
Sie veröffentlichen das neueste Software-Update, und schon gehen die ersten Berichte ein.
Plötzlich bestimmt eine einzige Metrik alles, von CSAT/NPS bis hin zu Roadmap-Verzögerungen: die Fehlerbehebungszeit.
Führungskräfte sehen darin eine Metrik, mit der sie ihre Versprechen einhalten können – können wir termingerecht liefern, lernen und den Umsatz sichern? Praktiker spüren die Probleme an vorderster Front – doppelte Tickets, unklare Eigentümerschaften, lautstarke Eskalationen und Kontextinformationen, die über Slack, Tabellenkalkulationen und separate tools verstreut sind.
Diese Fragmentierung verlängert Zyklen, verschleiert die Ursachen und macht die Priorisierung zu einer reinen Vermutungssache.
Das Ergebnis? Langsameres Lernen, verpasste Verpflichtungen und ein Rückstand, der jeden Sprint still und leise belastet.
Dieser Leitfaden ist Ihr umfassendes Handbuch zum Messen, Benchmarking und Verkürzen der Fehlerbehebungszeit und zeigt konkret, wie KI den Workflow im Vergleich zu herkömmlichen manuellen Prozessen verändert.
Was ist die Fehlerbehebungszeit?
Die Fehlerbehebungszeit ist die Zeit, die benötigt wird, um einen Fehler zu beheben, gemessen vom Zeitpunkt der Meldung des Fehlers bis zu seiner vollständigen Behebung.
In der Praxis beginnt die Zeitmessung, wenn ein Problem gemeldet oder erkannt wird (durch Benutzer, QA oder Überwachung), und endet, wenn die Korrektur implementiert und zusammengeführt wurde und zur Überprüfung oder Freigabe bereit ist – je nachdem, wie Ihr Team „erledigt“ definiert.
Beispiel: Ein P1-Absturz, der am Monday um 10:00 Uhr gemeldet und am Dienstag um 15:00 Uhr zusammengeführt wurde, hat eine Lösungszeit von ~29 Stunden.
Dies ist nicht dasselbe wie die Fehlererkennungszeit. Die Erkennungszeit misst, wie schnell Sie einen Fehler nach seinem Auftreten erkennen (Alarmauslösung, Erkennung durch QA-Tools, Berichterstellung durch Kunden).
Die Lösungszeit misst, wie schnell Sie von der Erkennung zur Behebung gelangen – Triage, Reproduktion, Diagnose, Implementierung, Überprüfung, Test und Vorbereitung für die Freigabe. Stellen Sie sich die Erkennung als „wir wissen, dass es defekt ist“ und die Lösung als „es ist repariert und bereit“ vor.
Teams verwenden leicht unterschiedliche Grenzen; wählen Sie eine aus und bleiben Sie dabei, damit Ihre Trends realistisch sind:
- Gemeldet → Gelöst: Endet, wenn die Code-Korrektur zusammengeführt und für die Qualitätssicherung bereit ist. Gut für den Durchsatz in der Entwicklung.
- Gemeldet → Geschlossen: Umfasst QA-Validierung und Freigabe. Am besten geeignet für SLAs mit Auswirkungen auf Kunden
- Erkannt → Gelöst: Beginnt, wenn die Überwachung/QA das Problem erkennt, noch bevor ein Ticket existiert. Nützlich für Teams mit hohem Produktionsaufkommen.
🧠 Wissenswertes: Ein skurriler, aber urkomischer Fehler in Final Fantasy XIV wurde dafür gelobt, dass er so spezifisch war, dass die Leser ihn als „spezifischsten Fehlerbehebungsfall in einem MMO 2025” bezeichneten. Er trat auf, wenn Spieler in einer bestimmten Zone während eines Ereignisses Elemente zu Preisen zwischen genau 44.442 Gil und 49.087 Gil bewerteten – was aufgrund eines möglichen Integer-Überlauf-Fehlers zu Verbindungsabbrüchen führte.
Warum das wichtig ist
Die Zeit bis zur Fehlerbehebung ist ein Hebel für die Release-Kadenz. Lange oder unvorhersehbare Zeiten zwingen zu Umfangskürzungen, Hotfixes und Release-Einfrierungen; sie verursachen Planungsrückstände, da die Long Tail (Ausreißer) Sprints stärker aus der Bahn werfen, als der Durchschnitt vermuten lässt.
Dies steht auch in direktem Zusammenhang mit der Kundenzufriedenheit. Kunden tolerieren Probleme, wenn sie schnell erkannt und vorhersehbar gelöst werden. Langsame oder, schlimmer noch, uneinheitliche Fehlerbehebungen führen zu Eskalationen, beeinträchtigen die CSAT/NPS und gefährden Vertragsverlängerungen.
Kurz gesagt: Wenn Sie die Zeit für die Fehlerbehebung sauber messen und systematisch reduzieren, verbessern sich Ihre Roadmaps und Beziehungen.
📖 Weiterlesen: Wie man Fehler priorisiert, um Probleme effizient zu beheben
Wie misst man die Zeit für die Fehlerbehebung?
Entscheiden Sie zunächst, wo Ihre Uhr startet und stoppt.
Die meisten Teams wählen entweder „Gemeldet → Gelöst“ (die Korrektur wurde zusammengeführt und kann überprüft werden) oder „Gemeldet → Geschlossen“ (die Qualitätssicherung hat die Änderung validiert und sie wurde veröffentlicht oder anderweitig geschlossen).
Wählen Sie eine Definition aus und verwenden Sie diese konsistent, damit Ihre Trends aussagekräftig sind.
Jetzt benötigen Sie einige beobachtbare Metriken. Lassen Sie uns diese skizzieren:
Wichtige Metriken zur Nachverfolgung von Fehlern, auf die Sie achten sollten:
| 📊 Metrik | 📌 Wofür es steht | 💡 So hilft es Ihnen | 🧮 Formel (falls zutreffend) |
|---|---|---|---|
| Fehleranzahl 🐞 | Gesamtzahl der gemeldeten Fehler | Verschafft eine Ansicht des Systemzustands. Hohe Zahl? Zeit für eine Untersuchung. | Gesamtzahl der Fehler = Alle im System protokollierten Fehler {offen + geschlossen} |
| Offene Fehler 🚧 | Fehler, die noch nicht behoben wurden | Zeigt den aktuellen Workload an. Hilft bei der Priorisierung. | Offene Fehler = Gesamtzahl der Fehler – geschlossene Fehler |
| Geschlossene Fehler ✅ | Behobene und verifizierte Fehler | Verfolgt den Fortschritt und die geleistete Arbeit. | Geschlossene Fehler = Anzahl der Fehler mit dem Status „Geschlossen” oder „Behoben” |
| Schweregrad von Bugs 🔥 | Kritikalität des Fehlers (z. B. kritisch, schwerwiegend, geringfügig) | Unterstützt die Triage auf der Grundlage der Auswirkungen. | Als kategoriales Feld mit Nachverfolgung, keine Formel. Verwenden Sie Filter/Gruppierungen. |
| Bug-Priorität 📅 | Wie dringend muss ein Fehler behoben werden? | Hilft bei der Planung von Sprints und Releases. | Auch ein kategoriales Feld, das in der Regel in Rangstufen unterteilt ist (z. B. P0, P1, P2). |
| Zeit bis zur Lösung ⏱️ | Zeit vom Fehlerbericht bis zur Behebung | Misst die Reaktionsfähigkeit. | Zeit bis zur Behebung = Datum der Schliessung – Datum der Berichterstellung |
| Wiedereröffnungsrate 🔄 | Prozentualer Anteil der Fehler, die nach ihrer Schließung erneut auftreten | Spiegelt die Qualität der Fehlerbehebung oder Regressionsprobleme wider. | Wiedereröffnungsrate (%) = {Wiedereröffnete Fehler ÷ Gesamtzahl der geschlossenen Fehler} × 100 |
| Bug-Leckage 🕳️ | Fehler, die in die Produktion gelangt sind | Zeigt die Effektivität von QA-/Softwaretests an. | Leckrate (%) = {Produktfehler ÷ Gesamtzahl der Fehler} × 100 |
| Fehlerdichte 🧮 | Fehler pro Einheit der Größe des Codes | Hebt risikobehaftete Code-Bereiche hervor. | Fehlerdichte = Anzahl der Fehler ÷ KLOC {Kilo Lines of Code} |
| Zugewiesene vs. nicht zugewiesene Fehler 👥 | Verteilung der Fehler nach Eigentümerschaft | Stellt sicher, dass nichts übersehen wird. | Verwenden Sie einen Filter: Nicht zugewiesen = Fehler, bei denen „Zugewiesen an” leer ist. |
| Alter offener Fehler 🧓 | Wie lange ein Fehler ungelöst bleibt | Erkennt Stagnations- und Rückstandsrisiken. | Fehleralter = aktuelles Datum – Datum der Meldung |
| Doppelte Fehler 🧬 | Anzahl doppelter Meldungen | Hebt Fehler in Aufnahmeprozessen hervor. | Duplikatsrate = Duplikate ÷ Gesamtzahl der Fehler × 100 |
| MTTD (Mean Time to Detect, durchschnittliche Erkennungszeit) 🔎 | Durchschnittliche Zeit für die Erkennung von Fehlern oder Incidents | Misst die Effizienz der Überwachung und das Bewusstsein. | MTTD = Σ(Zeitpunkt der Erkennung – Zeitpunkt des Auftretens) ÷ Anzahl der Fehler |
| MTTR (Mean Time to Resolve) 🔧 | Durchschnittliche Zeit bis zur vollständigen Behebung eines Fehlers nach dessen Erkennung | Verfolgt die Reaktionsfähigkeit der Entwickler und die Zeit bis zur Fehlerbehebung. | MTTR = Σ(Zeit bis zur Behebung – Zeit bis zur Erkennung) ÷ Anzahl der behobenen Fehler |
| MTTA (Mean Time to Acknowledge, durchschnittliche Zeit bis zur Bestätigung) 📬 | Zeit von der Erkennung bis zum Beginn der Arbeit an dem Fehler | Zeigt die Reaktionsfähigkeit des Teams und die Reaktionsgeschwindigkeit bei Warnmeldungen. | MTTA = Σ(Zeitpunkt der Bestätigung – Zeitpunkt der Erkennung) ÷ Anzahl der Fehler |
| MTBF (Mean Time Between Failures, mittlere Zeit zwischen Ausfällen) 🔁 | Zeit zwischen der Behebung eines Fehlers und dem Auftreten des nächsten Fehlers | Zeigt die Stabilität im Zeitverlauf an. | MTBF = Gesamtbetriebszeit ÷ Anzahl der Ausfälle |
⚡️ Vorlagenarchiv: 15 kostenlose Vorlagen und Formulare für Fehlerberichte zur Nachverfolgung von Fehlern
Faktoren, die die Fehlerbehebungszeit beeinflussen
Die Lösungszeit wird oft mit der „Geschwindigkeit, mit der Ingenieure Code schreiben“ gleichgesetzt.
Aber das ist nur ein Teil des Prozesses.
Die Fehlerbehebungszeit ist die Summe aus Qualität bei der Erfassung, Effizienz des Flows durch Ihr System und Abhängigkeitsrisiko. Wenn einer dieser Faktoren ins Stocken gerät, verlängert sich die Zykluszeit, sinkt die Vorhersagbarkeit und nehmen Eskalationen zu.
Die Qualität der Erfassung gibt den Ton an
Meldungen, die ohne klare Reproduktionsschritte, Umgebungsdetails, Protokolle oder Info zu Version und Build eingehen, erfordern zusätzlichen Aufwand. Doppelte Meldungen aus mehreren Kanälen (Support, Qualitätssicherung, Überwachung, Slack) sorgen für Unruhe und uneinheitliche Eigentümerschaften.
Je früher Sie den richtigen Kontext erfassen – und Duplikate entfernen –, desto weniger Übergaben und klärende Rückfragen sind später erforderlich.
Priorisierung und Weiterleitung bestimmen, wer sich wann um den Fehler kümmert.
Schweregradbeschreibungen, die nicht mit den Auswirkungen auf Kunden/Geschäft übereinstimmen (oder sich im Laufe der Zeit verschieben), verursachen Warteschlangen: Die lautesten Tickets springen in der Warteschlange nach vorne, während Fehler mit großen Auswirkungen unberücksichtigt bleiben.
Klare Weiterleitungsregeln nach Komponente/Eigentümer und eine einzige Warteschlange sorgen dafür, dass P0/P1-Arbeiten nicht unter „aktuellen und lauten“ Aufgaben begraben werden.
Eigentümerschaft und Übergaben sind stille Killer
Wenn unklar ist, ob ein Fehler zum Mobil-, Backend-Authentifizierungs- oder Plattform-Team gehört, wird er zurückgewiesen. Bei jeder Zurückweisung wird der Kontext zurückgesetzt.
Zeitzonen verschärfen dieses Problem noch: Ein Fehler, der spät am Tag gemeldet wird und für den kein Eigentümer benannt ist, kann 12 bis 24 Stunden verlieren, bevor überhaupt jemand mit der Reproduktion beginnt. Eine genaue Definition der Zuständigkeiten mit einem Bereitschaftsdienst oder wöchentlichen DRI beseitigt diese Verzögerung.
Reproduzierbarkeit ist von der Beobachtbarkeit abhängig
Lückenhafte Protokolle, fehlende Korrelations-IDs oder fehlende Absturzspuren machen die Diagnose zu einer reinen Vermutung. Fehler, die nur mit bestimmten Flags, Mandanten oder Formen auftreten, lassen sich in der Entwicklung nur schwer reproduzieren.
Wenn Ingenieure nicht sicher auf bereinigte, produktionsähnliche Daten zugreifen können, müssen sie Instrumentierungen vornehmen, neu bereitstellen und warten – und das nicht nur Stunden, sondern Tage lang.
Umgebung und Datenparität sorgen für Ehrlichkeit
„Funktioniert auf meinem Rechner“ bedeutet in der Regel „Produktionsdaten sind anders“. Je mehr sich Ihre Entwicklungs-/Staging-Umgebung von der Produktion unterscheidet (Konfiguration, Dienste, Versionen von Drittanbietern), desto mehr Zeit verbringen Sie damit, Geister zu jagen. Sichere Daten-Snapshots, Seed-Skripte und Paritätsprüfungen verringern diese Lücke.
In Bearbeitung (IB) und Fokus bestimmen den tatsächlichen Durchsatz
Überlastete Teams müssen zu viele Fehler auf einmal bearbeiten, ihre Aufmerksamkeit auf mehrere Dinge gleichzeitig richten und zwischen Aufgaben und Meetings hin- und herwechseln. Der Kontextwechsel kostet unsichtbare Stunden.
Eine sichtbare IB-Begrenzung und die Tendenz, begonnene Arbeiten zu Ende zu bringen, bevor neue Arbeiten in Angriff genommen werden, senken Ihren Median schneller als jeder einzelne Aufwand.
Codeüberprüfung, CI und QA-Geschwindigkeit sind klassische Engpässe.
Lange Erstellungszeiten, unzuverlässige Tests und unklare Review-SLAs verzögern ansonsten schnelle Fehlerbehebungen. Ein 10-minütiger Patch kann zwei Tage lang auf einen Reviewer warten oder in eine stundenlange Pipeline geraten.
Ebenso können QA-Warteschlangen, die Tests stapelweise durchführen oder auf manuelle Smoke-Tests angewiesen sind, den Zeitraum von „Gemeldet → Geschlossen“ um ganze Tage verlängern, selbst wenn „Gemeldet → Gelöst“ schnell geht.
Abhängigkeiten verlängern Warteschlangen
Teamübergreifende Änderungen (Schema, Plattformmigrationen, SDK-Updates), Fehler von Anbietern oder App-Store-Überprüfungen (Mobilgeräte) verursachen Wartezeiten. Ohne explizite Nachverfolgung von „Blockiert/Pausiert“ erhöhen diese Wartezeiten unbemerkt Ihre Durchschnittswerte und verschleiern, wo der eigentliche Engpass liegt.
Das Release-Modell und die Rollback-Strategie sind wichtig
Wenn Sie in großen Release-Zügen mit manuellen Gates ausliefern, bleiben selbst behobene Fehler bis zur Abfahrt des nächsten Zuges bestehen. Feature Flags, Canary-Releases und Hotfix-Lanes verkürzen die Nachlaufzeit – insbesondere bei P0/P1-Incidents –, indem sie Ihnen ermöglichen, die Bereitstellung von Korrekturen von vollständigen Zyklen zu entkoppeln.
Architektur und technische Schulden setzen Ihnen Grenzen
Enge Kopplungen, fehlende Testnahtstellen und undurchsichtige Legacy-Module machen einfache Korrekturen riskant. Teams kompensieren dies durch zusätzliche Tests und längere Überprüfungen, was die Zyklen verlängert. Umgekehrt ermöglicht modularer Code mit guten Vertragstests ein schnelles Vorankommen, ohne benachbarte Systeme zu beeinträchtigen.
Kommunikation und Status-Hygiene beeinflussen die Vorhersagbarkeit
Vage Updates („wir kümmern uns darum“) führen zu Nacharbeit, wenn Stakeholder nach voraussichtlichen Fertigstellungsterminen fragen, der Support Tickets erneut öffnet oder das Produkt eskaliert. Klare Statusübergänge, Notizen zur Reproduktion und zur Ursache sowie ein veröffentlichter voraussichtlicher Fertigstellungstermin reduzieren die Fluktuation und schützen den Fokus Ihres Engineering-Teams.
📮ClickUp Insight: Der durchschnittliche Berufstätige verbringt täglich mehr als 30 Minuten mit der Suche nach arbeitsbezogenen Informationen – das sind über 120 Stunden pro Jahr, die durch das Durchsuchen von E-Mails, Slack-Threads und verstreuten Dateien verloren gehen.
Ein intelligenter KI-Assistent, der in Ihren Workspace integriert ist, kann das ändern. Hier kommt ClickUp Brain ins Spiel. Es liefert sofortige Einblicke und Antworten, indem es innerhalb von Sekunden die richtigen Dokumente, Unterhaltungen und Aufgaben-Details anzeigt – so können Sie mit der Suche aufhören und mit der Arbeit beginnen.
💫 Echte Ergebnisse: Teams wie QubicaAMF haben durch die Abschaffung veralteter Wissensmanagementprozesse mit ClickUp mehr als 5 Stunden pro Woche eingespart – das sind über 250 Stunden pro Person und Jahr. Stellen Sie sich vor, was Ihr Team mit einer zusätzlichen Woche Produktivität pro Quartal alles erreichen könnte!
Führende Indikatoren dafür, dass sich Ihre Vorlaufzeit verzögern wird
❗️Steigende „Zeit bis zur Bestätigung“ und viele Tickets ohne Eigentümer für >12 Stunden
❗️Zunehmende „Time in Review/CI”-Segmente und häufige Testinstabilität
❗️Hohe Duplikatsrate bei der Erfassung und inkonsistente Beschreibungen der Schweregrade zwischen den Teams
❗️Mehrere Fehler befinden sich im Status „Blockiert“ ohne benannte externe Abhängigkeit.
❗️Die Wiedereröffnungsrate steigt (Korrekturen sind nicht reproduzierbar oder die Definitionen für „erledigt“ sind unklar)
Verschiedene Organisationen empfinden diese Faktoren unterschiedlich. Führungskräfte erleben sie als verpasste Zyklen des Lernens und Einbußen bei den Umsatzchancen; Mitarbeiter empfinden sie als Störfaktor bei der Triage und unklare Eigentümerschaft.
Durch die Optimierung von Eingabe, Flow und Abhängigkeiten können Sie die gesamte Kurve – Median und P90 – nach unten verschieben.
Möchten Sie weitere Informationen über das Verfassen besserer Fehlerberichte erhalten? Beginnen Sie hier. 👇🏼
📖 Weiterlesen: Der Software-Test-Zyklus (STLC): Übersicht und Phasen
Branchenbenchmarks für die Fehlerbehebungszeit
Die Benchmarks für die Fehlerbehebung variieren je nach Risikotoleranz, Release-Modell und der Geschwindigkeit, mit der Sie Änderungen ausliefern können.
Hier können Sie Mediane (P50) verwenden, um Ihren typischen Flow zu verstehen, und P90, um Versprechen und SLAs einzustellen – nach Schweregrad und Quelle (Kunde, Qualitätssicherung, Überwachung).
Schauen wir uns einmal genauer an, was das bedeutet:
| 🔑 Begriff | 📝 Beschreibung | 💡 Warum das wichtig ist |
|---|---|---|
| P50 (Median) | Der Mittelwert – 50 % der Fehlerbehebungen sind schneller als dieser Wert, 50 % sind langsamer. | 👉 Spiegelt Ihre typische oder häufigste Lösungszeit wider. Gut geeignet, um die normale Leistung zu verstehen. |
| P90 (90. Perzentil) | 90 % der Fehler werden innerhalb dieser Zeit behoben. Nur 10 % benötigen mehr Zeit. | 👉 Stellt eine Worst-Case-Situation (die jedoch realistisch ist) dar. Nützlich für die Einstellung externer Zusagen. |
| SLAs (Service Level Agreements) | Verpflichtungen, die Sie – intern oder gegenüber Kunden – hinsichtlich der Schnelligkeit der Problembearbeitung eingehen | 👉 Beispiel: „Wir beheben P1-Fehler in 90 % der Fälle innerhalb von 48 Stunden. “ Hilft beim Aufbau von Vertrauen und Verantwortungsbewusstsein |
| Nach Schweregrad und Ursache | Segmentieren Sie Ihre Metriken nach zwei Schlüsselkriterien: • Schweregrad (z. B. P0, P1, P2)• Quelle (z. B. Kunde, Qualitätssicherung, Überwachung) | 👉 Ermöglicht eine genauere Nachverfolgung und Priorisierung, sodass kritische Fehler schneller Aufmerksamkeit erhalten. |
Nachfolgend finden Sie Bereiche für verschiedene Branchen, die von erfahrenen Teams häufig als Einzelziele gesetzt werden. Betrachten Sie diese als Ausgangsbasis und passen Sie sie an Ihren Kontext an.
SaaS
Immer verfügbar und CI/CD-freundlich, sodass Hotfixes an der Tagesordnung sind. Kritische Probleme (P0/P1) werden oft innerhalb eines Arbeitstages behoben, wobei P90 innerhalb von 24 bis 48 Stunden liegt. Nicht kritische Probleme (P2+) werden in der Regel innerhalb von 3 bis 7 Tagen behoben, wobei P90 innerhalb von 10 bis 14 Tagen liegt. Teams mit robusten Feature Flags und automatisierten Tests tendieren zu schnelleren Lösungen.
E-Commerce-Plattformen
Da Konversions- und Warenkorb-Flows für den Umsatz entscheidend sind, liegt die Leiste höher. P0/P1-Probleme werden in der Regel innerhalb weniger Stunden behoben (Rollback, Markierung oder Konfiguration) und noch am selben Tag vollständig gelöst; P90 bis zum Ende des Tages oder <12 Stunden sind in Spitzenzeiten üblich. P2+-Probleme werden oft innerhalb von 2–5 Tagen gelöst, P90 innerhalb von 10 Tagen.
Enterprise-Software
Strengere Validierungs- und Kundenänderungsfenster verlangsamen den Rhythmus. Für P0/P1 streben die Teams eine Umgehungslösung innerhalb von 4 bis 24 Stunden und eine Behebung innerhalb von 1 bis 3 Werktagen an; für P90 innerhalb von 5 Werktagen. P2+-Elemente werden häufig in Release-Zügen gebündelt, mit einem Median von 2 bis 4 Wochen, abhängig von den Rollout-Zeitplänen der Kunden.
Gaming- und mobile Apps
Live-Service-Backends verhalten sich wie SaaS (Flags und Rollbacks innerhalb von Minuten bis Stunden; P90 am selben Tag). Client-Updates werden durch Store-Reviews eingeschränkt: P0/P1 nutzen oft sofort serverseitige Hebel und liefern einen Client-Patch innerhalb von 1–3 Tagen; P90 innerhalb einer Woche mit beschleunigter Überprüfung. P2+-Korrekturen werden in der Regel für den nächsten Sprint oder Inhalt eingeplant.
Bankwesen/Fintech
Risiko- und Compliance-Gates fördern ein Muster von „schneller Schadensbegrenzung und vorsichtigen Änderungen“. P0/P1 werden schnell begrenzt (Flags, Rollbacks, Traffic-Umleitungen innerhalb von Minuten bis Stunden) und innerhalb von 1–3 Tagen vollständig behoben; P90 innerhalb einer Woche, unter Berücksichtigung der Änderungskontrolle. P2+ dauert oft 2–6 Wochen, um Sicherheits-, Audit- und CAB-Prüfungen zu bestehen.
Wenn Ihre Nummern außerhalb dieser Bereiche liegen, überprüfen Sie die Qualität der Eingaben, die Weiterleitung/Eigentümerschaft, die Codeüberprüfung und den QA-Durchsatz sowie die Genehmigungen von Abhängigkeiten, bevor Sie davon ausgehen, dass die „Engineering-Geschwindigkeit” das Kernproblem ist.
🌼 Wussten Sie schon: Laut einer Stack Overflow-Umfrage aus dem Jahr 2024 nutzten Entwickler KI zunehmend als zuverlässigen Begleiter während des gesamten Programmierprozesses. Ganze 82 % nutzten KI, um tatsächlich Code zu schreiben – das nenne ich mal einen kreativen Mitarbeiter! Wenn sie nicht weiterkamen oder nach Lösungen suchten, verließen sich 67,5 % auf KI, um nach Antworten zu suchen, und mehr als die Hälfte (56,7 %) nutzte sie zum Debuggen und um Hilfe zu erhalten.
Für einige erwiesen sich KI-Tools auch als nützlich für die Dokumentation von Projekten (40,1 %) und sogar für die Erstellung synthetischer Daten oder Inhalte (34,8 %). Neugierig auf eine neue Codebasis? Fast ein Drittel (30,9 %) nutzt KI, um sich schnell einzuarbeiten. Das Testen von Code ist für viele immer noch eine manuelle Arbeit, aber 27,2 % setzen auch hier KI ein. In anderen Bereichen wie Code-Review, Projektplanung und Predictive Analytics ist die KI-Akzeptanz geringer, aber es ist klar, dass sich KI stetig in jede Phase der Softwareentwicklung einfügt.
📖 Weiterlesen: Wie man KI für die Qualitätssicherung einsetzt
So reduzieren Sie die Zeit für die Fehlerbehebung
Die Geschwindigkeit der Fehlerbehebung hängt davon ab, dass Reibungsverluste bei jedem Übergang von der Erfassung bis zur Freigabe beseitigt werden.
Die größten Gewinne erzielen Sie, indem Sie die ersten 30 Minuten intelligenter gestalten (saubere Erfassung, richtiger Eigentümer, richtige Priorität) und anschließend die folgenden Schleifen komprimieren (Reproduzieren, Überprüfen, Verifizieren).
Hier sind neun Strategien, die als System zusammenwirken. KI beschleunigt jeden Schritt, und der Workflow läuft übersichtlich an einem Ort ab, sodass Führungskräfte Vorhersagbarkeit und Praktiker einen reibungslosen Flow erhalten.
1. Zentralisieren Sie die Erfassung und erfassen Sie den Kontext an der Quelle.
Die Fehlerbehebungszeit verlängert sich, wenn Sie den Kontext aus Slack-Threads, Support-Tickets und Tabellenkalkulationen rekonstruieren müssen. Leiten Sie alle Berichte – Support, Qualitätssicherung, Überwachung – in eine einzige Warteschlange mit einer strukturierten Vorlage, die Komponenten, Schweregrad, Umgebung, App-Version/Build, Schritte zur Reproduktion, erwartete vs. tatsächliche Ergebnisse und Anhänge (Protokolle/HAR/Bildschirmaufnahmen) erfasst.
KI kann lange Berichte automatisch zusammenfassen, Reproduktionsschritte und Umgebungsdetails aus Anhängen extrahieren und mögliche Duplikate markieren, sodass die Triage mit einem kohärenten, angereicherten Datensatz beginnt.
Zu beobachtende Metriken: MTTA (Bestätigung innerhalb von Minuten, nicht Stunden), Duplikatsrate, Zeit für „Info erforderlich“.

📖 Weiterlesen: Die Leistungsfähigkeit von ClickUp-Formularen: Optimierung der Arbeit für Software-Teams
2. KI-gestützte Triage und Weiterleitung zur drastischen Verkürzung der MTTA
Die schnellsten Lösungen sind diejenigen, die sofort auf dem richtigen Schreibtisch landen.
Verwenden Sie einfache Regeln und KI, um den Schweregrad zu klassifizieren, mögliche Eigentümer nach Komponente/Code-Bereich zu identifizieren und automatisch mit einer SLA-Uhr zuzuweisen. Legen Sie klare Swimlanes für P0/P1 im Vergleich zu Alles fest und machen Sie „wer der Eigentümer ist“ eindeutig.
Automatisierungen können Prioritäten anhand von Feldern festlegen, Komponenten an ein Team weiterleiten, einen SLA-Timer starten und einen Bereitschaftsingenieur benachrichtigen. KI kann anhand vergangener Muster den Schweregrad und den Eigentümer vorschlagen. Wenn die Triage statt einer 30-minütigen Debatte nur noch 2 bis 5 Minuten dauert, sinkt Ihre MTTA und damit auch Ihre MTTR.
Zu beobachtende Metriken: MTTA, Qualität der ersten Antwort (werden in der ersten Antwort die richtigen Infos angefordert?), Anzahl der Übergaben pro Fehler.
So sieht das in der Praxis aus:
3. Priorisieren Sie nach geschäftlichen Auswirkungen mit expliziten SLA-Stufen.
„Die lauteste Stimme gewinnt“ macht Warteschlangen unvorhersehbar und untergräbt das Vertrauen der Führungskräfte, die CSAT/NPS und Vertragsverlängerungen beobachten.
Ersetzen Sie dies durch eine Bewertung, die Schweregrad, Häufigkeit, betroffene ARR, Kritikalität des Features und Nähe zu Verlängerungen/Einführungen berücksichtigt – und stützen Sie diese auf SLA-Stufen (z. B. P0: Behebung innerhalb von 1–2 Stunden, Lösung innerhalb eines Tages; P1: am selben Tag; P2: innerhalb eines Sprints).
Behalten Sie mit IB-Limits einen sichtbaren P0/P1-Bereich bei, damit nichts ins Stocken gerät.
Zu beobachtende Metriken: P50/P90-Lösung nach Stufe, SLA-Verstoßquote, Korrelation mit CSAT/NPS.
💡Profi-Tipp: Mit den Feldern „Aufgabenprioritäten“, „Benutzerdefinierte Felder“ und „Abhängigkeiten“ von ClickUp können Sie einen Auswirkungswert berechnen und Fehler mit Konten, Feedback oder Roadmap-Elementen verknüpfen. Außerdem helfen Ihnen die Ziele in ClickUp dabei, die Einhaltung von SLAs mit den Zielen auf Unternehmensebene zu verknüpfen, was direkt den Bedenken der Führungskräfte hinsichtlich der Abstimmung entgegenkommt.
4. Machen Sie die Reproduktion und Diagnose zu einer einmaligen Aktivität
Jede zusätzliche Schleife mit der Frage „Können Sie uns die Protokolle schicken?“ verlängert die Zeit bis zur Fehlerbehebung.
Standardisieren Sie, was „gut“ bedeutet: erforderliche Felder für Build/Committen, Umgebung, Reproduktionsschritte, erwartete vs. tatsächliche Werte sowie Anhänge für Protokolle, Crash-Dumps und HAR-Dateien. Richten Sie Client-/Server-Telemetrie ein, damit Crash-IDs und Anfrage-IDs mit Traces verknüpft werden können.
Nutzen Sie Sentry (oder ein ähnliches Tool) für Stack-Traces und verknüpfen Sie das Problem direkt mit dem Fehler. KI kann Protokolle und Traces lesen, um einen wahrscheinlichen Fehlerbereich vorzuschlagen und eine minimale Reproduktion zu generieren, wodurch aus einer Stunde Sichtprüfung nur wenige Minuten konzentrierter Arbeit werden.
Speichern Sie Runbooks für häufige Fehlerklassen, damit Ingenieure nicht bei Null anfangen müssen.
Metriken, die zu beobachten sind: Zeitaufwand für „Warten auf Info“, Prozentsatz der Reproduzierbarkeit beim ersten Durchlauf, Wiedereröffnungsrate in Verbindung mit fehlender Reproduzierbarkeit.
📖 Weitere Informationen: Einsatz von KI in der Softwareentwicklung (Anwendungsfälle und Tools)
5. Verkürzen Sie die Codeüberprüfung und den Testzyklus
Große PRs verzögern sich. Setzen Sie auf chirurgische Patches, trunkbasierte Entwicklung und Feature Flags, damit Korrekturen sicher ausgeliefert werden können. Weisen Sie Reviewer anhand der Eigentümerschaft des Codes vorab zu, um Leerlaufzeiten zu vermeiden, und verwenden Sie Checklisten (Tests aktualisiert, Telemetrie hinzugefügt, Flag hinter einem Kill-Switch), damit die Qualität gewährleistet ist.
Die Automatisierung sollte den Fehler bei PR-Öffnung in den Status „In Überprüfung“ und bei Zusammenführung in den Status „Behoben“ verschieben. KI kann Unit-Tests vorschlagen oder riskante Unterschiede hervorheben, um die Überprüfung zu fokussieren.
Zu beobachtende Metriken: Zeit in „In Review“, Änderungsfehlerrate für Bug-Fix-PRs und P90-Review-Latenz.
Sie können GitHub-/Gitlab-Integrationen in ClickUp verwenden, um Ihren Lösungsstatus synchron zu halten. Automatisierungen können die „Definition of Done“ durchsetzen.
📖 Weiterlesen: Wie man KI zur Automatisierung von Aufgaben einsetzt
6. Parallelisieren Sie die Überprüfung und sorgen Sie für eine echte Parität der QA-Umgebung.
Die Überprüfung sollte nicht erst Tage später oder in einer Umgebung beginnen, die keiner Ihrer Kunden nutzt.
Halten Sie „Ready for QA“ streng ein: Flag-gesteuerte Hotfixes, die in produktionsähnlichen Umgebungen mit Seed-Daten validiert wurden, die den gemeldeten Fällen entsprechen.
Richten Sie nach Möglichkeit temporäre Umgebungen aus dem Bug-Bereich ein, damit die Qualitätssicherung sofort validieren kann. Die KI kann dann anhand der Bug-Beschreibung und früherer Regressionen Testfälle generieren.
Zu beobachtende Metriken: Zeit in „QA/Überprüfung“, Rücklaufquote von QA zurück zu Dev, mittlere Zeit bis zum Abschluss nach der Zusammenführung.

📖 Weiterlesen: Wie man effektive Testfälle schreibt
7. Kommunizieren Sie den Status klar und deutlich, um den Koordinationsaufwand zu reduzieren.
Ein gutes Update verhindert drei Status-Pings und eine Eskalation.
Behandeln Sie Updates wie ein Produkt: kurz, spezifisch und zielgruppengerecht (Support, Führungskräfte, Kunden). Legen Sie einen Rhythmus für P0/P1 fest (z. B. stündlich bis zur Behebung, dann alle vier Stunden) und halten Sie eine einzige Quelle der Wahrheit ein.
KI kann aus dem Aufgabenverlauf kundensichere Updates und interne Zusammenfassungen erstellen, einschließlich Live-Status nach Schweregrad und Team. Für Führungskräfte wie Ihren Produktdirektor können Sie Fehler zu Initiativen zusammenfassen, damit diese erkennen können, ob kritische Qualitätsarbeiten die Lieferversprechen gefährden.
Zu beobachtende Metriken: Zeit zwischen Statusaktualisierungen zu P0/P1, CSAT der Stakeholder in Bezug auf die Kommunikation.
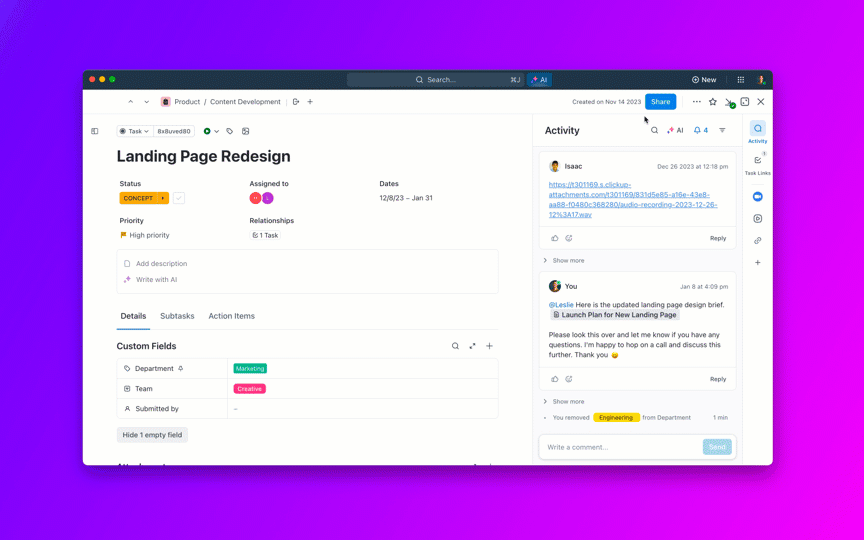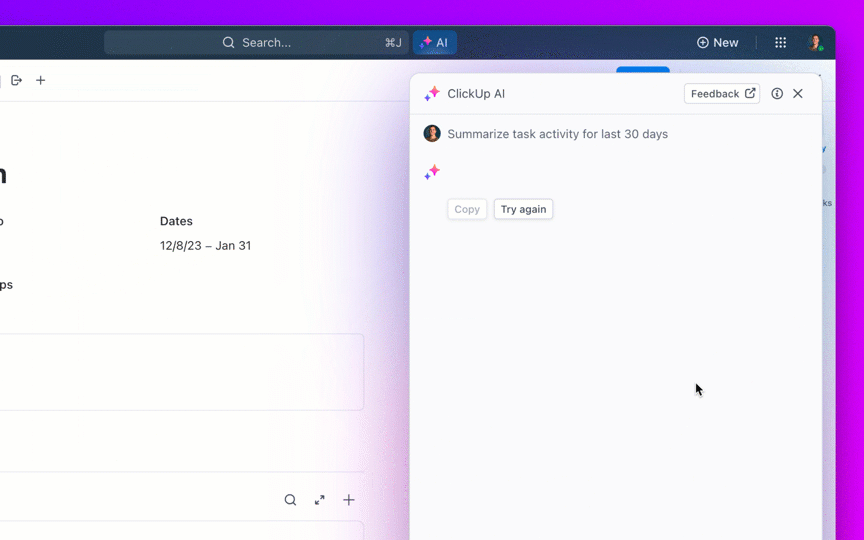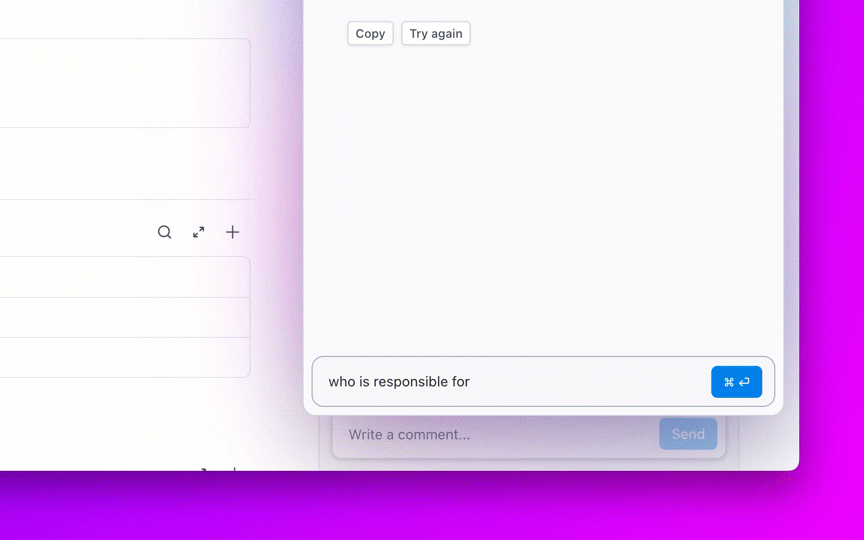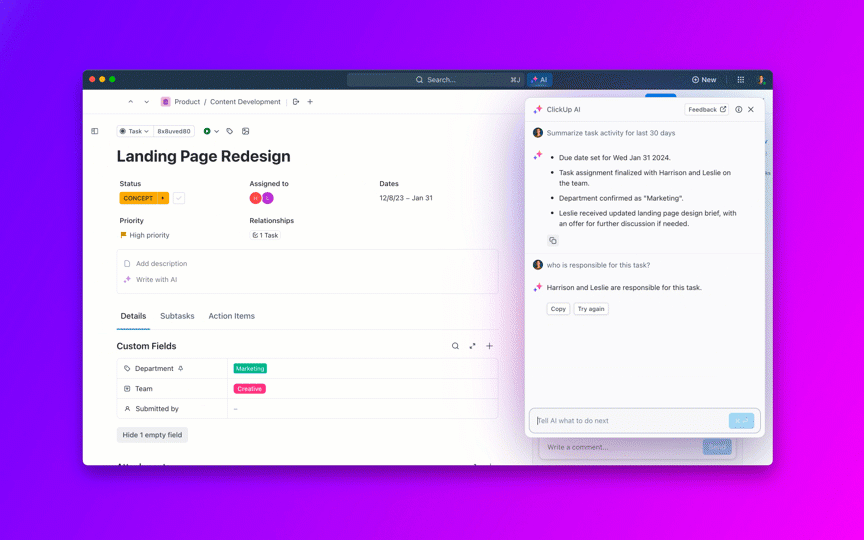
8. Kontrollieren Sie die Alterung von Backlogs und verhindern Sie „ewig offene“ Fälle.
Ein wachsender, veralteter Rückstand belastet jeden Sprint still und leise.
Legen Sie Alterungsrichtlinien fest (z. B. P2 > 30 Tage ist ein Auslöser für eine Überprüfung, P3 > 90 Tage erfordert eine Begründung) und planen Sie eine wöchentliche „Alterungs-Triage”, um Duplikate zusammenzuführen, veraltete Berichte zu schließen und Fehler mit geringem Wert in Produkt-Backlog-Elemente umzuwandeln.
Verwenden Sie KI, um den Rückstand nach Themen zu gruppieren (z. B. „Ablauf des Tokens für die Authentifizierung“, „Unzuverlässigkeit beim Hochladen von Bildern“), damit Sie thematische Korrekturwochen planen und eine ganze Klasse von Fehlern auf einmal beseitigen können.
Zu beobachtende Metriken: Anzahl der Rückstände nach Altersklasse, Prozentsatz der als Duplikate/veraltet geschlossenen Probleme, thematische Burn-Down-Geschwindigkeit.
9. Schließen Sie den Kreis mit Ursachenanalyse und Prävention
Wenn immer wieder Fehler derselben Art auftreten, verdecken Ihre MTTR-Verbesserungen ein größeres Problem.
Führen Sie schnelle, schuldfreie Ursachenanalysen für P0/P1 und hochfrequente P2 durch, kennzeichnen Sie Ursachen (Spezifikationslücken, Testlücken, Werkzeuglücken, Integrationsinstabilität), verknüpfen Sie sie mit betroffenen Komponenten und Incidents und verfolgen Sie Folgeaufgaben (Schutzmaßnahmen, Tests, Lint-Regeln) bis zur Fertigstellung.
/AI kann RCA-Zusammenfassungen erstellen und auf der Grundlage der Änderungshistorie vorbeugende Tests oder Lint-Regeln vorschlagen. So gelangen Sie von der Brandbekämpfung zu weniger Bränden.
Zu beobachtende Metriken: Wiedereröffnungsrate, Regressionsrate, Zeit zwischen Wiederholungen und Prozentsatz der RCAs, bei denen die Präventionsmaßnahmen fertiggestellt sind.

Zusammen verkürzen diese Änderungen den gesamten Prozess: schnellere Bestätigung, klarere Triage, intelligentere Priorisierung, weniger Verzögerungen bei der Überprüfung und Qualitätssicherung sowie klarere Kommunikation. Führungskräfte profitieren von einer besseren Vorhersagbarkeit in Bezug auf CSAT/NPS und Umsatz, während Mitarbeiter eine übersichtlichere Warteschlange mit weniger Kontextwechseln vorfinden.
📖 Weiterlesen: So führen Sie eine Ursachenanalyse durch
KI-Tools, die dabei helfen, die Zeit für die Fehlerbehebung zu reduzieren
KI kann die Lösungszeit in jedem Schritt verkürzen – bei der Erfassung, Triage, Weiterleitung, Behebung und Überprüfung.
Die wirklichen Vorteile zeigen sich jedoch erst, wenn tools den Kontext verstehen und die Arbeit ohne manuelle Eingriffe vorantreiben.
Suchen Sie nach Systemen, die Berichte automatisch ergänzen (Repro-Schritte, Umgebung, Duplikate), nach Auswirkungen priorisieren, an den richtigen Eigentümer weiterleiten, klare Updates entwerfen und sich nahtlos in Ihren Code, Ihre CI und Ihre Observability integrieren lassen.
Die besten Tools unterstützen auch agentenähnliche Workflows: Bots, die SLAs überwachen, Prüfer benachrichtigen, festgefahrene Elemente eskalieren und Ergebnisse für Stakeholder zusammenfassen. Hier ist unsere Auswahl an KI-Tools für eine bessere Fehlerbehebung:
1. ClickUp (am besten geeignet für kontextbezogene KI, Automatisierungen und agentenbasierte Workflows)
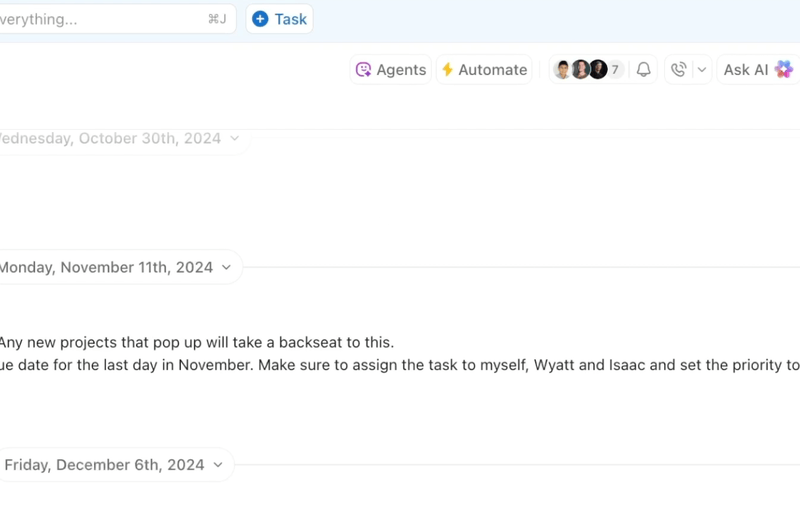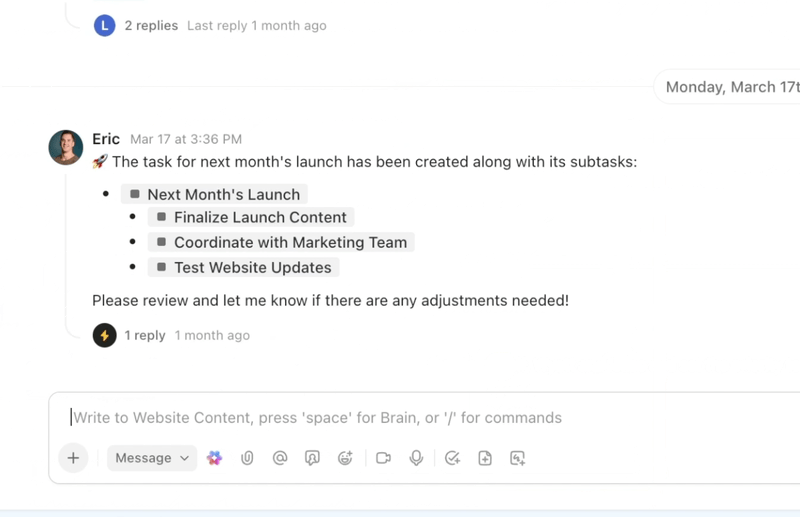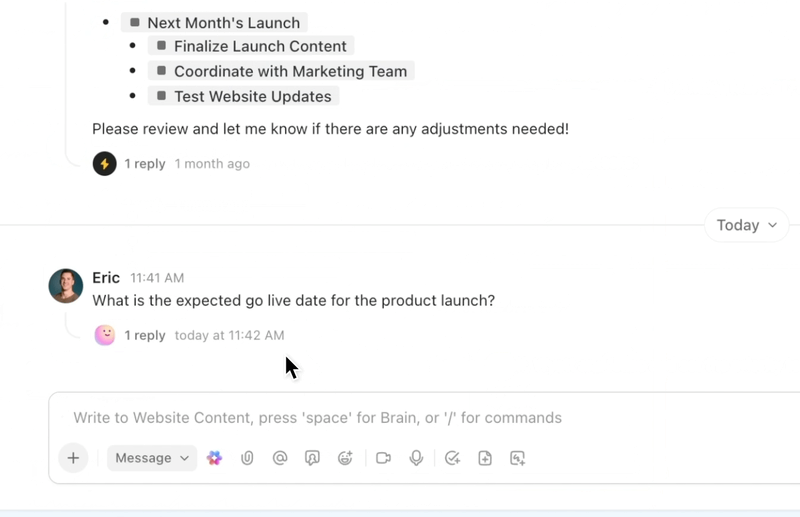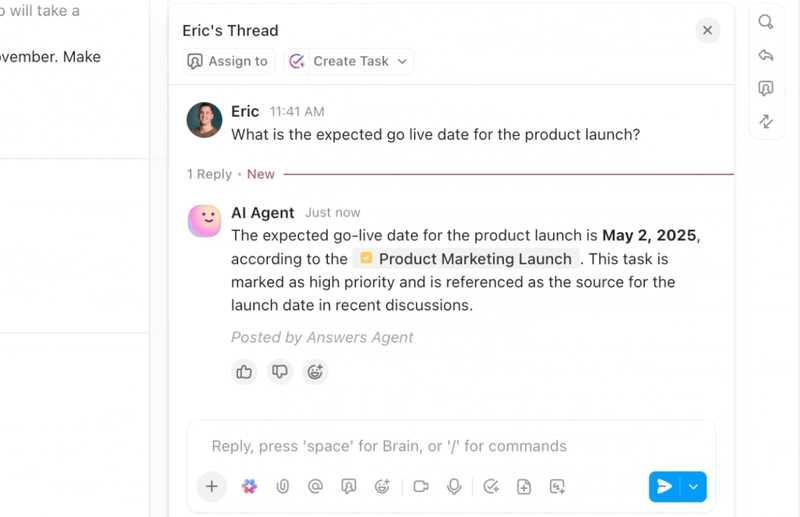
Wenn Sie einen optimierten, intelligenten Workflow zur Fehlerbehebung wünschen, bietet ClickUp, die Allround-App für die Arbeit, KI, Automatisierungen und agentenbasierte Workflow-Unterstützung an einem Ort.
ClickUp Brain zeigt sofort den richtigen Kontext an – es fasst lange Fehler-Threads zusammen, extrahiert Schritte zur Reproduktion und Umgebungsdetails aus Anhängen, markiert mögliche Duplikate und schlägt nächste Maßnahmen vor. Anstatt sich durch Slack, Tickets und Protokolle zu wühlen, erhalten Teams eine übersichtliche, angereicherte Aufzeichnung, auf die sie sofort reagieren können.
Automatisierungen und Autopilot-Agenten in ClickUp sorgen dafür, dass die Arbeit ohne ständige Überwachung vorangeht. Fehler werden automatisch an das richtige Team weitergeleitet, Eigentümer werden zugewiesen, SLAs und Fälligkeitstermine werden festgelegt, der Status wird im Laufe des Fortschritts aktualisiert und die Beteiligten erhalten zeitnah Benachrichtigungen.

Diese Agenten können sogar Probleme triagieren und kategorisieren, ähnliche Berichte gruppieren, auf historische Lösungen zurückgreifen, um mögliche Lösungswege vorzuschlagen, und dringende Elemente eskalieren – sodass MTTA und MTTR auch bei Volumenspitzen sinken.
🛠️ Sie möchten ein sofort einsatzbereites Toolkit? Die ClickUp-Vorlage für die Fehler- und Problemverfolgung ist eine leistungsstarke Lösung von ClickUp for Software , die Support-, Engineering- und Produktteams dabei unterstützt , Softwarefehler und -probleme mühelos im Griff zu behalten. Mit anpassbaren Ansichten wie Liste, Board, Workload, Formular und Zeitleiste können Teams ihren Fehlerverfolgungsprozess so visualisieren und verwalten, wie es für sie am besten passt.
Die 20 benutzerdefinierten Status und 7 benutzerdefinierten Felder der Vorlage ermöglichen einen maßgeschneiderten Workflow, der sicherstellt, dass jedes Problem von der Entdeckung bis zur Lösung nachverfolgt wird. Integrierte Automatisierungen übernehmen sich wiederholende Aufgaben, wodurch wertvolle Zeit gespart und der manuelle Aufwand reduziert wird.
💟 Bonus: Brain MAX ist Ihr KI-gestützter Desktop-Begleiter, der mit intelligenten, praktischen Features die Fehlerbehebung beschleunigt.
Wenn Sie auf einen Fehler stoßen, verwenden Sie einfach die Sprach-zu-Text-Funktion von Brain MAX, um das Problem zu diktieren – Ihre gesprochenen Notizen werden sofort transkribiert und können als Anhang an ein neues oder bestehendes Bug-Ticket angehängt werden. Die Enterprise-Suche durchsucht alle Ihre verbundenen Tools – wie ClickUp, GitHub, Google Drive und Slack – nach verwandten Fehlerberichten, Fehlerprotokollen, Code-Schnipseln und Dokumentationen, sodass Sie alle erforderlichen Informationen haben, ohne zwischen Apps wechseln zu müssen.
Müssen Sie eine Fehlerbehebung koordinieren? Mit Brain MAX können Sie den Fehler dem richtigen Entwickler zuweisen, automatische Erinnerungen für Updates zum Status einrichten und die Nachverfolgung des Fortschritts durchführen – alles von Ihrem Desktop aus!
2. Sentry (am besten geeignet für die Erfassung von Fehlern)
Sentry reduziert die MTTD und die Reproduktionszeit, indem es Fehler, Traces und Benutzersitzungen an einem Ort erfasst. Die KI-gesteuerte Gruppierung von Problemen reduziert Störsignale; „Suspect Commit”- und Regeln der Eigentümerschaft identifizieren den wahrscheinlichen Code-Eigentümer, sodass die Weiterleitung sofort erfolgt. Mit Session Replay erhalten Ingenieure den genauen Benutzerpfad und die Konsolen-/Netzwerkdetails, um Fehler ohne endloses Hin und Her zu reproduzieren.
Die Features von Sentry KI können den Kontext eines Problems zusammenfassen und in einigen Stacks Autofix-Patches vorschlagen, die auf den fehlerhaften Code verweisen. Der praktische Effekt: weniger doppelte Tickets, schnellere Zuweisung und ein kürzerer Weg vom Bericht zum funktionierenden Patch.
3. GitHub Copilot (am besten geeignet für eine schnellere Codeüberprüfung)
Copilot beschleunigt den Korrekturzyklus innerhalb des Editors. Es erklärt Stacktraces, schlägt Patches mit Einzelzielen vor, schreibt Unit-Tests, um die Korrektur zu sichern, und erstellt Repro-Skripte.
Copilot Chat kann fehlerhaften Code durchgehen, sicherere Refactorings vorschlagen und Kommentare oder PR-Beschreibungen generieren, die die Codeüberprüfung beschleunigen. In Kombination mit erforderlichen Überprüfungen und CI verkürzt es den Zeitaufwand für „Diagnose → Implementierung → Test“, insbesondere bei gut eingegrenzten Fehlern mit klarer Reproduzierbarkeit.
4. Snyk von DeepCode KI (am besten geeignet zum Erkennen von Mustern)
Die KI-gestützte statische Analyse von DeepCode findet Fehler und unsichere Muster während Sie Code schreiben und in PRs. Sie hebt problematische Flows hervor, erklärt, warum sie auftreten, und schlägt sichere Korrekturen vor, die zu Ihren Codebasis-Idiomen passen.
Indem Sie Regressionen vor dem Zusammenführen erkennen und Entwickler zu sichereren Mustern anleiten, reduzieren Sie die Häufigkeit neuer Fehler und beschleunigen die Behebung kniffliger Logikfehler, die bei der Überprüfung schwer zu erkennen sind. IDE- und PR-Integrationen sorgen dafür, dass dies nah am Ort der Arbeit geschieht.
5. Datadog Watchdog und AIOps (am besten geeignet für die Log-Analyse)
Datadog Watchdog nutzt ML, um Anomalien in Protokollen, Metriken, Traces und der Echtzeit-Benutzerüberwachung aufzudecken. Es korreliert Spitzenwerte mit Bereitstellungsmarkern, Infrastrukturänderungen und Topologie, um mögliche Ursachen vorzuschlagen.
Bei Fehlern, die sich auf Kunden auswirken, bedeutet dies eine Erkennung innerhalb von Minuten, eine automatische Gruppierung zur Reduzierung von Alarmgeräuschen und konkrete Hinweise darauf, wo gesucht werden muss. Die Triage-Zeit sinkt, da Sie mit „dieser Einsatz hat diese Dienste berührt und die Fehlerraten sind an diesem Endpunkt gestiegen“ beginnen, anstatt bei Null anzufangen.
⚡️ Vorlagenarchiv: Kostenlose Vorlagen für die Nachverfolgung von Problemen und Protokollierung in Excel und ClickUp
6. New Relic KI (am besten geeignet für die Identifizierung und Zusammenfassung von Trends)
Der Fehler-Posteingang von New Relic gruppiert ähnliche Fehler über Dienste und Versionen hinweg, während der KI-Assistent die Auswirkungen zusammenfasst, mögliche Ursachen hervorhebt und Links zu den betroffenen Traces/Transaktionen verknüpft.
Durch Korrelationen bei der Bereitstellung und Informationen zu Entitätsänderungen wird deutlich, wann eine kürzlich erfolgte Veröffentlichung dafür verantwortlich ist. Bei verteilten Systemen erspart dieser Kontext stundenlange teamübergreifende Absprachen und leitet den Fehler mit einer fundierten Hypothese an den richtigen Verantwortlichen weiter.
7. Rollbar (am besten geeignet für automatisierte Workflows)
Rollbar ist auf die Echtzeit-Fehlerüberwachung mit intelligenter Fingerabdruckerkennung spezialisiert, um Duplikate zu gruppieren und das Vorkommen von Fehlern zu verfolgen. Die KI-gesteuerten Zusammenfassungen und Hinweise auf die Ursachen helfen Teams, den Umfang (betroffene Benutzer, betroffene Versionen) zu verstehen, während Telemetrie und Stack-Traces schnelle Hinweise zur Reproduktion liefern.
Die Workflow-Regeln von Rollbar können automatisch Aufgaben erstellen, Schweregrade kennzeichnen und an die Eigentümer weiterleiten, wodurch laute Fehlerströme in priorisierte Warteschlangen mit Kontext umgewandelt werden.
8. PagerDuty AIOps und Runbook-Automatisierung (Beste Low-Touch-Diagnose)
PagerDuty nutzt Ereigniskorrelation und ML-basierte Rauschunterdrückung, um Alarmfluten zu handhabbaren Incidents zusammenzufassen.
Durch dynamisches Routing wird das Problem sofort an den richtigen Bereitschaftsdienst weitergeleitet, während die Runbook-Automatisierung Diagnosen oder Abhilfemaßnahmen (Neustart von Diensten, Rollback einer Bereitstellung, Umschalten von Feature Flags) einleiten kann, bevor ein Mensch eingreift. Für die Fehlerbehebungszeit bedeutet dies eine kürzere MTTA, schnellere Abhilfemaßnahmen für P0s und weniger Zeitverlust durch Alarmmüdigkeit.
Der rote Faden ist Automatisierung plus KI in jedem Schritt. Sie erkennen Fehler früher, leiten sie intelligenter weiter, gelangen schneller zum Code und kommunizieren den Status, ohne die Entwickler zu behindern – all dies führt zu einer deutlichen Verkürzung der Fehlerbehebungszeit.
📖 Weiterlesen: Wie man KI in DevOps einsetzt
Praxisbeispiele für den Einsatz von KI zur Fehlerbehebung
/AI hat also offiziell den Sprung aus dem Labor geschafft. Sie reduziert die Zeit für die Fehlerbehebung in der Praxis.
Schauen wir uns an, wie das funktioniert!
| Domäne/Organisation | Wie KI eingesetzt wurde | Auswirkungen/Vorteile |
|---|---|---|
| Ubisoft | Entwickelt wurde Commit Assistant, ein KI-Tool, das auf der Grundlage von zehn Jahren internem Code trainiert wurde und Fehler bereits in der Codierungsphase vorhersagt und verhindert. | Ziel ist es, Zeit und Kosten drastisch zu reduzieren – traditionell werden bis zu 70 % der Kosten für die Spieleentwicklung für die Fehlerbehebung aufgewendet. |
| Razer (Wyvrn-Plattform) | Einführung des KI-gestützten QA Copilot (integriert in Unreal und Unity) zur Automatisierung der Fehlererkennung und Erstellung von QA-Berichten. | Steigert die Fehlererkennung um bis zu 25 % und halbiert die QA-Zeit. |
| Google / DeepMind & Project Zero | Einführung von Big Sleep, einem KI-Tool, das selbstständig Sicherheitslücken in Open-Source-Software wie FFmpeg und ImageMagick erkennt. | 20 Fehler wurden identifiziert, alle von menschlichen Experten überprüft und für die Behebung vorgesehen. |
| Forscher der UC Berkeley | Mithilfe eines Benchmarks namens CyberGym analysierten KI-Modelle 188 Open-Source-Projekte, deckten 17 Schwachstellen auf – darunter 15 unbekannte „Zero-Day“-Fehler – und generierten Proof-of-Concept-Exploits. | Demonstriert die sich weiterentwickelnden Fähigkeiten der KI bei der Erkennung von Schwachstellen und der automatisierten Exploit-Prüfung. |
| Spur (Yale-Startup) | Entwicklung eines KI-Agenten, der Testfallbeschreibungen in einfacher Sprache in automatisierte Website-Testroutinen übersetzt – praktisch ein selbstschreibender QA-Workflow. | Ermöglicht autonome Tests mit minimalem menschlichem Aufwand. |
| Automatische Reproduktion von Android-Fehlerberichten | Verwendung von NLP + Reinforcement Learning zur Interpretation der Sprache in Fehlerberichten und zur Generierung von Schritten zur Reproduktion von Android-Fehlern. | Erreichte 67 % Genauigkeit, 77 % Wiederauffindbarkeit und reproduzierte 74 % der Fehlerberichte, was herkömmliche Methoden übertrifft. |
Häufige Fehler bei der Messung der Fehlerbehebungszeit
Wenn Ihre Messungen nicht stimmen, wird auch Ihr Plan zur Verbesserung nicht stimmen.
Die meisten „schlechten Zahlen” in Workflows zur Fehlerbehebung sind auf vage Definitionen, inkonsistente Workflows und oberflächliche Analysen zurückzuführen.
Beginnen Sie also zunächst mit den Grundlagen – was als Start/Stopp gilt, wie Sie mit Wartezeiten und Wiedereröffnungen umgehen – und lesen Sie dann die Daten so, wie Ihre Kunden sie erleben. Dazu gehören:
❌ Unklare Grenzen: Wenn Sie „Gemeldet→Behoben“ und „Gemeldet→Geschlossen“ im selben Dashboard mischen (oder von Monat zu Monat wechseln), werden Trends bedeutungslos. Wählen Sie eine Grenze, dokumentieren Sie sie und setzen Sie sie teamübergreifend durch. Wenn Sie beide benötigen, veröffentlichen Sie sie als separate Metriken mit eindeutigen Beschreibungen.
❌ Ansatz, der sich nur auf Durchschnittswerte stützt: Wenn Sie sich auf den Mittelwert verlassen, verschleiern Sie die Realität der Warteschlangen mit einigen wenigen langwierigen Ausreißern. Verwenden Sie den Median (P50) für Ihre „typische“ Zeit, P90 für Vorhersagbarkeit/SLAs und behalten Sie den Mittelwert für die Planung der Kapazität bei. Betrachten Sie immer die Verteilung und nicht nur eine einzelne Zahl.
❌ Keine Segmentierung: Wenn Sie alle Incidents zusammenfassen, werden P0-Incidents mit kosmetischen P3-Incidents vermischt. Segmentieren Sie nach Schweregrad, Quelle (Kunde vs. QA vs. Überwachung), Komponente/Team und „neu vs. Regression“. Ihr P0/P1 P90 entspricht dem, was die Stakeholder empfinden; Ihr P2+ Median ist das, worauf sich die Technikabteilung stützt.
❌ Ignorieren von „unterbrochener“ Zeit: Warten Sie auf Kundenprotokolle, einen externen Anbieter oder ein Release-Fenster? Wenn Sie „Blockiert/Unterbrochen“ nicht als erstklassigen Status verfolgen, wird Ihre Lösungszeit zum Argument. Melden Sie sowohl die Kalenderzeit als auch die aktive Zeit, damit Engpässe sichtbar werden und Debatten ein Ende finden.
❌ Lücken bei der Zeitnormalisierung: Das Mischen von Zeitzonen oder das Wechseln zwischen Geschäftszeiten und Kalenderstunden während des Prozesses verfälscht Vergleiche. Normalisieren Sie Zeitstempel auf eine Zeitzone (oder UTC) und legen Sie einmalig fest, ob SLAs in Geschäfts- oder Kalenderstunden gemessen werden; wenden Sie dies dann konsistent an.
❌ Unvollständige Erfassung und Duplikate: Fehlende Umgebungs-/Build-Info und doppelte Tickets verlängern die Bearbeitungszeit und verwirren die Eigentümerschaft. Standardisieren Sie die erforderlichen Felder bei der Erfassung, ergänzen Sie diese automatisch (Protokolle, Version, Gerät) und entfernen Sie Duplikate, ohne die Bearbeitungszeit zurückzusetzen – schließen Sie Duplikate als verknüpfte und nicht als „neue“ Probleme.
❌ Inkonsistente Statusmodelle: Maßgeschneiderte Status („QA Ready-ish“, „Pending Review 2“) verbergen die Verweildauer im Status und machen Statusübergänge unzuverlässig. Definieren Sie einen kanonischen Workflow (Neu → Triagiert → In Bearbeitung → In Überprüfung → Gelöst → Geschlossen) und prüfen Sie auf abweichende Status.
❌ Blind gegenüber der Zeit im Status: Eine einzige Nummer für die „Gesamtzeit” kann Ihnen nicht sagen, wo die Arbeit ins Stocken gerät. Erfassen und überprüfen Sie die Zeit, die in den Status „Triage”, „In Überprüfung”, „Blockiert” und „QA” verbracht wurde. Wenn die Codeüberprüfung P90 die Implementierung in den Schatten stellt, besteht Ihre Lösung nicht darin, „schneller zu programmieren”, sondern die Überprüfungskapazität freizugeben.
🧠 Interessante Tatsache: Die jüngste AI Cyber Challenge der DARPA zeigte einen bahnbrechenden Fortschritt in der Automatisierung der Cybersicherheit. Im Rahmen des Wettbewerbs wurden KI-Systeme vorgestellt, die in der Lage sind, Schwachstellen in Software autonom zu erkennen, auszunutzen und zu beheben – ohne menschliches Eingreifen. Das Gewinnerteam „Team Atlanta“ deckte beeindruckende 77 % der eingeschleusten Fehler auf und behob 61 % davon erfolgreich. Damit demonstrierte es die Leistungsfähigkeit von KI, die nicht nur Fehler findet, sondern diese auch aktiv behebt.
❌ Blindheit gegenüber Wiederaufnahmen: Wenn Wiederaufnahmen als neue Fehler behandelt werden, wird die Uhr zurückgesetzt und die MTTR verschleiert. Verfolgen Sie die Wiederaufnahmerate und die „Zeit bis zur stabilen Schließung“ (vom ersten Bericht bis zur endgültigen Schließung über alle Zyklen hinweg). Steigende Wiederaufnahmen deuten in der Regel auf eine schwache Reproduzierbarkeit, Testlücken oder eine vage Definition des Begriffs „erledigt“ hin.
❌ Keine MTTA: Teams konzentrieren sich zu sehr auf die MTTR und ignorieren die MTTA (Acknowledgement/Eigentümerschaft). Eine hohe MTTA ist ein Warnsignal für eine lange Lösungsdauer. Messen Sie sie, legen Sie SLAs nach Schweregrad fest und führen Sie die Automatisierung der Weiterleitung/Eskalation durch, um sie niedrig zu halten.
❌ KI/Automatisierung ohne Sicherheitsvorkehrungen: Wenn Sie KI ohne Überprüfung die Schweregrade einstellen oder Duplikate schließen lassen, kann dies zu Fehlklassifizierungen von Randfällen und einer stillschweigenden Verzerrung der Metriken führen. Verwenden Sie KI für Vorschläge, verlangen Sie eine menschliche Bestätigung für P0/P1 und überprüfen Sie die Modellleistung monatlich, damit Ihre Daten vertrauenswürdig bleiben.
Wenn Sie diese Lücken schließen, spiegeln Ihre Diagramme zur Fehlerbehebungszeit endlich die Realität wider. Von da an summieren sich die Verbesserungen: Eine bessere Erfassung verkürzt die MTTA, klarere Zustände zeigen echte Engpässe auf und segmentierte P90s geben Führungskräften Versprechen, die Sie einhalten können.
⚡️ Vorlagenarchiv: 10 Testfallvorlagen für Softwaretests
Best Practices für eine bessere Fehlerbehebung
Zusammenfassend sind hier die wichtigsten Punkte, die Sie beachten sollten!
| 🧩 Best Practices | 💡 Was das bedeutet | 🚀 Warum das wichtig ist |
| Verwenden Sie ein robustes System für die Nachverfolgung von Fehlern | Verfolgen Sie alle gemeldeten Fehler mit einem zentralisierten System für die Fehlernachverfolgung. | Stellt sicher, dass kein Fehler übersehen wird, und ermöglicht die Sichtbarkeit des Fehlestatus über alle Teams hinweg. |
| Erstellen Sie detaillierte Fehlerberichte | Beziehen Sie visuellen Kontext, Betriebssystem-Info, Schritte zur Reproduktion und Schweregrad mit ein. | Hilft Entwicklern, Fehler schneller zu beheben, da alle wichtigen Informationen im Voraus verfügbar sind. |
| Fehler kategorisieren und priorisieren | Verwenden Sie eine Matrix der Prioritäten, um Fehler nach Dringlichkeit und Auswirkung zu sortieren. | Konzentriert das Team zunächst auf kritische Fehler und dringende Probleme. |
| Nutzen Sie automatisierte Tests | Führen Sie Tests automatisch in Ihrer CI/CD-Pipeline durch. | Unterstützt die Früherkennung und verhindert Rückschritte. |
| Klare Richtlinien für die Berichterstellung festlegen | Stellen Sie Vorlagen und Schulungen zur Berichterstellung für die Meldung von Fehlern bereit. | Dies führt zu präzisen Informationen und einer reibungsloseren Kommunikation. |
| Verfolgen Sie wichtige Metriken | Messen Sie die Zeit bis zur Fehlerbehebung, die verstrichene Zeit und die Reaktionszeit. | Ermöglicht die Nachverfolgung der Leistung und ihre Verbesserung anhand von Verlaufsdaten. |
| Verwenden Sie einen proaktiven Ansatz | Warten Sie nicht, bis sich Benutzer beschweren – testen Sie proaktiv. | Steigert die Kundenzufriedenheit und reduziert die Auslastung des Supports. |
| Nutzen Sie intelligente tools und ML | Nutzen Sie maschinelles Lernen, um Fehler vorherzusagen und Korrekturen vorzuschlagen. | Verbessert die Effizienz bei der Identifizierung von Ursachen und der Behebung von Fehlern. |
| Anpassung an SLAs | Erfüllen Sie vereinbarte Service Level Agreements für die Fehlerbehebung. | Schafft Vertrauen und erfüllt die Erwartungen der Clients zeitnah. |
| Kontinuierlich überprüfen und verbessern | Analysieren Sie erneut gemeldete Fehler, sammeln Sie Feedback und optimieren Sie Prozesse. | Fördert die kontinuierliche Verbesserung Ihres Entwicklungsprozesses und Ihres Fehlermanagements. |
Fehlerbehebung leicht gemacht mit kontextbezogener KI
Die schnellsten Teams zur Fehlerbehebung verlassen sich nicht auf Heldentaten. Sie entwickeln ein System: klare Start-/Stopp-Definitionen, saubere Erfassung, Priorisierung nach Auswirkungen auf das Geschäft, klare Eigentümerschaft und enge Feedbackschleifen zwischen Support, Qualitätssicherung, Entwicklung und Release.
ClickUp kann diese KI-gestützte Command-Center-Lösung für Ihr Fehlerbehebungssystem sein. Zentralisieren Sie alle Berichte in einer Warteschlange, standardisieren Sie den Kontext mit strukturierten Feldern und lassen Sie ClickUp AI die Fehler triagieren, zusammenfassen und priorisieren, während Automatisierungen SLAs durchsetzen, bei Zeitüberschreitungen eskalieren und alle Beteiligten auf dem Laufenden halten. Verknüpfen Sie Fehler mit Kunden, Code und Releases, damit Führungskräfte die Auswirkungen sehen und die Mitarbeiter im Fluss bleiben.
Wenn Sie bereit sind, die Zeit für die Fehlerbehebung zu reduzieren und Ihre Roadmap vorhersehbarer zu gestalten, melden Sie sich bei ClickUp an und beginnen Sie, die Steigerung in Tagen statt in Quartalen zu messen.
Häufig gestellte Fragen
Was ist eine gute Fehlerbehebungszeit?
Es gibt keine allgemeingültige „gute“ Nummer – diese hängt vom Schweregrad, dem Release-Modell und der Risikotoleranz ab. Verwenden Sie Medianwerte (P50) für „typische“ Leistungen und P90 für Zusagen/SLAs und segmentieren Sie nach Schweregrad und Ursache.
Was ist der Unterschied zwischen Fehlerbehebung und Fehlerabschluss?
Die Lösung ist erreicht, wenn die Korrektur implementiert ist (z. B. Code zusammengeführt, Konfiguration angewendet) und das Team den Fehler als behoben betrachtet. Der Abschluss ist erreicht, wenn das Problem überprüft und offiziell geschlossen ist (z. B. QA in der Zielumgebung validiert, freigegeben oder mit Begründung als „nicht zu beheben/Duplikat“ gekennzeichnet). Viele Teams messen beides: „Gemeldet→Gelöst“ spiegelt die Geschwindigkeit der Entwicklung wider, „Gemeldet→Abgeschlossen“ spiegelt den End-to-End-Qualitätsflow wider. Verwenden Sie einheitliche Definitionen, damit Dashboards nicht verschiedene Phasen vermischen.
Was ist der Unterschied zwischen der Zeit bis zur Fehlerbehebung und der Zeit bis zur Fehlererkennung?
Die Erkennungszeit (MTTD) ist die Zeit, die benötigt wird, um einen Fehler nach seinem Auftreten oder seiner Auslieferung zu entdecken – durch Überwachung, Qualitätssicherung oder Benutzer. Die Behebungszeit ist die Zeit, die von der Erkennung/Meldung bis zur Implementierung der Korrektur (und, wenn Sie möchten, bis zur Validierung/Freigabe) benötigt wird. Zusammen definieren sie das Zeitfenster für die Auswirkungen auf den Kunden: schnelle Erkennung, schnelle Bestätigung, schnelle Behebung und sichere Freigabe. Sie können auch die MTTA (Zeit bis zur Bestätigung/Zuweisung) verfolgen, um Verzögerungen bei der Triage zu erkennen, die oft eine längere Behebungszeit bedeuten.
Wie hilft KI bei der Fehlerbehebung?
/AI komprimiert die Schleifen, die normalerweise Zeit kosten: Erfassung, Triage, Diagnose, Behebung und Überprüfung.
- Erfassung und Triage: Automatische Zusammenfassung langer Berichte, Extraktion von Reproduktionsschritten/Umgebungen, Markierung von Duplikaten und Vorschlag von Schweregrad/Priorität, damit Ingenieure mit einem klaren Kontext beginnen können (z. B. ClickUp AI, Sentry AI).
- Weiterleitung und SLAs: Prognostiziert den wahrscheinlichen Verantwortlichen/Eigentümer, setzt Timer und eskaliert, wenn MTTA oder Überprüfungszeiten überschritten werden – wodurch die Leerlaufzeit im Status reduziert wird (ClickUp-Automatisierungen und agentenähnliche Workflows).
- Diagnose: Gruppiert ähnliche Fehler, korreliert Spitzen mit aktuellen Commits/Releases und weist mit Stacktraces und Code-Kontext auf wahrscheinliche Ursachen hin (Sentry KI und ähnliche).
- Implementierung: Schlägt Codeänderungen und Tests basierend auf Mustern aus Ihrem Repo vor und beschleunigt so den „Write/Fix”-Zyklus (GitHub Copilot; Snyk Code KI von DeepCode).
- Überprüfung und Kommunikation: Verfasst Testfälle aus Reproduktionsschritten, entwirft Release-Notizen und Updates für Stakeholder und fasst den Status für Führungskräfte und Kunden zusammen (ClickUp AI). Durch die gemeinsame Nutzung von ClickUp als Command-Center mit Sentry/Copilot/DeepCode im Stack können Teams die MTTA/P90-Zeiten verkürzen, ohne sich auf Heldentaten verlassen zu müssen.