras combinar las ramas.

📖 Más información: Cómo escribir casos de prueba eficaces
7. Comunique el estado de forma clara para reducir los costes de coordinación.
Una buena actualización evita tres comprobaciones del estado y una escalada.
Trate las actualizaciones como un producto: breves, específicas y adaptadas al público (soporte técnico, ejecutivos, clientes). Establezca una cadencia para P0/P1 (por ejemplo, cada hora hasta que se mitigue, luego cada cuatro horas) y mantenga una única fuente de información veraz.
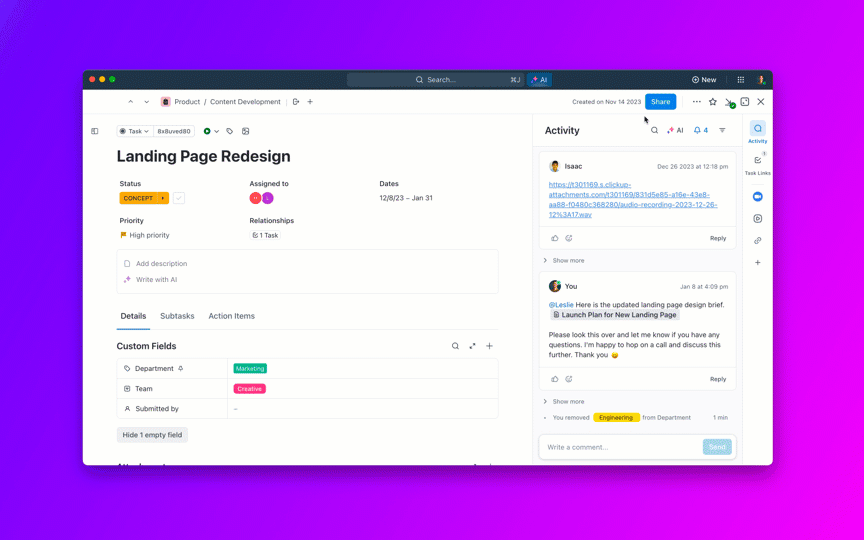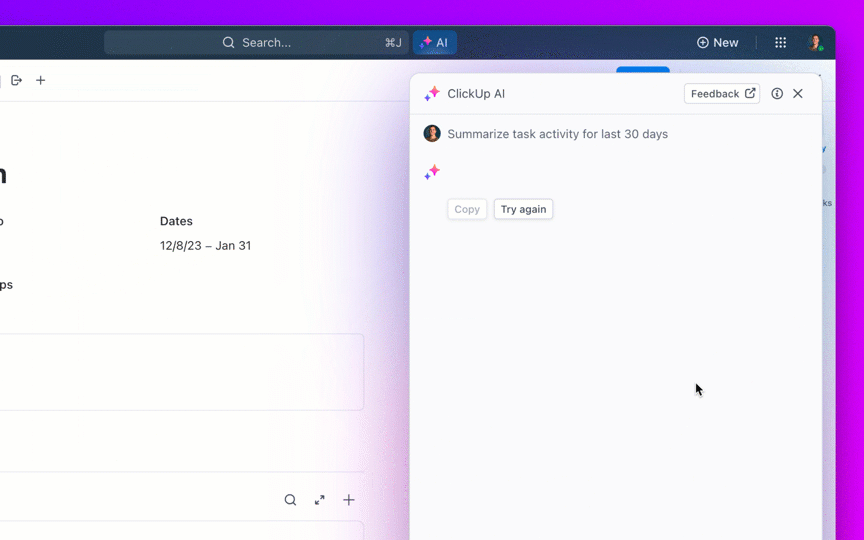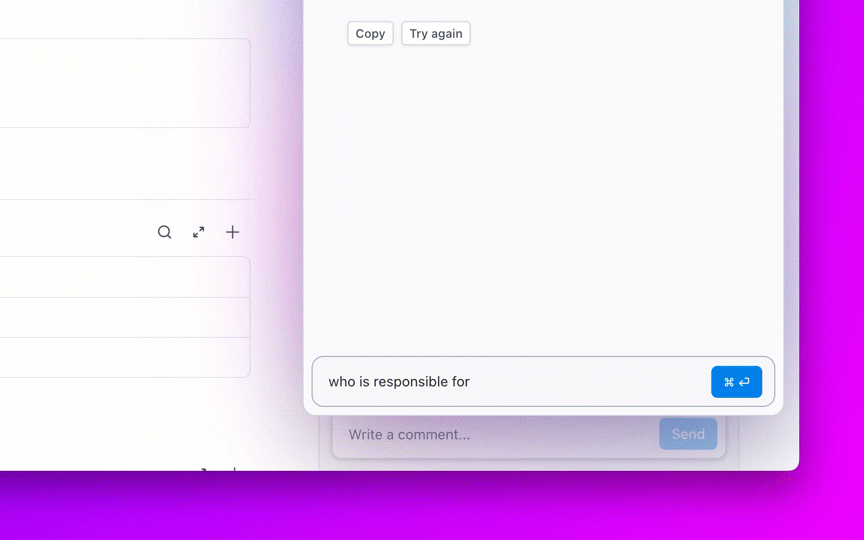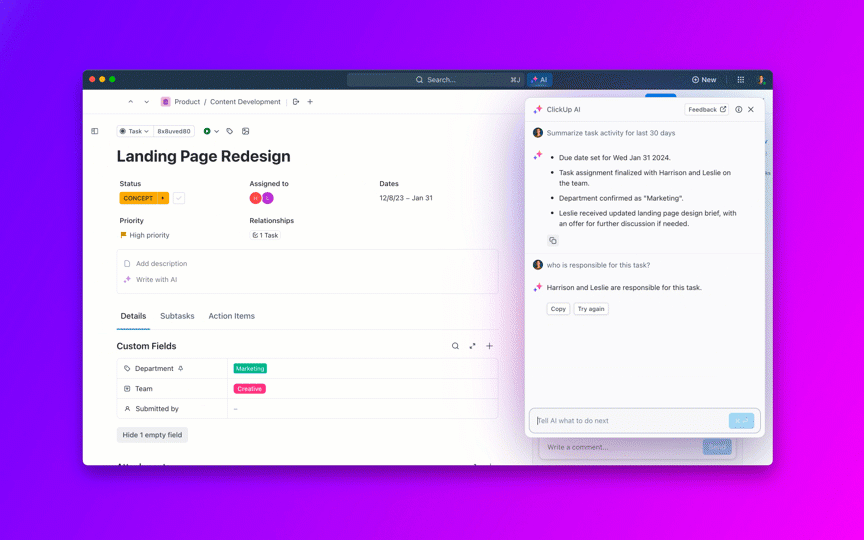
La IA puede redactar actualizaciones seguras para los clientes y resúmenes internos a partir del historial de tareas, incluyendo el estado en tiempo real por gravedad y equipo. Para ejecutivos como su director de producto, agrupe las incidencias en iniciativas para que puedan ver si el trabajo de calidad crítico amenaza las promesas de entrega.
Métricas a tener en cuenta: Tiempo entre actualizaciones de estado en P0/P1, satisfacción de las partes interesadas en las comunicaciones.
8. Controle el envejecimiento de los trabajos pendientes y evite que permanezcan «abiertos para siempre».
Una acumulación creciente y obsoleta de tareas pendientes supone una carga silenciosa para cada sprint.
Establezca políticas de antigüedad (por ejemplo, P2 > 30 días desencadena la revisión, P3 > 90 días requiere justificación) y programe una «clasificación por antigüedad» semanal para combinar duplicados, cerrar informes obsoletos y convertir las incidencias de bajo valor en elementos pendientes del producto.
Utilice la IA para agrupar los trabajos pendientes por tema (por ejemplo, «caducidad del token de autenticación», «inestabilidad en la carga de imágenes») para poder programar semanas temáticas de correcciones y eliminar una clase de defectos de una sola vez.
Métricas a tener en cuenta: número de tareas pendientes por antigüedad, porcentaje de problemas cerrados como duplicados u obsoletos, velocidad de burn-down temática.
9. Cierre el ciclo con la causa raíz y la prevención.
Si sigue repitiéndose el mismo tipo de defecto, las mejoras en el MTTR están ocultando un problema mayor.
Realice análisis rápidos y objetivos de las causas raíz en P0/P1 y P2 de alta frecuencia; etiquete las causas raíz (lagunas en las especificaciones, lagunas en las pruebas, lagunas en las herramientas, inestabilidad en la integración), vincule los componentes e incidencias afectadas y realice el seguimiento de las tareas de seguimiento (protecciones, pruebas, reglas de lint) hasta su completación.
La IA puede redactar resúmenes de RCA y proponer pruebas preventivas o reglas de lint basadas en el historial de cambios. Y así es como se pasa de apagar incendios a tener menos incendios.
Métricas a tener en cuenta: tasa de reapertura, tasa de regresión, tiempo entre repeticiones y porcentaje de RCA con acciones de prevención completadas.

En conjunto, estos cambios comprimen el proceso de principio a fin: reconocimiento más rápido, clasificación más clara, priorización más inteligente, menos retrasos en la revisión y el control de calidad, y una comunicación más clara. Los ejecutivos obtienen previsibilidad vinculada al CSAT/NPS y a los ingresos; los profesionales obtienen una cola más tranquila con menos cambios de contexto.
📖 Más información: Cómo realizar un análisis de la causa raíz
Herramientas de IA que ayudan a reducir el tiempo de resolución de incidencias
La IA puede reducir el tiempo de resolución en cada paso: recepción, clasificación, enrutamiento, reparación y verificación.
Sin embargo, las verdaderas ventajas se obtienen cuando las herramientas comprenden el contexto y mantienen el trabajo en marcha sin necesidad de supervisión.
Busque sistemas que enriquezcan los informes automáticamente (pasos de reproducción, entorno, duplicados), prioricen por impacto, dirijan al propietario adecuado, redacten actualizaciones claras y se integren perfectamente con su código, CI y observabilidad.
Las mejores herramientas también admiten flujos de trabajo similares a los de los agentes: bots que supervisan los SLA, avisan a los revisores, escalan los elementos bloqueados y resumen los resultados para las partes interesadas. Aquí está nuestra selección de herramientas de IA para una mejor resolución de incidencias:
1. ClickUp (ideal para IA contextual, automatizaciones y flujos de trabajo agenticos)
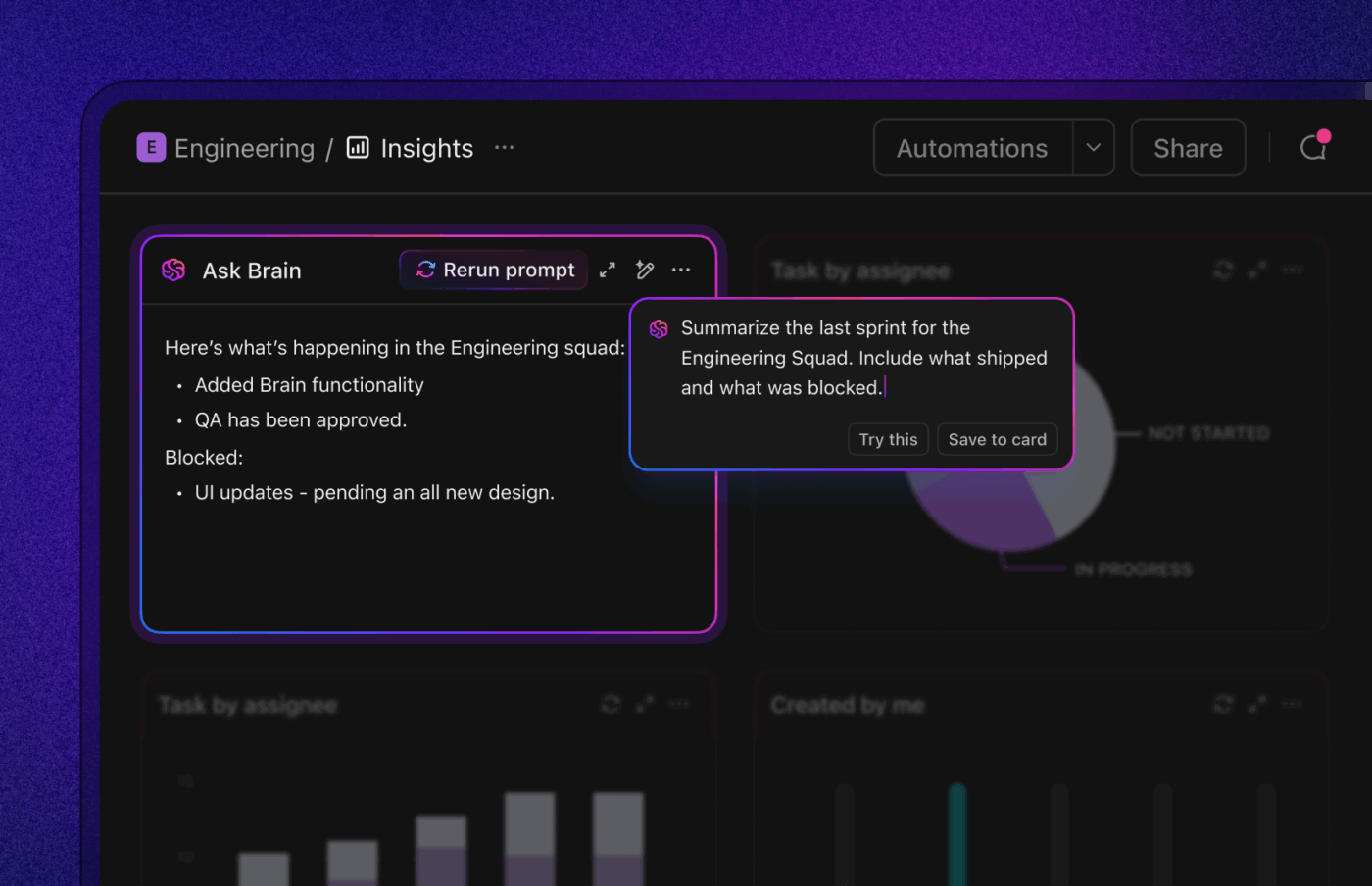
Si desea un flujo de trabajo optimizado e inteligente para la resolución de errores, ClickUp, la aplicación integral para el trabajo, reúne en un solo lugar la IA, las automatizaciones y la asistencia agencial para el flujo de trabajo.
ClickUp Brain muestra el contexto adecuado al instante: resume largos hilos de incidencias, extrae los pasos para reproducirlos y los detalles del entorno de los adjuntos, señala posibles duplicados y sugiere las siguientes acciones. En lugar de tener que revisar Slack, tickets y registros, los equipos obtienen un registro limpio y enriquecido sobre el que pueden actuar de inmediato.
Las automatizaciones y los agentes de piloto automático de ClickUp mantienen el trabajo en marcha sin necesidad de supervisión constante. Las incidencias se envían automáticamente al equipo adecuado, se asignan propietarios, se establecen acuerdos de nivel de servicio y fechas límite, se actualiza el estado a medida que avanza el trabajo y las partes interesadas reciben notificaciones oportunas.

Estos agentes pueden incluso clasificar y categorizar los problemas, agrupar informes similares, consultar soluciones históricas para sugerir posibles soluciones y escalar los elementos urgentes, de modo que el MTTA y el MTTR se reduzcan incluso cuando el volumen aumenta.
🛠️ ¿Quieres un kit de herramientas listo para usar? La plantilla de seguimiento de errores y problemas de ClickUp es una potente solución de ClickUp for Software diseñada para ayudar a los equipos de soporte, ingeniería y producto a controlar fácilmente los errores y problemas del software. Con vistas personalizables como Lista, Tablero, Carga de trabajo, Formulario y Cronograma, los equipos pueden visualizar y gestionar su proceso de seguimiento de errores de la forma que más les convenga.
Los 20 estados personalizados y los 7 Campos personalizados de la plantilla permiten crear un flujo de trabajo a medida, lo que garantiza el seguimiento de cada problema desde su detección hasta su resolución. Las automatizaciones integradas se encargan de las tareas repetitivas, lo que libera un tiempo valioso y reduce el esfuerzo manual.
💟 Bonificación: Brain MAX es su compañero de escritorio impulsado por IA, diseñado para acelerar la resolución de errores con funciones inteligentes y prácticas.
Cuando encuentre un error, simplemente utilice la función de conversión de voz a texto de Brain MAX para dictar el problema: sus notas habladas se transcribirán al instante y se podrán adjuntar a un ticket de error nuevo o existente. Su función Enterprise Search busca en todas sus herramientas conectadas, como ClickUp, GitHub, Google Drive y Slack, para mostrar informes de errores, registros de errores, fragmentos de código y documentación relacionados, de modo que disponga de todo el contexto que necesita sin tener que cambiar de aplicación.
¿Necesita coordinar una solución? Brain MAX le permite asignar el error al desarrollador adecuado, configurar recordatorios automáticos para las actualizaciones de estado y realizar el seguimiento del progreso, ¡todo desde su escritorio!
2. Sentry (ideal para detectar errores)
Sentry reduce el MTTD y el tiempo de reproducción al capturar errores, trazas y sesiones de usuario en un solo lugar. La agrupación de problemas basada en IA reduce el ruido; las reglas de «Suspect Commit» y propiedad identifican al probable propietario del código, por lo que el enrutamiento es instantáneo. Session Replay proporciona a los ingenieros la ruta exacta del usuario y los detalles de la consola/red para reproducir sin interminables idas y venidas.
Las funciones de Sentry IA pueden resumir el contexto del problema y, en algunas pilas, proponer parches de reparación automática que hacen referencia al código defectuoso. El impacto práctico: menos tickets duplicados, asignación más rápida y un camino más corto desde el informe hasta el parche funcional.
3. GitHub Copilot (ideal para revisar código más rápidamente)
Copilot acelera el ciclo de corrección dentro del editor. Explica los seguimientos de pila, sugiere parches con objetivos específicos, escribe pruebas unitarias para fijar la corrección y crea scripts de reproducción.
Copilot Chat puede revisar el código defectuoso, proponer refactorizaciones más seguras y generar comentarios o descripciones de relaciones públicas que agilizan la revisión del código. En combinación con las revisiones necesarias y la integración continua, reduce en horas el proceso de «diagnóstico → implementación → prueba», especialmente en el caso de errores bien definidos y con una reproducción clara.
4. Snyk de DeepCode IA (ideal para detectar patrones)
El análisis estático impulsado por IA de DeepCode detecta defectos y patrones inseguros mientras programa y en las solicitudes de incorporación de cambios. Destaca los flujos problemáticos, explica por qué se producen y propone soluciones seguras que se ajustan a los idiomas de su código base.
Al detectar las regresiones antes de combinar y orientar a los desarrolladores hacia patrones más seguros, se reduce la tasa de aparición de nuevos errores y se acelera la corrección de errores lógicos complejos que son difíciles de detectar en la revisión. Las integraciones IDE y PR mantienen esto cerca del lugar donde se realiza el trabajo.
5. Watchdog y AIOps de Datadog (lo mejor para el análisis de registros)
Watchdog de Datadog utiliza el aprendizaje automático para detectar anomalías en los registros, las métricas, los rastreos y la supervisión de usuarios reales. Correlaciona los picos con los marcadores de implementación, los cambios en la infraestructura y la topología para sugerir las posibles causas raíz.
En el caso de los defectos que afectan a los clientes, esto se traduce en minutos para la detección, agrupación automática para reducir el ruido de las alertas y pistas concretas sobre dónde buscar. El tiempo de clasificación se reduce porque se parte de «esta implementación afectó a estos servicios y las tasas de error aumentaron en este punto final», en lugar de partir de cero.
⚡️ Archivo de plantillas: Plantillas gratuitas para el seguimiento de problemas y registros en Excel y ClickUp.
6. New Relic IA (ideal para identificar y resumir tendencias)
La bandeja de entrada de errores de New Relic agrupa errores similares en todos los servicios y versiones, mientras que su asistente de IA resume el impacto, destaca las causas probables y proporciona enlaces a los rastros/transacciones involucrados.
Las correlaciones de implementación y la inteligencia de cambios de entidades dejan claro cuándo la culpa es de una versión reciente. En el caso de los sistemas distribuidos, ese contexto reduce horas de comunicaciones entre equipos y dirige la incidencia al propietario adecuado con una hipótesis sólida ya formulada.
7. Rollbar (ideal para flujos de trabajo automatizados)
Rollbar se especializa en la supervisión de errores en tiempo real con huellas digitales inteligentes para agrupar duplicados y realizar un seguimiento de las tendencias de repetición. Sus resúmenes impulsados por IA y sus sugerencias sobre las causas fundamentales ayudan a los equipos a comprender el alcance (usuarios afectados, versiones afectadas), mientras que la telemetría y los seguimientos de pila proporcionan pistas rápidas para la reproducción.
Las reglas de flujo de trabajo de Rollbar pueden crear tareas automáticamente, etiquetar la gravedad y enviarlas a los propietarios, convirtiendo los ruidosos flujos de errores en colas priorizadas con contexto adjunto.
8. PagerDuty AIOps y automatización de runbooks (lo mejor en diagnósticos de bajo contacto)
PagerDuty utiliza la correlación de eventos y la reducción de ruido basada en el aprendizaje automático para convertir las tormentas de alertas en incidencias procesables.
El enrutamiento dinámico dirige el problema al técnico de guardia adecuado al instante, mientras que la automatización de los libros de instrucciones puede iniciar diagnósticos o mitigaciones (reiniciar servicios, revertir una implementación, activar o desactivar los conmutadores de función) antes de que intervenga una persona. En cuanto al tiempo de resolución de errores, esto se traduce en un MTTA más corto, mitigaciones más rápidas para los P0 y menos horas perdidas por la fatiga de las alertas.
La clave es la automatización y la IA en cada paso. Detecta antes, deriva de forma más inteligente, llega antes al código y comunica el estado sin ralentizar a los ingenieros, lo que se traduce en una reducción significativa del tiempo de resolución de errores.
📖 Más información: Cómo utilizar la IA en DevOps
Ejemplos reales del uso de la IA para la resolución de errores
Así pues, la IA ha salido oficialmente del laboratorio. Está reduciendo el tiempo de resolución de incidencias en el mundo real.
¡Veamos cómo!
| Dominio/Organización | Cómo se utilizó la IA | Impacto/beneficio |
|---|---|---|
| Ubisoft | Desarrollamos Commit Assistant, una herramienta de IA entrenada con una década de código interno, que predice y previene incidencias en la fase de codificación. | El objetivo es reducir drásticamente el tiempo y los costes: tradicionalmente, hasta el 70 % de los gastos de desarrollo de videojuegos se destinan a la corrección de incidencias. |
| Razer (plataforma Wyvrn) | Lanzamiento de QA Copilot (integrado con Unreal y Unity), impulsado por IA, para automatizar la detección de errores y generar informes de control de calidad. | Aumenta la detección de errores hasta en un 25 % y reduce a la mitad el tiempo de control de calidad. |
| Google / DeepMind y Project Zero | Presentamos Big Sleep, una herramienta de IA que detecta de forma autónoma vulnerabilidades de seguridad en software de código abierto como FFmpeg e ImageMagick. | Se identificaron 20 incidencias, todas ellas verificadas por expertos humanos y programadas para su corrección. |
| Investigadores de la Universidad de California en Berkeley | Utilizando un punto de referencia denominado CyberGym, los modelos de IA analizaron 188 proyectos de código abierto, descubrieron 17 vulnerabilidades —incluidos 15 errores «zero-day» desconocidos— y generaron exploits de prueba de concepto. | Demuestra la capacidad evolutiva de la IA en la detección de vulnerabilidades y la revisión automatizada contra exploits. |
| Spur (startup de Yale) | Desarrollamos un agente de IA que traduce descripciones de casos de prueba en lenguaje sencillo a rutinas de automatización de pruebas de sitios web, lo que en la práctica es un flujo de trabajo de control de calidad que se escribe solo. | Permite realizar pruebas autónomas con una intervención humana mínima. |
| Reproducción automática de informes de incidencias de Android | Se utilizó el procesamiento del lenguaje natural (NLP) y el aprendizaje por refuerzo para interpretar el lenguaje de los informes de errores y generar pasos para reproducir incidencias de Android. | Se logró una precisión del 67 %, una recuperación del 77 % y se reprodujo el 74 % de los informes de incidencias, superando a los métodos tradicionales. |
Errores comunes en la medición del tiempo de resolución de incidencias
Si su medición no es correcta, su plan de mejora tampoco lo será.
La mayoría de los «malos números» en los flujos de trabajo de resolución de errores provienen de definiciones vagas, flujos de trabajo inconsistentes y análisis superficiales.
Empiece por lo básico: qué se considera inicio/fin, cómo gestionar las esperas y las reaberturas, y luego lea los datos tal y como los experimentan sus clientes. Esto incluye:
❌ Límites difusos: mezclar «Notificado→Resuelto» y «Notificado→Cerrada» en el mismo panel de control (o cambiar de un mes a otro) hace que las tendencias pierdan sentido. Elija un límite, documéntelo y aplíquelo en todos los equipos. Si necesita ambos, publíquelos como métricas separadas con rótulos claros.
❌ Enfoque basado únicamente en promedios: Basarse en la media oculta la realidad de las colas con unos pocos valores atípicos de larga duración. Utilice la mediana (P50) para su tiempo «típico», P90 para la previsibilidad/SLA, y mantenga la media para la planificación de la capacidad. Fíjese siempre en la distribución, no solo en un único número.
❌ Sin segmentación: agrupar todas las incidencias mezcla incidencias P0 con P3 cosméticos. Segmenta por gravedad, origen (cliente frente a control de calidad frente a supervisión), componente/equipo y «nuevo frente a regresión». Tu P0/P1 P90 es lo que sienten las partes interesadas; tu mediana P2+ es lo que planifica la ingeniería.
❌ Ignorar el tiempo «en pausa»: ¿Está esperando los registros de los clientes, un proveedor externo o una ventana de lanzamiento? Si no realiza un seguimiento de los estados «Bloqueado»/«En pausa» como un estado de primera clase, el tiempo de resolución se convierte en un argumento. Informe tanto del tiempo de calendario como del tiempo activo para que los cuellos de botella sean visibles y se acaben las discusiones.
❌ Diferencias en la normalización del tiempo: mezclar zonas horarias o cambiar entre horas laborables y horas naturales a mitad del proceso distorsiona las comparaciones. Normalice las marcas de tiempo a una zona (o UTC) y decida una vez por todas si los SLA se miden en horas laborables o naturales; aplíquelo de forma coherente.
❌ Entrada incorrecta y duplicados: La falta de información sobre el entorno o la compilación y los tickets duplicados aumentan el tiempo y confunden la propiedad. Estandarice los campos obligatorios en la entrada, enriquezca automáticamente (registros, versión, dispositivo) y elimine los duplicados sin restablecer el tiempo: cierre los duplicados como problemas enlazados, no como problemas «nuevos».
❌ Modelos de estado inconsistentes: los estados personalizados («QA Ready-ish», «Pending Review 2») ocultan el tiempo en cada estado y hacen que las transiciones de estado sean poco fiables. Defina un flujo de trabajo canónico (Nuevo → Clasificado → En curso → En revisión → Resuelto → Cerrada) y audite los estados que se desvían de la ruta.
❌ Ignorancia del tiempo en estado: un solo número de «tiempo total» no puede indicarle dónde se estanca el trabajo. Capture y revise el tiempo dedicado a la clasificación, la revisión, el bloqueo y el control de calidad. Si la revisión del código P90 eclipsa la implementación, la solución no es «codificar más rápido», sino desbloquear la capacidad de revisión.
🧠 Dato curioso: El último Cyber Challenge de IA de DARPA mostró un avance revolucionario en la automatización de la ciberseguridad. La competición contó con sistemas de IA diseñados para detectar, explotar y parchear vulnerabilidades en el software de forma autónoma, sin intervención humana. El equipo ganador, «Team Atlanta», descubrió de forma impresionante el 77 % de las incidencias introducidas y corrigió con éxito el 61 % de ellas, lo que demuestra el poder de la IA no solo para encontrar fallos, sino también para solucionarlos de forma activa.
❌ Ceguera ante las reabiertas: tratar las reabiertas como nuevos errores reinicia el reloj y engaña al MTTR. Realice un seguimiento de la tasa de reabiertas y del «tiempo hasta el cierre estable» (desde el primer informe hasta el cierre final en todos los ciclos). El aumento de las reabiertas suele indicar una reproducción débil, lagunas en las pruebas o una definición imprecisa de «terminado».
❌ Sin MTTA: los equipos se obsesionan con el MTTR y ignoran el MTTA (tiempo de reconocimiento/asunción de responsabilidad). Un MTTA elevado es una advertencia temprana de una resolución prolongada. Mídalo, establezca acuerdos de nivel de servicio (SLA) según la gravedad y realice la automatización del enrutamiento/escalado para mantenerlo bajo.
❌ IA/automatización sin medidas de seguridad: Dejar que la IA establezca la gravedad o cierre duplicados sin revisión puede clasificar erróneamente los casos extremos y sesgar silenciosamente las métricas. Utilice la IA para sugerencias, exija la confirmación humana en P0/P1 y audite el rendimiento del modelo mensualmente para que sus datos sigan siendo fiables.
Apriete estos tornillos y sus gráficos de tiempo de resolución finalmente reflejarán la realidad. A partir de ahí, las mejoras se acumulan: una mejor admisión reduce el MTTA, los estados más limpios revelan los verdaderos cuellos de botella y los P90 segmentados ofrecen a los líderes promesas que se pueden cumplir.
⚡️ Archivo de plantillas: 10 plantillas de casos de prueba para pruebas de software
Buenas prácticas para una mejor resolución de errores
En resumen, ¡aquí tienes los puntos clave que debes tener en cuenta!
| 🧩 Buenas prácticas | 💡 Qué significa | 🚀 Por qué es importante |
| Utilice un sistema robusto de seguimiento de incidencias. | Realice un seguimiento de todas las incidencias notificadas mediante un sistema centralizado de seguimiento de incidencias. | Garantiza que no se pierda ningún error y permite la visibilidad del estado de los errores en todos los equipos. |
| Redacte informes detallados de incidencias | Incluya contexto visual, información del sistema operativo, pasos para reproducir el error y gravedad. | Ayuda a los desarrolladores a corregir las incidencias más rápidamente con toda la información esencial por adelantado. |
| Clasifique y priorice las incidencias | Utilice una matriz de prioridades para clasificar las incidencias según su urgencia e impacto. | Permite al equipo centrarse primero en las incidencias críticas y los problemas urgentes. |
| Aproveche las pruebas de automatización | Ejecute pruebas automáticamente en su canalización de CI/CD. | Proporciona soporte para la detección temprana y previene las regresiones. |
| Defina directrices claras para la elaboración de informes. | Proporcione plantillas y formación sobre la elaboración de informes sobre incidencias. | Esto conduce a una información precisa y una comunicación más fluida. |
| Realice el seguimiento de las métricas clave | Mida el tiempo de resolución, el tiempo transcurrido y el tiempo de respuesta. | Permite realizar un seguimiento y mejorar el rendimiento utilizando datos históricos. |
| Utilice un enfoque proactivo | No espere a que los usuarios se quejen: realice pruebas de forma proactiva. | Aumenta la satisfacción del cliente y reduce la carga de soporte técnico. |
| Aproveche las herramientas inteligentes y el aprendizaje automático | Utilice el aprendizaje automático para predecir incidencias y sugerir soluciones. | Mejora la eficiencia en la identificación de las causas fundamentales y la corrección de incidencias. |
| Alineación con los SLA | Realice reuniones para cumplir con los acuerdos de nivel de servicio acordados para la resolución. | Genera confianza y satisface las expectativas de los clientes de manera oportuna. |
| Revise y mejore continuamente | Analice las incidencias reabiertas, recopile comentarios y ajuste los procesos. | Fomenta la mejora continua de su proceso de desarrollo y la gestión de incidencias. |
Resolución de errores simplificada con IA contextual
Los equipos de resolución de errores más rápidos no dependen de hazañas heroicas. Diseñan un sistema: definiciones claras de inicio/fin, admisión limpia, priorización del impacto en la empresa, propiedad clara y bucles de retroalimentación estrictos entre soporte, control de calidad, ingeniería y lanzamiento.
ClickUp puede ser ese centro de comandos impulsado por IA para su sistema de resolución de errores. Centralice todos los informes en una sola cola, estandarice el contexto con campos estructurados y deje que ClickUp AI clasifique, resuma y priorice, mientras que las automatizaciones hacen cumplir los SLA, escalan cuando se retrasan los plazos y mantienen a las partes interesadas alineadas. Vincule las incidencias a los clientes, el código y los lanzamientos para que los ejecutivos vean el impacto y los profesionales mantengan el flujo.
Si está listo para reducir el tiempo de resolución de incidencias y hacer que su hoja de ruta sea más predecible, regístrese en ClickUp y comience a medir la mejora en días, no en trimestres.
Preguntas frecuentes
¿Cuál es un buen tiempo de resolución de errores?
No existe un único número «correcto»: depende de la gravedad, el modelo de lanzamiento y la tolerancia al riesgo. Utilice medianas (P50) para el rendimiento «típico» y P90 para promesas/SLA, y segmente por gravedad y origen.
¿Cuál es la diferencia entre la resolución de incidencias y el cierre de incidencias?
La resolución se produce cuando se implementa la corrección (por ejemplo, se combina el código, se aplica la configuración) y el equipo considera que el defecto se ha solucionado. El cierre se produce cuando se verifica el problema y se da por terminado formalmente (por ejemplo, se valida el control de calidad en el entorno de destino, se lanza o se marca como «no se corregirá/duplicado» con una justificación). Muchos equipos miden ambos: «Notificado→Resuelto» refleja la velocidad de ingeniería; «Notificado→Cerrada» refleja el flujo de calidad de principio a fin. Utilice definiciones coherentes para que los paneles no mezclen fases.
¿Cuál es la diferencia entre el tiempo de resolución de incidencias y el tiempo de detección de incidencias?
El tiempo de detección (MTTD) es el tiempo que se tarda en descubrir un defecto después de que se produce o se envía, ya sea mediante supervisión, control de calidad o usuarios. El tiempo de resolución es el tiempo que se tarda desde la detección/notificación hasta la implementación de la solución (y, si lo prefiere, su validación/lanzamiento). Juntos, definen la ventana de impacto en el cliente: detectar rápidamente, reconocer rápidamente, resolver rápidamente y lanzar de forma segura. También puede realizar el seguimiento del MTTA (tiempo de reconocimiento/asignación) para detectar retrasos en la clasificación que a menudo predicen una resolución más larga.
¿Cómo ayuda la IA en la resolución de incidencias?
/IA comprime los bucles que suelen ralentizar el proceso: recepción, clasificación, diagnóstico, reparación y verificación.
- Recepción y clasificación: resumir automáticamente informes largos, extrae los pasos de reproducción/entorno, marca los duplicados y sugiere la gravedad/prioridad para que los ingenieros empiecen con un contexto limpio (por ejemplo, ClickUp AI, Sentry IA).
- Enrutamiento y acuerdos de nivel de servicio (SLA): predice el componente/propietario probable, establece cronómetros y escala cuando el MTTA o las esperas de revisión se retrasan, lo que reduce el «tiempo en estado» inactivo (automatizaciones de ClickUp y flujos de trabajo similares a los de los agentes).
- Diagnóstico: agrupa errores similares, correlaciona picos con confirmaciones/lanzamientos recientes y señala las posibles causas raíz con trazas de pila y contexto de código (Sentry IA y similares).
- Implementación: sugiere cambios en el código y pruebas basadas en patrones de su repositorio, lo que acelera el ciclo de «escritura/corrección» (GitHub Copilot; Snyk Code IA de DeepCode).
- Verificación y comunicaciones: redacta casos de prueba a partir de pasos de reproducción, borradores de notas de lanzamiento y actualizaciones para las partes interesadas, y resume el estado para los ejecutivos y los clientes (ClickUp AI). Al utilizarlos juntos (ClickUp como centro de comandos con Sentry/Copilot/DeepCode en la pila), los equipos reducen los tiempos MTTA/P90 sin depender de heroicidades.