Alle Beiträge
ClickUp verwenden
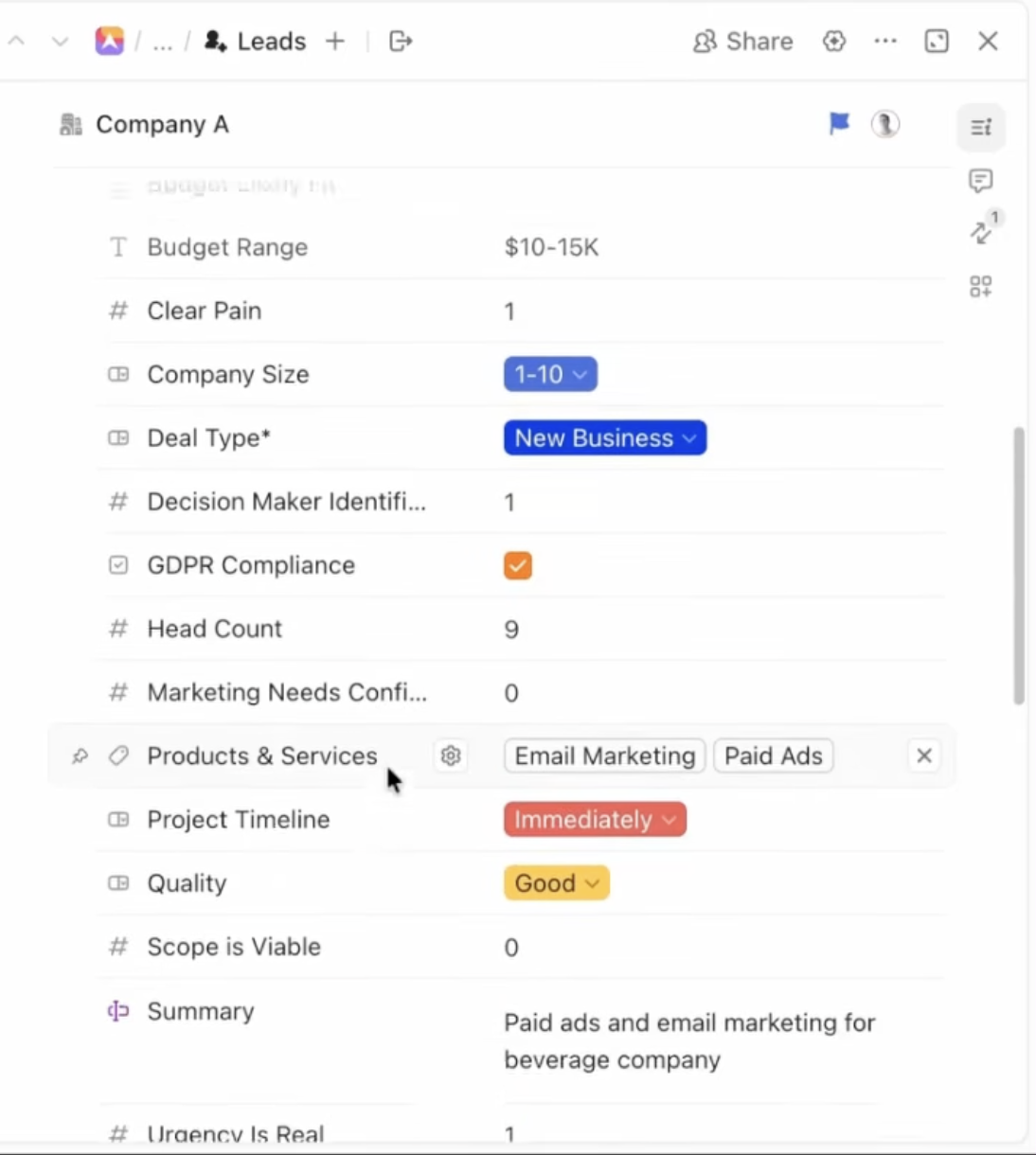
ClickUp-Benutzerdefinierte Felder nach Aufgabentyp: Wie ich übersichtlichere VertriebsWorkflows ohne überladene Felder erstelle
 Christopher Day
Christopher Day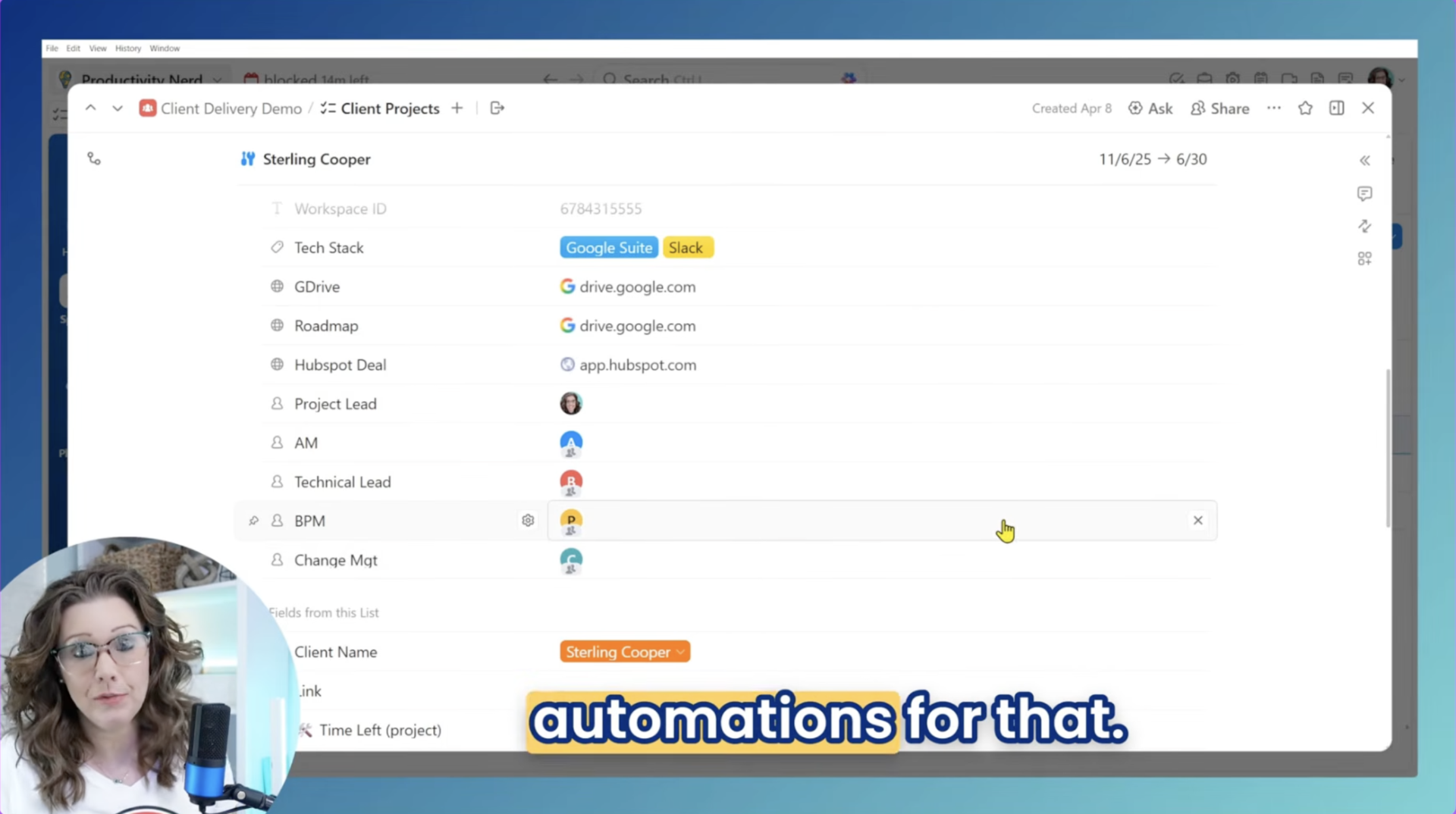
ClickUp verwenden
Benutzerdefinierte Felder nach Aufgabentyp in ClickUp: Wie ich einen Hub für Kundenlieferungen erstellt habe, der der Suche nach Informationen ein Ende setzt
 Jacqui Myslinski
Jacqui Myslinski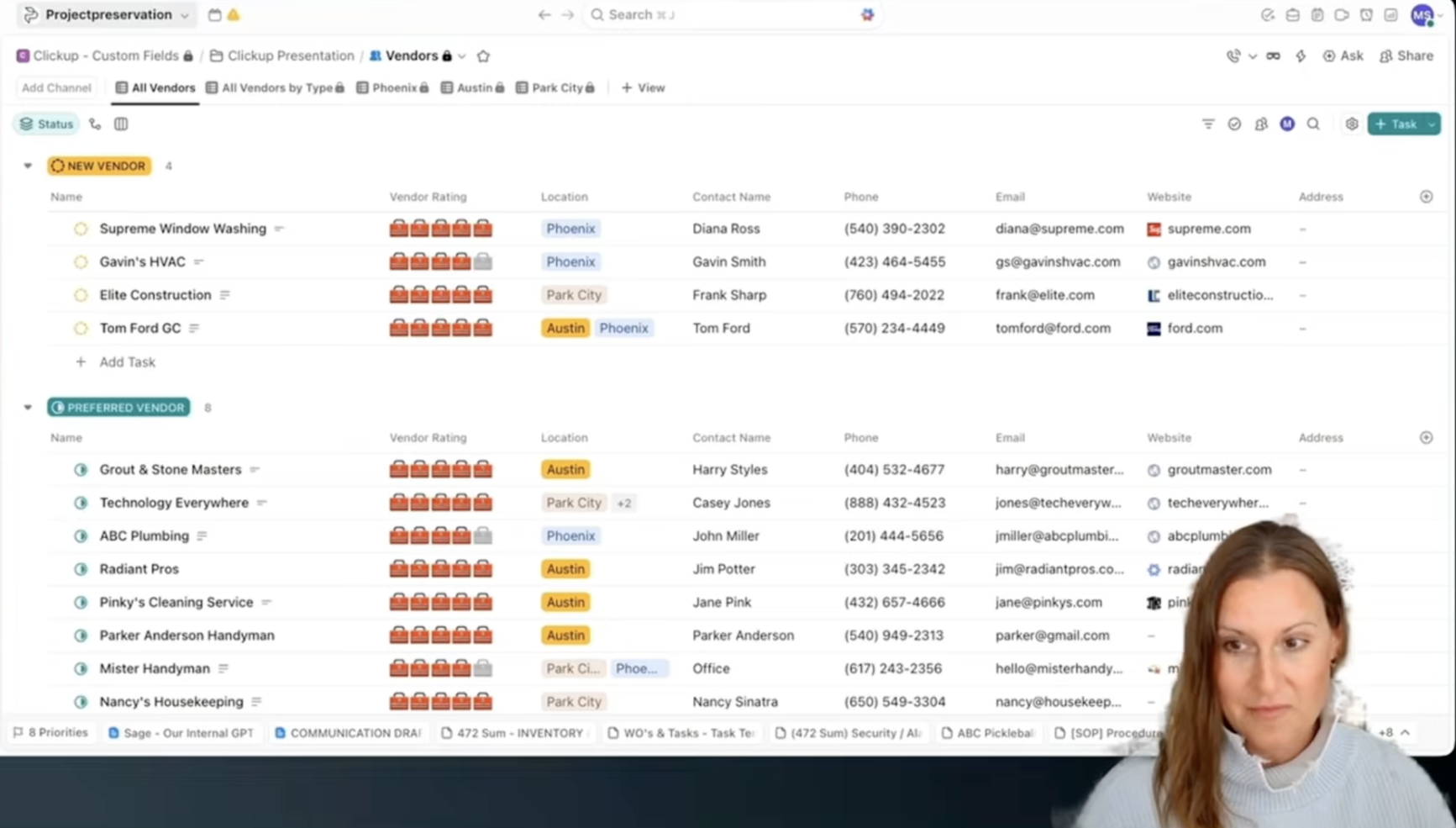
CRM
ClickUp-Benutzerdefinierte Felder: Wie ich ein vernetztes Immobilienverwaltungssystem für Lieferanten und Arbeitsaufträge aufgebaut habe
 Melissa Shymko
Melissa Shymko
Disclosures
27. April – Was ist mit unserer Feature Flags-Konfiguration passiert?
ClickUp Security Team
Feature-Releases
Wie wir durch die Einhaltung der SOC-2-Standards Vertrauen schaffen
 Erica Chappell
Erica Chappell
Software
8 Tools wie Smartsheet für die Kapazitätsplanung
 Preethi Anchan
Preethi Anchan
Vorlagen
10 Vorlagen für Unternehmensbetriebsmodelle in ClickUp
 Praburam
Praburam
Software
Base44 vs. Claude Code: Was sollten Sie verwenden?
 Arya Dinesh
Arya DineshVorlagen
10 Vorlagen für die Erfassung von Abonnementumsätzen, die tatsächlich Abwanderungssignale aufzeigen
Praburam
ClickUp verwenden
10 Beispiele für ClickUp-Dashboards für Teams
Praburam
Vorlagen
10 Vorlagen für Workflows zur Erkenntniszusammenfassung in ClickUp
Praburam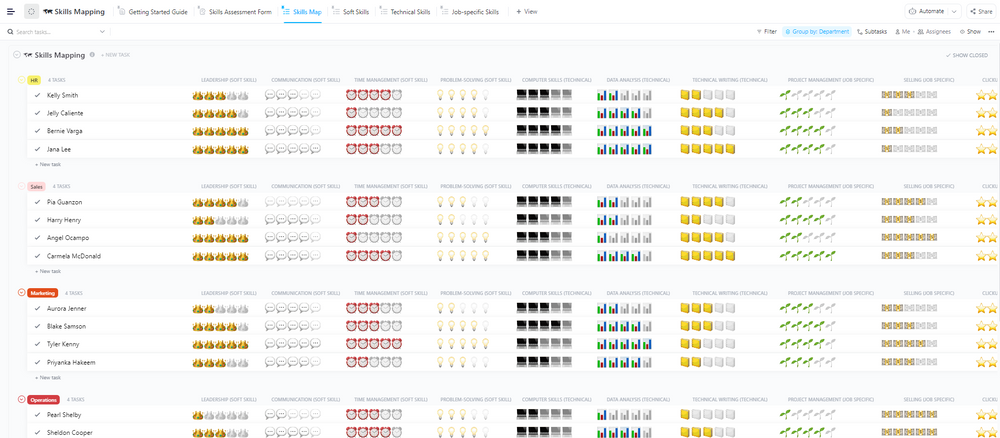
Vorlagen
10 ClickUp-Vorlagen für Strategien zur Talentmobilität
Praburam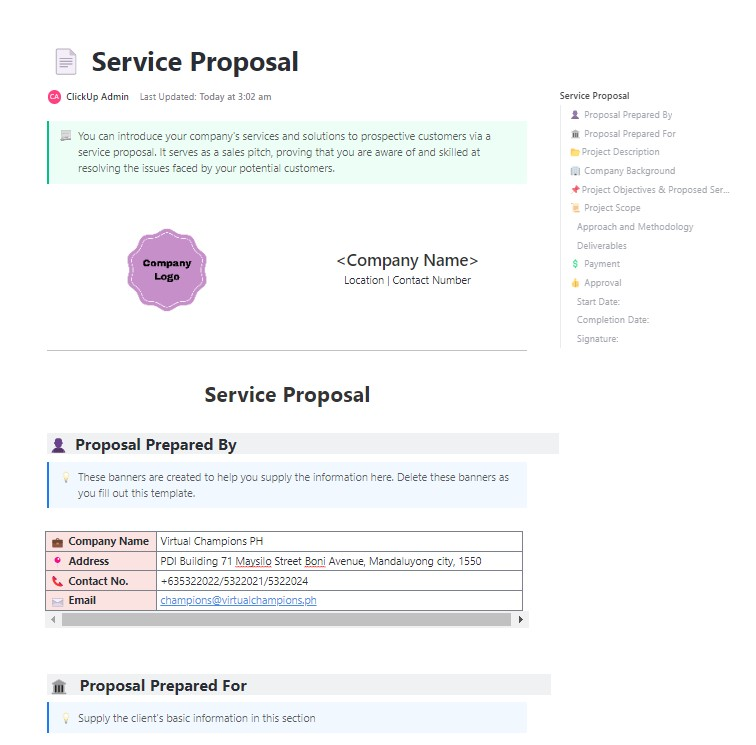
Vorlagen
10 Vorlagen für Servicepaket-Preise in ClickUp
Praburam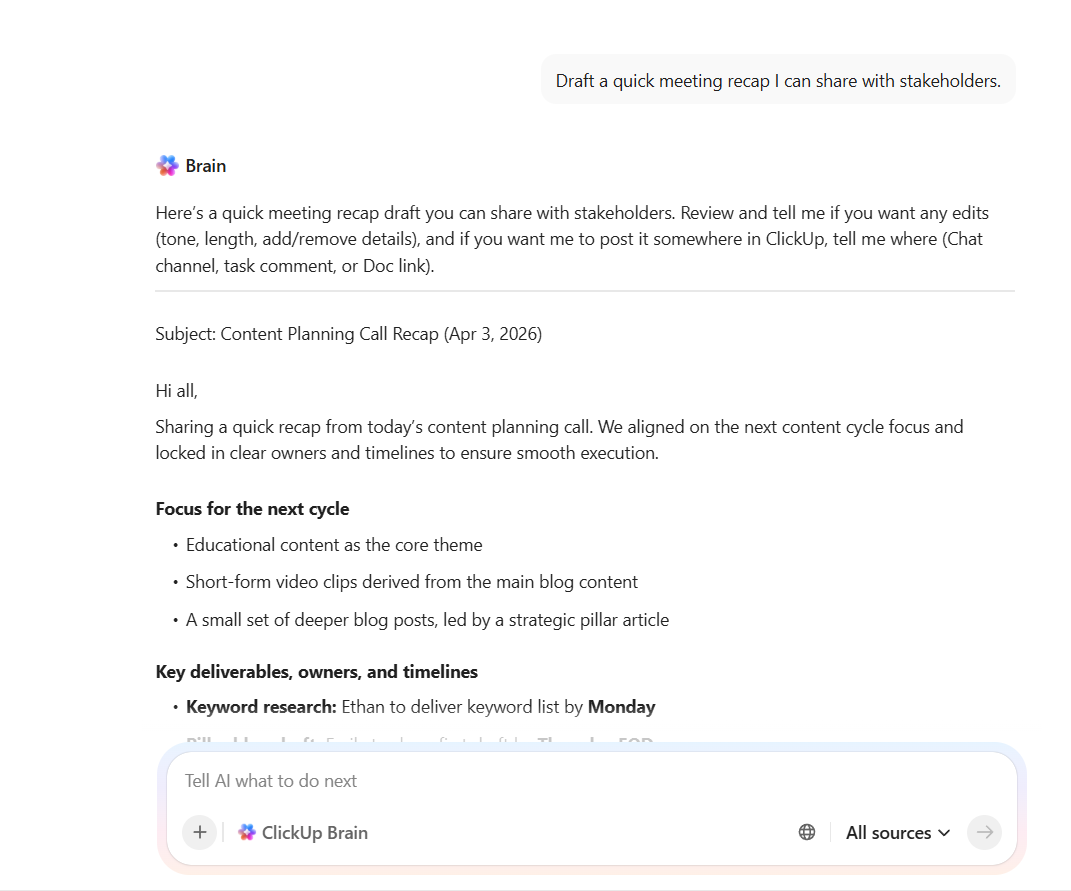
Software
Die 10 besten Fyntrix-KI-Alternativen im Jahr 2026
Preethi Anchan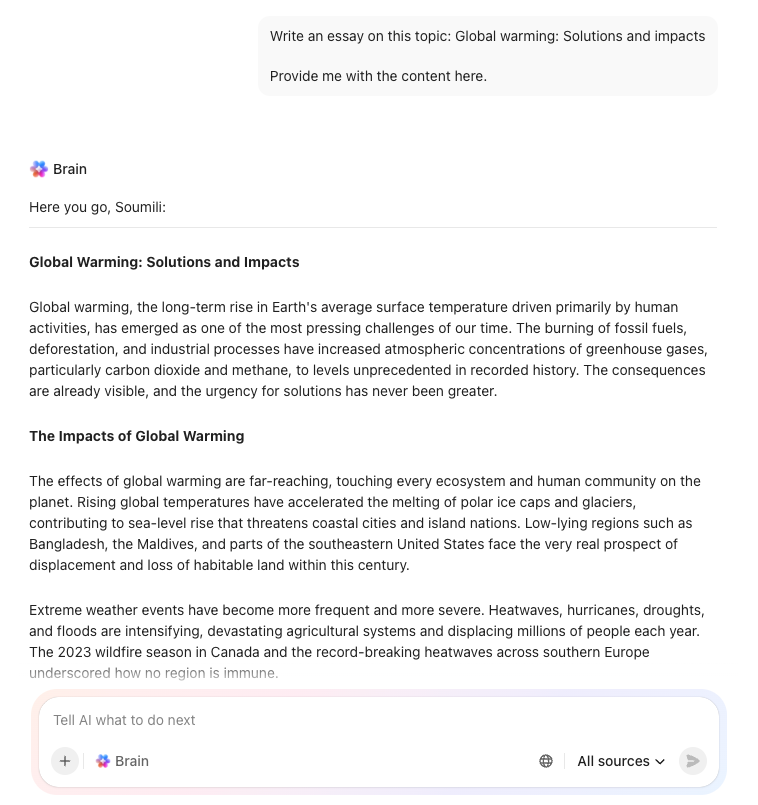
Software
Die 10 besten Olovka-KI-Alternativen im Jahr 2026
Preethi Anchan
Software
Base44 vs. Lovable: Welcher KI-Builder ist der richtige für Sie?
Arya Dinesh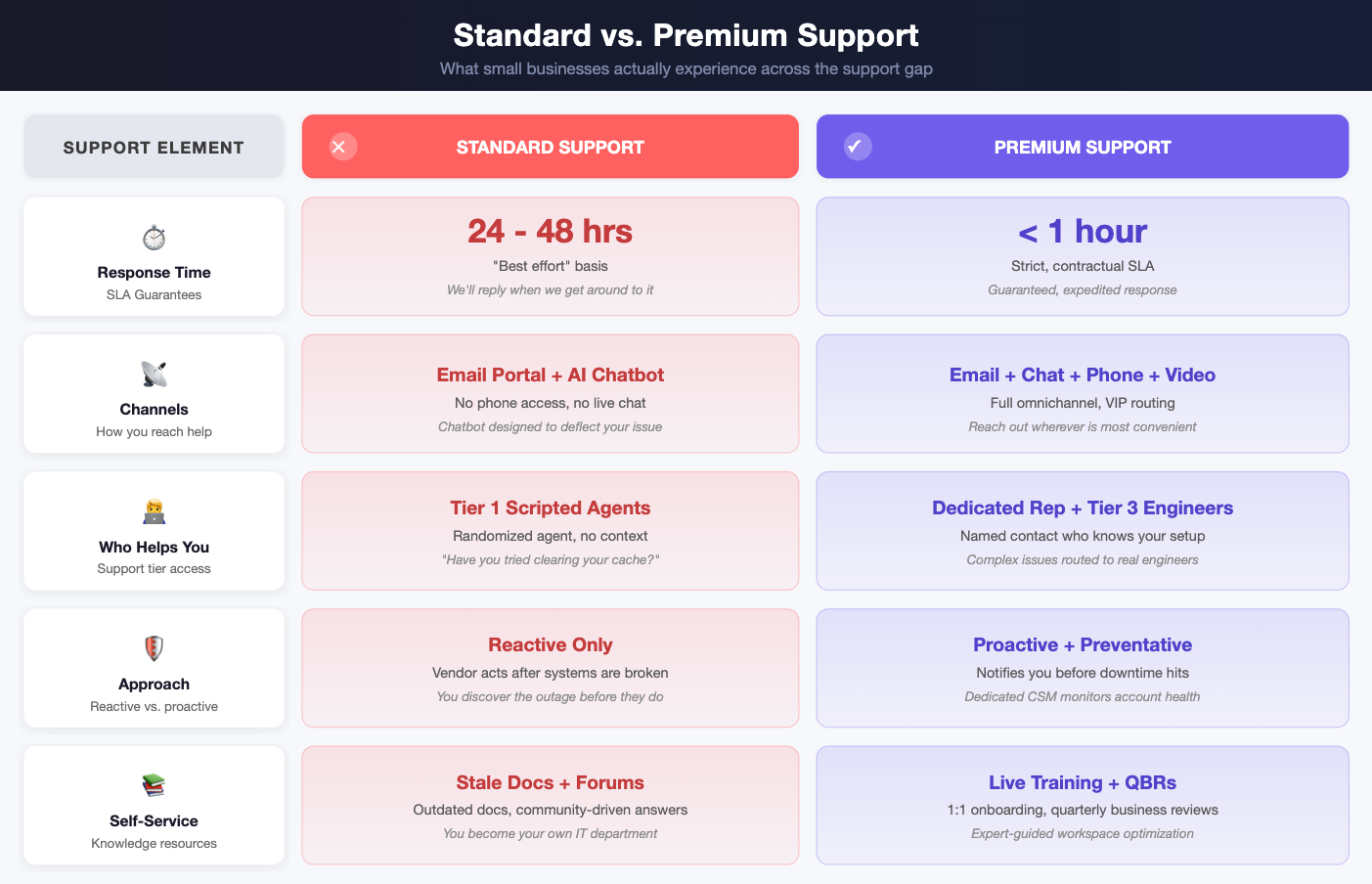
Business
Der verborgene Wert eines dedizierten Ansprechpartners für KMU
Arya Dinesh
Agenturen
So erstellen Sie ein Dashboard für den Agenturbetrieb in Google Tabellen
 Manasi Nair
Manasi Nair
Software
Base44 vs. ClickUp: Ein Vergleich im Jahr 2026
Arya Dinesh
Software
Claude Code vs. Copilot: Welches passt zu Ihrem Workflow?
Arya Dinesh
Software
So nutzen Sie Copilot in Microsoft Teams effektiv
Praburam
Software
So verwenden Sie das Bash-Tool für Gemini-Benutzer
Praburam
Vorlagen
So erstellen Sie eine Liste für die Zeiterfassung in Google Tabellen
Praburam
Software
ClickUp vs. Workzone: Welches tool passt am besten zu Ihnen?
Arya Dinesh