

Sono le 3 del mattino.
Un allarme assordante ti sveglia di soprassalto.
Ti alzi di scatto, attratto dal bagliore dello schermo del tuo computer. Un sistema critico è fuori uso. Il panico ti assale. Non è una scena tratta da un thriller fantascientifico, ma uno scenario da incubo per ogni professionista IT.
Ma è anche una realtà. Quando il mondo digitale si ferma, la pressione è enorme.
È qui che la gestione degli incidenti diventa fondamentale.
La gestione degli incidenti è fondamentale per affrontare e risolvere rapidamente le interruzioni dei progetti. Gestendo in modo efficiente queste interruzioni, potrai concentrarti maggiormente sul raggiungimento dei risultati e sul completamento efficace del tuo progetto.
In questo articolo esploreremo il processo di gestione degli incidenti e effettueremo la condivisione delle best practice per aiutarti a implementare un solido piano di emergenza. Ciò ti consentirà di gestire in modo efficace qualsiasi incidente futuro relativo ai progetti.
Comprendere la gestione degli incidenti
Gli incidenti sono interruzioni o potenziali minacce che incidono sulla qualità del servizio. Ad esempio, un'applicazione aziendale che si blocca o un server web che funziona in modo lento, causando problemi di produttività, sono considerati incidenti. Questi eventi possono variare da piccoli problemi che interessano pochi utenti a gravi interruzioni che incidono sui servizi globali.
La gestione degli incidenti è il processo di identificazione, prioritizzazione e risoluzione dei problemi IT al fine di ridurre al minimo le interruzioni delle operazioni aziendali, implementando al contempo misure volte a prevenire le occorrenze future di tali eventi. Questo processo di prevenzione proattiva degli incidenti è fondamentale per qualsiasi organizzazione, poiché le interruzioni del servizio possono comportare perdite significative per l'azienda. Una gestione efficiente degli incidenti consente ai team di stabilire le priorità e risolvere rapidamente i problemi, garantendo una migliore continuità del servizio.
Quando si affrontano gli incidenti, i team hanno bisogno di un piano ben definito che li aiuti a:
- Rispondi prontamente per ridurre al minimo i tempi di inattività
- Comunica in modo efficace con clienti, stakeholder, titolari dei servizi e altre parti interessate.
- Collabora senza intoppi per accelerare la risoluzione dei problemi ed eliminare gli ostacoli alla risoluzione.
- Migliora continuamente imparando dagli incidenti e applicando queste lezioni per migliorare la qualità del servizio e perfezionare i processi.
In questo contesto, è fondamentale anche sapere come redigere un rapporto sugli incidenti. Rapporti dettagliati sugli incidenti facilitano un'analisi approfondita, identificano le cause alla radice e consentono di sviluppare strategie preventive.
La relazione tra gestione degli incidenti, ITSM e DevOps
La gestione degli incidenti è una componente fondamentale dell'IT Service Management (ITSM), che garantisce la disponibilità e l'affidabilità dei servizi IT. Nel frattempo, DevOps integra i team di sviluppo e operazioni per migliorare la collaborazione e l'efficienza.
Allineare la gestione degli incidenti ai principi di project management DevOps può aiutare le organizzazioni a rispondere agli incidenti in modo rapido ed efficace. Questo allineamento promuove il miglioramento continuo, un recupero più rapido dagli incidenti e una migliore erogazione dei servizi.
Comprendere i processi di gestione degli incidenti
Un processo di gestione degli incidenti efficace consente ai team IT di indagare, documentare e risolvere in modo efficiente gli incidenti che causano interruzioni o disservizi.
Le diverse aziende adottano spesso tipi diversi di processi di gestione degli incidenti su misura per le loro esigenze specifiche. Poiché non esiste un approccio valido di dimensioni generali, troverai metodologie diverse nelle varie organizzazioni.
Alcuni team aderiscono ai tradizionali processi di gestione degli incidenti in ambito IT, come quelli descritti nelle certificazioni ITIL (Information Technology Infrastructure Library). Altri preferiscono un approccio più orientato alla Site Reliability Engineering (SRE) o al DevOps.
Il flusso di lavoro della gestione degli incidenti ITIL si concentra sulla riduzione dei tempi di inattività e sulla mitigazione dell'impatto degli incidenti sulla produttività dei dipendenti. Utilizzando modelli di segnalazione degli incidenti, i team possono stabilire un flusso di lavoro ripetibile per registrare, diagnosticare e risolvere gli incidenti, mantenendo al contempo registrazioni complete delle loro attività.
Il framework ITIL è utilizzato prevalentemente dai team IT che gestiscono i servizi all'interno delle aziende. Questi team spesso personalizzano l'ampia copertura di incidenti e processi offerta da ITIL in base alle loro esigenze.
ITIL è particolarmente utile per creare una cultura di risoluzione proattiva dei problemi. I suoi processi strutturati aiutano i team a effettuare il monitoraggio costante degli incidenti e delle azioni, migliorando la reportistica e l'analisi, con il risultato finale di servizi più solidi e team più efficaci.
IA e machine learning nella gestione degli incidenti
L'integrazione dell'IA e dell'apprendimento automatico nella gestione degli incidenti trasforma il modo in cui i team gestiscono gli incidenti. Gli strumenti basati sull'IA sono in grado di analizzare grandi quantità di dati per prevedere potenziali incidenti prima che si verifichino, consentendo di adottare misure preventive.
Gli algoritmi di apprendimento automatico sono in grado di identificare modelli e anomalie che potrebbero sfuggire agli analisti umani, fornendo informazioni più approfondite sulle cause alla radice e sulle potenziali soluzioni. Queste tecnologie possono anche automatizzare le attività di routine, come la registrazione degli incidenti e la diagnostica iniziale, liberando risorse umane per la risoluzione di problemi più complessi.
Alta disponibilità e tempi di inattività nella gestione degli incidenti
Ridurre al minimo i tempi di inattività è fondamentale per una gestione efficace degli incidenti. L'alta disponibilità garantisce che i sistemi siano operativi e accessibili in ogni momento, riducendo al minimo il rischio di interruzioni del servizio. Per ottenere un'alta disponibilità vengono utilizzati meccanismi di ridondanza, failover e bilanciamento del carico.
Ridurre i tempi di inattività è fondamentale per mantenere la produttività e la soddisfazione dei clienti. I processi di gestione degli incidenti devono includere piani solidi per una risposta e un ripristino rapidi, al fine di ridurre al minimo la durata e l'impatto delle interruzioni.
Il processo di gestione degli incidenti IT in dettaglio
La gestione degli incidenti comporta l'identificazione, la registrazione, la classificazione, la prioritizzazione e la risoluzione efficiente degli incidenti.
Comprendere questi passaggi aiuta a garantire un approccio sistematico alla gestione degli incidenti, riducendo al minimo i tempi di inattività e prevenendo le future occorrenze di incidenti simili.
Passaggi del processo di gestione degli incidenti IT
1. Identifica e registra l'incidente
Gli incidenti possono avere origini diverse, tra cui dipendenti, clienti, fornitori o sistemi di monitoraggio. Il primo passaggio consiste nell'identificare e registrare l'incidente. Questi registri, spesso denominati ticket di incidente, includono in genere:
- Il nome della persona che ha segnalato l'incidente
- La data e l'ora in cui è stato segnalato l'incidente
- Una descrizione dell'incidente che specifica cosa non funziona o è fuori uso
- Viene assegnato un numero di identificazione univoco a fini di monitoraggio.
2. Classifica l'incidente
È fondamentale assegnare a ogni incidente una categoria logica e intuitiva (e una sottocategoria, se necessario). Questa categorizzazione aiuta ad analizzare i dati per individuare tendenze e modelli, essenziali per una gestione efficace dei problemi e la prevenzione di incidenti futuri.
3. Dai priorità all'incidente
Ogni incidente deve essere classificato in base alla sua priorità, tenendo conto dell'impatto aziendale, del numero di persone coinvolte, degli SLA pertinenti e delle potenziali implicazioni finanziarie, di sicurezza e di conformità.
I team responsabili determinano la relativa priorità confrontandola con altri incidenti aperti. Determinare in anticipo i livelli di gravità e priorità è una best practice che consente ai responsabili della gestione degli incidenti di valutare rapidamente la priorità.
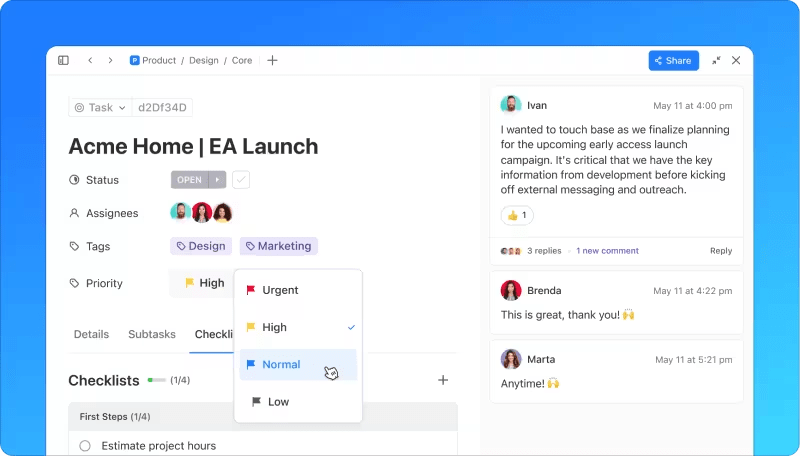
4. Rispondere all'incidente
La fase di risposta prevede diverse azioni chiave:
- Diagnosi iniziale: idealmente, il team del supporto in prima linea diagnostica e risolve l'incidente. Se non è in grado di farlo, registra tutte le informazioni pertinenti e le inoltra al team di livello superiore.
- Escalation: il team successivo continua il processo di diagnosi. Se non è in grado di risolvere l'incidente, lo sottopone a un livello superiore.
- Comunicazione: la condivisione degli aggiornamenti regolari avviene con gli stakeholder interni ed esterni interessati.
- Indagine e diagnosi: questa fase continua fino all'identificazione della natura dell'incidente. I team possono ricorrere a risorse esterne o membri di altri reparti per assistere nella risoluzione.
- Risoluzione e ripristino: una volta effettuata la diagnosi, il team esegue i passaggi necessari per risolvere l'incidente. Il ripristino comporta il tempo necessario per il completo ripristino delle operazioni, poiché alcune correzioni, come le patch per i bug, potrebbero richiedere test e implementazione anche dopo la risoluzione.
- Chiusura: se l'incidente è stato escalato, viene restituito al service desk per la chiusura. Solo i dipendenti del service desk possono chiudere gli incidenti, garantendo la qualità e la soddisfazione del cliente.
Gestione degli incidenti per i team DevOps e SRE
Gli approcci DevOps e SRE hanno guadagnato un'immensa popolarità, soprattutto con l'ascesa dei servizi cloud sempre attivi, delle applicazioni web accessibili a livello globale, dei microservizi e delle soluzioni software-as-a-service (SaaS).
I moderni software, fondamentali per l'uso personale e professionale, raramente sono ospitati su un server locale. Queste applicazioni sono invece tipicamente distribuite in data center, al servizio di migliaia o milioni di utenti in tutto il mondo. Agilità e velocità sono fondamentali per i team responsabili della manutenzione di questi servizi. Qualsiasi tempo di inattività può avere conseguenze di vasta portata, con un impatto simultaneo su numerose organizzazioni.
La filosofia "tu lo costruisci, tu lo gestisci" offre ai team agili la flessibilità necessaria. Tuttavia, può anche rendere meno chiari i confini delle responsabilità. Sebbene i team DevOps possano prosperare con processi di sviluppo meno rigidi, è essenziale standardizzare le pratiche fondamentali di gestione degli incidenti:
Responsabilità di reperibilità condivise
A differenza dei modelli tradizionali in cui alcuni membri del team sono designati come esperti di turno, i team DevOps adottano in genere un programma di turni a rotazione. Questo approccio garantisce che tutti i membri del team siano responsabili della risposta agli incidenti, compresi quelli che possono verificarsi al di fuori del normale orario di lavoro.
La familiarità favorisce la risoluzione
Al centro della filosofia DevOps c'è la convinzione che gli ingegneri che hanno sviluppato un servizio siano nella posizione migliore per risolvere i problemi quando si presentano. Questo principio sottolinea la mentalità "tu lo costruisci, tu lo gestisci", secondo la quale sono coloro che conoscono meglio l'architettura e le complessità del servizio ad affrontare interruzioni e disservizi.
Velocità e responsabilità
Il team DevOps deve sviluppare e distribuire software rapidamente. Ma questa velocità comporta un ulteriore livello di responsabilità. Sapere che dovranno risolvere gli incidenti motiva gli ingegneri a produrre codice affidabile e di alta qualità.
Anche l'analisi delle cause alla radice (RCA) è essenziale nella gestione degli incidenti DevOps. L'RCA comporta l'identificazione delle cause alla base degli incidenti, consentendo ai team di implementare soluzioni pratiche e prevenire la ricorrenza degli stessi.
Si tratta di un approccio proattivo che affronta i problemi immediati e rafforza il sistema nel suo complesso, riducendo la probabilità di incidenti gravi futuri e migliorando la resilienza dei servizi.
Mantenendo un flusso continuo e coerente nelle pratiche di gestione degli incidenti, i team DevOps possono bilanciare flessibilità e struttura. Ciò garantisce che siano ben preparati a gestire gli incidenti in modo rapido ed efficace, portando a servizi software più affidabili e robusti.
Ruoli nella gestione degli incidenti
Sebbene le organizzazioni possano adattare i ruoli e le responsabilità in base alle loro esigenze specifiche, di seguito sono riportati alcuni dei ruoli più diffusi nei team di gestione degli incidenti IT:
- Utente finale/richiedente: si tratta in genere della persona che subisce un'interruzione del servizio ed è responsabile dell'avvio del processo di gestione degli incidenti tramite l'invio di un ticket di incidente.
- Service desk di primo livello: il service desk di primo livello è il punto di contatto iniziale per i richiedenti. I tecnici gestiscono le richieste e i problemi di base. La loro competenza copre problemi comuni come il ripristino delle password e problemi di connessione come quelli relativi al Wi-Fi.
- Service desk di livello 2: i tecnici di questo livello possiedono competenze e conoscenze più avanzate rispetto a quelli di livello 1. Si occupano di problemi più complessi e gestiscono gli escalation provenienti dal livello 1. Il loro ruolo consiste nel risolvere problemi tecnici complessi e garantire una risoluzione efficace degli incidenti.
- Service desk di livello 3 e superiore: questo livello comprende specialisti con una profonda esperienza in aree specifiche dell'infrastruttura IT, come la manutenzione hardware o il supporto per server.
- Responsabile della gestione degli incidenti: il responsabile della gestione degli incidenti supervisiona il processo di gestione degli incidenti, ne valuta l'efficacia, suggerisce miglioramenti e garantisce il rispetto delle procedure stabilite.
- Titolare del processo: il titolare del processo supervisiona e perfeziona il processo di gestione degli incidenti. Analizza, modifica e migliora il processo per garantire che sia in linea con gli obiettivi dell'organizzazione e fornisca un supporto ottimale alle attività di gestione degli incidenti.
Questi ruoli contribuiscono collettivamente a un processo di identificazione e gestione degli incidenti ben strutturato ed efficiente, garantendo una risoluzione rapida ed efficace degli incidenti e migliorando continuamente l'approccio.
Strumenti e risorse per una gestione efficace degli incidenti
L'utilizzo degli strumenti e delle risorse adeguati per la gestione degli incidenti può migliorare significativamente l'efficienza e l'efficacia del processo di gestione degli incidenti.
I browser web, in particolare Google Chrome, sono fondamentali nella gestione degli incidenti. La versatilità e la compatibilità di Chrome con vari software di gestione degli incidenti basati sul web lo rendono uno strumento indispensabile per i team IT. La sua vasta libreria di estensioni, come strumenti di sviluppo, bug tracker e monitor delle prestazioni, consente la diagnostica e la risoluzione dei problemi in tempo reale.
Inoltre, il recupero di artefatti come dati cache, cronologia, download, ecc. tramite analisi forense del browser aiuta i team a identificare possibili fonti di attacchi virali e codice dannoso.
Chrome si integra perfettamente anche con ClickUp, un software di produttività e gestione degli incidenti con una valutazione molto alta e utilizzato dai team di piccole e grandi aziende.
Ecco alcuni dei vantaggi significativi dell'utilizzo di ClickUp per la gestione degli incidenti:
1. Monitoraggio centralizzato degli incidenti
ClickUp consolida tutte le informazioni relative agli incidenti in un'unica piattaforma. Questo approccio centralizzato garantisce che tutti i rapporti sugli incidenti, gli aggiornamenti e le risoluzioni siano accessibili in un unico posto, riducendo il rischio di perdita di informazioni e assicurando che i membri del team abbiano a portata di mano i dati più aggiornati.
2. Collaborazione in tempo reale
Le funzionalità di collaborazione di ClickUp facilitano la comunicazione tra i membri del team. Gli utenti possono commentare direttamente le attività, condividere file e aggiornare lo stato degli incidenti in tempo reale con la vista Chat di ClickUp. Questa funzionalità è utile per i team che lavorano in luoghi o fusi orari diversi, garantendo che tutti siano informati e allineati.

3. Gestione automatizzata del flusso di lavoro
ClickUp Automations aiuta a creare flussi di lavoro automatizzati che triggerno azioni specifiche in base a condizioni predefinite. Ad esempio, quando viene segnalato un incidente, è possibile inviare notifiche automatiche ai membri del team interessati e assegnare attività in base al tipo di incidente. Ciò riduce lo sforzo richiesto e accelera la risoluzione degli incidenti.
4. Reportistica e analisi integrate
La piattaforma fornisce strumenti affidabili di reportistica e analisi che aiutano a monitorare le tendenze degli incidenti e le metriche delle prestazioni. I team possono generare report dettagliati sulla priorità degli incidenti, i tempi di risoluzione degli incidenti, i tassi di ricorrenza e altri indicatori chiave di prestazione. Questo approccio basato sui dati aiuta a identificare i modelli, valutare l'efficacia delle strategie di risposta e prendere decisioni informate per migliorare i processi di gestione degli incidenti.
5. Dashboard personalizzabili
La piattaforma ti consente di creare dashboard personalizzate che mostrano metriche e KPI critici per la gestione degli incidenti. Le dashboard di ClickUp forniscono una panoramica visiva degli incidenti in corso, delle attività in sospeso e delle prestazioni del team, consentendo ai manager di valutare rapidamente lo stato attuale della gestione degli incidenti e risolvere eventuali problemi.
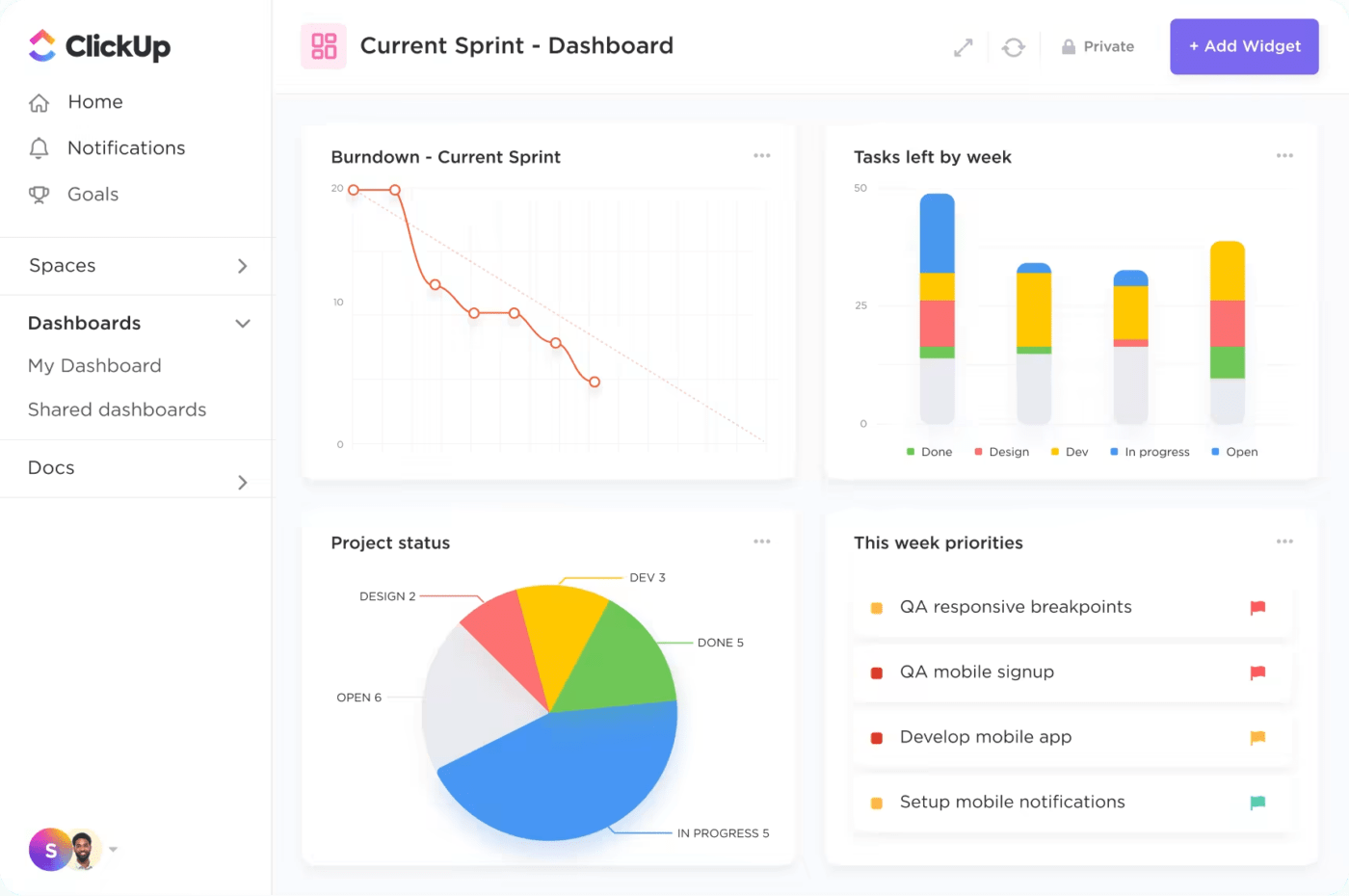
6. Modelli predefiniti
ClickUp offre un intervallo di modelli IT personalizzabilis progettati per la gestione degli incidenti. Questi modelli aiutano anche gli utenti a documentare i bug.
Ad esempio, il modello di rapporto sugli incidenti IT di ClickUp consente ai team IT di documentare, effettuare il monitoraggio e risolvere gli incidenti in modo rapido ed efficiente. Ciò non solo migliora la velocità del servizio, ma aiuta anche le aziende a identificare le tendenze a lungo termine che possono affrontare per migliorare la loro infrastruttura IT complessiva.
Questo modello semplifica:
- Documenta e segnala gli incidenti in modo accurato
- Monitora lo stato della risoluzione dei problemi in tempo reale
- Identifica gli schemi ricorrenti nei problemi segnalati per risolvere i problemi in modo proattivo.
Include componenti essenziali quali una descrizione dettagliata, una lista di controllo, attività secondarie e campi personalizzabili. Questa flessibilità garantisce che il modello possa essere adattato ai processi e alle procedure della tua organizzazione, creando un rapporto completo sugli incidenti IT.
Puoi anche utilizzare il modello di piano d'azione per gli incidenti di ClickUp, che semplifica lo sviluppo di piani d'azione completi per gli incidenti (IAP) per le aziende.
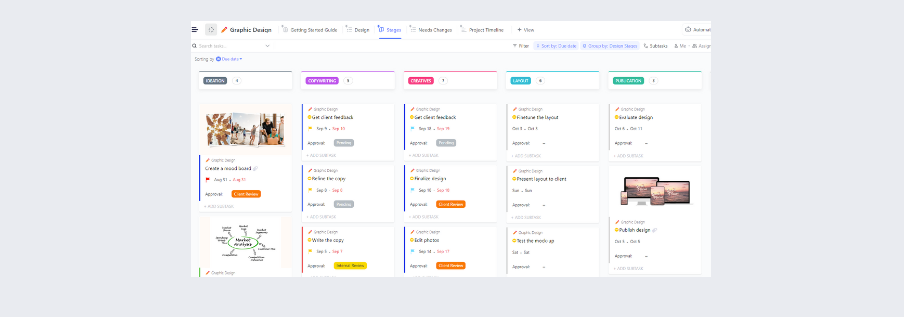
Questo modello include in modo sistematico tutte le informazioni cruciali, aiutandoti a creare registrazioni affidabili delle attività relative agli incidenti e ad attuare strategie di risposta efficaci.
Il modello presenta sezioni codificate con colori diversi per una documentazione organizzata:
- Riassunto della situazione: fornisce una panoramica concisa dell'incidente e del piano d'azione complessivo.
- Piano di esecuzione: descrive in dettaglio gli obiettivi e le strategie per la gestione degli incidenti.
- Informazioni di contatto del team addetto agli incidenti: elenco dei metodi di contatto del personale coinvolto nella risposta.
- Elenco di organizzazione degli incidenti: delinea i ruoli e le responsabilità dei team operativi, di pianificazione, logistici e finanziari.
- Elenco di assegnazione degli incidenti: assegna attività specifiche ai supervisori e ai membri del team.
- Mappa/riepilogo della situazione: include rappresentazioni grafiche del sito o della regione in cui si è verificato l'incidente.
- Approvazione del piano di gestione degli incidenti: registra dettagli quali il nome della persona che effettua l'invio del piano, la data di invio e le firme richieste.
Sfruttando questo modello, le aziende possono compilare in modo efficiente tutti i dettagli necessari per l'approvazione dell'IAP e mettere in atto una risposta agli incidenti ben coordinata e completa.
Best practice per la gestione degli incidenti
Una gestione efficace degli incidenti si basa su best practice che garantiscono una risoluzione rapida ed efficace.
Definisci aspettative chiare con gli SLA
Gli accordi sul livello di servizio (SLA) svolgono un ruolo significativo nel definire aspettative chiare sulla rapidità con cui i team devono affrontare gli incidenti in base alla loro gravità.
Gli SLA definiscono tempi di risposta e risoluzione specifici, che aiutano a stabilire le priorità degli incidenti e guidano i team nella gestione efficiente del loro carico di lavoro. Questo approccio strutturato ti aiuta a concentrare le risorse dove sono più necessarie, in modo da allineare la risoluzione degli incidenti alle priorità aziendali e ridurre al minimo i tempi di inattività.
Applica regolarmente le patch per prevenire gli incidenti
Un'altra pratica essenziale è l'applicazione regolare di patch, che aiuta a prevenire gli incidenti risolvendo le vulnerabilità prima che possano essere sfruttate. Si tratta di un processo continuo che affronta le falle di sicurezza nel software e nei sistemi, rendendo più difficile per gli aggressori sfruttare i punti deboli noti.
Questa pratica è una parte fondamentale di un quadro di gestione dei rischi di sicurezza informatica, poiché protegge l'infrastruttura IT dalle minacce emergenti e riduce il rischio di violazioni. Senza patch tempestive, le vulnerabilità rimangono aperte e possono portare a significativi problemi di sicurezza.
Dai priorità al monitoraggio dei data center
Anche la gestione dei data center svolge un ruolo fondamentale nella gestione degli incidenti. Una gestione adeguata garantisce che sia gli aspetti fisici che quelli virtuali del data center siano ben mantenuti. Ciò include la supervisione dei controlli ambientali, delle alimentazioni elettriche e della sicurezza fisica.
I sistemi di monitoraggio in tempo reale sono fondamentali in questo senso, poiché aiutano a individuare e risolvere i problemi prima che si aggravino. Una gestione efficace dei data center, se combinata con un framework di gestione dei rischi di sicurezza informatica ben implementato, consente di individuare tempestivamente i problemi, contribuendo a evitare gravi interruzioni e a mantenere la stabilità delle operazioni IT.
Vantaggi e sfide della gestione degli incidenti
Gli incidenti possono rallentare lo stato dei progetti e consumare risorse preziose, causando spesso significative interruzioni operative e potenziali perdite di dati critici. Ciò evidenzia l'importanza fondamentale di una gestione efficace degli incidenti.
I principali vantaggi della gestione degli incidenti includono:
1. Miglioramento della deviazione degli incidenti
La prevenzione degli incidenti consiste nell'identificare e mitigare in modo proattivo i potenziali problemi prima che si trasformino in problemi significativi. Sistemi efficaci di gestione degli incidenti consentono alle organizzazioni di implementare misure preventive e monitorare continuamente le prestazioni del sistema, riducendo così la frequenza e la gravità degli incidenti.
2. Processo di cambiamento ottimizzato
Un processo di cambiamento ben gestito garantisce che i dipendenti implementino aggiornamenti e modifiche in modo sistematico, seguendo procedure consolidate. L'utilizzo di procedure operative standard (SOP) per la gestione del cambiamento aiuta a standardizzare le procedure, garantendo coerenza e riducendo il rischio di errori.
3. Risoluzione e chiusura efficaci degli incidenti
Un processo di risoluzione chiaramente definito garantisce che i team affrontino gli incidenti tempestivamente e adottino tutte le misure necessarie per risolvere il problema. Una volta risolti, gli incidenti vengono formalmente chiusi con una documentazione completa e azioni di follow-up. Questo approccio strutturato migliora l'efficienza operativa e fornisce una preziosa documentazione per l'analisi post-incidente e il miglioramento continuo, contribuendo a perfezionare le strategie di gestione degli incidenti nel tempo.
Le sfide della gestione degli incidenti
Nonostante i vantaggi, la gestione degli incidenti presenta spesso diverse sfide.
1. Difficoltà nell'identificare le cause alla radice
Una sfida significativa è identificare la causa principale di un incidente, soprattutto quando si tratta di problemi complessi che coinvolgono più componenti di sistema e interdipendenze.
Una diagnosi accurata della causa sottostante richiede un'indagine approfondita e spesso comporta una collaborazione interfunzionale. Le procedure operative standard (SOP) possono aiutare a creare procedure standardizzate per l'analisi delle cause alla radice, ma l'implementazione efficace di tali procedure richiede strumenti e metodologie avanzati.
Stanley Security ha affrontato una sfida simile nella gestione dei propri processi di risposta agli incidenti. In qualità di leader globale nelle soluzioni di sicurezza, Stanley Security gestisce vari incidenti su diversi sistemi e in diverse regioni.
In precedenza, i team di marketing dell'azienda utilizzavano strumenti come Excel ed email per la comunicazione interna e la gestione delle attività. La pandemia di COVID-19 ha evidenziato la necessità di strumenti di project management più integrati e scalabili, per abbattere i silos e aumentare la produttività.
ClickUp ha fornito uno spazio di lavoro unificato per i team globali, facilitando la comunicazione e l'organizzazione dei documenti, nonché delle procedure operative standard (SOP), in un database mondiale. Questo allineamento ha consentito ai team di collaborare in modo più efficace e condividere le best practice. Di conseguenza, Stanley Security ha ottenuto un aumento dell'80% nel miglioramento del lavoro di squadra, risparmiando oltre 8 ore settimanali in riunioni e aggiornamenti. Ha inoltre osservato una riduzione del 50% del tempo dedicato alla creazione e alla condivisione dei report.
2. Ricorrenza degli incidenti
Un'altra sfida consiste nel prevenire il ripetersi degli incidenti. Ciò richiede una comprensione approfondita dei problemi sottostanti e l'implementazione di misure preventive efficaci. Identificare modelli e tendenze dagli incidenti passati è essenziale per sviluppare strategie volte a mitigare i rischi futuri.
ClickUp affronta questa sfida fornendo strumenti integrati di reportistica e analisi che offrono approfondimenti sulle metriche degli incidenti e sulle tendenze delle prestazioni. Questo approccio basato sui dati facilita l'identificazione di problemi ricorrenti e aiuta a sviluppare strategie di prevenzione mirate.

La soluzione IT & PMO di ClickUp può esserti d'aiuto in questo senso:
- Crea stati personalizzati (ad es. "Chiuso", "In attesa", "Lavoro in corso") e campi (ad es. "Richiedente", "Reparto") per classificare e gestire gli incidenti in modo efficace.
- Traccia e monitora gli incidenti in tempo reale, garantendo aggiornamenti rapidi e controlli dello stato.
- Aggiungi allegati, screenshot o registri pertinenti agli incidenti per l'analisi. Crea una knowledge base per una soluzione comune agli incidenti.
- Genera report sulla frequenza degli incidenti, sui tempi di risoluzione e sulle cause principali per identificare le tendenze e migliorare la risposta.
- Collega ClickUp ad altri strumenti IT per visualizzare gli incidenti in modo olistico
Padroneggiare la gestione degli incidenti per un esito positivo dei progetti
Padroneggiare la gestione degli incidenti non significa solo reagire ai problemi, ma anche creare un ambiente resiliente e agile in cui le interruzioni vengono gestite rapidamente e gli obiettivi del progetto vengono raggiunti con un impatto minimo.
L'adozione di queste strategie aiuterà il tuo team a evitare potenziali problemi e garantirà che i tuoi progetti procedano senza intoppi e con un esito positivo.
Con ClickUp, potrai sfruttare i vantaggi di una piattaforma all-in-one che integra la gestione degli incidenti con la gestione dei progetti e delle operazioni IT. Il monitoraggio in tempo reale, i flussi di lavoro automatizzati e gli strumenti collaborativi di ClickUp consentono al tuo team di affrontare e risolvere rapidamente i problemi, mantenendo i tuoi progetti in linea con gli obiettivi. Che si tratti di gestire le operazioni quotidiane o di districarsi tra i complessi requisiti di un progetto, ClickUp offre la visibilità e il controllo necessari per ottenere risultati eccezionali.
Sei pronto a migliorare la gestione degli incidenti e l'esito positivo dei tuoi progetti? Iscriviti oggi stesso a ClickUp e trasforma la tua gestione degli incidenti!