
Vous est-il déjà arrivé d'être en plein dîner lorsque votre téléphone vibre pour vous signaler une « alerte critique » qui s'avère n'être rien de plus qu'un message de routine ? C'est frustrant, mais au moins vous saviez qu'Opsgenie était là pour vous aider.
Mais voici le véritable défi : Atlassian a cessé de commercialiser Opsgenie et, bientôt, l'assistance complète prendra fin. Pour les équipes qui s'appuient sur cet outil pour la planification des astreintes, les escalades et les alertes, c'est un réveil brutal dont personne ne voulait.
La bonne nouvelle, c'est que vous n'avez pas besoin d'attendre la dernière minute. En prenant le temps d'explorer d'autres options dès maintenant, votre équipe pourra s'adapter à une nouvelle routine sans le stress des décisions prises à la hâte.
Dans cet article, nous passerons en revue les meilleures alternatives à Opsgenie, comparerons leurs points forts et montrerons pourquoi ClickUp offre à votre équipe une façon plus sereine et plus connectée de travailler.
⭐ Modèle présenté
Permettez à vos équipes informatiques d'enregistrer les incidents avec précision et de mettre en évidence les tendances qui permettent d'apporter des améliorations à long terme. Le modèle de rapport d'incident informatique de ClickUp vous aide à enregistrer les détails des incidents dans un format cohérent et fiable.

Aperçu des alternatives à Opsgenie
Voici une comparaison rapide des meilleures alternatives à Opsgenie pour vous aider à choisir celle qui vous convient le mieux en fonction des fonctionnalités clés, des tarifs et des évaluations des utilisateurs.
| Outil | Idéal pour | Principales fonctionnalités | Tarifs* | Évaluations |
| ClickUp | Gestion du travail tout-en-un avec flux de travail pour incidents, planification des ressources et automatisation pour les équipes de toutes tailles. | Notifications personnalisables, automatisation des escalades, tâches et listes d'incidents, statuts personnalisés, chat en temps réel, tableaux de bord pour les analyses post-incident, plus de 1 000 intégrations. | Forfait Free disponible ; personnalisations pour les entreprises. | G2 : 4,7/5 (10 500+) Capterra : 4,6/5 (4 500+) |
| PagerDuty | Alertes d'incident en temps réel et automatisation à grande échelle pour les grandes entreprises | Alertes multicanaux, politiques d'escalade, planification des astreintes, AIOps pour la réduction du bruit, intégrations avec plus de 600 outils | Forfait gratuit ; forfaits payants à partir de 25 $/mois par utilisateur | G2 : 4,5/5 (900+) Capterra : 4,6/5 (200+) |
| xMatters | Gestion des incidents et automatisation des flux de travail rentables pour les équipes en pleine croissance | Flux de travail automatisés, gestion adaptative des incidents, planification des astreintes, renseignement d'origine électromagnétique, plus de 200 intégrations | Forfait gratuit ; forfaits payants à partir de 9 $/mois par utilisateur | G2 : 4,5/5 (670+) Capterra : 4,6/5 (140+) |
| AlertOps | Réduction du bruit et réponse rapide grâce à l'IA pour les équipes de petite et moyenne taille | Réduction du bruit grâce à l'IA OpsIQ, escalades flexibles, couverture des astreintes, automatisation des flux de travail sans code, plus de 200 intégrations | Forfait Free ; forfaits payants à partir de 10 $/mois par utilisateur | G2 : 4,7/5 (150+) Capterra : 4,7/5 (20+) |
| Splunk On-Call | Simplifier la planification des astreintes et réduire l'épuisement professionnel des grandes équipes | Escalations automatisées, applications mobiles, équilibrage de la charge de travail, recommandations ML, pistes d'audit | Tarification personnalisée | G2 : 4,6/5 (50+) Capterra : 4,5/5 (30+) |
| Datadog | Observabilité complète avec surveillance de la sécurité pour les entreprises | Surveillance des infrastructures, des journaux et des applications, sécurité cloud, détection des anomalies grâce à l'IA, plus de 900 intégrations | Forfait Free ; forfaits payants à partir de 15 $/mois par utilisateur | G2 : 4,4/5 (660+) Capterra : 4,6/5 (320+) |
| Squadcast | Réponse unifiée aux incidents et aux appels avec une tarification avantageuse pour les équipes de taille moyenne. | Plannings automatisés, déduplication, runbooks, pages de statut, analyses rétrospectives | Forfait gratuit ; forfaits payants à partir de 12 $/mois par utilisateur | G2 : 4,4/5 (300+) Capterra : pas assez d'avis |
| FireHydrant | Runbooks automatisés et propriété des services pour les entreprises | Runbooks, planification des astreintes Signals, catalogue de services, collaboration Slack/Teams, rétrospectives enrichies par l'IA | Forfait Free ; forfaits payants à partir de 9 600 $/an par utilisateur | G2 : 4,5/5 (130+) Capterra : pas assez d'avis |
| TaskCall | Gestion des incidents abordable avec automatisation pour les équipes de taille moyenne à grande | Planification dynamique des astreintes, routage basé sur l'IA, alertes multicanaux, couverture DevOps + BizOps | Forfait gratuit ; forfaits payants à partir de 9 $/mois par utilisateur | G2 : pas assez d'avis Capterra : pas assez d'avis |
| ilert | Gestion des incidents axée sur l'IA et la confidentialité pour les équipes en pleine expansion | Alertes multicanaux, assistant de réponse IA, planification des astreintes, pages de statut automatisées, intégrations avec ITSM + outils de surveillance | Forfait Free ; forfaits payants à partir de 24 $/mois par utilisateur | G2 : pas assez d'avis Capterra : 4,7/5 (60+) |
| Zenduty | Réponse aux incidents à grande échelle basée sur l'IA pour les petites et grandes équipes | Gestion des incidents ZenAI, planification avancée des astreintes, playbooks automatisés, plus de 150 intégrations | Forfait Free ; forfaits payants à partir de 6 $/mois par utilisateur | G2 : 4,6/5 (135+) Capterra : pas assez d'avis |
| Incident. io | Réponse aux incidents native à Slack pour les entreprises de taille moyenne à grande | Incidents de bout en bout dans Slack, IA SRE, planification des astreintes, pages de statut automatisées, tableaux de bord d'informations | Forfait Free ; forfaits payants à partir de 19 $/mois par utilisateur | G2 : 4,8/5 (180+) Capterra : pas assez d'avis |
Critères clés pour évaluer les alternatives à Opsgenie
Je sais qu'il reste encore presque deux ans avant qu'il ne soit complètement retiré, mais je ne vois aucune raison d'attendre 😛
Je sais qu'il reste encore presque deux ans avant qu'il ne soit complètement retiré, mais je ne vois aucune raison d'attendre 😛
Ce commentaire d'un utilisateur de Reddit reflète la réalité à laquelle sont confrontées de nombreuses équipes PMO informatiques. Oui, Opsgenie a été un bon compagnon pendant des années, mais s'y fier uniquement parce qu'il est familier ne sera d'aucune aide une fois que l'assistance prendra fin.
La chose la plus judicieuse à faire maintenant est d'examiner ce qui a rendu Opsgenie utile au départ et d'utiliser ces mêmes qualités comme guide pour choisir votre prochaine plateforme de gestion des incidents.
Voici quelques-unes des caractéristiques qui méritent votre attention :
- Envoyez des alertes en temps opportun via plusieurs canaux tels que le téléphone, l'e-mail, les SMS ou les notifications push.
- Ciblez vos notifications afin que la bonne personne soit informée sans submerger le reste de l'équipe.
- Intégrez des politiques d'escalade qui garantissent que les incidents critiques ne sont jamais ignorés.
- Centralisez les mises à jour sur les incidents afin que les équipes puissent avoir une vue d'ensemble tout en gérant les incidents.
- Fournissez des analyses post-incident pour tirer des enseignements d'incidents similaires et vous améliorer au fil du temps.
- Offrez des capacités d'intégration avec les outils auxquels vos équipes informatiques font déjà une dépendance.
Opsgenie a bâti sa réputation en aidant les équipes DevOps à réduire la fatigue liée aux alertes, à clarifier les plannings d'astreinte et à résoudre les incidents sans confusion. Lorsque vous explorez chaque alternative à Opsgenie, gardez ces mêmes valeurs à l'esprit.
📖 À lire également : Les meilleurs outils logiciels de gestion des incidents pour les équipes informatiques
Les 12 meilleures alternatives à Opsgenie
Opsgenie est peut-être en train de fermer ses portes, mais cela ne signifie pas pour autant que votre équipe doit perdre son élan. Voici quelques solutions de remplacement adaptées qui donneront confiance à vos équipes opérationnelles dans les moments critiques.
Comment nous évaluons les logiciels chez ClickUp
Notre équipe éditoriale suit un processus transparent, fondé sur la recherche et indépendant des fournisseurs, vous pouvez donc être sûr que nos recommandations sont basées sur la valeur réelle des produits.
Voici un aperçu détaillé de la manière dont nous évaluons les logiciels chez ClickUp.
1. ClickUp (idéal pour gérer les flux de travail liés aux incidents parallèlement à une gestion de projet plus large)
Lorsqu'elles quittent Opsgenie, les équipes s'inquiètent moins de perdre des alertes que de devoir s'adapter à un nouveau flux de travail de gestion des incidents.
Le problème principal est la dispersion du travail, où les mises à jour, les plannings et les politiques sont éparpillés entre différentes applications, e-mails et documents. Cette fragmentation épuise l'énergie et oblige les équipes à repartir de zéro à chaque incident.
Des études montrent que les employés passent 117 minutes à parcourir leurs e-mails et 153 minutes à consulter leurs messages Teams chaque jour ouvrable, avec des interruptions toutes les deux minutes.
ClickUp s'impose comme une alternative à Opsgenie en regroupant toutes ces tâches disparates dans un espace de travail convergent. Voici comment ses fonctionnalités répondent en détail à ces défis.
Flux de travail de réponse automatisé
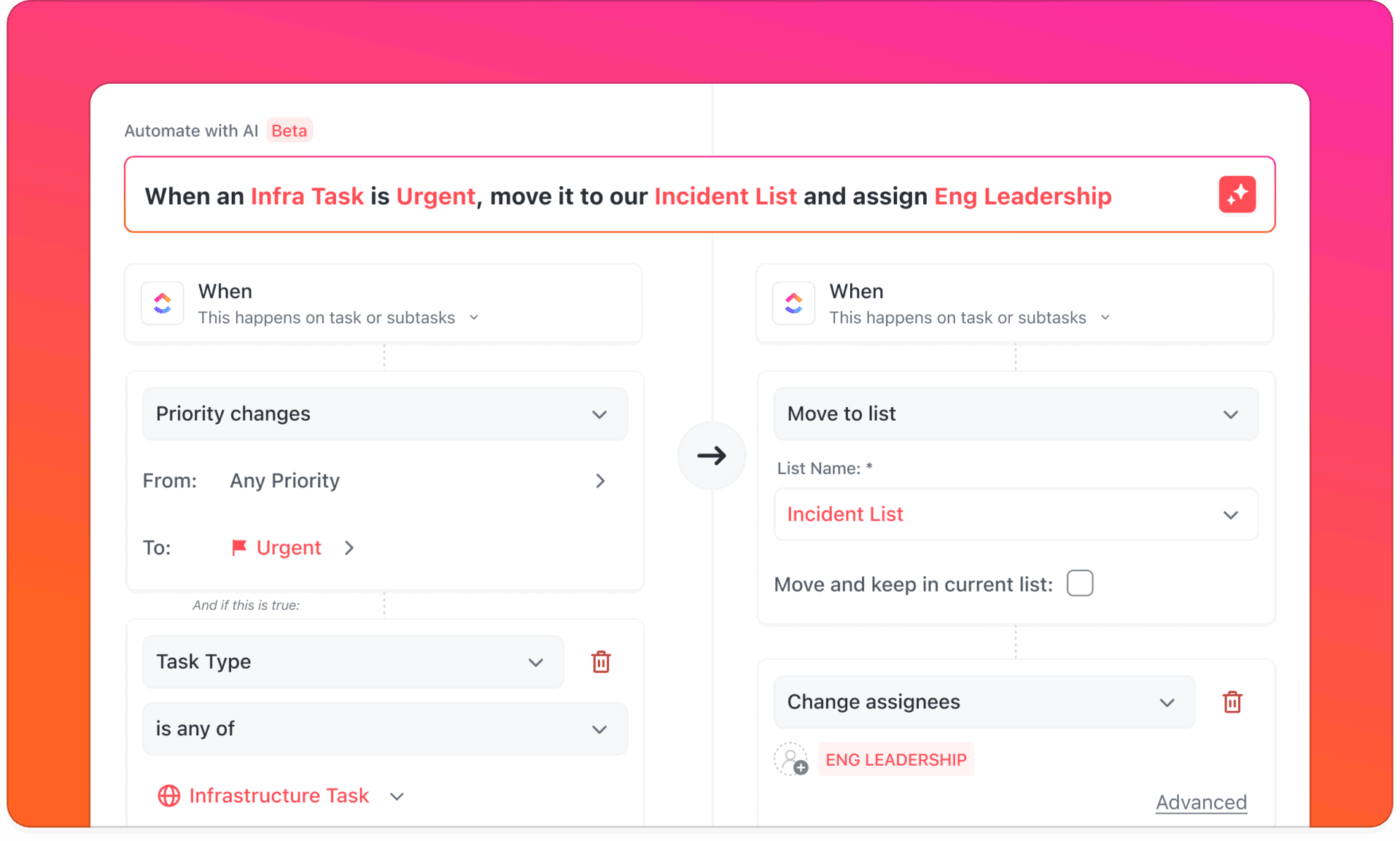
Avec les alertes provenant des outils de surveillance, des outils de chat et des e-mails, il est difficile de savoir ce qui est important et qui doit intervenir.
Grâce aux automatisations et aux agents IA de ClickUp, les alertes se transforment en actions significatives. Les alertes entrantes peuvent automatiquement créer et attribuer des tâches à l'ingénieur de garde, en avertissant la bonne personne sans distraire le reste de l'équipe.
Si aucune réponse n'est reçue dans un délai défini, le système escalade automatiquement le problème conformément à vos procédures standard.
📌 Exemple : Une panne de serveur à haute priorité est signalée. ClickUp Automatisations crée une nouvelle tâche dans votre liste d'incidents, la marque comme urgente, l'attribue à l'ingénieur de garde et envoie une alerte push mobile. Dans le même temps, votre agent IA personnalisé publie un court message dans le canal d'incidents dans ClickUp Chat afin que l'équipe soit informée sans être submergée.
Clarté et responsabilité autour des tâches
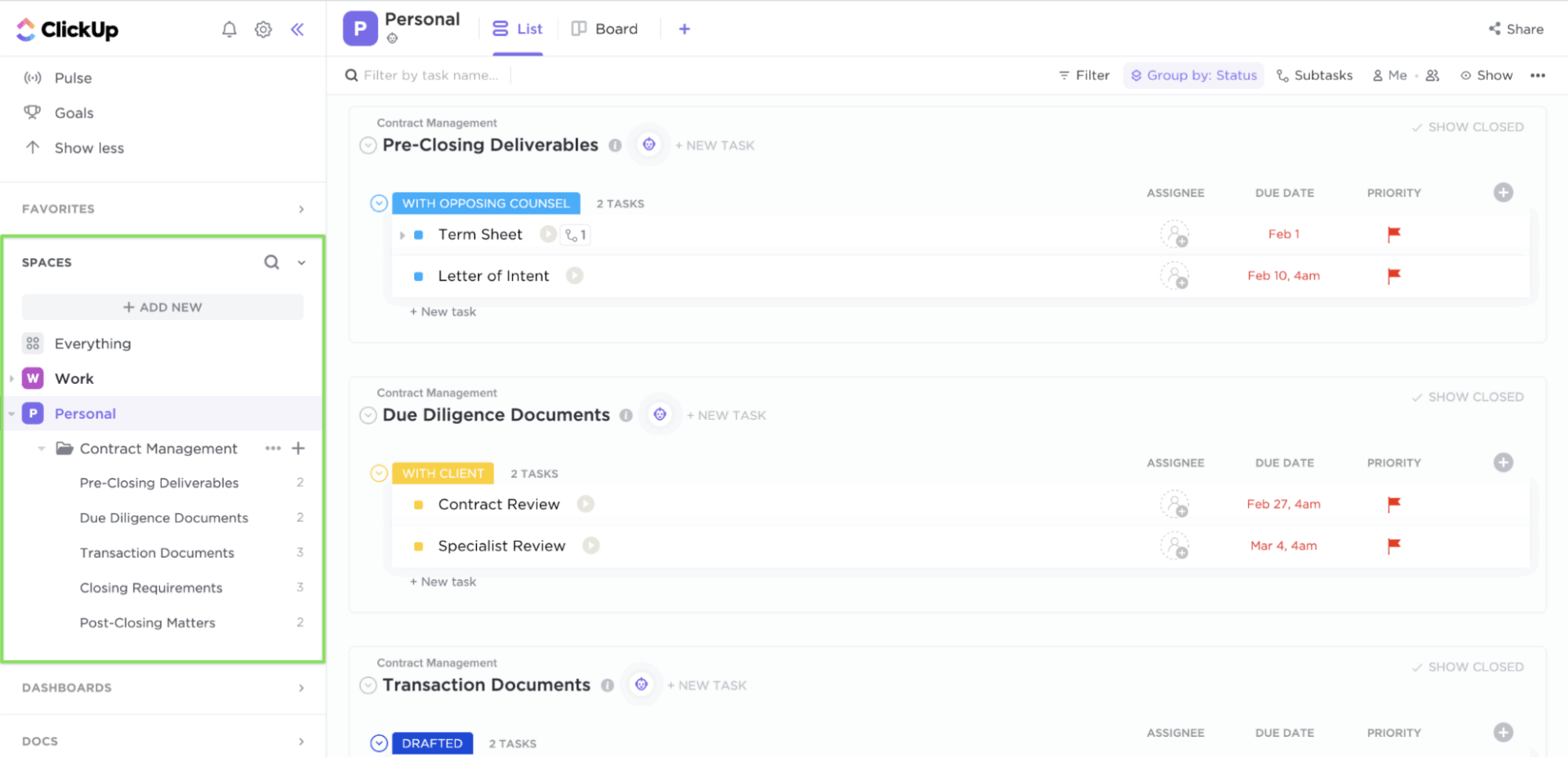
Lorsqu'un incident se produit, les équipes perdent souvent du temps à déterminer ce qu'il faut faire et la marche à suivre. Tâches ClickUp apportent de la clarté à vos processus de gestion des incidents.
Chaque tâche peut avoir un propriétaire, une priorité et une échéance clairement définis. Dans chaque tâche, vous pouvez ajouter des checklists, des liens vers des manuels d'intervention et des captures d'écran. Les champs personnalisés permettent de saisir la gravité, les services affectés ou l'étape d'escalade, tandis que les statuts et listes de tâches personnalisés de ClickUp éliminent toute incertitude en mappant le processus de réponse en une séquence claire.
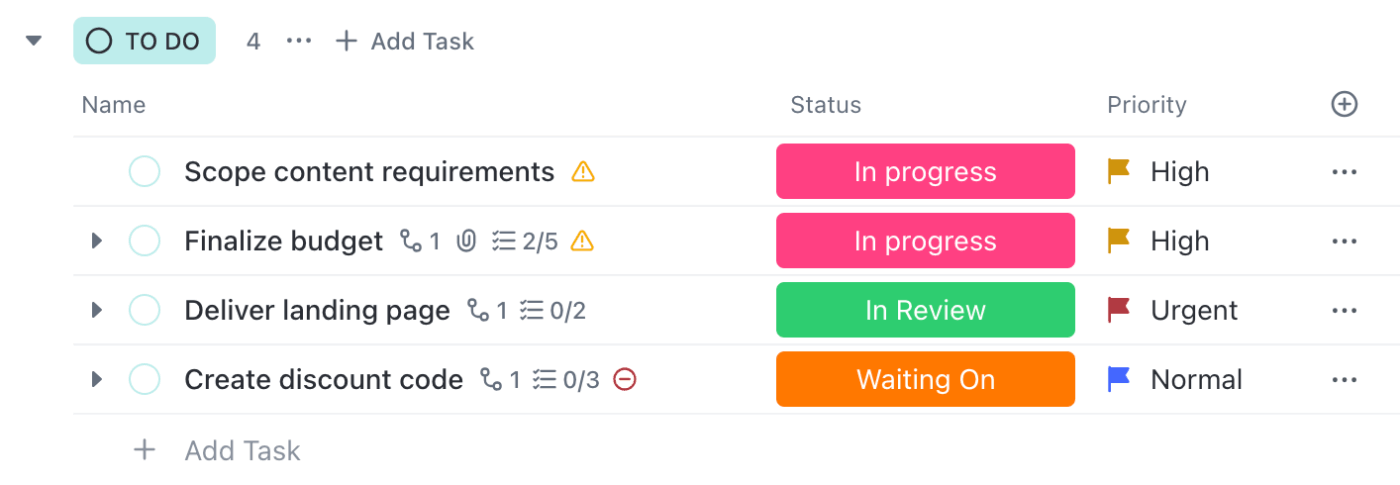
📌 Exemple : un incident « signalé » passe au statut « en cours d'investigation » dès que l'ingénieur ouvre la tâche. Les mesures d'atténuation sont suivies dans une checklist, avec des notes et des journaux ajoutés dans la description. Chaque changement de statut n'est notifié qu'aux personnes concernées, afin que les ingénieurs puissent travailler pendant que les responsables restent informés.
Des mises à jour qui ne perturbent pas le flux de travail
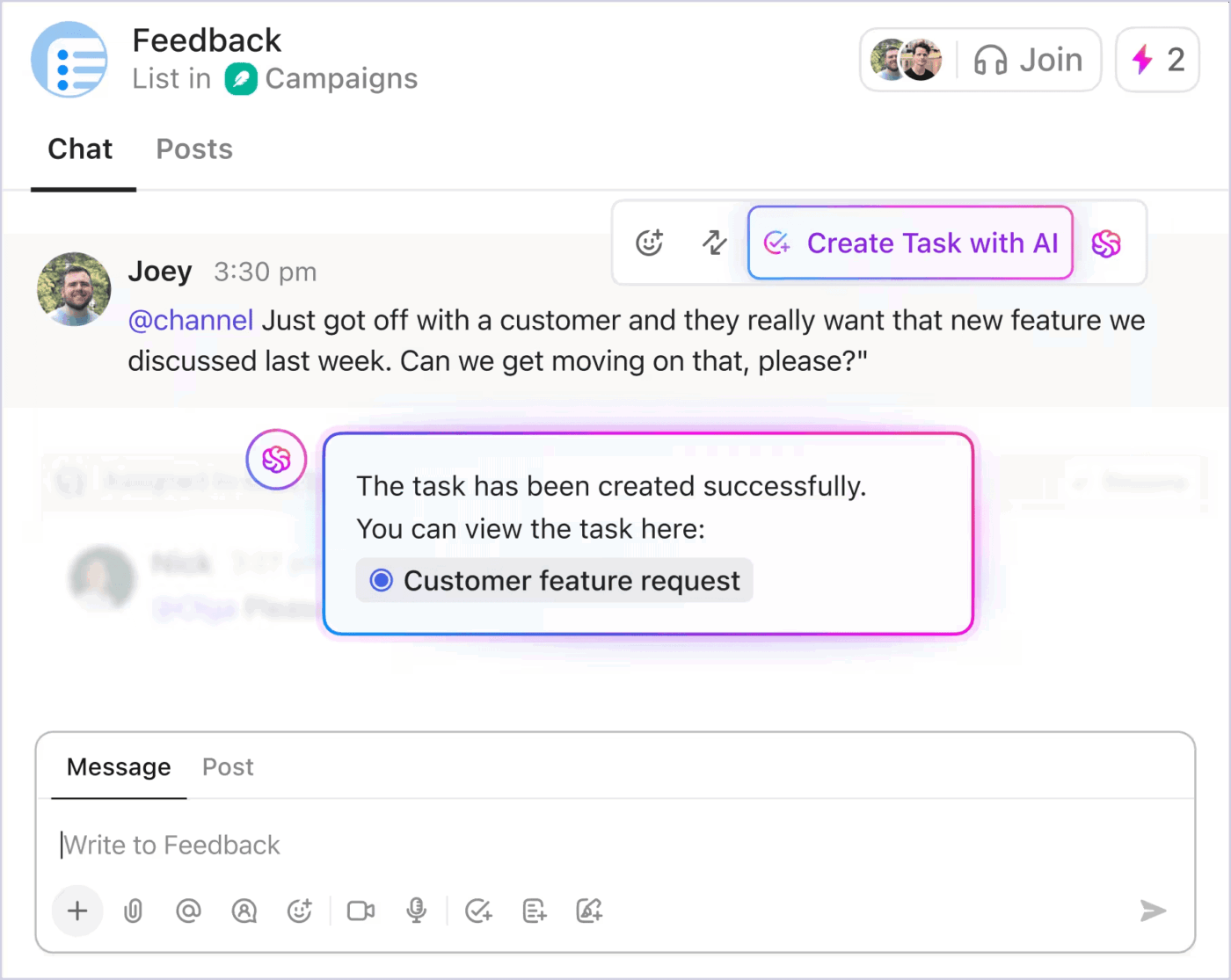
Lors d'incidents critiques, les mises à jour des parties prenantes ne doivent pas interrompre les efforts de réponse. ClickUp Chat résout ce problème en joignant la discussion directement à la tâche liée à l'incident. Les membres de l'équipe et les responsables peuvent suivre le fil de discussion, voir les décisions prises et ajouter des commentaires en temps réel.
ClickUp s'intègre également à Slack et Microsoft Teams, ce qui permet d'afficher les mises à jour dans les canaux que les utilisateurs suivent déjà.
Vous recherchez les meilleurs conseils en matière de collaboration en temps réel ? Voici un guide :
Des analyses post-incident qui mènent à des changements durables
Trop souvent, les rapports post-incident sont rédigés, mais ensuite oubliés. ClickUp Docs les conserve en stockant les analyses post-mortem standardisées directement à côté des tâches liées à l'incident.
Par ailleurs, les tableaux de bord ClickUp affichent des indicateurs tels que le temps moyen de résolution, la fréquence des incidents et les schémas récurrents. Cette visibilité aide les équipes informatiques et DevOps à passer d'une approche réactive à une approche proactive.
💡 Conseil de pro : les analyses post-incident peuvent nécessiter des heures de rédaction, de modification en cours et de recherche de contexte. ClickUp Brain change la donne en rassemblant automatiquement les notes, les échéanciers et les éléments à prendre en compte. Il peut résumer une tâche liée à un incident, rédiger un rapport post-mortem dans ClickUp Docs et même suggérer les prochaines étapes à suivre en se basant sur des incidents similaires.
Avec ClickUp Brain Max, vous bénéficiez de la vitesse supplémentaire de la fonction Talk to Text de ClickUp: dictez vos pensées en temps réel et regardez-les se transformer en notes soignées, prêtes à être partagées. Ensemble, ces outils aident les équipes à gagner près d'une journée entière par semaine en éliminant les tâches fastidieuses de rédaction et de recherche, afin que vous puissiez vous concentrer sur la prévention du prochain incident plutôt que sur le récit du dernier.
Structurez votre travail et gagnez du temps grâce aux modèles

En cas d'urgence, vous apprenez vraiment à apprécier la valeur d'un processus clair et étape par étape.
Le modèle de plan d'action en cas d'incident de ClickUp répond exactement à ces besoins. Il définit précisément ce qui doit être fait, qui doit le faire et dans quel ordre. Il permet à tout le monde de rester sur la même longueur d'onde, réduit les risques et garantit qu'aucune étape n'est négligée.
Un autre défi dans le domaine informatique consiste à documenter efficacement les incidents afin de pouvoir identifier les schémas récurrents et les prévenir à l'avenir. Le modèle de rapport d'incident informatique de ClickUp simplifie la création de rapports, transformant chaque problème en une donnée précieuse.
Les meilleures fonctionnalités de ClickUp
- Réduisez la fatigue liée aux alertes grâce aux notifications ClickUp personnalisables qui garantissent que seules les bonnes personnes sont alertées.
- Automatisez la création, l'attribution et les rapports liés aux incidents grâce aux automatisations et aux agents IA de ClickUp.
- Créez des flux de travail clairs pour les incidents grâce aux tâches ClickUp, listes et statuts, ainsi qu'aux modèles de rapports d'incident qui vous guident à chaque étape de la réponse.
- Facilitez la collaboration au sein de votre équipe grâce à ClickUp Chat et ClickUp Docs, afin que les discussions, les mises à jour et les conclusions soient disponibles en temps réel lors de l'incident.
- Suivez le statut des tâches et les rapports d'incident grâce aux tableaux de bord ClickUp.
- Tirez des enseignements des incidents et des tâches fermées, et créez ou mettez à jour des procédures opératoires normalisées pour de futures améliorations avec ClickUp Brain.
Limitations de ClickUp
- La flexibilité de la plateforme peut sembler écrasante pour les petites équipes qui souhaitent uniquement disposer de fonctionnalités basiques d'alerte et de gestion des astreintes.
Tarifs ClickUp
Évaluations et avis sur ClickUp
- G2 : 4,7/5 (plus de 10 500 avis)
- Capterra : 4,6/5 (plus de 4 500 avis)
Ce que les utilisateurs disent de ClickUp
Cet utilisateur G2 a déclaré :
Travailler ensemble sur un projet est devenu beaucoup plus facile depuis la mise en place de ClickUp, car les tâches peuvent être facilement attribuées aux membres et vous pouvez suivre la progression grâce au chat. Il va même jusqu'à envoyer des notifications par e-mail et des alertes en cas de retard pour les tâches non effectuées.
Travailler ensemble sur un projet est devenu beaucoup plus facile depuis la mise en place de ClickUp, car les tâches peuvent être facilement attribuées aux membres et vous pouvez suivre la progression grâce au chat. Il va même jusqu'à envoyer des notifications par e-mail et des alertes en cas de retard pour les tâches non effectuées.
📖 À lire également : Comment rédiger un rapport d'incident au travail
2. PagerDuty (le meilleur pour les alertes d'incidents en temps réel et l'automatisation à grande échelle)
Si vous quittez Opsgenie, votre première préoccupation est simple. La bonne personne recevra-t-elle l'alerte, au bon moment, sur le bon canal ?
PagerDuty est conçu pour éliminer ce stress. Vous définissez les services, les plannings et des politiques d'escalade claires afin que la propriété ne fasse jamais l'objet d'aucun doute. Les signaux provenant de CloudWatch, Prometheus, Datadog, Jira, ServiceNow, Slack, Zoom et bien d'autres encore sont regroupés en un seul endroit et classés dans un seul incident, et non dans 15 pings distincts.
Event Intelligence réduit les doublons et met en corrélation les problèmes connexes, ce qui réduit la fatigue liée aux alertes sans masquer les problèmes réels. Les intervenants peuvent accuser réception ou escalader depuis l'application mobile ou directement depuis Slack ou Teams, avec des salles d'incident et des ponts créés automatiquement.
Une fois le problème résolu, les analyses indiquent le temps nécessaire pour prendre en compte l'incident, le temps nécessaire pour le résoudre et les points chauds récurrents afin que vous puissiez vous attaquer aux causes profondes plutôt que de vous contenter de traiter les symptômes.
Les meilleures fonctionnalités de PagerDuty
- Permettez à chacun de personnaliser les alertes par SMS, téléphone, e-mail, notification push et Slack afin de réduire le bruit sans manquer les incidents critiques.
- Simplifiez l'installation grâce à des alertes test, des intégrations de services et une conception simple de la politique d'escalade.
- Assistance pour les plannings d'astreinte et les escalades qui informent la bonne personne et se poursuivent jusqu'à confirmation.
- Activez les actions liées aux incidents basées sur Slack, telles que la confirmation, la résolution et l'escalade, directement dans le chat.
- Réduisez la fatigue liée aux alertes grâce à AIOps, qui regroupe les doublons et met en évidence les incidents urgents.
Limitations de PagerDuty
- Les chefs d'équipe ne peuvent pas entièrement personnaliser les méthodes de transmission des alertes au niveau de l'équipe, ce qui limite la flexibilité lorsque les responsables souhaitent des règles d'escalade cohérentes.
- Les alertes par e-mail ne permettent pas de répondre directement, ce qui oblige les intervenants à cliquer sur le lien vers la plateforme au lieu de gérer directement depuis leur boîte de réception.
- Les fonctionnalités avancées telles que les licences AIOps et de communication avec les parties prenantes entraînent des coûts supplémentaires élevés.
Tarifs PagerDuty
- Free
- Professionnel : 25 $/mois par utilisateur
- Entreprise : 49 $/mois par utilisateur
- Entreprise : tarification personnalisée
Évaluations et avis sur PagerDuty
- G2 : 4,5/5 (plus de 900 avis)
- Capterra : 4,6/5 (plus de 200 avis)
Ce que les utilisateurs disent de PagerDuty
Cet utilisateur de G2 a mentionné :
J'adore le fait que Pager Duty propose plusieurs alertes sonores différentes, dont certaines sont hilarantes. Depuis que j'utilise Pager Duty, je suis en mesure de répondre aux incidents et de mobiliser les équipes plus efficacement.
J'adore le fait que Pager Duty propose plusieurs alertes sonores différentes, dont certaines sont hilarantes. Depuis que j'utilise Pager Duty, je suis en mesure de répondre aux incidents et de mobiliser les équipes plus efficacement.
📖 À lire également : Qu'est-ce qu'un plan d'urgence et comment en élaborer un ?
3. xMatters (le meilleur pour la gestion et l'automatisation rentables des incidents)
Un utilisateur de Reddit l'a très bien résumé :
Vous en avez pour votre argent, mais vous payez moins cher. Il offre tout ce que vous souhaitez, même s'il n'est certainement pas aussi sophistiqué que PagerDuty.
Vous en avez pour votre argent, mais vous payez moins cher. Il offre tout ce que vous souhaitez, même s'il n'est certainement pas aussi sophistiqué que PagerDuty.
Cette phrase résume parfaitement la position de xMatters : abordable, fiable et performant dans les domaines les plus importants.
Si vous quittez Opsgenie, votre problème est généralement double. Trop de bruit qui réveille les mauvaises personnes et l'incertitude quant à savoir qui est responsable de la prochaine action. xMatters résout ces deux problèmes en vous permettant de mapper les services et les plannings d'astreinte, puis d'acheminer les alertes avec un contexte précis afin que la bonne personne soit jointe sur le bon canal.
Les utilisateurs ont apprécié les notifications ciblées contenant des détails utiles, ainsi que la piste d'audit complète qui indique qui a été contacté, qui a accusé réception et à quel moment. Cet enregistrement facilite les examens post-incident et les contrôles de conformité.
Le générateur de flux de travail low-code transforme un signal provenant de Datadog, Prometheus ou ServiceNow en une séquence d'actions claire.
Grâce à l'automatisation des flux de travail et à la gestion de projet adaptative DevOps, xMatters aide les équipes à agir plus rapidement et à réduire le bruit des alertes.
Les meilleures fonctionnalités de xMatters
- Automatisez les flux de travail d'incident grâce à des intégrations sans code et à faible code qui accélèrent la résolution et réduisent les tâches manuelles.
- Gérez les plannings d'astreinte et les escalades de manière transparente afin que la bonne personne soit toujours alertée au bon moment.
- Appliquez une gestion adaptative des incidents afin de minimiser l'impact sur les clients et de tirer des enseignements de chaque évènement.
- Filtrez le bruit grâce à l'intelligence des signaux, à la corrélation des alertes et à des notifications enrichies pour un contexte plus clair.
- Accédez à des analyses exploitables pour identifier les inefficacités et améliorer la collaboration entre les équipes.
Limitations de xMatters
- L'interface et l'expérience de l'utilisateur semblent moins raffinées que celles de ses concurrents.
- Les fonctionnalités avancées pour la préparation de rapports et l'analyse sont limitées dans les forfaits d'entrée de gamme.
- La couverture mondiale de l'assistance varie en fonction du forfait sélectionné.
Tarifs xMatters
- Free
- Starter (Essentials) : 9 $/mois par utilisateur
- Base (Standard) : 39 $/mois par utilisateur
- Avancé : tarification personnalisée
Évaluations et avis sur xMatters
- G2 : 4,5/5 (plus de 670 avis)
- Capterra : 4,6/5 (plus de 140 avis)
Ce que les utilisateurs disent de xMatters
Cette critique de Capterra présentait les fonctionnalités suivantes :
Lorsque nous avons un incident de sécurité des données dans l'entreprise, Xmatters active immédiatement les protocoles d'intervention : il organise les protocoles d'action de l'équipe en fonction de leurs fonctions. Les notifications sont envoyées par divers moyens.
Lorsque nous avons un incident de sécurité des données dans l'entreprise, Xmatters active immédiatement les protocoles d'intervention : il organise les protocoles d'action de l'équipe en fonction de leurs fonctions. Les notifications sont envoyées par divers moyens.
📮 ClickUp Insight : 28 % des employés déclarent que leur travail les suit après les heures de bureau, et 8 % ont souvent du mal à se déconnecter. Cela représente plus d'un tiers des employés qui ramènent leur stress à la maison.
Utilisez les rappels ClickUp pour protéger votre routine du soir. Configurez un rappel quotidien pour terminer votre journée, désactivez les notifications en dehors des heures de travail et réservez du temps pour vous dans votre calendrier. Vous devez pouvoir choisir de vous déconnecter.
💫 Résultats concrets : Lulu Press gagne environ une heure par personne et par jour grâce aux automatisations ClickUp, ce qui se traduit par un gain d'efficacité de 12 %.
4. AlertOps (le meilleur pour la réduction du bruit grâce à l'IA et la réponse rapide aux incidents)
Le volume des alertes continue d'augmenter, 88 % des équipes ayant signalé une augmentation au cours de l'année écoulée et près de la moitié d'entre elles indiquant que ces pics dépassaient 25 %. Ce bruit constant entraîne une fatigue liée aux alertes, que 76 % des SOC (centres d'opérations de sécurité) citent désormais comme leur principal défi.
C'est la réalité que vous apportez à tout remplacement d'Opsgenie. Le prochain outil que vous choisirez devra être capable de déterminer quelles alertes méritent une action. AlertOps s'appuie sur OpsIQ, un noyau d'IA qui filtre les doublons, corrèle les signaux associés, résume le contexte et suggère les prochaines étapes afin que les intervenants voient un incident clair au lieu d'un flux défilant.
Vous pouvez commencer avec le planning de permanence par défaut ou créer le vôtre, puis acheminer les appels par téléphone, SMS, application mobile, chat ou e-mail avec des règles d'escalade qui continuent de fonctionner jusqu'à ce que quelqu'un prenne en charge le problème. L'acheminement des appels en direct envoie les clients vers le personnel de permanence actuel en fonction des plannings en temps réel, et les politiques basées sur les SLA sont escaladées avant une violation plutôt qu'après.
De plus, la plateforme s'intègre à plus de 200 outils, de la surveillance et la gestion des tickets à O365 et Slack, afin que le triage ne soit pas ralenti par un manque de contexte.
Les meilleures fonctionnalités d'AlertOps
- Filtrez et supprimez les alertes en double grâce à la réduction du bruit basée sur l'IA et optimisée par OpsIQ™, qui résume les alertes et suggère automatiquement des solutions.
- Gérez les plannings d'astreinte grâce à des règles d'escalade flexibles, une couverture 24 heures sur 24 et un routage des appels en direct pour les problèmes critiques des clients.
- Automatisez le triage et les flux de travail à l'aide de modèles informatiques sans code pour accélérer la réponse et garantir une gestion cohérente des incidents.
- Intégrez plus de 200 outils prêts à l'emploi, notamment Slack, O365, Jira, Dynatrace et ConnectWise, ainsi que des intégrations personnalisées pour les applications internes.
Limitations d'AlertOps
- L'installation de la planification peut sembler peu intuitive au premier abord et nécessiter plusieurs essais avant d'aboutir au résultat souhaité.
- L'interface utilisateur présente parfois quelques imperfections, certaines fonctionnalités avancées nécessitant des étapes supplémentaires pour être configurées.
- Des retards dans la synchronisation du Calendrier ont été signalés avec des systèmes externes tels qu'Outlook.
Tarifs AlertOps
- Starter : Gratuit
- Standard : 10 $/mois par utilisateur
- Premium : 22 $/mois par utilisateur
- Enterprise : 34 $/mois par utilisateur
Évaluations et avis sur AlertOps
- G2 : 4,7/5 (plus de 150 avis)
- Capterra : 4,7/5 (plus de 20 avis)
Ce que les utilisateurs disent d'AlertOps
Cette évaluation G2 le montre clairement :
Nous avons passé la majeure partie du troisième trimestre de l'année dernière à tester des outils de planification/alerte pour l'une de nos équipes informatiques. Après avoir découvert AlertOps, j'ai arrêté mes recherches. Ce produit est abordable, son équipe est incroyablement serviable et patiente dans le processus de configuration et de mise en œuvre, et depuis que tout est entièrement configuré et opérationnel, nous n'avons eu aucun problème !
Nous avons passé la majeure partie du troisième trimestre de l'année dernière à tester des outils de planification/alerte pour l'une de nos équipes informatiques. Après avoir découvert AlertOps, j'ai arrêté mes recherches. Ce produit est abordable, son équipe est incroyablement serviable et patiente dans le processus de configuration et de mise en œuvre, et depuis que tout est entièrement configuré et opérationnel, nous n'avons eu aucun problème !
📖 À lire également : Exemples de procédures opératoires normalisées : bonnes pratiques pour la productivité et la conformité
5. Splunk On-Call (idéal pour simplifier la planification des astreintes et réduire l'épuisement professionnel)
Si vous avez déjà regardé le sketch classique Abbott et Costello « Who's on First ? », vous connaissez la confusion qui règne lorsqu'il s'agit de déterminer qui est réellement responsable de quoi. Les rotations d'astreinte peuvent donner le même sentiment lorsqu'il n'y a pas de système clair en place.
C'est là que Splunk On-Call entre en jeu à l'étape suivante. ✨
Vous mappez les équipes et les plannings une seule fois, puis les alertes arrivent avec leur contexte sur n'importe quel appareil. Les intervenants peuvent accuser réception, rediriger ou reporter depuis l'application iOS ou Android, et la plateforme peut ouvrir une salle de collaboration et lancer l'examen de l'incident sans étapes supplémentaires.
Un moteur de règles associe des manuels d'intervention et des tableaux de bord aux incidents afin que la première personne alertée ne parte jamais à l'aveuglette. L'apprentissage automatique suggère les intervenants appropriés en fonction d'incidents similaires, ce qui permet de réduire le temps nécessaire pour prendre en compte et résoudre les incidents.
Les meilleures fonctionnalités de Splunk On-Call
- Effectuez l'automatisation des escalades et des flux de travail de réponse aux incidents pour une reconnaissance et une résolution plus rapides.
- Utilisez les applications iOS et Android pour recevoir, reporter, rediriger ou résoudre les alertes directement depuis un appareil mobile.
- Simplifiez la planification grâce à des rotations, des dérogations et des politiques d'escalade conçues pour équilibrer équitablement les charges de travail.
- Obtenez le contexte des incidents et les pistes d'audit historiques pour fournir de l'assistance au triage et à l'analyse post-incident.
- Appliquez les recommandations issues du machine learning pour identifier les intervenants les plus adaptés en fonction des données de résolution passées.
Limitations de Splunk On-Call
- L'interface peut sembler complexe au premier abord, et la navigation nécessite un certain temps d'adaptation.
- Les ralentissements occasionnels pendant les périodes de trafic intense ont un impact sur la réactivité en temps réel.
- Les options de licence et de gestion des utilisateurs sont plus limitées par rapport à certains concurrents.
Tarifs Splunk On-Call
- Tarification personnalisée
Évaluations et avis sur Splunk On-Call
- G2 : 4,6/5 (plus de 50 avis)
- Capterra : 4,5/5 (plus de 30 avis)
Ce que les utilisateurs disent de Splunk On-Call
Cette critique G2 note :
La possibilité de créer des équipes et de configurer des roulements entre elles est l'une des ressources les plus utiles disponibles sur cette plateforme. Splunk On-Call s'intègre facilement à plusieurs outils, ce qui rend sa configuration très simple à mettre en place.
La possibilité de créer des équipes et de configurer des roulements entre elles est l'une des ressources les plus utiles disponibles sur cette plateforme. Splunk On-Call s'intègre facilement à plusieurs outils, ce qui rend sa configuration très simple à mettre en place.
📝À lire également : Éliminer la prolifération de l'IA : comment l'IA contextuelle transforme la productivité au travail
6. Datadog (idéal pour une observabilité complète avec surveillance intégrée de la sécurité)
Pour les utilisateurs d'Opsgenie, le problème réside dans le contexte. Une alerte se déclenche, mais vous devez encore rechercher les journaux, les traces, les indicateurs et les signaux de sécurité pour savoir ce qui ne fonctionne pas réellement.
Datadog rassemble toutes ces informations dans un seul échéancier. L'infrastructure, les conteneurs, les serveurs, les bases de données et les applications côtoient les journaux, les traces et les RUM, afin que les intervenants n'aient pas à faire de suppositions.
Watchdog et les nouvelles capacités d'IA mettent en évidence les anomalies, regroupent les signaux associés et résument l'impact probable, ce qui réduit les allers-retours pendant le triage. Si vous disposez déjà d'un outil de radiomessagerie, vous pouvez y intégrer les alertes Datadog.
Si vous souhaitez rester dans Datadog, Incident Management vous permet de gérer les propriétaires, les échéanciers, les mises à jour des parties prenantes et les suivis sans quitter la plateforme.
Les avantages pratiques sont rapidement visibles. Moins de notifications bruyantes grâce à la suppression des doublons. Analyse plus rapide des causes profondes, car chaque alerte est accompagnée des indicateurs et des journaux qui l'expliquent. Sécurité renforcée, car les erreurs de configuration et les vulnérabilités apparaissent en même temps que les données de performance.
Avec plus de 900 intégrations, des SLO (objectifs de niveau de service) clairs et des tableaux de bord, votre équipe peut passer du signal à la correction en un seul endroit, sans avoir à passer d'un onglet à l'autre. C'est un bon choix pour les migrations Opsgenie qui souhaitent également combler les lacunes en matière d'observabilité.
Les meilleures fonctionnalités de Datadog
- Surveillez l'infrastructure, les journaux, les applications, les bases de données et les charges de travail sans serveur à partir d'une seule plateforme.
- Assurez la sécurité de vos environnements cloud grâce à la gestion intégrée des vulnérabilités, à la cartographie de la conformité et à la gestion des droits.
- Utilisez la surveillance synthétique et la surveillance des utilisateurs réels pour détecter les problèmes avant que les clients ne les remarquent.
- Automatisez vos flux de travail grâce à plus de 900 intégrations et tableaux de bord prédéfinis.
- Utilisez des fonctionnalités d'IA et d'apprentissage automatique telles que Watchdog et LLM Observability pour détecter les anomalies et obtenir des informations intelligentes.
Limitations de Datadog
- Les prix peuvent rapidement augmenter en fonction du nombre d'hôtes et des modules complémentaires.
- L'interface et les tableaux de bord peuvent sembler intimidants pour les nouveaux utilisateurs.
- Certaines fonctionnalités de sécurité avancées sont réservées aux forfaits supérieurs.
Tarifs Datadog
- Free
- Pro : 15 $/mois par hôte
- Enterprise : 23 $/mois par hôte
- DevSecOps Pro : 22 $/mois par hôte
- DevSecOps Enterprise : 34 $/mois par hôte
Évaluations et avis sur Datadog
- G2 : 4,4/5 (plus de 660 avis)
- Capterra : 4,6/5 (plus de 320 avis)
Ce que les utilisateurs disent de Datadog
Cette critique de Capterra cite :
Dans l'ensemble, après quelques hauts et bas, ils se sont révélés être un bon partenaire. Leur outil est extrêmement puissant et permet de nombreuses pratiques excellentes en matière d'observabilité, mais il faut payer pour l'utiliser.
Dans l'ensemble, après quelques hauts et bas, ils se sont révélés être un bon partenaire. Leur outil est extrêmement puissant et permet de nombreuses pratiques excellentes en matière d'observabilité, mais il faut payer pour l'utiliser.
📖 À lire également : Comment réduire les risques liés à la sécurité informatique dans la gestion de projet
7. Squadcast (le meilleur pour la gestion unifiée des astreintes et des incidents, avec une valeur élevée)
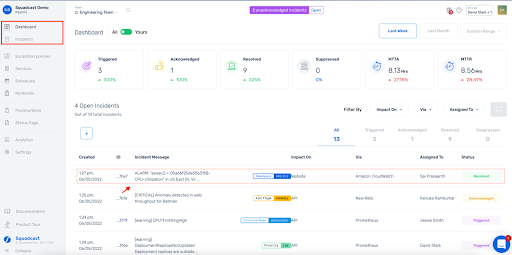
Lorsque vous gérez plusieurs roulements et des règles spécifiques aux clients en dehors des heures de bureau, vous avez besoin d'alertes pour respecter ces règles sans avoir à intervenir manuellement.
C'est dans ce créneau que Squadcast a su gagner la confiance de ses utilisateurs. 🌟
Les utilisateurs ont noté que les rotations et les dérogations sont faciles à modéliser et que l'application mobile continue d'escalader si le premier intervenant ne répond pas, afin que les problèmes critiques ne passent pas inaperçus.
Pour les MSP et les équipes ayant de nombreux clients, il est appréciable de pouvoir définir une couverture 24h/24 et 7j/7 pour certains clients, tout en permettant à d'autres de déclencher des alertes en dehors des heures de bureau uniquement pour les incidents critiques. L'interface utilisateur permet de voir facilement les incidents actifs et qui est en charge.
Il y a plus que la simple pagination. L'automatisation fiable traite les incidents grâce à des flux de travail cohérents avec des runbooks et des mises à jour de statut, le suivi des SLO et les échéanciers font apparaître des tendances sur lesquelles vous pouvez réellement agir, et les tarifs sont suffisamment transparents pour que les petites équipes ne se sentent pas exclues.
Les meilleures fonctionnalités de Squadcast
- Effectuez l'automatisation de la planification des astreintes grâce à des escalades et des dérogations flexibles.
- Réduisez la fatigue liée aux alertes en consolidant et en dédupliquant les notifications.
- Résolvez les incidents plus rapidement grâce aux runbooks et aux flux de travail.
- Tenez les parties prenantes informées grâce à des pages de statut personnalisables.
- Recueillez les analyses rétrospectives et les informations pour créer une culture d'apprentissage.
Limites de Squadcast
- Les vues de planification peuvent devenir encombrées lorsque de nombreux roulements sont actifs, ce qui rend plus difficile de voir d'un seul coup d'œil qui est de garde.
- Des retards occasionnels dans la synchronisation des alertes provenant de certaines intégrations ont été signalés.
- Le forfait Free est limité pour les équipes qui souhaitent disposer de pages d'état et d'analyses plus approfondies.
Tarifs Squadcast
- Pro : 12 $/mois par utilisateur
- Premium : 19 $/mois par utilisateur
- Enterprise : tarification personnalisée
Évaluations et avis sur Squadcast
- G2 : 4,4/5 (plus de 300 avis)
- Capterra : pas assez d'avis
Ce que les utilisateurs disent de Squadcast
Cette critique G2 mentionne :
Squadcast peut recevoir des données provenant de divers outils de surveillance dont nous disposons et il est facile de configurer des rotations et des dérogations pour déterminer qui doit être alerté pour différents types de problèmes.
Squadcast peut recevoir des données provenant de divers outils de surveillance dont nous disposons et il est facile de configurer des rotations et des dérogations pour déterminer qui doit être alerté pour différents types de problèmes.
📖 À lire également : Gestion des risques liés à la cybersécurité
8. FireHydrant (idéal pour les runbooks automatisés et la propriété des services)
Ce logiciel de gestion des incidents offre un processus bien structuré qui garantit le bon fonctionnement des services.
FireHydrant centralise les réponses autour de runbooks, d'un catalogue de services et d'un espace de travail partagé. Déclarez un incident et la plateforme crée un canal dans Slack ou Teams, joint le runbook approprié, extrait la propriété du catalogue de services et commence un échéancier vérifiable.
Par ailleurs, son IA réduit les frais généraux grâce à des résumés instantanés des incidents, des suggestions de mises à jour pour les parties prenantes et des transcriptions en direct des réunions, afin que l'équipe puisse se concentrer sur la résolution des incidents plutôt que sur la prise de notes.
Les équipes soulignent également la réactivité de l'assistance et l'approche API first avec Terraform, qui permet aux responsables opérationnels d'intégrer FireHydrant dans les flux de travail existants sans difficulté.
Les meilleures fonctionnalités de FireHydrant
- Automatisez la réponse aux incidents grâce à des manuels d'exploitation qui codifient les bonnes pratiques.
- Gérez les plannings d'astreinte et les alertes avec Signals, avec des politiques d'escalade achevées.
- Centralisez la propriété grâce au catalogue de services afin que les ingénieurs compétents puissent intervenir immédiatement.
- Collaborez directement dans Slack ou Teams grâce à des canaux et des mises à jour générés automatiquement.
- Utilisez des rétrospectives et des analyses enrichies par l'IA pour recueillir des informations et améliorer la fiabilité au fil du temps.
Limitations de FireHydrant
- Les fonctionnalités d'automatisation avancées nécessitent des forfaits de niveau supérieur.
- Courbe d'apprentissage pour la configuration de flux de travail et d'intégrations personnalisés
- Nombre limité de répondants et de manuels d'intervention dans le forfait d'entrée de gamme
Tarifs FireHydrant
- Free : essai gratuit pendant deux semaines
- Platform Pro : 9 600 $/an par utilisateur
- Enterprise : tarification personnalisée
Évaluations et avis sur FireHydrant
- G2 : 4,5/5 (plus de 130 avis)
- Capterra : pas assez d'avis
Ce que les utilisateurs disent de FireHydrant
Cet utilisateur G2 a déclaré :
Fonctionnant entièrement à partir de Slack ou d'un autre outil de chat/collaboration, FireHydrant s'intègre et vous permet d'ouvrir/mettre à jour/résoudre des incidents sans avoir à quitter l'endroit où se déroule l'intervention.
Fonctionnant entièrement à partir de Slack ou d'un autre outil de chat/collaboration, FireHydrant s'intègre et vous permet d'ouvrir/mettre à jour/résoudre des incidents sans avoir à quitter l'endroit où se déroule l'intervention.
9. TaskCall (le meilleur pour une gestion des incidents abordable et avec automatisation)
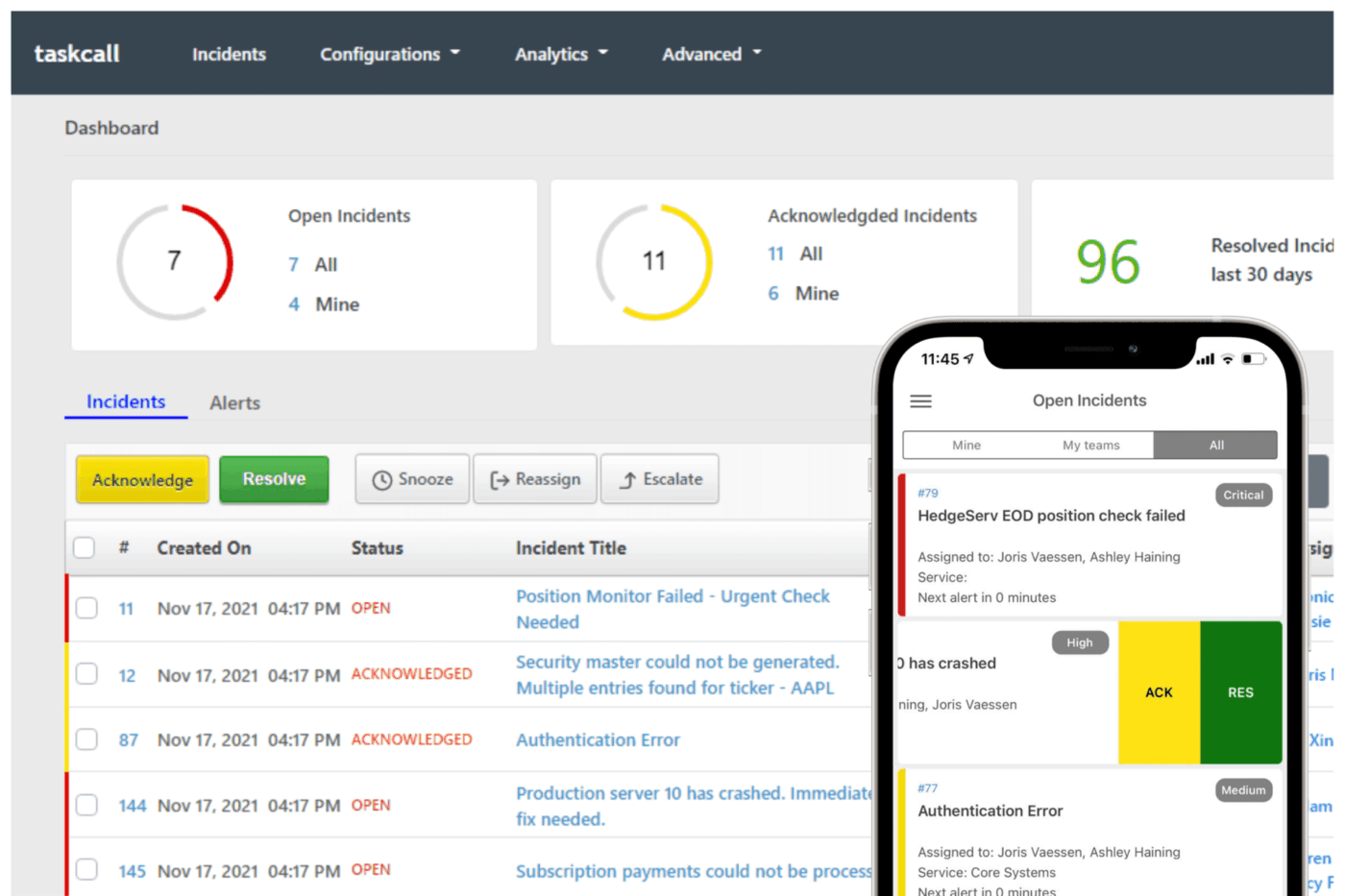
Dans une récente étude sur les cyberrisques, la réponse aux incidents a été identifiée comme l'un des principaux contrôles que les organisations doivent renforcer pour réduire leur exposition.
Cela souligne à quel point il est devenu essentiel de disposer de flux de travail rapides et fiables pour la gestion des incidents.
Les équipes échouent généralement non pas à cause de l'alerte elle-même, mais à cause de la confusion qui s'ensuit. Qui est vraiment responsable à ce moment-là ? L'alerte concerne-t-elle l'application, l'infrastructure ou les opérations clients ? Comment tenir les dirigeants informés sans prendre le contrôle de la résolution du problème ?
TaskCall s'occupe directement de ces situations. L'astreinte est déterminée en fonction du contenu de l'incident, de sorte que le routage aboutit au bon intervenant et que l'escalade automatique comble les lacunes. Les notifications sont envoyées par téléphone, SMS, push, e-mail ou chat.
Pour réduire le bruit, l'intelligence évènementielle corrèle les doublons et supprime les pings de faible valeur. Le contexte est reconstitué en extrayant des signaux d'outils tels que AWS, Datadog, Slack, Jira et Zendesk, ce qui signifie que les ingénieurs voient l'impact et la propriété plutôt qu'un flux d'alertes brutes.
Les meilleures fonctionnalités de TaskCall
- Effectuez l'automatisation de la planification des astreintes grâce à des rotations dynamiques et des escalades à plusieurs niveaux.
- Réduisez le bruit grâce à l'IA appliquée aux évènements et au routage conditionnel.
- Gérez les incidents liés au DevOps, à l'IT-Ops et au BizOps sur une plateforme unifiée.
- Intégrez des outils de surveillance, de journalisation et d'assistance tels que AWS, Jira, Zendesk et Slack.
- Bénéficiez d'une couverture complète grâce aux applications mobiles, aux notifications push, aux SMS et aux alertes vocales.
Limitations de TaskCall
- Forfait Free limité à cinq utilisateurs, ce qui peut ne pas convenir aux équipes en pleine croissance.
- La plupart des analyses et des tableaux de bord sont limités aux forfaits les plus chers.
Tarifs TaskCall
- Free
- Starter : 9 $/mois par utilisateur
- Entreprise : 19 $/mois par utilisateur
- Opérations numériques : 29 $/mois par utilisateur
Évaluations et avis sur TaskCall
- G2 : pas assez d'avis
- Capterra : pas assez d'avis
10. ilert (Idéal pour la gestion des incidents axée sur l'IA et la confidentialité)
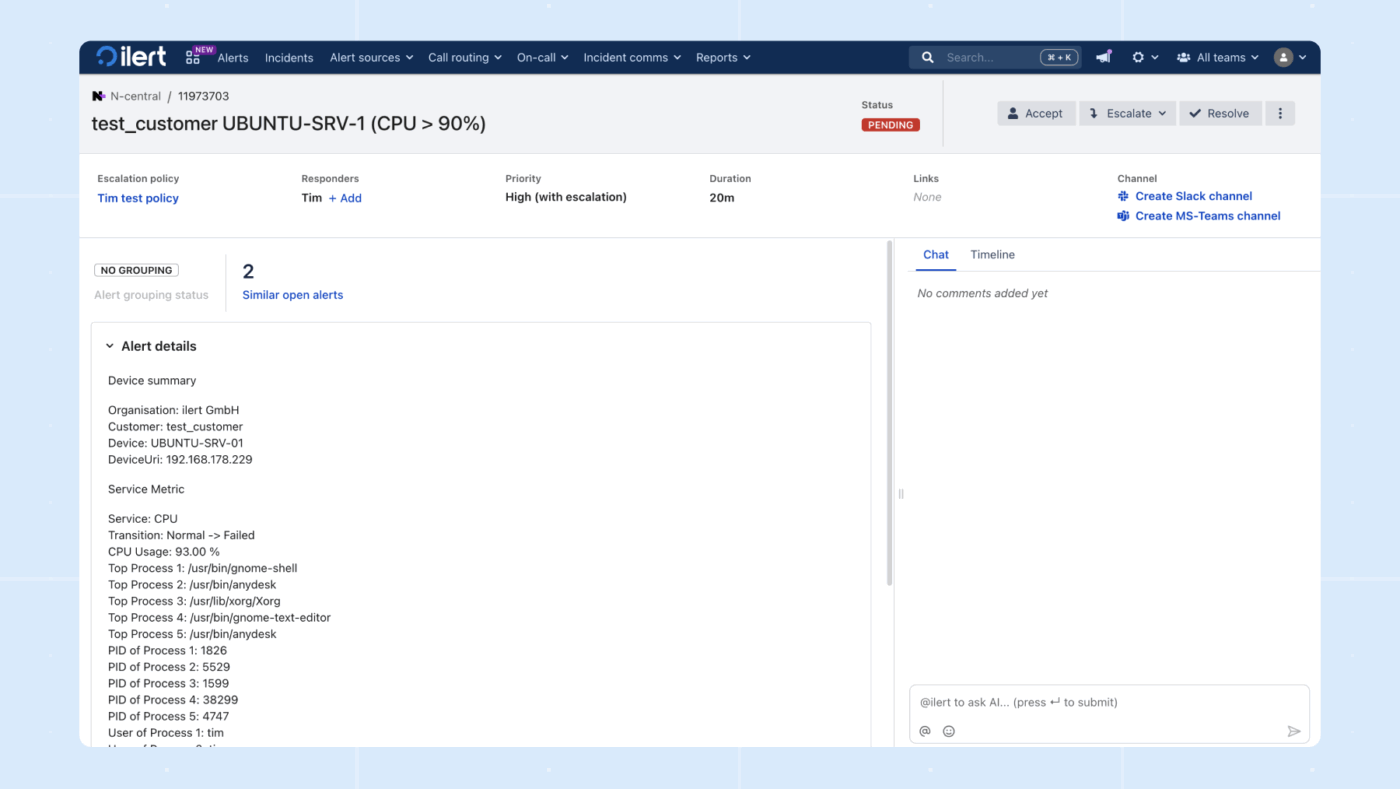
ilert est une plateforme de gestion des astreintes et d'alerte en cas d'incident qui met l'accent sur la fiabilité et la confidentialité des données. Elle aide les équipes à s'assurer que les alertes critiques provenant des systèmes de surveillance parviennent rapidement aux ingénieurs d'astreinte concernés.
La plateforme offre une planification flexible des astreintes, des politiques d'escalade à plusieurs niveaux et des notifications via de nombreux canaux, notamment des notifications push, des SMS et des appels vocaux.
Un routage qui respecte le planning actuel et la procédure d'escalade permet aux appels des clients d'atteindre la bonne personne au lieu d'être renvoyés d'un service à l'autre.
Dans Slack ou Teams, les intervenants traitent l'incident dans le chat tandis qu'Ilert capture le contexte, les échéanciers et les suivis.
L'agent vocal IA répond à votre hotline, recueille les informations nécessaires et avertit immédiatement l'ingénieur de garde. Responder analyse les indicateurs, les journaux et les modifications récentes sur l'ensemble de votre pile, identifie les causes profondes probables, suggère les personnes à impliquer et propose même une procédure de restauration pour une résolution plus rapide.
Vous gardez le contrôle à chaque étape.
Les meilleures fonctionnalités d'ilert
- Fournissez des alertes multicanales fiables par voix, SMS, push et chat.
- Automatisez la gestion des astreintes grâce à la planification et aux procédures d'escalade.
- Fournissez des mises à jour rapides grâce à des pages de statut alimentées par l'IA et à des communications avec les parties prenantes.
- Utilisez ilert Responder IA pour analyser les incidents, identifier leurs causes profondes et suggérer des mesures à prendre.
- Intégrez-le à des outils de surveillance et d'ITSM tels que Prometheus, Datadog, Jira et Slack.
Limitations d'ilert
- Les tarifs peuvent sembler élevés pour les petites équipes.
- Certaines intégrations nécessitent des efforts d’installation supplémentaires.
- L'application mobile pourrait bénéficier de fonctionnalités plus avancées.
Tarifs ilert
- Free
- Pro : 24 $/mois par utilisateur
- Échelle : 49 $/mois par utilisateur
- Enterprise : tarification personnalisée
Évaluations et avis sur ilert
- G2 : pas assez d'avis
- Capterra : 4,7/5 (plus de 60 avis)
Ce que les utilisateurs disent d'ilert
Cette critique de Capterra rapporte :
Je trouve cet outil très intuitif et efficace pour gérer les gardes au sein des équipes informatiques. Il offre une grande flexibilité en permettant de répondre directement via l'application, par SMS ou par appel téléphonique, ce qui le rend particulièrement pratique dans les situations réelles.
Je trouve cet outil très intuitif et efficace pour gérer les gardes au sein des équipes informatiques. Il offre une grande flexibilité en permettant de répondre directement via l'application, par SMS ou par appel téléphonique, ce qui le rend particulièrement pratique dans les situations réelles.
11. Zenduty (le meilleur pour la gestion des incidents à grande échelle basée sur l'IA)
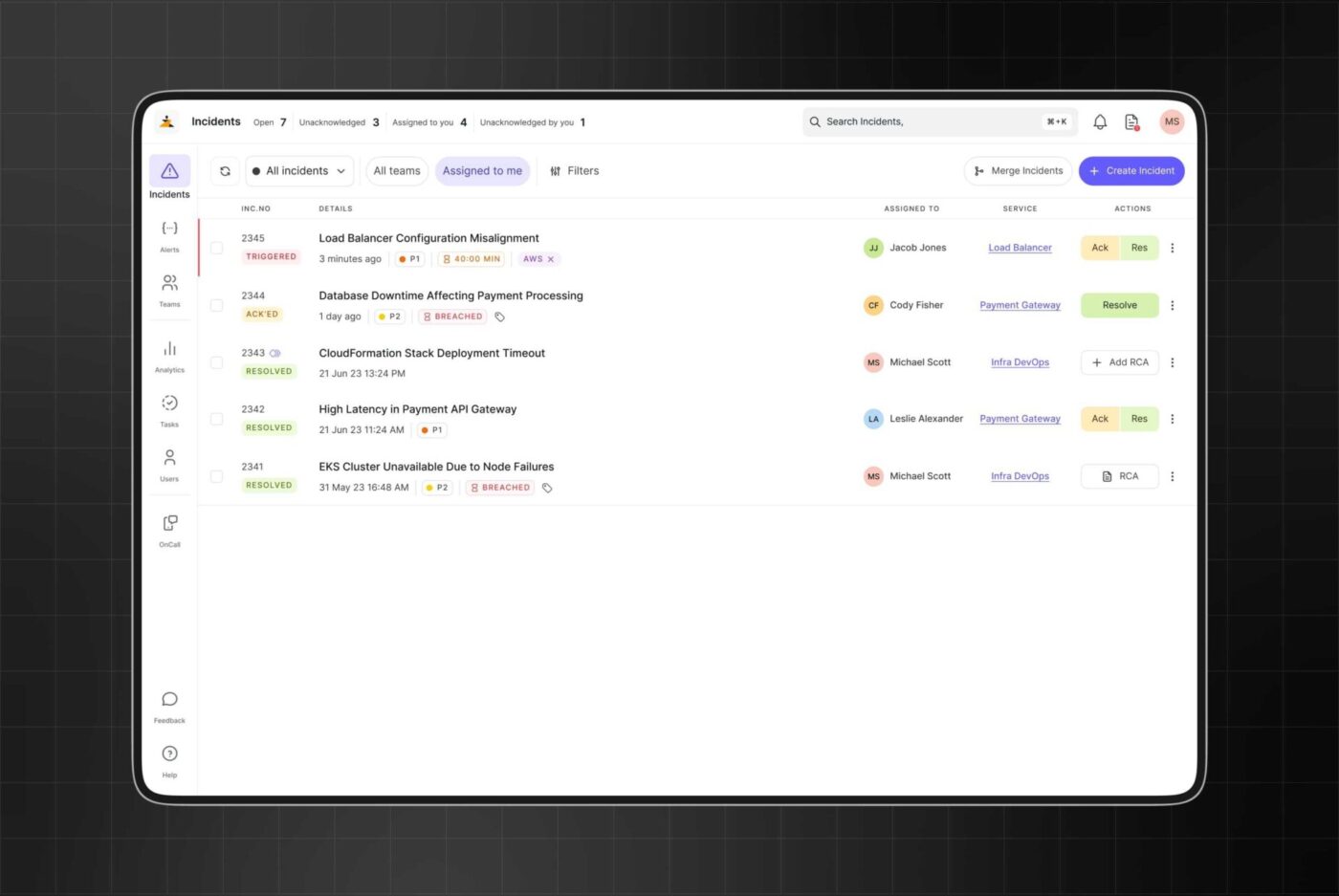
Zenduty aide les équipes d'ingénierie et de DevOps à rester concentrées sur les signaux importants, réduisant ainsi le MTTR (temps moyen de résolution) et offrant aux organisations une plateforme unique et fiable pour gérer les incidents.
Les utilisateurs louent régulièrement la rapidité et la fiabilité des alertes, avec des notifications push, des appels et des SMS qui arrivent sans délai, ce qui permet aux ingénieurs de garde de prendre connaissance de la notification et de se remettre au travail. Les équipes apprécient également de pouvoir personnaliser les notifications en fonction de la gravité, du service ou du type d'incident, afin que la bonne personne soit contactée au bon moment plutôt que tout le monde en même temps.
La plateforme fournit l'assistance pour la gestion collaborative des incidents, avec des rôles, des modèles de tâches et des canaux de communication intégrés. L'une de ses fonctionnalités importantes est son approche basée sur le système de commandement des interventions (ICS), qui fournit un cadre structuré pour la gestion des incidents à grande échelle.
Si vous souhaitez abandonner Opsgenie, Zenduty est une bonne option, son assistance à la migration ayant reçu des avis positifs.
Les meilleures fonctionnalités de Zenduty
- Fournisseur de gestion des incidents basée sur l'IA avec ZenAI.
- Assistance avancée pour la planification des astreintes avec rotations et escalades personnalisables
- Automatisez les plans d'action en cas d'incident afin que les tâches et les suivis soient suivis de manière cohérente.
- Intégrez-le de manière transparente à plus de 150 outils tels que Slack, Teams, Jira, Datadog et Grafana.
- Recevez des alertes mobiles en temps réel sur iOS, Android et même sur les montres connectées.
Limitations de Zenduty
- La fonction de recherche peut mélanger plusieurs incidents, ce qui rend le suivi plus difficile.
- Certaines fonctionnalités avancées sont réservées aux forfaits supérieurs.
- Les notifications qui se chevauchent dans les installations complexes peuvent entraîner des alertes en double.
Tarifs Zenduty
- Free
- Starter : 6 $/mois par utilisateur
- Croissance : 16 $/mois par utilisateur
- Enterprise : 25 $/mois par utilisateur
Évaluations et avis sur Zenduty
- G2 : 4,6/5 (plus de 135 avis)
- Capterra : pas assez d'avis
Ce que les utilisateurs disent de Zenduty
Cette critique G2 note :
Ce que j'apprécie le plus chez Zenduty, ce sont ses analyses basées sur des données. En analysant les incidents, nous pouvons suivre les tendances, par exemple les jours, les services ou les équipes qui ont connu le plus de problèmes, identifier ce qui n'a pas fonctionné et déterminer les domaines à améliorer.
Ce que j'apprécie le plus chez Zenduty, ce sont ses analyses basées sur des données. En analysant les incidents, nous pouvons suivre les tendances, par exemple les jours, les services ou les équipes qui ont connu le plus de problèmes, identifier ce qui n'a pas fonctionné et déterminer les domaines à améliorer.
📖 À lire également : Meilleurs logiciels de gestion des opérations informatiques
12. Incident. io (le meilleur pour la gestion des incidents native à Slack)
Imaginons un instant que nous sommes en pleine intervention. Le pager sonne. Tout le monde se réveille. Dans Opsgenie, vous acquittez l'alerte, puis vous recherchez la bonne salle, puis vous copiez le contexte dans un autre endroit afin que tout le monde puisse voir ce qui se passe.
C'est ce saut que la plupart des équipes veulent corriger. C'est là que incident.io fait la différence.
Vous faites votre déclaration directement dans Slack, et un espace clair apparaît avec les rôles, l’échéancier et les deux ou trois prochaines étapes déjà définies. Vous pouvez appeler, envoyer un SMS, un e-mail ou simplement appuyer pour confirmer. Le travail commence immédiatement et reste visible.
Les utilisateurs décrivent tous le même rythme une fois qu'ils ont changé. Un canal se crée avec uniquement le signal dont vous avez besoin. L'application vous invite à effectuer des suivis et rédige un résumé clair pendant que vous êtes encore en train de résoudre le problème. Les mises à jour de statut pour les clients sont prêtes à être envoyées sans quitter le fil de discussion. Cela permet à lui seul de réduire les discussions qui tourbillonnent généralement dans les salles annexes et les messages privés.
Son adoption a été facile pour des équipes de tailles très différentes. Les petits groupes parlent de le connecter à Linear et New Relic en quelques semaines et d'en tirer une réelle valeur dès le premier jour. Les grandes organisations indiquent qu'elles l'ont déployé dans plusieurs équipes en un mois environ et qu'elles n'ont pas retardé leur feuille de route pour le faire.
Les meilleures fonctionnalités d'Incident.io
- Gérez les incidents de bout en bout directement dans Slack ou Microsoft Teams.
- Utilisez l'IA SRE pour suggérer des corrections, enquêter sur les problèmes et rédiger des communications.
- Gérez les plannings d'astreinte grâce à la réduction du bruit basée sur l'IA.
- Automatisez les mises à jour de la page de statut pour les clients et les parties prenantes.
- Obtenez des informations sur les tendances, les échéanciers et les indicateurs MTTx grâce à des tableaux de bord.
Limitations d'Incident.io
- L'interface peut sembler encombrée avec de nombreuses notifications Slack.
- La configuration avancée (comme les chemins d'escalade) peut nécessiter des ajustements.
- Certaines fonctionnalités d'IA sont limitées à l'anglais uniquement.
Tarifs Incident.io
- Basique : Gratuit
- Équipe : 19 $/mois par utilisateur
- Pro : 25 $/mois par utilisateur
- Enterprise : tarification personnalisée
Évaluations et avis sur Incident.io
- G2 : 4,8/5 (plus de 180 avis)
- Capterra : pas assez d'avis
Ce que les utilisateurs disent à propos d'Incident. io
Cet avis partagé sur G2 indique :
Pour moi, incident.io offre le juste équilibre entre ne pas gêner et fournir une structure, des processus et la collecte de données pour la gestion des incidents.
Pour moi, incident.io offre le juste équilibre entre ne pas gêner et fournir une structure, des processus et la collecte de données pour la gestion des incidents.
💡Conseil de pro : utilisez des agents prédéfinis pour répondre aux questions de l'équipe ou partager des mises à jour, ou configurez un agent ClickUp AI personnalisé pour surveiller l'état d'avancement des tâches et les dates d'échéance, envoyer des rappels, escalader les problèmes ou mettre à jour les statuts si nécessaire, afin de faire avancer les choses.
Cette vidéo vous montre comment :
À quoi s'attendre pendant et après la migration depuis Opsgenie
Quitter Opsgenie peut donner l'impression de déménager d'une maison dans laquelle vous avez vécu pendant des années. Chaque planning, règle d'escalade et intégration a sa place, et l'idée de tout transporter dans une nouvelle maison peut sembler intimidante.
Atlassian propose un outil de migration intégré à l'application pour passer à Jira Service Management ou Compass. Le processus est structuré, prévisible et conçu pour minimiser les perturbations.
Si vous décidez d'opter pour l'un de ces outils, il vous suffit de revoir votre plan, de fixer la date de migration et de laisser l'outil faire le gros du travail. Voyons comment cela fonctionne et évaluons si c'est un bon choix pour votre organisation.
Aperçu du flux de migration
Étape 1 → Examinez et choisissez votre voie
Évaluez votre forfait Opsgenie et déterminez si Jira Service Management (axé sur l'ITSM) ou Compass (axé sur les développeurs) est le mieux adapté à vos besoins.
Étape 2 → Planifiez votre date de migration
Choisissez un échéancier adapté à votre cycle de facturation et à la disponibilité de votre équipe.
Étape 3 → Approuver la facturation
Votre administrateur de facturation Atlassian confirme le forfait afin que le nouveau produit puisse être fourni.
Étape 4 → Migration des données en arrière-plan
Les données Opsgenie commencent à se synchroniser pendant que votre équipe continue à travailler comme d'habitude.
Étape 5 → Transition et fermeture
Vous disposez de 120 jours pour finaliser la transition avant la désactivation d'Opsgenie.
En bref, voici ce à quoi vous pouvez vous attendre :
- Utilisez l'outil de migration guidée pour réaliser l'automatisation des tâches fastidieuses.
- Effectuez la maintenance de l'accès à Opsgenie pendant et après la migration, jusqu'à la fermeture.
- Suivez les guides de migration personnalisés dans Jira Service Management ou Compass.
- Ajustez les flux de travail et reconfigurez les paramètres pendant la période de transition de 120 jours.
- Assurez la continuité des alertes, des plannings et des intégrations sans interruption.
Avantages et inconvénients de la migration d'Opsgenie vers Jira Service Management
Avantages :
- Il permet de créer un flux de travail fluide et unifié.
- Pour les équipes qui ont déjà beaucoup investi dans l'écosystème Atlassian, cela peut être une décision pratique et rentable.
- L'analyse post-incident efficace de Jira simplifie le processus de suivi des actions de suivi.
- La consolidation des données d'incident dans JSM permet des rapports plus puissants et plus complets.
Inconvénients :
- Certaines des fonctions avancées d'Opsgenie autonome peuvent ne pas être immédiatement disponibles dans JSM.
- Le passage à un environnement JSM plus large peut accroître la complexité et le bruit.
- Les équipes devront être formées à la nouvelle interface et aux nouveaux flux de travail dans JSM.
Voici quelques réflexions de Redditors sur le sujet
Cet utilisateur de Reddit a estimé que cette décision avait globalement porté ses fruits :
Tout s'est plutôt bien passé pour nous. Je dois revoir la configuration des rôles et des permissions, mais tout semble s'être bien passé, sauf si vous avez exactement les mêmes noms d'équipe Jira que ceux d'OpsGenies. Ils ne se sont pas bien fusionnés et cela en a endommagé quelques-uns. Je vous recommande de les modifier si c'est le cas.
Tout s'est plutôt bien passé pour nous. Je dois revoir la configuration des rôles et des permissions, mais tout semble s'être bien passé, sauf si vous avez exactement les mêmes noms d'équipe Jira que ceux d'OpsGenies. Ils ne se sont pas bien fusionnés et cela en a endommagé quelques-uns. Je vous recommande de les modifier si c'est le cas.
Voici un autre utilisateur qui n'a clairement pas eu la meilleure expérience :
Au cas où quelqu'un envisagerait cette option : nous sommes passés à Jira Service Management, qui fait partie de notre forfait déjà payé (l'entreprise fait des économies agressives). C'est tellement mauvais que je ne peux même pas l'expliquer. Ne l'envisagez pas comme une option.
Au cas où quelqu'un envisagerait cette option : nous sommes passés à Jira Service Management, qui fait partie de notre forfait déjà payé (l'entreprise fait des économies agressives). C'est tellement mauvais que je ne peux même pas l'expliquer. Ne l'envisagez pas comme une option.
Et un autre qui envisage déjà de changer après six mois avec JSM :
JSM est horrible. Il n'est en aucun cas comparable à PagerDuty, Rootly ou Incident. io. Nous sommes également passés à cet outil il y a environ 6 mois au travail et nous recherchons déjà des alternatives. Il est tellement rigide, n'offre pratiquement aucune intégration, ne dispose pas d'un bon support Slack et les alertes et pages d'astreinte sont souvent manquées par les ingénieurs (nous n'avons jamais eu ce problème avec OpeGenie).
JSM est horrible. Il n'est en aucun cas comparable à PagerDuty, Rootly ou Incident. io. Nous sommes également passés à cet outil il y a environ 6 mois au travail et nous recherchons déjà des alternatives. Il est tellement rigide, n'offre pratiquement aucune intégration, ne dispose pas d'un bon support Slack et les alertes et pages d'astreinte sont souvent manquées par les ingénieurs (nous n'avons jamais eu ce problème avec OpeGenie).
L'autre alternative proposée par Atlassian, Compass, n'est pas une alternative directe à Opsgenie. Il s'agit plutôt d'une plateforme d'expérience développeur conçue pour cartographier et gérer les composants, les services et les dépendances d'une architecture logicielle complexe.
Nous vous recommandons de prendre en compte ces facteurs avant de choisir l'alternative à Opsgenie la mieux adaptée à votre équipe.
Opsgenie sonne, ClickUp répond
Abandonner Opsgenie peut sembler être une grande étape, mais considérez cela comme une opportunité de faciliter la vie de votre équipe.
Vous avez vu comment les autres outils se comparent, chacun avec ses propres forces, mais aussi ses limites.
Cependant, ClickUp conquiert discrètement les cœurs. 🤗
Voici pourquoi : Il regroupe vos tâches, vos communications et vos flux de travail en un seul endroit. Vous n'avez plus besoin de passer d'un écran à l'autre ou d'assembler différents outils. Au contraire, votre équipe reste connectée, claire sur les priorités et confiante quant à la suite des opérations.
Choisir la bonne solution de gestion des incidents ne se résume pas à des alertes : il s'agit de créer un cadre de gestion des incidents robuste qui favorise l'efficacité opérationnelle à long terme. Avec ClickUp, votre équipe peut gérer les incidents de manière proactive tout en réduisant le bruit et en assurant la cohérence de chaque réponse. 😌
Si vous êtes prêt à réduire vos maux de tête et à gagner en clarté, c'est le moment de vous inscrire à ClickUp!
Foire aux questions (FAQ)
Les migrations Opsgenie doivent être planifiées avant avril 2027. Après cette date, les données Opsgenie ne seront plus accessibles.
Parmi les alternatives les plus performantes, on trouve Jira Service Management, PagerDuty, FireHydrant, TaskCall, ilert, Zenduty et incident.io. Chacune offre un équilibre différent entre gestion des astreintes, automatisation et intégrations. Cependant, si vous recherchez une plateforme tout-en-un alimentée par l'IA qui regroupe vos flux de travail, vos communications et votre documentation en un seul endroit, choisissez ClickUp.
Jira Service Management inclut la plupart des fonctionnalités essentielles d'Opsgenie, telles que les alertes, la planification des astreintes et les flux de travail d'incidents, mais certaines fonctions avancées peuvent différer. Compass est une option pour les équipes de développement qui se concentrent sur les catalogues de services et le suivi des composants.
Oui. Atlassian fournit un outil de migration intégré à l'application qui transfère automatiquement les alertes, les plannings et les politiques d'escalade. Vous pouvez même tester la migration dans un compte de démonstration avant la validation.
Oui. Des outils tels que Cabot, OpenDuty et Alertmanager peuvent être personnalisés en tant que remplacements open source, mais ils peuvent nécessiter davantage d’installation et de maintenance.
Les coûts dépendent de la plateforme que vous choisissez. Jira Service Management, Compass et d'autres alternatives proposent des tarifs échelonnés, souvent par utilisateur et par mois. Certains outils open source sont gratuits, mais nécessitent des coûts d'infrastructure et d'assistance.
Oui. Votre équipe peut continuer à utiliser Opsgenie pendant la période de migration, et les intégrations restent actives jusqu'à ce qu'Opsgenie soit définitivement désactivé. Ensuite, elles devront être reconfigurées dans votre nouvelle plateforme.