

Bot do obsługi klienta, który uczy się na podstawie każdej interakcji. Asystent sprzedaży, który dostosowuje swoją strategię w oparciu o spostrzeżenia w czasie rzeczywistym. To nie są tylko koncepcje - to rzeczywistość, dzięki uczącym się agentom AI.
Co jednak sprawia, że agenci ci są wyjątkowi i jak funkcjonuje agent uczący się do zrobienia tego?
W przeciwieństwie do tradycyjnych systemów AI, które działają w oparciu o stałe programowanie, uczący się agenci ewoluują.
Dostosowują, poprawiają i udoskonalają swoje działania w czasie, co czyni je niezbędnymi w branżach takich jak pojazdy autonomiczne i opieka zdrowotna, gdzie elastyczność i precyzja nie podlegają negocjacjom.
AI staje się coraz mądrzejsze wraz z nabywanym doświadczeniem, podobnie jak ludzie.
Na tym blogu omówimy kluczowe komponenty, procesy, typy i zastosowania agentów uczących się w AI. 🤖
⏰ 60-sekundowe podsumowanie
Oto krótkie wprowadzenie do agentów uczących się w AI:
Do zrobienia: Dostosowują się poprzez interakcje, np. boty obsługi klienta udoskonalające odpowiedzi.
Kluczowe zastosowania: Robotyka, spersonalizowane usługi i inteligentne systemy, takie jak urządzenia domowe.
Główne komponenty:
- Element uczący się: Gromadzi wiedzę w celu poprawy wydajności
- Element wydajności: Wykonuje zadania w oparciu o zdobytą wiedzę
- Krytyk: Ocenia działania i jest dostawcą informacji zwrotnych
- Generator problemów: Identyfikuje możliwości dalszego uczenia się
Metody uczenia się:
- Uczenie się pod nadzorem: Rozpoznaje wzorce przy użyciu oznaczonych etykietą danych
- Uczenie bez nadzoru: identyfikuje struktury w nieoznakowanych danych
- Uczenie ze wzmocnieniem: Uczy się poprzez wersje próbne i błędy
Wpływ na rzeczywistość: Zwiększa zdolność adaptacji, wydajność i podejmowanie decyzji w różnych branżach.
⚙️ Bonus: Czujesz się przytłoczony żargonem AI? Sprawdź nasze kompleksowe słownik pojęć AI aby łatwo zrozumieć podstawowe pojęcia i zaawansowaną terminologię.
**Co to są uczące się agenty w AI?
**Agenci uczący się w AI to systemy, które doskonalą się w czasie, ucząc się na podstawie swojego środowiska. Dostosowują się, podejmują mądrzejsze decyzje i optymalizują działania w oparciu o informacje zwrotne i dane.
W przeciwieństwie do tradycyjnych systemów AI, które pozostają niezmienne, agenci uczący się stale ewoluują. To sprawia, że są one niezbędne w robotyce i spersonalizowanych rekomendacjach, gdzie warunki są nieprzewidywalne i stale się zmieniają.
**Agenci uczący się działają w pętli sprzężenia zwrotnego - postrzegają środowisko, uczą się na podstawie informacji zwrotnych i udoskonalają swoje działania. Jest to inspirowane sposobem, w jaki ludzie uczą się na podstawie doświadczenia.
Kluczowe komponenty uczących się agentów
Agenty uczące się składają się zazwyczaj z kilku połączonych ze sobą komponentów współpracujących ze sobą w celu zapewnienia zdolności adaptacyjnych i doskonalenia się w czasie.
Oto kilka krytycznych elementów tego procesu uczenia się. 📋
Element uczący się
Głównym zadaniem agenta jest zdobywanie wiedzy i poprawa wydajności poprzez analizę danych, interakcji i informacji zwrotnych.
Korzystanie z Techniki AI takich jak nadzorowane, wzmacniające i nienadzorowane uczenie się, agent dostosowuje i aktualizuje swoje zachowanie, aby zwiększyć swoją funkcję.
Przykład: Wirtualny asystent, taki jak Siri, z czasem uczy się preferencji dostawcy, takich jak często używane komendy lub specyficzne akcenty, aby zapewnić dokładniejsze i spersonalizowane odpowiedzi.
Element wydajności
Ten komponent wykonuje zadania poprzez interakcję ze środowiskiem i podejmowanie decyzji w oparciu o dostępne informacje. Jest to zasadniczo "ramię akcji" agenta.
Przykład: W pojazdach autonomicznych element wydajności przetwarza dane o ruchu drogowym i warunkach środowiskowych, aby podejmować decyzje w czasie rzeczywistym, takie jak zatrzymanie się na czerwonym świetle lub omijanie przeszkód.
Krytyk
Krytyk ocenia działania podejmowane przez element wydajności i jest dostawcą informacji zwrotnych. Ta informacja zwrotna pomaga elementowi uczącemu się określić, co działało dobrze, a co wymaga poprawy.
Przykład: W systemie rekomendacji, krytyk analizuje interakcje użytkownika (takie jak kliknięcia lub pominięcia), aby określić, które sugestie odniosły powodzenie i pomaga elementowi uczącemu się udoskonalić przyszłe rekomendacje.
Generator problemów
Ten komponent zachęca do eksploracji, sugerując nowe scenariusze lub działania do przetestowania przez agenta.
Wypycha agenta poza jego strefę komfortu, zapewniając ciągłe doskonalenie. Zapobiega również nieoptymalnym wynikom poprzez rozszerzenie zakresu doświadczenia agenta.
Przykład: W eCommerce AI, generator problemów może sugerować spersonalizowane strategie marketingowe lub symulować wzorce zachowań klientów. Pomaga to AI udoskonalić swoje podejście do dostarczania rekomendacji dostosowanych do różnych preferencji użytkowników.
Proces uczenia się w uczących się agentach
Agenci uczący się opierają się głównie na trzech kluczowych kategoriach w celu adaptacji i poprawy. Zostały one opisane poniżej. 👇
1. Uczenie nadzorowane
Agent uczy się na podstawie etykietowanych zestawów danych, gdzie każde wejście odpowiada konkretnemu wyjściu.
Metoda ta wymaga dużej ilości dokładnie etykietowanych danych do szkolenia i jest szeroko stosowana w aplikacjach takich jak rozpoznawanie obrazów, tłumaczenie języków i wykrywanie oszustw.
Przykład: System filtrowania poczty elektronicznej uczy się klasyfikować wiadomości e-mail jako spam lub nie na podstawie danych historycznych. Element uczący się identyfikuje wzorce między danymi wejściowymi (zawartością wiadomości e-mail) a danymi wyjściowymi (etykietami klasyfikacyjnymi) w celu tworzenia dokładnych prognoz.
2. Uczenie bez nadzoru
Ukryte wzorce lub powiązania w danych pojawiają się, gdy agent analizuje informacje bez wyraźnych etykiet. Podejście to sprawdza się w wykrywaniu anomalii, tworzeniu systemów rekomendacji i optymalizacji kompresji danych.
Pomaga również zidentyfikować spostrzeżenia, które mogą nie być natychmiast widoczne w przypadku danych z etykietami.
Przykład: Segmentacja klientów w marketingu może grupować użytkowników na podstawie ich zachowań w celu projektowania celowych kampanii. Nacisk kładziony jest na zrozumienie struktury i formowanie klastrów lub skojarzeń.
3. Uczenie ze wzmocnieniem
W przeciwieństwie do powyższego, uczenie ze wzmocnieniem (RL) obejmuje agentów podejmujących działania w środowisku w celu maksymalizacji skumulowanych nagród w czasie.
Agent uczy się metodą prób i błędów, otrzymując informacje zwrotne w postaci nagród lub kar.
pamiętaj: Wybór metody uczenia zależy od problemu, dostępności danych i złożoności środowiska. Uczenie ze wzmocnieniem jest kluczowe dla zadań bez bezpośredniego nadzoru, ponieważ wykorzystuje pętle sprzężenia zwrotnego do dostosowywania działań.
Techniki uczenia ze wzmocnieniem
- Iteracja polityki: Optymalizuje oczekiwania dotyczące nagród poprzez bezpośrednie uczenie się polityki, która mapuje stany na działania
- Iteracja wartości: Określa optymalne działania poprzez obliczenie wartości każdej pary stan-akcja
- Metody Monte Carlo: Symuluje wiele przyszłych scenariuszy, aby przewidzieć nagrody za działania, szczególnie przydatne w dynamicznych i probabilistycznych środowiskach
Przykłady rzeczywistych zastosowań RL
- Jazda autonomiczna: Algorytmy RL szkolą pojazdy w zakresie bezpiecznej nawigacji, optymalizacji tras i dostosowywania się do warunków drogowych poprzez ciągłe uczenie się z symulowanych środowisk
- AlphaGo i AI w grach: Uczenie ze wzmocnieniem pozwoliło AlphaGo od Google pokonać ludzkich mistrzów poprzez uczenie się optymalnych strategii dla złożonych gier, takich jak Go
- Dynamiczne ceny: Platformy e-commerce wykorzystują RL do dostosowywania strategii cenowych w oparciu o wzorce popytu i działania konkurencji w celu maksymalizacji przychodów
Zabawny fakt: Agenci uczący się pokonali ludzkich mistrzów w grach takich jak Szachy i Starcraft, pokazując ich zdolności adaptacyjne i inteligencję.
Podejścia oparte na uczeniu Q i sieciach neuronowych
Q-learning to szeroko stosowany algorytm RL, w którym agenci uczą się wartości każdej pary stan-akcja poprzez eksplorację i informacje zwrotne. Agent buduje tabelę Q, matrycę, która przypisuje oczekiwane nagrody do par stan-akcja.
Wybiera działanie o najwyższej wartości Q i udoskonala swoją tabelę iteracyjnie, aby poprawić dokładność.
Przykład: Dron oparty na AI, uczący się efektywnie dostarczać paczki, wykorzystuje Q-learning do oceny tras. Robi to poprzez przypisywanie nagród za dostawy na czas i kar za opóźnienia lub kolizje. Z czasem udoskonala swoją tabelę Q, aby wybrać najbardziej wydajne i bezpieczne ścieżki dostawy.
Tabele Q stają się jednak niepraktyczne w złożonych środowiskach z wielowymiarowymi przestrzeniami stanów.
Sieci neuronowe wkraczają tutaj, przybliżając wartości Q zamiast jawnie je przechowywać. Ta zmiana umożliwia uczeniu ze wzmocnieniem rozwiązywanie bardziej skomplikowanych problemów.
Głębokie sieci Q (DQN) idą o krok dalej, wykorzystując głębokie uczenie do przetwarzania surowych, nieustrukturyzowanych danych, takich jak obrazy lub dane wejściowe z czujników. Sieci te mogą bezpośrednio mapować informacje sensoryczne na działania, pomijając potrzebę rozszerzenia funkcji.
Przykład: W samochodach autonomicznych sieci DQN przetwarzają dane z czujników w czasie rzeczywistym, aby uczyć się strategii jazdy, takich jak zmiana pasa ruchu lub omijanie przeszkód, bez wcześniej zaprogramowanych reguł.
Te zaawansowane metody umożliwiają agentom skalowanie ich możliwości uczenia się do zadań wymagających dużej mocy obliczeniowej i zdolności adaptacyjnych.
⚙️ Bonus: Dowiedz się, jak tworzyć i udoskonalać strategie uczenia się Baza wiedzy AI która usprawnia zarządzanie informacjami, usprawnia podejmowanie decyzji i zwiększa wydajność zespołu.
Proces uczenia się agentów ma wartość tworzenia strategii inteligentnego podejmowania decyzji w czasie rzeczywistym. Oto kluczowe aspekty, które wspomagają podejmowanie decyzji:
- Eksploracja vs. eksploatacja: Agenci równoważą odkrywanie nowych działań w celu znalezienia lepszych strategii i wykorzystywanie znanych działań w celu maksymalizacji nagród
- Podejmowanie decyzji przez wielu agentów: W ustawieniach opartych na współpracy lub rywalizacji, agenci współdziałają i dostosowują strategie w oparciu o udostępniane cele lub taktyki przeciwnika
- Kompromisy strategiczne: Agenci uczą się również ustalać priorytety celów w oparciu o kontekst, np. równoważąc szybkość i dokładność w systemie dostarczania
🎤 Podcast Alert: Przejrzyj naszą wyselekcjonowaną listę popularnych podcastów Podcasty o AI aby pogłębić zrozumienie działania agentów uczących się.
Rodzaje agentów AI
Agenci uczący się w sztucznej inteligencji występują w różnych formularzach, z których każdy jest dostosowany do konkretnych zadań i wyzwań.
Przyjrzyjmy się ich mechanizmom działania, unikalnym cechom i przykładom z prawdziwego świata. 👀
Proste agenty refleksyjne
Tacy agenci reagują bezpośrednio na bodźce w oparciu o predefiniowane reguły. Używają mechanizmu warunek-działanie (jeśli-to), aby wybierać działania w oparciu o bieżące środowisko bez uwzględniania historii lub przyszłości.
Charakterystyka
- Działa w oparciu o logiczny system warunek-działanie
- Nie dostosowuje się do zmian ani nie wyciąga wniosków z przeszłych działań
- Działa najlepiej w przejrzystym i przewidywalnym środowisku
Przykład
Termostat pełni funkcję prostego agenta odruchowego, włączając ogrzewanie, gdy temperatura spadnie poniżej ustawionego progu i wyłączając je, gdy temperatura wzrośnie. Podejmuje decyzje wyłącznie na podstawie bieżących odczytów temperatury.
**Niektóre eksperymenty przypisują uczącym się agentom symulowane potrzeby, takie jak głód lub pragnienie, zachęcając ich do rozwijania zachowań zorientowanych na cel i uczenia się, jak skutecznie zaspokajać te "potrzeby".
Agenci odruchowi oparti na modelach
Agenci ci utrzymują wewnętrzny model świata, który pozwala im rozważyć skutki ich działań. Wnioskują również o stanie środowiska poza tym, co mogą natychmiast dostrzec.
Charakterystyka
- Wykorzystuje przechowywany model środowiska do podejmowania decyzji
- Szacuje bieżący stan, aby poradzić sobie z częściowo obserwowalnym środowiskiem
- Oferuje większą elastyczność i zdolność adaptacji w porównaniu do prostych agentów refleksyjnych
Przykład
Samojezdny samochód Tesla wykorzystuje agenta opartego na modelu do poruszania się po drogach. Wykrywa on widoczne przeszkody i przewiduje ruch pobliskich pojazdów, w tym tych znajdujących się w martwym polu, wykorzystując zaawansowane czujniki i dane w czasie rzeczywistym. Pozwala to samochodowi podejmować precyzyjne i świadome decyzje dotyczące jazdy, zwiększając bezpieczeństwo i wydajność.
**Koncepcja uczących się agentów często naśladuje zachowania obserwowane u zwierząt, takie jak uczenie się metodą prób i błędów lub uczenie się oparte na nagrodach.
Funkcje agentów programowych i wirtualnych asystentów
Agenci ci działają w środowiskach cyfrowych i autonomicznie wykonują określone zadania.
Wirtualni asystenci, tacy jak Siri lub Alexa, przetwarzają dane wejściowe użytkownika za pomocą przetwarzania języka naturalnego (NLP) i wykonują działania, takie jak odpowiadanie na zapytania lub sterowanie inteligentnymi urządzeniami.
Charakterystyka
- Upraszcza codzienne zadania, takie jak planowanie, ustawienie przypomnień lub sterowanie urządzeniami
- Ciągłe doskonalenie przy użyciu algorytmów uczenia się i danych dotyczących interakcji z użytkownikiem
- Działa asynchronicznie, reagując w czasie rzeczywistym lub w momencie wyzwalacza
Przykład
Alexa może odtwarzać muzykę, ustawiać przypomnienia i sterować inteligentnymi urządzeniami domowymi, interpretując komendy głosowe, łącząc się z systemami opartymi na chmurze i wykonując odpowiednie działania.
**Agenty oparte na użyteczności, które koncentrują się na maksymalizacji wyników poprzez ocenę różnych działań, często współpracują z agentami opartymi na uczeniu się w AI. Agenci uczący się z czasem udoskonalają swoje strategie w oparciu o doświadczenie i mogą wykorzystywać podejmowanie decyzji w oparciu o użyteczność, aby dokonywać mądrzejszych wyborów.
Systemy wieloagentowe i zastosowania teorii gier
Systemy te składają się z wielu interaktywnych agentów współpracujących, konkurujących lub pracujących niezależnie, aby osiągnąć indywidualne lub zbiorowe cele.
Ponadto zasady teorii gier często kierują ich zachowaniem w konkurencyjnych scenariuszach.
Charakterystyka
- Wymaga koordynacji lub negocjacji między agentami
- Dobrze sprawdza się w dynamicznych i rozproszonych środowiskach
- Symuluje lub zarządza złożonymi systemami, takimi jak łańcuchy dostaw lub ruch miejski
Przykład
W systemie automatyzacji magazynów Amazona roboty (agenci) współpracują ze sobą, aby wybierać, sortować i transportować elementy. Roboty te komunikują się ze sobą, aby uniknąć kolizji i zapewnić płynne działanie. Zasady teorii gier pomagają zarządzać konkurującymi priorytetami , takich jak równoważenie szybkości i zasobów, aby zapewnić wydajne działanie systemu.
Zastosowania uczących się agentów
Agenty uczące się przekształciły wiele branż, poprawiając wydajność i podejmowanie decyzji.
Oto kilka kluczowych zastosowań. 📚
Robotyka i automatyzacja
Agenci uczący się są podstawą nowoczesnej robotyki, umożliwiając robotom autonomiczne i adaptacyjne działanie w dynamicznych środowiskach.
W przeciwieństwie do tradycyjnych systemów, które wymagają szczegółowego programowania dla każdego zadania, agenci uczący się pozwalają robotom na samodoskonalenie poprzez interakcję i informacje zwrotne.
Jak to działa
Roboty wyposażone w agentów uczących się wykorzystują techniki takie jak uczenie ze wzmocnieniem do interakcji z otoczeniem i oceny wyników swoich działań. Z czasem udoskonalają swoje zachowanie, koncentrując się na maksymalizacji nagród i unikaniu kar.
Sieci neuronowe idą o krok dalej, umożliwiając robotom przetwarzanie złożonych danych, takich jak dane wizualne lub układy przestrzenne, ułatwiając podejmowanie zaawansowanych decyzji.
Przykłady
- Pojazdy autonomiczne: W rolnictwie, agenci uczący się napędzają autonomiczne ciągniki do poruszania się po polach, dostosowywania się do zmiennych warunków glebowych i optymalizacji procesów sadzenia lub zbiorów. Wykorzystują dane w czasie rzeczywistym, aby poprawić wydajność i zmniejszyć straty
- Roboty przemysłowe: W produkcji, ramiona robotów wyposażone w agentów uczących się dostosowują swoje ruchy w celu poprawy precyzji, wydajności i bezpieczeństwa, np. na liniach montażowych samochodów
Przeczytaj także: Hacki AI, które sprawią, że będziesz szybszy, mądrzejszy i lepszy Symulacja i modele oparte na agentach
Agenci uczący się zasilają symulacje, które oferują opłacalny i pozbawiony ryzyka sposób badania złożonych systemów.
Systemy te replikują dynamikę świata rzeczywistego, przewidują wyniki i optymalizują strategie poprzez modelowanie agentów o różnych zachowaniach i zdolnościach adaptacyjnych.
Jak to działa
Agenci uczący się w symulacjach obserwują swoje środowisko, testują działania i dostosowują swoje strategie, aby zmaksymalizować skuteczność. Nieustannie uczą się i doskonalą w czasie, umożliwiając optymalizację wyników.
Symulacje są bardzo skuteczne w zarządzaniu łańcuchem dostaw, planowaniu urbanistycznym i rozwoju robotyki.
Przykłady
- Zarządzanie ruchem: Symulowani agenci modelują przepływ ruchu w miastach. Umożliwia to badaczom testowanie interwencji, takich jak nowe drogi lub opłaty za zatory drogowe przed ich wdrożeniem
- Epidemiologia: W symulacjach pandemii, uczący się agenci naśladują ludzkie zachowanie, aby ocenić rozprzestrzenianie się chorób. Pomaga to również ocenić skuteczność środków ograniczających rozprzestrzenianie się choroby, takich jak dystans społeczny
Wskazówka dla profesjonalistów: Optymalizacja wstępnego przetwarzania danych w Uczenie maszynowe AI aby poprawić dokładność i wydajność uczących się agentów. Wysokiej jakości dane wejściowe zapewniają bardziej niezawodne podejmowanie decyzji.
Inteligentne systemy
Agenci uczący się napędzają inteligentne systemy, umożliwiając przetwarzanie danych w czasie rzeczywistym i dostosowywanie ich do zachowań i preferencji użytkowników.
Od inteligentnych urządzeń po autonomiczne urządzenia czyszczące, systemy te zmieniają sposób interakcji użytkowników z technologią, czyniąc codzienne zadania bardziej wydajnymi i spersonalizowanymi.
Jak to działa
Urządzenia takie jak Roomba wykorzystują wbudowane czujniki i agentów uczących się do tworzenia map układów głównych, unikania przeszkód i optymalizacji tras sprzątania. Nieustannie zbierają i analizują dane - takie jak obszary wymagające częstego sprzątania lub rozmieszczenie mebli - zwiększając swoją wydajność przy każdym użyciu.
Przykłady
- Inteligentne urządzenia domowe: Termostaty takie jak Nest uczą się harmonogramów użytkownika i preferencji temperaturowych. Automatycznie dostosowują ustawienia, aby oszczędzać energię przy jednoczesnym zachowaniu komfortu
- Odkurzacze robotyczne: Roomba zbiera wiele punktów danych na sekundę. Dzięki temu może poruszać się wokół mebli i identyfikować obszary o dużym natężeniu ruchu w celu efektywnego sprzątania
Te inteligentne systemy podkreślają praktyczne zastosowania uczących się agentów w codziennym życiu, takie jak usprawnianie cyklu pracy i automatyzacja powtarzalnych zadań w celu zwiększenia wydajności.
**Roomba zbiera ponad 230 400 punktów danych na sekundę do zrobienia mapy głównej strony domu.
Fora internetowe i wirtualni asystenci
Agenci uczący się odgrywają kluczową rolę w ulepszaniu interakcji online i pomocy cyfrowej. Umożliwiają one forom i wirtualnym asystentom dostarczanie spersonalizowanych doświadczeń.
Jak to działa
Agenci uczący się moderują dyskusje na forach oraz identyfikują i usuwają spam lub szkodliwą zawartość. Co ciekawe, rekomendują również użytkownikom odpowiednie tematy na podstawie ich historii przeglądania. Wirtualni asystenci AI tacy jak Alexa i Google Assistant, używają agentów uczących się do przetwarzania danych wejściowych w języku naturalnym, poprawiając z czasem ich kontekstowe zrozumienie.
Przykłady
- Fora internetowe: Boty moderujące Reddit wykorzystują agentów uczących się do skanowania postów pod kątem naruszeń zasad lub toksycznego języka. Taka higiena oparta na AI sprawia, że społeczności internetowe są bezpieczne i angażujące
- Wirtualni asystenci: Alexa uczy się preferencji użytkownika, takich jak ulubione listy odtwarzania lub często używane inteligentne komendy domowe, aby zapewnić spersonalizowaną i proaktywną pomoc
⚙️ Bonus: Dowiedz się jak wykorzystać AI w miejscu pracy aby zwiększyć wydajność i usprawnić zadania dzięki inteligentnym agentom.
Wyzwania w rozwoju uczących się agentów
Rozwój agentów uczących się wiąże się z wyzwaniami technicznymi, etycznymi i praktycznymi, w tym z projektowaniem algorytmów, wymaganiami obliczeniowymi i wdrażaniem w świecie rzeczywistym.
Przyjrzyjmy się kluczowym wyzwaniom stojącym przed rozwojem AI. 🚧
Zrównoważenie eksploracji i eksploatacji
Agenci uczący się stają przed dylematem zrównoważenia eksploracji i eksploatacji.
Chociaż algorytmy takie jak epsilon-greedy mogą pomóc, osiągnięcie właściwej równowagi jest wysoce zależne od kontekstu. Co więcej, nadmierna eksploracja może skutkować nieefektywnością, podczas gdy nadmierne poleganie na eksploatacji może prowadzić do nieoptymalnych rozwiązań.
Zarządzanie wysokimi kosztami obliczeniowymi
Szkolenie zaawansowanych agentów uczących się często wymaga rozszerzenia zasobów obliczeniowych. Ma to większe zastosowanie w środowiskach o złożonej dynamice lub dużych przestrzeniach stan-akcja.
Należy pamiętać, że algorytmy takie jak uczenie ze wzmocnieniem z sieciami neuronowymi, takie jak Deep Q-Learning, wymagają znacznej mocy obliczeniowej i pamięci. Będziesz potrzebował pomocy w praktycznym uczeniu się w czasie rzeczywistym w aplikacjach o ograniczonych zasobach.
Przezwyciężanie skalowalności i uczenie transferowe
Skalowanie agentów uczących się w celu skutecznego działania w dużych, wielowymiarowych środowiskach pozostaje wyzwaniem. Transfer learning, gdzie agenci stosują wiedzę z jednej domeny do innej, jest wciąż w powijakach.
Ogranicza to ich zdolność do generalizowania w różnych zadaniach lub środowiskach.
Przykład: Agent AI wyszkolony do gry w szachy miałby trudności z grą w Go ze względu na bardzo różne zasady i cele, co podkreśla wyzwanie związane z przenoszeniem wiedzy między domenami.
Jakość i dostępność danych
Wydajność uczących się agentów w dużej mierze zależy od jakości i różnorodności danych szkoleniowych.
Niewystarczające lub tendencyjne dane mogą prowadzić do niekompletnego lub błędnego uczenia się i w rezultacie do nieoptymalnych lub nieetycznych decyzji. Ponadto gromadzenie rzeczywistych danych do szkolenia może być kosztowne i czasochłonne.
⚙️ Bonus: Poznaj Kursy AI aby lepiej zrozumieć innych agentów.
Narzędzia i zasoby do nauki agentów
Deweloperzy i badacze polegają na różnych narzędziach do tworzenia i trenowania uczących się agentów. Frameworki takie jak TensorFlow, PyTorch i OpenAI Gym oferują podstawową infrastrukturę do wdrażania algorytmów uczenia maszynowego.
Narzędzia te pomagają również tworzyć symulowane środowiska. Niektóre Aplikacje AI również upraszczają i usprawniają ten proces.
W przypadku tradycyjnych podejść do uczenia maszynowego, narzędzia takie jak Scikit-learn pozostają niezawodne i skuteczne.
Do zarządzania projektami badawczo-rozwojowymi AI,
[ClickUp] oferuje więcej niż [zarządzanie zadaniami] - działa jako scentralizowany hub do organizowania zadań, śledzenia postępów i umożliwiania płynnej współpracy między Teams.
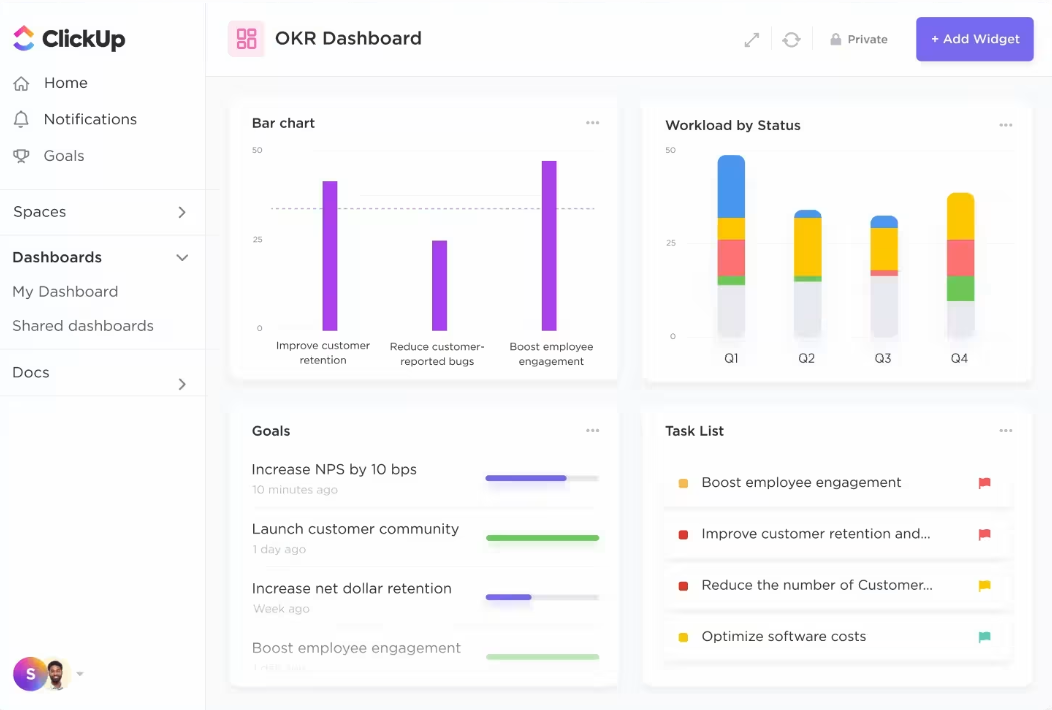
Użyj ClickUp for AI Project Management, aby poprawić wydajność swojego zespołu ClickUp do zarządzania projektami AI redukuje wysiłki związane z ręczną oceną statusów zadań i przydzielaniem obowiązków.
Zamiast ręcznie sprawdzać każde zadanie lub sprawdzać, kto jest dostępny, AI wykonuje ciężką pracę. Może automatycznie aktualizować postępy, identyfikować wąskie gardła i sugerować najlepszą osobę do każdego zadania w oparciu o jej obciążenie pracą i umiejętności.
W ten sposób spędzasz mniej czasu na żmudnym administrowaniu, a więcej na tym, co ważne - posuwaniu projektów do przodu.
Oto kilka funkcji opartych na AI, które wyróżniają się na tle innych. 🤩
ClickUp Brain
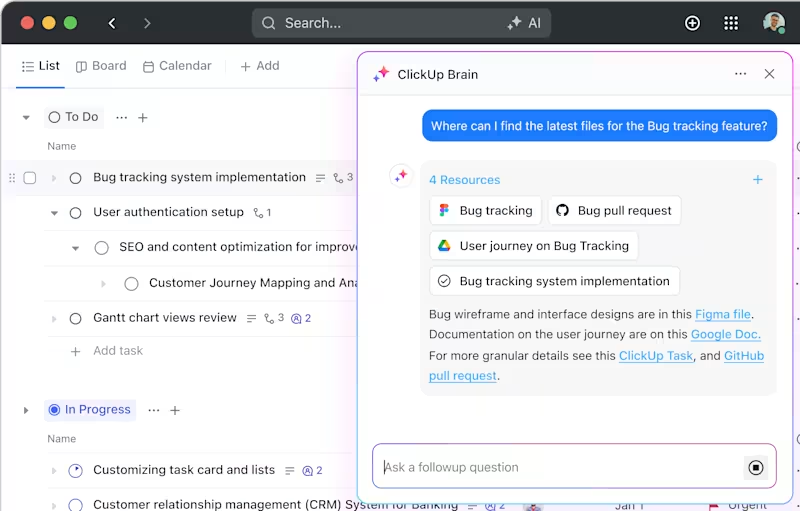
ClickUp Brain
ClickUp Brain wbudowany w platformę asystent oparty na AI, upraszcza nawet najbardziej złożone projekty. Rozbudowane badania są dzielone na łatwe w zarządzaniu zadania i podzadania, pomagając w organizacji i śledzeniu postępów.
Potrzebujesz szybkiego dostępu do wyników eksperymentów lub dokumentacji? Wystarczy wpisać zapytanie, a ClickUp Brain pobierze wszystko, czego potrzebujesz w ciągu kilku sekund. Pozwala nawet zadawać dodatkowe pytania w oparciu o istniejące dane, dzięki czemu można poczuć się jak osobisty asystent.
Ponadto automatycznie połączy zadania z odpowiednimi zasobami, oszczędzając czas i wysiłek.
Załóżmy, że prowadzisz badanie na temat tego, jak agenci uczący się ze wzmocnieniem poprawiają się w czasie.
Masz wiele scen - przegląd literatury, zbieranie danych, eksperymenty i analizy. Dzięki ClickUp Brain możesz zapytać: "Podziel to badanie na zadania", a ono automatycznie utworzy podzadania dla każdej fazy.
Następnie można poprosić ClickUp Brain do zrobienia przeglądu odpowiednich artykułów na temat Q-learningu lub pobrania zestawów danych dotyczących wydajności agentów, co robi natychmiast. Podczas pracy nad zadaniami, ClickUp Brain może połączyć konkretne artykuły naukowe lub wyniki eksperymentów bezpośrednio z zadaniami, utrzymując wszystko w porządku.
Niezależnie od tego, czy zajmujesz się ramami badawczymi, czy codziennymi projektami, ClickUp Brain zapewnia, że pracujesz mądrzej, a nie ciężej.
Automatyzacja ClickUp
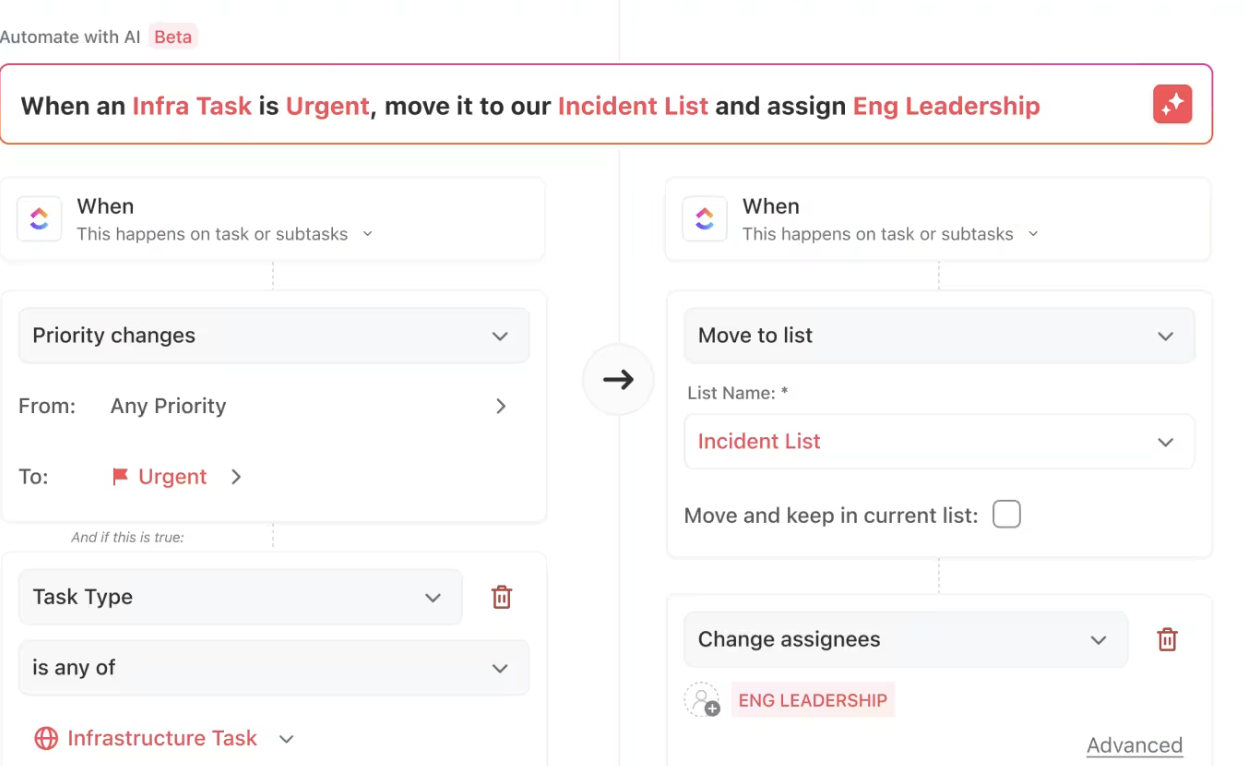
Zastosuj automatyzacje ClickUp, aby automatycznie aktualizować priorytety zadań, osoby przypisane i nie tylko Automatyzacja ClickUp to prosty, ale skuteczny sposób na usprawnienie cyklu pracy.
Umożliwia natychmiastowe przydzielanie zadań po zakończeniu warunków wstępnych, powiadamia interesariuszy o kamieniach milowych postępu i oznacza opóźnienia - wszystko bez ręcznej interwencji.
Można również używać komend w języku naturalnym, co jeszcze bardziej ułatwia zarządzanie przepływem pracy. Nie ma potrzeby zagłębiania się w skomplikowane ustawienia lub żargon techniczny - po prostu powiedz ClickUp, czego potrzebujesz, a on stworzy automatyzację za Ciebie.
Niezależnie od tego, czy chodzi o "przeniesienie zadań do następnej sceny, gdy zostaną oznaczone jako zakończone", czy "przypisanie zadania do Sary, gdy priorytet jest wysoki", ClickUp zrozumie Twoją prośbę i ustawi ją automatycznie.
Przeczytaj również: Jak wykorzystać AI do zwiększenia wydajności (przypadki użycia i narzędzia)
Rozwijaj uczących się agentów jak mistrz z ClickUp
Aby zbudować agentów uczących się AI, będziesz potrzebował eksperckiej mieszanki ustrukturyzowanych cykli pracy i narzędzi adaptacyjnych. Dodatkowe zapotrzebowanie na wiedzę techniczną sprawia, że jest to jeszcze trudniejsze, zwłaszcza biorąc pod uwagę statystyczny i oparty na danych charakter takich zadań.
Rozważ skorzystanie z ClickUp, aby usprawnić te projekty. Poza zwykłą organizacją, narzędzie to stanowi wsparcie dla innowacyjności zespołu, eliminując nieefektywności, których można uniknąć.
ClickUp Brain pomaga rozbijać złożone zadania, natychmiast pobierać odpowiednie zasoby i oferować wgląd oparty na AI, aby utrzymać projekty zorganizowane i na właściwym torze. Tymczasem ClickUp Automatyzacja obsługuje powtarzalne zadania, takie jak aktualizowanie statusów lub przypisywanie nowych zadań, dzięki czemu Twój zespół może skupić się na szerszej perspektywie.
Wspólnie funkcje te eliminują nieefektywności i pozwalają zespołowi pracować mądrzej, dzięki czemu innowacje i postęp są bez wysiłku.
Zarejestruj się w ClickUp za Free już dziś. ✅