
Gli incidenti informatici si verificano rapidamente. Il ransomware si diffonde in pochi minuti, il phishing generato dall'IA sfugge ai filtri e un singolo passo falso può trasformarsi in una violazione su vasta scala prima ancora che i team riescano a coordinarsi su ciò che sta accadendo. La pressione è reale, così come i costi.
Il rapporto IBM Cost of a Data Breach Report stima che la media globale sia pari a 4,44 milioni di dollari, con ritardi nella risposta e uno scarso coordinamento che fanno lievitare ulteriormente il numero.
In mezzo a quel caos, i team hanno bisogno di chiarezza. Un playbook di risposta agli incidenti fornisce al tuo team una procedura condivisa quando le cose si complicano. Definisce chi agisce per primo, quali passaggi seguire e come mantenere una comunicazione efficace mentre la situazione evolve.
In questo post del blog imparerai come creare un playbook di risposta agli incidenti progettato per le minacce odierne. Esploreremo scenari reali, azioni di risposta chiare e ClickUp, il primo spazio di lavoro AI convergente al mondo, come sistema che il tuo team può utilizzare anche in situazioni di stress.
Che cos'è un playbook di risposta agli incidenti?
Un playbook di risposta agli incidenti è una guida strutturata e dettagliata che aiuta i team di sicurezza a gestire tipi specifici di incidenti informatici in modo coerente ed efficiente. Descrive esattamente cosa fare quando si verifica un incidente, chi è responsabile di ciascuna azione e come passare dal rilevamento al contenimento e al ripristino senza confusione o ritardi.
Consideralo come un piano d'azione pronto all'uso per scenari reali quali attacchi di phishing, infezioni da ransomware o violazioni dei dati.
🧠 Curiosità: Il primo "virus" informatico non era dannoso. Nel 1971, un programma chiamato Creeper si spostava da un computer all'altro solo per visualizzare il messaggio: "Sono il Creeper, prendimi se ci riesci". Ciò portò alla creazione del primo antivirus, chiamato Reaper.
Manuale di risposta agli incidenti, piano e runbook
Spesso si fa confusione con la terminologia relativa alla documentazione sulla sicurezza. Questa confusione crea problemi concreti quando i team definiscono le loro procedure operative standard. Il risultato sono piani generici privi di passaggi concreti o guide operative eccessivamente tecniche che confondono la dirigenza.
Ecco in cosa differiscono questi tre documenti.
| Documento | Ambito | Livello di dettaglio | Quando viene utilizzato | Chi lo utilizza | Formato |
| Piano | Strategia a livello aziendale | Politiche di alto livello | Prima degli incidenti | Leadership e aspetti legali | Documento sulle politiche |
| Manuale | Risposta specifica per scenario | Passaggi tattici passo dopo passo | Durante un tipo specifico di incidente | Team di risposta agli incidenti | Flusso di lavoro basato su un albero decisionale |
| Runbook | Procedura tecnica unica | Passaggi automatizzati dettagliati | Durante un'attività specifica | Responsabili tecnici della risposta | Lista di controllo o script |
È necessario che tutti e tre gli elementi lavorino insieme. Un piano senza playbook è troppo vago per poter essere messo in pratica. Un playbook senza runbook lascia l'esecuzione tecnica all'improvvisazione.
📮 ClickUp Insight: Il 53% delle organizzazioni non dispone di una governance dell'IA o ha solo linee guida informali.
E quando le persone non sanno dove finiscono i loro dati, o se uno strumento possa creare un rischio di non conformità, esitano.
Se uno strumento di IA si trova al di fuori dei sistemi affidabili o ha pratiche di gestione dei dati poco chiare, il timore che "E se non fosse sicuro?" è sufficiente a bloccarne l'adozione sul nascere.
Non è così con l'ambiente completamente regolamentato e sicuro di ClickUp. ClickUp AI è conforme a GDPR, HIPAA e SOC 2 e detiene la certificazione ISO 42001, garantendo che i tuoi dati siano privati, protetti e gestiti in modo responsabile.
Ai fornitori di IA di terze parti è vietato addestrare o conservare qualsiasi dato dei clienti di ClickUp, e il supporto multimodello opera in base a autorizzazioni unificate, controlli sulla privacy e rigorosi standard di sicurezza. In questo modo, la governance dell'IA diventa parte integrante dell'area di lavoro di ClickUp stessa, consentendo ai team di utilizzare l'IA in tutta sicurezza, senza rischi aggiuntivi.
Componenti chiave di un playbook di risposta agli incidenti
Ogni playbook efficace per la risposta agli incidenti ha la stessa struttura di base. Prima di iniziare a crearlo, devi sapere cosa deve contenere.
Criteri di trigger e classificazione degli incidenti
I trigger sono le condizioni specifiche che attivano il playbook. Potrebbe trattarsi di un avviso SIEM relativo a modelli di accesso anomali o di un utente che segnala un'email sospetta. Abbina i tuoi trigger a un sistema di classificazione degli incidenti in modo che il tuo team sappia con quale rapidità agire.
- Gravità 1: Critica: Esfiltrazione di dati in stato attivo o crittografia da ransomware in atto
- Gravità 2: Alta: Compromissione confermata senza diffusione attiva
- Gravità 3: Media: Attività sospetta che richiede un'indagine
- Gravità 4: Bassa: Violazione delle politiche o anomalia minore
La classificazione determina quali azioni vengono attivate e con quale rapidità. Senza di essa, i team reagiscono in modo eccessivo agli avvisi di bassa priorità o in modo insufficiente alle minacce reali.
📖 Leggi anche: Modi per migliorare la sicurezza informatica nel project management
Ruoli e responsabilità
Un playbook è inutile se nessuno sa chi è responsabile di cosa. Definisci i ruoli chiave che dovrebbero essere presenti in ogni playbook.
- Responsabile del comando degli incidenti: è responsabile della risposta complessiva e prende le decisioni relative all'escalation
- Responsabile tecnico: Dirige le attività pratiche di indagine e contenimento
- Responsabile della comunicazione: Gestisce gli aggiornamenti interni e le notifiche esterne
- Referente legale: fornisce consulenza in materia di obblighi normativi e conservazione delle prove
- Sponsor esecutivo: approva le decisioni importanti, come l'arresto dei sistemi
Assegna i ruoli in base alla funzione piuttosto che solo al nome della persona. Le persone possono andare in ferie o lasciare l'azienda, quindi ogni ruolo deve avere un responsabile principale e un backup.
Procedure di rilevamento, contenimento e ripristino
Questo è il nucleo operativo del playbook. Il rilevamento e l'analisi verificano se il trigger è un incidente reale e raccolgono gli indicatori iniziali di compromissione.
Il contenimento prevede azioni immediate per impedire la diffusione dell'incidente. Ciò include l'isolamento dei sistemi interessati, il blocco degli IP dannosi e la disattivazione degli account compromessi. È necessario distinguere tra il contenimento a breve termine, volto ad arrestare l'emorragia, e il contenimento a lungo termine, volto a garantire la stabilità.
L'eradicazione e il ripristino eliminano completamente la minaccia tramite la rimozione del malware e l'applicazione di patch alle vulnerabilità. Questa fase riporta i sistemi al normale funzionamento e include test di convalida per garantire che la minaccia sia effettivamente stata eliminata.
🔍 Lo sapevi? Una delle più grandi minacce alla sicurezza di sempre è iniziata con un problema legato alle password. Nel 2012, LinkedIn ha subito una massiccia violazione in parte perché le password erano archiviate utilizzando metodi di hashing obsoleti, rendendo milioni di account facili da violare.
Protocolli di comunicazione ed escalation
Gli incidenti richiedono una comunicazione coordinata oltre alla risposta tecnica. L'escalation interna definisce quando il responsabile della gestione dell'incidente coinvolge il team esecutivo e il consulente legale.
La comunicazione esterna stabilisce chi deve interagire con i clienti, le autorità di regolamentazione o la stampa. Molti quadri normativi prevedono tempistiche di notifica obbligatorie a cui il tuo playbook dovrebbe fare riferimento.
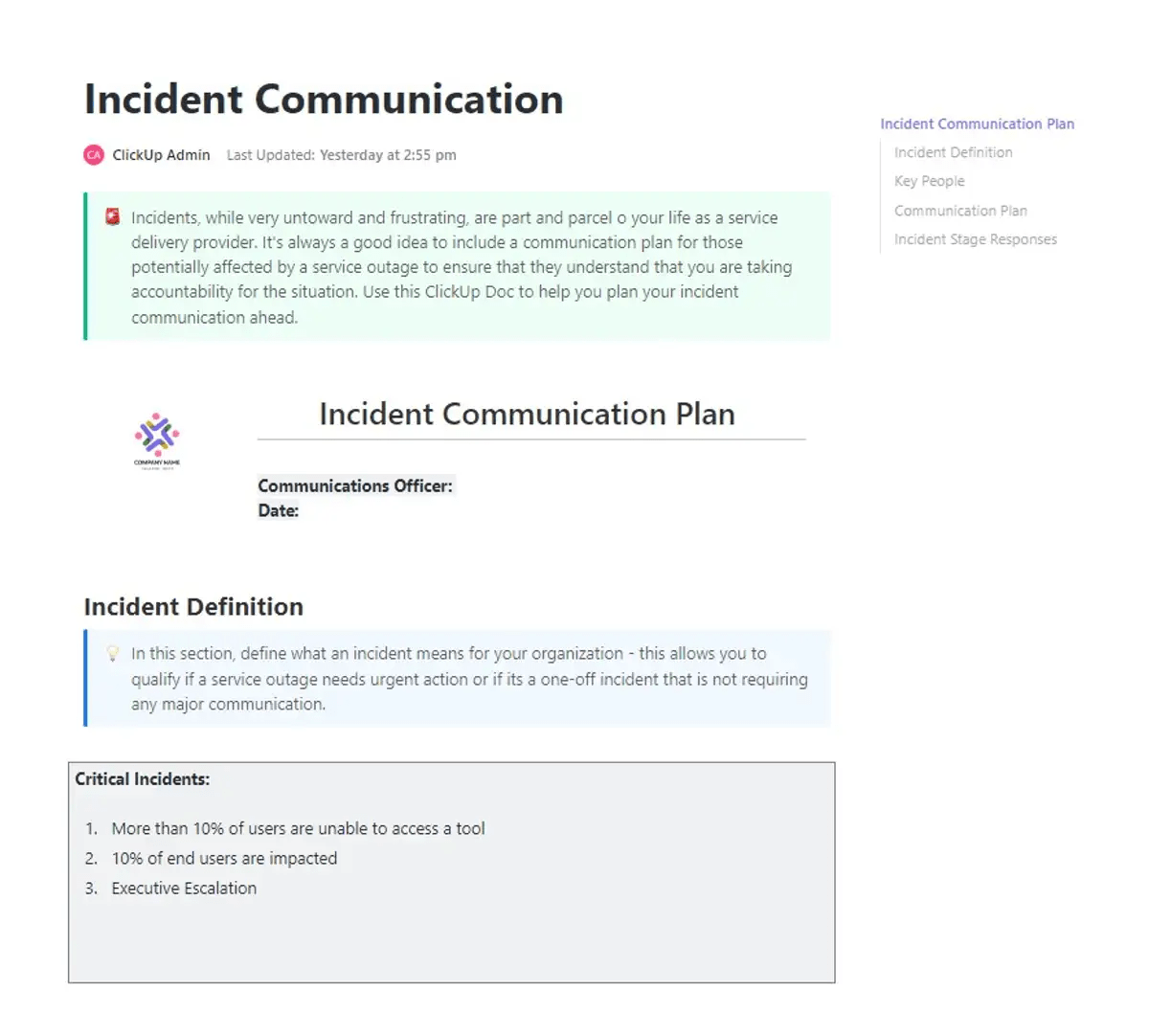
⚡ Archivio modelli: Quando si verificano degli incidenti, il rischio maggiore è spesso la confusione che ne deriva. Aggiornamenti ritardati, titolarità poco chiara e comunicazioni frammentarie possono rallentare i tempi di risposta e amplificare l'impatto. È proprio qui che il modello di piano di comunicazione degli incidenti di ClickUp offre un valore reale.
Questo modello offre ai team un framework pronto all'uso per comunicare in modo chiaro anche sotto pressione. È possibile definire i ruoli, mappare i canali di comunicazione e garantire che le parti interessate siano informate al momento giusto. Centralizza tutto, dai punti di contatto ai percorsi di escalation, in modo che i team rimangano allineati quando conta di più.
Come creare un manuale di risposta agli incidenti (passaggio dopo passaggio)
Un incidente di sicurezza senza un piano è una crisi. Un incidente di sicurezza con un playbook è un processo. Ecco come crearne uno che regga sotto pressione. 👀
Passaggio n. 1: Definire l'ambito e gli obiettivi
Prima di scrivere una sola procedura, stabilisci cosa il playbook copre e cosa non copre.
Lo scope creep compromette l'usabilità. Una guida che cerca di affrontare ogni possibile scenario finisce per non servire bene a nessuno di essi, e gli addetti alla risposta perdono tempo a cercare indicazioni che o non esistono o non si applicano alla loro situazione.
Inizia rispondendo a quattro domande:
- Quali tipi di incidenti rientrano nell'ambito di applicazione: ransomware, violazioni dei dati, minacce interne, attacchi DDoS, phishing, appropriazione indebita di account, compromissione della catena di approvvigionamento o tutte le precedenti
- A quali sistemi e ambienti si applica il playbook: infrastruttura cloud, server on-premise, ambienti ibridi, piattaforme SaaS, sistemi OT/ICS o specifiche unità aziendali con profili di rischio unici
- Cosa significa ottenere un esito positivo: un tempo di rilevamento medio (MTTD) inferiore a 60 minuti, un tempo di risposta medio (MTTR) inferiore a quattro ore o il raggiungimento della conformità con SOC 2, ISO 27001 o HIPAA
- Chi è responsabile del playbook: una persona o un team designato incaricato di mantenerlo aggiornato, effettuare la distribuzione alle persone giuste e programmare le revisioni
Definire l'ambito sembra semplice finché non ci si mette a farlo. I team spesso si bloccano in questa fase perché le informazioni provengono da incidenti passati, note sparpagliate e aspettative delle parti interessate.
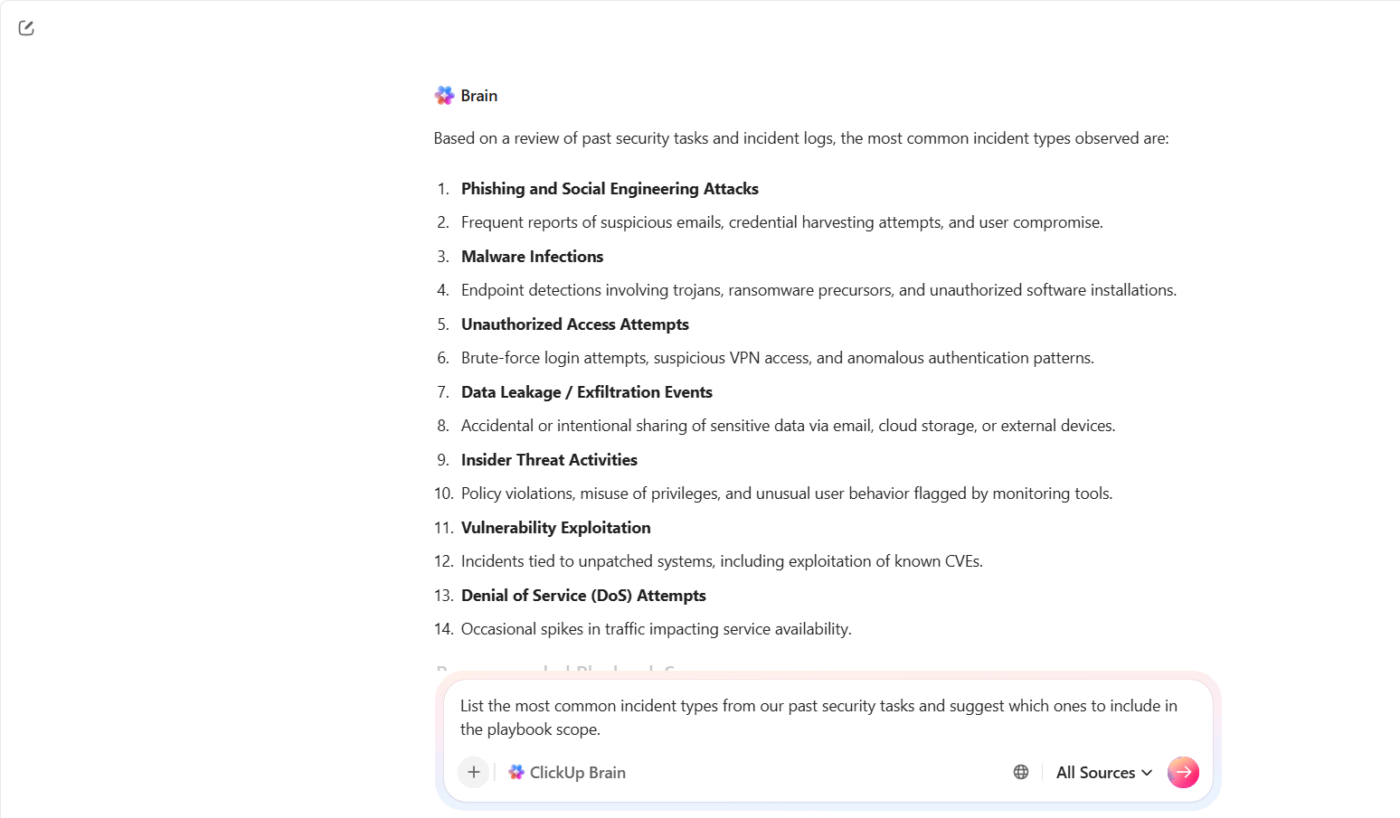
ClickUp Brain ti aiuta a mettere insieme tutte le informazioni e a trasformarle in un punto di partenza concreto. Non parti da zero. Parti da ciò che il tuo team già sa.
Ad esempio, supponiamo che il tuo team di sicurezza abbia gestito diversi incidenti di phishing e di appropriazione di account nell'ultimo trimestre. Invece di esaminare manualmente ogni singolo caso, puoi chiedere a ClickUp Brain: "Elenca i tipi di incidenti più comuni tra le nostre attività di sicurezza passate e suggerisci quali includere nell'ambito del playbook."
Passaggio 2: Identifica e classifica i tipi di incidenti
Non tutti gli incidenti sono uguali. Un bucket S3 configurato in modo errato e un attacco ransomware in corso richiedono risposte completamente diverse, membri del team diversi e percorsi di escalation diversi.
Creare un sistema di classificazione sin dall'inizio consente agli addetti alla risposta di prendere decisioni rapide e coerenti sin dal primo allarme, senza dover attendere l'approvazione della dirigenza per ogni intervento.
Un modello standard di gravità a quattro livelli funziona in questo modo:
- Critico (P1): Violazione attiva, esfiltrazione di dati o compromissione a livello di sistema: è richiesta una risposta immediata
- Elevato (P2): Sospetta intrusione, furto di credenziali o interruzione significativa del servizio
- Livello medio (P3): Malware rilevato ma contenuto, violazione delle politiche con rischio di esposizione dei dati
- Basso (P4): Tentativi di accesso non riusciti, violazioni minori delle politiche, avvisi informativi
Mappa ogni tipo di incidente a un livello di gravità, in modo che gli addetti alla risposta possano prendere decisioni rapide senza dover segnalare ogni chiamata ai livelli superiori.
Una volta definito l'ambito di applicazione, la sfida successiva riguarda la coerenza. Spesso i diversi operatori interpretano lo stesso avviso in modi diversi, il che rallenta le decisioni e crea inutili escalation.
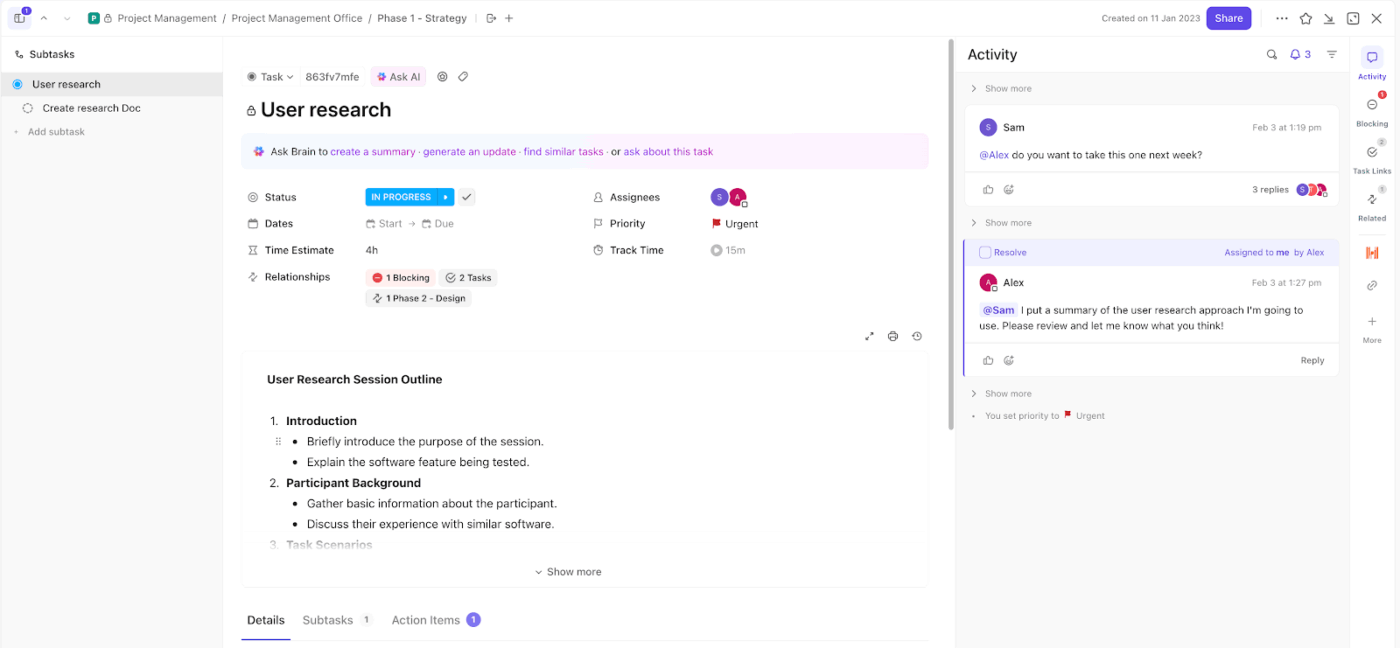
Inizia utilizzando le attività di ClickUp come unica unità di esecuzione. Ogni incidente diventa un'attività, il che significa che nulla sfugge attraverso canali non tracciati come email o chat.
Ad esempio, supponiamo che il tuo strumento di monitoraggio segnali un potenziale furto di credenziali. Crei un'attività con il titolo "Possibile compromissione delle credenziali – account finanziario". Quell'attività diventa ora il punto centrale per le indagini, gli aggiornamenti e la risoluzione.
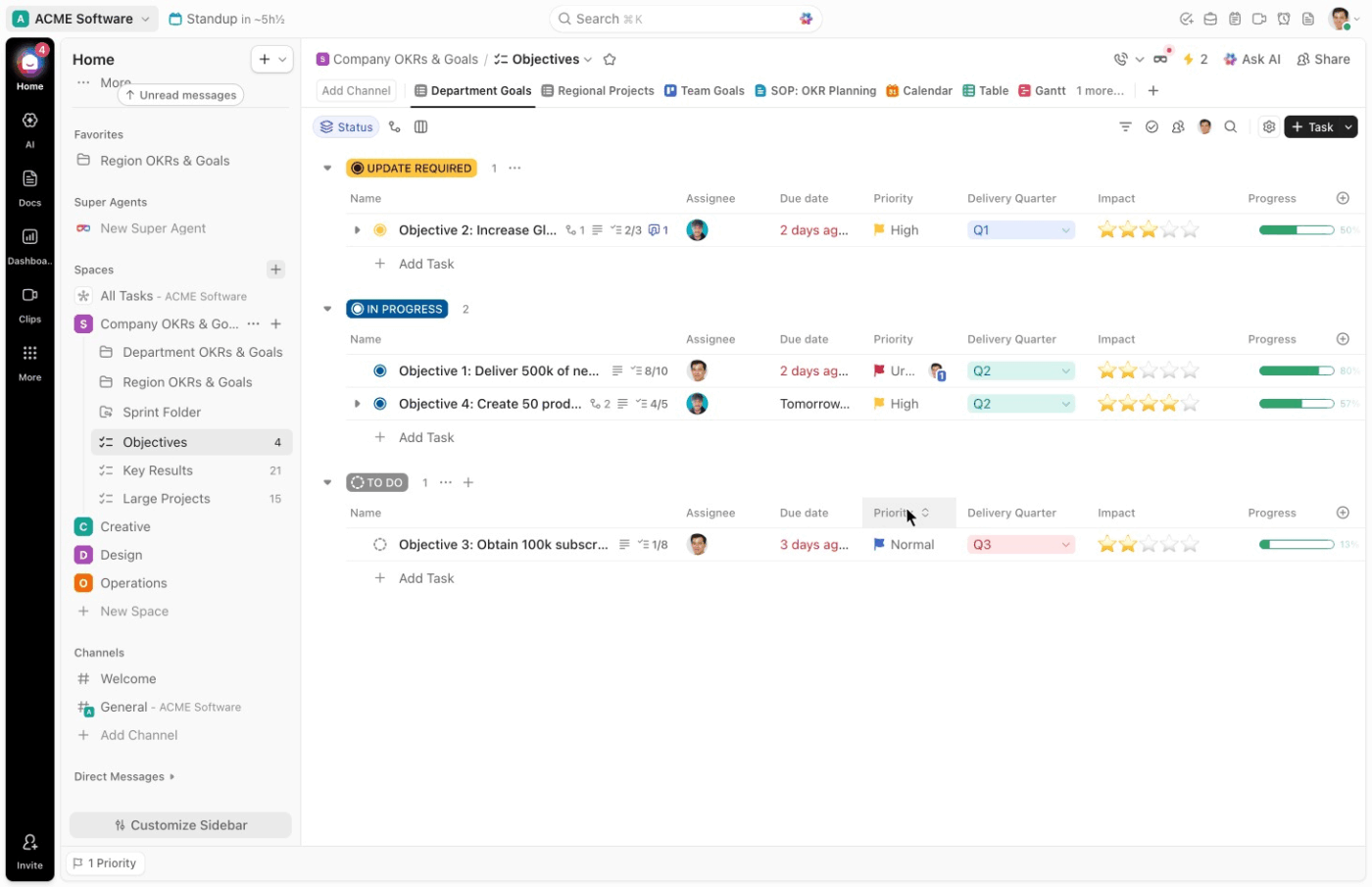
Da lì, i campi personalizzati di ClickUp ti offrono la struttura necessaria per una classificazione rapida. Puoi impostare campi come:
- Tipo di incidente: phishing, ransomware, DDoS, minacce interne
- Livello di gravità: P1, P2, P3, P4
- Sistemi interessati: Cloud, on-premise, SaaS, endpoint
- Sensibilità dei dati: Alta, media, bassa
Passaggio 3: Redigere procedure di risposta specifiche per ogni incidente
Questo è il nucleo operativo del playbook.
Per ogni tipo di incidente, redigi una procedura dedicata sufficientemente specifica da consentire a chi interviene di seguirla anche sotto pressione senza dover improvvisare. Le linee guida generiche vengono ignorate quando i sistemi sono inattivi.
Ogni procedura dovrebbe includere:
- Trigger: L'avviso o il rapporto specifico che avvia la risposta
- Passaggi iniziali di triage: le prime azioni intraprese da un responsabile della risposta entro 15 minuti, in base al tipo di incidente
- Lista di controllo per la raccolta delle prove: log, dump di memoria, acquisizioni di rete e intestazioni delle email: tutto ciò che serve prima che le azioni di contenimento lo distruggano
- Azioni di contenimento: Passaggi specifici ed eseguibili
- Criteri di escalation: le condizioni che trigger l'escalation verso i dirigenti, i consulenti legali o un fornitore esterno di servizi di risposta agli incidenti
- Modelli di comunicazione: bozze predefinite per aggiornamenti interni e notifiche ai clienti
Una procedura per il ransomware non ha nulla a che vedere con una procedura per il phishing. Redigile separatamente, tenendo conto delle specificità richieste da ciascuno scenario.

Con ClickUp Docs, puoi strutturare ogni procedura di gestione degli incidenti in modo da rispondere alle domande precise che un addetto alla risposta si pone in quel momento. Ad esempio, supponiamo che tu stia documentando uno scenario di ransomware.
Il documento può guidare il responsabile della risposta in questo modo:
- Cosa ha triggerato questo evento: "Avviso di crittografia degli endpoint rilevato tramite EDR"
- Cosa deve succedere nei primi 15 minuti: Isolare la macchina colpita, disabilitare l'accesso alla rete, confermare l'entità della diffusione
- Cosa occorre acquisire prima del contenimento: log di sistema, processi attivi, modifiche recenti ai file
- Quali condizioni richiedono l'escalation: diffusione della crittografia su più endpoint o accesso a unità in condivisione
- Cosa è necessario comunicare: un avviso interno alla direzione della sicurezza e un aggiornamento preparato per i team interessati
ClickUp Docs rafforza ulteriormente questo approccio grazie all'integrazione diretta nell'esecuzione:
- Allega la procedura alle attività relative all'incidente in ClickUp, in modo che gli addetti alla risposta possano aprire le linee guida nel momento esatto in cui devono agire
- Aggiungi delle liste di controllo all'interno di ogni sezione in modo che i passaggi critici non vengano saltati sotto pressione
- Assegna azioni specifiche ai membri del team durante l'escalation senza uscire dal documento
- Migliora le istruzioni subito dopo la risoluzione, in modo che le risposte future possano migliorare senza ritardi
Passaggio 4: Definire i protocolli di comunicazione e gli standard relativi alle prove
Due aspetti che vengono spesso trascurati durante lo sviluppo del playbook e che causano gravi problemi durante un incidente reale: come comunica il team e come vengono gestite le prove.
Per quanto riguarda la comunicazione, definisci in anticipo questi parametri:
- Canali primari e di backup
- Sequenza delle notifiche
- Requisiti di divulgazione esterna
- Un'unica fonte di verità
In base alle prove, il playbook dovrebbe specificare:
- Cosa raccogliere: registri degli eventi di sistema, registri di autenticazione, immagini di memoria, dati sul flusso di rete e screenshot delle attività degli aggressori
- Come raccoglierli: image forensi in sola lettura, dispositivi di blocco della scrittura e un registro di ogni operazione di raccolta con data e ora e il nome della persona che l'ha eseguita
- Dove conservarlo: un ambiente separato, con accesso controllato e isolato dai sistemi interessati
- Chi può accedervi: Accesso riservato a investigatori designati e approvato dal responsabile delle relazioni legali e di conformità
Quando si verifica un incidente, la comunicazione spesso si frammenta tra diversi strumenti. Gli aggiornamenti arrivano su Slack, le decisioni vengono prese durante le chiamate e i dettagli chiave finiscono sepolti in thread che nessuno rilegge. Questa mancanza di struttura crea confusione, ritarda l'escalation e rende le revisioni post-incidente più difficili di quanto dovrebbero essere.
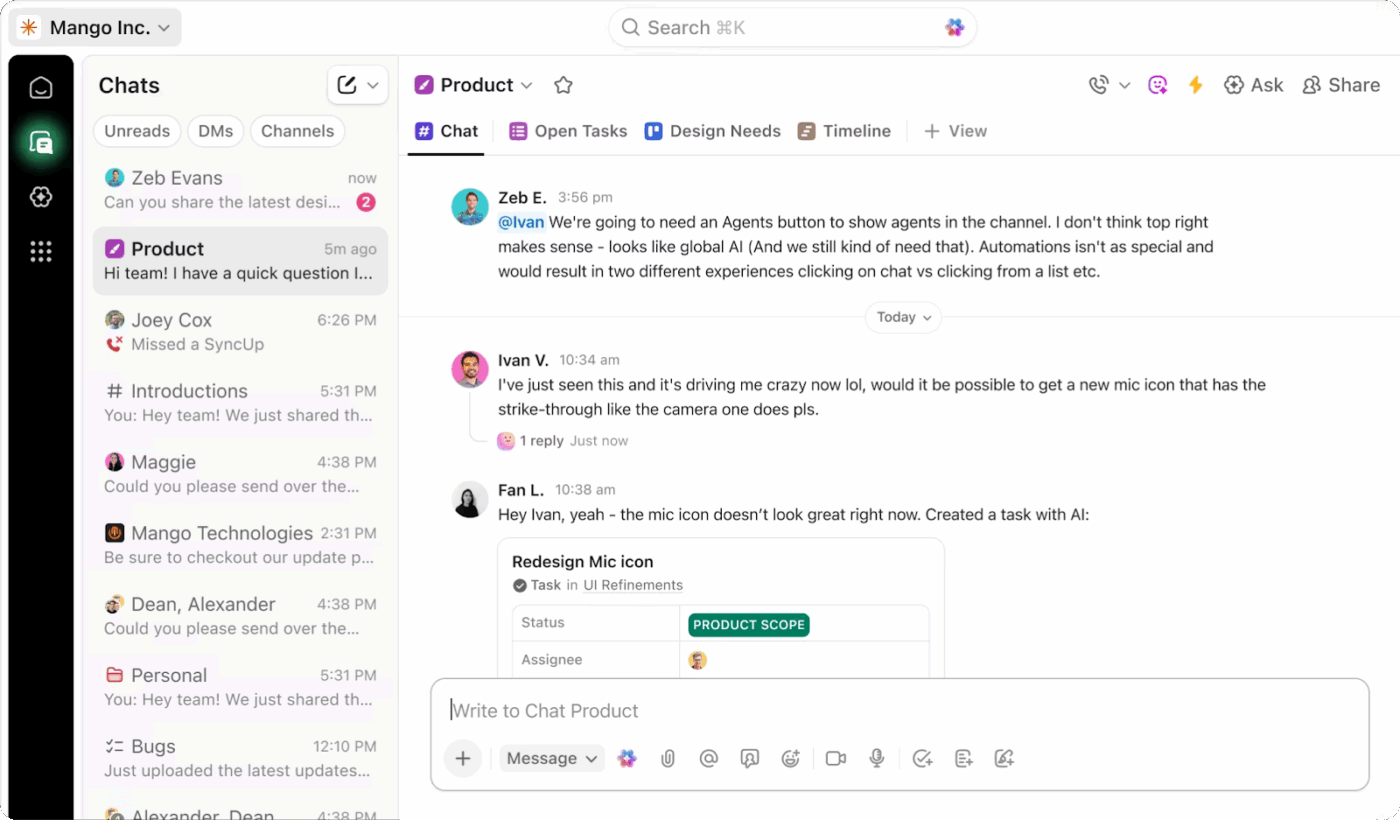
ClickUp Chat ti offre un canale dedicato e collegato in cui la comunicazione sugli incidenti rimane mirata, con visibilità e facile da seguire.
Puoi configurarlo come il tuo principale canale di comunicazione per la risposta agli incidenti, collegato direttamente al lavoro sottoposto a monitoraggio. Questa connessione cambia il modo in cui i team si coordinano durante le situazioni di forte pressione.
🀚 Il vantaggio di ClickUp: Trasforma ogni incidente in un'opportunità di apprendimento con il modello di report sulla risposta agli incidenti di ClickUp.
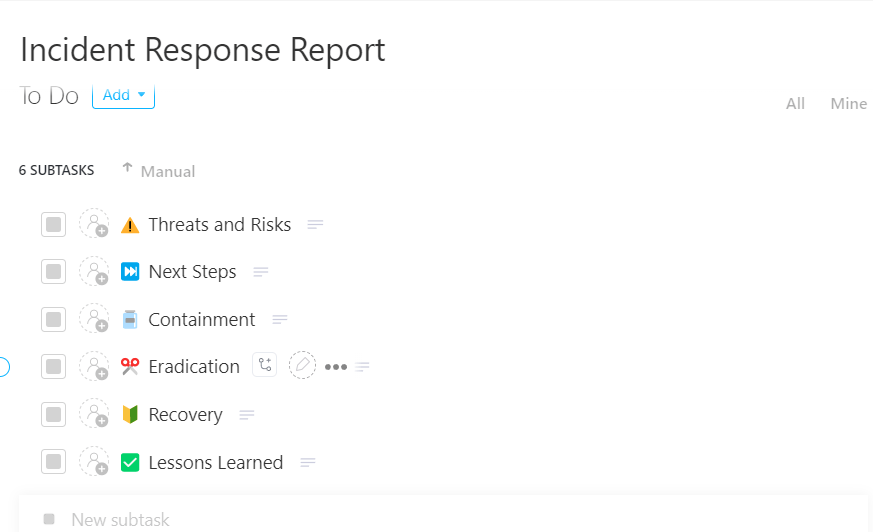
Registra ogni incidente in modo chiaro e senza omissioni utilizzando il modello di report di risposta agli incidenti di ClickUp
Progettato come un sistema basato su attività e pronto all'uso, ti consente di registrare, effettuare il monitoraggio e gestire gli incidenti dall'inizio alla fine in un unico posto, in modo che nulla vada perso tra strumenti o team.
Passaggio 5: Testare, integrare e definire una cadenza di revisione
Un playbook che non è mai stato testato è solo un insieme di ipotesi. Prima di considerarlo operativo, convalidatelo attraverso esercitazioni strutturate e integratelo con gli strumenti che il vostro team utilizza quotidianamente.
Per i test, esegui le esercitazioni in ordine di intensità:
- Esercitazione teorica: un facilitatore presenta uno scenario simulato e il team discute le decisioni verbalmente
- Esercitazione pratica: Il team esegue passaggi specifici in un ambiente controllato, come l'isolamento di un endpoint di prova
- Simulazione completa: un red team esegue uno scenario di attacco realistico mentre il team IR risponde in tempo reale
Per l'integrazione degli strumenti, mappa direttamente il playbook agli ID degli avvisi SIEM, alle azioni di contenimento EDR, ai flussi di lavoro di ticketing e alle procedure di trasferimento a fornitori IR esterni. Gli addetti alla risposta dovrebbero passare dall'avviso alla procedura e all'azione senza dover cambiare contesto.
Come ClickUp può aiutarti
L'esecuzione di esercitazioni teoriche e simulazioni rivela spesso la stessa lacuna. I team conoscono i passaggi in teoria, ma l'esecuzione rallenta perché nessun sistema guida attivamente la risposta in tempo reale.

Gli agenti ClickUp AI colmano questa lacuna. Osservano l'attività tra attività, campi e flussi di lavoro, quindi agiscono in base alla logica definita dall'utente. Ciò li rende estremamente utili quando si testa e si rende operativo il proprio playbook.
Inizia osservando come si svolge il processo durante un'esercitazione teorica.
Supponiamo che il tuo facilitatore presenti un attacco di phishing che degenera in una compromissione delle credenziali. Mentre il tuo team discute i prossimi passaggi, un agente IA può:
- Crea una lista di controllo di risposta strutturata in linea con la tua procedura di gestione del phishing
- Suggerisci le azioni successive in base ai campi relativi alle attività, come "tipo di incidente" e "gravità"
- Redigi un aggiornamento interno utilizzando i dettagli delle attività correnti
In questo modo le discussioni rimangono incentrate sui passaggi concreti di esecuzione.
💡 Suggerimento da esperto: Per la manutenzione continua, struttura le revisioni attorno a tre trigger:
- Un audit completo annuale con un'esercitazione teorica su qualsiasi procedura non testata negli ultimi 12 mesi
- Dopo ogni incidente significativo, mentre i dettagli sono ancora freschi
- Verifica trimestrale delle modifiche relative al personale e agli strumenti
Assegna un titolare specifico a ogni ciclo con la funzione " Assegnatari multipli" di ClickUp. Senza responsabilità, le revisioni vengono saltate e il playbook diventa silenziosamente un peso.
Esempi di playbook di risposta agli incidenti per tipo di minaccia
Ecco come si presenta il processo di creazione del playbook quando viene applicato ai tipi di minaccia più comuni.
Manuale di risposta agli incidenti ransomware
- Trigger: Avviso di rilevamento degli endpoint relativo ad attività di crittografia dei file o a modifiche insolite delle estensioni dei file
- Contenimento immediato: isolare immediatamente i sistemi interessati dalla rete e disabilitare le unità di condivisione
- Azioni chiave: Identificare la variante del ransomware, determinare l'ambito della crittografia e conservare le prove forensi
- Ripristino: esegui il ripristino da backup integri dopo aver verificato che non siano stati compromessi e applica le patch alla voce di ingresso
- Dopo l'incidente: documenta la sequenza dell'attacco e verifica le procedure di integrità dei backup
🔍 Lo sapevi? Uno dei primi hacker era un whistleblower. Negli anni '80, un gruppo noto come Chaos Computer Club ha reso note alcune falle di sicurezza nei sistemi bancari per dimostrarne le vulnerabilità, piuttosto che sfruttarle a scopo di lucro.
Manuale di risposta agli incidenti di phishing
- Trigger: L'utente segnala un'email sospetta o viene rilevata una pagina di raccolta delle credenziali
- Azioni immediate: mettere in quarantena l'email in tutte le caselle di posta e applicare il blocco al dominio del mittente
- Azioni chiave: imporre la reimpostazione delle password e revocare immediatamente le sessioni attive se sono state inserite credenziali
- Comunicazione: avvisare gli utenti interessati e inviare un avviso di sensibilizzazione a tutta l'organizzazione senza causare panico
- Ripristino: Verifica che non rimangano accessi persistenti e aggiorna le regole di filtraggio delle email
Manuale per gli accessi non autorizzati
- Trigger: attività di accesso anomala, avviso di escalation dei privilegi o accesso a risorse sensibili
- Contenimento immediato: disattiva l'account compromesso, chiudi le sessioni attive e limita l'accesso
- Azioni chiave: Determina come è stato ottenuto l'accesso ed esegui un audit di tutte le azioni intraprese dall'account compromesso
- Ripristino: reimposta le credenziali per tutti gli account potenzialmente interessati e rafforza i controlli di accesso
- Dopo l'incidente: Esegui una verifica completa degli accessi e aggiorna le politiche dei privilegi minimi
Best practice per i playbook di risposta agli incidenti
Ecco le best practice che distinguono i team in grado di risolvere gli incidenti in modo efficiente da quelli che, sei ore dopo, sono ancora riuniti nella sala operativa a discutere su chi debba occuparsi del rollback. Se le applichi correttamente, tutto il resto diventa più semplice. 🔥
Descrivi cosa da fare, non cosa pensare
La maggior parte dei playbook è piena di passaggi del tipo "valutare la gravità della situazione" o "identificare le parti interessate appropriate". Questi non sono passaggi. Sono promemoria per stimolare la riflessione.
Un playbook utile ti dice quale azione intraprendere, non solo che è necessaria un'azione. Sostituisci "valutare l'impatto sul cliente" con "controllare la dashboard delle sessioni attive e incollare il numero nel canale dedicato agli incidenti". La specificità è tutto.
Separare la persona che individua la soluzione da quella che gestisce l'incidente
Quando l'ingegnere più esperto presente alla riunione deve contemporaneamente individuare la causa principale, rispondere alle domande della dirigenza e decidere chi avvisare, tutte e tre le cose vanno male.
Il tuo playbook dovrebbe imporre una netta separazione: una persona è responsabile dell'indagine, un'altra dell'incidente. Il responsabile della gestione degli incidenti non prende decisioni tecniche. Si limita a delegare, sbloccare e comunicare. Potrebbe sembrare un onere in più, finché non ti farà risparmiare due ore per la prima volta.
🔍 Lo sapevi? Ben il 91% delle grandi organizzazioni ha già modificato le proprie strategie di sicurezza informatica a causa della volatilità geopolitica, trasformando le tensioni globali in un fattore determinante per le decisioni in materia di difesa informatica.
Esegui l'analisi post-incidente mentre le persone sono ancora irritate
Le migliori analisi post-incidente avvengono entro 48 ore, perché la frustrazione è ancora fresca. Il tecnico che riteneva che la soglia di allerta fosse troppo alta lo dirà il secondo giorno.
Entro il decimo giorno, hanno già voltato pagina e la riunione diventa una ricostruzione cortese della Sequenza degli eventi piuttosto che una conversazione sincera su ciò che non ha funzionato.
Metti alla prova il playbook cercando di aggirarlo
L'unico modo affidabile per scoprire se il tuo playbook funziona è utilizzarlo quando non c'è davvero alcun problema. Organizza una simulazione. Scegli uno scenario di guasto realistico, consegna il playbook a qualcuno senza alcuna preparazione e osserva dove esita.
Ogni esitazione è una lacuna. Ogni domanda che ti pongono è un passaggio mancante. Un playbook che non è mai stato sottoposto a stress test non è mai stato completato.
Un responsabile delle operazioni condivide le sue opinioni sull'uso di ClickUp:
ClickUp è stato uno strumento fantastico per mantenere il nostro team organizzato e allineato. Rende facile gestire i progetti, assegnare attività e effettuare il monitoraggio dei progressi, tutto in un unico posto. Apprezzo in particolare la flessibilità: è possibile personalizzare i flussi di lavoro, creare modelli e adattare la piattaforma ai diversi processi del team.
È stato molto utile per creare sistemi ripetibili per cose come le procedure operative standard (SOP), le valutazioni delle prestazioni e il monitoraggio dei progetti. Avere attività, documenti e comunicazioni collegati tra loro aiuta a ridurre gli scambi inutili e mantiene tutti allineati.
Crea e gestisci playbook di risposta agli incidenti con ClickUp
Mantenere le procedure operative e accessibili quando serve è una sfida enorme. La maggior parte dei team finisce per avere la documentazione sparpagliata tra wiki, Documenti Google e i segnalibri di Slack. Quando si verifica un incidente, nessuno sa con certezza quale sia la versione attuale o dove si trovi la matrice di escalation.
Elimina la proliferazione di strumenti e il cambio di contesto con ClickUp. Essendo uno spazio di lavoro convergente, la documentazione del playbook, i flussi di lavoro di risposta e la comunicazione del team risiedono tutti nello stesso unico posto.
Che tu stia creando il tuo primo playbook o consolidando documentazione sparsa, ClickUp offre al tuo team un unico posto dove pianificare, rispondere e migliorare. Iscriviti gratis oggi stesso!
Domande frequenti (FAQ)
1. Qual è la differenza tra un playbook di risposta agli incidenti e un runbook?
Un playbook copre l'intero ciclo di vita della risposta per un tipo specifico di incidente. Un runbook, invece, è una procedura tecnica più specifica per completare una singola attività nell'ambito di tale risposta.
2. Con quale frequenza dovresti aggiornare il tuo playbook di risposta agli incidenti?
Rivedi e aggiorna i playbook almeno una volta ogni tre mesi. Dovresti inoltre aggiornarli dopo ogni incidente reale e dopo ogni esercitazione teorica.
4. È possibile utilizzare un modello di playbook per la risposta agli incidenti come punto di partenza?
Sì, i modelli di framework come NIST o CISA offrono una struttura collaudata. Anche i modelli di ClickUp sono molto utili. Ciò ti consente di personalizzare le basi per il tuo ambiente invece di partire da una pagina vuota.
5. I team di piccole dimensioni hanno bisogno di un playbook per la risposta agli incidenti?
I team di piccole dimensioni hanno probabilmente più bisogno di playbook, poiché hanno meno margine di errore. Un semplice playbook per i tuoi scenari di minaccia più gravi è di gran lunga preferibile a una risposta improvvisata.